
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C22orf34-CDCA7 (FusionGDB2 ID:HG348645TG83879) |
Fusion Gene Summary for C22orf34-CDCA7 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C22orf34-CDCA7 | Fusion gene ID: hg348645tg83879 | Hgene | Tgene | Gene symbol | C22orf34 | CDCA7 | Gene ID | 348645 | 83879 |
| Gene name | chromosome 22 open reading frame 34 | cell division cycle associated 7 | |
| Synonyms | - | ICF3|JPO1 | |
| Cytomap | ('C22orf34')('CDCA7') 22q13.33 | 2q31.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | putative uncharacterized protein C22orf34uncharacterized protein C22orf34 | cell division cycle-associated protein 7c-Myc target JPO1 | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | Q6ZV56 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000400023, ENST00000405854, ENST00000444628, ENST00000498829, | ||
| Fusion gene scores | * DoF score | 6 X 3 X 4=72 | 4 X 3 X 3=36 |
| # samples | 6 | 4 | |
| ** MAII score | log2(6/72*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: C22orf34 [Title/Abstract] AND CDCA7 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C22orf34(50051053)-CDCA7(174223440), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | C22orf34-CDCA7 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C22orf34-CDCA7 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C22orf34-CDCA7 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. C22orf34-CDCA7 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CDCA7 | GO:0042127 | regulation of cell proliferation | 11598121 |
| Fusion gene breakpoints across C22orf34 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
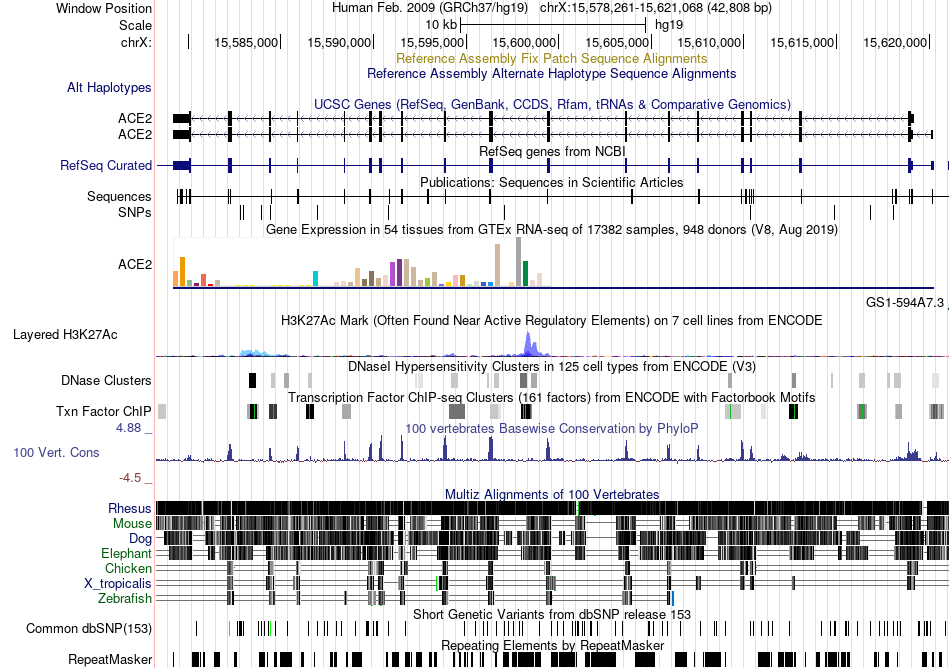 |
| Fusion gene breakpoints across CDCA7 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
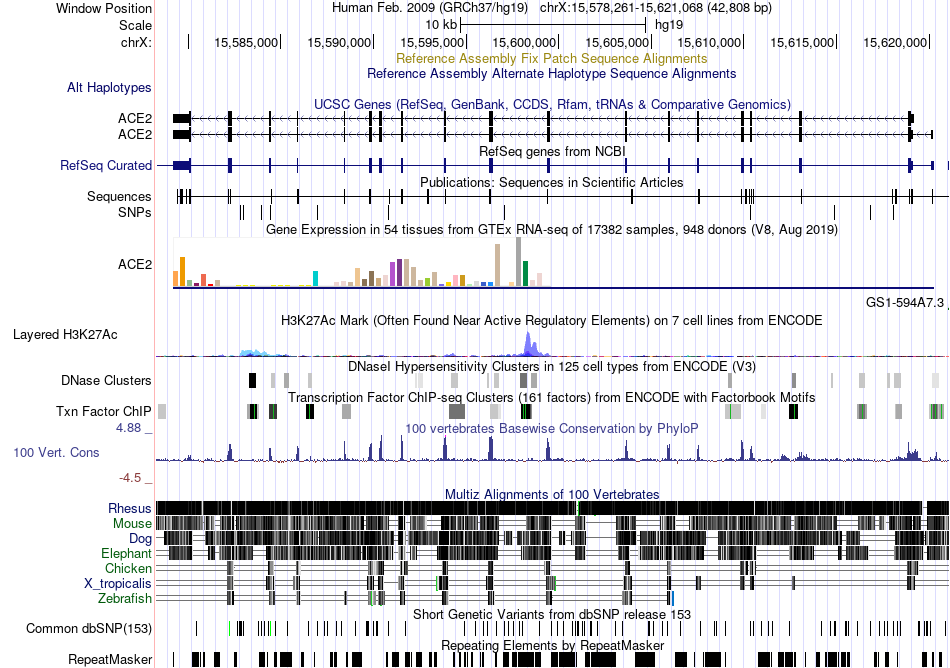 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CG-5721-01A | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
Top |
Fusion Gene ORF analysis for C22orf34-CDCA7 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000400023 | ENST00000410019 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| In-frame | ENST00000400023 | ENST00000306721 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| In-frame | ENST00000400023 | ENST00000347703 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| In-frame | ENST00000400023 | ENST00000392567 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| In-frame | ENST00000400023 | ENST00000410101 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000405854 | ENST00000306721 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000405854 | ENST00000347703 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000405854 | ENST00000392567 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000405854 | ENST00000410101 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000444628 | ENST00000306721 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000444628 | ENST00000347703 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000444628 | ENST00000392567 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000444628 | ENST00000410101 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000498829 | ENST00000306721 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000498829 | ENST00000347703 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000498829 | ENST00000392567 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-3CDS | ENST00000498829 | ENST00000410101 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-intron | ENST00000405854 | ENST00000410019 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-intron | ENST00000444628 | ENST00000410019 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| intron-intron | ENST00000498829 | ENST00000410019 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000400023 | C22orf34 | chr22 | 50051053 | - | ENST00000347703 | CDCA7 | chr2 | 174223440 | + | 2473 | 138 | 87 | 1232 | 381 |
| ENST00000400023 | C22orf34 | chr22 | 50051053 | - | ENST00000392567 | CDCA7 | chr2 | 174223440 | + | 2410 | 138 | 87 | 1082 | 331 |
| ENST00000400023 | C22orf34 | chr22 | 50051053 | - | ENST00000306721 | CDCA7 | chr2 | 174223440 | + | 2803 | 138 | 87 | 1469 | 460 |
| ENST00000400023 | C22orf34 | chr22 | 50051053 | - | ENST00000410101 | CDCA7 | chr2 | 174223440 | + | 1394 | 138 | 87 | 1337 | 416 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000400023 | ENST00000347703 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + | 0.000633701 | 0.99936634 |
| ENST00000400023 | ENST00000392567 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + | 0.000545652 | 0.9994543 |
| ENST00000400023 | ENST00000306721 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + | 0.000142222 | 0.9998578 |
| ENST00000400023 | ENST00000410101 | C22orf34 | chr22 | 50051053 | - | CDCA7 | chr2 | 174223440 | + | 0.003284676 | 0.9967153 |
Top |
Fusion Genomic Features for C22orf34-CDCA7 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| C22orf34 | chr22 | 50051052 | - | CDCA7 | chr2 | 174223439 | + | 0.000395295 | 0.99960476 |
| C22orf34 | chr22 | 50051052 | - | CDCA7 | chr2 | 174223439 | + | 0.000395295 | 0.99960476 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
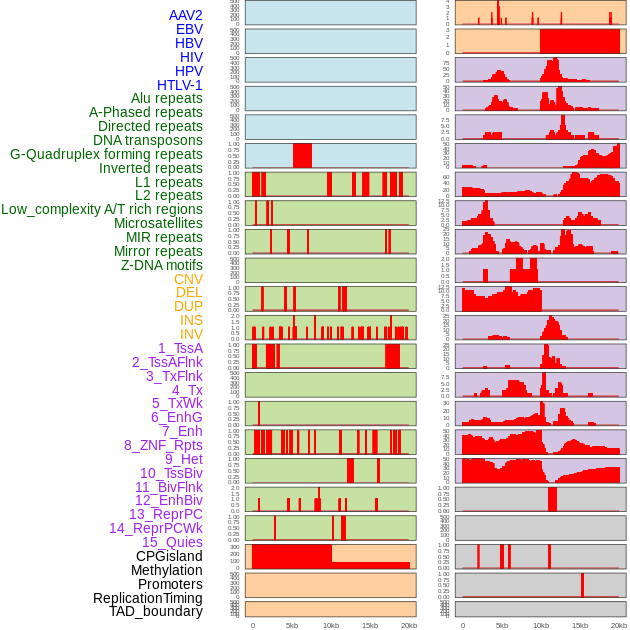 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
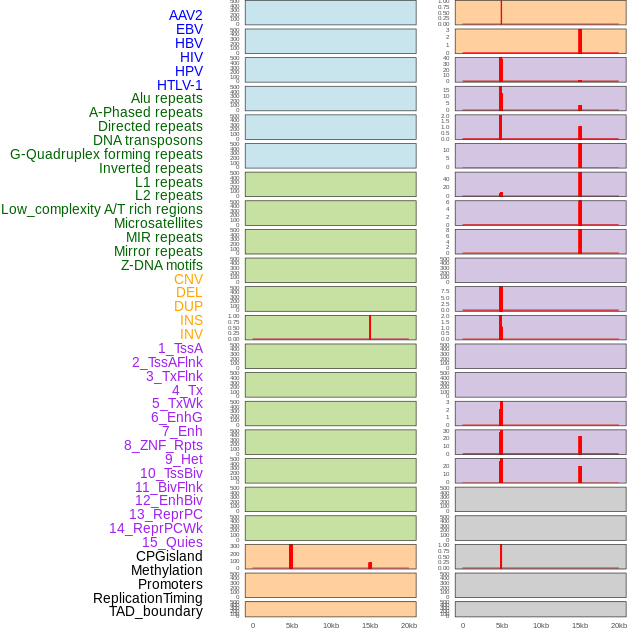 |
Top |
Fusion Protein Features for C22orf34-CDCA7 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:50051053/chr2:174223440) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| C22orf34 | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000306721 | 0 | 10 | 157_186 | 7 | 451.0 | Compositional bias | Note=Arg-rich | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000347703 | 0 | 9 | 157_186 | 7 | 372.0 | Compositional bias | Note=Arg-rich | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000392567 | 0 | 8 | 157_186 | 7 | 322.0 | Compositional bias | Note=Arg-rich | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000306721 | 0 | 10 | 160_176 | 7 | 451.0 | Motif | Nuclear localization signal | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000347703 | 0 | 9 | 160_176 | 7 | 372.0 | Motif | Nuclear localization signal | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000392567 | 0 | 8 | 160_176 | 7 | 322.0 | Motif | Nuclear localization signal | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000306721 | 0 | 10 | 247_371 | 7 | 451.0 | Region | Note=Mediates transcriptional activity | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000347703 | 0 | 9 | 247_371 | 7 | 372.0 | Region | Note=Mediates transcriptional activity | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000392567 | 0 | 8 | 247_371 | 7 | 322.0 | Region | Note=Mediates transcriptional activity |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | C22orf34 | chr22:50051053 | chr2:174223440 | ENST00000400023 | - | 1 | 4 | 79_98 | 18 | 184.0 | Compositional bias | Note=Cys-rich |
Top |
Fusion Gene Sequence for C22orf34-CDCA7 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >11566_11566_1_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000306721_length(transcript)=2803nt_BP=138nt CGTGTGCGGTCCCTCCCCCTCACGTTCTCTCTTCCTCTGCTCCGCCATGATGAGAAGCGCCTGCTTCCCCTTCCCCTTCCGCCATGATTG TGTTTCCTGAGACCTCCCAGCCACGCTTCCTGTACAGCCTGCAGAACTCAGAAAGATCTCAGAGTAAAGAAGAACTTAAAGAAATTCAGA TATGTGAAGTTGATTTCCATGGAAACCTCGTCATCCTCTGATGACAGTTGTGACAGCTTTGCTTCTGATAATTTTGCAAACACGAAACCT AAATTCAGGTCAGATATCAGTGAAGAACTGGCAAATGTTTTTTATGAGGACTCTGATAATGAATCTTTCTGCGGCTTTTCAGAAAGTGAG GTGCAAGATGTATTAGACCATTGTGGATTTTTACAGAAACCAAGGCCAGATGTCACTAACGAACTGGCCGGTATTTTTCATGCCGACTCT GACGATGAATCATTTTGCGGTTTCTCAGAGAGTGAGATACAAGATGGAATGAGGCTGCAGTCAGTTCGGGAAGGCTGTAGGACCCGCAGC CAGTGCAGGCACTCTGGACCTCTCAGGGTGGCGATGAAGTTTCCAGCGCGGAGTACCAGGGGAGCAACCAACAAAAAAGCAGAGTCCCGC CAGCCCTCAGAGAATTCTGTGACTGATTCCAACTCCGATTCAGAAGATGAAAGTGGAATGAATTTTTTGGAGAAAAGGGCTTTAAATATA AAGCAAAACAAAGCAATGCTTGCAAAACTCATGTCTGAATTAGAAAGCTTCCCTGGCTCGTTCCGTGGAAGACATCCCCTCCCAGGCTCC GACTCACAATCAAGGAGACCGCGAAGGCGTACATTCCCGGGTGTTGCTTCCAGGAGAAACCCTGAACGGAGAGCTCGTCCTCTTACCAGG TCAAGGTCCCGGATCCTCGGGTCCCTTGACGCTCTACCCATGGAGGAGGAGGAGGAAGAGGATAAGTACATGTTGGTGAGAAAGAGGAAG ACCGTGGATGGCTACATGAATGAAGATGACCTGCCCAGAAGCCGTCGCTCCAGATCATCCGTGACCCTTCCGCATATAATTCGCCCAGTG GAAGAAATTACAGAGGAGGAGTTGGAGAACGTCTGCAGCAATTCTCGAGAGAAGATATATAACCGTTCACTGGGCTCTACTTGTCATCAA TGCCGTCAGAAGACTATTGATACCAAAACAAACTGCAGAAACCCAGACTGCTGGGGCGTTCGAGGCCAGTTCTGTGGCCCCTGCCTTCGA AACCGTTATGGTGAAGAGGTCAGGGATGCTCTGCTGGATCCGAACTGGCATTGCCCGCCTTGTCGAGGAATCTGCAACTGCAGTTTCTGC CGGCAGCGAGATGGACGGTGTGCGACTGGGGTCCTTGTGTATTTAGCCAAATATCATGGCTTTGGGAATGTGCATGCCTACTTGAAAAGC CTGAAACAGGAATTTGAAATGCAAGCATAATATCTGGAAAATTTGCTGCCTGCCTTCTACTTCTCAAATCTTTCTTGTAAAAGTTTCCAA TTTTTTCACTGAAACCTGAGTTAAAAATCTTGATGATCAGCCTGTTTCATAAGAAACTCCAATCAAGTTAATCTTAGCAGACATGTGTTT CTGGAGCATCACAGAAGGTATATTGCTAGTTACACTTTGCCCTCCTGCAGTTTCTTCTCTGCTCCCAACCCCCATCTCACAGCATCCCCC TCTATTTCCAATGCTCCTCTCCAACCGCTTAGTTTCTGAATTTCTTTTAAATTACAGTTTTATGAAAGCATATTTTATTTACTTGGTGTT GAAATAGCCCTCATAAAACCTAAGCACTTGGAAACACAATAATAGTATTAACTAACTAGATCTATTGAATTTCAGAGAAGAGCCTTCTAA CTTGTTTACACAAAAACGAGTATGATTTAGCATTCATACTAGTTGAAATTTTTAATAGAATCAAGGCACAAAAGTCTTAAAACCATGTGG AAAAATTAGGTAATTATTGCAGATTGATGTCTCTCAATCCCATGTATTGCGCTTATGTTACAAGTTGTTGTCACAGTTGAGACTTAATTT CTCCTAATTTCTTCTGCCCGAAGGGTAAGTGGTGCGTCCAGCTTACACAATCATAATTCAAAGGTTGGTGGGCAATGTAATACTTAATTA AAATAATGATGGAAGAGCTATCTGGAGATTATGAGTAAGCTGATTTGAATTTTCAGTATAAAACTTTAGTATAATTGTAGTTTGCAAAGT TTATTTCAGTTCACATGTAAGGTATTGCAAATAAATTCTTGGACAATTTTGTATGGAAACTTGATATTAAAAACTAGTCTGTGGTTCTTT GCAGTTTCTTGTAAATTTATAAACCAGGCACAAGGTTCAAGTTTAGATTTTAAGCACTTTTATAACAATGATAAGTGCCTTTTTGGAGAT GTAACTTTTAGCAGTTTGTTAACCTGACATCTCTGCCAGTCTAGTTTCTGGGCAGGTTTCCTGTGTCAGTATTCCCCCTCCTCTTTGCAT TAATCAAGGTATTTGGTAGAGGTGGAATCTAAGTGTTTGTATGTCCAATTTACTTGCATATGTAAACCATTGCTGTGCCATTCAATGTTT GATGCATAATTGGACCTTGAATCGATAAGTGTAAATACAGCTTTTGATCTGTAATGCTTTTATACAAAAGTTTATTTTAATAATAAAATG TTTGTTCTAACTTGTCTGCTTTTTTAAAAATAATCTTACTGTACTTAATTCTAATTTTTTCCTCATATTTAAATAAAAGGCCATTTCCAC CTTTTCTAAAAAA >11566_11566_1_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000306721_length(amino acids)=460AA_BP=17 MCFLRPPSHASCTACRTQKDLRVKKNLKKFRYVKLISMETSSSSDDSCDSFASDNFANTKPKFRSDISEELANVFYEDSDNESFCGFSES EVQDVLDHCGFLQKPRPDVTNELAGIFHADSDDESFCGFSESEIQDGMRLQSVREGCRTRSQCRHSGPLRVAMKFPARSTRGATNKKAES RQPSENSVTDSNSDSEDESGMNFLEKRALNIKQNKAMLAKLMSELESFPGSFRGRHPLPGSDSQSRRPRRRTFPGVASRRNPERRARPLT RSRSRILGSLDALPMEEEEEEDKYMLVRKRKTVDGYMNEDDLPRSRRSRSSVTLPHIIRPVEEITEEELENVCSNSREKIYNRSLGSTCH QCRQKTIDTKTNCRNPDCWGVRGQFCGPCLRNRYGEEVRDALLDPNWHCPPCRGICNCSFCRQRDGRCATGVLVYLAKYHGFGNVHAYLK SLKQEFEMQA -------------------------------------------------------------- >11566_11566_2_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000347703_length(transcript)=2473nt_BP=138nt CGTGTGCGGTCCCTCCCCCTCACGTTCTCTCTTCCTCTGCTCCGCCATGATGAGAAGCGCCTGCTTCCCCTTCCCCTTCCGCCATGATTG TGTTTCCTGAGACCTCCCAGCCACGCTTCCTGTACAGCCTGCAGAACTCAGAAAGATCTCAGAGTAAAGAAGAACTTAAAGAAATTCAGA TATGTGAAGTTGATTTCCATGGAAACCTCGTCATCCTCTGATGACAGTTGTGACAGCTTTGCTTCTGATAATTTTGCAAACACGAGGCTG CAGTCAGTTCGGGAAGGCTGTAGGACCCGCAGCCAGTGCAGGCACTCTGGACCTCTCAGGGTGGCGATGAAGTTTCCAGCGCGGAGTACC AGGGGAGCAACCAACAAAAAAGCAGAGTCCCGCCAGCCCTCAGAGAATTCTGTGACTGATTCCAACTCCGATTCAGAAGATGAAAGTGGA ATGAATTTTTTGGAGAAAAGGGCTTTAAATATAAAGCAAAACAAAGCAATGCTTGCAAAACTCATGTCTGAATTAGAAAGCTTCCCTGGC TCGTTCCGTGGAAGACATCCCCTCCCAGGCTCCGACTCACAATCAAGGAGACCGCGAAGGCGTACATTCCCGGGTGTTGCTTCCAGGAGA AACCCTGAACGGAGAGCTCGTCCTCTTACCAGGTCAAGGTCCCGGATCCTCGGGTCCCTTGACGCTCTACCCATGGAGGAGGAGGAGGAA GAGGATAAGTACATGTTGGTGAGAAAGAGGAAGACCGTGGATGGCTACATGAATGAAGATGACCTGCCCAGAAGCCGTCGCTCCAGATCA TCCGTGACCCTTCCGCATATAATTCGCCCAGTGGAAGAAATTACAGAGGAGGAGTTGGAGAACGTCTGCAGCAATTCTCGAGAGAAGATA TATAACCGTTCACTGGGCTCTACTTGTCATCAATGCCGTCAGAAGACTATTGATACCAAAACAAACTGCAGAAACCCAGACTGCTGGGGC GTTCGAGGCCAGTTCTGTGGCCCCTGCCTTCGAAACCGTTATGGTGAAGAGGTCAGGGATGCTCTGCTGGATCCGAACTGGCATTGCCCG CCTTGTCGAGGAATCTGCAACTGCAGTTTCTGCCGGCAGCGAGATGGACGGTGTGCGACTGGGGTCCTTGTGTATTTAGCCAAATATCAT GGCTTTGGGAATGTGCATGCCTACTTGAAAAGCCTGAAACAGGAATTTGAAATGCAAGCATAATATCTGGAAAATTTGCTGCCTGCCTTC TACTTCTCAAATCTTTCTTGTAAAAGTTTCCAATTTTTTCACTGAAACCTGAGTTAAAAATCTTGATGATCAGCCTGTTTCATAAGAAAC TCCAATCAAGTTAATCTTAGCAGACATGTGTTTCTGGAGCATCACAGAAGGTATATTGCTAGTTACACTTTGCCCTCCTGCAGTTTCTTC TCTGCTCCCAACCCCCATCTCACAGCATCCCCCTCTATTTCCAATGCTCCTCTCCAACCGCTTAGTTTCTGAATTTCTTTTAAATTACAG TTTTATGAAAGCATATTTTATTTACTTGGTGTTGAAATAGCCCTCATAAAACCTAAGCACTTGGAAACACAATAATAGTATTAACTAACT AGATCTATTGAATTTCAGAGAAGAGCCTTCTAACTTGTTTACACAAAAACGAGTATGATTTAGCATTCATACTAGTTGAAATTTTTAATA GAATCAAGGCACAAAAGTCTTAAAACCATGTGGAAAAATTAGGTAATTATTGCAGATTGATGTCTCTCAATCCCATGTATTGCGCTTATG TTACAAGTTGTTGTCACAGTTGAGACTTAATTTCTCCTAATTTCTTCTGCCCGAAGGGTAAGTGGTGCGTCCAGCTTACACAATCATAAT TCAAAGGTTGGTGGGCAATGTAATACTTAATTAAAATAATGATGGAAGAGCTATCTGGAGATTATGAGTAAGCTGATTTGAATTTTCAGT ATAAAACTTTAGTATAATTGTAGTTTGCAAAGTTTATTTCAGTTCACATGTAAGGTATTGCAAATAAATTCTTGGACAATTTTGTATGGA AACTTGATATTAAAAACTAGTCTGTGGTTCTTTGCAGTTTCTTGTAAATTTATAAACCAGGCACAAGGTTCAAGTTTAGATTTTAAGCAC TTTTATAACAATGATAAGTGCCTTTTTGGAGATGTAACTTTTAGCAGTTTGTTAACCTGACATCTCTGCCAGTCTAGTTTCTGGGCAGGT TTCCTGTGTCAGTATTCCCCCTCCTCTTTGCATTAATCAAGGTATTTGGTAGAGGTGGAATCTAAGTGTTTGTATGTCCAATTTACTTGC ATATGTAAACCATTGCTGTGCCATTCAATGTTTGATGCATAATTGGACCTTGAATCGATAAGTGTAAATACAGCTTTTGATCTGTAATGC TTTTATACAAAAGTTTATTTTAATAATAAAATGTTTGTTCTAA >11566_11566_2_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000347703_length(amino acids)=381AA_BP=17 MCFLRPPSHASCTACRTQKDLRVKKNLKKFRYVKLISMETSSSSDDSCDSFASDNFANTRLQSVREGCRTRSQCRHSGPLRVAMKFPARS TRGATNKKAESRQPSENSVTDSNSDSEDESGMNFLEKRALNIKQNKAMLAKLMSELESFPGSFRGRHPLPGSDSQSRRPRRRTFPGVASR RNPERRARPLTRSRSRILGSLDALPMEEEEEEDKYMLVRKRKTVDGYMNEDDLPRSRRSRSSVTLPHIIRPVEEITEEELENVCSNSREK IYNRSLGSTCHQCRQKTIDTKTNCRNPDCWGVRGQFCGPCLRNRYGEEVRDALLDPNWHCPPCRGICNCSFCRQRDGRCATGVLVYLAKY HGFGNVHAYLKSLKQEFEMQA -------------------------------------------------------------- >11566_11566_3_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000392567_length(transcript)=2410nt_BP=138nt CGTGTGCGGTCCCTCCCCCTCACGTTCTCTCTTCCTCTGCTCCGCCATGATGAGAAGCGCCTGCTTCCCCTTCCCCTTCCGCCATGATTG TGTTTCCTGAGACCTCCCAGCCACGCTTCCTGTACAGCCTGCAGAACTCAGAAAGATCTCAGAGTAAAGAAGAACTTAAAGAAATTCAGA TATGTGAAGTTGATTTCCATGGAAACCTCGTCATCCTCTGATGACAGTTGTGACAGCTTTGCTTCTGATAATTTTGCAAACACGAGGCTG CAGTCAGTTCGGGAAGGCTGTAGGACCCGCAGCCAGTGCAGGCACTCTGGACCTCTCAGGGTGGCGATGAAGTTTCCAGCGCGGAGTACC AGGGGAGCAACCAACAAAAAAGCAGAGTCCCGCCAGCCCTCAGAGAATTCTGTGACTGATTCCAACTCCGATTCAGAAGATGAAAGTGGA ATGAATTTTTTGGAGAAAAGGGCTTTAAATATAAAGCAAAACAAAGCAATGCTTGCAAAACTCATGTCTGAATTAGAAAGCTTCCCTGGC TCGTTCCGTGGAAGACATCCCCTCCCAGGCTCCGACTCACAATCAAGGAGACCGCGAAGGCGTACATTCCCGGGTGTTGCTTCCAGGAGA AACCCTGAACGGAGAGCTCGTCCTCTTACCAGGTCAAGGTCCCGGATCCTCGGGTCCCTTGACGCTCTACCCATGGAGGAGGAGGAGGAA GAGGATAAGTACATGTTGGTGAGAAAGAGGAAGACCGTGGATGGCTACATGAATGAAGATGACCTGCCCAGAAGCCGTCGCTCCAGATCA TCCGTGACCCTTCCGCATATAATTCGCCCAGTGGAAGAAATTACAGAGGAGGAGTTGGAGAACGTCTGCAGCAATTCTCGAGAGAAGATA TATAACCGTTCACTGAACTGGCATTGCCCGCCTTGTCGAGGAATCTGCAACTGCAGTTTCTGCCGGCAGCGAGATGGACGGTGTGCGACT GGGGTCCTTGTGTATTTAGCCAAATATCATGGCTTTGGGAATGTGCATGCCTACTTGAAAAGCCTGAAACAGGAATTTGAAATGCAAGCA TAATATCTGGAAAATTTGCTGCCTGCCTTCTACTTCTCAAATCTTTCTTGTAAAAGTTTCCAATTTTTTCACTGAAACCTGAGTTAAAAA TCTTGATGATCAGCCTGTTTCATAAGAAACTCCAATCAAGTTAATCTTAGCAGACATGTGTTTCTGGAGCATCACAGAAGGTATATTGCT AGTTACACTTTGCCCTCCTGCAGTTTCTTCTCTGCTCCCAACCCCCATCTCACAGCATCCCCCTCTATTTCCAATGCTCCTCTCCAACCG CTTAGTTTCTGAATTTCTTTTAAATTACAGTTTTATGAAAGCATATTTTATTTACTTGGTGTTGAAATAGCCCTCATAAAACCTAAGCAC TTGGAAACACAATAATAGTATTAACTAACTAGATCTATTGAATTTCAGAGAAGAGCCTTCTAACTTGTTTACACAAAAACGAGTATGATT TAGCATTCATACTAGTTGAAATTTTTAATAGAATCAAGGCACAAAAGTCTTAAAACCATGTGGAAAAATTAGGTAATTATTGCAGATTGA TGTCTCTCAATCCCATGTATTGCGCTTATGTTACAAGTTGTTGTCACAGTTGAGACTTAATTTCTCCTAATTTCTTCTGCCCGAAGGGTA AGTGGTGCGTCCAGCTTACACAATCATAATTCAAAGGTTGGTGGGCAATGTAATACTTAATTAAAATAATGATGGAAGAGCTATCTGGAG ATTATGAGTAAGCTGATTTGAATTTTCAGTATAAAACTTTAGTATAATTGTAGTTTGCAAAGTTTATTTCAGTTCACATGTAAGGTATTG CAAATAAATTCTTGGACAATTTTGTATGGAAACTTGATATTAAAAACTAGTCTGTGGTTCTTTGCAGTTTCTTGTAAATTTATAAACCAG GCACAAGGTTCAAGTTTAGATTTTAAGCACTTTTATAACAATGATAAGTGCCTTTTTGGAGATGTAACTTTTAGCAGTTTGTTAACCTGA CATCTCTGCCAGTCTAGTTTCTGGGCAGGTTTCCTGTGTCAGTATTCCCCCTCCTCTTTGCATTAATCAAGGTATTTGGTAGAGGTGGAA TCTAAGTGTTTGTATGTCCAATTTACTTGCATATGTAAACCATTGCTGTGCCATTCAATGTTTGATGCATAATTGGACCTTGAATCGATA AGTGTAAATACAGCTTTTGATCTGTAATGCTTTTATACAAAAGTTTATTTTAATAATAAAATGTTTGTTCTAACTTGTCTGCTTTTTTAA AAATAATCTTACTGTACTTAATTCTAATTTTTTCCTCATATTTAAATAAAAGGCCATTTCCACCTTTTCT >11566_11566_3_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000392567_length(amino acids)=331AA_BP=17 MCFLRPPSHASCTACRTQKDLRVKKNLKKFRYVKLISMETSSSSDDSCDSFASDNFANTRLQSVREGCRTRSQCRHSGPLRVAMKFPARS TRGATNKKAESRQPSENSVTDSNSDSEDESGMNFLEKRALNIKQNKAMLAKLMSELESFPGSFRGRHPLPGSDSQSRRPRRRTFPGVASR RNPERRARPLTRSRSRILGSLDALPMEEEEEEDKYMLVRKRKTVDGYMNEDDLPRSRRSRSSVTLPHIIRPVEEITEEELENVCSNSREK IYNRSLNWHCPPCRGICNCSFCRQRDGRCATGVLVYLAKYHGFGNVHAYLKSLKQEFEMQA -------------------------------------------------------------- >11566_11566_4_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000410101_length(transcript)=1394nt_BP=138nt CGTGTGCGGTCCCTCCCCCTCACGTTCTCTCTTCCTCTGCTCCGCCATGATGAGAAGCGCCTGCTTCCCCTTCCCCTTCCGCCATGATTG TGTTTCCTGAGACCTCCCAGCCACGCTTCCTGTACAGCCTGCAGAACTCAGAAAGATCTCAGAGTAAAGAAGAACTTAAAGAAATTCAGA TATGTGAAGTTGATTTCCATGGAAACCTCGTCATCCTCTGATGACAGTTGTGACAGCTTTGCTTCTGATAATTTTGCAAACACGAAACCA AGGCCAGATGTCACTAACGAACTGGCCGGTATTTTTCATGCCGACTCTGACGATGAATCATTTTGCGGTTTCTCAGAGAGTGAGATACAA GATGGAATGAGGCTGCAGTCAGTTCGGGAAGGCTGTAGGACCCGCAGCCAGTGCAGGCACTCTGGACCTCTCAGGGTGGCGATGAAGTTT CCAGCGCGGAGTACCAGGGGAGCAACCAACAAAAAAGCAGAGTCCCGCCAGCCCTCAGAGAATTCTGTGACTGATTCCAACTCCGATTCA GAAGATGAAAGTGGAATGAATTTTTTGGAGAAAAGGGCTTTAAATATAAAGCAAAACAAAGCAATGCTTGCAAAACTCATGTCTGAATTA GAAAGCTTCCCTGGCTCGTTCCGTGGAAGACATCCCCTCCCAGGCTCCGACTCACAATCAAGGAGACCGCGAAGGCGTACATTCCCGGGT GTTGCTTCCAGGAGAAACCCTGAACGGAGAGCTCGTCCTCTTACCAGGTCAAGGTCCCGGATCCTCGGGTCCCTTGACGCTCTACCCATG GAGGAGGAGGAGGAAGAGGATAAGTACATGTTGGTGAGAAAGAGGAAGACCGTGGATGGCTACATGAATGAAGATGACCTGCCCAGAAGC CGTCGCTCCAGATCATCCGTGACCCTTCCGCATATAATTCGCCCAGTGGAAGAAATTACAGAGGAGGAGTTGGAGAACGTCTGCAGCAAT TCTCGAGAGAAGATATATAACCGTTCACTGGGCTCTACTTGTCATCAATGCCGTCAGAAGACTATTGATACCAAAACAAACTGCAGAAAC CCAGACTGCTGGGGCGTTCGAGGCCAGTTCTGTGGCCCCTGCCTTCGAAACCGTTATGGTGAAGAGGTCAGGGATGCTCTGCTGGATCCG AACTGGCATTGCCCGCCTTGTCGAGGAATCTGCAACTGCAGTTTCTGCCGGCAGCGAGATGGACGGTGTGCGACTGGGGTCCTTGTGTAT TTAGCCAAATATCATGGCTTTGGGAATGTGCATGCCTACTTGAAAAGCCTGAAACAGGAATTTGAAATGCAAGCATAATATCTGGAAAAT TTGCTGCCTGCCTTCTACTTCTCAAATCTTTCTTGTAAAAGTTT >11566_11566_4_C22orf34-CDCA7_C22orf34_chr22_50051053_ENST00000400023_CDCA7_chr2_174223440_ENST00000410101_length(amino acids)=416AA_BP=17 MCFLRPPSHASCTACRTQKDLRVKKNLKKFRYVKLISMETSSSSDDSCDSFASDNFANTKPRPDVTNELAGIFHADSDDESFCGFSESEI QDGMRLQSVREGCRTRSQCRHSGPLRVAMKFPARSTRGATNKKAESRQPSENSVTDSNSDSEDESGMNFLEKRALNIKQNKAMLAKLMSE LESFPGSFRGRHPLPGSDSQSRRPRRRTFPGVASRRNPERRARPLTRSRSRILGSLDALPMEEEEEEDKYMLVRKRKTVDGYMNEDDLPR SRRSRSSVTLPHIIRPVEEITEEELENVCSNSREKIYNRSLGSTCHQCRQKTIDTKTNCRNPDCWGVRGQFCGPCLRNRYGEEVRDALLD PNWHCPPCRGICNCSFCRQRDGRCATGVLVYLAKYHGFGNVHAYLKSLKQEFEMQA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C22orf34-CDCA7 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000306721 | 0 | 10 | 146_170 | 7.0 | 451.0 | MYC | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000347703 | 0 | 9 | 146_170 | 7.0 | 372.0 | MYC | |
| Tgene | CDCA7 | chr22:50051053 | chr2:174223440 | ENST00000392567 | 0 | 8 | 146_170 | 7.0 | 322.0 | MYC |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C22orf34-CDCA7 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C22orf34-CDCA7 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0021831 | Intestinal Diseases | 1 | GENOMICS_ENGLAND | |
| Tgene | C0086438 | Hypogammaglobulinemia | 1 | GENOMICS_ENGLAND | |
| Tgene | C0398788 | Immunodeficiency syndrome, variable | 1 | GENOMICS_ENGLAND | |
| Tgene | C2931456 | Prostate cancer, familial | 1 | CTD_human | |
| Tgene | C3806482 | Recurrent respiratory infections | 1 | GENOMICS_ENGLAND | |
| Tgene | C4310799 | IMMUNODEFICIENCY-CENTROMERIC INSTABILITY-FACIAL ANOMALIES SYNDROME 3 | 1 | CTD_human;GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C4316788 | Abnormality of the intestine | 1 | GENOMICS_ENGLAND | |
| Tgene | C4722327 | PROSTATE CANCER, HEREDITARY, 1 | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies