
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AS3MT-SUFU (FusionGDB2 ID:HG57412TG51684) |
Fusion Gene Summary for AS3MT-SUFU |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AS3MT-SUFU | Fusion gene ID: hg57412tg51684 | Hgene | Tgene | Gene symbol | AS3MT | SUFU | Gene ID | 57412 | 51684 |
| Gene name | arsenite methyltransferase | SUFU negative regulator of hedgehog signaling | |
| Synonyms | CYT19 | JBTS32|PRO1280|SUFUH|SUFUXL | |
| Cytomap | ('AS3MT')('SUFU') 10q24.32 | 10q24.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | arsenite methyltransferaseS-adenosyl-L-methionine:arsenic(III) methyltransferaseS-adenosylmethionine:arsenic (III) methyltransferasearsenic (+3 oxidation state) methyltransferasemethylarsonite methyltransferasemethyltransferase cyt19 | suppressor of fused homolog | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000369880, | ||
| Fusion gene scores | * DoF score | 3 X 2 X 3=18 | 8 X 8 X 8=512 |
| # samples | 3 | 12 | |
| ** MAII score | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(12/512*10)=-2.09310940439148 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AS3MT [Title/Abstract] AND SUFU [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AS3MT(104650435)-SUFU(104356897), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | AS3MT-SUFU seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. AS3MT-SUFU seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AS3MT | GO:0009404 | toxin metabolic process | 25997655 |
| Hgene | AS3MT | GO:0018872 | arsonoacetate metabolic process | 25997655 |
| Hgene | AS3MT | GO:0032259 | methylation | 25997655 |
| Tgene | SUFU | GO:0000122 | negative regulation of transcription by RNA polymerase II | 10564661 |
| Fusion gene breakpoints across AS3MT (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SUFU (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ACC | TCGA-OR-A5J7-01A | AS3MT | chr10 | 104650435 | - | SUFU | chr10 | 104356897 | + |
| ChimerDB4 | ACC | TCGA-OR-A5J7-01A | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + |
Top |
Fusion Gene ORF analysis for AS3MT-SUFU |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000369880 | ENST00000471000 | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + |
| In-frame | ENST00000369880 | ENST00000369899 | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + |
| In-frame | ENST00000369880 | ENST00000369902 | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + |
| In-frame | ENST00000369880 | ENST00000423559 | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000369880 | AS3MT | chr10 | 104650435 | + | ENST00000369902 | SUFU | chr10 | 104356897 | + | 5176 | 1097 | 77 | 1795 | 572 |
| ENST00000369880 | AS3MT | chr10 | 104650435 | + | ENST00000369899 | SUFU | chr10 | 104356897 | + | 2034 | 1097 | 77 | 1642 | 521 |
| ENST00000369880 | AS3MT | chr10 | 104650435 | + | ENST00000423559 | SUFU | chr10 | 104356897 | + | 2868 | 1097 | 77 | 1786 | 569 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000369880 | ENST00000369902 | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + | 0.003245112 | 0.9967548 |
| ENST00000369880 | ENST00000369899 | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + | 0.00812916 | 0.9918709 |
| ENST00000369880 | ENST00000423559 | AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356897 | + | 0.002516699 | 0.9974833 |
Top |
Fusion Genomic Features for AS3MT-SUFU |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356896 | + | 2.60E-09 | 1 |
| AS3MT | chr10 | 104650435 | + | SUFU | chr10 | 104356896 | + | 2.60E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
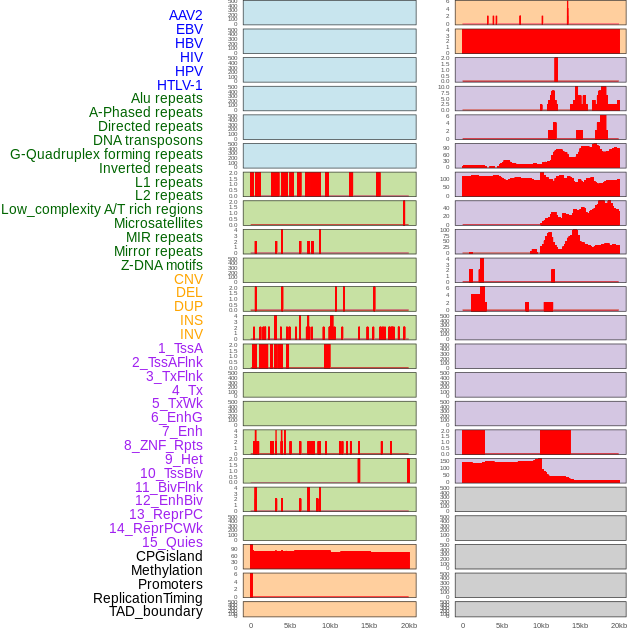 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
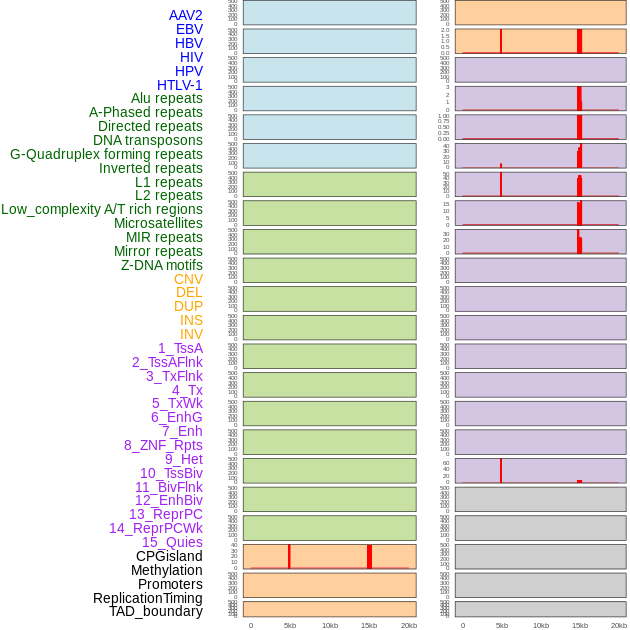 |
Top |
Fusion Protein Features for AS3MT-SUFU |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:104650435/chr10:104356897) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SUFU | chr10:104650435 | chr10:104356897 | ENST00000369899 | 5 | 11 | 279_360 | 252 | 434.0 | Region | Intrinsically disordered | |
| Tgene | SUFU | chr10:104650435 | chr10:104356897 | ENST00000369902 | 5 | 12 | 279_360 | 252 | 485.0 | Region | Intrinsically disordered | |
| Tgene | SUFU | chr10:104650435 | chr10:104356897 | ENST00000423559 | 5 | 10 | 279_360 | 252 | 482.0 | Region | Intrinsically disordered |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for AS3MT-SUFU |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6929_6929_1_AS3MT-SUFU_AS3MT_chr10_104650435_ENST00000369880_SUFU_chr10_104356897_ENST00000369899_length(transcript)=2034nt_BP=1097nt GAGACAGTGAGTGCGCGCCCTGAGTCGCAGGCCGAGGAGACAGTGAGTGCGCGCCCTGAGTCGCAGGCCGAGGAGACATGGCTGCACTTC GTGACGCTGAGATACAGAAGGACGTGCAGACCTACTACGGGCAGGTGCTGAAGAGATCGGCAGACCTCCAGACCAACGGCTGTGTCACCA CAGCCAGGCCGGTCCCCAAGCACATCCGGGAAGCCTTGCAAAATGTACACGAAGAAGTAGCCCTAAGATATTATGGCTGTGGTCTGGTGA TCCCTGAGCATCTAGAAAACTGCTGGATTTTGGATCTGGGTAGTGGAAGTGGCAGAGATTGCTATGTACTTAGCCAGCTGGTTGGTGAAA AAGGACACGTGACTGGAATAGACATGACCAAAGGCCAGGTGGAAGTGGCTGAAAAGTATCTTGACTATCACATGGAAAAATATGGCTTCC AGGCATCTAATGTGACTTTTATTCATGGCTACATTGAGAAGTTGGGAGAGGCTGGAATCAAGAATGAGAGCCATGATATTGTTGTATCAA ACTGTGTTATTAACCTTGTGCCTGATAAACAACAAGTGCTTCAGGAGGCATATCGGGTGCTGAAGCATGGTGGGGAGTTATATTTCAGTG ACGTCTATACGAGCCTTGAACTGCCAGAAGAAATCAGGACACACAAAGTTTTATGGGGTGAGTGTCTGGGTGGTGCTTTATACTGGAAGG AACTTGCTGTCCTTGCTCAAAAAATTGGGTTCTGCCCTCCACGTTTGGTCACTGCCAATCTCATTACAATTCAAAACAAGGAACTGGAAA GAGTTATCGGTGACTGTCGTTTTGTTTCTGCAACATTTCGCCTCTTCAAACACTCTAAGACAGGACCAACCAAGAGATGCCAAGTTATTT ACAATGGAGGAATTACAGGACATGAAAAAGAACTAATGTTTGATGCCAATTTTACATTTAAGGAAGGTGAAATTGTTGAAGTGGATGAAG AAACAGCAGCTATCTTGAAGAATTCAAGATTTGCTCAAGATTTTCTGATCAGACCAATTGGAGAGAAGTTGCCAACATCTGGAGGCTGTT CTGCTTTGGAGTTAAAGGAGAGAGTTGACAAAGGCATCGAGACAGATGGCTCCAACCTGAGTGGTGTCAGTGCCAAGTGTGCCTGGGATG ACCTGAGCCGGCCCCCCGAGGATGACGAGGACAGCCGGAGCATCTGCATCGGCACACAGCCCCGGCGACTCTCTGGCAAAGACACAGAGC AGATCCGGGAGACCCTGAGGAGAGGACTCGAGATCAACAGCAAACCTGTCCTTCCACCAATCAACCCTCAGCGGCAGAATGGCCTCGCCC ACGACCGGGCCCCGAGCCGCAAAGACAGCCTGGAAAGTGACAGCTCCACGGCCATCATTCCCCATGAGCTGATTCGCACGCGGCAGCTTG AGAGCGTACATCTGAAATTCAACCAGGAGTCCGGAGCCCTCATTCCTCTCTGCCTAAGGGGCAGGCTCCTGCATGGACGGCACTTTACAT ATAAAAGTATCACAGGTGACATGGCCATCACGTTTGTCTCCACGGGAGTGGAAGGCGCCTTTGCCACTGAGGAGCATCCTTACGCGGCTC ATGGACCCTGGTTACAACTCTGAACCTATCCTCGGAGCTCTGCCCTCCCGTCCTGGAACGTCTTTCTGCCCTGAGGAGAGGGTAGTCAGC ATCTCCAATTTTCAGCAGCTCAAGAACCTTGGCCCCCACAGGACTTCGCAGATGTCACATTGCCCCTCAGTCCCCTGAATGCCCTTCGGA CCCAACCCCAATTCCCCAAGCCCCTGACCCCCTAGCTGCCGGGGTTCCCACTCCCAGTGCCACAACCCCCTCACCTCCCTGGCAGCCCCT CAGCGAGCCTGAGGCCCAGCACCCGCTGGCTCCCCAGCACATGGTCCCCTCCCATGGGCTGTTGCCCAGGGAACCGGGGCGCGGTGGGAA CGAGCTGCTGGCCTCGGCATGTTTCAATAAAGTTGCTGTGCTGGGAGCTACTCA >6929_6929_1_AS3MT-SUFU_AS3MT_chr10_104650435_ENST00000369880_SUFU_chr10_104356897_ENST00000369899_length(amino acids)=521AA_BP=340 MAALRDAEIQKDVQTYYGQVLKRSADLQTNGCVTTARPVPKHIREALQNVHEEVALRYYGCGLVIPEHLENCWILDLGSGSGRDCYVLSQ LVGEKGHVTGIDMTKGQVEVAEKYLDYHMEKYGFQASNVTFIHGYIEKLGEAGIKNESHDIVVSNCVINLVPDKQQVLQEAYRVLKHGGE LYFSDVYTSLELPEEIRTHKVLWGECLGGALYWKELAVLAQKIGFCPPRLVTANLITIQNKELERVIGDCRFVSATFRLFKHSKTGPTKR CQVIYNGGITGHEKELMFDANFTFKEGEIVEVDEETAAILKNSRFAQDFLIRPIGEKLPTSGGCSALELKERVDKGIETDGSNLSGVSAK CAWDDLSRPPEDDEDSRSICIGTQPRRLSGKDTEQIRETLRRGLEINSKPVLPPINPQRQNGLAHDRAPSRKDSLESDSSTAIIPHELIR TRQLESVHLKFNQESGALIPLCLRGRLLHGRHFTYKSITGDMAITFVSTGVEGAFATEEHPYAAHGPWLQL -------------------------------------------------------------- >6929_6929_2_AS3MT-SUFU_AS3MT_chr10_104650435_ENST00000369880_SUFU_chr10_104356897_ENST00000369902_length(transcript)=5176nt_BP=1097nt GAGACAGTGAGTGCGCGCCCTGAGTCGCAGGCCGAGGAGACAGTGAGTGCGCGCCCTGAGTCGCAGGCCGAGGAGACATGGCTGCACTTC GTGACGCTGAGATACAGAAGGACGTGCAGACCTACTACGGGCAGGTGCTGAAGAGATCGGCAGACCTCCAGACCAACGGCTGTGTCACCA CAGCCAGGCCGGTCCCCAAGCACATCCGGGAAGCCTTGCAAAATGTACACGAAGAAGTAGCCCTAAGATATTATGGCTGTGGTCTGGTGA TCCCTGAGCATCTAGAAAACTGCTGGATTTTGGATCTGGGTAGTGGAAGTGGCAGAGATTGCTATGTACTTAGCCAGCTGGTTGGTGAAA AAGGACACGTGACTGGAATAGACATGACCAAAGGCCAGGTGGAAGTGGCTGAAAAGTATCTTGACTATCACATGGAAAAATATGGCTTCC AGGCATCTAATGTGACTTTTATTCATGGCTACATTGAGAAGTTGGGAGAGGCTGGAATCAAGAATGAGAGCCATGATATTGTTGTATCAA ACTGTGTTATTAACCTTGTGCCTGATAAACAACAAGTGCTTCAGGAGGCATATCGGGTGCTGAAGCATGGTGGGGAGTTATATTTCAGTG ACGTCTATACGAGCCTTGAACTGCCAGAAGAAATCAGGACACACAAAGTTTTATGGGGTGAGTGTCTGGGTGGTGCTTTATACTGGAAGG AACTTGCTGTCCTTGCTCAAAAAATTGGGTTCTGCCCTCCACGTTTGGTCACTGCCAATCTCATTACAATTCAAAACAAGGAACTGGAAA GAGTTATCGGTGACTGTCGTTTTGTTTCTGCAACATTTCGCCTCTTCAAACACTCTAAGACAGGACCAACCAAGAGATGCCAAGTTATTT ACAATGGAGGAATTACAGGACATGAAAAAGAACTAATGTTTGATGCCAATTTTACATTTAAGGAAGGTGAAATTGTTGAAGTGGATGAAG AAACAGCAGCTATCTTGAAGAATTCAAGATTTGCTCAAGATTTTCTGATCAGACCAATTGGAGAGAAGTTGCCAACATCTGGAGGCTGTT CTGCTTTGGAGTTAAAGGAGAGAGTTGACAAAGGCATCGAGACAGATGGCTCCAACCTGAGTGGTGTCAGTGCCAAGTGTGCCTGGGATG ACCTGAGCCGGCCCCCCGAGGATGACGAGGACAGCCGGAGCATCTGCATCGGCACACAGCCCCGGCGACTCTCTGGCAAAGACACAGAGC AGATCCGGGAGACCCTGAGGAGAGGACTCGAGATCAACAGCAAACCTGTCCTTCCACCAATCAACCCTCAGCGGCAGAATGGCCTCGCCC ACGACCGGGCCCCGAGCCGCAAAGACAGCCTGGAAAGTGACAGCTCCACGGCCATCATTCCCCATGAGCTGATTCGCACGCGGCAGCTTG AGAGCGTACATCTGAAATTCAACCAGGAGTCCGGAGCCCTCATTCCTCTCTGCCTAAGGGGCAGGCTCCTGCATGGACGGCACTTTACAT ATAAAAGTATCACAGGTGACATGGCCATCACGTTTGTCTCCACGGGAGTGGAAGGCGCCTTTGCCACTGAGGAGCATCCTTACGCGGCTC ATGGACCCTGGTTACAAATTCTGTTGACCGAAGAGTTTGTAGAGAAAATGTTGGAGGATTTAGAAGATTTGACTTCTCCAGAGGAATTCA AACTTCCCAAAGAGTACAGCTGGCCTGAAAAGAAGCTGAAGGTCTCCATCCTGCCTGACGTGGTGTTCGACAGTCCGCTACACTAGCCTG GGCTGGGCCCTGCAGTGGCCAGCAGGGAGCCCAGCTGCTCCCCAGTGACTTCCAGTGTAACAGTTGTGTCAACGAGATCTCCACAAATAA AAGGACAAGTGTGAGGAAGACTGCGCAGTGCCACCCCGCAGCCCAGTGGGGTGCCATGCACAGGCCACAGGCCCTCCACCTCACCTCCAG CTCAGGGGCCGCACCCCGCCGCTGGCTAAGCCTTGTGACCCATCAGGCCAGTGAGTGGGCAAATGCGGACCCTCCCTGCCTGCAGCCTGC ACAGATTCTGGTTTGAGGTTTGACTCTGGACCCTGGCTGTGCCCCTAGGTGGAGACAGCCCTCTTTCTCACCTACCCCCTGCCGCACAGC CCAGCAGGAGGGAGGCGGACAGCCAGATGCAGAGCGAGTGGATGCACTTCCCAGCTCATCTCTGGAAGCCTTTGCTACTCAAGCTCCTCT GGCCGCGGAACAATTCCTCTGATCATGTTTGGTTTTCTTCTTCCTTATTTTATTTTGTAGAAACCGGGTGGTATTTTATTGCTCTGCAAA GATGTCCAGAAGCCATGTATATAATGTTTTTTAAACAGAACTTCATTCCCCGTTGAACTTTCGCATTCTCTGACAGAGGCCTAGGGCTGT ATCTCTCCCTGGGCTGCCACCAGAGAAGGTGCTTGGTGTTCGCCTGCCAGCCCAGAGCCCTGGAGGAGCCGGCTGCACAGAGAGGCTTTT CTTCCCAGCTGGGCCTGGTGGAGCCCGGGGCAGGGGGAGAGTAGAGACACTCCCTTGTGCAGCTTTGAGCCTAGTTTAGCTGGGGCCAGG GAGGGGTGCTACTGTTTTCCAAGTGAATGGGTCTCAAAGACTTGGTGACCCCAGCCTCATCTTCTAGGCCTTTTCCACCCAACCAGGCCT ACCTGGGAGAGGGTGAGGTTCAGCACATCACACACCATCCCCACTGTCATTCAGGGCCTGGGTCTCCAGCTCTGTAACCAGTCCTGTCCC ATTTCCTCAGTCCCTGGGCCTCCCAGCCTTCAGGCTGTAGGGCTGCCTTACTAAAATTGAAAAATCCACCTCTTAACATCTCTTTCACTT TGGTTTTGCTAACACTGCTCTCTGCTGCCCTCCCATCCTCCCTGTATCCATTCATGCCCTATCTTTCATTCTCCACTCCTAATCCCTCTC CTTTCTGGCATCCTGGCCTCTCGTGGTCCTCAGCCCCTCACCCCCAGTACTGCAGATCTCACAGTTTGCCTTCCAGAAGCCAGCCTATCT CTAGCCCATGGTTTTGGAGTTCCTCTCGGGTTATCTCCCACGCCTGACCTGGAACCAGCAAGCCCCTTTCCTGCCTTCTTACCCCCAACT CTAGGGATGGGACTGTTACAATACTTCAAGATCACTCTTTACACCTCTTCAAAGCAAAGTCATGACAATGCAGGGCTCCTCATTGCTCCC ATCTGCCTCTGCTGCACACACAGGCACCAGCAGGGATGCCACAGGAGTGCCCACAGGGTGCAGGACTCCACTGATGAGAGATCCAGCCAA AGAGCTGCCCCCAGGGGTATGAGGGCACCAGCTGGGTTCTCCAGGGAGCAGGAGTTGGACCTCCATGGAGCCACTAGGCCTGGCCTCCTC TACACATCCCCAGGGCTATCTGGTTAATTCCATCAAGCTCAGAGTTAAAAGGCATATCAGCCTGGAGTATTTGGGAGAGACTGGCTGCAG ATCCCCGCCAGCCAAGATGCAAGCCACTCGGGACCTGATGTCGGCAGCTGTGCCTCTACTGCCCTGAGGACTTACCAGAGGGAGCCCTAC TGGCCTTCCCCCACCACAGCAGCCCTGCCTGTGAAGCTCTTGTTTCTGACATTTCACAGGCAGAGAGGTGCCATCAGTTCGCCTCCATTC CTTGCCACCATGACCAGCCTCTCCCTGAACTCTCTCTTGCTCGGGACCTGCCTGAGGGCTCCCTGCTGCAGTTCGCCGTACTTCCATCTG CTGGGTGCCTCCATCGTTGGTTGGGTGGGGATGGGGCATTTTCTGAGCTAAGCTTTGTCATTAGTTTGTGAAGCACCTGGTCAGCAACCT GCCCCAGACCTGGAGGGTCTTTGTGGACTGAAGGTAGACACCAGCCAGCATGGTGGCCCTGTTCTGGGGGAGCAGGGTAAGGCAGGAGGA AGTGGGTGAGCTCCGAGATGATGAGCACATGAAGCCTGTGGCCCCTTCGTACCTGCAATATGTCAGGAGCCTCACGCTCACCCAAGATCC TGCAGGGGCCAGGCTCCATCTCACTGGCTCTGAGGGCAGGACAGGGTATCACACATTTCTCACCAGGCCTCCTTTCCTATGGGCATTGGT GCCTCCCAGAGGTTTCTTGGGCTGCTGGCTGGTGAGAGAGGACCCTTAAAGAAGATCAAGCCAAGCTGACCTTGGACCCTGTCCAGCACA GCTTCTGGCACAGGATGCTTGGTGAATGTACCCTTTCTTTCCCTCCCTGCAGCTCTGAGGGAGCCCCTGACCTTGTAGTGGGTGGAGGAG GTAAGGGGCCTCCCTCCCTAAATCTGCCTCTTCTGCAAGCTACTTGGAGACTTGCCTAGTTGTACCCACCCCTCCAGGTCCCTGGTGCTA GAGCTTCTGAGAAGGGCCTTTCCCTTTCCTCTTTGCCTGCTATATAAGGCAGGCTCCTGTGGCTCTGCTGGCTCAGTGTGGGCTGCAGGA GGACTGCAGACTCAGCTGCAATTCTGAGGGGGGTTTGGGAGGCTTGTGCGAGGTCTCAGGCCTGTGTGGGGAGCTGGTGCCTCTTCCTGC CCGTATCTTTCTCTTCCAAGGGCAGTGCTCCAAGGCAGGGACTGGAGAAGCCAAGGGGAGAGTCTAAAAGGGCTAGAGCATTTTTAAAAA TAGACACAGGGTCTTGGGACTGGGGTTTCGGATTGAGTTGCAAGCAGGGAGAAAACCTGAAGGTCGGTGCCCCTATGGGGCTGACCAGTA GAGAATTTCCTTTACTGTATTTTTGTGTCTGGTCTTCCCTTTCTGGCTTCTAGGACATCCATGCCAGGTGAGGTGCCTGGGTCCCTGTTA CAAGTCAGGAGCCCTGTAGGGAGACCCCTCCTTTTGTACAAGTACCTGAATGCTGCGACAAGCAGATTTTTGTAAAATTTTATATTAGTT TTTAATGTCAGTGGCGACTCGGTTCCTGGGGCTGCAGCCAGCCTGGGACTTTTGTAAGAATTTTTGGGTGACTCACTTAGATGTCGTTTC CTTCTTGCCCCCTCTTCCTCTCTGTAATCTAAGTGCATTAAACATCTTTGCAGAAGTGCCTGGGTTGTGTGCTCATTTCTGGCTGCCTGA AGTAGTGGAGCCGGAAGCCCGGGGCCCTGGCAGAGGGAGTGGGTTG >6929_6929_2_AS3MT-SUFU_AS3MT_chr10_104650435_ENST00000369880_SUFU_chr10_104356897_ENST00000369902_length(amino acids)=572AA_BP=340 MAALRDAEIQKDVQTYYGQVLKRSADLQTNGCVTTARPVPKHIREALQNVHEEVALRYYGCGLVIPEHLENCWILDLGSGSGRDCYVLSQ LVGEKGHVTGIDMTKGQVEVAEKYLDYHMEKYGFQASNVTFIHGYIEKLGEAGIKNESHDIVVSNCVINLVPDKQQVLQEAYRVLKHGGE LYFSDVYTSLELPEEIRTHKVLWGECLGGALYWKELAVLAQKIGFCPPRLVTANLITIQNKELERVIGDCRFVSATFRLFKHSKTGPTKR CQVIYNGGITGHEKELMFDANFTFKEGEIVEVDEETAAILKNSRFAQDFLIRPIGEKLPTSGGCSALELKERVDKGIETDGSNLSGVSAK CAWDDLSRPPEDDEDSRSICIGTQPRRLSGKDTEQIRETLRRGLEINSKPVLPPINPQRQNGLAHDRAPSRKDSLESDSSTAIIPHELIR TRQLESVHLKFNQESGALIPLCLRGRLLHGRHFTYKSITGDMAITFVSTGVEGAFATEEHPYAAHGPWLQILLTEEFVEKMLEDLEDLTS PEEFKLPKEYSWPEKKLKVSILPDVVFDSPLH -------------------------------------------------------------- >6929_6929_3_AS3MT-SUFU_AS3MT_chr10_104650435_ENST00000369880_SUFU_chr10_104356897_ENST00000423559_length(transcript)=2868nt_BP=1097nt GAGACAGTGAGTGCGCGCCCTGAGTCGCAGGCCGAGGAGACAGTGAGTGCGCGCCCTGAGTCGCAGGCCGAGGAGACATGGCTGCACTTC GTGACGCTGAGATACAGAAGGACGTGCAGACCTACTACGGGCAGGTGCTGAAGAGATCGGCAGACCTCCAGACCAACGGCTGTGTCACCA CAGCCAGGCCGGTCCCCAAGCACATCCGGGAAGCCTTGCAAAATGTACACGAAGAAGTAGCCCTAAGATATTATGGCTGTGGTCTGGTGA TCCCTGAGCATCTAGAAAACTGCTGGATTTTGGATCTGGGTAGTGGAAGTGGCAGAGATTGCTATGTACTTAGCCAGCTGGTTGGTGAAA AAGGACACGTGACTGGAATAGACATGACCAAAGGCCAGGTGGAAGTGGCTGAAAAGTATCTTGACTATCACATGGAAAAATATGGCTTCC AGGCATCTAATGTGACTTTTATTCATGGCTACATTGAGAAGTTGGGAGAGGCTGGAATCAAGAATGAGAGCCATGATATTGTTGTATCAA ACTGTGTTATTAACCTTGTGCCTGATAAACAACAAGTGCTTCAGGAGGCATATCGGGTGCTGAAGCATGGTGGGGAGTTATATTTCAGTG ACGTCTATACGAGCCTTGAACTGCCAGAAGAAATCAGGACACACAAAGTTTTATGGGGTGAGTGTCTGGGTGGTGCTTTATACTGGAAGG AACTTGCTGTCCTTGCTCAAAAAATTGGGTTCTGCCCTCCACGTTTGGTCACTGCCAATCTCATTACAATTCAAAACAAGGAACTGGAAA GAGTTATCGGTGACTGTCGTTTTGTTTCTGCAACATTTCGCCTCTTCAAACACTCTAAGACAGGACCAACCAAGAGATGCCAAGTTATTT ACAATGGAGGAATTACAGGACATGAAAAAGAACTAATGTTTGATGCCAATTTTACATTTAAGGAAGGTGAAATTGTTGAAGTGGATGAAG AAACAGCAGCTATCTTGAAGAATTCAAGATTTGCTCAAGATTTTCTGATCAGACCAATTGGAGAGAAGTTGCCAACATCTGGAGGCTGTT CTGCTTTGGAGTTAAAGGAGAGAGTTGACAAAGGCATCGAGACAGATGGCTCCAACCTGAGTGGTGTCAGTGCCAAGTGTGCCTGGGATG ACCTGAGCCGGCCCCCCGAGGATGACGAGGACAGCCGGAGCATCTGCATCGGCACACAGCCCCGGCGACTCTCTGGCAAAGACACAGAGC AGATCCGGGAGACCCTGAGGAGAGGACTCGAGATCAACAGCAAACCTGTCCTTCCACCAATCAACCCTCAGCGGCAGAATGGCCTCGCCC ACGACCGGGCCCCGAGCCGCAAAGACAGCCTGGAAAGTGACAGCTCCACGGCCATCATTCCCCATGAGCTGATTCGCACGCGGCAGCTTG AGAGCGTACATCTGAAATTCAACCAGGAGTCCGGAGCCCTCATTCCTCTCTGCCTAAGGGGCAGGCTCCTGCATGGACGGCACTTTACAT ATAAAAGTATCACAGGTGACATGGCCATCACGTTTGTCTCCACGGGAGTGGAAGGCGCCTTTGCCACTGAGGAGCATCCTTACGCGGCTC ATGGACCCTGGTTACAAGTGAGAAGGCCCTTTTTCTTCTCCCTCCTTCCTTTCATAGACTTCCTTGCCCACCCCTCCTCTTCTCCCTTGG CAGCTCTTGATGGCACCCCTTCCTGGGGGGCTGGTCATGAATGCCTCATGGATTCAGGGCCTGGGGCCTGTGTGTAGGTATGGAGTGTGG ATGCTGCTACCCACTCCAGCAGCTTAGGAGCACTTCCTGACCTTCTCCCCCTGTCACCTGAGACACAAGTGTTAACTCTCCAGGCCCTGG CTCTTGGTAATTCTGGTTCCCCGTGGAAATCCAGGTTGGAGGGATATAAGACTTTCTGCACCTTGGGTAAACCAAGGTACAAGAACTCAA GGATGAAGCAAGATGGGAGGATGTGTGGAGGCCACTCTCCAATGGCTACATGGAAATCCCACCAGAATTCAGACAGTGGCATGTGTGCCT GGACCAGGGCTGGGCAGGCCTCAGTGGGAAGAGCCTCCCCTTCTTAGCCTACCCCCATCTGACAGCCCTCCCGTTCCTCCTGAGTTTGTG TGACCAGAGACCTGCTGGCTTATCCGGAGCACTTTGTCCTTCCTTTGCTCTTCTGGCTGGAGCGAGCTTCAGAGCTGTTGCCAAGCAGGG TACCAGGGCCTCAGAGCCATAGGCCTCCTTCCAGTCCCCACCCCGTCCCGGGTCTCTAACAGGTGCTCAACCTACTCCACCACACTCCCG AGTGTCTTGGAGGGACAGCATCCTTTTTTGGCATTTGTTTGTTGCGGGTGGGGAGAGGATTGAACCCTTAACCTCACCTCGCTCGCAAGT ATCAAGAAAGGGAACCTGACCCTAAACCTAAAGGTGGCCATACCTGGTTTGTGAATGTATTGGAGAGGCATGCAGCATTACAGTAGAGGG GAAGAGAATGATGCTAGGTTTGTGAGTTTCACCCAGTCTGGGGAGTCTGTGAAGCATATGTAGTCAATACAGACACACTTTTTGTCCCTG CATGTCTACAGAATTTCTCCTCCTTCAGGCCAGGCCCCTCTTCTCCCGCCACCACCAAAATACAACCCTTAATTAAAACAAACAGCAAAC AAAGGACACCAACCACACTCCCCAGACTAAGCCGAGATAGAAATGGAAGCTAGTGCTTTAGGGATATTGTGTTCCATAAATTATCTTGCC TTTTTCCACTGTTGTTATTATATCGTTTCATAACAAAATTACTTTGAACCATAAAGTTATAAATACATTTTAAAAGTC >6929_6929_3_AS3MT-SUFU_AS3MT_chr10_104650435_ENST00000369880_SUFU_chr10_104356897_ENST00000423559_length(amino acids)=569AA_BP=340 MAALRDAEIQKDVQTYYGQVLKRSADLQTNGCVTTARPVPKHIREALQNVHEEVALRYYGCGLVIPEHLENCWILDLGSGSGRDCYVLSQ LVGEKGHVTGIDMTKGQVEVAEKYLDYHMEKYGFQASNVTFIHGYIEKLGEAGIKNESHDIVVSNCVINLVPDKQQVLQEAYRVLKHGGE LYFSDVYTSLELPEEIRTHKVLWGECLGGALYWKELAVLAQKIGFCPPRLVTANLITIQNKELERVIGDCRFVSATFRLFKHSKTGPTKR CQVIYNGGITGHEKELMFDANFTFKEGEIVEVDEETAAILKNSRFAQDFLIRPIGEKLPTSGGCSALELKERVDKGIETDGSNLSGVSAK CAWDDLSRPPEDDEDSRSICIGTQPRRLSGKDTEQIRETLRRGLEINSKPVLPPINPQRQNGLAHDRAPSRKDSLESDSSTAIIPHELIR TRQLESVHLKFNQESGALIPLCLRGRLLHGRHFTYKSITGDMAITFVSTGVEGAFATEEHPYAAHGPWLQVRRPFFFSLLPFIDFLAHPS SSPLAALDGTPSWGAGHECLMDSGPGACV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AS3MT-SUFU |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AS3MT-SUFU |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AS3MT-SUFU |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | AS3MT | C0005684 | Malignant neoplasm of urinary bladder | 3 | CTD_human |
| Hgene | AS3MT | C0005695 | Bladder Neoplasm | 3 | CTD_human |
| Hgene | AS3MT | C0274861 | Arsenic Poisoning, Inorganic | 2 | CTD_human |
| Hgene | AS3MT | C0274862 | Nervous System, Organic Arsenic Poisoning | 2 | CTD_human |
| Hgene | AS3MT | C0311375 | Arsenic Poisoning | 2 | CTD_human |
| Hgene | AS3MT | C0751851 | Arsenic Encephalopathy | 2 | CTD_human |
| Hgene | AS3MT | C0751852 | Arsenic Induced Polyneuropathy | 2 | CTD_human |
| Hgene | AS3MT | C0005612 | Birth Weight | 1 | CTD_human |
| Hgene | AS3MT | C0008073 | Developmental Disabilities | 1 | CTD_human |
| Hgene | AS3MT | C0027660 | Neoplasms, Glandular and Epithelial | 1 | CTD_human |
| Hgene | AS3MT | C0041671 | Attention Deficit Disorder | 1 | CTD_human |
| Hgene | AS3MT | C0085996 | Child Development Deviations | 1 | CTD_human |
| Hgene | AS3MT | C0085997 | Child Development Disorders, Specific | 1 | CTD_human |
| Hgene | AS3MT | C0205854 | Glandular Neoplasms | 1 | CTD_human |
| Hgene | AS3MT | C1263846 | Attention deficit hyperactivity disorder | 1 | CTD_human |
| Hgene | AS3MT | C1321905 | Minimal Brain Dysfunction | 1 | CTD_human |
| Hgene | AS3MT | C1368683 | Epithelioma | 1 | CTD_human |
| Tgene | C0025149 | Medulloblastoma | 10 | CGI;CLINGEN;CTD_human;GENOMICS_ENGLAND | |
| Tgene | C1334410 | Localized Primitive Neuroectodermal Tumor | 10 | CLINGEN | |
| Tgene | C0004779 | Basal Cell Nevus Syndrome | 5 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C0751291 | Desmoplastic Medulloblastoma | 5 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C1334970 | Medulloblastoma with extensive nodularity | 4 | ORPHANET | |
| Tgene | C0812437 | Oculo-dento-digital syndrome | 3 | ORPHANET | |
| Tgene | C4540342 | JOUBERT SYNDROME 32 | 2 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C0025286 | Meningioma | 1 | ORPHANET | |
| Tgene | C0238198 | Gastrointestinal Stromal Tumors | 1 | CTD_human | |
| Tgene | C0796147 | Acrocallosal Syndrome | 1 | ORPHANET | |
| Tgene | C1368275 | Pigmented Basal Cell Carcinoma | 1 | CTD_human | |
| Tgene | C2931760 | Acrocallosal syndrome, Schinzel type | 1 | ORPHANET | |
| Tgene | C3179349 | Gastrointestinal Stromal Sarcoma | 1 | CTD_human | |
| Tgene | C4721806 | Carcinoma, Basal Cell | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies