
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ATP1A1-ATP1A3 (FusionGDB2 ID:HG476TG478) |
Fusion Gene Summary for ATP1A1-ATP1A3 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ATP1A1-ATP1A3 | Fusion gene ID: hg476tg478 | Hgene | Tgene | Gene symbol | ATP1A1 | ATP1A3 | Gene ID | 476 | 478 |
| Gene name | ATPase Na+/K+ transporting subunit alpha 1 | ATPase Na+/K+ transporting subunit alpha 3 | |
| Synonyms | CMT2DD|HOMGSMR2 | AHC2|ATP1A1|CAPOS|DYT12|RDP | |
| Cytomap | ('ATP1A1')('ATP1A3') 1p13.1 | 19q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | sodium/potassium-transporting ATPase subunit alpha-1ATPase, Na+/K+ transporting, alpha 1 polypeptideNa(+)/K(+) ATPase alpha-1 subunitNa+/K+ ATPase 1Na, K-ATPase, alpha-A catalytic polypeptideNa,K-ATPase alpha-1 subunitNa,K-ATPase catalytic subunit a | sodium/potassium-transporting ATPase subunit alpha-3ATPase, Na+/K+ transporting, alpha 3 polypeptideNa(+)/K(+) ATPase alpha(III) subunitNa(+)/K(+) ATPase alpha-3 subunitNa+, K+ activated adenosine triphosphatase alpha subunitNa+/K+ ATPase 3sodium pu | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P05023 | P13637 | |
| Ensembl transtripts involved in fusion gene | ENST00000295598, ENST00000369496, ENST00000537345, ENST00000491156, | ||
| Fusion gene scores | * DoF score | 16 X 18 X 7=2016 | 4 X 4 X 3=48 |
| # samples | 23 | 4 | |
| ** MAII score | log2(23/2016*10)=-3.13178987255554 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ATP1A1 [Title/Abstract] AND ATP1A3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ATP1A1(116939356)-ATP1A3(42480718), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ATP1A1-ATP1A3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ATP1A1-ATP1A3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ATP1A1-ATP1A3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ATP1A1-ATP1A3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ATP1A1 | GO:0006883 | cellular sodium ion homeostasis | 10636900|19542013 |
| Hgene | ATP1A1 | GO:0030007 | cellular potassium ion homeostasis | 10636900|19542013 |
| Hgene | ATP1A1 | GO:0036376 | sodium ion export across plasma membrane | 10636900|19542013 |
| Hgene | ATP1A1 | GO:0071383 | cellular response to steroid hormone stimulus | 11546672 |
| Hgene | ATP1A1 | GO:0086009 | membrane repolarization | 19542013 |
| Hgene | ATP1A1 | GO:1903416 | response to glycoside | 11546672 |
| Hgene | ATP1A1 | GO:1990573 | potassium ion import across plasma membrane | 10636900|19542013 |
| Tgene | ATP1A3 | GO:0006883 | cellular sodium ion homeostasis | 10636900 |
| Tgene | ATP1A3 | GO:0030007 | cellular potassium ion homeostasis | 10636900 |
| Tgene | ATP1A3 | GO:0036376 | sodium ion export across plasma membrane | 10636900 |
| Tgene | ATP1A3 | GO:1990573 | potassium ion import across plasma membrane | 10636900 |
| Fusion gene breakpoints across ATP1A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ATP1A3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 13N | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| ChimerDB4 | Non-Cancer | 5381N | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
Top |
Fusion Gene ORF analysis for ATP1A1-ATP1A3 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000295598 | ENST00000468774 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| 5CDS-intron | ENST00000369496 | ENST00000468774 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| 5CDS-intron | ENST00000537345 | ENST00000468774 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000295598 | ENST00000302102 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000295598 | ENST00000543770 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000295598 | ENST00000545399 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000295598 | ENST00000602133 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000369496 | ENST00000302102 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000369496 | ENST00000543770 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000369496 | ENST00000545399 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000369496 | ENST00000602133 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000537345 | ENST00000302102 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000537345 | ENST00000543770 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000537345 | ENST00000545399 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| In-frame | ENST00000537345 | ENST00000602133 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| intron-3CDS | ENST00000491156 | ENST00000302102 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| intron-3CDS | ENST00000491156 | ENST00000543770 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| intron-3CDS | ENST00000491156 | ENST00000545399 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| intron-3CDS | ENST00000491156 | ENST00000602133 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| intron-intron | ENST00000491156 | ENST00000468774 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000295598 | ATP1A1 | chr1 | 116939356 | + | ENST00000302102 | ATP1A3 | chr19 | 42480718 | - | 3679 | 2225 | 237 | 3323 | 1028 |
| ENST00000295598 | ATP1A1 | chr1 | 116939356 | + | ENST00000545399 | ATP1A3 | chr19 | 42480718 | - | 3677 | 2225 | 237 | 3323 | 1028 |
| ENST00000295598 | ATP1A1 | chr1 | 116939356 | + | ENST00000543770 | ATP1A3 | chr19 | 42480718 | - | 3640 | 2225 | 237 | 3323 | 1028 |
| ENST00000295598 | ATP1A1 | chr1 | 116939356 | + | ENST00000602133 | ATP1A3 | chr19 | 42480718 | - | 3479 | 2225 | 237 | 3323 | 1028 |
| ENST00000537345 | ATP1A1 | chr1 | 116939356 | + | ENST00000302102 | ATP1A3 | chr19 | 42480718 | - | 3790 | 2336 | 318 | 3434 | 1038 |
| ENST00000537345 | ATP1A1 | chr1 | 116939356 | + | ENST00000545399 | ATP1A3 | chr19 | 42480718 | - | 3788 | 2336 | 318 | 3434 | 1038 |
| ENST00000537345 | ATP1A1 | chr1 | 116939356 | + | ENST00000543770 | ATP1A3 | chr19 | 42480718 | - | 3751 | 2336 | 318 | 3434 | 1038 |
| ENST00000537345 | ATP1A1 | chr1 | 116939356 | + | ENST00000602133 | ATP1A3 | chr19 | 42480718 | - | 3590 | 2336 | 318 | 3434 | 1038 |
| ENST00000369496 | ATP1A1 | chr1 | 116939356 | + | ENST00000302102 | ATP1A3 | chr19 | 42480718 | - | 3599 | 2145 | 163 | 3243 | 1026 |
| ENST00000369496 | ATP1A1 | chr1 | 116939356 | + | ENST00000545399 | ATP1A3 | chr19 | 42480718 | - | 3597 | 2145 | 163 | 3243 | 1026 |
| ENST00000369496 | ATP1A1 | chr1 | 116939356 | + | ENST00000543770 | ATP1A3 | chr19 | 42480718 | - | 3560 | 2145 | 163 | 3243 | 1026 |
| ENST00000369496 | ATP1A1 | chr1 | 116939356 | + | ENST00000602133 | ATP1A3 | chr19 | 42480718 | - | 3399 | 2145 | 163 | 3243 | 1026 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000295598 | ENST00000302102 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002813831 | 0.9971861 |
| ENST00000295598 | ENST00000545399 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002800208 | 0.9971998 |
| ENST00000295598 | ENST00000543770 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002904276 | 0.9970957 |
| ENST00000295598 | ENST00000602133 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002927522 | 0.99707246 |
| ENST00000537345 | ENST00000302102 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002416669 | 0.99758327 |
| ENST00000537345 | ENST00000545399 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002409881 | 0.9975902 |
| ENST00000537345 | ENST00000543770 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002519399 | 0.9974806 |
| ENST00000537345 | ENST00000602133 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002528335 | 0.9974717 |
| ENST00000369496 | ENST00000302102 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002044038 | 0.9979559 |
| ENST00000369496 | ENST00000545399 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002036697 | 0.9979633 |
| ENST00000369496 | ENST00000543770 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002127731 | 0.99787223 |
| ENST00000369496 | ENST00000602133 | ATP1A1 | chr1 | 116939356 | + | ATP1A3 | chr19 | 42480718 | - | 0.002046306 | 0.99795365 |
Top |
Fusion Genomic Features for ATP1A1-ATP1A3 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
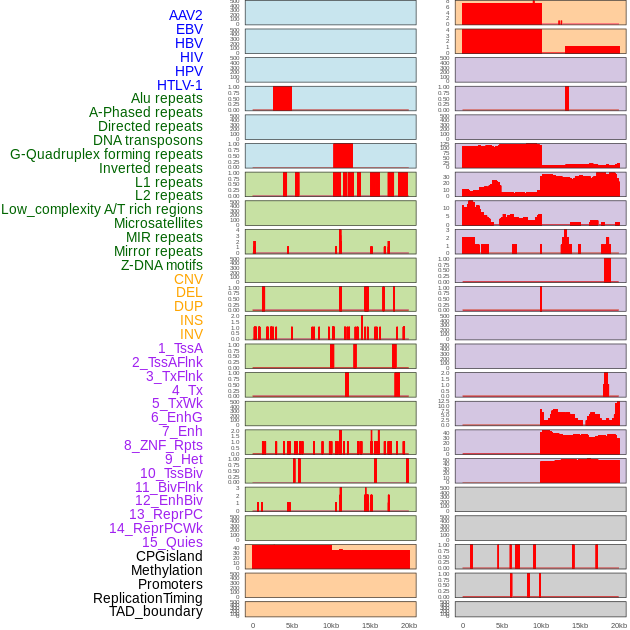 |
Top |
Fusion Protein Features for ATP1A1-ATP1A3 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:116939356/chr19:42480718) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ATP1A1 | ATP1A3 |
| FUNCTION: This is the catalytic component of the active enzyme, which catalyzes the hydrolysis of ATP coupled with the exchange of sodium and potassium ions across the plasma membrane. This action creates the electrochemical gradient of sodium and potassium ions, providing the energy for active transport of various nutrients. {ECO:0000269|PubMed:29499166, ECO:0000269|PubMed:30388404}. | FUNCTION: This is the catalytic component of the active enzyme, which catalyzes the hydrolysis of ATP coupled with the exchange of sodium and potassium ions across the plasma membrane. This action creates the electrochemical gradient of sodium and potassium ions, providing the energy for active transport of various nutrients. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 82_84 | 657 | 1024.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 82_84 | 626 | 993.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 82_84 | 657 | 1024.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 109_131 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 153_288 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 309_320 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 6_87 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 109_131 | 626 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 153_288 | 626 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 309_320 | 626 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 6_87 | 626 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 109_131 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 153_288 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 309_320 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 6_87 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 132_152 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 289_308 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 321_338 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 88_108 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 132_152 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 289_308 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 321_338 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 88_108 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 132_152 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 289_308 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 321_338 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 88_108 | 657 | 1024.0 | Transmembrane | Helical |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 783_792 | 647 | 1014.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 814_833 | 647 | 1014.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 857_908 | 647 | 1014.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 929_941 | 647 | 1014.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 961_975 | 647 | 1014.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 997_1013 | 647 | 1014.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 783_792 | 658 | 1025.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 814_833 | 658 | 1025.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 857_908 | 658 | 1025.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 929_941 | 658 | 1025.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 961_975 | 658 | 1025.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 997_1013 | 658 | 1025.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 783_792 | 660 | 1027.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 814_833 | 660 | 1027.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 857_908 | 660 | 1027.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 929_941 | 660 | 1027.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 961_975 | 660 | 1027.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 997_1013 | 660 | 1027.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 763_782 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 793_813 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 834_856 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 909_928 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 942_960 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 976_996 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 763_782 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 793_813 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 834_856 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 909_928 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 942_960 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 976_996 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 763_782 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 793_813 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 834_856 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 909_928 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 942_960 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 976_996 | 660 | 1027.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 1007_1023 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 339_772 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 793_802 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 824_843 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 867_918 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 939_951 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 971_985 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 1007_1023 | 626 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 339_772 | 626 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 793_802 | 626 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 824_843 | 626 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 867_918 | 626 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 939_951 | 626 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 971_985 | 626 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 1007_1023 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 339_772 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 793_802 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 824_843 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 867_918 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 939_951 | 657 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 971_985 | 657 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 773_792 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 803_823 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 844_866 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 919_938 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 952_970 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000295598 | + | 14 | 23 | 986_1006 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 773_792 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 803_823 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 844_866 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 919_938 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 952_970 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000369496 | + | 14 | 23 | 986_1006 | 626 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 773_792 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 803_823 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 844_866 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 919_938 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 952_970 | 657 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116939356 | chr19:42480718 | ENST00000537345 | + | 14 | 23 | 986_1006 | 657 | 1024.0 | Transmembrane | Helical |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 143_278 | 647 | 1014.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 1_77 | 647 | 1014.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 299_310 | 647 | 1014.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 329_762 | 647 | 1014.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 99_121 | 647 | 1014.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 143_278 | 658 | 1025.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 1_77 | 658 | 1025.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 299_310 | 658 | 1025.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 329_762 | 658 | 1025.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 99_121 | 658 | 1025.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 143_278 | 660 | 1027.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 1_77 | 660 | 1027.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 299_310 | 660 | 1027.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 329_762 | 660 | 1027.0 | Topological domain | Cytoplasmic | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 99_121 | 660 | 1027.0 | Topological domain | Extracellular | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 122_142 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 279_298 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 311_328 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 78_98 | 647 | 1014.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 122_142 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 279_298 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 311_328 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 78_98 | 658 | 1025.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 122_142 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 279_298 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 311_328 | 660 | 1027.0 | Transmembrane | Helical | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 78_98 | 660 | 1027.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for ATP1A1-ATP1A3 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >7778_7778_1_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000302102_length(transcript)=3679nt_BP=2225nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGTTGGA CGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGATGAACTGAAG AAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATTAACATCTGCT CGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTGTCGGCAGCTC TTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGAGGAACCTCAA AACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAAAAGTTCAAAG ATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGAGGAAGTTGTG GTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGTGGATAACTCC TCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGCCTTCTTTTCA ACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACTTGCTTCTGGG CTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGGTGTGTCTTTC TTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCCGGAAGGTTTG CTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGCTGTGGAGACC TTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTTTGACAATCAA ATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAGAATTGCAGGT CTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGAGTCAGCACTC TTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAACTCCACCAAC AAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAGGATCCTAGAC CGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTTGGAGCTGGGG GGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACACTGACGATGTG AATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGTGGGCAAATGT CGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCATCATCTCAGAA GGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTGCGTGATCCAC GGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCACATCCCCCCAG CAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCCCGCTCTGAAG AAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGACAACTTTGCC TCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAATATCCCGGAG ATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGGCACTGACATG GTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAAATTGGTCAAT GAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCTGGCAGAAAAT GGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGGGCAGCAGTGG ACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGATCTGATCATC TGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGCCCTGGCTGCC TTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCCCTACAGTTTC CTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTACTGACCTCAG CCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGGGGGAGGAGCC CTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGGCTTCTCTCCCCTGCCCCAAAC CTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCCCAGCCACCTCCCTGGGCTCTT TTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGGTTCTGGACAATTATCAAATATATCAGTGGGGAGAGAGAA >7778_7778_1_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000302102_length(amino acids)=1028AA_BP=29 MSTATMGKGVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPT TPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNG EKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRT VMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKN CLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKR AVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELK DAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAK AIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVT GDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTI TILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTV NDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKP SWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_2_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000543770_length(transcript)=3640nt_BP=2225nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGTTGGA CGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGATGAACTGAAG AAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATTAACATCTGCT CGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTGTCGGCAGCTC TTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGAGGAACCTCAA AACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAAAAGTTCAAAG ATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGAGGAAGTTGTG GTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGTGGATAACTCC TCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGCCTTCTTTTCA ACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACTTGCTTCTGGG CTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGGTGTGTCTTTC TTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCCGGAAGGTTTG CTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGCTGTGGAGACC TTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTTTGACAATCAA ATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAGAATTGCAGGT CTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGAGTCAGCACTC TTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAACTCCACCAAC AAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAGGATCCTAGAC CGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTTGGAGCTGGGG GGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACACTGACGATGTG AATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGTGGGCAAATGT CGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCATCATCTCAGAA GGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTGCGTGATCCAC GGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCACATCCCCCCAG CAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCCCGCTCTGAAG AAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGACAACTTTGCC TCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAATATCCCGGAG ATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGGCACTGACATG GTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAAATTGGTCAAT GAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCTGGCAGAAAAT GGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGGGCAGCAGTGG ACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGATCTGATCATC TGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGCCCTGGCTGCC TTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCCCTACAGTTTC CTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTACTGACCTCAG CCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGGGGGAGGAGCC CTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGGCTTCTCTCCCCTGCCCCAAAC CTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCCCAGCCACCTCCCTGGGCTCTT TTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGG >7778_7778_2_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000543770_length(amino acids)=1028AA_BP=29 MSTATMGKGVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPT TPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNG EKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRT VMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKN CLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKR AVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELK DAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAK AIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVT GDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTI TILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTV NDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKP SWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_3_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000545399_length(transcript)=3677nt_BP=2225nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGTTGGA CGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGATGAACTGAAG AAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATTAACATCTGCT CGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTGTCGGCAGCTC TTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGAGGAACCTCAA AACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAAAAGTTCAAAG ATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGAGGAAGTTGTG GTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGTGGATAACTCC TCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGCCTTCTTTTCA ACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACTTGCTTCTGGG CTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGGTGTGTCTTTC TTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCCGGAAGGTTTG CTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGCTGTGGAGACC TTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTTTGACAATCAA ATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAGAATTGCAGGT CTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGAGTCAGCACTC TTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAACTCCACCAAC AAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAGGATCCTAGAC CGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTTGGAGCTGGGG GGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACACTGACGATGTG AATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGTGGGCAAATGT CGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCATCATCTCAGAA GGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTGCGTGATCCAC GGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCACATCCCCCCAG CAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCCCGCTCTGAAG AAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGACAACTTTGCC TCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAATATCCCGGAG ATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGGCACTGACATG GTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAAATTGGTCAAT GAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCTGGCAGAAAAT GGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGGGCAGCAGTGG ACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGATCTGATCATC TGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGCCCTGGCTGCC TTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCCCTACAGTTTC CTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTACTGACCTCAG CCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGGGGGAGGAGCC CTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGGCTTCTCTCCCCTGCCCCAAAC CTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCCCAGCCACCTCCCTGGGCTCTT TTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGGTTCTGGACAATTATCAAATATATCAGTGGGGAGAGAG >7778_7778_3_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000545399_length(amino acids)=1028AA_BP=29 MSTATMGKGVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPT TPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNG EKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRT VMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKN CLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKR AVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELK DAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAK AIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVT GDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTI TILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTV NDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKP SWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_4_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000602133_length(transcript)=3479nt_BP=2225nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGTTGGA CGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGATGAACTGAAG AAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATTAACATCTGCT CGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTGTCGGCAGCTC TTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGAGGAACCTCAA AACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAAAAGTTCAAAG ATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGAGGAAGTTGTG GTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGTGGATAACTCC TCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGCCTTCTTTTCA ACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACTTGCTTCTGGG CTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGGTGTGTCTTTC TTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCCGGAAGGTTTG CTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGCTGTGGAGACC TTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTTTGACAATCAA ATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAGAATTGCAGGT CTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGAGTCAGCACTC TTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAACTCCACCAAC AAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAGGATCCTAGAC CGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTTGGAGCTGGGG GGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACACTGACGATGTG AATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGTGGGCAAATGT CGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCATCATCTCAGAA GGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTGCGTGATCCAC GGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCACATCCCCCCAG CAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCCCGCTCTGAAG AAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGACAACTTTGCC TCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAATATCCCGGAG ATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGGCACTGACATG GTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAAATTGGTCAAT GAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCTGGCAGAAAAT GGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGGGCAGCAGTGG ACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGATCTGATCATC TGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGCCCTGGCTGCC TTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCCCTACAGTTTC CTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTACTGACCTCAG CCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGGGGGAGGAGCC CTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCA >7778_7778_4_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000295598_ATP1A3_chr19_42480718_ENST00000602133_length(amino acids)=1028AA_BP=29 MSTATMGKGVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPT TPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNG EKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRT VMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKN CLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKR AVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELK DAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAK AIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVT GDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTI TILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTV NDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKP SWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_5_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000302102_length(transcript)=3599nt_BP=2145nt GATATGTAATAATGTCTTTGCAAAGCAAAGAATATAAACAGTATAAAAGTACTAGCATTTAGATGTATTGTATCATTTAATCCTTAAAAA CATGAAATGAGGTTGGCACTATTCTTTATCTCCACGCTGTGGAAGAGGAAATTGAAATGTAGAAGTTAGTAACTTGCCTAAGGATACACT GCTGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGA TGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATT AACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTG TCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGA GGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAA AAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGA GGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGT GGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGC CTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACT TGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGG TGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCC GGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGC TGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTT TGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAG AATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGA GTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAA CTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAG GATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTT GGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACAC TGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGT GGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCAT CATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTG CGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCAC ATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCC CGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGA CAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAA TATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGG CACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAA ATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCT GGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGG GCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGA TCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGC CCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCC CTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTA CTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGG GGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGGCTTCTCTCCCC TGCCCCAAACCTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCCCAGCCACCTCC CTGGGCTCTTTTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGGTTCTGGACAATTATCAAATATATCAGTGGGGAGAGAGAA >7778_7778_5_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000302102_length(amino acids)=1026AA_BP=27 MPKDTLLVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTP EWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEK MSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVM GRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCL VKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAV AGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDA FQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAI AKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGD GVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTITI LCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTVND LEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKPSW WFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_6_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000543770_length(transcript)=3560nt_BP=2145nt GATATGTAATAATGTCTTTGCAAAGCAAAGAATATAAACAGTATAAAAGTACTAGCATTTAGATGTATTGTATCATTTAATCCTTAAAAA CATGAAATGAGGTTGGCACTATTCTTTATCTCCACGCTGTGGAAGAGGAAATTGAAATGTAGAAGTTAGTAACTTGCCTAAGGATACACT GCTGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGA TGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATT AACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTG TCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGA GGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAA AAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGA GGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGT GGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGC CTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACT TGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGG TGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCC GGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGC TGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTT TGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAG AATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGA GTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAA CTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAG GATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTT GGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACAC TGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGT GGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCAT CATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTG CGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCAC ATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCC CGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGA CAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAA TATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGG CACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAA ATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCT GGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGG GCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGA TCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGC CCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCC CTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTA CTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGG GGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGGCTTCTCTCCCC TGCCCCAAACCTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCCCAGCCACCTCC CTGGGCTCTTTTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGG >7778_7778_6_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000543770_length(amino acids)=1026AA_BP=27 MPKDTLLVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTP EWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEK MSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVM GRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCL VKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAV AGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDA FQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAI AKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGD GVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTITI LCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTVND LEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKPSW WFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_7_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000545399_length(transcript)=3597nt_BP=2145nt GATATGTAATAATGTCTTTGCAAAGCAAAGAATATAAACAGTATAAAAGTACTAGCATTTAGATGTATTGTATCATTTAATCCTTAAAAA CATGAAATGAGGTTGGCACTATTCTTTATCTCCACGCTGTGGAAGAGGAAATTGAAATGTAGAAGTTAGTAACTTGCCTAAGGATACACT GCTGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGA TGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATT AACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTG TCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGA GGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAA AAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGA GGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGT GGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGC CTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACT TGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGG TGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCC GGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGC TGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTT TGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAG AATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGA GTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAA CTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAG GATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTT GGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACAC TGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGT GGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCAT CATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTG CGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCAC ATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCC CGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGA CAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAA TATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGG CACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAA ATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCT GGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGG GCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGA TCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGC CCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCC CTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTA CTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGG GGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGGCTTCTCTCCCC TGCCCCAAACCTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCCCAGCCACCTCC CTGGGCTCTTTTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGGTTCTGGACAATTATCAAATATATCAGTGGGGAGAGAG >7778_7778_7_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000545399_length(amino acids)=1026AA_BP=27 MPKDTLLVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTP EWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEK MSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVM GRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCL VKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAV AGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDA FQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAI AKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGD GVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTITI LCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTVND LEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKPSW WFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_8_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000602133_length(transcript)=3399nt_BP=2145nt GATATGTAATAATGTCTTTGCAAAGCAAAGAATATAAACAGTATAAAAGTACTAGCATTTAGATGTATTGTATCATTTAATCCTTAAAAA CATGAAATGAGGTTGGCACTATTCTTTATCTCCACGCTGTGGAAGAGGAAATTGAAATGTAGAAGTTAGTAACTTGCCTAAGGATACACT GCTGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGACAGGGACATGGA TGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTGAGCCGGGGATT AACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGGATCAAGTTTTG TCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCTGCTACAGAAGA GGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTATCAAGAAGCTAA AAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGCATAAATGCGGA GGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAATGGCTGCAAGGT GGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACGAGGAACATTGC CTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGAATTGCCACACT TGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCTGTGTTCCTGGG TGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTAGCCAATGTGCC GGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAGAACTTAGAAGC TGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCCCACATGTGGTT TGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTTGCTCTGTCCAG AATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGAGATGCCTCTGA GTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAGATACCCTTCAA CTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGCGCCCCAGAAAG GATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAGAACGCCTATTT GGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTCCAGTTTGACAC TGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTTCCTGATGCCGT GGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAAGGTGTGGGCAT CATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGATGCCAAGGCCTG CGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTCTTCGCCCGCAC ATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTGAACGACTCCCC CGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATCCTGCTGGACGA CAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACCCTGACCAGCAA TATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGCATCGATCTGGG CACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCGCGGACGGACAA ATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTACTTTGTGATCCT GGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAAGACAGTTACGG GCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTCCAGTGGGCCGA TCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTTGAGGAGACGGC CCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTCTGTGCCTTCCC CTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAGGAAACCTACTA CTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTTTGTATTCTGGG GGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCA >7778_7778_8_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000369496_ATP1A3_chr19_42480718_ENST00000602133_length(amino acids)=1026AA_BP=27 MPKDTLLVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARDGPNALTPPPTTP EWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMVPQQALVIRNGEK MSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTARGIVVYTGDRTVM GRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLTLTAKRMARKNCL VKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQANQENLPILKRAV AGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHGKEQPLDEELKDA FQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIMVTGDHPITAKAI AKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGCQRQGAIVAVTGD GVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIMANIPLPLGTITI LCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVGIRLNWDDRTVND LEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMDVALRMYPLKPSW WFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_9_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000302102_length(transcript)=3790nt_BP=2336nt AGCAGCGGGGGCGGCCCCGGGACTGAGCCGGCATCCCTGAGCCTGGCTCCCCTCCCTGCGACCGCCGTCACCTCCTTCTCCTTCCTTTTC CCTCCGCCCTCCGTGCCCTGAGGAAAGGCGCGCTCCTCCCCTTCCCCTGGGGCGCTCCGCCGGGGCCTCCTCCCGGGCCTCCGTTCCCGC CGCGGCCCCGGTTCCGGCGGGGGCAGCCTCCGGGTTCGGGGCTCCTTCTCCTGGGGACGCTGGGGCTTAGCTTGCTCCGCGCAGAGGCGG CCGCCCTCCCCCAAAGAAAAAACTGGCTGCTTCTAAGTGCGAAGCCGGCTGGGCGGGCTGGTGCCAGAAAGGGTGTGTCTTCACTGCCCT AAGATGGCCTTTAAGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGAC AGGGACATGGATGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTG AGCCGGGGATTAACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGG ATCAAGTTTTGTCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCT GCTACAGAAGAGGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTAT CAAGAAGCTAAAAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGC ATAAATGCGGAGGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAAT GGCTGCAAGGTGGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACG AGGAACATTGCCTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGA ATTGCCACACTTGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCT GTGTTCCTGGGTGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTA GCCAATGTGCCGGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAG AACTTAGAAGCTGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCC CACATGTGGTTTGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTT GCTCTGTCCAGAATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGA GATGCCTCTGAGTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAG ATACCCTTCAACTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGC GCCCCAGAAAGGATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAG AACGCCTATTTGGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTC CAGTTTGACACTGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTT CCTGATGCCGTGGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAA GGTGTGGGCATCATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGAT GCCAAGGCCTGCGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTC TTCGCCCGCACATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTG AACGACTCCCCCGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATC CTGCTGGACGACAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACC CTGACCAGCAATATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGC ATCGATCTGGGCACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCG CGGACGGACAAATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTAC TTTGTGATCCTGGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAA GACAGTTACGGGCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTC CAGTGGGCCGATCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTT GAGGAGACGGCCCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTC TGTGCCTTCCCCTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAG GAAACCTACTACTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTT TGTATTCTGGGGGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGG CTTCTCTCCCCTGCCCCAAACCTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCC CAGCCACCTCCCTGGGCTCTTTTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGGTTCTGGACAATTATCAAATATATCAGTGG GGAGAGAGAA >7778_7778_9_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000302102_length(amino acids)=1038AA_BP=39 MGGLVPERVCLHCPKMAFKVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARD GPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMV PQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTAR GIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLT LTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQA NQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHG KEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIM VTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGC QRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIM ANIPLPLGTITILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVG IRLNWDDRTVNDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMD VALRMYPLKPSWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_10_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000543770_length(transcript)=3751nt_BP=2336nt AGCAGCGGGGGCGGCCCCGGGACTGAGCCGGCATCCCTGAGCCTGGCTCCCCTCCCTGCGACCGCCGTCACCTCCTTCTCCTTCCTTTTC CCTCCGCCCTCCGTGCCCTGAGGAAAGGCGCGCTCCTCCCCTTCCCCTGGGGCGCTCCGCCGGGGCCTCCTCCCGGGCCTCCGTTCCCGC CGCGGCCCCGGTTCCGGCGGGGGCAGCCTCCGGGTTCGGGGCTCCTTCTCCTGGGGACGCTGGGGCTTAGCTTGCTCCGCGCAGAGGCGG CCGCCCTCCCCCAAAGAAAAAACTGGCTGCTTCTAAGTGCGAAGCCGGCTGGGCGGGCTGGTGCCAGAAAGGGTGTGTCTTCACTGCCCT AAGATGGCCTTTAAGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGAC AGGGACATGGATGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTG AGCCGGGGATTAACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGG ATCAAGTTTTGTCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCT GCTACAGAAGAGGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTAT CAAGAAGCTAAAAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGC ATAAATGCGGAGGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAAT GGCTGCAAGGTGGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACG AGGAACATTGCCTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGA ATTGCCACACTTGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCT GTGTTCCTGGGTGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTA GCCAATGTGCCGGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAG AACTTAGAAGCTGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCC CACATGTGGTTTGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTT GCTCTGTCCAGAATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGA GATGCCTCTGAGTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAG ATACCCTTCAACTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGC GCCCCAGAAAGGATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAG AACGCCTATTTGGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTC CAGTTTGACACTGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTT CCTGATGCCGTGGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAA GGTGTGGGCATCATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGAT GCCAAGGCCTGCGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTC TTCGCCCGCACATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTG AACGACTCCCCCGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATC CTGCTGGACGACAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACC CTGACCAGCAATATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGC ATCGATCTGGGCACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCG CGGACGGACAAATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTAC TTTGTGATCCTGGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAA GACAGTTACGGGCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTC CAGTGGGCCGATCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTT GAGGAGACGGCCCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTC TGTGCCTTCCCCTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAG GAAACCTACTACTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTT TGTATTCTGGGGGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGG CTTCTCTCCCCTGCCCCAAACCTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCC CAGCCACCTCCCTGGGCTCTTTTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGG >7778_7778_10_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000543770_length(amino acids)=1038AA_BP=39 MGGLVPERVCLHCPKMAFKVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARD GPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMV PQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTAR GIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLT LTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQA NQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHG KEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIM VTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGC QRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIM ANIPLPLGTITILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVG IRLNWDDRTVNDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMD VALRMYPLKPSWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_11_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000545399_length(transcript)=3788nt_BP=2336nt AGCAGCGGGGGCGGCCCCGGGACTGAGCCGGCATCCCTGAGCCTGGCTCCCCTCCCTGCGACCGCCGTCACCTCCTTCTCCTTCCTTTTC CCTCCGCCCTCCGTGCCCTGAGGAAAGGCGCGCTCCTCCCCTTCCCCTGGGGCGCTCCGCCGGGGCCTCCTCCCGGGCCTCCGTTCCCGC CGCGGCCCCGGTTCCGGCGGGGGCAGCCTCCGGGTTCGGGGCTCCTTCTCCTGGGGACGCTGGGGCTTAGCTTGCTCCGCGCAGAGGCGG CCGCCCTCCCCCAAAGAAAAAACTGGCTGCTTCTAAGTGCGAAGCCGGCTGGGCGGGCTGGTGCCAGAAAGGGTGTGTCTTCACTGCCCT AAGATGGCCTTTAAGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGAC AGGGACATGGATGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTG AGCCGGGGATTAACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGG ATCAAGTTTTGTCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCT GCTACAGAAGAGGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTAT CAAGAAGCTAAAAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGC ATAAATGCGGAGGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAAT GGCTGCAAGGTGGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACG AGGAACATTGCCTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGA ATTGCCACACTTGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCT GTGTTCCTGGGTGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTA GCCAATGTGCCGGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAG AACTTAGAAGCTGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCC CACATGTGGTTTGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTT GCTCTGTCCAGAATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGA GATGCCTCTGAGTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAG ATACCCTTCAACTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGC GCCCCAGAAAGGATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAG AACGCCTATTTGGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTC CAGTTTGACACTGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTT CCTGATGCCGTGGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAA GGTGTGGGCATCATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGAT GCCAAGGCCTGCGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTC TTCGCCCGCACATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTG AACGACTCCCCCGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATC CTGCTGGACGACAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACC CTGACCAGCAATATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGC ATCGATCTGGGCACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCG CGGACGGACAAATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTAC TTTGTGATCCTGGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAA GACAGTTACGGGCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTC CAGTGGGCCGATCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTT GAGGAGACGGCCCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTC TGTGCCTTCCCCTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAG GAAACCTACTACTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTT TGTATTCTGGGGGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCACTCTGGCTGG CTTCTCTCCCCTGCCCCAAACCTCTCTCCTCTCTCTTTTCTGTGTCAGTTTCTCTCCCTCTCCTCACCCCTCTATCCATTCCTCCCGCCC CAGCCACCTCCCTGGGCTCTTTTTTACTCCCCTTCAGCCCCCCGGCTGATGCCATCTCTGGTTCTGGACAATTATCAAATATATCAGTGG GGAGAGAG >7778_7778_11_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000545399_length(amino acids)=1038AA_BP=39 MGGLVPERVCLHCPKMAFKVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARD GPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMV PQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTAR GIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLT LTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQA NQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHG KEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIM VTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGC QRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIM ANIPLPLGTITILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVG IRLNWDDRTVNDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMD VALRMYPLKPSWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- >7778_7778_12_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000602133_length(transcript)=3590nt_BP=2336nt AGCAGCGGGGGCGGCCCCGGGACTGAGCCGGCATCCCTGAGCCTGGCTCCCCTCCCTGCGACCGCCGTCACCTCCTTCTCCTTCCTTTTC CCTCCGCCCTCCGTGCCCTGAGGAAAGGCGCGCTCCTCCCCTTCCCCTGGGGCGCTCCGCCGGGGCCTCCTCCCGGGCCTCCGTTCCCGC CGCGGCCCCGGTTCCGGCGGGGGCAGCCTCCGGGTTCGGGGCTCCTTCTCCTGGGGACGCTGGGGCTTAGCTTGCTCCGCGCAGAGGCGG CCGCCCTCCCCCAAAGAAAAAACTGGCTGCTTCTAAGTGCGAAGCCGGCTGGGCGGGCTGGTGCCAGAAAGGGTGTGTCTTCACTGCCCT AAGATGGCCTTTAAGGTTGGACGTGATAAGTATGAGCCTGCAGCTGTTTCAGAACAAGGTGATAAAAAGGGCAAAAAGGGCAAAAAAGAC AGGGACATGGATGAACTGAAGAAAGAAGTTTCTATGGATGATCATAAACTTAGCCTTGATGAACTTCATCGTAAATATGGAACAGACTTG AGCCGGGGATTAACATCTGCTCGTGCAGCTGAGATCCTGGCGCGAGATGGTCCCAACGCCCTCACTCCCCCTCCCACTACTCCTGAATGG ATCAAGTTTTGTCGGCAGCTCTTTGGGGGGTTCTCAATGTTACTGTGGATTGGAGCGATTCTTTGTTTCTTGGCTTATAGCATCCAAGCT GCTACAGAAGAGGAACCTCAAAACGATAATCTGTACCTGGGTGTGGTGCTATCAGCCGTTGTAATCATAACTGGTTGCTTCTCCTACTAT CAAGAAGCTAAAAGTTCAAAGATCATGGAATCCTTCAAAAACATGGTCCCTCAGCAAGCCCTTGTGATTCGAAATGGTGAGAAAATGAGC ATAAATGCGGAGGAAGTTGTGGTTGGGGATCTGGTGGAAGTAAAAGGAGGAGACCGAATTCCTGCTGACCTCAGAATCATATCTGCAAAT GGCTGCAAGGTGGATAACTCCTCGCTCACTGGTGAATCAGAACCCCAGACTAGGTCTCCAGATTTCACAAATGAAAACCCCCTGGAGACG AGGAACATTGCCTTCTTTTCAACCAATTGTGTTGAAGGCACCGCACGTGGTATTGTTGTCTACACTGGGGATCGCACTGTGATGGGAAGA ATTGCCACACTTGCTTCTGGGCTGGAAGGAGGCCAGACCCCCATTGCTGCAGAAATTGAACATTTTATCCACATCATCACGGGTGTGGCT GTGTTCCTGGGTGTGTCTTTCTTCATCCTTTCTCTCATCCTTGAGTACACCTGGCTTGAGGCTGTCATCTTCCTCATCGGTATCATCGTA GCCAATGTGCCGGAAGGTTTGCTGGCCACTGTCACGGTCTGTCTGACACTTACTGCCAAACGCATGGCAAGGAAAAACTGCTTAGTGAAG AACTTAGAAGCTGTGGAGACCTTGGGGTCCACGTCCACCATCTGCTCTGATAAAACTGGAACTCTGACTCAGAACCGGATGACAGTGGCC CACATGTGGTTTGACAATCAAATCCATGAAGCTGATACGACAGAGAATCAGAGTGGTGTCTCTTTTGACAAGACTTCAGCTACCTGGCTT GCTCTGTCCAGAATTGCAGGTCTTTGTAACAGGGCAGTGTTTCAGGCTAACCAGGAAAACCTACCTATTCTTAAGCGGGCAGTTGCAGGA GATGCCTCTGAGTCAGCACTCTTAAAGTGCATAGAGCTGTGCTGTGGTTCCGTGAAGGAGATGAGAGAAAGATACGCCAAAATCGTCGAG ATACCCTTCAACTCCACCAACAAGTACCAGTTGTCTATTCATAAGAACCCCAACACATCGGAGCCCCAACACCTGTTGGTGATGAAGGGC GCCCCAGAAAGGATCCTAGACCGTTGCAGCTCTATCCTCCTCCACGGCAAGGAGCAGCCCCTGGATGAGGAGCTGAAAGACGCCTTTCAG AACGCCTATTTGGAGCTGGGGGGCCTCGGAGAACGAGTCCTAGGTTTCTGCCACCTCTTTCTGCCAGATGAACAGTTTCCTGAAGGGTTC CAGTTTGACACTGACGATGTGAATTTCCCTATCGATAATCTGTGCTTTGTTGGGCTCATCTCCATGATTGACCCTCCACGGGCGGCCGTT CCTGATGCCGTGGGCAAATGTCGAAGTGCTGGAATTAAGGTCATCATGGTCACAGGAGACCATCCAATCACAGCTAAAGCTATTGCCAAA GGTGTGGGCATCATCTCAGAAGGCAATGAGACCGTGGAAGACATTGCTGCCCGCCTCAACATCCCAGTCAGCCAGGTGAACCCCAGGGAT GCCAAGGCCTGCGTGATCCACGGCACCGACCTCAAGGACTTCACCTCCGAGCAAATCGACGAGATCCTGCAGAATCACACCGAGATCGTC TTCGCCCGCACATCCCCCCAGCAGAAGCTCATCATTGTGGAGGGCTGTCAGAGACAGGGTGCAATTGTGGCTGTGACCGGGGATGGTGTG AACGACTCCCCCGCTCTGAAGAAGGCCGACATTGGGGTGGCCATGGGCATCGCTGGCTCTGACGTCTCCAAGCAGGCAGCTGACATGATC CTGCTGGACGACAACTTTGCCTCCATCGTCACAGGGGTGGAGGAGGGCCGCCTGATCTTCGACAACCTAAAGAAGTCCATTGCCTACACC CTGACCAGCAATATCCCGGAGATCACGCCCTTCCTGCTGTTCATCATGGCCAACATCCCGCTGCCCCTGGGCACCATCACCATCCTCTGC ATCGATCTGGGCACTGACATGGTCCCTGCCATCTCACTGGCGTACGAGGCTGCCGAAAGCGACATCATGAAGAGACAGCCCAGGAACCCG CGGACGGACAAATTGGTCAATGAGAGACTCATCAGCATGGCCTACGGGCAGATTGGAATGATCCAGGCTCTCGGTGGCTTCTTCTCTTAC TTTGTGATCCTGGCAGAAAATGGCTTCTTGCCCGGCAACCTGGTGGGCATCCGGCTGAACTGGGATGACCGCACCGTCAATGACCTGGAA GACAGTTACGGGCAGCAGTGGACATACGAGCAGAGGAAGGTGGTGGAGTTCACCTGCCACACGGCCTTCTTTGTGAGCATCGTTGTCGTC CAGTGGGCCGATCTGATCATCTGCAAGACCCGGAGGAACTCGGTCTTCCAGCAGGGCATGAAGAACAAGATCCTGATCTTCGGGCTGTTT GAGGAGACGGCCCTGGCTGCCTTCCTGTCCTACTGCCCCGGCATGGACGTGGCCCTGCGCATGTACCCTCTCAAGCCCAGCTGGTGGTTC TGTGCCTTCCCCTACAGTTTCCTCATCTTCGTCTACGACGAAATCCGCAAACTCATCCTGCGCAGGAACCCAGGGGGTTGGGTGGAGAAG GAAACCTACTACTGACCTCAGCCCCACCACATCGCCCATCTCTTCCCCGTCCCCCAGGCCCAGGACCGCCCCTGTCAGTCCCCCCAATTT TGTATTCTGGGGGGAGGAGCCCTCTCTTCCTGTGGCCCCACCTTGGCCCCCACCCCCTCCACTATCTCCTGCCGCCCCCA >7778_7778_12_ATP1A1-ATP1A3_ATP1A1_chr1_116939356_ENST00000537345_ATP1A3_chr19_42480718_ENST00000602133_length(amino acids)=1038AA_BP=39 MGGLVPERVCLHCPKMAFKVGRDKYEPAAVSEQGDKKGKKGKKDRDMDELKKEVSMDDHKLSLDELHRKYGTDLSRGLTSARAAEILARD GPNALTPPPTTPEWIKFCRQLFGGFSMLLWIGAILCFLAYSIQAATEEEPQNDNLYLGVVLSAVVIITGCFSYYQEAKSSKIMESFKNMV PQQALVIRNGEKMSINAEEVVVGDLVEVKGGDRIPADLRIISANGCKVDNSSLTGESEPQTRSPDFTNENPLETRNIAFFSTNCVEGTAR GIVVYTGDRTVMGRIATLASGLEGGQTPIAAEIEHFIHIITGVAVFLGVSFFILSLILEYTWLEAVIFLIGIIVANVPEGLLATVTVCLT LTAKRMARKNCLVKNLEAVETLGSTSTICSDKTGTLTQNRMTVAHMWFDNQIHEADTTENQSGVSFDKTSATWLALSRIAGLCNRAVFQA NQENLPILKRAVAGDASESALLKCIELCCGSVKEMRERYAKIVEIPFNSTNKYQLSIHKNPNTSEPQHLLVMKGAPERILDRCSSILLHG KEQPLDEELKDAFQNAYLELGGLGERVLGFCHLFLPDEQFPEGFQFDTDDVNFPIDNLCFVGLISMIDPPRAAVPDAVGKCRSAGIKVIM VTGDHPITAKAIAKGVGIISEGNETVEDIAARLNIPVSQVNPRDAKACVIHGTDLKDFTSEQIDEILQNHTEIVFARTSPQQKLIIVEGC QRQGAIVAVTGDGVNDSPALKKADIGVAMGIAGSDVSKQAADMILLDDNFASIVTGVEEGRLIFDNLKKSIAYTLTSNIPEITPFLLFIM ANIPLPLGTITILCIDLGTDMVPAISLAYEAAESDIMKRQPRNPRTDKLVNERLISMAYGQIGMIQALGGFFSYFVILAENGFLPGNLVG IRLNWDDRTVNDLEDSYGQQWTYEQRKVVEFTCHTAFFVSIVVVQWADLIICKTRRNSVFQQGMKNKILIFGLFEETALAAFLSYCPGMD VALRMYPLKPSWWFCAFPYSFLIFVYDEIRKLILRRNPGGWVEKETYY -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ATP1A1-ATP1A3 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000302102 | 13 | 23 | 72_74 | 647.6666666666666 | 1014.0 | phosphoinositide-3 kinase | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000543770 | 13 | 23 | 72_74 | 658.6666666666666 | 1025.0 | phosphoinositide-3 kinase | |
| Tgene | ATP1A3 | chr1:116939356 | chr19:42480718 | ENST00000545399 | 13 | 23 | 72_74 | 660.6666666666666 | 1027.0 | phosphoinositide-3 kinase |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ATP1A1-ATP1A3 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
| Hgene | ATP1A1 | P05023 | DB00390 | Digoxin | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB00511 | Acetyldigitoxin | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01078 | Deslanoside | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01092 | Ouabain | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01119 | Diazoxide | Other | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01158 | Bretylium | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01430 | Almitrine | Binder | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB13996 | Magnesium acetate | Small molecule | Approved | |
| Hgene | ATP1A1 | P05023 | DB14500 | Potassium | Regulator | Small molecule | Approved|Experimental |
| Hgene | ATP1A1 | P05023 | DB00903 | Etacrynic acid | Inhibitor | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB01188 | Ciclopirox | Binder | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB01345 | Potassium cation | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB01370 | Aluminium | Binder | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB01396 | Digitoxin | Inhibitor | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB14498 | Potassium acetate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB14499 | Potassium sulfate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB14517 | Aluminium phosphate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB14518 | Aluminum acetate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB00774 | Hydroflumethiazide | Inducer | Small molecule | Approved|Investigational|Withdrawn |
| Hgene | ATP1A1 | P05023 | DB01378 | Magnesium cation | Small molecule | Approved|Nutraceutical | |
| Hgene | ATP1A1 | P05023 | DB01021 | Trichlormethiazide | Inhibitor | Small molecule | Approved|Vet_approved |
| Hgene | ATP1A1 | P05023 | DB01244 | Bepridil | Inhibitor | Small molecule | Approved|Withdrawn |
| Tgene | ATP1A3 | P13637 | DB01092 | Ouabain | Inhibitor | Small molecule | Approved |
Top |
Related Diseases for ATP1A1-ATP1A3 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ATP1A1 | C0001430 | Adenoma | 2 | CTD_human |
| Hgene | ATP1A1 | C0205646 | Adenoma, Basal Cell | 2 | CTD_human |
| Hgene | ATP1A1 | C0205647 | Follicular adenoma | 2 | CTD_human |
| Hgene | ATP1A1 | C0205648 | Adenoma, Microcystic | 2 | CTD_human |
| Hgene | ATP1A1 | C0205649 | Adenoma, Monomorphic | 2 | CTD_human |
| Hgene | ATP1A1 | C0205650 | Papillary adenoma | 2 | CTD_human |
| Hgene | ATP1A1 | C0205651 | Adenoma, Trabecular | 2 | CTD_human |
| Hgene | ATP1A1 | C4747974 | CHARCOT-MARIE-TOOTH DISEASE, AXONAL, TYPE 2DD | 2 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | ATP1A1 | C0005586 | Bipolar Disorder | 1 | PSYGENET |
| Hgene | ATP1A1 | C0017162 | Gastroenteritis, Transmissible, of Swine | 1 | CTD_human |
| Hgene | ATP1A1 | C0020428 | Hyperaldosteronism | 1 | CTD_human |
| Hgene | ATP1A1 | C0020538 | Hypertensive disease | 1 | CTD_human |
| Hgene | ATP1A1 | C0027051 | Myocardial Infarction | 1 | CTD_human |
| Hgene | ATP1A1 | C0027055 | Myocardial Reperfusion Injury | 1 | CTD_human |
| Hgene | ATP1A1 | C0036572 | Seizures | 1 | GENOMICS_ENGLAND |
| Hgene | ATP1A1 | C0042594 | Vestibular Diseases | 1 | CTD_human |
| Hgene | ATP1A1 | C0151723 | Hypomagnesemia | 1 | GENOMICS_ENGLAND |
| Hgene | ATP1A1 | C0151744 | Myocardial Ischemia | 1 | CTD_human |
| Hgene | ATP1A1 | C1384514 | Conn Syndrome | 1 | CTD_human |
| Hgene | ATP1A1 | C3714756 | Intellectual Disability | 1 | GENOMICS_ENGLAND |
| Hgene | ATP1A1 | C4552839 | Hypomagnesemia, CTCAE | 1 | GENOMICS_ENGLAND |
| Tgene | C1868681 | DYSTONIA 12 | 6 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT | |
| Tgene | C3553788 | ALTERNATING HEMIPLEGIA OF CHILDHOOD 2 | 6 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C1832466 | CAPOS syndrome | 4 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT | |
| Tgene | C0338488 | Alternating hemiplegia of childhood | 3 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C0005586 | Bipolar Disorder | 2 | PSYGENET | |
| Tgene | C0011570 | Mental Depression | 1 | PSYGENET | |
| Tgene | C0011581 | Depressive disorder | 1 | PSYGENET | |
| Tgene | C0013421 | Dystonia | 1 | CTD_human | |
| Tgene | C0018801 | Heart failure | 1 | CTD_human | |
| Tgene | C0018802 | Congestive heart failure | 1 | CTD_human | |
| Tgene | C0023212 | Left-Sided Heart Failure | 1 | CTD_human | |
| Tgene | C0029408 | Degenerative polyarthritis | 1 | CTD_human | |
| Tgene | C0086743 | Osteoarthrosis Deformans | 1 | CTD_human | |
| Tgene | C0178417 | Anhedonia | 1 | PSYGENET | |
| Tgene | C0235527 | Heart Failure, Right-Sided | 1 | CTD_human | |
| Tgene | C0242422 | Parkinsonian Disorders | 1 | CTD_human | |
| Tgene | C0242423 | Ramsay Hunt Paralysis Syndrome | 1 | CTD_human | |
| Tgene | C0242698 | Ventricular Dysfunction, Left | 1 | CTD_human | |
| Tgene | C0393588 | Dystonia, Paroxysmal | 1 | CTD_human | |
| Tgene | C0393610 | Dystonia, Diurnal | 1 | CTD_human | |
| Tgene | C0751093 | Dystonia, Limb | 1 | CTD_human | |
| Tgene | C0752097 | Autosomal Dominant Juvenile Parkinson Disease | 1 | CTD_human | |
| Tgene | C0752098 | Autosomal Dominant Parkinsonism | 1 | CTD_human | |
| Tgene | C0752100 | Autosomal Recessive Parkinsonism | 1 | CTD_human | |
| Tgene | C0752101 | Parkinsonism, Experimental | 1 | CTD_human | |
| Tgene | C0752104 | Familial Juvenile Parkinsonism | 1 | CTD_human | |
| Tgene | C0752105 | Parkinsonism, Juvenile | 1 | CTD_human | |
| Tgene | C1868675 | PARKINSON DISEASE 2, AUTOSOMAL RECESSIVE JUVENILE | 1 | CTD_human | |
| Tgene | C1959583 | Myocardial Failure | 1 | CTD_human | |
| Tgene | C1961112 | Heart Decompensation | 1 | CTD_human | |
| Tgene | C3549447 | ALTERNATING HEMIPLEGIA OF CHILDHOOD 1 | 1 | GENOMICS_ENGLAND |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies