
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AKR7L-CAPZB (FusionGDB2 ID:HG246181TG832) |
Fusion Gene Summary for AKR7L-CAPZB |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AKR7L-CAPZB | Fusion gene ID: hg246181tg832 | Hgene | Tgene | Gene symbol | AKR7L | CAPZB | Gene ID | 246181 | 832 |
| Gene name | aldo-keto reductase family 7 like (gene/pseudogene) | capping actin protein of muscle Z-line subunit beta | |
| Synonyms | AFAR3|AFB1-AR 3|AFB1-AR3|AKR7A4 | CAPB|CAPPB|CAPZ | |
| Cytomap | ('AKR7L')('CAPZB') 1p36.13|1p35-p36.1 | 1p36.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | aflatoxin B1 aldehyde reductase member 4AFB1 aldehyde reductase 3aldo-keto reductase family 7 pseudogenealdo-keto reductase family 7-likealdoketoreductase 7-like | F-actin-capping protein subunit betacapZ betacapping actin protein of muscle Z-line beta subunitcapping protein (actin filament) muscle Z-line, betaepididymis secretory sperm binding protein | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | P47756 | |
| Ensembl transtripts involved in fusion gene | ENST00000420396, ENST00000429712, | ||
| Fusion gene scores | * DoF score | 3 X 2 X 3=18 | 23 X 15 X 8=2760 |
| # samples | 3 | 27 | |
| ** MAII score | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(27/2760*10)=-3.3536369546147 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AKR7L [Title/Abstract] AND CAPZB [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AKR7L(19595065)-CAPZB(19746244), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across AKR7L (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CAPZB (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
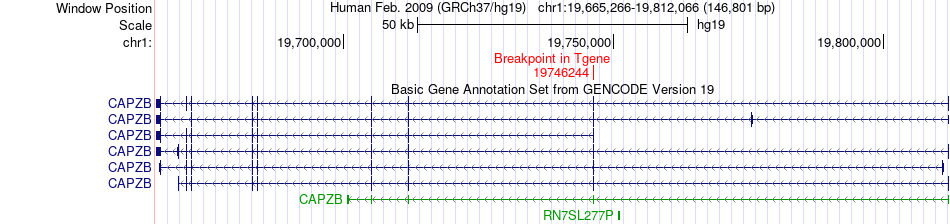 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-D8-A1JM | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
Top |
Fusion Gene ORF analysis for AKR7L-CAPZB |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000420396 | ENST00000375144 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000420396 | ENST00000482808 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000429712 | ENST00000375144 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| 5CDS-5UTR | ENST00000429712 | ENST00000482808 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000420396 | ENST00000264202 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000420396 | ENST00000264203 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000420396 | ENST00000375142 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000420396 | ENST00000401084 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000420396 | ENST00000433834 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000429712 | ENST00000264202 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000429712 | ENST00000264203 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000429712 | ENST00000375142 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000429712 | ENST00000401084 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| In-frame | ENST00000429712 | ENST00000433834 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000420396 | AKR7L | chr1 | 19595065 | - | ENST00000401084 | CAPZB | chr1 | 19746244 | - | 2210 | 637 | 337 | 1452 | 371 |
| ENST00000420396 | AKR7L | chr1 | 19595065 | - | ENST00000264203 | CAPZB | chr1 | 19746244 | - | 2130 | 637 | 337 | 1338 | 333 |
| ENST00000420396 | AKR7L | chr1 | 19595065 | - | ENST00000375142 | CAPZB | chr1 | 19746244 | - | 2273 | 637 | 337 | 1467 | 376 |
| ENST00000420396 | AKR7L | chr1 | 19595065 | - | ENST00000433834 | CAPZB | chr1 | 19746244 | - | 1624 | 637 | 337 | 1452 | 371 |
| ENST00000420396 | AKR7L | chr1 | 19595065 | - | ENST00000264202 | CAPZB | chr1 | 19746244 | - | 1468 | 637 | 337 | 1467 | 377 |
| ENST00000429712 | AKR7L | chr1 | 19595065 | - | ENST00000401084 | CAPZB | chr1 | 19746244 | - | 2527 | 954 | 492 | 1769 | 425 |
| ENST00000429712 | AKR7L | chr1 | 19595065 | - | ENST00000264203 | CAPZB | chr1 | 19746244 | - | 2447 | 954 | 492 | 1655 | 387 |
| ENST00000429712 | AKR7L | chr1 | 19595065 | - | ENST00000375142 | CAPZB | chr1 | 19746244 | - | 2590 | 954 | 492 | 1784 | 430 |
| ENST00000429712 | AKR7L | chr1 | 19595065 | - | ENST00000433834 | CAPZB | chr1 | 19746244 | - | 1941 | 954 | 492 | 1769 | 425 |
| ENST00000429712 | AKR7L | chr1 | 19595065 | - | ENST00000264202 | CAPZB | chr1 | 19746244 | - | 1785 | 954 | 492 | 1784 | 430 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000420396 | ENST00000401084 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.012024832 | 0.9879752 |
| ENST00000420396 | ENST00000264203 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.04283752 | 0.95716244 |
| ENST00000420396 | ENST00000375142 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.014919085 | 0.9850809 |
| ENST00000420396 | ENST00000433834 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.027848663 | 0.9721513 |
| ENST00000420396 | ENST00000264202 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.026583282 | 0.9734167 |
| ENST00000429712 | ENST00000401084 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.003869942 | 0.99613 |
| ENST00000429712 | ENST00000264203 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.004905052 | 0.995095 |
| ENST00000429712 | ENST00000375142 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.004557214 | 0.99544275 |
| ENST00000429712 | ENST00000433834 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.009583131 | 0.9904169 |
| ENST00000429712 | ENST00000264202 | AKR7L | chr1 | 19595065 | - | CAPZB | chr1 | 19746244 | - | 0.008652559 | 0.9913475 |
Top |
Fusion Genomic Features for AKR7L-CAPZB |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
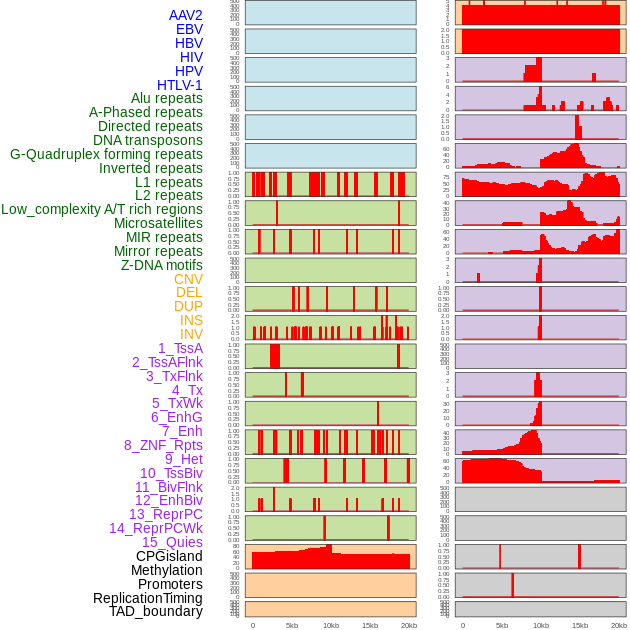 |
Top |
Fusion Protein Features for AKR7L-CAPZB |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:19595065/chr1:19746244) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CAPZB |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: F-actin-capping proteins bind in a Ca(2+)-independent manner to the fast growing ends of actin filaments (barbed end) thereby blocking the exchange of subunits at these ends. Unlike other capping proteins (such as gelsolin and severin), these proteins do not sever actin filaments. Plays a role in the regulation of cell morphology and cytoskeletal organization. {ECO:0000269|PubMed:21834987}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AKR7L | chr1:19595065 | chr1:19746244 | ENST00000420396 | - | 4 | 5 | 143_144 | 100 | 154.0 | Nucleotide binding | NADP |
| Hgene | AKR7L | chr1:19595065 | chr1:19746244 | ENST00000420396 | - | 4 | 5 | 198_208 | 100 | 154.0 | Nucleotide binding | NADP |
| Hgene | AKR7L | chr1:19595065 | chr1:19746244 | ENST00000420396 | - | 4 | 5 | 290_298 | 100 | 154.0 | Nucleotide binding | NADP |
Top |
Fusion Gene Sequence for AKR7L-CAPZB |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >3459_3459_1_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000264202_length(transcript)=1468nt_BP=637nt ATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGGCGCCGCATGGACGCGCCCACCAGCGCCGCA GTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGCGACGGCCAGTCCGAGACCATCCTTGGCGGC CTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCATGGATTGGGAACTCCCTGAAGCCTGACAGT GTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTCTATCTACATGCACCTGACCACAGCGCCCCG GTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTTGGCCTCTCCAACTATGCCGCCTGGGAAGTG GCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGCTTCTGGAAGGAGCACCACTTCGAGGGCATTGC CCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCTCCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACA GCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGAT CGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTA CCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCC GTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGT CTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGA TTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGAC CAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACA CATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATAT CGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCG CCAGATCTACATCCAGCCTGATAATTAA >3459_3459_1_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000264202_length(amino acids)=377AA_BP=99 MHLTTAPRWKRHCVPATSCTRRASSWSLASPTMPPGKWPRSVPSARATAGSCPLCTSFWKEHHFEGIALVEKALQAAYGASAPSMTSAAL RWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDP PLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTS TVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRE LSQVLTQRQIYIQPDNX -------------------------------------------------------------- >3459_3459_2_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000264203_length(transcript)=2130nt_BP=637nt ATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGGCGCCGCATGGACGCGCCCACCAGCGCCGCA GTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGCGACGGCCAGTCCGAGACCATCCTTGGCGGC CTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCATGGATTGGGAACTCCCTGAAGCCTGACAGT GTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTCTATCTACATGCACCTGACCACAGCGCCCCG GTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTTGGCCTCTCCAACTATGCCGCCTGGGAAGTG GCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGCTTCTGGAAGGAGCACCACTTCGAGGGCATTGC CCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCTCCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACA GCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGAT CGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTA CCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCC GTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGT CTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGA TTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGAC CAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACA CATAGCCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGG CTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGT TTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAAT AAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGG TTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCAC CTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATC TTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTC CTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTT CTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGA GCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAACTGGGGCGCAGTT >3459_3459_2_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000264203_length(amino acids)=333AA_BP=99 MHLTTAPRWKRHCVPATSCTRRASSWSLASPTMPPGKWPRSVPSARATAGSCPLCTSFWKEHHFEGIALVEKALQAAYGASAPSMTSAAL RWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDP PLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTS TVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEVCADFCRQIKTRSSEE -------------------------------------------------------------- >3459_3459_3_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000375142_length(transcript)=2273nt_BP=637nt ATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGGCGCCGCATGGACGCGCCCACCAGCGCCGCA GTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGCGACGGCCAGTCCGAGACCATCCTTGGCGGC CTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCATGGATTGGGAACTCCCTGAAGCCTGACAGT GTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTCTATCTACATGCACCTGACCACAGCGCCCCG GTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTTGGCCTCTCCAACTATGCCGCCTGGGAAGTG GCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGCTTCTGGAAGGAGCACCACTTCGAGGGCATTGC CCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCTCCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACA GCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGAT CGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTA CCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCC GTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGT CTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGA TTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGAC CAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACA CATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATAT CGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCG CCAGATCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGAC CTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTA GAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCT CCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGA GACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCT TCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAA ACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCT CGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCC AGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATC TTATACTTGAGCCTCCATACTTA >3459_3459_3_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000375142_length(amino acids)=376AA_BP=99 MHLTTAPRWKRHCVPATSCTRRASSWSLASPTMPPGKWPRSVPSARATAGSCPLCTSFWKEHHFEGIALVEKALQAAYGASAPSMTSAAL RWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDP PLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTS TVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRE LSQVLTQRQIYIQPDN -------------------------------------------------------------- >3459_3459_4_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000401084_length(transcript)=2210nt_BP=637nt ATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGGCGCCGCATGGACGCGCCCACCAGCGCCGCA GTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGCGACGGCCAGTCCGAGACCATCCTTGGCGGC CTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCATGGATTGGGAACTCCCTGAAGCCTGACAGT GTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTCTATCTACATGCACCTGACCACAGCGCCCCG GTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTTGGCCTCTCCAACTATGCCGCCTGGGAAGTG GCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGCTTCTGGAAGGAGCACCACTTCGAGGGCATTGC CCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCTCCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACA GCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGAT CGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTA CCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCC GTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGT CTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGA TTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGAC CAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACA CATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATAT CGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAA GCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTT CCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCC ACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCC GGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACAT TGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGT GTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCT CCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTA TGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTA AAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAACTGGGGCGCAGTTAGC >3459_3459_4_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000401084_length(amino acids)=371AA_BP=99 MHLTTAPRWKRHCVPATSCTRRASSWSLASPTMPPGKWPRSVPSARATAGSCPLCTSFWKEHHFEGIALVEKALQAAYGASAPSMTSAAL RWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDP PLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTS TVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKND LVEALKRKQQC -------------------------------------------------------------- >3459_3459_5_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000433834_length(transcript)=1624nt_BP=637nt ATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGGCGCCGCATGGACGCGCCCACCAGCGCCGCA GTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGCGACGGCCAGTCCGAGACCATCCTTGGCGGC CTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCATGGATTGGGAACTCCCTGAAGCCTGACAGT GTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTCTATCTACATGCACCTGACCACAGCGCCCCG GTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTTGGCCTCTCCAACTATGCCGCCTGGGAAGTG GCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGCTTCTGGAAGGAGCACCACTTCGAGGGCATTGC CCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCTCCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACA GCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATGAGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGAT CGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTA CCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCC GTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGT CTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGA TTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGAC CAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACA CATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATAT CGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAA GCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTT CCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCC ACCC >3459_3459_5_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000420396_CAPZB_chr1_19746244_ENST00000433834_length(amino acids)=371AA_BP=99 MHLTTAPRWKRHCVPATSCTRRASSWSLASPTMPPGKWPRSVPSARATAGSCPLCTSFWKEHHFEGIALVEKALQAAYGASAPSMTSAAL RWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSDLIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDP PLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTS TVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKND LVEALKRKQQC -------------------------------------------------------------- >3459_3459_6_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000264202_length(transcript)=1785nt_BP=954nt ACCACCGGTGGGCGCGGCCCGAGCCAGTCCCTAAAGCCACGAGGCCGCCCGCTCCGAGCCTGGTGCTTCCGACCGCTGCGCGCGGCTCCT GGGCTGTCACAGTCTCCCGTTGCCGCCGTCATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGG CGCCGCATGGACGCGCCCACCAGCGCCGCAGTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGC GACGGCCAGTCCGAGACCATCCTTGGCGGCCTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCA TGGATTGGGAACTCCCTGAAGCCTGACAGTGTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTC TATCTACATGCACCTGACCACAGCGCCCCGGTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTT GGCCTCTCCAACTATGCCGCCTGGGAAGTGGCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGGGC ATGTACAGCGCCACCACCCGGCAGGTGGAAACGGAGCTCTTCCCCTGCCTCAGGCACTTTGGACTGAGGTTCTATGCCTACAACCCTCTG GCTGGGGGCCTGCTGACCGGCAAGTACAAGTATGAGGACAAGGACGGGAAACAGCCCGTGGGCCGCTTCTTTGGGACTCAGTGGGCAGAG ATCTACAGGAATCACTTCTGGAAGGAGCACCACTTCGAGGGCATTGCCCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCT CCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACAGCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATG AGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTT GACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCA CCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCC TTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTC ATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGC ACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTT ACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAA ATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAA AAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAA >3459_3459_6_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000264202_length(amino acids)=430AA_BP=153 MRACHQLHQEGKFVELGLSNYAAWEVAEICTLCKSNGWILPTVYQGMYSATTRQVETELFPCLRHFGLRFYAYNPLAGGLLTGKYKYEDK DGKQPVGRFFGTQWAEIYRNHFWKEHHFEGIALVEKALQAAYGASAPSMTSAALRWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSD LIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVS SVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCS PHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDN -------------------------------------------------------------- >3459_3459_7_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000264203_length(transcript)=2447nt_BP=954nt ACCACCGGTGGGCGCGGCCCGAGCCAGTCCCTAAAGCCACGAGGCCGCCCGCTCCGAGCCTGGTGCTTCCGACCGCTGCGCGCGGCTCCT GGGCTGTCACAGTCTCCCGTTGCCGCCGTCATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGG CGCCGCATGGACGCGCCCACCAGCGCCGCAGTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGC GACGGCCAGTCCGAGACCATCCTTGGCGGCCTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCA TGGATTGGGAACTCCCTGAAGCCTGACAGTGTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTC TATCTACATGCACCTGACCACAGCGCCCCGGTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTT GGCCTCTCCAACTATGCCGCCTGGGAAGTGGCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGGGC ATGTACAGCGCCACCACCCGGCAGGTGGAAACGGAGCTCTTCCCCTGCCTCAGGCACTTTGGACTGAGGTTCTATGCCTACAACCCTCTG GCTGGGGGCCTGCTGACCGGCAAGTACAAGTATGAGGACAAGGACGGGAAACAGCCCGTGGGCCGCTTCTTTGGGACTCAGTGGGCAGAG ATCTACAGGAATCACTTCTGGAAGGAGCACCACTTCGAGGGCATTGCCCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCT CCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACAGCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATG AGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTT GACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCA CCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCC TTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTC ATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGC ACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTT ACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTT TGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTA ACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCAC ATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGC CACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCA TTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTT TATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGT GGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGC TGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATT TTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAA GAAACTGGGGCGCAGTT >3459_3459_7_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000264203_length(amino acids)=387AA_BP=153 MRACHQLHQEGKFVELGLSNYAAWEVAEICTLCKSNGWILPTVYQGMYSATTRQVETELFPCLRHFGLRFYAYNPLAGGLLTGKYKYEDK DGKQPVGRFFGTQWAEIYRNHFWKEHHFEGIALVEKALQAAYGASAPSMTSAALRWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSD LIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVS SVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCS PHIANIGRLVEVCADFCRQIKTRSSEE -------------------------------------------------------------- >3459_3459_8_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000375142_length(transcript)=2590nt_BP=954nt ACCACCGGTGGGCGCGGCCCGAGCCAGTCCCTAAAGCCACGAGGCCGCCCGCTCCGAGCCTGGTGCTTCCGACCGCTGCGCGCGGCTCCT GGGCTGTCACAGTCTCCCGTTGCCGCCGTCATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGG CGCCGCATGGACGCGCCCACCAGCGCCGCAGTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGC GACGGCCAGTCCGAGACCATCCTTGGCGGCCTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCA TGGATTGGGAACTCCCTGAAGCCTGACAGTGTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTC TATCTACATGCACCTGACCACAGCGCCCCGGTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTT GGCCTCTCCAACTATGCCGCCTGGGAAGTGGCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGGGC ATGTACAGCGCCACCACCCGGCAGGTGGAAACGGAGCTCTTCCCCTGCCTCAGGCACTTTGGACTGAGGTTCTATGCCTACAACCCTCTG GCTGGGGGCCTGCTGACCGGCAAGTACAAGTATGAGGACAAGGACGGGAAACAGCCCGTGGGCCGCTTCTTTGGGACTCAGTGGGCAGAG ATCTACAGGAATCACTTCTGGAAGGAGCACCACTTCGAGGGCATTGCCCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCT CCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACAGCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATG AGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTT GACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCA CCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCC TTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTC ATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGC ACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTT ACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAA ATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAA AAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTG TGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTG TTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCC GACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGC CTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCC TGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAAC AAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGT TGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCG GGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTT TTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTA >3459_3459_8_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000375142_length(amino acids)=430AA_BP=153 MRACHQLHQEGKFVELGLSNYAAWEVAEICTLCKSNGWILPTVYQGMYSATTRQVETELFPCLRHFGLRFYAYNPLAGGLLTGKYKYEDK DGKQPVGRFFGTQWAEIYRNHFWKEHHFEGIALVEKALQAAYGASAPSMTSAALRWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSD LIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVS SVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCS PHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDN -------------------------------------------------------------- >3459_3459_9_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000401084_length(transcript)=2527nt_BP=954nt ACCACCGGTGGGCGCGGCCCGAGCCAGTCCCTAAAGCCACGAGGCCGCCCGCTCCGAGCCTGGTGCTTCCGACCGCTGCGCGCGGCTCCT GGGCTGTCACAGTCTCCCGTTGCCGCCGTCATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGG CGCCGCATGGACGCGCCCACCAGCGCCGCAGTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGC GACGGCCAGTCCGAGACCATCCTTGGCGGCCTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCA TGGATTGGGAACTCCCTGAAGCCTGACAGTGTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTC TATCTACATGCACCTGACCACAGCGCCCCGGTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTT GGCCTCTCCAACTATGCCGCCTGGGAAGTGGCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGGGC ATGTACAGCGCCACCACCCGGCAGGTGGAAACGGAGCTCTTCCCCTGCCTCAGGCACTTTGGACTGAGGTTCTATGCCTACAACCCTCTG GCTGGGGGCCTGCTGACCGGCAAGTACAAGTATGAGGACAAGGACGGGAAACAGCCCGTGGGCCGCTTCTTTGGGACTCAGTGGGCAGAG ATCTACAGGAATCACTTCTGGAAGGAGCACCACTTCGAGGGCATTGCCCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCT CCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACAGCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATG AGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTT GACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCA CCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCC TTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTC ATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGC ACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTT ACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAA ATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCA AAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCG TGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCAT CATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCT CAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAA AATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTG TGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGAC AGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCC GCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTA AAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAACTGGGGCGC AGTTAGC >3459_3459_9_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000401084_length(amino acids)=425AA_BP=153 MRACHQLHQEGKFVELGLSNYAAWEVAEICTLCKSNGWILPTVYQGMYSATTRQVETELFPCLRHFGLRFYAYNPLAGGLLTGKYKYEDK DGKQPVGRFFGTQWAEIYRNHFWKEHHFEGIALVEKALQAAYGASAPSMTSAALRWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSD LIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVS SVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCS PHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- >3459_3459_10_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000433834_length(transcript)=1941nt_BP=954nt ACCACCGGTGGGCGCGGCCCGAGCCAGTCCCTAAAGCCACGAGGCCGCCCGCTCCGAGCCTGGTGCTTCCGACCGCTGCGCGCGGCTCCT GGGCTGTCACAGTCTCCCGTTGCCGCCGTCATGTCCCGGCAGCTGTCGCGGGCCCGGCCAGCCACGGTGCTGGGCGCCATGGAGATGGGG CGCCGCATGGACGCGCCCACCAGCGCCGCAGTCACGCGCGCCTTCCTGGAGCGCGGCCACACCGAGATAGACACGGCCTTCCTGTACAGC GACGGCCAGTCCGAGACCATCCTTGGCGGCCTGGGGCTCCGAATGGGCAGCAGCGACTGCAGAGTGAAAATTGCTACCAAGGCCAATCCA TGGATTGGGAACTCCCTGAAGCCTGACAGTGTCCGATCCCAGCTGGAGACGTCACTGAAGCGGCTGCAGTGTCCCTGAGTGGACCTCTTC TATCTACATGCACCTGACCACAGCGCCCCGGTGGAAGAGACACTGCGTGCCTGCCACCAGCTGCACCAGGAGGGCAAGTTCGTGGAGCTT GGCCTCTCCAACTATGCCGCCTGGGAAGTGGCCGAGATCTGTACCCTCTGCAAGAGCAACGGCTGGATCCTGCCCACTGTGTACCAGGGC ATGTACAGCGCCACCACCCGGCAGGTGGAAACGGAGCTCTTCCCCTGCCTCAGGCACTTTGGACTGAGGTTCTATGCCTACAACCCTCTG GCTGGGGGCCTGCTGACCGGCAAGTACAAGTATGAGGACAAGGACGGGAAACAGCCCGTGGGCCGCTTCTTTGGGACTCAGTGGGCAGAG ATCTACAGGAATCACTTCTGGAAGGAGCACCACTTCGAGGGCATTGCCCTGGTGGAGAAGGCCCTGCAGGCCGCGTATGGCGCCAGCGCT CCCAGCATGACCTCGGCCGCCCTCCGGTGGATGTACCACCACTCACAGCTGCAGAGTGATCAGCAGCTGGACTGTGCCTTGGACCTAATG AGGCGCCTGCCTCCCCAGCAAATCGAGAAAAACCTCAGCGACCTGATCGACCTGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTT GACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCA CCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCC TTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTC ATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGC ACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTT ACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAA ATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCA AAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCG TGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCAT CATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCC >3459_3459_10_AKR7L-CAPZB_AKR7L_chr1_19595065_ENST00000429712_CAPZB_chr1_19746244_ENST00000433834_length(amino acids)=425AA_BP=153 MRACHQLHQEGKFVELGLSNYAAWEVAEICTLCKSNGWILPTVYQGMYSATTRQVETELFPCLRHFGLRFYAYNPLAGGLLTGKYKYEDK DGKQPVGRFFGTQWAEIYRNHFWKEHHFEGIALVEKALQAAYGASAPSMTSAALRWMYHHSQLQSDQQLDCALDLMRRLPPQQIEKNLSD LIDLVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVS SVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCS PHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AKR7L-CAPZB |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AKR7L-CAPZB |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AKR7L-CAPZB |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0007097 | Carcinoma | 1 | CTD_human | |
| Tgene | C0024667 | Animal Mammary Neoplasms | 1 | CTD_human | |
| Tgene | C0024668 | Mammary Neoplasms, Experimental | 1 | CTD_human | |
| Tgene | C0205696 | Anaplastic carcinoma | 1 | CTD_human | |
| Tgene | C0205697 | Carcinoma, Spindle-Cell | 1 | CTD_human | |
| Tgene | C0205698 | Undifferentiated carcinoma | 1 | CTD_human | |
| Tgene | C0205699 | Carcinomatosis | 1 | CTD_human | |
| Tgene | C0948089 | Acute Coronary Syndrome | 1 | CTD_human | |
| Tgene | C1257925 | Mammary Carcinoma, Animal | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies