
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARID4B-GNPAT (FusionGDB2 ID:HG51742TG8443) |
Fusion Gene Summary for ARID4B-GNPAT |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARID4B-GNPAT | Fusion gene ID: hg51742tg8443 | Hgene | Tgene | Gene symbol | ARID4B | GNPAT | Gene ID | 51742 | 8443 |
| Gene name | AT-rich interaction domain 4B | glyceronephosphate O-acyltransferase | |
| Synonyms | BCAA|BRCAA1|RBBP1L1|RBP1L1|SAP180 | DAP-AT|DAPAT|DHAPAT|RCDP2 | |
| Cytomap | ('ARID4B')('GNPAT') 1q42.3 | 1q42.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AT-rich interactive domain-containing protein 4B180 kDa Sin3-associated polypeptideARID domain-containing protein 4BAT rich interactive domain 4B (RBP1-like)Rb-binding protein homologSIN3A-associated protein 180breast cancer-associated antigen 1bre | dihydroxyacetone phosphate acyltransferaseDHAP-ATacyl-CoA:dihydroxyacetonephosphateacyltransferaseglycerone-phosphate O-acyltransferase | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000264183, ENST00000349213, ENST00000366603, ENST00000494543, | ||
| Fusion gene scores | * DoF score | 23 X 20 X 9=4140 | 5 X 8 X 3=120 |
| # samples | 29 | 6 | |
| ** MAII score | log2(29/4140*10)=-3.83550596237175 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/120*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARID4B [Title/Abstract] AND GNPAT [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARID4B(235490229)-GNPAT(231398469), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | ARID4B-GNPAT seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARID4B-GNPAT seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARID4B-GNPAT seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ARID4B-GNPAT seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ARID4B-GNPAT seems lost the major protein functional domain in Hgene partner, which is a epigenetic factor due to the frame-shifted ORF. ARID4B-GNPAT seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. ARID4B-GNPAT seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | GNPAT | GO:0008611 | ether lipid biosynthetic process | 15687349 |
| Fusion gene breakpoints across ARID4B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GNPAT (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-13-1512-01A | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| ChimerDB4 | OV | TCGA-13-1512-01A | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| ChimerDB4 | OV | TCGA-13-1512 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| ChimerDB4 | OV | TCGA-13-1512 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
Top |
Fusion Gene ORF analysis for ARID4B-GNPAT |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000264183 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| 5CDS-intron | ENST00000264183 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| 5CDS-intron | ENST00000264183 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| 5CDS-intron | ENST00000264183 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| 5CDS-intron | ENST00000349213 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| 5CDS-intron | ENST00000349213 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| 5CDS-intron | ENST00000349213 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| 5CDS-intron | ENST00000349213 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| 5CDS-intron | ENST00000366603 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| 5CDS-intron | ENST00000366603 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| 5CDS-intron | ENST00000366603 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| 5CDS-intron | ENST00000366603 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| Frame-shift | ENST00000264183 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| Frame-shift | ENST00000264183 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| Frame-shift | ENST00000264183 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| Frame-shift | ENST00000264183 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| Frame-shift | ENST00000349213 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| Frame-shift | ENST00000349213 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| Frame-shift | ENST00000349213 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| Frame-shift | ENST00000349213 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| Frame-shift | ENST00000366603 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| Frame-shift | ENST00000366603 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| Frame-shift | ENST00000366603 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| Frame-shift | ENST00000366603 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| In-frame | ENST00000264183 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| In-frame | ENST00000264183 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| In-frame | ENST00000264183 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| In-frame | ENST00000264183 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| In-frame | ENST00000349213 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| In-frame | ENST00000349213 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| In-frame | ENST00000349213 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| In-frame | ENST00000349213 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| In-frame | ENST00000366603 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| In-frame | ENST00000366603 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| In-frame | ENST00000366603 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| In-frame | ENST00000366603 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| intron-3CDS | ENST00000494543 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| intron-3CDS | ENST00000494543 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| intron-3CDS | ENST00000494543 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| intron-3CDS | ENST00000494543 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| intron-3CDS | ENST00000494543 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| intron-3CDS | ENST00000494543 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| intron-3CDS | ENST00000494543 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| intron-3CDS | ENST00000494543 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| intron-intron | ENST00000494543 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231398469 | + |
| intron-intron | ENST00000494543 | ENST00000469332 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + |
| intron-intron | ENST00000494543 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + |
| intron-intron | ENST00000494543 | ENST00000469332 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000366603 | ARID4B | chr1 | 235490228 | - | ENST00000366647 | GNPAT | chr1 | 231401038 | + | 2289 | 383 | 388 | 1857 | 489 |
| ENST00000366603 | ARID4B | chr1 | 235490228 | - | ENST00000366646 | GNPAT | chr1 | 231401038 | + | 1907 | 383 | 388 | 1857 | 489 |
| ENST00000264183 | ARID4B | chr1 | 235490228 | - | ENST00000366647 | GNPAT | chr1 | 231401038 | + | 2410 | 504 | 509 | 1978 | 489 |
| ENST00000264183 | ARID4B | chr1 | 235490228 | - | ENST00000366646 | GNPAT | chr1 | 231401038 | + | 2028 | 504 | 509 | 1978 | 489 |
| ENST00000349213 | ARID4B | chr1 | 235490228 | - | ENST00000366647 | GNPAT | chr1 | 231401038 | + | 2412 | 506 | 511 | 1980 | 489 |
| ENST00000349213 | ARID4B | chr1 | 235490228 | - | ENST00000366646 | GNPAT | chr1 | 231401038 | + | 2030 | 506 | 511 | 1980 | 489 |
| ENST00000366603 | ARID4B | chr1 | 235490229 | - | ENST00000366647 | GNPAT | chr1 | 231401039 | + | 2289 | 383 | 388 | 1857 | 489 |
| ENST00000366603 | ARID4B | chr1 | 235490229 | - | ENST00000366646 | GNPAT | chr1 | 231401039 | + | 1907 | 383 | 388 | 1857 | 489 |
| ENST00000264183 | ARID4B | chr1 | 235490229 | - | ENST00000366647 | GNPAT | chr1 | 231401039 | + | 2410 | 504 | 509 | 1978 | 489 |
| ENST00000264183 | ARID4B | chr1 | 235490229 | - | ENST00000366646 | GNPAT | chr1 | 231401039 | + | 2028 | 504 | 509 | 1978 | 489 |
| ENST00000349213 | ARID4B | chr1 | 235490229 | - | ENST00000366647 | GNPAT | chr1 | 231401039 | + | 2412 | 506 | 511 | 1980 | 489 |
| ENST00000349213 | ARID4B | chr1 | 235490229 | - | ENST00000366646 | GNPAT | chr1 | 231401039 | + | 2030 | 506 | 511 | 1980 | 489 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000366603 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 0.000251415 | 0.9997485 |
| ENST00000366603 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 0.000326845 | 0.9996731 |
| ENST00000264183 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 0.000309957 | 0.99969006 |
| ENST00000264183 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 0.000442096 | 0.9995579 |
| ENST00000349213 | ENST00000366647 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 0.000312798 | 0.9996872 |
| ENST00000349213 | ENST00000366646 | ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 0.000447716 | 0.9995523 |
| ENST00000366603 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + | 0.000251415 | 0.9997485 |
| ENST00000366603 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + | 0.000326845 | 0.9996731 |
| ENST00000264183 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + | 0.000309957 | 0.99969006 |
| ENST00000264183 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + | 0.000442096 | 0.9995579 |
| ENST00000349213 | ENST00000366647 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + | 0.000312798 | 0.9996872 |
| ENST00000349213 | ENST00000366646 | ARID4B | chr1 | 235490229 | - | GNPAT | chr1 | 231401039 | + | 0.000447716 | 0.9995523 |
Top |
Fusion Genomic Features for ARID4B-GNPAT |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 2.71E-05 | 0.99997294 |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 2.71E-05 | 0.99997294 |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + | 9.37E-06 | 0.9999906 |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + | 9.37E-06 | 0.9999906 |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 2.71E-05 | 0.99997294 |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231401038 | + | 2.71E-05 | 0.99997294 |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + | 9.37E-06 | 0.9999906 |
| ARID4B | chr1 | 235490228 | - | GNPAT | chr1 | 231398468 | + | 9.37E-06 | 0.9999906 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
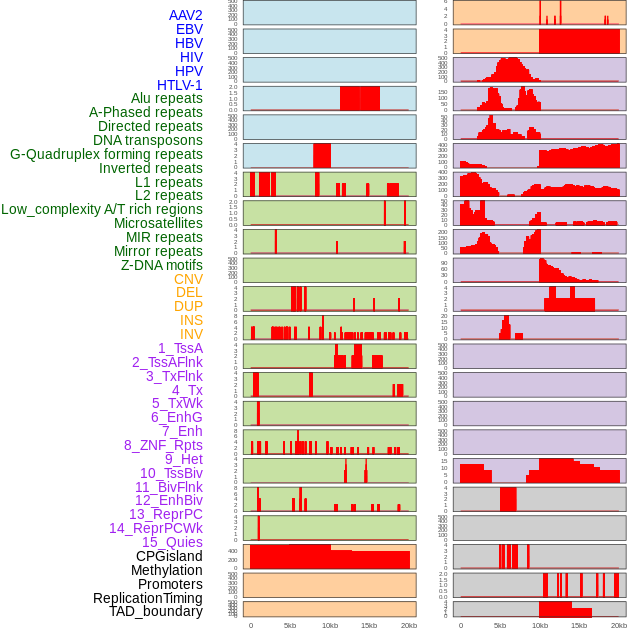 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
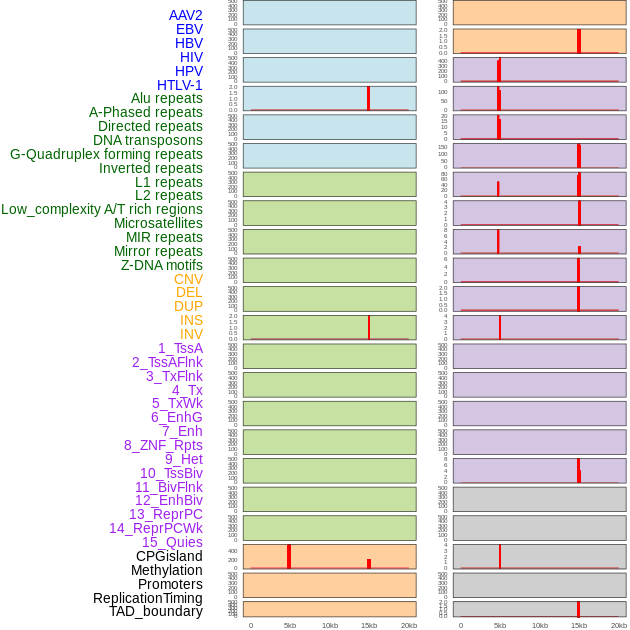 |
Top |
Fusion Protein Features for ARID4B-GNPAT |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:235490229/chr1:231398469) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GNPAT | chr1:235490228 | chr1:231401038 | ENST00000366647 | 3 | 16 | 678_680 | 189 | 681.0 | Motif | Microbody targeting signal | |
| Tgene | GNPAT | chr1:235490229 | chr1:231401039 | ENST00000366647 | 3 | 16 | 678_680 | 189 | 681.0 | Motif | Microbody targeting signal |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 1231_1270 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 728_754 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 1231_1270 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 728_754 | 2 | 1227.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 1231_1270 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 728_754 | 2 | 1313.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 1095_1101 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 1271_1303 | 2 | 1227.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 154_159 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 268_567 | 2 | 1227.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 1095_1101 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 1271_1303 | 2 | 1227.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 154_159 | 2 | 1227.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 268_567 | 2 | 1227.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 1095_1101 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 1271_1303 | 2 | 1313.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 154_159 | 2 | 1313.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 268_567 | 2 | 1313.0 | Compositional bias | Note=Glu-rich |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 306_398 | 2 | 1227.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 306_398 | 2 | 1227.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 306_398 | 2 | 1313.0 | Domain | ARID |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000264183 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 1130_1137 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000349213 | - | 2 | 23 | 465_473 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490228 | chr1:231401038 | ENST00000366603 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000264183 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 1130_1137 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000349213 | - | 2 | 23 | 465_473 | 2 | 1227.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 1130_1137 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Hgene | ARID4B | chr1:235490229 | chr1:231401039 | ENST00000366603 | - | 2 | 24 | 465_473 | 2 | 1313.0 | Region | Note=Antigenic epitope |
| Tgene | GNPAT | chr1:235490228 | chr1:231401038 | ENST00000366647 | 3 | 16 | 3_9 | 189 | 681.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GNPAT | chr1:235490229 | chr1:231401039 | ENST00000366647 | 3 | 16 | 3_9 | 189 | 681.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GNPAT | chr1:235490228 | chr1:231401038 | ENST00000366647 | 3 | 16 | 162_167 | 189 | 681.0 | Motif | Note=HXXXXD motif | |
| Tgene | GNPAT | chr1:235490229 | chr1:231401039 | ENST00000366647 | 3 | 16 | 162_167 | 189 | 681.0 | Motif | Note=HXXXXD motif |
Top |
Fusion Gene Sequence for ARID4B-GNPAT |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6474_6474_1_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000264183_GNPAT_chr1_231401038_ENST00000366646_length(transcript)=2028nt_BP=504nt AAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGAGG GAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTCCT CTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCGGC CGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTCCC CATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAAGG TGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTAC GAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTAC GGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATA TTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTC TTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTG GAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAA GATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGG TTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGC TAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGC ATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGC ACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGA CACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACA CACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAG GAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAG AGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATG TATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATAT TTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAAT AATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCG >6474_6474_1_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000264183_GNPAT_chr1_231401038_ENST00000366646_length(amino acids)=489AA_BP= MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_2_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000264183_GNPAT_chr1_231401038_ENST00000366647_length(transcript)=2410nt_BP=504nt AAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGAGG GAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTCCT CTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCGGC CGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTCCC CATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAAGG TGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTAC GAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTAC GGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATA TTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTC TTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTG GAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAA GATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGG TTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGC TAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGC ATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGC ACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGA CACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACA CACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAG GAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAG AGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATG TATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATAT TTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAAT AATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCGAAGGACTCATTACAACAAACAGGGAAGTAAAGGAAGAGACAC ATCCTCTCATACTCCCTGAGACTCTGAGAACAGTGGACGCAGAGGGAAGAGATGATCATTGGAAGCAATCAGTTTACTCTTCCCCACCAC AGTGGTTAAAAGGCGTTTGTATCTGACACTATGTGTGTGTTTTAAAATAAACTTTTGGAAACATGTTTGGAAAAGCAAAGCTCAGCTCAT TTCACTAACACTTTTCAGCTTACTATATGTATTAAACTTTTATGTTGACTTTTGAATTAAAGTATGACAACACTGAAAGCTCTGGATATT AAAAGAAAATGAAAAGGGCATATCTACGTTACTTGTAGCTTGCTTTAATTAAAGTTGCCTCAAACAAGTA >6474_6474_2_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000264183_GNPAT_chr1_231401038_ENST00000366647_length(amino acids)=489AA_BP= MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_3_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000349213_GNPAT_chr1_231401038_ENST00000366646_length(transcript)=2030nt_BP=506nt AGAAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGA GGGAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTC CTCTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCG GCCGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTC CCCATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAA GGTGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCT ACGAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTT ACGGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAA TATTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAAC TCTTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTT TGGAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCC AAGATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACAT GGTTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATG GCTAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCT GCATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCA GCACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGAT GACACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAA CACACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAA AGGAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGA AGAGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGA TGTATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTAT ATTTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTA ATAATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCG >6474_6474_3_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000349213_GNPAT_chr1_231401038_ENST00000366646_length(amino acids)=489AA_BP= MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_4_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000349213_GNPAT_chr1_231401038_ENST00000366647_length(transcript)=2412nt_BP=506nt AGAAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGA GGGAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTC CTCTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCG GCCGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTC CCCATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAA GGTGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCT ACGAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTT ACGGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAA TATTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAAC TCTTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTT TGGAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCC AAGATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACAT GGTTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATG GCTAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCT GCATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCA GCACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGAT GACACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAA CACACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAA AGGAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGA AGAGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGA TGTATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTAT ATTTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTA ATAATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCGAAGGACTCATTACAACAAACAGGGAAGTAAAGGAAGAGAC ACATCCTCTCATACTCCCTGAGACTCTGAGAACAGTGGACGCAGAGGGAAGAGATGATCATTGGAAGCAATCAGTTTACTCTTCCCCACC ACAGTGGTTAAAAGGCGTTTGTATCTGACACTATGTGTGTGTTTTAAAATAAACTTTTGGAAACATGTTTGGAAAAGCAAAGCTCAGCTC ATTTCACTAACACTTTTCAGCTTACTATATGTATTAAACTTTTATGTTGACTTTTGAATTAAAGTATGACAACACTGAAAGCTCTGGATA TTAAAAGAAAATGAAAAGGGCATATCTACGTTACTTGTAGCTTGCTTTAATTAAAGTTGCCTCAAACAAGTA >6474_6474_4_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000349213_GNPAT_chr1_231401038_ENST00000366647_length(amino acids)=489AA_BP= MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_5_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000366603_GNPAT_chr1_231401038_ENST00000366646_length(transcript)=1907nt_BP=383nt GGCGGGGCCAGATGTTGATCTCGCTCCCACTTGTCGGGTCTGAGCCCGGAACGGGACGTGGGCAGGGGCTCTGTGGCGGGCCGGTCCTGC CCGCGGCCCACAGGCCCTCCTGGCCCCTCGGTGGCCCCCGGCCGGCCTCTCGCTCGGACGCGGCGCGTGGGGGCGCGGATTCGCTCGGCC GGGCGCCGAGGCCCTAGGGGAGAGCGGCCGGCCCTGCGCCGGACGCCGGGCTTGTTGTGAGTTTCTTCTCTGACAGAAATGGCGTCATTG TCGTAGACGGGAAACTCCGTCGGGTCTCGACAATGGGGACGGGAAGCTGCCGAGCTGTGTGCAGCTGAACCTGGTGTTTTAGAGGATACC TTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTACGAATGTCGGGTGCCTTTTTCATGCGGCGTAC CTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTACGGAATGGTTATGCTCCTGTTGAATTTTTCCT CGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATATTGTGATGGAGCCATTTTTTAAAAGAGAAGT TTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTCTTTATGTGTATGAGCTTCTAGGGGTTCCTAA ACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTGGAAGCATCCATGTGTACTTTGGAGATCCTGT GTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAAGATACATTCCTCAGAAACAGTCTGAGGACAT GCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGGTTTTGAGCCCCTGGACCCTAATAGTTGCTGT TCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGCTAAAAGGCTTAACCCAGGCATTTGGAGGGTT TCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGCATTCCAACATTGCCAGCCTTGTCAAAGACCA GGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGCACATCACTCTCCTCATGTGCTCAGCTTATAG GAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGACACCAGGGTTCAGGAAAGAGGATGTCTACAG TTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACACACTAAAGGACTTTGAAGAAGGCTGTTACCT GCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAGGAAATACTGTGTTAGAATTTTTAGTAGGACT CTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAGAGGACCACTTCAGTGAGGAACAGTACTTGGC TGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATGTATTATCTTCTGATGTGCAGAAAAACGCCTT AGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATATTTAATGTGAATGAACCTGCCACAACCAAATT AGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAATAATCAACAAATAGTTATGGAAAATTCGGTCA CGTAATTACTCTCATCG >6474_6474_5_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000366603_GNPAT_chr1_231401038_ENST00000366646_length(amino acids)=489AA_BP= MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_6_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000366603_GNPAT_chr1_231401038_ENST00000366647_length(transcript)=2289nt_BP=383nt GGCGGGGCCAGATGTTGATCTCGCTCCCACTTGTCGGGTCTGAGCCCGGAACGGGACGTGGGCAGGGGCTCTGTGGCGGGCCGGTCCTGC CCGCGGCCCACAGGCCCTCCTGGCCCCTCGGTGGCCCCCGGCCGGCCTCTCGCTCGGACGCGGCGCGTGGGGGCGCGGATTCGCTCGGCC GGGCGCCGAGGCCCTAGGGGAGAGCGGCCGGCCCTGCGCCGGACGCCGGGCTTGTTGTGAGTTTCTTCTCTGACAGAAATGGCGTCATTG TCGTAGACGGGAAACTCCGTCGGGTCTCGACAATGGGGACGGGAAGCTGCCGAGCTGTGTGCAGCTGAACCTGGTGTTTTAGAGGATACC TTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTACGAATGTCGGGTGCCTTTTTCATGCGGCGTAC CTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTACGGAATGGTTATGCTCCTGTTGAATTTTTCCT CGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATATTGTGATGGAGCCATTTTTTAAAAGAGAAGT TTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTCTTTATGTGTATGAGCTTCTAGGGGTTCCTAA ACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTGGAAGCATCCATGTGTACTTTGGAGATCCTGT GTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAAGATACATTCCTCAGAAACAGTCTGAGGACAT GCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGGTTTTGAGCCCCTGGACCCTAATAGTTGCTGT TCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGCTAAAAGGCTTAACCCAGGCATTTGGAGGGTT TCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGCATTCCAACATTGCCAGCCTTGTCAAAGACCA GGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGCACATCACTCTCCTCATGTGCTCAGCTTATAG GAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGACACCAGGGTTCAGGAAAGAGGATGTCTACAG TTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACACACTAAAGGACTTTGAAGAAGGCTGTTACCT GCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAGGAAATACTGTGTTAGAATTTTTAGTAGGACT CTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAGAGGACCACTTCAGTGAGGAACAGTACTTGGC TGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATGTATTATCTTCTGATGTGCAGAAAAACGCCTT AGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATATTTAATGTGAATGAACCTGCCACAACCAAATT AGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAATAATCAACAAATAGTTATGGAAAATTCGGTCA CGTAATTACTCTCATCGAAGGACTCATTACAACAAACAGGGAAGTAAAGGAAGAGACACATCCTCTCATACTCCCTGAGACTCTGAGAAC AGTGGACGCAGAGGGAAGAGATGATCATTGGAAGCAATCAGTTTACTCTTCCCCACCACAGTGGTTAAAAGGCGTTTGTATCTGACACTA TGTGTGTGTTTTAAAATAAACTTTTGGAAACATGTTTGGAAAAGCAAAGCTCAGCTCATTTCACTAACACTTTTCAGCTTACTATATGTA TTAAACTTTTATGTTGACTTTTGAATTAAAGTATGACAACACTGAAAGCTCTGGATATTAAAAGAAAATGAAAAGGGCATATCTACGTTA CTTGTAGCTTGCTTTAATTAAAGTTGCCTCAAACAAGTA >6474_6474_6_ARID4B-GNPAT_ARID4B_chr1_235490228_ENST00000366603_GNPAT_chr1_231401038_ENST00000366647_length(amino acids)=489AA_BP= MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_7_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000264183_GNPAT_chr1_231401039_ENST00000366646_length(transcript)=2028nt_BP=504nt AAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGAGG GAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTCCT CTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCGGC CGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTCCC CATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAAGG TGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTAC GAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTAC GGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATA TTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTC TTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTG GAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAA GATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGG TTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGC TAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGC ATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGC ACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGA CACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACA CACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAG GAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAG AGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATG TATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATAT TTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAAT AATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCG >6474_6474_7_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000264183_GNPAT_chr1_231401039_ENST00000366646_length(amino acids)=489AA_BP=1 MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_8_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000264183_GNPAT_chr1_231401039_ENST00000366647_length(transcript)=2410nt_BP=504nt AAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGAGG GAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTCCT CTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCGGC CGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTCCC CATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAAGG TGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTAC GAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTAC GGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATA TTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTC TTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTG GAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAA GATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGG TTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGC TAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGC ATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGC ACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGA CACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACA CACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAG GAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAG AGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATG TATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATAT TTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAAT AATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCGAAGGACTCATTACAACAAACAGGGAAGTAAAGGAAGAGACAC ATCCTCTCATACTCCCTGAGACTCTGAGAACAGTGGACGCAGAGGGAAGAGATGATCATTGGAAGCAATCAGTTTACTCTTCCCCACCAC AGTGGTTAAAAGGCGTTTGTATCTGACACTATGTGTGTGTTTTAAAATAAACTTTTGGAAACATGTTTGGAAAAGCAAAGCTCAGCTCAT TTCACTAACACTTTTCAGCTTACTATATGTATTAAACTTTTATGTTGACTTTTGAATTAAAGTATGACAACACTGAAAGCTCTGGATATT AAAAGAAAATGAAAAGGGCATATCTACGTTACTTGTAGCTTGCTTTAATTAAAGTTGCCTCAAACAAGTA >6474_6474_8_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000264183_GNPAT_chr1_231401039_ENST00000366647_length(amino acids)=489AA_BP=1 MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_9_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000349213_GNPAT_chr1_231401039_ENST00000366646_length(transcript)=2030nt_BP=506nt AGAAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGA GGGAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTC CTCTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCG GCCGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTC CCCATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAA GGTGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCT ACGAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTT ACGGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAA TATTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAAC TCTTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTT TGGAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCC AAGATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACAT GGTTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATG GCTAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCT GCATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCA GCACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGAT GACACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAA CACACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAA AGGAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGA AGAGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGA TGTATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTAT ATTTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTA ATAATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCG >6474_6474_9_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000349213_GNPAT_chr1_231401039_ENST00000366646_length(amino acids)=489AA_BP=1 MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_10_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000349213_GNPAT_chr1_231401039_ENST00000366647_length(transcript)=2412nt_BP=506nt AGAAAGGGGGGGAACCTAGAGTCGGTGGGGGGGAAGCGATGTTTGCCCGTCAGTCGAGTCCGGAGTGAGGAGCTCGGTCGCCGAAGCGGA GGGAGACTCTTGAGCTTCATCTTGCCGCCGCCACGGCCACCGCCTGGACCTTTGCCCGGAGGGAGCTGCAGAGGGTCCATCGCCGCCGTC CTCTGGAGGGCAGCGCGATTGGGGGCCCGGACCTCCAGTCCGGGGGGGATTTTTCGTCGTCCCCCTCCCCCCAACCAGGGAGCCCGAGCG GCCGCCAAACAAAGGTACCAGTCGCCGCCGCGGGAGGAGGAGGAGCCGGAGCCTCTGCCTCAGCAGCCGCTGGACCCGCCGCCCTTCTTC CCCATCTCTCCCCCGGGCCTGCTGGTTTTGGGGGGGAGAAGGAGAGAGGGGACTCTGGACGTGCCAGGGTCAGATCTCGCCTCCGAGGAA GGTGCAGCTGAACCTGGTGTTTTAGAGGATACCTTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCT ACGAATGTCGGGTGCCTTTTTCATGCGGCGTACCTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTT ACGGAATGGTTATGCTCCTGTTGAATTTTTCCTCGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAA TATTGTGATGGAGCCATTTTTTAAAAGAGAAGTTTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAAC TCTTTATGTGTATGAGCTTCTAGGGGTTCCTAAACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTT TGGAAGCATCCATGTGTACTTTGGAGATCCTGTGTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCC AAGATACATTCCTCAGAAACAGTCTGAGGACATGCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACAT GGTTTTGAGCCCCTGGACCCTAATAGTTGCTGTTCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATG GCTAAAAGGCTTAACCCAGGCATTTGGAGGGTTTCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCT GCATTCCAACATTGCCAGCCTTGTCAAAGACCAGGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCA GCACATCACTCTCCTCATGTGCTCAGCTTATAGGAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGAT GACACCAGGGTTCAGGAAAGAGGATGTCTACAGTTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAA CACACTAAAGGACTTTGAAGAAGGCTGTTACCTGCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAA AGGAAATACTGTGTTAGAATTTTTAGTAGGACTCTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGA AGAGGACCACTTCAGTGAGGAACAGTACTTGGCTGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGA TGTATTATCTTCTGATGTGCAGAAAAACGCCTTAGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTAT ATTTAATGTGAATGAACCTGCCACAACCAAATTAGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTA ATAATCAACAAATAGTTATGGAAAATTCGGTCACGTAATTACTCTCATCGAAGGACTCATTACAACAAACAGGGAAGTAAAGGAAGAGAC ACATCCTCTCATACTCCCTGAGACTCTGAGAACAGTGGACGCAGAGGGAAGAGATGATCATTGGAAGCAATCAGTTTACTCTTCCCCACC ACAGTGGTTAAAAGGCGTTTGTATCTGACACTATGTGTGTGTTTTAAAATAAACTTTTGGAAACATGTTTGGAAAAGCAAAGCTCAGCTC ATTTCACTAACACTTTTCAGCTTACTATATGTATTAAACTTTTATGTTGACTTTTGAATTAAAGTATGACAACACTGAAAGCTCTGGATA TTAAAAGAAAATGAAAAGGGCATATCTACGTTACTTGTAGCTTGCTTTAATTAAAGTTGCCTCAAACAAGTA >6474_6474_10_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000349213_GNPAT_chr1_231401039_ENST00000366647_length(amino acids)=489AA_BP=1 MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_11_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000366603_GNPAT_chr1_231401039_ENST00000366646_length(transcript)=1907nt_BP=383nt GGCGGGGCCAGATGTTGATCTCGCTCCCACTTGTCGGGTCTGAGCCCGGAACGGGACGTGGGCAGGGGCTCTGTGGCGGGCCGGTCCTGC CCGCGGCCCACAGGCCCTCCTGGCCCCTCGGTGGCCCCCGGCCGGCCTCTCGCTCGGACGCGGCGCGTGGGGGCGCGGATTCGCTCGGCC GGGCGCCGAGGCCCTAGGGGAGAGCGGCCGGCCCTGCGCCGGACGCCGGGCTTGTTGTGAGTTTCTTCTCTGACAGAAATGGCGTCATTG TCGTAGACGGGAAACTCCGTCGGGTCTCGACAATGGGGACGGGAAGCTGCCGAGCTGTGTGCAGCTGAACCTGGTGTTTTAGAGGATACC TTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTACGAATGTCGGGTGCCTTTTTCATGCGGCGTAC CTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTACGGAATGGTTATGCTCCTGTTGAATTTTTCCT CGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATATTGTGATGGAGCCATTTTTTAAAAGAGAAGT TTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTCTTTATGTGTATGAGCTTCTAGGGGTTCCTAA ACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTGGAAGCATCCATGTGTACTTTGGAGATCCTGT GTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAAGATACATTCCTCAGAAACAGTCTGAGGACAT GCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGGTTTTGAGCCCCTGGACCCTAATAGTTGCTGT TCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGCTAAAAGGCTTAACCCAGGCATTTGGAGGGTT TCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGCATTCCAACATTGCCAGCCTTGTCAAAGACCA GGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGCACATCACTCTCCTCATGTGCTCAGCTTATAG GAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGACACCAGGGTTCAGGAAAGAGGATGTCTACAG TTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACACACTAAAGGACTTTGAAGAAGGCTGTTACCT GCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAGGAAATACTGTGTTAGAATTTTTAGTAGGACT CTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAGAGGACCACTTCAGTGAGGAACAGTACTTGGC TGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATGTATTATCTTCTGATGTGCAGAAAAACGCCTT AGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATATTTAATGTGAATGAACCTGCCACAACCAAATT AGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAATAATCAACAAATAGTTATGGAAAATTCGGTCA CGTAATTACTCTCATCG >6474_6474_11_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000366603_GNPAT_chr1_231401039_ENST00000366646_length(amino acids)=489AA_BP=1 MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- >6474_6474_12_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000366603_GNPAT_chr1_231401039_ENST00000366647_length(transcript)=2289nt_BP=383nt GGCGGGGCCAGATGTTGATCTCGCTCCCACTTGTCGGGTCTGAGCCCGGAACGGGACGTGGGCAGGGGCTCTGTGGCGGGCCGGTCCTGC CCGCGGCCCACAGGCCCTCCTGGCCCCTCGGTGGCCCCCGGCCGGCCTCTCGCTCGGACGCGGCGCGTGGGGGCGCGGATTCGCTCGGCC GGGCGCCGAGGCCCTAGGGGAGAGCGGCCGGCCCTGCGCCGGACGCCGGGCTTGTTGTGAGTTTCTTCTCTGACAGAAATGGCGTCATTG TCGTAGACGGGAAACTCCGTCGGGTCTCGACAATGGGGACGGGAAGCTGCCGAGCTGTGTGCAGCTGAACCTGGTGTTTTAGAGGATACC TTGGTCCCAGAGTCATCATGAAGACTTCCTGGGAATGAAAATGGTTGGTGAGCTGCTACGAATGTCGGGTGCCTTTTTCATGCGGCGTAC CTTTGGTGGCAATAAACTCTACTGGGCTGTATTCTCTGAATATGTAAAAACTATGTTACGGAATGGTTATGCTCCTGTTGAATTTTTCCT CGAAGGGACAAGAAGCCGCTCTGCCAAGACATTGACTCCTAAATTTGGTCTTCTGAATATTGTGATGGAGCCATTTTTTAAAAGAGAAGT TTTTGATACCTACCTTGTCCCAATTAGTATCAGTTATGATAAGATCTTGGAAGAAACTCTTTATGTGTATGAGCTTCTAGGGGTTCCTAA ACCAAAAGAGTCTACAACTGGGTTGCTGAAAGCCAGAAAGATTCTCTCTGAAAATTTTGGAAGCATCCATGTGTACTTTGGAGATCCTGT GTCACTTCGATCTTTGGCAGCTGGGAGGATGAGTCGGAGCTCATATAACTTGGTTCCAAGATACATTCCTCAGAAACAGTCTGAGGACAT GCATGCCTTTGTCACTGAAGTTGCCTACAAAATGGAGCTTCTGCAAATTGAAAACATGGTTTTGAGCCCCTGGACCCTAATAGTTGCTGT TCTGCTTCAGAACCGGCCATCCATGGACTTTGATGCTCTGGTGGAAAAGACTTTATGGCTAAAAGGCTTAACCCAGGCATTTGGAGGGTT TCTCATTTGGCCTGATAATAAACCTGCTGAAGAAGTTGTCCCGGCCAGCATTCTTCTGCATTCCAACATTGCCAGCCTTGTCAAAGACCA GGTGATTCTGAAAGTGGACTCCGGAGACTCGGAAGTGGTCGATGGGCTTATGCTCCAGCACATCACTCTCCTCATGTGCTCAGCTTATAG GAACCAGCTGCTCAACATTTTTGTGCGCCCATCCTTAGTAGCAGTAGCATTGCAGATGACACCAGGGTTCAGGAAAGAGGATGTCTACAG TTGCTTTCGCTTCCTACGTGATGTTTTTGCAGATGAGTTCATCTTCCTTCCAGGAAACACACTAAAGGACTTTGAAGAAGGCTGTTACCT GCTTTGTAAAAGTGAAGCCATACAAGTGACTACGAAAGACATCCTAGTTACAGAGAAAGGAAATACTGTGTTAGAATTTTTAGTAGGACT CTTTAAACCTTTTGTGGAAAGCTATCAGATAATTTGCAAGTACCTTTTGAGTGAAGAAGAGGACCACTTCAGTGAGGAACAGTACTTGGC TGCAGTCAGAAAATTCACAAGTCAGCTTCTCGATCAAGGTACCTCTCAATGTTATGATGTATTATCTTCTGATGTGCAGAAAAACGCCTT AGCAGCCTGTGTGAGGCTCGGAGTAGTGGAGAAGAAGAAGATAAATAATAACTGTATATTTAATGTGAATGAACCTGCCACAACCAAATT AGAAGAAATGCTTGGTTGTAAGACACCAATAGGAAAACCAGCCACTGCAAAACTTTAATAATCAACAAATAGTTATGGAAAATTCGGTCA CGTAATTACTCTCATCGAAGGACTCATTACAACAAACAGGGAAGTAAAGGAAGAGACACATCCTCTCATACTCCCTGAGACTCTGAGAAC AGTGGACGCAGAGGGAAGAGATGATCATTGGAAGCAATCAGTTTACTCTTCCCCACCACAGTGGTTAAAAGGCGTTTGTATCTGACACTA TGTGTGTGTTTTAAAATAAACTTTTGGAAACATGTTTGGAAAAGCAAAGCTCAGCTCATTTCACTAACACTTTTCAGCTTACTATATGTA TTAAACTTTTATGTTGACTTTTGAATTAAAGTATGACAACACTGAAAGCTCTGGATATTAAAAGAAAATGAAAAGGGCATATCTACGTTA CTTGTAGCTTGCTTTAATTAAAGTTGCCTCAAACAAGTA >6474_6474_12_ARID4B-GNPAT_ARID4B_chr1_235490229_ENST00000366603_GNPAT_chr1_231401039_ENST00000366647_length(amino acids)=489AA_BP=1 MGMKMVGELLRMSGAFFMRRTFGGNKLYWAVFSEYVKTMLRNGYAPVEFFLEGTRSRSAKTLTPKFGLLNIVMEPFFKREVFDTYLVPIS ISYDKILEETLYVYELLGVPKPKESTTGLLKARKILSENFGSIHVYFGDPVSLRSLAAGRMSRSSYNLVPRYIPQKQSEDMHAFVTEVAY KMELLQIENMVLSPWTLIVAVLLQNRPSMDFDALVEKTLWLKGLTQAFGGFLIWPDNKPAEEVVPASILLHSNIASLVKDQVILKVDSGD SEVVDGLMLQHITLLMCSAYRNQLLNIFVRPSLVAVALQMTPGFRKEDVYSCFRFLRDVFADEFIFLPGNTLKDFEEGCYLLCKSEAIQV TTKDILVTEKGNTVLEFLVGLFKPFVESYQIICKYLLSEEEDHFSEEQYLAAVRKFTSQLLDQGTSQCYDVLSSDVQKNALAACVRLGVV EKKKINNNCIFNVNEPATTKLEEMLGCKTPIGKPATAKL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARID4B-GNPAT |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARID4B-GNPAT |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARID4B-GNPAT |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ARID4B | C0010606 | Adenoid Cystic Carcinoma | 1 | CTD_human |
| Tgene | C1857242 | Rhizomelic chondrodysplasia punctata, type 2 | 5 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT | |
| Tgene | C0036341 | Schizophrenia | 1 | PSYGENET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies