
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:HSD3B2-MON2 (FusionGDB2 ID:HG3284TG23041) |
Fusion Gene Summary for HSD3B2-MON2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: HSD3B2-MON2 | Fusion gene ID: hg3284tg23041 | Hgene | Tgene | Gene symbol | HSD3B2 | MON2 | Gene ID | 3284 | 23041 |
| Gene name | hydroxy-delta-5-steroid dehydrogenase, 3 beta- and steroid delta-isomerase 2 | MON2 homolog, regulator of endosome-to-Golgi trafficking | |
| Synonyms | HSD3B|HSDB|SDR11E2 | - | |
| Cytomap | ('HSD3B2')('MON2') 1p12 | 12q14.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | 3 beta-hydroxysteroid dehydrogenase/Delta 5-->4-isomerase type 23 beta-HSD type II3 beta-hydroxysteroid dehydrogenase type II, delta 5-delta 4-isomerase type II, 3 beta-HSD type II3 beta-hydroxysteroid dehydrogenase/Delta 5-->4-isomerase type II3-beta | protein MON2 homologMON2 regulator of endosome-to-Golgi trafficking | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000471656, ENST00000369416, ENST00000543831, | ||
| Fusion gene scores | * DoF score | 4 X 4 X 1=16 | 15 X 11 X 6=990 |
| # samples | 4 | 17 | |
| ** MAII score | log2(4/16*10)=1.32192809488736 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(17/990*10)=-2.54189377882927 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: HSD3B2 [Title/Abstract] AND MON2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | HSD3B2(119958184)-MON2(62979094), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | HSD3B2 | GO:0006694 | steroid biosynthetic process | 1944309 |
| Fusion gene breakpoints across HSD3B2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MON2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
Top |
Fusion Gene ORF analysis for HSD3B2-MON2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000543831 | ENST00000280379 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.05581343 | 0.9441866 |
| ENST00000543831 | ENST00000393632 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.001918633 | 0.9980813 |
| ENST00000543831 | ENST00000393630 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.001038096 | 0.9989619 |
| ENST00000543831 | ENST00000546600 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.02049669 | 0.9795033 |
| ENST00000543831 | ENST00000552738 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.006299443 | 0.9937005 |
| ENST00000543831 | ENST00000393629 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.006299443 | 0.9937005 |
| ENST00000369416 | ENST00000280379 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.028883517 | 0.9711165 |
| ENST00000369416 | ENST00000393632 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.001793111 | 0.99820685 |
| ENST00000369416 | ENST00000393630 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.000984471 | 0.99901557 |
| ENST00000369416 | ENST00000546600 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.018004773 | 0.9819952 |
| ENST00000369416 | ENST00000552738 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.004385573 | 0.9956144 |
| ENST00000369416 | ENST00000393629 | HSD3B2 | chr1 | 119958184 | + | MON2 | chr12 | 62979094 | + | 0.004385573 | 0.9956144 |
Top |
Fusion Genomic Features for HSD3B2-MON2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
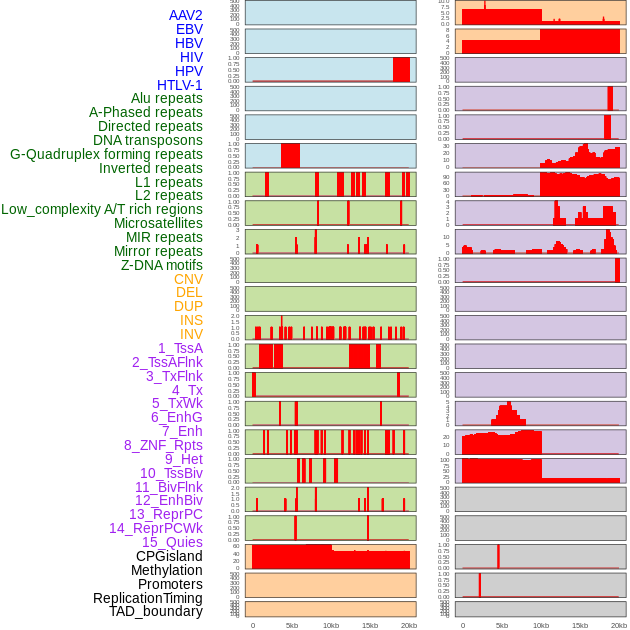 |
Top |
Fusion Protein Features for HSD3B2-MON2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:119958184/chr12:62979094) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HSD3B2 | chr1:119958184 | chr12:62979094 | ENST00000369416 | + | 2 | 4 | 287_307 | 47 | 373.0 | Transmembrane | Helical |
| Hgene | HSD3B2 | chr1:119958184 | chr12:62979094 | ENST00000543831 | + | 2 | 4 | 287_307 | 47 | 373.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for HSD3B2-MON2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >37690_37690_1_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000280379_length(transcript)=658nt_BP=350nt GTTCAAGGTAATAAGGGCTGAGACACAAGCCACAGAGCATAAAGCTCCAGTCCTTCCTCCAGGGATGAGGCAGTAAGGACTTGGACTCCT CTGTCCAGCTTTTAACAATCTAAGTTACGCCCTCTTCTGGGTCACGCTAGAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAG TGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTGACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCT GTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCCTTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGA ATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAATAAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGC ACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATAGAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCA ACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATTGATTCACTTAAGAAAACTCAGCCTGAGAATGCTTGTATCAG CCTATTTGGAATACCACCCTACTTTTAA >37690_37690_1_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000280379_length(amino acids)=170AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENACISLFGIPPYFX -------------------------------------------------------------- >37690_37690_2_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000393629_length(transcript)=900nt_BP=350nt GTTCAAGGTAATAAGGGCTGAGACACAAGCCACAGAGCATAAAGCTCCAGTCCTTCCTCCAGGGATGAGGCAGTAAGGACTTGGACTCCT CTGTCCAGCTTTTAACAATCTAAGTTACGCCCTCTTCTGGGTCACGCTAGAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAG TGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTGACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCT GTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCCTTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGA ATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAATAAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGC ACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATAGAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCA ACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATTGATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAA TACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATCACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGC ACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAAAATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGG AAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGGACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGC >37690_37690_2_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000393629_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- >37690_37690_3_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000393630_length(transcript)=5618nt_BP=350nt GTTCAAGGTAATAAGGGCTGAGACACAAGCCACAGAGCATAAAGCTCCAGTCCTTCCTCCAGGGATGAGGCAGTAAGGACTTGGACTCCT CTGTCCAGCTTTTAACAATCTAAGTTACGCCCTCTTCTGGGTCACGCTAGAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAG TGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTGACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCT GTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCCTTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGA ATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAATAAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGC ACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATAGAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCA ACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATTGATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAA TACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATCACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGC ACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAAAATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGG AAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGGACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGC CTCCTTTAAATTCTACTTACCTGAGTTCAGTAATTCATATTACAGGCTTGCACATCAACAAAGGCTCCTGAATGAACAGCAGTGTAAGGC TTTAATAAATTAAACTGATGGGAGGGATAATTAACACTACAGTATACATGCTACCATATCTCCAGTTGGTGATTTAAAGTGAGCTTATGT ACAGTTTGTGGTGTATGTGTTAATGATGTACTTTTTAAAAAGAAAGAAGAGATATTTCAATTCAGTCAGATTTATTAGTCTGGTGTTTTT GCACCCTTTTTCAAGTACAAAATCGTACTAGAATTTTATGCAAGATGGTACTGTAACATTCCATATTATCTATAACCAGCCTTTGTTAAC AAAGGGAACTGATATACTTGTGTGTATAATAAATGGTACAGTTCTGTATAAAATAGTGCATTTATTTAAATTTTAAAAGTATTGATAATG TTAAATGCTTAAAGCTCTATTTATTATTAATACAAAATTGTTTGCTTACATTTTTACTTATAATTTGCCTTCATATGTGGCGGATAAGCT CACCATATGATCATGCAGTTAGCTTCATGCTTATTTTAAATGTATTATTAGTGACCATTAAACATCTGACCAGTAAGGTCATGTGAACAC AGCAGCAAATAGTTTATGATTTGCTGATTTTGGAGCTTTGAAATATAGGTTCTTAATACATTGATACATATTGTAGCACTATGACTTCAT CATACCTCATTTCTTTAAACAGCTCTCCAAGCTTTCACTGAAGTCTGTCTGTTTTTTATATTGGCTGTCTGGATTTTAAAGACTTTTCAT ATTTTATATTTCTACTGATTTTGTTTCCCCTAACAACATTTGTCACTGTCTTTGAATTATGACCCAGGCAAGATGATTTCAGATTTTCTA AAATCTTGCCTGTGAGGTTTTGTTCATATCAGTGCTTCATTTTGTAATGTCTTCTCAAGAAAAATACCTATGTTAACTCACAAGTATAAA ATATGTGTGTATTATAAAACAATGAAAAGTGTATTTTTGGAGATAGTCAAGCATTTAGAAGTGCAGTGAACTTGCTGTCACGGAGTAAAA TGCTAATTATGTTTCACTTTCCTAGCCTAGTGAAAAAGAAAAGTGCTCTTGAGTACAATACCTTAATTATTTCTTAAAATACTGACTTTG ACCTAGCTCACTGTATTTTTTATTTAATGGATTATGGATTACAGTATTTTTCTTCTGAGTTAAATTTTCATAATTTATGTGAAGACACAA AGATGTTTAAAACAATGATTATTCATAAGAAATCATGATGGTCTCAGTATTATTTTAGTGTATTGGAAGGTCTTTGATCTTAATAGAATT TATAAATTTCAGCTTCTCCAGAATAATCATAAAACTGCAAAAAGATATTATAATTGAGTCATGATTGAGATACAGTTTTGAGGCTATTAT AATTGTATAATTATTTAATTTGCATTATCTGTAAAATGTAGTAAGGTCTTTGAGGGGATATTTTTTATTTACATGAATTACTGAATTTCT ATTTTATTATTTCACCTAAAATTAAGGTAAAATATGGCATTTCATAAGTTCTGCTTTCAGCATTTTCCTTAAAGTTGTAAAAAATCAAGC TATGTACTTATTTTCTATATTTGGGTGTGTTAAATTGAGGATTAGAAAAATCCACATAATCACTGATAAAGCATTGAAACAGAATAACCC AAGGGTAGTGTACCGATTCAGTAACATGTTAAAAATATTGCTATGCATTTATTCAAAGGAAAATGGTCTGTTCTTGAGAAATAAAAGATC AGTTGCAATTAGGATAATTAAATAGTTAAATATGAGTCAAGTGTATGCAATATACATTTATATGAACCAAAGCTTGCTTTATCAGGACCA TGCCCTACAGTTCAAAACATAAACATAGTGAATGTGTTAATATCATATAATAAGGTAATAAATGCCAGTCTTAGTGTGAAGCAAGTGGGT GGCCCCCTTGGTAGTATAATTGGACAGGATTTTCCTCCAGAATATTTCCTGTCACCCTCCAAGAGTCACTACAGTAATTGATTGCTGGCA TGGAACACATTGCCCTTGTCTTGTTAGTATGAATTGGGTTCTCCAGTGACTAGAAGAACTGGGGTGTGTGAAAGTATTCGATGCCAGGAG ATTCAAAAAGGAAGCTCTCAAAGATAAGATCATTTTATGGCACAATTGAGTCTATAACCAGCCCTTTAAGCAGTAGTAAAAATGTCCTTT GTCATACTTACTAGAAATACTATGAGTTTTTTTTTTTTTTTTCATTTGAGACGGAGTCTCGCTCTGTCACCCAGGCTGGAATGCAGTGGC ACGATCTTGGCTCACTGCAACCTCTGCTTCCCGGGTTCAAGCAGTTTCCTGCTTCAGACTTCCAAGTAGCTGGGATTACAGACATGCCAC CATGCCAGGCTAATTTTTTTAATATTTTTAGTAGAGATGGGGTTTCACCATTTTGGCCATTCTAGTCTTGAACTCCTGACCTCAGGTGAT CTGCCCGCCTTGGCCTCCCAAAGTGCTGACATTACAGGCCTGAGCCACTGCGCCCAGCCAATACCATGAGTTTTAAGCCTCACATCGTCA CTTGCTGTCACTGCCAGTGCCTGTTTTATTCATATTGCTGGACAACAGACATATGCCACCAATTGTATGATTAATAAAGTCTTTTTCTGG CCATTTTGTCCATTATAAAGGAAATAAACTAATTGTTAACTTGCATAGATTACTTCTTAGTTTCCTATGCTACCACCACTGCCAAGGGAG AAAAAAATACATCATTTTGTAATGTCTTTAGTATTTCTTTATAACTAGTGTTAAGGTTTTGTTAATTTTATTGTATACATTTGTAACATT TATTAGGAGCCTTTTAGGTTCCAAAACAAACAAAAGGCATAAAAAAGTCTAGCTTAGAACCACTTTTCACTTGCTTTCATTTTTAATTTT ATTCACTTAACAGCTAACATCTTTCTTGTTTCTTGTTTTTTCCATTATATGGTTATCGATTCAACTCTTGCTATATTCCTTAAATTTGTA TGTATCATCAGAAGAAAGAGATGAACAATTTAGTGTAGATATTTTATTCTGGAGAATAATATTCAATTAAATTATTTCTACAGCAGGCCA GTAACAACTAGATTATTTGTCCTTTCTCAGTATAATTTTAAAGAGCATTTTGTTTTATTGTCACAATTTGGTACCACTAGTCCCAGGTAA CCATTGGGCCAAAGGATCAGTTGAGAAACAGTTAAGGATGAATTAGCATAAGTTATGGAACAGTGTTAGAAAACAACTCAAAAGTATATT CTTTATTAATGAGGTGGTCATTATTACATTTGTGTCAATGAAGGGCAGTGTAGTTATTTTAAAATGACTAATATTTTCTCCCCAAATACA GAATAATTCAGATGGGCAACCAAGTTTTCAAGAGACTGCTGTAGGTGAAGTCTGTCTAGCCAAGGCAGAACACTTACAGGAGTCCCTAAC TGTGCCACCCTTGGAATGGGTTAGTGTACAGGCTCAGAATATTGTGGATTACAGTTTTTCAGAGAAAACTACCACAGATGTAGACAAAAA TGATCTCTGAAAGCATTGCCAGCAGCCAGGTATGTTCCTTAGATTTCCACTTAGGTTTGGCATTTTGGCAGATAAGCTAATCTTGTATAA AGCATCACATTTTACTATGCTTAGTGTTCCTGGGTTGTATTTATCTACATTATTAGAGGGAATTTTTATTTTAAAAAAATTGTCATTCAT GAGAAGAATGGGAGTTCATGCCACATAGTATTTTACCAATTTATATAAAGTGGGAAAAGTCTTTAATACTTCATGATCACTTGAATTAAA GTTTTTGTATCTCTGGAAAGTAGAATAGTGCTTTCATTTGAATGAAAAGTGTTTATAGATTCAGAAAGAGAGATGATATCTTTGTATCTT GATTTATATACAGACCATTTCAGAGGAAGTTAAATGTCTTACAAATCCAATACTTTCTAATGCTCTAACAGTGTTGGCTATTTAAAAGAA CATGTGGCAAGTTCTATATGAATATTCTTGGTCATCTCGACTAATTCTGAGGCAATGATGGACAGAGATGCTACTTCTTATTTAACTCTA GGCATGTTGACTTTTCAAAGCGGTTTCCTTATTTCTAAACAGAGATGATGATCAATGAGTTACTAATTCTTTAGAGGAAAAAATGCATAA TTTGAGTGTGGAGTTGATTTTAATGACAGGGTAATTCAAGTTGTTTGATAAATTTATTACTATATTGTAAGAGAGATCTTTGACCATTTT TCTTCCTTTTTCTTGGACATCACTTTCTTCCCTCCCCTTCTCTCTTTTATGTTTTTATCCTTGTTAAATTTTATGTTTACGTTACCATCT TTCTTATACTTTCCCCTGATTTTTCTCTTTTAATTCCTCTTTCATTCTCTGCCTCTTCTCTTTCAGCTCTTTCTCTAATTGTGCCTATTC CTTGTTCATAAGAAGTGGAGCTGTTAGTGGTAGAACCACTGCTCATGGTTCTACCACTACAAAGTGGAAAGTAGAAATACTTTGCACTTT GGCCACTGTTGCGTTTTTGCCAAGGTAAAGTTCCCCTGCCATTTTGAAATAGCTGAACAAGTTAAAGTAATATGTTCCAAAAACTGGAAG TGCCATAAAAAACTAAAAATAAAAAAAAATTGTGACTA >37690_37690_3_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000393630_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- >37690_37690_4_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000393632_length(transcript)=3645nt_BP=350nt GTTCAAGGTAATAAGGGCTGAGACACAAGCCACAGAGCATAAAGCTCCAGTCCTTCCTCCAGGGATGAGGCAGTAAGGACTTGGACTCCT CTGTCCAGCTTTTAACAATCTAAGTTACGCCCTCTTCTGGGTCACGCTAGAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAG TGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTGACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCT GTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCCTTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGA ATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAATAAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGC ACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATAGAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCA ACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATTGATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAA TACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATCACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGC ACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAAAATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGG AAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGGACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGC CTCCTTTAAATTCTACTTACCTGAGTTCAGTAATTCATATTACAGGCTTGCACATCAACAAAGGCTCCTGAATGAACAGCAGTGTAAGGC TTTAATAAATTAAACTGATGGGAGGGATAATTAACACTACAGTATACATGCTACCATATCTCCAGTTGGTGATTTAAAGTGAGCTTATGT ACAGTTTGTGGTGTATGTGTTAATGATGTACTTTTTAAAAAGAAAGAAGAGATATTTCAATTCAGTCAGATTTATTAGTCTGGTGTTTTT GCACCCTTTTTCAAGTACAAAATCGTACTAGAATTTTATGCAAGATGGTACTGTAACATTCCATATTATCTATAACCAGCCTTTGTTAAC AAAGGGAACTGATATACTTGTGTGTATAATAAATGGTACAGTTCTGTATAAAATAGTGCATTTATTTAAATTTTAAAAGTATTGATAATG TTAAATGCTTAAAGCTCTATTTATTATTAATACAAAATTGTTTGCTTACATTTTTACTTATAATTTGCCTTCATATGTGGCGGATAAGCT CACCATATGATCATGCAGTTAGCTTCATGCTTATTTTAAATGTATTATTAGTGACCATTAAACATCTGACCAGTAAGGTCATGTGAACAC AGCAGCAAATAGTTTATGATTTGCTGATTTTGGAGCTTTGAAATATAGGTTCTTAATACATTGATACATATTGTAGCACTATGACTTCAT CATACCTCATTTCTTTAAACAGCTCTCCAAGCTTTCACTGAAGTCTGTCTGTTTTTTATATTGGCTGTCTGGATTTTAAAGACTTTTCAT ATTTTATATTTCTACTGATTTTGTTTCCCCTAACAACATTTGTCACTGTCTTTGAATTATGACCCAGGCAAGATGATTTCAGATTTTCTA AAATCTTGCCTGTGAGGTTTTGTTCATATCAGTGCTTCATTTTGTAATGTCTTCTCAAGAAAAATACCTATGTTAACTCACAAGTATAAA ATATGTGTGTATTATAAAACAATGAAAAGTGTATTTTTGGAGATAGTCAAGCATTTAGAAGTGCAGTGAACTTGCTGTCACGGAGTAAAA TGCTAATTATGTTTCACTTTCCTAGCCTAGTGAAAAAGAAAAGTGCTCTTGAGTACAATACCTTAATTATTTCTTAAAATACTGACTTTG ACCTAGCTCACTGTATTTTTTATTTAATGGATTATGGATTACAGTATTTTTCTTCTGAGTTAAATTTTCATAATTTATGTGAAGACACAA AGATGTTTAAAACAATGATTATTCATAAGAAATCATGATGGTCTCAGTATTATTTTAGTGTATTGGAAGGTCTTTGATCTTAATAGAATT TATAAATTTCAGCTTCTCCAGAATAATCATAAAACTGCAAAAAGATATTATAATTGAGTCATGATTGAGATACAGTTTTGAGGCTATTAT AATTGTATAATTATTTAATTTGCATTATCTGTAAAATGTAGTAAGGTCTTTGAGGGGATATTTTTTATTTACATGAATTACTGAATTTCT ATTTTATTATTTCACCTAAAATTAAGGTAAAATATGGCATTTCATAAGTTCTGCTTTCAGCATTTTCCTTAAAGTTGTAAAAAATCAAGC TATGTACTTATTTTCTATATTTGGGTGTGTTAAATTGAGGATTAGAAAAATCCACATAATCACTGATAAAGCATTGAAACAGAATAACCC AAGGGTAGTGTACCGATTCAGTAACATGTTAAAAATATTGCTATGCATTTATTCAAAGGAAAATGGTCTGTTCTTGAGAAATAAAAGATC AGTTGCAATTAGGATAATTAAATAGTTAAATATGAGTCAAGTGTATGCAATATACATTTATATGAACCAAAGCTTGCTTTATCAGGACCA TGCCCTACAGTTCAAAACATAAACATAGTGAATGTGTTAATATCATATAATAAGGTAATAAATGCCAGTCTTAGTGTGAAGCAAGTGGGT GGCCCCCTTGGTAGTATAATTGGACAGGATTTTCCTCCAGAATATTTCCTGTCACCCTCCAAGAGTCACTACAGTAATTGATTGCTGGCA TGGAACACATTGCCCTTGTCTTGTTAGTATGAATTGGGTTCTCCAGTGACTAGAAGAACTGGGGTGTGTGAAAGTATTCGATGCCAGGAG ATTCAAAAAGGAAGCTCTCAAAGATAAGATCATTTTATGGCACAATTGAGTCTATAACCAGCCCTTTAAGCAGTAGTAAAAATGTCCTTT GTCATACTTACTAGAAATACTATGAGTTTTTTTTTTTTTTTTCATTTGAGACGGAGTCTCGCTCTGTCACCCAGGCTGGAATGCAGTGGC ACGATCTTGGCTCACTGCAACCTCTGCTTCCCGGGTTCAAGCAGTTTCCTGCTTCAGACTTCCAAGTAGCTGGGATTACAGACATGCCAC CATGCCAGGCTAATTTTTTTAATATTTTTAGTAGAGATGGGGTTTCACCATTTTGGCCATTCTAGTCTTGAACTCCTGACCTCAGGTGAT CTGCCCGCCTTGGCCTCCCAAAGTGCTGACATTACAGGCCTGAGCCACTGCGCCCAGCCAATACCATGAGTTTTAAGCCTCACATCGTCA CTTGCTGTCACTGCCAGTGCCTGTTTTATTCATATTGCTGGACAACAGACATATGCCACCAATTGTATGATTAATAAAGTCTTTTTCTGG CCATTTTGTCCATTATAAAGGAAATAAACTAATTGTTAACTTGCA >37690_37690_4_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000393632_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- >37690_37690_5_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000546600_length(transcript)=1374nt_BP=350nt GTTCAAGGTAATAAGGGCTGAGACACAAGCCACAGAGCATAAAGCTCCAGTCCTTCCTCCAGGGATGAGGCAGTAAGGACTTGGACTCCT CTGTCCAGCTTTTAACAATCTAAGTTACGCCCTCTTCTGGGTCACGCTAGAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAG TGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTGACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCT GTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCCTTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGA ATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAATAAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGC ACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATAGAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCA ACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATTGATTCACTTAAGAAAACTCAGCCTGAGAATGCTTGTATCAG CCTATTTGGAATACCACCCTACTTTTAAACCTTGTTTTTAATCTCTTAAAGTTGATGGAAATACCTGGGCACAAGTAATTGCCTTATACC CAACTTTAGTAGAATGCATCACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGCACTAGTTCCTTTTAAGGATTTCATGCAGC CACCAGCATCCAGAGTTCAAAATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGGAAGATAGTCTAAAAAATGTTTGCTCCTAA TTGAGTCTTCTGTGAGAAGGACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGCCTCCTTTAAATTCTACTTACCTGAGTTCA GTAATTCATATTACAGGCTTGCACATCAACAAAGGCTCCTGAATGAACAGCAGTGTAAGGCTTTAATAAATTAAACTGATGGGAGGGATA ATTAACACTACAGTATACATGCTACCATATCTCCAGTTGGTGATTTAAAGTGAGCTTATGTACAGTTTGTGGTGTATGTGTTAATGATGT ACTTTTTAAAAAGAAAGAAGAGATATTTCAATTCAGTCAGATTTATTAGTCTGGTGTTTTTGCACCCTTTTTCAAGTACAAAATCGTACT AGAATTTTATGCAAGATGGTACTGTAACATTCCATATTATCTATAACCAGCCTTTGTTAACAAAGGGAACTGATATACTTGTGTGTATAA TAAATGGTACAGTTCTGTATAAAA >37690_37690_5_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000546600_length(amino acids)=169AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENACISLFGIPPYF -------------------------------------------------------------- >37690_37690_6_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000552738_length(transcript)=900nt_BP=350nt GTTCAAGGTAATAAGGGCTGAGACACAAGCCACAGAGCATAAAGCTCCAGTCCTTCCTCCAGGGATGAGGCAGTAAGGACTTGGACTCCT CTGTCCAGCTTTTAACAATCTAAGTTACGCCCTCTTCTGGGTCACGCTAGAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAG TGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTGACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCT GTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCCTTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGA ATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAATAAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGC ACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATAGAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCA ACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATTGATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAA TACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATCACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGC ACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAAAATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGG AAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGGACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGC >37690_37690_6_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000369416_MON2_chr12_62979094_ENST00000552738_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- >37690_37690_7_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000280379_length(transcript)=699nt_BP=391nt AAGGCTAAAGCCAAGACTCTTTATCACACTGTGGCCTTAAGATTGGATTTCTCTTCCTGTTCCTGGGAAGAATTAGAGATATAACCTAAA GGTCACTATTATTCTGAGAAAAGGGATTCTGGAGGAGGAGGGAGCAATGAGTATGTGGCAGGAGTTCAAGCCCTCTTCTGGGTCACGCTA GAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAGTGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTG ACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCTGTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCC TTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGAATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAAT AAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGCACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATA GAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCAACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATT GATTCACTTAAGAAAACTCAGCCTGAGAATGCTTGTATCAGCCTATTTGGAATACCACCCTACTTTTAA >37690_37690_7_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000280379_length(amino acids)=169AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENACISLFGIPPYF -------------------------------------------------------------- >37690_37690_8_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000393629_length(transcript)=941nt_BP=391nt AAGGCTAAAGCCAAGACTCTTTATCACACTGTGGCCTTAAGATTGGATTTCTCTTCCTGTTCCTGGGAAGAATTAGAGATATAACCTAAA GGTCACTATTATTCTGAGAAAAGGGATTCTGGAGGAGGAGGGAGCAATGAGTATGTGGCAGGAGTTCAAGCCCTCTTCTGGGTCACGCTA GAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAGTGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTG ACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCTGTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCC TTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGAATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAAT AAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGCACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATA GAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCAACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATT GATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAATACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATC ACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGCACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAA AATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGGAAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGG ACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGC >37690_37690_8_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000393629_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- >37690_37690_9_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000393630_length(transcript)=5659nt_BP=391nt AAGGCTAAAGCCAAGACTCTTTATCACACTGTGGCCTTAAGATTGGATTTCTCTTCCTGTTCCTGGGAAGAATTAGAGATATAACCTAAA GGTCACTATTATTCTGAGAAAAGGGATTCTGGAGGAGGAGGGAGCAATGAGTATGTGGCAGGAGTTCAAGCCCTCTTCTGGGTCACGCTA GAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAGTGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTG ACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCTGTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCC TTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGAATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAAT AAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGCACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATA GAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCAACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATT GATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAATACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATC ACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGCACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAA AATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGGAAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGG ACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGCCTCCTTTAAATTCTACTTACCTGAGTTCAGTAATTCATATTACAGGCTT GCACATCAACAAAGGCTCCTGAATGAACAGCAGTGTAAGGCTTTAATAAATTAAACTGATGGGAGGGATAATTAACACTACAGTATACAT GCTACCATATCTCCAGTTGGTGATTTAAAGTGAGCTTATGTACAGTTTGTGGTGTATGTGTTAATGATGTACTTTTTAAAAAGAAAGAAG AGATATTTCAATTCAGTCAGATTTATTAGTCTGGTGTTTTTGCACCCTTTTTCAAGTACAAAATCGTACTAGAATTTTATGCAAGATGGT ACTGTAACATTCCATATTATCTATAACCAGCCTTTGTTAACAAAGGGAACTGATATACTTGTGTGTATAATAAATGGTACAGTTCTGTAT AAAATAGTGCATTTATTTAAATTTTAAAAGTATTGATAATGTTAAATGCTTAAAGCTCTATTTATTATTAATACAAAATTGTTTGCTTAC ATTTTTACTTATAATTTGCCTTCATATGTGGCGGATAAGCTCACCATATGATCATGCAGTTAGCTTCATGCTTATTTTAAATGTATTATT AGTGACCATTAAACATCTGACCAGTAAGGTCATGTGAACACAGCAGCAAATAGTTTATGATTTGCTGATTTTGGAGCTTTGAAATATAGG TTCTTAATACATTGATACATATTGTAGCACTATGACTTCATCATACCTCATTTCTTTAAACAGCTCTCCAAGCTTTCACTGAAGTCTGTC TGTTTTTTATATTGGCTGTCTGGATTTTAAAGACTTTTCATATTTTATATTTCTACTGATTTTGTTTCCCCTAACAACATTTGTCACTGT CTTTGAATTATGACCCAGGCAAGATGATTTCAGATTTTCTAAAATCTTGCCTGTGAGGTTTTGTTCATATCAGTGCTTCATTTTGTAATG TCTTCTCAAGAAAAATACCTATGTTAACTCACAAGTATAAAATATGTGTGTATTATAAAACAATGAAAAGTGTATTTTTGGAGATAGTCA AGCATTTAGAAGTGCAGTGAACTTGCTGTCACGGAGTAAAATGCTAATTATGTTTCACTTTCCTAGCCTAGTGAAAAAGAAAAGTGCTCT TGAGTACAATACCTTAATTATTTCTTAAAATACTGACTTTGACCTAGCTCACTGTATTTTTTATTTAATGGATTATGGATTACAGTATTT TTCTTCTGAGTTAAATTTTCATAATTTATGTGAAGACACAAAGATGTTTAAAACAATGATTATTCATAAGAAATCATGATGGTCTCAGTA TTATTTTAGTGTATTGGAAGGTCTTTGATCTTAATAGAATTTATAAATTTCAGCTTCTCCAGAATAATCATAAAACTGCAAAAAGATATT ATAATTGAGTCATGATTGAGATACAGTTTTGAGGCTATTATAATTGTATAATTATTTAATTTGCATTATCTGTAAAATGTAGTAAGGTCT TTGAGGGGATATTTTTTATTTACATGAATTACTGAATTTCTATTTTATTATTTCACCTAAAATTAAGGTAAAATATGGCATTTCATAAGT TCTGCTTTCAGCATTTTCCTTAAAGTTGTAAAAAATCAAGCTATGTACTTATTTTCTATATTTGGGTGTGTTAAATTGAGGATTAGAAAA ATCCACATAATCACTGATAAAGCATTGAAACAGAATAACCCAAGGGTAGTGTACCGATTCAGTAACATGTTAAAAATATTGCTATGCATT TATTCAAAGGAAAATGGTCTGTTCTTGAGAAATAAAAGATCAGTTGCAATTAGGATAATTAAATAGTTAAATATGAGTCAAGTGTATGCA ATATACATTTATATGAACCAAAGCTTGCTTTATCAGGACCATGCCCTACAGTTCAAAACATAAACATAGTGAATGTGTTAATATCATATA ATAAGGTAATAAATGCCAGTCTTAGTGTGAAGCAAGTGGGTGGCCCCCTTGGTAGTATAATTGGACAGGATTTTCCTCCAGAATATTTCC TGTCACCCTCCAAGAGTCACTACAGTAATTGATTGCTGGCATGGAACACATTGCCCTTGTCTTGTTAGTATGAATTGGGTTCTCCAGTGA CTAGAAGAACTGGGGTGTGTGAAAGTATTCGATGCCAGGAGATTCAAAAAGGAAGCTCTCAAAGATAAGATCATTTTATGGCACAATTGA GTCTATAACCAGCCCTTTAAGCAGTAGTAAAAATGTCCTTTGTCATACTTACTAGAAATACTATGAGTTTTTTTTTTTTTTTTCATTTGA GACGGAGTCTCGCTCTGTCACCCAGGCTGGAATGCAGTGGCACGATCTTGGCTCACTGCAACCTCTGCTTCCCGGGTTCAAGCAGTTTCC TGCTTCAGACTTCCAAGTAGCTGGGATTACAGACATGCCACCATGCCAGGCTAATTTTTTTAATATTTTTAGTAGAGATGGGGTTTCACC ATTTTGGCCATTCTAGTCTTGAACTCCTGACCTCAGGTGATCTGCCCGCCTTGGCCTCCCAAAGTGCTGACATTACAGGCCTGAGCCACT GCGCCCAGCCAATACCATGAGTTTTAAGCCTCACATCGTCACTTGCTGTCACTGCCAGTGCCTGTTTTATTCATATTGCTGGACAACAGA CATATGCCACCAATTGTATGATTAATAAAGTCTTTTTCTGGCCATTTTGTCCATTATAAAGGAAATAAACTAATTGTTAACTTGCATAGA TTACTTCTTAGTTTCCTATGCTACCACCACTGCCAAGGGAGAAAAAAATACATCATTTTGTAATGTCTTTAGTATTTCTTTATAACTAGT GTTAAGGTTTTGTTAATTTTATTGTATACATTTGTAACATTTATTAGGAGCCTTTTAGGTTCCAAAACAAACAAAAGGCATAAAAAAGTC TAGCTTAGAACCACTTTTCACTTGCTTTCATTTTTAATTTTATTCACTTAACAGCTAACATCTTTCTTGTTTCTTGTTTTTTCCATTATA TGGTTATCGATTCAACTCTTGCTATATTCCTTAAATTTGTATGTATCATCAGAAGAAAGAGATGAACAATTTAGTGTAGATATTTTATTC TGGAGAATAATATTCAATTAAATTATTTCTACAGCAGGCCAGTAACAACTAGATTATTTGTCCTTTCTCAGTATAATTTTAAAGAGCATT TTGTTTTATTGTCACAATTTGGTACCACTAGTCCCAGGTAACCATTGGGCCAAAGGATCAGTTGAGAAACAGTTAAGGATGAATTAGCAT AAGTTATGGAACAGTGTTAGAAAACAACTCAAAAGTATATTCTTTATTAATGAGGTGGTCATTATTACATTTGTGTCAATGAAGGGCAGT GTAGTTATTTTAAAATGACTAATATTTTCTCCCCAAATACAGAATAATTCAGATGGGCAACCAAGTTTTCAAGAGACTGCTGTAGGTGAA GTCTGTCTAGCCAAGGCAGAACACTTACAGGAGTCCCTAACTGTGCCACCCTTGGAATGGGTTAGTGTACAGGCTCAGAATATTGTGGAT TACAGTTTTTCAGAGAAAACTACCACAGATGTAGACAAAAATGATCTCTGAAAGCATTGCCAGCAGCCAGGTATGTTCCTTAGATTTCCA CTTAGGTTTGGCATTTTGGCAGATAAGCTAATCTTGTATAAAGCATCACATTTTACTATGCTTAGTGTTCCTGGGTTGTATTTATCTACA TTATTAGAGGGAATTTTTATTTTAAAAAAATTGTCATTCATGAGAAGAATGGGAGTTCATGCCACATAGTATTTTACCAATTTATATAAA GTGGGAAAAGTCTTTAATACTTCATGATCACTTGAATTAAAGTTTTTGTATCTCTGGAAAGTAGAATAGTGCTTTCATTTGAATGAAAAG TGTTTATAGATTCAGAAAGAGAGATGATATCTTTGTATCTTGATTTATATACAGACCATTTCAGAGGAAGTTAAATGTCTTACAAATCCA ATACTTTCTAATGCTCTAACAGTGTTGGCTATTTAAAAGAACATGTGGCAAGTTCTATATGAATATTCTTGGTCATCTCGACTAATTCTG AGGCAATGATGGACAGAGATGCTACTTCTTATTTAACTCTAGGCATGTTGACTTTTCAAAGCGGTTTCCTTATTTCTAAACAGAGATGAT GATCAATGAGTTACTAATTCTTTAGAGGAAAAAATGCATAATTTGAGTGTGGAGTTGATTTTAATGACAGGGTAATTCAAGTTGTTTGAT AAATTTATTACTATATTGTAAGAGAGATCTTTGACCATTTTTCTTCCTTTTTCTTGGACATCACTTTCTTCCCTCCCCTTCTCTCTTTTA TGTTTTTATCCTTGTTAAATTTTATGTTTACGTTACCATCTTTCTTATACTTTCCCCTGATTTTTCTCTTTTAATTCCTCTTTCATTCTC TGCCTCTTCTCTTTCAGCTCTTTCTCTAATTGTGCCTATTCCTTGTTCATAAGAAGTGGAGCTGTTAGTGGTAGAACCACTGCTCATGGT TCTACCACTACAAAGTGGAAAGTAGAAATACTTTGCACTTTGGCCACTGTTGCGTTTTTGCCAAGGTAAAGTTCCCCTGCCATTTTGAAA TAGCTGAACAAGTTAAAGTAATATGTTCCAAAAACTGGAAGTGCCATAAAAAACTAAAAATAAAAAAAAATTGTGACTA >37690_37690_9_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000393630_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- >37690_37690_10_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000393632_length(transcript)=3686nt_BP=391nt AAGGCTAAAGCCAAGACTCTTTATCACACTGTGGCCTTAAGATTGGATTTCTCTTCCTGTTCCTGGGAAGAATTAGAGATATAACCTAAA GGTCACTATTATTCTGAGAAAAGGGATTCTGGAGGAGGAGGGAGCAATGAGTATGTGGCAGGAGTTCAAGCCCTCTTCTGGGTCACGCTA GAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAGTGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTG ACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCTGTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCC TTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGAATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAAT AAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGCACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATA GAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCAACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATT GATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAATACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATC ACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGCACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAA AATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGGAAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGG ACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGCCTCCTTTAAATTCTACTTACCTGAGTTCAGTAATTCATATTACAGGCTT GCACATCAACAAAGGCTCCTGAATGAACAGCAGTGTAAGGCTTTAATAAATTAAACTGATGGGAGGGATAATTAACACTACAGTATACAT GCTACCATATCTCCAGTTGGTGATTTAAAGTGAGCTTATGTACAGTTTGTGGTGTATGTGTTAATGATGTACTTTTTAAAAAGAAAGAAG AGATATTTCAATTCAGTCAGATTTATTAGTCTGGTGTTTTTGCACCCTTTTTCAAGTACAAAATCGTACTAGAATTTTATGCAAGATGGT ACTGTAACATTCCATATTATCTATAACCAGCCTTTGTTAACAAAGGGAACTGATATACTTGTGTGTATAATAAATGGTACAGTTCTGTAT AAAATAGTGCATTTATTTAAATTTTAAAAGTATTGATAATGTTAAATGCTTAAAGCTCTATTTATTATTAATACAAAATTGTTTGCTTAC ATTTTTACTTATAATTTGCCTTCATATGTGGCGGATAAGCTCACCATATGATCATGCAGTTAGCTTCATGCTTATTTTAAATGTATTATT AGTGACCATTAAACATCTGACCAGTAAGGTCATGTGAACACAGCAGCAAATAGTTTATGATTTGCTGATTTTGGAGCTTTGAAATATAGG TTCTTAATACATTGATACATATTGTAGCACTATGACTTCATCATACCTCATTTCTTTAAACAGCTCTCCAAGCTTTCACTGAAGTCTGTC TGTTTTTTATATTGGCTGTCTGGATTTTAAAGACTTTTCATATTTTATATTTCTACTGATTTTGTTTCCCCTAACAACATTTGTCACTGT CTTTGAATTATGACCCAGGCAAGATGATTTCAGATTTTCTAAAATCTTGCCTGTGAGGTTTTGTTCATATCAGTGCTTCATTTTGTAATG TCTTCTCAAGAAAAATACCTATGTTAACTCACAAGTATAAAATATGTGTGTATTATAAAACAATGAAAAGTGTATTTTTGGAGATAGTCA AGCATTTAGAAGTGCAGTGAACTTGCTGTCACGGAGTAAAATGCTAATTATGTTTCACTTTCCTAGCCTAGTGAAAAAGAAAAGTGCTCT TGAGTACAATACCTTAATTATTTCTTAAAATACTGACTTTGACCTAGCTCACTGTATTTTTTATTTAATGGATTATGGATTACAGTATTT TTCTTCTGAGTTAAATTTTCATAATTTATGTGAAGACACAAAGATGTTTAAAACAATGATTATTCATAAGAAATCATGATGGTCTCAGTA TTATTTTAGTGTATTGGAAGGTCTTTGATCTTAATAGAATTTATAAATTTCAGCTTCTCCAGAATAATCATAAAACTGCAAAAAGATATT ATAATTGAGTCATGATTGAGATACAGTTTTGAGGCTATTATAATTGTATAATTATTTAATTTGCATTATCTGTAAAATGTAGTAAGGTCT TTGAGGGGATATTTTTTATTTACATGAATTACTGAATTTCTATTTTATTATTTCACCTAAAATTAAGGTAAAATATGGCATTTCATAAGT TCTGCTTTCAGCATTTTCCTTAAAGTTGTAAAAAATCAAGCTATGTACTTATTTTCTATATTTGGGTGTGTTAAATTGAGGATTAGAAAA ATCCACATAATCACTGATAAAGCATTGAAACAGAATAACCCAAGGGTAGTGTACCGATTCAGTAACATGTTAAAAATATTGCTATGCATT TATTCAAAGGAAAATGGTCTGTTCTTGAGAAATAAAAGATCAGTTGCAATTAGGATAATTAAATAGTTAAATATGAGTCAAGTGTATGCA ATATACATTTATATGAACCAAAGCTTGCTTTATCAGGACCATGCCCTACAGTTCAAAACATAAACATAGTGAATGTGTTAATATCATATA ATAAGGTAATAAATGCCAGTCTTAGTGTGAAGCAAGTGGGTGGCCCCCTTGGTAGTATAATTGGACAGGATTTTCCTCCAGAATATTTCC TGTCACCCTCCAAGAGTCACTACAGTAATTGATTGCTGGCATGGAACACATTGCCCTTGTCTTGTTAGTATGAATTGGGTTCTCCAGTGA CTAGAAGAACTGGGGTGTGTGAAAGTATTCGATGCCAGGAGATTCAAAAAGGAAGCTCTCAAAGATAAGATCATTTTATGGCACAATTGA GTCTATAACCAGCCCTTTAAGCAGTAGTAAAAATGTCCTTTGTCATACTTACTAGAAATACTATGAGTTTTTTTTTTTTTTTTCATTTGA GACGGAGTCTCGCTCTGTCACCCAGGCTGGAATGCAGTGGCACGATCTTGGCTCACTGCAACCTCTGCTTCCCGGGTTCAAGCAGTTTCC TGCTTCAGACTTCCAAGTAGCTGGGATTACAGACATGCCACCATGCCAGGCTAATTTTTTTAATATTTTTAGTAGAGATGGGGTTTCACC ATTTTGGCCATTCTAGTCTTGAACTCCTGACCTCAGGTGATCTGCCCGCCTTGGCCTCCCAAAGTGCTGACATTACAGGCCTGAGCCACT GCGCCCAGCCAATACCATGAGTTTTAAGCCTCACATCGTCACTTGCTGTCACTGCCAGTGCCTGTTTTATTCATATTGCTGGACAACAGA CATATGCCACCAATTGTATGATTAATAAAGTCTTTTTCTGGCCATTTTGTCCATTATAAAGGAAATAAACTAATTGTTAACTTGCA >37690_37690_10_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000393632_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- >37690_37690_11_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000546600_length(transcript)=1415nt_BP=391nt AAGGCTAAAGCCAAGACTCTTTATCACACTGTGGCCTTAAGATTGGATTTCTCTTCCTGTTCCTGGGAAGAATTAGAGATATAACCTAAA GGTCACTATTATTCTGAGAAAAGGGATTCTGGAGGAGGAGGGAGCAATGAGTATGTGGCAGGAGTTCAAGCCCTCTTCTGGGTCACGCTA GAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAGTGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTG ACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCTGTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCC TTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGAATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAAT AAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGCACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATA GAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCAACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATT GATTCACTTAAGAAAACTCAGCCTGAGAATGCTTGTATCAGCCTATTTGGAATACCACCCTACTTTTAAACCTTGTTTTTAATCTCTTAA AGTTGATGGAAATACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATCACCTGTTCTTCTTCAGAAGTCTGTTCTGC ACTTAAAGAGGCACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAAAATGGAGAATCTTGACCGGCTACAATATA TTTGAAAGCAGGAAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGGACATTTCTTACTGCAGATAATTCTTGGCA GCTGTTGTTGGCCTCCTTTAAATTCTACTTACCTGAGTTCAGTAATTCATATTACAGGCTTGCACATCAACAAAGGCTCCTGAATGAACA GCAGTGTAAGGCTTTAATAAATTAAACTGATGGGAGGGATAATTAACACTACAGTATACATGCTACCATATCTCCAGTTGGTGATTTAAA GTGAGCTTATGTACAGTTTGTGGTGTATGTGTTAATGATGTACTTTTTAAAAAGAAAGAAGAGATATTTCAATTCAGTCAGATTTATTAG TCTGGTGTTTTTGCACCCTTTTTCAAGTACAAAATCGTACTAGAATTTTATGCAAGATGGTACTGTAACATTCCATATTATCTATAACCA GCCTTTGTTAACAAAGGGAACTGATATACTTGTGTGTATAATAAATGGTACAGTTCTGTATAAAA >37690_37690_11_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000546600_length(amino acids)=169AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENACISLFGIPPYF -------------------------------------------------------------- >37690_37690_12_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000552738_length(transcript)=941nt_BP=391nt AAGGCTAAAGCCAAGACTCTTTATCACACTGTGGCCTTAAGATTGGATTTCTCTTCCTGTTCCTGGGAAGAATTAGAGATATAACCTAAA GGTCACTATTATTCTGAGAAAAGGGATTCTGGAGGAGGAGGGAGCAATGAGTATGTGGCAGGAGTTCAAGCCCTCTTCTGGGTCACGCTA GAATCAGATCTGCTCTCCAGCATCTTCTGTTTCCTGGCAAGTGTTTCCTGCTACTTTGGATTGGCCACGATGGGCTGGAGCTGCCTTGTG ACAGGAGCAGGAGGGCTTCTGGGTCAGAGGATCGTCCGCCTGTTGGTGGAAGAGAAGGAACTGAAGGAGATCAGGGCCTTGGACAAGGCC TTCAGACCAGAATTGAGAGAGGAATTTTCTATGAGAGAGGAATTTTCTAAAATGTGTTTTGAAACATTACTCCAGTTTTCCTTCAGTAAT AAAGTCACAACACCTCAAGAAGGCTACATCTCACGAATGGCACTCTCAGTGCTTTTAAAGAGGTCCCAAGATGTACTACATCGCTATATA GAGGATGAAAGATTAAGTGGTAAATGCCCTCTTCCAAGGCAACAAGTAACAGAAATTATATTTGTTTTAAAAGCAGTCAGTACTCTTATT GATTCACTTAAGAAAACTCAGCCTGAGAATGTTGATGGAAATACCTGGGCACAAGTAATTGCCTTATACCCAACTTTAGTAGAATGCATC ACCTGTTCTTCTTCAGAAGTCTGTTCTGCACTTAAAGAGGCACTAGTTCCTTTTAAGGATTTCATGCAGCCACCAGCATCCAGAGTTCAA AATGGAGAATCTTGACCGGCTACAATATATTTGAAAGCAGGAAGATAGTCTAAAAAATGTTTGCTCCTAATTGAGTCTTCTGTGAGAAGG ACATTTCTTACTGCAGATAATTCTTGGCAGCTGTTGTTGGC >37690_37690_12_HSD3B2-MON2_HSD3B2_chr1_119958184_ENST00000543831_MON2_chr12_62979094_ENST00000552738_length(amino acids)=211AA_BP=68 MLSSIFCFLASVSCYFGLATMGWSCLVTGAGGLLGQRIVRLLVEEKELKEIRALDKAFRPELREEFSMREEFSKMCFETLLQFSFSNKVT TPQEGYISRMALSVLLKRSQDVLHRYIEDERLSGKCPLPRQQVTEIIFVLKAVSTLIDSLKKTQPENVDGNTWAQVIALYPTLVECITCS SSEVCSALKEALVPFKDFMQPPASRVQNGES -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for HSD3B2-MON2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for HSD3B2-MON2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for HSD3B2-MON2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | HSD3B2 | C0342471 | 3 beta-Hydroxysteroid dehydrogenase deficiency | 18 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | HSD3B2 | C0001627 | Congenital adrenal hyperplasia | 1 | CTD_human |
| Hgene | HSD3B2 | C0010417 | Cryptorchidism | 1 | CTD_human |
| Hgene | HSD3B2 | C0032460 | Polycystic Ovary Syndrome | 1 | CTD_human |
| Hgene | HSD3B2 | C0033578 | Prostatic Neoplasms | 1 | CTD_human |
| Hgene | HSD3B2 | C0376358 | Malignant neoplasm of prostate | 1 | CTD_human |
| Hgene | HSD3B2 | C0431663 | Bilateral Cryptorchidism | 1 | CTD_human |
| Hgene | HSD3B2 | C0431664 | Unilateral Cryptorchidism | 1 | CTD_human |
| Hgene | HSD3B2 | C0848558 | Hypospadias | 1 | CTD_human |
| Hgene | HSD3B2 | C1136382 | Sclerocystic Ovaries | 1 | CTD_human |
| Hgene | HSD3B2 | C1456784 | Paranoia | 1 | CTD_human |
| Hgene | HSD3B2 | C1563730 | Abdominal Cryptorchidism | 1 | CTD_human |
| Hgene | HSD3B2 | C1563731 | Inguinal Cryptorchidism | 1 | CTD_human |
| Hgene | HSD3B2 | C2239176 | Liver carcinoma | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies