
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARRB1-ANKFN1 (FusionGDB2 ID:HG408TG162282) |
Fusion Gene Summary for ARRB1-ANKFN1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARRB1-ANKFN1 | Fusion gene ID: hg408tg162282 | Hgene | Tgene | Gene symbol | ARRB1 | ANKFN1 | Gene ID | 408 | 162282 |
| Gene name | arrestin beta 1 | ankyrin repeat and fibronectin type III domain containing 1 | |
| Synonyms | ARB1|ARR1 | - | |
| Cytomap | ('ARRB1')('ANKFN1') 11q13.4 | 17q22 | |
| Type of gene | protein-coding | protein-coding | |
| Description | beta-arrestin-1arrestin 2non-visual arrestin-2 | ankyrin repeat and fibronectin type-III domain-containing protein 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q8N957 | |
| Ensembl transtripts involved in fusion gene | ENST00000360025, ENST00000393505, ENST00000420843, | ||
| Fusion gene scores | * DoF score | 18 X 10 X 9=1620 | 17 X 16 X 6=1632 |
| # samples | 23 | 19 | |
| ** MAII score | log2(23/1620*10)=-2.81628804682761 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(19/1632*10)=-3.10256973364055 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARRB1 [Title/Abstract] AND ANKFN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARRB1(75062632)-ANKFN1(54262110), # samples:2 ARRB1(75062632)-ANKFN1(54305278), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ARRB1-ANKFN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARRB1-ANKFN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARRB1-ANKFN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ARRB1-ANKFN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARRB1 | GO:0031397 | negative regulation of protein ubiquitination | 16378096 |
| Hgene | ARRB1 | GO:0032088 | negative regulation of NF-kappaB transcription factor activity | 16378096 |
| Hgene | ARRB1 | GO:0032715 | negative regulation of interleukin-6 production | 16378096 |
| Hgene | ARRB1 | GO:0032717 | negative regulation of interleukin-8 production | 16378096 |
| Hgene | ARRB1 | GO:0070374 | positive regulation of ERK1 and ERK2 cascade | 10644702 |
| Fusion gene breakpoints across ARRB1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ANKFN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-E2-A155-01A | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| ChimerDB4 | BRCA | TCGA-E2-A155-01A | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
Top |
Fusion Gene ORF analysis for ARRB1-ANKFN1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000360025 | ENST00000574292 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-3UTR | ENST00000360025 | ENST00000574292 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| 5CDS-3UTR | ENST00000393505 | ENST00000574292 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-3UTR | ENST00000393505 | ENST00000574292 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| 5CDS-3UTR | ENST00000420843 | ENST00000574292 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-3UTR | ENST00000420843 | ENST00000574292 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| 5CDS-intron | ENST00000360025 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-intron | ENST00000360025 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-intron | ENST00000393505 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-intron | ENST00000393505 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-intron | ENST00000420843 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| 5CDS-intron | ENST00000420843 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54262110 | + |
| In-frame | ENST00000360025 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| In-frame | ENST00000360025 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| In-frame | ENST00000393505 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| In-frame | ENST00000393505 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| In-frame | ENST00000420843 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| In-frame | ENST00000420843 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000420843 | ARRB1 | chr11 | 75062632 | - | ENST00000318698 | ANKFN1 | chr17 | 54305278 | + | 2488 | 118 | 16 | 2388 | 790 |
| ENST00000420843 | ARRB1 | chr11 | 75062632 | - | ENST00000566473 | ANKFN1 | chr17 | 54305278 | + | 3937 | 118 | 16 | 3546 | 1176 |
| ENST00000393505 | ARRB1 | chr11 | 75062632 | - | ENST00000318698 | ANKFN1 | chr17 | 54305278 | + | 2612 | 242 | 44 | 2512 | 822 |
| ENST00000393505 | ARRB1 | chr11 | 75062632 | - | ENST00000566473 | ANKFN1 | chr17 | 54305278 | + | 4061 | 242 | 44 | 3670 | 1208 |
| ENST00000360025 | ARRB1 | chr11 | 75062632 | - | ENST00000318698 | ANKFN1 | chr17 | 54305278 | + | 2488 | 118 | 16 | 2388 | 790 |
| ENST00000360025 | ARRB1 | chr11 | 75062632 | - | ENST00000566473 | ANKFN1 | chr17 | 54305278 | + | 3937 | 118 | 16 | 3546 | 1176 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000420843 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + | 0.005415838 | 0.99458414 |
| ENST00000420843 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + | 0.00159349 | 0.9984066 |
| ENST00000393505 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + | 0.004974973 | 0.995025 |
| ENST00000393505 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + | 0.001792629 | 0.99820733 |
| ENST00000360025 | ENST00000318698 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + | 0.005415838 | 0.99458414 |
| ENST00000360025 | ENST00000566473 | ARRB1 | chr11 | 75062632 | - | ANKFN1 | chr17 | 54305278 | + | 0.00159349 | 0.9984066 |
Top |
Fusion Genomic Features for ARRB1-ANKFN1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARRB1 | chr11 | 75062631 | - | ANKFN1 | chr17 | 54262109 | + | 0.000834413 | 0.99916565 |
| ARRB1 | chr11 | 75062631 | - | ANKFN1 | chr17 | 54305277 | + | 5.22E-06 | 0.99999475 |
| ARRB1 | chr11 | 75062631 | - | ANKFN1 | chr17 | 54262109 | + | 0.000834413 | 0.99916565 |
| ARRB1 | chr11 | 75062631 | - | ANKFN1 | chr17 | 54305277 | + | 5.22E-06 | 0.99999475 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
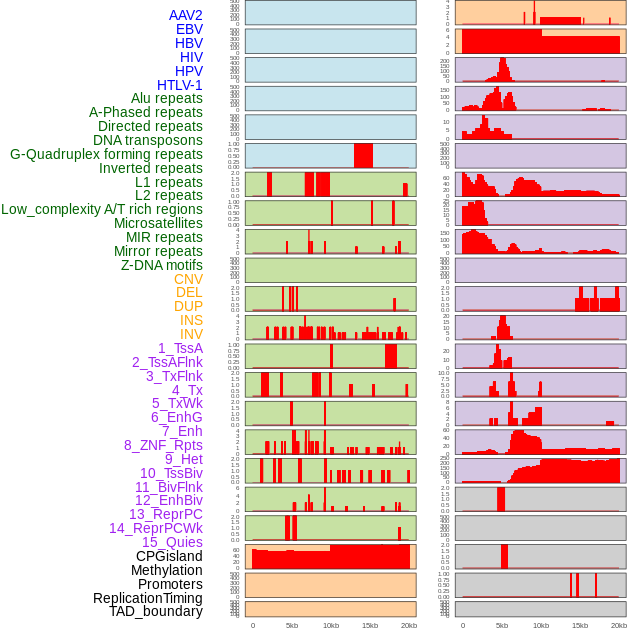 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
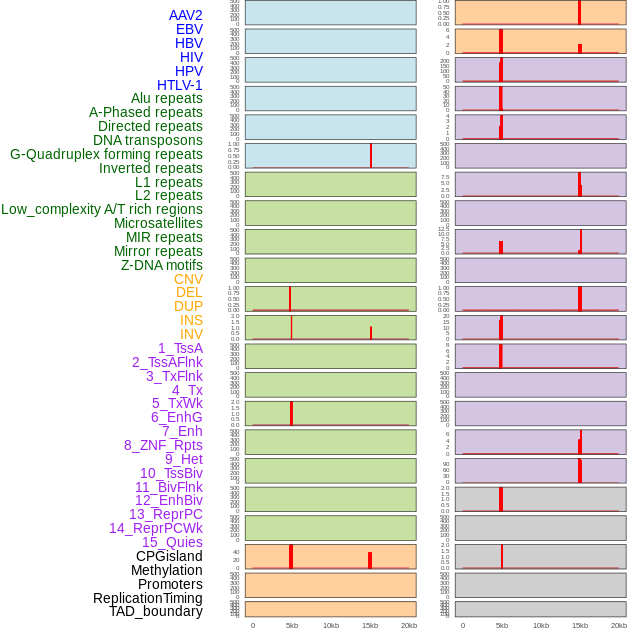 |
Top |
Fusion Protein Features for ARRB1-ANKFN1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:75062632/chr17:54262110) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | ANKFN1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ANKFN1 | chr11:75062632 | chr17:54305278 | ENST00000318698 | 0 | 17 | 205_236 | 7 | 764.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | ANKFN1 | chr11:75062632 | chr17:54305278 | ENST00000318698 | 0 | 17 | 273_369 | 7 | 764.0 | Domain | Fibronectin type-III | |
| Tgene | ANKFN1 | chr11:75062632 | chr17:54305278 | ENST00000318698 | 0 | 17 | 136_165 | 7 | 764.0 | Repeat | Note=ANK 1 | |
| Tgene | ANKFN1 | chr11:75062632 | chr17:54305278 | ENST00000318698 | 0 | 17 | 173_202 | 7 | 764.0 | Repeat | Note=ANK 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000360025 | - | 1 | 15 | 385_395 | 6 | 411.0 | Motif | Note=[DE]-X(1%2C2)-F-X-X-[FL]-X-X-X-R motif |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000420843 | - | 1 | 16 | 385_395 | 6 | 419.0 | Motif | Note=[DE]-X(1%2C2)-F-X-X-[FL]-X-X-X-R motif |
Top |
Fusion Gene Sequence for ARRB1-ANKFN1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6832_6832_1_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000360025_ANKFN1_chr17_54305278_ENST00000318698_length(transcript)=2488nt_BP=118nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGGCTACTCTTTAAAGACAGGCATTTTACTTGCAGCAAAATAATAGGAAGGAGATTCGCTTG CTTTGCACAGAGGCTGAGCCACAGGAGAAAGCAAAGCCAATGTGATTTATTGAATGAAAGCACTGGACAATTACCAACAACTTGTTCCTC TGCTGCCTCGAACAGCATAAACTGGAATTGTCGTGTGAAAATGACGCAACAAATGCAAAATTTACATCTCTGTCAGTCAAAAAAACATAG TGCTCCCTCATCTCCCAACGCAGCCAAACGCCTGTACAGGAACCTCTCTGAGAAACTGAAAGGGAGCCACTCTTCCTTCGATGAGGCCTA TTTTAGGACAAGAACTGATCGGCTGAGTCTCAGGAAGACCTCGGTGAATTTCCAGGGCAATGAAGCCATGTTTGAGGCAGTCGAACAGCA GGACATGGATGCTGTGCAGATCCTCCTGTATCAGTACACACCAGAAGAACTTGACCTCAACACACCTAACAGCGAGGGCTTGACACCCCT GGATATTGCCATCATGACCAACAATGTGCCCATTGCAAGGATTCTTCTGAGGACAGGGGCCCGAGAAAGTCCACACTTTGTCAGCCTGGA AAGCCGAGCAATGCACCTCAACACACTGGTCCAGGAAGCCCAGGAGAGGGTGAGTGAACTGTCTGCCCAGGTGGAGAATGAAGGATTCAC TCTGGACAACACAGAGAAAGAGAAGCAGCTGAAAGCTTGGGAGTGGAGGTATCGGCTCTACAGACGCATGAAAACAGGCTTTGAGCATGC CAGAGCCCCTGAGATGCCAACCAATGTCTGTCTCATGGTAACCAGCAGCACATCACTCACTGTCAGCTTCCAAGAGCCTCTTAGCGTCAA TGCAGCTGTAGTAACCAGGTATAAAGTGGAATGGAGTATGTCCGAAGACTTTTCTCCTTTGGCTGGAGAAATCATCATGGATAATCTGCA GACTCTGAGATGCACAATCACAGGACTTACAATGGGCCAACAGTATTTTGTTCAAGTCTCGGCTTACAATATGAAAGGATGGGGACCTGC TCAGACCACGACACCGGCATGTGCCTCTCCTTCTAACTGGAAAGACTATGACGACAGAGAGCCCAGACACAAGGGACAGAGTGAAGTTTT GGAAGGTCTGCTGCAGCAGGTCCGAGCCCTTCATCAGCATTACAGTTGCCGGGAAAGCACAAAATTACAAACCACAGGCCGCAAGCAGTC AGTCTCAAGAAGCCTGAAACACCTGTTCCATTCCTCGAACAAGTTTGTGAAGACCTTAAAACGGGGACTCTACATAGCCGTTATATTTTA TTACAAAGACAATATCTTAGTCACCAATGAAGATCAAGTACCAATTGTTGAAATAGATGACTCTCACACCAGTTCTATTACACAAGATTT TCTGTGGTTCACGAAGCTGTCTTGTATGTGGGAAGATATAAGGTGGCTGAGGCAAAGCATACCAATATCCTCATCCTCATCCACAGTGCT GCAAACTCGGCAGAAGATGCTCGCAGCAACAGCACAGCTACAGAATTTACTTGGGACACACAACTTGGGAAGAGTTTACTATGAGCCCAT TAAAGATCGACATGGAAACATACTCATAGTCACCATCAGGGAGGTGGAGATGCTTTATTCATTTTTTAATGGCAAATGGATGCAGATCTC AAAGCTGCAAAGCCAGAGAAAGTCTCTATCAACACCTGAGGAGCCAACAGCTTTAGACATTCTACTGATAACCATCCAGGATATTCTATC CTATCACAAAAGGAGTCATCAGCGTCTCTTTCCTGGATTATATCTGGGTTACCTAAAGCTCTGTAGCTCTGTGGATCAAATCAAAGTTCT TGTTACCCAAAAGTTGCCCAACATTCTCTGCCACGTGAAGATCCGTGAAAACAATAATATTTCTAGAGAGGAATGGGAATGGATCCAAAA GCTTTCTGGCTCTGAATCTATGGAAAGTGTGGATCATACTTCTGACTGCCCCATGCAATTGTTCTTCTACGAGCTCCAGATGGCAGTGAA AGCTCTCCTTCAGCAGATCAATATACCTCTACACCAGGCAAGGAACTTCCGCCTCTACACACAGGAGGTGTTGGAAATGGGTCACAATGT GTCCTTTCTTCTCCTGCTCCCTGCCTCAGACGACGTCTGTACAGCCCCAGGACAGAATAATCCTTACACCCCACACTCAGGGTTTCTTAA CCTCCCTCTTCAGATGTTTGAACTTGGTATAGTAGCTTGTTTCACCTAGAAATATTAACCCAGCCTCCTTATAATAAAATCACAAAGTTA TATCTGTTCCCCCTTGTCCCAGTGGAGGGTCAATAAATCACATGATGGCTTTGGCAAC >6832_6832_1_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000360025_ANKFN1_chr17_54305278_ENST00000318698_length(amino acids)=790AA_BP=34 MARAPPAGWGFSSLGADAADLPATVADHGRQRDPRLLFKDRHFTCSKIIGRRFACFAQRLSHRRKQSQCDLLNESTGQLPTTCSSAASNS INWNCRVKMTQQMQNLHLCQSKKHSAPSSPNAAKRLYRNLSEKLKGSHSSFDEAYFRTRTDRLSLRKTSVNFQGNEAMFEAVEQQDMDAV QILLYQYTPEELDLNTPNSEGLTPLDIAIMTNNVPIARILLRTGARESPHFVSLESRAMHLNTLVQEAQERVSELSAQVENEGFTLDNTE KEKQLKAWEWRYRLYRRMKTGFEHARAPEMPTNVCLMVTSSTSLTVSFQEPLSVNAAVVTRYKVEWSMSEDFSPLAGEIIMDNLQTLRCT ITGLTMGQQYFVQVSAYNMKGWGPAQTTTPACASPSNWKDYDDREPRHKGQSEVLEGLLQQVRALHQHYSCRESTKLQTTGRKQSVSRSL KHLFHSSNKFVKTLKRGLYIAVIFYYKDNILVTNEDQVPIVEIDDSHTSSITQDFLWFTKLSCMWEDIRWLRQSIPISSSSSTVLQTRQK MLAATAQLQNLLGTHNLGRVYYEPIKDRHGNILIVTIREVEMLYSFFNGKWMQISKLQSQRKSLSTPEEPTALDILLITIQDILSYHKRS HQRLFPGLYLGYLKLCSSVDQIKVLVTQKLPNILCHVKIRENNNISREEWEWIQKLSGSESMESVDHTSDCPMQLFFYELQMAVKALLQQ INIPLHQARNFRLYTQEVLEMGHNVSFLLLLPASDDVCTAPGQNNPYTPHSGFLNLPLQMFELGIVACFT -------------------------------------------------------------- >6832_6832_2_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000360025_ANKFN1_chr17_54305278_ENST00000566473_length(transcript)=3937nt_BP=118nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGGCTACTCTTTAAAGACAGGCATTTTACTTGCAGCAAAATAATAGGAAGGAGATTCGCTTG CTTTGCACAGAGGCTGAGCCACAGGAGAAAGCAAAGCCAATGTGATTTATTGAATGAAAGCACTGGACAATTACCAACAACTTGTTCCTC TGCTGCCTCGAACAGCATAAACTGGAATTGTCGTGTGAAAATGACGCAACAAATGCAAAATTTACATCTCTGTCAGTCAAAAAAACATAG TGCTCCCTCATCTCCCAACGCAGCCAAACGCCTGTACAGGAACCTCTCTGAGAAACTGAAAGGGAGCCACTCTTCCTTCGATGAGGCCTA TTTTAGGACAAGAACTGATCGGCTGAGTCTCAGGAAGACCTCGGTGAATTTCCAGGGCAATGAAGCCATGTTTGAGGCAGTCGAACAGCA GGACATGGATGCTGTGCAGATCCTCCTGTATCAGTACACACCAGAAGAACTTGACCTCAACACACCTAACAGCGAGGGCTTGACACCCCT GGATATTGCCATCATGACCAACAATGTGCCCATTGCAAGGATTCTTCTGAGGACAGGGGCCCGAGAAAGTCCACACTTTGTCAGCCTGGA AAGCCGAGCAATGCACCTCAACACACTGGTCCAGGAAGCCCAGGAGAGGGTGAGTGAACTGTCTGCCCAGGTGGAGAATGAAGGATTCAC TCTGGACAACACAGAGAAAGAGAAGCAGCTGAAAGCTTGGGAGTGGAGGTATCGGCTCTACAGACGCATGAAAACAGGCTTTGAGCATGC CAGAGCCCCTGAGATGCCAACCAATGTCTGTCTCATGGTAACCAGCAGCACATCACTCACTGTCAGCTTCCAAGAGCCTCTTAGCGTCAA TGCAGCTGTAGTAACCAGGTATAAAGTGGAATGGAGTATGTCCGAAGACTTTTCTCCTTTGGCTGGAGAAATCATCATGGATAATCTGCA GACTCTGAGATGCACAATCACAGGACTTACAATGGGCCAACAGTATTTTGTTCAAGTCTCGGCTTACAATATGAAAGGATGGGGACCTGC TCAGACCACGACACCGGCATGTGCCTCTCCTTCTAACTGGAAAGACTATGACGACAGAGAGCCCAGACACAAGGGACAGAGTGAAGTTTT GGAAGGTCTGCTGCAGCAGGTCCGAGCCCTTCATCAGCATTACAGTTGCCGGGAAAGCACAAAATTACAAACCACAGGCCGCAAGCAGTC AGTCTCAAGAAGCCTGAAACACCTGTTCCATTCCTCGAACAAGTTTGTGAAGACCTTAAAACGGGGACTCTACATAGCCGTTATATTTTA TTACAAAGACAATATCTTAGTCACCAATGAAGATCAAGTACCAATTGTTGAAATAGATGACTCTCACACCAGTTCTATTACACAAGATTT TCTGTGGTTCACGAAGCTGTCTTGTATGTGGGAAGATATAAGGTGGCTGAGGCAAAGCATACCAATATCCTCATCCTCATCCACAGTGCT GCAAACTCGGCAGAAGATGCTCGCAGCAACAGCACAGCTACAGAATTTACTTGGGACACACAACTTGGGAAGAGTTTACTATGAGCCCAT TAAAGATCGACATGGAAACATACTCATAGTCACCATCAGGGAGGTGGAGATGCTTTATTCATTTTTTAATGGCAAATGGATGCAGATCTC AAAGCTGCAAAGCCAGAGAAAGTCTCTATCAACACCTGAGGAGCCAACAGCTTTAGACATTCTACTGATAACCATCCAGGATATTCTATC CTATCACAAAAGGAGTCATCAGCGTCTCTTTCCTGGATTATATCTGGGTTACCTAAAGCTCTGTAGCTCTGTGGATCAAATCAAAGTTCT TGTTACCCAAAAGTTGCCCAACATTCTCTGCCACGTGAAGATCCGTGAAAACAATAATATTTCTAGAGAGGAATGGGAATGGATCCAAAA GCTTTCTGGCTCTGAATCTATGGAAAGTGTGGATCATACTTCTGACTGCCCCATGCAATTGTTCTTCTACGAGCTCCAGATGGCAGTGAA AGCTCTCCTTCAGCAGATCAATATACCTCTACACCAGGCAAGGAACTTCCGCCTCTACACACAGGAGGTGTTGGAAATGGGTCACAATGT GTCCTTTCTTCTCCTGCTCCCTGCCTCAGACGACGTCTGTACAGCCCCAGGACAGAATAATCCTTACACCCCACACTCAGGGTTTCTTAA CCTCCCTCTTCAGATGTTTGAACTTGTTCATTTTTGCAGCTACAGAGAGAAATTTATTAGTCTGTATTGCCGCCTTTCTGCTGTTGTGGA GCTGGATTCTCTGAACACCCAACAGTCCCTCAGGGAAGCAATCTCAGACAGCGAGGTTGCAGCTGCCAAACAAAGACACCAGCAAGTTTT AGATTTCATTCAGCAAATAGATGAAGTCTGGCGTGAAATGAGATGGATCATGGATGCTCTACAGTATGCAAGATACAAACAACCAGTTTC TGGCTTGCCCATCACTAAGCTGATAGACCCCTCAGATGAGCAGAGCCTAAAGAAGATCAATTCTACATCATCATCACATATAGACTGTCT TCCATCCCCACCCCCATCCCCAGAGATGCACAGAAGAAAGACAGTGAGTGATTCACAGCCCTGCTCTGATGAAGAAGCCTGCTCAGAAGT CTTCCTCCCCACCAACAGTGACTACGACTCCAGCGATGCCCTGAGCCCCAGAGACCTGGACCTGGTCTACCTATCATCTCACGACATTGC GCAGCAGACCCTTAGCGGCCTAAGCGGCAGCGCCCCCGACGTCCTGCAAGTGCACGACGTGAAAACCCCTCTGGGGCCGGGCCAGGATCC CCAGGGCGAGGGCCCAAATCCCGATCACTCATGTGCCGAGTTTCTCCATAGCCTGACCCTCACGGGGTTCACACCCAAGAACCACGCCAA GACTGTGTCCGGTGGGCGGCCCCCGCTAGGCTTCCTGGGAAAGCGGAAGCCAGGCAAGCACCCCCACTATGGCGGCTTCAGCCGCCATCA TCGCTGGTTGCGCATCCACAGCGAGACCCAGTCGCTATCGCTCTCTGAGGGCATTTATACACAGCACCTGTCCCAGGCCTGTGGTCTGGC CCAGGAGCCCAAGGAGGCCAAGCGGGCCGGCCCTGCCCTTGATGATCCCAGGGGCCTAACTCTGGCCCACGCTGCCAGCCTTCCTGAGGA GCGGAACAGCAGTCTCCAGGACGCGAGGCCTTCCGTCCGCCGCCTCTACGTGGAGCCCTACGCAGCGGCCGTGGTGGCCCAGGACGAAAA ACCATGGGCAAGCTTGAGCCCGCCCTCTGGAGGCCGCATCACCCTGCCCAGCCCCACTGGCCCCGATGTGAGTCAGGAGGGCCCCACCGC CTCTCCCATGTCAGAAATACTCAGCAGCATGCTTTAGGGAGGCCCATCCCGGCTGTCCACCCCTCCATGGCTGCTACCTGCGTTTTACAT CACCCTTACCCCCATCCTGCCCCACTGTGTACCCACTCATTTTCAAGCGTTTTGAATGTTATAAATACAAAGGTTACAAGTTCAAGGTCC TCTTTTTTTGGAACAGAGTGGTGGGTGGAGGCCAGAGTTGCCAGTGCCATTCCCACTTCAGCCTAGAAAGGGCATGGGGGAGTTGTGTCA ACATGGAATACGACATACAGTGACTCAAACATGCCACCCTGTTGGTGGCACCTATGACTGAAGCTGGCCATCCCAAAGAGAGACCCTCTG TTCTGCAGCTGGTTCTGTAATCTGACCCCTAGTTTAGGGCTCTTTCATGAATTTGTGATTGATGAAG >6832_6832_2_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000360025_ANKFN1_chr17_54305278_ENST00000566473_length(amino acids)=1176AA_BP=34 MARAPPAGWGFSSLGADAADLPATVADHGRQRDPRLLFKDRHFTCSKIIGRRFACFAQRLSHRRKQSQCDLLNESTGQLPTTCSSAASNS INWNCRVKMTQQMQNLHLCQSKKHSAPSSPNAAKRLYRNLSEKLKGSHSSFDEAYFRTRTDRLSLRKTSVNFQGNEAMFEAVEQQDMDAV QILLYQYTPEELDLNTPNSEGLTPLDIAIMTNNVPIARILLRTGARESPHFVSLESRAMHLNTLVQEAQERVSELSAQVENEGFTLDNTE KEKQLKAWEWRYRLYRRMKTGFEHARAPEMPTNVCLMVTSSTSLTVSFQEPLSVNAAVVTRYKVEWSMSEDFSPLAGEIIMDNLQTLRCT ITGLTMGQQYFVQVSAYNMKGWGPAQTTTPACASPSNWKDYDDREPRHKGQSEVLEGLLQQVRALHQHYSCRESTKLQTTGRKQSVSRSL KHLFHSSNKFVKTLKRGLYIAVIFYYKDNILVTNEDQVPIVEIDDSHTSSITQDFLWFTKLSCMWEDIRWLRQSIPISSSSSTVLQTRQK MLAATAQLQNLLGTHNLGRVYYEPIKDRHGNILIVTIREVEMLYSFFNGKWMQISKLQSQRKSLSTPEEPTALDILLITIQDILSYHKRS HQRLFPGLYLGYLKLCSSVDQIKVLVTQKLPNILCHVKIRENNNISREEWEWIQKLSGSESMESVDHTSDCPMQLFFYELQMAVKALLQQ INIPLHQARNFRLYTQEVLEMGHNVSFLLLLPASDDVCTAPGQNNPYTPHSGFLNLPLQMFELVHFCSYREKFISLYCRLSAVVELDSLN TQQSLREAISDSEVAAAKQRHQQVLDFIQQIDEVWREMRWIMDALQYARYKQPVSGLPITKLIDPSDEQSLKKINSTSSSHIDCLPSPPP SPEMHRRKTVSDSQPCSDEEACSEVFLPTNSDYDSSDALSPRDLDLVYLSSHDIAQQTLSGLSGSAPDVLQVHDVKTPLGPGQDPQGEGP NPDHSCAEFLHSLTLTGFTPKNHAKTVSGGRPPLGFLGKRKPGKHPHYGGFSRHHRWLRIHSETQSLSLSEGIYTQHLSQACGLAQEPKE AKRAGPALDDPRGLTLAHAASLPEERNSSLQDARPSVRRLYVEPYAAAVVAQDEKPWASLSPPSGGRITLPSPTGPDVSQEGPTASPMSE ILSSML -------------------------------------------------------------- >6832_6832_3_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000393505_ANKFN1_chr17_54305278_ENST00000318698_length(transcript)=2612nt_BP=242nt ACCCCGCGCGGTTCCACGCCCCTGGCCGCGGCCCGGGCGCTGCGCTGCTCGACGCGGCGGGCGGCGGGCGGGGACCGGGGGCGGGGGCGG CGGCGGCGGCCGGGAGAGCGGAGGAGGCGGAGCAGGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCC TGGGCGCTGACGCCGCGGACCTCCCTGCGACCGTCGCGGACCATGGGCGACAAAGGGACCCGAGGCTACTCTTTAAAGACAGGCATTTTA CTTGCAGCAAAATAATAGGAAGGAGATTCGCTTGCTTTGCACAGAGGCTGAGCCACAGGAGAAAGCAAAGCCAATGTGATTTATTGAATG AAAGCACTGGACAATTACCAACAACTTGTTCCTCTGCTGCCTCGAACAGCATAAACTGGAATTGTCGTGTGAAAATGACGCAACAAATGC AAAATTTACATCTCTGTCAGTCAAAAAAACATAGTGCTCCCTCATCTCCCAACGCAGCCAAACGCCTGTACAGGAACCTCTCTGAGAAAC TGAAAGGGAGCCACTCTTCCTTCGATGAGGCCTATTTTAGGACAAGAACTGATCGGCTGAGTCTCAGGAAGACCTCGGTGAATTTCCAGG GCAATGAAGCCATGTTTGAGGCAGTCGAACAGCAGGACATGGATGCTGTGCAGATCCTCCTGTATCAGTACACACCAGAAGAACTTGACC TCAACACACCTAACAGCGAGGGCTTGACACCCCTGGATATTGCCATCATGACCAACAATGTGCCCATTGCAAGGATTCTTCTGAGGACAG GGGCCCGAGAAAGTCCACACTTTGTCAGCCTGGAAAGCCGAGCAATGCACCTCAACACACTGGTCCAGGAAGCCCAGGAGAGGGTGAGTG AACTGTCTGCCCAGGTGGAGAATGAAGGATTCACTCTGGACAACACAGAGAAAGAGAAGCAGCTGAAAGCTTGGGAGTGGAGGTATCGGC TCTACAGACGCATGAAAACAGGCTTTGAGCATGCCAGAGCCCCTGAGATGCCAACCAATGTCTGTCTCATGGTAACCAGCAGCACATCAC TCACTGTCAGCTTCCAAGAGCCTCTTAGCGTCAATGCAGCTGTAGTAACCAGGTATAAAGTGGAATGGAGTATGTCCGAAGACTTTTCTC CTTTGGCTGGAGAAATCATCATGGATAATCTGCAGACTCTGAGATGCACAATCACAGGACTTACAATGGGCCAACAGTATTTTGTTCAAG TCTCGGCTTACAATATGAAAGGATGGGGACCTGCTCAGACCACGACACCGGCATGTGCCTCTCCTTCTAACTGGAAAGACTATGACGACA GAGAGCCCAGACACAAGGGACAGAGTGAAGTTTTGGAAGGTCTGCTGCAGCAGGTCCGAGCCCTTCATCAGCATTACAGTTGCCGGGAAA GCACAAAATTACAAACCACAGGCCGCAAGCAGTCAGTCTCAAGAAGCCTGAAACACCTGTTCCATTCCTCGAACAAGTTTGTGAAGACCT TAAAACGGGGACTCTACATAGCCGTTATATTTTATTACAAAGACAATATCTTAGTCACCAATGAAGATCAAGTACCAATTGTTGAAATAG ATGACTCTCACACCAGTTCTATTACACAAGATTTTCTGTGGTTCACGAAGCTGTCTTGTATGTGGGAAGATATAAGGTGGCTGAGGCAAA GCATACCAATATCCTCATCCTCATCCACAGTGCTGCAAACTCGGCAGAAGATGCTCGCAGCAACAGCACAGCTACAGAATTTACTTGGGA CACACAACTTGGGAAGAGTTTACTATGAGCCCATTAAAGATCGACATGGAAACATACTCATAGTCACCATCAGGGAGGTGGAGATGCTTT ATTCATTTTTTAATGGCAAATGGATGCAGATCTCAAAGCTGCAAAGCCAGAGAAAGTCTCTATCAACACCTGAGGAGCCAACAGCTTTAG ACATTCTACTGATAACCATCCAGGATATTCTATCCTATCACAAAAGGAGTCATCAGCGTCTCTTTCCTGGATTATATCTGGGTTACCTAA AGCTCTGTAGCTCTGTGGATCAAATCAAAGTTCTTGTTACCCAAAAGTTGCCCAACATTCTCTGCCACGTGAAGATCCGTGAAAACAATA ATATTTCTAGAGAGGAATGGGAATGGATCCAAAAGCTTTCTGGCTCTGAATCTATGGAAAGTGTGGATCATACTTCTGACTGCCCCATGC AATTGTTCTTCTACGAGCTCCAGATGGCAGTGAAAGCTCTCCTTCAGCAGATCAATATACCTCTACACCAGGCAAGGAACTTCCGCCTCT ACACACAGGAGGTGTTGGAAATGGGTCACAATGTGTCCTTTCTTCTCCTGCTCCCTGCCTCAGACGACGTCTGTACAGCCCCAGGACAGA ATAATCCTTACACCCCACACTCAGGGTTTCTTAACCTCCCTCTTCAGATGTTTGAACTTGGTATAGTAGCTTGTTTCACCTAGAAATATT AACCCAGCCTCCTTATAATAAAATCACAAAGTTATATCTGTTCCCCCTTGTCCCAGTGGAGGGTCAATAAATCACATGATGGCTTTGGCA AC >6832_6832_3_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000393505_ANKFN1_chr17_54305278_ENST00000318698_length(amino acids)=822AA_BP=66 MLDAAGGGRGPGAGAAAAAGRAEEAEQGAGSGLARAPPAGWGFSSLGADAADLPATVADHGRQRDPRLLFKDRHFTCSKIIGRRFACFAQ RLSHRRKQSQCDLLNESTGQLPTTCSSAASNSINWNCRVKMTQQMQNLHLCQSKKHSAPSSPNAAKRLYRNLSEKLKGSHSSFDEAYFRT RTDRLSLRKTSVNFQGNEAMFEAVEQQDMDAVQILLYQYTPEELDLNTPNSEGLTPLDIAIMTNNVPIARILLRTGARESPHFVSLESRA MHLNTLVQEAQERVSELSAQVENEGFTLDNTEKEKQLKAWEWRYRLYRRMKTGFEHARAPEMPTNVCLMVTSSTSLTVSFQEPLSVNAAV VTRYKVEWSMSEDFSPLAGEIIMDNLQTLRCTITGLTMGQQYFVQVSAYNMKGWGPAQTTTPACASPSNWKDYDDREPRHKGQSEVLEGL LQQVRALHQHYSCRESTKLQTTGRKQSVSRSLKHLFHSSNKFVKTLKRGLYIAVIFYYKDNILVTNEDQVPIVEIDDSHTSSITQDFLWF TKLSCMWEDIRWLRQSIPISSSSSTVLQTRQKMLAATAQLQNLLGTHNLGRVYYEPIKDRHGNILIVTIREVEMLYSFFNGKWMQISKLQ SQRKSLSTPEEPTALDILLITIQDILSYHKRSHQRLFPGLYLGYLKLCSSVDQIKVLVTQKLPNILCHVKIRENNNISREEWEWIQKLSG SESMESVDHTSDCPMQLFFYELQMAVKALLQQINIPLHQARNFRLYTQEVLEMGHNVSFLLLLPASDDVCTAPGQNNPYTPHSGFLNLPL QMFELGIVACFT -------------------------------------------------------------- >6832_6832_4_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000393505_ANKFN1_chr17_54305278_ENST00000566473_length(transcript)=4061nt_BP=242nt ACCCCGCGCGGTTCCACGCCCCTGGCCGCGGCCCGGGCGCTGCGCTGCTCGACGCGGCGGGCGGCGGGCGGGGACCGGGGGCGGGGGCGG CGGCGGCGGCCGGGAGAGCGGAGGAGGCGGAGCAGGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCC TGGGCGCTGACGCCGCGGACCTCCCTGCGACCGTCGCGGACCATGGGCGACAAAGGGACCCGAGGCTACTCTTTAAAGACAGGCATTTTA CTTGCAGCAAAATAATAGGAAGGAGATTCGCTTGCTTTGCACAGAGGCTGAGCCACAGGAGAAAGCAAAGCCAATGTGATTTATTGAATG AAAGCACTGGACAATTACCAACAACTTGTTCCTCTGCTGCCTCGAACAGCATAAACTGGAATTGTCGTGTGAAAATGACGCAACAAATGC AAAATTTACATCTCTGTCAGTCAAAAAAACATAGTGCTCCCTCATCTCCCAACGCAGCCAAACGCCTGTACAGGAACCTCTCTGAGAAAC TGAAAGGGAGCCACTCTTCCTTCGATGAGGCCTATTTTAGGACAAGAACTGATCGGCTGAGTCTCAGGAAGACCTCGGTGAATTTCCAGG GCAATGAAGCCATGTTTGAGGCAGTCGAACAGCAGGACATGGATGCTGTGCAGATCCTCCTGTATCAGTACACACCAGAAGAACTTGACC TCAACACACCTAACAGCGAGGGCTTGACACCCCTGGATATTGCCATCATGACCAACAATGTGCCCATTGCAAGGATTCTTCTGAGGACAG GGGCCCGAGAAAGTCCACACTTTGTCAGCCTGGAAAGCCGAGCAATGCACCTCAACACACTGGTCCAGGAAGCCCAGGAGAGGGTGAGTG AACTGTCTGCCCAGGTGGAGAATGAAGGATTCACTCTGGACAACACAGAGAAAGAGAAGCAGCTGAAAGCTTGGGAGTGGAGGTATCGGC TCTACAGACGCATGAAAACAGGCTTTGAGCATGCCAGAGCCCCTGAGATGCCAACCAATGTCTGTCTCATGGTAACCAGCAGCACATCAC TCACTGTCAGCTTCCAAGAGCCTCTTAGCGTCAATGCAGCTGTAGTAACCAGGTATAAAGTGGAATGGAGTATGTCCGAAGACTTTTCTC CTTTGGCTGGAGAAATCATCATGGATAATCTGCAGACTCTGAGATGCACAATCACAGGACTTACAATGGGCCAACAGTATTTTGTTCAAG TCTCGGCTTACAATATGAAAGGATGGGGACCTGCTCAGACCACGACACCGGCATGTGCCTCTCCTTCTAACTGGAAAGACTATGACGACA GAGAGCCCAGACACAAGGGACAGAGTGAAGTTTTGGAAGGTCTGCTGCAGCAGGTCCGAGCCCTTCATCAGCATTACAGTTGCCGGGAAA GCACAAAATTACAAACCACAGGCCGCAAGCAGTCAGTCTCAAGAAGCCTGAAACACCTGTTCCATTCCTCGAACAAGTTTGTGAAGACCT TAAAACGGGGACTCTACATAGCCGTTATATTTTATTACAAAGACAATATCTTAGTCACCAATGAAGATCAAGTACCAATTGTTGAAATAG ATGACTCTCACACCAGTTCTATTACACAAGATTTTCTGTGGTTCACGAAGCTGTCTTGTATGTGGGAAGATATAAGGTGGCTGAGGCAAA GCATACCAATATCCTCATCCTCATCCACAGTGCTGCAAACTCGGCAGAAGATGCTCGCAGCAACAGCACAGCTACAGAATTTACTTGGGA CACACAACTTGGGAAGAGTTTACTATGAGCCCATTAAAGATCGACATGGAAACATACTCATAGTCACCATCAGGGAGGTGGAGATGCTTT ATTCATTTTTTAATGGCAAATGGATGCAGATCTCAAAGCTGCAAAGCCAGAGAAAGTCTCTATCAACACCTGAGGAGCCAACAGCTTTAG ACATTCTACTGATAACCATCCAGGATATTCTATCCTATCACAAAAGGAGTCATCAGCGTCTCTTTCCTGGATTATATCTGGGTTACCTAA AGCTCTGTAGCTCTGTGGATCAAATCAAAGTTCTTGTTACCCAAAAGTTGCCCAACATTCTCTGCCACGTGAAGATCCGTGAAAACAATA ATATTTCTAGAGAGGAATGGGAATGGATCCAAAAGCTTTCTGGCTCTGAATCTATGGAAAGTGTGGATCATACTTCTGACTGCCCCATGC AATTGTTCTTCTACGAGCTCCAGATGGCAGTGAAAGCTCTCCTTCAGCAGATCAATATACCTCTACACCAGGCAAGGAACTTCCGCCTCT ACACACAGGAGGTGTTGGAAATGGGTCACAATGTGTCCTTTCTTCTCCTGCTCCCTGCCTCAGACGACGTCTGTACAGCCCCAGGACAGA ATAATCCTTACACCCCACACTCAGGGTTTCTTAACCTCCCTCTTCAGATGTTTGAACTTGTTCATTTTTGCAGCTACAGAGAGAAATTTA TTAGTCTGTATTGCCGCCTTTCTGCTGTTGTGGAGCTGGATTCTCTGAACACCCAACAGTCCCTCAGGGAAGCAATCTCAGACAGCGAGG TTGCAGCTGCCAAACAAAGACACCAGCAAGTTTTAGATTTCATTCAGCAAATAGATGAAGTCTGGCGTGAAATGAGATGGATCATGGATG CTCTACAGTATGCAAGATACAAACAACCAGTTTCTGGCTTGCCCATCACTAAGCTGATAGACCCCTCAGATGAGCAGAGCCTAAAGAAGA TCAATTCTACATCATCATCACATATAGACTGTCTTCCATCCCCACCCCCATCCCCAGAGATGCACAGAAGAAAGACAGTGAGTGATTCAC AGCCCTGCTCTGATGAAGAAGCCTGCTCAGAAGTCTTCCTCCCCACCAACAGTGACTACGACTCCAGCGATGCCCTGAGCCCCAGAGACC TGGACCTGGTCTACCTATCATCTCACGACATTGCGCAGCAGACCCTTAGCGGCCTAAGCGGCAGCGCCCCCGACGTCCTGCAAGTGCACG ACGTGAAAACCCCTCTGGGGCCGGGCCAGGATCCCCAGGGCGAGGGCCCAAATCCCGATCACTCATGTGCCGAGTTTCTCCATAGCCTGA CCCTCACGGGGTTCACACCCAAGAACCACGCCAAGACTGTGTCCGGTGGGCGGCCCCCGCTAGGCTTCCTGGGAAAGCGGAAGCCAGGCA AGCACCCCCACTATGGCGGCTTCAGCCGCCATCATCGCTGGTTGCGCATCCACAGCGAGACCCAGTCGCTATCGCTCTCTGAGGGCATTT ATACACAGCACCTGTCCCAGGCCTGTGGTCTGGCCCAGGAGCCCAAGGAGGCCAAGCGGGCCGGCCCTGCCCTTGATGATCCCAGGGGCC TAACTCTGGCCCACGCTGCCAGCCTTCCTGAGGAGCGGAACAGCAGTCTCCAGGACGCGAGGCCTTCCGTCCGCCGCCTCTACGTGGAGC CCTACGCAGCGGCCGTGGTGGCCCAGGACGAAAAACCATGGGCAAGCTTGAGCCCGCCCTCTGGAGGCCGCATCACCCTGCCCAGCCCCA CTGGCCCCGATGTGAGTCAGGAGGGCCCCACCGCCTCTCCCATGTCAGAAATACTCAGCAGCATGCTTTAGGGAGGCCCATCCCGGCTGT CCACCCCTCCATGGCTGCTACCTGCGTTTTACATCACCCTTACCCCCATCCTGCCCCACTGTGTACCCACTCATTTTCAAGCGTTTTGAA TGTTATAAATACAAAGGTTACAAGTTCAAGGTCCTCTTTTTTTGGAACAGAGTGGTGGGTGGAGGCCAGAGTTGCCAGTGCCATTCCCAC TTCAGCCTAGAAAGGGCATGGGGGAGTTGTGTCAACATGGAATACGACATACAGTGACTCAAACATGCCACCCTGTTGGTGGCACCTATG ACTGAAGCTGGCCATCCCAAAGAGAGACCCTCTGTTCTGCAGCTGGTTCTGTAATCTGACCCCTAGTTTAGGGCTCTTTCATGAATTTGT GATTGATGAAG >6832_6832_4_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000393505_ANKFN1_chr17_54305278_ENST00000566473_length(amino acids)=1208AA_BP=66 MLDAAGGGRGPGAGAAAAAGRAEEAEQGAGSGLARAPPAGWGFSSLGADAADLPATVADHGRQRDPRLLFKDRHFTCSKIIGRRFACFAQ RLSHRRKQSQCDLLNESTGQLPTTCSSAASNSINWNCRVKMTQQMQNLHLCQSKKHSAPSSPNAAKRLYRNLSEKLKGSHSSFDEAYFRT RTDRLSLRKTSVNFQGNEAMFEAVEQQDMDAVQILLYQYTPEELDLNTPNSEGLTPLDIAIMTNNVPIARILLRTGARESPHFVSLESRA MHLNTLVQEAQERVSELSAQVENEGFTLDNTEKEKQLKAWEWRYRLYRRMKTGFEHARAPEMPTNVCLMVTSSTSLTVSFQEPLSVNAAV VTRYKVEWSMSEDFSPLAGEIIMDNLQTLRCTITGLTMGQQYFVQVSAYNMKGWGPAQTTTPACASPSNWKDYDDREPRHKGQSEVLEGL LQQVRALHQHYSCRESTKLQTTGRKQSVSRSLKHLFHSSNKFVKTLKRGLYIAVIFYYKDNILVTNEDQVPIVEIDDSHTSSITQDFLWF TKLSCMWEDIRWLRQSIPISSSSSTVLQTRQKMLAATAQLQNLLGTHNLGRVYYEPIKDRHGNILIVTIREVEMLYSFFNGKWMQISKLQ SQRKSLSTPEEPTALDILLITIQDILSYHKRSHQRLFPGLYLGYLKLCSSVDQIKVLVTQKLPNILCHVKIRENNNISREEWEWIQKLSG SESMESVDHTSDCPMQLFFYELQMAVKALLQQINIPLHQARNFRLYTQEVLEMGHNVSFLLLLPASDDVCTAPGQNNPYTPHSGFLNLPL QMFELVHFCSYREKFISLYCRLSAVVELDSLNTQQSLREAISDSEVAAAKQRHQQVLDFIQQIDEVWREMRWIMDALQYARYKQPVSGLP ITKLIDPSDEQSLKKINSTSSSHIDCLPSPPPSPEMHRRKTVSDSQPCSDEEACSEVFLPTNSDYDSSDALSPRDLDLVYLSSHDIAQQT LSGLSGSAPDVLQVHDVKTPLGPGQDPQGEGPNPDHSCAEFLHSLTLTGFTPKNHAKTVSGGRPPLGFLGKRKPGKHPHYGGFSRHHRWL RIHSETQSLSLSEGIYTQHLSQACGLAQEPKEAKRAGPALDDPRGLTLAHAASLPEERNSSLQDARPSVRRLYVEPYAAAVVAQDEKPWA SLSPPSGGRITLPSPTGPDVSQEGPTASPMSEILSSML -------------------------------------------------------------- >6832_6832_5_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000420843_ANKFN1_chr17_54305278_ENST00000318698_length(transcript)=2488nt_BP=118nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGGCTACTCTTTAAAGACAGGCATTTTACTTGCAGCAAAATAATAGGAAGGAGATTCGCTTG CTTTGCACAGAGGCTGAGCCACAGGAGAAAGCAAAGCCAATGTGATTTATTGAATGAAAGCACTGGACAATTACCAACAACTTGTTCCTC TGCTGCCTCGAACAGCATAAACTGGAATTGTCGTGTGAAAATGACGCAACAAATGCAAAATTTACATCTCTGTCAGTCAAAAAAACATAG TGCTCCCTCATCTCCCAACGCAGCCAAACGCCTGTACAGGAACCTCTCTGAGAAACTGAAAGGGAGCCACTCTTCCTTCGATGAGGCCTA TTTTAGGACAAGAACTGATCGGCTGAGTCTCAGGAAGACCTCGGTGAATTTCCAGGGCAATGAAGCCATGTTTGAGGCAGTCGAACAGCA GGACATGGATGCTGTGCAGATCCTCCTGTATCAGTACACACCAGAAGAACTTGACCTCAACACACCTAACAGCGAGGGCTTGACACCCCT GGATATTGCCATCATGACCAACAATGTGCCCATTGCAAGGATTCTTCTGAGGACAGGGGCCCGAGAAAGTCCACACTTTGTCAGCCTGGA AAGCCGAGCAATGCACCTCAACACACTGGTCCAGGAAGCCCAGGAGAGGGTGAGTGAACTGTCTGCCCAGGTGGAGAATGAAGGATTCAC TCTGGACAACACAGAGAAAGAGAAGCAGCTGAAAGCTTGGGAGTGGAGGTATCGGCTCTACAGACGCATGAAAACAGGCTTTGAGCATGC CAGAGCCCCTGAGATGCCAACCAATGTCTGTCTCATGGTAACCAGCAGCACATCACTCACTGTCAGCTTCCAAGAGCCTCTTAGCGTCAA TGCAGCTGTAGTAACCAGGTATAAAGTGGAATGGAGTATGTCCGAAGACTTTTCTCCTTTGGCTGGAGAAATCATCATGGATAATCTGCA GACTCTGAGATGCACAATCACAGGACTTACAATGGGCCAACAGTATTTTGTTCAAGTCTCGGCTTACAATATGAAAGGATGGGGACCTGC TCAGACCACGACACCGGCATGTGCCTCTCCTTCTAACTGGAAAGACTATGACGACAGAGAGCCCAGACACAAGGGACAGAGTGAAGTTTT GGAAGGTCTGCTGCAGCAGGTCCGAGCCCTTCATCAGCATTACAGTTGCCGGGAAAGCACAAAATTACAAACCACAGGCCGCAAGCAGTC AGTCTCAAGAAGCCTGAAACACCTGTTCCATTCCTCGAACAAGTTTGTGAAGACCTTAAAACGGGGACTCTACATAGCCGTTATATTTTA TTACAAAGACAATATCTTAGTCACCAATGAAGATCAAGTACCAATTGTTGAAATAGATGACTCTCACACCAGTTCTATTACACAAGATTT TCTGTGGTTCACGAAGCTGTCTTGTATGTGGGAAGATATAAGGTGGCTGAGGCAAAGCATACCAATATCCTCATCCTCATCCACAGTGCT GCAAACTCGGCAGAAGATGCTCGCAGCAACAGCACAGCTACAGAATTTACTTGGGACACACAACTTGGGAAGAGTTTACTATGAGCCCAT TAAAGATCGACATGGAAACATACTCATAGTCACCATCAGGGAGGTGGAGATGCTTTATTCATTTTTTAATGGCAAATGGATGCAGATCTC AAAGCTGCAAAGCCAGAGAAAGTCTCTATCAACACCTGAGGAGCCAACAGCTTTAGACATTCTACTGATAACCATCCAGGATATTCTATC CTATCACAAAAGGAGTCATCAGCGTCTCTTTCCTGGATTATATCTGGGTTACCTAAAGCTCTGTAGCTCTGTGGATCAAATCAAAGTTCT TGTTACCCAAAAGTTGCCCAACATTCTCTGCCACGTGAAGATCCGTGAAAACAATAATATTTCTAGAGAGGAATGGGAATGGATCCAAAA GCTTTCTGGCTCTGAATCTATGGAAAGTGTGGATCATACTTCTGACTGCCCCATGCAATTGTTCTTCTACGAGCTCCAGATGGCAGTGAA AGCTCTCCTTCAGCAGATCAATATACCTCTACACCAGGCAAGGAACTTCCGCCTCTACACACAGGAGGTGTTGGAAATGGGTCACAATGT GTCCTTTCTTCTCCTGCTCCCTGCCTCAGACGACGTCTGTACAGCCCCAGGACAGAATAATCCTTACACCCCACACTCAGGGTTTCTTAA CCTCCCTCTTCAGATGTTTGAACTTGGTATAGTAGCTTGTTTCACCTAGAAATATTAACCCAGCCTCCTTATAATAAAATCACAAAGTTA TATCTGTTCCCCCTTGTCCCAGTGGAGGGTCAATAAATCACATGATGGCTTTGGCAAC >6832_6832_5_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000420843_ANKFN1_chr17_54305278_ENST00000318698_length(amino acids)=790AA_BP=34 MARAPPAGWGFSSLGADAADLPATVADHGRQRDPRLLFKDRHFTCSKIIGRRFACFAQRLSHRRKQSQCDLLNESTGQLPTTCSSAASNS INWNCRVKMTQQMQNLHLCQSKKHSAPSSPNAAKRLYRNLSEKLKGSHSSFDEAYFRTRTDRLSLRKTSVNFQGNEAMFEAVEQQDMDAV QILLYQYTPEELDLNTPNSEGLTPLDIAIMTNNVPIARILLRTGARESPHFVSLESRAMHLNTLVQEAQERVSELSAQVENEGFTLDNTE KEKQLKAWEWRYRLYRRMKTGFEHARAPEMPTNVCLMVTSSTSLTVSFQEPLSVNAAVVTRYKVEWSMSEDFSPLAGEIIMDNLQTLRCT ITGLTMGQQYFVQVSAYNMKGWGPAQTTTPACASPSNWKDYDDREPRHKGQSEVLEGLLQQVRALHQHYSCRESTKLQTTGRKQSVSRSL KHLFHSSNKFVKTLKRGLYIAVIFYYKDNILVTNEDQVPIVEIDDSHTSSITQDFLWFTKLSCMWEDIRWLRQSIPISSSSSTVLQTRQK MLAATAQLQNLLGTHNLGRVYYEPIKDRHGNILIVTIREVEMLYSFFNGKWMQISKLQSQRKSLSTPEEPTALDILLITIQDILSYHKRS HQRLFPGLYLGYLKLCSSVDQIKVLVTQKLPNILCHVKIRENNNISREEWEWIQKLSGSESMESVDHTSDCPMQLFFYELQMAVKALLQQ INIPLHQARNFRLYTQEVLEMGHNVSFLLLLPASDDVCTAPGQNNPYTPHSGFLNLPLQMFELGIVACFT -------------------------------------------------------------- >6832_6832_6_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000420843_ANKFN1_chr17_54305278_ENST00000566473_length(transcript)=3937nt_BP=118nt GGGAGCCGGGAGCGGGCTGGCCCGCGCTCCTCCTGCTGGCTGGGGATTTTCCAGCCTGGGCGCTGACGCCGCGGACCTCCCTGCGACCGT CGCGGACCATGGGCGACAAAGGGACCCGAGGCTACTCTTTAAAGACAGGCATTTTACTTGCAGCAAAATAATAGGAAGGAGATTCGCTTG CTTTGCACAGAGGCTGAGCCACAGGAGAAAGCAAAGCCAATGTGATTTATTGAATGAAAGCACTGGACAATTACCAACAACTTGTTCCTC TGCTGCCTCGAACAGCATAAACTGGAATTGTCGTGTGAAAATGACGCAACAAATGCAAAATTTACATCTCTGTCAGTCAAAAAAACATAG TGCTCCCTCATCTCCCAACGCAGCCAAACGCCTGTACAGGAACCTCTCTGAGAAACTGAAAGGGAGCCACTCTTCCTTCGATGAGGCCTA TTTTAGGACAAGAACTGATCGGCTGAGTCTCAGGAAGACCTCGGTGAATTTCCAGGGCAATGAAGCCATGTTTGAGGCAGTCGAACAGCA GGACATGGATGCTGTGCAGATCCTCCTGTATCAGTACACACCAGAAGAACTTGACCTCAACACACCTAACAGCGAGGGCTTGACACCCCT GGATATTGCCATCATGACCAACAATGTGCCCATTGCAAGGATTCTTCTGAGGACAGGGGCCCGAGAAAGTCCACACTTTGTCAGCCTGGA AAGCCGAGCAATGCACCTCAACACACTGGTCCAGGAAGCCCAGGAGAGGGTGAGTGAACTGTCTGCCCAGGTGGAGAATGAAGGATTCAC TCTGGACAACACAGAGAAAGAGAAGCAGCTGAAAGCTTGGGAGTGGAGGTATCGGCTCTACAGACGCATGAAAACAGGCTTTGAGCATGC CAGAGCCCCTGAGATGCCAACCAATGTCTGTCTCATGGTAACCAGCAGCACATCACTCACTGTCAGCTTCCAAGAGCCTCTTAGCGTCAA TGCAGCTGTAGTAACCAGGTATAAAGTGGAATGGAGTATGTCCGAAGACTTTTCTCCTTTGGCTGGAGAAATCATCATGGATAATCTGCA GACTCTGAGATGCACAATCACAGGACTTACAATGGGCCAACAGTATTTTGTTCAAGTCTCGGCTTACAATATGAAAGGATGGGGACCTGC TCAGACCACGACACCGGCATGTGCCTCTCCTTCTAACTGGAAAGACTATGACGACAGAGAGCCCAGACACAAGGGACAGAGTGAAGTTTT GGAAGGTCTGCTGCAGCAGGTCCGAGCCCTTCATCAGCATTACAGTTGCCGGGAAAGCACAAAATTACAAACCACAGGCCGCAAGCAGTC AGTCTCAAGAAGCCTGAAACACCTGTTCCATTCCTCGAACAAGTTTGTGAAGACCTTAAAACGGGGACTCTACATAGCCGTTATATTTTA TTACAAAGACAATATCTTAGTCACCAATGAAGATCAAGTACCAATTGTTGAAATAGATGACTCTCACACCAGTTCTATTACACAAGATTT TCTGTGGTTCACGAAGCTGTCTTGTATGTGGGAAGATATAAGGTGGCTGAGGCAAAGCATACCAATATCCTCATCCTCATCCACAGTGCT GCAAACTCGGCAGAAGATGCTCGCAGCAACAGCACAGCTACAGAATTTACTTGGGACACACAACTTGGGAAGAGTTTACTATGAGCCCAT TAAAGATCGACATGGAAACATACTCATAGTCACCATCAGGGAGGTGGAGATGCTTTATTCATTTTTTAATGGCAAATGGATGCAGATCTC AAAGCTGCAAAGCCAGAGAAAGTCTCTATCAACACCTGAGGAGCCAACAGCTTTAGACATTCTACTGATAACCATCCAGGATATTCTATC CTATCACAAAAGGAGTCATCAGCGTCTCTTTCCTGGATTATATCTGGGTTACCTAAAGCTCTGTAGCTCTGTGGATCAAATCAAAGTTCT TGTTACCCAAAAGTTGCCCAACATTCTCTGCCACGTGAAGATCCGTGAAAACAATAATATTTCTAGAGAGGAATGGGAATGGATCCAAAA GCTTTCTGGCTCTGAATCTATGGAAAGTGTGGATCATACTTCTGACTGCCCCATGCAATTGTTCTTCTACGAGCTCCAGATGGCAGTGAA AGCTCTCCTTCAGCAGATCAATATACCTCTACACCAGGCAAGGAACTTCCGCCTCTACACACAGGAGGTGTTGGAAATGGGTCACAATGT GTCCTTTCTTCTCCTGCTCCCTGCCTCAGACGACGTCTGTACAGCCCCAGGACAGAATAATCCTTACACCCCACACTCAGGGTTTCTTAA CCTCCCTCTTCAGATGTTTGAACTTGTTCATTTTTGCAGCTACAGAGAGAAATTTATTAGTCTGTATTGCCGCCTTTCTGCTGTTGTGGA GCTGGATTCTCTGAACACCCAACAGTCCCTCAGGGAAGCAATCTCAGACAGCGAGGTTGCAGCTGCCAAACAAAGACACCAGCAAGTTTT AGATTTCATTCAGCAAATAGATGAAGTCTGGCGTGAAATGAGATGGATCATGGATGCTCTACAGTATGCAAGATACAAACAACCAGTTTC TGGCTTGCCCATCACTAAGCTGATAGACCCCTCAGATGAGCAGAGCCTAAAGAAGATCAATTCTACATCATCATCACATATAGACTGTCT TCCATCCCCACCCCCATCCCCAGAGATGCACAGAAGAAAGACAGTGAGTGATTCACAGCCCTGCTCTGATGAAGAAGCCTGCTCAGAAGT CTTCCTCCCCACCAACAGTGACTACGACTCCAGCGATGCCCTGAGCCCCAGAGACCTGGACCTGGTCTACCTATCATCTCACGACATTGC GCAGCAGACCCTTAGCGGCCTAAGCGGCAGCGCCCCCGACGTCCTGCAAGTGCACGACGTGAAAACCCCTCTGGGGCCGGGCCAGGATCC CCAGGGCGAGGGCCCAAATCCCGATCACTCATGTGCCGAGTTTCTCCATAGCCTGACCCTCACGGGGTTCACACCCAAGAACCACGCCAA GACTGTGTCCGGTGGGCGGCCCCCGCTAGGCTTCCTGGGAAAGCGGAAGCCAGGCAAGCACCCCCACTATGGCGGCTTCAGCCGCCATCA TCGCTGGTTGCGCATCCACAGCGAGACCCAGTCGCTATCGCTCTCTGAGGGCATTTATACACAGCACCTGTCCCAGGCCTGTGGTCTGGC CCAGGAGCCCAAGGAGGCCAAGCGGGCCGGCCCTGCCCTTGATGATCCCAGGGGCCTAACTCTGGCCCACGCTGCCAGCCTTCCTGAGGA GCGGAACAGCAGTCTCCAGGACGCGAGGCCTTCCGTCCGCCGCCTCTACGTGGAGCCCTACGCAGCGGCCGTGGTGGCCCAGGACGAAAA ACCATGGGCAAGCTTGAGCCCGCCCTCTGGAGGCCGCATCACCCTGCCCAGCCCCACTGGCCCCGATGTGAGTCAGGAGGGCCCCACCGC CTCTCCCATGTCAGAAATACTCAGCAGCATGCTTTAGGGAGGCCCATCCCGGCTGTCCACCCCTCCATGGCTGCTACCTGCGTTTTACAT CACCCTTACCCCCATCCTGCCCCACTGTGTACCCACTCATTTTCAAGCGTTTTGAATGTTATAAATACAAAGGTTACAAGTTCAAGGTCC TCTTTTTTTGGAACAGAGTGGTGGGTGGAGGCCAGAGTTGCCAGTGCCATTCCCACTTCAGCCTAGAAAGGGCATGGGGGAGTTGTGTCA ACATGGAATACGACATACAGTGACTCAAACATGCCACCCTGTTGGTGGCACCTATGACTGAAGCTGGCCATCCCAAAGAGAGACCCTCTG TTCTGCAGCTGGTTCTGTAATCTGACCCCTAGTTTAGGGCTCTTTCATGAATTTGTGATTGATGAAG >6832_6832_6_ARRB1-ANKFN1_ARRB1_chr11_75062632_ENST00000420843_ANKFN1_chr17_54305278_ENST00000566473_length(amino acids)=1176AA_BP=34 MARAPPAGWGFSSLGADAADLPATVADHGRQRDPRLLFKDRHFTCSKIIGRRFACFAQRLSHRRKQSQCDLLNESTGQLPTTCSSAASNS INWNCRVKMTQQMQNLHLCQSKKHSAPSSPNAAKRLYRNLSEKLKGSHSSFDEAYFRTRTDRLSLRKTSVNFQGNEAMFEAVEQQDMDAV QILLYQYTPEELDLNTPNSEGLTPLDIAIMTNNVPIARILLRTGARESPHFVSLESRAMHLNTLVQEAQERVSELSAQVENEGFTLDNTE KEKQLKAWEWRYRLYRRMKTGFEHARAPEMPTNVCLMVTSSTSLTVSFQEPLSVNAAVVTRYKVEWSMSEDFSPLAGEIIMDNLQTLRCT ITGLTMGQQYFVQVSAYNMKGWGPAQTTTPACASPSNWKDYDDREPRHKGQSEVLEGLLQQVRALHQHYSCRESTKLQTTGRKQSVSRSL KHLFHSSNKFVKTLKRGLYIAVIFYYKDNILVTNEDQVPIVEIDDSHTSSITQDFLWFTKLSCMWEDIRWLRQSIPISSSSSTVLQTRQK MLAATAQLQNLLGTHNLGRVYYEPIKDRHGNILIVTIREVEMLYSFFNGKWMQISKLQSQRKSLSTPEEPTALDILLITIQDILSYHKRS HQRLFPGLYLGYLKLCSSVDQIKVLVTQKLPNILCHVKIRENNNISREEWEWIQKLSGSESMESVDHTSDCPMQLFFYELQMAVKALLQQ INIPLHQARNFRLYTQEVLEMGHNVSFLLLLPASDDVCTAPGQNNPYTPHSGFLNLPLQMFELVHFCSYREKFISLYCRLSAVVELDSLN TQQSLREAISDSEVAAAKQRHQQVLDFIQQIDEVWREMRWIMDALQYARYKQPVSGLPITKLIDPSDEQSLKKINSTSSSHIDCLPSPPP SPEMHRRKTVSDSQPCSDEEACSEVFLPTNSDYDSSDALSPRDLDLVYLSSHDIAQQTLSGLSGSAPDVLQVHDVKTPLGPGQDPQGEGP NPDHSCAEFLHSLTLTGFTPKNHAKTVSGGRPPLGFLGKRKPGKHPHYGGFSRHHRWLRIHSETQSLSLSEGIYTQHLSQACGLAQEPKE AKRAGPALDDPRGLTLAHAASLPEERNSSLQDARPSVRRLYVEPYAAAVVAQDEKPWASLSPPSGGRITLPSPTGPDVSQEGPTASPMSE ILSSML -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARRB1-ANKFN1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000360025 | - | 1 | 15 | 45_86 | 6.666666666666667 | 411.0 | CHRM2 |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000420843 | - | 1 | 16 | 45_86 | 6.666666666666667 | 419.0 | CHRM2 |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000360025 | - | 1 | 15 | 1_163 | 6.666666666666667 | 411.0 | SRC |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000420843 | - | 1 | 16 | 1_163 | 6.666666666666667 | 419.0 | SRC |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000360025 | - | 1 | 15 | 318_418 | 6.666666666666667 | 411.0 | TRAF6 |
| Hgene | ARRB1 | chr11:75062632 | chr17:54305278 | ENST00000420843 | - | 1 | 16 | 318_418 | 6.666666666666667 | 419.0 | TRAF6 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARRB1-ANKFN1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARRB1-ANKFN1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ARRB1 | C0023890 | Liver Cirrhosis | 1 | CTD_human |
| Hgene | ARRB1 | C0041696 | Unipolar Depression | 1 | PSYGENET |
| Hgene | ARRB1 | C0239946 | Fibrosis, Liver | 1 | CTD_human |
| Hgene | ARRB1 | C1269683 | Major Depressive Disorder | 1 | PSYGENET |
| Hgene | ARRB1 | C3178803 | Social Anhedonia | 1 | PSYGENET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies