
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C19orf10-CHAF1A (FusionGDB2 ID:HG56005TG10036) |
Fusion Gene Summary for C19orf10-CHAF1A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C19orf10-CHAF1A | Fusion gene ID: hg56005tg10036 | Hgene | Tgene | Gene symbol | C19orf10 | CHAF1A | Gene ID | 56005 | 10036 |
| Gene name | myeloid derived growth factor | chromatin assembly factor 1 subunit A | |
| Synonyms | C19orf10|EUROIMAGE1875335|IL25|IL27|IL27w|R33729_1|SF20 | CAF-1|CAF1|CAF1B|CAF1P150|P150 | |
| Cytomap | ('C19orf10')('CHAF1A') 19p13.3 | 19p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | myeloid-derived growth factorUPF0556 protein C19orf10interleukin 27 working designationinterleukin-25stromal cell-derived growth factor SF20 | chromatin assembly factor 1 subunit ACAF-1 subunit ACAF-I 150 kDa subunitCAF-I p150CTB-50L17.7chromatin assembly factor I (150 kDa)chromatin assembly factor I p150 subunithp150 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000262947, ENST00000599630, | ||
| Fusion gene scores | * DoF score | 4 X 4 X 4=64 | 5 X 6 X 6=180 |
| # samples | 5 | 7 | |
| ** MAII score | log2(5/64*10)=-0.356143810225275 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/180*10)=-1.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: C19orf10 [Title/Abstract] AND CHAF1A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C19orf10(4668607)-CHAF1A(4422563), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | C19orf10-CHAF1A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C19orf10-CHAF1A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C19orf10-CHAF1A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. C19orf10-CHAF1A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | C19orf10 | GO:0001938 | positive regulation of endothelial cell proliferation | 25581518 |
| Hgene | C19orf10 | GO:0045766 | positive regulation of angiogenesis | 25581518 |
| Tgene | CHAF1A | GO:0006335 | DNA replication-dependent nucleosome assembly | 14718166 |
| Tgene | CHAF1A | GO:0031497 | chromatin assembly | 8858152 |
| Fusion gene breakpoints across C19orf10 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
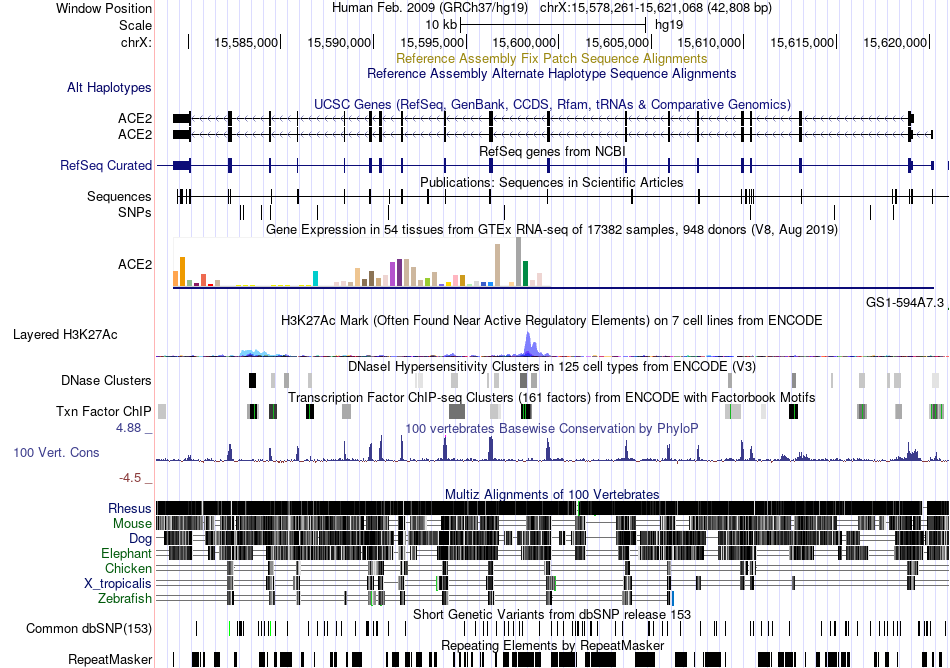 |
| Fusion gene breakpoints across CHAF1A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
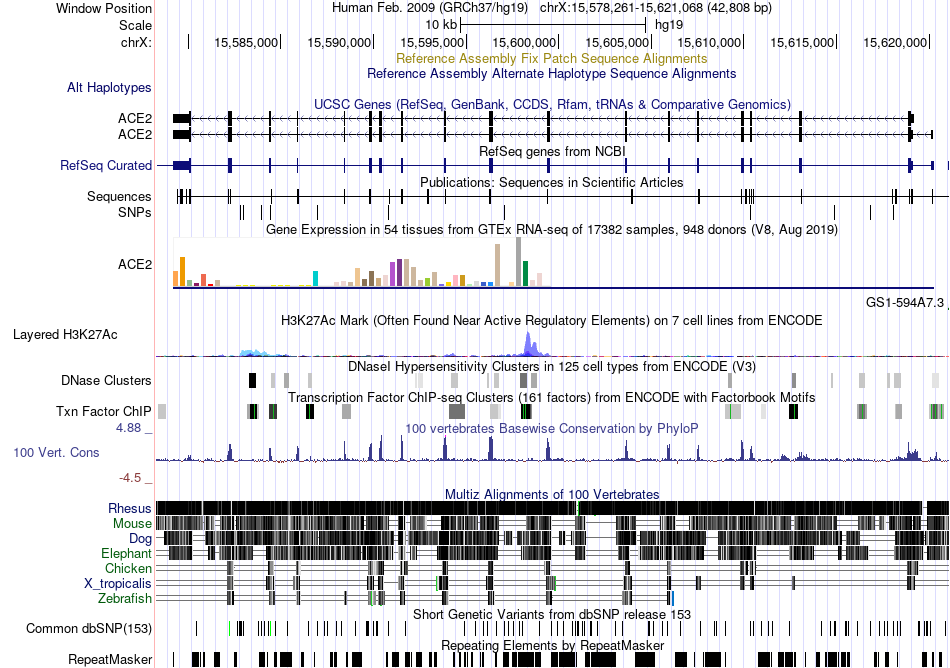 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-HU-A4GH-01A | C19orf10 | chr19 | 4668607 | - | CHAF1A | chr19 | 4422563 | + |
Top |
Fusion Gene ORF analysis for C19orf10-CHAF1A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000262947 | ENST00000587368 | C19orf10 | chr19 | 4668607 | - | CHAF1A | chr19 | 4422563 | + |
| 5CDS-intron | ENST00000599630 | ENST00000587368 | C19orf10 | chr19 | 4668607 | - | CHAF1A | chr19 | 4422563 | + |
| In-frame | ENST00000262947 | ENST00000301280 | C19orf10 | chr19 | 4668607 | - | CHAF1A | chr19 | 4422563 | + |
| In-frame | ENST00000599630 | ENST00000301280 | C19orf10 | chr19 | 4668607 | - | CHAF1A | chr19 | 4422563 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000262947 | C19orf10 | chr19 | 4668607 | - | ENST00000301280 | CHAF1A | chr19 | 4422563 | + | 2482 | 261 | 36 | 2114 | 692 |
| ENST00000599630 | C19orf10 | chr19 | 4668607 | - | ENST00000301280 | CHAF1A | chr19 | 4422563 | + | 2474 | 253 | 28 | 2106 | 692 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000262947 | ENST00000301280 | C19orf10 | chr19 | 4668607 | - | CHAF1A | chr19 | 4422563 | + | 0.012271577 | 0.9877285 |
| ENST00000599630 | ENST00000301280 | C19orf10 | chr19 | 4668607 | - | CHAF1A | chr19 | 4422563 | + | 0.012547402 | 0.98745257 |
Top |
Fusion Genomic Features for C19orf10-CHAF1A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| C19orf10 | chr19 | 4668606 | - | CHAF1A | chr19 | 4422562 | + | 6.04E-12 | 1 |
| C19orf10 | chr19 | 4668606 | - | CHAF1A | chr19 | 4422562 | + | 6.04E-12 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
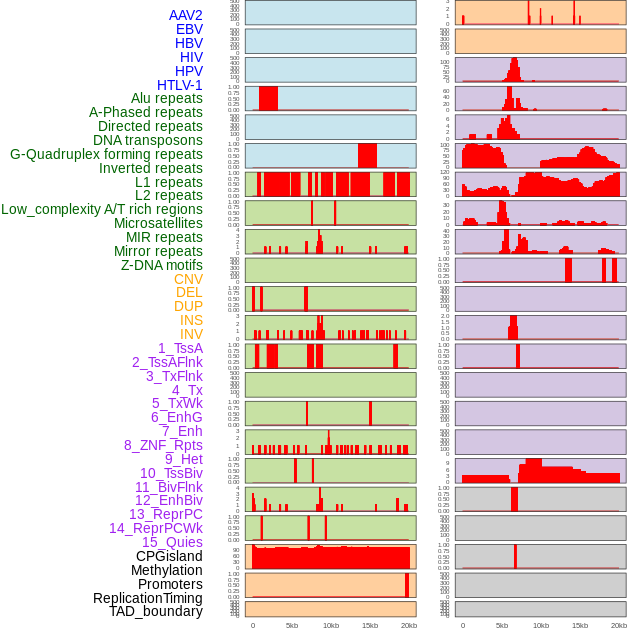 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for C19orf10-CHAF1A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:4668607/chr19:4422563) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 602_608 | 339 | 957.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 619_623 | 339 | 957.0 | Compositional bias | Note=Poly-Asp | |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 905_911 | 339 | 957.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 642_678 | 339 | 957.0 | Region | Note=Necessary for homodimerization and competence for chromatin assembly | |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 660_956 | 339 | 957.0 | Region | Note=Binds to p60 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 323_453 | 339 | 957.0 | Compositional bias | Note=Arg/Glu/Lys-rich | |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 233_246 | 339 | 957.0 | Motif | Note=PxVxL motif | |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 1_314 | 339 | 957.0 | Region | Note=Binds to CBX1 chromo shadow domain | |
| Tgene | CHAF1A | chr19:4668607 | chr19:4422563 | ENST00000301280 | 3 | 15 | 1_49 | 339 | 957.0 | Region | Note=Binds to PCNA |
Top |
Fusion Gene Sequence for C19orf10-CHAF1A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >11153_11153_1_C19orf10-CHAF1A_C19orf10_chr19_4668607_ENST00000262947_CHAF1A_chr19_4422563_ENST00000301280_length(transcript)=2482nt_BP=261nt GTCTACCCGCCCCTGCCCTGAGGACCCTAGTCCAACATGGCGGCGCCCAGCGGAGGGTGGAACGGCGTCGGCGCGAGCTTGTGGGCCGCG CTGCTCCTAGGGGCCGTGGCGCTGAGGCCGGCGGAGGCGGTGTCCGAGCCCACGACGGTGGCGTTTGACGTGCGGCCCGGCGGCGTCGTG CATTCCTTCTCCCATAACGTGGGCCCGGGGGACAAATATACGTGTATGTTCACTTACGCCTCTCAAGGAGGGACCAATGAGGATCAGGAG CGTCTGGGCAAGCAGCTCAAGTTACGTGCAGAAAGGGAAGAAAAGGAGAAGCTGAAAGAGGAGGCCAAGCGGGCCAAGGAGGAGGCCAAG AAGAAGAAGGAGGAAGAGAAGGAGCTTAAGGAAAAGGAGAGGCGGGAGAAGCGGGAGAAGGATGAGAAGGAGAAGGCGGAGAAGCAGCGG CTCAAGGAGGAGCGGCGCAAGGAGAGACAGGAAGCCCTGGAGGCTAAACTTGAGGAAAAAAGGAAAAAGGAAGAAGAGAAACGGTTAAGA GAAGAAGAGAAGCGCATTAAAGCAGAGAAGGCCGAAATCACGAGGTTCTTCCAGAAACCAAAGACTCCACAGGCCCCCAAGACCCTGGCC GGCTCCTGTGGGAAGTTTGCCCCCTTTGAAATTAAAGAGCACATGGTCCTGGCCCCTCGGCGTCGGACCGCTTTCCATCCAGACCTCTGC AGTCAGCTGGACCAGCTCCTCCAGCAGCAGAGCGGCGAGTTCTCCTTCTTGAAAGACCTCAAAGGCCGGCAGCCCCTGAGGTCCGGACCC ACGCACGTTTCCACCCGGAATGCAGATATTTTTAACAGTGATGTCGTCATCGTGGAGCGTGGGAAGGGCGACGGTGTTCCCGAGAGGAGG AAGTTTGGCAGGATGAAGCTCCTGCAGTTCTGTGAGAACCACCGGCCTGCCTACTGGGGTACCTGGAATAAGAAGACGGCACTCATCCGC GCGCGAGACCCCTGGGCCCAGGACACGAAGCTCCTGGACTATGAGGTGGACAGTGATGAGGAGTGGGAAGAAGAGGAGCCTGGGGAGTCC CTGTCCCACAGTGAGGGGGATGATGATGACGACATGGGAGAGGATGAAGATGAGGACGATGGTTTCTTTGTGCCCCATGGGTACCTGTCT GAGGACGAAGGTGTGACAGAGGAGTGTGCCGACCCTGAGAACCATAAGGTCCGCCAGAAACTGAAGGCCAAGGAGTGGGACGAGTTCCTG GCTAAGGGGAAGCGCTTTCGCGTCCTGCAACCTGTGAAGATCGGCTGCGTGTGGGCGGCTGACAGAGACTGCGCAGGCGATGACCTGAAG GTACTGCAGCAGTTCGCAGCCTGCTTCCTGGAGACCCTGCCGGCCCAGGAGGAGCAGACGCCCAAGGCCTCCAAGCGGGAGAGGAGAGAC GAGCAGATCCTGGCCCAGCTGCTGCCGCTCCTGCACGGCAATGTGAACGGGAGCAAGGTCATCATCCGGGAGTTCCAGGAGCACTGCCGC CGGGGACTGCTCAGCAACCACACCGGCAGCCCGCGGAGCCCCTCCACCACCTACCTGCACACCCCCACCCCCAGCGAGGATGCCGCCATC CCCTCTAAGTCCCGGCTCAAGCGGCTCATTTCCGAGAACTCAGTGTATGAGAAGCGGCCTGACTTCAGGATGTGCTGGTACGTGCACCCG CAGGTGCTACAGAGCTTCCAGCAGGAGCACCTGCCCGTGCCGTGCCAGTGGAGCTATGTGACATCGGTGCCCTCGGCCCCCAAAGAGGAC AGTGGCAGCGTCCCCTCCACGGGGCCCAGCCAGGGCACTCCCATCTCGCTGAAGAGGAAGTCAGCGGGCAGCATGTGCATCACCCAATTC ATGAAGAAGCGCAGGCACGACGGCCAGATTGGTGCTGAAGACATGGACGGCTTCCAGGCAGACACGGAGGAGGAGGAAGAGGAGGAGGGC GACTGTATGATCGTGGATGTCCCGGATGCTGCGGAGGTCCAAGCCCCGTGTGGAGCCGCTTCCGGAGCTGGGGGTGGTGTGGGGGTGGAC ACCGGCAAGGCCACCCTGACCTCGAGCCCACTGGGTGCATCCTGAGAGCAGGGGTGACGTATGTAGAATGCTTAGGGTGTCCTCCCCACA GAGCAGATACTTGAACCGACTCAATTCCTGTGTAAAGAGCACTTTGTCCTGCTTCACGGACCTCCCCAAAGTGTGCAGAGTTCTATATAG GATGCTGGATTAGTTCCTTTGATATTTGTAAAAATTCCCCCAAGAGCCGCATATGAATCTGCCCTTTAATAAAGCATTATTGAGATTGCT GGCCTATTGGGGAAGCCTGCGGGCACAGGAGCAGGCGTGGAATCCAATACTTGTAAATGAATTGAAGCGTCAGGACCACCCGCCTGGCCA CGTGCGCGGGCCCCTGGACCTAACGAGGCAGTGTATAAACTTATTCTCTAGC >11153_11153_1_C19orf10-CHAF1A_C19orf10_chr19_4668607_ENST00000262947_CHAF1A_chr19_4422563_ENST00000301280_length(amino acids)=692AA_BP=0 MAAPSGGWNGVGASLWAALLLGAVALRPAEAVSEPTTVAFDVRPGGVVHSFSHNVGPGDKYTCMFTYASQGGTNEDQERLGKQLKLRAER EEKEKLKEEAKRAKEEAKKKKEEEKELKEKERREKREKDEKEKAEKQRLKEERRKERQEALEAKLEEKRKKEEEKRLREEEKRIKAEKAE ITRFFQKPKTPQAPKTLAGSCGKFAPFEIKEHMVLAPRRRTAFHPDLCSQLDQLLQQQSGEFSFLKDLKGRQPLRSGPTHVSTRNADIFN SDVVIVERGKGDGVPERRKFGRMKLLQFCENHRPAYWGTWNKKTALIRARDPWAQDTKLLDYEVDSDEEWEEEEPGESLSHSEGDDDDDM GEDEDEDDGFFVPHGYLSEDEGVTEECADPENHKVRQKLKAKEWDEFLAKGKRFRVLQPVKIGCVWAADRDCAGDDLKVLQQFAACFLET LPAQEEQTPKASKRERRDEQILAQLLPLLHGNVNGSKVIIREFQEHCRRGLLSNHTGSPRSPSTTYLHTPTPSEDAAIPSKSRLKRLISE NSVYEKRPDFRMCWYVHPQVLQSFQQEHLPVPCQWSYVTSVPSAPKEDSGSVPSTGPSQGTPISLKRKSAGSMCITQFMKKRRHDGQIGA EDMDGFQADTEEEEEEEGDCMIVDVPDAAEVQAPCGAASGAGGGVGVDTGKATLTSSPLGAS -------------------------------------------------------------- >11153_11153_2_C19orf10-CHAF1A_C19orf10_chr19_4668607_ENST00000599630_CHAF1A_chr19_4422563_ENST00000301280_length(transcript)=2474nt_BP=253nt GCCCCTGCCCTGAGGACCCTAGTCCAACATGGCGGCGCCCAGCGGAGGGTGGAACGGCGTCGGCGCGAGCTTGTGGGCCGCGCTGCTCCT AGGGGCCGTGGCGCTGAGGCCGGCGGAGGCGGTGTCCGAGCCCACGACGGTGGCGTTTGACGTGCGGCCCGGCGGCGTCGTGCATTCCTT CTCCCATAACGTGGGCCCGGGGGACAAATATACGTGTATGTTCACTTACGCCTCTCAAGGAGGGACCAATGAGGATCAGGAGCGTCTGGG CAAGCAGCTCAAGTTACGTGCAGAAAGGGAAGAAAAGGAGAAGCTGAAAGAGGAGGCCAAGCGGGCCAAGGAGGAGGCCAAGAAGAAGAA GGAGGAAGAGAAGGAGCTTAAGGAAAAGGAGAGGCGGGAGAAGCGGGAGAAGGATGAGAAGGAGAAGGCGGAGAAGCAGCGGCTCAAGGA GGAGCGGCGCAAGGAGAGACAGGAAGCCCTGGAGGCTAAACTTGAGGAAAAAAGGAAAAAGGAAGAAGAGAAACGGTTAAGAGAAGAAGA GAAGCGCATTAAAGCAGAGAAGGCCGAAATCACGAGGTTCTTCCAGAAACCAAAGACTCCACAGGCCCCCAAGACCCTGGCCGGCTCCTG TGGGAAGTTTGCCCCCTTTGAAATTAAAGAGCACATGGTCCTGGCCCCTCGGCGTCGGACCGCTTTCCATCCAGACCTCTGCAGTCAGCT GGACCAGCTCCTCCAGCAGCAGAGCGGCGAGTTCTCCTTCTTGAAAGACCTCAAAGGCCGGCAGCCCCTGAGGTCCGGACCCACGCACGT TTCCACCCGGAATGCAGATATTTTTAACAGTGATGTCGTCATCGTGGAGCGTGGGAAGGGCGACGGTGTTCCCGAGAGGAGGAAGTTTGG CAGGATGAAGCTCCTGCAGTTCTGTGAGAACCACCGGCCTGCCTACTGGGGTACCTGGAATAAGAAGACGGCACTCATCCGCGCGCGAGA CCCCTGGGCCCAGGACACGAAGCTCCTGGACTATGAGGTGGACAGTGATGAGGAGTGGGAAGAAGAGGAGCCTGGGGAGTCCCTGTCCCA CAGTGAGGGGGATGATGATGACGACATGGGAGAGGATGAAGATGAGGACGATGGTTTCTTTGTGCCCCATGGGTACCTGTCTGAGGACGA AGGTGTGACAGAGGAGTGTGCCGACCCTGAGAACCATAAGGTCCGCCAGAAACTGAAGGCCAAGGAGTGGGACGAGTTCCTGGCTAAGGG GAAGCGCTTTCGCGTCCTGCAACCTGTGAAGATCGGCTGCGTGTGGGCGGCTGACAGAGACTGCGCAGGCGATGACCTGAAGGTACTGCA GCAGTTCGCAGCCTGCTTCCTGGAGACCCTGCCGGCCCAGGAGGAGCAGACGCCCAAGGCCTCCAAGCGGGAGAGGAGAGACGAGCAGAT CCTGGCCCAGCTGCTGCCGCTCCTGCACGGCAATGTGAACGGGAGCAAGGTCATCATCCGGGAGTTCCAGGAGCACTGCCGCCGGGGACT GCTCAGCAACCACACCGGCAGCCCGCGGAGCCCCTCCACCACCTACCTGCACACCCCCACCCCCAGCGAGGATGCCGCCATCCCCTCTAA GTCCCGGCTCAAGCGGCTCATTTCCGAGAACTCAGTGTATGAGAAGCGGCCTGACTTCAGGATGTGCTGGTACGTGCACCCGCAGGTGCT ACAGAGCTTCCAGCAGGAGCACCTGCCCGTGCCGTGCCAGTGGAGCTATGTGACATCGGTGCCCTCGGCCCCCAAAGAGGACAGTGGCAG CGTCCCCTCCACGGGGCCCAGCCAGGGCACTCCCATCTCGCTGAAGAGGAAGTCAGCGGGCAGCATGTGCATCACCCAATTCATGAAGAA GCGCAGGCACGACGGCCAGATTGGTGCTGAAGACATGGACGGCTTCCAGGCAGACACGGAGGAGGAGGAAGAGGAGGAGGGCGACTGTAT GATCGTGGATGTCCCGGATGCTGCGGAGGTCCAAGCCCCGTGTGGAGCCGCTTCCGGAGCTGGGGGTGGTGTGGGGGTGGACACCGGCAA GGCCACCCTGACCTCGAGCCCACTGGGTGCATCCTGAGAGCAGGGGTGACGTATGTAGAATGCTTAGGGTGTCCTCCCCACAGAGCAGAT ACTTGAACCGACTCAATTCCTGTGTAAAGAGCACTTTGTCCTGCTTCACGGACCTCCCCAAAGTGTGCAGAGTTCTATATAGGATGCTGG ATTAGTTCCTTTGATATTTGTAAAAATTCCCCCAAGAGCCGCATATGAATCTGCCCTTTAATAAAGCATTATTGAGATTGCTGGCCTATT GGGGAAGCCTGCGGGCACAGGAGCAGGCGTGGAATCCAATACTTGTAAATGAATTGAAGCGTCAGGACCACCCGCCTGGCCACGTGCGCG GGCCCCTGGACCTAACGAGGCAGTGTATAAACTTATTCTCTAGC >11153_11153_2_C19orf10-CHAF1A_C19orf10_chr19_4668607_ENST00000599630_CHAF1A_chr19_4422563_ENST00000301280_length(amino acids)=692AA_BP=0 MAAPSGGWNGVGASLWAALLLGAVALRPAEAVSEPTTVAFDVRPGGVVHSFSHNVGPGDKYTCMFTYASQGGTNEDQERLGKQLKLRAER EEKEKLKEEAKRAKEEAKKKKEEEKELKEKERREKREKDEKEKAEKQRLKEERRKERQEALEAKLEEKRKKEEEKRLREEEKRIKAEKAE ITRFFQKPKTPQAPKTLAGSCGKFAPFEIKEHMVLAPRRRTAFHPDLCSQLDQLLQQQSGEFSFLKDLKGRQPLRSGPTHVSTRNADIFN SDVVIVERGKGDGVPERRKFGRMKLLQFCENHRPAYWGTWNKKTALIRARDPWAQDTKLLDYEVDSDEEWEEEEPGESLSHSEGDDDDDM GEDEDEDDGFFVPHGYLSEDEGVTEECADPENHKVRQKLKAKEWDEFLAKGKRFRVLQPVKIGCVWAADRDCAGDDLKVLQQFAACFLET LPAQEEQTPKASKRERRDEQILAQLLPLLHGNVNGSKVIIREFQEHCRRGLLSNHTGSPRSPSTTYLHTPTPSEDAAIPSKSRLKRLISE NSVYEKRPDFRMCWYVHPQVLQSFQQEHLPVPCQWSYVTSVPSAPKEDSGSVPSTGPSQGTPISLKRKSAGSMCITQFMKKRRHDGQIGA EDMDGFQADTEEEEEEEGDCMIVDVPDAAEVQAPCGAASGAGGGVGVDTGKATLTSSPLGAS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C19orf10-CHAF1A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C19orf10-CHAF1A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C19orf10-CHAF1A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0026636 | Mouth Diseases | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies