
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ATP1A1-VANGL1 (FusionGDB2 ID:HG476TG81839) |
Fusion Gene Summary for ATP1A1-VANGL1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ATP1A1-VANGL1 | Fusion gene ID: hg476tg81839 | Hgene | Tgene | Gene symbol | ATP1A1 | VANGL1 | Gene ID | 476 | 81839 |
| Gene name | ATPase Na+/K+ transporting subunit alpha 1 | VANGL planar cell polarity protein 1 | |
| Synonyms | CMT2DD|HOMGSMR2 | KITENIN|LPP2|STB2|STBM2 | |
| Cytomap | ('ATP1A1')('VANGL1') 1p13.1 | 1p13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | sodium/potassium-transporting ATPase subunit alpha-1ATPase, Na+/K+ transporting, alpha 1 polypeptideNa(+)/K(+) ATPase alpha-1 subunitNa+/K+ ATPase 1Na, K-ATPase, alpha-A catalytic polypeptideNa,K-ATPase alpha-1 subunitNa,K-ATPase catalytic subunit a | vang-like protein 1KAI1 C-terminal interacting tetraspaninloop-tail protein 2 homologstrabismus 2van Gogh-like protein 1vang-like 1 (van gogh, Drosophila) | |
| Modification date | 20200313 | 20200322 | |
| UniProtAcc | P05023 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000295598, ENST00000369496, ENST00000491156, ENST00000537345, | ENST00000295598, ENST00000537345, ENST00000369496, ENST00000491156, | |
| Fusion gene scores | * DoF score | 16 X 18 X 7=2016 | 8 X 8 X 4=256 |
| # samples | 23 | 9 | |
| ** MAII score | log2(23/2016*10)=-3.13178987255554 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/256*10)=-1.50814690367033 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ATP1A1 [Title/Abstract] AND VANGL1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ATP1A1(116916145)-VANGL1(116206282), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | ATP1A1-VANGL1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ATP1A1-VANGL1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ATP1A1-VANGL1 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. ATP1A1-VANGL1 seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ATP1A1 | GO:0006883 | cellular sodium ion homeostasis | 10636900|19542013 |
| Hgene | ATP1A1 | GO:0030007 | cellular potassium ion homeostasis | 10636900|19542013 |
| Hgene | ATP1A1 | GO:0036376 | sodium ion export across plasma membrane | 10636900|19542013 |
| Hgene | ATP1A1 | GO:0071383 | cellular response to steroid hormone stimulus | 11546672 |
| Hgene | ATP1A1 | GO:0086009 | membrane repolarization | 19542013 |
| Hgene | ATP1A1 | GO:1903416 | response to glycoside | 11546672 |
| Hgene | ATP1A1 | GO:1990573 | potassium ion import across plasma membrane | 10636900|19542013 |
| Fusion gene breakpoints across ATP1A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across VANGL1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
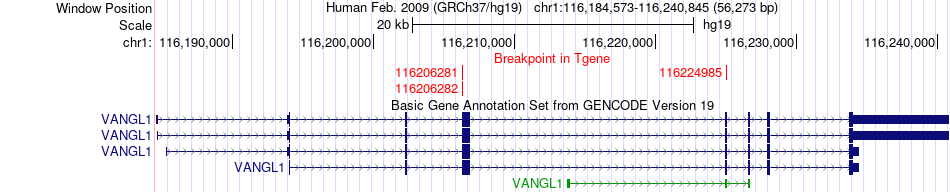 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-E2-A15A-01A | ATP1A1 | chr1 | 116916145 | - | VANGL1 | chr1 | 116206282 | + |
| ChimerDB4 | BRCA | TCGA-E2-A15A-01A | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| ChimerDB4 | BRCA | TCGA-E2-A15A-01A | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| ChimerDB4 | BRCA | TCGA-E2-A15A | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
Top |
Fusion Gene ORF analysis for ATP1A1-VANGL1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000295598 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| 5CDS-intron | ENST00000295598 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| 5CDS-intron | ENST00000295598 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| Frame-shift | ENST00000295598 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| Frame-shift | ENST00000295598 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| Frame-shift | ENST00000295598 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| Frame-shift | ENST00000295598 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| In-frame | ENST00000295598 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| In-frame | ENST00000295598 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| In-frame | ENST00000295598 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| In-frame | ENST00000295598 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| In-frame | ENST00000295598 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| In-frame | ENST00000295598 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| In-frame | ENST00000295598 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| In-frame | ENST00000295598 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000369496 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000369496 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000369496 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000369496 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000369496 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000369496 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000369496 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000369496 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000369496 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000369496 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000369496 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000369496 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000491156 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000491156 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000491156 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000491156 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000491156 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000491156 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000491156 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000491156 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000491156 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000491156 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000491156 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000491156 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000537345 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000537345 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000537345 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000537345 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000537345 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000537345 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000537345 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000537345 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000537345 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3CDS | ENST00000537345 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-3CDS | ENST00000537345 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3CDS | ENST00000537345 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-3UTR | ENST00000369496 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3UTR | ENST00000491156 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-3UTR | ENST00000537345 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224985 | + |
| intron-intron | ENST00000369496 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-intron | ENST00000369496 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-intron | ENST00000491156 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-intron | ENST00000491156 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| intron-intron | ENST00000537345 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + |
| intron-intron | ENST00000537345 | ENST00000474344 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000355485 | VANGL1 | chr1 | 116206282 | + | 8480 | 264 | 237 | 1634 | 465 |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000369510 | VANGL1 | chr1 | 116206282 | + | 8480 | 264 | 237 | 1634 | 465 |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000310260 | VANGL1 | chr1 | 116206282 | + | 2110 | 264 | 237 | 1634 | 465 |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000369509 | VANGL1 | chr1 | 116206282 | + | 2110 | 264 | 237 | 1634 | 465 |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000355485 | VANGL1 | chr1 | 116206281 | + | 8480 | 264 | 237 | 1634 | 465 |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000369510 | VANGL1 | chr1 | 116206281 | + | 8480 | 264 | 237 | 1634 | 465 |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000310260 | VANGL1 | chr1 | 116206281 | + | 2110 | 264 | 237 | 1634 | 465 |
| ENST00000295598 | ATP1A1 | chr1 | 116916145 | + | ENST00000369509 | VANGL1 | chr1 | 116206281 | + | 2110 | 264 | 237 | 1634 | 465 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000295598 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + | 0.000569855 | 0.9994301 |
| ENST00000295598 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + | 0.000569855 | 0.9994301 |
| ENST00000295598 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + | 0.004892091 | 0.9951079 |
| ENST00000295598 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206282 | + | 0.004892091 | 0.9951079 |
| ENST00000295598 | ENST00000355485 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 0.000569855 | 0.9994301 |
| ENST00000295598 | ENST00000369510 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 0.000569855 | 0.9994301 |
| ENST00000295598 | ENST00000310260 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 0.004892091 | 0.9951079 |
| ENST00000295598 | ENST00000369509 | ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 0.004892091 | 0.9951079 |
Top |
Fusion Genomic Features for ATP1A1-VANGL1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 3.74E-11 | 1 |
| ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 3.74E-11 | 1 |
| ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224984 | + | 3.15E-11 | 1 |
| ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 3.74E-11 | 1 |
| ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116206281 | + | 3.74E-11 | 1 |
| ATP1A1 | chr1 | 116916145 | + | VANGL1 | chr1 | 116224984 | + | 3.15E-11 | 1 |
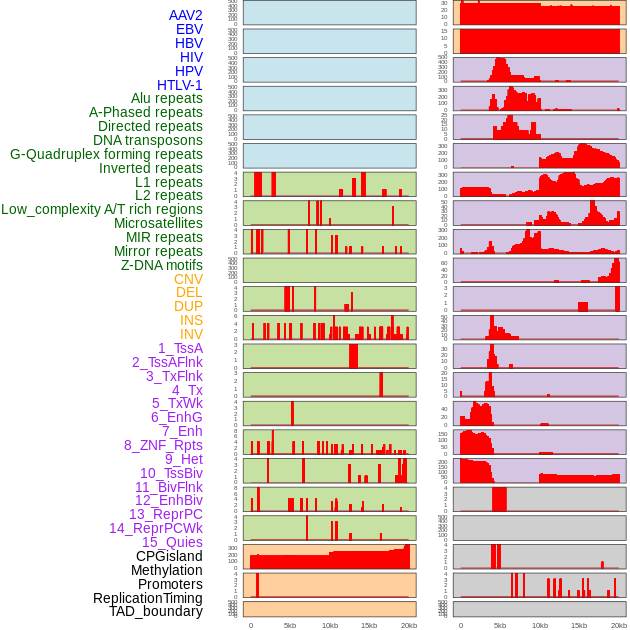
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
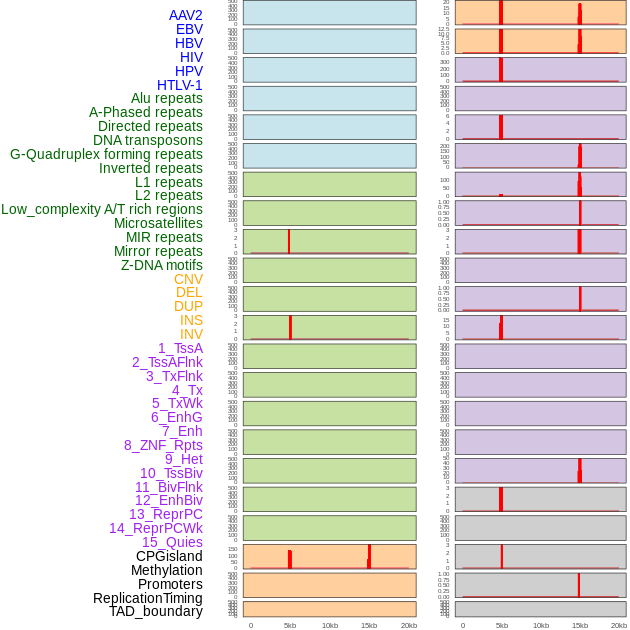
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for ATP1A1-VANGL1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:116916145/chr1:116206282) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ATP1A1 | . |
| FUNCTION: This is the catalytic component of the active enzyme, which catalyzes the hydrolysis of ATP coupled with the exchange of sodium and potassium ions across the plasma membrane. This action creates the electrochemical gradient of sodium and potassium ions, providing the energy for active transport of various nutrients. {ECO:0000269|PubMed:29499166, ECO:0000269|PubMed:30388404}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 139_151 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 173_182 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 204_222 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 244_524 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 139_151 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 173_182 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 204_222 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 244_524 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 139_151 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 173_182 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 204_222 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 244_524 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 139_151 | 66 | 523.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 173_182 | 66 | 523.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 204_222 | 66 | 523.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 244_524 | 66 | 523.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 139_151 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 173_182 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 204_222 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 244_524 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 139_151 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 173_182 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 204_222 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 244_524 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 139_151 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 173_182 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 204_222 | 68 | 525.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 244_524 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 139_151 | 66 | 523.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 173_182 | 66 | 523.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 204_222 | 66 | 523.0 | Topological domain | Extracellular | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 244_524 | 66 | 523.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 118_138 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 152_172 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 183_203 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 223_243 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 118_138 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 152_172 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 183_203 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 223_243 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 118_138 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 152_172 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 183_203 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 223_243 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 118_138 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 152_172 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 183_203 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 223_243 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 118_138 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 152_172 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 183_203 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 223_243 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 118_138 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 152_172 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 183_203 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 223_243 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 118_138 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 152_172 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 183_203 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 223_243 | 68 | 525.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 118_138 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 152_172 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 183_203 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 223_243 | 66 | 523.0 | Transmembrane | Helical%3B Name%3D4 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 82_84 | 4 | 1024.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 82_84 | 0 | 993.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 82_84 | 0 | 1024.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 82_84 | 4 | 1024.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 82_84 | 0 | 993.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 82_84 | 0 | 1024.0 | Region | Phosphoinositide-3 kinase binding |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 1007_1023 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 109_131 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 153_288 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 309_320 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 339_772 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 6_87 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 793_802 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 824_843 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 867_918 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 939_951 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 971_985 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 1007_1023 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 109_131 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 153_288 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 309_320 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 339_772 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 6_87 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 793_802 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 824_843 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 867_918 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 939_951 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 971_985 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 1007_1023 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 109_131 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 153_288 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 309_320 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 339_772 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 6_87 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 793_802 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 824_843 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 867_918 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 939_951 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 971_985 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 1007_1023 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 109_131 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 153_288 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 309_320 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 339_772 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 6_87 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 793_802 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 824_843 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 867_918 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 939_951 | 4 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 971_985 | 4 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 1007_1023 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 109_131 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 153_288 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 309_320 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 339_772 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 6_87 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 793_802 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 824_843 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 867_918 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 939_951 | 0 | 993.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 971_985 | 0 | 993.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 1007_1023 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 109_131 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 153_288 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 309_320 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 339_772 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 6_87 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 793_802 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 824_843 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 867_918 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 939_951 | 0 | 1024.0 | Topological domain | Cytoplasmic |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 971_985 | 0 | 1024.0 | Topological domain | Extracellular |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 132_152 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 289_308 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 321_338 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 773_792 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 803_823 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 844_866 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 88_108 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 919_938 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 952_970 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000295598 | + | 1 | 23 | 986_1006 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 132_152 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 289_308 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 321_338 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 773_792 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 803_823 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 844_866 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 88_108 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 919_938 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 952_970 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000369496 | + | 1 | 23 | 986_1006 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 132_152 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 289_308 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 321_338 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 773_792 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 803_823 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 844_866 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 88_108 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 919_938 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 952_970 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206281 | ENST00000537345 | + | 1 | 23 | 986_1006 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 132_152 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 289_308 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 321_338 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 773_792 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 803_823 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 844_866 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 88_108 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 919_938 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 952_970 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000295598 | + | 1 | 23 | 986_1006 | 4 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 132_152 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 289_308 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 321_338 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 773_792 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 803_823 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 844_866 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 88_108 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 919_938 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 952_970 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000369496 | + | 1 | 23 | 986_1006 | 0 | 993.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 132_152 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 289_308 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 321_338 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 773_792 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 803_823 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 844_866 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 88_108 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 919_938 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 952_970 | 0 | 1024.0 | Transmembrane | Helical |
| Hgene | ATP1A1 | chr1:116916145 | chr1:116206282 | ENST00000537345 | + | 1 | 23 | 986_1006 | 0 | 1024.0 | Transmembrane | Helical |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000310260 | 2 | 8 | 1_117 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000355485 | 2 | 8 | 1_117 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369509 | 1 | 7 | 1_117 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206281 | ENST00000369510 | 2 | 8 | 1_117 | 66 | 523.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000310260 | 2 | 8 | 1_117 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000355485 | 2 | 8 | 1_117 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369509 | 1 | 7 | 1_117 | 68 | 525.0 | Topological domain | Cytoplasmic | |
| Tgene | VANGL1 | chr1:116916145 | chr1:116206282 | ENST00000369510 | 2 | 8 | 1_117 | 66 | 523.0 | Topological domain | Cytoplasmic |
Top |
Fusion Gene Sequence for ATP1A1-VANGL1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >7793_7793_1_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000310260_length(transcript)=2110nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGT >7793_7793_1_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000310260_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- >7793_7793_2_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000355485_length(transcript)=8480nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGTCGTGGGCAGTTCAGGAGATACCTGCCTTCATCTTTGTTCTTTGTTGCCTT AGGTTCTTCAGAGAAAGATCACAACAAAAAATGTACACTGTCGTTTACAGCTATTAAGTGATTTGATTTTGTTTTTTTCCCAAAGAGAAA ACCTACCTGCCCTGTTTCTGATCCCACCCCTCTGCTGGCTTGAAGCAGGTAACCCTTTCCCAGCCCTGCAGCTGCCCACCTGGCCTCCAT GCCATCCTGCCCCCACCTGGCTGGCAGCCCTGGCTCTCCATGTGTGCCCTCCGGCTCTGTGTGAAGCCTCAAGTCAGTCCCAGCATTGTT TCCATAGGGAAGTGTGGGGTGCCCAGCAGGTAAAGCACAGGGAGAGAGGGCAGTGGGAATGCCACCTTTAGGCTGCAGCAGGAGCCCCAC ACTGCCCAGTTTTCCTCCCCACTGTTCTACACCAACCAGGGGAGACTAACACTGTGACTCTGGGATTGGCAGGTGCAACTTGGAGCCACT TAATTTCCTGGGGACGTAAGTTCTTCCCAAGCTTAGAGCAAGCTGCCCTGCCAAAGGAGACCAAACCATGCCAACCACGCTGGCAACTGC TGCTGTCCAGTCCCTGTGTTTTCTGACCACCGTCACTGTGCAACTCATCGCCTCTGCCACTTAGGACCAGGAAAGAGGCTGGTTTTGCTC CCACTCTTAGTTGCTGATAAAGTGGGGAGAAGGAAAATGGACACTCTACAGAGTTTGGGGAAGGGAGAGTAGGGAGCCCATCTTGTCCAG AAAGATTCATCTGTGGTCTGTCTGTTAAACACAGCTGATTTCAGTGGGCTTTCCCCTGGCCCTGGGGGAGCAGACACTGACTGGGTTGTG GGCAGAGGAGCCATCCTGGCGGAGCCCTGCTGCAGGGGAGCTCCTTCAGGAGCCCCATCCGGACCTCTTGCACTGGGCTGCCTTTGCCTC CATTTGCCTTCCTGTATCTGCAACAAACCTTTTAAAAGTGTTCACTCTTGCTTTTTCCAGTATTTCGGTAATCAGCCATCTTGCTGTAGT ACAGGATGACATTGTCGAATGCTCTTTGTATGTGTGCACACCCCCTTACTCCCTTACTGCTTCATACACTCCACAAGTGGTACAGTATTT TGTGTCATTGTAAAAATCAAAATTGGCTTTGGATCTTTGTAATACACCTGTACCTGAAAAAGTAAACAACATTCTTCAATTACTAGCCTT CAGCTTGAAAAGACATGCTGGAGAAGAAGGAAGGGGGAACCCATAGGTGTGGCGTGGAGCCAAGATGTACTATTCAACTATGTGTTTCTG TTTATAAAAAACACATACCATGGAACCATGGTGCTTTTGTTCTTAGTTTTTGCCGTTAGATCCCTTCAAACTGGAAGTTCCTTACAATAT CTTTCTCAGGAAATATTTTGGGAAATGGGGTAAGAGATGGCAAGTGTGAGACGGGCTGTGTCAGAGGTTGCTACGTCATGGATACAGTGC AGTTCCAAGTGCCATAAGTGTATGTACATATAGTTAATAATGACACTGTTCATCACCATTCTAAAATACTGTTCTTCCAACCCTATCTTC AATGACCAGTCCAGAAGGGGTTAAGCTGGATTCATTTGCTCTGGCATGTGCATTCCCAGCAGGGTGAAGAAAGGTTTAAATTAAAGAATT TATTTTCTCTCTCCCCCTTCCTCTTTCTCCCAGTCTTTGCATAGGAGAATGTTAGACATTCAGAAATTACTGTTTCTGTTTTAAATTGAG TATTGATTTTTTTATATTGACTTTGTATTGAGTTCTTTTTGAAAGAATAACAAAATAAAATGCAGGATCTTTGTAAAGCCTTTGCACTTT CAACCTCTTTATAGCTTGAGTTACTTTTGCAGTGGGAACAATGTAAATGACATTTAAAAGATTTAAGGTTTCAGAAAGCTGCATCCCACA ATTGAACACAATGCATTTTTATTTCAATTCTTGGAACTGGTAGGCTATTCTTTTTAAAAGGGGGTAAACTTCGCCCTAAGGCTGGTAGAA TGTATGTTCACATTATAGTAGACAGGATTTCATTTGCCTTATATGTTTATAGATTTTTTATAATTTTCATCCTACGTTATTAAAATTAGA GCATTGAGTGTTAAAGAACTTAATGAGGAGTCTATATCTGAGATTGCTCTCTTCCCTGGTGATGTTTTAACTGGTAGATAATTTGTTCTT AAATATGTACTTTTGAAGATAGGACAGTTTTTATAGTCCATGAACTGAATGTTAAAAAGTTCTGTATGCATTCTCAGAGAGGATTTTAAA GCTATATAGTTCATCCATCCTTTGCATTATCAAAATGTTAAGTCAAATCTGTAATACTTTGGCTAAAATTCATAAAGTAAGCCCTAGAGA AAATACTTGACCACCAAATTTTTGCCCAACTATCATCACCTCCCTTCCCCCGCCTCTGTTCTTGCCTTTTGACATCTACATGGAAGACAA GTTCTTTACAGCAAATGGTAAGAGGCAGGTGACCTGGTGTGTTTGCTGTGTTGTAGTTCATTGCCTGGGGCTTGGGACTCCTTTTTTAAT GGAGAGACTAGCTGTGCAGGTGTGTGTTGGATAGGGATAAAGTGCTCACCCCTGCCCTCTCTACAGTAGTTGGTGGTAGATTTCTCTCTC ATTTTGCCTCATAATCACTTTCGAGTGCATGTATTTACCTAAGGGCTGTAGCTCTGTGGGATGCTACCAGCATATTGGACTGACAGAAAT TGATTACCTTGCCACTCCAACCTACGTACTGAGTGAGTGCTCCAGCCACTCAGTGAAACCAACAAAAGTGAGTCCTTGGTTTACCTTCCA ATCTGGGTCCTGCTGTGTAAGTATCCCTAAGTGGGGATGCATATTTGTTTGTGCGTTTTTATTTCCATATATGTGAGCATTTCTCTGAGT GTATTACCAGACGGATAGCACATTTATATGTCAGACATCTTAACATCTGTGTTATCTGTAGCAGGTGTGTAGCTCAGCAGATACGTGTCA TTGTGTATATAGCTGAGTGTGTGAGGGTGTCTGTGTTTCTGCAGTCCCCTGTGTTTGAGAGATGACTTAATAACCCTGTGTTTTGAGAGG TCGCTCTAAACCAGTGACTTTTCCCTCCCCTGCTTTATTCCTTTCCCTCACTGACACTGGCTTCTCCCGCTAGAGTAAATGGCTTTAGCA CAGCACTGTCTTCTGGGGAGCCTGCTGTCCTGCAGGCAAGTCCATTAAACTCTTTCTTGCTTTAGGACTCTGAAAACAGCAAGAAACAAA CAAACAAAGGTCAAGCTCTAAGAAAATTACTGCTCAAACTTCACTACCCTGGAAGCCTTACTAGATATTTCTTAAGGTAACTTAAAAATT GGGCTTTATTTTTAAAAAGTGATAGGTTACTTACAGTAGCACAGAAATGTTAGCATATTTATTTAAATAGTCCTGCAGCAGAGACCCTGC GATTGTAAAGTGATTTAAGTATTTCTGGGTAGTGTTTGTGATTTACGGATTTGTTACTGAAAAACAAAAAAATCACTACTGTGAATTTAC TACTATGTAACCTTGTGGTCGTATTTCATTATAAATAAAATAAGAATTGCTCTTCTGCCCACCGTTCTTGATTGGTATTCAGTGCAGTAG CGAAATGAGATAGTTTAGACACTGTTGAAATAACTGCATTGAGCTTTAACCAAGTGTATGCTCAGAAAATTCAGTTTTGGATCACATTTT GACAAAACATGTTTTGGTCAAAGAAAGGAAAGGCTACTAACACATTTATCAGGTAATGTATGTCACAGTCCGTGTTCCACCCAGCCTTGT TATCCCCACATTCTTTCAAGATAGGAGTCATCTTGGTTTTTCGGGTGAAAAACGGAAGGTCAGAGAGGAAGGGGCTTGTCCAAGGTCTCA TGTCTGGTTAACAGAATTTCAAACTAGATGTTTGATTCTAACCCCTCAGTCCACTGTACCTTGAAGTATGGTCTAAATGATTCGGCACTT CTGGATGTTGAGGAAGGACCTAGAGACACATCCTTGAACTAGAACCTGGGGTGAGAGTTCATTGGGAGGCAGGATCTCTTCTTTCACTTT GGATTTACACCTTGTCCCTTGGAAAGCTTCTCCACTATGCTAGCAAATATCTTAGGATATTTGATGGAAAGAACTTGAGAATCCCTTCTG GAAAACCCAGCCTTTCAGTGTTAACACCTGCTGCAAGACAGGGATGCTGTTGTTCTGGCAGCCCCCCTTTGCTTTTGCCTGGCCCCACCT TCTGCTCCCACTCTGCTGGCTTGGGCAAGATGCGTGCCTTGGGCCTTGGGTGCAGGGAGGCAGGCAGGGGCTTGACCTGGCCTCTCTCTG GTGCCATGGCAACATTATGCCCCAAACTTCTTCCCTGGTTGGAGTGAGAGGGGCTGTCCACAGCCCCATCCTGTGGGGATCTCAAGCCGG AGTCCCTGGCCTGGCCTCCTTGACGTAGGTGTTCTCAGCAAGCAGTTTGCATCCCACCGTCTTTCTCACACTTGCCCCCAAGACTTTTGA CAGAGCAGACGTAAAACAGGACTCAGAAAACCATTTTTCTCTGTTCCCATATGTAGTAAGTTTTGATTCAGTTGTGCATAAACCATAGTT TTCTGCCCTGCTGTTTGCTTTCAATGGAAGACAGTAAAGGGAAGATGGTGCTCACATCTCTCCATGTGACATCTCATTAGGAATTAAGAT GCGATGGATTAGAAATGTAAAACTTCAGAATAAAATTAAATTTCAGGGCTCTATAAGTCCCGTTTTCCCAGGTCCTGTTCCGTTTCTACG TAGATAACCCAATTTGTTTTGTCTATGAAATAAGCCTCTTTAGTGGGTTGTTTTAGTCTCTCCAACAAAAGAGCAGATTCCTAAAGCCAG GTGCAGCACTGTGAAAAGTTTCTTTCAATATGGCACCAAGACTCTACCATTTATGTCTCTCTCAGCTTACAAACATCAGCGTTTTGTCCT TGTCATAGTGGAAGAAAGACACTTACTTTAAGCTTTGGGGACAAAGGTGACAAACCCCAGGCTTTTATCTTAAAAGTGTCTTTGGCACTT CTTTTGGCACTGAAATGGTATTTGGGAAGCATTATTTGAATGTACAGTTGTTTGGTTTTGTATGTGCTTATCTTTATCTGAGCTTTCACT TGTAGACATGGCCTTTTGTTGTGAAGTTGCTCATCATTTAGGAGTGTTTAATTCTAAAAAGCCTTCAGCCTAAGAAAGCTTCATCTGTGG GGACCAGAGACTTGTTGCTCAGGGAGTTAGTGATGGGACTTGGGCATCTGATCTGCAGGTGACAAGTTTAGTTCAACTGAAGTTGTAGGG AATTTAGACAGTTGCACATCATTGCCGTTCTAGGGGCCTTGTAGAAAGATGAAACAGTTGTTTTTCATTTACCAGCACCTCTCAGTTATA GAGGTAATGGAACATTCGCTTACTTTTCATCATCATTCTTTAAAAAGGGAACATACAAAAATCTAAACTATGGCAATAATTTATTTTTAT AATAGTTTACGGTAGGCTTTAATTAAATGGCAAACTCCTCTGGGACCCCTAAGTTATGGCGTGATTAGCCAAATTTGATTTCCAACAGTC ATTTATGGCCATAACTATTGCATAGAGTGCAGGATGCCAGCAAAGATGAGGGTGGGGGCAGATACTGGCTCAGTGATTTAACTCACATTA TAGATGACCCCTTCCTCAACAGAAATGCTACTGAGAGAACCAGAGAGGCCTGGGCCAGGCAGGTCTTATTTGAGAGGAGATTATTTGATA ATTGCTTTGGTTAGAAGGACTTTACATTTCCTGATTTCAAGTCCAGCACCAATTTAGAAAGTTCAGAGATGAAACCACCTGTCTTTACCT GACAGAGTCATAACGGTTTGTGTAAAAATGTGGTCAGGGACCTTTTTTGTTCTTTCTGATTAGTTAATACTGTACATTGTAACCAGGAGG GGCAGTTTTGCCAACCAGCCTCTGCTCATGGTCACCATATGTGTATGACAAGGCCTGAGTGAGTTCCTGCATAAACTGGGTAGTGGGCTC TTTTGACACATTTGCAAGCATGTAAATGAATGAATGACACTACCAGCAACCATCTGTACAGGTCCATTTACTTACATTCATAAGGTTTAT GCTATGAAACTTCTTCTCATTGTGATGTCAGTAACAGAGTTAGTGTCTCTGATGGAATAGTGTACCTGTCACCCAAGTTATTTTGTTCCT TTTTGGGTCCTCCAGTATAATCCCCCCCTCATCCCAATTAACTGTAAAATGTTTTACACATCACATTTTTTATACTGTAAACTTGGAAAA TAAACTGAAATATCAAATTG >7793_7793_2_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000355485_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- >7793_7793_3_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000369509_length(transcript)=2110nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGT >7793_7793_3_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000369509_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- >7793_7793_4_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000369510_length(transcript)=8480nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGTCGTGGGCAGTTCAGGAGATACCTGCCTTCATCTTTGTTCTTTGTTGCCTT AGGTTCTTCAGAGAAAGATCACAACAAAAAATGTACACTGTCGTTTACAGCTATTAAGTGATTTGATTTTGTTTTTTTCCCAAAGAGAAA ACCTACCTGCCCTGTTTCTGATCCCACCCCTCTGCTGGCTTGAAGCAGGTAACCCTTTCCCAGCCCTGCAGCTGCCCACCTGGCCTCCAT GCCATCCTGCCCCCACCTGGCTGGCAGCCCTGGCTCTCCATGTGTGCCCTCCGGCTCTGTGTGAAGCCTCAAGTCAGTCCCAGCATTGTT TCCATAGGGAAGTGTGGGGTGCCCAGCAGGTAAAGCACAGGGAGAGAGGGCAGTGGGAATGCCACCTTTAGGCTGCAGCAGGAGCCCCAC ACTGCCCAGTTTTCCTCCCCACTGTTCTACACCAACCAGGGGAGACTAACACTGTGACTCTGGGATTGGCAGGTGCAACTTGGAGCCACT TAATTTCCTGGGGACGTAAGTTCTTCCCAAGCTTAGAGCAAGCTGCCCTGCCAAAGGAGACCAAACCATGCCAACCACGCTGGCAACTGC TGCTGTCCAGTCCCTGTGTTTTCTGACCACCGTCACTGTGCAACTCATCGCCTCTGCCACTTAGGACCAGGAAAGAGGCTGGTTTTGCTC CCACTCTTAGTTGCTGATAAAGTGGGGAGAAGGAAAATGGACACTCTACAGAGTTTGGGGAAGGGAGAGTAGGGAGCCCATCTTGTCCAG AAAGATTCATCTGTGGTCTGTCTGTTAAACACAGCTGATTTCAGTGGGCTTTCCCCTGGCCCTGGGGGAGCAGACACTGACTGGGTTGTG GGCAGAGGAGCCATCCTGGCGGAGCCCTGCTGCAGGGGAGCTCCTTCAGGAGCCCCATCCGGACCTCTTGCACTGGGCTGCCTTTGCCTC CATTTGCCTTCCTGTATCTGCAACAAACCTTTTAAAAGTGTTCACTCTTGCTTTTTCCAGTATTTCGGTAATCAGCCATCTTGCTGTAGT ACAGGATGACATTGTCGAATGCTCTTTGTATGTGTGCACACCCCCTTACTCCCTTACTGCTTCATACACTCCACAAGTGGTACAGTATTT TGTGTCATTGTAAAAATCAAAATTGGCTTTGGATCTTTGTAATACACCTGTACCTGAAAAAGTAAACAACATTCTTCAATTACTAGCCTT CAGCTTGAAAAGACATGCTGGAGAAGAAGGAAGGGGGAACCCATAGGTGTGGCGTGGAGCCAAGATGTACTATTCAACTATGTGTTTCTG TTTATAAAAAACACATACCATGGAACCATGGTGCTTTTGTTCTTAGTTTTTGCCGTTAGATCCCTTCAAACTGGAAGTTCCTTACAATAT CTTTCTCAGGAAATATTTTGGGAAATGGGGTAAGAGATGGCAAGTGTGAGACGGGCTGTGTCAGAGGTTGCTACGTCATGGATACAGTGC AGTTCCAAGTGCCATAAGTGTATGTACATATAGTTAATAATGACACTGTTCATCACCATTCTAAAATACTGTTCTTCCAACCCTATCTTC AATGACCAGTCCAGAAGGGGTTAAGCTGGATTCATTTGCTCTGGCATGTGCATTCCCAGCAGGGTGAAGAAAGGTTTAAATTAAAGAATT TATTTTCTCTCTCCCCCTTCCTCTTTCTCCCAGTCTTTGCATAGGAGAATGTTAGACATTCAGAAATTACTGTTTCTGTTTTAAATTGAG TATTGATTTTTTTATATTGACTTTGTATTGAGTTCTTTTTGAAAGAATAACAAAATAAAATGCAGGATCTTTGTAAAGCCTTTGCACTTT CAACCTCTTTATAGCTTGAGTTACTTTTGCAGTGGGAACAATGTAAATGACATTTAAAAGATTTAAGGTTTCAGAAAGCTGCATCCCACA ATTGAACACAATGCATTTTTATTTCAATTCTTGGAACTGGTAGGCTATTCTTTTTAAAAGGGGGTAAACTTCGCCCTAAGGCTGGTAGAA TGTATGTTCACATTATAGTAGACAGGATTTCATTTGCCTTATATGTTTATAGATTTTTTATAATTTTCATCCTACGTTATTAAAATTAGA GCATTGAGTGTTAAAGAACTTAATGAGGAGTCTATATCTGAGATTGCTCTCTTCCCTGGTGATGTTTTAACTGGTAGATAATTTGTTCTT AAATATGTACTTTTGAAGATAGGACAGTTTTTATAGTCCATGAACTGAATGTTAAAAAGTTCTGTATGCATTCTCAGAGAGGATTTTAAA GCTATATAGTTCATCCATCCTTTGCATTATCAAAATGTTAAGTCAAATCTGTAATACTTTGGCTAAAATTCATAAAGTAAGCCCTAGAGA AAATACTTGACCACCAAATTTTTGCCCAACTATCATCACCTCCCTTCCCCCGCCTCTGTTCTTGCCTTTTGACATCTACATGGAAGACAA GTTCTTTACAGCAAATGGTAAGAGGCAGGTGACCTGGTGTGTTTGCTGTGTTGTAGTTCATTGCCTGGGGCTTGGGACTCCTTTTTTAAT GGAGAGACTAGCTGTGCAGGTGTGTGTTGGATAGGGATAAAGTGCTCACCCCTGCCCTCTCTACAGTAGTTGGTGGTAGATTTCTCTCTC ATTTTGCCTCATAATCACTTTCGAGTGCATGTATTTACCTAAGGGCTGTAGCTCTGTGGGATGCTACCAGCATATTGGACTGACAGAAAT TGATTACCTTGCCACTCCAACCTACGTACTGAGTGAGTGCTCCAGCCACTCAGTGAAACCAACAAAAGTGAGTCCTTGGTTTACCTTCCA ATCTGGGTCCTGCTGTGTAAGTATCCCTAAGTGGGGATGCATATTTGTTTGTGCGTTTTTATTTCCATATATGTGAGCATTTCTCTGAGT GTATTACCAGACGGATAGCACATTTATATGTCAGACATCTTAACATCTGTGTTATCTGTAGCAGGTGTGTAGCTCAGCAGATACGTGTCA TTGTGTATATAGCTGAGTGTGTGAGGGTGTCTGTGTTTCTGCAGTCCCCTGTGTTTGAGAGATGACTTAATAACCCTGTGTTTTGAGAGG TCGCTCTAAACCAGTGACTTTTCCCTCCCCTGCTTTATTCCTTTCCCTCACTGACACTGGCTTCTCCCGCTAGAGTAAATGGCTTTAGCA CAGCACTGTCTTCTGGGGAGCCTGCTGTCCTGCAGGCAAGTCCATTAAACTCTTTCTTGCTTTAGGACTCTGAAAACAGCAAGAAACAAA CAAACAAAGGTCAAGCTCTAAGAAAATTACTGCTCAAACTTCACTACCCTGGAAGCCTTACTAGATATTTCTTAAGGTAACTTAAAAATT GGGCTTTATTTTTAAAAAGTGATAGGTTACTTACAGTAGCACAGAAATGTTAGCATATTTATTTAAATAGTCCTGCAGCAGAGACCCTGC GATTGTAAAGTGATTTAAGTATTTCTGGGTAGTGTTTGTGATTTACGGATTTGTTACTGAAAAACAAAAAAATCACTACTGTGAATTTAC TACTATGTAACCTTGTGGTCGTATTTCATTATAAATAAAATAAGAATTGCTCTTCTGCCCACCGTTCTTGATTGGTATTCAGTGCAGTAG CGAAATGAGATAGTTTAGACACTGTTGAAATAACTGCATTGAGCTTTAACCAAGTGTATGCTCAGAAAATTCAGTTTTGGATCACATTTT GACAAAACATGTTTTGGTCAAAGAAAGGAAAGGCTACTAACACATTTATCAGGTAATGTATGTCACAGTCCGTGTTCCACCCAGCCTTGT TATCCCCACATTCTTTCAAGATAGGAGTCATCTTGGTTTTTCGGGTGAAAAACGGAAGGTCAGAGAGGAAGGGGCTTGTCCAAGGTCTCA TGTCTGGTTAACAGAATTTCAAACTAGATGTTTGATTCTAACCCCTCAGTCCACTGTACCTTGAAGTATGGTCTAAATGATTCGGCACTT CTGGATGTTGAGGAAGGACCTAGAGACACATCCTTGAACTAGAACCTGGGGTGAGAGTTCATTGGGAGGCAGGATCTCTTCTTTCACTTT GGATTTACACCTTGTCCCTTGGAAAGCTTCTCCACTATGCTAGCAAATATCTTAGGATATTTGATGGAAAGAACTTGAGAATCCCTTCTG GAAAACCCAGCCTTTCAGTGTTAACACCTGCTGCAAGACAGGGATGCTGTTGTTCTGGCAGCCCCCCTTTGCTTTTGCCTGGCCCCACCT TCTGCTCCCACTCTGCTGGCTTGGGCAAGATGCGTGCCTTGGGCCTTGGGTGCAGGGAGGCAGGCAGGGGCTTGACCTGGCCTCTCTCTG GTGCCATGGCAACATTATGCCCCAAACTTCTTCCCTGGTTGGAGTGAGAGGGGCTGTCCACAGCCCCATCCTGTGGGGATCTCAAGCCGG AGTCCCTGGCCTGGCCTCCTTGACGTAGGTGTTCTCAGCAAGCAGTTTGCATCCCACCGTCTTTCTCACACTTGCCCCCAAGACTTTTGA CAGAGCAGACGTAAAACAGGACTCAGAAAACCATTTTTCTCTGTTCCCATATGTAGTAAGTTTTGATTCAGTTGTGCATAAACCATAGTT TTCTGCCCTGCTGTTTGCTTTCAATGGAAGACAGTAAAGGGAAGATGGTGCTCACATCTCTCCATGTGACATCTCATTAGGAATTAAGAT GCGATGGATTAGAAATGTAAAACTTCAGAATAAAATTAAATTTCAGGGCTCTATAAGTCCCGTTTTCCCAGGTCCTGTTCCGTTTCTACG TAGATAACCCAATTTGTTTTGTCTATGAAATAAGCCTCTTTAGTGGGTTGTTTTAGTCTCTCCAACAAAAGAGCAGATTCCTAAAGCCAG GTGCAGCACTGTGAAAAGTTTCTTTCAATATGGCACCAAGACTCTACCATTTATGTCTCTCTCAGCTTACAAACATCAGCGTTTTGTCCT TGTCATAGTGGAAGAAAGACACTTACTTTAAGCTTTGGGGACAAAGGTGACAAACCCCAGGCTTTTATCTTAAAAGTGTCTTTGGCACTT CTTTTGGCACTGAAATGGTATTTGGGAAGCATTATTTGAATGTACAGTTGTTTGGTTTTGTATGTGCTTATCTTTATCTGAGCTTTCACT TGTAGACATGGCCTTTTGTTGTGAAGTTGCTCATCATTTAGGAGTGTTTAATTCTAAAAAGCCTTCAGCCTAAGAAAGCTTCATCTGTGG GGACCAGAGACTTGTTGCTCAGGGAGTTAGTGATGGGACTTGGGCATCTGATCTGCAGGTGACAAGTTTAGTTCAACTGAAGTTGTAGGG AATTTAGACAGTTGCACATCATTGCCGTTCTAGGGGCCTTGTAGAAAGATGAAACAGTTGTTTTTCATTTACCAGCACCTCTCAGTTATA GAGGTAATGGAACATTCGCTTACTTTTCATCATCATTCTTTAAAAAGGGAACATACAAAAATCTAAACTATGGCAATAATTTATTTTTAT AATAGTTTACGGTAGGCTTTAATTAAATGGCAAACTCCTCTGGGACCCCTAAGTTATGGCGTGATTAGCCAAATTTGATTTCCAACAGTC ATTTATGGCCATAACTATTGCATAGAGTGCAGGATGCCAGCAAAGATGAGGGTGGGGGCAGATACTGGCTCAGTGATTTAACTCACATTA TAGATGACCCCTTCCTCAACAGAAATGCTACTGAGAGAACCAGAGAGGCCTGGGCCAGGCAGGTCTTATTTGAGAGGAGATTATTTGATA ATTGCTTTGGTTAGAAGGACTTTACATTTCCTGATTTCAAGTCCAGCACCAATTTAGAAAGTTCAGAGATGAAACCACCTGTCTTTACCT GACAGAGTCATAACGGTTTGTGTAAAAATGTGGTCAGGGACCTTTTTTGTTCTTTCTGATTAGTTAATACTGTACATTGTAACCAGGAGG GGCAGTTTTGCCAACCAGCCTCTGCTCATGGTCACCATATGTGTATGACAAGGCCTGAGTGAGTTCCTGCATAAACTGGGTAGTGGGCTC TTTTGACACATTTGCAAGCATGTAAATGAATGAATGACACTACCAGCAACCATCTGTACAGGTCCATTTACTTACATTCATAAGGTTTAT GCTATGAAACTTCTTCTCATTGTGATGTCAGTAACAGAGTTAGTGTCTCTGATGGAATAGTGTACCTGTCACCCAAGTTATTTTGTTCCT TTTTGGGTCCTCCAGTATAATCCCCCCCTCATCCCAATTAACTGTAAAATGTTTTACACATCACATTTTTTATACTGTAAACTTGGAAAA TAAACTGAAATATCAAATTG >7793_7793_4_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206281_ENST00000369510_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- >7793_7793_5_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000310260_length(transcript)=2110nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGT >7793_7793_5_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000310260_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- >7793_7793_6_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000355485_length(transcript)=8480nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGTCGTGGGCAGTTCAGGAGATACCTGCCTTCATCTTTGTTCTTTGTTGCCTT AGGTTCTTCAGAGAAAGATCACAACAAAAAATGTACACTGTCGTTTACAGCTATTAAGTGATTTGATTTTGTTTTTTTCCCAAAGAGAAA ACCTACCTGCCCTGTTTCTGATCCCACCCCTCTGCTGGCTTGAAGCAGGTAACCCTTTCCCAGCCCTGCAGCTGCCCACCTGGCCTCCAT GCCATCCTGCCCCCACCTGGCTGGCAGCCCTGGCTCTCCATGTGTGCCCTCCGGCTCTGTGTGAAGCCTCAAGTCAGTCCCAGCATTGTT TCCATAGGGAAGTGTGGGGTGCCCAGCAGGTAAAGCACAGGGAGAGAGGGCAGTGGGAATGCCACCTTTAGGCTGCAGCAGGAGCCCCAC ACTGCCCAGTTTTCCTCCCCACTGTTCTACACCAACCAGGGGAGACTAACACTGTGACTCTGGGATTGGCAGGTGCAACTTGGAGCCACT TAATTTCCTGGGGACGTAAGTTCTTCCCAAGCTTAGAGCAAGCTGCCCTGCCAAAGGAGACCAAACCATGCCAACCACGCTGGCAACTGC TGCTGTCCAGTCCCTGTGTTTTCTGACCACCGTCACTGTGCAACTCATCGCCTCTGCCACTTAGGACCAGGAAAGAGGCTGGTTTTGCTC CCACTCTTAGTTGCTGATAAAGTGGGGAGAAGGAAAATGGACACTCTACAGAGTTTGGGGAAGGGAGAGTAGGGAGCCCATCTTGTCCAG AAAGATTCATCTGTGGTCTGTCTGTTAAACACAGCTGATTTCAGTGGGCTTTCCCCTGGCCCTGGGGGAGCAGACACTGACTGGGTTGTG GGCAGAGGAGCCATCCTGGCGGAGCCCTGCTGCAGGGGAGCTCCTTCAGGAGCCCCATCCGGACCTCTTGCACTGGGCTGCCTTTGCCTC CATTTGCCTTCCTGTATCTGCAACAAACCTTTTAAAAGTGTTCACTCTTGCTTTTTCCAGTATTTCGGTAATCAGCCATCTTGCTGTAGT ACAGGATGACATTGTCGAATGCTCTTTGTATGTGTGCACACCCCCTTACTCCCTTACTGCTTCATACACTCCACAAGTGGTACAGTATTT TGTGTCATTGTAAAAATCAAAATTGGCTTTGGATCTTTGTAATACACCTGTACCTGAAAAAGTAAACAACATTCTTCAATTACTAGCCTT CAGCTTGAAAAGACATGCTGGAGAAGAAGGAAGGGGGAACCCATAGGTGTGGCGTGGAGCCAAGATGTACTATTCAACTATGTGTTTCTG TTTATAAAAAACACATACCATGGAACCATGGTGCTTTTGTTCTTAGTTTTTGCCGTTAGATCCCTTCAAACTGGAAGTTCCTTACAATAT CTTTCTCAGGAAATATTTTGGGAAATGGGGTAAGAGATGGCAAGTGTGAGACGGGCTGTGTCAGAGGTTGCTACGTCATGGATACAGTGC AGTTCCAAGTGCCATAAGTGTATGTACATATAGTTAATAATGACACTGTTCATCACCATTCTAAAATACTGTTCTTCCAACCCTATCTTC AATGACCAGTCCAGAAGGGGTTAAGCTGGATTCATTTGCTCTGGCATGTGCATTCCCAGCAGGGTGAAGAAAGGTTTAAATTAAAGAATT TATTTTCTCTCTCCCCCTTCCTCTTTCTCCCAGTCTTTGCATAGGAGAATGTTAGACATTCAGAAATTACTGTTTCTGTTTTAAATTGAG TATTGATTTTTTTATATTGACTTTGTATTGAGTTCTTTTTGAAAGAATAACAAAATAAAATGCAGGATCTTTGTAAAGCCTTTGCACTTT CAACCTCTTTATAGCTTGAGTTACTTTTGCAGTGGGAACAATGTAAATGACATTTAAAAGATTTAAGGTTTCAGAAAGCTGCATCCCACA ATTGAACACAATGCATTTTTATTTCAATTCTTGGAACTGGTAGGCTATTCTTTTTAAAAGGGGGTAAACTTCGCCCTAAGGCTGGTAGAA TGTATGTTCACATTATAGTAGACAGGATTTCATTTGCCTTATATGTTTATAGATTTTTTATAATTTTCATCCTACGTTATTAAAATTAGA GCATTGAGTGTTAAAGAACTTAATGAGGAGTCTATATCTGAGATTGCTCTCTTCCCTGGTGATGTTTTAACTGGTAGATAATTTGTTCTT AAATATGTACTTTTGAAGATAGGACAGTTTTTATAGTCCATGAACTGAATGTTAAAAAGTTCTGTATGCATTCTCAGAGAGGATTTTAAA GCTATATAGTTCATCCATCCTTTGCATTATCAAAATGTTAAGTCAAATCTGTAATACTTTGGCTAAAATTCATAAAGTAAGCCCTAGAGA AAATACTTGACCACCAAATTTTTGCCCAACTATCATCACCTCCCTTCCCCCGCCTCTGTTCTTGCCTTTTGACATCTACATGGAAGACAA GTTCTTTACAGCAAATGGTAAGAGGCAGGTGACCTGGTGTGTTTGCTGTGTTGTAGTTCATTGCCTGGGGCTTGGGACTCCTTTTTTAAT GGAGAGACTAGCTGTGCAGGTGTGTGTTGGATAGGGATAAAGTGCTCACCCCTGCCCTCTCTACAGTAGTTGGTGGTAGATTTCTCTCTC ATTTTGCCTCATAATCACTTTCGAGTGCATGTATTTACCTAAGGGCTGTAGCTCTGTGGGATGCTACCAGCATATTGGACTGACAGAAAT TGATTACCTTGCCACTCCAACCTACGTACTGAGTGAGTGCTCCAGCCACTCAGTGAAACCAACAAAAGTGAGTCCTTGGTTTACCTTCCA ATCTGGGTCCTGCTGTGTAAGTATCCCTAAGTGGGGATGCATATTTGTTTGTGCGTTTTTATTTCCATATATGTGAGCATTTCTCTGAGT GTATTACCAGACGGATAGCACATTTATATGTCAGACATCTTAACATCTGTGTTATCTGTAGCAGGTGTGTAGCTCAGCAGATACGTGTCA TTGTGTATATAGCTGAGTGTGTGAGGGTGTCTGTGTTTCTGCAGTCCCCTGTGTTTGAGAGATGACTTAATAACCCTGTGTTTTGAGAGG TCGCTCTAAACCAGTGACTTTTCCCTCCCCTGCTTTATTCCTTTCCCTCACTGACACTGGCTTCTCCCGCTAGAGTAAATGGCTTTAGCA CAGCACTGTCTTCTGGGGAGCCTGCTGTCCTGCAGGCAAGTCCATTAAACTCTTTCTTGCTTTAGGACTCTGAAAACAGCAAGAAACAAA CAAACAAAGGTCAAGCTCTAAGAAAATTACTGCTCAAACTTCACTACCCTGGAAGCCTTACTAGATATTTCTTAAGGTAACTTAAAAATT GGGCTTTATTTTTAAAAAGTGATAGGTTACTTACAGTAGCACAGAAATGTTAGCATATTTATTTAAATAGTCCTGCAGCAGAGACCCTGC GATTGTAAAGTGATTTAAGTATTTCTGGGTAGTGTTTGTGATTTACGGATTTGTTACTGAAAAACAAAAAAATCACTACTGTGAATTTAC TACTATGTAACCTTGTGGTCGTATTTCATTATAAATAAAATAAGAATTGCTCTTCTGCCCACCGTTCTTGATTGGTATTCAGTGCAGTAG CGAAATGAGATAGTTTAGACACTGTTGAAATAACTGCATTGAGCTTTAACCAAGTGTATGCTCAGAAAATTCAGTTTTGGATCACATTTT GACAAAACATGTTTTGGTCAAAGAAAGGAAAGGCTACTAACACATTTATCAGGTAATGTATGTCACAGTCCGTGTTCCACCCAGCCTTGT TATCCCCACATTCTTTCAAGATAGGAGTCATCTTGGTTTTTCGGGTGAAAAACGGAAGGTCAGAGAGGAAGGGGCTTGTCCAAGGTCTCA TGTCTGGTTAACAGAATTTCAAACTAGATGTTTGATTCTAACCCCTCAGTCCACTGTACCTTGAAGTATGGTCTAAATGATTCGGCACTT CTGGATGTTGAGGAAGGACCTAGAGACACATCCTTGAACTAGAACCTGGGGTGAGAGTTCATTGGGAGGCAGGATCTCTTCTTTCACTTT GGATTTACACCTTGTCCCTTGGAAAGCTTCTCCACTATGCTAGCAAATATCTTAGGATATTTGATGGAAAGAACTTGAGAATCCCTTCTG GAAAACCCAGCCTTTCAGTGTTAACACCTGCTGCAAGACAGGGATGCTGTTGTTCTGGCAGCCCCCCTTTGCTTTTGCCTGGCCCCACCT TCTGCTCCCACTCTGCTGGCTTGGGCAAGATGCGTGCCTTGGGCCTTGGGTGCAGGGAGGCAGGCAGGGGCTTGACCTGGCCTCTCTCTG GTGCCATGGCAACATTATGCCCCAAACTTCTTCCCTGGTTGGAGTGAGAGGGGCTGTCCACAGCCCCATCCTGTGGGGATCTCAAGCCGG AGTCCCTGGCCTGGCCTCCTTGACGTAGGTGTTCTCAGCAAGCAGTTTGCATCCCACCGTCTTTCTCACACTTGCCCCCAAGACTTTTGA CAGAGCAGACGTAAAACAGGACTCAGAAAACCATTTTTCTCTGTTCCCATATGTAGTAAGTTTTGATTCAGTTGTGCATAAACCATAGTT TTCTGCCCTGCTGTTTGCTTTCAATGGAAGACAGTAAAGGGAAGATGGTGCTCACATCTCTCCATGTGACATCTCATTAGGAATTAAGAT GCGATGGATTAGAAATGTAAAACTTCAGAATAAAATTAAATTTCAGGGCTCTATAAGTCCCGTTTTCCCAGGTCCTGTTCCGTTTCTACG TAGATAACCCAATTTGTTTTGTCTATGAAATAAGCCTCTTTAGTGGGTTGTTTTAGTCTCTCCAACAAAAGAGCAGATTCCTAAAGCCAG GTGCAGCACTGTGAAAAGTTTCTTTCAATATGGCACCAAGACTCTACCATTTATGTCTCTCTCAGCTTACAAACATCAGCGTTTTGTCCT TGTCATAGTGGAAGAAAGACACTTACTTTAAGCTTTGGGGACAAAGGTGACAAACCCCAGGCTTTTATCTTAAAAGTGTCTTTGGCACTT CTTTTGGCACTGAAATGGTATTTGGGAAGCATTATTTGAATGTACAGTTGTTTGGTTTTGTATGTGCTTATCTTTATCTGAGCTTTCACT TGTAGACATGGCCTTTTGTTGTGAAGTTGCTCATCATTTAGGAGTGTTTAATTCTAAAAAGCCTTCAGCCTAAGAAAGCTTCATCTGTGG GGACCAGAGACTTGTTGCTCAGGGAGTTAGTGATGGGACTTGGGCATCTGATCTGCAGGTGACAAGTTTAGTTCAACTGAAGTTGTAGGG AATTTAGACAGTTGCACATCATTGCCGTTCTAGGGGCCTTGTAGAAAGATGAAACAGTTGTTTTTCATTTACCAGCACCTCTCAGTTATA GAGGTAATGGAACATTCGCTTACTTTTCATCATCATTCTTTAAAAAGGGAACATACAAAAATCTAAACTATGGCAATAATTTATTTTTAT AATAGTTTACGGTAGGCTTTAATTAAATGGCAAACTCCTCTGGGACCCCTAAGTTATGGCGTGATTAGCCAAATTTGATTTCCAACAGTC ATTTATGGCCATAACTATTGCATAGAGTGCAGGATGCCAGCAAAGATGAGGGTGGGGGCAGATACTGGCTCAGTGATTTAACTCACATTA TAGATGACCCCTTCCTCAACAGAAATGCTACTGAGAGAACCAGAGAGGCCTGGGCCAGGCAGGTCTTATTTGAGAGGAGATTATTTGATA ATTGCTTTGGTTAGAAGGACTTTACATTTCCTGATTTCAAGTCCAGCACCAATTTAGAAAGTTCAGAGATGAAACCACCTGTCTTTACCT GACAGAGTCATAACGGTTTGTGTAAAAATGTGGTCAGGGACCTTTTTTGTTCTTTCTGATTAGTTAATACTGTACATTGTAACCAGGAGG GGCAGTTTTGCCAACCAGCCTCTGCTCATGGTCACCATATGTGTATGACAAGGCCTGAGTGAGTTCCTGCATAAACTGGGTAGTGGGCTC TTTTGACACATTTGCAAGCATGTAAATGAATGAATGACACTACCAGCAACCATCTGTACAGGTCCATTTACTTACATTCATAAGGTTTAT GCTATGAAACTTCTTCTCATTGTGATGTCAGTAACAGAGTTAGTGTCTCTGATGGAATAGTGTACCTGTCACCCAAGTTATTTTGTTCCT TTTTGGGTCCTCCAGTATAATCCCCCCCTCATCCCAATTAACTGTAAAATGTTTTACACATCACATTTTTTATACTGTAAACTTGGAAAA TAAACTGAAATATCAAATTG >7793_7793_6_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000355485_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- >7793_7793_7_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000369509_length(transcript)=2110nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGT >7793_7793_7_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000369509_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- >7793_7793_8_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000369510_length(transcript)=8480nt_BP=264nt CTGGGGCGCAGAGCAGCGGCGGGAGGAGGCGGACACGTGGCAACAGCGGTAGCAGCCCGGGCGGCGGCAGCAACAGCGGCGGCGGCATCG GCCCGAGCCGCCGGCCGCCCTCCCACCCTCCCGCCCCGCGGCAGCCCTAGCTCCCTCCACTTGGCTCCCCTGGTCCCGCTCGCTCGGCCG GGAGCTGCTCTGTGCTTTTCTCTCTGATTCTCCAGCGACAGGACCCGGCGCCGGGCACTGAGCACCGCCACCATGGGGAAGGGGGATGAC AACTGGGGAGAGACCACCACGGCCATCACAGGCACCTCGGAGCACAGCATATCCCAAGAGGACATTGCCAGGATCAGCAAGGACATGGAG GACAGCGTGGGGCTGGATTGCAAACGCTACCTGGGCCTCACCGTCGCCTCTTTTCTTGGACTTCTAGTTTTCCTCACCCCTATTGCCTTC ATCCTTTTACCTCCGATCCTGTGGAGGGATGAGCTGGAGCCTTGTGGCACAATTTGTGAGGGGCTCTTTATCTCCATGGCATTCAAACTC CTCATTCTGCTCATAGGGACCTGGGCACTTTTTTTCCGCAAGCGGAGAGCTGACATGCCACGGGTGTTTGTGTTTCGTGCCCTTTTGTTG GTCCTCATCTTTCTCTTTGTGGTTTCCTATTGGCTTTTTTACGGGGTCCGCATTTTGGACTCTCGGGACCGGAATTACCAGGGCATTGTG CAATATGCAGTCTCCCTTGTGGATGCCCTCCTCTTCATCCATTACCTGGCCATCGTCCTGCTGGAGCTCAGGCAGCTGCAGCCCATGTTC ACGCTGCAGGTGGTCCGCTCCACCGATGGCGAGTCCCGCTTCTACAGCCTGGGACACCTGAGTATCCAGCGAGCAGCATTGGTGGTCCTA GAAAATTACTACAAAGATTTCACCATCTATAACCCAAACCTCCTAACAGCCTCCAAATTCCGAGCAGCCAAGCATATGGCCGGGCTGAAA GTCTACAATGTAGATGGCCCCAGTAACAATGCCACTGGCCAGTCCCGGGCCATGATTGCTGCAGCTGCTCGGCGCAGGGACTCAAGCCAC AACGAGTTGTATTATGAAGAGGCCGAACATGAACGGCGAGTAAAGAAGCGGAAAGCAAGGCTGGTGGTTGCAGTGGAAGAGGCCTTCATC CACATTCAGCGTCTCCAGGCTGAGGAGCAGCAGAAAGCCCCAGGGGAGGTGATGGACCCTAGGGAGGCCGCCCAGGCCATTTTCCCCTCC ATGGCCAGGGCTCTCCAGAAGTACCTGCGCATCACCCGGCAGCAGAACTACCACAGCATGGAGAGCATCCTGCAGCACCTGGCCTTCTGC ATCACCAACGGCATGACCCCCAAGGCCTTCCTAGAACGGTACCTCAGTGCGGGCCCCACCCTGCAATATGACAAGGACCGCTGGCTCTCT ACACAGTGGAGGCTTGTCAGTGATGAGGCTGTGACTAATGGATTACGGGATGGAATTGTGTTCGTCCTTAAGTGCTTGGACTTCAGCCTC GTAGTCAATGTGAAGAAAATTCCATTCATCATACTCTCTGAAGAGTTCATAGACCCCAAATCTCACAAATTTGTCCTTCGCTTACAGTCT GAGACATCCGTTTAAAAGTTCTATATTTGTGGCTTTATTAAAAAAAAAAGAAAAATATATAGAGAGATATATATCTATGCCAGAGGGGTG TCTTTTTTAAAAATTCTTCTTCATTGCTGACTGAAACTGGCAGATGATTGACCAGTATCCTTTGACCATCTGCACTTTATTTGGAAGGAA GCAGGGGCTGTCCACCCTGAAAAAGAGTGACTGATGACATCTGACTTTTGTCGATGGGACTTCTCAAGAAGCCATTCCTTGGAGCTTCTG TTACAGCTGTAAACCAAAGTGGAGCTGGTGCTTCTTGGGAGCCTCGCCTTACAACTAATTCCTGCCTTTCGTCCAGTACCAAGTCCCCCG TTGCTTCTGGTCAGCCCACTTGTAGACTTCCAGGGGACACATCTTTATTCTGTTTCAGGAAACCAGTCACGACACGTCCACATATGTATT TGTGTATGTTAATGTCCAGTATCACATCACCCATGAAAGTCGTGGGCAGTTCAGGAGATACCTGCCTTCATCTTTGTTCTTTGTTGCCTT AGGTTCTTCAGAGAAAGATCACAACAAAAAATGTACACTGTCGTTTACAGCTATTAAGTGATTTGATTTTGTTTTTTTCCCAAAGAGAAA ACCTACCTGCCCTGTTTCTGATCCCACCCCTCTGCTGGCTTGAAGCAGGTAACCCTTTCCCAGCCCTGCAGCTGCCCACCTGGCCTCCAT GCCATCCTGCCCCCACCTGGCTGGCAGCCCTGGCTCTCCATGTGTGCCCTCCGGCTCTGTGTGAAGCCTCAAGTCAGTCCCAGCATTGTT TCCATAGGGAAGTGTGGGGTGCCCAGCAGGTAAAGCACAGGGAGAGAGGGCAGTGGGAATGCCACCTTTAGGCTGCAGCAGGAGCCCCAC ACTGCCCAGTTTTCCTCCCCACTGTTCTACACCAACCAGGGGAGACTAACACTGTGACTCTGGGATTGGCAGGTGCAACTTGGAGCCACT TAATTTCCTGGGGACGTAAGTTCTTCCCAAGCTTAGAGCAAGCTGCCCTGCCAAAGGAGACCAAACCATGCCAACCACGCTGGCAACTGC TGCTGTCCAGTCCCTGTGTTTTCTGACCACCGTCACTGTGCAACTCATCGCCTCTGCCACTTAGGACCAGGAAAGAGGCTGGTTTTGCTC CCACTCTTAGTTGCTGATAAAGTGGGGAGAAGGAAAATGGACACTCTACAGAGTTTGGGGAAGGGAGAGTAGGGAGCCCATCTTGTCCAG AAAGATTCATCTGTGGTCTGTCTGTTAAACACAGCTGATTTCAGTGGGCTTTCCCCTGGCCCTGGGGGAGCAGACACTGACTGGGTTGTG GGCAGAGGAGCCATCCTGGCGGAGCCCTGCTGCAGGGGAGCTCCTTCAGGAGCCCCATCCGGACCTCTTGCACTGGGCTGCCTTTGCCTC CATTTGCCTTCCTGTATCTGCAACAAACCTTTTAAAAGTGTTCACTCTTGCTTTTTCCAGTATTTCGGTAATCAGCCATCTTGCTGTAGT ACAGGATGACATTGTCGAATGCTCTTTGTATGTGTGCACACCCCCTTACTCCCTTACTGCTTCATACACTCCACAAGTGGTACAGTATTT TGTGTCATTGTAAAAATCAAAATTGGCTTTGGATCTTTGTAATACACCTGTACCTGAAAAAGTAAACAACATTCTTCAATTACTAGCCTT CAGCTTGAAAAGACATGCTGGAGAAGAAGGAAGGGGGAACCCATAGGTGTGGCGTGGAGCCAAGATGTACTATTCAACTATGTGTTTCTG TTTATAAAAAACACATACCATGGAACCATGGTGCTTTTGTTCTTAGTTTTTGCCGTTAGATCCCTTCAAACTGGAAGTTCCTTACAATAT CTTTCTCAGGAAATATTTTGGGAAATGGGGTAAGAGATGGCAAGTGTGAGACGGGCTGTGTCAGAGGTTGCTACGTCATGGATACAGTGC AGTTCCAAGTGCCATAAGTGTATGTACATATAGTTAATAATGACACTGTTCATCACCATTCTAAAATACTGTTCTTCCAACCCTATCTTC AATGACCAGTCCAGAAGGGGTTAAGCTGGATTCATTTGCTCTGGCATGTGCATTCCCAGCAGGGTGAAGAAAGGTTTAAATTAAAGAATT TATTTTCTCTCTCCCCCTTCCTCTTTCTCCCAGTCTTTGCATAGGAGAATGTTAGACATTCAGAAATTACTGTTTCTGTTTTAAATTGAG TATTGATTTTTTTATATTGACTTTGTATTGAGTTCTTTTTGAAAGAATAACAAAATAAAATGCAGGATCTTTGTAAAGCCTTTGCACTTT CAACCTCTTTATAGCTTGAGTTACTTTTGCAGTGGGAACAATGTAAATGACATTTAAAAGATTTAAGGTTTCAGAAAGCTGCATCCCACA ATTGAACACAATGCATTTTTATTTCAATTCTTGGAACTGGTAGGCTATTCTTTTTAAAAGGGGGTAAACTTCGCCCTAAGGCTGGTAGAA TGTATGTTCACATTATAGTAGACAGGATTTCATTTGCCTTATATGTTTATAGATTTTTTATAATTTTCATCCTACGTTATTAAAATTAGA GCATTGAGTGTTAAAGAACTTAATGAGGAGTCTATATCTGAGATTGCTCTCTTCCCTGGTGATGTTTTAACTGGTAGATAATTTGTTCTT AAATATGTACTTTTGAAGATAGGACAGTTTTTATAGTCCATGAACTGAATGTTAAAAAGTTCTGTATGCATTCTCAGAGAGGATTTTAAA GCTATATAGTTCATCCATCCTTTGCATTATCAAAATGTTAAGTCAAATCTGTAATACTTTGGCTAAAATTCATAAAGTAAGCCCTAGAGA AAATACTTGACCACCAAATTTTTGCCCAACTATCATCACCTCCCTTCCCCCGCCTCTGTTCTTGCCTTTTGACATCTACATGGAAGACAA GTTCTTTACAGCAAATGGTAAGAGGCAGGTGACCTGGTGTGTTTGCTGTGTTGTAGTTCATTGCCTGGGGCTTGGGACTCCTTTTTTAAT GGAGAGACTAGCTGTGCAGGTGTGTGTTGGATAGGGATAAAGTGCTCACCCCTGCCCTCTCTACAGTAGTTGGTGGTAGATTTCTCTCTC ATTTTGCCTCATAATCACTTTCGAGTGCATGTATTTACCTAAGGGCTGTAGCTCTGTGGGATGCTACCAGCATATTGGACTGACAGAAAT TGATTACCTTGCCACTCCAACCTACGTACTGAGTGAGTGCTCCAGCCACTCAGTGAAACCAACAAAAGTGAGTCCTTGGTTTACCTTCCA ATCTGGGTCCTGCTGTGTAAGTATCCCTAAGTGGGGATGCATATTTGTTTGTGCGTTTTTATTTCCATATATGTGAGCATTTCTCTGAGT GTATTACCAGACGGATAGCACATTTATATGTCAGACATCTTAACATCTGTGTTATCTGTAGCAGGTGTGTAGCTCAGCAGATACGTGTCA TTGTGTATATAGCTGAGTGTGTGAGGGTGTCTGTGTTTCTGCAGTCCCCTGTGTTTGAGAGATGACTTAATAACCCTGTGTTTTGAGAGG TCGCTCTAAACCAGTGACTTTTCCCTCCCCTGCTTTATTCCTTTCCCTCACTGACACTGGCTTCTCCCGCTAGAGTAAATGGCTTTAGCA CAGCACTGTCTTCTGGGGAGCCTGCTGTCCTGCAGGCAAGTCCATTAAACTCTTTCTTGCTTTAGGACTCTGAAAACAGCAAGAAACAAA CAAACAAAGGTCAAGCTCTAAGAAAATTACTGCTCAAACTTCACTACCCTGGAAGCCTTACTAGATATTTCTTAAGGTAACTTAAAAATT GGGCTTTATTTTTAAAAAGTGATAGGTTACTTACAGTAGCACAGAAATGTTAGCATATTTATTTAAATAGTCCTGCAGCAGAGACCCTGC GATTGTAAAGTGATTTAAGTATTTCTGGGTAGTGTTTGTGATTTACGGATTTGTTACTGAAAAACAAAAAAATCACTACTGTGAATTTAC TACTATGTAACCTTGTGGTCGTATTTCATTATAAATAAAATAAGAATTGCTCTTCTGCCCACCGTTCTTGATTGGTATTCAGTGCAGTAG CGAAATGAGATAGTTTAGACACTGTTGAAATAACTGCATTGAGCTTTAACCAAGTGTATGCTCAGAAAATTCAGTTTTGGATCACATTTT GACAAAACATGTTTTGGTCAAAGAAAGGAAAGGCTACTAACACATTTATCAGGTAATGTATGTCACAGTCCGTGTTCCACCCAGCCTTGT TATCCCCACATTCTTTCAAGATAGGAGTCATCTTGGTTTTTCGGGTGAAAAACGGAAGGTCAGAGAGGAAGGGGCTTGTCCAAGGTCTCA TGTCTGGTTAACAGAATTTCAAACTAGATGTTTGATTCTAACCCCTCAGTCCACTGTACCTTGAAGTATGGTCTAAATGATTCGGCACTT CTGGATGTTGAGGAAGGACCTAGAGACACATCCTTGAACTAGAACCTGGGGTGAGAGTTCATTGGGAGGCAGGATCTCTTCTTTCACTTT GGATTTACACCTTGTCCCTTGGAAAGCTTCTCCACTATGCTAGCAAATATCTTAGGATATTTGATGGAAAGAACTTGAGAATCCCTTCTG GAAAACCCAGCCTTTCAGTGTTAACACCTGCTGCAAGACAGGGATGCTGTTGTTCTGGCAGCCCCCCTTTGCTTTTGCCTGGCCCCACCT TCTGCTCCCACTCTGCTGGCTTGGGCAAGATGCGTGCCTTGGGCCTTGGGTGCAGGGAGGCAGGCAGGGGCTTGACCTGGCCTCTCTCTG GTGCCATGGCAACATTATGCCCCAAACTTCTTCCCTGGTTGGAGTGAGAGGGGCTGTCCACAGCCCCATCCTGTGGGGATCTCAAGCCGG AGTCCCTGGCCTGGCCTCCTTGACGTAGGTGTTCTCAGCAAGCAGTTTGCATCCCACCGTCTTTCTCACACTTGCCCCCAAGACTTTTGA CAGAGCAGACGTAAAACAGGACTCAGAAAACCATTTTTCTCTGTTCCCATATGTAGTAAGTTTTGATTCAGTTGTGCATAAACCATAGTT TTCTGCCCTGCTGTTTGCTTTCAATGGAAGACAGTAAAGGGAAGATGGTGCTCACATCTCTCCATGTGACATCTCATTAGGAATTAAGAT GCGATGGATTAGAAATGTAAAACTTCAGAATAAAATTAAATTTCAGGGCTCTATAAGTCCCGTTTTCCCAGGTCCTGTTCCGTTTCTACG TAGATAACCCAATTTGTTTTGTCTATGAAATAAGCCTCTTTAGTGGGTTGTTTTAGTCTCTCCAACAAAAGAGCAGATTCCTAAAGCCAG GTGCAGCACTGTGAAAAGTTTCTTTCAATATGGCACCAAGACTCTACCATTTATGTCTCTCTCAGCTTACAAACATCAGCGTTTTGTCCT TGTCATAGTGGAAGAAAGACACTTACTTTAAGCTTTGGGGACAAAGGTGACAAACCCCAGGCTTTTATCTTAAAAGTGTCTTTGGCACTT CTTTTGGCACTGAAATGGTATTTGGGAAGCATTATTTGAATGTACAGTTGTTTGGTTTTGTATGTGCTTATCTTTATCTGAGCTTTCACT TGTAGACATGGCCTTTTGTTGTGAAGTTGCTCATCATTTAGGAGTGTTTAATTCTAAAAAGCCTTCAGCCTAAGAAAGCTTCATCTGTGG GGACCAGAGACTTGTTGCTCAGGGAGTTAGTGATGGGACTTGGGCATCTGATCTGCAGGTGACAAGTTTAGTTCAACTGAAGTTGTAGGG AATTTAGACAGTTGCACATCATTGCCGTTCTAGGGGCCTTGTAGAAAGATGAAACAGTTGTTTTTCATTTACCAGCACCTCTCAGTTATA GAGGTAATGGAACATTCGCTTACTTTTCATCATCATTCTTTAAAAAGGGAACATACAAAAATCTAAACTATGGCAATAATTTATTTTTAT AATAGTTTACGGTAGGCTTTAATTAAATGGCAAACTCCTCTGGGACCCCTAAGTTATGGCGTGATTAGCCAAATTTGATTTCCAACAGTC ATTTATGGCCATAACTATTGCATAGAGTGCAGGATGCCAGCAAAGATGAGGGTGGGGGCAGATACTGGCTCAGTGATTTAACTCACATTA TAGATGACCCCTTCCTCAACAGAAATGCTACTGAGAGAACCAGAGAGGCCTGGGCCAGGCAGGTCTTATTTGAGAGGAGATTATTTGATA ATTGCTTTGGTTAGAAGGACTTTACATTTCCTGATTTCAAGTCCAGCACCAATTTAGAAAGTTCAGAGATGAAACCACCTGTCTTTACCT GACAGAGTCATAACGGTTTGTGTAAAAATGTGGTCAGGGACCTTTTTTGTTCTTTCTGATTAGTTAATACTGTACATTGTAACCAGGAGG GGCAGTTTTGCCAACCAGCCTCTGCTCATGGTCACCATATGTGTATGACAAGGCCTGAGTGAGTTCCTGCATAAACTGGGTAGTGGGCTC TTTTGACACATTTGCAAGCATGTAAATGAATGAATGACACTACCAGCAACCATCTGTACAGGTCCATTTACTTACATTCATAAGGTTTAT GCTATGAAACTTCTTCTCATTGTGATGTCAGTAACAGAGTTAGTGTCTCTGATGGAATAGTGTACCTGTCACCCAAGTTATTTTGTTCCT TTTTGGGTCCTCCAGTATAATCCCCCCCTCATCCCAATTAACTGTAAAATGTTTTACACATCACATTTTTTATACTGTAAACTTGGAAAA TAAACTGAAATATCAAATTG >7793_7793_8_ATP1A1-VANGL1_ATP1A1_chr1_116916145_ENST00000295598_VANGL1_chr1_116206282_ENST00000369510_length(amino acids)=465AA_BP=9 MSTATMGKGDDNWGETTTAITGTSEHSISQEDIARISKDMEDSVGLDCKRYLGLTVASFLGLLVFLTPIAFILLPPILWRDELEPCGTIC EGLFISMAFKLLILLIGTWALFFRKRRADMPRVFVFRALLLVLIFLFVVSYWLFYGVRILDSRDRNYQGIVQYAVSLVDALLFIHYLAIV LLELRQLQPMFTLQVVRSTDGESRFYSLGHLSIQRAALVVLENYYKDFTIYNPNLLTASKFRAAKHMAGLKVYNVDGPSNNATGQSRAMI AAAARRRDSSHNELYYEEAEHERRVKKRKARLVVAVEEAFIHIQRLQAEEQQKAPGEVMDPREAAQAIFPSMARALQKYLRITRQQNYHS MESILQHLAFCITNGMTPKAFLERYLSAGPTLQYDKDRWLSTQWRLVSDEAVTNGLRDGIVFVLKCLDFSLVVNVKKIPFIILSEEFIDP KSHKFVLRLQSETSV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ATP1A1-VANGL1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ATP1A1-VANGL1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
| Hgene | ATP1A1 | P05023 | DB00390 | Digoxin | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB00511 | Acetyldigitoxin | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01078 | Deslanoside | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01092 | Ouabain | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01119 | Diazoxide | Other | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01158 | Bretylium | Inhibitor | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB01430 | Almitrine | Binder | Small molecule | Approved |
| Hgene | ATP1A1 | P05023 | DB13996 | Magnesium acetate | Small molecule | Approved | |
| Hgene | ATP1A1 | P05023 | DB14500 | Potassium | Regulator | Small molecule | Approved|Experimental |
| Hgene | ATP1A1 | P05023 | DB00903 | Etacrynic acid | Inhibitor | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB01188 | Ciclopirox | Binder | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB01345 | Potassium cation | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB01370 | Aluminium | Binder | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB01396 | Digitoxin | Inhibitor | Small molecule | Approved|Investigational |
| Hgene | ATP1A1 | P05023 | DB14498 | Potassium acetate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB14499 | Potassium sulfate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB14517 | Aluminium phosphate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB14518 | Aluminum acetate | Small molecule | Approved|Investigational | |
| Hgene | ATP1A1 | P05023 | DB00774 | Hydroflumethiazide | Inducer | Small molecule | Approved|Investigational|Withdrawn |
| Hgene | ATP1A1 | P05023 | DB01378 | Magnesium cation | Small molecule | Approved|Nutraceutical | |
| Hgene | ATP1A1 | P05023 | DB01021 | Trichlormethiazide | Inhibitor | Small molecule | Approved|Vet_approved |
| Hgene | ATP1A1 | P05023 | DB01244 | Bepridil | Inhibitor | Small molecule | Approved|Withdrawn |
Top |
Related Diseases for ATP1A1-VANGL1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ATP1A1 | C0001430 | Adenoma | 2 | CTD_human |
| Hgene | ATP1A1 | C0205646 | Adenoma, Basal Cell | 2 | CTD_human |
| Hgene | ATP1A1 | C0205647 | Follicular adenoma | 2 | CTD_human |
| Hgene | ATP1A1 | C0205648 | Adenoma, Microcystic | 2 | CTD_human |
| Hgene | ATP1A1 | C0205649 | Adenoma, Monomorphic | 2 | CTD_human |
| Hgene | ATP1A1 | C0205650 | Papillary adenoma | 2 | CTD_human |
| Hgene | ATP1A1 | C0205651 | Adenoma, Trabecular | 2 | CTD_human |
| Hgene | ATP1A1 | C4747974 | CHARCOT-MARIE-TOOTH DISEASE, AXONAL, TYPE 2DD | 2 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | ATP1A1 | C0005586 | Bipolar Disorder | 1 | PSYGENET |
| Hgene | ATP1A1 | C0017162 | Gastroenteritis, Transmissible, of Swine | 1 | CTD_human |
| Hgene | ATP1A1 | C0020428 | Hyperaldosteronism | 1 | CTD_human |
| Hgene | ATP1A1 | C0020538 | Hypertensive disease | 1 | CTD_human |
| Hgene | ATP1A1 | C0027051 | Myocardial Infarction | 1 | CTD_human |
| Hgene | ATP1A1 | C0027055 | Myocardial Reperfusion Injury | 1 | CTD_human |
| Hgene | ATP1A1 | C0036572 | Seizures | 1 | GENOMICS_ENGLAND |
| Hgene | ATP1A1 | C0042594 | Vestibular Diseases | 1 | CTD_human |
| Hgene | ATP1A1 | C0151723 | Hypomagnesemia | 1 | GENOMICS_ENGLAND |
| Hgene | ATP1A1 | C0151744 | Myocardial Ischemia | 1 | CTD_human |
| Hgene | ATP1A1 | C1384514 | Conn Syndrome | 1 | CTD_human |
| Hgene | ATP1A1 | C3714756 | Intellectual Disability | 1 | GENOMICS_ENGLAND |
| Hgene | ATP1A1 | C4552839 | Hypomagnesemia, CTCAE | 1 | GENOMICS_ENGLAND |
| Tgene | C0011999 | Diastematomyelia | 2 | CTD_human | |
| Tgene | C0027794 | Neural Tube Defects | 2 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C0027806 | Neurenteric Cyst | 2 | CTD_human | |
| Tgene | C0080218 | Tethered Cord Syndrome | 2 | CTD_human | |
| Tgene | C0152234 | Iniencephaly | 2 | CTD_human | |
| Tgene | C0152426 | Craniorachischisis | 2 | CTD_human | |
| Tgene | C0266453 | Exencephaly | 2 | CTD_human | |
| Tgene | C0344479 | Spinal Cord Myelodysplasia | 2 | CTD_human | |
| Tgene | C0702169 | Acrania | 2 | CTD_human | |
| Tgene | C1960883 | Spina bifida aperta of cervical spine | 2 | ORPHANET | |
| Tgene | C3891448 | NEURAL TUBE DEFECTS, SUSCEPTIBILITY TO | 2 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C0300948 | Caudal Regression Syndrome | 1 | GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C0344490 | Sacral agenesis | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C1838568 | Sacral defect and anterior sacral meningocele | 1 | CTD_human;GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C1867774 | Sacral Agenesis Syndrome | 1 | ORPHANET | |
| Tgene | C2609260 | Caudal dysplasia syndrome | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies