
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ANKRD17-PAK1 (FusionGDB2 ID:HG26057TG5058) |
Fusion Gene Summary for ANKRD17-PAK1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ANKRD17-PAK1 | Fusion gene ID: hg26057tg5058 | Hgene | Tgene | Gene symbol | ANKRD17 | PAK1 | Gene ID | 26057 | 5058 |
| Gene name | ankyrin repeat domain 17 | p21 (RAC1) activated kinase 1 | |
| Synonyms | GTAR|MASK2|NY-BR-16 | IDDMSSD|PAKalpha|alpha-PAK|p65-PAK | |
| Cytomap | ('ANKRD17')('PAK1') 4q13.3 | 11q13.5-q14.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | ankyrin repeat domain-containing protein 17gene trap ankyrin repeat proteinserologically defined breast cancer antigen NY-BR-16 | serine/threonine-protein kinase PAK 1STE20 homolog, yeastp21 protein (Cdc42/Rac)-activated kinase 1p21/Cdc42/Rac1-activated kinase 1 (STE20 homolog, yeast)p21/Cdc42/Rac1-activated kinase 1 (yeast Ste20-related) | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000330838, ENST00000358602, ENST00000509867, ENST00000514252, | ||
| Fusion gene scores | * DoF score | 14 X 22 X 6=1848 | 22 X 17 X 10=3740 |
| # samples | 25 | 26 | |
| ** MAII score | log2(25/1848*10)=-2.88596475675397 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(26/3740*10)=-3.84645474174655 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ANKRD17 [Title/Abstract] AND PAK1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ANKRD17(74123992)-PAK1(77070062), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ANKRD17-PAK1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ANKRD17-PAK1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ANKRD17-PAK1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ANKRD17-PAK1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ANKRD17 | GO:0042742 | defense response to bacterium | 23711367 |
| Hgene | ANKRD17 | GO:0043123 | positive regulation of I-kappaB kinase/NF-kappaB signaling | 22328336 |
| Hgene | ANKRD17 | GO:0045087 | innate immune response | 23711367 |
| Hgene | ANKRD17 | GO:1900245 | positive regulation of MDA-5 signaling pathway | 22328336 |
| Hgene | ANKRD17 | GO:1900246 | positive regulation of RIG-I signaling pathway | 22328336 |
| Tgene | PAK1 | GO:0000165 | MAPK cascade | 8805275 |
| Tgene | PAK1 | GO:0006338 | chromatin remodeling | 23260667 |
| Tgene | PAK1 | GO:0006468 | protein phosphorylation | 9852149|23260667 |
| Tgene | PAK1 | GO:0006974 | cellular response to DNA damage stimulus | 23260667 |
| Tgene | PAK1 | GO:0030335 | positive regulation of cell migration | 25766321 |
| Tgene | PAK1 | GO:0031532 | actin cytoskeleton reorganization | 9395435 |
| Tgene | PAK1 | GO:0033138 | positive regulation of peptidyl-serine phosphorylation | 19667065 |
| Tgene | PAK1 | GO:0033148 | positive regulation of intracellular estrogen receptor signaling pathway | 16278681 |
| Tgene | PAK1 | GO:0046777 | protein autophosphorylation | 8805275 |
| Fusion gene breakpoints across ANKRD17 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PAK1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-D1-A17C | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
Top |
Fusion Gene ORF analysis for ANKRD17-PAK1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000330838 | ENST00000525542 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| 5CDS-intron | ENST00000358602 | ENST00000525542 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000330838 | ENST00000278568 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000330838 | ENST00000356341 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000330838 | ENST00000528203 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000330838 | ENST00000530617 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000358602 | ENST00000278568 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000358602 | ENST00000356341 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000358602 | ENST00000528203 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| In-frame | ENST00000358602 | ENST00000530617 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000509867 | ENST00000278568 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000509867 | ENST00000356341 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000509867 | ENST00000528203 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000509867 | ENST00000530617 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000514252 | ENST00000278568 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000514252 | ENST00000356341 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000514252 | ENST00000528203 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-3CDS | ENST00000514252 | ENST00000530617 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-intron | ENST00000509867 | ENST00000525542 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| intron-intron | ENST00000514252 | ENST00000525542 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000358602 | ANKRD17 | chr4 | 74123992 | - | ENST00000356341 | PAK1 | chr11 | 77070062 | - | 3238 | 510 | 111 | 1670 | 519 |
| ENST00000358602 | ANKRD17 | chr4 | 74123992 | - | ENST00000530617 | PAK1 | chr11 | 77070062 | - | 2722 | 510 | 111 | 1601 | 496 |
| ENST00000358602 | ANKRD17 | chr4 | 74123992 | - | ENST00000278568 | PAK1 | chr11 | 77070062 | - | 2046 | 510 | 111 | 1694 | 527 |
| ENST00000358602 | ANKRD17 | chr4 | 74123992 | - | ENST00000528203 | PAK1 | chr11 | 77070062 | - | 1970 | 510 | 111 | 1694 | 527 |
| ENST00000330838 | ANKRD17 | chr4 | 74123992 | - | ENST00000356341 | PAK1 | chr11 | 77070062 | - | 3251 | 523 | 124 | 1683 | 519 |
| ENST00000330838 | ANKRD17 | chr4 | 74123992 | - | ENST00000530617 | PAK1 | chr11 | 77070062 | - | 2735 | 523 | 124 | 1614 | 496 |
| ENST00000330838 | ANKRD17 | chr4 | 74123992 | - | ENST00000278568 | PAK1 | chr11 | 77070062 | - | 2059 | 523 | 124 | 1707 | 527 |
| ENST00000330838 | ANKRD17 | chr4 | 74123992 | - | ENST00000528203 | PAK1 | chr11 | 77070062 | - | 1983 | 523 | 124 | 1707 | 527 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000358602 | ENST00000356341 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.001361983 | 0.998638 |
| ENST00000358602 | ENST00000530617 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.001497908 | 0.99850214 |
| ENST00000358602 | ENST00000278568 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.004643192 | 0.99535674 |
| ENST00000358602 | ENST00000528203 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.005291969 | 0.99470806 |
| ENST00000330838 | ENST00000356341 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.001380983 | 0.99861896 |
| ENST00000330838 | ENST00000530617 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.001493535 | 0.9985065 |
| ENST00000330838 | ENST00000278568 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.004733926 | 0.9952661 |
| ENST00000330838 | ENST00000528203 | ANKRD17 | chr4 | 74123992 | - | PAK1 | chr11 | 77070062 | - | 0.005395798 | 0.9946042 |
Top |
Fusion Genomic Features for ANKRD17-PAK1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
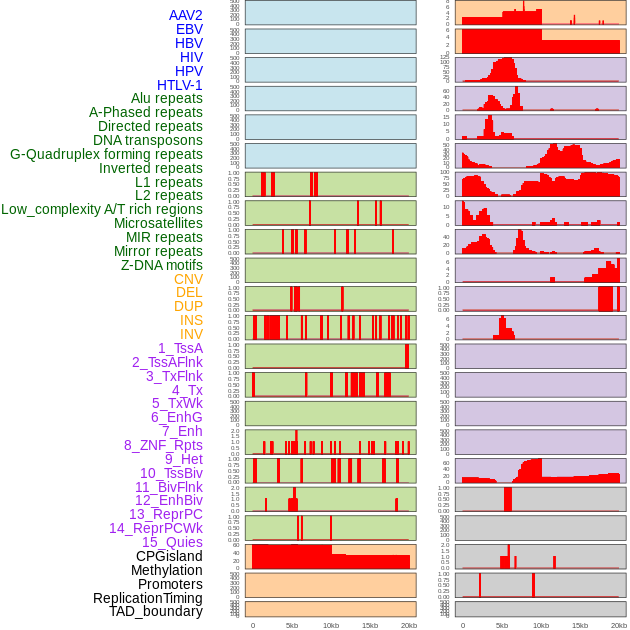 |
Top |
Fusion Protein Features for ANKRD17-PAK1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr4:74123992/chr11:77070062) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 96_110 | 131 | 2353.0 | Compositional bias | Note=Gly-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 96_110 | 131 | 2604.0 | Compositional bias | Note=Gly-rich |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000278568 | 4 | 16 | 270_521 | 159 | 554.0 | Domain | Protein kinase | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000356341 | 4 | 15 | 270_521 | 159 | 546.0 | Domain | Protein kinase | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000278568 | 4 | 16 | 276_284 | 159 | 554.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000278568 | 4 | 16 | 345_347 | 159 | 554.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000356341 | 4 | 15 | 276_284 | 159 | 546.0 | Nucleotide binding | Note=ATP | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000356341 | 4 | 15 | 345_347 | 159 | 546.0 | Nucleotide binding | Note=ATP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1442_1526 | 131 | 2353.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1442_1526 | 131 | 2604.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1603_1700 | 131 | 2353.0 | Compositional bias | Note=Ser-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1950_2106 | 131 | 2353.0 | Compositional bias | Note=Ser-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1966_2033 | 131 | 2353.0 | Compositional bias | Note=Thr-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 858_1008 | 131 | 2353.0 | Compositional bias | Note=Gln-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1603_1700 | 131 | 2604.0 | Compositional bias | Note=Ser-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1950_2106 | 131 | 2604.0 | Compositional bias | Note=Ser-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1966_2033 | 131 | 2604.0 | Compositional bias | Note=Thr-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 858_1008 | 131 | 2604.0 | Compositional bias | Note=Gln-rich |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1725_1789 | 131 | 2353.0 | Domain | KH |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1725_1789 | 131 | 2604.0 | Domain | KH |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1082_1111 | 131 | 2353.0 | Repeat | Note=ANK 16 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1115_1144 | 131 | 2353.0 | Repeat | Note=ANK 17 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1149_1178 | 131 | 2353.0 | Repeat | Note=ANK 18 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1182_1211 | 131 | 2353.0 | Repeat | Note=ANK 19 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1217_1246 | 131 | 2353.0 | Repeat | Note=ANK 20 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1251_1280 | 131 | 2353.0 | Repeat | Note=ANK 21 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1284_1313 | 131 | 2353.0 | Repeat | Note=ANK 22 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1319_1348 | 131 | 2353.0 | Repeat | Note=ANK 23 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1352_1381 | 131 | 2353.0 | Repeat | Note=ANK 24 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 1385_1414 | 131 | 2353.0 | Repeat | Note=ANK 25 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 233_262 | 131 | 2353.0 | Repeat | Note=ANK 1 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 266_295 | 131 | 2353.0 | Repeat | Note=ANK 2 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 300_329 | 131 | 2353.0 | Repeat | Note=ANK 3 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 333_362 | 131 | 2353.0 | Repeat | Note=ANK 4 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 366_395 | 131 | 2353.0 | Repeat | Note=ANK 5 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 400_429 | 131 | 2353.0 | Repeat | Note=ANK 6 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 433_462 | 131 | 2353.0 | Repeat | Note=ANK 7 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 466_495 | 131 | 2353.0 | Repeat | Note=ANK 8 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 499_528 | 131 | 2353.0 | Repeat | Note=ANK 9 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 533_562 | 131 | 2353.0 | Repeat | Note=ANK 10 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 563_592 | 131 | 2353.0 | Repeat | Note=ANK 11 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 596_625 | 131 | 2353.0 | Repeat | Note=ANK 12 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 629_658 | 131 | 2353.0 | Repeat | Note=ANK 13 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 663_692 | 131 | 2353.0 | Repeat | Note=ANK 14 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000330838 | - | 1 | 33 | 696_725 | 131 | 2353.0 | Repeat | Note=ANK 15 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1082_1111 | 131 | 2604.0 | Repeat | Note=ANK 16 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1115_1144 | 131 | 2604.0 | Repeat | Note=ANK 17 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1149_1178 | 131 | 2604.0 | Repeat | Note=ANK 18 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1182_1211 | 131 | 2604.0 | Repeat | Note=ANK 19 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1217_1246 | 131 | 2604.0 | Repeat | Note=ANK 20 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1251_1280 | 131 | 2604.0 | Repeat | Note=ANK 21 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1284_1313 | 131 | 2604.0 | Repeat | Note=ANK 22 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1319_1348 | 131 | 2604.0 | Repeat | Note=ANK 23 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1352_1381 | 131 | 2604.0 | Repeat | Note=ANK 24 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 1385_1414 | 131 | 2604.0 | Repeat | Note=ANK 25 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 233_262 | 131 | 2604.0 | Repeat | Note=ANK 1 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 266_295 | 131 | 2604.0 | Repeat | Note=ANK 2 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 300_329 | 131 | 2604.0 | Repeat | Note=ANK 3 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 333_362 | 131 | 2604.0 | Repeat | Note=ANK 4 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 366_395 | 131 | 2604.0 | Repeat | Note=ANK 5 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 400_429 | 131 | 2604.0 | Repeat | Note=ANK 6 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 433_462 | 131 | 2604.0 | Repeat | Note=ANK 7 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 466_495 | 131 | 2604.0 | Repeat | Note=ANK 8 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 499_528 | 131 | 2604.0 | Repeat | Note=ANK 9 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 533_562 | 131 | 2604.0 | Repeat | Note=ANK 10 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 563_592 | 131 | 2604.0 | Repeat | Note=ANK 11 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 596_625 | 131 | 2604.0 | Repeat | Note=ANK 12 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 629_658 | 131 | 2604.0 | Repeat | Note=ANK 13 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 663_692 | 131 | 2604.0 | Repeat | Note=ANK 14 |
| Hgene | ANKRD17 | chr4:74123992 | chr11:77070062 | ENST00000358602 | - | 1 | 34 | 696_725 | 131 | 2604.0 | Repeat | Note=ANK 15 |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000278568 | 4 | 16 | 75_88 | 159 | 554.0 | Domain | CRIB | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000356341 | 4 | 15 | 75_88 | 159 | 546.0 | Domain | CRIB | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000278568 | 4 | 16 | 70_140 | 159 | 554.0 | Region | Note=Autoregulatory region | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000278568 | 4 | 16 | 75_105 | 159 | 554.0 | Region | Note=GTPase-binding | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000356341 | 4 | 15 | 70_140 | 159 | 546.0 | Region | Note=Autoregulatory region | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000356341 | 4 | 15 | 75_105 | 159 | 546.0 | Region | Note=GTPase-binding |
Top |
Fusion Gene Sequence for ANKRD17-PAK1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >4606_4606_1_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000278568_length(transcript)=2059nt_BP=523nt AGTAGAGGTGACCGAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCC ACGCCCCTCCCCCGTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGA AGGGAGCCCCCCGGCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTC GGCCTCGTCTCCTCGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAA CCGGACTTGCCGACCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGG CGGCGGCGGCACCAGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTC TGAGACTCCTGCAGTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGA GCACACAAAATCTGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTAC TGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGA GAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTA CACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGA GATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGA ATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCA GGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCT AACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGT TGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCT CAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCG GGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGT GTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGG AGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCC AACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCC AGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTG GTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCT >4606_4606_1_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000278568_length(amino acids)=527AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQVRKLRFQVFSNFSMIAASIPEDCQAPLQPHSTDCCS -------------------------------------------------------------- >4606_4606_2_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000356341_length(transcript)=3251nt_BP=523nt AGTAGAGGTGACCGAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCC ACGCCCCTCCCCCGTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGA AGGGAGCCCCCCGGCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTC GGCCTCGTCTCCTCGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAA CCGGACTTGCCGACCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGG CGGCGGCGGCACCAGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTC TGAGACTCCTGCAGTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGA GCACACAAAATCTGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTAC TGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGA GAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTA CACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGA GATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGA ATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCA GGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCT AACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGT TGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCT CAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCG GGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGCATCAATTCCTGAAGATTGCCAA GCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGT GCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATC TAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTT CTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTG TCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAATC AATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCA TGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACC ACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGG CTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCAC ATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTT GTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTG GTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGG ACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTT GTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAG GTACTACTGCCTCTGCAGCACAAATTTCTATTTCTGTCAATAAAAGGAGATGAAAATATTCTATTGGAGTATGCCTTTCTTTTTTCTCTT CGTTTTTTCTTTCCTTTTCTAATTTTTTATATGAAATAATGAGTAGTTTCTTCCTGAACCATTTGAGAGTGGTAAGTTGCAGATAGAATG CCCCTTTACCACTATATACCTGAATGTGTATTCTTTCTTTTTAACACTTTTATTTTAAATATAAATTAAGAGAAATGGGCCAAAACCATT TGTATTGTTTAAAGAATAATTATAAACACACTTGTATCCACCAAATCAAGAAATGGAACACTGACAGTAAGAACCTTCTCTATCTTGTCC TTCCTTTCTCA >4606_4606_2_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000356341_length(amino acids)=519AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQHQFLKIAKPLSSLTPLIAAAKEATKNNH -------------------------------------------------------------- >4606_4606_3_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000528203_length(transcript)=1983nt_BP=523nt AGTAGAGGTGACCGAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCC ACGCCCCTCCCCCGTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGA AGGGAGCCCCCCGGCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTC GGCCTCGTCTCCTCGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAA CCGGACTTGCCGACCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGG CGGCGGCGGCACCAGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTC TGAGACTCCTGCAGTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGA GCACACAAAATCTGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTAC TGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGA GAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTA CACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGA GATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGA ATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCA GGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCT AACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGT TGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCT CAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCG GGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGT GTTTAGTAACTTTTCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGG AGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCC AACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCC AGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTG GTT >4606_4606_3_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000528203_length(amino acids)=527AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQVRKLRFQVFSNFSMIAASIPEDCQAPLQPHSTDCCS -------------------------------------------------------------- >4606_4606_4_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000530617_length(transcript)=2735nt_BP=523nt AGTAGAGGTGACCGAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCC ACGCCCCTCCCCCGTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGA AGGGAGCCCCCCGGCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTC GGCCTCGTCTCCTCGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAA CCGGACTTGCCGACCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGG CGGCGGCGGCACCAGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTC TGAGACTCCTGCAGTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGA GCACACAAAATCTGTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTAC TGAAAATAACACCACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGA GAAATTACGAAGCATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTA CACAGCAATGGATGTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGA GATCCTGGTCATGAGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGA ATACTTGGCTGGAGGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCA GGCTCTGGAGTTCTTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCT AACTGACTTTGGATTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGT TGTGACACGAAAGGCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCT CAATGAAAACCCTCTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCG GGACTTTCTGAACCGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGCACTCCTCAAGACTTTGATCCTT GGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTC ATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACC ATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTT TTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACA TGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAG CAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGC ATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAA GTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCC TTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAG AGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAA GCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTA GGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTCTGCAGCACAAATT TCTATTTCTGTCAATAAAAGGAGATGAAAATATTC >4606_4606_4_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000330838_PAK1_chr11_77070062_ENST00000530617_length(amino acids)=496AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQHSSRL -------------------------------------------------------------- >4606_4606_5_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000278568_length(transcript)=2046nt_BP=510nt GAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCCACGCCCCTCCCCC GTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGAAGGGAGCCCCCCG GCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTCGGCCTCGTCTCCT CGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAACCGGACTTGCCGA CCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGGCGGCGGCGGCACC AGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTCTGAGACTCCTGCA GTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGAGCACACAAAATCT GTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACC ACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGC ATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGAT GTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATG AGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGA GGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTC TTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGA TTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAG GCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCT CTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAAC CGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTT TCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAA CAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCC CTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGA ACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAG GGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCT >4606_4606_5_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000278568_length(amino acids)=527AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQVRKLRFQVFSNFSMIAASIPEDCQAPLQPHSTDCCS -------------------------------------------------------------- >4606_4606_6_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000356341_length(transcript)=3238nt_BP=510nt GAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCCACGCCCCTCCCCC GTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGAAGGGAGCCCCCCG GCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTCGGCCTCGTCTCCT CGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAACCGGACTTGCCGA CCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGGCGGCGGCGGCACC AGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTCTGAGACTCCTGCA GTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGAGCACACAAAATCT GTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACC ACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGC ATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGAT GTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATG AGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGA GGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTC TTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGA TTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAG GCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCT CTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAAC CGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGC CTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAACAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTG TGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCCCTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAA GACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAAT TTCCTCCCAATTCATGGATATGAGGGTGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCAC CTCCTTCATAACCATCTCCCACAATTAATTCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCT TTAGTGCTTGCTTTTCTGTGACTCAACTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAA TCTGCCAGGGACATGAAGAGGCTCAGCTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTG TGTGTGCTTCTAGCAGCTGTTCGGGAGGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCT TTTGATTCCCTGCATACCCTAGGCTGCTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGA GCAGTGTTGAGAAGTCGGGGAAAATGGTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCA GGAACTCAGCCCCTTTTTCTGCCTAGGATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGA GTCTCCAAATTAGAGACTGCATGTTAGTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAA GATGCATGGCCAAGCTCTCTGCAAATGGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTC TCCCACTATGGTAGGACCCCTGGCCAGCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTC TGCAGCACAAATTTCTATTTCTGTCAATAAAAGGAGATGAAAATATTCTATTGGAGTATGCCTTTCTTTTTTCTCTTCGTTTTTTCTTTC CTTTTCTAATTTTTTATATGAAATAATGAGTAGTTTCTTCCTGAACCATTTGAGAGTGGTAAGTTGCAGATAGAATGCCCCTTTACCACT ATATACCTGAATGTGTATTCTTTCTTTTTAACACTTTTATTTTAAATATAAATTAAGAGAAATGGGCCAAAACCATTTGTATTGTTTAAA GAATAATTATAAACACACTTGTATCCACCAAATCAAGAAATGGAACACTGACAGTAAGAACCTTCTCTATCTTGTCCTTCCTTTCTCA >4606_4606_6_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000356341_length(amino acids)=519AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQHQFLKIAKPLSSLTPLIAAAKEATKNNH -------------------------------------------------------------- >4606_4606_7_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000528203_length(transcript)=1970nt_BP=510nt GAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCCACGCCCCTCCCCC GTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGAAGGGAGCCCCCCG GCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTCGGCCTCGTCTCCT CGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAACCGGACTTGCCGA CCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGGCGGCGGCGGCACC AGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTCTGAGACTCCTGCA GTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGAGCACACAAAATCT GTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACC ACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGC ATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGAT GTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATG AGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGA GGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTC TTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGA TTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAG GCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCT CTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAAC CGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGGTGAGAAAACTGAGGTTTCAAGTGTTTAGTAACTTT TCCATGATAGCTGCATCAATTCCTGAAGATTGCCAAGCCCCTCTCCAGCCTCACTCCACTGATTGCTGCAGCTAAGGAGGCAACAAAGAA CAATCACTAAAACCACACTCACCCCAGCCTCATTGTGCCAAGCCTTCTGTGAGATAAATGCACATTTCAGAAATTCCAACTCCTGATGCC CTCTTCTCCTTGCCTTGCTTCTCCCATTTCCTGATCTAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGTCCAGCATTGAAGAGA ACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGGTGGTT >4606_4606_7_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000528203_length(amino acids)=527AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQVRKLRFQVFSNFSMIAASIPEDCQAPLQPHSTDCCS -------------------------------------------------------------- >4606_4606_8_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000530617_length(transcript)=2722nt_BP=510nt GAGGCGGTGGCGGCGGAGGCGGCACCGATTGCTGTGTCGGCCCCAGTGCGGCCGAAGTCGCGGTAGAGCGTAGCCCCACGCCCCTCCCCC GTCCGCGCCCTCCCTCTTTCCCTGGGGATGGAGAAGGCGACGGTTCCGGTGGCGGCGGCGACGGCTGCAGAAGGAGAAGGGAGCCCCCCG GCGGTGGCGGCTGTGGCGGGCCCCCCCGCGGCGGCGGAGGTCGGCGGCGGCGTTGGCGGCAGCAGCAGAGCTCGCTCGGCCTCGTCTCCT CGTGGGATGGTGCGAGTCTGCGACCTGCTCCTGAAGAAGAAGCCGCCGCAGCAGCAGCACCACAAGGCCAAGCGTAACCGGACTTGCCGA CCCCCCAGCAGCAGCGAAAGCAGCAGCGACAGCGACAACAGCGGCGGCGGTGGAGGCGGCGGTGGAGGCGGAGGTGGCGGCGGCGGCACC AGCAGTAACAACAGCGAGGAAGAAGAGGACGACGACGACGAGGAAGAGGAGGTTTCTGAGAATGTGAAGGCTGTGTCTGAGACTCCTGCA GTGCCACCAGTTTCAGAAGATGAGGATGATGATGATGATGATGCTACCCCACCACCAGTGATTGCTCCACGCCCAGAGCACACAAAATCT GTATACACACGGTCTGTGATTGAACCACTTCCTGTCACTCCAACTCGGGACGTGGCTACATCTCCCATTTCACCTACTGAAAATAACACC ACTCCACCAGATGCTTTGACCCGGAATACTGAGAAGCAGAAGAAGAAGCCTAAAATGTCTGATGAGGAGATCTTGGAGAAATTACGAAGC ATAGTGAGTGTGGGCGATCCTAAGAAGAAATATACACGGTTTGAGAAGATTGGACAAGGTGCTTCAGGCACCGTGTACACAGCAATGGAT GTGGCCACAGGACAGGAGGTGGCCATTAAGCAGATGAATCTTCAGCAGCAGCCCAAGAAAGAGCTGATTATTAATGAGATCCTGGTCATG AGGGAAAACAAGAACCCAAACATTGTGAATTACTTGGACAGTTACCTCGTGGGAGATGAGCTGTGGGTTGTTATGGAATACTTGGCTGGA GGCTCCTTGACAGATGTGGTGACAGAAACTTGCATGGATGAAGGCCAAATTGCAGCTGTGTGCCGTGAGTGTCTGCAGGCTCTGGAGTTC TTGCATTCGAACCAGGTCATTCACAGAGACATCAAGAGTGACAATATTCTGTTGGGAATGGATGGCTCTGTCAAGCTAACTGACTTTGGA TTCTGTGCACAGATAACCCCAGAGCAGAGCAAACGGAGCACCATGGTAGGAACCCCATACTGGATGGCACCAGAGGTTGTGACACGAAAG GCCTATGGGCCCAAGGTTGACATCTGGTCCCTGGGCATCATGGCCATCGAAATGATTGAAGGGGAGCCTCCATACCTCAATGAAAACCCT CTGAGAGCCTTGTACCTCATTGCCACCAATGGGACCCCAGAACTTCAGAACCCAGAGAAGCTGTCAGCTATCTTCCGGGACTTTCTGAAC CGCTGTCTCGAGATGGATGTGGAGAAGAGAGGTTCAGCTAAAGAGCTGCTACAGCACTCCTCAAGACTTTGATCCTTGGAAACCGTGTGT CCAGCATTGAAGAGAACTGCAACTGAATGACTAATCAGATGATGGCCATTTCTAAATAAGGAATTTCCTCCCAATTCATGGATATGAGGG TGGTTTATGATTAAGGGTTTATATAAATAAATGTTTCTAGTCTTCCGTGTGTCAAAATCCTCACCTCCTTCATAACCATCTCCCACAATT AATTCTTGACTATATAAATTTATGGTTTGATAATATTATCAATTTGTAATCAATTGAGATTTCTTTAGTGCTTGCTTTTCTGTGACTCAA CTGCCCAGACACCTCATTGTACTTGAAAACTGGAACAGCTTGGGAATGCCATGGGGTTTGATAATCTGCCAGGGACATGAAGAGGCTCAG CTTCCTGGACCATGACTTTGGCTCAGCTGATCCTGACATGGGAGAACAACCACATTTTTCTTTGTGTGTGCTTCTAGCAGCTGTTCGGGA GGACCTTGACCCAATAGTGTTCCCATGCTGTTTCTTGTGAAATGCTCTCGGCTATGTAGCAGCTTTTGATTCCCTGCATACCCTAGGCTG CTGCCCCTATCCTGTCCCTTGTTTATAACATTGAGAGGTTTTCTAGGGCACATACTGAGTGAGAGCAGTGTTGAGAAGTCGGGGAAAATG GTGACTACTTTTAGAGCAAGGCTGGGCATCAGCACCTGTCCAGCTCTACTTGTGTGATGTTTCAGGAACTCAGCCCCTTTTTCTGCCTAG GATAAGGAGCTGAAAGATTAACTTGGATCTTCTAATGGTCCAAATCTTTTGGTCACAATAAAGAGTCTCCAAATTAGAGACTGCATGTTA GTTCTGGATGGATTTGGTGGCCTGACATGATACCCTGCCAGCTGTGAGGGGACCCCGTTTTTAAGATGCATGGCCAAGCTCTCTGCAAAT GGAAATGCTTACACTGGGTGTTGGGGATGTTTGCTACCTCCTGCTATTTTTGTGGTTTTGGTTCTCCCACTATGGTAGGACCCCTGGCCA GCATTGTGGCTTGTCATGTCAGCCCCATTGACTACCTTCTCATGCTCTGAGGTACTACTGCCTCTGCAGCACAAATTTCTATTTCTGTCA ATAAAAGGAGATGAAAATATTC >4606_4606_8_ANKRD17-PAK1_ANKRD17_chr4_74123992_ENST00000358602_PAK1_chr11_77070062_ENST00000530617_length(amino acids)=496AA_BP=133 MGMEKATVPVAAATAAEGEGSPPAVAAVAGPPAAAEVGGGVGGSSRARSASSPRGMVRVCDLLLKKKPPQQQHHKAKRNRTCRPPSSSES SSDSDNSGGGGGGGGGGGGGGGTSSNNSEEEEDDDDEEEEVSENVKAVSETPAVPPVSEDEDDDDDDATPPPVIAPRPEHTKSVYTRSVI EPLPVTPTRDVATSPISPTENNTTPPDALTRNTEKQKKKPKMSDEEILEKLRSIVSVGDPKKKYTRFEKIGQGASGTVYTAMDVATGQEV AIKQMNLQQQPKKELIINEILVMRENKNPNIVNYLDSYLVGDELWVVMEYLAGGSLTDVVTETCMDEGQIAAVCRECLQALEFLHSNQVI HRDIKSDNILLGMDGSVKLTDFGFCAQITPEQSKRSTMVGTPYWMAPEVVTRKAYGPKVDIWSLGIMAIEMIEGEPPYLNENPLRALYLI ATNGTPELQNPEKLSAIFRDFLNRCLEMDVEKRGSAKELLQHSSRL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ANKRD17-PAK1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000278568 | 4 | 16 | 132_270 | 159.0 | 554.0 | CRIPAK | |
| Tgene | PAK1 | chr4:74123992 | chr11:77070062 | ENST00000356341 | 4 | 15 | 132_270 | 159.0 | 546.0 | CRIPAK |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ANKRD17-PAK1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ANKRD17-PAK1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C4748428 | INTELLECTUAL DEVELOPMENTAL DISORDER WITH MACROCEPHALY, SEIZURES, AND SPEECH DELAY | 2 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C0006142 | Malignant neoplasm of breast | 1 | CTD_human | |
| Tgene | C0007134 | Renal Cell Carcinoma | 1 | CTD_human | |
| Tgene | C0033687 | Proteinuria | 1 | CTD_human | |
| Tgene | C0279702 | Conventional (Clear Cell) Renal Cell Carcinoma | 1 | CTD_human | |
| Tgene | C0678222 | Breast Carcinoma | 1 | CTD_human | |
| Tgene | C1257931 | Mammary Neoplasms, Human | 1 | CTD_human | |
| Tgene | C1266042 | Chromophobe Renal Cell Carcinoma | 1 | CTD_human | |
| Tgene | C1266043 | Sarcomatoid Renal Cell Carcinoma | 1 | CTD_human | |
| Tgene | C1266044 | Collecting Duct Carcinoma of the Kidney | 1 | CTD_human | |
| Tgene | C1306837 | Papillary Renal Cell Carcinoma | 1 | CTD_human | |
| Tgene | C1458155 | Mammary Neoplasms | 1 | CTD_human | |
| Tgene | C1535926 | Neurodevelopmental Disorders | 1 | GENOMICS_ENGLAND | |
| Tgene | C4704874 | Mammary Carcinoma, Human | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies