
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARID1B-EZR (FusionGDB2 ID:HG57492TG7430) |
Fusion Gene Summary for ARID1B-EZR |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARID1B-EZR | Fusion gene ID: hg57492tg7430 | Hgene | Tgene | Gene symbol | ARID1B | EZR | Gene ID | 57492 | 7430 |
| Gene name | AT-rich interaction domain 1B | ezrin | |
| Synonyms | 6A3-5|BAF250B|BRIGHT|CSS1|DAN15|ELD/OSA1|MRD12|OSA2|P250R | CVIL|CVL|HEL-S-105|VIL2 | |
| Cytomap | ('ARID1B')('EZR') 6q25.3 | 6q25.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AT-rich interactive domain-containing protein 1BARID domain-containing protein 1BAT rich interactive domain 1B (SWI1-like)BRG1-associated factor 250bBRG1-binding protein ELD/OSA1ELD (eyelid)/OSA protein | ezrincytovillin 2epididymis secretory protein Li 105p81villin 2 (ezrin) | |
| Modification date | 20200320 | 20200322 | |
| UniProtAcc | . | P15311 | |
| Ensembl transtripts involved in fusion gene | ENST00000275248, ENST00000346085, ENST00000350026, ENST00000367148, ENST00000478761, | ||
| Fusion gene scores | * DoF score | 27 X 18 X 14=6804 | 25 X 24 X 6=3600 |
| # samples | 31 | 27 | |
| ** MAII score | log2(31/6804*10)=-4.45604302038915 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(27/3600*10)=-3.73696559416621 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARID1B [Title/Abstract] AND EZR [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARID1B(157256710)-EZR(159210403), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | ARID1B-EZR seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARID1B-EZR seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARID1B-EZR seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ARID1B-EZR seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | EZR | GO:0048015 | phosphatidylinositol-mediated signaling | 25591774 |
| Tgene | EZR | GO:0051017 | actin filament bundle assembly | 10793131 |
| Fusion gene breakpoints across ARID1B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across EZR (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-EY-A4KR-01A | ARID1B | chr6 | 157256710 | - | EZR | chr6 | 159210403 | - |
| ChimerDB4 | UCEC | TCGA-EY-A4KR-01A | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| ChimerDB4 | UCEC | TCGA-EY-A4KR | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
Top |
Fusion Gene ORF analysis for ARID1B-EZR |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000275248 | ENST00000476189 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| 5CDS-5UTR | ENST00000346085 | ENST00000476189 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| 5CDS-5UTR | ENST00000350026 | ENST00000476189 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| 5CDS-5UTR | ENST00000367148 | ENST00000476189 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000275248 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000275248 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000275248 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000346085 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000346085 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000346085 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000350026 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000350026 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000350026 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000367148 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000367148 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| In-frame | ENST00000367148 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| intron-3CDS | ENST00000478761 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| intron-3CDS | ENST00000478761 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| intron-3CDS | ENST00000478761 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| intron-5UTR | ENST00000478761 | ENST00000476189 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000350026 | ARID1B | chr6 | 157256710 | + | ENST00000337147 | EZR | chr6 | 159210403 | - | 4921 | 1999 | 1 | 3747 | 1248 |
| ENST00000350026 | ARID1B | chr6 | 157256710 | + | ENST00000367075 | EZR | chr6 | 159210403 | - | 4914 | 1999 | 1 | 3747 | 1248 |
| ENST00000350026 | ARID1B | chr6 | 157256710 | + | ENST00000392177 | EZR | chr6 | 159210403 | - | 3670 | 1999 | 1 | 3651 | 1216 |
| ENST00000346085 | ARID1B | chr6 | 157256710 | + | ENST00000337147 | EZR | chr6 | 159210403 | - | 4960 | 2038 | 1 | 3786 | 1261 |
| ENST00000346085 | ARID1B | chr6 | 157256710 | + | ENST00000367075 | EZR | chr6 | 159210403 | - | 4953 | 2038 | 1 | 3786 | 1261 |
| ENST00000346085 | ARID1B | chr6 | 157256710 | + | ENST00000392177 | EZR | chr6 | 159210403 | - | 3709 | 2038 | 1 | 3690 | 1229 |
| ENST00000367148 | ARID1B | chr6 | 157256710 | + | ENST00000337147 | EZR | chr6 | 159210403 | - | 4920 | 1998 | 0 | 3746 | 1248 |
| ENST00000367148 | ARID1B | chr6 | 157256710 | + | ENST00000367075 | EZR | chr6 | 159210403 | - | 4913 | 1998 | 0 | 3746 | 1248 |
| ENST00000367148 | ARID1B | chr6 | 157256710 | + | ENST00000392177 | EZR | chr6 | 159210403 | - | 3669 | 1998 | 0 | 3650 | 1216 |
| ENST00000275248 | ARID1B | chr6 | 157256710 | + | ENST00000337147 | EZR | chr6 | 159210403 | - | 4898 | 1976 | 77 | 3724 | 1215 |
| ENST00000275248 | ARID1B | chr6 | 157256710 | + | ENST00000367075 | EZR | chr6 | 159210403 | - | 4891 | 1976 | 77 | 3724 | 1215 |
| ENST00000275248 | ARID1B | chr6 | 157256710 | + | ENST00000392177 | EZR | chr6 | 159210403 | - | 3647 | 1976 | 77 | 3628 | 1183 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000350026 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.007520209 | 0.9924798 |
| ENST00000350026 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.007422142 | 0.99257785 |
| ENST00000350026 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.013975797 | 0.9860242 |
| ENST00000346085 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.006321513 | 0.9936785 |
| ENST00000346085 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.006218405 | 0.9937816 |
| ENST00000346085 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.013192873 | 0.98680717 |
| ENST00000367148 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.007501253 | 0.9924987 |
| ENST00000367148 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.007403441 | 0.9925965 |
| ENST00000367148 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.013991524 | 0.98600847 |
| ENST00000275248 | ENST00000337147 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.008839414 | 0.9911606 |
| ENST00000275248 | ENST00000367075 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.008734123 | 0.99126583 |
| ENST00000275248 | ENST00000392177 | ARID1B | chr6 | 157256710 | + | EZR | chr6 | 159210403 | - | 0.015118923 | 0.98488104 |
Top |
Fusion Genomic Features for ARID1B-EZR |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
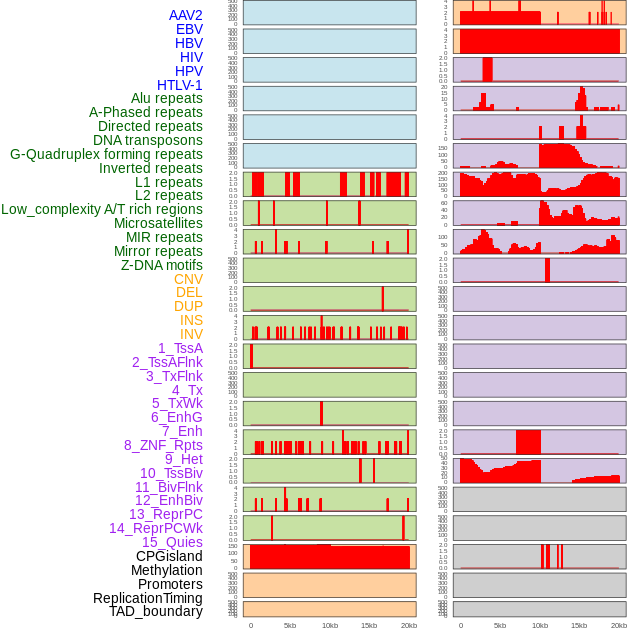 |
Top |
Fusion Protein Features for ARID1B-EZR |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr6:157256710/chr6:159210403) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | EZR |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Probably involved in connections of major cytoskeletal structures to the plasma membrane. In epithelial cells, required for the formation of microvilli and membrane ruffles on the apical pole. Along with PLEKHG6, required for normal macropinocytosis. {ECO:0000269|PubMed:17881735, ECO:0000269|PubMed:18270268, ECO:0000269|PubMed:19111582}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 107_131 | 679 | 2250.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 114_131 | 679 | 2250.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 141_401 | 679 | 2250.0 | Compositional bias | Note=Gly-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 2_47 | 679 | 2250.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 329_493 | 679 | 2250.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 35_57 | 679 | 2250.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 574_633 | 679 | 2250.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 81_104 | 679 | 2250.0 | Compositional bias | Note=His-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 107_131 | 666 | 2237.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 114_131 | 666 | 2237.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 141_401 | 666 | 2237.0 | Compositional bias | Note=Gly-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 2_47 | 666 | 2237.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 329_493 | 666 | 2237.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 35_57 | 666 | 2237.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 574_633 | 666 | 2237.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 81_104 | 666 | 2237.0 | Compositional bias | Note=His-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 107_131 | 666 | 2290.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 114_131 | 666 | 2290.0 | Compositional bias | Note=Poly-Gln |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 141_401 | 666 | 2290.0 | Compositional bias | Note=Gly-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 2_47 | 666 | 2290.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 329_493 | 666 | 2290.0 | Compositional bias | Note=Ala-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 35_57 | 666 | 2290.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 574_633 | 666 | 2290.0 | Compositional bias | Note=Gln-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 81_104 | 666 | 2290.0 | Compositional bias | Note=His-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 419_423 | 679 | 2250.0 | Motif | Note=LXXLL |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 419_423 | 666 | 2237.0 | Motif | Note=LXXLL |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 419_423 | 666 | 2290.0 | Motif | Note=LXXLL |
| Tgene | EZR | chr6:157256710 | chr6:159210403 | ENST00000337147 | 0 | 13 | 2_295 | 4 | 587.0 | Domain | FERM | |
| Tgene | EZR | chr6:157256710 | chr6:159210403 | ENST00000367075 | 1 | 14 | 2_295 | 4 | 587.0 | Domain | FERM | |
| Tgene | EZR | chr6:157256710 | chr6:159210403 | ENST00000337147 | 0 | 13 | 115_120 | 4 | 587.0 | Motif | [IL]-x-C-x-x-[DE] motif | |
| Tgene | EZR | chr6:157256710 | chr6:159210403 | ENST00000367075 | 1 | 14 | 115_120 | 4 | 587.0 | Motif | [IL]-x-C-x-x-[DE] motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 1034_1037 | 679 | 2250.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 1441_1444 | 679 | 2250.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 1459_1597 | 679 | 2250.0 | Compositional bias | Note=Pro-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 1833_1836 | 679 | 2250.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 684_771 | 679 | 2250.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 932_935 | 679 | 2250.0 | Compositional bias | Note=Poly-Ala |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 1034_1037 | 666 | 2237.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 1441_1444 | 666 | 2237.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 1459_1597 | 666 | 2237.0 | Compositional bias | Note=Pro-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 1833_1836 | 666 | 2237.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 684_771 | 666 | 2237.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 932_935 | 666 | 2237.0 | Compositional bias | Note=Poly-Ala |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 1034_1037 | 666 | 2290.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 1441_1444 | 666 | 2290.0 | Compositional bias | Note=Poly-Ser |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 1459_1597 | 666 | 2290.0 | Compositional bias | Note=Pro-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 1833_1836 | 666 | 2290.0 | Compositional bias | Note=Poly-Pro |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 684_771 | 666 | 2290.0 | Compositional bias | Note=Ser-rich |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 932_935 | 666 | 2290.0 | Compositional bias | Note=Poly-Ala |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 1053_1144 | 679 | 2250.0 | Domain | ARID |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 1053_1144 | 666 | 2237.0 | Domain | ARID |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 1053_1144 | 666 | 2290.0 | Domain | ARID |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 1358_1377 | 679 | 2250.0 | Motif | Nuclear localization signal |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000346085 | + | 5 | 20 | 2036_2040 | 679 | 2250.0 | Motif | Note=LXXLL |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 1358_1377 | 666 | 2237.0 | Motif | Nuclear localization signal |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000350026 | + | 4 | 19 | 2036_2040 | 666 | 2237.0 | Motif | Note=LXXLL |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 1358_1377 | 666 | 2290.0 | Motif | Nuclear localization signal |
| Hgene | ARID1B | chr6:157256710 | chr6:159210403 | ENST00000367148 | + | 4 | 20 | 2036_2040 | 666 | 2290.0 | Motif | Note=LXXLL |
Top |
Fusion Gene Sequence for ARID1B-EZR |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >6406_6406_1_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000275248_EZR_chr6_159210403_ENST00000337147_length(transcript)=4898nt_BP=1976nt CGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAGCGCCGCCGCGCTGTCCTCCTCCT CCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGAGACGGGGCTGCTCCCCAACCACA AACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGCCCACCACCACCACCACCATGCCC ACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCAGCAACAGCAGCAGCAGCAGCAGC AGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCCCGGCCCCGACATGGAGCAGCCGC AACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAGCAAGCCGGGCGACGAGGACGACG CGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCACGCAGCAGCCGCCGGTCGCCGTGC CCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGCGAGCGGCGGCCCCGGCGGCCGCG CTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTCCGCCGCCGCCGCCGGGGCCCCCG GCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGGCTACAGCCGGCCCGGCGCGGGCG GCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGGAGCAGGAGGAGCAGGAGCGGGAG CTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGGCTCGTCCGCGGGGTACGGGGTGC TGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCTCAGCAAGGCGGCCGCCGGCTCGG CGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAATCAGCTGCTCACCTCGCCCAGCC CCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCCGTCGCAGCCCCAGTCCCAGGCGG CGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGGCGCCCAGTACGCCGCTGCCAGCC CGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCATGGGCAGATCCCAGGGCAGCCCAA TGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCAGCAGAGCAGTCCGTACCCAGGAG GTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCATGGCCGGAATGCAGTACCCTCAGC AGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATATTACAGCCAGCAGCCGCAGCCCC CGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGACATGTCTCAGGAAGGCTATGGAA CTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAAAGACCATCAAGTTTACCAATCA ATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAGCTTTTTGATCAGGTGGTAAAGA CTATCGGCCTCCGGGAAGTGTGGTACTTTGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTGGCTGAAGCTGGATAAGAAGGTGT CTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGCTGAGGAGCTCATCCAGG ACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGAGACTGCCGTGCTCTTGG GGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGAGCGGCTGATCCCTCAAA GAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCGTGGGATGCTCAAAGATA ATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAACAAGAAAGGAACAGACC TTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTTTCCTTGGAGTGAAATCA GGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTATGCCCCACGTCTGAGAA TCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCATCGAGGTGCAGCAGATGA AGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAGAGAAACCGTGGAGAGAG AGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAAGGCAGAGAGAGAGCTCT CGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGAGGCTGACCGTATGGCTG CACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGAGCTTGCAGAATACACTG CCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAAAGAAGCCCAGGATGACC TGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCCGGTGAGCTACCATGTCC AGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGATGACCGCAATGAGGAGA AGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCAGGCCCGAGATGAGAATA AGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCAGATCCGGCAGGGCAACA CCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGCTCATAGCGGGCGCTGCCAGCCCC GCCACGCTTGTGTCTTTAGTGCTCCAAGTCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCAGTTACCCAACAGAAACATTCTGG GCTGGGAACCAGGGAGGCGCCCTGGTTTGTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTCTCGCGATTATTCTCGAATCACCT CCTGTGTTGTGCTGGGAGCAGGACTGATTGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAACTTCATGCTGGCCTGTGTGATACA AGAGTCAGCATCATTAAAGGAAACGTGGCAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAAATGAGCTCAAATTGATTTTTTAA TTTCTATGAAGGATCCATCTTTGTATATTTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGAGTCTGAAGCACTCTCGCACACAC AGTGATTCCCTCCTCCCGTCACTCCACGCAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGTGGAGGAGGACACTTGGATTTTTT TTTTTGTTTTTTTTTTTTTTGCTTAACAGTTTTAGAATACATTGTACTTATACACCTTATTAATGATCAGCTATATACTATTTATATACA AGTGATAATACAGATTTGTAACATTAGTTTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACCTTTTACAGAATAAAAGAATTACA TATGAAAAACCCTCTAAACCATGGCACTTGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACCTGCCTGCTGCAGTCACGTGTAAA CAGGATTATTATTAGTGTTTTATGCATGTAATGGACTATGCACACTTTTAATTTTGTCAGATTCACACATGCCACTATGAGCTTTCAGAC TCCAGCTGTGAAGAGACTCTGTTTGCTTGTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTGGCAGGCTGCTGGAAGGCAGCTTG TGGAGGCCGTTGGTTCCGCCCACTCATTCCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGCCATGTGCAGGTGGATTCCATGCC GCAGACATGAAATAAAAGCTTTGCAAAGGCACGAAGCA >6406_6406_1_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000275248_EZR_chr6_159210403_ENST00000337147_length(amino acids)=1215AA_BP=47 MSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHAHHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQ QQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLSKPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQP PVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSASAAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSR PGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGGSSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKA AAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPPSQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQY AAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQQSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGM QYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQDMSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPS SLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYFGLHYVDNKGFPTWLKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAE ELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRG MLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKIGFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYA PRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKKRRETVEREKEQMMREKEELMLRLQDYEEKTKKA ERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLAAELAEYTAKIALLEEARRRKEDEVEEWQHRAKE AQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGIRDDRNEEKRITEAEKNERVQRQLLTLSSELSQA RDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_2_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000275248_EZR_chr6_159210403_ENST00000367075_length(transcript)=4891nt_BP=1976nt CGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAGCGCCGCCGCGCTGTCCTCCTCCT CCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGAGACGGGGCTGCTCCCCAACCACA AACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGCCCACCACCACCACCACCATGCCC ACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCAGCAACAGCAGCAGCAGCAGCAGC AGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCCCGGCCCCGACATGGAGCAGCCGC AACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAGCAAGCCGGGCGACGAGGACGACG CGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCACGCAGCAGCCGCCGGTCGCCGTGC CCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGCGAGCGGCGGCCCCGGCGGCCGCG CTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTCCGCCGCCGCCGCCGGGGCCCCCG GCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGGCTACAGCCGGCCCGGCGCGGGCG GCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGGAGCAGGAGGAGCAGGAGCGGGAG CTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGGCTCGTCCGCGGGGTACGGGGTGC TGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCTCAGCAAGGCGGCCGCCGGCTCGG CGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAATCAGCTGCTCACCTCGCCCAGCC CCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCCGTCGCAGCCCCAGTCCCAGGCGG CGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGGCGCCCAGTACGCCGCTGCCAGCC CGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCATGGGCAGATCCCAGGGCAGCCCAA TGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCAGCAGAGCAGTCCGTACCCAGGAG GTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCATGGCCGGAATGCAGTACCCTCAGC AGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATATTACAGCCAGCAGCCGCAGCCCC CGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGACATGTCTCAGGAAGGCTATGGAA CTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAAAGACCATCAAGTTTACCAATCA ATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAGCTTTTTGATCAGGTGGTAAAGA CTATCGGCCTCCGGGAAGTGTGGTACTTTGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTGGCTGAAGCTGGATAAGAAGGTGT CTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGCTGAGGAGCTCATCCAGG ACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGAGACTGCCGTGCTCTTGG GGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGAGCGGCTGATCCCTCAAA GAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCGTGGGATGCTCAAAGATA ATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAACAAGAAAGGAACAGACC TTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTTTCCTTGGAGTGAAATCA GGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTATGCCCCACGTCTGAGAA TCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCATCGAGGTGCAGCAGATGA AGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAGAGAAACCGTGGAGAGAG AGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAAGGCAGAGAGAGAGCTCT CGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGAGGCTGACCGTATGGCTG CACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGAGCTTGCAGAATACACTG CCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAAAGAAGCCCAGGATGACC TGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCCGGTGAGCTACCATGTCC AGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGATGACCGCAATGAGGAGA AGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCAGGCCCGAGATGAGAATA AGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCAGATCCGGCAGGGCAACA CCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGCTCATAGCGGGCGCTGCCAGCCCC GCCACGCTTGTGTCTTTAGTGCTCCAAGTCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCAGTTACCCAACAGAAACATTCTGG GCTGGGAACCAGGGAGGCGCCCTGGTTTGTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTCTCGCGATTATTCTCGAATCACCT CCTGTGTTGTGCTGGGAGCAGGACTGATTGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAACTTCATGCTGGCCTGTGTGATACA AGAGTCAGCATCATTAAAGGAAACGTGGCAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAAATGAGCTCAAATTGATTTTTTAA TTTCTATGAAGGATCCATCTTTGTATATTTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGAGTCTGAAGCACTCTCGCACACAC AGTGATTCCCTCCTCCCGTCACTCCACGCAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGTGGAGGAGGACACTTGGATTTTTT TTTTTGTTTTTTTTTTTTTTGCTTAACAGTTTTAGAATACATTGTACTTATACACCTTATTAATGATCAGCTATATACTATTTATATACA AGTGATAATACAGATTTGTAACATTAGTTTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACCTTTTACAGAATAAAAGAATTACA TATGAAAAACCCTCTAAACCATGGCACTTGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACCTGCCTGCTGCAGTCACGTGTAAA CAGGATTATTATTAGTGTTTTATGCATGTAATGGACTATGCACACTTTTAATTTTGTCAGATTCACACATGCCACTATGAGCTTTCAGAC TCCAGCTGTGAAGAGACTCTGTTTGCTTGTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTGGCAGGCTGCTGGAAGGCAGCTTG TGGAGGCCGTTGGTTCCGCCCACTCATTCCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGCCATGTGCAGGTGGATTCCATGCC GCAGACATGAAATAAAAGCTTTGCAAAGGCA >6406_6406_2_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000275248_EZR_chr6_159210403_ENST00000367075_length(amino acids)=1215AA_BP=47 MSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHAHHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQ QQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLSKPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQP PVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSASAAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSR PGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGGSSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKA AAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPPSQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQY AAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQQSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGM QYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQDMSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPS SLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYFGLHYVDNKGFPTWLKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAE ELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRG MLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKIGFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYA PRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKKRRETVEREKEQMMREKEELMLRLQDYEEKTKKA ERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLAAELAEYTAKIALLEEARRRKEDEVEEWQHRAKE AQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGIRDDRNEEKRITEAEKNERVQRQLLTLSSELSQA RDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_3_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000275248_EZR_chr6_159210403_ENST00000392177_length(transcript)=3647nt_BP=1976nt CGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAGCGCCGCCGCGCTGTCCTCCTCCT CCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGAGACGGGGCTGCTCCCCAACCACA AACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGCCCACCACCACCACCACCATGCCC ACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCAGCAACAGCAGCAGCAGCAGCAGC AGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCCCGGCCCCGACATGGAGCAGCCGC AACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAGCAAGCCGGGCGACGAGGACGACG CGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCACGCAGCAGCCGCCGGTCGCCGTGC CCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGCGAGCGGCGGCCCCGGCGGCCGCG CTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTCCGCCGCCGCCGCCGGGGCCCCCG GCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGGCTACAGCCGGCCCGGCGCGGGCG GCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGGAGCAGGAGGAGCAGGAGCGGGAG CTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGGCTCGTCCGCGGGGTACGGGGTGC TGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCTCAGCAAGGCGGCCGCCGGCTCGG CGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAATCAGCTGCTCACCTCGCCCAGCC CCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCCGTCGCAGCCCCAGTCCCAGGCGG CGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGGCGCCCAGTACGCCGCTGCCAGCC CGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCATGGGCAGATCCCAGGGCAGCCCAA TGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCAGCAGAGCAGTCCGTACCCAGGAG GTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCATGGCCGGAATGCAGTACCCTCAGC AGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATATTACAGCCAGCAGCCGCAGCCCC CGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGACATGTCTCAGGAAGGCTATGGAA CTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAAAGACCATCAAGTTTACCAATCA ATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAGCTTTTTGATCAGGTGTCTGCCC AGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGCTGAGGAGCTCATCCAGGACATCA CCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGAGACTGCCGTGCTCTTGGGGTCCT ACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGAGCGGCTGATCCCTCAAAGAGTGA TGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCGTGGGATGCTCAAAGATAATGCTA TGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAACAAGAAAGGAACAGACCTTTGGC TTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTTTCCTTGGAGTGAAATCAGGAACA TCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTATGCCCCACGTCTGAGAATCAACA AGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCATCGAGGTGCAGCAGATGAAGGCCC AGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAGAGAAACCGTGGAGAGAGAGAAAG AGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAAGGCAGAGAGAGAGCTCTCGGAGC AGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGAGGCTGACCGTATGGCTGCACTGC GGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGAGCTTGCAGAATACACTGCCAAGA TTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAAAGAAGCCCAGGATGACCTGGTGA AGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCCGGTGAGCTACCATGTCCAGGAGA GCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGATGACCGCAATGAGGAGAAGCGCA TCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCAGGCCCGAGATGAGAATAAGAGGA CCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCAGATCCGGCAGGGCAACACCAAGC AGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAA >6406_6406_3_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000275248_EZR_chr6_159210403_ENST00000392177_length(amino acids)=1183AA_BP=47 MSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHAHHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQ QQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLSKPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQP PVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSASAAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSR PGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGGSSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKA AAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPPSQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQY AAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQQSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGM QYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQDMSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPS SLPINVRVTTMDAELEFAIQPNTTGKQLFDQVSAQEVRKENPLQFKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAV LLGSYAVQAKFGDYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKG TDLWLGVDALGLNIYEKDDKLTPKIGFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQ QMKAQAREEKHQKQLERQQLETEKKRRETVEREKEQMMREKEELMLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADR MAALRAKEELERQAVDQIKSQEQLAAELAEYTAKIALLEEARRRKEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSY HVQESLQDEGAEPTGYSAELSSEGIRDDRNEEKRITEAEKNERVQRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQ GNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_4_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000346085_EZR_chr6_159210403_ENST00000337147_length(transcript)=4960nt_BP=2038nt CATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAG CGCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGA GACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGC CCACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCA GCAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCC CGGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAG CAAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCAC GCAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGC GAGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTC CGCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGG CTACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGG AGCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGG CTCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCT CAGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAA TCAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCC GTCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGG CGCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCAT GGGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCA GCAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCAT GGCCGGAATGCAGTACCCTCAGCAGCAGGACTCTGGAGATGCCACATGGAAAGAAACATTCTGGTTGATGCCACCTCAGTATGGACAGCA AGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATATTACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCT GCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGACATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGG AAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAAAGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGA GCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAGCTTTTTGATCAGGTGGTAAAGACTATCGGCCTCCGGGAAGTGTGGTACTT TGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTGGCTGAAGCTGGATAAGAAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCC CCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGCTGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCA AGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGAGACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGG GGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGAGCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAG GGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCGTGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGC TCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAACAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACT GAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTTTCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTT TGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTATGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCAT GGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCATCGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCA GAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAGAGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGA GGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAAGGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCT GGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGAGGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAG ACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGAGCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCG GAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAAAGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCT GGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCCGGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGA GCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGATGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGA GCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCAGGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAA CGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCAGATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGC CCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGCTCATAGCGGGCGCTGCCAGCCCCGCCACGCTTGTGTCTTTAGTGCTCCAAG TCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCAGTTACCCAACAGAAACATTCTGGGCTGGGAACCAGGGAGGCGCCCTGGTTT GTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTCTCGCGATTATTCTCGAATCACCTCCTGTGTTGTGCTGGGAGCAGGACTGAT TGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAACTTCATGCTGGCCTGTGTGATACAAGAGTCAGCATCATTAAAGGAAACGTGG CAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAAATGAGCTCAAATTGATTTTTTAATTTCTATGAAGGATCCATCTTTGTATAT TTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGAGTCTGAAGCACTCTCGCACACACAGTGATTCCCTCCTCCCGTCACTCCACG CAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGTGGAGGAGGACACTTGGATTTTTTTTTTTGTTTTTTTTTTTTTTGCTTAACA GTTTTAGAATACATTGTACTTATACACCTTATTAATGATCAGCTATATACTATTTATATACAAGTGATAATACAGATTTGTAACATTAGT TTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACCTTTTACAGAATAAAAGAATTACATATGAAAAACCCTCTAAACCATGGCACT TGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACCTGCCTGCTGCAGTCACGTGTAAACAGGATTATTATTAGTGTTTTATGCATG TAATGGACTATGCACACTTTTAATTTTGTCAGATTCACACATGCCACTATGAGCTTTCAGACTCCAGCTGTGAAGAGACTCTGTTTGCTT GTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTGGCAGGCTGCTGGAAGGCAGCTTGTGGAGGCCGTTGGTTCCGCCCACTCATT CCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGCCATGTGCAGGTGGATTCCATGCCGCAGACATGAAATAAAAGCTTTGCAAAG GCACGAAGCA >6406_6406_4_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000346085_EZR_chr6_159210403_ENST00000337147_length(amino acids)=1261AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQDSGDATWKETFWLMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYL PSQSQQRYQPQQDMSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYF GLHYVDNKGFPTWLKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFG DYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGL NIYEKDDKLTPKIGFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQ KQLERQQLETEKKRRETVEREKEQMMREKEELMLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELER QAVDQIKSQEQLAAELAEYTAKIALLEEARRRKEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAE PTGYSAELSSEGIRDDRNEEKRITEAEKNERVQRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEA L -------------------------------------------------------------- >6406_6406_5_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000346085_EZR_chr6_159210403_ENST00000367075_length(transcript)=4953nt_BP=2038nt CATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAG CGCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGA GACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGC CCACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCA GCAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCC CGGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAG CAAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCAC GCAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGC GAGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTC CGCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGG CTACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGG AGCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGG CTCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCT CAGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAA TCAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCC GTCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGG CGCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCAT GGGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCA GCAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCAT GGCCGGAATGCAGTACCCTCAGCAGCAGGACTCTGGAGATGCCACATGGAAAGAAACATTCTGGTTGATGCCACCTCAGTATGGACAGCA AGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATATTACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCT GCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGACATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGG AAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAAAGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGA GCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAGCTTTTTGATCAGGTGGTAAAGACTATCGGCCTCCGGGAAGTGTGGTACTT TGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTGGCTGAAGCTGGATAAGAAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCC CCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGCTGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCA AGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGAGACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGG GGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGAGCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAG GGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCGTGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGC TCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAACAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACT GAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTTTCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTT TGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTATGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCAT GGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCATCGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCA GAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAGAGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGA GGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAAGGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCT GGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGAGGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAG ACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGAGCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCG GAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAAAGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCT GGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCCGGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGA GCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGATGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGA GCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCAGGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAA CGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCAGATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGC CCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGCTCATAGCGGGCGCTGCCAGCCCCGCCACGCTTGTGTCTTTAGTGCTCCAAG TCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCAGTTACCCAACAGAAACATTCTGGGCTGGGAACCAGGGAGGCGCCCTGGTTT GTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTCTCGCGATTATTCTCGAATCACCTCCTGTGTTGTGCTGGGAGCAGGACTGAT TGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAACTTCATGCTGGCCTGTGTGATACAAGAGTCAGCATCATTAAAGGAAACGTGG CAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAAATGAGCTCAAATTGATTTTTTAATTTCTATGAAGGATCCATCTTTGTATAT TTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGAGTCTGAAGCACTCTCGCACACACAGTGATTCCCTCCTCCCGTCACTCCACG CAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGTGGAGGAGGACACTTGGATTTTTTTTTTTGTTTTTTTTTTTTTTGCTTAACA GTTTTAGAATACATTGTACTTATACACCTTATTAATGATCAGCTATATACTATTTATATACAAGTGATAATACAGATTTGTAACATTAGT TTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACCTTTTACAGAATAAAAGAATTACATATGAAAAACCCTCTAAACCATGGCACT TGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACCTGCCTGCTGCAGTCACGTGTAAACAGGATTATTATTAGTGTTTTATGCATG TAATGGACTATGCACACTTTTAATTTTGTCAGATTCACACATGCCACTATGAGCTTTCAGACTCCAGCTGTGAAGAGACTCTGTTTGCTT GTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTGGCAGGCTGCTGGAAGGCAGCTTGTGGAGGCCGTTGGTTCCGCCCACTCATT CCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGCCATGTGCAGGTGGATTCCATGCCGCAGACATGAAATAAAAGCTTTGCAAAG GCA >6406_6406_5_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000346085_EZR_chr6_159210403_ENST00000367075_length(amino acids)=1261AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQDSGDATWKETFWLMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYL PSQSQQRYQPQQDMSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYF GLHYVDNKGFPTWLKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFG DYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGL NIYEKDDKLTPKIGFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQ KQLERQQLETEKKRRETVEREKEQMMREKEELMLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELER QAVDQIKSQEQLAAELAEYTAKIALLEEARRRKEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAE PTGYSAELSSEGIRDDRNEEKRITEAEKNERVQRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEA L -------------------------------------------------------------- >6406_6406_6_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000346085_EZR_chr6_159210403_ENST00000392177_length(transcript)=3709nt_BP=2038nt CATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAG CGCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGA GACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGC CCACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCA GCAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCC CGGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAG CAAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCAC GCAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGC GAGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTC CGCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGG CTACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGG AGCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGG CTCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCT CAGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAA TCAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCC GTCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGG CGCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCAT GGGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCA GCAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCAT GGCCGGAATGCAGTACCCTCAGCAGCAGGACTCTGGAGATGCCACATGGAAAGAAACATTCTGGTTGATGCCACCTCAGTATGGACAGCA AGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATATTACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCT GCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGACATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGG AAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAAAGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGA GCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAGCTTTTTGATCAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCA GTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGCTGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCAAGTGAA GGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGAGACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTA CAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGAGCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAGGGACCA GTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCGTGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGCTCAGGA CCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAACAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACTGAATAT TTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTTTCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTTTGTCAT TAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTATGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCATGGGCAA CCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCATCGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCA GCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAGAGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTT GATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAAGGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGA GGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGAGGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGC GGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGAGCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCG CAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAAAGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCTGGTGAT GACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCCGGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCAC GGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGATGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGAGCGTGT GCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCAGGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAACGAGAA CATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCAGATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTA ACAGCCAGGCCAGGACCAA >6406_6406_6_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000346085_EZR_chr6_159210403_ENST00000392177_length(amino acids)=1229AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQDSGDATWKETFWLMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYL PSQSQQRYQPQQDMSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVSAQEVRKENPLQ FKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQ WEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKIGFPWSEIRNISFNDKKFVI KPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKKRRETVEREKEQMMREKEEL MLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLAAELAEYTAKIALLEEARRR KEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGIRDDRNEEKRITEAEKNERV QRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_7_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000350026_EZR_chr6_159210403_ENST00000337147_length(transcript)=4921nt_BP=1999nt CATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAG CGCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGA GACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGC CCACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCA GCAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCC CGGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAG CAAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCAC GCAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGC GAGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTC CGCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGG CTACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGG AGCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGG CTCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCT CAGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAA TCAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCC GTCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGG CGCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCAT GGGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCA GCAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCAT GGCCGGAATGCAGTACCCTCAGCAGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATA TTACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGA CATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGA AAGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACA GCTTTTTGATCAGGTGGTAAAGACTATCGGCCTCCGGGAAGTGTGGTACTTTGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTG GCTGAAGCTGGATAAGAAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGA TGTGGCTGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCC CCCTGAGACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAG CTCTGAGCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGA ACACCGTGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGAT AAAAAACAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGAT TGGCTTTCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGT GTTTTATGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGA CACCATCGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAA AAGGAGAGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGAC AAAGAAGGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCG CCTAGAGGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGC TGCGGAGCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAG GGCCAAAGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTA CGAGCCGGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCAT CCGGGATGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCT GTCCCAGGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCT GCGGCAGATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGC TCATAGCGGGCGCTGCCAGCCCCGCCACGCTTGTGTCTTTAGTGCTCCAAGTCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCA GTTACCCAACAGAAACATTCTGGGCTGGGAACCAGGGAGGCGCCCTGGTTTGTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTC TCGCGATTATTCTCGAATCACCTCCTGTGTTGTGCTGGGAGCAGGACTGATTGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAAC TTCATGCTGGCCTGTGTGATACAAGAGTCAGCATCATTAAAGGAAACGTGGCAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAA ATGAGCTCAAATTGATTTTTTAATTTCTATGAAGGATCCATCTTTGTATATTTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGA GTCTGAAGCACTCTCGCACACACAGTGATTCCCTCCTCCCGTCACTCCACGCAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGT GGAGGAGGACACTTGGATTTTTTTTTTTGTTTTTTTTTTTTTTGCTTAACAGTTTTAGAATACATTGTACTTATACACCTTATTAATGAT CAGCTATATACTATTTATATACAAGTGATAATACAGATTTGTAACATTAGTTTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACC TTTTACAGAATAAAAGAATTACATATGAAAAACCCTCTAAACCATGGCACTTGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACC TGCCTGCTGCAGTCACGTGTAAACAGGATTATTATTAGTGTTTTATGCATGTAATGGACTATGCACACTTTTAATTTTGTCAGATTCACA CATGCCACTATGAGCTTTCAGACTCCAGCTGTGAAGAGACTCTGTTTGCTTGTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTG GCAGGCTGCTGGAAGGCAGCTTGTGGAGGCCGTTGGTTCCGCCCACTCATTCCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGC CATGTGCAGGTGGATTCCATGCCGCAGACATGAAATAAAAGCTTTGCAAAGGCACGAAGCA >6406_6406_7_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000350026_EZR_chr6_159210403_ENST00000337147_length(amino acids)=1248AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQD MSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYFGLHYVDNKGFPTW LKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLS SERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKI GFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKK RRETVEREKEQMMREKEELMLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLA AELAEYTAKIALLEEARRRKEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGI RDDRNEEKRITEAEKNERVQRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_8_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000350026_EZR_chr6_159210403_ENST00000367075_length(transcript)=4914nt_BP=1999nt CATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAG CGCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGA GACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGC CCACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCA GCAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCC CGGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAG CAAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCAC GCAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGC GAGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTC CGCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGG CTACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGG AGCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGG CTCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCT CAGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAA TCAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCC GTCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGG CGCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCAT GGGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCA GCAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCAT GGCCGGAATGCAGTACCCTCAGCAGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATA TTACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGA CATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGA AAGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACA GCTTTTTGATCAGGTGGTAAAGACTATCGGCCTCCGGGAAGTGTGGTACTTTGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTG GCTGAAGCTGGATAAGAAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGA TGTGGCTGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCC CCCTGAGACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAG CTCTGAGCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGA ACACCGTGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGAT AAAAAACAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGAT TGGCTTTCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGT GTTTTATGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGA CACCATCGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAA AAGGAGAGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGAC AAAGAAGGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCG CCTAGAGGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGC TGCGGAGCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAG GGCCAAAGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTA CGAGCCGGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCAT CCGGGATGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCT GTCCCAGGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCT GCGGCAGATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGC TCATAGCGGGCGCTGCCAGCCCCGCCACGCTTGTGTCTTTAGTGCTCCAAGTCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCA GTTACCCAACAGAAACATTCTGGGCTGGGAACCAGGGAGGCGCCCTGGTTTGTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTC TCGCGATTATTCTCGAATCACCTCCTGTGTTGTGCTGGGAGCAGGACTGATTGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAAC TTCATGCTGGCCTGTGTGATACAAGAGTCAGCATCATTAAAGGAAACGTGGCAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAA ATGAGCTCAAATTGATTTTTTAATTTCTATGAAGGATCCATCTTTGTATATTTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGA GTCTGAAGCACTCTCGCACACACAGTGATTCCCTCCTCCCGTCACTCCACGCAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGT GGAGGAGGACACTTGGATTTTTTTTTTTGTTTTTTTTTTTTTTGCTTAACAGTTTTAGAATACATTGTACTTATACACCTTATTAATGAT CAGCTATATACTATTTATATACAAGTGATAATACAGATTTGTAACATTAGTTTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACC TTTTACAGAATAAAAGAATTACATATGAAAAACCCTCTAAACCATGGCACTTGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACC TGCCTGCTGCAGTCACGTGTAAACAGGATTATTATTAGTGTTTTATGCATGTAATGGACTATGCACACTTTTAATTTTGTCAGATTCACA CATGCCACTATGAGCTTTCAGACTCCAGCTGTGAAGAGACTCTGTTTGCTTGTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTG GCAGGCTGCTGGAAGGCAGCTTGTGGAGGCCGTTGGTTCCGCCCACTCATTCCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGC CATGTGCAGGTGGATTCCATGCCGCAGACATGAAATAAAAGCTTTGCAAAGGCA >6406_6406_8_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000350026_EZR_chr6_159210403_ENST00000367075_length(amino acids)=1248AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQD MSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYFGLHYVDNKGFPTW LKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLS SERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKI GFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKK RRETVEREKEQMMREKEELMLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLA AELAEYTAKIALLEEARRRKEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGI RDDRNEEKRITEAEKNERVQRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_9_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000350026_EZR_chr6_159210403_ENST00000392177_length(transcript)=3670nt_BP=1999nt CATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAG CGCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGA GACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGC CCACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCA GCAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCC CGGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAG CAAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCAC GCAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGC GAGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTC CGCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGG CTACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGG AGCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGG CTCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCT CAGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAA TCAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCC GTCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGG CGCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCAT GGGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCA GCAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCAT GGCCGGAATGCAGTACCCTCAGCAGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATA TTACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGA CATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGA AAGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACA GCTTTTTGATCAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGC TGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGA GACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGA GCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCG TGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAA CAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTT TCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTA TGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCAT CGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAG AGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAA GGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGA GGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGA GCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAA AGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCC GGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGA TGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCA GGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCA GATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAA >6406_6406_9_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000350026_EZR_chr6_159210403_ENST00000392177_length(amino acids)=1216AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQD MSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVSAQEVRKENPLQFKFRAKFYPEDVA EELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQWEDRIQVWHAEHR GMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKIGFPWSEIRNISFNDKKFVIKPIDKKAPDFVFY APRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKKRRETVEREKEQMMREKEELMLRLQDYEEKTKK AERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLAAELAEYTAKIALLEEARRRKEDEVEEWQHRAK EAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGIRDDRNEEKRITEAEKNERVQRQLLTLSSELSQ ARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_10_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000367148_EZR_chr6_159210403_ENST00000337147_length(transcript)=4920nt_BP=1998nt ATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAGC GCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGAG ACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGCC CACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCAG CAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCCC GGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAGC AAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCACG CAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGCG AGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTCC GCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGGC TACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGGA GCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGGC TCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCTC AGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAAT CAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCCG TCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGGC GCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCATG GGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCAG CAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCATG GCCGGAATGCAGTACCCTCAGCAGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATAT TACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGAC ATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAA AGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAG CTTTTTGATCAGGTGGTAAAGACTATCGGCCTCCGGGAAGTGTGGTACTTTGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTGG CTGAAGCTGGATAAGAAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGAT GTGGCTGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCC CCTGAGACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGC TCTGAGCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAA CACCGTGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATA AAAAACAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATT GGCTTTCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTG TTTTATGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGAC ACCATCGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAA AGGAGAGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACA AAGAAGGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGC CTAGAGGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCT GCGGAGCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGG GCCAAAGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTAC GAGCCGGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATC CGGGATGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTG TCCCAGGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTG CGGCAGATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGCT CATAGCGGGCGCTGCCAGCCCCGCCACGCTTGTGTCTTTAGTGCTCCAAGTCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCAG TTACCCAACAGAAACATTCTGGGCTGGGAACCAGGGAGGCGCCCTGGTTTGTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTCT CGCGATTATTCTCGAATCACCTCCTGTGTTGTGCTGGGAGCAGGACTGATTGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAACT TCATGCTGGCCTGTGTGATACAAGAGTCAGCATCATTAAAGGAAACGTGGCAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAAA TGAGCTCAAATTGATTTTTTAATTTCTATGAAGGATCCATCTTTGTATATTTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGAG TCTGAAGCACTCTCGCACACACAGTGATTCCCTCCTCCCGTCACTCCACGCAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGTG GAGGAGGACACTTGGATTTTTTTTTTTGTTTTTTTTTTTTTTGCTTAACAGTTTTAGAATACATTGTACTTATACACCTTATTAATGATC AGCTATATACTATTTATATACAAGTGATAATACAGATTTGTAACATTAGTTTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACCT TTTACAGAATAAAAGAATTACATATGAAAAACCCTCTAAACCATGGCACTTGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACCT GCCTGCTGCAGTCACGTGTAAACAGGATTATTATTAGTGTTTTATGCATGTAATGGACTATGCACACTTTTAATTTTGTCAGATTCACAC ATGCCACTATGAGCTTTCAGACTCCAGCTGTGAAGAGACTCTGTTTGCTTGTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTGG CAGGCTGCTGGAAGGCAGCTTGTGGAGGCCGTTGGTTCCGCCCACTCATTCCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGCC ATGTGCAGGTGGATTCCATGCCGCAGACATGAAATAAAAGCTTTGCAAAGGCACGAAGCA >6406_6406_10_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000367148_EZR_chr6_159210403_ENST00000337147_length(amino acids)=1248AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQD MSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYFGLHYVDNKGFPTW LKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLS SERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKI GFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKK RRETVEREKEQMMREKEELMLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLA AELAEYTAKIALLEEARRRKEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGI RDDRNEEKRITEAEKNERVQRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_11_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000367148_EZR_chr6_159210403_ENST00000367075_length(transcript)=4913nt_BP=1998nt ATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAGC GCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGAG ACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGCC CACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCAG CAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCCC GGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAGC AAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCACG CAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGCG AGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTCC GCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGGC TACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGGA GCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGGC TCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCTC AGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAAT CAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCCG TCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGGC GCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCATG GGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCAG CAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCATG GCCGGAATGCAGTACCCTCAGCAGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATAT TACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGAC ATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAA AGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAG CTTTTTGATCAGGTGGTAAAGACTATCGGCCTCCGGGAAGTGTGGTACTTTGGCCTCCACTATGTGGATAATAAAGGATTTCCTACCTGG CTGAAGCTGGATAAGAAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGAT GTGGCTGAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCC CCTGAGACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGC TCTGAGCGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAA CACCGTGGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATA AAAAACAAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATT GGCTTTCCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTG TTTTATGCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGAC ACCATCGAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAA AGGAGAGAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACA AAGAAGGCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGC CTAGAGGCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCT GCGGAGCTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGG GCCAAAGAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTAC GAGCCGGTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATC CGGGATGACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTG TCCCAGGCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTG CGGCAGATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAAGGGCAGAGGGGTGCT CATAGCGGGCGCTGCCAGCCCCGCCACGCTTGTGTCTTTAGTGCTCCAAGTCTAGGAACTCCCTCAGATCCCAGTTCCTTTAGAAAGCAG TTACCCAACAGAAACATTCTGGGCTGGGAACCAGGGAGGCGCCCTGGTTTGTTTTCCCCAGTTGTAATAGTGCCAAGCAGGCCTGATTCT CGCGATTATTCTCGAATCACCTCCTGTGTTGTGCTGGGAGCAGGACTGATTGAATTACGGAAAATGCCTGTAAAGTCTGAGTAAGAAACT TCATGCTGGCCTGTGTGATACAAGAGTCAGCATCATTAAAGGAAACGTGGCAGGACTTCCATCTGTGCCATACTTGTTCTGTATTCGAAA TGAGCTCAAATTGATTTTTTAATTTCTATGAAGGATCCATCTTTGTATATTTACATGCTTAGAGGGGTGAAAATTATTTTGGAAATTGAG TCTGAAGCACTCTCGCACACACAGTGATTCCCTCCTCCCGTCACTCCACGCAGCTGGCAGAGAGCACAGTGATCACCAGCGTGAGTGGTG GAGGAGGACACTTGGATTTTTTTTTTTGTTTTTTTTTTTTTTGCTTAACAGTTTTAGAATACATTGTACTTATACACCTTATTAATGATC AGCTATATACTATTTATATACAAGTGATAATACAGATTTGTAACATTAGTTTTAAAAAGGGAAAGTTTTGTTCTGTATATTTTGTTACCT TTTACAGAATAAAAGAATTACATATGAAAAACCCTCTAAACCATGGCACTTGATGTGATGTGGCAGGAGGGCAGTGGTGGAGCTGGACCT GCCTGCTGCAGTCACGTGTAAACAGGATTATTATTAGTGTTTTATGCATGTAATGGACTATGCACACTTTTAATTTTGTCAGATTCACAC ATGCCACTATGAGCTTTCAGACTCCAGCTGTGAAGAGACTCTGTTTGCTTGTGTTTGTTTGTTTGCAGTCTCTCTCTGCCATGGCCTTGG CAGGCTGCTGGAAGGCAGCTTGTGGAGGCCGTTGGTTCCGCCCACTCATTCCTTCTCGTGCACTGCTTTCTCCTTCACAGCTAAGATGCC ATGTGCAGGTGGATTCCATGCCGCAGACATGAAATAAAAGCTTTGCAAAGGCA >6406_6406_11_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000367148_EZR_chr6_159210403_ENST00000367075_length(amino acids)=1248AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQD MSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVVKTIGLREVWYFGLHYVDNKGFPTW LKLDKKVSAQEVRKENPLQFKFRAKFYPEDVAEELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLS SERLIPQRVMDQHKLTRDQWEDRIQVWHAEHRGMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKI GFPWSEIRNISFNDKKFVIKPIDKKAPDFVFYAPRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKK RRETVEREKEQMMREKEELMLRLQDYEEKTKKAERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLA AELAEYTAKIALLEEARRRKEDEVEEWQHRAKEAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGI RDDRNEEKRITEAEKNERVQRQLLTLSSELSQARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- >6406_6406_12_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000367148_EZR_chr6_159210403_ENST00000392177_length(transcript)=3669nt_BP=1998nt ATGGCCCATAACGCGGGCGCCGCGGCCGCCGCCGGCACCCACAGCGCCAAGAGCGGCGGCTCCGAGGCGGCTCTCAAGGAGGGTGGAAGC GCCGCCGCGCTGTCCTCCTCCTCCTCCTCCTCCGCGGCGGCAGCGGCGGCATCCTCTTCCTCCTCGTCGGGCCCGGGCTCGGCCATGGAG ACGGGGCTGCTCCCCAACCACAAACTGAAAACCGTTGGCGAAGCCCCCGCCGCGCCGCCCCACCAGCAGCACCACCACCACCACCATGCC CACCACCACCACCACCATGCCCACCACCTCCACCACCACCACGCACTACAGCAGCAGCTAAACCAGTTCCAGCAGCAGCAGCAGCAGCAG CAACAGCAGCAGCAGCAGCAGCAGCAACAGCAACATCCCATTTCCAACAACAACAGCTTGGGCGGCGCGGGCGGCGGCGCGCCTCAGCCC GGCCCCGACATGGAGCAGCCGCAACATGGAGGCGCCAAGGACAGTGCTGCGGGCGGCCAGGCCGACCCCCCGGGCCCGCCGCTGCTGAGC AAGCCGGGCGACGAGGACGACGCGCCGCCCAAGATGGGGGAGCCGGCGGGCGGCCGCTACGAGCACCCGGGCTTGGGCGCCCTGGGCACG CAGCAGCCGCCGGTCGCCGTGCCCGGGGGCGGCGGCGGCCCGGCGGCCGTCCCGGAGTTTAATAATTACTATGGCAGCGCTGCCCCTGCG AGCGGCGGCCCCGGCGGCCGCGCTGGGCCTTGCTTTGATCAACATGGCGGACAACAAAGCCCCGGGATGGGGATGATGCACTCCGCCTCC GCCGCCGCCGCCGGGGCCCCCGGCAGCATGGACCCCCTGCAGAACTCCCACGAAGGGTACCCCAACAGCCAGTGCAACCATTATCCGGGC TACAGCCGGCCCGGCGCGGGCGGCGGCGGCGGCGGCGGCGGCGGAGGAGGAGGAGGCAGCGGAGGAGGAGGAGGAGGAGGAGGAGCAGGA GCAGGAGGAGCAGGAGCGGGAGCTGTGGCGGCGGCGGCCGCGGCGGCGGCGGCAGCAGCAGGAGGCGGCGGCGGCGGCGGCTATGGGGGC TCGTCCGCGGGGTACGGGGTGCTGAGCTCCCCCCGGCAGCAGGGCGGCGGCATGATGATGGGCCCCGGGGGCGGCGGGGCCGCGAGCCTC AGCAAGGCGGCCGCCGGCTCGGCGGCGGGGGGCTTCCAGCGCTTCGCCGGCCAGAACCAGCACCCGTCGGGGGCCACCCCGACCCTCAAT CAGCTGCTCACCTCGCCCAGCCCCATGATGCGGAGCTACGGCGGCAGCTACCCCGAGTACAGCAGCCCCAGCGCGCCGCCGCCGCCGCCG TCGCAGCCCCAGTCCCAGGCGGCGGCGGCGGGGGCGGCGGCGGGCGGCCAGCAGGCGGCCGCGGGCATGGGCTTGGGCAAGGACATGGGC GCCCAGTACGCCGCTGCCAGCCCGGCCTGGGCGGCCGCGCAACAAAGGAGTCACCCGGCGATGAGCCCCGGCACCCCCGGACCGACCATG GGCAGATCCCAGGGCAGCCCAATGGATCCAATGGTGATGAAGAGACCTCAGTTGTATGGCATGGGCAGTAACCCTCATTCTCAGCCTCAG CAGAGCAGTCCGTACCCAGGAGGTTCCTATGGCCCTCCAGGCCCACAGCGGTATCCAATTGGCATCCAGGGTCGGACTCCCGGGGCCATG GCCGGAATGCAGTACCCTCAGCAGCAGATGCCACCTCAGTATGGACAGCAAGGTGTGAGTGGTTACTGCCAGCAGGGCCAACAGCCATAT TACAGCCAGCAGCCGCAGCCCCCGCACCTCCCACCCCAGGCGCAGTATCTGCCGTCCCAGTCCCAGCAGAGGTACCAGCCGCAGCAGGAC ATGTCTCAGGAAGGCTATGGAACTAGATCTCAACCTCCTCTGGCCCCCGGAAAACCTAACCATGAAGACTTGAACTTAATACAGCAAGAA AGACCATCAAGTTTACCAATCAATGTCCGAGTTACCACCATGGATGCAGAGCTGGAGTTTGCAATCCAGCCAAATACAACTGGAAAACAG CTTTTTGATCAGGTGTCTGCCCAGGAGGTCAGGAAGGAGAATCCCCTCCAGTTCAAGTTCCGGGCCAAGTTCTACCCTGAAGATGTGGCT GAGGAGCTCATCCAGGACATCACCCAGAAACTTTTCTTCCTCCAAGTGAAGGAAGGAATCCTTAGCGATGAGATCTACTGCCCCCCTGAG ACTGCCGTGCTCTTGGGGTCCTACGCTGTGCAGGCCAAGTTTGGGGACTACAACAAAGAAGTGCACAAGTCTGGGTACCTCAGCTCTGAG CGGCTGATCCCTCAAAGAGTGATGGACCAGCACAAACTTACCAGGGACCAGTGGGAGGACCGGATCCAGGTGTGGCATGCGGAACACCGT GGGATGCTCAAAGATAATGCTATGTTGGAATACCTGAAGATTGCTCAGGACCTGGAAATGTATGGAATCAACTATTTCGAGATAAAAAAC AAGAAAGGAACAGACCTTTGGCTTGGAGTTGATGCCCTTGGACTGAATATTTATGAGAAAGATGATAAGTTAACCCCAAAGATTGGCTTT CCTTGGAGTGAAATCAGGAACATCTCTTTCAATGACAAAAAGTTTGTCATTAAACCCATCGACAAGAAGGCACCTGACTTTGTGTTTTAT GCCCCACGTCTGAGAATCAACAAGCGGATCCTGCAGCTCTGCATGGGCAACCATGAGTTGTATATGCGCCGCAGGAAGCCTGACACCATC GAGGTGCAGCAGATGAAGGCCCAGGCCCGGGAGGAGAAGCATCAGAAGCAGCTGGAGCGGCAACAGCTGGAAACAGAGAAGAAAAGGAGA GAAACCGTGGAGAGAGAGAAAGAGCAGATGATGCGCGAGAAGGAGGAGTTGATGCTGCGGCTGCAGGACTATGAGGAGAAGACAAAGAAG GCAGAGAGAGAGCTCTCGGAGCAGATTCAGAGGGCCCTGCAGCTGGAGGAGGAGAGGAAGCGGGCACAGGAGGAGGCCGAGCGCCTAGAG GCTGACCGTATGGCTGCACTGCGGGCTAAGGAGGAGCTGGAGAGACAGGCGGTGGATCAGATAAAGAGCCAGGAGCAGCTGGCTGCGGAG CTTGCAGAATACACTGCCAAGATTGCCCTCCTGGAAGAGGCGCGGAGGCGCAAGGAGGATGAAGTTGAAGAGTGGCAGCACAGGGCCAAA GAAGCCCAGGATGACCTGGTGAAGACCAAGGAGGAGCTGCACCTGGTGATGACAGCACCCCCGCCCCCACCACCCCCCGTGTACGAGCCG GTGAGCTACCATGTCCAGGAGAGCTTGCAGGATGAGGGCGCAGAGCCCACGGGCTACAGCGCGGAGCTGTCTAGTGAGGGCATCCGGGAT GACCGCAATGAGGAGAAGCGCATCACTGAGGCAGAGAAGAACGAGCGTGTGCAGCGGCAGCTGCTGACGCTGAGCAGCGAGCTGTCCCAG GCCCGAGATGAGAATAAGAGGACCCACAATGACATCATCCACAACGAGAACATGAGGCAAGGCCGGGACAAGTACAAGACGCTGCGGCAG ATCCGGCAGGGCAACACCAAGCAGCGCATCGACGAGTTCGAGGCCCTGTAACAGCCAGGCCAGGACCAA >6406_6406_12_ARID1B-EZR_ARID1B_chr6_157256710_ENST00000367148_EZR_chr6_159210403_ENST00000392177_length(amino acids)=1216AA_BP=80 MAHNAGAAAAAGTHSAKSGGSEAALKEGGSAAALSSSSSSSAAAAAASSSSSSGPGSAMETGLLPNHKLKTVGEAPAAPPHQQHHHHHHA HHHHHHAHHLHHHHALQQQLNQFQQQQQQQQQQQQQQQQQQHPISNNNSLGGAGGGAPQPGPDMEQPQHGGAKDSAAGGQADPPGPPLLS KPGDEDDAPPKMGEPAGGRYEHPGLGALGTQQPPVAVPGGGGGPAAVPEFNNYYGSAAPASGGPGGRAGPCFDQHGGQQSPGMGMMHSAS AAAAGAPGSMDPLQNSHEGYPNSQCNHYPGYSRPGAGGGGGGGGGGGGGSGGGGGGGGAGAGGAGAGAVAAAAAAAAAAAGGGGGGGYGG SSAGYGVLSSPRQQGGGMMMGPGGGGAASLSKAAAGSAAGGFQRFAGQNQHPSGATPTLNQLLTSPSPMMRSYGGSYPEYSSPSAPPPPP SQPQSQAAAAGAAAGGQQAAAGMGLGKDMGAQYAAASPAWAAAQQRSHPAMSPGTPGPTMGRSQGSPMDPMVMKRPQLYGMGSNPHSQPQ QSSPYPGGSYGPPGPQRYPIGIQGRTPGAMAGMQYPQQQMPPQYGQQGVSGYCQQGQQPYYSQQPQPPHLPPQAQYLPSQSQQRYQPQQD MSQEGYGTRSQPPLAPGKPNHEDLNLIQQERPSSLPINVRVTTMDAELEFAIQPNTTGKQLFDQVSAQEVRKENPLQFKFRAKFYPEDVA EELIQDITQKLFFLQVKEGILSDEIYCPPETAVLLGSYAVQAKFGDYNKEVHKSGYLSSERLIPQRVMDQHKLTRDQWEDRIQVWHAEHR GMLKDNAMLEYLKIAQDLEMYGINYFEIKNKKGTDLWLGVDALGLNIYEKDDKLTPKIGFPWSEIRNISFNDKKFVIKPIDKKAPDFVFY APRLRINKRILQLCMGNHELYMRRRKPDTIEVQQMKAQAREEKHQKQLERQQLETEKKRRETVEREKEQMMREKEELMLRLQDYEEKTKK AERELSEQIQRALQLEEERKRAQEEAERLEADRMAALRAKEELERQAVDQIKSQEQLAAELAEYTAKIALLEEARRRKEDEVEEWQHRAK EAQDDLVKTKEELHLVMTAPPPPPPPVYEPVSYHVQESLQDEGAEPTGYSAELSSEGIRDDRNEEKRITEAEKNERVQRQLLTLSSELSQ ARDENKRTHNDIIHNENMRQGRDKYKTLRQIRQGNTKQRIDEFEAL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARID1B-EZR |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Tgene | EZR | chr6:157256710 | chr6:159210403 | ENST00000337147 | 0 | 13 | 244_586 | 4.0 | 587.0 | SCYL3 | |
| Tgene | EZR | chr6:157256710 | chr6:159210403 | ENST00000367075 | 1 | 14 | 244_586 | 4.0 | 587.0 | SCYL3 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARID1B-EZR |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARID1B-EZR |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ARID1B | C0265338 | Coffin-Siris syndrome | 7 | CLINGEN;CTD_human;GENOMICS_ENGLAND |
| Hgene | ARID1B | C1535926 | Neurodevelopmental Disorders | 2 | CTD_human |
| Hgene | ARID1B | C3281201 | MENTAL RETARDATION, AUTOSOMAL DOMINANT 12 | 2 | GENOMICS_ENGLAND |
| Hgene | ARID1B | C0014544 | Epilepsy | 1 | CTD_human |
| Hgene | ARID1B | C0019569 | Hirschsprung Disease | 1 | GENOMICS_ENGLAND |
| Hgene | ARID1B | C0027819 | Neuroblastoma | 1 | CTD_human |
| Hgene | ARID1B | C0086237 | Epilepsy, Cryptogenic | 1 | CTD_human |
| Hgene | ARID1B | C0236018 | Aura | 1 | CTD_human |
| Hgene | ARID1B | C0751111 | Awakening Epilepsy | 1 | CTD_human |
| Hgene | ARID1B | C2239176 | Liver carcinoma | 1 | CGI;CTD_human |
| Hgene | ARID1B | C3150215 | CHROMOSOME 6q24-q25 DELETION SYNDROME | 1 | ORPHANET |
| Tgene | C0033578 | Prostatic Neoplasms | 3 | CTD_human | |
| Tgene | C0376358 | Malignant neoplasm of prostate | 3 | CTD_human | |
| Tgene | C0007097 | Carcinoma | 1 | CTD_human | |
| Tgene | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human | |
| Tgene | C0024667 | Animal Mammary Neoplasms | 1 | CTD_human | |
| Tgene | C0024668 | Mammary Neoplasms, Experimental | 1 | CTD_human | |
| Tgene | C0027627 | Neoplasm Metastasis | 1 | CTD_human | |
| Tgene | C0029408 | Degenerative polyarthritis | 1 | CTD_human | |
| Tgene | C0086743 | Osteoarthrosis Deformans | 1 | CTD_human | |
| Tgene | C0205696 | Anaplastic carcinoma | 1 | CTD_human | |
| Tgene | C0205697 | Carcinoma, Spindle-Cell | 1 | CTD_human | |
| Tgene | C0205698 | Undifferentiated carcinoma | 1 | CTD_human | |
| Tgene | C0205699 | Carcinomatosis | 1 | CTD_human | |
| Tgene | C1257925 | Mammary Carcinoma, Animal | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies