
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ADC-ISOC1 (FusionGDB2 ID:HG339896TG51015) |
Fusion Gene Summary for ADC-ISOC1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ADC-ISOC1 | Fusion gene ID: hg339896tg51015 | Hgene | Tgene | Gene symbol | ADC | ISOC1 | Gene ID | 339896 | 51015 |
| Gene name | glutamate decarboxylase like 1 | isochorismatase domain containing 1 | |
| Synonyms | ADC|CSADC|HuADC|HuCSADC | CGI-111 | |
| Cytomap | ('ADC')('ISOC1') 3p24.1-p23 | 5q23.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | acidic amino acid decarboxylase GADL1aspartate 1-decarboxylasecysteine sulfinic acid decarboxylaseglutamate decarboxylase-like protein 1 | isochorismatase domain-containing protein 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000484656, ENST00000294517, ENST00000358680, ENST00000373440, ENST00000373441, ENST00000373443, ENST00000398167, | ||
| Fusion gene scores | * DoF score | 2 X 1 X 2=4 | 2 X 2 X 2=8 |
| # samples | 2 | 2 | |
| ** MAII score | log2(2/4*10)=2.32192809488736 | log2(2/8*10)=1.32192809488736 | |
| Context | PubMed: ADC [Title/Abstract] AND ISOC1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ADC(33563780)-ISOC1(128440648), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ADC-ISOC1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ADC-ISOC1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ADC (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ISOC1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-CN-4735 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
Top |
Fusion Gene ORF analysis for ADC-ISOC1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000484656 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
| In-frame | ENST00000294517 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
| In-frame | ENST00000358680 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
| In-frame | ENST00000373440 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
| In-frame | ENST00000373441 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
| In-frame | ENST00000373443 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
| In-frame | ENST00000398167 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000358680 | ADC | chr1 | 33563780 | + | ENST00000173527 | ISOC1 | chr5 | 128440648 | + | 2757 | 1142 | 542 | 1729 | 395 |
| ENST00000294517 | ADC | chr1 | 33563780 | + | ENST00000173527 | ISOC1 | chr5 | 128440648 | + | 3231 | 1616 | 542 | 2203 | 553 |
| ENST00000398167 | ADC | chr1 | 33563780 | + | ENST00000173527 | ISOC1 | chr5 | 128440648 | + | 3022 | 1407 | 243 | 1994 | 583 |
| ENST00000373443 | ADC | chr1 | 33563780 | + | ENST00000173527 | ISOC1 | chr5 | 128440648 | + | 2962 | 1347 | 243 | 1934 | 563 |
| ENST00000373440 | ADC | chr1 | 33563780 | + | ENST00000173527 | ISOC1 | chr5 | 128440648 | + | 2170 | 555 | 0 | 1142 | 380 |
| ENST00000373441 | ADC | chr1 | 33563780 | + | ENST00000173527 | ISOC1 | chr5 | 128440648 | + | 2704 | 1089 | 0 | 1676 | 558 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000358680 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.000566032 | 0.99943393 |
| ENST00000294517 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.001327307 | 0.9986727 |
| ENST00000398167 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.000983544 | 0.9990164 |
| ENST00000373443 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.001119644 | 0.9988803 |
| ENST00000373440 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.000296589 | 0.99970335 |
| ENST00000373441 | ENST00000173527 | ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.000603882 | 0.9993961 |
Top |
Fusion Genomic Features for ADC-ISOC1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.002513655 | 0.99748635 |
| ADC | chr1 | 33563780 | + | ISOC1 | chr5 | 128440648 | + | 0.002513655 | 0.99748635 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
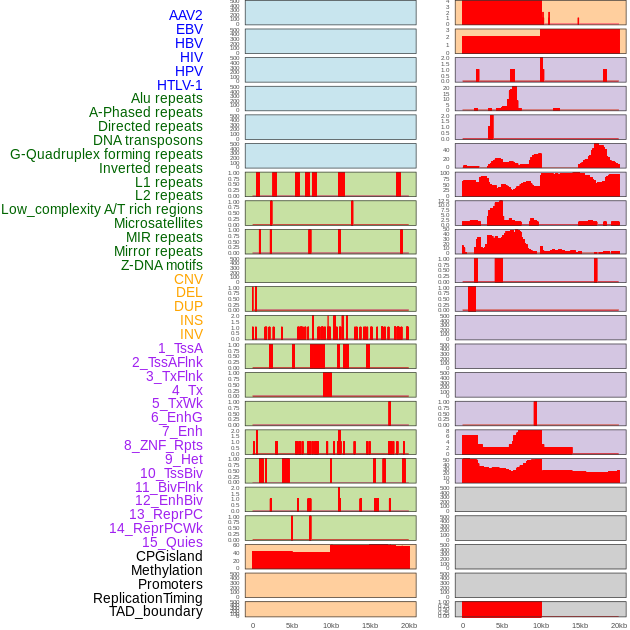 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
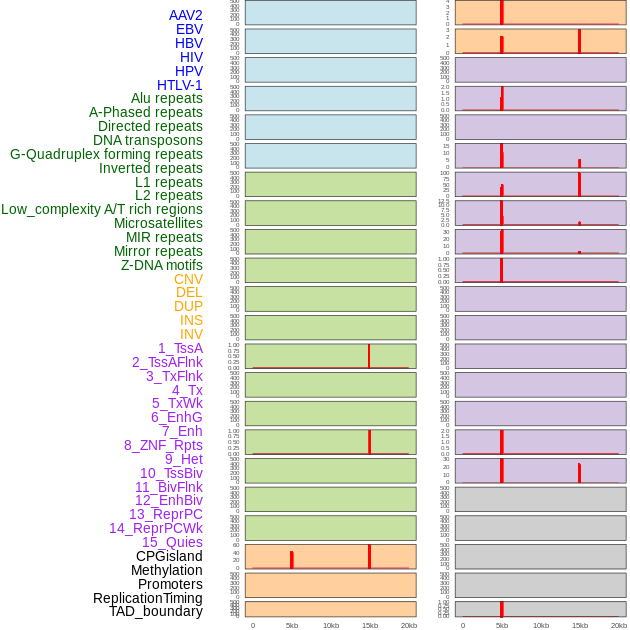 |
Top |
Fusion Protein Features for ADC-ISOC1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:33563780/chr5:128440648) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ADC | chr1:33563780 | chr5:128440648 | ENST00000294517 | + | 10 | 12 | 117_140 | 343 | 461.0 | Region | Necessary for polyamine uptake stimulation |
| Hgene | ADC | chr1:33563780 | chr5:128440648 | ENST00000358680 | + | 7 | 8 | 117_140 | 185 | 205.0 | Region | Necessary for polyamine uptake stimulation |
| Hgene | ADC | chr1:33563780 | chr5:128440648 | ENST00000373440 | + | 4 | 5 | 117_140 | 185 | 205.0 | Region | Necessary for polyamine uptake stimulation |
| Hgene | ADC | chr1:33563780 | chr5:128440648 | ENST00000373441 | + | 7 | 9 | 117_140 | 363 | 481.0 | Region | Necessary for polyamine uptake stimulation |
| Hgene | ADC | chr1:33563780 | chr5:128440648 | ENST00000373443 | + | 9 | 11 | 117_140 | 343 | 461.0 | Region | Necessary for polyamine uptake stimulation |
| Hgene | ADC | chr1:33563780 | chr5:128440648 | ENST00000398167 | + | 9 | 11 | 117_140 | 363 | 481.0 | Region | Necessary for polyamine uptake stimulation |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for ADC-ISOC1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >2189_2189_1_ADC-ISOC1_ADC_chr1_33563780_ENST00000294517_ISOC1_chr5_128440648_ENST00000173527_length(transcript)=3231nt_BP=1616nt TGGGCGGGGTTATATAAGCCAGCGGCGGGCGGAAGGCGGGGCGTGGGGGTCTGTGGCTGCTGGGCTGGCGGGGCGCAGGCCGCGGGACCC GAGCCCGGGGAAGCGAGAGAGCGGAGGCGCCGAGGATCCGATTCACTCCCTGGGGAGACCTATGGGCCGAAGCCGTGTAAATGCGTTTTA AGCAGAGGCCTCGGCTCCGCAACTGCCACTCCTCCTCGGGGTGTTGCACAAGTTTCGAGGTCACCGGCGACCCCCCCTAGCAGCGCGCCT GGCTCTGGCCCCCGCGAAGGAGGACGGAGTTTGGAGCTTGCGGCCCCCACCCACCGCGTGGCGTCCCCAGGCACGCCTAGAATTCTAGCA CCTCAGGATCAGTCCAGCCCCCATTTACAATTGGGGAAACTGCGGCTCCGAAAGGGTCAGAGGGTACCCGAGGTCAAGCAGTAGAGAGCG GACTCGAACTTAAGCTCTTGCTCTTAGGCTGAGACGCCTTGATGTGGCCACCGGCTACCCTCTAGTGTGTTGCATACTTTCTAAGGCGGC GGCTGCAGCAGCGGCTCCATCCAGCCCGTCAGCTCCTCCTGCAAGGCATGGCTGGCTACCTGAGTGAATCGGACTTTGTGATGGTGGAGG AGGGCTTCAGTACCCGAGACCTGCTGAAGGAACTCACTCTGGGGGCCTCACAGGCCACCACGGACGAGGTAGCTGCCTTCTTCGTGGCTG ACCTGGGTGCCATAGTGAGGAAGCACTTTTGCTTTCTGAAGTGCCTGCCACGAGTCCGGCCCTTTTATGCTGTCAAGTGCAACAGCAGCC CAGGTGTGCTGAAGGTTCTGGCCCAGCTGGGGCTGGGCTTTAGCTGTGCCAACAAGGCAGAGATGGAGTTGGTCCAGCATATTGGAATCC CTGCCAGTAAGATCATCTGCGCCAACCCCTGTAAGCAAATTGCACAGATCAAATATGCTGCCAAGCATGGGATCCAGCTGCTGAGCTTTG ACAATGAGATGGAGCTGGCAAAGGTGGTAAAGAGCCACCCCAGTGCCAAGATGGTTCTGTGCATTGCTACCGATGACTCCCACTCCCTGA GCTGCCTGAGCCTAAAGTTTGGAGTGTCACTGAAATCCTGCAGACACCTGCTTGAAAATGCGAAGAAGCACCATGTGGAGGTGGTGGGTG TGAGTTTTCACATTGGCAGTGGCTGTCCTGACCCTCAGGCCTATGCTCAGTCCATCGCAGACGCCCGGCTCGTGTTTGAAATGGGCACCG AGCTGGGTCACAAGATGCACGTTCTGGACCTTGGTGGTGGCTTCCCTGGCACAGAAGGGGCCAAAGTGAGATTTGAAGAGATTGCTTCCG TGATCAACTCAGCCTTGGACCTGTACTTCCCAGAGGGCTGTGGCGTGGACATCTTTGCTGAGCTGGGGCGCTACTACGTGACCTCGGCCT TCACTGTGGCAGTCAGCATCATTGCCAAGAAGGAGGTTCTGCTAGACCAGCCTGGCAGGGAGGAGGAAAATGGTTCCACCTCCAAGACCA TCGTGTACCACCTTGATGAGGGCGTGTATGGGATCTTCAACTCAGTCCTGTTTGACAACATCTGCCCTACCCCCATCCTGCAGAAGCTCA CTACCCTGGGAAATCTTACACCTTCAAGCACTGTGTTTTTCTGCTGTGATATGCAGGAAAGGTTCAGACCAGCCATCAAGTATTTTGGGG ATATTATTAGCGTGGGACAGAGATTGTTGCAAGGGGCCCGGATTTTAGGAATTCCTGTTATTGTAACAGAACAATACCCTAAAGGTCTTG GGAGCACGGTTCAAGAAATTGATTTAACAGGTGTAAAACTGGTACTTCCAAAGACCAAGTTTTCAATGGTATTACCAGAAGTAGAAGCGG CATTAGCAGAGATTCCCGGAGTCAGGAGTGTTGTATTATTTGGAGTAGAAACTCATGTGTGCATCCAACAAACTGCCCTGGAGCTAGTTG GCCGAGGAGTCGAGGTTCACATTGTTGCTGATGCCACCTCATCAAGAAGCATGATGGACAGGATGTTTGCCCTCGAGCGTCTCGCTCGAA CCGGGATCATAGTGACCACGAGTGAGGCTGTTCTGCTTCAGCTGGTAGCTGATAAGGACCATCCAAAATTCAAGGAAATTCAGAATCTAA TTAAGGCGAGTGCTCCAGAGTCGGGTCTGCTTTCCAAAGTATAGGACATTTGAAGAACTGGTATGCTACTCACTGGTGAAGGACAGTCAG GTGAAGGACTGTAAGCCCACACAAGCTCTTCTTATCTCTACTAGAATTAAAATGTTAAGTCAAAAACGGCTCCTTTTTTGCGCCTCCTAG TGAAACTTAACCAGCTAGACCATTTGAGTACCAGCATTTAGTTACAAACGTCAAAGGCTTCCGGTGCTGCTTACCTTCCTTTTTTGTTAA TGTGCTTTTATTTATTAAAAAAAATTACAATGAAGATGCCTGTTTTGTCTCTACTGTGTACTCTGATCGTATCTTTCCAAAGTGCAGACT CTTGTGAAGTTTTCTTAAATTGTTCACTTTAAAGAAAATGACGTACCAACAATGATTTGGCTTTTATATTACTGTAAGATGTTATAATGT TAATGTGGATGTAGTGCTTTTACTTTACAGATTGATTGGAATAAGATTATTGCATATGAATTTACCCACAGGACTCTGAATCATGTTACC CACTCCCCTCACAATGTTGTCCACTTAGTGAGTTGCATTGATCTATCCGTACCAAATGATGTTGAATAATTACATATCTTTCTTGACTAT ACTGATTTCTTATTTTGGTCACTATTACTAAATCTCTGTTAATATTCTCTCTTTTAACTGAAAAGGGATGGGATAGAAGGGTTTGCAATG CCATATTATTGGTGGAGGGCTGTTTTAACATCTTTGAAGTATGGCTTGCTGAATATCTTTACCAACATCTTGAATATATATTCTAGTGTC CACAAGATTTAGCAAAAAGATAAAGCTTGGGTGGAATATCATTTTAAAATGTTCATGTTCTGTTCTATATTTTCTTCACCTACTCTCCAA ATATTGTAATGCAAAAAGTCTCAGTAATGATTTGGTAGTATTAATTTTGTGGTCATTGTTTCTCTTCGATAAATTTATTTTCATTAAATA CTTGTTAGAGGGTTTTGAAATGTTTTTCAAATATGTGAAATGTGAAACTGCTGTCTTTTATATTAAAGTAATTAAAGAAAA >2189_2189_1_ADC-ISOC1_ADC_chr1_33563780_ENST00000294517_ISOC1_chr5_128440648_ENST00000173527_length(amino acids)=553AA_BP=358 MQQRLHPARQLLLQGMAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSP GVLKVLAQLGLGFSCANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKMVLCIATDDSHSLS CLSLKFGVSLKSCRHLLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGAKVRFEEIASV INSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPTPILQKLT TLGNLTPSSTVFFCCDMQERFRPAIKYFGDIISVGQRLLQGARILGIPVIVTEQYPKGLGSTVQEIDLTGVKLVLPKTKFSMVLPEVEAA LAEIPGVRSVVLFGVETHVCIQQTALELVGRGVEVHIVADATSSRSMMDRMFALERLARTGIIVTTSEAVLLQLVADKDHPKFKEIQNLI KASAPESGLLSKV -------------------------------------------------------------- >2189_2189_2_ADC-ISOC1_ADC_chr1_33563780_ENST00000358680_ISOC1_chr5_128440648_ENST00000173527_length(transcript)=2757nt_BP=1142nt TGGGCGGGGTTATATAAGCCAGCGGCGGGCGGAAGGCGGGGCGTGGGGGTCTGTGGCTGCTGGGCTGGCGGGGCGCAGGCCGCGGGACCC GAGCCCGGGGAAGCGAGAGAGCGGAGGCGCCGAGGATCCGATTCACTCCCTGGGGAGACCTATGGGCCGAAGCCGTGTAAATGCGTTTTA AGCAGAGGCCTCGGCTCCGCAACTGCCACTCCTCCTCGGGGTGTTGCACAAGTTTCGAGGTCACCGGCGACCCCCCCTAGCAGCGCGCCT GGCTCTGGCCCCCGCGAAGGAGGACGGAGTTTGGAGCTTGCGGCCCCCACCCACCGCGTGGCGTCCCCAGGCACGCCTAGAATTCTAGCA CCTCAGGATCAGTCCAGCCCCCATTTACAATTGGGGAAACTGCGGCTCCGAAAGGGTCAGAGGGTACCCGAGGTCAAGCAGTAGAGAGCG GACTCGAACTTAAGCTCTTGCTCTTAGGCTGAGACGCCTTGATGTGGCCACCGGCTACCCTCTAGTGTGTTGCATACTTTCTAAGGCGGC GGCTGCAGCAGCGGCTCCATCCAGCCCGTCAGCTCCTCCTGCAAGGCATGGCTGGCTACCTGAGTGAATCGGACTTTGTGATGGTGGAGG AGGGCTTCAGTACCCGAGACCTGCTGAAGGAACTCACTCTGGGGGCCTCACAGGCCACCACGGACGAGGTAGCTGCCTTCTTCGTGGCTG ACCTGGGTGCCATAGTGAGGAAGCACTTTTGCTTTCTGAAGTGCCTGCCACGAGTCCGGCCCTTTTATGCTGTCAAGTGCAACAGCAGCC CAGGTGTGCTGAAGGTTCTGGCCCAGCTGGGGCTGGGCTTTAGCTGTGCCAACAAGATTGCTTCCGTGATCAACTCAGCCTTGGACCTGT ACTTCCCAGAGGGCTGTGGCGTGGACATCTTTGCTGAGCTGGGGCGCTACTACGTGACCTCGGCCTTCACTGTGGCAGTCAGCATCATTG CCAAGAAGGAGGTTCTGCTAGACCAGCCTGGCAGGGAGGAGGAAAATGGTTCCACCTCCAAGACCATCGTGTACCACCTTGATGAGGGCG TGTATGGGATCTTCAACTCAGTCCTGTTTGACAACATCTGCCCTACCCCCATCCTGCAGAAGCTCACTACCCTGGGAAATCTTACACCTT CAAGCACTGTGTTTTTCTGCTGTGATATGCAGGAAAGGTTCAGACCAGCCATCAAGTATTTTGGGGATATTATTAGCGTGGGACAGAGAT TGTTGCAAGGGGCCCGGATTTTAGGAATTCCTGTTATTGTAACAGAACAATACCCTAAAGGTCTTGGGAGCACGGTTCAAGAAATTGATT TAACAGGTGTAAAACTGGTACTTCCAAAGACCAAGTTTTCAATGGTATTACCAGAAGTAGAAGCGGCATTAGCAGAGATTCCCGGAGTCA GGAGTGTTGTATTATTTGGAGTAGAAACTCATGTGTGCATCCAACAAACTGCCCTGGAGCTAGTTGGCCGAGGAGTCGAGGTTCACATTG TTGCTGATGCCACCTCATCAAGAAGCATGATGGACAGGATGTTTGCCCTCGAGCGTCTCGCTCGAACCGGGATCATAGTGACCACGAGTG AGGCTGTTCTGCTTCAGCTGGTAGCTGATAAGGACCATCCAAAATTCAAGGAAATTCAGAATCTAATTAAGGCGAGTGCTCCAGAGTCGG GTCTGCTTTCCAAAGTATAGGACATTTGAAGAACTGGTATGCTACTCACTGGTGAAGGACAGTCAGGTGAAGGACTGTAAGCCCACACAA GCTCTTCTTATCTCTACTAGAATTAAAATGTTAAGTCAAAAACGGCTCCTTTTTTGCGCCTCCTAGTGAAACTTAACCAGCTAGACCATT TGAGTACCAGCATTTAGTTACAAACGTCAAAGGCTTCCGGTGCTGCTTACCTTCCTTTTTTGTTAATGTGCTTTTATTTATTAAAAAAAA TTACAATGAAGATGCCTGTTTTGTCTCTACTGTGTACTCTGATCGTATCTTTCCAAAGTGCAGACTCTTGTGAAGTTTTCTTAAATTGTT CACTTTAAAGAAAATGACGTACCAACAATGATTTGGCTTTTATATTACTGTAAGATGTTATAATGTTAATGTGGATGTAGTGCTTTTACT TTACAGATTGATTGGAATAAGATTATTGCATATGAATTTACCCACAGGACTCTGAATCATGTTACCCACTCCCCTCACAATGTTGTCCAC TTAGTGAGTTGCATTGATCTATCCGTACCAAATGATGTTGAATAATTACATATCTTTCTTGACTATACTGATTTCTTATTTTGGTCACTA TTACTAAATCTCTGTTAATATTCTCTCTTTTAACTGAAAAGGGATGGGATAGAAGGGTTTGCAATGCCATATTATTGGTGGAGGGCTGTT TTAACATCTTTGAAGTATGGCTTGCTGAATATCTTTACCAACATCTTGAATATATATTCTAGTGTCCACAAGATTTAGCAAAAAGATAAA GCTTGGGTGGAATATCATTTTAAAATGTTCATGTTCTGTTCTATATTTTCTTCACCTACTCTCCAAATATTGTAATGCAAAAAGTCTCAG TAATGATTTGGTAGTATTAATTTTGTGGTCATTGTTTCTCTTCGATAAATTTATTTTCATTAAATACTTGTTAGAGGGTTTTGAAATGTT TTTCAAATATGTGAAATGTGAAACTGCTGTCTTTTATATTAAAGTAATTAAAGAAAA >2189_2189_2_ADC-ISOC1_ADC_chr1_33563780_ENST00000358680_ISOC1_chr5_128440648_ENST00000173527_length(amino acids)=395AA_BP=200 MQQRLHPARQLLLQGMAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSP GVLKVLAQLGLGFSCANKIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGV YGIFNSVLFDNICPTPILQKLTTLGNLTPSSTVFFCCDMQERFRPAIKYFGDIISVGQRLLQGARILGIPVIVTEQYPKGLGSTVQEIDL TGVKLVLPKTKFSMVLPEVEAALAEIPGVRSVVLFGVETHVCIQQTALELVGRGVEVHIVADATSSRSMMDRMFALERLARTGIIVTTSE AVLLQLVADKDHPKFKEIQNLIKASAPESGLLSKV -------------------------------------------------------------- >2189_2189_3_ADC-ISOC1_ADC_chr1_33563780_ENST00000373440_ISOC1_chr5_128440648_ENST00000173527_length(transcript)=2170nt_BP=555nt ATGGCTGGCTACCTGAGTGAATCGGACTTTGTGATGGTGGAGGAGGGCTTCAGTACCCGAGACCTGCTGAAGGAACTCACTCTGGGGGCC TCACAGGCCACCACGGACGAGGTAGCTGCCTTCTTCGTGGCTGACCTGGGTGCCATAGTGAGGAAGCACTTTTGCTTTCTGAAGTGCCTG CCACGAGTCCGGCCCTTTTATGCTGTCAAGTGCAACAGCAGCCCAGGTGTGCTGAAGGTTCTGGCCCAGCTGGGGCTGGGCTTTAGCTGT GCCAACAAGATTGCTTCCGTGATCAACTCAGCCTTGGACCTGTACTTCCCAGAGGGCTGTGGCGTGGACATCTTTGCTGAGCTGGGGCGC TACTACGTGACCTCGGCCTTCACTGTGGCAGTCAGCATCATTGCCAAGAAGGAGGTTCTGCTAGACCAGCCTGGCAGGGAGGAGGAAAAT GGTTCCACCTCCAAGACCATCGTGTACCACCTTGATGAGGGCGTGTATGGGATCTTCAACTCAGTCCTGTTTGACAACATCTGCCCTACC CCCATCCTGCAGAAGCTCACTACCCTGGGAAATCTTACACCTTCAAGCACTGTGTTTTTCTGCTGTGATATGCAGGAAAGGTTCAGACCA GCCATCAAGTATTTTGGGGATATTATTAGCGTGGGACAGAGATTGTTGCAAGGGGCCCGGATTTTAGGAATTCCTGTTATTGTAACAGAA CAATACCCTAAAGGTCTTGGGAGCACGGTTCAAGAAATTGATTTAACAGGTGTAAAACTGGTACTTCCAAAGACCAAGTTTTCAATGGTA TTACCAGAAGTAGAAGCGGCATTAGCAGAGATTCCCGGAGTCAGGAGTGTTGTATTATTTGGAGTAGAAACTCATGTGTGCATCCAACAA ACTGCCCTGGAGCTAGTTGGCCGAGGAGTCGAGGTTCACATTGTTGCTGATGCCACCTCATCAAGAAGCATGATGGACAGGATGTTTGCC CTCGAGCGTCTCGCTCGAACCGGGATCATAGTGACCACGAGTGAGGCTGTTCTGCTTCAGCTGGTAGCTGATAAGGACCATCCAAAATTC AAGGAAATTCAGAATCTAATTAAGGCGAGTGCTCCAGAGTCGGGTCTGCTTTCCAAAGTATAGGACATTTGAAGAACTGGTATGCTACTC ACTGGTGAAGGACAGTCAGGTGAAGGACTGTAAGCCCACACAAGCTCTTCTTATCTCTACTAGAATTAAAATGTTAAGTCAAAAACGGCT CCTTTTTTGCGCCTCCTAGTGAAACTTAACCAGCTAGACCATTTGAGTACCAGCATTTAGTTACAAACGTCAAAGGCTTCCGGTGCTGCT TACCTTCCTTTTTTGTTAATGTGCTTTTATTTATTAAAAAAAATTACAATGAAGATGCCTGTTTTGTCTCTACTGTGTACTCTGATCGTA TCTTTCCAAAGTGCAGACTCTTGTGAAGTTTTCTTAAATTGTTCACTTTAAAGAAAATGACGTACCAACAATGATTTGGCTTTTATATTA CTGTAAGATGTTATAATGTTAATGTGGATGTAGTGCTTTTACTTTACAGATTGATTGGAATAAGATTATTGCATATGAATTTACCCACAG GACTCTGAATCATGTTACCCACTCCCCTCACAATGTTGTCCACTTAGTGAGTTGCATTGATCTATCCGTACCAAATGATGTTGAATAATT ACATATCTTTCTTGACTATACTGATTTCTTATTTTGGTCACTATTACTAAATCTCTGTTAATATTCTCTCTTTTAACTGAAAAGGGATGG GATAGAAGGGTTTGCAATGCCATATTATTGGTGGAGGGCTGTTTTAACATCTTTGAAGTATGGCTTGCTGAATATCTTTACCAACATCTT GAATATATATTCTAGTGTCCACAAGATTTAGCAAAAAGATAAAGCTTGGGTGGAATATCATTTTAAAATGTTCATGTTCTGTTCTATATT TTCTTCACCTACTCTCCAAATATTGTAATGCAAAAAGTCTCAGTAATGATTTGGTAGTATTAATTTTGTGGTCATTGTTTCTCTTCGATA AATTTATTTTCATTAAATACTTGTTAGAGGGTTTTGAAATGTTTTTCAAATATGTGAAATGTGAAACTGCTGTCTTTTATATTAAAGTAA TTAAAGAAAA >2189_2189_3_ADC-ISOC1_ADC_chr1_33563780_ENST00000373440_ISOC1_chr5_128440648_ENST00000173527_length(amino acids)=380AA_BP=185 MAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSPGVLKVLAQLGLGFSC ANKIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPT PILQKLTTLGNLTPSSTVFFCCDMQERFRPAIKYFGDIISVGQRLLQGARILGIPVIVTEQYPKGLGSTVQEIDLTGVKLVLPKTKFSMV LPEVEAALAEIPGVRSVVLFGVETHVCIQQTALELVGRGVEVHIVADATSSRSMMDRMFALERLARTGIIVTTSEAVLLQLVADKDHPKF KEIQNLIKASAPESGLLSKV -------------------------------------------------------------- >2189_2189_4_ADC-ISOC1_ADC_chr1_33563780_ENST00000373441_ISOC1_chr5_128440648_ENST00000173527_length(transcript)=2704nt_BP=1089nt ATGGCTGGCTACCTGAGTGAATCGGACTTTGTGATGGTGGAGGAGGGCTTCAGTACCCGAGACCTGCTGAAGGAACTCACTCTGGGGGCC TCACAGGCCACCACGGACGAGGTAGCTGCCTTCTTCGTGGCTGACCTGGGTGCCATAGTGAGGAAGCACTTTTGCTTTCTGAAGTGCCTG CCACGAGTCCGGCCCTTTTATGCTGTCAAGTGCAACAGCAGCCCAGGTGTGCTGAAGGTTCTGGCCCAGCTGGGGCTGGGCTTTAGCTGT GCCAACAAGGCAGAGATGGAGTTGGTCCAGCATATTGGAATCCCTGCCAGTAAGATCATCTGCGCCAACCCCTGTAAGCAAATTGCACAG ATCAAATATGCTGCCAAGCATGGGATCCAGCTGCTGAGCTTTGACAATGAGATGGAGCTGGCAAAGGTGGTAAAGAGCCACCCCAGTGCC AAGATGGTTCTGTGCATTGCTACCGATGACTCCCACTCCCTGAGCTGCCTGAGCCTAAAGTTTGGAGTGTCACTGAAATCCTGCAGACAC CTGCTTGAAAATGCGAAGAAGCACCATGTGGAGGTGGTGGGTGTGAGTTTTCACATTGGCAGTGGCTGTCCTGACCCTCAGGCCTATGCT CAGTCCATCGCAGACGCCCGGCTCGTGTTTGAAATGGGCACCGAGCTGGGTCACAAGATGCACGTTCTGGACCTTGGTGGTGGCTTCCCT GGCACAGAAGGGGCCAAAGTGAGATTTGAAGAGATTGCTTCCGTGATCAACTCAGCCTTGGACCTGTACTTCCCAGAGGGCTGTGGCGTG GACATCTTTGCTGAGCTGGGGCGCTACTACGTGACCTCGGCCTTCACTGTGGCAGTCAGCATCATTGCCAAGAAGGAGGTTCTGCTAGAC CAGCCTGGCAGGGAGGCCCCACTACCACCCCCTCACATTGCTACTTGTGCTGCCTCTGAACCCTCCCCTCCTGCAGAGGAAAATGGTTCC ACCTCCAAGACCATCGTGTACCACCTTGATGAGGGCGTGTATGGGATCTTCAACTCAGTCCTGTTTGACAACATCTGCCCTACCCCCATC CTGCAGAAGCTCACTACCCTGGGAAATCTTACACCTTCAAGCACTGTGTTTTTCTGCTGTGATATGCAGGAAAGGTTCAGACCAGCCATC AAGTATTTTGGGGATATTATTAGCGTGGGACAGAGATTGTTGCAAGGGGCCCGGATTTTAGGAATTCCTGTTATTGTAACAGAACAATAC CCTAAAGGTCTTGGGAGCACGGTTCAAGAAATTGATTTAACAGGTGTAAAACTGGTACTTCCAAAGACCAAGTTTTCAATGGTATTACCA GAAGTAGAAGCGGCATTAGCAGAGATTCCCGGAGTCAGGAGTGTTGTATTATTTGGAGTAGAAACTCATGTGTGCATCCAACAAACTGCC CTGGAGCTAGTTGGCCGAGGAGTCGAGGTTCACATTGTTGCTGATGCCACCTCATCAAGAAGCATGATGGACAGGATGTTTGCCCTCGAG CGTCTCGCTCGAACCGGGATCATAGTGACCACGAGTGAGGCTGTTCTGCTTCAGCTGGTAGCTGATAAGGACCATCCAAAATTCAAGGAA ATTCAGAATCTAATTAAGGCGAGTGCTCCAGAGTCGGGTCTGCTTTCCAAAGTATAGGACATTTGAAGAACTGGTATGCTACTCACTGGT GAAGGACAGTCAGGTGAAGGACTGTAAGCCCACACAAGCTCTTCTTATCTCTACTAGAATTAAAATGTTAAGTCAAAAACGGCTCCTTTT TTGCGCCTCCTAGTGAAACTTAACCAGCTAGACCATTTGAGTACCAGCATTTAGTTACAAACGTCAAAGGCTTCCGGTGCTGCTTACCTT CCTTTTTTGTTAATGTGCTTTTATTTATTAAAAAAAATTACAATGAAGATGCCTGTTTTGTCTCTACTGTGTACTCTGATCGTATCTTTC CAAAGTGCAGACTCTTGTGAAGTTTTCTTAAATTGTTCACTTTAAAGAAAATGACGTACCAACAATGATTTGGCTTTTATATTACTGTAA GATGTTATAATGTTAATGTGGATGTAGTGCTTTTACTTTACAGATTGATTGGAATAAGATTATTGCATATGAATTTACCCACAGGACTCT GAATCATGTTACCCACTCCCCTCACAATGTTGTCCACTTAGTGAGTTGCATTGATCTATCCGTACCAAATGATGTTGAATAATTACATAT CTTTCTTGACTATACTGATTTCTTATTTTGGTCACTATTACTAAATCTCTGTTAATATTCTCTCTTTTAACTGAAAAGGGATGGGATAGA AGGGTTTGCAATGCCATATTATTGGTGGAGGGCTGTTTTAACATCTTTGAAGTATGGCTTGCTGAATATCTTTACCAACATCTTGAATAT ATATTCTAGTGTCCACAAGATTTAGCAAAAAGATAAAGCTTGGGTGGAATATCATTTTAAAATGTTCATGTTCTGTTCTATATTTTCTTC ACCTACTCTCCAAATATTGTAATGCAAAAAGTCTCAGTAATGATTTGGTAGTATTAATTTTGTGGTCATTGTTTCTCTTCGATAAATTTA TTTTCATTAAATACTTGTTAGAGGGTTTTGAAATGTTTTTCAAATATGTGAAATGTGAAACTGCTGTCTTTTATATTAAAGTAATTAAAG AAAA >2189_2189_4_ADC-ISOC1_ADC_chr1_33563780_ENST00000373441_ISOC1_chr5_128440648_ENST00000173527_length(amino acids)=558AA_BP=363 MAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRPFYAVKCNSSPGVLKVLAQLGLGFSC ANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKMVLCIATDDSHSLSCLSLKFGVSLKSCRH LLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGAKVRFEEIASVINSALDLYFPEGCGV DIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREAPLPPPHIATCAASEPSPPAEENGSTSKTIVYHLDEGVYGIFNSVLFDNICPTPI LQKLTTLGNLTPSSTVFFCCDMQERFRPAIKYFGDIISVGQRLLQGARILGIPVIVTEQYPKGLGSTVQEIDLTGVKLVLPKTKFSMVLP EVEAALAEIPGVRSVVLFGVETHVCIQQTALELVGRGVEVHIVADATSSRSMMDRMFALERLARTGIIVTTSEAVLLQLVADKDHPKFKE IQNLIKASAPESGLLSKV -------------------------------------------------------------- >2189_2189_5_ADC-ISOC1_ADC_chr1_33563780_ENST00000373443_ISOC1_chr5_128440648_ENST00000173527_length(transcript)=2962nt_BP=1347nt GGCTGCTGGGCTGGCGGGGCGCAGGCCGCGGGACCCGAGCCCGGGGAAGCGAGAGAGCGGAGGCGCCGAGGATCCGATTCACTCCCTGGG GAGACCTATGGGCCGAAGCCGTGTAAATGCGTTTTAAGAGGCCTCGGCTCCGCAACTGCCACTCCTCCTCGGGGTGTTGCACAAGTTTCG AGGTCACCGGCGACCCCCCCTAGCAGCGCGCCTGGCTCTGGCCCCCGCGAAGGAGGACGGAGTTTGTGTGTTGCATACTTTCTAAGGCGG CGGCTGCAGCAGCGGCTCCATCCAGCCCGTCAGCTCCTCCTGCAAGGCATGGCTGGCTACCTGAGTGAATCGGACTTTGTGATGGTGGAG GAGGGCTTCAGTACCCGAGACCTGCTGAAGGAACTCACTCTGGGGGCCTCACAGGCCACCACGGACGAGGTAGCTGCCTTCTTCGTGGCT GACCTGGGTGCCATAGTGAGGAAGCACTTTTGCTTTCTGAAGTGCCTGCCACGAGTCCGGCCCTTTTATGCTGTCAAGTGCAACAGCAGC CCAGGTGTGCTGAAGGTTCTGGCCCAGCTGGGGCTGGGCTTTAGCTGTGCCAACAAGGCAGAGATGGAGTTGGTCCAGCATATTGGAATC CCTGCCAGTAAGATCATCTGCGCCAACCCCTGTAAGCAAATTGCACAGATCAAATATGCTGCCAAGCATGGGATCCAGCTGCTGAGCTTT GACAATGAGATGGAGCTGGCAAAGGTGGTAAAGAGCCACCCCAGTGCCAAGATGGTTCTGTGCATTGCTACCGATGACTCCCACTCCCTG AGCTGCCTGAGCCTAAAGTTTGGAGTGTCACTGAAATCCTGCAGACACCTGCTTGAAAATGCGAAGAAGCACCATGTGGAGGTGGTGGGT GTGAGTTTTCACATTGGCAGTGGCTGTCCTGACCCTCAGGCCTATGCTCAGTCCATCGCAGACGCCCGGCTCGTGTTTGAAATGGGCACC GAGCTGGGTCACAAGATGCACGTTCTGGACCTTGGTGGTGGCTTCCCTGGCACAGAAGGGGCCAAAGTGAGATTTGAAGAGATTGCTTCC GTGATCAACTCAGCCTTGGACCTGTACTTCCCAGAGGGCTGTGGCGTGGACATCTTTGCTGAGCTGGGGCGCTACTACGTGACCTCGGCC TTCACTGTGGCAGTCAGCATCATTGCCAAGAAGGAGGTTCTGCTAGACCAGCCTGGCAGGGAGGAGGAAAATGGTTCCACCTCCAAGACC ATCGTGTACCACCTTGATGAGGGCGTGTATGGGATCTTCAACTCAGTCCTGTTTGACAACATCTGCCCTACCCCCATCCTGCAGAAGCTC ACTACCCTGGGAAATCTTACACCTTCAAGCACTGTGTTTTTCTGCTGTGATATGCAGGAAAGGTTCAGACCAGCCATCAAGTATTTTGGG GATATTATTAGCGTGGGACAGAGATTGTTGCAAGGGGCCCGGATTTTAGGAATTCCTGTTATTGTAACAGAACAATACCCTAAAGGTCTT GGGAGCACGGTTCAAGAAATTGATTTAACAGGTGTAAAACTGGTACTTCCAAAGACCAAGTTTTCAATGGTATTACCAGAAGTAGAAGCG GCATTAGCAGAGATTCCCGGAGTCAGGAGTGTTGTATTATTTGGAGTAGAAACTCATGTGTGCATCCAACAAACTGCCCTGGAGCTAGTT GGCCGAGGAGTCGAGGTTCACATTGTTGCTGATGCCACCTCATCAAGAAGCATGATGGACAGGATGTTTGCCCTCGAGCGTCTCGCTCGA ACCGGGATCATAGTGACCACGAGTGAGGCTGTTCTGCTTCAGCTGGTAGCTGATAAGGACCATCCAAAATTCAAGGAAATTCAGAATCTA ATTAAGGCGAGTGCTCCAGAGTCGGGTCTGCTTTCCAAAGTATAGGACATTTGAAGAACTGGTATGCTACTCACTGGTGAAGGACAGTCA GGTGAAGGACTGTAAGCCCACACAAGCTCTTCTTATCTCTACTAGAATTAAAATGTTAAGTCAAAAACGGCTCCTTTTTTGCGCCTCCTA GTGAAACTTAACCAGCTAGACCATTTGAGTACCAGCATTTAGTTACAAACGTCAAAGGCTTCCGGTGCTGCTTACCTTCCTTTTTTGTTA ATGTGCTTTTATTTATTAAAAAAAATTACAATGAAGATGCCTGTTTTGTCTCTACTGTGTACTCTGATCGTATCTTTCCAAAGTGCAGAC TCTTGTGAAGTTTTCTTAAATTGTTCACTTTAAAGAAAATGACGTACCAACAATGATTTGGCTTTTATATTACTGTAAGATGTTATAATG TTAATGTGGATGTAGTGCTTTTACTTTACAGATTGATTGGAATAAGATTATTGCATATGAATTTACCCACAGGACTCTGAATCATGTTAC CCACTCCCCTCACAATGTTGTCCACTTAGTGAGTTGCATTGATCTATCCGTACCAAATGATGTTGAATAATTACATATCTTTCTTGACTA TACTGATTTCTTATTTTGGTCACTATTACTAAATCTCTGTTAATATTCTCTCTTTTAACTGAAAAGGGATGGGATAGAAGGGTTTGCAAT GCCATATTATTGGTGGAGGGCTGTTTTAACATCTTTGAAGTATGGCTTGCTGAATATCTTTACCAACATCTTGAATATATATTCTAGTGT CCACAAGATTTAGCAAAAAGATAAAGCTTGGGTGGAATATCATTTTAAAATGTTCATGTTCTGTTCTATATTTTCTTCACCTACTCTCCA AATATTGTAATGCAAAAAGTCTCAGTAATGATTTGGTAGTATTAATTTTGTGGTCATTGTTTCTCTTCGATAAATTTATTTTCATTAAAT ACTTGTTAGAGGGTTTTGAAATGTTTTTCAAATATGTGAAATGTGAAACTGCTGTCTTTTATATTAAAGTAATTAAAGAAAA >2189_2189_5_ADC-ISOC1_ADC_chr1_33563780_ENST00000373443_ISOC1_chr5_128440648_ENST00000173527_length(amino acids)=563AA_BP=368 MCVAYFLRRRLQQRLHPARQLLLQGMAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRP FYAVKCNSSPGVLKVLAQLGLGFSCANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKMVLC IATDDSHSLSCLSLKFGVSLKSCRHLLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGA KVRFEEIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREEENGSTSKTIVYHLDEGVYGIFNSVLFDNI CPTPILQKLTTLGNLTPSSTVFFCCDMQERFRPAIKYFGDIISVGQRLLQGARILGIPVIVTEQYPKGLGSTVQEIDLTGVKLVLPKTKF SMVLPEVEAALAEIPGVRSVVLFGVETHVCIQQTALELVGRGVEVHIVADATSSRSMMDRMFALERLARTGIIVTTSEAVLLQLVADKDH PKFKEIQNLIKASAPESGLLSKV -------------------------------------------------------------- >2189_2189_6_ADC-ISOC1_ADC_chr1_33563780_ENST00000398167_ISOC1_chr5_128440648_ENST00000173527_length(transcript)=3022nt_BP=1407nt GGCTGCTGGGCTGGCGGGGCGCAGGCCGCGGGACCCGAGCCCGGGGAAGCGAGAGAGCGGAGGCGCCGAGGATCCGATTCACTCCCTGGG GAGACCTATGGGCCGAAGCCGTGTAAATGCGTTTTAAGAGGCCTCGGCTCCGCAACTGCCACTCCTCCTCGGGGTGTTGCACAAGTTTCG AGGTCACCGGCGACCCCCCCTAGCAGCGCGCCTGGCTCTGGCCCCCGCGAAGGAGGACGGAGTTTGTGTGTTGCATACTTTCTAAGGCGG CGGCTGCAGCAGCGGCTCCATCCAGCCCGTCAGCTCCTCCTGCAAGGCATGGCTGGCTACCTGAGTGAATCGGACTTTGTGATGGTGGAG GAGGGCTTCAGTACCCGAGACCTGCTGAAGGAACTCACTCTGGGGGCCTCACAGGCCACCACGGACGAGGTAGCTGCCTTCTTCGTGGCT GACCTGGGTGCCATAGTGAGGAAGCACTTTTGCTTTCTGAAGTGCCTGCCACGAGTCCGGCCCTTTTATGCTGTCAAGTGCAACAGCAGC CCAGGTGTGCTGAAGGTTCTGGCCCAGCTGGGGCTGGGCTTTAGCTGTGCCAACAAGGCAGAGATGGAGTTGGTCCAGCATATTGGAATC CCTGCCAGTAAGATCATCTGCGCCAACCCCTGTAAGCAAATTGCACAGATCAAATATGCTGCCAAGCATGGGATCCAGCTGCTGAGCTTT GACAATGAGATGGAGCTGGCAAAGGTGGTAAAGAGCCACCCCAGTGCCAAGATGGTTCTGTGCATTGCTACCGATGACTCCCACTCCCTG AGCTGCCTGAGCCTAAAGTTTGGAGTGTCACTGAAATCCTGCAGACACCTGCTTGAAAATGCGAAGAAGCACCATGTGGAGGTGGTGGGT GTGAGTTTTCACATTGGCAGTGGCTGTCCTGACCCTCAGGCCTATGCTCAGTCCATCGCAGACGCCCGGCTCGTGTTTGAAATGGGCACC GAGCTGGGTCACAAGATGCACGTTCTGGACCTTGGTGGTGGCTTCCCTGGCACAGAAGGGGCCAAAGTGAGATTTGAAGAGATTGCTTCC GTGATCAACTCAGCCTTGGACCTGTACTTCCCAGAGGGCTGTGGCGTGGACATCTTTGCTGAGCTGGGGCGCTACTACGTGACCTCGGCC TTCACTGTGGCAGTCAGCATCATTGCCAAGAAGGAGGTTCTGCTAGACCAGCCTGGCAGGGAGGCCCCACTACCACCCCCTCACATTGCT ACTTGTGCTGCCTCTGAACCCTCCCCTCCTGCAGAGGAAAATGGTTCCACCTCCAAGACCATCGTGTACCACCTTGATGAGGGCGTGTAT GGGATCTTCAACTCAGTCCTGTTTGACAACATCTGCCCTACCCCCATCCTGCAGAAGCTCACTACCCTGGGAAATCTTACACCTTCAAGC ACTGTGTTTTTCTGCTGTGATATGCAGGAAAGGTTCAGACCAGCCATCAAGTATTTTGGGGATATTATTAGCGTGGGACAGAGATTGTTG CAAGGGGCCCGGATTTTAGGAATTCCTGTTATTGTAACAGAACAATACCCTAAAGGTCTTGGGAGCACGGTTCAAGAAATTGATTTAACA GGTGTAAAACTGGTACTTCCAAAGACCAAGTTTTCAATGGTATTACCAGAAGTAGAAGCGGCATTAGCAGAGATTCCCGGAGTCAGGAGT GTTGTATTATTTGGAGTAGAAACTCATGTGTGCATCCAACAAACTGCCCTGGAGCTAGTTGGCCGAGGAGTCGAGGTTCACATTGTTGCT GATGCCACCTCATCAAGAAGCATGATGGACAGGATGTTTGCCCTCGAGCGTCTCGCTCGAACCGGGATCATAGTGACCACGAGTGAGGCT GTTCTGCTTCAGCTGGTAGCTGATAAGGACCATCCAAAATTCAAGGAAATTCAGAATCTAATTAAGGCGAGTGCTCCAGAGTCGGGTCTG CTTTCCAAAGTATAGGACATTTGAAGAACTGGTATGCTACTCACTGGTGAAGGACAGTCAGGTGAAGGACTGTAAGCCCACACAAGCTCT TCTTATCTCTACTAGAATTAAAATGTTAAGTCAAAAACGGCTCCTTTTTTGCGCCTCCTAGTGAAACTTAACCAGCTAGACCATTTGAGT ACCAGCATTTAGTTACAAACGTCAAAGGCTTCCGGTGCTGCTTACCTTCCTTTTTTGTTAATGTGCTTTTATTTATTAAAAAAAATTACA ATGAAGATGCCTGTTTTGTCTCTACTGTGTACTCTGATCGTATCTTTCCAAAGTGCAGACTCTTGTGAAGTTTTCTTAAATTGTTCACTT TAAAGAAAATGACGTACCAACAATGATTTGGCTTTTATATTACTGTAAGATGTTATAATGTTAATGTGGATGTAGTGCTTTTACTTTACA GATTGATTGGAATAAGATTATTGCATATGAATTTACCCACAGGACTCTGAATCATGTTACCCACTCCCCTCACAATGTTGTCCACTTAGT GAGTTGCATTGATCTATCCGTACCAAATGATGTTGAATAATTACATATCTTTCTTGACTATACTGATTTCTTATTTTGGTCACTATTACT AAATCTCTGTTAATATTCTCTCTTTTAACTGAAAAGGGATGGGATAGAAGGGTTTGCAATGCCATATTATTGGTGGAGGGCTGTTTTAAC ATCTTTGAAGTATGGCTTGCTGAATATCTTTACCAACATCTTGAATATATATTCTAGTGTCCACAAGATTTAGCAAAAAGATAAAGCTTG GGTGGAATATCATTTTAAAATGTTCATGTTCTGTTCTATATTTTCTTCACCTACTCTCCAAATATTGTAATGCAAAAAGTCTCAGTAATG ATTTGGTAGTATTAATTTTGTGGTCATTGTTTCTCTTCGATAAATTTATTTTCATTAAATACTTGTTAGAGGGTTTTGAAATGTTTTTCA AATATGTGAAATGTGAAACTGCTGTCTTTTATATTAAAGTAATTAAAGAAAA >2189_2189_6_ADC-ISOC1_ADC_chr1_33563780_ENST00000398167_ISOC1_chr5_128440648_ENST00000173527_length(amino acids)=583AA_BP=388 MCVAYFLRRRLQQRLHPARQLLLQGMAGYLSESDFVMVEEGFSTRDLLKELTLGASQATTDEVAAFFVADLGAIVRKHFCFLKCLPRVRP FYAVKCNSSPGVLKVLAQLGLGFSCANKAEMELVQHIGIPASKIICANPCKQIAQIKYAAKHGIQLLSFDNEMELAKVVKSHPSAKMVLC IATDDSHSLSCLSLKFGVSLKSCRHLLENAKKHHVEVVGVSFHIGSGCPDPQAYAQSIADARLVFEMGTELGHKMHVLDLGGGFPGTEGA KVRFEEIASVINSALDLYFPEGCGVDIFAELGRYYVTSAFTVAVSIIAKKEVLLDQPGREAPLPPPHIATCAASEPSPPAEENGSTSKTI VYHLDEGVYGIFNSVLFDNICPTPILQKLTTLGNLTPSSTVFFCCDMQERFRPAIKYFGDIISVGQRLLQGARILGIPVIVTEQYPKGLG STVQEIDLTGVKLVLPKTKFSMVLPEVEAALAEIPGVRSVVLFGVETHVCIQQTALELVGRGVEVHIVADATSSRSMMDRMFALERLART GIIVTTSEAVLLQLVADKDHPKFKEIQNLIKASAPESGLLSKV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ADC-ISOC1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ADC-ISOC1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ADC-ISOC1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies