
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EIF2D-CHMP1A (FusionGDB2 ID:HG1939TG5119) |
Fusion Gene Summary for EIF2D-CHMP1A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EIF2D-CHMP1A | Fusion gene ID: hg1939tg5119 | Hgene | Tgene | Gene symbol | EIF2D | CHMP1A | Gene ID | 1939 | 5119 |
| Gene name | eukaryotic translation initiation factor 2D | charged multivesicular body protein 1A | |
| Synonyms | HCA56|LGTN | CHMP1|PCH8|PCOLN3|PRSM1|VPS46-1|VPS46A | |
| Cytomap | ('EIF2D')('CHMP1A') 1q32.1 | 16q24.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | eukaryotic translation initiation factor 2Dhepatocellular carcinoma-associated antigen 56ligatin | charged multivesicular body protein 1acharged multivesicular body protein 1/chromatin modifying protein 1chromatin modifying protein 1Aprocollagen (type III) N-endopeptidaseprotease, metallo, 1, 33kDvacuolar protein sorting-associated protein 46-1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000271764, ENST00000367114, ENST00000472709, | ||
| Fusion gene scores | * DoF score | 4 X 4 X 3=48 | 45 X 11 X 21=10395 |
| # samples | 4 | 48 | |
| ** MAII score | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(48/10395*10)=-4.43671154213721 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: EIF2D [Title/Abstract] AND CHMP1A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | EIF2D(206769067)-CHMP1A(89713739), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | EIF2D-CHMP1A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EIF2D-CHMP1A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EIF2D-CHMP1A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. EIF2D-CHMP1A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | EIF2D | GO:0001731 | formation of translation preinitiation complex | 20713520 |
| Hgene | EIF2D | GO:0032790 | ribosome disassembly | 20713520 |
| Hgene | EIF2D | GO:0075522 | IRES-dependent viral translational initiation | 20713520 |
| Tgene | CHMP1A | GO:0007076 | mitotic chromosome condensation | 11559747 |
| Tgene | CHMP1A | GO:0016192 | vesicle-mediated transport | 11559748 |
| Tgene | CHMP1A | GO:0016458 | gene silencing | 11559747 |
| Tgene | CHMP1A | GO:0045892 | negative regulation of transcription, DNA-templated | 11559747 |
| Fusion gene breakpoints across EIF2D (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CHMP1A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
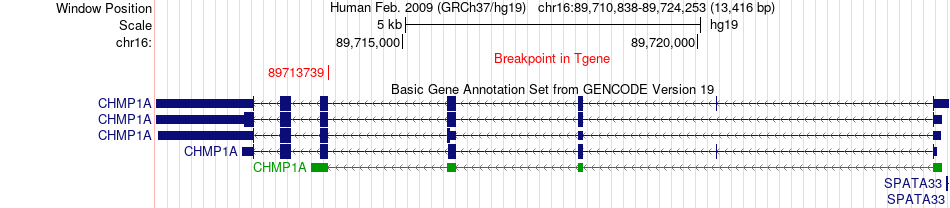 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | GBM | TCGA-27-2519-01A | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
Top |
Fusion Gene ORF analysis for EIF2D-CHMP1A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000271764 | ENST00000547614 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000367114 | ENST00000547614 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| 5UTR-3CDS | ENST00000472709 | ENST00000253475 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| 5UTR-3CDS | ENST00000472709 | ENST00000397901 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| 5UTR-3CDS | ENST00000472709 | ENST00000535997 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| 5UTR-3CDS | ENST00000472709 | ENST00000550102 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| 5UTR-5UTR | ENST00000472709 | ENST00000547614 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000271764 | ENST00000253475 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000367114 | ENST00000253475 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000271764 | ENST00000397901 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000271764 | ENST00000535997 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000271764 | ENST00000550102 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367114 | ENST00000397901 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367114 | ENST00000535997 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000367114 | ENST00000550102 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000367114 | EIF2D | chr1 | 206769067 | - | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 3228 | 1254 | 21 | 1592 | 523 |
| ENST00000367114 | EIF2D | chr1 | 206769067 | - | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 3196 | 1254 | 21 | 1592 | 523 |
| ENST00000367114 | EIF2D | chr1 | 206769067 | - | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 1770 | 1254 | 21 | 1592 | 523 |
| ENST00000271764 | EIF2D | chr1 | 206769067 | - | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 3692 | 1718 | 17 | 2056 | 679 |
| ENST00000271764 | EIF2D | chr1 | 206769067 | - | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 3660 | 1718 | 17 | 2056 | 679 |
| ENST00000271764 | EIF2D | chr1 | 206769067 | - | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 2234 | 1718 | 17 | 2056 | 679 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000367114 | ENST00000397901 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - | 0.003229088 | 0.9967709 |
| ENST00000367114 | ENST00000535997 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - | 0.003365208 | 0.9966348 |
| ENST00000367114 | ENST00000550102 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - | 0.00597145 | 0.99402857 |
| ENST00000271764 | ENST00000397901 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - | 0.004439001 | 0.995561 |
| ENST00000271764 | ENST00000535997 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - | 0.004632301 | 0.99536777 |
| ENST00000271764 | ENST00000550102 | EIF2D | chr1 | 206769067 | - | CHMP1A | chr16 | 89713739 | - | 0.007542128 | 0.99245787 |
Top |
Fusion Genomic Features for EIF2D-CHMP1A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
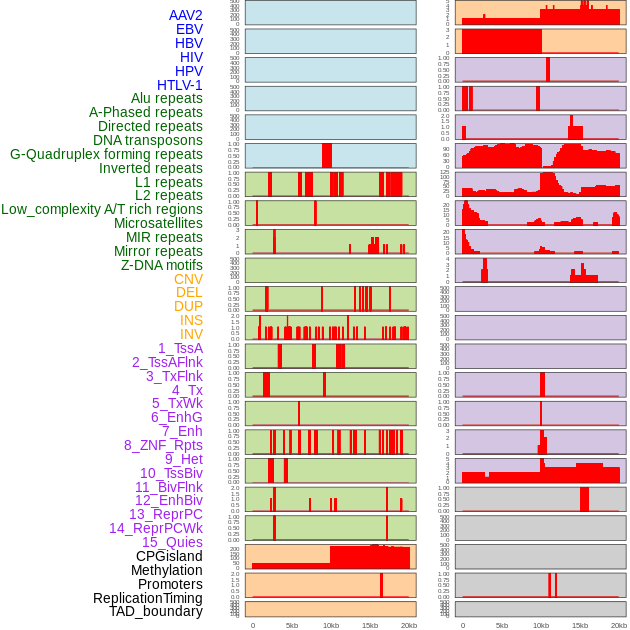 |
Top |
Fusion Protein Features for EIF2D-CHMP1A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:206769067/chr16:89713739) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EIF2D | chr1:206769067 | chr16:89713739 | ENST00000271764 | - | 13 | 15 | 383_467 | 503 | 585.0 | Domain | SWIB/MDM2 |
| Hgene | EIF2D | chr1:206769067 | chr16:89713739 | ENST00000271764 | - | 13 | 15 | 93_173 | 503 | 585.0 | Domain | PUA |
| Hgene | EIF2D | chr1:206769067 | chr16:89713739 | ENST00000367114 | - | 11 | 13 | 93_173 | 379 | 461.0 | Domain | PUA |
| Tgene | CHMP1A | chr1:206769067 | chr16:89713739 | ENST00000397901 | 3 | 7 | 102_124 | 84 | 197.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CHMP1A | chr1:206769067 | chr16:89713739 | ENST00000397901 | 3 | 7 | 185_195 | 84 | 197.0 | Motif | Note=MIT-interacting motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EIF2D | chr1:206769067 | chr16:89713739 | ENST00000271764 | - | 13 | 15 | 491_564 | 503 | 585.0 | Domain | SUI1 |
| Hgene | EIF2D | chr1:206769067 | chr16:89713739 | ENST00000367114 | - | 11 | 13 | 383_467 | 379 | 461.0 | Domain | SWIB/MDM2 |
| Hgene | EIF2D | chr1:206769067 | chr16:89713739 | ENST00000367114 | - | 11 | 13 | 491_564 | 379 | 461.0 | Domain | SUI1 |
| Tgene | CHMP1A | chr1:206769067 | chr16:89713739 | ENST00000397901 | 3 | 7 | 5_47 | 84 | 197.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for EIF2D-CHMP1A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >25724_25724_1_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000271764_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=3692nt_BP=1718nt AGTTCCAGGTACCGCCACTGGGGGCGGCCGCGGCCTCCCCAGCGGCAACGGCCACGAAGCTGCGCGGCCCTGGTTTCCAGCCGGGCCCTT TTCGCGGCCGGGCCCCAGCATGGCTGCCCCCACGGCTGAGGGCCTGGCAGCTGCTGCGCCCTCGCTTTCTTGACATTCCCTGGCTTCTGT GCTCTCTTCCCCAGGCCACCCCAGCAGACATGTTTGCCAAGGCCTTTCGGGTCAAGTCCAACACGGCCATCAAGGGGTCGGACAGGAGAA AGCTTCGAGCTGATGTGACAACTGCTTTCCCCACCCTTGGAACTGATCAAGTCTCTGAGTTAGTACCTGGAAAGGAGGAGCTCAACATTG TGAAGTTGTATGCTCACAAAGGGGATGCAGTGACTGTGTACGTGAGTGGTGGTAACCCCATCCTCTTTGAACTGGAGAAAAATCTGTATC CAACAGTGTACACGCTGTGGTCCTATCCTGATCTTCTGCCAACCTTTACAACATGGCCTCTGGTGCTCGAGAAACTGGTAGGGGGAGCAG ATTTGATGCTGCCTGGACTGGTGATGCCCCCTGCTGGTCTGCCTCAGGTACAGAAGGGCGACCTCTGTGCCATTTCTTTGGTGGGGAACA GAGCCCCTGTAGCCATTGGAGTTGCAGCCATGTCCACAGCTGAGATGCTCACGTCAGGCCTGAAGGGAAGGGGCTTCTCTGTGCTCCACA CTTACCAGGACCACTTGTGGCGGTCTGGAAACAAGTCCTCTCCACCTTCCATTGCTCCACTGGCCCTGGATTCAGCAGATCTCAGTGAAG AGAAGGGGTCTGTCCAGATGGACTCCACCCTGCAGGGAGACATGAGGCACATGACCCTGGAGGGGGAAGAGGAGAATGGGGAGGTTCACC AGGCACGTGAAGACAAGTCTCTCTCAGAAGCCCCAGAAGACACCAGCACCAGGGGCCTGAACCAAGACTCCACAGATAGCAAAACGCTTC AAGAACAAATGGATGAGCTGTTACAGCAATGCTTCTTACATGCCTTGAAGTGCCGAGTCAAAAAGGCTGACCTCCCTTTACTCACCAGCA CTTTCCTTGGCAGCCACATGTTCTCCTGCTGCCCTGAAGGACGACAACTGGACATAAAGAAGTCAAGCTACAAAAAGCTCTCTAAGTTCC TGCAGCAAATGCAGCAGGAGCAGATTATACAGGTGAAGGAGCTGAGCAAAGGGGTGGAGAGCATTGTGGCTGTGGACTGGAAACACCCGA GGATTACATCTTTCGTCATACCCGAGCCCTCCCCGACCTCCCAGACTATCCAGGAGGGTAGCAGGGAACAGCCCTATCACCCTCCAGATA TAAAACCCCTCTACTGTGTCCCAGCCAGCATGACCCTGCTCTTCCAGGAGTCTGGCCACAAGAAGGGGAGCTTTCTGGAGGGCAGTGAGG TCCGAACGATCGTCATTAACTACGCCAAGAAAAATGACCTGGTTGATGCAGACAACAAAAATCTTGTGAGATTGGATCCCATCCTATGTG ACTGCATCTTAGAGAAAAATGAACAGCATACAGTCATGAAGCTTCCATGGGACAGTCTTCTGACCAGGTGTTTGGAAAAATTACAGCCTG CCTATCAAGTGACCCTTCCCGGACAAGAGCCCATTGTGAAGAAAGGGAGAATCTGTCCAATTGACATCACCCTAGCACAAAGAGCGTCTA ATAAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGA TGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGC CGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCG CCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCG GTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCG GCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTC CTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCA CCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAAC AACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATG TGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCT CGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAG AACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACAT GTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCA GCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTG CCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTG GGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGA GGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAA GTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCC CGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTT CTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGT GTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTC AGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAATGGATCCCTGGAAACT TT >25724_25724_1_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000271764_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=679AA_BP=567 MGAAAASPAATATKLRGPGFQPGPFRGRAPAWLPPRLRAWQLLRPRFLDIPWLLCSLPQATPADMFAKAFRVKSNTAIKGSDRRKLRADV TTAFPTLGTDQVSELVPGKEELNIVKLYAHKGDAVTVYVSGGNPILFELEKNLYPTVYTLWSYPDLLPTFTTWPLVLEKLVGGADLMLPG LVMPPAGLPQVQKGDLCAISLVGNRAPVAIGVAAMSTAEMLTSGLKGRGFSVLHTYQDHLWRSGNKSSPPSIAPLALDSADLSEEKGSVQ MDSTLQGDMRHMTLEGEEENGEVHQAREDKSLSEAPEDTSTRGLNQDSTDSKTLQEQMDELLQQCFLHALKCRVKKADLPLLTSTFLGSH MFSCCPEGRQLDIKKSSYKKLSKFLQQMQQEQIIQVKELSKGVESIVAVDWKHPRITSFVIPEPSPTSQTIQEGSREQPYHPPDIKPLYC VPASMTLLFQESGHKKGSFLEGSEVRTIVINYAKKNDLVDADNKNLVRLDPILCDCILEKNEQHTVMKLPWDSLLTRCLEKLQPAYQVTL PGQEPIVKKGRICPIDITLAQRASNKKVTKNMAQVTKALDKALSTMDLQKVSSVMDRFEQQVQNLDVHTSVMEDSMSSATTLTTPQEQVD SLIMQIAEENGLEVLDQLSQLPEGASAVGESSVRSQEDQLSRRLAALRN -------------------------------------------------------------- >25724_25724_2_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000271764_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=3660nt_BP=1718nt AGTTCCAGGTACCGCCACTGGGGGCGGCCGCGGCCTCCCCAGCGGCAACGGCCACGAAGCTGCGCGGCCCTGGTTTCCAGCCGGGCCCTT TTCGCGGCCGGGCCCCAGCATGGCTGCCCCCACGGCTGAGGGCCTGGCAGCTGCTGCGCCCTCGCTTTCTTGACATTCCCTGGCTTCTGT GCTCTCTTCCCCAGGCCACCCCAGCAGACATGTTTGCCAAGGCCTTTCGGGTCAAGTCCAACACGGCCATCAAGGGGTCGGACAGGAGAA AGCTTCGAGCTGATGTGACAACTGCTTTCCCCACCCTTGGAACTGATCAAGTCTCTGAGTTAGTACCTGGAAAGGAGGAGCTCAACATTG TGAAGTTGTATGCTCACAAAGGGGATGCAGTGACTGTGTACGTGAGTGGTGGTAACCCCATCCTCTTTGAACTGGAGAAAAATCTGTATC CAACAGTGTACACGCTGTGGTCCTATCCTGATCTTCTGCCAACCTTTACAACATGGCCTCTGGTGCTCGAGAAACTGGTAGGGGGAGCAG ATTTGATGCTGCCTGGACTGGTGATGCCCCCTGCTGGTCTGCCTCAGGTACAGAAGGGCGACCTCTGTGCCATTTCTTTGGTGGGGAACA GAGCCCCTGTAGCCATTGGAGTTGCAGCCATGTCCACAGCTGAGATGCTCACGTCAGGCCTGAAGGGAAGGGGCTTCTCTGTGCTCCACA CTTACCAGGACCACTTGTGGCGGTCTGGAAACAAGTCCTCTCCACCTTCCATTGCTCCACTGGCCCTGGATTCAGCAGATCTCAGTGAAG AGAAGGGGTCTGTCCAGATGGACTCCACCCTGCAGGGAGACATGAGGCACATGACCCTGGAGGGGGAAGAGGAGAATGGGGAGGTTCACC AGGCACGTGAAGACAAGTCTCTCTCAGAAGCCCCAGAAGACACCAGCACCAGGGGCCTGAACCAAGACTCCACAGATAGCAAAACGCTTC AAGAACAAATGGATGAGCTGTTACAGCAATGCTTCTTACATGCCTTGAAGTGCCGAGTCAAAAAGGCTGACCTCCCTTTACTCACCAGCA CTTTCCTTGGCAGCCACATGTTCTCCTGCTGCCCTGAAGGACGACAACTGGACATAAAGAAGTCAAGCTACAAAAAGCTCTCTAAGTTCC TGCAGCAAATGCAGCAGGAGCAGATTATACAGGTGAAGGAGCTGAGCAAAGGGGTGGAGAGCATTGTGGCTGTGGACTGGAAACACCCGA GGATTACATCTTTCGTCATACCCGAGCCCTCCCCGACCTCCCAGACTATCCAGGAGGGTAGCAGGGAACAGCCCTATCACCCTCCAGATA TAAAACCCCTCTACTGTGTCCCAGCCAGCATGACCCTGCTCTTCCAGGAGTCTGGCCACAAGAAGGGGAGCTTTCTGGAGGGCAGTGAGG TCCGAACGATCGTCATTAACTACGCCAAGAAAAATGACCTGGTTGATGCAGACAACAAAAATCTTGTGAGATTGGATCCCATCCTATGTG ACTGCATCTTAGAGAAAAATGAACAGCATACAGTCATGAAGCTTCCATGGGACAGTCTTCTGACCAGGTGTTTGGAAAAATTACAGCCTG CCTATCAAGTGACCCTTCCCGGACAAGAGCCCATTGTGAAGAAAGGGAGAATCTGTCCAATTGACATCACCCTAGCACAAAGAGCGTCTA ATAAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGA TGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGC CGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCG CCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCG GTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCG GCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTC CTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCA CCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAAC AACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATG TGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCT CGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAG AACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACAT GTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCA GCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTG CCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTG GGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGA GGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAA GTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCC CGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTT CTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGT GTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTC AGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGT >25724_25724_2_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000271764_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=679AA_BP=567 MGAAAASPAATATKLRGPGFQPGPFRGRAPAWLPPRLRAWQLLRPRFLDIPWLLCSLPQATPADMFAKAFRVKSNTAIKGSDRRKLRADV TTAFPTLGTDQVSELVPGKEELNIVKLYAHKGDAVTVYVSGGNPILFELEKNLYPTVYTLWSYPDLLPTFTTWPLVLEKLVGGADLMLPG LVMPPAGLPQVQKGDLCAISLVGNRAPVAIGVAAMSTAEMLTSGLKGRGFSVLHTYQDHLWRSGNKSSPPSIAPLALDSADLSEEKGSVQ MDSTLQGDMRHMTLEGEEENGEVHQAREDKSLSEAPEDTSTRGLNQDSTDSKTLQEQMDELLQQCFLHALKCRVKKADLPLLTSTFLGSH MFSCCPEGRQLDIKKSSYKKLSKFLQQMQQEQIIQVKELSKGVESIVAVDWKHPRITSFVIPEPSPTSQTIQEGSREQPYHPPDIKPLYC VPASMTLLFQESGHKKGSFLEGSEVRTIVINYAKKNDLVDADNKNLVRLDPILCDCILEKNEQHTVMKLPWDSLLTRCLEKLQPAYQVTL PGQEPIVKKGRICPIDITLAQRASNKKVTKNMAQVTKALDKALSTMDLQKVSSVMDRFEQQVQNLDVHTSVMEDSMSSATTLTTPQEQVD SLIMQIAEENGLEVLDQLSQLPEGASAVGESSVRSQEDQLSRRLAALRN -------------------------------------------------------------- >25724_25724_3_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000271764_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=2234nt_BP=1718nt AGTTCCAGGTACCGCCACTGGGGGCGGCCGCGGCCTCCCCAGCGGCAACGGCCACGAAGCTGCGCGGCCCTGGTTTCCAGCCGGGCCCTT TTCGCGGCCGGGCCCCAGCATGGCTGCCCCCACGGCTGAGGGCCTGGCAGCTGCTGCGCCCTCGCTTTCTTGACATTCCCTGGCTTCTGT GCTCTCTTCCCCAGGCCACCCCAGCAGACATGTTTGCCAAGGCCTTTCGGGTCAAGTCCAACACGGCCATCAAGGGGTCGGACAGGAGAA AGCTTCGAGCTGATGTGACAACTGCTTTCCCCACCCTTGGAACTGATCAAGTCTCTGAGTTAGTACCTGGAAAGGAGGAGCTCAACATTG TGAAGTTGTATGCTCACAAAGGGGATGCAGTGACTGTGTACGTGAGTGGTGGTAACCCCATCCTCTTTGAACTGGAGAAAAATCTGTATC CAACAGTGTACACGCTGTGGTCCTATCCTGATCTTCTGCCAACCTTTACAACATGGCCTCTGGTGCTCGAGAAACTGGTAGGGGGAGCAG ATTTGATGCTGCCTGGACTGGTGATGCCCCCTGCTGGTCTGCCTCAGGTACAGAAGGGCGACCTCTGTGCCATTTCTTTGGTGGGGAACA GAGCCCCTGTAGCCATTGGAGTTGCAGCCATGTCCACAGCTGAGATGCTCACGTCAGGCCTGAAGGGAAGGGGCTTCTCTGTGCTCCACA CTTACCAGGACCACTTGTGGCGGTCTGGAAACAAGTCCTCTCCACCTTCCATTGCTCCACTGGCCCTGGATTCAGCAGATCTCAGTGAAG AGAAGGGGTCTGTCCAGATGGACTCCACCCTGCAGGGAGACATGAGGCACATGACCCTGGAGGGGGAAGAGGAGAATGGGGAGGTTCACC AGGCACGTGAAGACAAGTCTCTCTCAGAAGCCCCAGAAGACACCAGCACCAGGGGCCTGAACCAAGACTCCACAGATAGCAAAACGCTTC AAGAACAAATGGATGAGCTGTTACAGCAATGCTTCTTACATGCCTTGAAGTGCCGAGTCAAAAAGGCTGACCTCCCTTTACTCACCAGCA CTTTCCTTGGCAGCCACATGTTCTCCTGCTGCCCTGAAGGACGACAACTGGACATAAAGAAGTCAAGCTACAAAAAGCTCTCTAAGTTCC TGCAGCAAATGCAGCAGGAGCAGATTATACAGGTGAAGGAGCTGAGCAAAGGGGTGGAGAGCATTGTGGCTGTGGACTGGAAACACCCGA GGATTACATCTTTCGTCATACCCGAGCCCTCCCCGACCTCCCAGACTATCCAGGAGGGTAGCAGGGAACAGCCCTATCACCCTCCAGATA TAAAACCCCTCTACTGTGTCCCAGCCAGCATGACCCTGCTCTTCCAGGAGTCTGGCCACAAGAAGGGGAGCTTTCTGGAGGGCAGTGAGG TCCGAACGATCGTCATTAACTACGCCAAGAAAAATGACCTGGTTGATGCAGACAACAAAAATCTTGTGAGATTGGATCCCATCCTATGTG ACTGCATCTTAGAGAAAAATGAACAGCATACAGTCATGAAGCTTCCATGGGACAGTCTTCTGACCAGGTGTTTGGAAAAATTACAGCCTG CCTATCAAGTGACCCTTCCCGGACAAGAGCCCATTGTGAAGAAAGGGAGAATCTGTCCAATTGACATCACCCTAGCACAAAGAGCGTCTA ATAAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGA TGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGC CGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCG CCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCG GTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCG GCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGG >25724_25724_3_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000271764_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=679AA_BP=567 MGAAAASPAATATKLRGPGFQPGPFRGRAPAWLPPRLRAWQLLRPRFLDIPWLLCSLPQATPADMFAKAFRVKSNTAIKGSDRRKLRADV TTAFPTLGTDQVSELVPGKEELNIVKLYAHKGDAVTVYVSGGNPILFELEKNLYPTVYTLWSYPDLLPTFTTWPLVLEKLVGGADLMLPG LVMPPAGLPQVQKGDLCAISLVGNRAPVAIGVAAMSTAEMLTSGLKGRGFSVLHTYQDHLWRSGNKSSPPSIAPLALDSADLSEEKGSVQ MDSTLQGDMRHMTLEGEEENGEVHQAREDKSLSEAPEDTSTRGLNQDSTDSKTLQEQMDELLQQCFLHALKCRVKKADLPLLTSTFLGSH MFSCCPEGRQLDIKKSSYKKLSKFLQQMQQEQIIQVKELSKGVESIVAVDWKHPRITSFVIPEPSPTSQTIQEGSREQPYHPPDIKPLYC VPASMTLLFQESGHKKGSFLEGSEVRTIVINYAKKNDLVDADNKNLVRLDPILCDCILEKNEQHTVMKLPWDSLLTRCLEKLQPAYQVTL PGQEPIVKKGRICPIDITLAQRASNKKVTKNMAQVTKALDKALSTMDLQKVSSVMDRFEQQVQNLDVHTSVMEDSMSSATTLTTPQEQVD SLIMQIAEENGLEVLDQLSQLPEGASAVGESSVRSQEDQLSRRLAALRN -------------------------------------------------------------- >25724_25724_4_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000367114_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=3228nt_BP=1254nt CGCGGCCGGGCCCCAGCATGGCTGCCCCCACGGCTGAGGGCCTGGCAGCTGCTGCGCCCTCGCTTTCTTGACATTCCCTGGCTTCTGTGC TCTCTTCCCCAGGCCACCCCAGCAGACATGTTTGCCAAGGCCTTTCGGGTCAAGTCCAACACGGCCATCAAGGGGTCGGACAGGAGAAAG CTTCGAGCTGATGTGACAACTGCTTTCCCCACCCTTGGAACTGATCAAGTCTCTGAGTTAGTACCTGGAAAGGAGGAGCTCAACATTGTG AAGTTGTATGCTCACAAAGGGGATGCAGTGACTGTGTACGTGAGTGGTGGTAACCCCATCCTCTTTGAACTGGAGAAAAATCTGTATCCA ACAGTGTACACGCTGTGGTCCTATCCTGATCTTCTGCCAACCTTTACAACATGGCCTCTGGTGCTCGAGAAACTGGTAGGGGGAGCAGAT TTGATGCTGCCTGGACTGGTGATGCCCCCTGCTGGTCTGCCTCAGGTACAGAAGGGCGACCTCTGTGCCATTTCTTTGGTGGGGAACAGA GCCCCTGTAGCCATTGGAGTTGCAGCCATGTCCACAGCTGAGATGCTCACGTCAGGCCTGAAGGGAAGGGGCTTCTCTGTGCTCCACACT TACCAGGACCACTTGTGCCCTGAAGGACGACAACTGGACATAAAGAAGTCAAGCTACAAAAAGCTCTCTAAGTTCCTGCAGCAAATGCAG CAGGAGCAGATTATACAGGTGAAGGAGCTGAGCAAAGGGGTGGAGAGCATTGTGGCTGTGGACTGGAAACACCCGAGGATTACATCTTTC GTCATACCCGAGCCCTCCCCGACCTCCCAGACTATCCAGGAGGGTAGCAGGGAACAGCCCTATCACCCTCCAGATATAAAACCCCTCTAC TGTGTCCCAGCCAGCATGACCCTGCTCTTCCAGGAGTCTGGCCACAAGAAGGGGAGCTTTCTGGAGGGCAGTGAGGTCCGAACGATCGTC ATTAACTACGCCAAGAAAAATGACCTGGTTGATGCAGACAACAAAAATCTTGTGAGATTGGATCCCATCCTATGTGACTGCATCTTAGAG AAAAATGAACAGCATACAGTCATGAAGCTTCCATGGGACAGTCTTCTGACCAGGTGTTTGGAAAAATTACAGCCTGCCTATCAAGTGACC CTTCCCGGACAAGAGCCCATTGTGAAGAAAGGGAGAATCTGTCCAATTGACATCACCCTAGCACAAAGAGCGTCTAATAAAAAGGTGACC AAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAG CAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTG GACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGC GAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTC TGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTC TGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTT CTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGG GGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCC TCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATG TCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACC AGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGA TCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTT GTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCG GAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTGCCTTCCCCGACCAC ACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCT GTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAG CCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGG TGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGC TGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTG GGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTC CTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTT GGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAATGGATCCCTGGAAACTTT >25724_25724_4_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000367114_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=523AA_BP=411 MPPRLRAWQLLRPRFLDIPWLLCSLPQATPADMFAKAFRVKSNTAIKGSDRRKLRADVTTAFPTLGTDQVSELVPGKEELNIVKLYAHKG DAVTVYVSGGNPILFELEKNLYPTVYTLWSYPDLLPTFTTWPLVLEKLVGGADLMLPGLVMPPAGLPQVQKGDLCAISLVGNRAPVAIGV AAMSTAEMLTSGLKGRGFSVLHTYQDHLCPEGRQLDIKKSSYKKLSKFLQQMQQEQIIQVKELSKGVESIVAVDWKHPRITSFVIPEPSP TSQTIQEGSREQPYHPPDIKPLYCVPASMTLLFQESGHKKGSFLEGSEVRTIVINYAKKNDLVDADNKNLVRLDPILCDCILEKNEQHTV MKLPWDSLLTRCLEKLQPAYQVTLPGQEPIVKKGRICPIDITLAQRASNKKVTKNMAQVTKALDKALSTMDLQKVSSVMDRFEQQVQNLD VHTSVMEDSMSSATTLTTPQEQVDSLIMQIAEENGLEVLDQLSQLPEGASAVGESSVRSQEDQLSRRLAALRN -------------------------------------------------------------- >25724_25724_5_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000367114_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=3196nt_BP=1254nt CGCGGCCGGGCCCCAGCATGGCTGCCCCCACGGCTGAGGGCCTGGCAGCTGCTGCGCCCTCGCTTTCTTGACATTCCCTGGCTTCTGTGC TCTCTTCCCCAGGCCACCCCAGCAGACATGTTTGCCAAGGCCTTTCGGGTCAAGTCCAACACGGCCATCAAGGGGTCGGACAGGAGAAAG CTTCGAGCTGATGTGACAACTGCTTTCCCCACCCTTGGAACTGATCAAGTCTCTGAGTTAGTACCTGGAAAGGAGGAGCTCAACATTGTG AAGTTGTATGCTCACAAAGGGGATGCAGTGACTGTGTACGTGAGTGGTGGTAACCCCATCCTCTTTGAACTGGAGAAAAATCTGTATCCA ACAGTGTACACGCTGTGGTCCTATCCTGATCTTCTGCCAACCTTTACAACATGGCCTCTGGTGCTCGAGAAACTGGTAGGGGGAGCAGAT TTGATGCTGCCTGGACTGGTGATGCCCCCTGCTGGTCTGCCTCAGGTACAGAAGGGCGACCTCTGTGCCATTTCTTTGGTGGGGAACAGA GCCCCTGTAGCCATTGGAGTTGCAGCCATGTCCACAGCTGAGATGCTCACGTCAGGCCTGAAGGGAAGGGGCTTCTCTGTGCTCCACACT TACCAGGACCACTTGTGCCCTGAAGGACGACAACTGGACATAAAGAAGTCAAGCTACAAAAAGCTCTCTAAGTTCCTGCAGCAAATGCAG CAGGAGCAGATTATACAGGTGAAGGAGCTGAGCAAAGGGGTGGAGAGCATTGTGGCTGTGGACTGGAAACACCCGAGGATTACATCTTTC GTCATACCCGAGCCCTCCCCGACCTCCCAGACTATCCAGGAGGGTAGCAGGGAACAGCCCTATCACCCTCCAGATATAAAACCCCTCTAC TGTGTCCCAGCCAGCATGACCCTGCTCTTCCAGGAGTCTGGCCACAAGAAGGGGAGCTTTCTGGAGGGCAGTGAGGTCCGAACGATCGTC ATTAACTACGCCAAGAAAAATGACCTGGTTGATGCAGACAACAAAAATCTTGTGAGATTGGATCCCATCCTATGTGACTGCATCTTAGAG AAAAATGAACAGCATACAGTCATGAAGCTTCCATGGGACAGTCTTCTGACCAGGTGTTTGGAAAAATTACAGCCTGCCTATCAAGTGACC CTTCCCGGACAAGAGCCCATTGTGAAGAAAGGGAGAATCTGTCCAATTGACATCACCCTAGCACAAAGAGCGTCTAATAAAAAGGTGACC AAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAG CAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTG GACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGC GAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTC TGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTC TGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTT CTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGG GGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCC TCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATG TCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACC AGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGA TCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTT GTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCG GAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTGCCTTCCCCGACCAC ACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCT GTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAG CCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGG TGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGC TGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTG GGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTC CTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTT GGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGT >25724_25724_5_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000367114_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=523AA_BP=411 MPPRLRAWQLLRPRFLDIPWLLCSLPQATPADMFAKAFRVKSNTAIKGSDRRKLRADVTTAFPTLGTDQVSELVPGKEELNIVKLYAHKG DAVTVYVSGGNPILFELEKNLYPTVYTLWSYPDLLPTFTTWPLVLEKLVGGADLMLPGLVMPPAGLPQVQKGDLCAISLVGNRAPVAIGV AAMSTAEMLTSGLKGRGFSVLHTYQDHLCPEGRQLDIKKSSYKKLSKFLQQMQQEQIIQVKELSKGVESIVAVDWKHPRITSFVIPEPSP TSQTIQEGSREQPYHPPDIKPLYCVPASMTLLFQESGHKKGSFLEGSEVRTIVINYAKKNDLVDADNKNLVRLDPILCDCILEKNEQHTV MKLPWDSLLTRCLEKLQPAYQVTLPGQEPIVKKGRICPIDITLAQRASNKKVTKNMAQVTKALDKALSTMDLQKVSSVMDRFEQQVQNLD VHTSVMEDSMSSATTLTTPQEQVDSLIMQIAEENGLEVLDQLSQLPEGASAVGESSVRSQEDQLSRRLAALRN -------------------------------------------------------------- >25724_25724_6_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000367114_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=1770nt_BP=1254nt CGCGGCCGGGCCCCAGCATGGCTGCCCCCACGGCTGAGGGCCTGGCAGCTGCTGCGCCCTCGCTTTCTTGACATTCCCTGGCTTCTGTGC TCTCTTCCCCAGGCCACCCCAGCAGACATGTTTGCCAAGGCCTTTCGGGTCAAGTCCAACACGGCCATCAAGGGGTCGGACAGGAGAAAG CTTCGAGCTGATGTGACAACTGCTTTCCCCACCCTTGGAACTGATCAAGTCTCTGAGTTAGTACCTGGAAAGGAGGAGCTCAACATTGTG AAGTTGTATGCTCACAAAGGGGATGCAGTGACTGTGTACGTGAGTGGTGGTAACCCCATCCTCTTTGAACTGGAGAAAAATCTGTATCCA ACAGTGTACACGCTGTGGTCCTATCCTGATCTTCTGCCAACCTTTACAACATGGCCTCTGGTGCTCGAGAAACTGGTAGGGGGAGCAGAT TTGATGCTGCCTGGACTGGTGATGCCCCCTGCTGGTCTGCCTCAGGTACAGAAGGGCGACCTCTGTGCCATTTCTTTGGTGGGGAACAGA GCCCCTGTAGCCATTGGAGTTGCAGCCATGTCCACAGCTGAGATGCTCACGTCAGGCCTGAAGGGAAGGGGCTTCTCTGTGCTCCACACT TACCAGGACCACTTGTGCCCTGAAGGACGACAACTGGACATAAAGAAGTCAAGCTACAAAAAGCTCTCTAAGTTCCTGCAGCAAATGCAG CAGGAGCAGATTATACAGGTGAAGGAGCTGAGCAAAGGGGTGGAGAGCATTGTGGCTGTGGACTGGAAACACCCGAGGATTACATCTTTC GTCATACCCGAGCCCTCCCCGACCTCCCAGACTATCCAGGAGGGTAGCAGGGAACAGCCCTATCACCCTCCAGATATAAAACCCCTCTAC TGTGTCCCAGCCAGCATGACCCTGCTCTTCCAGGAGTCTGGCCACAAGAAGGGGAGCTTTCTGGAGGGCAGTGAGGTCCGAACGATCGTC ATTAACTACGCCAAGAAAAATGACCTGGTTGATGCAGACAACAAAAATCTTGTGAGATTGGATCCCATCCTATGTGACTGCATCTTAGAG AAAAATGAACAGCATACAGTCATGAAGCTTCCATGGGACAGTCTTCTGACCAGGTGTTTGGAAAAATTACAGCCTGCCTATCAAGTGACC CTTCCCGGACAAGAGCCCATTGTGAAGAAAGGGAGAATCTGTCCAATTGACATCACCCTAGCACAAAGAGCGTCTAATAAAAAGGTGACC AAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAG CAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTG GACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGC GAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTC TGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTC TGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGG >25724_25724_6_EIF2D-CHMP1A_EIF2D_chr1_206769067_ENST00000367114_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=523AA_BP=411 MPPRLRAWQLLRPRFLDIPWLLCSLPQATPADMFAKAFRVKSNTAIKGSDRRKLRADVTTAFPTLGTDQVSELVPGKEELNIVKLYAHKG DAVTVYVSGGNPILFELEKNLYPTVYTLWSYPDLLPTFTTWPLVLEKLVGGADLMLPGLVMPPAGLPQVQKGDLCAISLVGNRAPVAIGV AAMSTAEMLTSGLKGRGFSVLHTYQDHLCPEGRQLDIKKSSYKKLSKFLQQMQQEQIIQVKELSKGVESIVAVDWKHPRITSFVIPEPSP TSQTIQEGSREQPYHPPDIKPLYCVPASMTLLFQESGHKKGSFLEGSEVRTIVINYAKKNDLVDADNKNLVRLDPILCDCILEKNEQHTV MKLPWDSLLTRCLEKLQPAYQVTLPGQEPIVKKGRICPIDITLAQRASNKKVTKNMAQVTKALDKALSTMDLQKVSSVMDRFEQQVQNLD VHTSVMEDSMSSATTLTTPQEQVDSLIMQIAEENGLEVLDQLSQLPEGASAVGESSVRSQEDQLSRRLAALRN -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EIF2D-CHMP1A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EIF2D-CHMP1A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EIF2D-CHMP1A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0266468 | Congenital pontocerebellar hypoplasia | 1 | GENOMICS_ENGLAND | |
| Tgene | C3554209 | Congenital pontocerebellar hypoplasia type 8 | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies