
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CAMK1D-MCM5 (FusionGDB2 ID:HG57118TG4174) |
Fusion Gene Summary for CAMK1D-MCM5 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CAMK1D-MCM5 | Fusion gene ID: hg57118tg4174 | Hgene | Tgene | Gene symbol | CAMK1D | MCM5 | Gene ID | 57118 | 4174 |
| Gene name | calcium/calmodulin dependent protein kinase ID | minichromosome maintenance complex component 5 | |
| Synonyms | CKLiK|CaM-K1|CaMKID | CDC46|MGORS8|P1-CDC46 | |
| Cytomap | ('CAMK1D')('MCM5') 10p13 | 22q12.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | calcium/calmodulin-dependent protein kinase type 1DCAMK1D/ANAPC5 fusionCaM kinase IDCamKI-like protein kinasecaM kinase I deltacaM-KI deltacaMKI delta | DNA replication licensing factor MCM5CDC46 homologMCM5 minichromosome maintenance deficient 5, cell division cycle 46minichromosome maintenance deficient 5 (cell division cycle 46) | |
| Modification date | 20200313 | 20200315 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000487696, ENST00000378845, ENST00000378847, | ||
| Fusion gene scores | * DoF score | 24 X 22 X 7=3696 | 15 X 12 X 2=360 |
| # samples | 28 | 15 | |
| ** MAII score | log2(28/3696*10)=-3.72246602447109 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/360*10)=-1.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CAMK1D [Title/Abstract] AND MCM5 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CAMK1D(12391909)-MCM5(35806736), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CAMK1D-MCM5 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CAMK1D-MCM5 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CAMK1D-MCM5 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CAMK1D-MCM5 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CAMK1D | GO:0032793 | positive regulation of CREB transcription factor activity | 16324104 |
| Fusion gene breakpoints across CAMK1D (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MCM5 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | KIRC | TCGA-BP-4790 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
Top |
Fusion Gene ORF analysis for CAMK1D-MCM5 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000487696 | ENST00000216122 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| 3UTR-3CDS | ENST00000487696 | ENST00000382011 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| 3UTR-intron | ENST00000487696 | ENST00000465557 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| 5CDS-intron | ENST00000378845 | ENST00000465557 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| 5CDS-intron | ENST00000378847 | ENST00000465557 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| In-frame | ENST00000378845 | ENST00000216122 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| In-frame | ENST00000378845 | ENST00000382011 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| In-frame | ENST00000378847 | ENST00000216122 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| In-frame | ENST00000378847 | ENST00000382011 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000378847 | CAMK1D | chr10 | 12391909 | + | ENST00000216122 | MCM5 | chr22 | 35806736 | + | 3057 | 429 | 337 | 1881 | 514 |
| ENST00000378847 | CAMK1D | chr10 | 12391909 | + | ENST00000382011 | MCM5 | chr22 | 35806736 | + | 2128 | 429 | 337 | 1881 | 514 |
| ENST00000378845 | CAMK1D | chr10 | 12391909 | + | ENST00000216122 | MCM5 | chr22 | 35806736 | + | 2806 | 178 | 86 | 1630 | 514 |
| ENST00000378845 | CAMK1D | chr10 | 12391909 | + | ENST00000382011 | MCM5 | chr22 | 35806736 | + | 1877 | 178 | 86 | 1630 | 514 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000378847 | ENST00000216122 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + | 0.002936258 | 0.9970637 |
| ENST00000378847 | ENST00000382011 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + | 0.008122165 | 0.9918778 |
| ENST00000378845 | ENST00000216122 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + | 0.002443145 | 0.9975568 |
| ENST00000378845 | ENST00000382011 | CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + | 0.00719419 | 0.9928058 |
Top |
Fusion Genomic Features for CAMK1D-MCM5 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + | 7.60E-11 | 1 |
| CAMK1D | chr10 | 12391909 | + | MCM5 | chr22 | 35806736 | + | 7.60E-11 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
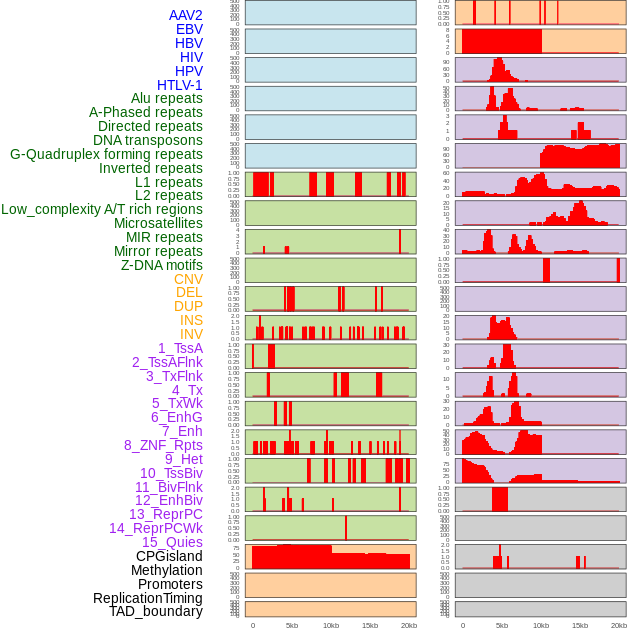 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
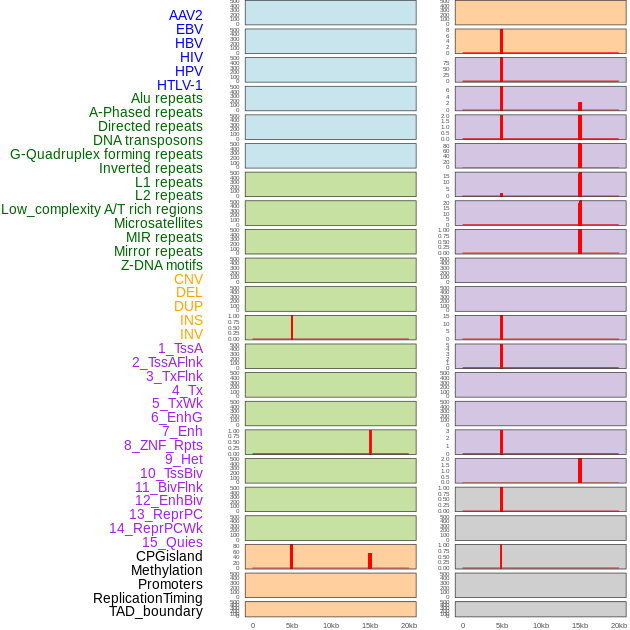 |
Top |
Fusion Protein Features for CAMK1D-MCM5 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:12391909/chr22:35806736) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | MCM5 | chr10:12391909 | chr22:35806736 | ENST00000216122 | 5 | 17 | 331_537 | 250 | 735.0 | Domain | Note=MCM | |
| Tgene | MCM5 | chr10:12391909 | chr22:35806736 | ENST00000216122 | 5 | 17 | 381_388 | 250 | 735.0 | Nucleotide binding | ATP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378845 | + | 1 | 10 | 326_364 | 30 | 358.0 | Compositional bias | Note=Ser-rich |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378847 | + | 1 | 11 | 326_364 | 30 | 386.0 | Compositional bias | Note=Ser-rich |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378845 | + | 1 | 10 | 23_279 | 30 | 358.0 | Domain | Protein kinase |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378847 | + | 1 | 11 | 23_279 | 30 | 386.0 | Domain | Protein kinase |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378845 | + | 1 | 10 | 318_324 | 30 | 358.0 | Motif | Nuclear export signal |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378847 | + | 1 | 11 | 318_324 | 30 | 386.0 | Motif | Nuclear export signal |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378845 | + | 1 | 10 | 29_37 | 30 | 358.0 | Nucleotide binding | ATP |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378847 | + | 1 | 11 | 29_37 | 30 | 386.0 | Nucleotide binding | ATP |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378845 | + | 1 | 10 | 279_319 | 30 | 358.0 | Region | Autoinhibitory domain |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378845 | + | 1 | 10 | 299_320 | 30 | 358.0 | Region | Calmodulin-binding |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378847 | + | 1 | 11 | 279_319 | 30 | 386.0 | Region | Autoinhibitory domain |
| Hgene | CAMK1D | chr10:12391909 | chr22:35806736 | ENST00000378847 | + | 1 | 11 | 299_320 | 30 | 386.0 | Region | Calmodulin-binding |
Top |
Fusion Gene Sequence for CAMK1D-MCM5 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12648_12648_1_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378845_MCM5_chr22_35806736_ENST00000216122_length(transcript)=2806nt_BP=178nt CCCGCCGCCTCTGCGCCCGCGCCGCGCCCCCGGCGCCCCCTCCCCAGCGCGCCCCCGGCCGCTCCTCCGCGCCGCGCTCGTCGGCCATGG CCCGGGAGAACGGCGAGAGCAGCTCCTCCTGGAAAAAGCAAGCTGAAGACATCAAGAAGATCTTCGAGTTCAAAGAGACCCTCGGAACGT ACCTGTGTGACAAGGTCGTCCCTGGGAACAGGGTTACCATCATGGGCATCTACTCCATCAAGAAGTTTGGCCTGACTACCAGCAGGGGCC GTGACAGGGTGGGCGTGGGCATCCGAAGCTCCTACATCCGTGTCCTGGGCATCCAGGTGGACACAGATGGCTCTGGCCGCAGCTTTGCTG GGGCCGTGAGCCCCCAGGAGGAGGAGGAGTTCCGTCGCCTGGCTGCCCTCCCAAATGTCTATGAGGTCATCTCCAAGAGCATCGCCCCCT CCATCTTTGGGGGCACAGACATGAAGAAGGCCATTGCCTGCCTGCTCTTTGGGGGCTCCCGAAAGAGGCTCCCTGATGGACTTACTCGCC GAGGAGACATCAACCTGCTGATGCTAGGGGACCCTGGGACAGCCAAGTCCCAGCTTCTGAAGTTTGTGGAGAAGTGTTCTCCCATTGGGG TATACACGTCTGGGAAAGGCAGCAGCGCAGCTGGACTGACAGCCTCGGTGATGAGGGACCCTTCGTCCCGGAATTTCATCATGGAGGGCG GAGCCATGGTCCTGGCCGATGGTGGGGTCGTCTGTATTGACGAGTTTGACAAGATGCGAGAAGATGACCGTGTGGCAATCCACGAAGCCA TGGAGCAGCAGACCATCTCTATCGCCAAGGCTGGGATCACCACCACCCTGAACTCCCGCTGCTCCGTCCTGGCTGCTGCCAACTCAGTGT TCGGCCGCTGGGATGAGACGAAGGGGGAGGACAACATTGACTTCATGCCCACCATCTTGTCGCGCTTCGACATGATCTTCATCGTCAAGG ATGAGCACAATGAGGAGAGGGATGTGATGCTGGCCAAGCATGTCATCACTCTGCACGTGAGCGCACTGACACAGACACAGGCTGTGGAGG GCGAGATTGACCTGGCCAAGCTGAAGAAGTTTATTGCCTACTGCCGAGTGAAGTGTGGCCCCCGGCTGTCAGCAGAGGCTGCAGAGAAAC TGAAGAACCGCTACATCATCATGCGGAGCGGGGCCCGTCAGCACGAGAGGGACAGTGACCGCCGCTCCAGCATCCCCATCACTGTGCGGC AGCTGGAGGCCATTGTGCGCATCGCGGAAGCCCTCAGCAAGATGAAGCTGCAGCCCTTCGCCACAGAGGCAGATGTGGAGGAGGCCCTGC GGCTCTTCCAAGTGTCCACGTTGGATGCTGCCTTGTCCGGTACCCTGTCAGGGGTGGAGGGCTTCACCAGCCAGGAGGACCAGGAGATGC TGAGCCGCATCGAGAAGCAGCTCAAGCGCCGCTTTGCCATTGGCTCCCAGGTGTCTGAGCACAGCATCATCAAGGACTTCACCAAGCAGA AATACCCGGAGCACGCCATCCACAAGGTGCTGCAGCTCATGCTGCGGCGCGGCGAGATCCAGCATCGCATGCAGCGCAAGGTTCTCTACC GCCTCAAGTGAGTCGCGCCGCCTCACTGGACTCATGGACTCGCCCACGCCTCGCCCCTCCTGCCGCTGCCTGCCATTGACAATGTTGCTG GGACCTCTGCCTCCCCACTGCAGCCCTCGAACTTCCCAGGCACCCTCCTTTCTGCCCCAGAGGAAGGAGCTGTAGTGTCCTGCTGCCTCT GGGCGCCCGCCTCTAGCGCGGTTCTGGGAAGTGTGCTTTTGGCATCCGTTAATAATAAAGCCACGGTGTGTTCAGGTATCTGTGGGTTTG TGCACTCGGTGACCTGTCACCTCCATCGTGCCCTCATGGCAGGGTAAGTGTGAGGGAACAGGGTCTGGAGGCAGACTGGCCAGGGTTTCT GACTTGGATCTGCCACTCAGACTTCTGGGTAAGTCACGTGACTTGAGTGCTCCGGTTTCTTCATCTGTTTAGCGGGGCTCATAAAGCCAC TCCCTTGATGCTGGGAATCCAGTGAGACCAGGGAGTGGGGAAGCGCTTCTCAAAGTGTGTGATTTTGATCCGCCTCACCTGTTCCCCAGT AACTTATTGGGGGGCTGCGAGCCGTGGTGCGGCGGTCAGACTGCCTGGATTCATGGACCCTCTCCATGCCTTAGTTTCCTTATCTGTAAG CAGGCTGATACTAGAACCTGCTTCACAGGGTTGTGCTTAGGGTCAGTGAGCAGCTGTTAGTGAGGGGAATGTAGTGGCCACCAGGCAGGA ACTAGGACTCCAGCCAGTTCTTTCCTGGTGGGCCACGTGTAACTGTGTGGCCTTGGGCGAGACATTTCACTTTTCTGTGCCTGAGTTTAT CAGTAAACTGGAGATGGGGGGATTCCTCACCCTGAGTTGTGAGGATTGAATGACAGAAGGCACTAGTGACAGTGATGCTGGAGGAAGGAG TGTTGCCAAGTGCCTCGGTCACTTTGCCTAATTTCAGAAAGTCACTCTGAGTTGGTATGTTTTGTGTTTTTAAAAAAGCTAGGATTCATA AAATTAAATAGAAATCAGTGAAATAAAATATTTGATATTTAAAATACATTTAGAAATACAAAGTGTCAAGCAAAACGTGAATTTGGAAAT CTATGGAACATTAGATAAGGTATTTAAAAGTAATTGCCATGTAAAAATGACACGAACTTGAAGTAAGATTATTTGATTTTTCTAAAAATA CAAGAAAGCTTGGTGC >12648_12648_1_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378845_MCM5_chr22_35806736_ENST00000216122_length(amino acids)=514AA_BP=31 MARENGESSSSWKKQAEDIKKIFEFKETLGTYLCDKVVPGNRVTIMGIYSIKKFGLTTSRGRDRVGVGIRSSYIRVLGIQVDTDGSGRSF AGAVSPQEEEEFRRLAALPNVYEVISKSIAPSIFGGTDMKKAIACLLFGGSRKRLPDGLTRRGDINLLMLGDPGTAKSQLLKFVEKCSPI GVYTSGKGSSAAGLTASVMRDPSSRNFIMEGGAMVLADGGVVCIDEFDKMREDDRVAIHEAMEQQTISIAKAGITTTLNSRCSVLAAANS VFGRWDETKGEDNIDFMPTILSRFDMIFIVKDEHNEERDVMLAKHVITLHVSALTQTQAVEGEIDLAKLKKFIAYCRVKCGPRLSAEAAE KLKNRYIIMRSGARQHERDSDRRSSIPITVRQLEAIVRIAEALSKMKLQPFATEADVEEALRLFQVSTLDAALSGTLSGVEGFTSQEDQE MLSRIEKQLKRRFAIGSQVSEHSIIKDFTKQKYPEHAIHKVLQLMLRRGEIQHRMQRKVLYRLK -------------------------------------------------------------- >12648_12648_2_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378845_MCM5_chr22_35806736_ENST00000382011_length(transcript)=1877nt_BP=178nt CCCGCCGCCTCTGCGCCCGCGCCGCGCCCCCGGCGCCCCCTCCCCAGCGCGCCCCCGGCCGCTCCTCCGCGCCGCGCTCGTCGGCCATGG CCCGGGAGAACGGCGAGAGCAGCTCCTCCTGGAAAAAGCAAGCTGAAGACATCAAGAAGATCTTCGAGTTCAAAGAGACCCTCGGAACGT ACCTGTGTGACAAGGTCGTCCCTGGGAACAGGGTTACCATCATGGGCATCTACTCCATCAAGAAGTTTGGCCTGACTACCAGCAGGGGCC GTGACAGGGTGGGCGTGGGCATCCGAAGCTCCTACATCCGTGTCCTGGGCATCCAGGTGGACACAGATGGCTCTGGCCGCAGCTTTGCTG GGGCCGTGAGCCCCCAGGAGGAGGAGGAGTTCCGTCGCCTGGCTGCCCTCCCAAATGTCTATGAGGTCATCTCCAAGAGCATCGCCCCCT CCATCTTTGGGGGCACAGACATGAAGAAGGCCATTGCCTGCCTGCTCTTTGGGGGCTCCCGAAAGAGGCTCCCTGATGGACTTACTCGCC GAGGAGACATCAACCTGCTGATGCTAGGGGACCCTGGGACAGCCAAGTCCCAGCTTCTGAAGTTTGTGGAGAAGTGTTCTCCCATTGGGG TATACACGTCTGGGAAAGGCAGCAGCGCAGCTGGACTGACAGCCTCGGTGATGAGGGACCCTTCGTCCCGGAATTTCATCATGGAGGGCG GAGCCATGGTCCTGGCCGATGGTGGGGTCGTCTGTATTGACGAGTTTGACAAGATGCGAGAAGATGACCGTGTGGCAATCCACGAAGCCA TGGAGCAGCAGACCATCTCTATCGCCAAGGCTGGGATCACCACCACCCTGAACTCCCGCTGCTCCGTCCTGGCTGCTGCCAACTCAGTGT TCGGCCGCTGGGATGAGACGAAGGGGGAGGACAACATTGACTTCATGCCCACCATCTTGTCGCGCTTCGACATGATCTTCATCGTCAAGG ATGAGCACAATGAGGAGAGGGATGTGATGCTGGCCAAGCATGTCATCACTCTGCACGTGAGCGCACTGACACAGACACAGGCTGTGGAGG GCGAGATTGACCTGGCCAAGCTGAAGAAGTTTATTGCCTACTGCCGAGTGAAGTGTGGCCCCCGGCTGTCAGCAGAGGCTGCAGAGAAAC TGAAGAACCGCTACATCATCATGCGGAGCGGGGCCCGTCAGCACGAGAGGGACAGTGACCGCCGCTCCAGCATCCCCATCACTGTGCGGC AGCTGGAGGCCATTGTGCGCATCGCGGAAGCCCTCAGCAAGATGAAGCTGCAGCCCTTCGCCACAGAGGCAGATGTGGAGGAGGCCCTGC GGCTCTTCCAAGTGTCCACGTTGGATGCTGCCTTGTCCGGTACCCTGTCAGGGGTGGAGGGCTTCACCAGCCAGGAGGACCAGGAGATGC TGAGCCGCATCGAGAAGCAGCTCAAGCGCCGCTTTGCCATTGGCTCCCAGGTGTCTGAGCACAGCATCATCAAGGACTTCACCAAGCAGA AATACCCGGAGCACGCCATCCACAAGGTGCTGCAGCTCATGCTGCGGCGCGGCGAGATCCAGCATCGCATGCAGCGCAAGGTTCTCTACC GCCTCAAGTGAGTCGCGCCGCCTCACTGGACTCATGGACTCGCCCACGCCTCGCCCCTCCTGCCGCTGCCTGCCATTGACAATGTTGCTG GGACCTCTGCCTCCCCACTGCAGCCCTCGAACTTCCCAGGCACCCTCCTTTCTGCCCCAGAGGAAGGAGCTGTAGTGTCCTGCTGCCTCT GGGCGCCCGCCTCTAGCGCGGTTCTGGGAAGTGTGCTTTTGGCATCCGTTAATAATAAAGCCACGGTGTGTTCAGGT >12648_12648_2_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378845_MCM5_chr22_35806736_ENST00000382011_length(amino acids)=514AA_BP=31 MARENGESSSSWKKQAEDIKKIFEFKETLGTYLCDKVVPGNRVTIMGIYSIKKFGLTTSRGRDRVGVGIRSSYIRVLGIQVDTDGSGRSF AGAVSPQEEEEFRRLAALPNVYEVISKSIAPSIFGGTDMKKAIACLLFGGSRKRLPDGLTRRGDINLLMLGDPGTAKSQLLKFVEKCSPI GVYTSGKGSSAAGLTASVMRDPSSRNFIMEGGAMVLADGGVVCIDEFDKMREDDRVAIHEAMEQQTISIAKAGITTTLNSRCSVLAAANS VFGRWDETKGEDNIDFMPTILSRFDMIFIVKDEHNEERDVMLAKHVITLHVSALTQTQAVEGEIDLAKLKKFIAYCRVKCGPRLSAEAAE KLKNRYIIMRSGARQHERDSDRRSSIPITVRQLEAIVRIAEALSKMKLQPFATEADVEEALRLFQVSTLDAALSGTLSGVEGFTSQEDQE MLSRIEKQLKRRFAIGSQVSEHSIIKDFTKQKYPEHAIHKVLQLMLRRGEIQHRMQRKVLYRLK -------------------------------------------------------------- >12648_12648_3_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378847_MCM5_chr22_35806736_ENST00000216122_length(transcript)=3057nt_BP=429nt GGAGGAGGCGCGAGGTGGGGGGGAGCGCGGCGGGCGGCAGGGAGGGAGCGGGAGGGAGGCAAGAAAGTAGCAGAAAGTGAGGCTGGCAGG CGGCGGCAAAGGAGCCGGCGCGCGGCGGCGGCAGGAAGTCTGTGCCCGAGAACAGCAGAAATAAGAGCCAGGGAGGGACCGCGGCCGCGG CGGCGGCGGCGAGAGCGAAAGAGGAAACTGCAGAGGAGGAAGCTGCGCCGCAGCCCGAGCCGCCCGGCATCCCCGCCGCCTCTGCGCCCG CGCCGCGCCCCCGGCGCCCCCTCCCCAGCGCGCCCCCGGCCGCTCCTCCGCGCCGCGCTCGTCGGCCATGGCCCGGGAGAACGGCGAGAG CAGCTCCTCCTGGAAAAAGCAAGCTGAAGACATCAAGAAGATCTTCGAGTTCAAAGAGACCCTCGGAACGTACCTGTGTGACAAGGTCGT CCCTGGGAACAGGGTTACCATCATGGGCATCTACTCCATCAAGAAGTTTGGCCTGACTACCAGCAGGGGCCGTGACAGGGTGGGCGTGGG CATCCGAAGCTCCTACATCCGTGTCCTGGGCATCCAGGTGGACACAGATGGCTCTGGCCGCAGCTTTGCTGGGGCCGTGAGCCCCCAGGA GGAGGAGGAGTTCCGTCGCCTGGCTGCCCTCCCAAATGTCTATGAGGTCATCTCCAAGAGCATCGCCCCCTCCATCTTTGGGGGCACAGA CATGAAGAAGGCCATTGCCTGCCTGCTCTTTGGGGGCTCCCGAAAGAGGCTCCCTGATGGACTTACTCGCCGAGGAGACATCAACCTGCT GATGCTAGGGGACCCTGGGACAGCCAAGTCCCAGCTTCTGAAGTTTGTGGAGAAGTGTTCTCCCATTGGGGTATACACGTCTGGGAAAGG CAGCAGCGCAGCTGGACTGACAGCCTCGGTGATGAGGGACCCTTCGTCCCGGAATTTCATCATGGAGGGCGGAGCCATGGTCCTGGCCGA TGGTGGGGTCGTCTGTATTGACGAGTTTGACAAGATGCGAGAAGATGACCGTGTGGCAATCCACGAAGCCATGGAGCAGCAGACCATCTC TATCGCCAAGGCTGGGATCACCACCACCCTGAACTCCCGCTGCTCCGTCCTGGCTGCTGCCAACTCAGTGTTCGGCCGCTGGGATGAGAC GAAGGGGGAGGACAACATTGACTTCATGCCCACCATCTTGTCGCGCTTCGACATGATCTTCATCGTCAAGGATGAGCACAATGAGGAGAG GGATGTGATGCTGGCCAAGCATGTCATCACTCTGCACGTGAGCGCACTGACACAGACACAGGCTGTGGAGGGCGAGATTGACCTGGCCAA GCTGAAGAAGTTTATTGCCTACTGCCGAGTGAAGTGTGGCCCCCGGCTGTCAGCAGAGGCTGCAGAGAAACTGAAGAACCGCTACATCAT CATGCGGAGCGGGGCCCGTCAGCACGAGAGGGACAGTGACCGCCGCTCCAGCATCCCCATCACTGTGCGGCAGCTGGAGGCCATTGTGCG CATCGCGGAAGCCCTCAGCAAGATGAAGCTGCAGCCCTTCGCCACAGAGGCAGATGTGGAGGAGGCCCTGCGGCTCTTCCAAGTGTCCAC GTTGGATGCTGCCTTGTCCGGTACCCTGTCAGGGGTGGAGGGCTTCACCAGCCAGGAGGACCAGGAGATGCTGAGCCGCATCGAGAAGCA GCTCAAGCGCCGCTTTGCCATTGGCTCCCAGGTGTCTGAGCACAGCATCATCAAGGACTTCACCAAGCAGAAATACCCGGAGCACGCCAT CCACAAGGTGCTGCAGCTCATGCTGCGGCGCGGCGAGATCCAGCATCGCATGCAGCGCAAGGTTCTCTACCGCCTCAAGTGAGTCGCGCC GCCTCACTGGACTCATGGACTCGCCCACGCCTCGCCCCTCCTGCCGCTGCCTGCCATTGACAATGTTGCTGGGACCTCTGCCTCCCCACT GCAGCCCTCGAACTTCCCAGGCACCCTCCTTTCTGCCCCAGAGGAAGGAGCTGTAGTGTCCTGCTGCCTCTGGGCGCCCGCCTCTAGCGC GGTTCTGGGAAGTGTGCTTTTGGCATCCGTTAATAATAAAGCCACGGTGTGTTCAGGTATCTGTGGGTTTGTGCACTCGGTGACCTGTCA CCTCCATCGTGCCCTCATGGCAGGGTAAGTGTGAGGGAACAGGGTCTGGAGGCAGACTGGCCAGGGTTTCTGACTTGGATCTGCCACTCA GACTTCTGGGTAAGTCACGTGACTTGAGTGCTCCGGTTTCTTCATCTGTTTAGCGGGGCTCATAAAGCCACTCCCTTGATGCTGGGAATC CAGTGAGACCAGGGAGTGGGGAAGCGCTTCTCAAAGTGTGTGATTTTGATCCGCCTCACCTGTTCCCCAGTAACTTATTGGGGGGCTGCG AGCCGTGGTGCGGCGGTCAGACTGCCTGGATTCATGGACCCTCTCCATGCCTTAGTTTCCTTATCTGTAAGCAGGCTGATACTAGAACCT GCTTCACAGGGTTGTGCTTAGGGTCAGTGAGCAGCTGTTAGTGAGGGGAATGTAGTGGCCACCAGGCAGGAACTAGGACTCCAGCCAGTT CTTTCCTGGTGGGCCACGTGTAACTGTGTGGCCTTGGGCGAGACATTTCACTTTTCTGTGCCTGAGTTTATCAGTAAACTGGAGATGGGG GGATTCCTCACCCTGAGTTGTGAGGATTGAATGACAGAAGGCACTAGTGACAGTGATGCTGGAGGAAGGAGTGTTGCCAAGTGCCTCGGT CACTTTGCCTAATTTCAGAAAGTCACTCTGAGTTGGTATGTTTTGTGTTTTTAAAAAAGCTAGGATTCATAAAATTAAATAGAAATCAGT GAAATAAAATATTTGATATTTAAAATACATTTAGAAATACAAAGTGTCAAGCAAAACGTGAATTTGGAAATCTATGGAACATTAGATAAG GTATTTAAAAGTAATTGCCATGTAAAAATGACACGAACTTGAAGTAAGATTATTTGATTTTTCTAAAAATACAAGAAAGCTTGGTGC >12648_12648_3_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378847_MCM5_chr22_35806736_ENST00000216122_length(amino acids)=514AA_BP=31 MARENGESSSSWKKQAEDIKKIFEFKETLGTYLCDKVVPGNRVTIMGIYSIKKFGLTTSRGRDRVGVGIRSSYIRVLGIQVDTDGSGRSF AGAVSPQEEEEFRRLAALPNVYEVISKSIAPSIFGGTDMKKAIACLLFGGSRKRLPDGLTRRGDINLLMLGDPGTAKSQLLKFVEKCSPI GVYTSGKGSSAAGLTASVMRDPSSRNFIMEGGAMVLADGGVVCIDEFDKMREDDRVAIHEAMEQQTISIAKAGITTTLNSRCSVLAAANS VFGRWDETKGEDNIDFMPTILSRFDMIFIVKDEHNEERDVMLAKHVITLHVSALTQTQAVEGEIDLAKLKKFIAYCRVKCGPRLSAEAAE KLKNRYIIMRSGARQHERDSDRRSSIPITVRQLEAIVRIAEALSKMKLQPFATEADVEEALRLFQVSTLDAALSGTLSGVEGFTSQEDQE MLSRIEKQLKRRFAIGSQVSEHSIIKDFTKQKYPEHAIHKVLQLMLRRGEIQHRMQRKVLYRLK -------------------------------------------------------------- >12648_12648_4_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378847_MCM5_chr22_35806736_ENST00000382011_length(transcript)=2128nt_BP=429nt GGAGGAGGCGCGAGGTGGGGGGGAGCGCGGCGGGCGGCAGGGAGGGAGCGGGAGGGAGGCAAGAAAGTAGCAGAAAGTGAGGCTGGCAGG CGGCGGCAAAGGAGCCGGCGCGCGGCGGCGGCAGGAAGTCTGTGCCCGAGAACAGCAGAAATAAGAGCCAGGGAGGGACCGCGGCCGCGG CGGCGGCGGCGAGAGCGAAAGAGGAAACTGCAGAGGAGGAAGCTGCGCCGCAGCCCGAGCCGCCCGGCATCCCCGCCGCCTCTGCGCCCG CGCCGCGCCCCCGGCGCCCCCTCCCCAGCGCGCCCCCGGCCGCTCCTCCGCGCCGCGCTCGTCGGCCATGGCCCGGGAGAACGGCGAGAG CAGCTCCTCCTGGAAAAAGCAAGCTGAAGACATCAAGAAGATCTTCGAGTTCAAAGAGACCCTCGGAACGTACCTGTGTGACAAGGTCGT CCCTGGGAACAGGGTTACCATCATGGGCATCTACTCCATCAAGAAGTTTGGCCTGACTACCAGCAGGGGCCGTGACAGGGTGGGCGTGGG CATCCGAAGCTCCTACATCCGTGTCCTGGGCATCCAGGTGGACACAGATGGCTCTGGCCGCAGCTTTGCTGGGGCCGTGAGCCCCCAGGA GGAGGAGGAGTTCCGTCGCCTGGCTGCCCTCCCAAATGTCTATGAGGTCATCTCCAAGAGCATCGCCCCCTCCATCTTTGGGGGCACAGA CATGAAGAAGGCCATTGCCTGCCTGCTCTTTGGGGGCTCCCGAAAGAGGCTCCCTGATGGACTTACTCGCCGAGGAGACATCAACCTGCT GATGCTAGGGGACCCTGGGACAGCCAAGTCCCAGCTTCTGAAGTTTGTGGAGAAGTGTTCTCCCATTGGGGTATACACGTCTGGGAAAGG CAGCAGCGCAGCTGGACTGACAGCCTCGGTGATGAGGGACCCTTCGTCCCGGAATTTCATCATGGAGGGCGGAGCCATGGTCCTGGCCGA TGGTGGGGTCGTCTGTATTGACGAGTTTGACAAGATGCGAGAAGATGACCGTGTGGCAATCCACGAAGCCATGGAGCAGCAGACCATCTC TATCGCCAAGGCTGGGATCACCACCACCCTGAACTCCCGCTGCTCCGTCCTGGCTGCTGCCAACTCAGTGTTCGGCCGCTGGGATGAGAC GAAGGGGGAGGACAACATTGACTTCATGCCCACCATCTTGTCGCGCTTCGACATGATCTTCATCGTCAAGGATGAGCACAATGAGGAGAG GGATGTGATGCTGGCCAAGCATGTCATCACTCTGCACGTGAGCGCACTGACACAGACACAGGCTGTGGAGGGCGAGATTGACCTGGCCAA GCTGAAGAAGTTTATTGCCTACTGCCGAGTGAAGTGTGGCCCCCGGCTGTCAGCAGAGGCTGCAGAGAAACTGAAGAACCGCTACATCAT CATGCGGAGCGGGGCCCGTCAGCACGAGAGGGACAGTGACCGCCGCTCCAGCATCCCCATCACTGTGCGGCAGCTGGAGGCCATTGTGCG CATCGCGGAAGCCCTCAGCAAGATGAAGCTGCAGCCCTTCGCCACAGAGGCAGATGTGGAGGAGGCCCTGCGGCTCTTCCAAGTGTCCAC GTTGGATGCTGCCTTGTCCGGTACCCTGTCAGGGGTGGAGGGCTTCACCAGCCAGGAGGACCAGGAGATGCTGAGCCGCATCGAGAAGCA GCTCAAGCGCCGCTTTGCCATTGGCTCCCAGGTGTCTGAGCACAGCATCATCAAGGACTTCACCAAGCAGAAATACCCGGAGCACGCCAT CCACAAGGTGCTGCAGCTCATGCTGCGGCGCGGCGAGATCCAGCATCGCATGCAGCGCAAGGTTCTCTACCGCCTCAAGTGAGTCGCGCC GCCTCACTGGACTCATGGACTCGCCCACGCCTCGCCCCTCCTGCCGCTGCCTGCCATTGACAATGTTGCTGGGACCTCTGCCTCCCCACT GCAGCCCTCGAACTTCCCAGGCACCCTCCTTTCTGCCCCAGAGGAAGGAGCTGTAGTGTCCTGCTGCCTCTGGGCGCCCGCCTCTAGCGC GGTTCTGGGAAGTGTGCTTTTGGCATCCGTTAATAATAAAGCCACGGTGTGTTCAGGT >12648_12648_4_CAMK1D-MCM5_CAMK1D_chr10_12391909_ENST00000378847_MCM5_chr22_35806736_ENST00000382011_length(amino acids)=514AA_BP=31 MARENGESSSSWKKQAEDIKKIFEFKETLGTYLCDKVVPGNRVTIMGIYSIKKFGLTTSRGRDRVGVGIRSSYIRVLGIQVDTDGSGRSF AGAVSPQEEEEFRRLAALPNVYEVISKSIAPSIFGGTDMKKAIACLLFGGSRKRLPDGLTRRGDINLLMLGDPGTAKSQLLKFVEKCSPI GVYTSGKGSSAAGLTASVMRDPSSRNFIMEGGAMVLADGGVVCIDEFDKMREDDRVAIHEAMEQQTISIAKAGITTTLNSRCSVLAAANS VFGRWDETKGEDNIDFMPTILSRFDMIFIVKDEHNEERDVMLAKHVITLHVSALTQTQAVEGEIDLAKLKKFIAYCRVKCGPRLSAEAAE KLKNRYIIMRSGARQHERDSDRRSSIPITVRQLEAIVRIAEALSKMKLQPFATEADVEEALRLFQVSTLDAALSGTLSGVEGFTSQEDQE MLSRIEKQLKRRFAIGSQVSEHSIIKDFTKQKYPEHAIHKVLQLMLRRGEIQHRMQRKVLYRLK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CAMK1D-MCM5 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CAMK1D-MCM5 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CAMK1D-MCM5 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0001956 | Alcohol Use Disorder | 1 | PSYGENET | |
| Tgene | C4479655 | MEIER-GORLIN SYNDROME 8 | 1 | GENOMICS_ENGLAND;UNIPROT |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies