
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DNAJC11-CAMTA1 (FusionGDB2 ID:HG55735TG23261) |
Fusion Gene Summary for DNAJC11-CAMTA1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DNAJC11-CAMTA1 | Fusion gene ID: hg55735tg23261 | Hgene | Tgene | Gene symbol | DNAJC11 | CAMTA1 | Gene ID | 55735 | 23261 |
| Gene name | DnaJ heat shock protein family (Hsp40) member C11 | calmodulin binding transcription activator 1 | |
| Synonyms | dJ126A5.1 | CANPMR | |
| Cytomap | ('DNAJC11')('CAMTA1') 1p36.31 | 1p36.31-p36.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dnaJ homolog subfamily C member 11DnaJ (Hsp40) homolog, subfamily C, member 11novel DnaJ domain-containing protein | calmodulin-binding transcription activator 1 | |
| Modification date | 20200327 | 20200315 | |
| UniProtAcc | Q9NVH1 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000294401, ENST00000377577, ENST00000377573, ENST00000349363, ENST00000465508, ENST00000542246, | ||
| Fusion gene scores | * DoF score | 5 X 5 X 5=125 | 21 X 19 X 8=3192 |
| # samples | 5 | 24 | |
| ** MAII score | log2(5/125*10)=-1.32192809488736 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(24/3192*10)=-3.73335434061383 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DNAJC11 [Title/Abstract] AND CAMTA1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DNAJC11(6761789)-CAMTA1(6880241), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | DNAJC11-CAMTA1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DNAJC11-CAMTA1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DNAJC11-CAMTA1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. DNAJC11-CAMTA1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across DNAJC11 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CAMTA1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
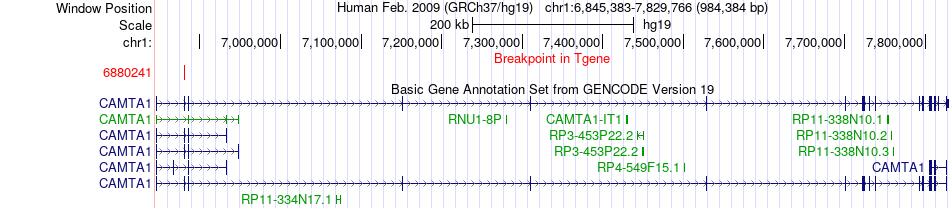 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | GBM | TCGA-16-1045-01B | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
Top |
Fusion Gene ORF analysis for DNAJC11-CAMTA1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000294401 | ENST00000467404 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000294401 | ENST00000473578 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000294401 | ENST00000476163 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000294401 | ENST00000476864 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000294401 | ENST00000557126 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000377577 | ENST00000467404 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000377577 | ENST00000473578 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000377577 | ENST00000476163 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000377577 | ENST00000476864 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5CDS-intron | ENST00000377577 | ENST00000557126 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5UTR-3CDS | ENST00000377573 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5UTR-3CDS | ENST00000377573 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5UTR-intron | ENST00000377573 | ENST00000467404 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5UTR-intron | ENST00000377573 | ENST00000473578 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5UTR-intron | ENST00000377573 | ENST00000476163 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5UTR-intron | ENST00000377573 | ENST00000476864 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| 5UTR-intron | ENST00000377573 | ENST00000557126 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| In-frame | ENST00000294401 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| In-frame | ENST00000294401 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| In-frame | ENST00000377577 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| In-frame | ENST00000377577 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-3CDS | ENST00000349363 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-3CDS | ENST00000349363 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-3CDS | ENST00000465508 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-3CDS | ENST00000465508 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-3CDS | ENST00000542246 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-3CDS | ENST00000542246 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000349363 | ENST00000467404 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000349363 | ENST00000473578 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000349363 | ENST00000476163 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000349363 | ENST00000476864 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000349363 | ENST00000557126 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000465508 | ENST00000467404 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000465508 | ENST00000473578 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000465508 | ENST00000476163 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000465508 | ENST00000476864 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000465508 | ENST00000557126 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000542246 | ENST00000467404 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000542246 | ENST00000473578 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000542246 | ENST00000476163 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000542246 | ENST00000476864 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| intron-intron | ENST00000542246 | ENST00000557126 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000377577 | DNAJC11 | chr1 | 6761789 | - | ENST00000303635 | CAMTA1 | chr1 | 6880241 | + | 8388 | 196 | 124 | 5172 | 1682 |
| ENST00000377577 | DNAJC11 | chr1 | 6761789 | - | ENST00000439411 | CAMTA1 | chr1 | 6880241 | + | 5131 | 196 | 124 | 5130 | 1669 |
| ENST00000294401 | DNAJC11 | chr1 | 6761789 | - | ENST00000303635 | CAMTA1 | chr1 | 6880241 | + | 8388 | 196 | 124 | 5172 | 1682 |
| ENST00000294401 | DNAJC11 | chr1 | 6761789 | - | ENST00000439411 | CAMTA1 | chr1 | 6880241 | + | 5131 | 196 | 124 | 5130 | 1669 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000377577 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + | 0.000368869 | 0.99963117 |
| ENST00000377577 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + | 0.003576219 | 0.9964238 |
| ENST00000294401 | ENST00000303635 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + | 0.000368869 | 0.99963117 |
| ENST00000294401 | ENST00000439411 | DNAJC11 | chr1 | 6761789 | - | CAMTA1 | chr1 | 6880241 | + | 0.003576219 | 0.9964238 |
Top |
Fusion Genomic Features for DNAJC11-CAMTA1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DNAJC11 | chr1 | 6761788 | - | CAMTA1 | chr1 | 6880240 | + | 7.55E-08 | 0.9999999 |
| DNAJC11 | chr1 | 6761788 | - | CAMTA1 | chr1 | 6880240 | + | 7.55E-08 | 0.9999999 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
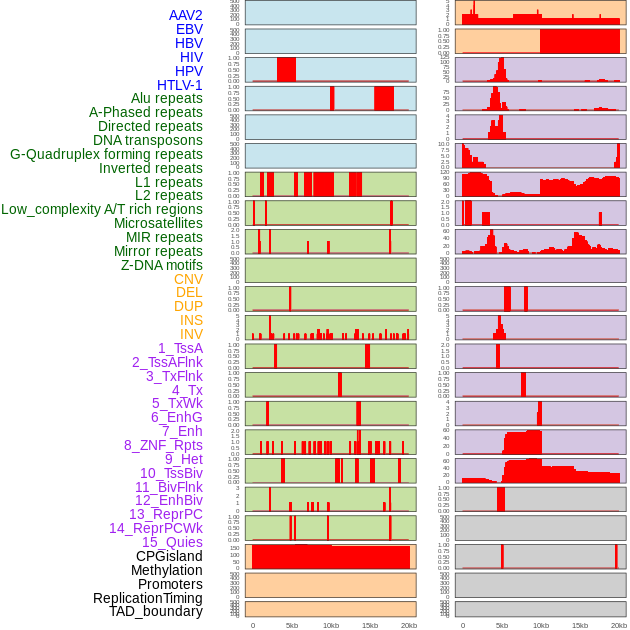 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
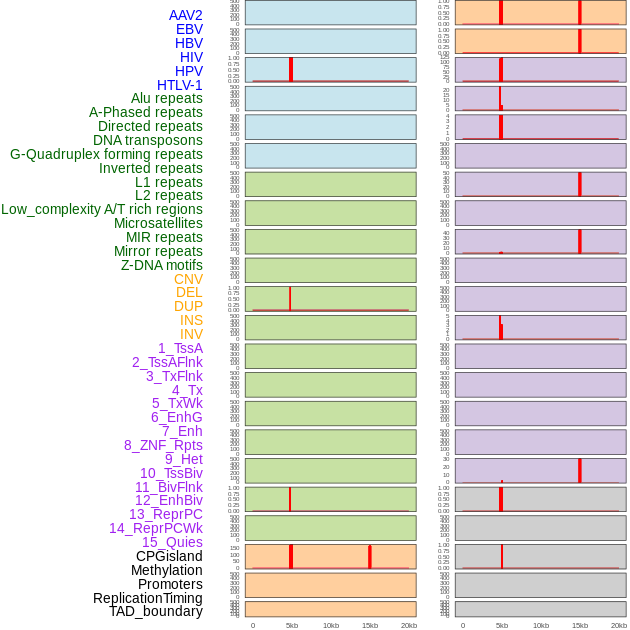 |
Top |
Fusion Protein Features for DNAJC11-CAMTA1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:6761789/chr1:6880241) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| DNAJC11 | . |
| FUNCTION: [Isoform 1]: Required for mitochondrial inner membrane organization. Seems to function through its association with the MICOS complex and the mitochondrial outer membrane sorting assembly machinery (SAM) complex. {ECO:0000269|PubMed:25111180, ECO:0000305}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 1038_1041 | 15 | 1674.0 | Compositional bias | Note=Poly-Val | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 499_502 | 15 | 1674.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 1038_1041 | 15 | 1660.0 | Compositional bias | Note=Poly-Val | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 499_502 | 15 | 1660.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 1038_1041 | 15 | 81.0 | Compositional bias | Note=Poly-Val | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 499_502 | 15 | 81.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 1038_1041 | 0 | 238.0 | Compositional bias | Note=Poly-Val | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 499_502 | 0 | 238.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 1038_1041 | 15 | 102.0 | Compositional bias | Note=Poly-Val | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 499_502 | 15 | 102.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 63_188 | 15 | 1674.0 | DNA binding | CG-1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 63_188 | 15 | 1660.0 | DNA binding | CG-1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 63_188 | 15 | 81.0 | DNA binding | CG-1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 63_188 | 0 | 238.0 | DNA binding | CG-1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 63_188 | 15 | 102.0 | DNA binding | CG-1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 1547_1576 | 15 | 1674.0 | Domain | IQ 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 1577_1599 | 15 | 1674.0 | Domain | IQ 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 1600_1622 | 15 | 1674.0 | Domain | IQ 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 873_953 | 15 | 1674.0 | Domain | Note=IPT/TIG | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 1547_1576 | 15 | 1660.0 | Domain | IQ 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 1577_1599 | 15 | 1660.0 | Domain | IQ 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 1600_1622 | 15 | 1660.0 | Domain | IQ 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 873_953 | 15 | 1660.0 | Domain | Note=IPT/TIG | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 1547_1576 | 15 | 81.0 | Domain | IQ 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 1577_1599 | 15 | 81.0 | Domain | IQ 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 1600_1622 | 15 | 81.0 | Domain | IQ 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 873_953 | 15 | 81.0 | Domain | Note=IPT/TIG | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 1547_1576 | 0 | 238.0 | Domain | IQ 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 1577_1599 | 0 | 238.0 | Domain | IQ 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 1600_1622 | 0 | 238.0 | Domain | IQ 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 873_953 | 0 | 238.0 | Domain | Note=IPT/TIG | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 1547_1576 | 15 | 102.0 | Domain | IQ 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 1577_1599 | 15 | 102.0 | Domain | IQ 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 1600_1622 | 15 | 102.0 | Domain | IQ 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 873_953 | 15 | 102.0 | Domain | Note=IPT/TIG | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 112_119 | 15 | 1674.0 | Motif | Nuclear localization signal | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 112_119 | 15 | 1660.0 | Motif | Nuclear localization signal | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 112_119 | 15 | 81.0 | Motif | Nuclear localization signal | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 112_119 | 0 | 238.0 | Motif | Nuclear localization signal | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 112_119 | 15 | 102.0 | Motif | Nuclear localization signal | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 1064_1093 | 15 | 1674.0 | Repeat | Note=ANK 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 1109_1129 | 15 | 1674.0 | Repeat | Note=ANK 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000303635 | 0 | 23 | 1143_1172 | 15 | 1674.0 | Repeat | Note=ANK 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 1064_1093 | 15 | 1660.0 | Repeat | Note=ANK 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 1109_1129 | 15 | 1660.0 | Repeat | Note=ANK 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000439411 | 0 | 22 | 1143_1172 | 15 | 1660.0 | Repeat | Note=ANK 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 1064_1093 | 15 | 81.0 | Repeat | Note=ANK 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 1109_1129 | 15 | 81.0 | Repeat | Note=ANK 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000473578 | 0 | 4 | 1143_1172 | 15 | 81.0 | Repeat | Note=ANK 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 1064_1093 | 0 | 238.0 | Repeat | Note=ANK 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 1109_1129 | 0 | 238.0 | Repeat | Note=ANK 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000476864 | 0 | 6 | 1143_1172 | 0 | 238.0 | Repeat | Note=ANK 3 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 1064_1093 | 15 | 102.0 | Repeat | Note=ANK 1 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 1109_1129 | 15 | 102.0 | Repeat | Note=ANK 2 | |
| Tgene | CAMTA1 | chr1:6761789 | chr1:6880241 | ENST00000557126 | 0 | 4 | 1143_1172 | 15 | 102.0 | Repeat | Note=ANK 3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DNAJC11 | chr1:6761789 | chr1:6880241 | ENST00000294401 | - | 1 | 15 | 417_457 | 24 | 508.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DNAJC11 | chr1:6761789 | chr1:6880241 | ENST00000377577 | - | 1 | 16 | 417_457 | 24 | 560.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DNAJC11 | chr1:6761789 | chr1:6880241 | ENST00000294401 | - | 1 | 15 | 14_82 | 24 | 508.0 | Domain | J |
| Hgene | DNAJC11 | chr1:6761789 | chr1:6880241 | ENST00000377577 | - | 1 | 16 | 14_82 | 24 | 560.0 | Domain | J |
Top |
Fusion Gene Sequence for DNAJC11-CAMTA1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >23450_23450_1_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000294401_CAMTA1_chr1_6880241_ENST00000303635_length(transcript)=8388nt_BP=196nt GACGGCTCCGGGCCGCCAGGGGCCGCTGTGGCGCAGCCGGGCTGGCCCGCGCTGTCCCTGACGCGGATCACTGGCCCCTCTTGAGCACGG CCTTGCCGGTTTGGCGGGGTGAAAGGTTGCGAAGATGGCGACGGCCTTGAGCGAGGAGGAGCTGGACAATGAAGACTATTACTCGTTGCT GAACGTGCGCAGGGAGAGCGTTTCCCAAAGTGTATTCTGCGGAACTAGCACCTACTGTGTTCTCAACACCGTGCCACCTATAGAAGATGA TCATGGGAACAGCAATAGTAGTCATGTAAAAATCTTTTTACCGAAAAAGCTGCTTGAATGTCTGCCGAAATGTTCAAGTTTACCAAAAGA GAGGCACCGCTGGAACACTAATGAGGAAATTGCAGCTTATTTAATAACATTTGAGAAACACGAAGAATGGCTAACCACCTCCCCTAAGAC AAGACCACAGAATGGCTCAATGATACTCTACAACAGGAAGAAAGTGAAATACAGGAAAGATGGGTATTGCTGGAAAAAGAGGAAAGATGG GAAAACGACCAGAGAGGACCACATGAAACTCAAGGTCCAGGGAGTGGAGTGCTTGTACGGCTGCTATGTCCATTCCTCCATCATCCCCAC CTTCCACCGGAGGTGCTACTGGCTCCTTCAGAACCCCGACATCGTCCTGGTGCACTACCTGAACGTGCCGGCCATCGAGGACTGCGGCAA GCCTTGCGGCCCCATCCTCTGCTCCATCAACACCGACAAGAAGGAGTGGGCGAAATGGACGAAAGAAGAGCTCATCGGGCAGCTGAAACC CATGTTCCATGGCATCAAGTGGACCTGCAGCAATGGGAACAGCAGCTCAGGCTTCTCGGTGGAACAGCTGGTGCAGCAGATCCTCGACAG CCACCAGACCAAGCCCCAGCCGCGGACCCACAACTGCCTCTGCACCGGCAGCCTGGGAGCTGGCGGCAGCGTGCATCACAAGTGTAACAG CGCCAAACACCGCATCATCTCGCCCAAGGTGGAGCCACGGACAGGGGGGTACGGGAGCCACTCGGAGGTGCAGCACAATGACGTGTCGGA GGGCAAGCACGAGCACAGCCACAGCAAGGGCTCCAGCCGTGAGAAGAGGAACGGCAAGGTGGCCAAGCCCGTGCTCCTGCACCAGAGCAG CACCGAGGTCTCCTCCACCAACCAGGTGGAAGTCCCCGACACCACCCAGAGCTCCCCTGTGTCCATCAGCAGCGGGCTCAACAGCGACCC GGACATGGTGGACAGCCCGGTGGTCACAGGTGTGTCCGGTATGGCGGTGGCCTCTGTGATGGGGAGCTTGTCCCAGAGCGCCACGGTGTT CATGTCAGAGGTCACCAATGAGGCCGTGTACACCATGTCCCCCACCGCTGGCCCCAACCACCACCTCCTCTCACCTGACGCCTCTCAGGG CCTCGTCCTGGCCGTGAGCTCTGATGGCCACAAGTTCGCCTTTCCCACCACGGGCAGCTCGGAGAGCCTGTCCATGCTGCCCACCAACGT GTCCGAAGAGCTGGTCCTCTCCACCACCCTCGACGGTGGCCGGAAGATTCCAGAAACCACCATGAACTTTGACCCCGACTGTTTCCTTAA TAACCCAAAGCAGGGCCAGACGTACGGGGGTGGAGGCCTGAAAGCCGAGATGGTCAGCTCCAACATCCGGCACTCGCCACCCGGGGAGCG GAGCTTCAGCTTTACCACCGTCCTCACCAAGGAGATCAAGACCGAGGACACCTCCTTCGAGCAGCAGATGGCCAAAGAAGCGTACTCCTC CTCCGCGGCGGCTGTGGCAGCCAGCTCCCTCACCCTGACCGCCGGCTCCAGCCTCCTGCCGTCGGGCGGCGGCCTGAGTCCCAGCACCAC CCTGGAGCAGATGGACTTCAGCGCCATCGACTCCAACAAGGACTACACGTCCAGCTTCAGCCAGACGGGCCACAGCCCCCACATCCACCA GACCCCCTCCCCGAGCTTCTTCCTGCAGGACGCCAGCAAACCCCTCCCCGTCGAGCAGAACACCCACAGCAGCCTGAGTGACTCTGGGGG CACCTTCGTGATGCCCACGGTGAAAACGGAGGCCTCGTCCCAAACCAGCTCCTGCAGCGGTCACGTGGAGACGCGGATCGAGTCCACTTC CTCCCTCCACCTCATGCAGTTCCAGGCCAACTTCCAGGCCATGACGGCAGAAGGGGAGGTCACCATGGAGACCTCGCAGGCGGCGGAAGG GAGCGAGGTCCTGCTCAAGTCTGGGGAGCTGCAGGCTTGCAGCTCTGAGCACTACCTGCAGCCGGAGACCAACGGGGTAATCCGAAGCGC CGGCGGCGTCCCCATCCTCCCGGGCAACGTGGTGCAGGGACTCTACCCCGTGGCCCAGCCCAGCCTCGGCAACGCCTCCAACATGGAGCT CAGCCTGGACCACTTTGACATCTCCTTCAGCAACCAGTTCTCCGACCTGATCAACGACTTCATCTCCGTGGAGGGGGGCAGCAGCACCAT CTATGGGCACCAGCTGGTGTCGGGGGACAGCACGGCGCTCTCACAGTCAGAGGACGGGGCGCGGGCCCCCTTCACCCAGGCAGAGATGTG CCTCCCCTGCTGTAGCCCCCAGCAGGGTAGCCTGCAGCTGAGCAGCTCGGAGGGCGGGGCCAGCACCATGGCCTACATGCACGTCGCCGA GGTGGTCTCGGCCGCCTCGGCCCAGGGCACCCTAGGCATGCTGCAGCAGAGCGGACGGGTGTTCATGGTGACCGACTACTCCCCAGAGTG GTCTTACCCAGAGGGAGGAGTGAAGGTCCTCATCACAGGCCCGTGGCAAGAAGCCAGCAATAACTACAGCTGCCTGTTTGACCAGATCTC AGTGCCTGCATCCCTGATTCAGCCTGGGGTGCTGCGCTGCTACTGCCCAGCCCATGACACTGGTCTTGTGACCCTACAAGTTGCCTTCAA CAACCAGATCATCTCCAACTCGGTGGTGTTTGAGTACAAAGCCCGGGCTCTGCCCACGCTCCCTTCCTCCCAGCACGACTGGCTGTCGTT GGACGATAACCAGTTCAGGATGTCCATCCTGGAACGACTGGAGCAGATGGAGAGGAGGATGGCCGAGATGACGGGGTCCCAGCAGCACAA ACAGGCGAGCGGAGGCGGCAGCAGTGGAGGCGGCAGCGGGAGCGGGAATGGAGGGAGCCAGGCACAGTGTGCTTCTGGGACTGGGGCCTT GGGGAGCTGCTTTGAGAGCCGTGTGGTCGTGGTATGCGAGAAGATGATGAGCCGAGCCTGCTGGGCGAAGTCCAAGCACTTGATCCACTC AAAGACTTTCCGCGGAATGACCCTACTCCACCTGGCCGCTGCCCAGGGCTATGCCACCCTAATCCAGACCCTCATCAAATGGCGTACAAA GCACGCGGATAGCATTGACCTGGAACTGGAAGTTGACCCCTTGAATGTGGACCACTTCTCCTGTACTCCTCTGATGTGGGCGTGTGCCCT AGGGCACTTGGAAGCTGCCGTCGTGCTGTACAAGTGGGACCGTCGGGCCATCTCGATTCCCGACTCTCTAGGAAGGCTGCCTTTGGGAAT TGCCAGGTCACGGGGTCATGTGAAATTAGCAGAGTGTCTGGAGCACCTGCAGAGAGATGAGCAGGCTCAGCTGGGACAGAACCCCAGAAT CCACTGTCCTGCAAGCGAAGAGCCCAGCACAGAGAGCTGGATGGCCCAGTGGCACAGCGAAGCCATCAGCTCTCCAGAAATACCCAAGGG AGTCACTGTTATTGCAAGCACCAACCCAGAGCTGAGAAGACCTCGTTCTGAACCCTCTAATTACTACAGCAGTGAGAGCCACAAAGATTA TCCGGCTCCCAAAAAGCATAAATTGAACCCTGAGTACTTCCAGACAAGGCAGGAGAAGCTGCTTCCCACTGCACTGAGTCTGGAAGAGCC AAATATCAGGAAGCAAAGCCCTAGTTCTAAGCAGTCTGTCCCCGAGACACTCAGCCCCAGTGAAGGAGTGAGGGACTTCAGCCGGGAACT CTCCCCTCCCACTCCAGAGACTGCAGCATTTCAAGCCTCTGGATCTCAGCCTGTAGGAAAGTGGAATTCCAAAGATCTTTACATTGGTGT GTCTACAGTACAGGTGACTGGAAATCCGAAGGGGACCAGTGTAGGAAAGGAGGCAGCACCTTCACAGGTGCGTCCACGGGAACCAATGAG TGTCCTGATGATGGCTAACAGAGAGGTGGTGAATACAGAGCTGGGGTCCTACCGTGATAGTGCAGAAAATGAAGAATGCGGCCAGCCCAT GGATGACATACAGGTGAACATGATGACCTTGGCAGAACACATTATTGAAGCCACACCTGACCGAATCAAGCAGGAGAATTTTGTGCCCAT GGAGTCCTCAGGATTGGAAAGAACAGACCCTGCCACCATTAGCAGTACAATGAGCTGGCTGGCCAGTTATCTAGCGGATGCTGACTGCCT TCCCAGTGCTGCCCAGATCCGAAGTGCATATAACGAGCCTCTAACCCCTTCTTCTAATACCAGCTTGAGCCCTGTTGGCTCTCCCGTCAG TGAAATCGCTTTCGAGAAACCTAACCTTCCCTCCGCCGCGGATTGGTCAGAATTCCTGAGTGCATCTACCAGTGAGAAGGTAGAGAATGA GTTTGCTCAGCTCACTCTGTCTGATCATGAACAGAGAGAACTCTATGAGGCTGCCAGGCTTGTCCAGACAGCTTTCCGGAAATACAAGGG CCGACCCTTGCGGGAACAGCAAGAAGTAGCTGCTGCTGTTATTCAGCGTTGTTACAGAAAATATAAACAGTACGCACTTTATAAAAAGAT GACACAGGCTGCCATCCTTATCCAGAGCAAATTCCGAAGTTACTATGAACAAAAAAAATTCCAGCAGAGCCGACGGGCTGCTGTGCTCAT CCAAAAGTACTACCGAAGTTATAAGAAATGTGGCAAAAGACGGCAGGCTCGCCGGACGGCTGTGATTGTACAACAGAAACTCAGGAGCAG TTTGCTAACCAAAAAGCAGGATCAAGCTGCTCGAAAAATAATGAGGTTTCTTCGCCGCTGTCGCCACAGCCCCCTGGTGGACCATAGGCT GTACAAAAGGAGTGAAAGAATTGAAAAAGGCCAAGGAACTTGAAGACATACAGCAGCATCCCTTAGCAATGTGACATTGCTTTTCAGACT GTTTTCATTTCTGTTTTTAGCAGAGACATGCAACAACAACACACACGCACACACGCACACACACACACGTACACACACATACAAAATCCC TCTGCAGTTTTGGGGAGATCAGCTGCAGGATTTTAACAGGAATGTTTTGGTCATTGCATTTGCACTTTCATGGACAACTTTTAATTTGAT CAGCAAGACATCTTGGAACTCAATCTTCTGTTGGATCACGGGAAATCAAGACACCCAGGAGGAATTGAAAGAGGCTTCCTCTTCTCAGGA AGAAGCCATTTCCTTCTCATATAGGGCTGTATTCAAACATCGTGTGGAACTGTACAAATATTTATACCAAAAATATAGATAAGAAAAGGT GGGGCTATACTAGCAACAAAAAAAGAATGCTGTTCCTGCACCTGCCGGTTATTTCCAAGAAGCTGAATCTTTGGGACTGATTCTCAGTGG AGGGCTTAGATCATACAAAAATCTTTATTGGGTCCGTGTGTTCTCATTTCCTTCACTGTTTATTTTTGTTTGTTTGTTTGTTTGTTTTAA TCTCTACAGCACATTTAATGCAACTTTTGAAATCTGCAGGTTTTTAATGTCTTGTGGAAATTTGCAGAGGGGCAGGTGTGTGGTAAACGG GTAATGCATGGGAAATAATGAGAAGCAGCTCACAGAGTTTAAACTATTTTCTTGTCCCCACCACCTTCCAAGAACCTGCGAGGGTAGTAA TCATCTTGTCCCCTTTTTCATGTTCAGCACTTTAATTTTTTTGCCTTACTTTCATGTGCAATGAGAATTACTTAAGAATTGGTAACGCAT GTAGCCTTTTTTAGTAACCTTGGAAGCTGTAGTAATTCTAAGGAATCATGAACCTTGCCTGGACATTTGCCACCTAAACGATCAGTGTGG TGCTGCGTTCTGGCCAGTAAATTCCATGTTTTTGGCTATATCTCATCCAAACTGAGCAGTTTCTGTGTATATATAGAAGGTAGAAATGAA AAGTGAGAAAATATTTGAAAGGGATTATATTAATTGCTAAATATTTTATTCACAAAGGTCAATAACATGGCAAGATAAAATTATTTGTAT AGTTTTGTCTGAATGAGCGAGAAAAATGTGGATGTACTGTTTGTATATATTGTATATATTAAAACAGAGATATGTGCATGAAATCAAGAA AAAAGAAATGAACAAAAGCAAAGCATTAGTGGCTATGGTCTGTAAAATGAAACAAAAAAACTTTATTTCACTATAAGAGTACTTTATTTT AAATGTTCTTTAGGAGAACATTTTGCTAAAGCATGACTAAACTGCAAAAAAAAAAAAAGAGCTACTGTATTTAGACTTAGGAAAAAAGGC AGAGTAACATTACTTAAAAAAAAAAGGATATGTTTACATTTAATTTTGGCTACCAGGAGTTTAGTTTATTTTATTTAAAATTTTTTTGCC AATGGTGCCAAGTAATGTGAATGCTAATACTGCTTAAGAAAATTAAGTTACTTTTGCAAAACAGATAATCATAAGATGAATCAGTATGTA GCTTAACACCATCCACTCACTCCAACAAAGAACACTTAGAATGATAAAAAAAAAAAAAAAAAACCTGACAAAAGAAATAGTATGAAAAGT AGAAAAATGTCACGTTTCCATATCTCCTGCTGGAAATCAGAAAATATAATAAAATTGCACAAAAAAAAAAATGAAAAAGATGCAGACTGG TCTTTTAGAGACGGCATGGTATATTACTATTTCCACATAATGAGGAGCCAAAGAAATCTGATGTTTTTAACAATTAAACTGCTAATGTTA AATTGAGAGAATAAAGTTCGTATTTGCTGATGCCAGTTTAAAATTCCCAGGTTACGTCTGAGGATCAGTTGGTGTAAAGCTGAGATGTTT TTTCTTGGTTCTGGCTGCCAACTGTGAGTTAAAACTCAAGGCTTGTTGTGAAGCCTAAAAATATTCACAAATAAGCTTTTAAACTGGTGT CTTTGGAAGGAAGGTAGATACAAAAAGATTGTGGTAAAAACTGGGGTCAGTGCTCTTGGTGCCTTTTCTATAATTGTACTTGTTTTTTAA TTACTTCCTTTCACTGCCAACCTCGAATTACTGTACAGTATATGTCTTTCTGCTTGTGATCAGCTTTGACAACAGTGACAGCCCCACAAC TAGTAGCCACCTGTACATTTGTAAACTGACCTGACTCCATTTTGTTTTTAAATGTGTGGGTTATGTTGCAGCTGTTGCAGTCCCCCAGAT ACCTATTATTTTACACAATTTGACCTATAGGAGGACACTGAGTAATTTACAAACACAACTGCATTCATAAATGGGAATAGAACGTGAAAG CCAGCTCTTTCAGAATATCCTCTATTAATACTGAATTTAGATATCTTTATTCCATTTATTATGGTACAAATAACTGATGTTTTAACCAGA GTAATGACCTCAGTGGATTTGCTTTAACCCTCACATTTTTTTTTTAATGTTTCACATGTTACATTATTAGCTGAATACGTTAGAAAATGA CAGATGGTAGAGACTTCCATAGAATTAAGAGGGTTCTCATGGAGGGGATAGGAAGTAGGTTTAAAGCCTACCAGTGTAACCTACCAGTAC AACTGTGAATCCTAGGCAAGGCAAAAATGCACTTCCACTGAAACGAAGCATTTCTGACCGCTTTTTCTTGGTTATGAATCTTAATTTCGA ATATAAGATGATAGGTAAGCGCAGCTTTCTTGGATAATCTGAATTCCCAAGTGCCAGGAGTAGGATTTCATTATAAAATTAATAGCTAAT CTTATTCTATCTCCTGAAGATTTAATTGCTATTGTTACCCATTCGAAATCAGCTGTACTGTGTGAACGAAATAAAGACAATAATACGAAC CCCTCTCTGGCTGCACGGTCGCTTATGGCAGTTCCACACAGTAGTTGGCGCCCAATGGGGGGTCCCTGAGACTTGCATGTAAAACTAGTC TAGATGTCTTCTTTTTTTGTAAGTTTTATTTTTGTAATTGTGCATGTAAAGCATCATTGAATCAATGGATCTGTTGAAGAACTCAGCTGC TGGAAACCATGCAAAATGTTTTGAATTGCCCTTAAAATATGGAAAATGTTTTCTGAATGCTTTATATTCTTTCTGCTGTAAATTAAAAAT GAAGAAAATTTCCCCATA >23450_23450_1_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000294401_CAMTA1_chr1_6880241_ENST00000303635_length(amino acids)=1682AA_BP=24 MATALSEEELDNEDYYSLLNVRRESVSQSVFCGTSTYCVLNTVPPIEDDHGNSNSSHVKIFLPKKLLECLPKCSSLPKERHRWNTNEEIA AYLITFEKHEEWLTTSPKTRPQNGSMILYNRKKVKYRKDGYCWKKRKDGKTTREDHMKLKVQGVECLYGCYVHSSIIPTFHRRCYWLLQN PDIVLVHYLNVPAIEDCGKPCGPILCSINTDKKEWAKWTKEELIGQLKPMFHGIKWTCSNGNSSSGFSVEQLVQQILDSHQTKPQPRTHN CLCTGSLGAGGSVHHKCNSAKHRIISPKVEPRTGGYGSHSEVQHNDVSEGKHEHSHSKGSSREKRNGKVAKPVLLHQSSTEVSSTNQVEV PDTTQSSPVSISSGLNSDPDMVDSPVVTGVSGMAVASVMGSLSQSATVFMSEVTNEAVYTMSPTAGPNHHLLSPDASQGLVLAVSSDGHK FAFPTTGSSESLSMLPTNVSEELVLSTTLDGGRKIPETTMNFDPDCFLNNPKQGQTYGGGGLKAEMVSSNIRHSPPGERSFSFTTVLTKE IKTEDTSFEQQMAKEAYSSSAAAVAASSLTLTAGSSLLPSGGGLSPSTTLEQMDFSAIDSNKDYTSSFSQTGHSPHIHQTPSPSFFLQDA SKPLPVEQNTHSSLSDSGGTFVMPTVKTEASSQTSSCSGHVETRIESTSSLHLMQFQANFQAMTAEGEVTMETSQAAEGSEVLLKSGELQ ACSSEHYLQPETNGVIRSAGGVPILPGNVVQGLYPVAQPSLGNASNMELSLDHFDISFSNQFSDLINDFISVEGGSSTIYGHQLVSGDST ALSQSEDGARAPFTQAEMCLPCCSPQQGSLQLSSSEGGASTMAYMHVAEVVSAASAQGTLGMLQQSGRVFMVTDYSPEWSYPEGGVKVLI TGPWQEASNNYSCLFDQISVPASLIQPGVLRCYCPAHDTGLVTLQVAFNNQIISNSVVFEYKARALPTLPSSQHDWLSLDDNQFRMSILE RLEQMERRMAEMTGSQQHKQASGGGSSGGGSGSGNGGSQAQCASGTGALGSCFESRVVVVCEKMMSRACWAKSKHLIHSKTFRGMTLLHL AAAQGYATLIQTLIKWRTKHADSIDLELEVDPLNVDHFSCTPLMWACALGHLEAAVVLYKWDRRAISIPDSLGRLPLGIARSRGHVKLAE CLEHLQRDEQAQLGQNPRIHCPASEEPSTESWMAQWHSEAISSPEIPKGVTVIASTNPELRRPRSEPSNYYSSESHKDYPAPKKHKLNPE YFQTRQEKLLPTALSLEEPNIRKQSPSSKQSVPETLSPSEGVRDFSRELSPPTPETAAFQASGSQPVGKWNSKDLYIGVSTVQVTGNPKG TSVGKEAAPSQVRPREPMSVLMMANREVVNTELGSYRDSAENEECGQPMDDIQVNMMTLAEHIIEATPDRIKQENFVPMESSGLERTDPA TISSTMSWLASYLADADCLPSAAQIRSAYNEPLTPSSNTSLSPVGSPVSEIAFEKPNLPSAADWSEFLSASTSEKVENEFAQLTLSDHEQ RELYEAARLVQTAFRKYKGRPLREQQEVAAAVIQRCYRKYKQYALYKKMTQAAILIQSKFRSYYEQKKFQQSRRAAVLIQKYYRSYKKCG KRRQARRTAVIVQQKLRSSLLTKKQDQAARKIMRFLRRCRHSPLVDHRLYKRSERIEKGQGT -------------------------------------------------------------- >23450_23450_2_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000294401_CAMTA1_chr1_6880241_ENST00000439411_length(transcript)=5131nt_BP=196nt GACGGCTCCGGGCCGCCAGGGGCCGCTGTGGCGCAGCCGGGCTGGCCCGCGCTGTCCCTGACGCGGATCACTGGCCCCTCTTGAGCACGG CCTTGCCGGTTTGGCGGGGTGAAAGGTTGCGAAGATGGCGACGGCCTTGAGCGAGGAGGAGCTGGACAATGAAGACTATTACTCGTTGCT GAACGTGCGCAGGGAGAGCGTTTCCCAAAGTGTATTCTGCGGAACTAGCACCTACTGTGTTCTCAACACCGTGCCACCTATAGAAGATGA TCATGGGAACAGCAATAGTAGTCATGTAAAAATCTTTTTACCGAAAAAGCTGCTTGAATGTCTGCCGAAATGTTCAAGTTTACCAAAAGA GAGGCACCGCTGGAACACTAATGAGGAAATTGCAGCTTATTTAATAACATTTGAGAAACACGAAGAATGGCTAACCACCTCCCCTAAGAC AAGACCACAGAATGGCTCAATGATACTCTACAACAGGAAGAAAGTGAAATACAGGAAAGATGGGTATTGCTGGAAAAAGAGGAAAGATGG GAAAACGACCAGAGAGGACCACATGAAACTCAAGGTCCAGGGAGTGGAGTGCTTGTACGGCTGCTATGTCCATTCCTCCATCATCCCCAC CTTCCACCGGAGGTGCTACTGGCTCCTTCAGAACCCCGACATCGTCCTGGTGCACTACCTGAACGTGCCGGCCATCGAGGACTGCGGCAA GCCTTGCGGCCCCATCCTCTGCTCCATCAACACCGACAAGAAGGAGTGGGCGAAATGGACGAAAGAAGAGCTCATCGGGCAGCTGAAACC CATGTTCCATGGCATCAAGTGGACCTGCAGCAATGGGAACAGCAGCTCAGGCTTCTCGGTGGAACAGCTGGTGCAGCAGATCCTCGACAG CCACCAGACCAAGCCCCAGCCGCGGACCCACAACTGCCTCTGCACCGGCAGCCTGGGAGCTGGCGGCAGCGTGCATCACAAGTGTAACAG CGCCAAACACCGCATCATCTCGCCCAAGGTGGAGCCACGGACAGGGGGGTACGGGAGCCACTCGGAGGTGCAGCACAATGACGTGTCGGA GGGCAAGCACGAGCACAGCCACAGCAAGGGCTCCAGCCGTGAGAAGAGGAACGGCAAGGTGGCCAAGCCCGTGCTCCTGCACCAGAGCAG CACCGAGGTCTCCTCCACCAACCAGGTGGAAGTCCCCGACACCACCCAGAGCTCCCCTGTGTCCATCAGCAGCGGGCTCAACAGCGACCC GGACATGGTGGACAGCCCGGTGGTCACAGGTGTGTCCGGTATGGCGGTGGCCTCTGTGATGGGGAGCTTGTCCCAGAGCGCCACGGTGTT CATGTCAGAGGTCACCAATGAGGCCGTGTACACCATGTCCCCCACCGCTGGCCCCAACCACCACCTCCTCTCACCTGACGCCTCTCAGGG CCTCGTCCTGGCCGTGAGCTCTGATGGCCACAAGTTCGCCTTTCCCACCACGGGCAGCTCGGAGAGCCTGTCCATGCTGCCCACCAACGT GTCCGAAGAGCTGGTCCTCTCCACCACCCTCGACGGTGGCCGGAAGATTCCAGAAACCACCATGAACTTTGACCCCGACTGTTTCCTTAA TAACCCAAAGCAGGGCCAGACGTACGGGGGTGGAGGCCTGAAAGCCGAGATGGTCAGCTCCAACATCCGGCACTCGCCACCCGGGGAGCG GAGCTTCAGCTTTACCACCGTCCTCACCAAGGAGATCAAGACCGAGGACACCTCCTTCGAGCAGCAGATGGCCAAAGAAGCGTACTCCTC CTCCGCGGCGGCTGTGGCAGCCAGCTCCCTCACCCTGACCGCCGGCTCCAGCCTCCTGCCGTCGGGCGGCGGCCTGAGTCCCAGCACCAC CCTGGAGCAGATGGACTTCAGCGCCATCGACTCCAACAAGGACTACACGTCCAGCTTCAGCCAGACGGGCCACAGCCCCCACATCCACCA GACCCCCTCCCCGAGCTTCTTCCTGCAGGACGCCAGCAAACCCCTCCCCGTCGAGCAGAACACCCACAGCAGCCTGAGTGACTCTGGGGG CACCTTCGTGATGCCCACGGTGAAAACGGAGGCCTCGTCCCAAACCAGCTCCTGCAGCGGTCACGTGGAGACGCGGATCGAGTCCACTTC CTCCCTCCACCTCATGCAGTTCCAGGCCAACTTCCAGGCCATGACGGCAGAAGGGGAGGTCACCATGGAGACCTCGCAGGCGGCGGAAGG GAGCGAGGTCCTGCTCAAGTCTGGGGAGCTGCAGGCTTGCAGCTCTGAGCACTACCTGCAGCCGGAGACCAACGGGGTAATCCGAAGCGC CGGCGGCGTCCCCATCCTCCCGGGCAACGTGGTGCAGGGACTCTACCCCGTGGCCCAGCCCAGCCTCGGCAACGCCTCCAACATGGAGCT CAGCCTGGACCACTTTGACATCTCCTTCAGCAACCAGTTCTCCGACCTGATCAACGACTTCATCTCCGTGGAGGGGGGCAGCAGCACCAT CTATGGGCACCAGCTGGTGTCGGGGGACAGCACGGCGCTCTCACAGTCAGAGGACGGGGCGCGGGCCCCCTTCACCCAGGCAGAGATGTG CCTCCCCTGCTGTAGCCCCCAGCAGGGTAGCCTGCAGCTGAGCAGCTCGGAGGGCGGGGCCAGCACCATGGCCTACATGCACGTCGCCGA GGTGGTCTCGGCCGCCTCGGCCCAGGGCACCCTAGGCATGCTGCAGCAGAGCGGACGGGTGTTCATGGTGACCGACTACTCCCCAGAGTG GTCTTACCCAGAGGGAGGAGTGAAGGTCCTCATCACAGGCCCGTGGCAAGAAGCCAGCAATAACTACAGCTGCCTGTTTGACCAGATCTC AGTGCCTGCATCCCTGATTCAGCCTGGGGTGCTGCGCTGCTACTGCCCAGCCCATGACACTGGTCTTGTGACCCTACAAGTTGCCTTCAA CAACCAGATCATCTCCAACTCGGTGGTGTTTGAGTACAAAGCCCGGGCTCTGCCCACGCTCCCTTCCTCCCAGCACGACTGGCTGTCGTT GGACGATAACCAGTTCAGGATGTCCATCCTGGAACGACTGGAGCAGATGGAGAGGAGGATGGCCGAGATGACGGGGTCCCAGCAGCACAA ACAGGCGAGCGGAGGCGGCAGCAGTGGAGGCGGCAGCGGGAGCGGGAATGGAGGGAGCCAGGCACAGTGTGCTTCTGGGACTGGGGCCTT GGGGAGCTGCTTTGAGAGCCGTGTGGTCGTGGTATGCGAGAAGATGATGAGCCGAGCCTGCTGGGCGAAGTCCAAGCACTTGATCCACTC AAAGACTTTCCGCGGAATGACCCTACTCCACCTGGCCGCTGCCCAGGGCTATGCCACCCTAATCCAGACCCTCATCAAATGGCGTACAAA GCACGCGGATAGCATTGACCTGGAACTGGAAGTTGACCCCTTGAATGTGGACCACTTCTCCTGTACTCCTCTGATGTGGGCGTGTGCCCT AGGGCACTTGGAAGCTGCCGTCGTGCTGTACAAGTGGGACCGTCGGGCCATCTCGATTCCCGACTCTCTAGGAAGGCTGCCTTTGGGAAT TGCCAGGTCACGGGGTCATGTGAAATTAGCAGAGTGTCTGGAGCACCTGCAGAGAGATGAGCAGGCTCAGCTGGGACAGAACCCCAGAAT CCACTGTCCTGCAAGCGAAGAGCCCAGCACAGAGAGCTGGATGGCCCAGTGGCACAGCGAAGCCATCAGCTCTCCAGAAATACCCAAGGG AGTCACTGTTATTGCAAGCACCAACCCAGAGCTGAGAAGACCTCGTTCTGAACCCTCTAATTACTACAGCAGTGAGAGCCACAAAGATTA TCCGGCTCCCAAAAAGCATAAATTGAACCCTGAGTACTTCCAGACAAGGCAGGAGAAGCTGCTTCCCACTGCACTGAGTCTGGAAGAGCC AAATATCAGGAAGCAAAGCCCTAGTTCTAAGCAGTCTGTCCCCGAGACACTCAGCCCCAGTGAAGGAGTGAGGGACTTCAGCCGGGAACT CTCCCCTCCCACTCCAGAGACTGCAGCATTTCAAGCCTCTGGATCTCAGCCTGTAGGAAAGTGGAATTCCAAAGATCTTTACATTGGTGT GTCTACAGTACAGGTGACTGGAAATCCGAAGGGGACCAGTGTAGGAAAGGAGGCAGCACCTTCACAGGTGCGTCCACGGGAACCAATGAG TGTCCTGATGATGGCTAACAGAGAGGTGGTGAATACAGAGCTGGGGTCCTACCGTGATAGTGCAGAAAATGAAGAATGCGGCCAGCCCAT GGATGACATACAGGTGAACATGATGACCTTGGCAGAACACATTATTGAAGCCACACCTGACCGAATCAAGCAGGAGAATTTTGTGCCCAT GGAGTCCTCAGGATTGGAAAGAACAGACCCTGCCACCATTAGCAGTACAATGAGCTGGCTGGCCAGTTATCTAGCGGATGCTGACTGCCT TCCCAGTGCTGCCCAGATCCGCTTGAGCCCTGTTGGCTCTCCCGTCAGTGAAATCGCTTTCGAGAAACCTAACCTTCCCTCCGCCGCGGA TTGGTCAGAATTCCTGAGTGCATCTACCAGTGAGAAGGTAGAGAATGAGTTTGCTCAGCTCACTCTGTCTGATCATGAACAGAGAGAACT CTATGAGGCTGCCAGGCTTGTCCAGACAGCTTTCCGGAAATACAAGGGCCGACCCTTGCGGGAACAGCAAGAAGTAGCTGCTGCTGTTAT TCAGCGTTGTTACAGAAAATATAAACAGTACGCACTTTATAAAAAGATGACACAGGCTGCCATCCTTATCCAGAGCAAATTCCGAAGTTA CTATGAACAAAAAAAATTCCAGCAGAGCCGACGGGCTGCTGTGCTCATCCAAAAGTACTACCGAAGTTATAAGAAATGTGGCAAAAGACG GCAGGCTCGCCGGACGGCTGTGATTGTACAACAGAAACTCAGGAGCAGTTTGCTAACCAAAAAGCAGGATCAAGCTGCTCGAAAAATAAT GAGGTTTCTTCGCCGCTGTCGCCACAGAGTGAAAGAATTGAAAAAGGCCAAGGAACTTGAAGACATACAGCAGCATCCCTTAGCAATGTG A >23450_23450_2_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000294401_CAMTA1_chr1_6880241_ENST00000439411_length(amino acids)=1669AA_BP=24 MATALSEEELDNEDYYSLLNVRRESVSQSVFCGTSTYCVLNTVPPIEDDHGNSNSSHVKIFLPKKLLECLPKCSSLPKERHRWNTNEEIA AYLITFEKHEEWLTTSPKTRPQNGSMILYNRKKVKYRKDGYCWKKRKDGKTTREDHMKLKVQGVECLYGCYVHSSIIPTFHRRCYWLLQN PDIVLVHYLNVPAIEDCGKPCGPILCSINTDKKEWAKWTKEELIGQLKPMFHGIKWTCSNGNSSSGFSVEQLVQQILDSHQTKPQPRTHN CLCTGSLGAGGSVHHKCNSAKHRIISPKVEPRTGGYGSHSEVQHNDVSEGKHEHSHSKGSSREKRNGKVAKPVLLHQSSTEVSSTNQVEV PDTTQSSPVSISSGLNSDPDMVDSPVVTGVSGMAVASVMGSLSQSATVFMSEVTNEAVYTMSPTAGPNHHLLSPDASQGLVLAVSSDGHK FAFPTTGSSESLSMLPTNVSEELVLSTTLDGGRKIPETTMNFDPDCFLNNPKQGQTYGGGGLKAEMVSSNIRHSPPGERSFSFTTVLTKE IKTEDTSFEQQMAKEAYSSSAAAVAASSLTLTAGSSLLPSGGGLSPSTTLEQMDFSAIDSNKDYTSSFSQTGHSPHIHQTPSPSFFLQDA SKPLPVEQNTHSSLSDSGGTFVMPTVKTEASSQTSSCSGHVETRIESTSSLHLMQFQANFQAMTAEGEVTMETSQAAEGSEVLLKSGELQ ACSSEHYLQPETNGVIRSAGGVPILPGNVVQGLYPVAQPSLGNASNMELSLDHFDISFSNQFSDLINDFISVEGGSSTIYGHQLVSGDST ALSQSEDGARAPFTQAEMCLPCCSPQQGSLQLSSSEGGASTMAYMHVAEVVSAASAQGTLGMLQQSGRVFMVTDYSPEWSYPEGGVKVLI TGPWQEASNNYSCLFDQISVPASLIQPGVLRCYCPAHDTGLVTLQVAFNNQIISNSVVFEYKARALPTLPSSQHDWLSLDDNQFRMSILE RLEQMERRMAEMTGSQQHKQASGGGSSGGGSGSGNGGSQAQCASGTGALGSCFESRVVVVCEKMMSRACWAKSKHLIHSKTFRGMTLLHL AAAQGYATLIQTLIKWRTKHADSIDLELEVDPLNVDHFSCTPLMWACALGHLEAAVVLYKWDRRAISIPDSLGRLPLGIARSRGHVKLAE CLEHLQRDEQAQLGQNPRIHCPASEEPSTESWMAQWHSEAISSPEIPKGVTVIASTNPELRRPRSEPSNYYSSESHKDYPAPKKHKLNPE YFQTRQEKLLPTALSLEEPNIRKQSPSSKQSVPETLSPSEGVRDFSRELSPPTPETAAFQASGSQPVGKWNSKDLYIGVSTVQVTGNPKG TSVGKEAAPSQVRPREPMSVLMMANREVVNTELGSYRDSAENEECGQPMDDIQVNMMTLAEHIIEATPDRIKQENFVPMESSGLERTDPA TISSTMSWLASYLADADCLPSAAQIRLSPVGSPVSEIAFEKPNLPSAADWSEFLSASTSEKVENEFAQLTLSDHEQRELYEAARLVQTAF RKYKGRPLREQQEVAAAVIQRCYRKYKQYALYKKMTQAAILIQSKFRSYYEQKKFQQSRRAAVLIQKYYRSYKKCGKRRQARRTAVIVQQ KLRSSLLTKKQDQAARKIMRFLRRCRHRVKELKKAKELEDIQQHPLAMX -------------------------------------------------------------- >23450_23450_3_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000377577_CAMTA1_chr1_6880241_ENST00000303635_length(transcript)=8388nt_BP=196nt GACGGCTCCGGGCCGCCAGGGGCCGCTGTGGCGCAGCCGGGCTGGCCCGCGCTGTCCCTGACGCGGATCACTGGCCCCTCTTGAGCACGG CCTTGCCGGTTTGGCGGGGTGAAAGGTTGCGAAGATGGCGACGGCCTTGAGCGAGGAGGAGCTGGACAATGAAGACTATTACTCGTTGCT GAACGTGCGCAGGGAGAGCGTTTCCCAAAGTGTATTCTGCGGAACTAGCACCTACTGTGTTCTCAACACCGTGCCACCTATAGAAGATGA TCATGGGAACAGCAATAGTAGTCATGTAAAAATCTTTTTACCGAAAAAGCTGCTTGAATGTCTGCCGAAATGTTCAAGTTTACCAAAAGA GAGGCACCGCTGGAACACTAATGAGGAAATTGCAGCTTATTTAATAACATTTGAGAAACACGAAGAATGGCTAACCACCTCCCCTAAGAC AAGACCACAGAATGGCTCAATGATACTCTACAACAGGAAGAAAGTGAAATACAGGAAAGATGGGTATTGCTGGAAAAAGAGGAAAGATGG GAAAACGACCAGAGAGGACCACATGAAACTCAAGGTCCAGGGAGTGGAGTGCTTGTACGGCTGCTATGTCCATTCCTCCATCATCCCCAC CTTCCACCGGAGGTGCTACTGGCTCCTTCAGAACCCCGACATCGTCCTGGTGCACTACCTGAACGTGCCGGCCATCGAGGACTGCGGCAA GCCTTGCGGCCCCATCCTCTGCTCCATCAACACCGACAAGAAGGAGTGGGCGAAATGGACGAAAGAAGAGCTCATCGGGCAGCTGAAACC CATGTTCCATGGCATCAAGTGGACCTGCAGCAATGGGAACAGCAGCTCAGGCTTCTCGGTGGAACAGCTGGTGCAGCAGATCCTCGACAG CCACCAGACCAAGCCCCAGCCGCGGACCCACAACTGCCTCTGCACCGGCAGCCTGGGAGCTGGCGGCAGCGTGCATCACAAGTGTAACAG CGCCAAACACCGCATCATCTCGCCCAAGGTGGAGCCACGGACAGGGGGGTACGGGAGCCACTCGGAGGTGCAGCACAATGACGTGTCGGA GGGCAAGCACGAGCACAGCCACAGCAAGGGCTCCAGCCGTGAGAAGAGGAACGGCAAGGTGGCCAAGCCCGTGCTCCTGCACCAGAGCAG CACCGAGGTCTCCTCCACCAACCAGGTGGAAGTCCCCGACACCACCCAGAGCTCCCCTGTGTCCATCAGCAGCGGGCTCAACAGCGACCC GGACATGGTGGACAGCCCGGTGGTCACAGGTGTGTCCGGTATGGCGGTGGCCTCTGTGATGGGGAGCTTGTCCCAGAGCGCCACGGTGTT CATGTCAGAGGTCACCAATGAGGCCGTGTACACCATGTCCCCCACCGCTGGCCCCAACCACCACCTCCTCTCACCTGACGCCTCTCAGGG CCTCGTCCTGGCCGTGAGCTCTGATGGCCACAAGTTCGCCTTTCCCACCACGGGCAGCTCGGAGAGCCTGTCCATGCTGCCCACCAACGT GTCCGAAGAGCTGGTCCTCTCCACCACCCTCGACGGTGGCCGGAAGATTCCAGAAACCACCATGAACTTTGACCCCGACTGTTTCCTTAA TAACCCAAAGCAGGGCCAGACGTACGGGGGTGGAGGCCTGAAAGCCGAGATGGTCAGCTCCAACATCCGGCACTCGCCACCCGGGGAGCG GAGCTTCAGCTTTACCACCGTCCTCACCAAGGAGATCAAGACCGAGGACACCTCCTTCGAGCAGCAGATGGCCAAAGAAGCGTACTCCTC CTCCGCGGCGGCTGTGGCAGCCAGCTCCCTCACCCTGACCGCCGGCTCCAGCCTCCTGCCGTCGGGCGGCGGCCTGAGTCCCAGCACCAC CCTGGAGCAGATGGACTTCAGCGCCATCGACTCCAACAAGGACTACACGTCCAGCTTCAGCCAGACGGGCCACAGCCCCCACATCCACCA GACCCCCTCCCCGAGCTTCTTCCTGCAGGACGCCAGCAAACCCCTCCCCGTCGAGCAGAACACCCACAGCAGCCTGAGTGACTCTGGGGG CACCTTCGTGATGCCCACGGTGAAAACGGAGGCCTCGTCCCAAACCAGCTCCTGCAGCGGTCACGTGGAGACGCGGATCGAGTCCACTTC CTCCCTCCACCTCATGCAGTTCCAGGCCAACTTCCAGGCCATGACGGCAGAAGGGGAGGTCACCATGGAGACCTCGCAGGCGGCGGAAGG GAGCGAGGTCCTGCTCAAGTCTGGGGAGCTGCAGGCTTGCAGCTCTGAGCACTACCTGCAGCCGGAGACCAACGGGGTAATCCGAAGCGC CGGCGGCGTCCCCATCCTCCCGGGCAACGTGGTGCAGGGACTCTACCCCGTGGCCCAGCCCAGCCTCGGCAACGCCTCCAACATGGAGCT CAGCCTGGACCACTTTGACATCTCCTTCAGCAACCAGTTCTCCGACCTGATCAACGACTTCATCTCCGTGGAGGGGGGCAGCAGCACCAT CTATGGGCACCAGCTGGTGTCGGGGGACAGCACGGCGCTCTCACAGTCAGAGGACGGGGCGCGGGCCCCCTTCACCCAGGCAGAGATGTG CCTCCCCTGCTGTAGCCCCCAGCAGGGTAGCCTGCAGCTGAGCAGCTCGGAGGGCGGGGCCAGCACCATGGCCTACATGCACGTCGCCGA GGTGGTCTCGGCCGCCTCGGCCCAGGGCACCCTAGGCATGCTGCAGCAGAGCGGACGGGTGTTCATGGTGACCGACTACTCCCCAGAGTG GTCTTACCCAGAGGGAGGAGTGAAGGTCCTCATCACAGGCCCGTGGCAAGAAGCCAGCAATAACTACAGCTGCCTGTTTGACCAGATCTC AGTGCCTGCATCCCTGATTCAGCCTGGGGTGCTGCGCTGCTACTGCCCAGCCCATGACACTGGTCTTGTGACCCTACAAGTTGCCTTCAA CAACCAGATCATCTCCAACTCGGTGGTGTTTGAGTACAAAGCCCGGGCTCTGCCCACGCTCCCTTCCTCCCAGCACGACTGGCTGTCGTT GGACGATAACCAGTTCAGGATGTCCATCCTGGAACGACTGGAGCAGATGGAGAGGAGGATGGCCGAGATGACGGGGTCCCAGCAGCACAA ACAGGCGAGCGGAGGCGGCAGCAGTGGAGGCGGCAGCGGGAGCGGGAATGGAGGGAGCCAGGCACAGTGTGCTTCTGGGACTGGGGCCTT GGGGAGCTGCTTTGAGAGCCGTGTGGTCGTGGTATGCGAGAAGATGATGAGCCGAGCCTGCTGGGCGAAGTCCAAGCACTTGATCCACTC AAAGACTTTCCGCGGAATGACCCTACTCCACCTGGCCGCTGCCCAGGGCTATGCCACCCTAATCCAGACCCTCATCAAATGGCGTACAAA GCACGCGGATAGCATTGACCTGGAACTGGAAGTTGACCCCTTGAATGTGGACCACTTCTCCTGTACTCCTCTGATGTGGGCGTGTGCCCT AGGGCACTTGGAAGCTGCCGTCGTGCTGTACAAGTGGGACCGTCGGGCCATCTCGATTCCCGACTCTCTAGGAAGGCTGCCTTTGGGAAT TGCCAGGTCACGGGGTCATGTGAAATTAGCAGAGTGTCTGGAGCACCTGCAGAGAGATGAGCAGGCTCAGCTGGGACAGAACCCCAGAAT CCACTGTCCTGCAAGCGAAGAGCCCAGCACAGAGAGCTGGATGGCCCAGTGGCACAGCGAAGCCATCAGCTCTCCAGAAATACCCAAGGG AGTCACTGTTATTGCAAGCACCAACCCAGAGCTGAGAAGACCTCGTTCTGAACCCTCTAATTACTACAGCAGTGAGAGCCACAAAGATTA TCCGGCTCCCAAAAAGCATAAATTGAACCCTGAGTACTTCCAGACAAGGCAGGAGAAGCTGCTTCCCACTGCACTGAGTCTGGAAGAGCC AAATATCAGGAAGCAAAGCCCTAGTTCTAAGCAGTCTGTCCCCGAGACACTCAGCCCCAGTGAAGGAGTGAGGGACTTCAGCCGGGAACT CTCCCCTCCCACTCCAGAGACTGCAGCATTTCAAGCCTCTGGATCTCAGCCTGTAGGAAAGTGGAATTCCAAAGATCTTTACATTGGTGT GTCTACAGTACAGGTGACTGGAAATCCGAAGGGGACCAGTGTAGGAAAGGAGGCAGCACCTTCACAGGTGCGTCCACGGGAACCAATGAG TGTCCTGATGATGGCTAACAGAGAGGTGGTGAATACAGAGCTGGGGTCCTACCGTGATAGTGCAGAAAATGAAGAATGCGGCCAGCCCAT GGATGACATACAGGTGAACATGATGACCTTGGCAGAACACATTATTGAAGCCACACCTGACCGAATCAAGCAGGAGAATTTTGTGCCCAT GGAGTCCTCAGGATTGGAAAGAACAGACCCTGCCACCATTAGCAGTACAATGAGCTGGCTGGCCAGTTATCTAGCGGATGCTGACTGCCT TCCCAGTGCTGCCCAGATCCGAAGTGCATATAACGAGCCTCTAACCCCTTCTTCTAATACCAGCTTGAGCCCTGTTGGCTCTCCCGTCAG TGAAATCGCTTTCGAGAAACCTAACCTTCCCTCCGCCGCGGATTGGTCAGAATTCCTGAGTGCATCTACCAGTGAGAAGGTAGAGAATGA GTTTGCTCAGCTCACTCTGTCTGATCATGAACAGAGAGAACTCTATGAGGCTGCCAGGCTTGTCCAGACAGCTTTCCGGAAATACAAGGG CCGACCCTTGCGGGAACAGCAAGAAGTAGCTGCTGCTGTTATTCAGCGTTGTTACAGAAAATATAAACAGTACGCACTTTATAAAAAGAT GACACAGGCTGCCATCCTTATCCAGAGCAAATTCCGAAGTTACTATGAACAAAAAAAATTCCAGCAGAGCCGACGGGCTGCTGTGCTCAT CCAAAAGTACTACCGAAGTTATAAGAAATGTGGCAAAAGACGGCAGGCTCGCCGGACGGCTGTGATTGTACAACAGAAACTCAGGAGCAG TTTGCTAACCAAAAAGCAGGATCAAGCTGCTCGAAAAATAATGAGGTTTCTTCGCCGCTGTCGCCACAGCCCCCTGGTGGACCATAGGCT GTACAAAAGGAGTGAAAGAATTGAAAAAGGCCAAGGAACTTGAAGACATACAGCAGCATCCCTTAGCAATGTGACATTGCTTTTCAGACT GTTTTCATTTCTGTTTTTAGCAGAGACATGCAACAACAACACACACGCACACACGCACACACACACACGTACACACACATACAAAATCCC TCTGCAGTTTTGGGGAGATCAGCTGCAGGATTTTAACAGGAATGTTTTGGTCATTGCATTTGCACTTTCATGGACAACTTTTAATTTGAT CAGCAAGACATCTTGGAACTCAATCTTCTGTTGGATCACGGGAAATCAAGACACCCAGGAGGAATTGAAAGAGGCTTCCTCTTCTCAGGA AGAAGCCATTTCCTTCTCATATAGGGCTGTATTCAAACATCGTGTGGAACTGTACAAATATTTATACCAAAAATATAGATAAGAAAAGGT GGGGCTATACTAGCAACAAAAAAAGAATGCTGTTCCTGCACCTGCCGGTTATTTCCAAGAAGCTGAATCTTTGGGACTGATTCTCAGTGG AGGGCTTAGATCATACAAAAATCTTTATTGGGTCCGTGTGTTCTCATTTCCTTCACTGTTTATTTTTGTTTGTTTGTTTGTTTGTTTTAA TCTCTACAGCACATTTAATGCAACTTTTGAAATCTGCAGGTTTTTAATGTCTTGTGGAAATTTGCAGAGGGGCAGGTGTGTGGTAAACGG GTAATGCATGGGAAATAATGAGAAGCAGCTCACAGAGTTTAAACTATTTTCTTGTCCCCACCACCTTCCAAGAACCTGCGAGGGTAGTAA TCATCTTGTCCCCTTTTTCATGTTCAGCACTTTAATTTTTTTGCCTTACTTTCATGTGCAATGAGAATTACTTAAGAATTGGTAACGCAT GTAGCCTTTTTTAGTAACCTTGGAAGCTGTAGTAATTCTAAGGAATCATGAACCTTGCCTGGACATTTGCCACCTAAACGATCAGTGTGG TGCTGCGTTCTGGCCAGTAAATTCCATGTTTTTGGCTATATCTCATCCAAACTGAGCAGTTTCTGTGTATATATAGAAGGTAGAAATGAA AAGTGAGAAAATATTTGAAAGGGATTATATTAATTGCTAAATATTTTATTCACAAAGGTCAATAACATGGCAAGATAAAATTATTTGTAT AGTTTTGTCTGAATGAGCGAGAAAAATGTGGATGTACTGTTTGTATATATTGTATATATTAAAACAGAGATATGTGCATGAAATCAAGAA AAAAGAAATGAACAAAAGCAAAGCATTAGTGGCTATGGTCTGTAAAATGAAACAAAAAAACTTTATTTCACTATAAGAGTACTTTATTTT AAATGTTCTTTAGGAGAACATTTTGCTAAAGCATGACTAAACTGCAAAAAAAAAAAAAGAGCTACTGTATTTAGACTTAGGAAAAAAGGC AGAGTAACATTACTTAAAAAAAAAAGGATATGTTTACATTTAATTTTGGCTACCAGGAGTTTAGTTTATTTTATTTAAAATTTTTTTGCC AATGGTGCCAAGTAATGTGAATGCTAATACTGCTTAAGAAAATTAAGTTACTTTTGCAAAACAGATAATCATAAGATGAATCAGTATGTA GCTTAACACCATCCACTCACTCCAACAAAGAACACTTAGAATGATAAAAAAAAAAAAAAAAAACCTGACAAAAGAAATAGTATGAAAAGT AGAAAAATGTCACGTTTCCATATCTCCTGCTGGAAATCAGAAAATATAATAAAATTGCACAAAAAAAAAAATGAAAAAGATGCAGACTGG TCTTTTAGAGACGGCATGGTATATTACTATTTCCACATAATGAGGAGCCAAAGAAATCTGATGTTTTTAACAATTAAACTGCTAATGTTA AATTGAGAGAATAAAGTTCGTATTTGCTGATGCCAGTTTAAAATTCCCAGGTTACGTCTGAGGATCAGTTGGTGTAAAGCTGAGATGTTT TTTCTTGGTTCTGGCTGCCAACTGTGAGTTAAAACTCAAGGCTTGTTGTGAAGCCTAAAAATATTCACAAATAAGCTTTTAAACTGGTGT CTTTGGAAGGAAGGTAGATACAAAAAGATTGTGGTAAAAACTGGGGTCAGTGCTCTTGGTGCCTTTTCTATAATTGTACTTGTTTTTTAA TTACTTCCTTTCACTGCCAACCTCGAATTACTGTACAGTATATGTCTTTCTGCTTGTGATCAGCTTTGACAACAGTGACAGCCCCACAAC TAGTAGCCACCTGTACATTTGTAAACTGACCTGACTCCATTTTGTTTTTAAATGTGTGGGTTATGTTGCAGCTGTTGCAGTCCCCCAGAT ACCTATTATTTTACACAATTTGACCTATAGGAGGACACTGAGTAATTTACAAACACAACTGCATTCATAAATGGGAATAGAACGTGAAAG CCAGCTCTTTCAGAATATCCTCTATTAATACTGAATTTAGATATCTTTATTCCATTTATTATGGTACAAATAACTGATGTTTTAACCAGA GTAATGACCTCAGTGGATTTGCTTTAACCCTCACATTTTTTTTTTAATGTTTCACATGTTACATTATTAGCTGAATACGTTAGAAAATGA CAGATGGTAGAGACTTCCATAGAATTAAGAGGGTTCTCATGGAGGGGATAGGAAGTAGGTTTAAAGCCTACCAGTGTAACCTACCAGTAC AACTGTGAATCCTAGGCAAGGCAAAAATGCACTTCCACTGAAACGAAGCATTTCTGACCGCTTTTTCTTGGTTATGAATCTTAATTTCGA ATATAAGATGATAGGTAAGCGCAGCTTTCTTGGATAATCTGAATTCCCAAGTGCCAGGAGTAGGATTTCATTATAAAATTAATAGCTAAT CTTATTCTATCTCCTGAAGATTTAATTGCTATTGTTACCCATTCGAAATCAGCTGTACTGTGTGAACGAAATAAAGACAATAATACGAAC CCCTCTCTGGCTGCACGGTCGCTTATGGCAGTTCCACACAGTAGTTGGCGCCCAATGGGGGGTCCCTGAGACTTGCATGTAAAACTAGTC TAGATGTCTTCTTTTTTTGTAAGTTTTATTTTTGTAATTGTGCATGTAAAGCATCATTGAATCAATGGATCTGTTGAAGAACTCAGCTGC TGGAAACCATGCAAAATGTTTTGAATTGCCCTTAAAATATGGAAAATGTTTTCTGAATGCTTTATATTCTTTCTGCTGTAAATTAAAAAT GAAGAAAATTTCCCCATA >23450_23450_3_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000377577_CAMTA1_chr1_6880241_ENST00000303635_length(amino acids)=1682AA_BP=24 MATALSEEELDNEDYYSLLNVRRESVSQSVFCGTSTYCVLNTVPPIEDDHGNSNSSHVKIFLPKKLLECLPKCSSLPKERHRWNTNEEIA AYLITFEKHEEWLTTSPKTRPQNGSMILYNRKKVKYRKDGYCWKKRKDGKTTREDHMKLKVQGVECLYGCYVHSSIIPTFHRRCYWLLQN PDIVLVHYLNVPAIEDCGKPCGPILCSINTDKKEWAKWTKEELIGQLKPMFHGIKWTCSNGNSSSGFSVEQLVQQILDSHQTKPQPRTHN CLCTGSLGAGGSVHHKCNSAKHRIISPKVEPRTGGYGSHSEVQHNDVSEGKHEHSHSKGSSREKRNGKVAKPVLLHQSSTEVSSTNQVEV PDTTQSSPVSISSGLNSDPDMVDSPVVTGVSGMAVASVMGSLSQSATVFMSEVTNEAVYTMSPTAGPNHHLLSPDASQGLVLAVSSDGHK FAFPTTGSSESLSMLPTNVSEELVLSTTLDGGRKIPETTMNFDPDCFLNNPKQGQTYGGGGLKAEMVSSNIRHSPPGERSFSFTTVLTKE IKTEDTSFEQQMAKEAYSSSAAAVAASSLTLTAGSSLLPSGGGLSPSTTLEQMDFSAIDSNKDYTSSFSQTGHSPHIHQTPSPSFFLQDA SKPLPVEQNTHSSLSDSGGTFVMPTVKTEASSQTSSCSGHVETRIESTSSLHLMQFQANFQAMTAEGEVTMETSQAAEGSEVLLKSGELQ ACSSEHYLQPETNGVIRSAGGVPILPGNVVQGLYPVAQPSLGNASNMELSLDHFDISFSNQFSDLINDFISVEGGSSTIYGHQLVSGDST ALSQSEDGARAPFTQAEMCLPCCSPQQGSLQLSSSEGGASTMAYMHVAEVVSAASAQGTLGMLQQSGRVFMVTDYSPEWSYPEGGVKVLI TGPWQEASNNYSCLFDQISVPASLIQPGVLRCYCPAHDTGLVTLQVAFNNQIISNSVVFEYKARALPTLPSSQHDWLSLDDNQFRMSILE RLEQMERRMAEMTGSQQHKQASGGGSSGGGSGSGNGGSQAQCASGTGALGSCFESRVVVVCEKMMSRACWAKSKHLIHSKTFRGMTLLHL AAAQGYATLIQTLIKWRTKHADSIDLELEVDPLNVDHFSCTPLMWACALGHLEAAVVLYKWDRRAISIPDSLGRLPLGIARSRGHVKLAE CLEHLQRDEQAQLGQNPRIHCPASEEPSTESWMAQWHSEAISSPEIPKGVTVIASTNPELRRPRSEPSNYYSSESHKDYPAPKKHKLNPE YFQTRQEKLLPTALSLEEPNIRKQSPSSKQSVPETLSPSEGVRDFSRELSPPTPETAAFQASGSQPVGKWNSKDLYIGVSTVQVTGNPKG TSVGKEAAPSQVRPREPMSVLMMANREVVNTELGSYRDSAENEECGQPMDDIQVNMMTLAEHIIEATPDRIKQENFVPMESSGLERTDPA TISSTMSWLASYLADADCLPSAAQIRSAYNEPLTPSSNTSLSPVGSPVSEIAFEKPNLPSAADWSEFLSASTSEKVENEFAQLTLSDHEQ RELYEAARLVQTAFRKYKGRPLREQQEVAAAVIQRCYRKYKQYALYKKMTQAAILIQSKFRSYYEQKKFQQSRRAAVLIQKYYRSYKKCG KRRQARRTAVIVQQKLRSSLLTKKQDQAARKIMRFLRRCRHSPLVDHRLYKRSERIEKGQGT -------------------------------------------------------------- >23450_23450_4_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000377577_CAMTA1_chr1_6880241_ENST00000439411_length(transcript)=5131nt_BP=196nt GACGGCTCCGGGCCGCCAGGGGCCGCTGTGGCGCAGCCGGGCTGGCCCGCGCTGTCCCTGACGCGGATCACTGGCCCCTCTTGAGCACGG CCTTGCCGGTTTGGCGGGGTGAAAGGTTGCGAAGATGGCGACGGCCTTGAGCGAGGAGGAGCTGGACAATGAAGACTATTACTCGTTGCT GAACGTGCGCAGGGAGAGCGTTTCCCAAAGTGTATTCTGCGGAACTAGCACCTACTGTGTTCTCAACACCGTGCCACCTATAGAAGATGA TCATGGGAACAGCAATAGTAGTCATGTAAAAATCTTTTTACCGAAAAAGCTGCTTGAATGTCTGCCGAAATGTTCAAGTTTACCAAAAGA GAGGCACCGCTGGAACACTAATGAGGAAATTGCAGCTTATTTAATAACATTTGAGAAACACGAAGAATGGCTAACCACCTCCCCTAAGAC AAGACCACAGAATGGCTCAATGATACTCTACAACAGGAAGAAAGTGAAATACAGGAAAGATGGGTATTGCTGGAAAAAGAGGAAAGATGG GAAAACGACCAGAGAGGACCACATGAAACTCAAGGTCCAGGGAGTGGAGTGCTTGTACGGCTGCTATGTCCATTCCTCCATCATCCCCAC CTTCCACCGGAGGTGCTACTGGCTCCTTCAGAACCCCGACATCGTCCTGGTGCACTACCTGAACGTGCCGGCCATCGAGGACTGCGGCAA GCCTTGCGGCCCCATCCTCTGCTCCATCAACACCGACAAGAAGGAGTGGGCGAAATGGACGAAAGAAGAGCTCATCGGGCAGCTGAAACC CATGTTCCATGGCATCAAGTGGACCTGCAGCAATGGGAACAGCAGCTCAGGCTTCTCGGTGGAACAGCTGGTGCAGCAGATCCTCGACAG CCACCAGACCAAGCCCCAGCCGCGGACCCACAACTGCCTCTGCACCGGCAGCCTGGGAGCTGGCGGCAGCGTGCATCACAAGTGTAACAG CGCCAAACACCGCATCATCTCGCCCAAGGTGGAGCCACGGACAGGGGGGTACGGGAGCCACTCGGAGGTGCAGCACAATGACGTGTCGGA GGGCAAGCACGAGCACAGCCACAGCAAGGGCTCCAGCCGTGAGAAGAGGAACGGCAAGGTGGCCAAGCCCGTGCTCCTGCACCAGAGCAG CACCGAGGTCTCCTCCACCAACCAGGTGGAAGTCCCCGACACCACCCAGAGCTCCCCTGTGTCCATCAGCAGCGGGCTCAACAGCGACCC GGACATGGTGGACAGCCCGGTGGTCACAGGTGTGTCCGGTATGGCGGTGGCCTCTGTGATGGGGAGCTTGTCCCAGAGCGCCACGGTGTT CATGTCAGAGGTCACCAATGAGGCCGTGTACACCATGTCCCCCACCGCTGGCCCCAACCACCACCTCCTCTCACCTGACGCCTCTCAGGG CCTCGTCCTGGCCGTGAGCTCTGATGGCCACAAGTTCGCCTTTCCCACCACGGGCAGCTCGGAGAGCCTGTCCATGCTGCCCACCAACGT GTCCGAAGAGCTGGTCCTCTCCACCACCCTCGACGGTGGCCGGAAGATTCCAGAAACCACCATGAACTTTGACCCCGACTGTTTCCTTAA TAACCCAAAGCAGGGCCAGACGTACGGGGGTGGAGGCCTGAAAGCCGAGATGGTCAGCTCCAACATCCGGCACTCGCCACCCGGGGAGCG GAGCTTCAGCTTTACCACCGTCCTCACCAAGGAGATCAAGACCGAGGACACCTCCTTCGAGCAGCAGATGGCCAAAGAAGCGTACTCCTC CTCCGCGGCGGCTGTGGCAGCCAGCTCCCTCACCCTGACCGCCGGCTCCAGCCTCCTGCCGTCGGGCGGCGGCCTGAGTCCCAGCACCAC CCTGGAGCAGATGGACTTCAGCGCCATCGACTCCAACAAGGACTACACGTCCAGCTTCAGCCAGACGGGCCACAGCCCCCACATCCACCA GACCCCCTCCCCGAGCTTCTTCCTGCAGGACGCCAGCAAACCCCTCCCCGTCGAGCAGAACACCCACAGCAGCCTGAGTGACTCTGGGGG CACCTTCGTGATGCCCACGGTGAAAACGGAGGCCTCGTCCCAAACCAGCTCCTGCAGCGGTCACGTGGAGACGCGGATCGAGTCCACTTC CTCCCTCCACCTCATGCAGTTCCAGGCCAACTTCCAGGCCATGACGGCAGAAGGGGAGGTCACCATGGAGACCTCGCAGGCGGCGGAAGG GAGCGAGGTCCTGCTCAAGTCTGGGGAGCTGCAGGCTTGCAGCTCTGAGCACTACCTGCAGCCGGAGACCAACGGGGTAATCCGAAGCGC CGGCGGCGTCCCCATCCTCCCGGGCAACGTGGTGCAGGGACTCTACCCCGTGGCCCAGCCCAGCCTCGGCAACGCCTCCAACATGGAGCT CAGCCTGGACCACTTTGACATCTCCTTCAGCAACCAGTTCTCCGACCTGATCAACGACTTCATCTCCGTGGAGGGGGGCAGCAGCACCAT CTATGGGCACCAGCTGGTGTCGGGGGACAGCACGGCGCTCTCACAGTCAGAGGACGGGGCGCGGGCCCCCTTCACCCAGGCAGAGATGTG CCTCCCCTGCTGTAGCCCCCAGCAGGGTAGCCTGCAGCTGAGCAGCTCGGAGGGCGGGGCCAGCACCATGGCCTACATGCACGTCGCCGA GGTGGTCTCGGCCGCCTCGGCCCAGGGCACCCTAGGCATGCTGCAGCAGAGCGGACGGGTGTTCATGGTGACCGACTACTCCCCAGAGTG GTCTTACCCAGAGGGAGGAGTGAAGGTCCTCATCACAGGCCCGTGGCAAGAAGCCAGCAATAACTACAGCTGCCTGTTTGACCAGATCTC AGTGCCTGCATCCCTGATTCAGCCTGGGGTGCTGCGCTGCTACTGCCCAGCCCATGACACTGGTCTTGTGACCCTACAAGTTGCCTTCAA CAACCAGATCATCTCCAACTCGGTGGTGTTTGAGTACAAAGCCCGGGCTCTGCCCACGCTCCCTTCCTCCCAGCACGACTGGCTGTCGTT GGACGATAACCAGTTCAGGATGTCCATCCTGGAACGACTGGAGCAGATGGAGAGGAGGATGGCCGAGATGACGGGGTCCCAGCAGCACAA ACAGGCGAGCGGAGGCGGCAGCAGTGGAGGCGGCAGCGGGAGCGGGAATGGAGGGAGCCAGGCACAGTGTGCTTCTGGGACTGGGGCCTT GGGGAGCTGCTTTGAGAGCCGTGTGGTCGTGGTATGCGAGAAGATGATGAGCCGAGCCTGCTGGGCGAAGTCCAAGCACTTGATCCACTC AAAGACTTTCCGCGGAATGACCCTACTCCACCTGGCCGCTGCCCAGGGCTATGCCACCCTAATCCAGACCCTCATCAAATGGCGTACAAA GCACGCGGATAGCATTGACCTGGAACTGGAAGTTGACCCCTTGAATGTGGACCACTTCTCCTGTACTCCTCTGATGTGGGCGTGTGCCCT AGGGCACTTGGAAGCTGCCGTCGTGCTGTACAAGTGGGACCGTCGGGCCATCTCGATTCCCGACTCTCTAGGAAGGCTGCCTTTGGGAAT TGCCAGGTCACGGGGTCATGTGAAATTAGCAGAGTGTCTGGAGCACCTGCAGAGAGATGAGCAGGCTCAGCTGGGACAGAACCCCAGAAT CCACTGTCCTGCAAGCGAAGAGCCCAGCACAGAGAGCTGGATGGCCCAGTGGCACAGCGAAGCCATCAGCTCTCCAGAAATACCCAAGGG AGTCACTGTTATTGCAAGCACCAACCCAGAGCTGAGAAGACCTCGTTCTGAACCCTCTAATTACTACAGCAGTGAGAGCCACAAAGATTA TCCGGCTCCCAAAAAGCATAAATTGAACCCTGAGTACTTCCAGACAAGGCAGGAGAAGCTGCTTCCCACTGCACTGAGTCTGGAAGAGCC AAATATCAGGAAGCAAAGCCCTAGTTCTAAGCAGTCTGTCCCCGAGACACTCAGCCCCAGTGAAGGAGTGAGGGACTTCAGCCGGGAACT CTCCCCTCCCACTCCAGAGACTGCAGCATTTCAAGCCTCTGGATCTCAGCCTGTAGGAAAGTGGAATTCCAAAGATCTTTACATTGGTGT GTCTACAGTACAGGTGACTGGAAATCCGAAGGGGACCAGTGTAGGAAAGGAGGCAGCACCTTCACAGGTGCGTCCACGGGAACCAATGAG TGTCCTGATGATGGCTAACAGAGAGGTGGTGAATACAGAGCTGGGGTCCTACCGTGATAGTGCAGAAAATGAAGAATGCGGCCAGCCCAT GGATGACATACAGGTGAACATGATGACCTTGGCAGAACACATTATTGAAGCCACACCTGACCGAATCAAGCAGGAGAATTTTGTGCCCAT GGAGTCCTCAGGATTGGAAAGAACAGACCCTGCCACCATTAGCAGTACAATGAGCTGGCTGGCCAGTTATCTAGCGGATGCTGACTGCCT TCCCAGTGCTGCCCAGATCCGCTTGAGCCCTGTTGGCTCTCCCGTCAGTGAAATCGCTTTCGAGAAACCTAACCTTCCCTCCGCCGCGGA TTGGTCAGAATTCCTGAGTGCATCTACCAGTGAGAAGGTAGAGAATGAGTTTGCTCAGCTCACTCTGTCTGATCATGAACAGAGAGAACT CTATGAGGCTGCCAGGCTTGTCCAGACAGCTTTCCGGAAATACAAGGGCCGACCCTTGCGGGAACAGCAAGAAGTAGCTGCTGCTGTTAT TCAGCGTTGTTACAGAAAATATAAACAGTACGCACTTTATAAAAAGATGACACAGGCTGCCATCCTTATCCAGAGCAAATTCCGAAGTTA CTATGAACAAAAAAAATTCCAGCAGAGCCGACGGGCTGCTGTGCTCATCCAAAAGTACTACCGAAGTTATAAGAAATGTGGCAAAAGACG GCAGGCTCGCCGGACGGCTGTGATTGTACAACAGAAACTCAGGAGCAGTTTGCTAACCAAAAAGCAGGATCAAGCTGCTCGAAAAATAAT GAGGTTTCTTCGCCGCTGTCGCCACAGAGTGAAAGAATTGAAAAAGGCCAAGGAACTTGAAGACATACAGCAGCATCCCTTAGCAATGTG A >23450_23450_4_DNAJC11-CAMTA1_DNAJC11_chr1_6761789_ENST00000377577_CAMTA1_chr1_6880241_ENST00000439411_length(amino acids)=1669AA_BP=24 MATALSEEELDNEDYYSLLNVRRESVSQSVFCGTSTYCVLNTVPPIEDDHGNSNSSHVKIFLPKKLLECLPKCSSLPKERHRWNTNEEIA AYLITFEKHEEWLTTSPKTRPQNGSMILYNRKKVKYRKDGYCWKKRKDGKTTREDHMKLKVQGVECLYGCYVHSSIIPTFHRRCYWLLQN PDIVLVHYLNVPAIEDCGKPCGPILCSINTDKKEWAKWTKEELIGQLKPMFHGIKWTCSNGNSSSGFSVEQLVQQILDSHQTKPQPRTHN CLCTGSLGAGGSVHHKCNSAKHRIISPKVEPRTGGYGSHSEVQHNDVSEGKHEHSHSKGSSREKRNGKVAKPVLLHQSSTEVSSTNQVEV PDTTQSSPVSISSGLNSDPDMVDSPVVTGVSGMAVASVMGSLSQSATVFMSEVTNEAVYTMSPTAGPNHHLLSPDASQGLVLAVSSDGHK FAFPTTGSSESLSMLPTNVSEELVLSTTLDGGRKIPETTMNFDPDCFLNNPKQGQTYGGGGLKAEMVSSNIRHSPPGERSFSFTTVLTKE IKTEDTSFEQQMAKEAYSSSAAAVAASSLTLTAGSSLLPSGGGLSPSTTLEQMDFSAIDSNKDYTSSFSQTGHSPHIHQTPSPSFFLQDA SKPLPVEQNTHSSLSDSGGTFVMPTVKTEASSQTSSCSGHVETRIESTSSLHLMQFQANFQAMTAEGEVTMETSQAAEGSEVLLKSGELQ ACSSEHYLQPETNGVIRSAGGVPILPGNVVQGLYPVAQPSLGNASNMELSLDHFDISFSNQFSDLINDFISVEGGSSTIYGHQLVSGDST ALSQSEDGARAPFTQAEMCLPCCSPQQGSLQLSSSEGGASTMAYMHVAEVVSAASAQGTLGMLQQSGRVFMVTDYSPEWSYPEGGVKVLI TGPWQEASNNYSCLFDQISVPASLIQPGVLRCYCPAHDTGLVTLQVAFNNQIISNSVVFEYKARALPTLPSSQHDWLSLDDNQFRMSILE RLEQMERRMAEMTGSQQHKQASGGGSSGGGSGSGNGGSQAQCASGTGALGSCFESRVVVVCEKMMSRACWAKSKHLIHSKTFRGMTLLHL AAAQGYATLIQTLIKWRTKHADSIDLELEVDPLNVDHFSCTPLMWACALGHLEAAVVLYKWDRRAISIPDSLGRLPLGIARSRGHVKLAE CLEHLQRDEQAQLGQNPRIHCPASEEPSTESWMAQWHSEAISSPEIPKGVTVIASTNPELRRPRSEPSNYYSSESHKDYPAPKKHKLNPE YFQTRQEKLLPTALSLEEPNIRKQSPSSKQSVPETLSPSEGVRDFSRELSPPTPETAAFQASGSQPVGKWNSKDLYIGVSTVQVTGNPKG TSVGKEAAPSQVRPREPMSVLMMANREVVNTELGSYRDSAENEECGQPMDDIQVNMMTLAEHIIEATPDRIKQENFVPMESSGLERTDPA TISSTMSWLASYLADADCLPSAAQIRLSPVGSPVSEIAFEKPNLPSAADWSEFLSASTSEKVENEFAQLTLSDHEQRELYEAARLVQTAF RKYKGRPLREQQEVAAAVIQRCYRKYKQYALYKKMTQAAILIQSKFRSYYEQKKFQQSRRAAVLIQKYYRSYKKCGKRRQARRTAVIVQQ KLRSSLLTKKQDQAARKIMRFLRRCRHRVKELKKAKELEDIQQHPLAMX -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DNAJC11-CAMTA1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DNAJC11-CAMTA1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DNAJC11-CAMTA1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0206732 | Epithelioid hemangioendothelioma | 1 | ORPHANET | |
| Tgene | C3553661 | CEREBELLAR ATAXIA, NONPROGRESSIVE, WITH MENTAL RETARDATION | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies