
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARHGEF10L-GPR137B (FusionGDB2 ID:HG55160TG7107) |
Fusion Gene Summary for ARHGEF10L-GPR137B |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARHGEF10L-GPR137B | Fusion gene ID: hg55160tg7107 | Hgene | Tgene | Gene symbol | ARHGEF10L | GPR137B | Gene ID | 55160 | 7107 |
| Gene name | Rho guanine nucleotide exchange factor 10 like | G protein-coupled receptor 137B | |
| Synonyms | GrinchGEF | TM7SF1 | |
| Cytomap | ('ARHGEF10L')('GPR137B') 1p36.13 | 1q42.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | rho guanine nucleotide exchange factor 10-like proteinRho guanine nucleotide exchange factor (GEF) 10-like | integral membrane protein GPR137Btransmembrane 7 superfamily member 1 (upregulated in kidney)transmembrane 7 superfamily member 1 protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000469726, ENST00000167825, ENST00000361221, ENST00000375408, ENST00000375415, ENST00000434513, ENST00000452522, ENST00000375420, | ||
| Fusion gene scores | * DoF score | 12 X 12 X 12=1728 | 4 X 3 X 2=24 |
| # samples | 17 | 4 | |
| ** MAII score | log2(17/1728*10)=-3.34549656602577 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/24*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: ARHGEF10L [Title/Abstract] AND GPR137B [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARHGEF10L(17991090)-GPR137B(236368426), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ARHGEF10L-GPR137B seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARHGEF10L-GPR137B seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ARHGEF10L | GO:0032933 | SREBP signaling pathway | 16112081 |
| Hgene | ARHGEF10L | GO:0051496 | positive regulation of stress fiber assembly | 16112081 |
| Fusion gene breakpoints across ARHGEF10L (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GPR137B (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-VQ-A922-01A | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
Top |
Fusion Gene ORF analysis for ARHGEF10L-GPR137B |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000469726 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 3UTR-3UTR | ENST00000469726 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 3UTR-intron | ENST00000469726 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-3UTR | ENST00000167825 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-3UTR | ENST00000361221 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-3UTR | ENST00000375408 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-3UTR | ENST00000375415 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-3UTR | ENST00000434513 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-3UTR | ENST00000452522 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-intron | ENST00000167825 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-intron | ENST00000361221 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-intron | ENST00000375408 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-intron | ENST00000375415 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-intron | ENST00000434513 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| 5CDS-intron | ENST00000452522 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| In-frame | ENST00000167825 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| In-frame | ENST00000361221 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| In-frame | ENST00000375408 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| In-frame | ENST00000375415 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| In-frame | ENST00000434513 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| In-frame | ENST00000452522 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| intron-3CDS | ENST00000375420 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| intron-3UTR | ENST00000375420 | ENST00000477559 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| intron-intron | ENST00000375420 | ENST00000366591 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000434513 | ARHGEF10L | chr1 | 17991090 | + | ENST00000366592 | GPR137B | chr1 | 236368426 | + | 4135 | 3153 | 156 | 3386 | 1076 |
| ENST00000361221 | ARHGEF10L | chr1 | 17991090 | + | ENST00000366592 | GPR137B | chr1 | 236368426 | + | 4150 | 3168 | 156 | 3401 | 1081 |
| ENST00000452522 | ARHGEF10L | chr1 | 17991090 | + | ENST00000366592 | GPR137B | chr1 | 236368426 | + | 4033 | 3051 | 156 | 3284 | 1042 |
| ENST00000375415 | ARHGEF10L | chr1 | 17991090 | + | ENST00000366592 | GPR137B | chr1 | 236368426 | + | 3917 | 2935 | 40 | 3168 | 1042 |
| ENST00000375408 | ARHGEF10L | chr1 | 17991090 | + | ENST00000366592 | GPR137B | chr1 | 236368426 | + | 3348 | 2366 | 38 | 2599 | 853 |
| ENST00000167825 | ARHGEF10L | chr1 | 17991090 | + | ENST00000366592 | GPR137B | chr1 | 236368426 | + | 3100 | 2118 | 0 | 2351 | 783 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000434513 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + | 0.001156483 | 0.99884343 |
| ENST00000361221 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + | 0.002153787 | 0.99784625 |
| ENST00000452522 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + | 0.001462639 | 0.9985374 |
| ENST00000375415 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + | 0.001272399 | 0.9987276 |
| ENST00000375408 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + | 0.006961115 | 0.99303895 |
| ENST00000167825 | ENST00000366592 | ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368426 | + | 0.01222341 | 0.98777664 |
Top |
Fusion Genomic Features for ARHGEF10L-GPR137B |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368425 | + | 0.000629145 | 0.9993709 |
| ARHGEF10L | chr1 | 17991090 | + | GPR137B | chr1 | 236368425 | + | 0.000629145 | 0.9993709 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
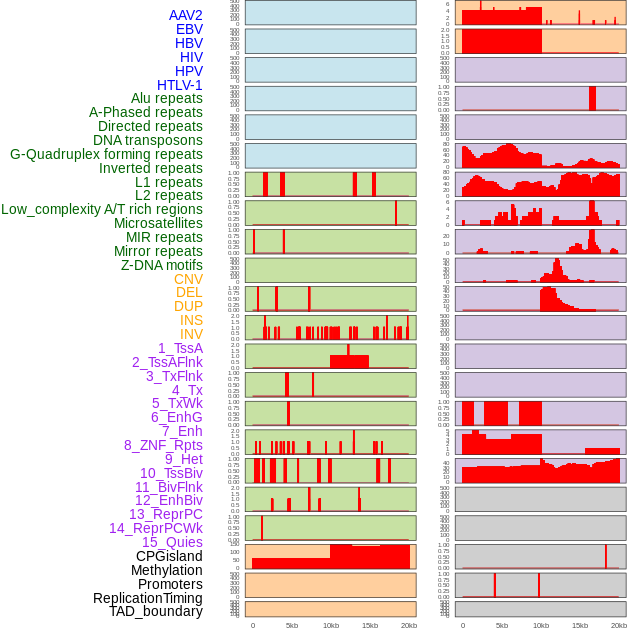 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
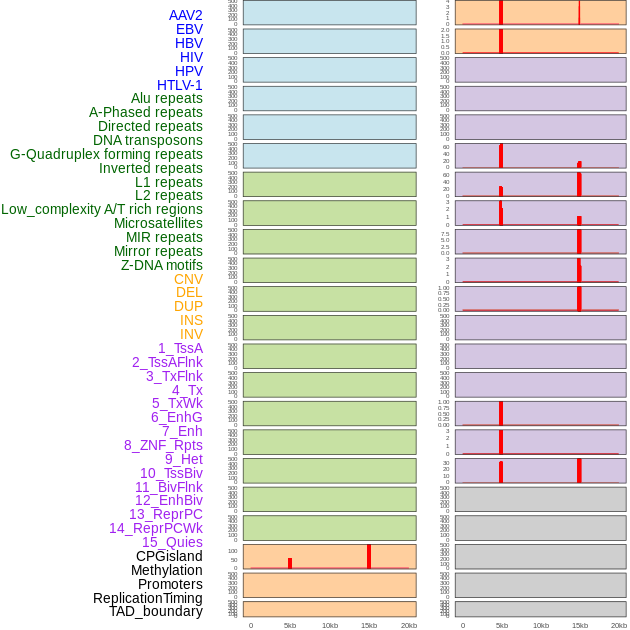 |
Top |
Fusion Protein Features for ARHGEF10L-GPR137B |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:17991090/chr1:236368426) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARHGEF10L | chr1:17991090 | chr1:236368426 | ENST00000167825 | + | 15 | 18 | 316_503 | 706 | 983.0 | Domain | DH |
| Hgene | ARHGEF10L | chr1:17991090 | chr1:236368426 | ENST00000361221 | + | 26 | 29 | 316_503 | 1003 | 1280.0 | Domain | DH |
| Hgene | ARHGEF10L | chr1:17991090 | chr1:236368426 | ENST00000375415 | + | 24 | 27 | 316_503 | 964 | 1241.0 | Domain | DH |
| Hgene | ARHGEF10L | chr1:17991090 | chr1:236368426 | ENST00000434513 | + | 25 | 27 | 316_503 | 998 | 1068.0 | Domain | DH |
| Hgene | ARHGEF10L | chr1:17991090 | chr1:236368426 | ENST00000452522 | + | 25 | 28 | 316_503 | 964 | 1241.0 | Domain | DH |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 101_111 | 322 | 400.0 | Topological domain | Lumenal | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 133_159 | 322 | 400.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 181_188 | 322 | 400.0 | Topological domain | Lumenal | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 1_46 | 322 | 400.0 | Topological domain | Lumenal | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 210_237 | 322 | 400.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 259_292 | 322 | 400.0 | Topological domain | Lumenal | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 314_399 | 322 | 400.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 68_79 | 322 | 400.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 112_132 | 322 | 400.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 160_180 | 322 | 400.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 189_209 | 322 | 400.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 238_258 | 322 | 400.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 293_313 | 322 | 400.0 | Transmembrane | Helical%3B Name%3D7 | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 47_67 | 322 | 400.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | GPR137B | chr1:17991090 | chr1:236368426 | ENST00000366592 | 4 | 7 | 80_100 | 322 | 400.0 | Transmembrane | Helical%3B Name%3D2 |
Top |
Fusion Gene Sequence for ARHGEF10L-GPR137B |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6180_6180_1_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000167825_GPR137B_chr1_236368426_ENST00000366592_length(transcript)=3100nt_BP=2118nt ATGTTACCCAGCAGCTCGTGGGGGAAGAGGAAGCTGCGAGGCAGGCTGGGGTGGGTGCGGAGTGATGCCCGGGGCGTGATGTGGGCCCGG CAGGAGGGTCTGCACCACCCCCACCCCCACGCCGTCATCCGCTGTCCCTCCTCCTCCTCCTCCTCTGTCTCCTGCTCAGGTGACTCGGAG GAGGAGGACATGGGGCTCCTGGAGGTCAGCGTTTCGGACATCAAGCCCCCAGCCCCAGAGCTGGGCCCCATGCCAGAGGGCCTGAGCCCT CAGCAGGTGGTCCGGAGGCATATCCTGGGCTCCATCGTGCAGAGCGAAGGCAGCTACGTGGAGTCTCTGAAGCGGATACTCCAGGACTAC CGCAACCCCCTGATGGAGATGGAGCCCAAGGCGCTGAGCGCCCGCAAGTGCCAGGTGGTGTTCTTCCGCGTGAAGGAGATCCTGCACTGC CACTCCATGTTCCAGATCGCCCTGTCCTCCCGCGTGGCTGAGTGGGATTCCACCGAGAAGATCGGGGACCTCTTCGTGGCCTCGGACATG CTGAAGAACACCCCCAGGGGCCATCCGGACAGGCTGTCGCTGCAGCTGGCCCTCACAGAGCTGGAGACGCTGGCTGAGAAGCTGAACGAG CAGAAGCGGCTGGCTGACCAGGTGGCTGAGATCCAGCAGCTGACCAAGAGCGTCAGTGACCGCAGCAGCCTCAACAAGCTGTTGACCTCA GGCCAGCGGCAGCTGCTCCTGTGTGAGACGTTGACGGAGACCGTGTACGGTGACCGCGGGCAGCTAATTAAGTCCAAGGAGCGTCGGGTC TTCCTGCTCAACGACATGCTTGTCTGTGCCAACATCAACTTCAAGGGCCAGCTGGAGATCAGCAGCCTGGTGCCCCTGGGGCCCAAGTAT GTGGTGAAGTGGAACACGGCGCTGCCCCAGGTGCAGGTGGTGGAGGTGGGCCAGGACGGTGGCACCTATGACAAGGACAATGTGCTCATC CAGCACTCAGGCGCCAAGAAGGCCTCTGCCTCAGGGCAGGCTCAGAATAAGGTGTACCTCGGCCCCCCACGCCTCTTCCAGGAGCTGCAG GACCTGCAGAAGGACCTGGCCGTGGTGGAGCAGATCACGCTTCTCATCAGCACGCTGCACGGCACCTACCAGAACCTGAACATGACTGTG GCTCAAGACTGGTGCCTGGCCCTGCAGAGGCTGATGCGGGTGAAGGAGGAAGAGATCCACTCGGCCAACAAGTGCCGTCTCAGGCTCCTG CTTCCTGGGAAACCCGACAAGTCCGGCCGCCCCATTAGCTTCATGGTGGTTTTCATCACCCCCAACCCCCTGAGCAAGATTTCCTGGGTC AACAGGTTACATTTGGCCAAAATCGGACTCCGGGAGGAGAACCAGCCAGGCTGGCTATGCCCGGATGAGGACAAGAAGAGCAAAGCCCCA TTCTGGTGCCCGATCCTGGCCTGCTGCATCCCTGCCTTCTCCTCCCGGGCACTCAGCCTGCAGCTTGGGGCCCTGGTCCACAGTCCTGTC AACTGTCCCCTGCTGGGTTTCTCAGCAGTCAGCACCTCCCTTCCACAGGGCTACCTCTGGGTCGGGGGCGGACAGGAAGGCGCAGGGGGC CAGGTGGAAATCTTTTCCTTGAACCGGCCCTCGCCCCGCACCGTCAAGTCCTTCCCACTGGCAGCCCCTGTGCTCTGCATGGAGTATATC CCGGAGCTGGAGGAGGAGGCGGAGAGCAGAGACGAGAGCCCGACAGTTGCTGACCCCTCGGCCACGGTGCATCCAACCATCTGCCTCGGG CTCCAGGATGGCAGCATCCTCCTCTACAGCAGTGTGGACACTGGCACCCAGTGCCTGGTGAGCTGCAGGAGCCCAGGTCTGCAGCCTGTG CTCTGCCTGCGACACAGCCCCTTCCACCTGCTCGCTGGCCTGCAGGATGGGACCCTTGCTGCTTACCCTCGGACCAGCGGAGGTGTCCTG TGGGACCTGGAGAGCCCTCCCGTGTGCCTGACTGTGGGGCCCGGGCCTGTCCGCACCCTGTTGAGCCTGGAGGATGCCGTGTGGGCCAGC TGTGGGCCCTGGGTCACTGTCCTGGAAGCCACCACCCTGCAGCCTCAGACCAACCCTGGAATGGTCCCCAGCCATGGATTCAGTCCCAGA TCTTATTTCTTTGACAACCCTCGAAGATATGACAGTGATGATGACCTTGCCTGGAACATTGCCCCTCAGGGACTTCAGGGAGGTTTTGCT CCAGATTACTATGATTGGGGACAACAAACTAACAGCTTCCTGGCACAAGCAGGAACTTTGCAAGACTCAACTTTGGATCCTGACAAACCA AGCCTTGGGTAGCATCAGTTAACAGTTTTATGGACGATTCCTCAGATGAAAAGCTTCAGAAAAGCATAGTGACAGCTGAATTTTTAGGGC ACTTTTCCTTAAGAAATAGAACTTGATTTTTATTTGTTACAGGTTTCCAATGGCCCCATAGGAATAAGCAATAATGTAGACTGATAAACC CTTATTTTAGTACTAAAGAGGGAGCCTTGCTATTTCAGTGGGTATAATTTAAACTTTTTAAAGAAAATCTGTACTTTTATAAAGATGTAT TTTGTATAACTTAAATAATAATGCTAAAGTATACTAGGGTTTTTTTTTCTTGAGAATGTTACTGCAATCATGTTGTAGTTTGCACAGACT TTTATGCATAATTCACTTTAAAAATATAGAATATATGGTCTAATAGTTTTTTAAAGCTTTTGGACTAAAGTATTCCACAAATCTTACCTC TTTAGGTCACTGATGGTCACTCCGATTCTGAGTGCCACATTGGTAGACTCCTAAAATACAGTTGACAACTTAGCCAATTGCAACTCCAGT GTTGATAATTAAAATGAAATGGTAAAGCAGCAGACTGTAAGGTCTTTAGAGATTTTTTTTTTAAGGTTCAGGCCGTAGGTTCCTCAAGGA ATCTCTTAAGTTTTGCCCAAAGACTGGTACTTCCTTTCAGTAGGGCGCTAATGTATACACATTAATGATAAGTTGATAACATTAAAAATG TAGCTGACTTATCCTATTAAACCTCCTCTGCTATGTTCAC >6180_6180_1_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000167825_GPR137B_chr1_236368426_ENST00000366592_length(amino acids)=783AA_BP=706 MLPSSSWGKRKLRGRLGWVRSDARGVMWARQEGLHHPHPHAVIRCPSSSSSSVSCSGDSEEEDMGLLEVSVSDIKPPAPELGPMPEGLSP QQVVRRHILGSIVQSEGSYVESLKRILQDYRNPLMEMEPKALSARKCQVVFFRVKEILHCHSMFQIALSSRVAEWDSTEKIGDLFVASDM LKNTPRGHPDRLSLQLALTELETLAEKLNEQKRLADQVAEIQQLTKSVSDRSSLNKLLTSGQRQLLLCETLTETVYGDRGQLIKSKERRV FLLNDMLVCANINFKGQLEISSLVPLGPKYVVKWNTALPQVQVVEVGQDGGTYDKDNVLIQHSGAKKASASGQAQNKVYLGPPRLFQELQ DLQKDLAVVEQITLLISTLHGTYQNLNMTVAQDWCLALQRLMRVKEEEIHSANKCRLRLLLPGKPDKSGRPISFMVVFITPNPLSKISWV NRLHLAKIGLREENQPGWLCPDEDKKSKAPFWCPILACCIPAFSSRALSLQLGALVHSPVNCPLLGFSAVSTSLPQGYLWVGGGQEGAGG QVEIFSLNRPSPRTVKSFPLAAPVLCMEYIPELEEEAESRDESPTVADPSATVHPTICLGLQDGSILLYSSVDTGTQCLVSCRSPGLQPV LCLRHSPFHLLAGLQDGTLAAYPRTSGGVLWDLESPPVCLTVGPGPVRTLLSLEDAVWASCGPWVTVLEATTLQPQTNPGMVPSHGFSPR SYFFDNPRRYDSDDDLAWNIAPQGLQGGFAPDYYDWGQQTNSFLAQAGTLQDSTLDPDKPSLG -------------------------------------------------------------- >6180_6180_2_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000361221_GPR137B_chr1_236368426_ENST00000366592_length(transcript)=4150nt_BP=3168nt GCGCCGTCCCGGCCATGGGCGCCCGCGGCGGCCTGCGGAGCTGGAGGCGCGGCGCCGGCCGCCAGGCGCCTTTGTGAGCGGCGCGGACGA CAAAGGCGCGGGCCCGGGCAGCCGAGGTGTGTAGCTGGGACGGTGCTGGTCTGAGCTGGACCTTGTCTGATGGCTTCCTCCAACCCTCCT CCACAGCCTGCCATAGGAGATCAGCTGGTTCCAGGAGTCCCAGGCCCCTCCTCTGAGGCAGAGGACGACCCAGGAGAGGCGTTTGAGTTT GATGACAGTGATGATGAAGAGGACACCAGCGCAGCCCTGGGCGTCCCCAGCCTTGCTCCTGAGAGGGACACAGACCCCCCACTGATCCAC TTGGACTCCATCCCTGTCACTGACCCAGACCCAGCAGCTGCTCCACCCGGCACAGGGGTGCCAGCCTGGGTGAGCAATGGGGATGCAGCG GACGCAGCCTTCTCCGGGGCCCGGCACTCCAGCTGGAAGCGGAAGAGTTCCCGTCGCATTGACCGGTTCACTTTCCCCGCCCTGGAAGAG GATGTGATTTATGACGACGTCCCCTGCGAGAGCCCAGATGCGCATCAGCCCGGGGCAGAGAGGAACCTGCTCTACGAGGATGCGCACCGG GCTGGGGCCCCTCGGCAGGCGGAGGACCTAGGCTGGAGCTCCAGTGAGTTCGAGAGCTACAGCGAGGACTCGGGGGAGGAGGCCAAGCCG GAGGTCGAGGTCGAGCCCGCCAAGCACCGAGTGTCCTTCCAGCCCAAGCTTTCTCCAGACCTGACTAGGCTAAAGGAGAGATACGCCAGG ACTAAGAGAGACATCTTGGCTTTGAGAGTTGGGGGGAGAGACATGCAGGAGCTGAAGCACAAGTACGATTGTAAGATGACCCAGCTCATG AAGGCCGCCAAGAGCGGGACCAAGGATGGGCTGGAGAAGACACGGATGGCCGTGATGCGCAAAGTCTCCTTCCTGCACAGGAAGGACGTC CTCGGTGACTCGGAGGAGGAGGACATGGGGCTCCTGGAGGTCAGCGTTTCGGACATCAAGCCCCCAGCCCCAGAGCTGGGCCCCATGCCA GAGGGCCTGAGCCCTCAGCAGGTGGTCCGGAGGCATATCCTGGGCTCCATCGTGCAGAGCGAAGGCAGCTACGTGGAGTCTCTGAAGCGG ATACTCCAGGACTACCGCAACCCCCTGATGGAGATGGAGCCCAAGGCGCTGAGCGCCCGCAAGTGCCAGGTGGTGTTCTTCCGCGTGAAG GAGATCCTGCACTGCCACTCCATGTTCCAGATCGCCCTGTCCTCCCGCGTGGCTGAGTGGGATTCCACCGAGAAGATCGGGGACCTCTTC GTGGCCTCGTTTTCCAAGTCCATGGTGCTAGATGTGTACAGTGACTACGTGAACAACTTCACCAGTGCCATGTCCATCATCAAGAAGGCC TGCCTCACCAAGCCTGCCTTCCTCGAGTTCCTCAAGCGACGGCAGGTGTGCAGCCCAGACCGTGTCACCCTCTACGGGCTGATGGTCAAG CCCATCCAGAGGTTCCCACAGTTCATACTCCTGCTTCAGGACATGCTGAAGAACACCCCCAGGGGCCATCCGGACAGGCTGTCGCTGCAG CTGGCCCTCACAGAGCTGGAGACGCTGGCTGAGAAGCTGAACGAGCAGAAGCGGCTGGCTGACCAGGTGGCTGAGATCCAGCAGCTGACC AAGAGCGTCAGTGACCGCAGCAGCCTCAACAAGCTGTTGACCTCAGGCCAGCGGCAGCTGCTCCTGTGTGAGACGTTGACGGAGACCGTG TACGGTGACCGCGGGCAGCTAATTAAGTCCAAGGAGCGTCGGGTCTTCCTGCTCAACGACATGCTTGTCTGTGCCAACATCAACTTCAAG CCTGCCAACCACAGGGGCCAGCTGGAGATCAGCAGCCTGGTGCCCCTGGGGCCCAAGTATGTGGTGAAGTGGAACACGGCGCTGCCCCAG GTGCAGGTGGTGGAGGTGGGCCAGGACGGTGGCACCTATGACAAGGACAATGTGCTCATCCAGCACTCAGGCGCCAAGAAGGCCTCTGCC TCAGGGCAGGCTCAGAATAAGGTGTACCTCGGCCCCCCACGCCTCTTCCAGGAGCTGCAGGACCTGCAGAAGGACCTGGCCGTGGTGGAG CAGATCACGCTTCTCATCAGCACGCTGCACGGCACCTACCAGAACCTGAACATGACTGTGGCTCAAGACTGGTGCCTGGCCCTGCAGAGG CTGATGCGGGTGAAGGAGGAAGAGATCCACTCGGCCAACAAGTGCCGTCTCAGGCTCCTGCTTCCTGGGAAACCCGACAAGTCCGGCCGC CCCATTAGCTTCATGGTGGTTTTCATCACCCCCAACCCCCTGAGCAAGATTTCCTGGGTCAACAGGTTACATTTGGCCAAAATCGGACTC CGGGAGGAGAACCAGCCAGGCTGGCTATGCCCGGATGAGGACAAGAAGAGCAAAGCCCCATTCTGGTGCCCGATCCTGGCCTGCTGCATC CCTGCCTTCTCCTCCCGGGCACTCAGCCTGCAGCTTGGGGCCCTGGTCCACAGTCCTGTCAACTGTCCCCTGCTGGGTTTCTCAGCAGTC AGCACCTCCCTTCCACAGGGCTACCTCTGGGTCGGGGGCGGACAGGAAGGCGCAGGGGGCCAGGTGGAAATCTTTTCCTTGAACCGGCCC TCGCCCCGCACCGTCAAGTCCTTCCCACTGGCAGCCCCTGTGCTCTGCATGGAGTATATCCCGGAGCTGGAGGAGGAGGCGGAGAGCAGA GACGAGAGCCCGACAGTTGCTGACCCCTCGGCCACGGTGCATCCAACCATCTGCCTCGGGCTCCAGGATGGCAGCATCCTCCTCTACAGC AGTGTGGACACTGGCACCCAGTGCCTGGTGAGCTGCAGGAGCCCAGGTCTGCAGCCTGTGCTCTGCCTGCGACACAGCCCCTTCCACCTG CTCGCTGGCCTGCAGGATGGGACCCTTGCTGCTTACCCTCGGACCAGCGGAGGTGTCCTGTGGGACCTGGAGAGCCCTCCCGTGTGCCTG ACTGTGGGGCCCGGGCCTGTCCGCACCCTGTTGAGCCTGGAGGATGCCGTGTGGGCCAGCTGTGGGCCCTGGGTCACTGTCCTGGAAGCC ACCACCCTGCAGCCTCAGACCAACCCTGGAATGGTCCCCAGCCATGGATTCAGTCCCAGATCTTATTTCTTTGACAACCCTCGAAGATAT GACAGTGATGATGACCTTGCCTGGAACATTGCCCCTCAGGGACTTCAGGGAGGTTTTGCTCCAGATTACTATGATTGGGGACAACAAACT AACAGCTTCCTGGCACAAGCAGGAACTTTGCAAGACTCAACTTTGGATCCTGACAAACCAAGCCTTGGGTAGCATCAGTTAACAGTTTTA TGGACGATTCCTCAGATGAAAAGCTTCAGAAAAGCATAGTGACAGCTGAATTTTTAGGGCACTTTTCCTTAAGAAATAGAACTTGATTTT TATTTGTTACAGGTTTCCAATGGCCCCATAGGAATAAGCAATAATGTAGACTGATAAACCCTTATTTTAGTACTAAAGAGGGAGCCTTGC TATTTCAGTGGGTATAATTTAAACTTTTTAAAGAAAATCTGTACTTTTATAAAGATGTATTTTGTATAACTTAAATAATAATGCTAAAGT ATACTAGGGTTTTTTTTTCTTGAGAATGTTACTGCAATCATGTTGTAGTTTGCACAGACTTTTATGCATAATTCACTTTAAAAATATAGA ATATATGGTCTAATAGTTTTTTAAAGCTTTTGGACTAAAGTATTCCACAAATCTTACCTCTTTAGGTCACTGATGGTCACTCCGATTCTG AGTGCCACATTGGTAGACTCCTAAAATACAGTTGACAACTTAGCCAATTGCAACTCCAGTGTTGATAATTAAAATGAAATGGTAAAGCAG CAGACTGTAAGGTCTTTAGAGATTTTTTTTTTAAGGTTCAGGCCGTAGGTTCCTCAAGGAATCTCTTAAGTTTTGCCCAAAGACTGGTAC TTCCTTTCAGTAGGGCGCTAATGTATACACATTAATGATAAGTTGATAACATTAAAAATGTAGCTGACTTATCCTATTAAACCTCCTCTG CTATGTTCAC >6180_6180_2_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000361221_GPR137B_chr1_236368426_ENST00000366592_length(amino acids)=1081AA_BP=1004 MMASSNPPPQPAIGDQLVPGVPGPSSEAEDDPGEAFEFDDSDDEEDTSAALGVPSLAPERDTDPPLIHLDSIPVTDPDPAAAPPGTGVPA WVSNGDAADAAFSGARHSSWKRKSSRRIDRFTFPALEEDVIYDDVPCESPDAHQPGAERNLLYEDAHRAGAPRQAEDLGWSSSEFESYSE DSGEEAKPEVEVEPAKHRVSFQPKLSPDLTRLKERYARTKRDILALRVGGRDMQELKHKYDCKMTQLMKAAKSGTKDGLEKTRMAVMRKV SFLHRKDVLGDSEEEDMGLLEVSVSDIKPPAPELGPMPEGLSPQQVVRRHILGSIVQSEGSYVESLKRILQDYRNPLMEMEPKALSARKC QVVFFRVKEILHCHSMFQIALSSRVAEWDSTEKIGDLFVASFSKSMVLDVYSDYVNNFTSAMSIIKKACLTKPAFLEFLKRRQVCSPDRV TLYGLMVKPIQRFPQFILLLQDMLKNTPRGHPDRLSLQLALTELETLAEKLNEQKRLADQVAEIQQLTKSVSDRSSLNKLLTSGQRQLLL CETLTETVYGDRGQLIKSKERRVFLLNDMLVCANINFKPANHRGQLEISSLVPLGPKYVVKWNTALPQVQVVEVGQDGGTYDKDNVLIQH SGAKKASASGQAQNKVYLGPPRLFQELQDLQKDLAVVEQITLLISTLHGTYQNLNMTVAQDWCLALQRLMRVKEEEIHSANKCRLRLLLP GKPDKSGRPISFMVVFITPNPLSKISWVNRLHLAKIGLREENQPGWLCPDEDKKSKAPFWCPILACCIPAFSSRALSLQLGALVHSPVNC PLLGFSAVSTSLPQGYLWVGGGQEGAGGQVEIFSLNRPSPRTVKSFPLAAPVLCMEYIPELEEEAESRDESPTVADPSATVHPTICLGLQ DGSILLYSSVDTGTQCLVSCRSPGLQPVLCLRHSPFHLLAGLQDGTLAAYPRTSGGVLWDLESPPVCLTVGPGPVRTLLSLEDAVWASCG PWVTVLEATTLQPQTNPGMVPSHGFSPRSYFFDNPRRYDSDDDLAWNIAPQGLQGGFAPDYYDWGQQTNSFLAQAGTLQDSTLDPDKPSL G -------------------------------------------------------------- >6180_6180_3_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000375408_GPR137B_chr1_236368426_ENST00000366592_length(transcript)=3348nt_BP=2366nt ATTAATAGCCGTGGCAGGGCTCGAATCACAGGCCAAGAATGTTACCCAGCAGCTCGTGGGGGAAGAGGAAGCTGCGAGGCAGGCTGGGGT GGGTGCGGAGTGATGCCCGGGGCGTGATGTGGGCCCGGCAGGAGGGTCTGCACCACCCCCACCCCCACGCCGTCATCCGCTGTCCCTCCT CCTCCTCCTCCTCTGTCTCCTGCTCAGGTGACTCGGAGGAGGAGGACATGGGGCTCCTGGAGGTCAGCGTTTCGGACATCAAGCCCCCAG CCCCAGAGCTGGGCCCCATGCCAGAGGGCCTGAGCCCTCAGCAGGTGGTCCGGAGGCATATCCTGGGCTCCATCGTGCAGAGCGAAGGCA GCTACGTGGAGTCTCTGAAGCGGATACTCCAGGACTACCGCAACCCCCTGATGGAGATGGAGCCCAAGGCGCTGAGCGCCCGCAAGTGCC AGGTGGTGTTCTTCCGCGTGAAGGAGATCCTGCACTGCCACTCCATGTTCCAGATCGCCCTGTCCTCCCGCGTGGCTGAGTGGGATTCCA CCGAGAAGATCGGGGACCTCTTCGTGGCCTCGTTTTCCAAGTCCATGGTGCTAGATGTGTACAGTGACTACGTGAACAACTTCACCAGTG CCATGTCCATCATCAAGAAGGCCTGCCTCACCAAGCCTGCCTTCCTCGAGTTCCTCAAGCGACGGCAGGTGTGCAGCCCAGACCGTGTCA CCCTCTACGGGCTGATGGTCAAGCCCATCCAGAGGTTCCCACAGTTCATACTCCTGCTTCAGGACATGCTGAAGAACACCCCCAGGGGCC ATCCGGACAGGCTGTCGCTGCAGCTGGCCCTCACAGAGCTGGAGACGCTGGCTGAGAAGCTGAACGAGCAGAAGCGGCTGGCTGACCAGG TGGCTGAGATCCAGCAGCTGACCAAGAGCGTCAGTGACCGCAGCAGCCTCAACAAGCTGTTGACCTCAGGCCAGCGGCAGCTGCTCCTGT GTGAGACGTTGACGGAGACCGTGTACGGTGACCGCGGGCAGCTAATTAAGTCCAAGGAGCGTCGGGTCTTCCTGCTCAACGACATGCTTG TCTGTGCCAACATCAACTTCAAGGGCCAGCTGGAGATCAGCAGCCTGGTGCCCCTGGGGCCCAAGTATGTGGTGAAGTGGAACACGGCGC TGCCCCAGGTGCAGGTGGTGGAGGTGGGCCAGGACGGTGGCACCTATGACAAGGACAATGTGCTCATCCAGCACTCAGGCGCCAAGAAGG CCTCTGCCTCAGGGCAGGCTCAGAATAAGGTGTACCTCGGCCCCCCACGCCTCTTCCAGGAGCTGCAGGACCTGCAGAAGGACCTGGCCG TGGTGGAGCAGATCACGCTTCTCATCAGCACGCTGCACGGCACCTACCAGAACCTGAACATGACTGTGGCTCAAGACTGGTGCCTGGCCC TGCAGAGGCTGATGCGGGTGAAGGAGGAAGAGATCCACTCGGCCAACAAGTGCCGTCTCAGGCTCCTGCTTCCTGGGAAACCCGACAAGT CCGGCCGCCCCATTAGCTTCATGGTGGTTTTCATCACCCCCAACCCCCTGAGCAAGATTTCCTGGGTCAACAGGTTACATTTGGCCAAAA TCGGACTCCGGGAGGAGAACCAGCCAGGCTGGCTATGCCCGGATGAGGACAAGAAGAGCAAAGCCCCATTCTGGTGCCCGATCCTGGCCT GCTGCATCCCTGCCTTCTCCTCCCGGGCACTCAGCCTGCAGCTTGGGGCCCTGGTCCACAGTCCTGTCAACTGTCCCCTGCTGGGTTTCT CAGCAGTCAGCACCTCCCTTCCACAGGGCTACCTCTGGGTCGGGGGCGGACAGGAAGGCGCAGGGGGCCAGGTGGAAATCTTTTCCTTGA ACCGGCCCTCGCCCCGCACCGTCAAGTCCTTCCCACTGGCAGCCCCTGTGCTCTGCATGGAGTATATCCCGGAGCTGGAGGAGGAGGCGG AGAGCAGAGACGAGAGCCCGACAGTTGCTGACCCCTCGGCCACGGTGCATCCAACCATCTGCCTCGGGCTCCAGGATGGCAGCATCCTCC TCTACAGCAGTGTGGACACTGGCACCCAGTGCCTGGTGAGCTGCAGGAGCCCAGGTCTGCAGCCTGTGCTCTGCCTGCGACACAGCCCCT TCCACCTGCTCGCTGGCCTGCAGGATGGGACCCTTGCTGCTTACCCTCGGACCAGCGGAGGTGTCCTGTGGGACCTGGAGAGCCCTCCCG TGTGCCTGACTGTGGGGCCCGGGCCTGTCCGCACCCTGTTGAGCCTGGAGGATGCCGTGTGGGCCAGCTGTGGGCCCTGGGTCACTGTCC TGGAAGCCACCACCCTGCAGCCTCAGACCAACCCTGGAATGGTCCCCAGCCATGGATTCAGTCCCAGATCTTATTTCTTTGACAACCCTC GAAGATATGACAGTGATGATGACCTTGCCTGGAACATTGCCCCTCAGGGACTTCAGGGAGGTTTTGCTCCAGATTACTATGATTGGGGAC AACAAACTAACAGCTTCCTGGCACAAGCAGGAACTTTGCAAGACTCAACTTTGGATCCTGACAAACCAAGCCTTGGGTAGCATCAGTTAA CAGTTTTATGGACGATTCCTCAGATGAAAAGCTTCAGAAAAGCATAGTGACAGCTGAATTTTTAGGGCACTTTTCCTTAAGAAATAGAAC TTGATTTTTATTTGTTACAGGTTTCCAATGGCCCCATAGGAATAAGCAATAATGTAGACTGATAAACCCTTATTTTAGTACTAAAGAGGG AGCCTTGCTATTTCAGTGGGTATAATTTAAACTTTTTAAAGAAAATCTGTACTTTTATAAAGATGTATTTTGTATAACTTAAATAATAAT GCTAAAGTATACTAGGGTTTTTTTTTCTTGAGAATGTTACTGCAATCATGTTGTAGTTTGCACAGACTTTTATGCATAATTCACTTTAAA AATATAGAATATATGGTCTAATAGTTTTTTAAAGCTTTTGGACTAAAGTATTCCACAAATCTTACCTCTTTAGGTCACTGATGGTCACTC CGATTCTGAGTGCCACATTGGTAGACTCCTAAAATACAGTTGACAACTTAGCCAATTGCAACTCCAGTGTTGATAATTAAAATGAAATGG TAAAGCAGCAGACTGTAAGGTCTTTAGAGATTTTTTTTTTAAGGTTCAGGCCGTAGGTTCCTCAAGGAATCTCTTAAGTTTTGCCCAAAG ACTGGTACTTCCTTTCAGTAGGGCGCTAATGTATACACATTAATGATAAGTTGATAACATTAAAAATGTAGCTGACTTATCCTATTAAAC CTCCTCTGCTATGTTCAC >6180_6180_3_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000375408_GPR137B_chr1_236368426_ENST00000366592_length(amino acids)=853AA_BP=776 MLPSSSWGKRKLRGRLGWVRSDARGVMWARQEGLHHPHPHAVIRCPSSSSSSVSCSGDSEEEDMGLLEVSVSDIKPPAPELGPMPEGLSP QQVVRRHILGSIVQSEGSYVESLKRILQDYRNPLMEMEPKALSARKCQVVFFRVKEILHCHSMFQIALSSRVAEWDSTEKIGDLFVASFS KSMVLDVYSDYVNNFTSAMSIIKKACLTKPAFLEFLKRRQVCSPDRVTLYGLMVKPIQRFPQFILLLQDMLKNTPRGHPDRLSLQLALTE LETLAEKLNEQKRLADQVAEIQQLTKSVSDRSSLNKLLTSGQRQLLLCETLTETVYGDRGQLIKSKERRVFLLNDMLVCANINFKGQLEI SSLVPLGPKYVVKWNTALPQVQVVEVGQDGGTYDKDNVLIQHSGAKKASASGQAQNKVYLGPPRLFQELQDLQKDLAVVEQITLLISTLH GTYQNLNMTVAQDWCLALQRLMRVKEEEIHSANKCRLRLLLPGKPDKSGRPISFMVVFITPNPLSKISWVNRLHLAKIGLREENQPGWLC PDEDKKSKAPFWCPILACCIPAFSSRALSLQLGALVHSPVNCPLLGFSAVSTSLPQGYLWVGGGQEGAGGQVEIFSLNRPSPRTVKSFPL AAPVLCMEYIPELEEEAESRDESPTVADPSATVHPTICLGLQDGSILLYSSVDTGTQCLVSCRSPGLQPVLCLRHSPFHLLAGLQDGTLA AYPRTSGGVLWDLESPPVCLTVGPGPVRTLLSLEDAVWASCGPWVTVLEATTLQPQTNPGMVPSHGFSPRSYFFDNPRRYDSDDDLAWNI APQGLQGGFAPDYYDWGQQTNSFLAQAGTLQDSTLDPDKPSLG -------------------------------------------------------------- >6180_6180_4_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000375415_GPR137B_chr1_236368426_ENST00000366592_length(transcript)=3917nt_BP=2935nt GTGTGTAGCTGGGACGGTGCTGGTCTGAGCTGGACCTTGTCTGATGGCTTCCTCCAACCCTCCTCCACAGCCTGCCATAGGAGATCAGCT GGTTCCAGGAGTCCCAGGCCCCTCCTCTGAGGCAGAGGACGACCCAGGAGAGGCGTTTGAGTTTGATGACAGTGATGATGAAGAGGACAC CAGCGCAGCCCTGGGCGTCCCCAGCCTTGCTCCTGAGAGGGACACAGACCCCCCACTGATCCACTTGGACTCCATCCCTGTCACTGACCC AGACCCAGCAGCTGCTCCACCCGGCACAGGGGTGCCAGCCTGGGTGAGCAATGGGGATGCAGCGGACGCAGCCTTCTCCGGGGCCCGGCA CTCCAGCTGGAAGCGGAAGAGTTCCCGTCGCATTGACCGGTTCACTTTCCCCGCCCTGGAAGAGGATGTGATTTATGACGACGTCCCCTG CGAGAGCCCAGATGCGCATCAGCCCGGGGCAGAGAGGAACCTGCTCTACGAGGATGCGCACCGGGCTGGGGCCCCTCGGCAGGCGGAGGA CCTAGGCTGGAGCTCCAGTGAGTTCGAGAGCTACAGCGAGGACTCGGGGGAGGAGGCCAAGCCGGAGGTCGAGGTCGAGCCCGCCAAGCA CCGAGTGTCCTTCCAGCCCAAGATGACCCAGCTCATGAAGGCCGCCAAGAGCGGGACCAAGGATGGGCTGGAGAAGACACGGATGGCCGT GATGCGCAAAGTCTCCTTCCTGCACAGGAAGGACGTCCTCGGTGACTCGGAGGAGGAGGACATGGGGCTCCTGGAGGTCAGCGTTTCGGA CATCAAGCCCCCAGCCCCAGAGCTGGGCCCCATGCCAGAGGGCCTGAGCCCTCAGCAGGTGGTCCGGAGGCATATCCTGGGCTCCATCGT GCAGAGCGAAGGCAGCTACGTGGAGTCTCTGAAGCGGATACTCCAGGACTACCGCAACCCCCTGATGGAGATGGAGCCCAAGGCGCTGAG CGCCCGCAAGTGCCAGGTGGTGTTCTTCCGCGTGAAGGAGATCCTGCACTGCCACTCCATGTTCCAGATCGCCCTGTCCTCCCGCGTGGC TGAGTGGGATTCCACCGAGAAGATCGGGGACCTCTTCGTGGCCTCGTTTTCCAAGTCCATGGTGCTAGATGTGTACAGTGACTACGTGAA CAACTTCACCAGTGCCATGTCCATCATCAAGAAGGCCTGCCTCACCAAGCCTGCCTTCCTCGAGTTCCTCAAGCGACGGCAGGTGTGCAG CCCAGACCGTGTCACCCTCTACGGGCTGATGGTCAAGCCCATCCAGAGGTTCCCACAGTTCATACTCCTGCTTCAGGACATGCTGAAGAA CACCCCCAGGGGCCATCCGGACAGGCTGTCGCTGCAGCTGGCCCTCACAGAGCTGGAGACGCTGGCTGAGAAGCTGAACGAGCAGAAGCG GCTGGCTGACCAGGTGGCTGAGATCCAGCAGCTGACCAAGAGCGTCAGTGACCGCAGCAGCCTCAACAAGCTGTTGACCTCAGGCCAGCG GCAGCTGCTCCTGTGTGAGACGTTGACGGAGACCGTGTACGGTGACCGCGGGCAGCTAATTAAGTCCAAGGAGCGTCGGGTCTTCCTGCT CAACGACATGCTTGTCTGTGCCAACATCAACTTCAAGCCTGCCAACCACAGGGGCCAGCTGGAGATCAGCAGCCTGGTGCCCCTGGGGCC CAAGTATGTGGTGAAGTGGAACACGGCGCTGCCCCAGGTGCAGGTGGTGGAGGTGGGCCAGGACGGTGGCACCTATGACAAGGACAATGT GCTCATCCAGCACTCAGGCGCCAAGAAGGCCTCTGCCTCAGGGCAGGCTCAGAATAAGGTGTACCTCGGCCCCCCACGCCTCTTCCAGGA GCTGCAGGACCTGCAGAAGGACCTGGCCGTGGTGGAGCAGATCACGCTTCTCATCAGCACGCTGCACGGCACCTACCAGAACCTGAACAT GACTGTGGCTCAAGACTGGTGCCTGGCCCTGCAGAGGCTGATGCGGGTGAAGGAGGAAGAGATCCACTCGGCCAACAAGTGCCGTCTCAG GCTCCTGCTTCCTGGGAAACCCGACAAGTCCGGCCGCCCCATTAGCTTCATGGTGGTTTTCATCACCCCCAACCCCCTGAGCAAGATTTC CTGGGTCAACAGGTTACATTTGGCCAAAATCGGACTCCGGGAGGAGAACCAGCCAGGCTGGCTATGCCCGGATGAGGACAAGAAGAGCAA AGCCCCATTCTGGTGCCCGATCCTGGCCTGCTGCATCCCTGCCTTCTCCTCCCGGGCACTCAGCCTGCAGCTTGGGGCCCTGGTCCACAG TCCTGTCAACTGTCCCCTGCTGGGTTTCTCAGCAGTCAGCACCTCCCTTCCACAGGGCTACCTCTGGGTCGGGGGCGGACAGGAAGGCGC AGGGGGCCAGGTGGAAATCTTTTCCTTGAACCGGCCCTCGCCCCGCACCGTCAAGTCCTTCCCACTGGCAGCCCCTGTGCTCTGCATGGA GTATATCCCGGAGCTGGAGGAGGAGGCGGAGAGCAGAGACGAGAGCCCGACAGTTGCTGACCCCTCGGCCACGGTGCATCCAACCATCTG CCTCGGGCTCCAGGATGGCAGCATCCTCCTCTACAGCAGTGTGGACACTGGCACCCAGTGCCTGGTGAGCTGCAGGAGCCCAGGTCTGCA GCCTGTGCTCTGCCTGCGACACAGCCCCTTCCACCTGCTCGCTGGCCTGCAGGATGGGACCCTTGCTGCTTACCCTCGGACCAGCGGAGG TGTCCTGTGGGACCTGGAGAGCCCTCCCGTGTGCCTGACTGTGGGGCCCGGGCCTGTCCGCACCCTGTTGAGCCTGGAGGATGCCGTGTG GGCCAGCTGTGGGCCCTGGGTCACTGTCCTGGAAGCCACCACCCTGCAGCCTCAGACCAACCCTGGAATGGTCCCCAGCCATGGATTCAG TCCCAGATCTTATTTCTTTGACAACCCTCGAAGATATGACAGTGATGATGACCTTGCCTGGAACATTGCCCCTCAGGGACTTCAGGGAGG TTTTGCTCCAGATTACTATGATTGGGGACAACAAACTAACAGCTTCCTGGCACAAGCAGGAACTTTGCAAGACTCAACTTTGGATCCTGA CAAACCAAGCCTTGGGTAGCATCAGTTAACAGTTTTATGGACGATTCCTCAGATGAAAAGCTTCAGAAAAGCATAGTGACAGCTGAATTT TTAGGGCACTTTTCCTTAAGAAATAGAACTTGATTTTTATTTGTTACAGGTTTCCAATGGCCCCATAGGAATAAGCAATAATGTAGACTG ATAAACCCTTATTTTAGTACTAAAGAGGGAGCCTTGCTATTTCAGTGGGTATAATTTAAACTTTTTAAAGAAAATCTGTACTTTTATAAA GATGTATTTTGTATAACTTAAATAATAATGCTAAAGTATACTAGGGTTTTTTTTTCTTGAGAATGTTACTGCAATCATGTTGTAGTTTGC ACAGACTTTTATGCATAATTCACTTTAAAAATATAGAATATATGGTCTAATAGTTTTTTAAAGCTTTTGGACTAAAGTATTCCACAAATC TTACCTCTTTAGGTCACTGATGGTCACTCCGATTCTGAGTGCCACATTGGTAGACTCCTAAAATACAGTTGACAACTTAGCCAATTGCAA CTCCAGTGTTGATAATTAAAATGAAATGGTAAAGCAGCAGACTGTAAGGTCTTTAGAGATTTTTTTTTTAAGGTTCAGGCCGTAGGTTCC TCAAGGAATCTCTTAAGTTTTGCCCAAAGACTGGTACTTCCTTTCAGTAGGGCGCTAATGTATACACATTAATGATAAGTTGATAACATT AAAAATGTAGCTGACTTATCCTATTAAACCTCCTCTGCTATGTTCAC >6180_6180_4_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000375415_GPR137B_chr1_236368426_ENST00000366592_length(amino acids)=1042AA_BP=965 MMASSNPPPQPAIGDQLVPGVPGPSSEAEDDPGEAFEFDDSDDEEDTSAALGVPSLAPERDTDPPLIHLDSIPVTDPDPAAAPPGTGVPA WVSNGDAADAAFSGARHSSWKRKSSRRIDRFTFPALEEDVIYDDVPCESPDAHQPGAERNLLYEDAHRAGAPRQAEDLGWSSSEFESYSE DSGEEAKPEVEVEPAKHRVSFQPKMTQLMKAAKSGTKDGLEKTRMAVMRKVSFLHRKDVLGDSEEEDMGLLEVSVSDIKPPAPELGPMPE GLSPQQVVRRHILGSIVQSEGSYVESLKRILQDYRNPLMEMEPKALSARKCQVVFFRVKEILHCHSMFQIALSSRVAEWDSTEKIGDLFV ASFSKSMVLDVYSDYVNNFTSAMSIIKKACLTKPAFLEFLKRRQVCSPDRVTLYGLMVKPIQRFPQFILLLQDMLKNTPRGHPDRLSLQL ALTELETLAEKLNEQKRLADQVAEIQQLTKSVSDRSSLNKLLTSGQRQLLLCETLTETVYGDRGQLIKSKERRVFLLNDMLVCANINFKP ANHRGQLEISSLVPLGPKYVVKWNTALPQVQVVEVGQDGGTYDKDNVLIQHSGAKKASASGQAQNKVYLGPPRLFQELQDLQKDLAVVEQ ITLLISTLHGTYQNLNMTVAQDWCLALQRLMRVKEEEIHSANKCRLRLLLPGKPDKSGRPISFMVVFITPNPLSKISWVNRLHLAKIGLR EENQPGWLCPDEDKKSKAPFWCPILACCIPAFSSRALSLQLGALVHSPVNCPLLGFSAVSTSLPQGYLWVGGGQEGAGGQVEIFSLNRPS PRTVKSFPLAAPVLCMEYIPELEEEAESRDESPTVADPSATVHPTICLGLQDGSILLYSSVDTGTQCLVSCRSPGLQPVLCLRHSPFHLL AGLQDGTLAAYPRTSGGVLWDLESPPVCLTVGPGPVRTLLSLEDAVWASCGPWVTVLEATTLQPQTNPGMVPSHGFSPRSYFFDNPRRYD SDDDLAWNIAPQGLQGGFAPDYYDWGQQTNSFLAQAGTLQDSTLDPDKPSLG -------------------------------------------------------------- >6180_6180_5_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000434513_GPR137B_chr1_236368426_ENST00000366592_length(transcript)=4135nt_BP=3153nt GCGCCGTCCCGGCCATGGGCGCCCGCGGCGGCCTGCGGAGCTGGAGGCGCGGCGCCGGCCGCCAGGCGCCTTTGTGAGCGGCGCGGACGA CAAAGGCGCGGGCCCGGGCAGCCGAGGTGTGTAGCTGGGACGGTGCTGGTCTGAGCTGGACCTTGTCTGATGGCTTCCTCCAACCCTCCT CCACAGCCTGCCATAGGAGATCAGCTGGTTCCAGGAGTCCCAGGCCCCTCCTCTGAGGCAGAGGACGACCCAGGAGAGGCGTTTGAGTTT GATGACAGTGATGATGAAGAGGACACCAGCGCAGCCCTGGGCGTCCCCAGCCTTGCTCCTGAGAGGGACACAGACCCCCCACTGATCCAC TTGGACTCCATCCCTGTCACTGACCCAGACCCAGCAGCTGCTCCACCCGGCACAGGGGTGCCAGCCTGGGTGAGCAATGGGGATGCAGCG GACGCAGCCTTCTCCGGGGCCCGGCACTCCAGCTGGAAGCGGAAGAGTTCCCGTCGCATTGACCGGTTCACTTTCCCCGCCCTGGAAGAG GATGTGATTTATGACGACGTCCCCTGCGAGAGCCCAGATGCGCATCAGCCCGGGGCAGAGAGGAACCTGCTCTACGAGGATGCGCACCGG GCTGGGGCCCCTCGGCAGGCGGAGGACCTAGGCTGGAGCTCCAGTGAGTTCGAGAGCTACAGCGAGGACTCGGGGGAGGAGGCCAAGCCG GAGGTCGAGGTCGAGCCCGCCAAGCACCGAGTGTCCTTCCAGCCCAAGCTTTCTCCAGACCTGACTAGGCTAAAGGAGAGATACGCCAGG ACTAAGAGAGACATCTTGGCTTTGAGAGTTGGGGGGAGAGACATGCAGGAGCTGAAGCACAAGTACGATTGTAAGATGACCCAGCTCATG AAGGCCGCCAAGAGCGGGACCAAGGATGGGCTGGAGAAGACACGGATGGCCGTGATGCGCAAAGTCTCCTTCCTGCACAGGAAGGACGTC CTCGGTGACTCGGAGGAGGAGGACATGGGGCTCCTGGAGGTCAGCGTTTCGGACATCAAGCCCCCAGCCCCAGAGCTGGGCCCCATGCCA GAGGGCCTGAGCCCTCAGCAGGTGGTCCGGAGGCATATCCTGGGCTCCATCGTGCAGAGCGAAGGCAGCTACGTGGAGTCTCTGAAGCGG ATACTCCAGGACTACCGCAACCCCCTGATGGAGATGGAGCCCAAGGCGCTGAGCGCCCGCAAGTGCCAGGTGGTGTTCTTCCGCGTGAAG GAGATCCTGCACTGCCACTCCATGTTCCAGATCGCCCTGTCCTCCCGCGTGGCTGAGTGGGATTCCACCGAGAAGATCGGGGACCTCTTC GTGGCCTCGTTTTCCAAGTCCATGGTGCTAGATGTGTACAGTGACTACGTGAACAACTTCACCAGTGCCATGTCCATCATCAAGAAGGCC TGCCTCACCAAGCCTGCCTTCCTCGAGTTCCTCAAGCGACGGCAGGTGTGCAGCCCAGACCGTGTCACCCTCTACGGGCTGATGGTCAAG CCCATCCAGAGGTTCCCACAGTTCATACTCCTGCTTCAGGACATGCTGAAGAACACCCCCAGGGGCCATCCGGACAGGCTGTCGCTGCAG CTGGCCCTCACAGAGCTGGAGACGCTGGCTGAGAAGCTGAACGAGCAGAAGCGGCTGGCTGACCAGGTGGCTGAGATCCAGCAGCTGACC AAGAGCGTCAGTGACCGCAGCAGCCTCAACAAGCTGTTGACCTCAGGCCAGCGGCAGCTGCTCCTGTGTGAGACGTTGACGGAGACCGTG TACGGTGACCGCGGGCAGCTAATTAAGTCCAAGGAGCGTCGGGTCTTCCTGCTCAACGACATGCTTGTCTGTGCCAACATCAACTTCAAG GGCCAGCTGGAGATCAGCAGCCTGGTGCCCCTGGGGCCCAAGTATGTGGTGAAGTGGAACACGGCGCTGCCCCAGGTGCAGGTGGTGGAG GTGGGCCAGGACGGTGGCACCTATGACAAGGACAATGTGCTCATCCAGCACTCAGGCGCCAAGAAGGCCTCTGCCTCAGGGCAGGCTCAG AATAAGGTGTACCTCGGCCCCCCACGCCTCTTCCAGGAGCTGCAGGACCTGCAGAAGGACCTGGCCGTGGTGGAGCAGATCACGCTTCTC ATCAGCACGCTGCACGGCACCTACCAGAACCTGAACATGACTGTGGCTCAAGACTGGTGCCTGGCCCTGCAGAGGCTGATGCGGGTGAAG GAGGAAGAGATCCACTCGGCCAACAAGTGCCGTCTCAGGCTCCTGCTTCCTGGGAAACCCGACAAGTCCGGCCGCCCCATTAGCTTCATG GTGGTTTTCATCACCCCCAACCCCCTGAGCAAGATTTCCTGGGTCAACAGGTTACATTTGGCCAAAATCGGACTCCGGGAGGAGAACCAG CCAGGCTGGCTATGCCCGGATGAGGACAAGAAGAGCAAAGCCCCATTCTGGTGCCCGATCCTGGCCTGCTGCATCCCTGCCTTCTCCTCC CGGGCACTCAGCCTGCAGCTTGGGGCCCTGGTCCACAGTCCTGTCAACTGTCCCCTGCTGGGTTTCTCAGCAGTCAGCACCTCCCTTCCA CAGGGCTACCTCTGGGTCGGGGGCGGACAGGAAGGCGCAGGGGGCCAGGTGGAAATCTTTTCCTTGAACCGGCCCTCGCCCCGCACCGTC AAGTCCTTCCCACTGGCAGCCCCTGTGCTCTGCATGGAGTATATCCCGGAGCTGGAGGAGGAGGCGGAGAGCAGAGACGAGAGCCCGACA GTTGCTGACCCCTCGGCCACGGTGCATCCAACCATCTGCCTCGGGCTCCAGGATGGCAGCATCCTCCTCTACAGCAGTGTGGACACTGGC ACCCAGTGCCTGGTGAGCTGCAGGAGCCCAGGTCTGCAGCCTGTGCTCTGCCTGCGACACAGCCCCTTCCACCTGCTCGCTGGCCTGCAG GATGGGACCCTTGCTGCTTACCCTCGGACCAGCGGAGGTGTCCTGTGGGACCTGGAGAGCCCTCCCGTGTGCCTGACTGTGGGGCCCGGG CCTGTCCGCACCCTGTTGAGCCTGGAGGATGCCGTGTGGGCCAGCTGTGGGCCCTGGGTCACTGTCCTGGAAGCCACCACCCTGCAGCCT CAGACCAACCCTGGAATGGTCCCCAGCCATGGATTCAGTCCCAGATCTTATTTCTTTGACAACCCTCGAAGATATGACAGTGATGATGAC CTTGCCTGGAACATTGCCCCTCAGGGACTTCAGGGAGGTTTTGCTCCAGATTACTATGATTGGGGACAACAAACTAACAGCTTCCTGGCA CAAGCAGGAACTTTGCAAGACTCAACTTTGGATCCTGACAAACCAAGCCTTGGGTAGCATCAGTTAACAGTTTTATGGACGATTCCTCAG ATGAAAAGCTTCAGAAAAGCATAGTGACAGCTGAATTTTTAGGGCACTTTTCCTTAAGAAATAGAACTTGATTTTTATTTGTTACAGGTT TCCAATGGCCCCATAGGAATAAGCAATAATGTAGACTGATAAACCCTTATTTTAGTACTAAAGAGGGAGCCTTGCTATTTCAGTGGGTAT AATTTAAACTTTTTAAAGAAAATCTGTACTTTTATAAAGATGTATTTTGTATAACTTAAATAATAATGCTAAAGTATACTAGGGTTTTTT TTTCTTGAGAATGTTACTGCAATCATGTTGTAGTTTGCACAGACTTTTATGCATAATTCACTTTAAAAATATAGAATATATGGTCTAATA GTTTTTTAAAGCTTTTGGACTAAAGTATTCCACAAATCTTACCTCTTTAGGTCACTGATGGTCACTCCGATTCTGAGTGCCACATTGGTA GACTCCTAAAATACAGTTGACAACTTAGCCAATTGCAACTCCAGTGTTGATAATTAAAATGAAATGGTAAAGCAGCAGACTGTAAGGTCT TTAGAGATTTTTTTTTTAAGGTTCAGGCCGTAGGTTCCTCAAGGAATCTCTTAAGTTTTGCCCAAAGACTGGTACTTCCTTTCAGTAGGG CGCTAATGTATACACATTAATGATAAGTTGATAACATTAAAAATGTAGCTGACTTATCCTATTAAACCTCCTCTGCTATGTTCAC >6180_6180_5_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000434513_GPR137B_chr1_236368426_ENST00000366592_length(amino acids)=1076AA_BP=999 MMASSNPPPQPAIGDQLVPGVPGPSSEAEDDPGEAFEFDDSDDEEDTSAALGVPSLAPERDTDPPLIHLDSIPVTDPDPAAAPPGTGVPA WVSNGDAADAAFSGARHSSWKRKSSRRIDRFTFPALEEDVIYDDVPCESPDAHQPGAERNLLYEDAHRAGAPRQAEDLGWSSSEFESYSE DSGEEAKPEVEVEPAKHRVSFQPKLSPDLTRLKERYARTKRDILALRVGGRDMQELKHKYDCKMTQLMKAAKSGTKDGLEKTRMAVMRKV SFLHRKDVLGDSEEEDMGLLEVSVSDIKPPAPELGPMPEGLSPQQVVRRHILGSIVQSEGSYVESLKRILQDYRNPLMEMEPKALSARKC QVVFFRVKEILHCHSMFQIALSSRVAEWDSTEKIGDLFVASFSKSMVLDVYSDYVNNFTSAMSIIKKACLTKPAFLEFLKRRQVCSPDRV TLYGLMVKPIQRFPQFILLLQDMLKNTPRGHPDRLSLQLALTELETLAEKLNEQKRLADQVAEIQQLTKSVSDRSSLNKLLTSGQRQLLL CETLTETVYGDRGQLIKSKERRVFLLNDMLVCANINFKGQLEISSLVPLGPKYVVKWNTALPQVQVVEVGQDGGTYDKDNVLIQHSGAKK ASASGQAQNKVYLGPPRLFQELQDLQKDLAVVEQITLLISTLHGTYQNLNMTVAQDWCLALQRLMRVKEEEIHSANKCRLRLLLPGKPDK SGRPISFMVVFITPNPLSKISWVNRLHLAKIGLREENQPGWLCPDEDKKSKAPFWCPILACCIPAFSSRALSLQLGALVHSPVNCPLLGF SAVSTSLPQGYLWVGGGQEGAGGQVEIFSLNRPSPRTVKSFPLAAPVLCMEYIPELEEEAESRDESPTVADPSATVHPTICLGLQDGSIL LYSSVDTGTQCLVSCRSPGLQPVLCLRHSPFHLLAGLQDGTLAAYPRTSGGVLWDLESPPVCLTVGPGPVRTLLSLEDAVWASCGPWVTV LEATTLQPQTNPGMVPSHGFSPRSYFFDNPRRYDSDDDLAWNIAPQGLQGGFAPDYYDWGQQTNSFLAQAGTLQDSTLDPDKPSLG -------------------------------------------------------------- >6180_6180_6_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000452522_GPR137B_chr1_236368426_ENST00000366592_length(transcript)=4033nt_BP=3051nt GCGCCGTCCCGGCCATGGGCGCCCGCGGCGGCCTGCGGAGCTGGAGGCGCGGCGCCGGCCGCCAGGCGCCTTTGTGAGCGGCGCGGACGA CAAAGGCGCGGGCCCGGGCAGCCGAGGTGTGTAGCTGGGACGGTGCTGGTCTGAGCTGGACCTTGTCTGATGGCTTCCTCCAACCCTCCT CCACAGCCTGCCATAGGAGATCAGCTGGTTCCAGGAGTCCCAGGCCCCTCCTCTGAGGCAGAGGACGACCCAGGAGAGGCGTTTGAGTTT GATGACAGTGATGATGAAGAGGACACCAGCGCAGCCCTGGGCGTCCCCAGCCTTGCTCCTGAGAGGGACACAGACCCCCCACTGATCCAC TTGGACTCCATCCCTGTCACTGACCCAGACCCAGCAGCTGCTCCACCCGGCACAGGGGTGCCAGCCTGGGTGAGCAATGGGGATGCAGCG GACGCAGCCTTCTCCGGGGCCCGGCACTCCAGCTGGAAGCGGAAGAGTTCCCGTCGCATTGACCGGTTCACTTTCCCCGCCCTGGAAGAG GATGTGATTTATGACGACGTCCCCTGCGAGAGCCCAGATGCGCATCAGCCCGGGGCAGAGAGGAACCTGCTCTACGAGGATGCGCACCGG GCTGGGGCCCCTCGGCAGGCGGAGGACCTAGGCTGGAGCTCCAGTGAGTTCGAGAGCTACAGCGAGGACTCGGGGGAGGAGGCCAAGCCG GAGGTCGAGGTCGAGCCCGCCAAGCACCGAGTGTCCTTCCAGCCCAAGATGACCCAGCTCATGAAGGCCGCCAAGAGCGGGACCAAGGAT GGGCTGGAGAAGACACGGATGGCCGTGATGCGCAAAGTCTCCTTCCTGCACAGGAAGGACGTCCTCGGTGACTCGGAGGAGGAGGACATG GGGCTCCTGGAGGTCAGCGTTTCGGACATCAAGCCCCCAGCCCCAGAGCTGGGCCCCATGCCAGAGGGCCTGAGCCCTCAGCAGGTGGTC CGGAGGCATATCCTGGGCTCCATCGTGCAGAGCGAAGGCAGCTACGTGGAGTCTCTGAAGCGGATACTCCAGGACTACCGCAACCCCCTG ATGGAGATGGAGCCCAAGGCGCTGAGCGCCCGCAAGTGCCAGGTGGTGTTCTTCCGCGTGAAGGAGATCCTGCACTGCCACTCCATGTTC CAGATCGCCCTGTCCTCCCGCGTGGCTGAGTGGGATTCCACCGAGAAGATCGGGGACCTCTTCGTGGCCTCGTTTTCCAAGTCCATGGTG CTAGATGTGTACAGTGACTACGTGAACAACTTCACCAGTGCCATGTCCATCATCAAGAAGGCCTGCCTCACCAAGCCTGCCTTCCTCGAG TTCCTCAAGCGACGGCAGGTGTGCAGCCCAGACCGTGTCACCCTCTACGGGCTGATGGTCAAGCCCATCCAGAGGTTCCCACAGTTCATA CTCCTGCTTCAGGACATGCTGAAGAACACCCCCAGGGGCCATCCGGACAGGCTGTCGCTGCAGCTGGCCCTCACAGAGCTGGAGACGCTG GCTGAGAAGCTGAACGAGCAGAAGCGGCTGGCTGACCAGGTGGCTGAGATCCAGCAGCTGACCAAGAGCGTCAGTGACCGCAGCAGCCTC AACAAGCTGTTGACCTCAGGCCAGCGGCAGCTGCTCCTGTGTGAGACGTTGACGGAGACCGTGTACGGTGACCGCGGGCAGCTAATTAAG TCCAAGGAGCGTCGGGTCTTCCTGCTCAACGACATGCTTGTCTGTGCCAACATCAACTTCAAGCCTGCCAACCACAGGGGCCAGCTGGAG ATCAGCAGCCTGGTGCCCCTGGGGCCCAAGTATGTGGTGAAGTGGAACACGGCGCTGCCCCAGGTGCAGGTGGTGGAGGTGGGCCAGGAC GGTGGCACCTATGACAAGGACAATGTGCTCATCCAGCACTCAGGCGCCAAGAAGGCCTCTGCCTCAGGGCAGGCTCAGAATAAGGTGTAC CTCGGCCCCCCACGCCTCTTCCAGGAGCTGCAGGACCTGCAGAAGGACCTGGCCGTGGTGGAGCAGATCACGCTTCTCATCAGCACGCTG CACGGCACCTACCAGAACCTGAACATGACTGTGGCTCAAGACTGGTGCCTGGCCCTGCAGAGGCTGATGCGGGTGAAGGAGGAAGAGATC CACTCGGCCAACAAGTGCCGTCTCAGGCTCCTGCTTCCTGGGAAACCCGACAAGTCCGGCCGCCCCATTAGCTTCATGGTGGTTTTCATC ACCCCCAACCCCCTGAGCAAGATTTCCTGGGTCAACAGGTTACATTTGGCCAAAATCGGACTCCGGGAGGAGAACCAGCCAGGCTGGCTA TGCCCGGATGAGGACAAGAAGAGCAAAGCCCCATTCTGGTGCCCGATCCTGGCCTGCTGCATCCCTGCCTTCTCCTCCCGGGCACTCAGC CTGCAGCTTGGGGCCCTGGTCCACAGTCCTGTCAACTGTCCCCTGCTGGGTTTCTCAGCAGTCAGCACCTCCCTTCCACAGGGCTACCTC TGGGTCGGGGGCGGACAGGAAGGCGCAGGGGGCCAGGTGGAAATCTTTTCCTTGAACCGGCCCTCGCCCCGCACCGTCAAGTCCTTCCCA CTGGCAGCCCCTGTGCTCTGCATGGAGTATATCCCGGAGCTGGAGGAGGAGGCGGAGAGCAGAGACGAGAGCCCGACAGTTGCTGACCCC TCGGCCACGGTGCATCCAACCATCTGCCTCGGGCTCCAGGATGGCAGCATCCTCCTCTACAGCAGTGTGGACACTGGCACCCAGTGCCTG GTGAGCTGCAGGAGCCCAGGTCTGCAGCCTGTGCTCTGCCTGCGACACAGCCCCTTCCACCTGCTCGCTGGCCTGCAGGATGGGACCCTT GCTGCTTACCCTCGGACCAGCGGAGGTGTCCTGTGGGACCTGGAGAGCCCTCCCGTGTGCCTGACTGTGGGGCCCGGGCCTGTCCGCACC CTGTTGAGCCTGGAGGATGCCGTGTGGGCCAGCTGTGGGCCCTGGGTCACTGTCCTGGAAGCCACCACCCTGCAGCCTCAGACCAACCCT GGAATGGTCCCCAGCCATGGATTCAGTCCCAGATCTTATTTCTTTGACAACCCTCGAAGATATGACAGTGATGATGACCTTGCCTGGAAC ATTGCCCCTCAGGGACTTCAGGGAGGTTTTGCTCCAGATTACTATGATTGGGGACAACAAACTAACAGCTTCCTGGCACAAGCAGGAACT TTGCAAGACTCAACTTTGGATCCTGACAAACCAAGCCTTGGGTAGCATCAGTTAACAGTTTTATGGACGATTCCTCAGATGAAAAGCTTC AGAAAAGCATAGTGACAGCTGAATTTTTAGGGCACTTTTCCTTAAGAAATAGAACTTGATTTTTATTTGTTACAGGTTTCCAATGGCCCC ATAGGAATAAGCAATAATGTAGACTGATAAACCCTTATTTTAGTACTAAAGAGGGAGCCTTGCTATTTCAGTGGGTATAATTTAAACTTT TTAAAGAAAATCTGTACTTTTATAAAGATGTATTTTGTATAACTTAAATAATAATGCTAAAGTATACTAGGGTTTTTTTTTCTTGAGAAT GTTACTGCAATCATGTTGTAGTTTGCACAGACTTTTATGCATAATTCACTTTAAAAATATAGAATATATGGTCTAATAGTTTTTTAAAGC TTTTGGACTAAAGTATTCCACAAATCTTACCTCTTTAGGTCACTGATGGTCACTCCGATTCTGAGTGCCACATTGGTAGACTCCTAAAAT ACAGTTGACAACTTAGCCAATTGCAACTCCAGTGTTGATAATTAAAATGAAATGGTAAAGCAGCAGACTGTAAGGTCTTTAGAGATTTTT TTTTTAAGGTTCAGGCCGTAGGTTCCTCAAGGAATCTCTTAAGTTTTGCCCAAAGACTGGTACTTCCTTTCAGTAGGGCGCTAATGTATA CACATTAATGATAAGTTGATAACATTAAAAATGTAGCTGACTTATCCTATTAAACCTCCTCTGCTATGTTCAC >6180_6180_6_ARHGEF10L-GPR137B_ARHGEF10L_chr1_17991090_ENST00000452522_GPR137B_chr1_236368426_ENST00000366592_length(amino acids)=1042AA_BP=965 MMASSNPPPQPAIGDQLVPGVPGPSSEAEDDPGEAFEFDDSDDEEDTSAALGVPSLAPERDTDPPLIHLDSIPVTDPDPAAAPPGTGVPA WVSNGDAADAAFSGARHSSWKRKSSRRIDRFTFPALEEDVIYDDVPCESPDAHQPGAERNLLYEDAHRAGAPRQAEDLGWSSSEFESYSE DSGEEAKPEVEVEPAKHRVSFQPKMTQLMKAAKSGTKDGLEKTRMAVMRKVSFLHRKDVLGDSEEEDMGLLEVSVSDIKPPAPELGPMPE GLSPQQVVRRHILGSIVQSEGSYVESLKRILQDYRNPLMEMEPKALSARKCQVVFFRVKEILHCHSMFQIALSSRVAEWDSTEKIGDLFV ASFSKSMVLDVYSDYVNNFTSAMSIIKKACLTKPAFLEFLKRRQVCSPDRVTLYGLMVKPIQRFPQFILLLQDMLKNTPRGHPDRLSLQL ALTELETLAEKLNEQKRLADQVAEIQQLTKSVSDRSSLNKLLTSGQRQLLLCETLTETVYGDRGQLIKSKERRVFLLNDMLVCANINFKP ANHRGQLEISSLVPLGPKYVVKWNTALPQVQVVEVGQDGGTYDKDNVLIQHSGAKKASASGQAQNKVYLGPPRLFQELQDLQKDLAVVEQ ITLLISTLHGTYQNLNMTVAQDWCLALQRLMRVKEEEIHSANKCRLRLLLPGKPDKSGRPISFMVVFITPNPLSKISWVNRLHLAKIGLR EENQPGWLCPDEDKKSKAPFWCPILACCIPAFSSRALSLQLGALVHSPVNCPLLGFSAVSTSLPQGYLWVGGGQEGAGGQVEIFSLNRPS PRTVKSFPLAAPVLCMEYIPELEEEAESRDESPTVADPSATVHPTICLGLQDGSILLYSSVDTGTQCLVSCRSPGLQPVLCLRHSPFHLL AGLQDGTLAAYPRTSGGVLWDLESPPVCLTVGPGPVRTLLSLEDAVWASCGPWVTVLEATTLQPQTNPGMVPSHGFSPRSYFFDNPRRYD SDDDLAWNIAPQGLQGGFAPDYYDWGQQTNSFLAQAGTLQDSTLDPDKPSLG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARHGEF10L-GPR137B |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARHGEF10L-GPR137B |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARHGEF10L-GPR137B |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies