
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EIF2C2-PCMTD1 (FusionGDB2 ID:HG27161TG115294) |
Fusion Gene Summary for EIF2C2-PCMTD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EIF2C2-PCMTD1 | Fusion gene ID: hg27161tg115294 | Hgene | Tgene | Gene symbol | EIF2C2 | PCMTD1 | Gene ID | 27161 | 115294 |
| Gene name | argonaute RISC catalytic component 2 | protein-L-isoaspartate (D-aspartate) O-methyltransferase domain containing 1 | |
| Synonyms | CASC7|EIF2C2|LINC00980|PPD|Q10 | - | |
| Cytomap | ('AGO2','EIF2C2')('PCMTD1','PCMTD1') 8q24.3 | 8q11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein argonaute-2PAZ Piwi domain proteinargonaute 2, RISC catalytic componentcancer susceptibility candidate 7cancer susceptibility candidate 7 (non-protein coding)eukaryotic translation initiation factor 2C, 2long intergenic non-protein coding RN | protein-L-isoaspartate O-methyltransferase domain-containing protein 1 | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000220592, ENST00000519980, ENST00000517293, | ||
| Fusion gene scores | * DoF score | 13 X 13 X 12=2028 | 10 X 7 X 6=420 |
| # samples | 28 | 10 | |
| ** MAII score | log2(28/2028*10)=-2.85655892005837 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/420*10)=-2.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: EIF2C2 [Title/Abstract] AND PCMTD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AGO2(141595218)-PCMTD1(52746249), # samples:2 EIF2C2(141595218)-PCMTD1(52746249), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | AGO2-PCMTD1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AGO2-PCMTD1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | EIF2C2 | GO:0010501 | RNA secondary structure unwinding | 19966796 |
| Hgene | EIF2C2 | GO:0031054 | pre-miRNA processing | 16424907|17671087|18178619|19966796 |
| Hgene | EIF2C2 | GO:0035087 | siRNA loading onto RISC involved in RNA interference | 19966796 |
| Hgene | EIF2C2 | GO:0035196 | production of miRNAs involved in gene silencing by miRNA | 19966796|23661684 |
| Hgene | EIF2C2 | GO:0035278 | miRNA mediated inhibition of translation | 17671087|19801630 |
| Hgene | EIF2C2 | GO:0035279 | mRNA cleavage involved in gene silencing by miRNA | 15260970|17524464 |
| Hgene | EIF2C2 | GO:0035280 | miRNA loading onto RISC involved in gene silencing by miRNA | 18178619|19966796 |
| Hgene | EIF2C2 | GO:0045766 | positive regulation of angiogenesis | 27208409 |
| Hgene | EIF2C2 | GO:0045947 | negative regulation of translational initiation | 17524464|19801630 |
| Hgene | EIF2C2 | GO:0090625 | mRNA cleavage involved in gene silencing by siRNA | 15260970 |
| Hgene | EIF2C2 | GO:1905618 | positive regulation of miRNA mediated inhibition of translation | 23409027 |
| Fusion gene breakpoints across AGO2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PCMTD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
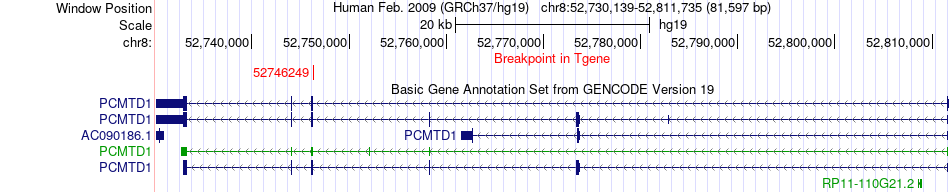 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AC-A6IW-01A | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| ChimerDB4 | BRCA | TCGA-AC-A6IW-01A | EIF2C2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
Top |
Fusion Gene ORF analysis for EIF2C2-PCMTD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000220592 | ENST00000519559 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5CDS-5UTR | ENST00000220592 | ENST00000522514 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5CDS-5UTR | ENST00000519980 | ENST00000519559 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5CDS-5UTR | ENST00000519980 | ENST00000522514 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5CDS-intron | ENST00000220592 | ENST00000521344 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5CDS-intron | ENST00000519980 | ENST00000521344 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5UTR-3CDS | ENST00000517293 | ENST00000360540 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5UTR-3CDS | ENST00000517293 | ENST00000544451 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5UTR-5UTR | ENST00000517293 | ENST00000519559 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5UTR-5UTR | ENST00000517293 | ENST00000522514 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| 5UTR-intron | ENST00000517293 | ENST00000521344 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| In-frame | ENST00000220592 | ENST00000360540 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| In-frame | ENST00000220592 | ENST00000544451 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| In-frame | ENST00000519980 | ENST00000360540 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| In-frame | ENST00000519980 | ENST00000544451 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000220592 | AGO2 | chr8 | 141595218 | - | ENST00000360540 | PCMTD1 | chr8 | 52746249 | - | 3763 | 328 | 113 | 991 | 292 |
| ENST00000220592 | AGO2 | chr8 | 141595218 | - | ENST00000544451 | PCMTD1 | chr8 | 52746249 | - | 3763 | 328 | 113 | 991 | 292 |
| ENST00000519980 | AGO2 | chr8 | 141595218 | - | ENST00000360540 | PCMTD1 | chr8 | 52746249 | - | 3690 | 255 | 40 | 918 | 292 |
| ENST00000519980 | AGO2 | chr8 | 141595218 | - | ENST00000544451 | PCMTD1 | chr8 | 52746249 | - | 3690 | 255 | 40 | 918 | 292 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000220592 | ENST00000360540 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - | 0.000109854 | 0.9998901 |
| ENST00000220592 | ENST00000544451 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - | 0.000109854 | 0.9998901 |
| ENST00000519980 | ENST00000360540 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - | 0.000106557 | 0.9998934 |
| ENST00000519980 | ENST00000544451 | AGO2 | chr8 | 141595218 | - | PCMTD1 | chr8 | 52746249 | - | 0.000106557 | 0.9998934 |
Top |
Fusion Genomic Features for EIF2C2-PCMTD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
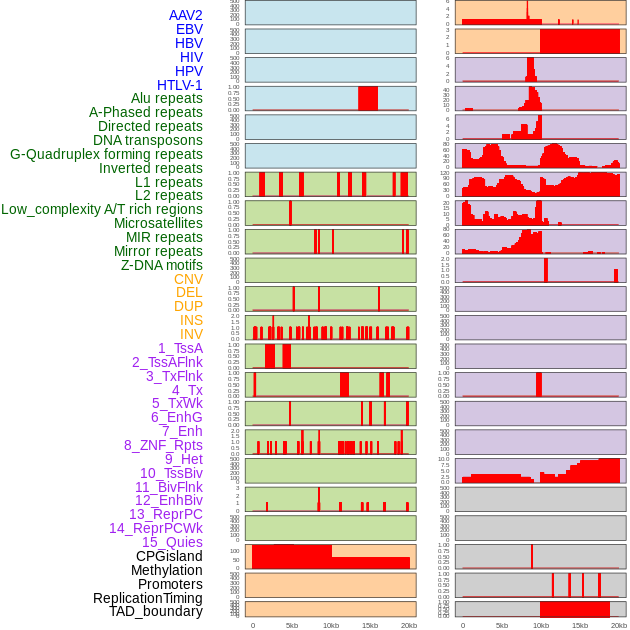 |
Top |
Fusion Protein Features for EIF2C2-PCMTD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/:141595218/:52746249) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 235_348 | 71 | 860.0 | Domain | PAZ |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 517_818 | 71 | 860.0 | Domain | Piwi |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 235_348 | 71 | 826.0 | Domain | PAZ |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 517_818 | 71 | 826.0 | Domain | Piwi |
Top |
Fusion Gene Sequence for EIF2C2-PCMTD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2911_2911_1_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000220592_PCMTD1_chr8_52746249_ENST00000360540_length(transcript)=3763nt_BP=328nt GGCCGCGCCGGGGCGGATCGTGCGGCCGGCGGCTCCCTCGCGGCTCGCGGCGTCGGGGCCCGTGGCGCGCGCGCGGCCGCCCCTCGGCCC CGGAGCCCCTCGGCGGCGCCACCATGTACTCGGGAGCCGGCCCCGCACTTGCACCTCCTGCGCCGCCGCCCCCCATCCAAGGATATGCCT TCAAGCCTCCACCTAGACCCGACTTTGGGACCTCCGGGAGAACAATCAAATTACAGGCCAATTTCTTCGAAATGGACATCCCCAAAATTG ACATCTATCATTATGAATTGGATATCAAGCCAGAGAAGTGCCCGAGGAGAGTTAACAGATTTGAGTTCTGTGAACCTGCATTTGTTGTTG GTAATTGCCTCCAGATAGCTTCTGACAGTCATCAGTATGATCGAATTTATTGTGGAGCTGGAGTGCAGAAAGACCATGAAAACTACATGA AAATATTACTAAAAGTTGGAGGCATATTAGTCATGCCTATAGAGGATCAGTTAACACAGATTATGCGAACTGGACAGAACACTTGGGAAA GTAAAAATATCCTTGCTGTTTCATTTGCTCCACTTGTGCAACCAAGTAAGAATGATAATGGCAAACCAGATTCTGTGGGACTCCCTCCCT GTGCTGTCAGGAATCTACAGGACTTGGCTCGTATTTACATTCGACGCACACTTAGAAATTTCATAAATGATGAGATGCAGGCCAAGGGGA TTCCTCAAAGGGCTCCACCCAAAAGGAAAAGAAAGAGAGTTAAACAGAGAATTAACACTTACGTATTTGTGGGTAATCAGCTTATTCCTC AGCCTCTAGACAGTGAAGAGGATGAAAAAATGGAAGAGGATAACAAAGAAGAGGAGGAAAAAGATCACAATGAAGCAATGAAGCCAGAGG AGCCACCTCAAAATTTACTGAGAGAAAAAATCATGAAGCTGCCCCTCCCTGAATCTTTAAAAGCTTACTTGACATATTTTAGAGACAAAT AACTTAGATCAAGAAGAAAAATGCCTACTGATAATTCCTTTAGTCTTGAAAATGTAGCATTTGTTAGGAGTTAAAAGAGAGAATTATTTC TTTCATCAGAGCAAATTATAGTGGAAAAAAAATCACTTGTTTCTGTCAGTAACACAAATGATGTATTCAGTGAATAAAAGAATCCCTTTT ATAAAATCTATTTTTCTTTAAATCTTGGAAAAATGTTGTTTTAGCTCAGAGTGATTTCAAAGTGGAATGCAACAGTAGTCAAGACTTGTG TACTATAAATCCTTTTCTGATTCCTTACAGATTTGTAGTGATGAGGTTTAGATTTAATTTTATATATGGTTTAAATAATTGTTAAGCTTA TATAACCTGATCTGAATTGCAGTTGTTTGCATTTCCTCTATGAAAACTTCATTTATCTAATAAGGAAGTCAAATGCTTTGTAGACTATTT ACCTTACTTTTGTTGCAATCACTGTTGTTGGGTTGCTGTATATATATTCCGGGCAATATATGAGTGCAATAACAATACAAGATATTGAAT AATTTAGCTTTAAAAAATCCCACAAATTTTATGAAATTTTACAGCCCTGCTACTTTTGCTTTTGAATCTCTTGCCAAAAGACATGGGTAA AATATCTGCCTCTCTCATAGAGATTTTAAGAGCACAGCAAGTGAATTATTAAAACAAAGTCTATACTTAATACAACTCTTTATATGGACC CTTTACATTTTCAGTATTTAAAAAAATGAGGTTATCTTAACTCTATAGAATTTTAAAAGTATATTTAGAATTGTTTTTTCTGTAGTTCAC TGTATAAAGTATTTGGTTTTTTAAAAAAAGCAAAACCATTGTTATGTGTGACTCTTGATAGGACACAGAACGAGTGAATGAGCATGAGTG AGGCCACTTTCTTGGATGGCTGTAAGTAGCAGGGCCAGGGTAGACCTGGTCAGCGGATGCACTTTAGCAGATGGAACTTCTAGTTTATCT GAATATTTATCTTTGACAAGGTAGGGCTGAGCCTACATTTGCTTTTGATCTATCTAGTATAAGAAATATTCACAGAAATTGTATGTAGAT ACCCTTTGTTTTGAAAATGCTGTTCAGAATCATAGTGTAATCTTTGGGACCTATGCCATGTTCATTTCACTCCTTCCCATATTTTTTGTG TTTCTTTTGGTAAAACTATAATGGTTTTCATTTTTTACTTAATATCACACAGTTAAACTGTCCATATTTGAGCTTTATTTTAGCTTATCA GTGATAAAAAACAGGTAGTAACTGCCATTGTTTGTTTGTTTTCCTAATAAGGCCTGAAAACAGCCATTCCTTGTTAAGAAAGTGTACAAT GTAACATATTTGCTAGAGTTACATGGATTATATATTTCTTAAAGGGAAAAATTTGAGAGTATCATGGACTACCACCAGCATTATTATTAC AGTAGTTACTCAGATTTGGTTAAGGAAGCCCAAGCAATGTATAGTGAAAGGATTATTATCTCTCTGCTAAGATTCAGATATTGTTTCAGA AATCTCAGCTCCAGTAATTCCACAACATCTAAAAACAAATGTTTGTGATCATGTGTAAGCATGAAATTGTTCCAAGTAAGTGAGGATATT TTAGTTATGTGAAAGACAGTTTCATGGAAGGTATTTGTTTTATACCAGTGGCTGGGATGGTGGAATTGGGGTTATTTCTACAATTATTCT TAGACGATTACTAAACTGTTAAGAAATGCCCCATATCATTTTTGTATCTAGGAAAGAAAAAAATCAGTTTCATACTGTTGTCATCTGTCA GAAATGCTCATTTTATTTTGAATTAAATGTGGCTTTTGAAGTACCTAGTTACCTTGAATTCCTGGTGACCACATGTTTTTATCTGGAAAA CCTGGAGAAAGTTATCTGTCCCATCTCCCCTGCTTGTTTTTTTTTTTTTTTTTGGTTGGAGCTGCTGTTTAGATGATGCTTTTACTATGC AGGAGAGAGTTTTTGTTAAGGATATATTTGAAGATTGGCTTTTCCATATTGTCCTTCATTCTTTGACCATGGCAAAGTGTACAGTAGATT TTCATGATCATTGCATATTTCTTGTCATTGAAATGTATCTTTTATGTTTTTAAATGCATTCATTTTACACTTGTGAGTTTATCATTGACT TTAAGAGGTAGAAATGAAAAATGAAAATTAAAGCTAAAGCCTTTTTATCTATTAATGCAGATATATTAGAATAAGAATATTTTGGGTTTG TGTTTATTTTTTAATGAATTTATGTTTACTTGATATGGAAAATTACGCTTTATAGGTGGAAAAGTAGCAAATAAAGATTAAGTAAAAGTA AGTGAAAATGATGGGGAATATAGTATTGGAATTTTATAGCTAGTTAAAACAGTAAGTATCATCTAATTTGGGTGTTTATTTTGCAGATGA GAAAACAGACCTAGAACCGTGGCATGTTTTGCCTGAAACATACAGTGAGTTAGAGACAGGGCCTAAGATAGCTTCTAGCATCAGATCAAT CCCAAGAATCCATCAGCAACCTCAGACCAACCCAAGAAGATAATTTAAATCTATACTGCTTATTGGTCAATATATTTGGTTCTAGTATTA ATAAAGAAAAATGTTATTAAAATAGCATACATAGTAGTAAAATAAAATACAAAAAGTGTGTTGATTTATAGCTGTTTGAGATGATAAAAG TGAAGCAAAGCCTGTTAAATCATTGGAAGACTTGGAAAATTATTTTAAATAAACAATTACATGTAATTAAGCA >2911_2911_1_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000220592_PCMTD1_chr8_52746249_ENST00000360540_length(amino acids)=292AA_BP=71 MYSGAGPALAPPAPPPPIQGYAFKPPPRPDFGTSGRTIKLQANFFEMDIPKIDIYHYELDIKPEKCPRRVNRFEFCEPAFVVGNCLQIAS DSHQYDRIYCGAGVQKDHENYMKILLKVGGILVMPIEDQLTQIMRTGQNTWESKNILAVSFAPLVQPSKNDNGKPDSVGLPPCAVRNLQD LARIYIRRTLRNFINDEMQAKGIPQRAPPKRKRKRVKQRINTYVFVGNQLIPQPLDSEEDEKMEEDNKEEEEKDHNEAMKPEEPPQNLLR EKIMKLPLPESLKAYLTYFRDK -------------------------------------------------------------- >2911_2911_2_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000220592_PCMTD1_chr8_52746249_ENST00000544451_length(transcript)=3763nt_BP=328nt GGCCGCGCCGGGGCGGATCGTGCGGCCGGCGGCTCCCTCGCGGCTCGCGGCGTCGGGGCCCGTGGCGCGCGCGCGGCCGCCCCTCGGCCC CGGAGCCCCTCGGCGGCGCCACCATGTACTCGGGAGCCGGCCCCGCACTTGCACCTCCTGCGCCGCCGCCCCCCATCCAAGGATATGCCT TCAAGCCTCCACCTAGACCCGACTTTGGGACCTCCGGGAGAACAATCAAATTACAGGCCAATTTCTTCGAAATGGACATCCCCAAAATTG ACATCTATCATTATGAATTGGATATCAAGCCAGAGAAGTGCCCGAGGAGAGTTAACAGATTTGAGTTCTGTGAACCTGCATTTGTTGTTG GTAATTGCCTCCAGATAGCTTCTGACAGTCATCAGTATGATCGAATTTATTGTGGAGCTGGAGTGCAGAAAGACCATGAAAACTACATGA AAATATTACTAAAAGTTGGAGGCATATTAGTCATGCCTATAGAGGATCAGTTAACACAGATTATGCGAACTGGACAGAACACTTGGGAAA GTAAAAATATCCTTGCTGTTTCATTTGCTCCACTTGTGCAACCAAGTAAGAATGATAATGGCAAACCAGATTCTGTGGGACTCCCTCCCT GTGCTGTCAGGAATCTACAGGACTTGGCTCGTATTTACATTCGACGCACACTTAGAAATTTCATAAATGATGAGATGCAGGCCAAGGGGA TTCCTCAAAGGGCTCCACCCAAAAGGAAAAGAAAGAGAGTTAAACAGAGAATTAACACTTACGTATTTGTGGGTAATCAGCTTATTCCTC AGCCTCTAGACAGTGAAGAGGATGAAAAAATGGAAGAGGATAACAAAGAAGAGGAGGAAAAAGATCACAATGAAGCAATGAAGCCAGAGG AGCCACCTCAAAATTTACTGAGAGAAAAAATCATGAAGCTGCCCCTCCCTGAATCTTTAAAAGCTTACTTGACATATTTTAGAGACAAAT AACTTAGATCAAGAAGAAAAATGCCTACTGATAATTCCTTTAGTCTTGAAAATGTAGCATTTGTTAGGAGTTAAAAGAGAGAATTATTTC TTTCATCAGAGCAAATTATAGTGGAAAAAAAATCACTTGTTTCTGTCAGTAACACAAATGATGTATTCAGTGAATAAAAGAATCCCTTTT ATAAAATCTATTTTTCTTTAAATCTTGGAAAAATGTTGTTTTAGCTCAGAGTGATTTCAAAGTGGAATGCAACAGTAGTCAAGACTTGTG TACTATAAATCCTTTTCTGATTCCTTACAGATTTGTAGTGATGAGGTTTAGATTTAATTTTATATATGGTTTAAATAATTGTTAAGCTTA TATAACCTGATCTGAATTGCAGTTGTTTGCATTTCCTCTATGAAAACTTCATTTATCTAATAAGGAAGTCAAATGCTTTGTAGACTATTT ACCTTACTTTTGTTGCAATCACTGTTGTTGGGTTGCTGTATATATATTCCGGGCAATATATGAGTGCAATAACAATACAAGATATTGAAT AATTTAGCTTTAAAAAATCCCACAAATTTTATGAAATTTTACAGCCCTGCTACTTTTGCTTTTGAATCTCTTGCCAAAAGACATGGGTAA AATATCTGCCTCTCTCATAGAGATTTTAAGAGCACAGCAAGTGAATTATTAAAACAAAGTCTATACTTAATACAACTCTTTATATGGACC CTTTACATTTTCAGTATTTAAAAAAATGAGGTTATCTTAACTCTATAGAATTTTAAAAGTATATTTAGAATTGTTTTTTCTGTAGTTCAC TGTATAAAGTATTTGGTTTTTTAAAAAAAGCAAAACCATTGTTATGTGTGACTCTTGATAGGACACAGAACGAGTGAATGAGCATGAGTG AGGCCACTTTCTTGGATGGCTGTAAGTAGCAGGGCCAGGGTAGACCTGGTCAGCGGATGCACTTTAGCAGATGGAACTTCTAGTTTATCT GAATATTTATCTTTGACAAGGTAGGGCTGAGCCTACATTTGCTTTTGATCTATCTAGTATAAGAAATATTCACAGAAATTGTATGTAGAT ACCCTTTGTTTTGAAAATGCTGTTCAGAATCATAGTGTAATCTTTGGGACCTATGCCATGTTCATTTCACTCCTTCCCATATTTTTTGTG TTTCTTTTGGTAAAACTATAATGGTTTTCATTTTTTACTTAATATCACACAGTTAAACTGTCCATATTTGAGCTTTATTTTAGCTTATCA GTGATAAAAAACAGGTAGTAACTGCCATTGTTTGTTTGTTTTCCTAATAAGGCCTGAAAACAGCCATTCCTTGTTAAGAAAGTGTACAAT GTAACATATTTGCTAGAGTTACATGGATTATATATTTCTTAAAGGGAAAAATTTGAGAGTATCATGGACTACCACCAGCATTATTATTAC AGTAGTTACTCAGATTTGGTTAAGGAAGCCCAAGCAATGTATAGTGAAAGGATTATTATCTCTCTGCTAAGATTCAGATATTGTTTCAGA AATCTCAGCTCCAGTAATTCCACAACATCTAAAAACAAATGTTTGTGATCATGTGTAAGCATGAAATTGTTCCAAGTAAGTGAGGATATT TTAGTTATGTGAAAGACAGTTTCATGGAAGGTATTTGTTTTATACCAGTGGCTGGGATGGTGGAATTGGGGTTATTTCTACAATTATTCT TAGACGATTACTAAACTGTTAAGAAATGCCCCATATCATTTTTGTATCTAGGAAAGAAAAAAATCAGTTTCATACTGTTGTCATCTGTCA GAAATGCTCATTTTATTTTGAATTAAATGTGGCTTTTGAAGTACCTAGTTACCTTGAATTCCTGGTGACCACATGTTTTTATCTGGAAAA CCTGGAGAAAGTTATCTGTCCCATCTCCCCTGCTTGTTTTTTTTTTTTTTTTTGGTTGGAGCTGCTGTTTAGATGATGCTTTTACTATGC AGGAGAGAGTTTTTGTTAAGGATATATTTGAAGATTGGCTTTTCCATATTGTCCTTCATTCTTTGACCATGGCAAAGTGTACAGTAGATT TTCATGATCATTGCATATTTCTTGTCATTGAAATGTATCTTTTATGTTTTTAAATGCATTCATTTTACACTTGTGAGTTTATCATTGACT TTAAGAGGTAGAAATGAAAAATGAAAATTAAAGCTAAAGCCTTTTTATCTATTAATGCAGATATATTAGAATAAGAATATTTTGGGTTTG TGTTTATTTTTTAATGAATTTATGTTTACTTGATATGGAAAATTACGCTTTATAGGTGGAAAAGTAGCAAATAAAGATTAAGTAAAAGTA AGTGAAAATGATGGGGAATATAGTATTGGAATTTTATAGCTAGTTAAAACAGTAAGTATCATCTAATTTGGGTGTTTATTTTGCAGATGA GAAAACAGACCTAGAACCGTGGCATGTTTTGCCTGAAACATACAGTGAGTTAGAGACAGGGCCTAAGATAGCTTCTAGCATCAGATCAAT CCCAAGAATCCATCAGCAACCTCAGACCAACCCAAGAAGATAATTTAAATCTATACTGCTTATTGGTCAATATATTTGGTTCTAGTATTA ATAAAGAAAAATGTTATTAAAATAGCATACATAGTAGTAAAATAAAATACAAAAAGTGTGTTGATTTATAGCTGTTTGAGATGATAAAAG TGAAGCAAAGCCTGTTAAATCATTGGAAGACTTGGAAAATTATTTTAAATAAACAATTACATGTAATTAAGCA >2911_2911_2_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000220592_PCMTD1_chr8_52746249_ENST00000544451_length(amino acids)=292AA_BP=71 MYSGAGPALAPPAPPPPIQGYAFKPPPRPDFGTSGRTIKLQANFFEMDIPKIDIYHYELDIKPEKCPRRVNRFEFCEPAFVVGNCLQIAS DSHQYDRIYCGAGVQKDHENYMKILLKVGGILVMPIEDQLTQIMRTGQNTWESKNILAVSFAPLVQPSKNDNGKPDSVGLPPCAVRNLQD LARIYIRRTLRNFINDEMQAKGIPQRAPPKRKRKRVKQRINTYVFVGNQLIPQPLDSEEDEKMEEDNKEEEEKDHNEAMKPEEPPQNLLR EKIMKLPLPESLKAYLTYFRDK -------------------------------------------------------------- >2911_2911_3_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000519980_PCMTD1_chr8_52746249_ENST00000360540_length(transcript)=3690nt_BP=255nt CGGCCGCCCCTCGGCCCCGGAGCCCCTCGGCGGCGCCACCATGTACTCGGGAGCCGGCCCCGCACTTGCACCTCCTGCGCCGCCGCCCCC CATCCAAGGATATGCCTTCAAGCCTCCACCTAGACCCGACTTTGGGACCTCCGGGAGAACAATCAAATTACAGGCCAATTTCTTCGAAAT GGACATCCCCAAAATTGACATCTATCATTATGAATTGGATATCAAGCCAGAGAAGTGCCCGAGGAGAGTTAACAGATTTGAGTTCTGTGA ACCTGCATTTGTTGTTGGTAATTGCCTCCAGATAGCTTCTGACAGTCATCAGTATGATCGAATTTATTGTGGAGCTGGAGTGCAGAAAGA CCATGAAAACTACATGAAAATATTACTAAAAGTTGGAGGCATATTAGTCATGCCTATAGAGGATCAGTTAACACAGATTATGCGAACTGG ACAGAACACTTGGGAAAGTAAAAATATCCTTGCTGTTTCATTTGCTCCACTTGTGCAACCAAGTAAGAATGATAATGGCAAACCAGATTC TGTGGGACTCCCTCCCTGTGCTGTCAGGAATCTACAGGACTTGGCTCGTATTTACATTCGACGCACACTTAGAAATTTCATAAATGATGA GATGCAGGCCAAGGGGATTCCTCAAAGGGCTCCACCCAAAAGGAAAAGAAAGAGAGTTAAACAGAGAATTAACACTTACGTATTTGTGGG TAATCAGCTTATTCCTCAGCCTCTAGACAGTGAAGAGGATGAAAAAATGGAAGAGGATAACAAAGAAGAGGAGGAAAAAGATCACAATGA AGCAATGAAGCCAGAGGAGCCACCTCAAAATTTACTGAGAGAAAAAATCATGAAGCTGCCCCTCCCTGAATCTTTAAAAGCTTACTTGAC ATATTTTAGAGACAAATAACTTAGATCAAGAAGAAAAATGCCTACTGATAATTCCTTTAGTCTTGAAAATGTAGCATTTGTTAGGAGTTA AAAGAGAGAATTATTTCTTTCATCAGAGCAAATTATAGTGGAAAAAAAATCACTTGTTTCTGTCAGTAACACAAATGATGTATTCAGTGA ATAAAAGAATCCCTTTTATAAAATCTATTTTTCTTTAAATCTTGGAAAAATGTTGTTTTAGCTCAGAGTGATTTCAAAGTGGAATGCAAC AGTAGTCAAGACTTGTGTACTATAAATCCTTTTCTGATTCCTTACAGATTTGTAGTGATGAGGTTTAGATTTAATTTTATATATGGTTTA AATAATTGTTAAGCTTATATAACCTGATCTGAATTGCAGTTGTTTGCATTTCCTCTATGAAAACTTCATTTATCTAATAAGGAAGTCAAA TGCTTTGTAGACTATTTACCTTACTTTTGTTGCAATCACTGTTGTTGGGTTGCTGTATATATATTCCGGGCAATATATGAGTGCAATAAC AATACAAGATATTGAATAATTTAGCTTTAAAAAATCCCACAAATTTTATGAAATTTTACAGCCCTGCTACTTTTGCTTTTGAATCTCTTG CCAAAAGACATGGGTAAAATATCTGCCTCTCTCATAGAGATTTTAAGAGCACAGCAAGTGAATTATTAAAACAAAGTCTATACTTAATAC AACTCTTTATATGGACCCTTTACATTTTCAGTATTTAAAAAAATGAGGTTATCTTAACTCTATAGAATTTTAAAAGTATATTTAGAATTG TTTTTTCTGTAGTTCACTGTATAAAGTATTTGGTTTTTTAAAAAAAGCAAAACCATTGTTATGTGTGACTCTTGATAGGACACAGAACGA GTGAATGAGCATGAGTGAGGCCACTTTCTTGGATGGCTGTAAGTAGCAGGGCCAGGGTAGACCTGGTCAGCGGATGCACTTTAGCAGATG GAACTTCTAGTTTATCTGAATATTTATCTTTGACAAGGTAGGGCTGAGCCTACATTTGCTTTTGATCTATCTAGTATAAGAAATATTCAC AGAAATTGTATGTAGATACCCTTTGTTTTGAAAATGCTGTTCAGAATCATAGTGTAATCTTTGGGACCTATGCCATGTTCATTTCACTCC TTCCCATATTTTTTGTGTTTCTTTTGGTAAAACTATAATGGTTTTCATTTTTTACTTAATATCACACAGTTAAACTGTCCATATTTGAGC TTTATTTTAGCTTATCAGTGATAAAAAACAGGTAGTAACTGCCATTGTTTGTTTGTTTTCCTAATAAGGCCTGAAAACAGCCATTCCTTG TTAAGAAAGTGTACAATGTAACATATTTGCTAGAGTTACATGGATTATATATTTCTTAAAGGGAAAAATTTGAGAGTATCATGGACTACC ACCAGCATTATTATTACAGTAGTTACTCAGATTTGGTTAAGGAAGCCCAAGCAATGTATAGTGAAAGGATTATTATCTCTCTGCTAAGAT TCAGATATTGTTTCAGAAATCTCAGCTCCAGTAATTCCACAACATCTAAAAACAAATGTTTGTGATCATGTGTAAGCATGAAATTGTTCC AAGTAAGTGAGGATATTTTAGTTATGTGAAAGACAGTTTCATGGAAGGTATTTGTTTTATACCAGTGGCTGGGATGGTGGAATTGGGGTT ATTTCTACAATTATTCTTAGACGATTACTAAACTGTTAAGAAATGCCCCATATCATTTTTGTATCTAGGAAAGAAAAAAATCAGTTTCAT ACTGTTGTCATCTGTCAGAAATGCTCATTTTATTTTGAATTAAATGTGGCTTTTGAAGTACCTAGTTACCTTGAATTCCTGGTGACCACA TGTTTTTATCTGGAAAACCTGGAGAAAGTTATCTGTCCCATCTCCCCTGCTTGTTTTTTTTTTTTTTTTTGGTTGGAGCTGCTGTTTAGA TGATGCTTTTACTATGCAGGAGAGAGTTTTTGTTAAGGATATATTTGAAGATTGGCTTTTCCATATTGTCCTTCATTCTTTGACCATGGC AAAGTGTACAGTAGATTTTCATGATCATTGCATATTTCTTGTCATTGAAATGTATCTTTTATGTTTTTAAATGCATTCATTTTACACTTG TGAGTTTATCATTGACTTTAAGAGGTAGAAATGAAAAATGAAAATTAAAGCTAAAGCCTTTTTATCTATTAATGCAGATATATTAGAATA AGAATATTTTGGGTTTGTGTTTATTTTTTAATGAATTTATGTTTACTTGATATGGAAAATTACGCTTTATAGGTGGAAAAGTAGCAAATA AAGATTAAGTAAAAGTAAGTGAAAATGATGGGGAATATAGTATTGGAATTTTATAGCTAGTTAAAACAGTAAGTATCATCTAATTTGGGT GTTTATTTTGCAGATGAGAAAACAGACCTAGAACCGTGGCATGTTTTGCCTGAAACATACAGTGAGTTAGAGACAGGGCCTAAGATAGCT TCTAGCATCAGATCAATCCCAAGAATCCATCAGCAACCTCAGACCAACCCAAGAAGATAATTTAAATCTATACTGCTTATTGGTCAATAT ATTTGGTTCTAGTATTAATAAAGAAAAATGTTATTAAAATAGCATACATAGTAGTAAAATAAAATACAAAAAGTGTGTTGATTTATAGCT GTTTGAGATGATAAAAGTGAAGCAAAGCCTGTTAAATCATTGGAAGACTTGGAAAATTATTTTAAATAAACAATTACATGTAATTAAGCA >2911_2911_3_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000519980_PCMTD1_chr8_52746249_ENST00000360540_length(amino acids)=292AA_BP=71 MYSGAGPALAPPAPPPPIQGYAFKPPPRPDFGTSGRTIKLQANFFEMDIPKIDIYHYELDIKPEKCPRRVNRFEFCEPAFVVGNCLQIAS DSHQYDRIYCGAGVQKDHENYMKILLKVGGILVMPIEDQLTQIMRTGQNTWESKNILAVSFAPLVQPSKNDNGKPDSVGLPPCAVRNLQD LARIYIRRTLRNFINDEMQAKGIPQRAPPKRKRKRVKQRINTYVFVGNQLIPQPLDSEEDEKMEEDNKEEEEKDHNEAMKPEEPPQNLLR EKIMKLPLPESLKAYLTYFRDK -------------------------------------------------------------- >2911_2911_4_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000519980_PCMTD1_chr8_52746249_ENST00000544451_length(transcript)=3690nt_BP=255nt CGGCCGCCCCTCGGCCCCGGAGCCCCTCGGCGGCGCCACCATGTACTCGGGAGCCGGCCCCGCACTTGCACCTCCTGCGCCGCCGCCCCC CATCCAAGGATATGCCTTCAAGCCTCCACCTAGACCCGACTTTGGGACCTCCGGGAGAACAATCAAATTACAGGCCAATTTCTTCGAAAT GGACATCCCCAAAATTGACATCTATCATTATGAATTGGATATCAAGCCAGAGAAGTGCCCGAGGAGAGTTAACAGATTTGAGTTCTGTGA ACCTGCATTTGTTGTTGGTAATTGCCTCCAGATAGCTTCTGACAGTCATCAGTATGATCGAATTTATTGTGGAGCTGGAGTGCAGAAAGA CCATGAAAACTACATGAAAATATTACTAAAAGTTGGAGGCATATTAGTCATGCCTATAGAGGATCAGTTAACACAGATTATGCGAACTGG ACAGAACACTTGGGAAAGTAAAAATATCCTTGCTGTTTCATTTGCTCCACTTGTGCAACCAAGTAAGAATGATAATGGCAAACCAGATTC TGTGGGACTCCCTCCCTGTGCTGTCAGGAATCTACAGGACTTGGCTCGTATTTACATTCGACGCACACTTAGAAATTTCATAAATGATGA GATGCAGGCCAAGGGGATTCCTCAAAGGGCTCCACCCAAAAGGAAAAGAAAGAGAGTTAAACAGAGAATTAACACTTACGTATTTGTGGG TAATCAGCTTATTCCTCAGCCTCTAGACAGTGAAGAGGATGAAAAAATGGAAGAGGATAACAAAGAAGAGGAGGAAAAAGATCACAATGA AGCAATGAAGCCAGAGGAGCCACCTCAAAATTTACTGAGAGAAAAAATCATGAAGCTGCCCCTCCCTGAATCTTTAAAAGCTTACTTGAC ATATTTTAGAGACAAATAACTTAGATCAAGAAGAAAAATGCCTACTGATAATTCCTTTAGTCTTGAAAATGTAGCATTTGTTAGGAGTTA AAAGAGAGAATTATTTCTTTCATCAGAGCAAATTATAGTGGAAAAAAAATCACTTGTTTCTGTCAGTAACACAAATGATGTATTCAGTGA ATAAAAGAATCCCTTTTATAAAATCTATTTTTCTTTAAATCTTGGAAAAATGTTGTTTTAGCTCAGAGTGATTTCAAAGTGGAATGCAAC AGTAGTCAAGACTTGTGTACTATAAATCCTTTTCTGATTCCTTACAGATTTGTAGTGATGAGGTTTAGATTTAATTTTATATATGGTTTA AATAATTGTTAAGCTTATATAACCTGATCTGAATTGCAGTTGTTTGCATTTCCTCTATGAAAACTTCATTTATCTAATAAGGAAGTCAAA TGCTTTGTAGACTATTTACCTTACTTTTGTTGCAATCACTGTTGTTGGGTTGCTGTATATATATTCCGGGCAATATATGAGTGCAATAAC AATACAAGATATTGAATAATTTAGCTTTAAAAAATCCCACAAATTTTATGAAATTTTACAGCCCTGCTACTTTTGCTTTTGAATCTCTTG CCAAAAGACATGGGTAAAATATCTGCCTCTCTCATAGAGATTTTAAGAGCACAGCAAGTGAATTATTAAAACAAAGTCTATACTTAATAC AACTCTTTATATGGACCCTTTACATTTTCAGTATTTAAAAAAATGAGGTTATCTTAACTCTATAGAATTTTAAAAGTATATTTAGAATTG TTTTTTCTGTAGTTCACTGTATAAAGTATTTGGTTTTTTAAAAAAAGCAAAACCATTGTTATGTGTGACTCTTGATAGGACACAGAACGA GTGAATGAGCATGAGTGAGGCCACTTTCTTGGATGGCTGTAAGTAGCAGGGCCAGGGTAGACCTGGTCAGCGGATGCACTTTAGCAGATG GAACTTCTAGTTTATCTGAATATTTATCTTTGACAAGGTAGGGCTGAGCCTACATTTGCTTTTGATCTATCTAGTATAAGAAATATTCAC AGAAATTGTATGTAGATACCCTTTGTTTTGAAAATGCTGTTCAGAATCATAGTGTAATCTTTGGGACCTATGCCATGTTCATTTCACTCC TTCCCATATTTTTTGTGTTTCTTTTGGTAAAACTATAATGGTTTTCATTTTTTACTTAATATCACACAGTTAAACTGTCCATATTTGAGC TTTATTTTAGCTTATCAGTGATAAAAAACAGGTAGTAACTGCCATTGTTTGTTTGTTTTCCTAATAAGGCCTGAAAACAGCCATTCCTTG TTAAGAAAGTGTACAATGTAACATATTTGCTAGAGTTACATGGATTATATATTTCTTAAAGGGAAAAATTTGAGAGTATCATGGACTACC ACCAGCATTATTATTACAGTAGTTACTCAGATTTGGTTAAGGAAGCCCAAGCAATGTATAGTGAAAGGATTATTATCTCTCTGCTAAGAT TCAGATATTGTTTCAGAAATCTCAGCTCCAGTAATTCCACAACATCTAAAAACAAATGTTTGTGATCATGTGTAAGCATGAAATTGTTCC AAGTAAGTGAGGATATTTTAGTTATGTGAAAGACAGTTTCATGGAAGGTATTTGTTTTATACCAGTGGCTGGGATGGTGGAATTGGGGTT ATTTCTACAATTATTCTTAGACGATTACTAAACTGTTAAGAAATGCCCCATATCATTTTTGTATCTAGGAAAGAAAAAAATCAGTTTCAT ACTGTTGTCATCTGTCAGAAATGCTCATTTTATTTTGAATTAAATGTGGCTTTTGAAGTACCTAGTTACCTTGAATTCCTGGTGACCACA TGTTTTTATCTGGAAAACCTGGAGAAAGTTATCTGTCCCATCTCCCCTGCTTGTTTTTTTTTTTTTTTTTGGTTGGAGCTGCTGTTTAGA TGATGCTTTTACTATGCAGGAGAGAGTTTTTGTTAAGGATATATTTGAAGATTGGCTTTTCCATATTGTCCTTCATTCTTTGACCATGGC AAAGTGTACAGTAGATTTTCATGATCATTGCATATTTCTTGTCATTGAAATGTATCTTTTATGTTTTTAAATGCATTCATTTTACACTTG TGAGTTTATCATTGACTTTAAGAGGTAGAAATGAAAAATGAAAATTAAAGCTAAAGCCTTTTTATCTATTAATGCAGATATATTAGAATA AGAATATTTTGGGTTTGTGTTTATTTTTTAATGAATTTATGTTTACTTGATATGGAAAATTACGCTTTATAGGTGGAAAAGTAGCAAATA AAGATTAAGTAAAAGTAAGTGAAAATGATGGGGAATATAGTATTGGAATTTTATAGCTAGTTAAAACAGTAAGTATCATCTAATTTGGGT GTTTATTTTGCAGATGAGAAAACAGACCTAGAACCGTGGCATGTTTTGCCTGAAACATACAGTGAGTTAGAGACAGGGCCTAAGATAGCT TCTAGCATCAGATCAATCCCAAGAATCCATCAGCAACCTCAGACCAACCCAAGAAGATAATTTAAATCTATACTGCTTATTGGTCAATAT ATTTGGTTCTAGTATTAATAAAGAAAAATGTTATTAAAATAGCATACATAGTAGTAAAATAAAATACAAAAAGTGTGTTGATTTATAGCT GTTTGAGATGATAAAAGTGAAGCAAAGCCTGTTAAATCATTGGAAGACTTGGAAAATTATTTTAAATAAACAATTACATGTAATTAAGCA >2911_2911_4_AGO2-PCMTD1_AGO2_chr8_141595218_ENST00000519980_PCMTD1_chr8_52746249_ENST00000544451_length(amino acids)=292AA_BP=71 MYSGAGPALAPPAPPPPIQGYAFKPPPRPDFGTSGRTIKLQANFFEMDIPKIDIYHYELDIKPEKCPRRVNRFEFCEPAFVVGNCLQIAS DSHQYDRIYCGAGVQKDHENYMKILLKVGGILVMPIEDQLTQIMRTGQNTWESKNILAVSFAPLVQPSKNDNGKPDSVGLPPCAVRNLQD LARIYIRRTLRNFINDEMQAKGIPQRAPPKRKRKRVKQRINTYVFVGNQLIPQPLDSEEDEKMEEDNKEEEEKDHNEAMKPEEPPQNLLR EKIMKLPLPESLKAYLTYFRDK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EIF2C2-PCMTD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 311_316 | 71.66666666666667 | 860.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 524_566 | 71.66666666666667 | 860.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 709_710 | 71.66666666666667 | 860.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 753_761 | 71.66666666666667 | 860.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 790_812 | 71.66666666666667 | 860.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 311_316 | 71.66666666666667 | 826.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 524_566 | 71.66666666666667 | 826.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 709_710 | 71.66666666666667 | 826.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 753_761 | 71.66666666666667 | 826.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 790_812 | 71.66666666666667 | 826.0 | guide RNA |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 587_590 | 71.66666666666667 | 860.0 | GW182 family members |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000220592 | - | 2 | 19 | 650_660 | 71.66666666666667 | 860.0 | GW182 family members |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 587_590 | 71.66666666666667 | 826.0 | GW182 family members |
| Hgene | AGO2 | chr8:141595218 | chr8:52746249 | ENST00000519980 | - | 2 | 18 | 650_660 | 71.66666666666667 | 826.0 | GW182 family members |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EIF2C2-PCMTD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EIF2C2-PCMTD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | AGO2 | C0001973 | Alcoholic Intoxication, Chronic | 1 | PSYGENET |
| Hgene | AGO2 | C0009171 | Cocaine Abuse | 1 | CTD_human |
| Hgene | AGO2 | C0023466 | Leukemia, Monocytic, Chronic | 1 | CTD_human |
| Hgene | AGO2 | C0023470 | Myeloid Leukemia | 1 | CTD_human |
| Hgene | AGO2 | C0236736 | Cocaine-Related Disorders | 1 | CTD_human |
| Hgene | AGO2 | C0345967 | Malignant mesothelioma | 1 | CTD_human |
| Hgene | AGO2 | C0600427 | Cocaine Dependence | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies