
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EGFR-ERBB3 (FusionGDB2 ID:HG1956TG2065) |
Fusion Gene Summary for EGFR-ERBB3 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EGFR-ERBB3 | Fusion gene ID: hg1956tg2065 | Hgene | Tgene | Gene symbol | EGFR | ERBB3 | Gene ID | 1956 | 2065 |
| Gene name | epidermal growth factor receptor | erb-b2 receptor tyrosine kinase 3 | |
| Synonyms | ERBB|ERBB1|HER1|NISBD2|PIG61|mENA | ErbB-3|FERLK|HER3|LCCS2|MDA-BF-1|c-erbB-3|c-erbB3|erbB3-S|p180-ErbB3|p45-sErbB3|p85-sErbB3 | |
| Cytomap | ('EGFR')('ERBB3') 7p11.2 | 12q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | epidermal growth factor receptoravian erythroblastic leukemia viral (v-erb-b) oncogene homologcell growth inhibiting protein 40cell proliferation-inducing protein 61epidermal growth factor receptor tyrosine kinase domainerb-b2 receptor tyrosine kinas | receptor tyrosine-protein kinase erbB-3human epidermal growth factor receptor 3proto-oncogene-like protein c-ErbB-3tyrosine kinase-type cell surface receptor HER3v-erb-b2 avian erythroblastic leukemia viral oncogene homolog 3 | |
| Modification date | 20200329 | 20200327 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000463948, ENST00000275493, ENST00000342916, ENST00000344576, ENST00000420316, ENST00000442591, ENST00000455089, ENST00000454757, | ENST00000275493, ENST00000342916, ENST00000344576, ENST00000420316, ENST00000442591, ENST00000454757, ENST00000463948, ENST00000455089, | |
| Fusion gene scores | * DoF score | 41 X 25 X 14=14350 | 28 X 12 X 14=4704 |
| # samples | 53 | 28 | |
| ** MAII score | log2(53/14350*10)=-4.75891456699985 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(28/4704*10)=-4.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: EGFR [Title/Abstract] AND ERBB3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | EGFR(55087058)-ERBB3(56492542), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | EGFR-ERBB3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EGFR-ERBB3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. EGFR-ERBB3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. EGFR-ERBB3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ERBB3-EGFR seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ERBB3-EGFR seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | EGFR | GO:0001934 | positive regulation of protein phosphorylation | 20551055 |
| Hgene | EGFR | GO:0007165 | signal transduction | 10572067 |
| Hgene | EGFR | GO:0007166 | cell surface receptor signaling pathway | 7736574 |
| Hgene | EGFR | GO:0007173 | epidermal growth factor receptor signaling pathway | 7736574|12435727 |
| Hgene | EGFR | GO:0008283 | cell proliferation | 17115032 |
| Hgene | EGFR | GO:0008284 | positive regulation of cell proliferation | 7736574 |
| Hgene | EGFR | GO:0010750 | positive regulation of nitric oxide mediated signal transduction | 12828935 |
| Hgene | EGFR | GO:0018108 | peptidyl-tyrosine phosphorylation | 22732145 |
| Hgene | EGFR | GO:0030307 | positive regulation of cell growth | 15467833 |
| Hgene | EGFR | GO:0042177 | negative regulation of protein catabolic process | 17115032 |
| Hgene | EGFR | GO:0042327 | positive regulation of phosphorylation | 15082764 |
| Hgene | EGFR | GO:0043406 | positive regulation of MAP kinase activity | 10572067 |
| Hgene | EGFR | GO:0045739 | positive regulation of DNA repair | 17115032 |
| Hgene | EGFR | GO:0045740 | positive regulation of DNA replication | 17115032 |
| Hgene | EGFR | GO:0045944 | positive regulation of transcription by RNA polymerase II | 20551055 |
| Hgene | EGFR | GO:0050679 | positive regulation of epithelial cell proliferation | 10572067 |
| Hgene | EGFR | GO:0050999 | regulation of nitric-oxide synthase activity | 12828935 |
| Hgene | EGFR | GO:0070141 | response to UV-A | 18483258 |
| Hgene | EGFR | GO:0070374 | positive regulation of ERK1 and ERK2 cascade | 20551055 |
| Hgene | EGFR | GO:0071392 | cellular response to estradiol stimulus | 20551055 |
| Hgene | EGFR | GO:1900020 | positive regulation of protein kinase C activity | 22732145 |
| Hgene | EGFR | GO:1903078 | positive regulation of protein localization to plasma membrane | 22732145 |
| Tgene | ERBB3 | GO:0007162 | negative regulation of cell adhesion | 7556068 |
| Tgene | ERBB3 | GO:0007165 | signal transduction | 10572067 |
| Tgene | ERBB3 | GO:0009968 | negative regulation of signal transduction | 11389077 |
| Tgene | ERBB3 | GO:0014065 | phosphatidylinositol 3-kinase signaling | 7556068 |
| Tgene | ERBB3 | GO:0042127 | regulation of cell proliferation | 11389077 |
| Tgene | ERBB3 | GO:0051048 | negative regulation of secretion | 10559227 |
| Fusion gene breakpoints across EGFR (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
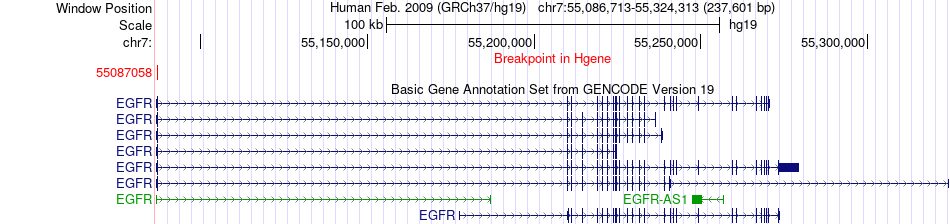 |
| Fusion gene breakpoints across ERBB3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
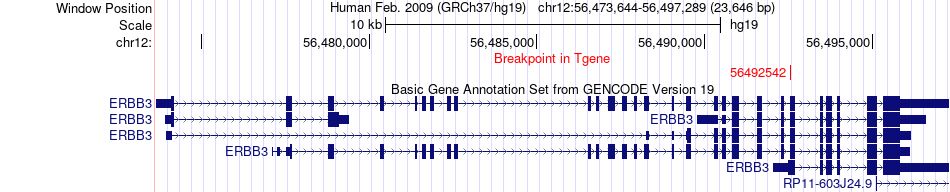 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-A486 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
Top |
Fusion Gene ORF analysis for EGFR-ERBB3 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000463948 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 3UTR-3CDS | ENST00000463948 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 3UTR-3CDS | ENST00000463948 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 3UTR-3CDS | ENST00000463948 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 3UTR-intron | ENST00000463948 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 3UTR-intron | ENST00000463948 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000275493 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000275493 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000342916 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000342916 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000344576 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000344576 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000420316 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000420316 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000442591 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000442591 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000455089 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| 5CDS-intron | ENST00000455089 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000275493 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000275493 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000275493 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000275493 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000342916 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000342916 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000342916 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000342916 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000344576 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000344576 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000344576 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000344576 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000420316 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000420316 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000420316 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000420316 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000442591 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000442591 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000442591 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000442591 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000455089 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000455089 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000455089 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| In-frame | ENST00000455089 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| intron-3CDS | ENST00000454757 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| intron-3CDS | ENST00000454757 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| intron-3CDS | ENST00000454757 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| intron-3CDS | ENST00000454757 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| intron-intron | ENST00000454757 | ENST00000411731 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| intron-intron | ENST00000454757 | ENST00000549832 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000455089 | EGFR | chr7 | 55087058 | + | ENST00000267101 | ERBB3 | chr12 | 56492542 | + | 3132 | 345 | 257 | 1681 | 474 |
| ENST00000455089 | EGFR | chr7 | 55087058 | + | ENST00000450146 | ERBB3 | chr12 | 56492542 | + | 2001 | 345 | 257 | 1681 | 474 |
| ENST00000455089 | EGFR | chr7 | 55087058 | + | ENST00000415288 | ERBB3 | chr12 | 56492542 | + | 1963 | 345 | 257 | 1681 | 474 |
| ENST00000455089 | EGFR | chr7 | 55087058 | + | ENST00000553131 | ERBB3 | chr12 | 56492542 | + | 2433 | 345 | 257 | 1681 | 474 |
| ENST00000342916 | EGFR | chr7 | 55087058 | + | ENST00000267101 | ERBB3 | chr12 | 56492542 | + | 3121 | 334 | 246 | 1670 | 474 |
| ENST00000342916 | EGFR | chr7 | 55087058 | + | ENST00000450146 | ERBB3 | chr12 | 56492542 | + | 1990 | 334 | 246 | 1670 | 474 |
| ENST00000342916 | EGFR | chr7 | 55087058 | + | ENST00000415288 | ERBB3 | chr12 | 56492542 | + | 1952 | 334 | 246 | 1670 | 474 |
| ENST00000342916 | EGFR | chr7 | 55087058 | + | ENST00000553131 | ERBB3 | chr12 | 56492542 | + | 2422 | 334 | 246 | 1670 | 474 |
| ENST00000344576 | EGFR | chr7 | 55087058 | + | ENST00000267101 | ERBB3 | chr12 | 56492542 | + | 3120 | 333 | 245 | 1669 | 474 |
| ENST00000344576 | EGFR | chr7 | 55087058 | + | ENST00000450146 | ERBB3 | chr12 | 56492542 | + | 1989 | 333 | 245 | 1669 | 474 |
| ENST00000344576 | EGFR | chr7 | 55087058 | + | ENST00000415288 | ERBB3 | chr12 | 56492542 | + | 1951 | 333 | 245 | 1669 | 474 |
| ENST00000344576 | EGFR | chr7 | 55087058 | + | ENST00000553131 | ERBB3 | chr12 | 56492542 | + | 2421 | 333 | 245 | 1669 | 474 |
| ENST00000420316 | EGFR | chr7 | 55087058 | + | ENST00000267101 | ERBB3 | chr12 | 56492542 | + | 3119 | 332 | 244 | 1668 | 474 |
| ENST00000420316 | EGFR | chr7 | 55087058 | + | ENST00000450146 | ERBB3 | chr12 | 56492542 | + | 1988 | 332 | 244 | 1668 | 474 |
| ENST00000420316 | EGFR | chr7 | 55087058 | + | ENST00000415288 | ERBB3 | chr12 | 56492542 | + | 1950 | 332 | 244 | 1668 | 474 |
| ENST00000420316 | EGFR | chr7 | 55087058 | + | ENST00000553131 | ERBB3 | chr12 | 56492542 | + | 2420 | 332 | 244 | 1668 | 474 |
| ENST00000275493 | EGFR | chr7 | 55087058 | + | ENST00000267101 | ERBB3 | chr12 | 56492542 | + | 3052 | 265 | 177 | 1601 | 474 |
| ENST00000275493 | EGFR | chr7 | 55087058 | + | ENST00000450146 | ERBB3 | chr12 | 56492542 | + | 1921 | 265 | 177 | 1601 | 474 |
| ENST00000275493 | EGFR | chr7 | 55087058 | + | ENST00000415288 | ERBB3 | chr12 | 56492542 | + | 1883 | 265 | 177 | 1601 | 474 |
| ENST00000275493 | EGFR | chr7 | 55087058 | + | ENST00000553131 | ERBB3 | chr12 | 56492542 | + | 2353 | 265 | 177 | 1601 | 474 |
| ENST00000442591 | EGFR | chr7 | 55087058 | + | ENST00000267101 | ERBB3 | chr12 | 56492542 | + | 3035 | 248 | 160 | 1584 | 474 |
| ENST00000442591 | EGFR | chr7 | 55087058 | + | ENST00000450146 | ERBB3 | chr12 | 56492542 | + | 1904 | 248 | 160 | 1584 | 474 |
| ENST00000442591 | EGFR | chr7 | 55087058 | + | ENST00000415288 | ERBB3 | chr12 | 56492542 | + | 1866 | 248 | 160 | 1584 | 474 |
| ENST00000442591 | EGFR | chr7 | 55087058 | + | ENST00000553131 | ERBB3 | chr12 | 56492542 | + | 2336 | 248 | 160 | 1584 | 474 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000455089 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.001068056 | 0.99893194 |
| ENST00000455089 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003316779 | 0.9966832 |
| ENST00000455089 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003487088 | 0.99651295 |
| ENST00000455089 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.002356968 | 0.99764305 |
| ENST00000342916 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.001050261 | 0.9989498 |
| ENST00000342916 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003303079 | 0.99669695 |
| ENST00000342916 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003464836 | 0.9965352 |
| ENST00000342916 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.002335505 | 0.9976646 |
| ENST00000344576 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.001044626 | 0.99895537 |
| ENST00000344576 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003261719 | 0.99673826 |
| ENST00000344576 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003415711 | 0.9965843 |
| ENST00000344576 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.00230784 | 0.9976922 |
| ENST00000420316 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.001048503 | 0.99895144 |
| ENST00000420316 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003263816 | 0.9967361 |
| ENST00000420316 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003419306 | 0.99658066 |
| ENST00000420316 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.00231241 | 0.9976876 |
| ENST00000275493 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.000959126 | 0.9990409 |
| ENST00000275493 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003112942 | 0.996887 |
| ENST00000275493 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003270369 | 0.9967296 |
| ENST00000275493 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.002142704 | 0.9978573 |
| ENST00000442591 | ENST00000267101 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.000915118 | 0.99908483 |
| ENST00000442591 | ENST00000450146 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003002028 | 0.99699795 |
| ENST00000442591 | ENST00000415288 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.003122724 | 0.9968773 |
| ENST00000442591 | ENST00000553131 | EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.002050794 | 0.9979492 |
Top |
Fusion Genomic Features for EGFR-ERBB3 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.19671807 | 0.8032819 |
| EGFR | chr7 | 55087058 | + | ERBB3 | chr12 | 56492542 | + | 0.19671807 | 0.8032819 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
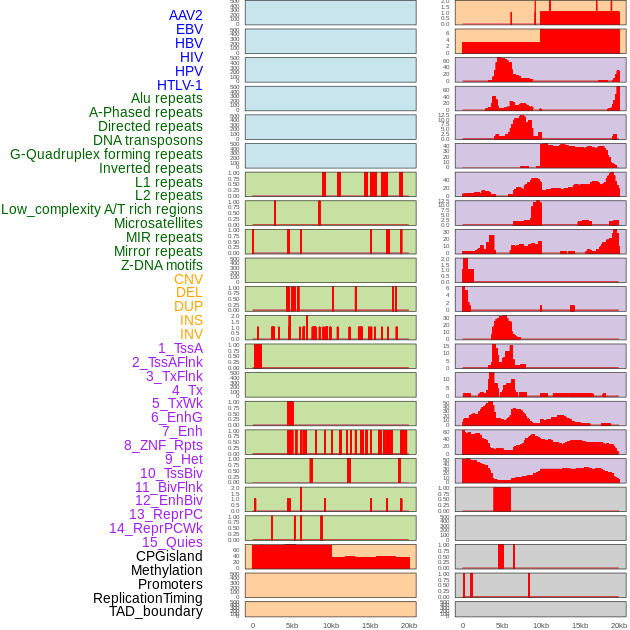 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
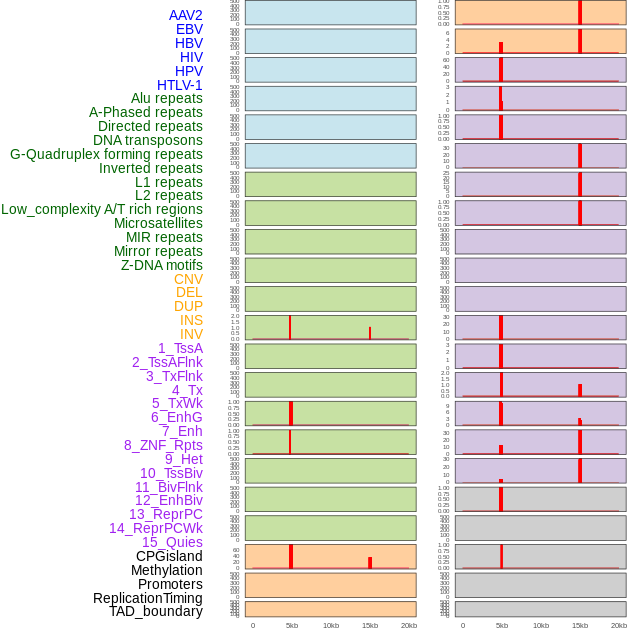 |
Top |
Fusion Protein Features for EGFR-ERBB3 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:55087058/chr12:56492542) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000411731 | 0 | 3 | 709_966 | 0 | 184.0 | Domain | Protein kinase | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000450146 | 8 | 15 | 709_966 | 254 | 700.0 | Domain | Protein kinase | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000411731 | 0 | 3 | 715_723 | 0 | 184.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000411731 | 0 | 3 | 788_790 | 0 | 184.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000411731 | 0 | 3 | 834_839 | 0 | 184.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000450146 | 8 | 15 | 715_723 | 254 | 700.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000450146 | 8 | 15 | 788_790 | 254 | 700.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000450146 | 8 | 15 | 834_839 | 254 | 700.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000411731 | 0 | 3 | 20_643 | 0 | 184.0 | Topological domain | Extracellular | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000411731 | 0 | 3 | 665_1342 | 0 | 184.0 | Topological domain | Cytoplasmic | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000450146 | 8 | 15 | 665_1342 | 254 | 700.0 | Topological domain | Cytoplasmic | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000411731 | 0 | 3 | 644_664 | 0 | 184.0 | Transmembrane | Helical | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000450146 | 8 | 15 | 644_664 | 254 | 700.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 712_979 | 29 | 1211.0 | Domain | Protein kinase |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 712_979 | 29 | 629.0 | Domain | Protein kinase |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 712_979 | 29 | 706.0 | Domain | Protein kinase |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 712_979 | 29 | 406.0 | Domain | Protein kinase |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 718_726 | 29 | 1211.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 790_791 | 29 | 1211.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 718_726 | 29 | 629.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 790_791 | 29 | 629.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 718_726 | 29 | 706.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 790_791 | 29 | 706.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 718_726 | 29 | 406.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 790_791 | 29 | 406.0 | Nucleotide binding | ATP |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 688_704 | 29 | 1211.0 | Region | Note=Important for dimerization%2C phosphorylation and activation |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 688_704 | 29 | 629.0 | Region | Note=Important for dimerization%2C phosphorylation and activation |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 688_704 | 29 | 706.0 | Region | Note=Important for dimerization%2C phosphorylation and activation |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 688_704 | 29 | 406.0 | Region | Note=Important for dimerization%2C phosphorylation and activation |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 390_600 | 29 | 1211.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 75_300 | 29 | 1211.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 390_600 | 29 | 629.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 75_300 | 29 | 629.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 390_600 | 29 | 706.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 75_300 | 29 | 706.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 390_600 | 29 | 406.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 75_300 | 29 | 406.0 | Repeat | Note=Approximate |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 25_645 | 29 | 1211.0 | Topological domain | Extracellular |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 669_1210 | 29 | 1211.0 | Topological domain | Cytoplasmic |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 25_645 | 29 | 629.0 | Topological domain | Extracellular |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 669_1210 | 29 | 629.0 | Topological domain | Cytoplasmic |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 25_645 | 29 | 706.0 | Topological domain | Extracellular |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 669_1210 | 29 | 706.0 | Topological domain | Cytoplasmic |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 25_645 | 29 | 406.0 | Topological domain | Extracellular |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 669_1210 | 29 | 406.0 | Topological domain | Cytoplasmic |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000275493 | + | 1 | 28 | 646_668 | 29 | 1211.0 | Transmembrane | Helical |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000342916 | + | 1 | 16 | 646_668 | 29 | 629.0 | Transmembrane | Helical |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000344576 | + | 1 | 16 | 646_668 | 29 | 706.0 | Transmembrane | Helical |
| Hgene | EGFR | chr7:55087058 | chr12:56492542 | ENST00000420316 | + | 1 | 10 | 646_668 | 29 | 406.0 | Transmembrane | Helical |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000267101 | 21 | 28 | 709_966 | 897 | 1343.0 | Domain | Protein kinase | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000415288 | 22 | 29 | 709_966 | 838 | 1284.0 | Domain | Protein kinase | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000267101 | 21 | 28 | 715_723 | 897 | 1343.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000267101 | 21 | 28 | 788_790 | 897 | 1343.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000267101 | 21 | 28 | 834_839 | 897 | 1343.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000415288 | 22 | 29 | 715_723 | 838 | 1284.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000415288 | 22 | 29 | 788_790 | 838 | 1284.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000415288 | 22 | 29 | 834_839 | 838 | 1284.0 | Nucleotide binding | Note=ATP | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000267101 | 21 | 28 | 20_643 | 897 | 1343.0 | Topological domain | Extracellular | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000267101 | 21 | 28 | 665_1342 | 897 | 1343.0 | Topological domain | Cytoplasmic | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000415288 | 22 | 29 | 20_643 | 838 | 1284.0 | Topological domain | Extracellular | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000415288 | 22 | 29 | 665_1342 | 838 | 1284.0 | Topological domain | Cytoplasmic | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000450146 | 8 | 15 | 20_643 | 254 | 700.0 | Topological domain | Extracellular | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000267101 | 21 | 28 | 644_664 | 897 | 1343.0 | Transmembrane | Helical | |
| Tgene | ERBB3 | chr7:55087058 | chr12:56492542 | ENST00000415288 | 22 | 29 | 644_664 | 838 | 1284.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for EGFR-ERBB3 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >25452_25452_1_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000267101_length(transcript)=3052nt_BP=265nt GCCGGAGTCCCGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGC CGCCAACGCCACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATG CGACCCTCCGGGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTG ACAGTTTGGGAGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGG TTGGCACAGCCCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAA GAACTAGCCAATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGG CCAGAGCCCCATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAG GACAACCTGGCAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGT CCATCATCTGGATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCC CGTCCAGTCTCTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAG GAGAAAGTGTCAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTG CTGACTCCTGTTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACT CCCTCCTCCCGGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATAC ATGAACCGGAGGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCA GACCTCAGTGCCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGAC TATGAATATATGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTAT GAAGAGATGAGAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACA GACTCTGCCTTTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCA CTCAGGGAGCATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCC CAGTCCCAGACAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTT CTCTTTCCCAACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATAT GAAGGATTACTCTCCATATCCCTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTC AAGAAGAGGAAAGGGAGGAAACCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCT GTGAAGAAAGAGGTTAGGAGTAGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACAT TATCTCACTTAGTCCTTTATCATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCT CATGCCTGTAATCTCAGCACTTTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGA CCCCCATCTCTTTAAAAAAAAAAAAAAAAAAAAAAAAAAAACTTTAGAACTGGGTGCAGTGGCTCATGCCTGTAATCCCAGCCAGCACTT TGGGAGGCTGAGATGGGAAGATCACTTGAGCCCAGAATTAGAGATAAGCCTATGGAAACATAGCAAGACACTGTCTCTACAGGGGAAAAA AAAAAAAGAAACTGAGCCTTAAAGAGATGAAATAAATTAAGCAGTAGATCCAGGATGCAAAATCCTCCCAATTCCTGTGCATGTGCTCTT ATTGTAAGGTGCCAAGAAAAACTGATTTAAGTTACAGCCCTTGTTTAAGGGGCACTGTTTCTTGTTTTTGCACTGAATCAAGTCTAACCC CAACAGCCACATCCTCCTATACCTAGACATCTCATCTCAGGAAGTGGTGGTGGGGGTAGTCAGAAGGAAAAATAACTGGACATCTTTGTG TAAACCATAATCCACATGTGCCGTAAATGATCTTCACTCCTTATCCGAGGGCAAATTCACAAGGATCCCCAAGATCCACTTTTAGAAGCC ATTCTCATCCAGCAGTGAGAAGCTTCCAGGTAGGACAGAAAAAAGATCCAGCTTCAGCTGCACACCTCTGTCCCCTTGGATGGGGAACTA AGGGAAAACGTCTGTTGTATCACTGAAGTTTTTTGTTTTGTTTTTATACGTGTCTGAATAAAAATGCCAAAGTTTTTTTTCA >25452_25452_1_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000267101_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_2_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000415288_length(transcript)=1883nt_BP=265nt GCCGGAGTCCCGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGC CGCCAACGCCACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATG CGACCCTCCGGGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTG ACAGTTTGGGAGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGG TTGGCACAGCCCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAA GAACTAGCCAATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGG CCAGAGCCCCATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAG GACAACCTGGCAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGT CCATCATCTGGATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCC CGTCCAGTCTCTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAG GAGAAAGTGTCAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTG CTGACTCCTGTTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACT CCCTCCTCCCGGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATAC ATGAACCGGAGGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCA GACCTCAGTGCCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGAC TATGAATATATGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTAT GAAGAGATGAGAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACA GACTCTGCCTTTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCA CTCAGGGAGCATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCC CAGTCCCAGACAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTT CTCTTTCCCAACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTG >25452_25452_2_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000415288_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_3_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000450146_length(transcript)=1921nt_BP=265nt GCCGGAGTCCCGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGC CGCCAACGCCACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATG CGACCCTCCGGGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTG ACAGTTTGGGAGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGG TTGGCACAGCCCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAA GAACTAGCCAATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGG CCAGAGCCCCATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAG GACAACCTGGCAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGT CCATCATCTGGATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCC CGTCCAGTCTCTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAG GAGAAAGTGTCAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTG CTGACTCCTGTTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACT CCCTCCTCCCGGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATAC ATGAACCGGAGGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCA GACCTCAGTGCCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGAC TATGAATATATGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTAT GAAGAGATGAGAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACA GACTCTGCCTTTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCA CTCAGGGAGCATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCC CAGTCCCAGACAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTT CTCTTTCCCAACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATAT GAAGGATTACTCTCCATATCCCTTCCTCTCA >25452_25452_3_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000450146_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_4_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000553131_length(transcript)=2353nt_BP=265nt GCCGGAGTCCCGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGC CGCCAACGCCACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATG CGACCCTCCGGGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTG ACAGTTTGGGAGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGG TTGGCACAGCCCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAA GAACTAGCCAATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGG CCAGAGCCCCATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAG GACAACCTGGCAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGT CCATCATCTGGATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCC CGTCCAGTCTCTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAG GAGAAAGTGTCAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTG CTGACTCCTGTTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACT CCCTCCTCCCGGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATAC ATGAACCGGAGGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCA GACCTCAGTGCCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGAC TATGAATATATGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTAT GAAGAGATGAGAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACA GACTCTGCCTTTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCA CTCAGGGAGCATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCC CAGTCCCAGACAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTT CTCTTTCCCAACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATAT GAAGGATTACTCTCCATATCCCTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTC AAGAAGAGGAAAGGGAGGAAACCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCT GTGAAGAAAGAGGTTAGGAGTAGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACAT TATCTCACTTAGTCCTTTATCATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCT CATGCCTGTAATCTCAGCACTTTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGA CCCCCATCTCTTT >25452_25452_4_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000275493_ERBB3_chr12_56492542_ENST00000553131_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_5_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000267101_length(transcript)=3121nt_BP=334nt CCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCC CGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGC GCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGG GCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACC TTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGC ACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACC AGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACA AACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACA CTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCC ATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCA ATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGG AGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTC TCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACC CTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCAC AGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGC AGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAA CGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAG GGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCT GATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCA GCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTC AATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAA GGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCC CTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAGGAAA CCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAGGAGT AGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTTTATC ATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAGCACT TTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTTAAAAAAAA AAAAAAAAAAAAAAAAAAAACTTTAGAACTGGGTGCAGTGGCTCATGCCTGTAATCCCAGCCAGCACTTTGGGAGGCTGAGATGGGAAGA TCACTTGAGCCCAGAATTAGAGATAAGCCTATGGAAACATAGCAAGACACTGTCTCTACAGGGGAAAAAAAAAAAAGAAACTGAGCCTTA AAGAGATGAAATAAATTAAGCAGTAGATCCAGGATGCAAAATCCTCCCAATTCCTGTGCATGTGCTCTTATTGTAAGGTGCCAAGAAAAA CTGATTTAAGTTACAGCCCTTGTTTAAGGGGCACTGTTTCTTGTTTTTGCACTGAATCAAGTCTAACCCCAACAGCCACATCCTCCTATA CCTAGACATCTCATCTCAGGAAGTGGTGGTGGGGGTAGTCAGAAGGAAAAATAACTGGACATCTTTGTGTAAACCATAATCCACATGTGC CGTAAATGATCTTCACTCCTTATCCGAGGGCAAATTCACAAGGATCCCCAAGATCCACTTTTAGAAGCCATTCTCATCCAGCAGTGAGAA GCTTCCAGGTAGGACAGAAAAAAGATCCAGCTTCAGCTGCACACCTCTGTCCCCTTGGATGGGGAACTAAGGGAAAACGTCTGTTGTATC ACTGAAGTTTTTTGTTTTGTTTTTATACGTGTCTGAATAAAAATGCCAAAGTTTTTTTTCA >25452_25452_5_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000267101_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_6_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000415288_length(transcript)=1952nt_BP=334nt CCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCC CGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGC GCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGG GCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACC TTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGC ACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACC AGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACA AACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACA CTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCC ATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCA ATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGG AGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTC TCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACC CTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCAC AGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGC AGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAA CGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAG GGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCT GATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCA GCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTC AATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAA GGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTG >25452_25452_6_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000415288_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_7_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000450146_length(transcript)=1990nt_BP=334nt CCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCC CGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGC GCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGG GCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACC TTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGC ACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACC AGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACA AACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACA CTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCC ATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCA ATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGG AGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTC TCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACC CTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCAC AGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGC AGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAA CGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAG GGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCT GATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCA GCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTC AATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAA GGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCC CTTCCTCTCA >25452_25452_7_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000450146_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_8_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000553131_length(transcript)=2422nt_BP=334nt CCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCC CGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGC GCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGG GCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACC TTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGC ACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACC AGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACA AACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACA CTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCC ATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCA ATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGG AGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTC TCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACC CTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCAC AGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGC AGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAA CGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAG GGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCT GATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCA GCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTC AATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAA GGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCC CTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAGGAAA CCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAGGAGT AGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTTTATC ATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAGCACT TTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTT >25452_25452_8_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000342916_ERBB3_chr12_56492542_ENST00000553131_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_9_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000267101_length(transcript)=3120nt_BP=333nt CCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCC GGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCG CACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGG CAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCT TCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCA CAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCA GGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAA ACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACAC TGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCA TGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAA TGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGA GCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCT CCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCC TTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACA GTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCA GCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAAC GAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGG GGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTG ATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAG CTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCA ATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAG GTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCCC TTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAGGAAAC CTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAGGAGTA GATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTTTATCA TCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAGCACTT TGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTTAAAAAAAAA AAAAAAAAAAAAAAAAAAACTTTAGAACTGGGTGCAGTGGCTCATGCCTGTAATCCCAGCCAGCACTTTGGGAGGCTGAGATGGGAAGAT CACTTGAGCCCAGAATTAGAGATAAGCCTATGGAAACATAGCAAGACACTGTCTCTACAGGGGAAAAAAAAAAAAGAAACTGAGCCTTAA AGAGATGAAATAAATTAAGCAGTAGATCCAGGATGCAAAATCCTCCCAATTCCTGTGCATGTGCTCTTATTGTAAGGTGCCAAGAAAAAC TGATTTAAGTTACAGCCCTTGTTTAAGGGGCACTGTTTCTTGTTTTTGCACTGAATCAAGTCTAACCCCAACAGCCACATCCTCCTATAC CTAGACATCTCATCTCAGGAAGTGGTGGTGGGGGTAGTCAGAAGGAAAAATAACTGGACATCTTTGTGTAAACCATAATCCACATGTGCC GTAAATGATCTTCACTCCTTATCCGAGGGCAAATTCACAAGGATCCCCAAGATCCACTTTTAGAAGCCATTCTCATCCAGCAGTGAGAAG CTTCCAGGTAGGACAGAAAAAAGATCCAGCTTCAGCTGCACACCTCTGTCCCCTTGGATGGGGAACTAAGGGAAAACGTCTGTTGTATCA CTGAAGTTTTTTGTTTTGTTTTTATACGTGTCTGAATAAAAATGCCAAAGTTTTTTTTCA >25452_25452_9_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000267101_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_10_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000415288_length(transcript)=1951nt_BP=333nt CCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCC GGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCG CACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGG CAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCT TCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCA CAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCA GGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAA ACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACAC TGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCA TGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAA TGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGA GCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCT CCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCC TTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACA GTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCA GCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAAC GAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGG GGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTG ATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAG CTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCA ATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAG GTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTG >25452_25452_10_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000415288_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_11_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000450146_length(transcript)=1989nt_BP=333nt CCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCC GGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCG CACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGG CAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCT TCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCA CAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCA GGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAA ACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACAC TGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCA TGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAA TGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGA GCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCT CCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCC TTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACA GTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCA GCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAAC GAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGG GGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTG ATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAG CTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCA ATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAG GTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCCC TTCCTCTCA >25452_25452_11_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000450146_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_12_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000553131_length(transcript)=2421nt_BP=333nt CCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCC GGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCG CACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGG CAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCT TCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCA CAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCA GGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAA ACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACAC TGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCA TGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAA TGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGA GCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCT CCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCC TTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACA GTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCA GCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAAC GAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGG GGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTG ATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAG CTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCA ATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAG GTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCCC TTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAGGAAAC CTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAGGAGTA GATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTTTATCA TCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAGCACTT TGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTT >25452_25452_12_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000344576_ERBB3_chr12_56492542_ENST00000553131_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_13_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000267101_length(transcript)=3119nt_BP=332nt CCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCCG GCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCGC ACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGGC AGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCTT CGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCAC AATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCAG GATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAAA CAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACACT GGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCAT GAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAAT GCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGAG CCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCTC CCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCCT TTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACAG TCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCAG CACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAACG AGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGGG GCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTGA TTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAGC TAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCAA TCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAGG TTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCCCT TCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAGGAAACC TAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAGGAGTAG ATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTTTATCAT CCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAGCACTTT GGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTTAAAAAAAAAA AAAAAAAAAAAAAAAAAACTTTAGAACTGGGTGCAGTGGCTCATGCCTGTAATCCCAGCCAGCACTTTGGGAGGCTGAGATGGGAAGATC ACTTGAGCCCAGAATTAGAGATAAGCCTATGGAAACATAGCAAGACACTGTCTCTACAGGGGAAAAAAAAAAAAGAAACTGAGCCTTAAA GAGATGAAATAAATTAAGCAGTAGATCCAGGATGCAAAATCCTCCCAATTCCTGTGCATGTGCTCTTATTGTAAGGTGCCAAGAAAAACT GATTTAAGTTACAGCCCTTGTTTAAGGGGCACTGTTTCTTGTTTTTGCACTGAATCAAGTCTAACCCCAACAGCCACATCCTCCTATACC TAGACATCTCATCTCAGGAAGTGGTGGTGGGGGTAGTCAGAAGGAAAAATAACTGGACATCTTTGTGTAAACCATAATCCACATGTGCCG TAAATGATCTTCACTCCTTATCCGAGGGCAAATTCACAAGGATCCCCAAGATCCACTTTTAGAAGCCATTCTCATCCAGCAGTGAGAAGC TTCCAGGTAGGACAGAAAAAAGATCCAGCTTCAGCTGCACACCTCTGTCCCCTTGGATGGGGAACTAAGGGAAAACGTCTGTTGTATCAC TGAAGTTTTTTGTTTTGTTTTTATACGTGTCTGAATAAAAATGCCAAAGTTTTTTTTCA >25452_25452_13_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000267101_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_14_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000415288_length(transcript)=1950nt_BP=332nt CCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCCG GCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCGC ACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGGC AGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCTT CGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCAC AATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCAG GATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAAA CAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACACT GGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCAT GAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAAT GCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGAG CCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCTC CCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCCT TTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACAG TCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCAG CACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAACG AGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGGG GCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTGA TTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAGC TAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCAA TCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAGG TTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTG >25452_25452_14_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000415288_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_15_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000450146_length(transcript)=1988nt_BP=332nt CCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCCG GCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCGC ACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGGC AGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCTT CGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCAC AATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCAG GATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAAA CAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACACT GGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCAT GAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAAT GCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGAG CCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCTC CCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCCT TTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACAG TCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCAG CACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAACG AGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGGG GCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTGA TTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAGC TAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCAA TCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAGG TTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCCCT TCCTCTCA >25452_25452_15_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000450146_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_16_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000553131_length(transcript)=2420nt_BP=332nt CCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCCCGAGCTAGCCCCG GCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCACCGCGC ACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGCCGGGGC AGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGATGACCTT CGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGATCTGCAC AATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTTCACCAG GATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCTGACAAA CAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCACCACACT GGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACATGCCCAT GAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACACCCAAT GCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTGTAGGAG CCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCCACTCTC CCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGGCACCCT TTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAGGCACAG TCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCTGGGCAG CACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCGGCAACG AGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTTTCAGGG GCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAACCCTGA TTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAATGGCAGC TAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCCATTCAA TCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAGGAAAGG TTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCATATCCCT TCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAGGAAACC TAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAGGAGTAG ATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTTTATCAT CCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAGCACTTT GGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTT >25452_25452_16_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000420316_ERBB3_chr12_56492542_ENST00000553131_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_17_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000267101_length(transcript)=3035nt_BP=248nt GCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCA CCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGC CGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGAT GACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGAT CTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTT CACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCT GACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCAC CACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACAT GCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACA CCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTG TAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCC ACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGG CACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAG GCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCT GGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCG GCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTT TCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAA CCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAAT GGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCC ATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAG GAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCAT ATCCCTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAG GAAACCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAG GAGTAGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTT TATCATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAG CACTTTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTTAAAA AAAAAAAAAAAAAAAAAAAAAAAACTTTAGAACTGGGTGCAGTGGCTCATGCCTGTAATCCCAGCCAGCACTTTGGGAGGCTGAGATGGG AAGATCACTTGAGCCCAGAATTAGAGATAAGCCTATGGAAACATAGCAAGACACTGTCTCTACAGGGGAAAAAAAAAAAAGAAACTGAGC CTTAAAGAGATGAAATAAATTAAGCAGTAGATCCAGGATGCAAAATCCTCCCAATTCCTGTGCATGTGCTCTTATTGTAAGGTGCCAAGA AAAACTGATTTAAGTTACAGCCCTTGTTTAAGGGGCACTGTTTCTTGTTTTTGCACTGAATCAAGTCTAACCCCAACAGCCACATCCTCC TATACCTAGACATCTCATCTCAGGAAGTGGTGGTGGGGGTAGTCAGAAGGAAAAATAACTGGACATCTTTGTGTAAACCATAATCCACAT GTGCCGTAAATGATCTTCACTCCTTATCCGAGGGCAAATTCACAAGGATCCCCAAGATCCACTTTTAGAAGCCATTCTCATCCAGCAGTG AGAAGCTTCCAGGTAGGACAGAAAAAAGATCCAGCTTCAGCTGCACACCTCTGTCCCCTTGGATGGGGAACTAAGGGAAAACGTCTGTTG TATCACTGAAGTTTTTTGTTTTGTTTTTATACGTGTCTGAATAAAAATGCCAAAGTTTTTTTTCA >25452_25452_17_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000267101_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_18_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000415288_length(transcript)=1866nt_BP=248nt GCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCA CCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGC CGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGAT GACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGAT CTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTT CACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCT GACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCAC CACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACAT GCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACA CCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTG TAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCC ACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGG CACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAG GCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCT GGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCG GCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTT TCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAA CCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAAT GGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCC ATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAG GAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTG >25452_25452_18_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000415288_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_19_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000450146_length(transcript)=1904nt_BP=248nt GCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCA CCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGC CGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGAT GACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGAT CTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTT CACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCT GACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCAC CACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACAT GCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACA CCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTG TAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCC ACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGG CACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAG GCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCT GGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCG GCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTT TCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAA CCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAAT GGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCC ATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAG GAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCAT ATCCCTTCCTCTCA >25452_25452_19_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000450146_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_20_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000553131_length(transcript)=2336nt_BP=248nt GCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCCACAACCA CCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCGGGACGGC CGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGGAGTTGAT GACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGCCCCAGAT CTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCAATGAGTT CACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCCATGGTCT GACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGGCAACCAC CACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTGGATACAT GCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCTCTCTACA CCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGTCAATGTG TAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTGTTACCCC ACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCCGGGAAGG CACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGAGGAGAAG GCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTGCCTCTCT GGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATATGAATCG GCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGAGAGCTTT TCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCTTTGATAA CCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGCATTTAAT GGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGACAATTCC ATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCAACCCCAG GAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTACTCTCCAT ATCCCTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGAAAGGGAG GAAACCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAGAGGTTAG GAGTAGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTTAGTCCTT TATCATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTAATCTCAG CACTTTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTCTTT >25452_25452_20_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000442591_ERBB3_chr12_56492542_ENST00000553131_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_21_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000267101_length(transcript)=3132nt_BP=345nt GTCCGGGCAGCCCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCC CGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCC ACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCG GGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGG AGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGC CCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCA ATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCC ATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGG CAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTG GATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCT CTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGT CAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTG TTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCC GGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGA GGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTG CCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATA TGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGA GAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCT TTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGC ATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGA CAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCA ACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTAC TCTCCATATCCCTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGA AAGGGAGGAAACCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAG AGGTTAGGAGTAGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTT AGTCCTTTATCATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTA ATCTCAGCACTTTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTC TTTAAAAAAAAAAAAAAAAAAAAAAAAAAAACTTTAGAACTGGGTGCAGTGGCTCATGCCTGTAATCCCAGCCAGCACTTTGGGAGGCTG AGATGGGAAGATCACTTGAGCCCAGAATTAGAGATAAGCCTATGGAAACATAGCAAGACACTGTCTCTACAGGGGAAAAAAAAAAAAGAA ACTGAGCCTTAAAGAGATGAAATAAATTAAGCAGTAGATCCAGGATGCAAAATCCTCCCAATTCCTGTGCATGTGCTCTTATTGTAAGGT GCCAAGAAAAACTGATTTAAGTTACAGCCCTTGTTTAAGGGGCACTGTTTCTTGTTTTTGCACTGAATCAAGTCTAACCCCAACAGCCAC ATCCTCCTATACCTAGACATCTCATCTCAGGAAGTGGTGGTGGGGGTAGTCAGAAGGAAAAATAACTGGACATCTTTGTGTAAACCATAA TCCACATGTGCCGTAAATGATCTTCACTCCTTATCCGAGGGCAAATTCACAAGGATCCCCAAGATCCACTTTTAGAAGCCATTCTCATCC AGCAGTGAGAAGCTTCCAGGTAGGACAGAAAAAAGATCCAGCTTCAGCTGCACACCTCTGTCCCCTTGGATGGGGAACTAAGGGAAAACG TCTGTTGTATCACTGAAGTTTTTTGTTTTGTTTTTATACGTGTCTGAATAAAAATGCCAAAGTTTTTTTTCA >25452_25452_21_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000267101_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_22_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000415288_length(transcript)=1963nt_BP=345nt GTCCGGGCAGCCCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCC CGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCC ACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCG GGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGG AGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGC CCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCA ATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCC ATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGG CAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTG GATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCT CTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGT CAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTG TTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCC GGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGA GGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTG CCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATA TGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGA GAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCT TTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGC ATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGA CAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCA ACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTG >25452_25452_22_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000415288_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_23_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000450146_length(transcript)=2001nt_BP=345nt GTCCGGGCAGCCCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCC CGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCC ACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCG GGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGG AGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGC CCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCA ATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCC ATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGG CAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTG GATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCT CTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGT CAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTG TTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCC GGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGA GGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTG CCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATA TGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGA GAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCT TTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGC ATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGA CAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCA ACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTAC TCTCCATATCCCTTCCTCTCA >25452_25452_23_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000450146_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- >25452_25452_24_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000553131_length(transcript)=2433nt_BP=345nt GTCCGGGCAGCCCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGGCCGGAGTCC CGAGCTAGCCCCGGCGGCCGCCGCCGCCCAGACCGGACGACAGGCCACCTCGTCGGCGTCCGCCCGAGTCCCCGCCTCGCCGCCAACGCC ACAACCACCGCGCACGGCCCCCTGACTCCGTCCAGTATTGATCGGGAGAGCCGGAGCGAGCTCTTCGGGGAGCAGCGATGCGACCCTCCG GGACGGCCGGGGCAGCGCTCCTGGCGCTGCTGGCTGCGCTCTGCCCGGCGAGTCGGGCTCTGGAGGAAAAGAAAGGTGTGACAGTTTGGG AGTTGATGACCTTCGGGGCAGAGCCCTATGCAGGGCTACGATTGGCTGAAGTACCAGACCTGCTAGAGAAGGGGGAGCGGTTGGCACAGC CCCAGATCTGCACAATTGATGTCTACATGGTGATGGTCAAGTGTTGGATGATTGATGAGAACATTCGCCCAACCTTTAAAGAACTAGCCA ATGAGTTCACCAGGATGGCCCGAGACCCACCACGGTATCTGGTCATAAAGAGAGAGAGTGGGCCTGGAATAGCCCCTGGGCCAGAGCCCC ATGGTCTGACAAACAAGAAGCTAGAGGAAGTAGAGCTGGAGCCAGAACTAGACCTAGACCTAGACTTGGAAGCAGAGGAGGACAACCTGG CAACCACCACACTGGGCTCCGCCCTCAGCCTACCAGTTGGAACACTTAATCGGCCACGTGGGAGCCAGAGCCTTTTAAGTCCATCATCTG GATACATGCCCATGAACCAGGGTAATCTTGGGGAGTCTTGCCAGGAGTCTGCAGTTTCTGGGAGCAGTGAACGGTGCCCCCGTCCAGTCT CTCTACACCCAATGCCACGGGGATGCCTGGCATCAGAGTCATCAGAGGGGCATGTAACAGGCTCTGAGGCTGAGCTCCAGGAGAAAGTGT CAATGTGTAGGAGCCGGAGCAGGAGCCGGAGCCCACGGCCACGCGGAGATAGCGCCTACCATTCCCAGCGCCACAGTCTGCTGACTCCTG TTACCCCACTCTCCCCACCCGGGTTAGAGGAAGAGGATGTCAACGGTTATGTCATGCCAGATACACACCTCAAAGGTACTCCCTCCTCCC GGGAAGGCACCCTTTCTTCAGTGGGTCTCAGTTCTGTCCTGGGTACTGAAGAAGAAGATGAAGATGAGGAGTATGAATACATGAACCGGA GGAGAAGGCACAGTCCACCTCATCCCCCTAGGCCAAGTTCCCTTGAGGAGCTGGGTTATGAGTACATGGATGTGGGGTCAGACCTCAGTG CCTCTCTGGGCAGCACACAGAGTTGCCCACTCCACCCTGTACCCATCATGCCCACTGCAGGCACAACTCCAGATGAAGACTATGAATATA TGAATCGGCAACGAGATGGAGGTGGTCCTGGGGGTGATTATGCAGCCATGGGGGCCTGCCCAGCATCTGAGCAAGGGTATGAAGAGATGA GAGCTTTTCAGGGGCCTGGACATCAGGCCCCCCATGTCCATTATGCCCGCCTAAAAACTCTACGTAGCTTAGAGGCTACAGACTCTGCCT TTGATAACCCTGATTACTGGCATAGCAGGCTTTTCCCCAAGGCTAATGCCCAGAGAACGTAACTCCTGCTCCCTGTGGCACTCAGGGAGC ATTTAATGGCAGCTAGTGCCTTTAGAGGGTACCGTCTTCTCCCTATTCCCTCTCTCTCCCAGGTCCCAGCCCCTTTTCCCCAGTCCCAGA CAATTCCATTCAATCTTTGGAGGCTTTTAAACATTTTGACACAAAATTCTTATGGTATGTAGCCAGCTGTGCACTTTCTTCTCTTTCCCA ACCCCAGGAAAGGTTTTCCTTATTTTGTGTGCTTTCCCAGTCCCATTCCTCAGCTTCTTCACAGGCACTCCTGGAGATATGAAGGATTAC TCTCCATATCCCTTCCTCTCAGGCTCTTGACTACTTGGAACTAGGCTCTTATGTGTGCCTTTGTTTCCCATCAGACTGTCAAGAAGAGGA AAGGGAGGAAACCTAGCAGAGGAAAGTGTAATTTTGGTTTATGACTCTTAACCCCCTAGAAAGACAGAAGCTTAAAATCTGTGAAGAAAG AGGTTAGGAGTAGATATTGATTACTATCATAATTCAGCACTTAACTATGAGCCAGGCATCATACTAAACTTCACCTACATTATCTCACTT AGTCCTTTATCATCCTTAAAACAATTCTGTGACATACATATTATCTCATTTTACACAAAGGGAAGTCGGGCATGGTGGCTCATGCCTGTA ATCTCAGCACTTTGGGAGGCTGAGGCAGAAGGATTACCTGAGGCAAGGAGTTTGAGACCAGCTTAGCCAACATAGTAAGACCCCCATCTC TTT >25452_25452_24_EGFR-ERBB3_EGFR_chr7_55087058_ENST00000455089_ERBB3_chr12_56492542_ENST00000553131_length(amino acids)=474AA_BP=29 MRPSGTAGAALLALLAALCPASRALEEKKGVTVWELMTFGAEPYAGLRLAEVPDLLEKGERLAQPQICTIDVYMVMVKCWMIDENIRPTF KELANEFTRMARDPPRYLVIKRESGPGIAPGPEPHGLTNKKLEEVELEPELDLDLDLEAEEDNLATTTLGSALSLPVGTLNRPRGSQSLL SPSSGYMPMNQGNLGESCQESAVSGSSERCPRPVSLHPMPRGCLASESSEGHVTGSEAELQEKVSMCRSRSRSRSPRPRGDSAYHSQRHS LLTPVTPLSPPGLEEEDVNGYVMPDTHLKGTPSSREGTLSSVGLSSVLGTEEEDEDEEYEYMNRRRRHSPPHPPRPSSLEELGYEYMDVG SDLSASLGSTQSCPLHPVPIMPTAGTTPDEDYEYMNRQRDGGGPGGDYAAMGACPASEQGYEEMRAFQGPGHQAPHVHYARLKTLRSLEA TDSAFDNPDYWHSRLFPKANAQRT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EGFR-ERBB3 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EGFR-ERBB3 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EGFR-ERBB3 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | EGFR | C0007131 | Non-Small Cell Lung Carcinoma | 16 | CGI;CTD_human |
| Hgene | EGFR | C0024121 | Lung Neoplasms | 7 | CGI;CTD_human |
| Hgene | EGFR | C0242379 | Malignant neoplasm of lung | 7 | CGI;CTD_human |
| Hgene | EGFR | C0006142 | Malignant neoplasm of breast | 6 | CTD_human |
| Hgene | EGFR | C0678222 | Breast Carcinoma | 6 | CTD_human |
| Hgene | EGFR | C1257931 | Mammary Neoplasms, Human | 6 | CTD_human |
| Hgene | EGFR | C1458155 | Mammary Neoplasms | 6 | CTD_human |
| Hgene | EGFR | C4704874 | Mammary Carcinoma, Human | 6 | CTD_human |
| Hgene | EGFR | C0001418 | Adenocarcinoma | 5 | CTD_human |
| Hgene | EGFR | C0205641 | Adenocarcinoma, Basal Cell | 5 | CTD_human |
| Hgene | EGFR | C0205642 | Adenocarcinoma, Oxyphilic | 5 | CTD_human |
| Hgene | EGFR | C0205643 | Carcinoma, Cribriform | 5 | CTD_human |
| Hgene | EGFR | C0205644 | Carcinoma, Granular Cell | 5 | CTD_human |
| Hgene | EGFR | C0205645 | Adenocarcinoma, Tubular | 5 | CTD_human |
| Hgene | EGFR | C0334588 | Giant Cell Glioblastoma | 5 | CTD_human;ORPHANET |
| Hgene | EGFR | C0007137 | Squamous cell carcinoma | 3 | CTD_human |
| Hgene | EGFR | C0007873 | Uterine Cervical Neoplasm | 3 | CTD_human |
| Hgene | EGFR | C0014859 | Esophageal Neoplasms | 3 | CGI;CTD_human |
| Hgene | EGFR | C0017636 | Glioblastoma | 3 | CGI;CTD_human |
| Hgene | EGFR | C0018671 | Head and Neck Neoplasms | 3 | CGI;CTD_human |
| Hgene | EGFR | C0018675 | Head Neoplasms | 3 | CTD_human |
| Hgene | EGFR | C0024623 | Malignant neoplasm of stomach | 3 | CTD_human |
| Hgene | EGFR | C0027533 | Neck Neoplasms | 3 | CTD_human |
| Hgene | EGFR | C0027627 | Neoplasm Metastasis | 3 | CTD_human |
| Hgene | EGFR | C0033578 | Prostatic Neoplasms | 3 | CTD_human |
| Hgene | EGFR | C0038356 | Stomach Neoplasms | 3 | CTD_human |
| Hgene | EGFR | C0278996 | Malignant Head and Neck Neoplasm | 3 | CGI;CTD_human |
| Hgene | EGFR | C0376358 | Malignant neoplasm of prostate | 3 | CTD_human |
| Hgene | EGFR | C0546837 | Malignant neoplasm of esophagus | 3 | CGI;CTD_human |
| Hgene | EGFR | C0746787 | Cancer of Neck | 3 | CTD_human |
| Hgene | EGFR | C0751177 | Cancer of Head | 3 | CTD_human |
| Hgene | EGFR | C0887900 | Upper Aerodigestive Tract Neoplasms | 3 | CTD_human |
| Hgene | EGFR | C1621958 | Glioblastoma Multiforme | 3 | CTD_human |
| Hgene | EGFR | C1708349 | Hereditary Diffuse Gastric Cancer | 3 | CTD_human |
| Hgene | EGFR | C4048328 | cervical cancer | 3 | CTD_human |
| Hgene | EGFR | C0005684 | Malignant neoplasm of urinary bladder | 2 | CTD_human |
| Hgene | EGFR | C0005695 | Bladder Neoplasm | 2 | CTD_human |
| Hgene | EGFR | C0007102 | Malignant tumor of colon | 2 | CTD_human |
| Hgene | EGFR | C0009375 | Colonic Neoplasms | 2 | CTD_human |
| Hgene | EGFR | C0009402 | Colorectal Carcinoma | 2 | CTD_human |
| Hgene | EGFR | C0009404 | Colorectal Neoplasms | 2 | CTD_human |
| Hgene | EGFR | C0024668 | Mammary Neoplasms, Experimental | 2 | CTD_human |
| Hgene | EGFR | C0027626 | Neoplasm Invasiveness | 2 | CTD_human |
| Hgene | EGFR | C0027643 | Neoplasm Recurrence, Local | 2 | CTD_human |
| Hgene | EGFR | C0152013 | Adenocarcinoma of lung (disorder) | 2 | CGI;CTD_human |
| Hgene | EGFR | C0206726 | gliosarcoma | 2 | ORPHANET |
| Hgene | EGFR | C0919267 | ovarian neoplasm | 2 | CTD_human |
| Hgene | EGFR | C1140680 | Malignant neoplasm of ovary | 2 | CTD_human |
| Hgene | EGFR | C4015130 | INFLAMMATORY SKIN AND BOWEL DISEASE, NEONATAL, 2 | 2 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | EGFR | C0001973 | Alcoholic Intoxication, Chronic | 1 | PSYGENET |
| Hgene | EGFR | C0003865 | Arthritis, Adjuvant-Induced | 1 | CTD_human |
| Hgene | EGFR | C0005396 | Bile Duct Neoplasms | 1 | CTD_human |
| Hgene | EGFR | C0007097 | Carcinoma | 1 | CTD_human |
| Hgene | EGFR | C0007113 | Rectal Carcinoma | 1 | CTD_human |
| Hgene | EGFR | C0007193 | Cardiomyopathy, Dilated | 1 | CTD_human |
| Hgene | EGFR | C0011603 | Dermatitis | 1 | CTD_human |
| Hgene | EGFR | C0011860 | Diabetes Mellitus, Non-Insulin-Dependent | 1 | CTD_human |
| Hgene | EGFR | C0014175 | Endometriosis | 1 | CTD_human |
| Hgene | EGFR | C0016978 | gallbladder neoplasm | 1 | CTD_human |
| Hgene | EGFR | C0021655 | Insulin Resistance | 1 | CTD_human |
| Hgene | EGFR | C0022660 | Kidney Failure, Acute | 1 | CTD_human |
| Hgene | EGFR | C0024667 | Animal Mammary Neoplasms | 1 | CTD_human |
| Hgene | EGFR | C0024809 | Marijuana Abuse | 1 | PSYGENET |
| Hgene | EGFR | C0025500 | Mesothelioma | 1 | CTD_human |
| Hgene | EGFR | C0027439 | Nasopharyngeal Neoplasms | 1 | CTD_human |
| Hgene | EGFR | C0029463 | Osteosarcoma | 1 | CTD_human |
| Hgene | EGFR | C0030297 | Pancreatic Neoplasm | 1 | CTD_human |
| Hgene | EGFR | C0030354 | Papilloma | 1 | CTD_human |
| Hgene | EGFR | C0032580 | Adenomatous Polyposis Coli | 1 | CTD_human |
| Hgene | EGFR | C0034885 | Rectal Neoplasms | 1 | CTD_human |
| Hgene | EGFR | C0041696 | Unipolar Depression | 1 | PSYGENET |
| Hgene | EGFR | C0085548 | Autosomal Recessive Polycystic Kidney Disease | 1 | CTD_human |
| Hgene | EGFR | C0085762 | Alcohol abuse | 1 | PSYGENET |
| Hgene | EGFR | C0149925 | Small cell carcinoma of lung | 1 | CTD_human |
| Hgene | EGFR | C0153452 | Malignant neoplasm of gallbladder | 1 | CTD_human |
| Hgene | EGFR | C0205696 | Anaplastic carcinoma | 1 | CTD_human |
| Hgene | EGFR | C0205697 | Carcinoma, Spindle-Cell | 1 | CTD_human |
| Hgene | EGFR | C0205698 | Undifferentiated carcinoma | 1 | CTD_human |
| Hgene | EGFR | C0205699 | Carcinomatosis | 1 | CTD_human |
| Hgene | EGFR | C0205874 | Papilloma, Squamous Cell | 1 | CTD_human |
| Hgene | EGFR | C0205875 | Papillomatosis | 1 | CTD_human |
| Hgene | EGFR | C0206686 | Adrenocortical carcinoma | 1 | CTD_human |
| Hgene | EGFR | C0206698 | Cholangiocarcinoma | 1 | CTD_human |
| Hgene | EGFR | C0235874 | Disease Exacerbation | 1 | CTD_human |
| Hgene | EGFR | C0238301 | Cancer of Nasopharynx | 1 | CTD_human |
| Hgene | EGFR | C0263454 | Chloracne | 1 | CTD_human |
| Hgene | EGFR | C0269102 | Endometrioma | 1 | CTD_human |
| Hgene | EGFR | C0279626 | Squamous cell carcinoma of esophagus | 1 | CGI;CTD_human |
| Hgene | EGFR | C0345905 | Intrahepatic Cholangiocarcinoma | 1 | CTD_human |
| Hgene | EGFR | C0345967 | Malignant mesothelioma | 1 | CTD_human |
| Hgene | EGFR | C0346647 | Malignant neoplasm of pancreas | 1 | CTD_human |
| Hgene | EGFR | C0376634 | Craniofacial Abnormalities | 1 | CTD_human |
| Hgene | EGFR | C0740277 | Bile duct carcinoma | 1 | CTD_human |
| Hgene | EGFR | C0920563 | Insulin Sensitivity | 1 | CTD_human |
| Hgene | EGFR | C0971858 | Arthritis, Collagen-Induced | 1 | CTD_human |
| Hgene | EGFR | C0993582 | Arthritis, Experimental | 1 | CTD_human |
| Hgene | EGFR | C1257925 | Mammary Carcinoma, Animal | 1 | CTD_human |
| Hgene | EGFR | C1269683 | Major Depressive Disorder | 1 | PSYGENET |
| Hgene | EGFR | C1449563 | Cardiomyopathy, Familial Idiopathic | 1 | CTD_human |
| Hgene | EGFR | C1565662 | Acute Kidney Insufficiency | 1 | CTD_human |
| Hgene | EGFR | C2239176 | Liver carcinoma | 1 | CTD_human |
| Hgene | EGFR | C2609414 | Acute kidney injury | 1 | CTD_human |
| Hgene | EGFR | C2713442 | Polyposis, Adenomatous Intestinal | 1 | CTD_human |
| Hgene | EGFR | C2713443 | Familial Intestinal Polyposis | 1 | CTD_human |
| Hgene | EGFR | C3805278 | Extrahepatic Cholangiocarcinoma | 1 | CTD_human |
| Hgene | EGFR | C4751120 | Neonatal inflammatory skin and bowel disease | 1 | ORPHANET |
| Tgene | C0036341 | Schizophrenia | 3 | PSYGENET | |
| Tgene | C1843478 | Lethal Congenital Contracture Syndrome 2 | 3 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C0006142 | Malignant neoplasm of breast | 2 | CTD_human | |
| Tgene | C0678222 | Breast Carcinoma | 2 | CTD_human | |
| Tgene | C1257931 | Mammary Neoplasms, Human | 2 | CTD_human | |
| Tgene | C1458155 | Mammary Neoplasms | 2 | CTD_human | |
| Tgene | C4704874 | Mammary Carcinoma, Human | 2 | CTD_human | |
| Tgene | C0005586 | Bipolar Disorder | 1 | PSYGENET | |
| Tgene | C0011570 | Mental Depression | 1 | PSYGENET | |
| Tgene | C0016978 | gallbladder neoplasm | 1 | CTD_human | |
| Tgene | C0024121 | Lung Neoplasms | 1 | CTD_human | |
| Tgene | C0027627 | Neoplasm Metastasis | 1 | CTD_human | |
| Tgene | C0033578 | Prostatic Neoplasms | 1 | CTD_human | |
| Tgene | C0041696 | Unipolar Depression | 1 | PSYGENET | |
| Tgene | C0153452 | Malignant neoplasm of gallbladder | 1 | CTD_human | |
| Tgene | C0235874 | Disease Exacerbation | 1 | CTD_human | |
| Tgene | C0242379 | Malignant neoplasm of lung | 1 | CTD_human | |
| Tgene | C0376358 | Malignant neoplasm of prostate | 1 | CTD_human | |
| Tgene | C1269683 | Major Depressive Disorder | 1 | PSYGENET | |
| Tgene | C2931822 | Nasopharyngeal carcinoma | 1 | CTD_human | |
| Tgene | C4746575 | ERYTHROLEUKEMIA, FAMILIAL, SUSCEPTIBILITY TO | 1 | UNIPROT |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies