
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ANO1-CDC42BPG (FusionGDB2 ID:HG55107TG55561) |
Fusion Gene Summary for ANO1-CDC42BPG |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ANO1-CDC42BPG | Fusion gene ID: hg55107tg55561 | Hgene | Tgene | Gene symbol | ANO1 | CDC42BPG | Gene ID | 55107 | 55561 |
| Gene name | anoctamin 1 | CDC42 binding protein kinase gamma | |
| Synonyms | DOG1|ORAOV2|TAOS2|TMEM16A | DMPK2|HSMDPKIN|KAPPA-200|MRCKG|MRCKgamma | |
| Cytomap | ('ANO1')('CDC42BPG') 11q13.3 | 11q13.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | anoctamin-1Ca2+-activated Cl- channelanoctamin 1, calcium activated chloride channelcalcium activated chloride channeldiscovered on gastrointestinal stromal tumors protein 1oral cancer overexpressed 2transmembrane protein 16A (eight membrane-spannin | serine/threonine-protein kinase MRCK gammaCDC42 binding protein kinase gamma (DMPK-like)DMPK-like gammaMRCK gammamyotonic dystrophy kinase-related CDC42-binding kinase gammamyotonic dystrophy protein kinase like proteinmyotonic dystrophy protein kin | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000316296, ENST00000355303, ENST00000398543, ENST00000530676, ENST00000538023, ENST00000525494, ENST00000531349, | ||
| Fusion gene scores | * DoF score | 20 X 18 X 9=3240 | 5 X 5 X 5=125 |
| # samples | 20 | 5 | |
| ** MAII score | log2(20/3240*10)=-4.01792190799726 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/125*10)=-1.32192809488736 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ANO1 [Title/Abstract] AND CDC42BPG [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ANO1(69951894)-CDC42BPG(64606374), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ANO1-CDC42BPG seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ANO1-CDC42BPG seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ANO1-CDC42BPG seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ANO1-CDC42BPG seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ANO1 | GO:0006812 | cation transport | 22946059 |
| Tgene | CDC42BPG | GO:0006468 | protein phosphorylation | 15194684 |
| Fusion gene breakpoints across ANO1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CDC42BPG (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | TGCT | TCGA-2G-AAGP-01A | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
Top |
Fusion Gene ORF analysis for ANO1-CDC42BPG |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000316296 | ENST00000491280 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| 5CDS-intron | ENST00000355303 | ENST00000491280 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| 5CDS-intron | ENST00000398543 | ENST00000491280 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| 5CDS-intron | ENST00000530676 | ENST00000491280 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| 5CDS-intron | ENST00000538023 | ENST00000491280 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| In-frame | ENST00000316296 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| In-frame | ENST00000355303 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| In-frame | ENST00000398543 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| In-frame | ENST00000530676 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| In-frame | ENST00000538023 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| intron-3CDS | ENST00000525494 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| intron-3CDS | ENST00000531349 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| intron-intron | ENST00000525494 | ENST00000491280 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| intron-intron | ENST00000531349 | ENST00000491280 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000355303 | ANO1 | chr11 | 69951894 | - | ENST00000342711 | CDC42BPG | chr11 | 64606374 | - | 5918 | 1052 | 221 | 4831 | 1536 |
| ENST00000398543 | ANO1 | chr11 | 69951894 | - | ENST00000342711 | CDC42BPG | chr11 | 64606374 | - | 5662 | 796 | 49 | 4575 | 1508 |
| ENST00000538023 | ANO1 | chr11 | 69951894 | - | ENST00000342711 | CDC42BPG | chr11 | 64606374 | - | 5662 | 796 | 49 | 4575 | 1508 |
| ENST00000316296 | ANO1 | chr11 | 69951894 | - | ENST00000342711 | CDC42BPG | chr11 | 64606374 | - | 5634 | 768 | 105 | 4547 | 1480 |
| ENST00000530676 | ANO1 | chr11 | 69951894 | - | ENST00000342711 | CDC42BPG | chr11 | 64606374 | - | 5754 | 888 | 249 | 4667 | 1472 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000355303 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - | 0.004933232 | 0.99506676 |
| ENST00000398543 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - | 0.003783811 | 0.99621624 |
| ENST00000538023 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - | 0.003783811 | 0.99621624 |
| ENST00000316296 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - | 0.004074206 | 0.9959258 |
| ENST00000530676 | ENST00000342711 | ANO1 | chr11 | 69951894 | - | CDC42BPG | chr11 | 64606374 | - | 0.00577666 | 0.9942233 |
Top |
Fusion Genomic Features for ANO1-CDC42BPG |
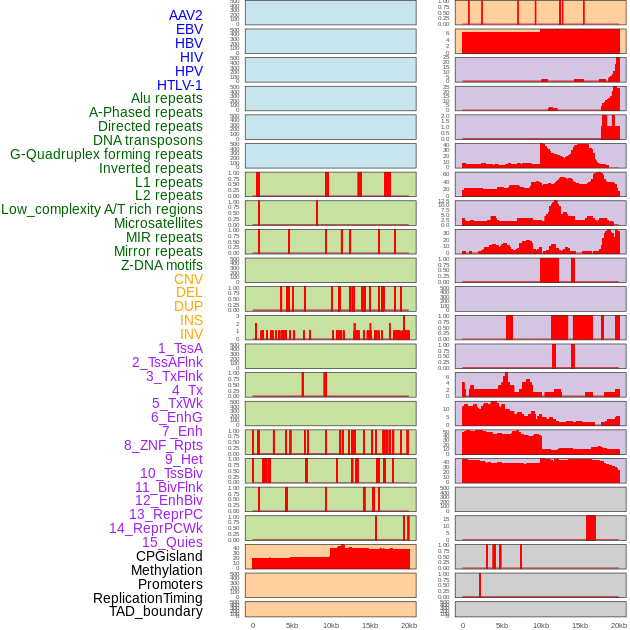
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for ANO1-CDC42BPG |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:69951894/chr11:64606374) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 406_678 | 292 | 1552.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 730_802 | 292 | 1552.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 1092_1366 | 292 | 1552.0 | Domain | CNH | |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 1437_1450 | 292 | 1552.0 | Domain | CRIB | |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 338_408 | 292 | 1552.0 | Domain | AGC-kinase C-terminal | |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 947_1066 | 292 | 1552.0 | Domain | PH | |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 878_927 | 292 | 1552.0 | Zinc finger | Phorbol-ester/DAG-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 1_333 | 221 | 643.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 355_406 | 221 | 643.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 428_519 | 221 | 643.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 541_568 | 221 | 643.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 590_607 | 221 | 643.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 629_657 | 221 | 643.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 679_725 | 221 | 643.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 768_784 | 221 | 643.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 806_892 | 221 | 643.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 914_986 | 221 | 643.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 1_333 | 249 | 987.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 355_406 | 249 | 987.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 428_519 | 249 | 987.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 541_568 | 249 | 987.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 590_607 | 249 | 987.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 629_657 | 249 | 987.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 679_725 | 249 | 987.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 768_784 | 249 | 987.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 806_892 | 249 | 987.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 914_986 | 249 | 987.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 1_333 | 133 | 841.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 355_406 | 133 | 841.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 428_519 | 133 | 841.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 541_568 | 133 | 841.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 590_607 | 133 | 841.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 629_657 | 133 | 841.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 679_725 | 133 | 841.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 768_784 | 133 | 841.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 806_892 | 133 | 841.0 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 914_986 | 133 | 841.0 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 1_333 | 133 | 819.3333333333334 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 355_406 | 133 | 819.3333333333334 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 428_519 | 133 | 819.3333333333334 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 541_568 | 133 | 819.3333333333334 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 590_607 | 133 | 819.3333333333334 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 629_657 | 133 | 819.3333333333334 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 679_725 | 133 | 819.3333333333334 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 768_784 | 133 | 819.3333333333334 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 806_892 | 133 | 819.3333333333334 | Topological domain | Extracellular |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 914_986 | 133 | 819.3333333333334 | Topological domain | Cytoplasmic |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 334_354 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 407_427 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 520_540 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 569_589 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 608_628 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 658_678 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 726_746 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 747_767 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 785_805 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000316296 | - | 5 | 17 | 893_913 | 221 | 643.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 334_354 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 407_427 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 520_540 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 569_589 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 608_628 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 658_678 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 726_746 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 747_767 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 785_805 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000355303 | - | 5 | 26 | 893_913 | 249 | 987.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 334_354 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 407_427 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 520_540 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 569_589 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 608_628 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 658_678 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 726_746 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 747_767 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 785_805 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000398543 | - | 5 | 24 | 893_913 | 133 | 841.0 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 334_354 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 407_427 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 520_540 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 569_589 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 608_628 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 658_678 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 726_746 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 747_767 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 785_805 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Hgene | ANO1 | chr11:69951894 | chr11:64606374 | ENST00000530676 | - | 5 | 25 | 893_913 | 133 | 819.3333333333334 | Transmembrane | Helical |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 71_337 | 292 | 1552.0 | Domain | Protein kinase | |
| Tgene | CDC42BPG | chr11:69951894 | chr11:64606374 | ENST00000342711 | 6 | 37 | 77_85 | 292 | 1552.0 | Nucleotide binding | ATP |
Top |
Fusion Gene Sequence for ANO1-CDC42BPG |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >4847_4847_1_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000316296_CDC42BPG_chr11_64606374_ENST00000342711_length(transcript)=5634nt_BP=768nt ACGCACACTGAGTCCAGGTCCTCCTGAAGGTCACCAGCACAGCGGGGCCCTGTGTTACTGTAGAGAGAAGTCAGTTGCTTAGTTTCAGCC TCCTGCCGGCACCAGATGCTGACCAGGCCCTCCCAGGTGCTGCTGAACTCCTTATCTGTGGACCCTGATGCCGAGTGCAAGTATGGCCTG TACTTCAGGGACGGCCGGCGCAAGGTGGACTACATCCTGGTGTACCATCACAAGAGGCCCTCGGGCAACCGGACCCTGGTCAGGAGGGTG CAGCACAGCGACACCCCCTCTGGGGCTCGCAGCGTCAAGCAGGACCACCCCCTGCCGGGCAAGGGGGCGTCGCTGGATGCAGGCTCGGGG GAGCCCCCGATGGACTACCACGAGGATGACAAGCGCTTCCGCAGGGAGGAGTACGAGGGCAACCTCCTGGAGGCGGGCCTGGAGCTGGAG CGGGACGAGGACACTAAAATCCACGGAGTCGGGTTTGTGAAAATCCATGCCCCCTGGAACGTGCTGTGCAGAGAGGCCGAGTTTCTGAAA CTGAAGATGCCGACGAAGAAGATGTACCACATTAATGAGACCCGTGGCCTCCTGAAAAAAATCAACTCTGTGCTCCAGAAAATCACAGAT CCCATCCAGCCCAAAGTGGCTGAGCACAGGCCCCAGACCATGAAGAGACTCTCCTATCCCTTCTCCCGGGAGAAGCAGCATCTATTTGAC TTGTCTGATAAGGATTCCTTTTTCGACAGCAAAACCCGGAGCACGATTGACCACCTGCAGTTCCCCCCGGACGTGCCTGACGTGCCAGCC AGCGCCCAAGACCTGATCCGCCAGCTGCTGTGTCGCCAGGAAGAGCGGCTAGGCCGTGGTGGGCTGGATGACTTCCGGAACCATCCTTTC TTCGAAGGCGTGGACTGGGAGCGGCTGGCGAGCAGCACGGCCCCCTATATTCCTGAGCTGCGGGGGCCCATGGACACCTCCAACTTTGAT GTGGATGACGACACCCTCAACCATCCAGGGACCCTGCCACCGCCCTCCCACGGGGCCTTCTCCGGCCATCACCTGCCATTCGTGGGCTTC ACCTACACCTCAGGCAGTCACAGTCCTGAGAGCAGCTCTGAGGCTTGGGCTGCCCTGGAGCGGAAGCTCCAGTGTCTGGAGCAGGAGAAG GTGGAGCTGAGCAGGAAGCACCAAGAGGCCCTGCACGCCCCCACAGACCATCGGGAGCTGGAGCAGCTACGGAAGGAAGTGCAGACTCTG CGGGACAGGCTGCCAGAGATGCTGAGGGACAAGGCCTCATTGTCCCAGACGGATGGGCCCCCAGCTGGTAGCCCAGGTCAGGACAGTGAC CTACGGCAGGAGCTTGACCGACTTCACCGGGAGCTGGCCGAGGGTCGGGCAGGGCTGCAGGCTCAGGAGCAGGAGCTCTGCAGGGCCCAG GGGCAGCAGGAGGAGCTGCTTCAGAGGCTACAGGAGGCCCAGGAGAGAGAGGCGGCCACAGCTAGCCAGACCCGGGCCCTGAGCTCCCAG CTGGAGGAAGCCCGGGCTGCCCAGAGGGAGCTGGAGGCCCAGGTGTCCTCCCTGAGCCGGCAGGTGACGCAGCTGCAGGGACAGTGGGAG CAACGCCTTGAGGAGTCGTCCCAGGCCAAGACCATCCACACAGCCTCTGAGACCAACGGGATGGGACCCCCTGAGGGTGGGCCTCAGGAG GCCCAACTGAGGAAGGAGGTGGCCGCCCTGCGAGAGCAGCTGGAGCAGGCCCACAGCCACAGGCCGAGTGGTAAGGAGGAGGCTCTGTGC CAGCTGCAGGAGGAAAACCGGAGGCTGAGCCGGGAGCAGGAGCGGCTAGAAGCAGAGCTGGCCCAGGAGCAGGAGAGCAAGCAGCGGCTG GAGGGTGAGCGGCGGGAGACGGAGAGCAACTGGGAGGCCCAGCTCGCCGACATCCTCAGCTGGGTGAATGATGAGAAGGTCTCAAGAGGC TACCTGCAGGCCCTGGCCACCAAGATGGCAGAGGAGCTGGAGTCCTTGAGGAACGTAGGCACCCAGACGCTCCCTGCCCGGCCACTGGAC CACCAGTGGAAGGCGCGGCGACTGCAGAAGATGGAGGCCTCGGCCAGGCTGGAGCTGCAGTCAGCGCTGGAGGCCGAGATCCGCGCCAAG CAGGGCCTGCAGGAGCGGCTGACACAGGTGCAGGAGGCCCAGCTGCAGGCTGAGCGCCGTCTGCAGGAGGCCGAGAAGCAGAGCCAGGCC CTGCAACAGGAGCTCGCCATGCTGCGGGAGGAGCTGCGGGCCCGAGGGCCAGTGGACACCAAGCCCTCAAACTCCCTGATTCCCTTCCTG TCCTTCCGGAGCTCAGAGAAGGATTCTGCCAAGGACCCTGGCATCTCAGGAGAGGCCACAAGGCATGGAGGAGAGCCAGATCTGAGGCCG GAGGGCCGACGCAGCCTGCGCATGGGGGCTGTGTTCCCCAGAGCACCCACTGCCAACACAGCCTCTACAGAAGGTCTTCCTGCTAAGCCC GGCTCACACACGCTGCGCCCCCGGAGCTTCCCATCCCCGACCAAGTGTCTCCGCTGCACCTCGCTGATGCTGGGCCTGGGCCGCCAGGGC CTGGGTTGTGATGCCTGCGGCTACTTTTGTCACACAACCTGTGCCCCACAGGCCCCACCCTGCCCCGTGCCCCCTGACCTCCTCCGCACA GCCCTGGGAGTACACCCCGAAACAGGCACAGGCACTGCCTATGAGGGCTTTCTGTCGGTGCCGCGGCCCTCAGGTGTCCGGCGGGGCTGG CAGCGCGTGTTTGCTGCCCTGAGTGACTCACGCCTGCTGCTGTTTGACGCCCCTGACCTGAGGCTCAGCCCGCCCAGTGGGGCCCTCCTG CAGGTCCTAGATCTGAGGGACCCCCAGTTCTCGGCTACCCCTGTCCTGGCCTCTGATGTTATCCATGCCCAATCCAGGGACCTGCCACGC ATCTTTAGGGTGACAACCTCCCAGCTGGCAGTGCCGCCCACCACGTGCACTGTGCTGCTGCTGGCAGAGAGCGAGGGGGAGCGGGAACGC TGGCTGCAGGTGCTGGGTGAGCTGCAGCGGCTGCTGCTGGACGCGCGGCCAAGACCCCGGCCCGTGTACACACTCAAGGAGGCTTACGAC AACGGGCTGCCGCTGCTGCCTCACACGCTCTGCGCTGCCATCCTCGACCAGGATCGACTTGCGCTTGGCACCGAGGAGGGGCTCTTTGTC ATCCATCTGCGCAGCAACGACATCTTCCAGGTGGGGGAGTGCCGGCGCGTGCAGCAGCTGACCTTGAGCCCCAGTGCAGGCCTGCTGGTC GTGCTGTGTGGCCGCGGCCCCAGCGTGCGTCTCTTTGCCCTGGCGGAGCTGGAGAACATAGAGGTAGCAGGTGCCAAGATCCCCGAGTCT CGAGGCTGCCAGGTGCTGGCAGCTGGAAGCATCCTGCAGGCCCGCACCCCGGTGCTCTGTGTAGCCGTCAAGCGCCAGGTGCTCTGCTAC CAGCTGGGCCCGGGCCCTGGGCCCTGGCAGCGCCGCATCCGTGAGCTGCAGGCACCTGCCACTGTGCAGAGCCTGGGGCTGCTGGGCGAC CGGCTATGTGTGGGCGCCGCCGGTGGCTTTGCACTCTACCCGCTGCTCAACGAGGCTGCGCCGTTGGCGCTGGGGGCCGGTTTGGTGCCT GAGGAGCTGCCACCATCCCGCGGGGGCCTGGGTGAGGCACTGGGTGCCGTGGAGCTTAGCCTCAGCGAGTTCCTGCTACTCTTCACCACT GCTGGCATCTACGTGGATGGCGCAGGCCGCAAGTCTCGTGGCCACGAGCTGTTGTGGCCAGCAGCGCCCATGGGCTGGGGGTATGCGGCC CCCTACCTGACAGTGTTCAGCGAGAACTCCATCGATGTGTTTGACGTGAGGAGGGCAGAATGGGTGCAGACCGTGCCGCTCAAGAAGGTG CGGCCCCTCAATCCAGAGGGCTCCCTGTTCCTCTACGGCACCGAGAAGGTCCGCCTGACCTACCTCAGGAACCAGCTGGCAGAGAAGGAC GAGTTCGACATCCCGGACCTCACCGACAACAGCCGGCGCCAGCTGTTCCGCACCAAGAGCAAGCGCCGCTTCTTTTTCCGCGTGTCGGAG GAGCAGCAGAAGCAGCAGCGCAGGGAGATGCTGAAGGACCCTTTTGTGCGCTCCAAGCTCATCTCGCCGCCTACCAACTTCAACCACCTA GTACACGTGGGCCCTGCCAACGGGCGGCCCGGCGCCAGGGACAAGTCCCCGGCTCCCGAAGAGAAGGGCCGAGTTGCCCGCGGCTCCGGC CCACAGCGGCCCCACAGCTTCTCCGAGGCGTTGCGGCGCCCAGCCTCCATGGGCAGCGAAGGCCTCGGTGGAGACGCAGACCCCATGAAG AGGAAACCCTGGACATCCCTGTCCAGCGAGTCTGTGTCCTGCCCCCAGGGATCGCTGAGCCCTGCAACCTCCCTAATGCAGGTCTCAGAA CGGCCCCGAAGCCTCCCCCTATCCCCTGAATTGGAGAGCTCTCCTTGATGCCCTCTGTTAGGGCCCACCCCAATCCCAGGGCAGAAGGAC ATGAGGGAGCAAAGAGCTTGAGGAATGCCATACTCCGGCTGGTCCGGGACATGGAAATTCGGACTCAGGGAGGACCCGGGCTGGGCAATG ACTGGGAGACTTGCCTGGGTTCCCAGGACTTGGGGGTCCTGACTCCCAGCCCTCATCCTGCCTTACCCCTCTGTTCCCAGCCCCAGCCTT TCTAAGCCATTGGGAATAGAATGGCCCCTTTTGTTCTGGTGTCCAGGGGTGATTGTGCCAAAGCTCTTATTTCCAGTGCCAAGCCCCCAG AGGCTTGTAAGAGTTGGGATGAGGGATGGAGAGGGACTGGGTCTCTGGGAACAGGTTGGAGGTCTTATCTGTGGACTGTCTGACTCCCAG CTGAGGCCAAGATGGGGCATGTCCCCGTCTCTGCTTAGCGTCTGGGTGAGAAAAACAGGCTGTGATCCAGAAGAAGGGAAGATAGAGAAG GAGGGAAAGGATGTAGGCGAAGGAGGTGAGAGACAGGATAGGAGGAAGGAAGTGGAGGAGGAGGTGATAGGAATTGGAAGGAGGTAGAAG CCGTGCAGAGGAAGAGGGGAGAGGGACGAAGGAGGAGCGATGAAGAAGAGGAGGGAGACAAAAAGAGGGATGGAGGAGAGAGGGAGTCTG GAGAACAAAGGGTCCTTTCTCTGGGGAGGGGTGCAGTGGGCGGGGCTGACACTGTCAGCCAATCCTCCCATCGGGGAAGAGAATCCTGGA CAGGGACAGGATGGGGAGGGTATTTATAAGGGCTTTTTGGTGGGAGATGGGTACCCAGTGGGGGCCACTGGAGGGTCTCCGGGCACACTC TGGCCCTTCCCAGAAAGGGGGTCGTTTTTCTCGAATCTTCAACCAGTTGTGTATTGGAAACTAGGGCGCATTTTACTATTGATCACAGTC ATTATATTGTTATTATATTACTATTTTTATTAAACCTCCCCCCACTGAAGTGTGGGGGGCAAAATAAGTATTTATCTCCTCAAATGCCAC ATTCCCAGGAGGGACAGACCCTGATGCTCTGTGAGGCGCAAGAAACCAATAAAG >4847_4847_1_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000316296_CDC42BPG_chr11_64606374_ENST00000342711_length(amino acids)=1480AA_BP=221 MLTRPSQVLLNSLSVDPDAECKYGLYFRDGRRKVDYILVYHHKRPSGNRTLVRRVQHSDTPSGARSVKQDHPLPGKGASLDAGSGEPPMD YHEDDKRFRREEYEGNLLEAGLELERDEDTKIHGVGFVKIHAPWNVLCREAEFLKLKMPTKKMYHINETRGLLKKINSVLQKITDPIQPK VAEHRPQTMKRLSYPFSREKQHLFDLSDKDSFFDSKTRSTIDHLQFPPDVPDVPASAQDLIRQLLCRQEERLGRGGLDDFRNHPFFEGVD WERLASSTAPYIPELRGPMDTSNFDVDDDTLNHPGTLPPPSHGAFSGHHLPFVGFTYTSGSHSPESSSEAWAALERKLQCLEQEKVELSR KHQEALHAPTDHRELEQLRKEVQTLRDRLPEMLRDKASLSQTDGPPAGSPGQDSDLRQELDRLHRELAEGRAGLQAQEQELCRAQGQQEE LLQRLQEAQEREAATASQTRALSSQLEEARAAQRELEAQVSSLSRQVTQLQGQWEQRLEESSQAKTIHTASETNGMGPPEGGPQEAQLRK EVAALREQLEQAHSHRPSGKEEALCQLQEENRRLSREQERLEAELAQEQESKQRLEGERRETESNWEAQLADILSWVNDEKVSRGYLQAL ATKMAEELESLRNVGTQTLPARPLDHQWKARRLQKMEASARLELQSALEAEIRAKQGLQERLTQVQEAQLQAERRLQEAEKQSQALQQEL AMLREELRARGPVDTKPSNSLIPFLSFRSSEKDSAKDPGISGEATRHGGEPDLRPEGRRSLRMGAVFPRAPTANTASTEGLPAKPGSHTL RPRSFPSPTKCLRCTSLMLGLGRQGLGCDACGYFCHTTCAPQAPPCPVPPDLLRTALGVHPETGTGTAYEGFLSVPRPSGVRRGWQRVFA ALSDSRLLLFDAPDLRLSPPSGALLQVLDLRDPQFSATPVLASDVIHAQSRDLPRIFRVTTSQLAVPPTTCTVLLLAESEGERERWLQVL GELQRLLLDARPRPRPVYTLKEAYDNGLPLLPHTLCAAILDQDRLALGTEEGLFVIHLRSNDIFQVGECRRVQQLTLSPSAGLLVVLCGR GPSVRLFALAELENIEVAGAKIPESRGCQVLAAGSILQARTPVLCVAVKRQVLCYQLGPGPGPWQRRIRELQAPATVQSLGLLGDRLCVG AAGGFALYPLLNEAAPLALGAGLVPEELPPSRGGLGEALGAVELSLSEFLLLFTTAGIYVDGAGRKSRGHELLWPAAPMGWGYAAPYLTV FSENSIDVFDVRRAEWVQTVPLKKVRPLNPEGSLFLYGTEKVRLTYLRNQLAEKDEFDIPDLTDNSRRQLFRTKSKRRFFFRVSEEQQKQ QRREMLKDPFVRSKLISPPTNFNHLVHVGPANGRPGARDKSPAPEEKGRVARGSGPQRPHSFSEALRRPASMGSEGLGGDADPMKRKPWT SLSSESVSCPQGSLSPATSLMQVSERPRSLPLSPELESSP -------------------------------------------------------------- >4847_4847_2_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000355303_CDC42BPG_chr11_64606374_ENST00000342711_length(transcript)=5918nt_BP=1052nt AAAGGCGGGCCGGCTGGCGTCCAAGTTCCTGACCAGGCGCGGGCCGGCCCGCGGGACCAGCAGCCGGGTGGCGGCGCGATCGGCCCCGAG AGGCTCAGGCGCCCCCCGCATCGAGCGCGCGGGCCGGGCGGGCCAGGGCGGCGGGCGGAGCGGGAGGCGGCCACGTCCCCGGCGGGCCTG GGCGCGGGGAGGCCCGGCCCCCTGCGAGCGCGCCGCGAACGCTGCGGTCTCCGCCCGCAGAGGCCGCCGGGGCCGTGGATGGGGAGGGCG CGCCGCCCGGCGGTCCCAGCGCACAGGCGGCCACGATGAGGGTCAACGAGAAGTACTCGACGCTCCCGGCCGAGGACCGCAGCGTCCACA TCATCAACATCTGCGCCATCGAGGACATCGGCTACCTGCCGTCCGAGGGCACGCTGCTGAACTCCTTATCTGTGGACCCTGATGCCGAGT GCAAGTATGGCCTGTACTTCAGGGACGGCCGGCGCAAGGTGGACTACATCCTGGTGTACCATCACAAGAGGCCCTCGGGCAACCGGACCC TGGTCAGGAGGGTGCAGCACAGCGACACCCCCTCTGGGGCTCGCAGCGTCAAGCAGGACCACCCCCTGCCGGGCAAGGGGGCGTCGCTGG ATGCAGGCTCGGGGGAGCCCCCGATGGACTACCACGAGGATGACAAGCGCTTCCGCAGGGAGGAGTACGAGGGCAACCTCCTGGAGGCGG GCCTGGAGCTGGAGCGGGACGAGGACACTAAAATCCACGGAGTCGGGTTTGTGAAAATCCATGCCCCCTGGAACGTGCTGTGCAGAGAGG CCGAGTTTCTGAAACTGAAGATGCCGACGAAGAAGATGTACCACATTAATGAGACCCGTGGCCTCCTGAAAAAAATCAACTCTGTGCTCC AGAAAATCACAGATCCCATCCAGCCCAAAGTGGCTGAGCACAGGCCCCAGACCATGAAGAGACTCTCCTATCCCTTCTCCCGGGAGAAGC AGCATCTATTTGACTTGTCTGATAAGGATTCCTTTTTCGACAGCAAAACCCGGAGCACGATTGACCACCTGCAGTTCCCCCCGGACGTGC CTGACGTGCCAGCCAGCGCCCAAGACCTGATCCGCCAGCTGCTGTGTCGCCAGGAAGAGCGGCTAGGCCGTGGTGGGCTGGATGACTTCC GGAACCATCCTTTCTTCGAAGGCGTGGACTGGGAGCGGCTGGCGAGCAGCACGGCCCCCTATATTCCTGAGCTGCGGGGGCCCATGGACA CCTCCAACTTTGATGTGGATGACGACACCCTCAACCATCCAGGGACCCTGCCACCGCCCTCCCACGGGGCCTTCTCCGGCCATCACCTGC CATTCGTGGGCTTCACCTACACCTCAGGCAGTCACAGTCCTGAGAGCAGCTCTGAGGCTTGGGCTGCCCTGGAGCGGAAGCTCCAGTGTC TGGAGCAGGAGAAGGTGGAGCTGAGCAGGAAGCACCAAGAGGCCCTGCACGCCCCCACAGACCATCGGGAGCTGGAGCAGCTACGGAAGG AAGTGCAGACTCTGCGGGACAGGCTGCCAGAGATGCTGAGGGACAAGGCCTCATTGTCCCAGACGGATGGGCCCCCAGCTGGTAGCCCAG GTCAGGACAGTGACCTACGGCAGGAGCTTGACCGACTTCACCGGGAGCTGGCCGAGGGTCGGGCAGGGCTGCAGGCTCAGGAGCAGGAGC TCTGCAGGGCCCAGGGGCAGCAGGAGGAGCTGCTTCAGAGGCTACAGGAGGCCCAGGAGAGAGAGGCGGCCACAGCTAGCCAGACCCGGG CCCTGAGCTCCCAGCTGGAGGAAGCCCGGGCTGCCCAGAGGGAGCTGGAGGCCCAGGTGTCCTCCCTGAGCCGGCAGGTGACGCAGCTGC AGGGACAGTGGGAGCAACGCCTTGAGGAGTCGTCCCAGGCCAAGACCATCCACACAGCCTCTGAGACCAACGGGATGGGACCCCCTGAGG GTGGGCCTCAGGAGGCCCAACTGAGGAAGGAGGTGGCCGCCCTGCGAGAGCAGCTGGAGCAGGCCCACAGCCACAGGCCGAGTGGTAAGG AGGAGGCTCTGTGCCAGCTGCAGGAGGAAAACCGGAGGCTGAGCCGGGAGCAGGAGCGGCTAGAAGCAGAGCTGGCCCAGGAGCAGGAGA GCAAGCAGCGGCTGGAGGGTGAGCGGCGGGAGACGGAGAGCAACTGGGAGGCCCAGCTCGCCGACATCCTCAGCTGGGTGAATGATGAGA AGGTCTCAAGAGGCTACCTGCAGGCCCTGGCCACCAAGATGGCAGAGGAGCTGGAGTCCTTGAGGAACGTAGGCACCCAGACGCTCCCTG CCCGGCCACTGGACCACCAGTGGAAGGCGCGGCGACTGCAGAAGATGGAGGCCTCGGCCAGGCTGGAGCTGCAGTCAGCGCTGGAGGCCG AGATCCGCGCCAAGCAGGGCCTGCAGGAGCGGCTGACACAGGTGCAGGAGGCCCAGCTGCAGGCTGAGCGCCGTCTGCAGGAGGCCGAGA AGCAGAGCCAGGCCCTGCAACAGGAGCTCGCCATGCTGCGGGAGGAGCTGCGGGCCCGAGGGCCAGTGGACACCAAGCCCTCAAACTCCC TGATTCCCTTCCTGTCCTTCCGGAGCTCAGAGAAGGATTCTGCCAAGGACCCTGGCATCTCAGGAGAGGCCACAAGGCATGGAGGAGAGC CAGATCTGAGGCCGGAGGGCCGACGCAGCCTGCGCATGGGGGCTGTGTTCCCCAGAGCACCCACTGCCAACACAGCCTCTACAGAAGGTC TTCCTGCTAAGCCCGGCTCACACACGCTGCGCCCCCGGAGCTTCCCATCCCCGACCAAGTGTCTCCGCTGCACCTCGCTGATGCTGGGCC TGGGCCGCCAGGGCCTGGGTTGTGATGCCTGCGGCTACTTTTGTCACACAACCTGTGCCCCACAGGCCCCACCCTGCCCCGTGCCCCCTG ACCTCCTCCGCACAGCCCTGGGAGTACACCCCGAAACAGGCACAGGCACTGCCTATGAGGGCTTTCTGTCGGTGCCGCGGCCCTCAGGTG TCCGGCGGGGCTGGCAGCGCGTGTTTGCTGCCCTGAGTGACTCACGCCTGCTGCTGTTTGACGCCCCTGACCTGAGGCTCAGCCCGCCCA GTGGGGCCCTCCTGCAGGTCCTAGATCTGAGGGACCCCCAGTTCTCGGCTACCCCTGTCCTGGCCTCTGATGTTATCCATGCCCAATCCA GGGACCTGCCACGCATCTTTAGGGTGACAACCTCCCAGCTGGCAGTGCCGCCCACCACGTGCACTGTGCTGCTGCTGGCAGAGAGCGAGG GGGAGCGGGAACGCTGGCTGCAGGTGCTGGGTGAGCTGCAGCGGCTGCTGCTGGACGCGCGGCCAAGACCCCGGCCCGTGTACACACTCA AGGAGGCTTACGACAACGGGCTGCCGCTGCTGCCTCACACGCTCTGCGCTGCCATCCTCGACCAGGATCGACTTGCGCTTGGCACCGAGG AGGGGCTCTTTGTCATCCATCTGCGCAGCAACGACATCTTCCAGGTGGGGGAGTGCCGGCGCGTGCAGCAGCTGACCTTGAGCCCCAGTG CAGGCCTGCTGGTCGTGCTGTGTGGCCGCGGCCCCAGCGTGCGTCTCTTTGCCCTGGCGGAGCTGGAGAACATAGAGGTAGCAGGTGCCA AGATCCCCGAGTCTCGAGGCTGCCAGGTGCTGGCAGCTGGAAGCATCCTGCAGGCCCGCACCCCGGTGCTCTGTGTAGCCGTCAAGCGCC AGGTGCTCTGCTACCAGCTGGGCCCGGGCCCTGGGCCCTGGCAGCGCCGCATCCGTGAGCTGCAGGCACCTGCCACTGTGCAGAGCCTGG GGCTGCTGGGCGACCGGCTATGTGTGGGCGCCGCCGGTGGCTTTGCACTCTACCCGCTGCTCAACGAGGCTGCGCCGTTGGCGCTGGGGG CCGGTTTGGTGCCTGAGGAGCTGCCACCATCCCGCGGGGGCCTGGGTGAGGCACTGGGTGCCGTGGAGCTTAGCCTCAGCGAGTTCCTGC TACTCTTCACCACTGCTGGCATCTACGTGGATGGCGCAGGCCGCAAGTCTCGTGGCCACGAGCTGTTGTGGCCAGCAGCGCCCATGGGCT GGGGGTATGCGGCCCCCTACCTGACAGTGTTCAGCGAGAACTCCATCGATGTGTTTGACGTGAGGAGGGCAGAATGGGTGCAGACCGTGC CGCTCAAGAAGGTGCGGCCCCTCAATCCAGAGGGCTCCCTGTTCCTCTACGGCACCGAGAAGGTCCGCCTGACCTACCTCAGGAACCAGC TGGCAGAGAAGGACGAGTTCGACATCCCGGACCTCACCGACAACAGCCGGCGCCAGCTGTTCCGCACCAAGAGCAAGCGCCGCTTCTTTT TCCGCGTGTCGGAGGAGCAGCAGAAGCAGCAGCGCAGGGAGATGCTGAAGGACCCTTTTGTGCGCTCCAAGCTCATCTCGCCGCCTACCA ACTTCAACCACCTAGTACACGTGGGCCCTGCCAACGGGCGGCCCGGCGCCAGGGACAAGTCCCCGGCTCCCGAAGAGAAGGGCCGAGTTG CCCGCGGCTCCGGCCCACAGCGGCCCCACAGCTTCTCCGAGGCGTTGCGGCGCCCAGCCTCCATGGGCAGCGAAGGCCTCGGTGGAGACG CAGACCCCATGAAGAGGAAACCCTGGACATCCCTGTCCAGCGAGTCTGTGTCCTGCCCCCAGGGATCGCTGAGCCCTGCAACCTCCCTAA TGCAGGTCTCAGAACGGCCCCGAAGCCTCCCCCTATCCCCTGAATTGGAGAGCTCTCCTTGATGCCCTCTGTTAGGGCCCACCCCAATCC CAGGGCAGAAGGACATGAGGGAGCAAAGAGCTTGAGGAATGCCATACTCCGGCTGGTCCGGGACATGGAAATTCGGACTCAGGGAGGACC CGGGCTGGGCAATGACTGGGAGACTTGCCTGGGTTCCCAGGACTTGGGGGTCCTGACTCCCAGCCCTCATCCTGCCTTACCCCTCTGTTC CCAGCCCCAGCCTTTCTAAGCCATTGGGAATAGAATGGCCCCTTTTGTTCTGGTGTCCAGGGGTGATTGTGCCAAAGCTCTTATTTCCAG TGCCAAGCCCCCAGAGGCTTGTAAGAGTTGGGATGAGGGATGGAGAGGGACTGGGTCTCTGGGAACAGGTTGGAGGTCTTATCTGTGGAC TGTCTGACTCCCAGCTGAGGCCAAGATGGGGCATGTCCCCGTCTCTGCTTAGCGTCTGGGTGAGAAAAACAGGCTGTGATCCAGAAGAAG GGAAGATAGAGAAGGAGGGAAAGGATGTAGGCGAAGGAGGTGAGAGACAGGATAGGAGGAAGGAAGTGGAGGAGGAGGTGATAGGAATTG GAAGGAGGTAGAAGCCGTGCAGAGGAAGAGGGGAGAGGGACGAAGGAGGAGCGATGAAGAAGAGGAGGGAGACAAAAAGAGGGATGGAGG AGAGAGGGAGTCTGGAGAACAAAGGGTCCTTTCTCTGGGGAGGGGTGCAGTGGGCGGGGCTGACACTGTCAGCCAATCCTCCCATCGGGG AAGAGAATCCTGGACAGGGACAGGATGGGGAGGGTATTTATAAGGGCTTTTTGGTGGGAGATGGGTACCCAGTGGGGGCCACTGGAGGGT CTCCGGGCACACTCTGGCCCTTCCCAGAAAGGGGGTCGTTTTTCTCGAATCTTCAACCAGTTGTGTATTGGAAACTAGGGCGCATTTTAC TATTGATCACAGTCATTATATTGTTATTATATTACTATTTTTATTAAACCTCCCCCCACTGAAGTGTGGGGGGCAAAATAAGTATTTATC TCCTCAAATGCCACATTCCCAGGAGGGACAGACCCTGATGCTCTGTGAGGCGCAAGAAACCAATAAAG >4847_4847_2_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000355303_CDC42BPG_chr11_64606374_ENST00000342711_length(amino acids)=1536AA_BP=277 MRSPPAEAAGAVDGEGAPPGGPSAQAATMRVNEKYSTLPAEDRSVHIINICAIEDIGYLPSEGTLLNSLSVDPDAECKYGLYFRDGRRKV DYILVYHHKRPSGNRTLVRRVQHSDTPSGARSVKQDHPLPGKGASLDAGSGEPPMDYHEDDKRFRREEYEGNLLEAGLELERDEDTKIHG VGFVKIHAPWNVLCREAEFLKLKMPTKKMYHINETRGLLKKINSVLQKITDPIQPKVAEHRPQTMKRLSYPFSREKQHLFDLSDKDSFFD SKTRSTIDHLQFPPDVPDVPASAQDLIRQLLCRQEERLGRGGLDDFRNHPFFEGVDWERLASSTAPYIPELRGPMDTSNFDVDDDTLNHP GTLPPPSHGAFSGHHLPFVGFTYTSGSHSPESSSEAWAALERKLQCLEQEKVELSRKHQEALHAPTDHRELEQLRKEVQTLRDRLPEMLR DKASLSQTDGPPAGSPGQDSDLRQELDRLHRELAEGRAGLQAQEQELCRAQGQQEELLQRLQEAQEREAATASQTRALSSQLEEARAAQR ELEAQVSSLSRQVTQLQGQWEQRLEESSQAKTIHTASETNGMGPPEGGPQEAQLRKEVAALREQLEQAHSHRPSGKEEALCQLQEENRRL SREQERLEAELAQEQESKQRLEGERRETESNWEAQLADILSWVNDEKVSRGYLQALATKMAEELESLRNVGTQTLPARPLDHQWKARRLQ KMEASARLELQSALEAEIRAKQGLQERLTQVQEAQLQAERRLQEAEKQSQALQQELAMLREELRARGPVDTKPSNSLIPFLSFRSSEKDS AKDPGISGEATRHGGEPDLRPEGRRSLRMGAVFPRAPTANTASTEGLPAKPGSHTLRPRSFPSPTKCLRCTSLMLGLGRQGLGCDACGYF CHTTCAPQAPPCPVPPDLLRTALGVHPETGTGTAYEGFLSVPRPSGVRRGWQRVFAALSDSRLLLFDAPDLRLSPPSGALLQVLDLRDPQ FSATPVLASDVIHAQSRDLPRIFRVTTSQLAVPPTTCTVLLLAESEGERERWLQVLGELQRLLLDARPRPRPVYTLKEAYDNGLPLLPHT LCAAILDQDRLALGTEEGLFVIHLRSNDIFQVGECRRVQQLTLSPSAGLLVVLCGRGPSVRLFALAELENIEVAGAKIPESRGCQVLAAG SILQARTPVLCVAVKRQVLCYQLGPGPGPWQRRIRELQAPATVQSLGLLGDRLCVGAAGGFALYPLLNEAAPLALGAGLVPEELPPSRGG LGEALGAVELSLSEFLLLFTTAGIYVDGAGRKSRGHELLWPAAPMGWGYAAPYLTVFSENSIDVFDVRRAEWVQTVPLKKVRPLNPEGSL FLYGTEKVRLTYLRNQLAEKDEFDIPDLTDNSRRQLFRTKSKRRFFFRVSEEQQKQQRREMLKDPFVRSKLISPPTNFNHLVHVGPANGR PGARDKSPAPEEKGRVARGSGPQRPHSFSEALRRPASMGSEGLGGDADPMKRKPWTSLSSESVSCPQGSLSPATSLMQVSERPRSLPLSP ELESSP -------------------------------------------------------------- >4847_4847_3_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000398543_CDC42BPG_chr11_64606374_ENST00000342711_length(transcript)=5662nt_BP=796nt GGATGGGGAGGGCGCGCCGCCCGGCGGTCCCAGCGCACAGGCGGCCACGATGAGGGTCAACGAGAAGTACTCGACGCTCCCGGCCGAGGA CCGCAGCGTCCACATCATCAACATCTGCGCCATCGAGGACATCGGCTACCTGCCGTCCGAGGGCACGCTGCTGAACTCCTTATCTGTGGA CCCTGATGCCGAGTGCAAGTATGGCCTGTACTTCAGGGACGGCCGGCGCAAGGTGGACTACATCCTGGTGTACCATCACAAGAGGCCCTC GGGCAACCGGACCCTGGTCAGGAGGGTGCAGCACAGCGACACCCCCTCTGGGGCTCGCAGCGTCAAGCAGGACCACCCCCTGCCGGGCAA GGGGGCGTCGCTGGATGCAGGCTCGGGGGAGCCCCCGATGGACTACCACGAGGATGACAAGCGCTTCCGCAGGGAGGAGTACGAGGGCAA CCTCCTGGAGGCGGGCCTGGAGCTGGAGCGGGACGAGGACACTAAAATCCACGGAGTCGGGTTTGTGAAAATCCATGCCCCCTGGAACGT GCTGTGCAGAGAGGCCGAGTTTCTGAAACTGAAGATGCCGACGAAGAAGATGTACCACATTAATGAGACCCGTGGCCTCCTGAAAAAAAT CAACTCTGTGCTCCAGAAAATCACAGATCCCATCCAGCCCAAAGTGGCTGAGCACAGGCCCCAGACCATGAAGAGACTCTCCTATCCCTT CTCCCGGGAGAAGCAGCATCTATTTGACTTGTCTGATAAGGATTCCTTTTTCGACAGCAAAACCCGGAGCACGATTGACCACCTGCAGTT CCCCCCGGACGTGCCTGACGTGCCAGCCAGCGCCCAAGACCTGATCCGCCAGCTGCTGTGTCGCCAGGAAGAGCGGCTAGGCCGTGGTGG GCTGGATGACTTCCGGAACCATCCTTTCTTCGAAGGCGTGGACTGGGAGCGGCTGGCGAGCAGCACGGCCCCCTATATTCCTGAGCTGCG GGGGCCCATGGACACCTCCAACTTTGATGTGGATGACGACACCCTCAACCATCCAGGGACCCTGCCACCGCCCTCCCACGGGGCCTTCTC CGGCCATCACCTGCCATTCGTGGGCTTCACCTACACCTCAGGCAGTCACAGTCCTGAGAGCAGCTCTGAGGCTTGGGCTGCCCTGGAGCG GAAGCTCCAGTGTCTGGAGCAGGAGAAGGTGGAGCTGAGCAGGAAGCACCAAGAGGCCCTGCACGCCCCCACAGACCATCGGGAGCTGGA GCAGCTACGGAAGGAAGTGCAGACTCTGCGGGACAGGCTGCCAGAGATGCTGAGGGACAAGGCCTCATTGTCCCAGACGGATGGGCCCCC AGCTGGTAGCCCAGGTCAGGACAGTGACCTACGGCAGGAGCTTGACCGACTTCACCGGGAGCTGGCCGAGGGTCGGGCAGGGCTGCAGGC TCAGGAGCAGGAGCTCTGCAGGGCCCAGGGGCAGCAGGAGGAGCTGCTTCAGAGGCTACAGGAGGCCCAGGAGAGAGAGGCGGCCACAGC TAGCCAGACCCGGGCCCTGAGCTCCCAGCTGGAGGAAGCCCGGGCTGCCCAGAGGGAGCTGGAGGCCCAGGTGTCCTCCCTGAGCCGGCA GGTGACGCAGCTGCAGGGACAGTGGGAGCAACGCCTTGAGGAGTCGTCCCAGGCCAAGACCATCCACACAGCCTCTGAGACCAACGGGAT GGGACCCCCTGAGGGTGGGCCTCAGGAGGCCCAACTGAGGAAGGAGGTGGCCGCCCTGCGAGAGCAGCTGGAGCAGGCCCACAGCCACAG GCCGAGTGGTAAGGAGGAGGCTCTGTGCCAGCTGCAGGAGGAAAACCGGAGGCTGAGCCGGGAGCAGGAGCGGCTAGAAGCAGAGCTGGC CCAGGAGCAGGAGAGCAAGCAGCGGCTGGAGGGTGAGCGGCGGGAGACGGAGAGCAACTGGGAGGCCCAGCTCGCCGACATCCTCAGCTG GGTGAATGATGAGAAGGTCTCAAGAGGCTACCTGCAGGCCCTGGCCACCAAGATGGCAGAGGAGCTGGAGTCCTTGAGGAACGTAGGCAC CCAGACGCTCCCTGCCCGGCCACTGGACCACCAGTGGAAGGCGCGGCGACTGCAGAAGATGGAGGCCTCGGCCAGGCTGGAGCTGCAGTC AGCGCTGGAGGCCGAGATCCGCGCCAAGCAGGGCCTGCAGGAGCGGCTGACACAGGTGCAGGAGGCCCAGCTGCAGGCTGAGCGCCGTCT GCAGGAGGCCGAGAAGCAGAGCCAGGCCCTGCAACAGGAGCTCGCCATGCTGCGGGAGGAGCTGCGGGCCCGAGGGCCAGTGGACACCAA GCCCTCAAACTCCCTGATTCCCTTCCTGTCCTTCCGGAGCTCAGAGAAGGATTCTGCCAAGGACCCTGGCATCTCAGGAGAGGCCACAAG GCATGGAGGAGAGCCAGATCTGAGGCCGGAGGGCCGACGCAGCCTGCGCATGGGGGCTGTGTTCCCCAGAGCACCCACTGCCAACACAGC CTCTACAGAAGGTCTTCCTGCTAAGCCCGGCTCACACACGCTGCGCCCCCGGAGCTTCCCATCCCCGACCAAGTGTCTCCGCTGCACCTC GCTGATGCTGGGCCTGGGCCGCCAGGGCCTGGGTTGTGATGCCTGCGGCTACTTTTGTCACACAACCTGTGCCCCACAGGCCCCACCCTG CCCCGTGCCCCCTGACCTCCTCCGCACAGCCCTGGGAGTACACCCCGAAACAGGCACAGGCACTGCCTATGAGGGCTTTCTGTCGGTGCC GCGGCCCTCAGGTGTCCGGCGGGGCTGGCAGCGCGTGTTTGCTGCCCTGAGTGACTCACGCCTGCTGCTGTTTGACGCCCCTGACCTGAG GCTCAGCCCGCCCAGTGGGGCCCTCCTGCAGGTCCTAGATCTGAGGGACCCCCAGTTCTCGGCTACCCCTGTCCTGGCCTCTGATGTTAT CCATGCCCAATCCAGGGACCTGCCACGCATCTTTAGGGTGACAACCTCCCAGCTGGCAGTGCCGCCCACCACGTGCACTGTGCTGCTGCT GGCAGAGAGCGAGGGGGAGCGGGAACGCTGGCTGCAGGTGCTGGGTGAGCTGCAGCGGCTGCTGCTGGACGCGCGGCCAAGACCCCGGCC CGTGTACACACTCAAGGAGGCTTACGACAACGGGCTGCCGCTGCTGCCTCACACGCTCTGCGCTGCCATCCTCGACCAGGATCGACTTGC GCTTGGCACCGAGGAGGGGCTCTTTGTCATCCATCTGCGCAGCAACGACATCTTCCAGGTGGGGGAGTGCCGGCGCGTGCAGCAGCTGAC CTTGAGCCCCAGTGCAGGCCTGCTGGTCGTGCTGTGTGGCCGCGGCCCCAGCGTGCGTCTCTTTGCCCTGGCGGAGCTGGAGAACATAGA GGTAGCAGGTGCCAAGATCCCCGAGTCTCGAGGCTGCCAGGTGCTGGCAGCTGGAAGCATCCTGCAGGCCCGCACCCCGGTGCTCTGTGT AGCCGTCAAGCGCCAGGTGCTCTGCTACCAGCTGGGCCCGGGCCCTGGGCCCTGGCAGCGCCGCATCCGTGAGCTGCAGGCACCTGCCAC TGTGCAGAGCCTGGGGCTGCTGGGCGACCGGCTATGTGTGGGCGCCGCCGGTGGCTTTGCACTCTACCCGCTGCTCAACGAGGCTGCGCC GTTGGCGCTGGGGGCCGGTTTGGTGCCTGAGGAGCTGCCACCATCCCGCGGGGGCCTGGGTGAGGCACTGGGTGCCGTGGAGCTTAGCCT CAGCGAGTTCCTGCTACTCTTCACCACTGCTGGCATCTACGTGGATGGCGCAGGCCGCAAGTCTCGTGGCCACGAGCTGTTGTGGCCAGC AGCGCCCATGGGCTGGGGGTATGCGGCCCCCTACCTGACAGTGTTCAGCGAGAACTCCATCGATGTGTTTGACGTGAGGAGGGCAGAATG GGTGCAGACCGTGCCGCTCAAGAAGGTGCGGCCCCTCAATCCAGAGGGCTCCCTGTTCCTCTACGGCACCGAGAAGGTCCGCCTGACCTA CCTCAGGAACCAGCTGGCAGAGAAGGACGAGTTCGACATCCCGGACCTCACCGACAACAGCCGGCGCCAGCTGTTCCGCACCAAGAGCAA GCGCCGCTTCTTTTTCCGCGTGTCGGAGGAGCAGCAGAAGCAGCAGCGCAGGGAGATGCTGAAGGACCCTTTTGTGCGCTCCAAGCTCAT CTCGCCGCCTACCAACTTCAACCACCTAGTACACGTGGGCCCTGCCAACGGGCGGCCCGGCGCCAGGGACAAGTCCCCGGCTCCCGAAGA GAAGGGCCGAGTTGCCCGCGGCTCCGGCCCACAGCGGCCCCACAGCTTCTCCGAGGCGTTGCGGCGCCCAGCCTCCATGGGCAGCGAAGG CCTCGGTGGAGACGCAGACCCCATGAAGAGGAAACCCTGGACATCCCTGTCCAGCGAGTCTGTGTCCTGCCCCCAGGGATCGCTGAGCCC TGCAACCTCCCTAATGCAGGTCTCAGAACGGCCCCGAAGCCTCCCCCTATCCCCTGAATTGGAGAGCTCTCCTTGATGCCCTCTGTTAGG GCCCACCCCAATCCCAGGGCAGAAGGACATGAGGGAGCAAAGAGCTTGAGGAATGCCATACTCCGGCTGGTCCGGGACATGGAAATTCGG ACTCAGGGAGGACCCGGGCTGGGCAATGACTGGGAGACTTGCCTGGGTTCCCAGGACTTGGGGGTCCTGACTCCCAGCCCTCATCCTGCC TTACCCCTCTGTTCCCAGCCCCAGCCTTTCTAAGCCATTGGGAATAGAATGGCCCCTTTTGTTCTGGTGTCCAGGGGTGATTGTGCCAAA GCTCTTATTTCCAGTGCCAAGCCCCCAGAGGCTTGTAAGAGTTGGGATGAGGGATGGAGAGGGACTGGGTCTCTGGGAACAGGTTGGAGG TCTTATCTGTGGACTGTCTGACTCCCAGCTGAGGCCAAGATGGGGCATGTCCCCGTCTCTGCTTAGCGTCTGGGTGAGAAAAACAGGCTG TGATCCAGAAGAAGGGAAGATAGAGAAGGAGGGAAAGGATGTAGGCGAAGGAGGTGAGAGACAGGATAGGAGGAAGGAAGTGGAGGAGGA GGTGATAGGAATTGGAAGGAGGTAGAAGCCGTGCAGAGGAAGAGGGGAGAGGGACGAAGGAGGAGCGATGAAGAAGAGGAGGGAGACAAA AAGAGGGATGGAGGAGAGAGGGAGTCTGGAGAACAAAGGGTCCTTTCTCTGGGGAGGGGTGCAGTGGGCGGGGCTGACACTGTCAGCCAA TCCTCCCATCGGGGAAGAGAATCCTGGACAGGGACAGGATGGGGAGGGTATTTATAAGGGCTTTTTGGTGGGAGATGGGTACCCAGTGGG GGCCACTGGAGGGTCTCCGGGCACACTCTGGCCCTTCCCAGAAAGGGGGTCGTTTTTCTCGAATCTTCAACCAGTTGTGTATTGGAAACT AGGGCGCATTTTACTATTGATCACAGTCATTATATTGTTATTATATTACTATTTTTATTAAACCTCCCCCCACTGAAGTGTGGGGGGCAA AATAAGTATTTATCTCCTCAAATGCCACATTCCCAGGAGGGACAGACCCTGATGCTCTGTGAGGCGCAAGAAACCAATAAAG >4847_4847_3_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000398543_CDC42BPG_chr11_64606374_ENST00000342711_length(amino acids)=1508AA_BP=249 MRVNEKYSTLPAEDRSVHIINICAIEDIGYLPSEGTLLNSLSVDPDAECKYGLYFRDGRRKVDYILVYHHKRPSGNRTLVRRVQHSDTPS GARSVKQDHPLPGKGASLDAGSGEPPMDYHEDDKRFRREEYEGNLLEAGLELERDEDTKIHGVGFVKIHAPWNVLCREAEFLKLKMPTKK MYHINETRGLLKKINSVLQKITDPIQPKVAEHRPQTMKRLSYPFSREKQHLFDLSDKDSFFDSKTRSTIDHLQFPPDVPDVPASAQDLIR QLLCRQEERLGRGGLDDFRNHPFFEGVDWERLASSTAPYIPELRGPMDTSNFDVDDDTLNHPGTLPPPSHGAFSGHHLPFVGFTYTSGSH SPESSSEAWAALERKLQCLEQEKVELSRKHQEALHAPTDHRELEQLRKEVQTLRDRLPEMLRDKASLSQTDGPPAGSPGQDSDLRQELDR LHRELAEGRAGLQAQEQELCRAQGQQEELLQRLQEAQEREAATASQTRALSSQLEEARAAQRELEAQVSSLSRQVTQLQGQWEQRLEESS QAKTIHTASETNGMGPPEGGPQEAQLRKEVAALREQLEQAHSHRPSGKEEALCQLQEENRRLSREQERLEAELAQEQESKQRLEGERRET ESNWEAQLADILSWVNDEKVSRGYLQALATKMAEELESLRNVGTQTLPARPLDHQWKARRLQKMEASARLELQSALEAEIRAKQGLQERL TQVQEAQLQAERRLQEAEKQSQALQQELAMLREELRARGPVDTKPSNSLIPFLSFRSSEKDSAKDPGISGEATRHGGEPDLRPEGRRSLR MGAVFPRAPTANTASTEGLPAKPGSHTLRPRSFPSPTKCLRCTSLMLGLGRQGLGCDACGYFCHTTCAPQAPPCPVPPDLLRTALGVHPE TGTGTAYEGFLSVPRPSGVRRGWQRVFAALSDSRLLLFDAPDLRLSPPSGALLQVLDLRDPQFSATPVLASDVIHAQSRDLPRIFRVTTS QLAVPPTTCTVLLLAESEGERERWLQVLGELQRLLLDARPRPRPVYTLKEAYDNGLPLLPHTLCAAILDQDRLALGTEEGLFVIHLRSND IFQVGECRRVQQLTLSPSAGLLVVLCGRGPSVRLFALAELENIEVAGAKIPESRGCQVLAAGSILQARTPVLCVAVKRQVLCYQLGPGPG PWQRRIRELQAPATVQSLGLLGDRLCVGAAGGFALYPLLNEAAPLALGAGLVPEELPPSRGGLGEALGAVELSLSEFLLLFTTAGIYVDG AGRKSRGHELLWPAAPMGWGYAAPYLTVFSENSIDVFDVRRAEWVQTVPLKKVRPLNPEGSLFLYGTEKVRLTYLRNQLAEKDEFDIPDL TDNSRRQLFRTKSKRRFFFRVSEEQQKQQRREMLKDPFVRSKLISPPTNFNHLVHVGPANGRPGARDKSPAPEEKGRVARGSGPQRPHSF SEALRRPASMGSEGLGGDADPMKRKPWTSLSSESVSCPQGSLSPATSLMQVSERPRSLPLSPELESSP -------------------------------------------------------------- >4847_4847_4_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000530676_CDC42BPG_chr11_64606374_ENST00000342711_length(transcript)=5754nt_BP=888nt TGAGTCCAGGTCCTCCTGAAGGTCACCAGCACAGCGGGGCCCTGTGTTACTGTAGAGAGAAGTCAGTTGCTTAGTTTCAGCCTCCTGCCG GCACCAGATGCTGACCAGGCCCTCCCAGGTGGTGAGCAATGCTGTTTCCAGGAGAGGCATCCTAGGGCCAGAGAGGCCAAGGTGCCAGGG ACATGGCCCCAACTGTCCCCTAACCAGGGGTAGAGGAGTCTAGACCCTTGACATCAACACCTATGAAAGCTGCTGAACTCCTTATCTGTG GACCCTGATGCCGAGTGCAAGTATGGCCTGTACTTCAGGGACGGCCGGCGCAAGGTGGACTACATCCTGGTGTACCATCACAAGAGGCCC TCGGGCAACCGGACCCTGGTCAGGAGGGTGCAGCACAGCGACACCCCCTCTGGGGCTCGCAGCGTCAAGCAGGACCACCCCCTGCCGGGC AAGGGGGCGTCGCTGGATGCAGGCTCGGGGGAGCCCCCGATGGACTACCACGAGGATGACAAGCGCTTCCGCAGGGAGGAGTACGAGGGC AACCTCCTGGAGGCGGGCCTGGAGCTGGAGCGGGACGAGGACACTAAAATCCACGGAGTCGGGTTTGTGAAAATCCATGCCCCCTGGAAC GTGCTGTGCAGAGAGGCCGAGTTTCTGAAACTGAAGATGCCGACGAAGAAGATGTACCACATTAATGAGACCCGTGGCCTCCTGAAAAAA ATCAACTCTGTGCTCCAGAAAATCACAGATCCCATCCAGCCCAAAGTGGCTGAGCACAGGCCCCAGACCATGAAGAGACTCTCCTATCCC TTCTCCCGGGAGAAGCAGCATCTATTTGACTTGTCTGATAAGGATTCCTTTTTCGACAGCAAAACCCGGAGCACGATTGACCACCTGCAG TTCCCCCCGGACGTGCCTGACGTGCCAGCCAGCGCCCAAGACCTGATCCGCCAGCTGCTGTGTCGCCAGGAAGAGCGGCTAGGCCGTGGT GGGCTGGATGACTTCCGGAACCATCCTTTCTTCGAAGGCGTGGACTGGGAGCGGCTGGCGAGCAGCACGGCCCCCTATATTCCTGAGCTG CGGGGGCCCATGGACACCTCCAACTTTGATGTGGATGACGACACCCTCAACCATCCAGGGACCCTGCCACCGCCCTCCCACGGGGCCTTC TCCGGCCATCACCTGCCATTCGTGGGCTTCACCTACACCTCAGGCAGTCACAGTCCTGAGAGCAGCTCTGAGGCTTGGGCTGCCCTGGAG CGGAAGCTCCAGTGTCTGGAGCAGGAGAAGGTGGAGCTGAGCAGGAAGCACCAAGAGGCCCTGCACGCCCCCACAGACCATCGGGAGCTG GAGCAGCTACGGAAGGAAGTGCAGACTCTGCGGGACAGGCTGCCAGAGATGCTGAGGGACAAGGCCTCATTGTCCCAGACGGATGGGCCC CCAGCTGGTAGCCCAGGTCAGGACAGTGACCTACGGCAGGAGCTTGACCGACTTCACCGGGAGCTGGCCGAGGGTCGGGCAGGGCTGCAG GCTCAGGAGCAGGAGCTCTGCAGGGCCCAGGGGCAGCAGGAGGAGCTGCTTCAGAGGCTACAGGAGGCCCAGGAGAGAGAGGCGGCCACA GCTAGCCAGACCCGGGCCCTGAGCTCCCAGCTGGAGGAAGCCCGGGCTGCCCAGAGGGAGCTGGAGGCCCAGGTGTCCTCCCTGAGCCGG CAGGTGACGCAGCTGCAGGGACAGTGGGAGCAACGCCTTGAGGAGTCGTCCCAGGCCAAGACCATCCACACAGCCTCTGAGACCAACGGG ATGGGACCCCCTGAGGGTGGGCCTCAGGAGGCCCAACTGAGGAAGGAGGTGGCCGCCCTGCGAGAGCAGCTGGAGCAGGCCCACAGCCAC AGGCCGAGTGGTAAGGAGGAGGCTCTGTGCCAGCTGCAGGAGGAAAACCGGAGGCTGAGCCGGGAGCAGGAGCGGCTAGAAGCAGAGCTG GCCCAGGAGCAGGAGAGCAAGCAGCGGCTGGAGGGTGAGCGGCGGGAGACGGAGAGCAACTGGGAGGCCCAGCTCGCCGACATCCTCAGC TGGGTGAATGATGAGAAGGTCTCAAGAGGCTACCTGCAGGCCCTGGCCACCAAGATGGCAGAGGAGCTGGAGTCCTTGAGGAACGTAGGC ACCCAGACGCTCCCTGCCCGGCCACTGGACCACCAGTGGAAGGCGCGGCGACTGCAGAAGATGGAGGCCTCGGCCAGGCTGGAGCTGCAG TCAGCGCTGGAGGCCGAGATCCGCGCCAAGCAGGGCCTGCAGGAGCGGCTGACACAGGTGCAGGAGGCCCAGCTGCAGGCTGAGCGCCGT CTGCAGGAGGCCGAGAAGCAGAGCCAGGCCCTGCAACAGGAGCTCGCCATGCTGCGGGAGGAGCTGCGGGCCCGAGGGCCAGTGGACACC AAGCCCTCAAACTCCCTGATTCCCTTCCTGTCCTTCCGGAGCTCAGAGAAGGATTCTGCCAAGGACCCTGGCATCTCAGGAGAGGCCACA AGGCATGGAGGAGAGCCAGATCTGAGGCCGGAGGGCCGACGCAGCCTGCGCATGGGGGCTGTGTTCCCCAGAGCACCCACTGCCAACACA GCCTCTACAGAAGGTCTTCCTGCTAAGCCCGGCTCACACACGCTGCGCCCCCGGAGCTTCCCATCCCCGACCAAGTGTCTCCGCTGCACC TCGCTGATGCTGGGCCTGGGCCGCCAGGGCCTGGGTTGTGATGCCTGCGGCTACTTTTGTCACACAACCTGTGCCCCACAGGCCCCACCC TGCCCCGTGCCCCCTGACCTCCTCCGCACAGCCCTGGGAGTACACCCCGAAACAGGCACAGGCACTGCCTATGAGGGCTTTCTGTCGGTG CCGCGGCCCTCAGGTGTCCGGCGGGGCTGGCAGCGCGTGTTTGCTGCCCTGAGTGACTCACGCCTGCTGCTGTTTGACGCCCCTGACCTG AGGCTCAGCCCGCCCAGTGGGGCCCTCCTGCAGGTCCTAGATCTGAGGGACCCCCAGTTCTCGGCTACCCCTGTCCTGGCCTCTGATGTT ATCCATGCCCAATCCAGGGACCTGCCACGCATCTTTAGGGTGACAACCTCCCAGCTGGCAGTGCCGCCCACCACGTGCACTGTGCTGCTG CTGGCAGAGAGCGAGGGGGAGCGGGAACGCTGGCTGCAGGTGCTGGGTGAGCTGCAGCGGCTGCTGCTGGACGCGCGGCCAAGACCCCGG CCCGTGTACACACTCAAGGAGGCTTACGACAACGGGCTGCCGCTGCTGCCTCACACGCTCTGCGCTGCCATCCTCGACCAGGATCGACTT GCGCTTGGCACCGAGGAGGGGCTCTTTGTCATCCATCTGCGCAGCAACGACATCTTCCAGGTGGGGGAGTGCCGGCGCGTGCAGCAGCTG ACCTTGAGCCCCAGTGCAGGCCTGCTGGTCGTGCTGTGTGGCCGCGGCCCCAGCGTGCGTCTCTTTGCCCTGGCGGAGCTGGAGAACATA GAGGTAGCAGGTGCCAAGATCCCCGAGTCTCGAGGCTGCCAGGTGCTGGCAGCTGGAAGCATCCTGCAGGCCCGCACCCCGGTGCTCTGT GTAGCCGTCAAGCGCCAGGTGCTCTGCTACCAGCTGGGCCCGGGCCCTGGGCCCTGGCAGCGCCGCATCCGTGAGCTGCAGGCACCTGCC ACTGTGCAGAGCCTGGGGCTGCTGGGCGACCGGCTATGTGTGGGCGCCGCCGGTGGCTTTGCACTCTACCCGCTGCTCAACGAGGCTGCG CCGTTGGCGCTGGGGGCCGGTTTGGTGCCTGAGGAGCTGCCACCATCCCGCGGGGGCCTGGGTGAGGCACTGGGTGCCGTGGAGCTTAGC CTCAGCGAGTTCCTGCTACTCTTCACCACTGCTGGCATCTACGTGGATGGCGCAGGCCGCAAGTCTCGTGGCCACGAGCTGTTGTGGCCA GCAGCGCCCATGGGCTGGGGGTATGCGGCCCCCTACCTGACAGTGTTCAGCGAGAACTCCATCGATGTGTTTGACGTGAGGAGGGCAGAA TGGGTGCAGACCGTGCCGCTCAAGAAGGTGCGGCCCCTCAATCCAGAGGGCTCCCTGTTCCTCTACGGCACCGAGAAGGTCCGCCTGACC TACCTCAGGAACCAGCTGGCAGAGAAGGACGAGTTCGACATCCCGGACCTCACCGACAACAGCCGGCGCCAGCTGTTCCGCACCAAGAGC AAGCGCCGCTTCTTTTTCCGCGTGTCGGAGGAGCAGCAGAAGCAGCAGCGCAGGGAGATGCTGAAGGACCCTTTTGTGCGCTCCAAGCTC ATCTCGCCGCCTACCAACTTCAACCACCTAGTACACGTGGGCCCTGCCAACGGGCGGCCCGGCGCCAGGGACAAGTCCCCGGCTCCCGAA GAGAAGGGCCGAGTTGCCCGCGGCTCCGGCCCACAGCGGCCCCACAGCTTCTCCGAGGCGTTGCGGCGCCCAGCCTCCATGGGCAGCGAA GGCCTCGGTGGAGACGCAGACCCCATGAAGAGGAAACCCTGGACATCCCTGTCCAGCGAGTCTGTGTCCTGCCCCCAGGGATCGCTGAGC CCTGCAACCTCCCTAATGCAGGTCTCAGAACGGCCCCGAAGCCTCCCCCTATCCCCTGAATTGGAGAGCTCTCCTTGATGCCCTCTGTTA GGGCCCACCCCAATCCCAGGGCAGAAGGACATGAGGGAGCAAAGAGCTTGAGGAATGCCATACTCCGGCTGGTCCGGGACATGGAAATTC GGACTCAGGGAGGACCCGGGCTGGGCAATGACTGGGAGACTTGCCTGGGTTCCCAGGACTTGGGGGTCCTGACTCCCAGCCCTCATCCTG CCTTACCCCTCTGTTCCCAGCCCCAGCCTTTCTAAGCCATTGGGAATAGAATGGCCCCTTTTGTTCTGGTGTCCAGGGGTGATTGTGCCA AAGCTCTTATTTCCAGTGCCAAGCCCCCAGAGGCTTGTAAGAGTTGGGATGAGGGATGGAGAGGGACTGGGTCTCTGGGAACAGGTTGGA GGTCTTATCTGTGGACTGTCTGACTCCCAGCTGAGGCCAAGATGGGGCATGTCCCCGTCTCTGCTTAGCGTCTGGGTGAGAAAAACAGGC TGTGATCCAGAAGAAGGGAAGATAGAGAAGGAGGGAAAGGATGTAGGCGAAGGAGGTGAGAGACAGGATAGGAGGAAGGAAGTGGAGGAG GAGGTGATAGGAATTGGAAGGAGGTAGAAGCCGTGCAGAGGAAGAGGGGAGAGGGACGAAGGAGGAGCGATGAAGAAGAGGAGGGAGACA AAAAGAGGGATGGAGGAGAGAGGGAGTCTGGAGAACAAAGGGTCCTTTCTCTGGGGAGGGGTGCAGTGGGCGGGGCTGACACTGTCAGCC AATCCTCCCATCGGGGAAGAGAATCCTGGACAGGGACAGGATGGGGAGGGTATTTATAAGGGCTTTTTGGTGGGAGATGGGTACCCAGTG GGGGCCACTGGAGGGTCTCCGGGCACACTCTGGCCCTTCCCAGAAAGGGGGTCGTTTTTCTCGAATCTTCAACCAGTTGTGTATTGGAAA CTAGGGCGCATTTTACTATTGATCACAGTCATTATATTGTTATTATATTACTATTTTTATTAAACCTCCCCCCACTGAAGTGTGGGGGGC AAAATAAGTATTTATCTCCTCAAATGCCACATTCCCAGGAGGGACAGACCCTGATGCTCTGTGAGGCGCAAGAAACCAATAAAG >4847_4847_4_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000530676_CDC42BPG_chr11_64606374_ENST00000342711_length(amino acids)=1472AA_BP=213 MLNSLSVDPDAECKYGLYFRDGRRKVDYILVYHHKRPSGNRTLVRRVQHSDTPSGARSVKQDHPLPGKGASLDAGSGEPPMDYHEDDKRF RREEYEGNLLEAGLELERDEDTKIHGVGFVKIHAPWNVLCREAEFLKLKMPTKKMYHINETRGLLKKINSVLQKITDPIQPKVAEHRPQT MKRLSYPFSREKQHLFDLSDKDSFFDSKTRSTIDHLQFPPDVPDVPASAQDLIRQLLCRQEERLGRGGLDDFRNHPFFEGVDWERLASST APYIPELRGPMDTSNFDVDDDTLNHPGTLPPPSHGAFSGHHLPFVGFTYTSGSHSPESSSEAWAALERKLQCLEQEKVELSRKHQEALHA PTDHRELEQLRKEVQTLRDRLPEMLRDKASLSQTDGPPAGSPGQDSDLRQELDRLHRELAEGRAGLQAQEQELCRAQGQQEELLQRLQEA QEREAATASQTRALSSQLEEARAAQRELEAQVSSLSRQVTQLQGQWEQRLEESSQAKTIHTASETNGMGPPEGGPQEAQLRKEVAALREQ LEQAHSHRPSGKEEALCQLQEENRRLSREQERLEAELAQEQESKQRLEGERRETESNWEAQLADILSWVNDEKVSRGYLQALATKMAEEL ESLRNVGTQTLPARPLDHQWKARRLQKMEASARLELQSALEAEIRAKQGLQERLTQVQEAQLQAERRLQEAEKQSQALQQELAMLREELR ARGPVDTKPSNSLIPFLSFRSSEKDSAKDPGISGEATRHGGEPDLRPEGRRSLRMGAVFPRAPTANTASTEGLPAKPGSHTLRPRSFPSP TKCLRCTSLMLGLGRQGLGCDACGYFCHTTCAPQAPPCPVPPDLLRTALGVHPETGTGTAYEGFLSVPRPSGVRRGWQRVFAALSDSRLL LFDAPDLRLSPPSGALLQVLDLRDPQFSATPVLASDVIHAQSRDLPRIFRVTTSQLAVPPTTCTVLLLAESEGERERWLQVLGELQRLLL DARPRPRPVYTLKEAYDNGLPLLPHTLCAAILDQDRLALGTEEGLFVIHLRSNDIFQVGECRRVQQLTLSPSAGLLVVLCGRGPSVRLFA LAELENIEVAGAKIPESRGCQVLAAGSILQARTPVLCVAVKRQVLCYQLGPGPGPWQRRIRELQAPATVQSLGLLGDRLCVGAAGGFALY PLLNEAAPLALGAGLVPEELPPSRGGLGEALGAVELSLSEFLLLFTTAGIYVDGAGRKSRGHELLWPAAPMGWGYAAPYLTVFSENSIDV FDVRRAEWVQTVPLKKVRPLNPEGSLFLYGTEKVRLTYLRNQLAEKDEFDIPDLTDNSRRQLFRTKSKRRFFFRVSEEQQKQQRREMLKD PFVRSKLISPPTNFNHLVHVGPANGRPGARDKSPAPEEKGRVARGSGPQRPHSFSEALRRPASMGSEGLGGDADPMKRKPWTSLSSESVS CPQGSLSPATSLMQVSERPRSLPLSPELESSP -------------------------------------------------------------- >4847_4847_5_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000538023_CDC42BPG_chr11_64606374_ENST00000342711_length(transcript)=5662nt_BP=796nt GGATGGGGAGGGCGCGCCGCCCGGCGGTCCCAGCGCACAGGCGGCCACGATGAGGGTCAACGAGAAGTACTCGACGCTCCCGGCCGAGGA CCGCAGCGTCCACATCATCAACATCTGCGCCATCGAGGACATCGGCTACCTGCCGTCCGAGGGCACGCTGCTGAACTCCTTATCTGTGGA CCCTGATGCCGAGTGCAAGTATGGCCTGTACTTCAGGGACGGCCGGCGCAAGGTGGACTACATCCTGGTGTACCATCACAAGAGGCCCTC GGGCAACCGGACCCTGGTCAGGAGGGTGCAGCACAGCGACACCCCCTCTGGGGCTCGCAGCGTCAAGCAGGACCACCCCCTGCCGGGCAA GGGGGCGTCGCTGGATGCAGGCTCGGGGGAGCCCCCGATGGACTACCACGAGGATGACAAGCGCTTCCGCAGGGAGGAGTACGAGGGCAA CCTCCTGGAGGCGGGCCTGGAGCTGGAGCGGGACGAGGACACTAAAATCCACGGAGTCGGGTTTGTGAAAATCCATGCCCCCTGGAACGT GCTGTGCAGAGAGGCCGAGTTTCTGAAACTGAAGATGCCGACGAAGAAGATGTACCACATTAATGAGACCCGTGGCCTCCTGAAAAAAAT CAACTCTGTGCTCCAGAAAATCACAGATCCCATCCAGCCCAAAGTGGCTGAGCACAGGCCCCAGACCATGAAGAGACTCTCCTATCCCTT CTCCCGGGAGAAGCAGCATCTATTTGACTTGTCTGATAAGGATTCCTTTTTCGACAGCAAAACCCGGAGCACGATTGACCACCTGCAGTT CCCCCCGGACGTGCCTGACGTGCCAGCCAGCGCCCAAGACCTGATCCGCCAGCTGCTGTGTCGCCAGGAAGAGCGGCTAGGCCGTGGTGG GCTGGATGACTTCCGGAACCATCCTTTCTTCGAAGGCGTGGACTGGGAGCGGCTGGCGAGCAGCACGGCCCCCTATATTCCTGAGCTGCG GGGGCCCATGGACACCTCCAACTTTGATGTGGATGACGACACCCTCAACCATCCAGGGACCCTGCCACCGCCCTCCCACGGGGCCTTCTC CGGCCATCACCTGCCATTCGTGGGCTTCACCTACACCTCAGGCAGTCACAGTCCTGAGAGCAGCTCTGAGGCTTGGGCTGCCCTGGAGCG GAAGCTCCAGTGTCTGGAGCAGGAGAAGGTGGAGCTGAGCAGGAAGCACCAAGAGGCCCTGCACGCCCCCACAGACCATCGGGAGCTGGA GCAGCTACGGAAGGAAGTGCAGACTCTGCGGGACAGGCTGCCAGAGATGCTGAGGGACAAGGCCTCATTGTCCCAGACGGATGGGCCCCC AGCTGGTAGCCCAGGTCAGGACAGTGACCTACGGCAGGAGCTTGACCGACTTCACCGGGAGCTGGCCGAGGGTCGGGCAGGGCTGCAGGC TCAGGAGCAGGAGCTCTGCAGGGCCCAGGGGCAGCAGGAGGAGCTGCTTCAGAGGCTACAGGAGGCCCAGGAGAGAGAGGCGGCCACAGC TAGCCAGACCCGGGCCCTGAGCTCCCAGCTGGAGGAAGCCCGGGCTGCCCAGAGGGAGCTGGAGGCCCAGGTGTCCTCCCTGAGCCGGCA GGTGACGCAGCTGCAGGGACAGTGGGAGCAACGCCTTGAGGAGTCGTCCCAGGCCAAGACCATCCACACAGCCTCTGAGACCAACGGGAT GGGACCCCCTGAGGGTGGGCCTCAGGAGGCCCAACTGAGGAAGGAGGTGGCCGCCCTGCGAGAGCAGCTGGAGCAGGCCCACAGCCACAG GCCGAGTGGTAAGGAGGAGGCTCTGTGCCAGCTGCAGGAGGAAAACCGGAGGCTGAGCCGGGAGCAGGAGCGGCTAGAAGCAGAGCTGGC CCAGGAGCAGGAGAGCAAGCAGCGGCTGGAGGGTGAGCGGCGGGAGACGGAGAGCAACTGGGAGGCCCAGCTCGCCGACATCCTCAGCTG GGTGAATGATGAGAAGGTCTCAAGAGGCTACCTGCAGGCCCTGGCCACCAAGATGGCAGAGGAGCTGGAGTCCTTGAGGAACGTAGGCAC CCAGACGCTCCCTGCCCGGCCACTGGACCACCAGTGGAAGGCGCGGCGACTGCAGAAGATGGAGGCCTCGGCCAGGCTGGAGCTGCAGTC AGCGCTGGAGGCCGAGATCCGCGCCAAGCAGGGCCTGCAGGAGCGGCTGACACAGGTGCAGGAGGCCCAGCTGCAGGCTGAGCGCCGTCT GCAGGAGGCCGAGAAGCAGAGCCAGGCCCTGCAACAGGAGCTCGCCATGCTGCGGGAGGAGCTGCGGGCCCGAGGGCCAGTGGACACCAA GCCCTCAAACTCCCTGATTCCCTTCCTGTCCTTCCGGAGCTCAGAGAAGGATTCTGCCAAGGACCCTGGCATCTCAGGAGAGGCCACAAG GCATGGAGGAGAGCCAGATCTGAGGCCGGAGGGCCGACGCAGCCTGCGCATGGGGGCTGTGTTCCCCAGAGCACCCACTGCCAACACAGC CTCTACAGAAGGTCTTCCTGCTAAGCCCGGCTCACACACGCTGCGCCCCCGGAGCTTCCCATCCCCGACCAAGTGTCTCCGCTGCACCTC GCTGATGCTGGGCCTGGGCCGCCAGGGCCTGGGTTGTGATGCCTGCGGCTACTTTTGTCACACAACCTGTGCCCCACAGGCCCCACCCTG CCCCGTGCCCCCTGACCTCCTCCGCACAGCCCTGGGAGTACACCCCGAAACAGGCACAGGCACTGCCTATGAGGGCTTTCTGTCGGTGCC GCGGCCCTCAGGTGTCCGGCGGGGCTGGCAGCGCGTGTTTGCTGCCCTGAGTGACTCACGCCTGCTGCTGTTTGACGCCCCTGACCTGAG GCTCAGCCCGCCCAGTGGGGCCCTCCTGCAGGTCCTAGATCTGAGGGACCCCCAGTTCTCGGCTACCCCTGTCCTGGCCTCTGATGTTAT CCATGCCCAATCCAGGGACCTGCCACGCATCTTTAGGGTGACAACCTCCCAGCTGGCAGTGCCGCCCACCACGTGCACTGTGCTGCTGCT GGCAGAGAGCGAGGGGGAGCGGGAACGCTGGCTGCAGGTGCTGGGTGAGCTGCAGCGGCTGCTGCTGGACGCGCGGCCAAGACCCCGGCC CGTGTACACACTCAAGGAGGCTTACGACAACGGGCTGCCGCTGCTGCCTCACACGCTCTGCGCTGCCATCCTCGACCAGGATCGACTTGC GCTTGGCACCGAGGAGGGGCTCTTTGTCATCCATCTGCGCAGCAACGACATCTTCCAGGTGGGGGAGTGCCGGCGCGTGCAGCAGCTGAC CTTGAGCCCCAGTGCAGGCCTGCTGGTCGTGCTGTGTGGCCGCGGCCCCAGCGTGCGTCTCTTTGCCCTGGCGGAGCTGGAGAACATAGA GGTAGCAGGTGCCAAGATCCCCGAGTCTCGAGGCTGCCAGGTGCTGGCAGCTGGAAGCATCCTGCAGGCCCGCACCCCGGTGCTCTGTGT AGCCGTCAAGCGCCAGGTGCTCTGCTACCAGCTGGGCCCGGGCCCTGGGCCCTGGCAGCGCCGCATCCGTGAGCTGCAGGCACCTGCCAC TGTGCAGAGCCTGGGGCTGCTGGGCGACCGGCTATGTGTGGGCGCCGCCGGTGGCTTTGCACTCTACCCGCTGCTCAACGAGGCTGCGCC GTTGGCGCTGGGGGCCGGTTTGGTGCCTGAGGAGCTGCCACCATCCCGCGGGGGCCTGGGTGAGGCACTGGGTGCCGTGGAGCTTAGCCT CAGCGAGTTCCTGCTACTCTTCACCACTGCTGGCATCTACGTGGATGGCGCAGGCCGCAAGTCTCGTGGCCACGAGCTGTTGTGGCCAGC AGCGCCCATGGGCTGGGGGTATGCGGCCCCCTACCTGACAGTGTTCAGCGAGAACTCCATCGATGTGTTTGACGTGAGGAGGGCAGAATG GGTGCAGACCGTGCCGCTCAAGAAGGTGCGGCCCCTCAATCCAGAGGGCTCCCTGTTCCTCTACGGCACCGAGAAGGTCCGCCTGACCTA CCTCAGGAACCAGCTGGCAGAGAAGGACGAGTTCGACATCCCGGACCTCACCGACAACAGCCGGCGCCAGCTGTTCCGCACCAAGAGCAA GCGCCGCTTCTTTTTCCGCGTGTCGGAGGAGCAGCAGAAGCAGCAGCGCAGGGAGATGCTGAAGGACCCTTTTGTGCGCTCCAAGCTCAT CTCGCCGCCTACCAACTTCAACCACCTAGTACACGTGGGCCCTGCCAACGGGCGGCCCGGCGCCAGGGACAAGTCCCCGGCTCCCGAAGA GAAGGGCCGAGTTGCCCGCGGCTCCGGCCCACAGCGGCCCCACAGCTTCTCCGAGGCGTTGCGGCGCCCAGCCTCCATGGGCAGCGAAGG CCTCGGTGGAGACGCAGACCCCATGAAGAGGAAACCCTGGACATCCCTGTCCAGCGAGTCTGTGTCCTGCCCCCAGGGATCGCTGAGCCC TGCAACCTCCCTAATGCAGGTCTCAGAACGGCCCCGAAGCCTCCCCCTATCCCCTGAATTGGAGAGCTCTCCTTGATGCCCTCTGTTAGG GCCCACCCCAATCCCAGGGCAGAAGGACATGAGGGAGCAAAGAGCTTGAGGAATGCCATACTCCGGCTGGTCCGGGACATGGAAATTCGG ACTCAGGGAGGACCCGGGCTGGGCAATGACTGGGAGACTTGCCTGGGTTCCCAGGACTTGGGGGTCCTGACTCCCAGCCCTCATCCTGCC TTACCCCTCTGTTCCCAGCCCCAGCCTTTCTAAGCCATTGGGAATAGAATGGCCCCTTTTGTTCTGGTGTCCAGGGGTGATTGTGCCAAA GCTCTTATTTCCAGTGCCAAGCCCCCAGAGGCTTGTAAGAGTTGGGATGAGGGATGGAGAGGGACTGGGTCTCTGGGAACAGGTTGGAGG TCTTATCTGTGGACTGTCTGACTCCCAGCTGAGGCCAAGATGGGGCATGTCCCCGTCTCTGCTTAGCGTCTGGGTGAGAAAAACAGGCTG TGATCCAGAAGAAGGGAAGATAGAGAAGGAGGGAAAGGATGTAGGCGAAGGAGGTGAGAGACAGGATAGGAGGAAGGAAGTGGAGGAGGA GGTGATAGGAATTGGAAGGAGGTAGAAGCCGTGCAGAGGAAGAGGGGAGAGGGACGAAGGAGGAGCGATGAAGAAGAGGAGGGAGACAAA AAGAGGGATGGAGGAGAGAGGGAGTCTGGAGAACAAAGGGTCCTTTCTCTGGGGAGGGGTGCAGTGGGCGGGGCTGACACTGTCAGCCAA TCCTCCCATCGGGGAAGAGAATCCTGGACAGGGACAGGATGGGGAGGGTATTTATAAGGGCTTTTTGGTGGGAGATGGGTACCCAGTGGG GGCCACTGGAGGGTCTCCGGGCACACTCTGGCCCTTCCCAGAAAGGGGGTCGTTTTTCTCGAATCTTCAACCAGTTGTGTATTGGAAACT AGGGCGCATTTTACTATTGATCACAGTCATTATATTGTTATTATATTACTATTTTTATTAAACCTCCCCCCACTGAAGTGTGGGGGGCAA AATAAGTATTTATCTCCTCAAATGCCACATTCCCAGGAGGGACAGACCCTGATGCTCTGTGAGGCGCAAGAAACCAATAAAG >4847_4847_5_ANO1-CDC42BPG_ANO1_chr11_69951894_ENST00000538023_CDC42BPG_chr11_64606374_ENST00000342711_length(amino acids)=1508AA_BP=249 MRVNEKYSTLPAEDRSVHIINICAIEDIGYLPSEGTLLNSLSVDPDAECKYGLYFRDGRRKVDYILVYHHKRPSGNRTLVRRVQHSDTPS GARSVKQDHPLPGKGASLDAGSGEPPMDYHEDDKRFRREEYEGNLLEAGLELERDEDTKIHGVGFVKIHAPWNVLCREAEFLKLKMPTKK MYHINETRGLLKKINSVLQKITDPIQPKVAEHRPQTMKRLSYPFSREKQHLFDLSDKDSFFDSKTRSTIDHLQFPPDVPDVPASAQDLIR QLLCRQEERLGRGGLDDFRNHPFFEGVDWERLASSTAPYIPELRGPMDTSNFDVDDDTLNHPGTLPPPSHGAFSGHHLPFVGFTYTSGSH SPESSSEAWAALERKLQCLEQEKVELSRKHQEALHAPTDHRELEQLRKEVQTLRDRLPEMLRDKASLSQTDGPPAGSPGQDSDLRQELDR LHRELAEGRAGLQAQEQELCRAQGQQEELLQRLQEAQEREAATASQTRALSSQLEEARAAQRELEAQVSSLSRQVTQLQGQWEQRLEESS QAKTIHTASETNGMGPPEGGPQEAQLRKEVAALREQLEQAHSHRPSGKEEALCQLQEENRRLSREQERLEAELAQEQESKQRLEGERRET ESNWEAQLADILSWVNDEKVSRGYLQALATKMAEELESLRNVGTQTLPARPLDHQWKARRLQKMEASARLELQSALEAEIRAKQGLQERL TQVQEAQLQAERRLQEAEKQSQALQQELAMLREELRARGPVDTKPSNSLIPFLSFRSSEKDSAKDPGISGEATRHGGEPDLRPEGRRSLR MGAVFPRAPTANTASTEGLPAKPGSHTLRPRSFPSPTKCLRCTSLMLGLGRQGLGCDACGYFCHTTCAPQAPPCPVPPDLLRTALGVHPE TGTGTAYEGFLSVPRPSGVRRGWQRVFAALSDSRLLLFDAPDLRLSPPSGALLQVLDLRDPQFSATPVLASDVIHAQSRDLPRIFRVTTS QLAVPPTTCTVLLLAESEGERERWLQVLGELQRLLLDARPRPRPVYTLKEAYDNGLPLLPHTLCAAILDQDRLALGTEEGLFVIHLRSND IFQVGECRRVQQLTLSPSAGLLVVLCGRGPSVRLFALAELENIEVAGAKIPESRGCQVLAAGSILQARTPVLCVAVKRQVLCYQLGPGPG PWQRRIRELQAPATVQSLGLLGDRLCVGAAGGFALYPLLNEAAPLALGAGLVPEELPPSRGGLGEALGAVELSLSEFLLLFTTAGIYVDG AGRKSRGHELLWPAAPMGWGYAAPYLTVFSENSIDVFDVRRAEWVQTVPLKKVRPLNPEGSLFLYGTEKVRLTYLRNQLAEKDEFDIPDL TDNSRRQLFRTKSKRRFFFRVSEEQQKQQRREMLKDPFVRSKLISPPTNFNHLVHVGPANGRPGARDKSPAPEEKGRVARGSGPQRPHSF SEALRRPASMGSEGLGGDADPMKRKPWTSLSSESVSCPQGSLSPATSLMQVSERPRSLPLSPELESSP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ANO1-CDC42BPG |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ANO1-CDC42BPG |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ANO1-CDC42BPG |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies