
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ASAH1-ANKZF1 (FusionGDB2 ID:HG427TG55139) |
Fusion Gene Summary for ASAH1-ANKZF1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ASAH1-ANKZF1 | Fusion gene ID: hg427tg55139 | Hgene | Tgene | Gene symbol | ASAH1 | ANKZF1 | Gene ID | 427 | 55139 |
| Gene name | N-acylsphingosine amidohydrolase 1 | ankyrin repeat and zinc finger peptidyl tRNA hydrolase 1 | |
| Synonyms | AC|ACDase|ASAH|PHP|PHP32|SMAPME | Vms1|ZNF744 | |
| Cytomap | ('ASAH1')('ANKZF1') 8p22 | 2q35 | |
| Type of gene | protein-coding | protein-coding | |
| Description | acid ceramidaseN-acylethanolamine hydrolase ASAH1N-acylsphingosine amidohydrolase (acid ceramidase) 1acid CDaseacylsphingosine deacylaseputative 32 kDa heart protein | ankyrin repeat and zinc finger domain-containing protein 1ankyrin repeat and zinc finger domain containing 1zinc finger protein 744 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000262097, ENST00000314146, ENST00000381733, ENST00000417108, ENST00000520051, ENST00000520781, | ||
| Fusion gene scores | * DoF score | 15 X 16 X 7=1680 | 4 X 4 X 3=48 |
| # samples | 16 | 4 | |
| ** MAII score | log2(16/1680*10)=-3.39231742277876 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ASAH1 [Title/Abstract] AND ANKZF1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ASAH1(17921965)-ANKZF1(220099547), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ASAH1-ANKZF1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ASAH1-ANKZF1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ASAH1-ANKZF1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ASAH1-ANKZF1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ASAH1 | GO:0046512 | sphingosine biosynthetic process | 12815059 |
| Hgene | ASAH1 | GO:0046513 | ceramide biosynthetic process | 12764132|12815059 |
| Hgene | ASAH1 | GO:0046514 | ceramide catabolic process | 12815059 |
| Fusion gene breakpoints across ASAH1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ANKZF1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-VR-A8EQ | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
Top |
Fusion Gene ORF analysis for ASAH1-ANKZF1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000262097 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000262097 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000262097 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000314146 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000314146 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000314146 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000381733 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000381733 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| In-frame | ENST00000381733 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000417108 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000417108 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000417108 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000520051 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000520051 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000520051 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000520781 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000520781 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| intron-3CDS | ENST00000520781 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000262097 | ASAH1 | chr8 | 17921965 | - | ENST00000323348 | ANKZF1 | chr2 | 220099547 | + | 1970 | 769 | 15 | 1745 | 576 |
| ENST00000262097 | ASAH1 | chr8 | 17921965 | - | ENST00000409849 | ANKZF1 | chr2 | 220099547 | + | 1970 | 769 | 15 | 1745 | 576 |
| ENST00000262097 | ASAH1 | chr8 | 17921965 | - | ENST00000410034 | ANKZF1 | chr2 | 220099547 | + | 1950 | 769 | 15 | 1745 | 576 |
| ENST00000381733 | ASAH1 | chr8 | 17921965 | - | ENST00000323348 | ANKZF1 | chr2 | 220099547 | + | 1873 | 672 | 5 | 1648 | 547 |
| ENST00000381733 | ASAH1 | chr8 | 17921965 | - | ENST00000409849 | ANKZF1 | chr2 | 220099547 | + | 1873 | 672 | 5 | 1648 | 547 |
| ENST00000381733 | ASAH1 | chr8 | 17921965 | - | ENST00000410034 | ANKZF1 | chr2 | 220099547 | + | 1853 | 672 | 5 | 1648 | 547 |
| ENST00000314146 | ASAH1 | chr8 | 17921965 | - | ENST00000323348 | ANKZF1 | chr2 | 220099547 | + | 1824 | 623 | 22 | 1599 | 525 |
| ENST00000314146 | ASAH1 | chr8 | 17921965 | - | ENST00000409849 | ANKZF1 | chr2 | 220099547 | + | 1824 | 623 | 22 | 1599 | 525 |
| ENST00000314146 | ASAH1 | chr8 | 17921965 | - | ENST00000410034 | ANKZF1 | chr2 | 220099547 | + | 1804 | 623 | 22 | 1599 | 525 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000262097 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.010715942 | 0.989284 |
| ENST00000262097 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.010715942 | 0.989284 |
| ENST00000262097 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.011571411 | 0.98842865 |
| ENST00000381733 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.034553163 | 0.9654468 |
| ENST00000381733 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.034553163 | 0.9654468 |
| ENST00000381733 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.038056437 | 0.9619436 |
| ENST00000314146 | ENST00000323348 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.04032652 | 0.9596735 |
| ENST00000314146 | ENST00000409849 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.04032652 | 0.9596735 |
| ENST00000314146 | ENST00000410034 | ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.044402696 | 0.95559734 |
Top |
Fusion Genomic Features for ASAH1-ANKZF1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.9992374 | 0.00076265 |
| ASAH1 | chr8 | 17921965 | - | ANKZF1 | chr2 | 220099547 | + | 0.9992374 | 0.00076265 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
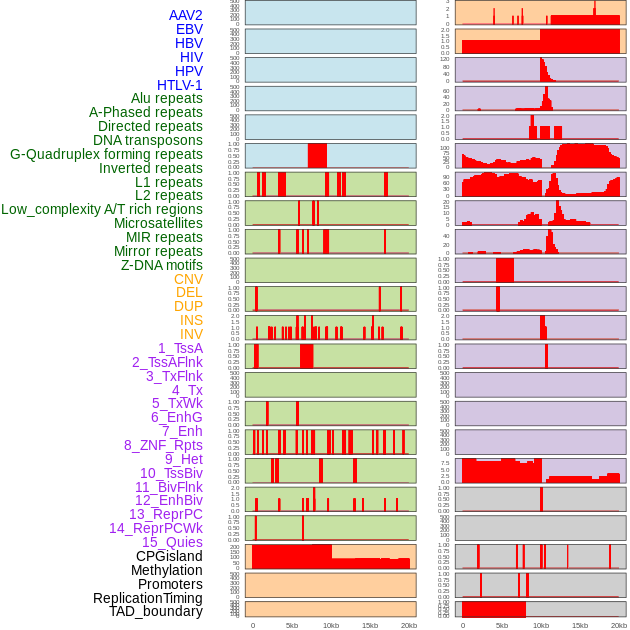 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
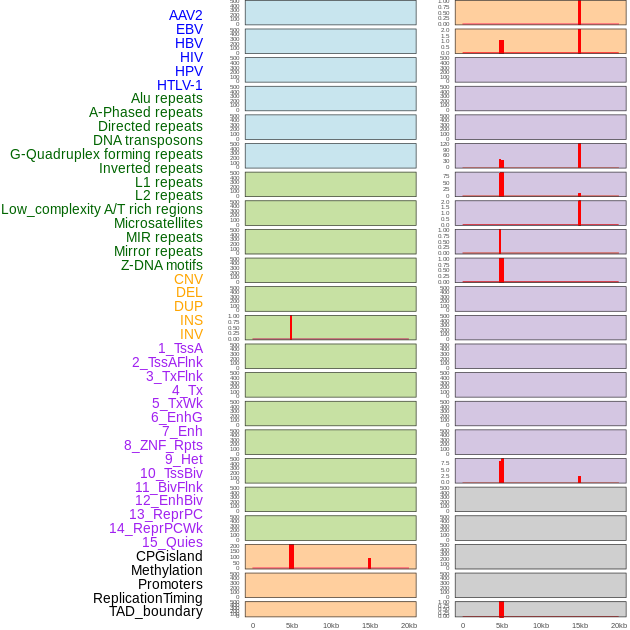 |
Top |
Fusion Protein Features for ASAH1-ANKZF1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:17921965/chr2:220099547) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000323348 | 8 | 14 | 609_659 | 401 | 727.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000410034 | 8 | 14 | 609_659 | 401 | 727.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000323348 | 8 | 14 | 654_666 | 401 | 727.0 | Region | VCP/p97-interacting motif (VIM) | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000410034 | 8 | 14 | 654_666 | 401 | 727.0 | Region | VCP/p97-interacting motif (VIM) | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000323348 | 8 | 14 | 493_526 | 401 | 727.0 | Repeat | Note=ANK 1 | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000323348 | 8 | 14 | 534_563 | 401 | 727.0 | Repeat | Note=ANK 2 | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000410034 | 8 | 14 | 493_526 | 401 | 727.0 | Repeat | Note=ANK 1 | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000410034 | 8 | 14 | 534_563 | 401 | 727.0 | Repeat | Note=ANK 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000323348 | 8 | 14 | 72_96 | 401 | 727.0 | Zinc finger | Note=C2H2-type | |
| Tgene | ANKZF1 | chr8:17921965 | chr2:220099547 | ENST00000410034 | 8 | 14 | 72_96 | 401 | 727.0 | Zinc finger | Note=C2H2-type |
Top |
Fusion Gene Sequence for ASAH1-ANKZF1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6930_6930_1_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000262097_ANKZF1_chr2_220099547_ENST00000323348_length(transcript)=1970nt_BP=769nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGGAGAGATTATTTCATTCAATATTTTT TATGAATTATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGGGTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTG GAGCTAGTGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCCCAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAG AAAAGCCGAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGAAGAGGAGCCTTCCACACAGTCATCCCAGGCAGTT GCTGCCCCCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCTCTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGA GATGTTGGAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCTGTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGC TTTACTCTCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCTGCTGGAAGCAGGTGCTGACCCCACTGTGCAGGAC TCTCGGGCCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTTCCGAAGGTTCATGGAGAAGAATCCAGATGCCTAC GATTACAACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCAGGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGG CGGCAACGGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGAAGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGA GAGAAGAGAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTACCTCTCCAATCCCTGACTCTGCAATCGTCAATACT CGACGCTGCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCTCGACTTCTCTTTCTGCTCCACACGTTGCCTCCAG GATCATCGCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGGGGCCAACTCAGGGACCTGAGAGGGCACATTCACA GCAGCCCTAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGTGAAGGACACTCGGGAACTAGGGCAAAGACAGGGC TAGAGGTATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGCAAGGAATGTGTACTTGTACTTACA >6930_6930_1_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000262097_ANKZF1_chr2_220099547_ENST00000323348_length(amino acids)=576AA_BP=251 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLGEIISFNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVEL TVGTLDLCESEVLPKRRRRKRNKKEKSRDQEAGAHRTLLQQTQEEEPSTQSSQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVL KLQLAPSPADPRVLSLLSAPLGSGGFTLLHAAAAAGRGSVVRLLLEAGADPTVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKA QVPGPLTPEMEARQATRKREQKAARRQREEQQQRQQEQEEREREEQRRFAALSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWS CGASLQGLTPFHYLDFSFCSTRCLQDHRRQAGRPSS -------------------------------------------------------------- >6930_6930_2_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000262097_ANKZF1_chr2_220099547_ENST00000409849_length(transcript)=1970nt_BP=769nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGGAGAGATTATTTCATTCAATATTTTT TATGAATTATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGGGTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTG GAGCTAGTGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCCCAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAG AAAAGCCGAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGAAGAGGAGCCTTCCACACAGTCATCCCAGGCAGTT GCTGCCCCCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCTCTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGA GATGTTGGAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCTGTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGC TTTACTCTCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCTGCTGGAAGCAGGTGCTGACCCCACTGTGCAGGAC TCTCGGGCCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTTCCGAAGGTTCATGGAGAAGAATCCAGATGCCTAC GATTACAACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCAGGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGG CGGCAACGGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGAAGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGA GAGAAGAGAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTACCTCTCCAATCCCTGACTCTGCAATCGTCAATACT CGACGCTGCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCTCGACTTCTCTTTCTGCTCCACACGTTGCCTCCAG GATCATCGCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGGGGCCAACTCAGGGACCTGAGAGGGCACATTCACA GCAGCCCTAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGTGAAGGACACTCGGGAACTAGGGCAAAGACAGGGC TAGAGGTATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGCAAGGAATGTGTACTTGTACTTACA >6930_6930_2_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000262097_ANKZF1_chr2_220099547_ENST00000409849_length(amino acids)=576AA_BP=251 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLGEIISFNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVEL TVGTLDLCESEVLPKRRRRKRNKKEKSRDQEAGAHRTLLQQTQEEEPSTQSSQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVL KLQLAPSPADPRVLSLLSAPLGSGGFTLLHAAAAAGRGSVVRLLLEAGADPTVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKA QVPGPLTPEMEARQATRKREQKAARRQREEQQQRQQEQEEREREEQRRFAALSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWS CGASLQGLTPFHYLDFSFCSTRCLQDHRRQAGRPSS -------------------------------------------------------------- >6930_6930_3_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000262097_ANKZF1_chr2_220099547_ENST00000410034_length(transcript)=1950nt_BP=769nt GGCTCGGTCCGACTATTGCCCGCGGTGGGGGAGGGGGATGGATCACGCCACGCGCCAAAGGCGATCGCGACTCTCCTTCTGCAGGTAGCC TGGAAGGCTCTCTCTCTTTCTCTACGCCACCCTTTTCGTGGCACTGAAAAGCCCCGTCCTCTCCTCCCAGTCCCGCCTCCTCCGAGCGTT CCCCCTACTGCCTGGAATGGTGCGGTCCCAGGTCGCGGGTCACGCGGCGGAGGGGGCGTGGCCTGCCCCCGGCCCAGCCGGCTCTTCTTT GCCTCTGCTGGAGTCCGGGGAGTGGCGTTGGCTGCTAGAGCGATGCCGGGCCGGAGTTGCGTCGCCTTAGTCCTCCTGGCTGCCGCCGTC AGCTGTGCCGTCGCGCAGCACGCGCCGCCGTGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCA GTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATA GTGAATTCTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGC AACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGGAGAGATTATTTCATTCAATATTTTT TATGAATTATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGGGTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTG GAGCTAGTGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCCCAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAG AAAAGCCGAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGAAGAGGAGCCTTCCACACAGTCATCCCAGGCAGTT GCTGCCCCCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCTCTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGA GATGTTGGAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCTGTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGC TTTACTCTCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCTGCTGGAAGCAGGTGCTGACCCCACTGTGCAGGAC TCTCGGGCCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTTCCGAAGGTTCATGGAGAAGAATCCAGATGCCTAC GATTACAACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCAGGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGG CGGCAACGGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGAAGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGA GAGAAGAGAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTACCTCTCCAATCCCTGACTCTGCAATCGTCAATACT CGACGCTGCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCTCGACTTCTCTTTCTGCTCCACACGTTGCCTCCAG GATCATCGCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGGGGCCAACTCAGGGACCTGAGAGGGCACATTCACA GCAGCCCTAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGTGAAGGACACTCGGGAACTAGGGCAAAGACAGGGC TAGAGGTATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGCAAGG >6930_6930_3_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000262097_ANKZF1_chr2_220099547_ENST00000410034_length(amino acids)=576AA_BP=251 MPAVGEGDGSRHAPKAIATLLLQVAWKALSLSLRHPFRGTEKPRPLLPVPPPPSVPPTAWNGAVPGRGSRGGGGVACPRPSRLFFASAGV RGVALAARAMPGRSCVALVLLAAAVSCAVAQHAPPWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLK NMINTFVPSGKIMQVVDEKLPGLLGNFPGPFEEEMKGIAAVTDIPLGEIISFNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVEL TVGTLDLCESEVLPKRRRRKRNKKEKSRDQEAGAHRTLLQQTQEEEPSTQSSQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVL KLQLAPSPADPRVLSLLSAPLGSGGFTLLHAAAAAGRGSVVRLLLEAGADPTVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKA QVPGPLTPEMEARQATRKREQKAARRQREEQQQRQQEQEEREREEQRRFAALSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWS CGASLQGLTPFHYLDFSFCSTRCLQDHRRQAGRPSS -------------------------------------------------------------- >6930_6930_4_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000314146_ANKZF1_chr2_220099547_ENST00000323348_length(transcript)=1824nt_BP=623nt GGGCAGGATTTCCTGCTGGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCC CCCTGCCGAGCTACTCGCGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCG CTTAATGAACTGCTGCATCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGC CTCAATTCTGGGATTTGGCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACTGT CTTCCCTGCTGTTATAAGGTACAGAGGTGCAGTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGAT GCTTGACAAGGCACCAGTGCCTGGCCTACTTGGCAACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATAT ACCTTTAGGAGAGATTATTTCATTCAATATTTTTTATGAATTATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGG GTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTGGAGCTAGTGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCC CAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAGAAAAGCCGAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGA AGAGGAGCCTTCCACACAGTCATCCCAGGCAGTTGCTGCCCCCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCT CTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGAGATGTTGGAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCT GTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGCTTTACTCTCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCT GCTGGAAGCAGGTGCTGACCCCACTGTGCAGGACTCTCGGGCCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTT CCGAAGGTTCATGGAGAAGAATCCAGATGCCTACGATTACAACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCA GGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGGCGGCAACGGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGA AGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGAGAGAAGAGAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTAC CTCTCCAATCCCTGACTCTGCAATCGTCAATACTCGACGCTGCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCT CGACTTCTCTTTCTGCTCCACACGTTGCCTCCAGGATCATCGCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGG GGCCAACTCAGGGACCTGAGAGGGCACATTCACAGCAGCCCTAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGT GAAGGACACTCGGGAACTAGGGCAAAGACAGGGCTAGAGGTATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGC AAGGAATGTGTACTTGTACTTACA >6930_6930_4_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000314146_ANKZF1_chr2_220099547_ENST00000323348_length(amino acids)=525AA_BP=200 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTVFPAVIRYRGAVPWYTINLDLPPYKRWHELMLDKAPVPGLLGNFPGPFEEEMKGIAAVTDIPLGEIIS FNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVELTVGTLDLCESEVLPKRRRRKRNKKEKSRDQEAGAHRTLLQQTQEEEPSTQS SQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVLKLQLAPSPADPRVLSLLSAPLGSGGFTLLHAAAAAGRGSVVRLLLEAGADP TVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKAQVPGPLTPEMEARQATRKREQKAARRQREEQQQRQQEQEEREREEQRRFAA LSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWSCGASLQGLTPFHYLDFSFCSTRCLQDHRRQAGRPSS -------------------------------------------------------------- >6930_6930_5_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000314146_ANKZF1_chr2_220099547_ENST00000409849_length(transcript)=1824nt_BP=623nt GGGCAGGATTTCCTGCTGGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCC CCCTGCCGAGCTACTCGCGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCG CTTAATGAACTGCTGCATCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGC CTCAATTCTGGGATTTGGCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACTGT CTTCCCTGCTGTTATAAGGTACAGAGGTGCAGTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGAT GCTTGACAAGGCACCAGTGCCTGGCCTACTTGGCAACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATAT ACCTTTAGGAGAGATTATTTCATTCAATATTTTTTATGAATTATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGG GTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTGGAGCTAGTGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCC CAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAGAAAAGCCGAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGA AGAGGAGCCTTCCACACAGTCATCCCAGGCAGTTGCTGCCCCCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCT CTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGAGATGTTGGAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCT GTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGCTTTACTCTCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCT GCTGGAAGCAGGTGCTGACCCCACTGTGCAGGACTCTCGGGCCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTT CCGAAGGTTCATGGAGAAGAATCCAGATGCCTACGATTACAACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCA GGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGGCGGCAACGGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGA AGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGAGAGAAGAGAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTAC CTCTCCAATCCCTGACTCTGCAATCGTCAATACTCGACGCTGCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCT CGACTTCTCTTTCTGCTCCACACGTTGCCTCCAGGATCATCGCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGG GGCCAACTCAGGGACCTGAGAGGGCACATTCACAGCAGCCCTAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGT GAAGGACACTCGGGAACTAGGGCAAAGACAGGGCTAGAGGTATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGC AAGGAATGTGTACTTGTACTTACA >6930_6930_5_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000314146_ANKZF1_chr2_220099547_ENST00000409849_length(amino acids)=525AA_BP=200 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTVFPAVIRYRGAVPWYTINLDLPPYKRWHELMLDKAPVPGLLGNFPGPFEEEMKGIAAVTDIPLGEIIS FNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVELTVGTLDLCESEVLPKRRRRKRNKKEKSRDQEAGAHRTLLQQTQEEEPSTQS SQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVLKLQLAPSPADPRVLSLLSAPLGSGGFTLLHAAAAAGRGSVVRLLLEAGADP TVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKAQVPGPLTPEMEARQATRKREQKAARRQREEQQQRQQEQEEREREEQRRFAA LSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWSCGASLQGLTPFHYLDFSFCSTRCLQDHRRQAGRPSS -------------------------------------------------------------- >6930_6930_6_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000314146_ANKZF1_chr2_220099547_ENST00000410034_length(transcript)=1804nt_BP=623nt GGGCAGGATTTCCTGCTGGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCC CCCTGCCGAGCTACTCGCGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCG CTTAATGAACTGCTGCATCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGC CTCAATTCTGGGATTTGGCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACTGT CTTCCCTGCTGTTATAAGGTACAGAGGTGCAGTTCCATGGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGAT GCTTGACAAGGCACCAGTGCCTGGCCTACTTGGCAACTTTCCTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATAT ACCTTTAGGAGAGATTATTTCATTCAATATTTTTTATGAATTATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGG GTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTGGAGCTAGTGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCC CAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAGAAAAGCCGAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGA AGAGGAGCCTTCCACACAGTCATCCCAGGCAGTTGCTGCCCCCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCT CTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGAGATGTTGGAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCT GTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGCTTTACTCTCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCT GCTGGAAGCAGGTGCTGACCCCACTGTGCAGGACTCTCGGGCCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTT CCGAAGGTTCATGGAGAAGAATCCAGATGCCTACGATTACAACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCA GGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGGCGGCAACGGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGA AGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGAGAGAAGAGAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTAC CTCTCCAATCCCTGACTCTGCAATCGTCAATACTCGACGCTGCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCT CGACTTCTCTTTCTGCTCCACACGTTGCCTCCAGGATCATCGCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGG GGCCAACTCAGGGACCTGAGAGGGCACATTCACAGCAGCCCTAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGT GAAGGACACTCGGGAACTAGGGCAAAGACAGGGCTAGAGGTATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGC AAGG >6930_6930_6_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000314146_ANKZF1_chr2_220099547_ENST00000410034_length(amino acids)=525AA_BP=200 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTVFPAVIRYRGAVPWYTINLDLPPYKRWHELMLDKAPVPGLLGNFPGPFEEEMKGIAAVTDIPLGEIIS FNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVELTVGTLDLCESEVLPKRRRRKRNKKEKSRDQEAGAHRTLLQQTQEEEPSTQS SQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVLKLQLAPSPADPRVLSLLSAPLGSGGFTLLHAAAAAGRGSVVRLLLEAGADP TVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKAQVPGPLTPEMEARQATRKREQKAARRQREEQQQRQQEQEEREREEQRRFAA LSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWSCGASLQGLTPFHYLDFSFCSTRCLQDHRRQAGRPSS -------------------------------------------------------------- >6930_6930_7_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000381733_ANKZF1_chr2_220099547_ENST00000323348_length(transcript)=1873nt_BP=672nt GGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCCCCCTGCCGAGCTACTCG CGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCGCTTAATGAACTGCTGCA TCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGCCTCAATTCTGGGATTTG GCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCAT GGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAATT CTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTTC CTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGGAGAGATTATTTCATTCAATATTTTTTATGAAT TATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGGGTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTGGAGCTAG TGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCCCAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAGAAAAGCC GAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGAAGAGGAGCCTTCCACACAGTCATCCCAGGCAGTTGCTGCCC CCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCTCTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGAGATGTTG GAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCTGTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGCTTTACTC TCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCTGCTGGAAGCAGGTGCTGACCCCACTGTGCAGGACTCTCGGG CCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTTCCGAAGGTTCATGGAGAAGAATCCAGATGCCTACGATTACA ACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCAGGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGGCGGCAAC GGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGAAGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGAGAGAAGA GAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTACCTCTCCAATCCCTGACTCTGCAATCGTCAATACTCGACGCT GCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCTCGACTTCTCTTTCTGCTCCACACGTTGCCTCCAGGATCATC GCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGGGGCCAACTCAGGGACCTGAGAGGGCACATTCACAGCAGCCC TAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGTGAAGGACACTCGGGAACTAGGGCAAAGACAGGGCTAGAGGT ATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGCAAGGAATGTGTACTTGTACTTACA >6930_6930_7_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000381733_ANKZF1_chr2_220099547_ENST00000323348_length(amino acids)=547AA_BP=222 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMINTFVPSGKIMQVVDEKLPGLLGNFPG PFEEEMKGIAAVTDIPLGEIISFNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVELTVGTLDLCESEVLPKRRRRKRNKKEKSRD QEAGAHRTLLQQTQEEEPSTQSSQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVLKLQLAPSPADPRVLSLLSAPLGSGGFTLL HAAAAAGRGSVVRLLLEAGADPTVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKAQVPGPLTPEMEARQATRKREQKAARRQRE EQQQRQQEQEEREREEQRRFAALSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWSCGASLQGLTPFHYLDFSFCSTRCLQDHRR QAGRPSS -------------------------------------------------------------- >6930_6930_8_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000381733_ANKZF1_chr2_220099547_ENST00000409849_length(transcript)=1873nt_BP=672nt GGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCCCCCTGCCGAGCTACTCG CGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCGCTTAATGAACTGCTGCA TCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGCCTCAATTCTGGGATTTG GCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCAT GGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAATT CTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTTC CTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGGAGAGATTATTTCATTCAATATTTTTTATGAAT TATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGGGTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTGGAGCTAG TGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCCCAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAGAAAAGCC GAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGAAGAGGAGCCTTCCACACAGTCATCCCAGGCAGTTGCTGCCC CCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCTCTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGAGATGTTG GAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCTGTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGCTTTACTC TCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCTGCTGGAAGCAGGTGCTGACCCCACTGTGCAGGACTCTCGGG CCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTTCCGAAGGTTCATGGAGAAGAATCCAGATGCCTACGATTACA ACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCAGGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGGCGGCAAC GGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGAAGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGAGAGAAGA GAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTACCTCTCCAATCCCTGACTCTGCAATCGTCAATACTCGACGCT GCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCTCGACTTCTCTTTCTGCTCCACACGTTGCCTCCAGGATCATC GCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGGGGCCAACTCAGGGACCTGAGAGGGCACATTCACAGCAGCCC TAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGTGAAGGACACTCGGGAACTAGGGCAAAGACAGGGCTAGAGGT ATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGCAAGGAATGTGTACTTGTACTTACA >6930_6930_8_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000381733_ANKZF1_chr2_220099547_ENST00000409849_length(amino acids)=547AA_BP=222 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMINTFVPSGKIMQVVDEKLPGLLGNFPG PFEEEMKGIAAVTDIPLGEIISFNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVELTVGTLDLCESEVLPKRRRRKRNKKEKSRD QEAGAHRTLLQQTQEEEPSTQSSQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVLKLQLAPSPADPRVLSLLSAPLGSGGFTLL HAAAAAGRGSVVRLLLEAGADPTVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKAQVPGPLTPEMEARQATRKREQKAARRQRE EQQQRQQEQEEREREEQRRFAALSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWSCGASLQGLTPFHYLDFSFCSTRCLQDHRR QAGRPSS -------------------------------------------------------------- >6930_6930_9_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000381733_ANKZF1_chr2_220099547_ENST00000410034_length(transcript)=1853nt_BP=672nt GGACTTTGAAATCCAACCCGGTCACCTACCCGCGCGACTGTGTCCACGGATGGCACGAAAGCCAAGCGAGTCCCCCTGCCGAGCTACTCG CGTCCGCCTCCTCCCAAGCTGAGCTCTGCTCCGCCCACCTGAGTCCTTCGCCAGTTAGGAGGAAACACAGCCGCTTAATGAACTGCTGCA TCGGGCTGGGAGAGAAAGCTCGCGGGTCCCACCGGGCCTCCTACCCAAGTCTCAGCGCGCTTTTCACCGAGGCCTCAATTCTGGGATTTG GCAGCTTTGCTGTGAAAGCCCAATGGACAGAGGACTGCAGAAAATCAACCTATCCTCCTTCAGGACCAACGTACAGAGGTGCAGTTCCAT GGTACACCATAAATCTTGACTTACCACCCTACAAAAGATGGCATGAATTGATGCTTGACAAGGCACCAGTGCTAAAGGTTATAGTGAATT CTCTGAAGAATATGATAAATACATTCGTGCCAAGTGGAAAAATTATGCAGGTGGTGGATGAAAAATTGCCTGGCCTACTTGGCAACTTTC CTGGCCCTTTTGAAGAGGAAATGAAGGGTATTGCCGCTGTTACTGATATACCTTTAGGAGAGATTATTTCATTCAATATTTTTTATGAAT TATTTACCATTTGTACTTCAATAGTAGCAGAAGACAAAAAAGGTTCAGGGTCGGAGGGAGAAGATGGCTTTCAGGTAGAGTTGGAGCTAG TGGAGTTGACTGTGGGGACTCTGGATCTTTGTGAGTCTGAAGTATTGCCCAAGCGGAGGAGGAGAAAAAGGAATAAGAAGGAGAAAAGCC GAGACCAGGAGGCTGGGGCACATCGGACTCTTCTCCAGCAAACTCAAGAAGAGGAGCCTTCCACACAGTCATCCCAGGCAGTTGCTGCCC CCTTGGGCCCTTTGCTGGATGAGGCCAAAGCCCCTGGTCAGCCAGAGCTCTGGAATGCACTGCTTGCTGCTTGCCGAGCTGGAGATGTTG GAGTGCTAAAGCTGCAGCTAGCTCCCAGCCCTGCAGACCCTAGAGTTCTGTCTCTGCTCAGTGCCCCCTTGGGCTCCGGTGGCTTTACTC TCCTGCATGCAGCAGCTGCAGCTGGAAGAGGCTCAGTGGTTCGTCTGCTGCTGGAAGCAGGTGCTGACCCCACTGTGCAGGACTCTCGGG CCCGGCCACCTTATACTGTTGCGGCTGACAAATCAACACGTAATGAGTTCCGAAGGTTCATGGAGAAGAATCCAGATGCCTACGATTACA ACAAGGCTCAGGTGCCAGGACCATTGACACCAGAAATGGAGGCACGGCAGGCTACACGGAAAAGGGAGCAGAAGGCAGCCCGGCGGCAAC GGGAGGAACAGCAGCAGAGGCAGCAGGAGCAGGAGGAGCGTGAACGAGAAGAGCAGCGGCGATTTGCCGCCCTCAGTGACCGAGAGAAGA GAGCTCTGGCTGCAGAGCGCCGACTCGCTGCCCAGTTGGGAGCCCCTACCTCTCCAATCCCTGACTCTGCAATCGTCAATACTCGACGCT GCTGGAGTTGTGGGGCATCCCTCCAAGGCCTGACTCCCTTTCACTACCTCGACTTCTCTTTCTGCTCCACACGTTGCCTCCAGGATCATC GCCGTCAGGCAGGGAGGCCCTCTTCCTGATCTCTTACAGCTCTACCTGGGGCCAACTCAGGGACCTGAGAGGGCACATTCACAGCAGCCC TAGGTTTTTTCTTCCCCGTGAAACCAGAGATGATTTGGAAGATGGGGGTGAAGGACACTCGGGAACTAGGGCAAAGACAGGGCTAGAGGT ATGTGGAGCTGGTACTGTCTCTGGAATTTTAATCACAATAAAGTTTGGCAAGG >6930_6930_9_ASAH1-ANKZF1_ASAH1_chr8_17921965_ENST00000381733_ANKZF1_chr2_220099547_ENST00000410034_length(amino acids)=547AA_BP=222 MKSNPVTYPRDCVHGWHESQASPPAELLASASSQAELCSAHLSPSPVRRKHSRLMNCCIGLGEKARGSHRASYPSLSALFTEASILGFGS FAVKAQWTEDCRKSTYPPSGPTYRGAVPWYTINLDLPPYKRWHELMLDKAPVLKVIVNSLKNMINTFVPSGKIMQVVDEKLPGLLGNFPG PFEEEMKGIAAVTDIPLGEIISFNIFYELFTICTSIVAEDKKGSGSEGEDGFQVELELVELTVGTLDLCESEVLPKRRRRKRNKKEKSRD QEAGAHRTLLQQTQEEEPSTQSSQAVAAPLGPLLDEAKAPGQPELWNALLAACRAGDVGVLKLQLAPSPADPRVLSLLSAPLGSGGFTLL HAAAAAGRGSVVRLLLEAGADPTVQDSRARPPYTVAADKSTRNEFRRFMEKNPDAYDYNKAQVPGPLTPEMEARQATRKREQKAARRQRE EQQQRQQEQEEREREEQRRFAALSDREKRALAAERRLAAQLGAPTSPIPDSAIVNTRRCWSCGASLQGLTPFHYLDFSFCSTRCLQDHRR QAGRPSS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ASAH1-ANKZF1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ASAH1-ANKZF1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ASAH1-ANKZF1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ASAH1 | C0268255 | Farber Lipogranulomatosis | 15 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | ASAH1 | C1834569 | Jankovic Rivera syndrome | 4 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | ASAH1 | C0004238 | Atrial Fibrillation | 2 | CTD_human |
| Hgene | ASAH1 | C0023794 | Lipoidosis | 2 | CTD_human |
| Hgene | ASAH1 | C0235480 | Paroxysmal atrial fibrillation | 2 | CTD_human |
| Hgene | ASAH1 | C2585653 | Persistent atrial fibrillation | 2 | CTD_human |
| Hgene | ASAH1 | C3468561 | familial atrial fibrillation | 2 | CTD_human |
| Hgene | ASAH1 | C0020305 | Hydrops Fetalis | 1 | GENOMICS_ENGLAND |
| Hgene | ASAH1 | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
| Hgene | ASAH1 | C0036341 | Schizophrenia | 1 | PSYGENET |
| Hgene | ASAH1 | C0221765 | Chronic schizophrenia | 1 | PSYGENET |
| Hgene | ASAH1 | C0455988 | Hydrops Fetalis, Non-Immune | 1 | GENOMICS_ENGLAND |
| Hgene | ASAH1 | C3714756 | Intellectual Disability | 1 | GENOMICS_ENGLAND |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies