
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EEF2-SMARCA4 (FusionGDB2 ID:HG1938TG6597) |
Fusion Gene Summary for EEF2-SMARCA4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EEF2-SMARCA4 | Fusion gene ID: hg1938tg6597 | Hgene | Tgene | Gene symbol | EEF2 | SMARCA4 | Gene ID | 1938 | 6597 |
| Gene name | eukaryotic translation elongation factor 2 | SWI/SNF related, matrix associated, actin dependent regulator of chromatin, subfamily a, member 4 | |
| Synonyms | EEF-2|EF-2|EF2|SCA26 | BAF190|BAF190A|BRG1|CSS4|MRD16|RTPS2|SNF2|SNF2-beta|SNF2L4|SNF2LB|SWI2|hSNF2b | |
| Cytomap | ('EEF2')('SMARCA4') 19p13.3 | 19p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | elongation factor 2epididymis secretory sperm binding proteinpolypeptidyl-tRNA translocase | transcription activator BRG1ATP-dependent helicase SMARCA4BRG1-associated factor 190ABRM/SWI2-related gene 1SNF2-like 4brahma protein-like 1global transcription activator homologous sequencehomeotic gene regulatormitotic growth and transcription a | |
| Modification date | 20200313 | 20200315 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000309311, ENST00000600720, | ||
| Fusion gene scores | * DoF score | 44 X 37 X 16=26048 | 20 X 28 X 15=8400 |
| # samples | 56 | 32 | |
| ** MAII score | log2(56/26048*10)=-5.53960196732128 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(32/8400*10)=-4.71424551766612 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: EEF2 [Title/Abstract] AND SMARCA4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | EEF2(3982805)-SMARCA4(11151983), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | EEF2-SMARCA4 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EEF2-SMARCA4 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EEF2-SMARCA4 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. EEF2-SMARCA4 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | SMARCA4 | GO:0006337 | nucleosome disassembly | 8895581 |
| Tgene | SMARCA4 | GO:0006338 | chromatin remodeling | 10943845|11726552 |
| Tgene | SMARCA4 | GO:0045892 | negative regulation of transcription, DNA-templated | 12065415 |
| Tgene | SMARCA4 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 15774904|17938176 |
| Tgene | SMARCA4 | GO:0051091 | positive regulation of DNA-binding transcription factor activity | 11950834|17938176 |
| Tgene | SMARCA4 | GO:1902661 | positive regulation of glucose mediated signaling pathway | 22368283 |
| Fusion gene breakpoints across EEF2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SMARCA4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
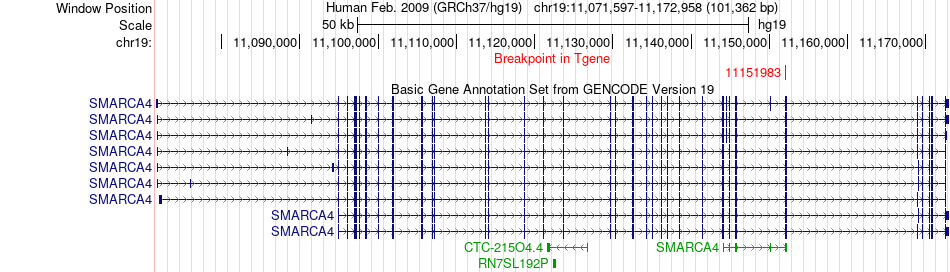 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | TCGA-K1-A3PO-11A | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
Top |
Fusion Gene ORF analysis for EEF2-SMARCA4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000309311 | ENST00000538456 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000344626 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000358026 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000413806 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000429416 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000444061 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000450717 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000541122 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000589677 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| In-frame | ENST00000309311 | ENST00000590574 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000344626 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000358026 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000413806 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000429416 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000444061 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000450717 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000541122 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000589677 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3CDS | ENST00000600720 | ENST00000590574 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| intron-3UTR | ENST00000600720 | ENST00000538456 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000358026 | SMARCA4 | chr19 | 11151983 | + | 1941 | 701 | 89 | 1474 | 461 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000344626 | SMARCA4 | chr19 | 11151983 | + | 1718 | 701 | 89 | 1474 | 461 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000429416 | SMARCA4 | chr19 | 11151983 | + | 1941 | 701 | 89 | 1474 | 461 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000541122 | SMARCA4 | chr19 | 11151983 | + | 1474 | 701 | 478 | 1473 | 332 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000589677 | SMARCA4 | chr19 | 11151983 | + | 1471 | 701 | 478 | 1470 | 331 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000444061 | SMARCA4 | chr19 | 11151983 | + | 1472 | 701 | 89 | 1471 | 461 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000590574 | SMARCA4 | chr19 | 11151983 | + | 1475 | 701 | 89 | 1474 | 462 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000413806 | SMARCA4 | chr19 | 11151983 | + | 1940 | 701 | 478 | 1473 | 331 |
| ENST00000309311 | EEF2 | chr19 | 3982805 | - | ENST00000450717 | SMARCA4 | chr19 | 11151983 | + | 1937 | 701 | 478 | 1470 | 330 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000309311 | ENST00000358026 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.004341185 | 0.9956589 |
| ENST00000309311 | ENST00000344626 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.005086862 | 0.9949131 |
| ENST00000309311 | ENST00000429416 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.004341185 | 0.9956589 |
| ENST00000309311 | ENST00000541122 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.014419458 | 0.9855805 |
| ENST00000309311 | ENST00000589677 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.016031928 | 0.983968 |
| ENST00000309311 | ENST00000444061 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.004027261 | 0.9959727 |
| ENST00000309311 | ENST00000590574 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.003726899 | 0.99627316 |
| ENST00000309311 | ENST00000413806 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.025827985 | 0.97417206 |
| ENST00000309311 | ENST00000450717 | EEF2 | chr19 | 3982805 | - | SMARCA4 | chr19 | 11151983 | + | 0.027561065 | 0.9724389 |
Top |
Fusion Genomic Features for EEF2-SMARCA4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| EEF2 | chr19 | 3982804 | - | SMARCA4 | chr19 | 11151982 | + | 7.10E-07 | 0.9999993 |
| EEF2 | chr19 | 3982804 | - | SMARCA4 | chr19 | 11151982 | + | 7.10E-07 | 0.9999993 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
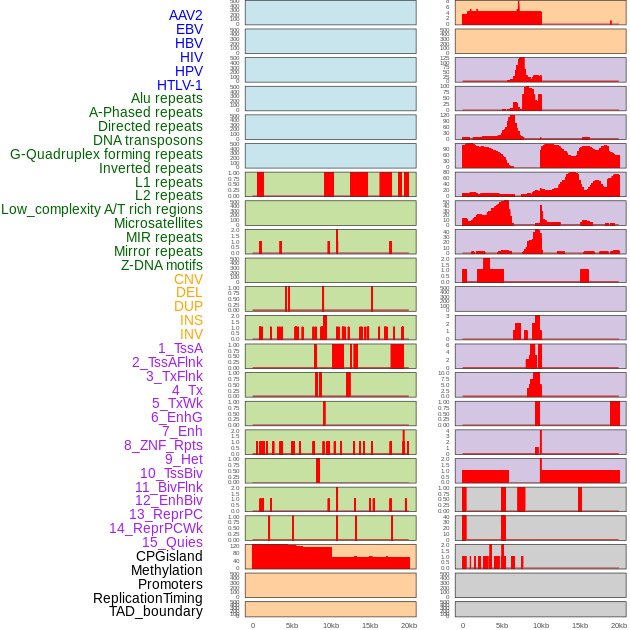 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
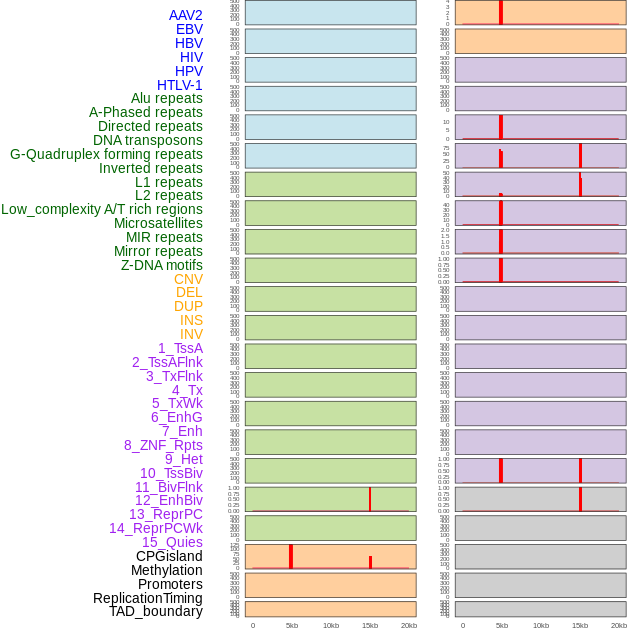 |
Top |
Fusion Protein Features for EEF2-SMARCA4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:3982805/chr19:11151983) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EEF2 | chr19:3982805 | chr19:11151983 | ENST00000309311 | - | 4 | 15 | 104_108 | 204 | 859.0 | Nucleotide binding | GTP |
| Hgene | EEF2 | chr19:3982805 | chr19:11151983 | ENST00000309311 | - | 4 | 15 | 158_161 | 204 | 859.0 | Nucleotide binding | GTP |
| Hgene | EEF2 | chr19:3982805 | chr19:11151983 | ENST00000309311 | - | 4 | 15 | 26_33 | 204 | 859.0 | Nucleotide binding | GTP |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 1571_1584 | 1390 | 1648.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 1360_1364 | 0 | 1618.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 1571_1584 | 0 | 1618.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 578_588 | 0 | 1618.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 663_672 | 0 | 1618.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 1571_1584 | 1390 | 1648.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 1360_1364 | 1357 | 1614.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 1571_1584 | 1357 | 1614.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 1360_1364 | 0 | 1617.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 1571_1584 | 0 | 1617.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 578_588 | 0 | 1617.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 663_672 | 0 | 1617.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 1360_1364 | 0 | 1618.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 1571_1584 | 0 | 1618.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 578_588 | 0 | 1618.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 663_672 | 0 | 1618.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 1360_1364 | 0 | 1617.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 1571_1584 | 0 | 1617.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 578_588 | 0 | 1617.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 663_672 | 0 | 1617.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 1360_1364 | 1357 | 1615.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 1571_1584 | 1357 | 1615.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 1477_1547 | 1390 | 1648.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 1084_1246 | 0 | 1618.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 1477_1547 | 0 | 1618.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 171_206 | 0 | 1618.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 460_532 | 0 | 1618.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 766_931 | 0 | 1618.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 1477_1547 | 1390 | 1648.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 1477_1547 | 1357 | 1614.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 1084_1246 | 0 | 1617.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 1477_1547 | 0 | 1617.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 171_206 | 0 | 1617.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 460_532 | 0 | 1617.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 766_931 | 0 | 1617.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 1084_1246 | 0 | 1618.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 1477_1547 | 0 | 1618.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 171_206 | 0 | 1618.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 460_532 | 0 | 1618.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 766_931 | 0 | 1618.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 1084_1246 | 0 | 1617.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 1477_1547 | 0 | 1617.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 171_206 | 0 | 1617.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 460_532 | 0 | 1617.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 766_931 | 0 | 1617.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 1477_1547 | 1357 | 1615.0 | Domain | Bromo | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 881_884 | 0 | 1618.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 881_884 | 0 | 1617.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 881_884 | 0 | 1618.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 881_884 | 0 | 1617.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 779_786 | 0 | 1618.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 779_786 | 0 | 1617.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 779_786 | 0 | 1618.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 779_786 | 0 | 1617.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000413806 | 0 | 33 | 462_728 | 0 | 1618.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000450717 | 0 | 33 | 462_728 | 0 | 1617.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000541122 | 0 | 35 | 462_728 | 0 | 1618.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000589677 | 0 | 35 | 462_728 | 0 | 1617.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EEF2 | chr19:3982805 | chr19:11151983 | ENST00000309311 | - | 4 | 15 | 17_362 | 204 | 859.0 | Domain | tr-type G |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 1360_1364 | 1390 | 1648.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 578_588 | 1390 | 1648.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 663_672 | 1390 | 1648.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 1360_1364 | 1390 | 1648.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 578_588 | 1390 | 1648.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 663_672 | 1390 | 1648.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 578_588 | 1357 | 1614.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 663_672 | 1357 | 1614.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 578_588 | 1357 | 1615.0 | Compositional bias | Note=Poly-Lys | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 663_672 | 1357 | 1615.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 1084_1246 | 1390 | 1648.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 171_206 | 1390 | 1648.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 460_532 | 1390 | 1648.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 766_931 | 1390 | 1648.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 1084_1246 | 1390 | 1648.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 171_206 | 1390 | 1648.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 460_532 | 1390 | 1648.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 766_931 | 1390 | 1648.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 1084_1246 | 1357 | 1614.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 171_206 | 1357 | 1614.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 460_532 | 1357 | 1614.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 766_931 | 1357 | 1614.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 1084_1246 | 1357 | 1615.0 | Domain | Helicase C-terminal | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 171_206 | 1357 | 1615.0 | Domain | QLQ | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 460_532 | 1357 | 1615.0 | Domain | HSA | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 766_931 | 1357 | 1615.0 | Domain | Helicase ATP-binding | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 881_884 | 1390 | 1648.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 881_884 | 1390 | 1648.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 881_884 | 1357 | 1614.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 881_884 | 1357 | 1615.0 | Motif | Note=DEGH box | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 779_786 | 1390 | 1648.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 779_786 | 1390 | 1648.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 779_786 | 1357 | 1614.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 779_786 | 1357 | 1615.0 | Nucleotide binding | ATP | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000344626 | 28 | 35 | 462_728 | 1390 | 1648.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000429416 | 29 | 36 | 462_728 | 1390 | 1648.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000444061 | 28 | 35 | 462_728 | 1357 | 1614.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 | |
| Tgene | SMARCA4 | chr19:3982805 | chr19:11151983 | ENST00000590574 | 27 | 34 | 462_728 | 1357 | 1615.0 | Region | RNA-binding region which is sufficient for binding to lncRNA Evf2 |
Top |
Fusion Gene Sequence for EEF2-SMARCA4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >25260_25260_1_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000344626_length(transcript)=1718nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGGCCATCGAGGAGGGCACGC TGGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCA GCACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCA ACCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCC AGCTGCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACC ACAAGTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCT ATGAAGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGG AGGAGGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGG ACCGGCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGG AGGACCGCTCAGGAAGTGGCAGCGAAGAAGACTGAGCCCCGACATTCCAGTCTCGACCCCGAGCCCCTCGTTCCAGAGCTGAGATGGCAT AGGCCTTAGCAGTAACGGGTAGCAGCAGATGTAGTTTCAGACTTGGAGTAAAACTGTATAAACAAAAGAATCTTCCATATTTATACAGCA GAGAAGCTGTAGGACTGTTTGTGACTGGCCCTGTCCTGGCATCAGTAGCATCTGTAACAGCATTAACTGTCTTAAAGAGAGAGAGAGAGA ATTCCGAA >25260_25260_1_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000344626_length(amino acids)=461AA_BP=204 MVNFTVDQIRAIMDKKANIRNMSVIAHVDHGKSTLTDSLVCKAGIIASARAGETRFTDTRKDEQERCITIKSTAISLFYELSENDLNFIK QSKDGAGFLINLIDSPGHVDFSSEVTAALRVTDGALVVVDCVSGVCVQTETVLRQAIAERIKPVLMMNKMDRALLELQLEPEELYQTFQR IVENVNVIISTYGEGESGPMGNIMAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPP NLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLI YEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQE EDRSGSGSEED -------------------------------------------------------------- >25260_25260_2_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000358026_length(transcript)=1941nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGGCCATCGAGGAGGGCACGC TGGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCA GCACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCA ACCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCC AGCTGCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACC ACAAGTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCT ATGAAGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGG AGGAGGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGG ACCGGCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGG AGGACCGCTCAGGAAGTGGCAGCGAAGAAGACTGAGCCCCGACATTCCAGTCTCGACCCCGAGCCCCTCGTTCCAGAGCTGAGATGGCAT AGGCCTTAGCAGTAACGGGTAGCAGCAGATGTAGTTTCAGACTTGGAGTAAAACTGTATAAACAAAAGAATCTTCCATATTTATACAGCA GAGAAGCTGTAGGACTGTTTGTGACTGGCCCTGTCCTGGCATCAGTAGCATCTGTAACAGCATTAACTGTCTTAAAGAGAGAGAGAGAGA ATTCCGAATTGGGGAACACACGATACCTGTTTTTCTTTTCCGTTGCTGGCAGTACTGTTGCGCCGCAGTTTGGAGTCACTGTAGTTAAGT GTGGATGCATGTGCGTCACCGTCCACTCCTCCTACTGTATTTTATTGGACAGGTCAGACTCGCCGGGGGCCCGGCGAGGGTATGTCAGTG TCACTGGATGTCAAACAGTAATAAATTAAACCAACAACAAAACGCACAGCC >25260_25260_2_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000358026_length(amino acids)=461AA_BP=204 MVNFTVDQIRAIMDKKANIRNMSVIAHVDHGKSTLTDSLVCKAGIIASARAGETRFTDTRKDEQERCITIKSTAISLFYELSENDLNFIK QSKDGAGFLINLIDSPGHVDFSSEVTAALRVTDGALVVVDCVSGVCVQTETVLRQAIAERIKPVLMMNKMDRALLELQLEPEELYQTFQR IVENVNVIISTYGEGESGPMGNIMAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPP NLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLI YEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQE EDRSGSGSEED -------------------------------------------------------------- >25260_25260_3_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000413806_length(transcript)=1940nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGCCATCGAGGAGGGCACGCT GGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCAG CACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCAA CCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCCA GCTGCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACCA CAAGTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCTA TGAAGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGGA GGAGGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGGA CCGGCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGGA GGACCGCTCAGGAAGTGGCAGCGAAGAAGACTGAGCCCCGACATTCCAGTCTCGACCCCGAGCCCCTCGTTCCAGAGCTGAGATGGCATA GGCCTTAGCAGTAACGGGTAGCAGCAGATGTAGTTTCAGACTTGGAGTAAAACTGTATAAACAAAAGAATCTTCCATATTTATACAGCAG AGAAGCTGTAGGACTGTTTGTGACTGGCCCTGTCCTGGCATCAGTAGCATCTGTAACAGCATTAACTGTCTTAAAGAGAGAGAGAGAGAA TTCCGAATTGGGGAACACACGATACCTGTTTTTCTTTTCCGTTGCTGGCAGTACTGTTGCGCCGCAGTTTGGAGTCACTGTAGTTAAGTG TGGATGCATGTGCGTCACCGTCCACTCCTCCTACTGTATTTTATTGGACAGGTCAGACTCGCCGGGGGCCCGGCGAGGGTATGTCAGTGT CACTGGATGTCAAACAGTAATAAATTAAACCAACAACAAAACGCACAGCC >25260_25260_3_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000413806_length(amino acids)=331AA_BP=74 MRVRRVRADGDSAAAGHCRAHQACADDEQDGPRPAGAAAGARGALPDFPAHRGERERHHLHLRRGRERPHGQHHAIEEGTLEEIEEEVRQ KKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPE YYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGS ESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEED -------------------------------------------------------------- >25260_25260_4_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000429416_length(transcript)=1941nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGGCCATCGAGGAGGGCACGC TGGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCA GCACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCA ACCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCC AGCTGCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACC ACAAGTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCT ATGAAGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGG AGGAGGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGG ACCGGCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGG AGGACCGCTCAGGAAGTGGCAGCGAAGAAGACTGAGCCCCGACATTCCAGTCTCGACCCCGAGCCCCTCGTTCCAGAGCTGAGATGGCAT AGGCCTTAGCAGTAACGGGTAGCAGCAGATGTAGTTTCAGACTTGGAGTAAAACTGTATAAACAAAAGAATCTTCCATATTTATACAGCA GAGAAGCTGTAGGACTGTTTGTGACTGGCCCTGTCCTGGCATCAGTAGCATCTGTAACAGCATTAACTGTCTTAAAGAGAGAGAGAGAGA ATTCCGAATTGGGGAACACACGATACCTGTTTTTCTTTTCCGTTGCTGGCAGTACTGTTGCGCCGCAGTTTGGAGTCACTGTAGTTAAGT GTGGATGCATGTGCGTCACCGTCCACTCCTCCTACTGTATTTTATTGGACAGGTCAGACTCGCCGGGGGCCCGGCGAGGGTATGTCAGTG TCACTGGATGTCAAACAGTAATAAATTAAACCAACAACAAAACGCACAGCC >25260_25260_4_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000429416_length(amino acids)=461AA_BP=204 MVNFTVDQIRAIMDKKANIRNMSVIAHVDHGKSTLTDSLVCKAGIIASARAGETRFTDTRKDEQERCITIKSTAISLFYELSENDLNFIK QSKDGAGFLINLIDSPGHVDFSSEVTAALRVTDGALVVVDCVSGVCVQTETVLRQAIAERIKPVLMMNKMDRALLELQLEPEELYQTFQR IVENVNVIISTYGEGESGPMGNIMAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPP NLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLI YEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQE EDRSGSGSEED -------------------------------------------------------------- >25260_25260_5_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000444061_length(transcript)=1472nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGGCCATCGAGGAGGGCACGC TGGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCA GCACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCA ACCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCCAGC TGCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACCACA AGTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCTATG AAGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGGAGG AGGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGGACC GGCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGGAGG ACCGCTCAGGAAGTGGCAGCGAAGAAGACTGA >25260_25260_5_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000444061_length(amino acids)=461AA_BP=204 MVNFTVDQIRAIMDKKANIRNMSVIAHVDHGKSTLTDSLVCKAGIIASARAGETRFTDTRKDEQERCITIKSTAISLFYELSENDLNFIK QSKDGAGFLINLIDSPGHVDFSSEVTAALRVTDGALVVVDCVSGVCVQTETVLRQAIAERIKPVLMMNKMDRALLELQLEPEELYQTFQR IVENVNVIISTYGEGESGPMGNIMAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPP NLTKKMKKIVDAVIKYKDSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIY EDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEE DRSGSGSEEDX -------------------------------------------------------------- >25260_25260_6_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000450717_length(transcript)=1937nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGCCATCGAGGAGGGCACGCT GGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCAG CACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCAA CCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCCAGCT GCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACCACAA GTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCTATGA AGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGGAGGA GGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGGACCG GCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGGAGGA CCGCTCAGGAAGTGGCAGCGAAGAAGACTGAGCCCCGACATTCCAGTCTCGACCCCGAGCCCCTCGTTCCAGAGCTGAGATGGCATAGGC CTTAGCAGTAACGGGTAGCAGCAGATGTAGTTTCAGACTTGGAGTAAAACTGTATAAACAAAAGAATCTTCCATATTTATACAGCAGAGA AGCTGTAGGACTGTTTGTGACTGGCCCTGTCCTGGCATCAGTAGCATCTGTAACAGCATTAACTGTCTTAAAGAGAGAGAGAGAGAATTC CGAATTGGGGAACACACGATACCTGTTTTTCTTTTCCGTTGCTGGCAGTACTGTTGCGCCGCAGTTTGGAGTCACTGTAGTTAAGTGTGG ATGCATGTGCGTCACCGTCCACTCCTCCTACTGTATTTTATTGGACAGGTCAGACTCGCCGGGGGCCCGGCGAGGGTATGTCAGTGTCAC TGGATGTCAAACAGTAATAAATTAAACCAACAACAAAACGCACAGCC >25260_25260_6_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000450717_length(amino acids)=330AA_BP=74 MRVRRVRADGDSAAAGHCRAHQACADDEQDGPRPAGAAAGARGALPDFPAHRGERERHHLHLRRGRERPHGQHHAIEEGTLEEIEEEVRQ KKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSGRQLSEVFIQLPSRKELPEY YELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSE SESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEED -------------------------------------------------------------- >25260_25260_7_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000541122_length(transcript)=1474nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGCCATCGAGGAGGGCACGCT GGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCAG CACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCAA CCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCCA GCTGCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACCA CAAGTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCTA TGAAGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGGA GGAGGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGGA CCGGCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGGA GGACCGCTCAGGAAGTGGCAGCGAAGAAGACTGA >25260_25260_7_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000541122_length(amino acids)=332AA_BP=74 MRVRRVRADGDSAAAGHCRAHQACADDEQDGPRPAGAAAGARGALPDFPAHRGERERHHLHLRRGRERPHGQHHAIEEGTLEEIEEEVRQ KKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPE YYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGS ESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEEDX -------------------------------------------------------------- >25260_25260_8_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000589677_length(transcript)=1471nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGCCATCGAGGAGGGCACGCT GGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCAG CACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCAA CCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCCAGCT GCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACCACAA GTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCTATGA AGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGGAGGA GGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGGACCG GCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGGAGGA CCGCTCAGGAAGTGGCAGCGAAGAAGACTGA >25260_25260_8_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000589677_length(amino acids)=331AA_BP=74 MRVRRVRADGDSAAAGHCRAHQACADDEQDGPRPAGAAAGARGALPDFPAHRGERERHHLHLRRGRERPHGQHHAIEEGTLEEIEEEVRQ KKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPPNLTKKMKKIVDAVIKYKDSSGRQLSEVFIQLPSRKELPEY YELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLIYEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSE SESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQEEDRSGSGSEEDX -------------------------------------------------------------- >25260_25260_9_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000590574_length(transcript)=1475nt_BP=701nt AGCGTTCTCTTCCGCCGTCGTCGCCGCCATCCTCGGCGCGACTCGCTTCTTTCGGTTCTACCTGGGAGAATCCACCGCCATCCGCCACCA TGGTGAACTTCACGGTAGACCAGATCCGCGCCATCATGGACAAGAAGGCCAACATCCGCAACATGTCTGTCATCGCCCACGTGGACCATG GCAAGTCCACGCTGACAGACTCCCTGGTGTGCAAGGCGGGCATCATCGCCTCGGCCCGGGCCGGGGAGACACGCTTCACTGATACCCGGA AGGACGAGCAGGAGCGTTGCATCACCATCAAGTCAACTGCCATCTCCCTCTTCTACGAGCTCTCGGAGAATGACTTGAACTTCATCAAGC AGAGCAAGGACGGTGCCGGCTTCCTCATCAACCTCATTGACTCCCCCGGGCATGTCGACTTCTCCTCGGAGGTGACTGCTGCCCTCCGAG TCACCGATGGCGCATTGGTGGTGGTGGACTGCGTGTCAGGCGTGTGCGTGCAGACGGAGACAGTGCTGCGGCAGGCCATTGCCGAGCGCA TCAAGCCTGTGCTGATGATGAACAAGATGGACCGCGCCCTGCTGGAGCTGCAGCTGGAGCCCGAGGAGCTCTACCAGACTTTCCAGCGCA TCGTGGAGAACGTGAACGTCATCATCTCCACCTACGGCGAGGGCGAGAGCGGCCCCATGGGCAACATCATGGCCATCGAGGAGGGCACGC TGGAGGAGATCGAAGAGGAGGTCCGGCAGAAGAAATCATCACGGAAGCGCAAGCGAGACAGCGACGCCGGCTCCTCCACCCCGACCACCA GCACCCGCAGCCGCGACAAGGACGACGAGAGCAAGAAGCAGAAGAAGCGCGGGCGGCCGCCTGCCGAGAAACTCTCCCCTAACCCACCCA ACCTCACCAAGAAGATGAAGAAGATTGTGGATGCCGTGATCAAGTACAAGGACAGCAGCAGTGGACGTCAGCTCAGCGAGGTCTTCATCC AGCTGCCCTCGCGAAAGGAGCTGCCCGAGTACTACGAGCTCATCCGCAAGCCCGTGGACTTCAAGAAGATAAAGGAGCGCATTCGCAACC ACAAGTACCGCAGCCTCAACGACCTAGAGAAGGACGTCATGCTCCTGTGCCAGAACGCACAGACCTTCAACCTGGAGGGCTCCCTGATCT ATGAAGACTCCATCGTCTTGCAGTCGGTCTTCACCAGCGTGCGGCAGAAAATCGAGAAGGAGGATGACAGTGAAGGCGAGGAGAGTGAGG AGGAGGAAGAGGGCGAGGAGGAAGGCTCCGAATCCGAATCTCGGTCCGTCAAAGTGAAGATCAAGCTTGGCCGGAAGGAGAAGGCACAGG ACCGGCTGAAGGGCGGCCGGCGGCGGCCGAGCCGAGGGTCCCGAGCCAAGCCGGTCGTGAGTGACGATGACAGTGAGGAGGAACAAGAGG AGGACCGCTCAGGAAGTGGCAGCGAAGAAGACTGA >25260_25260_9_EEF2-SMARCA4_EEF2_chr19_3982805_ENST00000309311_SMARCA4_chr19_11151983_ENST00000590574_length(amino acids)=462AA_BP=204 MVNFTVDQIRAIMDKKANIRNMSVIAHVDHGKSTLTDSLVCKAGIIASARAGETRFTDTRKDEQERCITIKSTAISLFYELSENDLNFIK QSKDGAGFLINLIDSPGHVDFSSEVTAALRVTDGALVVVDCVSGVCVQTETVLRQAIAERIKPVLMMNKMDRALLELQLEPEELYQTFQR IVENVNVIISTYGEGESGPMGNIMAIEEGTLEEIEEEVRQKKSSRKRKRDSDAGSSTPTTSTRSRDKDDESKKQKKRGRPPAEKLSPNPP NLTKKMKKIVDAVIKYKDSSSGRQLSEVFIQLPSRKELPEYYELIRKPVDFKKIKERIRNHKYRSLNDLEKDVMLLCQNAQTFNLEGSLI YEDSIVLQSVFTSVRQKIEKEDDSEGEESEEEEEGEEEGSESESRSVKVKIKLGRKEKAQDRLKGGRRRPSRGSRAKPVVSDDDSEEEQE EDRSGSGSEEDX -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EEF2-SMARCA4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EEF2-SMARCA4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EEF2-SMARCA4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | EEF2 | C0001418 | Adenocarcinoma | 1 | CTD_human |
| Hgene | EEF2 | C0006142 | Malignant neoplasm of breast | 1 | CTD_human |
| Hgene | EEF2 | C0007134 | Renal Cell Carcinoma | 1 | CTD_human |
| Hgene | EEF2 | C0024121 | Lung Neoplasms | 1 | CTD_human |
| Hgene | EEF2 | C0027626 | Neoplasm Invasiveness | 1 | CTD_human |
| Hgene | EEF2 | C0027627 | Neoplasm Metastasis | 1 | CTD_human |
| Hgene | EEF2 | C0029408 | Degenerative polyarthritis | 1 | CTD_human |
| Hgene | EEF2 | C0086743 | Osteoarthrosis Deformans | 1 | CTD_human |
| Hgene | EEF2 | C0205641 | Adenocarcinoma, Basal Cell | 1 | CTD_human |
| Hgene | EEF2 | C0205642 | Adenocarcinoma, Oxyphilic | 1 | CTD_human |
| Hgene | EEF2 | C0205643 | Carcinoma, Cribriform | 1 | CTD_human |
| Hgene | EEF2 | C0205644 | Carcinoma, Granular Cell | 1 | CTD_human |
| Hgene | EEF2 | C0205645 | Adenocarcinoma, Tubular | 1 | CTD_human |
| Hgene | EEF2 | C0242379 | Malignant neoplasm of lung | 1 | CTD_human |
| Hgene | EEF2 | C0279702 | Conventional (Clear Cell) Renal Cell Carcinoma | 1 | CTD_human |
| Hgene | EEF2 | C0678222 | Breast Carcinoma | 1 | CTD_human |
| Hgene | EEF2 | C1257931 | Mammary Neoplasms, Human | 1 | CTD_human |
| Hgene | EEF2 | C1266042 | Chromophobe Renal Cell Carcinoma | 1 | CTD_human |
| Hgene | EEF2 | C1266043 | Sarcomatoid Renal Cell Carcinoma | 1 | CTD_human |
| Hgene | EEF2 | C1266044 | Collecting Duct Carcinoma of the Kidney | 1 | CTD_human |
| Hgene | EEF2 | C1306837 | Papillary Renal Cell Carcinoma | 1 | CTD_human |
| Hgene | EEF2 | C1458155 | Mammary Neoplasms | 1 | CTD_human |
| Hgene | EEF2 | C1836395 | SPINOCEREBELLAR ATAXIA 26 | 1 | CTD_human;ORPHANET;UNIPROT |
| Hgene | EEF2 | C4704874 | Mammary Carcinoma, Human | 1 | CTD_human |
| Tgene | C2750074 | Rhabdoid Tumor Predisposition Syndrome 2 | 7 | CLINGEN;CTD_human;GENOMICS_ENGLAND | |
| Tgene | C0262584 | Carcinoma, Small Cell | 4 | CTD_human | |
| Tgene | C0919267 | ovarian neoplasm | 4 | CGI;CTD_human | |
| Tgene | C1140680 | Malignant neoplasm of ovary | 4 | CGI;CTD_human | |
| Tgene | C0009405 | Hereditary Nonpolyposis Colorectal Neoplasms | 2 | CLINGEN | |
| Tgene | C1112155 | Hereditary non-polyposis colorectal cancer syndrome | 2 | CLINGEN | |
| Tgene | C1333990 | Hereditary Nonpolyposis Colorectal Cancer | 2 | CLINGEN | |
| Tgene | C1333991 | Hereditary Non-Polyposis Colon Cancer Type 2 | 2 | CLINGEN | |
| Tgene | C2936783 | Colorectal cancer, hereditary nonpolyposis, type 1 | 2 | CLINGEN | |
| Tgene | C2985524 | Rhabdoid tumor predisposition syndrome | 2 | ORPHANET | |
| Tgene | C0006413 | Burkitt Lymphoma | 1 | CTD_human | |
| Tgene | C0009171 | Cocaine Abuse | 1 | CTD_human | |
| Tgene | C0036920 | Sezary Syndrome | 1 | CTD_human | |
| Tgene | C0039981 | Thoracic Neoplasms | 1 | CTD_human | |
| Tgene | C0149925 | Small cell carcinoma of lung | 1 | CTD_human | |
| Tgene | C0205944 | Sarcoma, Epithelioid | 1 | CTD_human | |
| Tgene | C0205945 | Sarcoma, Spindle Cell | 1 | CTD_human | |
| Tgene | C0236736 | Cocaine-Related Disorders | 1 | CTD_human | |
| Tgene | C0265338 | Coffin-Siris syndrome | 1 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C0343640 | African Burkitt's lymphoma | 1 | CTD_human | |
| Tgene | C0600427 | Cocaine Dependence | 1 | CTD_human | |
| Tgene | C1261473 | Sarcoma | 1 | CTD_human | |
| Tgene | C1961099 | Precursor T-Cell Lymphoblastic Leukemia-Lymphoma | 1 | CTD_human | |
| Tgene | C2239246 | Endometrial stromal sarcoma, high grade | 1 | GENOMICS_ENGLAND | |
| Tgene | C3281201 | MENTAL RETARDATION, AUTOSOMAL DOMINANT 12 | 1 | GENOMICS_ENGLAND | |
| Tgene | C3553249 | COFFIN-SIRIS SYNDROME 4 | 1 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C4721444 | Burkitt Leukemia | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies