
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ASS1-NCS1 (FusionGDB2 ID:HG445TG23413) |
Fusion Gene Summary for ASS1-NCS1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ASS1-NCS1 | Fusion gene ID: hg445tg23413 | Hgene | Tgene | Gene symbol | ASS1 | NCS1 | Gene ID | 445 | 23413 |
| Gene name | argininosuccinate synthase 1 | neuronal calcium sensor 1 | |
| Synonyms | ASS|CTLN1 | FLUP|FREQ | |
| Cytomap | ('ASS1')('NCS1') 9q34.11 | 9q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | argininosuccinate synthaseargininosuccinate synthetase 1citrulline-aspartate ligaseepididymis secretory sperm binding protein | neuronal calcium sensor 1frequenin homologfrequenin-like proteinfrequenin-like ubiquitous protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000493984, ENST00000352480, ENST00000372393, ENST00000372394, | ||
| Fusion gene scores | * DoF score | 3 X 5 X 4=60 | 6 X 6 X 4=144 |
| # samples | 4 | 6 | |
| ** MAII score | log2(4/60*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/144*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ASS1 [Title/Abstract] AND NCS1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ASS1(133355836)-NCS1(132963237), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ASS1-NCS1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ASS1-NCS1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ASS1 | GO:0007623 | circadian rhythm | 28985504 |
| Fusion gene breakpoints across ASS1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NCS1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A8-A0A4-01A | ASS1 | chr9 | 133355836 | - | NCS1 | chr9 | 132963237 | + |
| ChimerDB4 | BRCA | TCGA-A8-A0A4-01A | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
Top |
Fusion Gene ORF analysis for ASS1-NCS1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000493984 | ENST00000372398 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 3UTR-3UTR | ENST00000493984 | ENST00000458469 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 3UTR-3UTR | ENST00000493984 | ENST00000493042 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 5CDS-3UTR | ENST00000352480 | ENST00000458469 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 5CDS-3UTR | ENST00000352480 | ENST00000493042 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 5CDS-3UTR | ENST00000372393 | ENST00000458469 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 5CDS-3UTR | ENST00000372393 | ENST00000493042 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 5CDS-3UTR | ENST00000372394 | ENST00000458469 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| 5CDS-3UTR | ENST00000372394 | ENST00000493042 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| In-frame | ENST00000352480 | ENST00000372398 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| In-frame | ENST00000372393 | ENST00000372398 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| In-frame | ENST00000372394 | ENST00000372398 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000352480 | ASS1 | chr9 | 133355836 | + | ENST00000372398 | NCS1 | chr9 | 132963237 | + | 5751 | 910 | 9 | 1418 | 469 |
| ENST00000372394 | ASS1 | chr9 | 133355836 | + | ENST00000372398 | NCS1 | chr9 | 132963237 | + | 6160 | 1319 | 253 | 1827 | 524 |
| ENST00000372393 | ASS1 | chr9 | 133355836 | + | ENST00000372398 | NCS1 | chr9 | 132963237 | + | 5754 | 913 | 75 | 1421 | 448 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000352480 | ENST00000372398 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + | 0.001862837 | 0.9981371 |
| ENST00000372394 | ENST00000372398 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + | 0.003394084 | 0.9966059 |
| ENST00000372393 | ENST00000372398 | ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963237 | + | 0.001768141 | 0.9982318 |
Top |
Fusion Genomic Features for ASS1-NCS1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963236 | + | 0.51100713 | 0.48899284 |
| ASS1 | chr9 | 133355836 | + | NCS1 | chr9 | 132963236 | + | 0.51100713 | 0.48899284 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
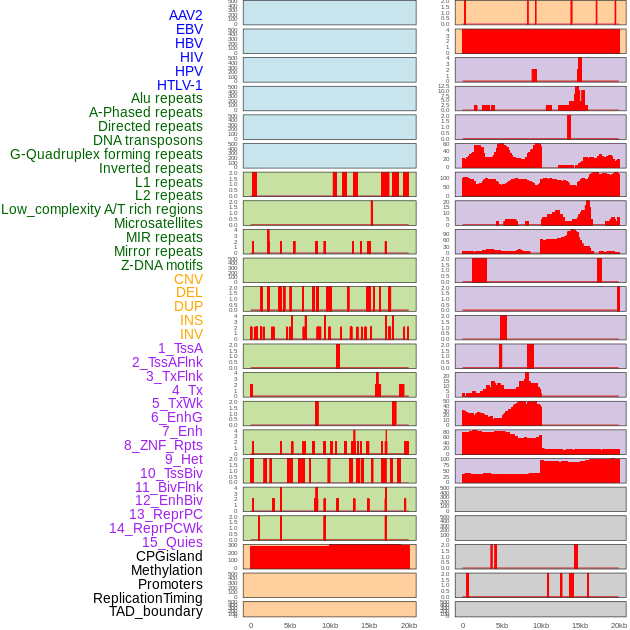 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
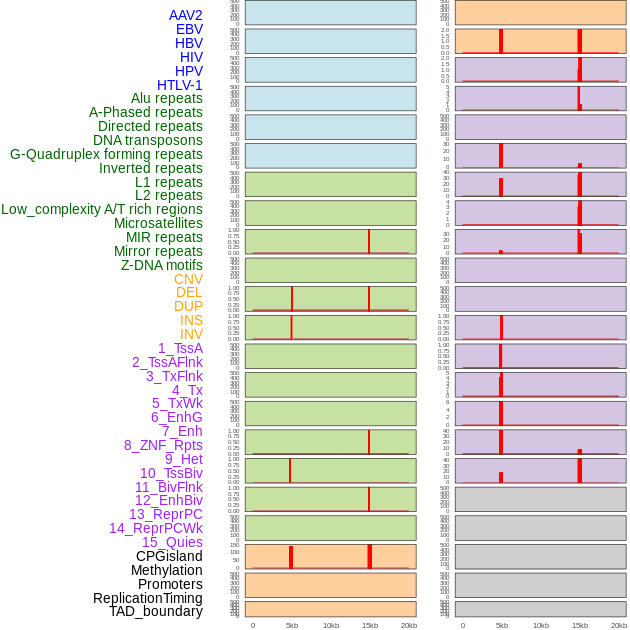 |
Top |
Fusion Protein Features for ASS1-NCS1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:133355836/chr9:132963237) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ASS1 | chr9:133355836 | chr9:132963237 | ENST00000352480 | + | 11 | 15 | 10_18 | 279 | 413.0 | Nucleotide binding | ATP |
| Hgene | ASS1 | chr9:133355836 | chr9:132963237 | ENST00000352480 | + | 11 | 15 | 115_123 | 279 | 413.0 | Nucleotide binding | ATP |
| Hgene | ASS1 | chr9:133355836 | chr9:132963237 | ENST00000372393 | + | 12 | 16 | 10_18 | 279 | 413.0 | Nucleotide binding | ATP |
| Hgene | ASS1 | chr9:133355836 | chr9:132963237 | ENST00000372393 | + | 12 | 16 | 115_123 | 279 | 413.0 | Nucleotide binding | ATP |
| Hgene | ASS1 | chr9:133355836 | chr9:132963237 | ENST00000372394 | + | 12 | 16 | 10_18 | 279 | 413.0 | Nucleotide binding | ATP |
| Hgene | ASS1 | chr9:133355836 | chr9:132963237 | ENST00000372394 | + | 12 | 16 | 115_123 | 279 | 413.0 | Nucleotide binding | ATP |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 109_120 | 21 | 1579.3333333333333 | Calcium binding | 2 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 157_168 | 21 | 1579.3333333333333 | Calcium binding | 3 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 73_84 | 21 | 1579.3333333333333 | Calcium binding | 1 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 109_120 | 3 | 1605.0 | Calcium binding | 2 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 157_168 | 3 | 1605.0 | Calcium binding | 3 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 73_84 | 3 | 1605.0 | Calcium binding | 1 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 144_179 | 21 | 1579.3333333333333 | Domain | EF-hand 4 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 24_59 | 21 | 1579.3333333333333 | Domain | EF-hand 1 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 60_95 | 21 | 1579.3333333333333 | Domain | EF-hand 2 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 96_131 | 21 | 1579.3333333333333 | Domain | EF-hand 3 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 144_179 | 3 | 1605.0 | Domain | EF-hand 4 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 24_59 | 3 | 1605.0 | Domain | EF-hand 1 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 60_95 | 3 | 1605.0 | Domain | EF-hand 2 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 96_131 | 3 | 1605.0 | Domain | EF-hand 3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for ASS1-NCS1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >7258_7258_1_ASS1-NCS1_ASS1_chr9_133355836_ENST00000352480_NCS1_chr9_132963237_ENST00000372398_length(transcript)=5751nt_BP=910nt GCTTATAACCTGGGATGGGCACCCCTGCCAGTCCTGCTCTGCCGCCTGCCACCGCTGCCCGAGCCCGACGCTATGTCCAGCAAAGGCTCC GTGGTTCTGGCCTACAGTGGCGGCCTGGACACCTCGTGCATCCTCGTGTGGCTGAAGGAACAAGGCTATGACGTCATTGCCTATCTGGCC AACATTGGCCAGAAGGAAGACTTCGAGGAAGCCAGGAAGAAGGCACTGAAGCTTGGGGCCAAAAAGGTGTTCATTGAGGATGTCAGCAGG GAGTTTGTGGAGGAGTTCATCTGGCCGGCCATCCAGTCCAGCGCACTGTATGAGGACCGCTACCTCCTGGGCACCTCTCTTGCCAGGCCC TGCATCGCCCGCAAACAAGTGGAAATCGCCCAGCGGGAGGGGGCCAAGTATGTGTCCCACGGCGCCACAGGAAAGGGGAACGATCAGGTC CGGTTTGAGCTCAGCTGCTACTCACTGGCCCCCCAGATAAAGGTCATTGCTCCCTGGAGGATGCCTGAATTCTACAACCGGTTCAAGGGC CGCAATGACCTGATGGAGTACGCAAAGCAACACGGGATTCCCATCCCGGTCACTCCCAAGAACCCGTGGAGCATGGATGAGAACCTCATG CACATCAGCTACGAGGCTGGAATCCTGGAGAACCCCAAGAACCAAGCGCCTCCAGGTCTCTACACGAAGACCCAGGACCCAGCCAAAGCC CCCAACACCCCTGACATTCTCGAGATCGAGTTCAAAAAAGGGGTCCCTGTGAAGGTGACCAACGTCAAGGATGGCACCACCCACCAGACC TCCTTGGAGCTCTTCATGTACCTGAACGAAGTCGCGGGCAAGCATGGCGTGGGCCGTATTGACATCGTGGAGAACCGCTTCATTGGAATG AAGTCCCGAGTTACCGAGAAGGAGGTCCAGCAGTGGTACAAAGGCTTCATCAAGGACTGCCCCAGTGGGCAGCTGGATGCGGCAGGCTTC CAGAAGATCTACAAGCAATTCTTCCCGTTCGGAGACCCCACCAAGTTTGCCACATTTGTTTTCAACGTCTTTGATGAAAACAAGGACGGG CGAATTGAGTTCTCCGAGTTCATCCAGGCGCTGTCGGTGACCTCACGGGGAACCCTGGATGAGAAGCTACGGTGGGCCTTCAAGCTCTAC GACTTGGACAATGATGGCTACATCACCAGGAATGAGATGCTGGACATTGTGGATGCCATTTACCAGATGGTGGGGAATACCGTGGAGCTC CCAGAGGAGGAGAACACTCCTGAGAAGAGGGTGGACCGGATCTTTGCCATGATGGATAAGAATGCCGACGGGAAGCTGACCCTGCAGGAG TTCCAGGAGGGTTCCAAGGCAGACCCGTCCATTGTGCAGGCGCTGTCCCTCTACGACGGGCTGGTATAGTCCCAGGCTGGAGCTGGATGC CTGGGAACCACTCACCTCCTTCTGTGCCATGAGGCCACCTCAGCCCTGACACCAACCCCGTGCGTCCACCCAGCCTTCTTCCGCATCCAC ACACAGCCGGCTGCCCTTGACCCGGGAGGCCCCGGCTCTCCTCTCCCCTGTCCTGCACCCATCCCCCGCCTGAAGCCACCGGCTCCAATT GCCAGCAACCTCTGCTTGTCCGGAAAACGACAACACGAAATGGAAAAGGCTACAGCCCTCTGCATAAACCAAGGACTTGGCTGCCTCGCA GGCAGCCTCCGTTCCTCCCGCTCTCTTGCGCGTGTGCTTTTGTTTTTTATTTTGAACAGACGTTTTAAAAGAAAAAAAAACAACTACCTT CTGTCCTAGAAGACACAGACTGACAGATGGGGTGAAGGCCTGGGGACCTCAGAGAACTCTGCCTTGCCCTCGTCCCTCGTCCTTCGGCAG CCGGAGAGGCTGTGGGTGGGCCGAGGGTGTCTAGGGGTTCTGCCTGGTCAACGTTATTTGTCGTCCCATCTTTTGGCAGCAAAACCACCT GCGTGGCTAGGATGATTAATTATGAGGATGATGATTTTTTTTGTGATAACAGTATTGTGCTTTTTGTGGGGAAAGTGAGGTTTTTTTTTA TATACATATATAATTGATATCTTTAATTTATTGGTTGTTAACTGTTGCTGCTGCCTGGTGTGTCCTCAGCTCCCAGGGCTGCGGGCCCAC CGTTTACATGTGCACGCCCTGACCCACCTGCCCACGCCGACTTGGGAGGATGGTGGCCTGCAGCGGCCAAGAAGCCAAAAAAAATTTTTT TTTTTTCAGATACTGTGCTTGATTTTTGGAGAGGGGAGAGGTGGAAATTCCTAAATGGCTAATGCACTGTTCCCTCCAGCCCGAATGCCT CCTGCCAAACCCCTTTTCCCTGCTGCCTCTGTCCCCGCATCCTTGTTCTCCCCTGGGTCCGTAACATTTTTTCCGAGGATGAACAGGGGA CATCTTTAGGTTTCTCAACTCTTGCTTTGGTGTTTGCCGCAGCATGGAAAACAGGGCGCCTAAGGCTGGGAGCTGGAAGAAGGGGCATTG GGTACCCAGGCAGAGTCAGGAGAGGTGGTCTTTGAAGTAAGTTAGCAGAAATCAAGGGGACCCCCGCCTCCTTGGGCTGGGGAGGGGATT TCAAGATAGTTCATGACTCTCTCCCGCTCTGCCTTCCCTCCTTCCTATCTGCTTTTTCCAGTAAACTGCATGGTGTCCTTCCCTGGCCTT CTCTTGGCTCAAAGGCTGGGAGGGAGGGAAGGAGAGAAGAGTTCCAGGCAATCCCATCAATATAGTCCCTACACCTGGGGCTGCGGCCCA CATGTCTTCACGGAGGCTTCCAGCGGTGCCTGCCACTGAGGCAGGTGCGGCCCCAGGACCATCACCAGGAATGCGAGGCCACCCTGGACC AGAGGTAGGAGCCCAAGGTCCGGCCCTTGCTCTTTGATTGTGGGCAGCCTCCTGCCCTCTCTGGGTCTCAGTTGCCCCATCTGCAGAGCG AGGAGGCCCGGGCTGGTTGGTCTTGAAGGCCCTTTTCCATGCCGACATCATGTCACTCTAGGCCTGGGGTTCAGTTTCCTGTGGCTGGTG ATGCTGTGGTTAAGTTTGCTTGACCCCAGCAGCCCGAGGGACTGTCTGAGTCACAGCACAGCCCCTATTGCGTGGCTGCTGGTGTGTGGG GTCAGTTCCAGCAGATGAATGTGTCATGTGGCACACCTTGTCCCTTCCCGCAGCATTTCCTGGTTCCCCCCAGACCCTTGAGCGCTCTTT GGGACCCAGAAGGAGTCCTTGCACAGGGAAGGCTTGAGGTGAGAAGCCGCTTCCCAGACTGTCAGGGCCAGGCCTGGGTCTAGAATTCTT GCTGCTGCTTTGCAGAGTCAACAGCCCATCAGCCCATGTTTTAGAGGGGACACTTTGGTCCTCGGTTCCCACCCTCAGCAAGCAGGCCTC CAGCCCGAGGAAGGCCTCTGCCGTAGTGACGTTGCCGTGTGGGGCTGCGTGGCTGTTCCCCTTGGCTGGAGCATTCAGCCAACCCCAGCG TCCCCCCTGAGGCGTTCATTGGCAGCCCCCTAGGACTGCACGCTGGCCCCACGGTAACCCCCCCTCCCCCACCAACATCCTGCAGGGATG GGGTCAGTGGTTCCACCTTCACAGGCCACTTTGAAGGGTGGATTCTTTGAGGCCCCTGCCAGTCGGCTCCCTGCTCAGCTGCTGGCCCGG GCGACCTGGGACTCAGCACCAACGGCTGAAGTTTCTCAGCTGGGCTCTGACCTGGGGTCTGGGGCAGGGAACGAACATGGTGGCTTTGGG CTGAGAGGATGAGGGAGGTCTTTCCCAGGTCAAATTACTTTCCTTTGGCCTCTGCCTGAGGCTCGATTTGCCTCTCTGGTCCAATGGGAC TGACACTGTTGTACAACCTGACCTGTGGCTGAGGGTGTCTGGGCTTAAGCATGTGGACCCCTTCGGTGTGTCCGGCCTTCCTCCATCGTC CTGCCCTTTGGCCTTTTGGTTTGAAGCCACAGGTGTGGCTTCTGGCCTTAGCAGATGGTATGCTTGCGGACCGCAGCCCAGCATGCCGGT GGGCCCACAGCCCGAGCCAGCCCAGAGCTGCCGGAAGGGCCGCCCTTCCCGGCCCTGGCGGGGTGCTGGACACTGGCCATTTTCACTAGA GTTTGCCTGGCAGGGACCGATCTCTGCCCCCTCCTCTCCCCAGGCCTCTGGCTGCAGTGATGCCGCAGAATCCTGAGCCAGGTGCCTCCT GAGCAGCCCGTGCGCCTCTCCACAGCGGCGTTTGCCACCCAATGCGGCTCGCTTCAGATGCTCTGATGCAGAGGGCACGCCCATAGTCCC TCTGCAGAGCCTCGCACTGGGGCCAGGGCAGGCACCAGCCCCAGGCGGCCAGTCGGCCACGGCCTGTCCTCTTCCTCGTAGCGTCTGCTC CTCACTTTGTGTTGATGGTGACTTAGGAGAATGTTCCGATTTTCCATGATCTAAGCAGGCCACGTTTAAAATAACATCAAGGCAAGCGTA CGTGTCACCCTCTGTACTGACATCTCTTCCCCTGAAATGCTTTTCAGTTTGACAGCCCGTTTCCTAGACAAGTGCACCTGGGGTTTCAGG AACTTTGTGTTTTTTCGGAGGGGGTTGGTGGGGAGGTCGGGATGCCTGGGATCCCTTCCTGGAGAGGCAGGCTGTCTCTGGAAAAAGCCT CCATTGCCCACCCGCCAGGCGGAAAGTCACCCTGTTCCCAGCGCGGTTTCAGCATTTAATTTTAAGGGAGCTAAGGAAGCGCGGCGCGCC CCCTGGTGGTGGTAAGCCGCCAACGCACCTGGGGGCTGCAACCCCACCGGACGGGTGGTCCGGAGGGAGGCTGGAGCGGGGAGGCGAGGA GGGGGCTGTGAGTCCTCAGAGGCCCTGGGCCACCACATTTCTGGCAGCGTTTCCCAGACACCCCTCTGCTAGGCCATCCCTGGATAGCAA GTGAATTAACTTAAGGGCACTGTGATGGGAAGCCTTGCCCCCCTCTTTTTTTTTTTTTTTTAATATCTGCGGAATAAACCCAATGGTTAA TTTTTGAATGAATAAAAGGCTTTTGTTGAATAAACAGCTGGTCCCATCTTCTGTCTTGGCATCTTAGCATCCAGGCTCAGGCTCTGCCCC TTCTCCAGGATGGGGTAGCCCCGAGTCGCCCTCCCCAGTCTGCACATTCCCTGTTGTCCCTGTTCCTGCAGTGGCTCCCGGCCCCAGGGA GGCCCACCTCACTCCCAGCCTGACTCGGTGGCTGGCTTCCTTCAGGACTTTGCGCAAGTCAGTTCTGCTCATTGGGTCTCAATTTCCCCA TCCCTTGGATGGGAGCAAGAGTCTCTGCTGGGCCTGCCTCGCAGGGGCCTGGTGAGACCCAAATGTGAGTGTCATCATCAAAGCCCCTCA CAGAAGTGGAGGACGGTGCCCAAGAGTAGCGGTTTGGACTGCTGCTGCCTCCCACCCGGAGCCTGCCACTTGGGGGAGAAATTGGTATAA TGCTTGCAAAAACAAACAAACAAAAGGCAATGTCTTCTGGTTGTGGTTATTTCCTTTCCTGCTTGCCTCCCCAGCCCCCTTTGAGTCTCT TTTTGGGGTGCCGTCCTGTCTGAACCTGCCGGTGTGTGTCTCTGGGGCCAGGGTCAGGGCGAGGCCCAGGGGTGGACAGGGGCCGTGTAG CATGCCCCAGCCTCCCCAAGCTCCTGCTGTATGTCGTCCATGTCACGCCAATTAAACACGCTTCCTGGACTTGTCCTCGCC >7258_7258_1_ASS1-NCS1_ASS1_chr9_133355836_ENST00000352480_NCS1_chr9_132963237_ENST00000372398_length(amino acids)=469AA_BP=300 MGWAPLPVLLCRLPPLPEPDAMSSKGSVVLAYSGGLDTSCILVWLKEQGYDVIAYLANIGQKEDFEEARKKALKLGAKKVFIEDVSREFV EEFIWPAIQSSALYEDRYLLGTSLARPCIARKQVEIAQREGAKYVSHGATGKGNDQVRFELSCYSLAPQIKVIAPWRMPEFYNRFKGRND LMEYAKQHGIPIPVTPKNPWSMDENLMHISYEAGILENPKNQAPPGLYTKTQDPAKAPNTPDILEIEFKKGVPVKVTNVKDGTTHQTSLE LFMYLNEVAGKHGVGRIDIVENRFIGMKSRVTEKEVQQWYKGFIKDCPSGQLDAAGFQKIYKQFFPFGDPTKFATFVFNVFDENKDGRIE FSEFIQALSVTSRGTLDEKLRWAFKLYDLDNDGYITRNEMLDIVDAIYQMVGNTVELPEEENTPEKRVDRIFAMMDKNADGKLTLQEFQE GSKADPSIVQALSLYDGLV -------------------------------------------------------------- >7258_7258_2_ASS1-NCS1_ASS1_chr9_133355836_ENST00000372393_NCS1_chr9_132963237_ENST00000372398_length(transcript)=5754nt_BP=913nt CGAGCCCGAGTGGTTCACTGCACTGTGAAAACAGATTCCAGACGCCGGGAACTCACGCCTCCAATCCCAGACGCTATGTCCAGCAAAGGC TCCGTGGTTCTGGCCTACAGTGGCGGCCTGGACACCTCGTGCATCCTCGTGTGGCTGAAGGAACAAGGCTATGACGTCATTGCCTATCTG GCCAACATTGGCCAGAAGGAAGACTTCGAGGAAGCCAGGAAGAAGGCACTGAAGCTTGGGGCCAAAAAGGTGTTCATTGAGGATGTCAGC AGGGAGTTTGTGGAGGAGTTCATCTGGCCGGCCATCCAGTCCAGCGCACTGTATGAGGACCGCTACCTCCTGGGCACCTCTCTTGCCAGG CCCTGCATCGCCCGCAAACAAGTGGAAATCGCCCAGCGGGAGGGGGCCAAGTATGTGTCCCACGGCGCCACAGGAAAGGGGAACGATCAG GTCCGGTTTGAGCTCAGCTGCTACTCACTGGCCCCCCAGATAAAGGTCATTGCTCCCTGGAGGATGCCTGAATTCTACAACCGGTTCAAG GGCCGCAATGACCTGATGGAGTACGCAAAGCAACACGGGATTCCCATCCCGGTCACTCCCAAGAACCCGTGGAGCATGGATGAGAACCTC ATGCACATCAGCTACGAGGCTGGAATCCTGGAGAACCCCAAGAACCAAGCGCCTCCAGGTCTCTACACGAAGACCCAGGACCCAGCCAAA GCCCCCAACACCCCTGACATTCTCGAGATCGAGTTCAAAAAAGGGGTCCCTGTGAAGGTGACCAACGTCAAGGATGGCACCACCCACCAG ACCTCCTTGGAGCTCTTCATGTACCTGAACGAAGTCGCGGGCAAGCATGGCGTGGGCCGTATTGACATCGTGGAGAACCGCTTCATTGGA ATGAAGTCCCGAGTTACCGAGAAGGAGGTCCAGCAGTGGTACAAAGGCTTCATCAAGGACTGCCCCAGTGGGCAGCTGGATGCGGCAGGC TTCCAGAAGATCTACAAGCAATTCTTCCCGTTCGGAGACCCCACCAAGTTTGCCACATTTGTTTTCAACGTCTTTGATGAAAACAAGGAC GGGCGAATTGAGTTCTCCGAGTTCATCCAGGCGCTGTCGGTGACCTCACGGGGAACCCTGGATGAGAAGCTACGGTGGGCCTTCAAGCTC TACGACTTGGACAATGATGGCTACATCACCAGGAATGAGATGCTGGACATTGTGGATGCCATTTACCAGATGGTGGGGAATACCGTGGAG CTCCCAGAGGAGGAGAACACTCCTGAGAAGAGGGTGGACCGGATCTTTGCCATGATGGATAAGAATGCCGACGGGAAGCTGACCCTGCAG GAGTTCCAGGAGGGTTCCAAGGCAGACCCGTCCATTGTGCAGGCGCTGTCCCTCTACGACGGGCTGGTATAGTCCCAGGCTGGAGCTGGA TGCCTGGGAACCACTCACCTCCTTCTGTGCCATGAGGCCACCTCAGCCCTGACACCAACCCCGTGCGTCCACCCAGCCTTCTTCCGCATC CACACACAGCCGGCTGCCCTTGACCCGGGAGGCCCCGGCTCTCCTCTCCCCTGTCCTGCACCCATCCCCCGCCTGAAGCCACCGGCTCCA ATTGCCAGCAACCTCTGCTTGTCCGGAAAACGACAACACGAAATGGAAAAGGCTACAGCCCTCTGCATAAACCAAGGACTTGGCTGCCTC GCAGGCAGCCTCCGTTCCTCCCGCTCTCTTGCGCGTGTGCTTTTGTTTTTTATTTTGAACAGACGTTTTAAAAGAAAAAAAAACAACTAC CTTCTGTCCTAGAAGACACAGACTGACAGATGGGGTGAAGGCCTGGGGACCTCAGAGAACTCTGCCTTGCCCTCGTCCCTCGTCCTTCGG CAGCCGGAGAGGCTGTGGGTGGGCCGAGGGTGTCTAGGGGTTCTGCCTGGTCAACGTTATTTGTCGTCCCATCTTTTGGCAGCAAAACCA CCTGCGTGGCTAGGATGATTAATTATGAGGATGATGATTTTTTTTGTGATAACAGTATTGTGCTTTTTGTGGGGAAAGTGAGGTTTTTTT TTATATACATATATAATTGATATCTTTAATTTATTGGTTGTTAACTGTTGCTGCTGCCTGGTGTGTCCTCAGCTCCCAGGGCTGCGGGCC CACCGTTTACATGTGCACGCCCTGACCCACCTGCCCACGCCGACTTGGGAGGATGGTGGCCTGCAGCGGCCAAGAAGCCAAAAAAAATTT TTTTTTTTTCAGATACTGTGCTTGATTTTTGGAGAGGGGAGAGGTGGAAATTCCTAAATGGCTAATGCACTGTTCCCTCCAGCCCGAATG CCTCCTGCCAAACCCCTTTTCCCTGCTGCCTCTGTCCCCGCATCCTTGTTCTCCCCTGGGTCCGTAACATTTTTTCCGAGGATGAACAGG GGACATCTTTAGGTTTCTCAACTCTTGCTTTGGTGTTTGCCGCAGCATGGAAAACAGGGCGCCTAAGGCTGGGAGCTGGAAGAAGGGGCA TTGGGTACCCAGGCAGAGTCAGGAGAGGTGGTCTTTGAAGTAAGTTAGCAGAAATCAAGGGGACCCCCGCCTCCTTGGGCTGGGGAGGGG ATTTCAAGATAGTTCATGACTCTCTCCCGCTCTGCCTTCCCTCCTTCCTATCTGCTTTTTCCAGTAAACTGCATGGTGTCCTTCCCTGGC CTTCTCTTGGCTCAAAGGCTGGGAGGGAGGGAAGGAGAGAAGAGTTCCAGGCAATCCCATCAATATAGTCCCTACACCTGGGGCTGCGGC CCACATGTCTTCACGGAGGCTTCCAGCGGTGCCTGCCACTGAGGCAGGTGCGGCCCCAGGACCATCACCAGGAATGCGAGGCCACCCTGG ACCAGAGGTAGGAGCCCAAGGTCCGGCCCTTGCTCTTTGATTGTGGGCAGCCTCCTGCCCTCTCTGGGTCTCAGTTGCCCCATCTGCAGA GCGAGGAGGCCCGGGCTGGTTGGTCTTGAAGGCCCTTTTCCATGCCGACATCATGTCACTCTAGGCCTGGGGTTCAGTTTCCTGTGGCTG GTGATGCTGTGGTTAAGTTTGCTTGACCCCAGCAGCCCGAGGGACTGTCTGAGTCACAGCACAGCCCCTATTGCGTGGCTGCTGGTGTGT GGGGTCAGTTCCAGCAGATGAATGTGTCATGTGGCACACCTTGTCCCTTCCCGCAGCATTTCCTGGTTCCCCCCAGACCCTTGAGCGCTC TTTGGGACCCAGAAGGAGTCCTTGCACAGGGAAGGCTTGAGGTGAGAAGCCGCTTCCCAGACTGTCAGGGCCAGGCCTGGGTCTAGAATT CTTGCTGCTGCTTTGCAGAGTCAACAGCCCATCAGCCCATGTTTTAGAGGGGACACTTTGGTCCTCGGTTCCCACCCTCAGCAAGCAGGC CTCCAGCCCGAGGAAGGCCTCTGCCGTAGTGACGTTGCCGTGTGGGGCTGCGTGGCTGTTCCCCTTGGCTGGAGCATTCAGCCAACCCCA GCGTCCCCCCTGAGGCGTTCATTGGCAGCCCCCTAGGACTGCACGCTGGCCCCACGGTAACCCCCCCTCCCCCACCAACATCCTGCAGGG ATGGGGTCAGTGGTTCCACCTTCACAGGCCACTTTGAAGGGTGGATTCTTTGAGGCCCCTGCCAGTCGGCTCCCTGCTCAGCTGCTGGCC CGGGCGACCTGGGACTCAGCACCAACGGCTGAAGTTTCTCAGCTGGGCTCTGACCTGGGGTCTGGGGCAGGGAACGAACATGGTGGCTTT GGGCTGAGAGGATGAGGGAGGTCTTTCCCAGGTCAAATTACTTTCCTTTGGCCTCTGCCTGAGGCTCGATTTGCCTCTCTGGTCCAATGG GACTGACACTGTTGTACAACCTGACCTGTGGCTGAGGGTGTCTGGGCTTAAGCATGTGGACCCCTTCGGTGTGTCCGGCCTTCCTCCATC GTCCTGCCCTTTGGCCTTTTGGTTTGAAGCCACAGGTGTGGCTTCTGGCCTTAGCAGATGGTATGCTTGCGGACCGCAGCCCAGCATGCC GGTGGGCCCACAGCCCGAGCCAGCCCAGAGCTGCCGGAAGGGCCGCCCTTCCCGGCCCTGGCGGGGTGCTGGACACTGGCCATTTTCACT AGAGTTTGCCTGGCAGGGACCGATCTCTGCCCCCTCCTCTCCCCAGGCCTCTGGCTGCAGTGATGCCGCAGAATCCTGAGCCAGGTGCCT CCTGAGCAGCCCGTGCGCCTCTCCACAGCGGCGTTTGCCACCCAATGCGGCTCGCTTCAGATGCTCTGATGCAGAGGGCACGCCCATAGT CCCTCTGCAGAGCCTCGCACTGGGGCCAGGGCAGGCACCAGCCCCAGGCGGCCAGTCGGCCACGGCCTGTCCTCTTCCTCGTAGCGTCTG CTCCTCACTTTGTGTTGATGGTGACTTAGGAGAATGTTCCGATTTTCCATGATCTAAGCAGGCCACGTTTAAAATAACATCAAGGCAAGC GTACGTGTCACCCTCTGTACTGACATCTCTTCCCCTGAAATGCTTTTCAGTTTGACAGCCCGTTTCCTAGACAAGTGCACCTGGGGTTTC AGGAACTTTGTGTTTTTTCGGAGGGGGTTGGTGGGGAGGTCGGGATGCCTGGGATCCCTTCCTGGAGAGGCAGGCTGTCTCTGGAAAAAG CCTCCATTGCCCACCCGCCAGGCGGAAAGTCACCCTGTTCCCAGCGCGGTTTCAGCATTTAATTTTAAGGGAGCTAAGGAAGCGCGGCGC GCCCCCTGGTGGTGGTAAGCCGCCAACGCACCTGGGGGCTGCAACCCCACCGGACGGGTGGTCCGGAGGGAGGCTGGAGCGGGGAGGCGA GGAGGGGGCTGTGAGTCCTCAGAGGCCCTGGGCCACCACATTTCTGGCAGCGTTTCCCAGACACCCCTCTGCTAGGCCATCCCTGGATAG CAAGTGAATTAACTTAAGGGCACTGTGATGGGAAGCCTTGCCCCCCTCTTTTTTTTTTTTTTTTAATATCTGCGGAATAAACCCAATGGT TAATTTTTGAATGAATAAAAGGCTTTTGTTGAATAAACAGCTGGTCCCATCTTCTGTCTTGGCATCTTAGCATCCAGGCTCAGGCTCTGC CCCTTCTCCAGGATGGGGTAGCCCCGAGTCGCCCTCCCCAGTCTGCACATTCCCTGTTGTCCCTGTTCCTGCAGTGGCTCCCGGCCCCAG GGAGGCCCACCTCACTCCCAGCCTGACTCGGTGGCTGGCTTCCTTCAGGACTTTGCGCAAGTCAGTTCTGCTCATTGGGTCTCAATTTCC CCATCCCTTGGATGGGAGCAAGAGTCTCTGCTGGGCCTGCCTCGCAGGGGCCTGGTGAGACCCAAATGTGAGTGTCATCATCAAAGCCCC TCACAGAAGTGGAGGACGGTGCCCAAGAGTAGCGGTTTGGACTGCTGCTGCCTCCCACCCGGAGCCTGCCACTTGGGGGAGAAATTGGTA TAATGCTTGCAAAAACAAACAAACAAAAGGCAATGTCTTCTGGTTGTGGTTATTTCCTTTCCTGCTTGCCTCCCCAGCCCCCTTTGAGTC TCTTTTTGGGGTGCCGTCCTGTCTGAACCTGCCGGTGTGTGTCTCTGGGGCCAGGGTCAGGGCGAGGCCCAGGGGTGGACAGGGGCCGTG TAGCATGCCCCAGCCTCCCCAAGCTCCTGCTGTATGTCGTCCATGTCACGCCAATTAAACACGCTTCCTGGACTTGTCCTCGCC >7258_7258_2_ASS1-NCS1_ASS1_chr9_133355836_ENST00000372393_NCS1_chr9_132963237_ENST00000372398_length(amino acids)=448AA_BP=279 MSSKGSVVLAYSGGLDTSCILVWLKEQGYDVIAYLANIGQKEDFEEARKKALKLGAKKVFIEDVSREFVEEFIWPAIQSSALYEDRYLLG TSLARPCIARKQVEIAQREGAKYVSHGATGKGNDQVRFELSCYSLAPQIKVIAPWRMPEFYNRFKGRNDLMEYAKQHGIPIPVTPKNPWS MDENLMHISYEAGILENPKNQAPPGLYTKTQDPAKAPNTPDILEIEFKKGVPVKVTNVKDGTTHQTSLELFMYLNEVAGKHGVGRIDIVE NRFIGMKSRVTEKEVQQWYKGFIKDCPSGQLDAAGFQKIYKQFFPFGDPTKFATFVFNVFDENKDGRIEFSEFIQALSVTSRGTLDEKLR WAFKLYDLDNDGYITRNEMLDIVDAIYQMVGNTVELPEEENTPEKRVDRIFAMMDKNADGKLTLQEFQEGSKADPSIVQALSLYDGLV -------------------------------------------------------------- >7258_7258_3_ASS1-NCS1_ASS1_chr9_133355836_ENST00000372394_NCS1_chr9_132963237_ENST00000372398_length(transcript)=6160nt_BP=1319nt CTGCTCTGCCGCCTGCCACCGCTGCCCGAGCCCGGTGGGCGGCGGCACTGCGTGCTGGGGAAGCACAGATTCTTGTGCCCTCTGTGACCT TGAGCCTGCCACTGACCTCTCTGAGCCCTGCTGGCTGCCTCCCCAATAGGAATGACAACTCCTACTTCATGAGGTTGTAGTGGGGGCTCA GGGGCACAGGGAGATCCCGCTGAGGCTCCCAGGGCCCTGCCTGGTGCTTGGCAAGGAGCAGTTCTGATGGGGGATGTGTCAGCTGCCAGA GGCTCAGAGCCAAGGCCCCTCCCACATCTCCTGCCTGCGTGCATTCCTCACATCCTGGCCTTGGGCCAAACTGCTCAGCCTCAGCCGCCT TCCCTCGATGCTGGAGGATCAGGTCCAAGAGATGCCTCTCCCCGACCAGCCTAGGACTGCAGTCAGCATTCCCAGGCCCCAGTGTGGTCT GTGGGGCTGTGTGCAGAGTGTGCGAGACGCTATGTCCAGCAAAGGCTCCGTGGTTCTGGCCTACAGTGGCGGCCTGGACACCTCGTGCAT CCTCGTGTGGCTGAAGGAACAAGGCTATGACGTCATTGCCTATCTGGCCAACATTGGCCAGAAGGAAGACTTCGAGGAAGCCAGGAAGAA GGCACTGAAGCTTGGGGCCAAAAAGGTGTTCATTGAGGATGTCAGCAGGGAGTTTGTGGAGGAGTTCATCTGGCCGGCCATCCAGTCCAG CGCACTGTATGAGGACCGCTACCTCCTGGGCACCTCTCTTGCCAGGCCCTGCATCGCCCGCAAACAAGTGGAAATCGCCCAGCGGGAGGG GGCCAAGTATGTGTCCCACGGCGCCACAGGAAAGGGGAACGATCAGGTCCGGTTTGAGCTCAGCTGCTACTCACTGGCCCCCCAGATAAA GGTCATTGCTCCCTGGAGGATGCCTGAATTCTACAACCGGTTCAAGGGCCGCAATGACCTGATGGAGTACGCAAAGCAACACGGGATTCC CATCCCGGTCACTCCCAAGAACCCGTGGAGCATGGATGAGAACCTCATGCACATCAGCTACGAGGCTGGAATCCTGGAGAACCCCAAGAA CCAAGCGCCTCCAGGTCTCTACACGAAGACCCAGGACCCAGCCAAAGCCCCCAACACCCCTGACATTCTCGAGATCGAGTTCAAAAAAGG GGTCCCTGTGAAGGTGACCAACGTCAAGGATGGCACCACCCACCAGACCTCCTTGGAGCTCTTCATGTACCTGAACGAAGTCGCGGGCAA GCATGGCGTGGGCCGTATTGACATCGTGGAGAACCGCTTCATTGGAATGAAGTCCCGAGTTACCGAGAAGGAGGTCCAGCAGTGGTACAA AGGCTTCATCAAGGACTGCCCCAGTGGGCAGCTGGATGCGGCAGGCTTCCAGAAGATCTACAAGCAATTCTTCCCGTTCGGAGACCCCAC CAAGTTTGCCACATTTGTTTTCAACGTCTTTGATGAAAACAAGGACGGGCGAATTGAGTTCTCCGAGTTCATCCAGGCGCTGTCGGTGAC CTCACGGGGAACCCTGGATGAGAAGCTACGGTGGGCCTTCAAGCTCTACGACTTGGACAATGATGGCTACATCACCAGGAATGAGATGCT GGACATTGTGGATGCCATTTACCAGATGGTGGGGAATACCGTGGAGCTCCCAGAGGAGGAGAACACTCCTGAGAAGAGGGTGGACCGGAT CTTTGCCATGATGGATAAGAATGCCGACGGGAAGCTGACCCTGCAGGAGTTCCAGGAGGGTTCCAAGGCAGACCCGTCCATTGTGCAGGC GCTGTCCCTCTACGACGGGCTGGTATAGTCCCAGGCTGGAGCTGGATGCCTGGGAACCACTCACCTCCTTCTGTGCCATGAGGCCACCTC AGCCCTGACACCAACCCCGTGCGTCCACCCAGCCTTCTTCCGCATCCACACACAGCCGGCTGCCCTTGACCCGGGAGGCCCCGGCTCTCC TCTCCCCTGTCCTGCACCCATCCCCCGCCTGAAGCCACCGGCTCCAATTGCCAGCAACCTCTGCTTGTCCGGAAAACGACAACACGAAAT GGAAAAGGCTACAGCCCTCTGCATAAACCAAGGACTTGGCTGCCTCGCAGGCAGCCTCCGTTCCTCCCGCTCTCTTGCGCGTGTGCTTTT GTTTTTTATTTTGAACAGACGTTTTAAAAGAAAAAAAAACAACTACCTTCTGTCCTAGAAGACACAGACTGACAGATGGGGTGAAGGCCT GGGGACCTCAGAGAACTCTGCCTTGCCCTCGTCCCTCGTCCTTCGGCAGCCGGAGAGGCTGTGGGTGGGCCGAGGGTGTCTAGGGGTTCT GCCTGGTCAACGTTATTTGTCGTCCCATCTTTTGGCAGCAAAACCACCTGCGTGGCTAGGATGATTAATTATGAGGATGATGATTTTTTT TGTGATAACAGTATTGTGCTTTTTGTGGGGAAAGTGAGGTTTTTTTTTATATACATATATAATTGATATCTTTAATTTATTGGTTGTTAA CTGTTGCTGCTGCCTGGTGTGTCCTCAGCTCCCAGGGCTGCGGGCCCACCGTTTACATGTGCACGCCCTGACCCACCTGCCCACGCCGAC TTGGGAGGATGGTGGCCTGCAGCGGCCAAGAAGCCAAAAAAAATTTTTTTTTTTTCAGATACTGTGCTTGATTTTTGGAGAGGGGAGAGG TGGAAATTCCTAAATGGCTAATGCACTGTTCCCTCCAGCCCGAATGCCTCCTGCCAAACCCCTTTTCCCTGCTGCCTCTGTCCCCGCATC CTTGTTCTCCCCTGGGTCCGTAACATTTTTTCCGAGGATGAACAGGGGACATCTTTAGGTTTCTCAACTCTTGCTTTGGTGTTTGCCGCA GCATGGAAAACAGGGCGCCTAAGGCTGGGAGCTGGAAGAAGGGGCATTGGGTACCCAGGCAGAGTCAGGAGAGGTGGTCTTTGAAGTAAG TTAGCAGAAATCAAGGGGACCCCCGCCTCCTTGGGCTGGGGAGGGGATTTCAAGATAGTTCATGACTCTCTCCCGCTCTGCCTTCCCTCC TTCCTATCTGCTTTTTCCAGTAAACTGCATGGTGTCCTTCCCTGGCCTTCTCTTGGCTCAAAGGCTGGGAGGGAGGGAAGGAGAGAAGAG TTCCAGGCAATCCCATCAATATAGTCCCTACACCTGGGGCTGCGGCCCACATGTCTTCACGGAGGCTTCCAGCGGTGCCTGCCACTGAGG CAGGTGCGGCCCCAGGACCATCACCAGGAATGCGAGGCCACCCTGGACCAGAGGTAGGAGCCCAAGGTCCGGCCCTTGCTCTTTGATTGT GGGCAGCCTCCTGCCCTCTCTGGGTCTCAGTTGCCCCATCTGCAGAGCGAGGAGGCCCGGGCTGGTTGGTCTTGAAGGCCCTTTTCCATG CCGACATCATGTCACTCTAGGCCTGGGGTTCAGTTTCCTGTGGCTGGTGATGCTGTGGTTAAGTTTGCTTGACCCCAGCAGCCCGAGGGA CTGTCTGAGTCACAGCACAGCCCCTATTGCGTGGCTGCTGGTGTGTGGGGTCAGTTCCAGCAGATGAATGTGTCATGTGGCACACCTTGT CCCTTCCCGCAGCATTTCCTGGTTCCCCCCAGACCCTTGAGCGCTCTTTGGGACCCAGAAGGAGTCCTTGCACAGGGAAGGCTTGAGGTG AGAAGCCGCTTCCCAGACTGTCAGGGCCAGGCCTGGGTCTAGAATTCTTGCTGCTGCTTTGCAGAGTCAACAGCCCATCAGCCCATGTTT TAGAGGGGACACTTTGGTCCTCGGTTCCCACCCTCAGCAAGCAGGCCTCCAGCCCGAGGAAGGCCTCTGCCGTAGTGACGTTGCCGTGTG GGGCTGCGTGGCTGTTCCCCTTGGCTGGAGCATTCAGCCAACCCCAGCGTCCCCCCTGAGGCGTTCATTGGCAGCCCCCTAGGACTGCAC GCTGGCCCCACGGTAACCCCCCCTCCCCCACCAACATCCTGCAGGGATGGGGTCAGTGGTTCCACCTTCACAGGCCACTTTGAAGGGTGG ATTCTTTGAGGCCCCTGCCAGTCGGCTCCCTGCTCAGCTGCTGGCCCGGGCGACCTGGGACTCAGCACCAACGGCTGAAGTTTCTCAGCT GGGCTCTGACCTGGGGTCTGGGGCAGGGAACGAACATGGTGGCTTTGGGCTGAGAGGATGAGGGAGGTCTTTCCCAGGTCAAATTACTTT CCTTTGGCCTCTGCCTGAGGCTCGATTTGCCTCTCTGGTCCAATGGGACTGACACTGTTGTACAACCTGACCTGTGGCTGAGGGTGTCTG GGCTTAAGCATGTGGACCCCTTCGGTGTGTCCGGCCTTCCTCCATCGTCCTGCCCTTTGGCCTTTTGGTTTGAAGCCACAGGTGTGGCTT CTGGCCTTAGCAGATGGTATGCTTGCGGACCGCAGCCCAGCATGCCGGTGGGCCCACAGCCCGAGCCAGCCCAGAGCTGCCGGAAGGGCC GCCCTTCCCGGCCCTGGCGGGGTGCTGGACACTGGCCATTTTCACTAGAGTTTGCCTGGCAGGGACCGATCTCTGCCCCCTCCTCTCCCC AGGCCTCTGGCTGCAGTGATGCCGCAGAATCCTGAGCCAGGTGCCTCCTGAGCAGCCCGTGCGCCTCTCCACAGCGGCGTTTGCCACCCA ATGCGGCTCGCTTCAGATGCTCTGATGCAGAGGGCACGCCCATAGTCCCTCTGCAGAGCCTCGCACTGGGGCCAGGGCAGGCACCAGCCC CAGGCGGCCAGTCGGCCACGGCCTGTCCTCTTCCTCGTAGCGTCTGCTCCTCACTTTGTGTTGATGGTGACTTAGGAGAATGTTCCGATT TTCCATGATCTAAGCAGGCCACGTTTAAAATAACATCAAGGCAAGCGTACGTGTCACCCTCTGTACTGACATCTCTTCCCCTGAAATGCT TTTCAGTTTGACAGCCCGTTTCCTAGACAAGTGCACCTGGGGTTTCAGGAACTTTGTGTTTTTTCGGAGGGGGTTGGTGGGGAGGTCGGG ATGCCTGGGATCCCTTCCTGGAGAGGCAGGCTGTCTCTGGAAAAAGCCTCCATTGCCCACCCGCCAGGCGGAAAGTCACCCTGTTCCCAG CGCGGTTTCAGCATTTAATTTTAAGGGAGCTAAGGAAGCGCGGCGCGCCCCCTGGTGGTGGTAAGCCGCCAACGCACCTGGGGGCTGCAA CCCCACCGGACGGGTGGTCCGGAGGGAGGCTGGAGCGGGGAGGCGAGGAGGGGGCTGTGAGTCCTCAGAGGCCCTGGGCCACCACATTTC TGGCAGCGTTTCCCAGACACCCCTCTGCTAGGCCATCCCTGGATAGCAAGTGAATTAACTTAAGGGCACTGTGATGGGAAGCCTTGCCCC CCTCTTTTTTTTTTTTTTTTAATATCTGCGGAATAAACCCAATGGTTAATTTTTGAATGAATAAAAGGCTTTTGTTGAATAAACAGCTGG TCCCATCTTCTGTCTTGGCATCTTAGCATCCAGGCTCAGGCTCTGCCCCTTCTCCAGGATGGGGTAGCCCCGAGTCGCCCTCCCCAGTCT GCACATTCCCTGTTGTCCCTGTTCCTGCAGTGGCTCCCGGCCCCAGGGAGGCCCACCTCACTCCCAGCCTGACTCGGTGGCTGGCTTCCT TCAGGACTTTGCGCAAGTCAGTTCTGCTCATTGGGTCTCAATTTCCCCATCCCTTGGATGGGAGCAAGAGTCTCTGCTGGGCCTGCCTCG CAGGGGCCTGGTGAGACCCAAATGTGAGTGTCATCATCAAAGCCCCTCACAGAAGTGGAGGACGGTGCCCAAGAGTAGCGGTTTGGACTG CTGCTGCCTCCCACCCGGAGCCTGCCACTTGGGGGAGAAATTGGTATAATGCTTGCAAAAACAAACAAACAAAAGGCAATGTCTTCTGGT TGTGGTTATTTCCTTTCCTGCTTGCCTCCCCAGCCCCCTTTGAGTCTCTTTTTGGGGTGCCGTCCTGTCTGAACCTGCCGGTGTGTGTCT CTGGGGCCAGGGTCAGGGCGAGGCCCAGGGGTGGACAGGGGCCGTGTAGCATGCCCCAGCCTCCCCAAGCTCCTGCTGTATGTCGTCCAT GTCACGCCAATTAAACACGCTTCCTGGACTTGTCCTCGCC >7258_7258_3_ASS1-NCS1_ASS1_chr9_133355836_ENST00000372394_NCS1_chr9_132963237_ENST00000372398_length(amino acids)=524AA_BP=355 MCQLPEAQSQGPSHISCLRAFLTSWPWAKLLSLSRLPSMLEDQVQEMPLPDQPRTAVSIPRPQCGLWGCVQSVRDAMSSKGSVVLAYSGG LDTSCILVWLKEQGYDVIAYLANIGQKEDFEEARKKALKLGAKKVFIEDVSREFVEEFIWPAIQSSALYEDRYLLGTSLARPCIARKQVE IAQREGAKYVSHGATGKGNDQVRFELSCYSLAPQIKVIAPWRMPEFYNRFKGRNDLMEYAKQHGIPIPVTPKNPWSMDENLMHISYEAGI LENPKNQAPPGLYTKTQDPAKAPNTPDILEIEFKKGVPVKVTNVKDGTTHQTSLELFMYLNEVAGKHGVGRIDIVENRFIGMKSRVTEKE VQQWYKGFIKDCPSGQLDAAGFQKIYKQFFPFGDPTKFATFVFNVFDENKDGRIEFSEFIQALSVTSRGTLDEKLRWAFKLYDLDNDGYI TRNEMLDIVDAIYQMVGNTVELPEEENTPEKRVDRIFAMMDKNADGKLTLQEFQEGSKADPSIVQALSLYDGLV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ASS1-NCS1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000372398 | 0 | 8 | 174_190 | 21.333333333333332 | 1579.3333333333333 | IL1RAPL1 | |
| Tgene | NCS1 | chr9:133355836 | chr9:132963237 | ENST00000458469 | 0 | 8 | 174_190 | 3.3333333333333335 | 1605.0 | IL1RAPL1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ASS1-NCS1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ASS1-NCS1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ASS1 | C4721769 | Citrullinemia Type 1 | 22 | CLINGEN;CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Hgene | ASS1 | C0175683 | Citrullinemia | 10 | CLINGEN;CTD_human;GENOMICS_ENGLAND |
| Hgene | ASS1 | C0751751 | Argininosuccinic Acid Synthetase Deficiency, Complete | 9 | CLINGEN;CTD_human |
| Hgene | ASS1 | C0011875 | Diabetic Angiopathies | 1 | CTD_human |
| Hgene | ASS1 | C0025945 | Microangiopathy, Diabetic | 1 | CTD_human |
| Hgene | ASS1 | C3714756 | Intellectual Disability | 1 | GENOMICS_ENGLAND |
| Tgene | C0005586 | Bipolar Disorder | 2 | PSYGENET | |
| Tgene | C0036341 | Schizophrenia | 2 | PSYGENET | |
| Tgene | C0600427 | Cocaine Dependence | 1 | PSYGENET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies