
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DOCK1-PPAPDC1A (FusionGDB2 ID:HG1793TG196051) |
Fusion Gene Summary for DOCK1-PPAPDC1A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DOCK1-PPAPDC1A | Fusion gene ID: hg1793tg196051 | Hgene | Tgene | Gene symbol | DOCK1 | PPAPDC1A | Gene ID | 1793 | 196051 |
| Gene name | dedicator of cytokinesis 1 | phospholipid phosphatase 4 | |
| Synonyms | DOCK180|ced5 | DPPL2|PPAPDC1|PPAPDC1A | |
| Cytomap | ('DOCK1','DOCK1')('PLPP4','PPAPDC1A') 10q26.2 | 10q26.12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dedicator of cytokinesis protein 1180 kDa protein downstream of CRKDOwnstream of CrK | phospholipid phosphatase 4diacylglycerol pyrophosphate like 2diacylglycerol pyrophosphate phosphatase-like 2phosphatidate phosphatase PPAPDC1Aphosphatidic acid phosphatase type 2 domain containing 1Aphosphatidic acid phosphatase type 2 domain-contain | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | Q14185 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000280333, ENST00000484400, | ||
| Fusion gene scores | * DoF score | 17 X 17 X 11=3179 | 8 X 6 X 6=288 |
| # samples | 20 | 13 | |
| ** MAII score | log2(20/3179*10)=-3.99050111136325 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(13/288*10)=-1.14755718841386 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DOCK1 [Title/Abstract] AND PPAPDC1A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DOCK1(128796513)-PPAPDC1A(122263330), # samples:2 DOCK1(128788867)-PLPP4(122263330), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | DOCK1-PPAPDC1A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DOCK1-PPAPDC1A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DOCK1-PPAPDC1A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. DOCK1-PPAPDC1A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PPAPDC1A | GO:0046839 | phospholipid dephosphorylation | 17590538 |
| Fusion gene breakpoints across DOCK1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PPAPDC1A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A2-A04U-01A | DOCK1 | chr10 | 128788867 | + | PLPP4 | chr10 | 122263330 | + |
| ChimerDB4 | BRCA | TCGA-A2-A04U-01A | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| ChimerDB4 | BRCA | TCGA-A2-A04U-01A | DOCK1 | chr10 | 128796513 | - | PPAPDC1A | chr10 | 122263330 | + |
| ChimerDB4 | BRCA | TCGA-A2-A04U-01A | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| ChimerDB4 | BRCA | TCGA-A2-A04U | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
Top |
Fusion Gene ORF analysis for DOCK1-PPAPDC1A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000280333 | ENST00000496437 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| 5CDS-intron | ENST00000280333 | ENST00000496437 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| 5CDS-intron | ENST00000280333 | ENST00000496437 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| In-frame | ENST00000280333 | ENST00000369073 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000369073 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000369073 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| In-frame | ENST00000280333 | ENST00000398248 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000398248 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000398248 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| In-frame | ENST00000280333 | ENST00000398250 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000398250 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000398250 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| In-frame | ENST00000280333 | ENST00000439221 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000439221 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000439221 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| In-frame | ENST00000280333 | ENST00000541332 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000541332 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| In-frame | ENST00000280333 | ENST00000541332 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| intron-3CDS | ENST00000484400 | ENST00000369073 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000369073 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000369073 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| intron-3CDS | ENST00000484400 | ENST00000398248 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000398248 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000398248 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| intron-3CDS | ENST00000484400 | ENST00000398250 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000398250 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000398250 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| intron-3CDS | ENST00000484400 | ENST00000439221 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000439221 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000439221 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| intron-3CDS | ENST00000484400 | ENST00000541332 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000541332 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-3CDS | ENST00000484400 | ENST00000541332 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| intron-intron | ENST00000484400 | ENST00000496437 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-intron | ENST00000484400 | ENST00000496437 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + |
| intron-intron | ENST00000484400 | ENST00000496437 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000398250 | PPAPDC1A | chr10 | 122263329 | + | 1989 | 876 | 28 | 1635 | 535 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000439221 | PPAPDC1A | chr10 | 122263329 | + | 1800 | 876 | 28 | 1446 | 472 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000398248 | PPAPDC1A | chr10 | 122263329 | + | 1538 | 876 | 28 | 1110 | 360 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000541332 | PPAPDC1A | chr10 | 122263329 | + | 2185 | 876 | 28 | 1521 | 497 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000369073 | PPAPDC1A | chr10 | 122263329 | + | 1985 | 876 | 28 | 1635 | 535 |
| ENST00000280333 | DOCK1 | chr10 | 128788867 | + | ENST00000398250 | PPAPDC1A | chr10 | 122263330 | + | 1695 | 582 | 28 | 1341 | 437 |
| ENST00000280333 | DOCK1 | chr10 | 128788867 | + | ENST00000439221 | PPAPDC1A | chr10 | 122263330 | + | 1506 | 582 | 28 | 1152 | 374 |
| ENST00000280333 | DOCK1 | chr10 | 128788867 | + | ENST00000398248 | PPAPDC1A | chr10 | 122263330 | + | 1244 | 582 | 28 | 816 | 262 |
| ENST00000280333 | DOCK1 | chr10 | 128788867 | + | ENST00000541332 | PPAPDC1A | chr10 | 122263330 | + | 1891 | 582 | 28 | 1227 | 399 |
| ENST00000280333 | DOCK1 | chr10 | 128788867 | + | ENST00000369073 | PPAPDC1A | chr10 | 122263330 | + | 1691 | 582 | 28 | 1341 | 437 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000398250 | PPAPDC1A | chr10 | 122263330 | + | 1989 | 876 | 28 | 1635 | 535 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000439221 | PPAPDC1A | chr10 | 122263330 | + | 1800 | 876 | 28 | 1446 | 472 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000398248 | PPAPDC1A | chr10 | 122263330 | + | 1538 | 876 | 28 | 1110 | 360 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000541332 | PPAPDC1A | chr10 | 122263330 | + | 2185 | 876 | 28 | 1521 | 497 |
| ENST00000280333 | DOCK1 | chr10 | 128796513 | + | ENST00000369073 | PPAPDC1A | chr10 | 122263330 | + | 1985 | 876 | 28 | 1635 | 535 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000280333 | ENST00000398250 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.000879565 | 0.9991204 |
| ENST00000280333 | ENST00000439221 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.00085958 | 0.9991404 |
| ENST00000280333 | ENST00000398248 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.000479425 | 0.99952054 |
| ENST00000280333 | ENST00000541332 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.0020613 | 0.9979387 |
| ENST00000280333 | ENST00000369073 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.000906656 | 0.9990934 |
| ENST00000280333 | ENST00000398250 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + | 0.001185716 | 0.99881434 |
| ENST00000280333 | ENST00000439221 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + | 0.000572412 | 0.9994276 |
| ENST00000280333 | ENST00000398248 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + | 0.000818037 | 0.9991819 |
| ENST00000280333 | ENST00000541332 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + | 0.006312026 | 0.99368805 |
| ENST00000280333 | ENST00000369073 | DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263330 | + | 0.00123649 | 0.99876356 |
| ENST00000280333 | ENST00000398250 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + | 0.000879565 | 0.9991204 |
| ENST00000280333 | ENST00000439221 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + | 0.00085958 | 0.9991404 |
| ENST00000280333 | ENST00000398248 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + | 0.000479425 | 0.99952054 |
| ENST00000280333 | ENST00000541332 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + | 0.0020613 | 0.9979387 |
| ENST00000280333 | ENST00000369073 | DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263330 | + | 0.000906656 | 0.9990934 |
Top |
Fusion Genomic Features for DOCK1-PPAPDC1A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.00208578 | 0.99791425 |
| DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.00208578 | 0.99791425 |
| DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263329 | + | 1.16E-05 | 0.99998844 |
| DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.00208578 | 0.99791425 |
| DOCK1 | chr10 | 128796513 | + | PPAPDC1A | chr10 | 122263329 | + | 0.00208578 | 0.99791425 |
| DOCK1 | chr10 | 128788867 | + | PPAPDC1A | chr10 | 122263329 | + | 1.16E-05 | 0.99998844 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
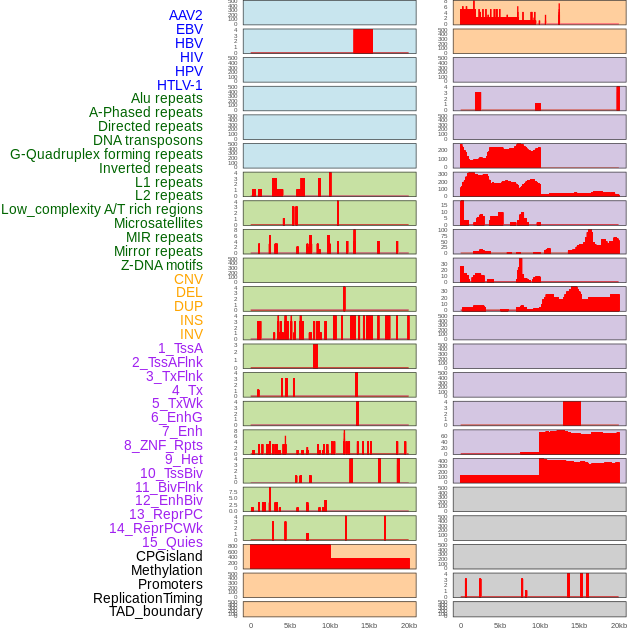 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
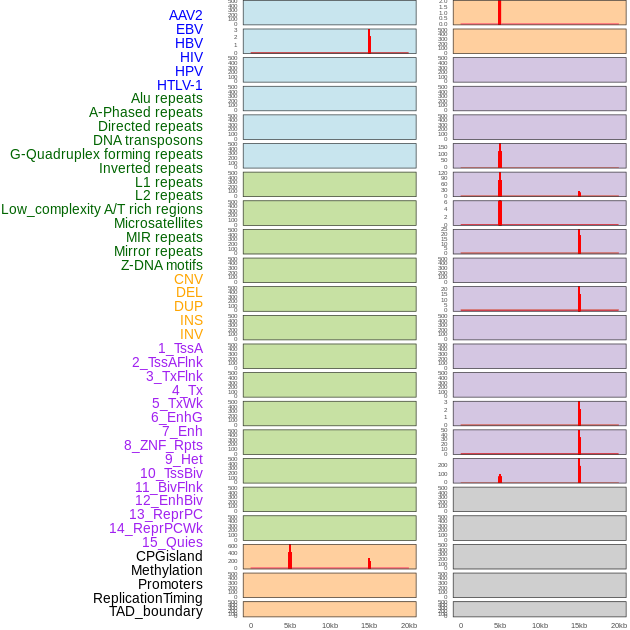 |
Top |
Fusion Protein Features for DOCK1-PPAPDC1A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:128796513/chr10:122263330) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DOCK1 | . |
| FUNCTION: Involved in cytoskeletal rearrangements required for phagocytosis of apoptotic cells and cell motility. Along with DOCK1, mediates CRK/CRKL regulation of epithelial and endothelial cell spreading and migration on type IV collagen (PubMed:19004829). Functions as a guanine nucleotide exchange factor (GEF), which activates Rac Rho small GTPases by exchanging bound GDP for free GTP. Its GEF activity may be enhanced by ELMO1 (PubMed:8657152). {ECO:0000269|PubMed:19004829, ECO:0000269|PubMed:8657152}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DOCK1 | chr10:128788867 | chr10:122263330 | ENST00000280333 | + | 6 | 52 | 9_70 | 157 | 1866.0 | Domain | SH3 |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263329 | ENST00000280333 | + | 8 | 52 | 9_70 | 255 | 1866.0 | Domain | SH3 |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263330 | ENST00000280333 | + | 8 | 52 | 9_70 | 255 | 1866.0 | Domain | SH3 |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 102_110 | 18 | 97.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 143_146 | 18 | 97.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 195_205 | 18 | 97.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 102_110 | 18 | 272.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 143_146 | 18 | 272.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 195_205 | 18 | 272.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 102_110 | 18 | 209.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 143_146 | 18 | 209.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 195_205 | 18 | 209.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 102_110 | 18 | 97.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 143_146 | 18 | 97.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 195_205 | 18 | 97.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 102_110 | 18 | 272.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 143_146 | 18 | 272.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 195_205 | 18 | 272.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 102_110 | 18 | 209.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 143_146 | 18 | 209.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 195_205 | 18 | 209.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 102_110 | 18 | 97.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 143_146 | 18 | 97.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 195_205 | 18 | 97.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 102_110 | 18 | 272.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 143_146 | 18 | 272.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 195_205 | 18 | 272.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 102_110 | 18 | 209.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 143_146 | 18 | 209.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 195_205 | 18 | 209.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 142_162 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 179_199 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 202_222 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 49_69 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 84_104 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 142_162 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 179_199 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 202_222 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 49_69 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 84_104 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 142_162 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 179_199 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 202_222 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 49_69 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 84_104 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 142_162 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 179_199 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 202_222 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 49_69 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 84_104 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 142_162 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 179_199 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 202_222 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 49_69 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 84_104 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 142_162 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 179_199 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 202_222 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 49_69 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 84_104 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 142_162 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 179_199 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 202_222 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 49_69 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 84_104 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 142_162 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 179_199 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 202_222 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 49_69 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 84_104 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 142_162 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 179_199 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 202_222 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 49_69 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 84_104 | 18 | 209.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DOCK1 | chr10:128788867 | chr10:122263330 | ENST00000280333 | + | 6 | 52 | 1207_1617 | 157 | 1866.0 | Domain | DOCKER |
| Hgene | DOCK1 | chr10:128788867 | chr10:122263330 | ENST00000280333 | + | 6 | 52 | 425_609 | 157 | 1866.0 | Domain | C2 DOCK-type |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263329 | ENST00000280333 | + | 8 | 52 | 1207_1617 | 255 | 1866.0 | Domain | DOCKER |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263329 | ENST00000280333 | + | 8 | 52 | 425_609 | 255 | 1866.0 | Domain | C2 DOCK-type |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263330 | ENST00000280333 | + | 8 | 52 | 1207_1617 | 255 | 1866.0 | Domain | DOCKER |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263330 | ENST00000280333 | + | 8 | 52 | 425_609 | 255 | 1866.0 | Domain | C2 DOCK-type |
| Hgene | DOCK1 | chr10:128788867 | chr10:122263330 | ENST00000280333 | + | 6 | 52 | 1687_1695 | 157 | 1866.0 | Region | Phosphoinositide-binding |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263329 | ENST00000280333 | + | 8 | 52 | 1687_1695 | 255 | 1866.0 | Region | Phosphoinositide-binding |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263330 | ENST00000280333 | + | 8 | 52 | 1687_1695 | 255 | 1866.0 | Region | Phosphoinositide-binding |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398248 | 0 | 3 | 4_24 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000398250 | 0 | 7 | 4_24 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128788867 | chr10:122263330 | ENST00000439221 | 0 | 5 | 4_24 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398248 | 0 | 3 | 4_24 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000398250 | 0 | 7 | 4_24 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263329 | ENST00000439221 | 0 | 5 | 4_24 | 18 | 209.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398248 | 0 | 3 | 4_24 | 18 | 97.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000398250 | 0 | 7 | 4_24 | 18 | 272.0 | Transmembrane | Helical | |
| Tgene | PPAPDC1A | chr10:128796513 | chr10:122263330 | ENST00000439221 | 0 | 5 | 4_24 | 18 | 209.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for DOCK1-PPAPDC1A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >23770_23770_1_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000369073_length(transcript)=1691nt_BP=582nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGTTTTACAGAGTTTTTGGATCCGTTCCAGAGAGTCATCCAGCCAGAAGA GATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAATTTCTTTCCTCACACCCCTGGCTGT TATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGTGTCCTTGGCTCTTGCTTTGAATGG AGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTTTCCAGATGGAGTGATGAACTCGGA AATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTCCTCCTTTGCCTTTTCGGGCCTTGG CTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTGGCGGCTCTGTGCTGCCATCCTGCC CTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTCCTTTGTGGGTGGAGTCATCGGCCT CATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCCTACGTTAGTCTGCGAGTCCCAGC CTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACCGAAGGCCCGGTATGACCAGTGTC CTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGTTTTCTGTAGTGTATTTTTCATCA GTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGTCTACTTCCAACATCCTTGAATTT GCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCTTGGCCGATTCGTCTATCTGAAAT GTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGAAGAC >23770_23770_1_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000369073_length(amino acids)=437AA_BP=184 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNSFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGVCTNTIKLI VGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPLYCAMMIAL SRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKKEERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_2_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398248_length(transcript)=1244nt_BP=582nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGTTTTACAGAGTTTTTGGATCCGTTCCAGAGAGTCATCCAGCCAGAAGA GATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTATTCCTTTGTGGGTGGAGTCATCGGCCTC ATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCCTACGTTAGTCTGCGAGTCCCAGCC TCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACCGAAGGCCCGGTATGACCAGTGTCC TGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGTTTTCTGTAGTGTATTTTTCATCAG TTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGTCTACTTCCAACATCCTTGAATTTG CAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCTTGGCCGATTCGTCTATCTGAAATG TTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGAAGACTTGG >23770_23770_2_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398248_length(amino acids)=262AA_BP=184 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNSFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFIPLWVESSASFLHTFATDSTILLWPTQLAINPTLVCESQPH -------------------------------------------------------------- >23770_23770_3_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398250_length(transcript)=1695nt_BP=582nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGTTTTACAGAGTTTTTGGATCCGTTCCAGAGAGTCATCCAGCCAGAAGA GATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAATTTCTTTCCTCACACCCCTGGCTGT TATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGTGTCCTTGGCTCTTGCTTTGAATGG AGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTTTCCAGATGGAGTGATGAACTCGGA AATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTCCTCCTTTGCCTTTTCGGGCCTTGG CTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTGGCGGCTCTGTGCTGCCATCCTGCC CTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTCCTTTGTGGGTGGAGTCATCGGCCT CATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCCTACGTTAGTCTGCGAGTCCCAGC CTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACCGAAGGCCCGGTATGACCAGTGTC CTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGTTTTCTGTAGTGTATTTTTCATCA GTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGTCTACTTCCAACATCCTTGAATTT GCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCTTGGCCGATTCGTCTATCTGAAAT GTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGAAGACTTGG >23770_23770_3_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398250_length(amino acids)=437AA_BP=184 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNSFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGVCTNTIKLI VGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPLYCAMMIAL SRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKKEERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_4_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000439221_length(transcript)=1506nt_BP=582nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGTTTTACAGAGTTTTTGGATCCGTTCCAGAGAGTCATCCAGCCAGAAGA GATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAATTTCTTTCCTCACACCCCTGGCTGT TATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGTTGCCTTTTCGGGCCTTGGCTTCACGAC GTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTGGCGGCTCTGTGCTGCCATCCTGCCCTTGTACTG CGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTCCTTTGTGGGTGGAGTCATCGGCCTCATTTTTGC ATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCCTACGTTAGTCTGCGAGTCCCAGCCTCACTGAA GAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACCGAAGGCCCGGTATGACCAGTGTCCTGGGAGGA TGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGTTTTCTGTAGTGTATTTTTCATCAGTTGTTTCT CAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGTCTACTTCCAACATCCTTGAATTTGCAAGTGAA GGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCTTGGCCGATTCGTCTATCTGAAATGTTTGCTGT AACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGAAGACTTGG >23770_23770_4_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000439221_length(amino acids)=374AA_BP=184 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNSFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLVAFSGLGFTTFYLAGKLHC FTESGRGKSWRLCAAILPLYCAMMIALSRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKKEERPTADS APSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_5_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000541332_length(transcript)=1891nt_BP=582nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGTTTTACAGAGTTTTTGGATCCGTTCCAGAGAGTCATCCAGCCAGAAGA GATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAATTTCTTTCCTCACACCCCTGGCTGT TATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGTGTCCTTGGCTCTTGCTTTGAATGG AGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTTTCCAGATGGAGTGATGAACTCGGA AATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTCCTCCTTTGCCTTTTCGGGCCTTGG CTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTGGCGGCTCTGTGCTGCCATCCTGCC CTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGTTGGCTGCTGTGTATGGCAGGGCCCACA GTCACATTTACCATCGGCTGCCAACCCCCGCCTCTGTCTGGGAACCTCTGAACCTTGACTGCCCATCTAAGTCCACCCGCCTCTGTGTTG GTGCCTAGGAGAGCGTAAGAAGCCTCAGCCCCTGGCTCACCCCTCCCTCCGGTCAAAGTCCACTGCATATCCTGCTTTCAGCCTCAAGAG AGGCATTCTCAGTCAGGACTTCTGCCCTCTTCCTGCCTCCAGGATAGCCCTGGTGTTTCCCCGTGATGTAATTCCCAGGGAAGATGGACG TTGATTGCTCCCAAGTCTCACTGGCATCCTTCCTTTGTTTTACTCAAGGGAACCTGTCTCTTCTCAGCTTTCTGTGGTGTTCTGTGGTTC CTCCTGCTCAGCATATTTATAGACTCCAACTTTTCCTTCCCACTCTGGTCTAGTGATCCTCAGTTGTTGCCTGAATCATTGCAGAAGCCT CTCAGCCTGGCTCCCTCCTTCCTTCTTTGGCCCTCAACTGCATTTGGAATGTGCCTTTAGAGCCTGCGTTAGCACATGTCACTTTTGCAA AAATCCTCCAGTGATTCTCATTTCACTCAGCATCACAGCCTGTGTCCTGCCATGGTCCATAAGATCTGCTCCCTCCGTACTTCTTTGATG CTATGTTCAAGCTACTTGTCCTCCTCGTTCACATGATTGCATCGCTTGAGCTTCTTGCTACTCCTTGAACAGGCCCGTCCCATCCCACCT C >23770_23770_5_DOCK1-PPAPDC1A_DOCK1_chr10_128788867_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000541332_length(amino acids)=399AA_BP=184 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNSFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGVCTNTIKLI VGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPLYCAMMIAL SRMCDYKHHWQVGCCVWQGPQSHLPSAANPRLCLGTSEP -------------------------------------------------------------- >23770_23770_6_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000369073_length(transcript)=1985nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGT GTCCTTGGCTCTTGCTTTGAATGGAGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTT TCCAGATGGAGTGATGAACTCGGAAATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTC CTCCTTTGCCTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTG GCGGCTCTGTGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTC CTTTGTGGGTGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACC CTACGTTAGTCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCAC CGAAGGCCCGGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGG TTTTCTGTAGTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATG TCTACTTCCAACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGC TTGGCCGATTCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGG AAGAC >23770_23770_6_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000369073_length(amino acids)=535AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGV CTNTIKLIVGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPL YCAMMIALSRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKKEERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_7_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000398248_length(transcript)=1538nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTATTCC TTTGTGGGTGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCC TACGTTAGTCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACC GAAGGCCCGGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGT TTTCTGTAGTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGT CTACTTCCAACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCT TGGCCGATTCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGA AGACTTGG >23770_23770_7_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000398248_length(amino acids)=360AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFIPLWVESSASFLHTFATDSTILLWPTQLAINPTLVCESQPH -------------------------------------------------------------- >23770_23770_8_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000398250_length(transcript)=1989nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGT GTCCTTGGCTCTTGCTTTGAATGGAGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTT TCCAGATGGAGTGATGAACTCGGAAATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTC CTCCTTTGCCTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTG GCGGCTCTGTGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTC CTTTGTGGGTGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACC CTACGTTAGTCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCAC CGAAGGCCCGGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGG TTTTCTGTAGTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATG TCTACTTCCAACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGC TTGGCCGATTCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGG AAGACTTGG >23770_23770_8_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000398250_length(amino acids)=535AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGV CTNTIKLIVGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPL YCAMMIALSRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKKEERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_9_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000439221_length(transcript)=1800nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGTTGC CTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTGGCGGCTCTG TGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTCCTTTGTGGG TGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCCTACGTTAG TCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACCGAAGGCCC GGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGTTTTCTGTA GTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGTCTACTTCC AACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCTTGGCCGAT TCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGAAGACTTGG >23770_23770_9_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000439221_length(amino acids)=472AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLVAFSGLGFTTF YLAGKLHCFTESGRGKSWRLCAAILPLYCAMMIALSRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKK EERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_10_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000541332_length(transcript)=2185nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGT GTCCTTGGCTCTTGCTTTGAATGGAGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTT TCCAGATGGAGTGATGAACTCGGAAATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTC CTCCTTTGCCTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTG GCGGCTCTGTGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGTTGG CTGCTGTGTATGGCAGGGCCCACAGTCACATTTACCATCGGCTGCCAACCCCCGCCTCTGTCTGGGAACCTCTGAACCTTGACTGCCCAT CTAAGTCCACCCGCCTCTGTGTTGGTGCCTAGGAGAGCGTAAGAAGCCTCAGCCCCTGGCTCACCCCTCCCTCCGGTCAAAGTCCACTGC ATATCCTGCTTTCAGCCTCAAGAGAGGCATTCTCAGTCAGGACTTCTGCCCTCTTCCTGCCTCCAGGATAGCCCTGGTGTTTCCCCGTGA TGTAATTCCCAGGGAAGATGGACGTTGATTGCTCCCAAGTCTCACTGGCATCCTTCCTTTGTTTTACTCAAGGGAACCTGTCTCTTCTCA GCTTTCTGTGGTGTTCTGTGGTTCCTCCTGCTCAGCATATTTATAGACTCCAACTTTTCCTTCCCACTCTGGTCTAGTGATCCTCAGTTG TTGCCTGAATCATTGCAGAAGCCTCTCAGCCTGGCTCCCTCCTTCCTTCTTTGGCCCTCAACTGCATTTGGAATGTGCCTTTAGAGCCTG CGTTAGCACATGTCACTTTTGCAAAAATCCTCCAGTGATTCTCATTTCACTCAGCATCACAGCCTGTGTCCTGCCATGGTCCATAAGATC TGCTCCCTCCGTACTTCTTTGATGCTATGTTCAAGCTACTTGTCCTCCTCGTTCACATGATTGCATCGCTTGAGCTTCTTGCTACTCCTT GAACAGGCCCGTCCCATCCCACCTC >23770_23770_10_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263329_ENST00000541332_length(amino acids)=497AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGV CTNTIKLIVGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPL YCAMMIALSRMCDYKHHWQVGCCVWQGPQSHLPSAANPRLCLGTSEP -------------------------------------------------------------- >23770_23770_11_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000369073_length(transcript)=1985nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGT GTCCTTGGCTCTTGCTTTGAATGGAGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTT TCCAGATGGAGTGATGAACTCGGAAATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTC CTCCTTTGCCTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTG GCGGCTCTGTGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTC CTTTGTGGGTGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACC CTACGTTAGTCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCAC CGAAGGCCCGGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGG TTTTCTGTAGTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATG TCTACTTCCAACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGC TTGGCCGATTCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGG AAGAC >23770_23770_11_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000369073_length(amino acids)=535AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGV CTNTIKLIVGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPL YCAMMIALSRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKKEERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_12_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398248_length(transcript)=1538nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTATTCC TTTGTGGGTGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCC TACGTTAGTCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACC GAAGGCCCGGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGT TTTCTGTAGTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGT CTACTTCCAACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCT TGGCCGATTCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGA AGACTTGG >23770_23770_12_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398248_length(amino acids)=360AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFIPLWVESSASFLHTFATDSTILLWPTQLAINPTLVCESQPH -------------------------------------------------------------- >23770_23770_13_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398250_length(transcript)=1989nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGT GTCCTTGGCTCTTGCTTTGAATGGAGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTT TCCAGATGGAGTGATGAACTCGGAAATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTC CTCCTTTGCCTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTG GCGGCTCTGTGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTC CTTTGTGGGTGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACC CTACGTTAGTCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCAC CGAAGGCCCGGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGG TTTTCTGTAGTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATG TCTACTTCCAACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGC TTGGCCGATTCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGG AAGACTTGG >23770_23770_13_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000398250_length(amino acids)=535AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGV CTNTIKLIVGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPL YCAMMIALSRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKKEERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_14_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000439221_length(transcript)=1800nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGTTGC CTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTGGCGGCTCTG TGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGATTCCTTTGTGGG TGGAGTCATCGGCCTCATTTTTGCATACATTTGCTACAGACAGCACTATCCTCCTCTGGCCAACACAGCTTGCCATAAACCCTACGTTAG TCTGCGAGTCCCAGCCTCACTGAAGAAAGAGGAGAGGCCCACAGCTGACAGCGCACCCAGCTTGCCTCTGGAGGGGATCACCGAAGGCCC GGTATGACCAGTGTCCTGGGAGGATGGACACTAAGCCCTGGGCACATCTGCCACCCTGACATCATAACACAATAGAAATGGTTTTCTGTA GTGTATTTTTCATCAGTTGTTTCTCAAAGTCATCGTACTTCTGCTTCTGTTTCACTGATGGTGTTCCTGCTACTTTAAATGTCTACTTCC AACATCCTTGAATTTGCAAGTGAAGGACAACAATCTCTGAGAGACGTGTGGAAGAGGCTGTGAAGGTGGGGTTTGGGGAGCTTGGCCGAT TCGTCTATCTGAAATGTTTGCTGTAACAGCCACCTTCCTATGTTTTCATGGTTGTAAAACATAATAAAACCTCCCACGTGGAAGACTTGG >23770_23770_14_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000439221_length(amino acids)=472AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLVAFSGLGFTTF YLAGKLHCFTESGRGKSWRLCAAILPLYCAMMIALSRMCDYKHHWQDSFVGGVIGLIFAYICYRQHYPPLANTACHKPYVSLRVPASLKK EERPTADSAPSLPLEGITEGPV -------------------------------------------------------------- >23770_23770_15_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000541332_length(transcript)=2185nt_BP=876nt CTCCGCCGCAAACTTTTTCCTCCCCATCCTGTCGCGGCTCGAAAGGAATGGAAAATGGCGGCCTAGACGCGGAGTTTCCTGCCCGACCCG CGGCGGCTCCGGCGGCGCCATGACGCGCTGGGTGCCCACCAAGCGCGAGGAGAAGTACGGCGTGGCTTTTTATAACTATGATGCCAGAGG AGCGGATGAACTTTCTTTACAGATCGGAGACACTGTGCACATCTTAGAAACATATGAAGGGTGGTACCGAGGTTACACGTTACGAAAAAA GTCTAAGAAGGGTATATTTCCTGCTTCATATATTCATCTTAAAGAAGCGATAGTTGAAGGAAAAGGGCAACATGAAACAGTCATCCCGGG TGACCTCCCCCTCATCCAGGAAGTCACCACGACACTCCGAGAGTGGTCCACCATCTGGAGGCAGCTCTACGTGCAAGATAACAGGGAGAT GTTTCGAAGTGTGCGGCACATGATCTATGACCTTATTGAATGGCGATCACAAATTCTTTCTGGAACTCTGCCTCAGGATGAACTCAAAGA ACTGAAGAAGAAGGTCACAGCCAAAATTGATTATGGAAACAGAATTCTAGATTTGGACCTGGTGGTTAGAGATGAAGATGGGAATATTTT GGATCCAGAATTAACTAGCACGATTAGTCTCTTCAGAGCTCATGAAATAGCTTCTAAACAAGTGGAGGAAAGGTTACAAGAGGAAAAATC TCAAAAGCAGAACATAGATATTAACAGACAAGCCAAGTTTGCTGCAACCCCTTCTCTGGCCTTGTTTGTGAACCTCAAAAATGTGGTTTG TAAAATAGGAGAAGATGCTGAAGTCCTCATGTCTCTATATGACCCTGTGGAGTCCAAATTCATCAGTTTTACAGAGTTTTTGGATCCGTT CCAGAGAGTCATCCAGCCAGAAGAGATCTGGCTCTATAAAAATCCTTTGGTGCAATCAGATAACATACCTACCCGCCTCATGTTTGCAAT TTCTTTCCTCACACCCCTGGCTGTTATTTGTGTGGTGAAAATTATCCGGCGAACAGACAAGACTGAAATTAAGGAAGCCTTCTTAGCGGT GTCCTTGGCTCTTGCTTTGAATGGAGTCTGCACAAACACTATTAAATTAATAGTGGGAAGACCTCGCCCCGATTTCTTTTACCGCTGCTT TCCAGATGGAGTGATGAACTCGGAAATGCATTGCACAGGTGACCCCGATCTGGTGTCCGAGGGCCGCAAAAGCTTCCCCAGCATCCATTC CTCCTTTGCCTTTTCGGGCCTTGGCTTCACGACGTTCTACTTGGCGGGCAAGCTGCACTGCTTCACCGAGAGTGGGCGGGGAAAGAGCTG GCGGCTCTGTGCTGCCATCCTGCCCTTGTACTGCGCCATGATGATTGCCCTGTCCCGCATGTGCGACTACAAGCATCACTGGCAAGTTGG CTGCTGTGTATGGCAGGGCCCACAGTCACATTTACCATCGGCTGCCAACCCCCGCCTCTGTCTGGGAACCTCTGAACCTTGACTGCCCAT CTAAGTCCACCCGCCTCTGTGTTGGTGCCTAGGAGAGCGTAAGAAGCCTCAGCCCCTGGCTCACCCCTCCCTCCGGTCAAAGTCCACTGC ATATCCTGCTTTCAGCCTCAAGAGAGGCATTCTCAGTCAGGACTTCTGCCCTCTTCCTGCCTCCAGGATAGCCCTGGTGTTTCCCCGTGA TGTAATTCCCAGGGAAGATGGACGTTGATTGCTCCCAAGTCTCACTGGCATCCTTCCTTTGTTTTACTCAAGGGAACCTGTCTCTTCTCA GCTTTCTGTGGTGTTCTGTGGTTCCTCCTGCTCAGCATATTTATAGACTCCAACTTTTCCTTCCCACTCTGGTCTAGTGATCCTCAGTTG TTGCCTGAATCATTGCAGAAGCCTCTCAGCCTGGCTCCCTCCTTCCTTCTTTGGCCCTCAACTGCATTTGGAATGTGCCTTTAGAGCCTG CGTTAGCACATGTCACTTTTGCAAAAATCCTCCAGTGATTCTCATTTCACTCAGCATCACAGCCTGTGTCCTGCCATGGTCCATAAGATC TGCTCCCTCCGTACTTCTTTGATGCTATGTTCAAGCTACTTGTCCTCCTCGTTCACATGATTGCATCGCTTGAGCTTCTTGCTACTCCTT GAACAGGCCCGTCCCATCCCACCTC >23770_23770_15_DOCK1-PPAPDC1A_DOCK1_chr10_128796513_ENST00000280333_PPAPDC1A_chr10_122263330_ENST00000541332_length(amino acids)=497AA_BP=282 MSRLERNGKWRPRRGVSCPTRGGSGGAMTRWVPTKREEKYGVAFYNYDARGADELSLQIGDTVHILETYEGWYRGYTLRKKSKKGIFPAS YIHLKEAIVEGKGQHETVIPGDLPLIQEVTTTLREWSTIWRQLYVQDNREMFRSVRHMIYDLIEWRSQILSGTLPQDELKELKKKVTAKI DYGNRILDLDLVVRDEDGNILDPELTSTISLFRAHEIASKQVEERLQEEKSQKQNIDINRQAKFAATPSLALFVNLKNVVCKIGEDAEVL MSLYDPVESKFISFTEFLDPFQRVIQPEEIWLYKNPLVQSDNIPTRLMFAISFLTPLAVICVVKIIRRTDKTEIKEAFLAVSLALALNGV CTNTIKLIVGRPRPDFFYRCFPDGVMNSEMHCTGDPDLVSEGRKSFPSIHSSFAFSGLGFTTFYLAGKLHCFTESGRGKSWRLCAAILPL YCAMMIALSRMCDYKHHWQVGCCVWQGPQSHLPSAANPRLCLGTSEP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DOCK1-PPAPDC1A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | DOCK1 | chr10:128788867 | chr10:122263330 | ENST00000280333 | + | 6 | 52 | 1837_1852 | 157.66666666666666 | 1866.0 | NCK2 (minor) |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263329 | ENST00000280333 | + | 8 | 52 | 1837_1852 | 255.66666666666666 | 1866.0 | NCK2 (minor) |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263330 | ENST00000280333 | + | 8 | 52 | 1837_1852 | 255.66666666666666 | 1866.0 | NCK2 (minor) |
| Hgene | DOCK1 | chr10:128788867 | chr10:122263330 | ENST00000280333 | + | 6 | 52 | 1793_1819 | 157.66666666666666 | 1866.0 | NCK2 second and third SH3 domain (minor) |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263329 | ENST00000280333 | + | 8 | 52 | 1793_1819 | 255.66666666666666 | 1866.0 | NCK2 second and third SH3 domain (minor) |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263330 | ENST00000280333 | + | 8 | 52 | 1793_1819 | 255.66666666666666 | 1866.0 | NCK2 second and third SH3 domain (minor) |
| Hgene | DOCK1 | chr10:128788867 | chr10:122263330 | ENST00000280333 | + | 6 | 52 | 1820_1836 | 157.66666666666666 | 1866.0 | NCK2 third SH3 domain (major) |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263329 | ENST00000280333 | + | 8 | 52 | 1820_1836 | 255.66666666666666 | 1866.0 | NCK2 third SH3 domain (major) |
| Hgene | DOCK1 | chr10:128796513 | chr10:122263330 | ENST00000280333 | + | 8 | 52 | 1820_1836 | 255.66666666666666 | 1866.0 | NCK2 third SH3 domain (major) |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DOCK1-PPAPDC1A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DOCK1-PPAPDC1A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | DOCK1 | C0013146 | Drug abuse | 1 | CTD_human |
| Hgene | DOCK1 | C0013170 | Drug habituation | 1 | CTD_human |
| Hgene | DOCK1 | C0013222 | Drug Use Disorders | 1 | CTD_human |
| Hgene | DOCK1 | C0029231 | Organic Mental Disorders, Substance-Induced | 1 | CTD_human |
| Hgene | DOCK1 | C0038580 | Substance Dependence | 1 | CTD_human |
| Hgene | DOCK1 | C0038586 | Substance Use Disorders | 1 | CTD_human |
| Hgene | DOCK1 | C0236969 | Substance-Related Disorders | 1 | CTD_human |
| Hgene | DOCK1 | C0740858 | Substance abuse problem | 1 | CTD_human |
| Hgene | DOCK1 | C1510472 | Drug Dependence | 1 | CTD_human |
| Hgene | DOCK1 | C4316881 | Prescription Drug Abuse | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies