
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NPNT-PPA2 (FusionGDB2 ID:HG255743TG27068) |
Fusion Gene Summary for NPNT-PPA2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NPNT-PPA2 | Fusion gene ID: hg255743tg27068 | Hgene | Tgene | Gene symbol | NPNT | PPA2 | Gene ID | 255743 | 27068 |
| Gene name | nephronectin | inorganic pyrophosphatase 2 | |
| Synonyms | EGFL6L|POEM | HSPC124|SCFAI|SCFI|SID6-306 | |
| Cytomap | ('NPNT')('PPA2') 4q24 | 4q24 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nephronectinpreosteoblast EGF-like repeat protein with MAM domain | inorganic pyrophosphatase 2, mitochondrialPPase 2pyrophosphatase (inorganic) 2pyrophosphatase SID6-306pyrophosphate phospho-hydrolase 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000513430, ENST00000305572, ENST00000379987, ENST00000427316, ENST00000453617, ENST00000506666, ENST00000514622, | ||
| Fusion gene scores | * DoF score | 6 X 4 X 5=120 | 17 X 10 X 8=1360 |
| # samples | 7 | 18 | |
| ** MAII score | log2(7/120*10)=-0.777607578663552 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(18/1360*10)=-2.91753783980803 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NPNT [Title/Abstract] AND PPA2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NPNT(106848585)-PPA2(106377902), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | NPNT-PPA2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NPNT-PPA2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. NPNT-PPA2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. NPNT-PPA2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across NPNT (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
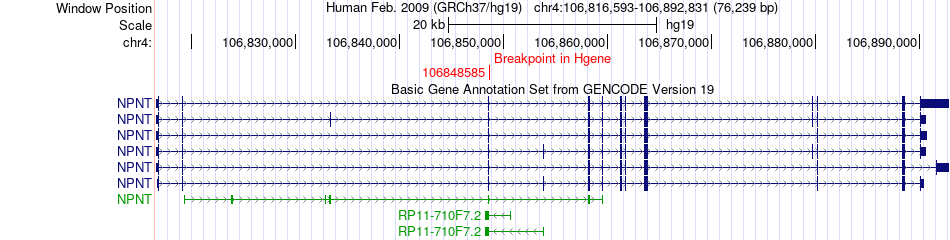 |
| Fusion gene breakpoints across PPA2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
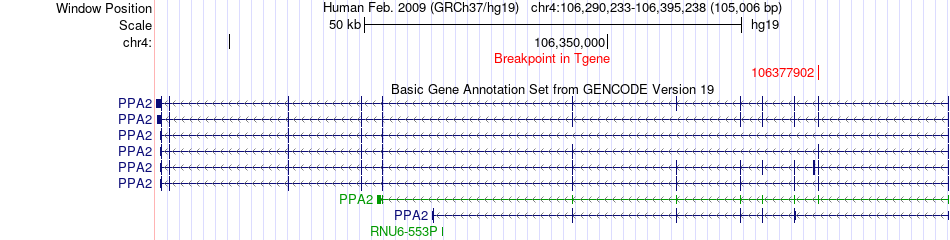 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | ERR315445 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
Top |
Fusion Gene ORF analysis for NPNT-PPA2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000513430 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 3UTR-3CDS | ENST00000513430 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 3UTR-3CDS | ENST00000513430 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 3UTR-5UTR | ENST00000513430 | ENST00000509426 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 3UTR-intron | ENST00000513430 | ENST00000310267 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 3UTR-intron | ENST00000513430 | ENST00000354147 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 3UTR-intron | ENST00000513430 | ENST00000357415 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 3UTR-intron | ENST00000513430 | ENST00000380004 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-5UTR | ENST00000305572 | ENST00000509426 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-5UTR | ENST00000379987 | ENST00000509426 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-5UTR | ENST00000427316 | ENST00000509426 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-5UTR | ENST00000453617 | ENST00000509426 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-5UTR | ENST00000506666 | ENST00000509426 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-5UTR | ENST00000514622 | ENST00000509426 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000305572 | ENST00000310267 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000305572 | ENST00000354147 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000305572 | ENST00000357415 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000305572 | ENST00000380004 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000379987 | ENST00000310267 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000379987 | ENST00000354147 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000379987 | ENST00000357415 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000379987 | ENST00000380004 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000427316 | ENST00000310267 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000427316 | ENST00000354147 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000427316 | ENST00000357415 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000427316 | ENST00000380004 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000453617 | ENST00000310267 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000453617 | ENST00000354147 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000453617 | ENST00000357415 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000453617 | ENST00000380004 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000506666 | ENST00000310267 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000506666 | ENST00000354147 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000506666 | ENST00000357415 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000506666 | ENST00000380004 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000514622 | ENST00000310267 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000514622 | ENST00000354147 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000514622 | ENST00000357415 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| 5CDS-intron | ENST00000514622 | ENST00000380004 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000305572 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000305572 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000305572 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000379987 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000379987 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000379987 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000427316 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000427316 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000427316 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000453617 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000453617 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000453617 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000506666 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000506666 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000506666 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000514622 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000514622 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| In-frame | ENST00000514622 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000379987 | NPNT | chr4 | 106848585 | + | ENST00000341695 | PPA2 | chr4 | 106377902 | - | 1977 | 481 | 45 | 1328 | 427 |
| ENST00000379987 | NPNT | chr4 | 106848585 | + | ENST00000348706 | PPA2 | chr4 | 106377902 | - | 1724 | 481 | 45 | 1241 | 398 |
| ENST00000379987 | NPNT | chr4 | 106848585 | + | ENST00000432483 | PPA2 | chr4 | 106377902 | - | 1183 | 481 | 45 | 1022 | 325 |
| ENST00000453617 | NPNT | chr4 | 106848585 | + | ENST00000341695 | PPA2 | chr4 | 106377902 | - | 2025 | 529 | 42 | 1376 | 444 |
| ENST00000453617 | NPNT | chr4 | 106848585 | + | ENST00000348706 | PPA2 | chr4 | 106377902 | - | 1772 | 529 | 42 | 1289 | 415 |
| ENST00000453617 | NPNT | chr4 | 106848585 | + | ENST00000432483 | PPA2 | chr4 | 106377902 | - | 1231 | 529 | 42 | 1070 | 342 |
| ENST00000427316 | NPNT | chr4 | 106848585 | + | ENST00000341695 | PPA2 | chr4 | 106377902 | - | 1973 | 477 | 41 | 1324 | 427 |
| ENST00000427316 | NPNT | chr4 | 106848585 | + | ENST00000348706 | PPA2 | chr4 | 106377902 | - | 1720 | 477 | 41 | 1237 | 398 |
| ENST00000427316 | NPNT | chr4 | 106848585 | + | ENST00000432483 | PPA2 | chr4 | 106377902 | - | 1179 | 477 | 41 | 1018 | 325 |
| ENST00000514622 | NPNT | chr4 | 106848585 | + | ENST00000341695 | PPA2 | chr4 | 106377902 | - | 1973 | 477 | 41 | 1324 | 427 |
| ENST00000514622 | NPNT | chr4 | 106848585 | + | ENST00000348706 | PPA2 | chr4 | 106377902 | - | 1720 | 477 | 41 | 1237 | 398 |
| ENST00000514622 | NPNT | chr4 | 106848585 | + | ENST00000432483 | PPA2 | chr4 | 106377902 | - | 1179 | 477 | 41 | 1018 | 325 |
| ENST00000305572 | NPNT | chr4 | 106848585 | + | ENST00000341695 | PPA2 | chr4 | 106377902 | - | 1963 | 467 | 31 | 1314 | 427 |
| ENST00000305572 | NPNT | chr4 | 106848585 | + | ENST00000348706 | PPA2 | chr4 | 106377902 | - | 1710 | 467 | 31 | 1227 | 398 |
| ENST00000305572 | NPNT | chr4 | 106848585 | + | ENST00000432483 | PPA2 | chr4 | 106377902 | - | 1169 | 467 | 31 | 1008 | 325 |
| ENST00000506666 | NPNT | chr4 | 106848585 | + | ENST00000341695 | PPA2 | chr4 | 106377902 | - | 1921 | 425 | 13 | 1272 | 419 |
| ENST00000506666 | NPNT | chr4 | 106848585 | + | ENST00000348706 | PPA2 | chr4 | 106377902 | - | 1668 | 425 | 13 | 1185 | 390 |
| ENST00000506666 | NPNT | chr4 | 106848585 | + | ENST00000432483 | PPA2 | chr4 | 106377902 | - | 1127 | 425 | 13 | 966 | 317 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000379987 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000560674 | 0.9994393 |
| ENST00000379987 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.00062101 | 0.9993789 |
| ENST00000379987 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000980868 | 0.99901915 |
| ENST00000453617 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000771983 | 0.999228 |
| ENST00000453617 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000933254 | 0.99906677 |
| ENST00000453617 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.001302539 | 0.99869746 |
| ENST00000427316 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000514857 | 0.99948514 |
| ENST00000427316 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000562974 | 0.99943703 |
| ENST00000427316 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000878753 | 0.99912125 |
| ENST00000514622 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000514857 | 0.99948514 |
| ENST00000514622 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000562974 | 0.99943703 |
| ENST00000514622 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000878753 | 0.99912125 |
| ENST00000305572 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000521405 | 0.99947864 |
| ENST00000305572 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000568306 | 0.99943167 |
| ENST00000305572 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000909414 | 0.99909055 |
| ENST00000506666 | ENST00000341695 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000425249 | 0.9995747 |
| ENST00000506666 | ENST00000348706 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.00049378 | 0.99950624 |
| ENST00000506666 | ENST00000432483 | NPNT | chr4 | 106848585 | + | PPA2 | chr4 | 106377902 | - | 0.000774647 | 0.9992254 |
Top |
Fusion Genomic Features for NPNT-PPA2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
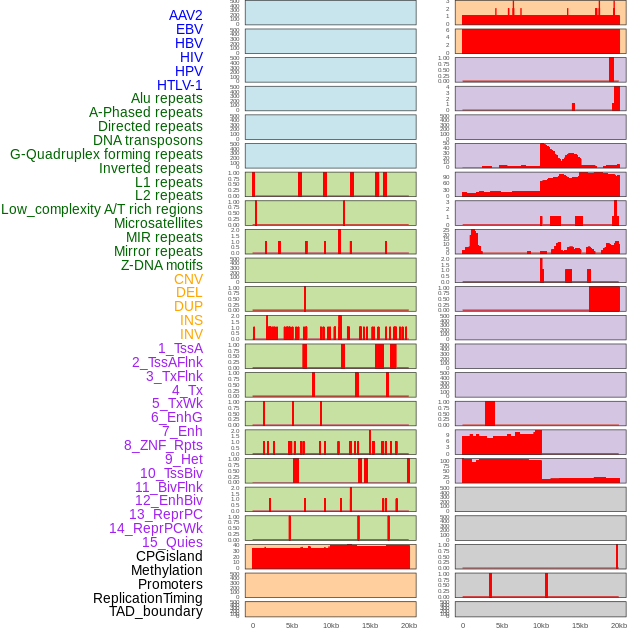 |
Top |
Fusion Protein Features for NPNT-PPA2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr4:106848585/chr4:106377902) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000305572 | + | 3 | 11 | 52_87 | 88 | 510.0 | Domain | EGF-like 1 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000379987 | + | 3 | 12 | 52_87 | 88 | 566.0 | Domain | EGF-like 1 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000427316 | + | 3 | 13 | 52_87 | 88 | 596.0 | Domain | EGF-like 1 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000453617 | + | 4 | 13 | 52_87 | 105 | 583.0 | Domain | EGF-like 1 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000506666 | + | 3 | 12 | 52_87 | 88 | 567.0 | Domain | EGF-like 1 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000514622 | + | 3 | 11 | 52_87 | 88 | 537.0 | Domain | EGF-like 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000305572 | + | 3 | 11 | 296_365 | 88 | 510.0 | Compositional bias | Note=Pro-rich |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000379987 | + | 3 | 12 | 296_365 | 88 | 566.0 | Compositional bias | Note=Pro-rich |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000427316 | + | 3 | 13 | 296_365 | 88 | 596.0 | Compositional bias | Note=Pro-rich |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000453617 | + | 4 | 13 | 296_365 | 105 | 583.0 | Compositional bias | Note=Pro-rich |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000506666 | + | 3 | 12 | 296_365 | 88 | 567.0 | Compositional bias | Note=Pro-rich |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000514622 | + | 3 | 11 | 296_365 | 88 | 537.0 | Compositional bias | Note=Pro-rich |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000305572 | + | 3 | 11 | 132_168 | 88 | 510.0 | Domain | EGF-like 3 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000305572 | + | 3 | 11 | 169_213 | 88 | 510.0 | Domain | EGF-like 4%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000305572 | + | 3 | 11 | 214_254 | 88 | 510.0 | Domain | EGF-like 5%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000305572 | + | 3 | 11 | 420_563 | 88 | 510.0 | Domain | MAM |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000305572 | + | 3 | 11 | 89_128 | 88 | 510.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000379987 | + | 3 | 12 | 132_168 | 88 | 566.0 | Domain | EGF-like 3 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000379987 | + | 3 | 12 | 169_213 | 88 | 566.0 | Domain | EGF-like 4%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000379987 | + | 3 | 12 | 214_254 | 88 | 566.0 | Domain | EGF-like 5%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000379987 | + | 3 | 12 | 420_563 | 88 | 566.0 | Domain | MAM |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000379987 | + | 3 | 12 | 89_128 | 88 | 566.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000427316 | + | 3 | 13 | 132_168 | 88 | 596.0 | Domain | EGF-like 3 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000427316 | + | 3 | 13 | 169_213 | 88 | 596.0 | Domain | EGF-like 4%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000427316 | + | 3 | 13 | 214_254 | 88 | 596.0 | Domain | EGF-like 5%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000427316 | + | 3 | 13 | 420_563 | 88 | 596.0 | Domain | MAM |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000427316 | + | 3 | 13 | 89_128 | 88 | 596.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000453617 | + | 4 | 13 | 132_168 | 105 | 583.0 | Domain | EGF-like 3 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000453617 | + | 4 | 13 | 169_213 | 105 | 583.0 | Domain | EGF-like 4%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000453617 | + | 4 | 13 | 214_254 | 105 | 583.0 | Domain | EGF-like 5%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000453617 | + | 4 | 13 | 420_563 | 105 | 583.0 | Domain | MAM |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000453617 | + | 4 | 13 | 89_128 | 105 | 583.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000506666 | + | 3 | 12 | 132_168 | 88 | 567.0 | Domain | EGF-like 3 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000506666 | + | 3 | 12 | 169_213 | 88 | 567.0 | Domain | EGF-like 4%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000506666 | + | 3 | 12 | 214_254 | 88 | 567.0 | Domain | EGF-like 5%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000506666 | + | 3 | 12 | 420_563 | 88 | 567.0 | Domain | MAM |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000506666 | + | 3 | 12 | 89_128 | 88 | 567.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000514622 | + | 3 | 11 | 132_168 | 88 | 537.0 | Domain | EGF-like 3 |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000514622 | + | 3 | 11 | 169_213 | 88 | 537.0 | Domain | EGF-like 4%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000514622 | + | 3 | 11 | 214_254 | 88 | 537.0 | Domain | EGF-like 5%3B calcium-binding |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000514622 | + | 3 | 11 | 420_563 | 88 | 537.0 | Domain | MAM |
| Hgene | NPNT | chr4:106848585 | chr4:106377902 | ENST00000514622 | + | 3 | 11 | 89_128 | 88 | 537.0 | Domain | EGF-like 2%3B calcium-binding |
Top |
Fusion Gene Sequence for NPNT-PPA2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >60002_60002_1_NPNT-PPA2_NPNT_chr4_106848585_ENST00000305572_PPA2_chr4_106377902_ENST00000341695_length(transcript)=1963nt_BP=467nt GGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTAGCCCGGGCGG CGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCCACTGCGCTGC GCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCGAGTTCGACGG GAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTCGCCAGTCTTG GGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGG AAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGGAAAATGG CATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATGCTAAAATGGA GATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCCCTTACAAGGG TTATATATGGAATTATGGTACCCTCCCTCAGACTTGGGAAGATCCCCATGAAAAAGATAAGAGCACGAACTGCTTTGGAGATAATGATCC TATTGATGTTTGCGAAATAGGCTCAAAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGA AGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAA ACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGA ATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGC TATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTC ACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCA TCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGC TATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGCCAGGCACGGT GGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCCAGTATGTTGA AACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGAGGCAGAAGAA CTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACTCCGTCTCAAA AAAAAAAAAAAGATTTTGTTTCATTTCATAGCACAAATTTAGAGGCATTGAGTTGACCATTTCTAGTTTCTATACCTGAAGGAACCCATT GATTTTACCAGTTTTTATTTCTGTAGATTGGATGTAAAAATCACAGATTCAATAAATTAATAAACTTTGTGTA >60002_60002_1_NPNT-PPA2_NPNT_chr4_106848585_ENST00000305572_PPA2_chr4_106377902_ENST00000341695_length(amino acids)=427AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQTWEDPHEKDKSTNCFGDNDPIDVCEIGSKI LSCGEVIHVKILGILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEV IKSTHQCWKALLMKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_2_NPNT-PPA2_NPNT_chr4_106848585_ENST00000305572_PPA2_chr4_106377902_ENST00000348706_length(transcript)=1710nt_BP=467nt GGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTAGCCCGGGCGG CGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCCACTGCGCTGC GCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCGAGTTCGACGG GAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTCGCCAGTCTTG GGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGG AAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGGAAAATGG CATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATGCTAAAATGGA GATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCCCTTACAAGGG TTATATATGGAATTATGGTACCCTCCCTCAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGA TGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTT CAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGG AGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGG AGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATC TTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTC CCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTG AGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGCCAGGCAC GGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCCAGTATGT TGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGAGGCAGAA GAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACTCCGTCTC >60002_60002_2_NPNT-PPA2_NPNT_chr4_106848585_ENST00000305572_PPA2_chr4_106377902_ENST00000348706_length(amino acids)=398AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQILSCGEVIHVKILGILALIDEGETDWKLIA INANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALLMKKCNGGAINCTNVQIS DSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_3_NPNT-PPA2_NPNT_chr4_106848585_ENST00000305572_PPA2_chr4_106377902_ENST00000432483_length(transcript)=1169nt_BP=467nt GGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTAGCCCGGGCGG CGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCCACTGCGCTGC GCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCGAGTTCGACGG GAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTCGCCAGTCTTG GGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGG AAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGATTCTTTC TTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGC GAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAG ATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAA ATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCC TTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTG GCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTC TATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAA >60002_60002_3_NPNT-PPA2_NPNT_chr4_106848585_ENST00000305572_PPA2_chr4_106377902_ENST00000432483_length(amino acids)=325AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEILSCGEVIHVKIL GILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALL MKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_4_NPNT-PPA2_NPNT_chr4_106848585_ENST00000379987_PPA2_chr4_106377902_ENST00000341695_length(transcript)=1977nt_BP=481nt AGCTAGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGC AGTAGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCG CGCCACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCC GCCGAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGG GCTCGCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCAT CCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCT AAAGAGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACA AATGCTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATC TTCCCTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGACTTGGGAAGATCCCCATGAAAAAGATAAGAGCACGAACTGCTTT GGAGATAATGATCCTATTGATGTTTGCGAAATAGGCTCAAAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTG GCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGAT GTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTT GCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAG TGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAA TCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGC TGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTT CAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTT TGGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCT GGCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGG CTGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGA GACTCCGTCTCAAAAAAAAAAAAAAGATTTTGTTTCATTTCATAGCACAAATTTAGAGGCATTGAGTTGACCATTTCTAGTTTCTATACC TGAAGGAACCCATTGATTTTACCAGTTTTTATTTCTGTAGATTGGATGTAAAAATCACAGATTCAATAAATTAATAAACTTTGTGTA >60002_60002_4_NPNT-PPA2_NPNT_chr4_106848585_ENST00000379987_PPA2_chr4_106377902_ENST00000341695_length(amino acids)=427AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQTWEDPHEKDKSTNCFGDNDPIDVCEIGSKI LSCGEVIHVKILGILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEV IKSTHQCWKALLMKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_5_NPNT-PPA2_NPNT_chr4_106848585_ENST00000379987_PPA2_chr4_106377902_ENST00000348706_length(transcript)=1724nt_BP=481nt AGCTAGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGC AGTAGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCG CGCCACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCC GCCGAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGG GCTCGCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCAT CCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCT AAAGAGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACA AATGCTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATC TTCCCTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATT TTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGAT GATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAG TTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAG AAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTT GAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTC TGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTT TTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGA TTTTGGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAG CCTGGCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGG AGGCTGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAG AGAGACTCCGTCTC >60002_60002_5_NPNT-PPA2_NPNT_chr4_106848585_ENST00000379987_PPA2_chr4_106377902_ENST00000348706_length(amino acids)=398AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQILSCGEVIHVKILGILALIDEGETDWKLIA INANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALLMKKCNGGAINCTNVQIS DSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_6_NPNT-PPA2_NPNT_chr4_106848585_ENST00000379987_PPA2_chr4_106377902_ENST00000432483_length(transcript)=1183nt_BP=481nt AGCTAGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGC AGTAGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCG CGCCACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCC GCCGAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGG GCTCGCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCAT CCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCT AAAGAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTA ATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACT CTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCT CTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAG ATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAA GAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTA GAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAG TAAGAATTTTAAA >60002_60002_6_NPNT-PPA2_NPNT_chr4_106848585_ENST00000379987_PPA2_chr4_106377902_ENST00000432483_length(amino acids)=325AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEILSCGEVIHVKIL GILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALL MKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_7_NPNT-PPA2_NPNT_chr4_106848585_ENST00000427316_PPA2_chr4_106377902_ENST00000341695_length(transcript)=1973nt_BP=477nt AGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTA GCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCC ACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCG AGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTC GCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTG GTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAG AGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATG CTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCC CTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGACTTGGGAAGATCCCCATGAAAAAGATAAGAGCACGAACTGCTTTGGAG ATAATGATCCTATTGATGTTTGCGAAATAGGCTCAAAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTC TTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTA AGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTT TTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTA ATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGG TATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTC AAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAA CTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGC CAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCC AGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGA GGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACT CCGTCTCAAAAAAAAAAAAAAGATTTTGTTTCATTTCATAGCACAAATTTAGAGGCATTGAGTTGACCATTTCTAGTTTCTATACCTGAA GGAACCCATTGATTTTACCAGTTTTTATTTCTGTAGATTGGATGTAAAAATCACAGATTCAATAAATTAATAAACTTTGTGTA >60002_60002_7_NPNT-PPA2_NPNT_chr4_106848585_ENST00000427316_PPA2_chr4_106377902_ENST00000341695_length(amino acids)=427AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQTWEDPHEKDKSTNCFGDNDPIDVCEIGSKI LSCGEVIHVKILGILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEV IKSTHQCWKALLMKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_8_NPNT-PPA2_NPNT_chr4_106848585_ENST00000427316_PPA2_chr4_106377902_ENST00000348706_length(transcript)=1720nt_BP=477nt AGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTA GCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCC ACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCG AGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTC GCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTG GTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAG AGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATG CTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCC CTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGG CTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATG TTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTG CTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGT GTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAAT CGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCT GTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTC AAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTT GGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTG GCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGC TGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAG ACTCCGTCTC >60002_60002_8_NPNT-PPA2_NPNT_chr4_106848585_ENST00000427316_PPA2_chr4_106377902_ENST00000348706_length(amino acids)=398AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQILSCGEVIHVKILGILALIDEGETDWKLIA INANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALLMKKCNGGAINCTNVQIS DSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_9_NPNT-PPA2_NPNT_chr4_106848585_ENST00000427316_PPA2_chr4_106377902_ENST00000432483_length(transcript)=1179nt_BP=477nt AGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTA GCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCC ACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCG AGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTC GCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTG GTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAG AGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTG CTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTA ATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTG AAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATAT CTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAG AGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGA CAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAG AATTTTAAA >60002_60002_9_NPNT-PPA2_NPNT_chr4_106848585_ENST00000427316_PPA2_chr4_106377902_ENST00000432483_length(amino acids)=325AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEILSCGEVIHVKIL GILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALL MKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_10_NPNT-PPA2_NPNT_chr4_106848585_ENST00000453617_PPA2_chr4_106377902_ENST00000341695_length(transcript)=2025nt_BP=529nt TAGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGT AGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGC CACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCC GAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCT CGCCAGTCTTGGGGACAGTGTCAGCCTTTCTACGTCTTAAGGCAGAGAATAGCCAGGATAAGGTGCCAGCTCAAAGCTGTGTGCCAACCA CGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACT GGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGAT GAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATGCTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCC ATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCCCTTACAAGGGTTATATATGGAATTATGGTACCCTCCCT CAGACTTGGGAAGATCCCCATGAAAAAGATAAGAGCACGAACTGCTTTGGAGATAATGATCCTATTGATGTTTGCGAAATAGGCTCAAAG ATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCT ATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAAT TGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAA GTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCT GATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAG CAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACA AGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAA TTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTG GGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAA TTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGC AGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACTCCGTCTCAAAAAAAAAAAAAAGATTTTGTTTCATTTCA TAGCACAAATTTAGAGGCATTGAGTTGACCATTTCTAGTTTCTATACCTGAAGGAACCCATTGATTTTACCAGTTTTTATTTCTGTAGAT TGGATGTAAAAATCACAGATTCAATAAATTAATAAACTTTGTGTA >60002_60002_10_NPNT-PPA2_NPNT_chr4_106848585_ENST00000453617_PPA2_chr4_106377902_ENST00000341695_length(amino acids)=444AA_BP=162 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPFYVLRQRIARIRCQLKAVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKV NSKEENGIPMKKARNDEYENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQTWEDPHEKDKSTN CFGDNDPIDVCEIGSKILSCGEVIHVKILGILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPEN QFAFNGEFKNKAFALEVIKSTHQCWKALLMKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_11_NPNT-PPA2_NPNT_chr4_106848585_ENST00000453617_PPA2_chr4_106377902_ENST00000348706_length(transcript)=1772nt_BP=529nt TAGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGT AGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGC CACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCC GAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCT CGCCAGTCTTGGGGACAGTGTCAGCCTTTCTACGTCTTAAGGCAGAGAATAGCCAGGATAAGGTGCCAGCTCAAAGCTGTGTGCCAACCA CGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACT GGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGAT GAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATGCTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCC ATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCCCTTACAAGGGTTATATATGGAATTATGGTACCCTCCCT CAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATT GCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTT AATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTT GAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATA TCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAA GAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAG ACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAA GAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACT TTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAA AAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGT TGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACTCCGTCTC >60002_60002_11_NPNT-PPA2_NPNT_chr4_106848585_ENST00000453617_PPA2_chr4_106377902_ENST00000348706_length(amino acids)=415AA_BP=162 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPFYVLRQRIARIRCQLKAVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKV NSKEENGIPMKKARNDEYENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQILSCGEVIHVKIL GILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALL MKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_12_NPNT-PPA2_NPNT_chr4_106848585_ENST00000453617_PPA2_chr4_106377902_ENST00000432483_length(transcript)=1231nt_BP=529nt TAGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGT AGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGC CACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCC GAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCT CGCCAGTCTTGGGGACAGTGTCAGCCTTTCTACGTCTTAAGGCAGAGAATAGCCAGGATAAGGTGCCAGCTCAAAGCTGTGTGCCAACCA CGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACT GGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATC CTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCAT GATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCA GAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTG CTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGA TCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACAT CTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAA ACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAA >60002_60002_12_NPNT-PPA2_NPNT_chr4_106848585_ENST00000453617_PPA2_chr4_106377902_ENST00000432483_length(amino acids)=342AA_BP=162 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPFYVLRQRIARIRCQLKAVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKV NSKEILSCGEVIHVKILGILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKA FALEVIKSTHQCWKALLMKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_13_NPNT-PPA2_NPNT_chr4_106848585_ENST00000506666_PPA2_chr4_106377902_ENST00000341695_length(transcript)=1921nt_BP=425nt GCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTAGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCC CATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCCACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCT GGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCGAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCG TTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTCGCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGG TGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTC CCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCT GTTTAATATGATTGTAGAAATACCTCGGTGGACAAATGCTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGT AAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCCCTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGACTTGGGAAGA TCCCCATGAAAAAGATAAGAGCACGAACTGCTTTGGAGATAATGATCCTATTGATGTTTGCGAAATAGGCTCAAAGATTCTTTCTTGTGG AGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGA TCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATA TAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCAC TCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCG TTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTT CCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAG CATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCT CCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGG GCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGG TGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATT GTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACTCCGTCTCAAAAAAAAAAAAAAGATTTTGTTTCATTTCATAGCACAAATTTAG AGGCATTGAGTTGACCATTTCTAGTTTCTATACCTGAAGGAACCCATTGATTTTACCAGTTTTTATTTCTGTAGATTGGATGTAAAAATC ACAGATTCAATAAATTAATAAACTTTGTGTA >60002_60002_13_NPNT-PPA2_NPNT_chr4_106848585_ENST00000506666_PPA2_chr4_106377902_ENST00000341695_length(amino acids)=419AA_BP=137 MSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSIGLCRYGGR IDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDEYENLFNMI VEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQTWEDPHEKDKSTNCFGDNDPIDVCEIGSKILSCGEVIH VKILGILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCW KALLMKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_14_NPNT-PPA2_NPNT_chr4_106848585_ENST00000506666_PPA2_chr4_106377902_ENST00000348706_length(transcript)=1668nt_BP=425nt GCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTAGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCC CATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCCACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCT GGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCGAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCG TTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTCGCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGG TGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTC CCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCT GTTTAATATGATTGTAGAAATACCTCGGTGGACAAATGCTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGT AAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCCCTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGATTCTTTCTTG TGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAA TGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATT ATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATC CACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTT CCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCA CTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTAT GAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTAC TCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGG TGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCG TGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAG ATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACTCCGTCTC >60002_60002_14_NPNT-PPA2_NPNT_chr4_106848585_ENST00000506666_PPA2_chr4_106377902_ENST00000348706_length(amino acids)=390AA_BP=137 MSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSIGLCRYGGR IDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDEYENLFNMI VEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQILSCGEVIHVKILGILALIDEGETDWKLIAINANDPEA SKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALLMKKCNGGAINCTNVQISDSPFRCTQ EEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_15_NPNT-PPA2_NPNT_chr4_106848585_ENST00000506666_PPA2_chr4_106377902_ENST00000432483_length(transcript)=1127nt_BP=425nt GCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTAGCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCC CATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCCACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCT GGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCGAGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCG TTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTCGCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGG TGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTGGTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTC CCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAGAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGC TCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGT TAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGC TTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTG TAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATC GGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTG TCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCA AACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAA >60002_60002_15_NPNT-PPA2_NPNT_chr4_106848585_ENST00000506666_PPA2_chr4_106377902_ENST00000432483_length(amino acids)=317AA_BP=137 MSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSIGLCRYGGR IDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEILSCGEVIHVKILGILALIDE GETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALLMKKCNGGA INCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_16_NPNT-PPA2_NPNT_chr4_106848585_ENST00000514622_PPA2_chr4_106377902_ENST00000341695_length(transcript)=1973nt_BP=477nt AGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTA GCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCC ACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCG AGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTC GCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTG GTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAG AGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATG CTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCC CTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGACTTGGGAAGATCCCCATGAAAAAGATAAGAGCACGAACTGCTTTGGAG ATAATGATCCTATTGATGTTTGCGAAATAGGCTCAAAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTC TTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTA AGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTT TTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTA ATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGG TATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTC AAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAA CTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTTGGC CAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTGGCC AGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGCTGA GGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAGACT CCGTCTCAAAAAAAAAAAAAAGATTTTGTTTCATTTCATAGCACAAATTTAGAGGCATTGAGTTGACCATTTCTAGTTTCTATACCTGAA GGAACCCATTGATTTTACCAGTTTTTATTTCTGTAGATTGGATGTAAAAATCACAGATTCAATAAATTAATAAACTTTGTGTA >60002_60002_16_NPNT-PPA2_NPNT_chr4_106848585_ENST00000514622_PPA2_chr4_106377902_ENST00000341695_length(amino acids)=427AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQTWEDPHEKDKSTNCFGDNDPIDVCEIGSKI LSCGEVIHVKILGILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEV IKSTHQCWKALLMKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_17_NPNT-PPA2_NPNT_chr4_106848585_ENST00000514622_PPA2_chr4_106377902_ENST00000348706_length(transcript)=1720nt_BP=477nt AGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTA GCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCC ACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCG AGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTC GCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTG GTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAG AGGAAAATGGCATTCCTATGAAGAAAGCACGAAATGATGAATATGAGAATCTGTTTAATATGATTGTAGAAATACCTCGGTGGACAAATG CTAAAATGGAGATTGCCACCAAGGAGCCAATGAATCCCATTAAACAATATGTAAAGGATGGAAAGCTACGCTATGTGGCGAATATCTTCC CTTACAAGGGTTATATATGGAATTATGGTACCCTCCCTCAGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGG CTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTGCTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATG TTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTAATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTG CTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTGAAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGT GTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATATCTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAAT CGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAGAGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCT GTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGACAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTC AAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAGAATTTTAAATTACTCTCCTTTGGACATTTATTGATATAAAAAGAAGATTTT GGCCAGGCACGGTGGCTCATGCCTGTAATTTCAGCACTTTGGGAGGCCGAGGTGGGCAGATCACAAGGTCAGGAGTTCAAGACCAGCCTG GCCAGTATGTTGAAACCCCATCTCTATTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCATGCCTGTAGACCCAGCTACTCAGGAGGC TGAGGCAGAAGAACTGCTTGAGCCCAGGAGGCAGAGGTTGCAGTGAGCAGAGATTGTGCCACTGCACTCCAGCCTAGGCGACAGAGAGAG ACTCCGTCTC >60002_60002_17_NPNT-PPA2_NPNT_chr4_106848585_ENST00000514622_PPA2_chr4_106377902_ENST00000348706_length(amino acids)=398AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEENGIPMKKARNDE YENLFNMIVEIPRWTNAKMEIATKEPMNPIKQYVKDGKLRYVANIFPYKGYIWNYGTLPQILSCGEVIHVKILGILALIDEGETDWKLIA INANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALLMKKCNGGAINCTNVQIS DSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- >60002_60002_18_NPNT-PPA2_NPNT_chr4_106848585_ENST00000514622_PPA2_chr4_106377902_ENST00000432483_length(transcript)=1179nt_BP=477nt AGAAGGGAGCGGGAGGGGGCTCCGGGCGCCGCGCAGCAGACCTGCTCCGGCCGCGCGCCTCGCCGCTGTCCTCCGGGAGCGGCAGCAGTA GCCCGGGCGGCGAGGGCTGGGGGTTCCTCGAGACTCTCAGAGGGGCGCCTCCCATCGGCGCCCACCACCCCAACCTGTTCCTCGCGCGCC ACTGCGCTGCGCCCCAGGACCCGCTGCCCAACATGGATTTTCTCCTGGCGCTGGTGCTGGTATCCTCGCTCTACCTGCAGGCGGCCGCCG AGTTCGACGGGAGGTGGCCCAGGCAAATAGTGTCATCGATTGGCCTATGTCGTTATGGTGGGAGGATTGACTGCTGCTGGGGCTGGGCTC GCCAGTCTTGGGGACAGTGTCAGCCTGTGTGCCAACCACGATGCAAACATGGTGAATGTATCGGGCCAAACAAGTGCAAGTGTCATCCTG GTTATGCTGGAAAAACCTGTAATCAAGAGAATGTAACTGGTCACTACATTTCCCCCTTTCATGATATTCCTCTGAAGGTGAACTCTAAAG AGATTCTTTCTTGTGGAGAAGTTATTCATGTGAAGATCCTTGGAATTTTGGCTCTTATTGATGAAGGTGAAACAGATTGGAAATTAATTG CTATCAATGCGAATGATCCTGAAGCCTCAAAGTTTCATGATATTGATGATGTTAAGAAGTTCAAACCGGGTTACCTGGAAGCTACTCTTA ATTGGTTTAGATTATATAAGGTACCAGATGGAAAACCAGAAAACCAGTTTGCTTTTAATGGAGAATTCAAAAACAAGGCTTTTGCTCTTG AAGTTATTAAATCCACTCATCAATGTTGGAAAGCATTGCTTATGAAGAAGTGTAATGGAGGAGCTATAAATTGCACAAACGTGCAGATAT CTGATAGCCCTTTCCGTTGCACTCAAGAGGAAGCAAGATCATTAGTTGAATCGGTATCATCTTCACCAAATAAAGAAAGTAATGAAGAAG AGCAAGTGTGGCACTTCCTTGGCAAGTGATTGAAACATCTGAAATTCTGCTGTCAAGATTCCCATCTCTAAGGACTCCAAGTGCTAGAGA CAAGGGGGTCTATGAGCATTTACTGACTTCCTGTTAAAACTTCATTTTTTCAAACTTTTTGAGCTATGCAATATATAAATAAACAGTAAG AATTTTAAA >60002_60002_18_NPNT-PPA2_NPNT_chr4_106848585_ENST00000514622_PPA2_chr4_106377902_ENST00000432483_length(amino acids)=325AA_BP=145 MLRPRASPLSSGSGSSSPGGEGWGFLETLRGAPPIGAHHPNLFLARHCAAPQDPLPNMDFLLALVLVSSLYLQAAAEFDGRWPRQIVSSI GLCRYGGRIDCCWGWARQSWGQCQPVCQPRCKHGECIGPNKCKCHPGYAGKTCNQENVTGHYISPFHDIPLKVNSKEILSCGEVIHVKIL GILALIDEGETDWKLIAINANDPEASKFHDIDDVKKFKPGYLEATLNWFRLYKVPDGKPENQFAFNGEFKNKAFALEVIKSTHQCWKALL MKKCNGGAINCTNVQISDSPFRCTQEEARSLVESVSSSPNKESNEEEQVWHFLGK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NPNT-PPA2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NPNT-PPA2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NPNT-PPA2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C4310663 | SUDDEN CARDIAC FAILURE, ALCOHOL-INDUCED | 2 | CTD_human;GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C4310664 | SUDDEN CARDIAC FAILURE, INFANTILE | 2 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies