
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARSG-AP2B1 (FusionGDB2 ID:HG22901TG163) |
Fusion Gene Summary for ARSG-AP2B1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARSG-AP2B1 | Fusion gene ID: hg22901tg163 | Hgene | Tgene | Gene symbol | ARSG | AP2B1 | Gene ID | 22901 | 163 |
| Gene name | arylsulfatase G | adaptor related protein complex 2 subunit beta 1 | |
| Synonyms | USH4 | ADTB2|AP105B|AP2-BETA|CLAPB1 | |
| Cytomap | ('ARSG')('AP2B1') 17q24.2 | 17q12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | arylsulfatase GASG | AP-2 complex subunit betaadapter-related protein complex 2 beta subunitadapter-related protein complex 2 subunit betaadaptin, beta 2 (beta)adaptor protein complex AP-2 subunit betaadaptor related protein complex 2 beta 1 subunitadaptor-related prote | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000582154, ENST00000448504, ENST00000452479, | ||
| Fusion gene scores | * DoF score | 18 X 13 X 7=1638 | 14 X 18 X 9=2268 |
| # samples | 18 | 19 | |
| ** MAII score | log2(18/1638*10)=-3.18586654531133 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/2268*10)=-3.57734931661128 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARSG [Title/Abstract] AND AP2B1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARSG(66366665)-AP2B1(34044214), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ARSG-AP2B1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARSG-AP2B1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARSG-AP2B1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ARSG-AP2B1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARSG | GO:0006790 | sulfur compound metabolic process | 18283100 |
| Tgene | AP2B1 | GO:0072583 | clathrin-dependent endocytosis | 23676497 |
| Fusion gene breakpoints across ARSG (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
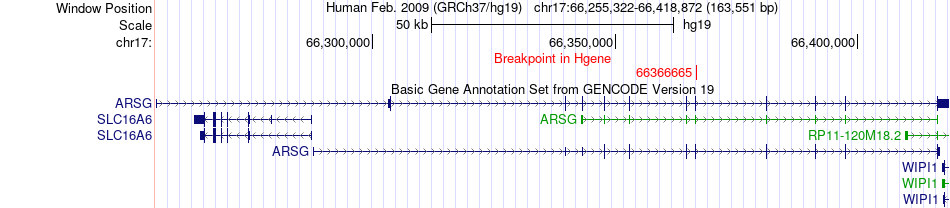 |
| Fusion gene breakpoints across AP2B1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
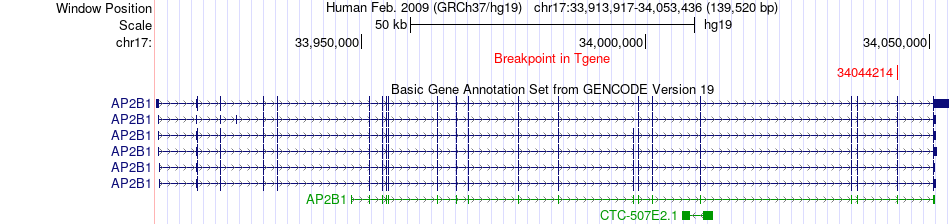 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-1103-01A | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
Top |
Fusion Gene ORF analysis for ARSG-AP2B1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000582154 | ENST00000262325 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 3UTR-3CDS | ENST00000582154 | ENST00000312678 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 3UTR-3CDS | ENST00000582154 | ENST00000537622 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 3UTR-3CDS | ENST00000582154 | ENST00000538556 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 3UTR-3CDS | ENST00000582154 | ENST00000589344 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 3UTR-3CDS | ENST00000582154 | ENST00000592545 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 3UTR-3UTR | ENST00000582154 | ENST00000545922 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 5CDS-3UTR | ENST00000448504 | ENST00000545922 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| 5CDS-3UTR | ENST00000452479 | ENST00000545922 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000448504 | ENST00000262325 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000448504 | ENST00000312678 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000448504 | ENST00000537622 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000448504 | ENST00000538556 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000448504 | ENST00000589344 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000448504 | ENST00000592545 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000452479 | ENST00000262325 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000452479 | ENST00000312678 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000452479 | ENST00000537622 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000452479 | ENST00000538556 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000452479 | ENST00000589344 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| In-frame | ENST00000452479 | ENST00000592545 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000448504 | ARSG | chr17 | 66366665 | + | ENST00000262325 | AP2B1 | chr17 | 34044214 | + | 4726 | 1778 | 796 | 2007 | 403 |
| ENST00000448504 | ARSG | chr17 | 66366665 | + | ENST00000592545 | AP2B1 | chr17 | 34044214 | + | 2395 | 1778 | 796 | 2007 | 403 |
| ENST00000448504 | ARSG | chr17 | 66366665 | + | ENST00000538556 | AP2B1 | chr17 | 34044214 | + | 2395 | 1778 | 796 | 2007 | 403 |
| ENST00000448504 | ARSG | chr17 | 66366665 | + | ENST00000312678 | AP2B1 | chr17 | 34044214 | + | 2684 | 1778 | 796 | 2007 | 403 |
| ENST00000448504 | ARSG | chr17 | 66366665 | + | ENST00000589344 | AP2B1 | chr17 | 34044214 | + | 2074 | 1778 | 796 | 2007 | 403 |
| ENST00000448504 | ARSG | chr17 | 66366665 | + | ENST00000537622 | AP2B1 | chr17 | 34044214 | + | 2398 | 1778 | 796 | 2007 | 403 |
| ENST00000452479 | ARSG | chr17 | 66366665 | + | ENST00000262325 | AP2B1 | chr17 | 34044214 | + | 3763 | 815 | 103 | 1044 | 313 |
| ENST00000452479 | ARSG | chr17 | 66366665 | + | ENST00000592545 | AP2B1 | chr17 | 34044214 | + | 1432 | 815 | 103 | 1044 | 313 |
| ENST00000452479 | ARSG | chr17 | 66366665 | + | ENST00000538556 | AP2B1 | chr17 | 34044214 | + | 1432 | 815 | 103 | 1044 | 313 |
| ENST00000452479 | ARSG | chr17 | 66366665 | + | ENST00000312678 | AP2B1 | chr17 | 34044214 | + | 1721 | 815 | 103 | 1044 | 313 |
| ENST00000452479 | ARSG | chr17 | 66366665 | + | ENST00000589344 | AP2B1 | chr17 | 34044214 | + | 1111 | 815 | 103 | 1044 | 313 |
| ENST00000452479 | ARSG | chr17 | 66366665 | + | ENST00000537622 | AP2B1 | chr17 | 34044214 | + | 1435 | 815 | 103 | 1044 | 313 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000448504 | ENST00000262325 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.003345499 | 0.9966545 |
| ENST00000448504 | ENST00000592545 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.007582328 | 0.9924177 |
| ENST00000448504 | ENST00000538556 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.007582328 | 0.9924177 |
| ENST00000448504 | ENST00000312678 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.005819935 | 0.9941801 |
| ENST00000448504 | ENST00000589344 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.009421509 | 0.9905785 |
| ENST00000448504 | ENST00000537622 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.007558933 | 0.99244106 |
| ENST00000452479 | ENST00000262325 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.007521416 | 0.9924786 |
| ENST00000452479 | ENST00000592545 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.010813984 | 0.989186 |
| ENST00000452479 | ENST00000538556 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.010813984 | 0.989186 |
| ENST00000452479 | ENST00000312678 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.008108827 | 0.99189115 |
| ENST00000452479 | ENST00000589344 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.010494021 | 0.98950595 |
| ENST00000452479 | ENST00000537622 | ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044214 | + | 0.010602013 | 0.989398 |
Top |
Fusion Genomic Features for ARSG-AP2B1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044213 | + | 3.84E-05 | 0.9999616 |
| ARSG | chr17 | 66366665 | + | AP2B1 | chr17 | 34044213 | + | 3.84E-05 | 0.9999616 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
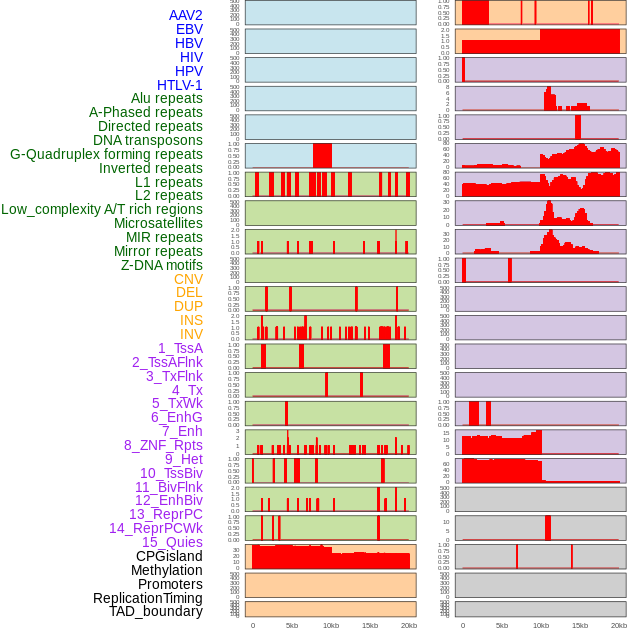 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
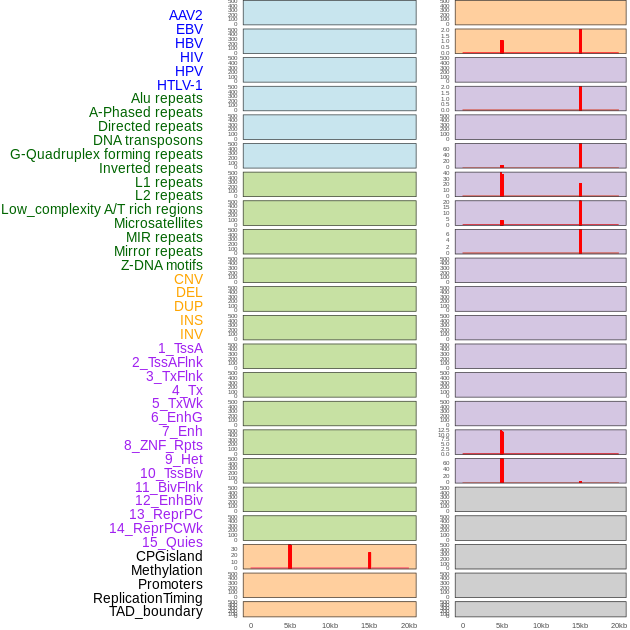 |
Top |
Fusion Protein Features for ARSG-AP2B1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:66366665/chr17:34044214) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000262325 | 18 | 21 | 576_716 | 861 | 938.0 | Compositional bias | Note=Pro-rich (stalk region) | |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000312678 | 19 | 22 | 576_716 | 875 | 952.0 | Compositional bias | Note=Pro-rich (stalk region) | |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000537622 | 19 | 22 | 576_716 | 875 | 952.0 | Compositional bias | Note=Pro-rich (stalk region) | |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000538556 | 19 | 22 | 576_716 | 804 | 881.0 | Compositional bias | Note=Pro-rich (stalk region) | |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000589344 | 19 | 22 | 576_716 | 875 | 952.0 | Compositional bias | Note=Pro-rich (stalk region) |
Top |
Fusion Gene Sequence for ARSG-AP2B1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6890_6890_1_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000262325_length(transcript)=4726nt_BP=1778nt GGCTGCGCCCAGGCCGGCGGGCCCAGCAGCTGCGAACCGCCGGCGCACCACCTGTTTCCGCGCCCGGGGACTTCCCCGGCGGGGCTCAGA AGTGTGGGATCGGTCGCTTGGCTTCCCCTGGCGTCAGCGACCCAGGGTAACCTCCTCCACTGCTGCGTGCCGTGCAGGCCTGCCTGTGTG AGAGCCACGTGTGCCGCGCTCTGGGCACAGCCTTGGAAAGTCAGGACCGCGACGGCAGCAGAGCAGAAACCTTACAGAAACATGAAGCCC TCAACCATCTGCTACTCAGTTATTCGGGGCTGACGGCGGCTTCTAGAACATCCAGGTGTTCTGCAGATGCGAGAACTCATCCTGTAGTCA CCAGATGGAGTCCCAAACAGCCAAGCAGATGTAAGGCCTGTGCTGTGGCTCTGAGGCCCTGAATACAGAAGGGTCACTTTCTTAGTGGCC AAAGAGCAGTTGTTGACATTGATGTCTAATTATTGAACACGACCAGTCATTTTACTGAGCTGCGGTGAGGAAACACTGACCATAGAAGAT CAAGCCAAATGAGGGATTGCAAATTTCCTGATTCTTTTGAATTAGGATTCCAGATGGGGGCCTCATTTCTACAGCCCCCAACATTCCTAT AGCCGTTATCACTGCCATCACCACTGCCACCAGCATCTTCTTGCAGATTCCACCCCTGCTCCCCAGAGACTTCCTGCTTTGAAAGTGAGC AGAAAGGAAGCTCTCAGAAAAATCTCTAGTGGTGGCTGCCGTCGCTCCAGACAATCGGAATCCTGCCTTCACCACCATGGGCTGGCTTTT TCTAAAGGTTTTGTTGGCGGGAGTGAGTTTCTCAGGATTTCTTTATCCTCTTGTGGATTTTTGCATCAGTGGGAAAACAAGAGGACAGAA GCCAAACTTTGTGATTATTTTGGCCGATGACATGGGGTGGGGTGACCTGGGAGCAAACTGGGCAGAAACAAAGGACACTGCCAACCTTGA TAAGATGGCTTCGGAGGGAATGAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACCCTCCCGGGCTTCCTTGCTCACCGGCCG GCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCTCAACGAGACCACCTTGGCAGAGGTGCT GCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTATCACCCCAACTTCCGTGGTTTTGATTA CTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCCTCCTTGTCCAGCGTGTCCACAGGGTGA TGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAACCTCAACATTGTGGAGCAGCCGGTGAA CTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCACCAGCGGGAGGCCCTTCCTGCTCTATGT GGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAGAAGCCTGTATGGTGCAGGGCTCTGGGA GATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATTCCTCTGGTTTACAGGAGACAATGGCCC GTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCGTCAAGACACTGTTTCCAGCAAGTTGCA AAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATCCCTGAAGCTCACTAATGGCATTTGGAT TTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGCTCCTGAAGTCTCTCAATACATCTATCA GGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGATCGGTGCAAGTCAAGAACTCTTAACTG GAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTAGTCTAACCTGTGCTAACATTAGGGCAC AACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCACCTCTTGCCACCTGCTGCTGCTATCTGT CCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGTGTAGTTTGGTATTTTGTAATTGAGAGC TCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTGAAACACTGCACTTTACTGTTTTATACTTTTGTACA TATGAGAAATCAAGGGATTAGTGCAACCAGTAGAAAGCATTGAAATGACTGTCATTAACCACACAGTCCTGGAGGCAGAGATGCAGTTAC CTACCCTAGCTTTTGATGGGTTCTCTTACCTGTAGTAGCCTTATCCCTGGTCATTTGGATTTTCAGTTTGCTTTTTTCTTTTTTTCCCCT CCAAACTCCTTTTCCTTGGCCAAGCCTTCATGCTTCCCCCTTTCCATATTATAATCTCATTTGATTGCTCTGCAGTTGGGAACGGTGATC TTCTTGAATGATGTTTCAGTGTGCAAAAACTATAGAGCCTGTCAGCACCAAAGCTGACAGAAGTTATACCTTACTCCTTTCCTTTCCCCT GAACAAACCTGCTAATCCCACTAATTCAGGAATTTGAGTAGAGATGGGGAACAAGAACCCAGATGCTGTCCCCTCACCCCCTCTCCTGTA TTTCTCAGGTCCAGTTCAAATCTAAAATTCTACTTTTAGAGTTGAAACAGAGTAATAACTTATCTAACCCTCTTTTCCTACAAAGGAGAA AGATAAAAGGCACAAAGGTTACCGCCAAGGCCCGTCAGCTGTGTAGTGGCAAAGCCGAGACCGAGTCTCCTAAGTCCCCGTCAGTGTGGT TTTCACCACAGGACTGTCTCTTGTCGTTTTCCCCTAATGCCTTCTCCTGCCTTTTCTGTGCCTAGTTTTTGGCTCTTCACATATTCCATA TTGATTTTGACGCTCTGTATATTGGCATCAGGTGGCAGCTGAATATCTTTTGAATTACTCGAAGGTAAAGCCAGATGCCAGAATGAAGGT GTAGCCAGTGTTTCCCATATGCCCCTGGAGCCCCACTTATTGAGGCCAGCAGAATAGGTGCAGAGATGAAGTGAGCTTAGAGATGTTGCA AATGCTCTTTATCCCTTCAGCTCTCTGATCTGCTCTTTCTTCATGATACTTAGTCTGCAGGGCATATTAAGATCATCCCAGAGGTTCAGG CAGTTCCTGTCATCTCTGAAAAGACTGGGGGATATGAAATCTTCCCCCTACCCCACTTAATGCGTTGGATATGATTTTTCAAAGAATGCT TCATGCCCAAAATACCAGCCTGTTTAGCAGTGTTACACTGTTTGATCTGCGGGCACTTGTTGCATTGCCTGGCACCCAATATTCAGGGTC CATGACTAAGACTGGTCTTCTCAGATGCCCTGCTTAAATCAGGGGCACTTCAGGCTCCACAGGCGTCATGTTGGACTGAGACCTAACTCA CTGGACTCAGAGGAGGAATCGTGGAAAACAAGAGCAAAACTACCCCACACCCCTATTTCATGTCTGAAATAACCCTGTTTCATACCAGTT GCAAAGCTTGTGGGGAGCGGTCCCACAAAGCACTTTCTTAAACCTTGAGAATCTCCAAGAGAAAAATATTTGGGGAAGGAGGGAGGAAAT ATGTCCCTTGCACACCACCCCTGAAGCACATGGCAGTAGGAAACAGCATAGGATTGTATGTGGGAGGTGGATAGGTCGGTGATGTGTGGA GCGGAAAAGCAGGTTGGTAAAGTTCCCTTCTTGGGACTTATTCCTGGAGTCAGTGGATACAAGTAGTGCAGAAGGTTCACACTGCAAATA GTGTTCTCATCTCAAAGCAAACTATCATTCCAGAAGGAAAAGTGTGTCAGGGCAAGCAGACAACACAATTTCCTATCAGAATATGTCCCT CAACCCCCGAAACAAGGCTTCTCTCAGCCTCCCCACCAGTGATGGATAACAGCTCCTATTCTCAGCTGACCTGACTGAGCCAACCCATGA ACTCTTCACTCCTTGGGGAAGCCACCTCCCATCACACCCCTGAGCAGAGTTAGGGAGGAATTCTACTTCCCATAAAAGGACCTCTCCTGA GAGGCAAAACCTGTTGCCTCCACCACGGCTTCCCTCTTGGCTCATTCCAAGCTTGGCCAAATTGGGGAAGTGGGATGGAGGTTGCCCTGC ATCCCCCCTCCTCTGCCTGAGTGTGTCTTTGTAATGTCAGCTGGCATCATACAAAGAGCAGGAGAAGCAAACACCCAGAACTCTTTTGCT GGTCAGAGATTCCCTGAGTGTCTGTCCTCACCCAAGCCTGCTCTGTGTCTGTGTTGTGAAGCTTGAGACTCTGGAAAGAAATGGGGAGGG GGGGCAGGGGAAATGTTGCCCTAAGAATGCTTCTCATTCCTCTGTTCTTATTGGGTCCTGTTTTTCGGGAGGGTGGGGGTTGGGGGAAGC TTGACCTTGTGTCTTCGTCAATAAACTCACATTTACACAAAATGAA >6890_6890_1_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000262325_length(amino acids)=403AA_BP=327 MGWLFLKVLLAGVSFSGFLYPLVDFCISGKTRGQKPNFVIILADDMGWGDLGANWAETKDTANLDKMASEGMRFVDFHAAASTCSPSRAS LLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_2_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000312678_length(transcript)=2684nt_BP=1778nt GGCTGCGCCCAGGCCGGCGGGCCCAGCAGCTGCGAACCGCCGGCGCACCACCTGTTTCCGCGCCCGGGGACTTCCCCGGCGGGGCTCAGA AGTGTGGGATCGGTCGCTTGGCTTCCCCTGGCGTCAGCGACCCAGGGTAACCTCCTCCACTGCTGCGTGCCGTGCAGGCCTGCCTGTGTG AGAGCCACGTGTGCCGCGCTCTGGGCACAGCCTTGGAAAGTCAGGACCGCGACGGCAGCAGAGCAGAAACCTTACAGAAACATGAAGCCC TCAACCATCTGCTACTCAGTTATTCGGGGCTGACGGCGGCTTCTAGAACATCCAGGTGTTCTGCAGATGCGAGAACTCATCCTGTAGTCA CCAGATGGAGTCCCAAACAGCCAAGCAGATGTAAGGCCTGTGCTGTGGCTCTGAGGCCCTGAATACAGAAGGGTCACTTTCTTAGTGGCC AAAGAGCAGTTGTTGACATTGATGTCTAATTATTGAACACGACCAGTCATTTTACTGAGCTGCGGTGAGGAAACACTGACCATAGAAGAT CAAGCCAAATGAGGGATTGCAAATTTCCTGATTCTTTTGAATTAGGATTCCAGATGGGGGCCTCATTTCTACAGCCCCCAACATTCCTAT AGCCGTTATCACTGCCATCACCACTGCCACCAGCATCTTCTTGCAGATTCCACCCCTGCTCCCCAGAGACTTCCTGCTTTGAAAGTGAGC AGAAAGGAAGCTCTCAGAAAAATCTCTAGTGGTGGCTGCCGTCGCTCCAGACAATCGGAATCCTGCCTTCACCACCATGGGCTGGCTTTT TCTAAAGGTTTTGTTGGCGGGAGTGAGTTTCTCAGGATTTCTTTATCCTCTTGTGGATTTTTGCATCAGTGGGAAAACAAGAGGACAGAA GCCAAACTTTGTGATTATTTTGGCCGATGACATGGGGTGGGGTGACCTGGGAGCAAACTGGGCAGAAACAAAGGACACTGCCAACCTTGA TAAGATGGCTTCGGAGGGAATGAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACCCTCCCGGGCTTCCTTGCTCACCGGCCG GCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCTCAACGAGACCACCTTGGCAGAGGTGCT GCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTATCACCCCAACTTCCGTGGTTTTGATTA CTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCCTCCTTGTCCAGCGTGTCCACAGGGTGA TGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAACCTCAACATTGTGGAGCAGCCGGTGAA CTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCACCAGCGGGAGGCCCTTCCTGCTCTATGT GGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAGAAGCCTGTATGGTGCAGGGCTCTGGGA GATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATTCCTCTGGTTTACAGGAGACAATGGCCC GTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCGTCAAGACACTGTTTCCAGCAAGTTGCA AAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATCCCTGAAGCTCACTAATGGCATTTGGAT TTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGCTCCTGAAGTCTCTCAATACATCTATCA GGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGATCGGTGCAAGTCAAGAACTCTTAACTG GAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTAGTCTAACCTGTGCTAACATTAGGGCAC AACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCACCTCTTGCCACCTGCTGCTGCTATCTGT CCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGTGTAGTTTGGTATTTTGTAATTGAGAGC TCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTGAAACACTGCACTTTACTGTTTTATACTTTTGTACA TATGAGAAATCAAGGGATTAGTGCAACCAGTAGAAAGCATTGAAATGACTGTCATTAACCACACAGTCCTGGAGGCAGAGATGCAGTTAC CTACCCTAGCTTTTGATGGGTTCTCTTACCTGTAGTAGCCTTATCCCTGGTCATTTGGATTTTCAGTTTGCTTTTTTCTTTTTTTCCCCT CCAAACTCCTTTTCCTTGGCCAAGCCTTCATGCTTCCCCCTTTCCATATTATAATCTCATTTGATTGCTCTGCA >6890_6890_2_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000312678_length(amino acids)=403AA_BP=327 MGWLFLKVLLAGVSFSGFLYPLVDFCISGKTRGQKPNFVIILADDMGWGDLGANWAETKDTANLDKMASEGMRFVDFHAAASTCSPSRAS LLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_3_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000537622_length(transcript)=2398nt_BP=1778nt GGCTGCGCCCAGGCCGGCGGGCCCAGCAGCTGCGAACCGCCGGCGCACCACCTGTTTCCGCGCCCGGGGACTTCCCCGGCGGGGCTCAGA AGTGTGGGATCGGTCGCTTGGCTTCCCCTGGCGTCAGCGACCCAGGGTAACCTCCTCCACTGCTGCGTGCCGTGCAGGCCTGCCTGTGTG AGAGCCACGTGTGCCGCGCTCTGGGCACAGCCTTGGAAAGTCAGGACCGCGACGGCAGCAGAGCAGAAACCTTACAGAAACATGAAGCCC TCAACCATCTGCTACTCAGTTATTCGGGGCTGACGGCGGCTTCTAGAACATCCAGGTGTTCTGCAGATGCGAGAACTCATCCTGTAGTCA CCAGATGGAGTCCCAAACAGCCAAGCAGATGTAAGGCCTGTGCTGTGGCTCTGAGGCCCTGAATACAGAAGGGTCACTTTCTTAGTGGCC AAAGAGCAGTTGTTGACATTGATGTCTAATTATTGAACACGACCAGTCATTTTACTGAGCTGCGGTGAGGAAACACTGACCATAGAAGAT CAAGCCAAATGAGGGATTGCAAATTTCCTGATTCTTTTGAATTAGGATTCCAGATGGGGGCCTCATTTCTACAGCCCCCAACATTCCTAT AGCCGTTATCACTGCCATCACCACTGCCACCAGCATCTTCTTGCAGATTCCACCCCTGCTCCCCAGAGACTTCCTGCTTTGAAAGTGAGC AGAAAGGAAGCTCTCAGAAAAATCTCTAGTGGTGGCTGCCGTCGCTCCAGACAATCGGAATCCTGCCTTCACCACCATGGGCTGGCTTTT TCTAAAGGTTTTGTTGGCGGGAGTGAGTTTCTCAGGATTTCTTTATCCTCTTGTGGATTTTTGCATCAGTGGGAAAACAAGAGGACAGAA GCCAAACTTTGTGATTATTTTGGCCGATGACATGGGGTGGGGTGACCTGGGAGCAAACTGGGCAGAAACAAAGGACACTGCCAACCTTGA TAAGATGGCTTCGGAGGGAATGAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACCCTCCCGGGCTTCCTTGCTCACCGGCCG GCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCTCAACGAGACCACCTTGGCAGAGGTGCT GCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTATCACCCCAACTTCCGTGGTTTTGATTA CTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCCTCCTTGTCCAGCGTGTCCACAGGGTGA TGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAACCTCAACATTGTGGAGCAGCCGGTGAA CTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCACCAGCGGGAGGCCCTTCCTGCTCTATGT GGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAGAAGCCTGTATGGTGCAGGGCTCTGGGA GATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATTCCTCTGGTTTACAGGAGACAATGGCCC GTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCGTCAAGACACTGTTTCCAGCAAGTTGCA AAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATCCCTGAAGCTCACTAATGGCATTTGGAT TTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGCTCCTGAAGTCTCTCAATACATCTATCA GGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGATCGGTGCAAGTCAAGAACTCTTAACTG GAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTAGTCTAACCTGTGCTAACATTAGGGCAC AACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCACCTCTTGCCACCTGCTGCTGCTATCTGT CCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGTGTAGTTTGGTATTTTGTAATTGAGAGC TCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTGAAA >6890_6890_3_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000537622_length(amino acids)=403AA_BP=327 MGWLFLKVLLAGVSFSGFLYPLVDFCISGKTRGQKPNFVIILADDMGWGDLGANWAETKDTANLDKMASEGMRFVDFHAAASTCSPSRAS LLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_4_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000538556_length(transcript)=2395nt_BP=1778nt GGCTGCGCCCAGGCCGGCGGGCCCAGCAGCTGCGAACCGCCGGCGCACCACCTGTTTCCGCGCCCGGGGACTTCCCCGGCGGGGCTCAGA AGTGTGGGATCGGTCGCTTGGCTTCCCCTGGCGTCAGCGACCCAGGGTAACCTCCTCCACTGCTGCGTGCCGTGCAGGCCTGCCTGTGTG AGAGCCACGTGTGCCGCGCTCTGGGCACAGCCTTGGAAAGTCAGGACCGCGACGGCAGCAGAGCAGAAACCTTACAGAAACATGAAGCCC TCAACCATCTGCTACTCAGTTATTCGGGGCTGACGGCGGCTTCTAGAACATCCAGGTGTTCTGCAGATGCGAGAACTCATCCTGTAGTCA CCAGATGGAGTCCCAAACAGCCAAGCAGATGTAAGGCCTGTGCTGTGGCTCTGAGGCCCTGAATACAGAAGGGTCACTTTCTTAGTGGCC AAAGAGCAGTTGTTGACATTGATGTCTAATTATTGAACACGACCAGTCATTTTACTGAGCTGCGGTGAGGAAACACTGACCATAGAAGAT CAAGCCAAATGAGGGATTGCAAATTTCCTGATTCTTTTGAATTAGGATTCCAGATGGGGGCCTCATTTCTACAGCCCCCAACATTCCTAT AGCCGTTATCACTGCCATCACCACTGCCACCAGCATCTTCTTGCAGATTCCACCCCTGCTCCCCAGAGACTTCCTGCTTTGAAAGTGAGC AGAAAGGAAGCTCTCAGAAAAATCTCTAGTGGTGGCTGCCGTCGCTCCAGACAATCGGAATCCTGCCTTCACCACCATGGGCTGGCTTTT TCTAAAGGTTTTGTTGGCGGGAGTGAGTTTCTCAGGATTTCTTTATCCTCTTGTGGATTTTTGCATCAGTGGGAAAACAAGAGGACAGAA GCCAAACTTTGTGATTATTTTGGCCGATGACATGGGGTGGGGTGACCTGGGAGCAAACTGGGCAGAAACAAAGGACACTGCCAACCTTGA TAAGATGGCTTCGGAGGGAATGAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACCCTCCCGGGCTTCCTTGCTCACCGGCCG GCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCTCAACGAGACCACCTTGGCAGAGGTGCT GCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTATCACCCCAACTTCCGTGGTTTTGATTA CTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCCTCCTTGTCCAGCGTGTCCACAGGGTGA TGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAACCTCAACATTGTGGAGCAGCCGGTGAA CTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCACCAGCGGGAGGCCCTTCCTGCTCTATGT GGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAGAAGCCTGTATGGTGCAGGGCTCTGGGA GATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATTCCTCTGGTTTACAGGAGACAATGGCCC GTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCGTCAAGACACTGTTTCCAGCAAGTTGCA AAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATCCCTGAAGCTCACTAATGGCATTTGGAT TTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGCTCCTGAAGTCTCTCAATACATCTATCA GGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGATCGGTGCAAGTCAAGAACTCTTAACTG GAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTAGTCTAACCTGTGCTAACATTAGGGCAC AACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCACCTCTTGCCACCTGCTGCTGCTATCTGT CCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGTGTAGTTTGGTATTTTGTAATTGAGAGC TCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTG >6890_6890_4_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000538556_length(amino acids)=403AA_BP=327 MGWLFLKVLLAGVSFSGFLYPLVDFCISGKTRGQKPNFVIILADDMGWGDLGANWAETKDTANLDKMASEGMRFVDFHAAASTCSPSRAS LLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_5_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000589344_length(transcript)=2074nt_BP=1778nt GGCTGCGCCCAGGCCGGCGGGCCCAGCAGCTGCGAACCGCCGGCGCACCACCTGTTTCCGCGCCCGGGGACTTCCCCGGCGGGGCTCAGA AGTGTGGGATCGGTCGCTTGGCTTCCCCTGGCGTCAGCGACCCAGGGTAACCTCCTCCACTGCTGCGTGCCGTGCAGGCCTGCCTGTGTG AGAGCCACGTGTGCCGCGCTCTGGGCACAGCCTTGGAAAGTCAGGACCGCGACGGCAGCAGAGCAGAAACCTTACAGAAACATGAAGCCC TCAACCATCTGCTACTCAGTTATTCGGGGCTGACGGCGGCTTCTAGAACATCCAGGTGTTCTGCAGATGCGAGAACTCATCCTGTAGTCA CCAGATGGAGTCCCAAACAGCCAAGCAGATGTAAGGCCTGTGCTGTGGCTCTGAGGCCCTGAATACAGAAGGGTCACTTTCTTAGTGGCC AAAGAGCAGTTGTTGACATTGATGTCTAATTATTGAACACGACCAGTCATTTTACTGAGCTGCGGTGAGGAAACACTGACCATAGAAGAT CAAGCCAAATGAGGGATTGCAAATTTCCTGATTCTTTTGAATTAGGATTCCAGATGGGGGCCTCATTTCTACAGCCCCCAACATTCCTAT AGCCGTTATCACTGCCATCACCACTGCCACCAGCATCTTCTTGCAGATTCCACCCCTGCTCCCCAGAGACTTCCTGCTTTGAAAGTGAGC AGAAAGGAAGCTCTCAGAAAAATCTCTAGTGGTGGCTGCCGTCGCTCCAGACAATCGGAATCCTGCCTTCACCACCATGGGCTGGCTTTT TCTAAAGGTTTTGTTGGCGGGAGTGAGTTTCTCAGGATTTCTTTATCCTCTTGTGGATTTTTGCATCAGTGGGAAAACAAGAGGACAGAA GCCAAACTTTGTGATTATTTTGGCCGATGACATGGGGTGGGGTGACCTGGGAGCAAACTGGGCAGAAACAAAGGACACTGCCAACCTTGA TAAGATGGCTTCGGAGGGAATGAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACCCTCCCGGGCTTCCTTGCTCACCGGCCG GCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCTCAACGAGACCACCTTGGCAGAGGTGCT GCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTATCACCCCAACTTCCGTGGTTTTGATTA CTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCCTCCTTGTCCAGCGTGTCCACAGGGTGA TGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAACCTCAACATTGTGGAGCAGCCGGTGAA CTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCACCAGCGGGAGGCCCTTCCTGCTCTATGT GGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAGAAGCCTGTATGGTGCAGGGCTCTGGGA GATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATTCCTCTGGTTTACAGGAGACAATGGCCC GTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCGTCAAGACACTGTTTCCAGCAAGTTGCA AAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATCCCTGAAGCTCACTAATGGCATTTGGAT TTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGCTCCTGAAGTCTCTCAATACATCTATCA GGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGATCGGTGCAAGTCAAGAACTCTTAACTG GAAG >6890_6890_5_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000589344_length(amino acids)=403AA_BP=327 MGWLFLKVLLAGVSFSGFLYPLVDFCISGKTRGQKPNFVIILADDMGWGDLGANWAETKDTANLDKMASEGMRFVDFHAAASTCSPSRAS LLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_6_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000592545_length(transcript)=2395nt_BP=1778nt GGCTGCGCCCAGGCCGGCGGGCCCAGCAGCTGCGAACCGCCGGCGCACCACCTGTTTCCGCGCCCGGGGACTTCCCCGGCGGGGCTCAGA AGTGTGGGATCGGTCGCTTGGCTTCCCCTGGCGTCAGCGACCCAGGGTAACCTCCTCCACTGCTGCGTGCCGTGCAGGCCTGCCTGTGTG AGAGCCACGTGTGCCGCGCTCTGGGCACAGCCTTGGAAAGTCAGGACCGCGACGGCAGCAGAGCAGAAACCTTACAGAAACATGAAGCCC TCAACCATCTGCTACTCAGTTATTCGGGGCTGACGGCGGCTTCTAGAACATCCAGGTGTTCTGCAGATGCGAGAACTCATCCTGTAGTCA CCAGATGGAGTCCCAAACAGCCAAGCAGATGTAAGGCCTGTGCTGTGGCTCTGAGGCCCTGAATACAGAAGGGTCACTTTCTTAGTGGCC AAAGAGCAGTTGTTGACATTGATGTCTAATTATTGAACACGACCAGTCATTTTACTGAGCTGCGGTGAGGAAACACTGACCATAGAAGAT CAAGCCAAATGAGGGATTGCAAATTTCCTGATTCTTTTGAATTAGGATTCCAGATGGGGGCCTCATTTCTACAGCCCCCAACATTCCTAT AGCCGTTATCACTGCCATCACCACTGCCACCAGCATCTTCTTGCAGATTCCACCCCTGCTCCCCAGAGACTTCCTGCTTTGAAAGTGAGC AGAAAGGAAGCTCTCAGAAAAATCTCTAGTGGTGGCTGCCGTCGCTCCAGACAATCGGAATCCTGCCTTCACCACCATGGGCTGGCTTTT TCTAAAGGTTTTGTTGGCGGGAGTGAGTTTCTCAGGATTTCTTTATCCTCTTGTGGATTTTTGCATCAGTGGGAAAACAAGAGGACAGAA GCCAAACTTTGTGATTATTTTGGCCGATGACATGGGGTGGGGTGACCTGGGAGCAAACTGGGCAGAAACAAAGGACACTGCCAACCTTGA TAAGATGGCTTCGGAGGGAATGAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACCCTCCCGGGCTTCCTTGCTCACCGGCCG GCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCTCAACGAGACCACCTTGGCAGAGGTGCT GCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTATCACCCCAACTTCCGTGGTTTTGATTA CTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCCTCCTTGTCCAGCGTGTCCACAGGGTGA TGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAACCTCAACATTGTGGAGCAGCCGGTGAA CTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCACCAGCGGGAGGCCCTTCCTGCTCTATGT GGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAGAAGCCTGTATGGTGCAGGGCTCTGGGA GATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATTCCTCTGGTTTACAGGAGACAATGGCCC GTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCGTCAAGACACTGTTTCCAGCAAGTTGCA AAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATCCCTGAAGCTCACTAATGGCATTTGGAT TTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGCTCCTGAAGTCTCTCAATACATCTATCA GGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGATCGGTGCAAGTCAAGAACTCTTAACTG GAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTAGTCTAACCTGTGCTAACATTAGGGCAC AACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCACCTCTTGCCACCTGCTGCTGCTATCTGT CCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGTGTAGTTTGGTATTTTGTAATTGAGAGC TCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTG >6890_6890_6_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000448504_AP2B1_chr17_34044214_ENST00000592545_length(amino acids)=403AA_BP=327 MGWLFLKVLLAGVSFSGFLYPLVDFCISGKTRGQKPNFVIILADDMGWGDLGANWAETKDTANLDKMASEGMRFVDFHAAASTCSPSRAS LLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_7_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000262325_length(transcript)=3763nt_BP=815nt GCGCCGGTCGCGCGCCCGCCAGCCTGCCGCCTGGGCTGGGGGTCACGAAAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACC CTCCCGGGCTTCCTTGCTCACCGGCCGGCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCT CAACGAGACCACCTTGGCAGAGGTGCTGCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTA TCACCCCAACTTCCGTGGTTTTGATTACTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCC TCCTTGTCCAGCGTGTCCACAGGGTGATGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAA CCTCAACATTGTGGAGCAGCCGGTGAACTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCAC CAGCGGGAGGCCCTTCCTGCTCTATGTGGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAG AAGCCTGTATGGTGCAGGGCTCTGGGAGATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATT CCTCTGGTTTACAGGAGACAATGGCCCGTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCG TCAAGACACTGTTTCCAGCAAGTTGCAAAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATC CCTGAAGCTCACTAATGGCATTTGGATTTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGC TCCTGAAGTCTCTCAATACATCTATCAGGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGA TCGGTGCAAGTCAAGAACTCTTAACTGGAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTA GTCTAACCTGTGCTAACATTAGGGCACAACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCAC CTCTTGCCACCTGCTGCTGCTATCTGTCCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGT GTAGTTTGGTATTTTGTAATTGAGAGCTCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTGAAACACTG CACTTTACTGTTTTATACTTTTGTACATATGAGAAATCAAGGGATTAGTGCAACCAGTAGAAAGCATTGAAATGACTGTCATTAACCACA CAGTCCTGGAGGCAGAGATGCAGTTACCTACCCTAGCTTTTGATGGGTTCTCTTACCTGTAGTAGCCTTATCCCTGGTCATTTGGATTTT CAGTTTGCTTTTTTCTTTTTTTCCCCTCCAAACTCCTTTTCCTTGGCCAAGCCTTCATGCTTCCCCCTTTCCATATTATAATCTCATTTG ATTGCTCTGCAGTTGGGAACGGTGATCTTCTTGAATGATGTTTCAGTGTGCAAAAACTATAGAGCCTGTCAGCACCAAAGCTGACAGAAG TTATACCTTACTCCTTTCCTTTCCCCTGAACAAACCTGCTAATCCCACTAATTCAGGAATTTGAGTAGAGATGGGGAACAAGAACCCAGA TGCTGTCCCCTCACCCCCTCTCCTGTATTTCTCAGGTCCAGTTCAAATCTAAAATTCTACTTTTAGAGTTGAAACAGAGTAATAACTTAT CTAACCCTCTTTTCCTACAAAGGAGAAAGATAAAAGGCACAAAGGTTACCGCCAAGGCCCGTCAGCTGTGTAGTGGCAAAGCCGAGACCG AGTCTCCTAAGTCCCCGTCAGTGTGGTTTTCACCACAGGACTGTCTCTTGTCGTTTTCCCCTAATGCCTTCTCCTGCCTTTTCTGTGCCT AGTTTTTGGCTCTTCACATATTCCATATTGATTTTGACGCTCTGTATATTGGCATCAGGTGGCAGCTGAATATCTTTTGAATTACTCGAA GGTAAAGCCAGATGCCAGAATGAAGGTGTAGCCAGTGTTTCCCATATGCCCCTGGAGCCCCACTTATTGAGGCCAGCAGAATAGGTGCAG AGATGAAGTGAGCTTAGAGATGTTGCAAATGCTCTTTATCCCTTCAGCTCTCTGATCTGCTCTTTCTTCATGATACTTAGTCTGCAGGGC ATATTAAGATCATCCCAGAGGTTCAGGCAGTTCCTGTCATCTCTGAAAAGACTGGGGGATATGAAATCTTCCCCCTACCCCACTTAATGC GTTGGATATGATTTTTCAAAGAATGCTTCATGCCCAAAATACCAGCCTGTTTAGCAGTGTTACACTGTTTGATCTGCGGGCACTTGTTGC ATTGCCTGGCACCCAATATTCAGGGTCCATGACTAAGACTGGTCTTCTCAGATGCCCTGCTTAAATCAGGGGCACTTCAGGCTCCACAGG CGTCATGTTGGACTGAGACCTAACTCACTGGACTCAGAGGAGGAATCGTGGAAAACAAGAGCAAAACTACCCCACACCCCTATTTCATGT CTGAAATAACCCTGTTTCATACCAGTTGCAAAGCTTGTGGGGAGCGGTCCCACAAAGCACTTTCTTAAACCTTGAGAATCTCCAAGAGAA AAATATTTGGGGAAGGAGGGAGGAAATATGTCCCTTGCACACCACCCCTGAAGCACATGGCAGTAGGAAACAGCATAGGATTGTATGTGG GAGGTGGATAGGTCGGTGATGTGTGGAGCGGAAAAGCAGGTTGGTAAAGTTCCCTTCTTGGGACTTATTCCTGGAGTCAGTGGATACAAG TAGTGCAGAAGGTTCACACTGCAAATAGTGTTCTCATCTCAAAGCAAACTATCATTCCAGAAGGAAAAGTGTGTCAGGGCAAGCAGACAA CACAATTTCCTATCAGAATATGTCCCTCAACCCCCGAAACAAGGCTTCTCTCAGCCTCCCCACCAGTGATGGATAACAGCTCCTATTCTC AGCTGACCTGACTGAGCCAACCCATGAACTCTTCACTCCTTGGGGAAGCCACCTCCCATCACACCCCTGAGCAGAGTTAGGGAGGAATTC TACTTCCCATAAAAGGACCTCTCCTGAGAGGCAAAACCTGTTGCCTCCACCACGGCTTCCCTCTTGGCTCATTCCAAGCTTGGCCAAATT GGGGAAGTGGGATGGAGGTTGCCCTGCATCCCCCCTCCTCTGCCTGAGTGTGTCTTTGTAATGTCAGCTGGCATCATACAAAGAGCAGGA GAAGCAAACACCCAGAACTCTTTTGCTGGTCAGAGATTCCCTGAGTGTCTGTCCTCACCCAAGCCTGCTCTGTGTCTGTGTTGTGAAGCT TGAGACTCTGGAAAGAAATGGGGAGGGGGGGCAGGGGAAATGTTGCCCTAAGAATGCTTCTCATTCCTCTGTTCTTATTGGGTCCTGTTT TTCGGGAGGGTGGGGGTTGGGGGAAGCTTGACCTTGTGTCTTCGTCAATAAACTCACATTTACACAAAATGAA >6890_6890_7_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000262325_length(amino acids)=313AA_BP=237 MLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_8_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000312678_length(transcript)=1721nt_BP=815nt GCGCCGGTCGCGCGCCCGCCAGCCTGCCGCCTGGGCTGGGGGTCACGAAAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACC CTCCCGGGCTTCCTTGCTCACCGGCCGGCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCT CAACGAGACCACCTTGGCAGAGGTGCTGCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTA TCACCCCAACTTCCGTGGTTTTGATTACTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCC TCCTTGTCCAGCGTGTCCACAGGGTGATGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAA CCTCAACATTGTGGAGCAGCCGGTGAACTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCAC CAGCGGGAGGCCCTTCCTGCTCTATGTGGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAG AAGCCTGTATGGTGCAGGGCTCTGGGAGATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATT CCTCTGGTTTACAGGAGACAATGGCCCGTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCG TCAAGACACTGTTTCCAGCAAGTTGCAAAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATC CCTGAAGCTCACTAATGGCATTTGGATTTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGC TCCTGAAGTCTCTCAATACATCTATCAGGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGA TCGGTGCAAGTCAAGAACTCTTAACTGGAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTA GTCTAACCTGTGCTAACATTAGGGCACAACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCAC CTCTTGCCACCTGCTGCTGCTATCTGTCCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGT GTAGTTTGGTATTTTGTAATTGAGAGCTCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTGAAACACTG CACTTTACTGTTTTATACTTTTGTACATATGAGAAATCAAGGGATTAGTGCAACCAGTAGAAAGCATTGAAATGACTGTCATTAACCACA CAGTCCTGGAGGCAGAGATGCAGTTACCTACCCTAGCTTTTGATGGGTTCTCTTACCTGTAGTAGCCTTATCCCTGGTCATTTGGATTTT CAGTTTGCTTTTTTCTTTTTTTCCCCTCCAAACTCCTTTTCCTTGGCCAAGCCTTCATGCTTCCCCCTTTCCATATTATAATCTCATTTG ATTGCTCTGCA >6890_6890_8_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000312678_length(amino acids)=313AA_BP=237 MLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_9_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000537622_length(transcript)=1435nt_BP=815nt GCGCCGGTCGCGCGCCCGCCAGCCTGCCGCCTGGGCTGGGGGTCACGAAAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACC CTCCCGGGCTTCCTTGCTCACCGGCCGGCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCT CAACGAGACCACCTTGGCAGAGGTGCTGCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTA TCACCCCAACTTCCGTGGTTTTGATTACTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCC TCCTTGTCCAGCGTGTCCACAGGGTGATGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAA CCTCAACATTGTGGAGCAGCCGGTGAACTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCAC CAGCGGGAGGCCCTTCCTGCTCTATGTGGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAG AAGCCTGTATGGTGCAGGGCTCTGGGAGATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATT CCTCTGGTTTACAGGAGACAATGGCCCGTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCG TCAAGACACTGTTTCCAGCAAGTTGCAAAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATC CCTGAAGCTCACTAATGGCATTTGGATTTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGC TCCTGAAGTCTCTCAATACATCTATCAGGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGA TCGGTGCAAGTCAAGAACTCTTAACTGGAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTA GTCTAACCTGTGCTAACATTAGGGCACAACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCAC CTCTTGCCACCTGCTGCTGCTATCTGTCCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGT GTAGTTTGGTATTTTGTAATTGAGAGCTCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTGAAA >6890_6890_9_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000537622_length(amino acids)=313AA_BP=237 MLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_10_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000538556_length(transcript)=1432nt_BP=815nt GCGCCGGTCGCGCGCCCGCCAGCCTGCCGCCTGGGCTGGGGGTCACGAAAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACC CTCCCGGGCTTCCTTGCTCACCGGCCGGCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCT CAACGAGACCACCTTGGCAGAGGTGCTGCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTA TCACCCCAACTTCCGTGGTTTTGATTACTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCC TCCTTGTCCAGCGTGTCCACAGGGTGATGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAA CCTCAACATTGTGGAGCAGCCGGTGAACTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCAC CAGCGGGAGGCCCTTCCTGCTCTATGTGGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAG AAGCCTGTATGGTGCAGGGCTCTGGGAGATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATT CCTCTGGTTTACAGGAGACAATGGCCCGTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCG TCAAGACACTGTTTCCAGCAAGTTGCAAAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATC CCTGAAGCTCACTAATGGCATTTGGATTTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGC TCCTGAAGTCTCTCAATACATCTATCAGGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGA TCGGTGCAAGTCAAGAACTCTTAACTGGAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTA GTCTAACCTGTGCTAACATTAGGGCACAACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCAC CTCTTGCCACCTGCTGCTGCTATCTGTCCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGT GTAGTTTGGTATTTTGTAATTGAGAGCTCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTG >6890_6890_10_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000538556_length(amino acids)=313AA_BP=237 MLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_11_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000589344_length(transcript)=1111nt_BP=815nt GCGCCGGTCGCGCGCCCGCCAGCCTGCCGCCTGGGCTGGGGGTCACGAAAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACC CTCCCGGGCTTCCTTGCTCACCGGCCGGCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCT CAACGAGACCACCTTGGCAGAGGTGCTGCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTA TCACCCCAACTTCCGTGGTTTTGATTACTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCC TCCTTGTCCAGCGTGTCCACAGGGTGATGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAA CCTCAACATTGTGGAGCAGCCGGTGAACTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCAC CAGCGGGAGGCCCTTCCTGCTCTATGTGGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAG AAGCCTGTATGGTGCAGGGCTCTGGGAGATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATT CCTCTGGTTTACAGGAGACAATGGCCCGTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCG TCAAGACACTGTTTCCAGCAAGTTGCAAAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATC CCTGAAGCTCACTAATGGCATTTGGATTTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGC TCCTGAAGTCTCTCAATACATCTATCAGGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGA TCGGTGCAAGTCAAGAACTCTTAACTGGAAG >6890_6890_11_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000589344_length(amino acids)=313AA_BP=237 MLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- >6890_6890_12_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000592545_length(transcript)=1432nt_BP=815nt GCGCCGGTCGCGCGCCCGCCAGCCTGCCGCCTGGGCTGGGGGTCACGAAAGGTTTGTGGATTTCCATGCAGCTGCCTCCACCTGCTCACC CTCCCGGGCTTCCTTGCTCACCGGCCGGCTTGGCCTTCGCAATGGAGTCACACGCAACTTTGCAGTCACTTCTGTGGGAGGCCTTCCGCT CAACGAGACCACCTTGGCAGAGGTGCTGCAGCAGGCGGGTTACGTCACTGGGATAATAGGCAAATGGCATCTTGGACACCACGGCTCTTA TCACCCCAACTTCCGTGGTTTTGATTACTACTTTGGAATCCCATATAGCCATGATATGGGCTGTACTGATACTCCAGGCTACAACCACCC TCCTTGTCCAGCGTGTCCACAGGGTGATGGACCATCAAGGAACCTTCAAAGAGACTGTTACACTGACGTGGCCCTCCCTCTTTATGAAAA CCTCAACATTGTGGAGCAGCCGGTGAACTTGAGCAGCCTTGCCCAGAAGTATGCTGAGAAAGCAACCCAGTTCATCCAGCGTGCAAGCAC CAGCGGGAGGCCCTTCCTGCTCTATGTGGCTCTGGCCCACATGCACGTGCCCTTACCTGTGACTCAGCTACCAGCAGCGCCACGGGGCAG AAGCCTGTATGGTGCAGGGCTCTGGGAGATGGACAGTCTGGTGGGCCAGATCAAGGACAAAGTTGACCACACAGTGAAGGAAAACACATT CCTCTGGTTTACAGGAGACAATGGCCCGTGGGCTCAGAAGTGTGAGCTAGCGGGCAGTGTGGGTCCCTTCACTGGATTTTGGCAAACTCG TCAAGACACTGTTTCCAGCAAGTTGCAAAACAACAATGTTTATACTATTGCCAAGAGGAATGTGGAAGGGCAGGACATGCTGTACCAATC CCTGAAGCTCACTAATGGCATTTGGATTTTGGCCGAACTACGTATCCAGCCAGGAAACCCCAATTACACGCTGTCACTGAAGTGTAGAGC TCCTGAAGTCTCTCAATACATCTATCAGGTCTACGACAGCATTTTGAAAAACTAACAAGACTGGTCCAGTACCCTTCAACCATGCTGTGA TCGGTGCAAGTCAAGAACTCTTAACTGGAAGAAATTGTATTGCTGCGTAGAATCTGAACACACTGAGGCCACCTAGCAAGGTAGTAACTA GTCTAACCTGTGCTAACATTAGGGCACAACCTGTTGGATAGTTTTAGCTTCCTGTGAACATTTGTAACCACTGCTTCAGTCACCTCCCAC CTCTTGCCACCTGCTGCTGCTATCTGTCCTTACTTGTGGGCTTCTCCATGCTGTGCCAATGGCTGGCTTTTTCTACACCCTCTTTTGAGT GTAGTTTGGTATTTTGTAATTGAGAGCTCATTTCAAAAGCAGAAAAAGACAACAAATATTAAAGCAAGGAAAAGTGTAACTG >6890_6890_12_ARSG-AP2B1_ARSG_chr17_66366665_ENST00000452479_AP2B1_chr17_34044214_ENST00000592545_length(amino acids)=313AA_BP=237 MLTGRLGLRNGVTRNFAVTSVGGLPLNETTLAEVLQQAGYVTGIIGKWHLGHHGSYHPNFRGFDYYFGIPYSHDMGCTDTPGYNHPPCPA CPQGDGPSRNLQRDCYTDVALPLYENLNIVEQPVNLSSLAQKYAEKATQFIQRASTSGRPFLLYVALAHMHVPLPVTQLPAAPRGRSLYG AGLWEMDSLVGQIKDKVDHTVKENTFLWFTGDNGPWAQKCELAGSVGPFTGFWQTRQDTVSSKLQNNNVYTIAKRNVEGQDMLYQSLKLT NGIWILAELRIQPGNPNYTLSLKCRAPEVSQYIYQVYDSILKN -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARSG-AP2B1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000538556 | 19 | 22 | 841_937 | 804.3333333333334 | 881.0 | ARRB1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000262325 | 18 | 21 | 841_937 | 861.3333333333334 | 938.0 | ARRB1 | |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000312678 | 19 | 22 | 841_937 | 875.3333333333334 | 952.0 | ARRB1 | |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000537622 | 19 | 22 | 841_937 | 875.3333333333334 | 952.0 | ARRB1 | |
| Tgene | AP2B1 | chr17:66366665 | chr17:34044214 | ENST00000589344 | 19 | 22 | 841_937 | 875.3333333333334 | 952.0 | ARRB1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARSG-AP2B1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARSG-AP2B1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ARSG | C4748364 | USHER SYNDROME, TYPE IV | 2 | GENOMICS_ENGLAND;UNIPROT |
| Hgene | ARSG | C0027877 | Neuronal Ceroid-Lipofuscinoses | 1 | GENOMICS_ENGLAND |
| Hgene | ARSG | C1568248 | Usher Syndrome, Type III | 1 | ORPHANET |
| Tgene | C0086132 | Depressive Symptoms | 1 | PSYGENET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies