
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:BICD1-NAPB (FusionGDB2 ID:HG636TG63908) |
Fusion Gene Summary for BICD1-NAPB |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: BICD1-NAPB | Fusion gene ID: hg636tg63908 | Hgene | Tgene | Gene symbol | BICD1 | NAPB | Gene ID | 636 | 63908 |
| Gene name | BICD cargo adaptor 1 | NSF attachment protein beta | |
| Synonyms | BICD|bic-D 1 | SNAP-BETA|SNAPB | |
| Cytomap | ('BICD1')('NAPB') 12p11.21 | 20p11.21 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein bicaudal D homolog 1bicaudal D homolog 1cytoskeleton-like bicaudal D protein homolog 1 | beta-soluble NSF attachment proteinN-ethylmaleimide-sensitive factor attachment protein, beta | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | Q96G01 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000281474, ENST00000548411, ENST00000550207, ENST00000551086, ENST00000551848, | ||
| Fusion gene scores | * DoF score | 22 X 18 X 10=3960 | 4 X 3 X 3=36 |
| # samples | 25 | 4 | |
| ** MAII score | log2(25/3960*10)=-3.98550043030488 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: BICD1 [Title/Abstract] AND NAPB [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | BICD1(32260478)-NAPB(23361954), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | BICD1-NAPB seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | BICD1 | GO:0033365 | protein localization to organelle | 12447383|20089649 |
| Fusion gene breakpoints across BICD1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NAPB (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-55-8094-01A | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
Top |
Fusion Gene ORF analysis for BICD1-NAPB |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000281474 | ENST00000472855 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| 5CDS-5UTR | ENST00000548411 | ENST00000472855 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| 5CDS-5UTR | ENST00000550207 | ENST00000472855 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| 5CDS-5UTR | ENST00000551086 | ENST00000472855 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| 5CDS-5UTR | ENST00000551848 | ENST00000472855 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| Frame-shift | ENST00000551848 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| Frame-shift | ENST00000551848 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| Frame-shift | ENST00000551848 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000281474 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000281474 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000281474 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000548411 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000548411 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000548411 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000550207 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000550207 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000550207 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000551086 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000551086 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| In-frame | ENST00000551086 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000548411 | BICD1 | chr12 | 32260478 | + | ENST00000377026 | NAPB | chr20 | 23361954 | - | 3584 | 394 | 160 | 729 | 189 |
| ENST00000548411 | BICD1 | chr12 | 32260478 | + | ENST00000398425 | NAPB | chr20 | 23361954 | - | 3577 | 394 | 160 | 729 | 189 |
| ENST00000548411 | BICD1 | chr12 | 32260478 | + | ENST00000432543 | NAPB | chr20 | 23361954 | - | 1245 | 394 | 160 | 729 | 189 |
| ENST00000281474 | BICD1 | chr12 | 32260478 | + | ENST00000377026 | NAPB | chr20 | 23361954 | - | 3506 | 316 | 82 | 651 | 189 |
| ENST00000281474 | BICD1 | chr12 | 32260478 | + | ENST00000398425 | NAPB | chr20 | 23361954 | - | 3499 | 316 | 82 | 651 | 189 |
| ENST00000281474 | BICD1 | chr12 | 32260478 | + | ENST00000432543 | NAPB | chr20 | 23361954 | - | 1167 | 316 | 82 | 651 | 189 |
| ENST00000550207 | BICD1 | chr12 | 32260478 | + | ENST00000377026 | NAPB | chr20 | 23361954 | - | 3850 | 660 | 222 | 995 | 257 |
| ENST00000550207 | BICD1 | chr12 | 32260478 | + | ENST00000398425 | NAPB | chr20 | 23361954 | - | 3843 | 660 | 222 | 995 | 257 |
| ENST00000550207 | BICD1 | chr12 | 32260478 | + | ENST00000432543 | NAPB | chr20 | 23361954 | - | 1511 | 660 | 222 | 995 | 257 |
| ENST00000551086 | BICD1 | chr12 | 32260478 | + | ENST00000377026 | NAPB | chr20 | 23361954 | - | 3439 | 249 | 15 | 584 | 189 |
| ENST00000551086 | BICD1 | chr12 | 32260478 | + | ENST00000398425 | NAPB | chr20 | 23361954 | - | 3432 | 249 | 15 | 584 | 189 |
| ENST00000551086 | BICD1 | chr12 | 32260478 | + | ENST00000432543 | NAPB | chr20 | 23361954 | - | 1100 | 249 | 15 | 584 | 189 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000548411 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000318529 | 0.9996815 |
| ENST00000548411 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000602998 | 0.99939704 |
| ENST00000548411 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000531853 | 0.99946815 |
| ENST00000281474 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000338348 | 0.9996617 |
| ENST00000281474 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000640954 | 0.9993591 |
| ENST00000281474 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.00072139 | 0.9992786 |
| ENST00000550207 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000313526 | 0.9996865 |
| ENST00000550207 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000592425 | 0.99940753 |
| ENST00000550207 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000718508 | 0.99928147 |
| ENST00000551086 | ENST00000377026 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000348125 | 0.9996519 |
| ENST00000551086 | ENST00000398425 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000657978 | 0.999342 |
| ENST00000551086 | ENST00000432543 | BICD1 | chr12 | 32260478 | + | NAPB | chr20 | 23361954 | - | 0.000642862 | 0.99935716 |
Top |
Fusion Genomic Features for BICD1-NAPB |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
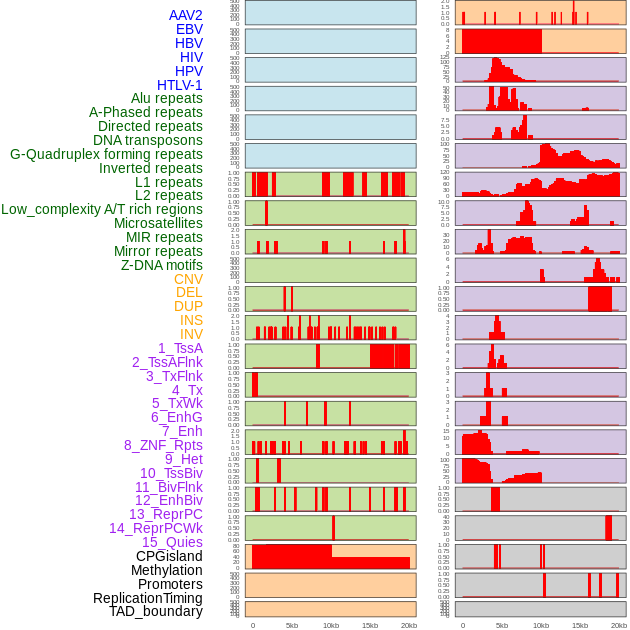 |
Top |
Fusion Protein Features for BICD1-NAPB |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:32260478/chr20:23361954) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| BICD1 | . |
| FUNCTION: Regulates coat complex coatomer protein I (COPI)-independent Golgi-endoplasmic reticulum transport by recruiting the dynein-dynactin motor complex. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000281474 | + | 1 | 10 | 1_265 | 71 | 976.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000281474 | + | 1 | 10 | 319_496 | 71 | 976.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000281474 | + | 1 | 10 | 663_803 | 71 | 976.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000548411 | + | 1 | 9 | 1_265 | 71 | 2736.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000548411 | + | 1 | 9 | 319_496 | 71 | 2736.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000548411 | + | 1 | 9 | 663_803 | 71 | 2736.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000551848 | + | 1 | 1 | 1_265 | 0 | 94.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000551848 | + | 1 | 1 | 319_496 | 0 | 94.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | BICD1 | chr12:32260478 | chr20:23361954 | ENST00000551848 | + | 1 | 1 | 663_803 | 0 | 94.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for BICD1-NAPB |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >9694_9694_1_BICD1-NAPB_BICD1_chr12_32260478_ENST00000281474_NAPB_chr20_23361954_ENST00000377026_length(transcript)=3506nt_BP=316nt CCGTTTCCACCCATCCCTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCC ATCCACCGGGGCTATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGA GACCACCCACGAGAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGA GGCTGAGTACGACAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGC AAAGGATTACTTCTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTT TCCAGCATTTACTGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGC AGTGAAGGAATTTGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGA AGGAGATGGAGACCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTA TGGGATGCCTATTTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAA ATGAATGAAGGAGAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTT CAGAATCTCATTCCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAG TACTCAGCCCAGTTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGA CAGTTACTAGGAATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAGTTT CTTTGCTTTTTGTGTTGTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTGTAGGCATCACATTGTGAGGAAGG GAGCTTTCTGGAAGTACTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGACACACGCGTTTACACACACACACA TATCACAAGATCTGTTAGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGAGTGGAAATCCCTTTATATTTACA TTGAAGTATTTTAATTGGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGTGGTGTGTTCTGTGCTGTGACTAT AGAAATCTTGGTCAGGGCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCCTGTTTATTGTACATGATGGGTTA GGTGGGGTGAATGTGGTACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTCAGGGGACTTGATTGTTCTCTTAG CTGGTGGAATATGTTGGCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTATGCTATCTTGATTCATGAACTTG ATCCTATTAATTTATATGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAATATTTATAGTTAAATGATTTATAT TTGAAATGTGTTGCCAGACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGTAACGAAACTTCCTATGTTATGTC AGGTAGTAGTAAGTAGTATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTGTTTCCAGGCCAAGGGTCGACTGC AGGTTGTTTGAGAAATGATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGGGAAGGGCCAGCCAAGGACAGACT GTAGAGGATCCACATCAGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAGGTGGGCTGGTAGAGCAGGAAGCT CTGTGATGTCAGAGCATCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATGAAGACACTCTGTCTGTTGGGCCC TAGAATTTAATGTGGATTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCTTCTAGAGGTAAGACCTGGAATGG AGTCCAGTTGGTACTTTTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTGGGGTTTTGTTTCCCCACCTAATA ATATATCCTACAACCAGCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTGAGTCCTCTGGTTTTAAGTAGTTT GTTTCTACTTGTTTAAAGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCGGGCAATTATGTTTAGCTTTCATC ATTATACTCCAACAGACCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTTGTGTCAATTAGAGGGTCACTTGT TTGTATTGCAATAAACACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCACATGAAAAGAATCAAAGTAATTGT AATGGCTAGAAGAGACCTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTGCAAACTTACTTCCTTTAAATGTC CCATGGATGTAGGACAGTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATGTTACTTATGAACAAAATATAATT ATTTATGGTACAATTCTTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATTTCTTAGAGGAAAGTTTTGCTTTT TGTGGCAACATTTTTATAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGCACAGTCGTGACCGTGTGTGGTGG CGTCACTGTAACCAAAGTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATTTAAATGTCCAAATGCAAACCTTT GTGACTTCCTTTGGAGGACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTATGACCAAGAGCAGGCTTCCTGCT CCATGGAGTCCTGAGTTGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAAATCTACCTTAGCAGAAAAA >9694_9694_1_BICD1-NAPB_BICD1_chr12_32260478_ENST00000281474_NAPB_chr20_23361954_ENST00000377026_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_2_BICD1-NAPB_BICD1_chr12_32260478_ENST00000281474_NAPB_chr20_23361954_ENST00000398425_length(transcript)=3499nt_BP=316nt CCGTTTCCACCCATCCCTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCC ATCCACCGGGGCTATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGA GACCACCCACGAGAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGA GGCTGAGTACGACAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGC AAAGGATTACTTCTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTT TCCAGCATTTACTGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGC AGTGAAGGAATTTGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGA AGGAGATGGAGACCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTA TGGGATGCCTATTTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAA ATGAATGAAGGAGAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTT CAGAATCTCATTCCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAG TACTCAGCCCAGTTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGA CAGTTACTAGGAATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAGTTT CTTTGCTTTTTGTGTTGTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTGTAGGCATCACATTGTGAGGAAGG GAGCTTTCTGGAAGTACTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGACACACGCGTTTACACACACACACA TATCACAAGATCTGTTAGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGAGTGGAAATCCCTTTATATTTACA TTGAAGTATTTTAATTGGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGTGGTGTGTTCTGTGCTGTGACTAT AGAAATCTTGGTCAGGGCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCCTGTTTATTGTACATGATGGGTTA GGTGGGGTGAATGTGGTACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTCAGGGGACTTGATTGTTCTCTTAG CTGGTGGAATATGTTGGCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTATGCTATCTTGATTCATGAACTTG ATCCTATTAATTTATATGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAATATTTATAGTTAAATGATTTATAT TTGAAATGTGTTGCCAGACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGTAACGAAACTTCCTATGTTATGTC AGGTAGTAGTAAGTAGTATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTGTTTCCAGGCCAAGGGTCGACTGC AGGTTGTTTGAGAAATGATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGGGAAGGGCCAGCCAAGGACAGACT GTAGAGGATCCACATCAGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAGGTGGGCTGGTAGAGCAGGAAGCT CTGTGATGTCAGAGCATCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATGAAGACACTCTGTCTGTTGGGCCC TAGAATTTAATGTGGATTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCTTCTAGAGGTAAGACCTGGAATGG AGTCCAGTTGGTACTTTTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTGGGGTTTTGTTTCCCCACCTAATA ATATATCCTACAACCAGCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTGAGTCCTCTGGTTTTAAGTAGTTT GTTTCTACTTGTTTAAAGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCGGGCAATTATGTTTAGCTTTCATC ATTATACTCCAACAGACCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTTGTGTCAATTAGAGGGTCACTTGT TTGTATTGCAATAAACACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCACATGAAAAGAATCAAAGTAATTGT AATGGCTAGAAGAGACCTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTGCAAACTTACTTCCTTTAAATGTC CCATGGATGTAGGACAGTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATGTTACTTATGAACAAAATATAATT ATTTATGGTACAATTCTTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATTTCTTAGAGGAAAGTTTTGCTTTT TGTGGCAACATTTTTATAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGCACAGTCGTGACCGTGTGTGGTGG CGTCACTGTAACCAAAGTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATTTAAATGTCCAAATGCAAACCTTT GTGACTTCCTTTGGAGGACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTATGACCAAGAGCAGGCTTCCTGCT CCATGGAGTCCTGAGTTGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAAATCTACCTTAGC >9694_9694_2_BICD1-NAPB_BICD1_chr12_32260478_ENST00000281474_NAPB_chr20_23361954_ENST00000398425_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_3_BICD1-NAPB_BICD1_chr12_32260478_ENST00000281474_NAPB_chr20_23361954_ENST00000432543_length(transcript)=1167nt_BP=316nt CCGTTTCCACCCATCCCTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCC ATCCACCGGGGCTATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGA GACCACCCACGAGAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGA GGCTGAGTACGACAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGC AAAGGATTACTTCTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTT TCCAGCATTTACTGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGC AGTGAAGGAATTTGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGA AGGAGATGGAGACCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTA TGGGATGCCTATTTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAA ATGAATGAAGGAGAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTT CAGAATCTCATTCCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAG TACTCAGCCCAGTTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGA CAGTTACTAGGAATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAG >9694_9694_3_BICD1-NAPB_BICD1_chr12_32260478_ENST00000281474_NAPB_chr20_23361954_ENST00000432543_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_4_BICD1-NAPB_BICD1_chr12_32260478_ENST00000548411_NAPB_chr20_23361954_ENST00000377026_length(transcript)=3584nt_BP=394nt CTCGGGCGGTGTAGCTGCCGCTGCCACCAGAGCCGGCGGGGCATCGCGCTGCTCATTCATCCGGCCGCACTTTCTTTTCCGTTTCCACCC ATCCCTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGC TATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGAGACCACCCACGA GAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGAGGCTGAGTACGA CAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGCAAAGGATTACTT CTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTTTCCAGCATTTAC TGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGCAGTGAAGGAATT TGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGA CCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTATGGGATGCCTAT TTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGA GAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATT CCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAG TTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGA ATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAGTTTCTTTGCTTTTTG TGTTGTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTGTAGGCATCACATTGTGAGGAAGGGAGCTTTCTGGA AGTACTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGACACACGCGTTTACACACACACACATATCACAAGATC TGTTAGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGAGTGGAAATCCCTTTATATTTACATTGAAGTATTTT AATTGGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGTGGTGTGTTCTGTGCTGTGACTATAGAAATCTTGGT CAGGGCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCCTGTTTATTGTACATGATGGGTTAGGTGGGGTGAAT GTGGTACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTCAGGGGACTTGATTGTTCTCTTAGCTGGTGGAATAT GTTGGCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTATGCTATCTTGATTCATGAACTTGATCCTATTAATT TATATGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAATATTTATAGTTAAATGATTTATATTTGAAATGTGTT GCCAGACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGTAACGAAACTTCCTATGTTATGTCAGGTAGTAGTAA GTAGTATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTGTTTCCAGGCCAAGGGTCGACTGCAGGTTGTTTGAG AAATGATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGGGAAGGGCCAGCCAAGGACAGACTGTAGAGGATCCA CATCAGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAGGTGGGCTGGTAGAGCAGGAAGCTCTGTGATGTCAG AGCATCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATGAAGACACTCTGTCTGTTGGGCCCTAGAATTTAATG TGGATTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCTTCTAGAGGTAAGACCTGGAATGGAGTCCAGTTGGT ACTTTTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTGGGGTTTTGTTTCCCCACCTAATAATATATCCTACA ACCAGCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTGAGTCCTCTGGTTTTAAGTAGTTTGTTTCTACTTGT TTAAAGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCGGGCAATTATGTTTAGCTTTCATCATTATACTCCAA CAGACCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTTGTGTCAATTAGAGGGTCACTTGTTTGTATTGCAAT AAACACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCACATGAAAAGAATCAAAGTAATTGTAATGGCTAGAAG AGACCTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTGCAAACTTACTTCCTTTAAATGTCCCATGGATGTAG GACAGTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATGTTACTTATGAACAAAATATAATTATTTATGGTACA ATTCTTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATTTCTTAGAGGAAAGTTTTGCTTTTTGTGGCAACATT TTTATAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGCACAGTCGTGACCGTGTGTGGTGGCGTCACTGTAAC CAAAGTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATTTAAATGTCCAAATGCAAACCTTTGTGACTTCCTTT GGAGGACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTATGACCAAGAGCAGGCTTCCTGCTCCATGGAGTCCT GAGTTGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAAATCTACCTTAGCAGAAAAA >9694_9694_4_BICD1-NAPB_BICD1_chr12_32260478_ENST00000548411_NAPB_chr20_23361954_ENST00000377026_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_5_BICD1-NAPB_BICD1_chr12_32260478_ENST00000548411_NAPB_chr20_23361954_ENST00000398425_length(transcript)=3577nt_BP=394nt CTCGGGCGGTGTAGCTGCCGCTGCCACCAGAGCCGGCGGGGCATCGCGCTGCTCATTCATCCGGCCGCACTTTCTTTTCCGTTTCCACCC ATCCCTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGC TATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGAGACCACCCACGA GAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGAGGCTGAGTACGA CAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGCAAAGGATTACTT CTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTTTCCAGCATTTAC TGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGCAGTGAAGGAATT TGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGA CCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTATGGGATGCCTAT TTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGA GAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATT CCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAG TTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGA ATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAGTTTCTTTGCTTTTTG TGTTGTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTGTAGGCATCACATTGTGAGGAAGGGAGCTTTCTGGA AGTACTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGACACACGCGTTTACACACACACACATATCACAAGATC TGTTAGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGAGTGGAAATCCCTTTATATTTACATTGAAGTATTTT AATTGGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGTGGTGTGTTCTGTGCTGTGACTATAGAAATCTTGGT CAGGGCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCCTGTTTATTGTACATGATGGGTTAGGTGGGGTGAAT GTGGTACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTCAGGGGACTTGATTGTTCTCTTAGCTGGTGGAATAT GTTGGCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTATGCTATCTTGATTCATGAACTTGATCCTATTAATT TATATGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAATATTTATAGTTAAATGATTTATATTTGAAATGTGTT GCCAGACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGTAACGAAACTTCCTATGTTATGTCAGGTAGTAGTAA GTAGTATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTGTTTCCAGGCCAAGGGTCGACTGCAGGTTGTTTGAG AAATGATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGGGAAGGGCCAGCCAAGGACAGACTGTAGAGGATCCA CATCAGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAGGTGGGCTGGTAGAGCAGGAAGCTCTGTGATGTCAG AGCATCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATGAAGACACTCTGTCTGTTGGGCCCTAGAATTTAATG TGGATTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCTTCTAGAGGTAAGACCTGGAATGGAGTCCAGTTGGT ACTTTTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTGGGGTTTTGTTTCCCCACCTAATAATATATCCTACA ACCAGCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTGAGTCCTCTGGTTTTAAGTAGTTTGTTTCTACTTGT TTAAAGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCGGGCAATTATGTTTAGCTTTCATCATTATACTCCAA CAGACCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTTGTGTCAATTAGAGGGTCACTTGTTTGTATTGCAAT AAACACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCACATGAAAAGAATCAAAGTAATTGTAATGGCTAGAAG AGACCTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTGCAAACTTACTTCCTTTAAATGTCCCATGGATGTAG GACAGTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATGTTACTTATGAACAAAATATAATTATTTATGGTACA ATTCTTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATTTCTTAGAGGAAAGTTTTGCTTTTTGTGGCAACATT TTTATAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGCACAGTCGTGACCGTGTGTGGTGGCGTCACTGTAAC CAAAGTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATTTAAATGTCCAAATGCAAACCTTTGTGACTTCCTTT GGAGGACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTATGACCAAGAGCAGGCTTCCTGCTCCATGGAGTCCT GAGTTGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAAATCTACCTTAGC >9694_9694_5_BICD1-NAPB_BICD1_chr12_32260478_ENST00000548411_NAPB_chr20_23361954_ENST00000398425_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_6_BICD1-NAPB_BICD1_chr12_32260478_ENST00000548411_NAPB_chr20_23361954_ENST00000432543_length(transcript)=1245nt_BP=394nt CTCGGGCGGTGTAGCTGCCGCTGCCACCAGAGCCGGCGGGGCATCGCGCTGCTCATTCATCCGGCCGCACTTTCTTTTCCGTTTCCACCC ATCCCTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGC TATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGAGACCACCCACGA GAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGAGGCTGAGTACGA CAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGCAAAGGATTACTT CTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTTTCCAGCATTTAC TGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGCAGTGAAGGAATT TGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGA CCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTATGGGATGCCTAT TTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGA GAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATT CCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAG TTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGA ATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAG >9694_9694_6_BICD1-NAPB_BICD1_chr12_32260478_ENST00000548411_NAPB_chr20_23361954_ENST00000432543_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_7_BICD1-NAPB_BICD1_chr12_32260478_ENST00000550207_NAPB_chr20_23361954_ENST00000377026_length(transcript)=3850nt_BP=660nt GGTGGAGCGAGAGAGCGAGCCGCGAGCCGGAGCGCGCCAGACCCAGGGCGAGACTGCAGTGACGCGGCCCGGGAGACATGGCGGACGGGC GTCTCTGAATAAGCAGAATCCGGAGCCCCTCGCTACCCGCGGCCGCCGCAGCCCGGGCCATGCCGCACGGCTGCTGACCGCACGCAGGGG CCGGCCCCGAGGACACATGCGGCGGCCTTTGCCGCCTCGCCCCTGACCCTCTGCCCTGTTCTCCATGTTGCATTTCTCGTCAGTTTCTCG GGCGGTGTAGCTGCCGCTGCCACCAGAGCCGGCGGGGCATCGCGCTGCTCATTCATCCGGCCGCACTTTCTTTTCCGTTTCCACCCATCC CTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGCTATG GCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGAGACCACCCACGAGAAG ATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGAGGCTGAGTACGACAGC CTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGCAAAGGATTACTTCTTC AAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTTTCCAGCATTTACTGAT TCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGCAGTGAAGGAATTTGAC TCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGACCTA AAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTATGGGATGCCTATTTAA TGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGAGAGG CTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATTCCTC ATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAGTTGT TCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGAATGA GTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAGTTTCTTTGCTTTTTGTGTT GTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTGTAGGCATCACATTGTGAGGAAGGGAGCTTTCTGGAAGTA CTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGACACACGCGTTTACACACACACACATATCACAAGATCTGTT AGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGAGTGGAAATCCCTTTATATTTACATTGAAGTATTTTAATT GGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGTGGTGTGTTCTGTGCTGTGACTATAGAAATCTTGGTCAGG GCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCCTGTTTATTGTACATGATGGGTTAGGTGGGGTGAATGTGG TACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTCAGGGGACTTGATTGTTCTCTTAGCTGGTGGAATATGTTG GCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTATGCTATCTTGATTCATGAACTTGATCCTATTAATTTATA TGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAATATTTATAGTTAAATGATTTATATTTGAAATGTGTTGCCA GACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGTAACGAAACTTCCTATGTTATGTCAGGTAGTAGTAAGTAG TATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTGTTTCCAGGCCAAGGGTCGACTGCAGGTTGTTTGAGAAAT GATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGGGAAGGGCCAGCCAAGGACAGACTGTAGAGGATCCACATC AGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAGGTGGGCTGGTAGAGCAGGAAGCTCTGTGATGTCAGAGCA TCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATGAAGACACTCTGTCTGTTGGGCCCTAGAATTTAATGTGGA TTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCTTCTAGAGGTAAGACCTGGAATGGAGTCCAGTTGGTACTT TTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTGGGGTTTTGTTTCCCCACCTAATAATATATCCTACAACCA GCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTGAGTCCTCTGGTTTTAAGTAGTTTGTTTCTACTTGTTTAA AGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCGGGCAATTATGTTTAGCTTTCATCATTATACTCCAACAGA CCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTTGTGTCAATTAGAGGGTCACTTGTTTGTATTGCAATAAAC ACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCACATGAAAAGAATCAAAGTAATTGTAATGGCTAGAAGAGAC CTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTGCAAACTTACTTCCTTTAAATGTCCCATGGATGTAGGACA GTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATGTTACTTATGAACAAAATATAATTATTTATGGTACAATTC TTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATTTCTTAGAGGAAAGTTTTGCTTTTTGTGGCAACATTTTTA TAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGCACAGTCGTGACCGTGTGTGGTGGCGTCACTGTAACCAAA GTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATTTAAATGTCCAAATGCAAACCTTTGTGACTTCCTTTGGAG GACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTATGACCAAGAGCAGGCTTCCTGCTCCATGGAGTCCTGAGT TGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAAATCTACCTTAGCAGAAAAA >9694_9694_7_BICD1-NAPB_BICD1_chr12_32260478_ENST00000550207_NAPB_chr20_23361954_ENST00000377026_length(amino acids)=257AA_BP=146 MTLCPVLHVAFLVSFSGGVAAAATRAGGASRCSFIRPHFLFRFHPSLPISFSLSPPASHPSPPPRNPLLPPSTGAMAAEEVLQTVDHYKT EIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLKYSAKDYFFKAALCHFIVDELNA KLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQGDGEGDGDLK -------------------------------------------------------------- >9694_9694_8_BICD1-NAPB_BICD1_chr12_32260478_ENST00000550207_NAPB_chr20_23361954_ENST00000398425_length(transcript)=3843nt_BP=660nt GGTGGAGCGAGAGAGCGAGCCGCGAGCCGGAGCGCGCCAGACCCAGGGCGAGACTGCAGTGACGCGGCCCGGGAGACATGGCGGACGGGC GTCTCTGAATAAGCAGAATCCGGAGCCCCTCGCTACCCGCGGCCGCCGCAGCCCGGGCCATGCCGCACGGCTGCTGACCGCACGCAGGGG CCGGCCCCGAGGACACATGCGGCGGCCTTTGCCGCCTCGCCCCTGACCCTCTGCCCTGTTCTCCATGTTGCATTTCTCGTCAGTTTCTCG GGCGGTGTAGCTGCCGCTGCCACCAGAGCCGGCGGGGCATCGCGCTGCTCATTCATCCGGCCGCACTTTCTTTTCCGTTTCCACCCATCC CTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGCTATG GCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGAGACCACCCACGAGAAG ATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGAGGCTGAGTACGACAGC CTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGCAAAGGATTACTTCTTC AAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTTTCCAGCATTTACTGAT TCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGCAGTGAAGGAATTTGAC TCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGACCTA AAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTATGGGATGCCTATTTAA TGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGAGAGG CTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATTCCTC ATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAGTTGT TCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGAATGA GTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAGTTTCTTTGCTTTTTGTGTT GTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTGTAGGCATCACATTGTGAGGAAGGGAGCTTTCTGGAAGTA CTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGACACACGCGTTTACACACACACACATATCACAAGATCTGTT AGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGAGTGGAAATCCCTTTATATTTACATTGAAGTATTTTAATT GGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGTGGTGTGTTCTGTGCTGTGACTATAGAAATCTTGGTCAGG GCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCCTGTTTATTGTACATGATGGGTTAGGTGGGGTGAATGTGG TACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTCAGGGGACTTGATTGTTCTCTTAGCTGGTGGAATATGTTG GCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTATGCTATCTTGATTCATGAACTTGATCCTATTAATTTATA TGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAATATTTATAGTTAAATGATTTATATTTGAAATGTGTTGCCA GACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGTAACGAAACTTCCTATGTTATGTCAGGTAGTAGTAAGTAG TATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTGTTTCCAGGCCAAGGGTCGACTGCAGGTTGTTTGAGAAAT GATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGGGAAGGGCCAGCCAAGGACAGACTGTAGAGGATCCACATC AGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAGGTGGGCTGGTAGAGCAGGAAGCTCTGTGATGTCAGAGCA TCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATGAAGACACTCTGTCTGTTGGGCCCTAGAATTTAATGTGGA TTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCTTCTAGAGGTAAGACCTGGAATGGAGTCCAGTTGGTACTT TTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTGGGGTTTTGTTTCCCCACCTAATAATATATCCTACAACCA GCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTGAGTCCTCTGGTTTTAAGTAGTTTGTTTCTACTTGTTTAA AGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCGGGCAATTATGTTTAGCTTTCATCATTATACTCCAACAGA CCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTTGTGTCAATTAGAGGGTCACTTGTTTGTATTGCAATAAAC ACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCACATGAAAAGAATCAAAGTAATTGTAATGGCTAGAAGAGAC CTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTGCAAACTTACTTCCTTTAAATGTCCCATGGATGTAGGACA GTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATGTTACTTATGAACAAAATATAATTATTTATGGTACAATTC TTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATTTCTTAGAGGAAAGTTTTGCTTTTTGTGGCAACATTTTTA TAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGCACAGTCGTGACCGTGTGTGGTGGCGTCACTGTAACCAAA GTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATTTAAATGTCCAAATGCAAACCTTTGTGACTTCCTTTGGAG GACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTATGACCAAGAGCAGGCTTCCTGCTCCATGGAGTCCTGAGT TGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAAATCTACCTTAGC >9694_9694_8_BICD1-NAPB_BICD1_chr12_32260478_ENST00000550207_NAPB_chr20_23361954_ENST00000398425_length(amino acids)=257AA_BP=146 MTLCPVLHVAFLVSFSGGVAAAATRAGGASRCSFIRPHFLFRFHPSLPISFSLSPPASHPSPPPRNPLLPPSTGAMAAEEVLQTVDHYKT EIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLKYSAKDYFFKAALCHFIVDELNA KLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQGDGEGDGDLK -------------------------------------------------------------- >9694_9694_9_BICD1-NAPB_BICD1_chr12_32260478_ENST00000550207_NAPB_chr20_23361954_ENST00000432543_length(transcript)=1511nt_BP=660nt GGTGGAGCGAGAGAGCGAGCCGCGAGCCGGAGCGCGCCAGACCCAGGGCGAGACTGCAGTGACGCGGCCCGGGAGACATGGCGGACGGGC GTCTCTGAATAAGCAGAATCCGGAGCCCCTCGCTACCCGCGGCCGCCGCAGCCCGGGCCATGCCGCACGGCTGCTGACCGCACGCAGGGG CCGGCCCCGAGGACACATGCGGCGGCCTTTGCCGCCTCGCCCCTGACCCTCTGCCCTGTTCTCCATGTTGCATTTCTCGTCAGTTTCTCG GGCGGTGTAGCTGCCGCTGCCACCAGAGCCGGCGGGGCATCGCGCTGCTCATTCATCCGGCCGCACTTTCTTTTCCGTTTCCACCCATCC CTTCCCATTTCCTTCTCCCTTTCCCCGCCAGCTTCGCATCCATCTCCCCCACCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGCTATG GCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAGAGGCTAACCAAGGAGCTCACGGAGACCACCCACGAGAAG ATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTCAAACAGCAGTATGATGAACTGGAGGCTGAGTACGACAGC CTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGATAATCCTTTGTTGAAATACAGTGCAAAGGATTACTTCTTC AAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCTCTTGAGAAATATGAGGAAATGTTTCCAGCATTTACTGAT TCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAGAACAGTGAAGCTTACACTGAAGCAGTGAAGGAATTTGAC TCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAAAAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGACCTA AAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTTGTCTTAGGGTCAAGTGATCTTTATGGGATGCCTATTTAA TGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCTCGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGAGAGG CTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCCCCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATTCCTC ATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTTATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAGTTGT TCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCTTTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGAATGA GTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATTTTGATGGTGCTAGTGACTAG >9694_9694_9_BICD1-NAPB_BICD1_chr12_32260478_ENST00000550207_NAPB_chr20_23361954_ENST00000432543_length(amino acids)=257AA_BP=146 MTLCPVLHVAFLVSFSGGVAAAATRAGGASRCSFIRPHFLFRFHPSLPISFSLSPPASHPSPPPRNPLLPPSTGAMAAEEVLQTVDHYKT EIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLKYSAKDYFFKAALCHFIVDELNA KLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQGDGEGDGDLK -------------------------------------------------------------- >9694_9694_10_BICD1-NAPB_BICD1_chr12_32260478_ENST00000551086_NAPB_chr20_23361954_ENST00000377026_length(transcript)=3439nt_BP=249nt CCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGCTATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAG AGGCTAACCAAGGAGCTCACGGAGACCACCCACGAGAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTC AAACAGCAGTATGATGAACTGGAGGCTGAGTACGACAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGAT AATCCTTTGTTGAAATACAGTGCAAAGGATTACTTCTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCT CTTGAGAAATATGAGGAAATGTTTCCAGCATTTACTGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAG AACAGTGAAGCTTACACTGAAGCAGTGAAGGAATTTGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAA AAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGACCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTT GTCTTAGGGTCAAGTGATCTTTATGGGATGCCTATTTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCT CGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGAGAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCC CCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATTCCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTT ATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAGTTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCT TTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGAATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATT TTGATGGTGCTAGTGACTAGTTTCTTTGCTTTTTGTGTTGTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTG TAGGCATCACATTGTGAGGAAGGGAGCTTTCTGGAAGTACTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGAC ACACGCGTTTACACACACACACATATCACAAGATCTGTTAGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGA GTGGAAATCCCTTTATATTTACATTGAAGTATTTTAATTGGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGT GGTGTGTTCTGTGCTGTGACTATAGAAATCTTGGTCAGGGCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCC TGTTTATTGTACATGATGGGTTAGGTGGGGTGAATGTGGTACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTC AGGGGACTTGATTGTTCTCTTAGCTGGTGGAATATGTTGGCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTA TGCTATCTTGATTCATGAACTTGATCCTATTAATTTATATGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAAT ATTTATAGTTAAATGATTTATATTTGAAATGTGTTGCCAGACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGT AACGAAACTTCCTATGTTATGTCAGGTAGTAGTAAGTAGTATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTG TTTCCAGGCCAAGGGTCGACTGCAGGTTGTTTGAGAAATGATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGG GAAGGGCCAGCCAAGGACAGACTGTAGAGGATCCACATCAGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAG GTGGGCTGGTAGAGCAGGAAGCTCTGTGATGTCAGAGCATCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATG AAGACACTCTGTCTGTTGGGCCCTAGAATTTAATGTGGATTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCT TCTAGAGGTAAGACCTGGAATGGAGTCCAGTTGGTACTTTTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTG GGGTTTTGTTTCCCCACCTAATAATATATCCTACAACCAGCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTG AGTCCTCTGGTTTTAAGTAGTTTGTTTCTACTTGTTTAAAGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCG GGCAATTATGTTTAGCTTTCATCATTATACTCCAACAGACCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTT GTGTCAATTAGAGGGTCACTTGTTTGTATTGCAATAAACACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCAC ATGAAAAGAATCAAAGTAATTGTAATGGCTAGAAGAGACCTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTG CAAACTTACTTCCTTTAAATGTCCCATGGATGTAGGACAGTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATG TTACTTATGAACAAAATATAATTATTTATGGTACAATTCTTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATT TCTTAGAGGAAAGTTTTGCTTTTTGTGGCAACATTTTTATAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGC ACAGTCGTGACCGTGTGTGGTGGCGTCACTGTAACCAAAGTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATT TAAATGTCCAAATGCAAACCTTTGTGACTTCCTTTGGAGGACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTA TGACCAAGAGCAGGCTTCCTGCTCCATGGAGTCCTGAGTTGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAA ATCTACCTTAGCAGAAAAA >9694_9694_10_BICD1-NAPB_BICD1_chr12_32260478_ENST00000551086_NAPB_chr20_23361954_ENST00000377026_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_11_BICD1-NAPB_BICD1_chr12_32260478_ENST00000551086_NAPB_chr20_23361954_ENST00000398425_length(transcript)=3432nt_BP=249nt CCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGCTATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAG AGGCTAACCAAGGAGCTCACGGAGACCACCCACGAGAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTC AAACAGCAGTATGATGAACTGGAGGCTGAGTACGACAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGAT AATCCTTTGTTGAAATACAGTGCAAAGGATTACTTCTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCT CTTGAGAAATATGAGGAAATGTTTCCAGCATTTACTGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAG AACAGTGAAGCTTACACTGAAGCAGTGAAGGAATTTGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAA AAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGACCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTT GTCTTAGGGTCAAGTGATCTTTATGGGATGCCTATTTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCT CGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGAGAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCC CCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATTCCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTT ATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAGTTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCT TTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGAATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATT TTGATGGTGCTAGTGACTAGTTTCTTTGCTTTTTGTGTTGTTCCGTATGCTAACATGTGCATGGCAAAAATTTAGAATAGCCAGGGTCTG TAGGCATCACATTGTGAGGAAGGGAGCTTTCTGGAAGTACTTGCTTCATGTATGGATGAGTGTCAAAGTGAATTTGATTTGTACTTAGAC ACACGCGTTTACACACACACACATATCACAAGATCTGTTAGAAATGGAATTTTTCTCTTTTTCTGGAGATAGTTTTCACTTTTAGTTGGA GTGGAAATCCCTTTATATTTACATTGAAGTATTTTAATTGGCATAGCCTGCTCATTATTTTCATGTTTATACACTTTCCCACGTTGAGGT GGTGTGTTCTGTGCTGTGACTATAGAAATCTTGGTCAGGGCTGGATAGATTATCTAAGTCAAGCTTGAGAATGAATGTATGTAATTTTCC TGTTTATTGTACATGATGGGTTAGGTGGGGTGAATGTGGTACAGGAATGTCCTGTATGCCCAAGTGGGCAAGAACCCCAACTTGTTTCTC AGGGGACTTGATTGTTCTCTTAGCTGGTGGAATATGTTGGCTTATGTGTTTGAACTCTGTCGTGTTTAATTGGTTTATATAATATATGTA TGCTATCTTGATTCATGAACTTGATCCTATTAATTTATATGCTGATATTGTACTTTAGACATACGCTTGTCTCCTGAATGTCCTCTGAAT ATTTATAGTTAAATGATTTATATTTGAAATGTGTTGCCAGACTTAACCCAGCAGACACTCTGACATCACGGAGCTTCACTGATGACAGGT AACGAAACTTCCTATGTTATGTCAGGTAGTAGTAAGTAGTATTGGAATGATGTTTTCATTTTTGGTGGCTCTCAACTGGAATTGGTAGTG TTTCCAGGCCAAGGGTCGACTGCAGGTTGTTTGAGAAATGATGAGTAGGTCAGTCTAGGAAGAAAGAGAAAGTAGCAGGAAAGGAAGTGG GAAGGGCCAGCCAAGGACAGACTGTAGAGGATCCACATCAGGTGGCCACGAGGACTTGCAGGCTATAGTTATGGTGGTGACATGCATGAG GTGGGCTGGTAGAGCAGGAAGCTCTGTGATGTCAGAGCATCTACTGGGACTACAGGTGCACTGTAGTCCCCACTACTGGGGGTGGCAATG AAGACACTCTGTCTGTTGGGCCCTAGAATTTAATGTGGATTTCCTCCTTCCTTCCAAGTTCTGAGATTCTTAAATGAGAGCTGGCTGTCT TCTAGAGGTAAGACCTGGAATGGAGTCCAGTTGGTACTTTTTCACTCCCTCTTAGAATCTCTTATGAAAAAATGATCAGAGAGAAAAGTG GGGTTTTGTTTCCCCACCTAATAATATATCCTACAACCAGCCAAATGCACTTTTGTGAAAATGGGGTGTGAGGAGTGGTTCTGCAGCTTG AGTCCTCTGGTTTTAAGTAGTTTGTTTCTACTTGTTTAAAGAATCTTCTGGTCTGACCACTTAAAGTAAAAACTACATGATTTATTTTCG GGCAATTATGTTTAGCTTTCATCATTATACTCCAACAGACCCGTCTGAAGGGGTATTTTTTTTTAACAATAATGTTTGTAACATTTTGTT GTGTCAATTAGAGGGTCACTTGTTTGTATTGCAATAAACACTGGGACCAGTTCCGGGGTTAAGAATTAATTTTTGTTTTTAATATTTCAC ATGAAAAGAATCAAAGTAATTGTAATGGCTAGAAGAGACCTGCCAGAAGATTAAAAAAAAGAATGAGAGAAAAGCCCAGTTAGTGGTGTG CAAACTTACTTCCTTTAAATGTCCCATGGATGTAGGACAGTGCCATGTTTCAAGATGCCTGTGAGCTAGGTCTTCAAGATTTATAGAATG TTACTTATGAACAAAATATAATTATTTATGGTACAATTCTTGTACTTTAGCAAATCTGGAGTTAGTTCATAGTCAAAGTCAGTTAATATT TCTTAGAGGAAAGTTTTGCTTTTTGTGGCAACATTTTTATAGCTTGTGTGAGTTCTTTTTTATTTAATGATTTGAAAGCAGTATTTTTGC ACAGTCGTGACCGTGTGTGGTGGCGTCACTGTAACCAAAGTATATGCACCAGCCCTTGTGCATTTATTGTTTCTCCTGATTTTGTGGATT TAAATGTCCAAATGCAAACCTTTGTGACTTCCTTTGGAGGACTTGGCAGCACAGCATGCCCCCGTGACCTGCCTGCTGTGGTATGAGCTA TGACCAAGAGCAGGCTTCCTGCTCCATGGAGTCCTGAGTTGCTCTGGGGCAGGGGATTACGTTATGAAAACTAACCATGTGTAACAATAA ATCTACCTTAGC >9694_9694_11_BICD1-NAPB_BICD1_chr12_32260478_ENST00000551086_NAPB_chr20_23361954_ENST00000398425_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- >9694_9694_12_BICD1-NAPB_BICD1_chr12_32260478_ENST00000551086_NAPB_chr20_23361954_ENST00000432543_length(transcript)=1100nt_BP=249nt CCCCGTAACCCCCTCCTGCCTCCATCCACCGGGGCTATGGCCGCAGAAGAGGTATTGCAGACGGTGGACCATTATAAGACTGAGATAGAG AGGCTAACCAAGGAGCTCACGGAGACCACCCACGAGAAGATCCAGGCTGCCGAGTACGGGCTGGTGGTGCTGGAGGAGAAGCTGACCCTC AAACAGCAGTATGATGAACTGGAGGCTGAGTACGACAGCCTCAAACAGGAGCTGGAGCAGCTCAAAGAGGTTGGGGCAAACACAATGGAT AATCCTTTGTTGAAATACAGTGCAAAGGATTACTTCTTCAAAGCTGCCCTCTGCCACTTCATAGTAGACGAGTTGAATGCCAAGCTTGCT CTTGAGAAATATGAGGAAATGTTTCCAGCATTTACTGATTCAAGAGAATGTAAATTATTGAAAAAACTCCTAGAAGCTCATGAAGAACAG AACAGTGAAGCTTACACTGAAGCAGTGAAGGAATTTGACTCAATATCTCGCTTGGATCAGTGGCTGACCACCATGTTGCTTCGCATCAAA AAGTCCATCCAAGGGGATGGAGAAGGAGATGGAGACCTAAAATGAAATGTTTTTGTCTTTGTGGCATGCAGCTAACTCCTCTTTAGTTTT GTCTTAGGGTCAAGTGATCTTTATGGGATGCCTATTTAATGGCTTAATTTTGTTGCATATGAGCCAGACGGCCTGTGTATTGTTTAAGCT CGCCAAGTCTGTGTTGCTGTGAAATGAATGAAGGAGAGGCTCCTGTTCATCTTGTGGTAATGATGGGTTGTTTCATGCTTATCAGAACCC CCAGCGTTTTCTGAGAAGTACTTCAGAATCTCATTCCTCATATTTCATTGGTATTTGTGGAGCCTATGTTTAATGTTGCCACGTGTTTTT ATGTCCTTTTTGTTGGACTTGAGTACTCAGCCCAGTTGTTCTCATAGATGCTTTGCATTTTCTCTGTGCTTTGGCATCTGAATATGTTCT TTAAATGTGTGTTTAGTTTAGGACAGTTACTAGGAATGAGTTTATAACTTCATTAGAAATCATTTCTATTTTTGTTATCCTGTGATTATT TTGATGGTGCTAGTGACTAG >9694_9694_12_BICD1-NAPB_BICD1_chr12_32260478_ENST00000551086_NAPB_chr20_23361954_ENST00000432543_length(amino acids)=189AA_BP=78 MPPSTGAMAAEEVLQTVDHYKTEIERLTKELTETTHEKIQAAEYGLVVLEEKLTLKQQYDELEAEYDSLKQELEQLKEVGANTMDNPLLK YSAKDYFFKAALCHFIVDELNAKLALEKYEEMFPAFTDSRECKLLKKLLEAHEEQNSEAYTEAVKEFDSISRLDQWLTTMLLRIKKSIQG DGEGDGDLK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for BICD1-NAPB |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for BICD1-NAPB |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for BICD1-NAPB |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies