
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CLSTN2-FSD1L (FusionGDB2 ID:HG64084TG83856) |
Fusion Gene Summary for CLSTN2-FSD1L |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CLSTN2-FSD1L | Fusion gene ID: hg64084tg83856 | Hgene | Tgene | Gene symbol | CLSTN2 | FSD1L | Gene ID | 64084 | 83856 |
| Gene name | calsyntenin 2 | fibronectin type III and SPRY domain containing 1 like | |
| Synonyms | ALC-GAMMA|CDHR13|CS2|CSTN2|alcagamma | CCDC10|CSDUFD1|FSD1CL|FSD1NL|MIR1 | |
| Cytomap | ('CLSTN2')('FSD1L') 3q23 | 9q31.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | calsyntenin-2alcadein gammacadherin-related family member 13 | FSD1-like proteinFSD1 C-terminal likeFSD1 N-terminal likecoiled-coil domain containing 10cystatin and DUF19 domain containing 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000458420, | ||
| Fusion gene scores | * DoF score | 5 X 7 X 3=105 | 3 X 3 X 3=27 |
| # samples | 5 | 3 | |
| ** MAII score | log2(5/105*10)=-1.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: CLSTN2 [Title/Abstract] AND FSD1L [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CLSTN2(139894915)-FSD1L(108268679), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CLSTN2-FSD1L seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CLSTN2-FSD1L seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CLSTN2-FSD1L seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CLSTN2-FSD1L seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CLSTN2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across FSD1L (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-KB-A6F7 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
Top |
Fusion Gene ORF analysis for CLSTN2-FSD1L |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000458420 | ENST00000480279 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| 5CDS-5UTR | ENST00000458420 | ENST00000374707 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| 5CDS-intron | ENST00000458420 | ENST00000374716 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| In-frame | ENST00000458420 | ENST00000374710 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| In-frame | ENST00000458420 | ENST00000394926 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| In-frame | ENST00000458420 | ENST00000481272 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| In-frame | ENST00000458420 | ENST00000484973 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| In-frame | ENST00000458420 | ENST00000495708 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| In-frame | ENST00000458420 | ENST00000539376 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000458420 | CLSTN2 | chr3 | 139894915 | + | ENST00000495708 | FSD1L | chr9 | 108268679 | + | 1317 | 422 | 172 | 981 | 269 |
| ENST00000458420 | CLSTN2 | chr3 | 139894915 | + | ENST00000374710 | FSD1L | chr9 | 108268679 | + | 7379 | 422 | 172 | 1428 | 418 |
| ENST00000458420 | CLSTN2 | chr3 | 139894915 | + | ENST00000481272 | FSD1L | chr9 | 108268679 | + | 1521 | 422 | 172 | 1428 | 418 |
| ENST00000458420 | CLSTN2 | chr3 | 139894915 | + | ENST00000484973 | FSD1L | chr9 | 108268679 | + | 1545 | 422 | 172 | 1425 | 417 |
| ENST00000458420 | CLSTN2 | chr3 | 139894915 | + | ENST00000539376 | FSD1L | chr9 | 108268679 | + | 1778 | 422 | 172 | 1458 | 428 |
| ENST00000458420 | CLSTN2 | chr3 | 139894915 | + | ENST00000394926 | FSD1L | chr9 | 108268679 | + | 1781 | 422 | 172 | 1461 | 429 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000458420 | ENST00000495708 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 0.000856118 | 0.99914384 |
| ENST00000458420 | ENST00000374710 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 3.04E-05 | 0.9999696 |
| ENST00000458420 | ENST00000481272 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 0.000427051 | 0.99957293 |
| ENST00000458420 | ENST00000484973 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 0.000422834 | 0.9995772 |
| ENST00000458420 | ENST00000539376 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 0.000234881 | 0.9997651 |
| ENST00000458420 | ENST00000394926 | CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 0.000213903 | 0.9997861 |
Top |
Fusion Genomic Features for CLSTN2-FSD1L |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 3.39E-08 | 1 |
| CLSTN2 | chr3 | 139894915 | + | FSD1L | chr9 | 108268679 | + | 3.39E-08 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
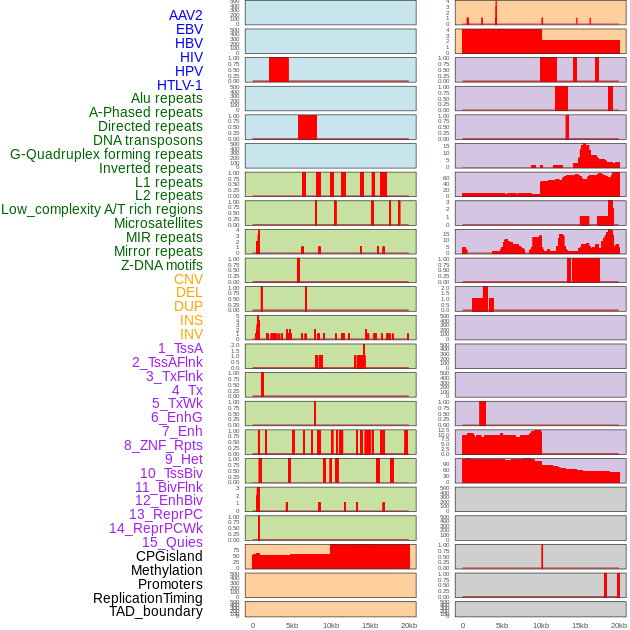 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
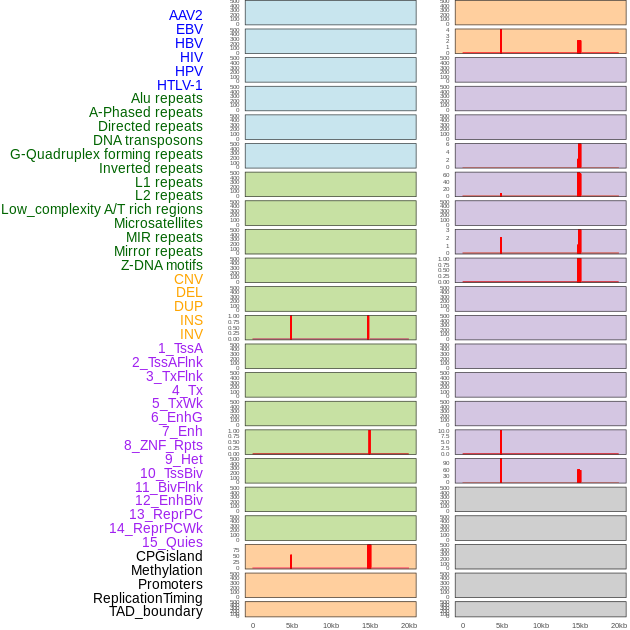 |
Top |
Fusion Protein Features for CLSTN2-FSD1L |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:139894915/chr9:108268679) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374716 | 0 | 4 | 102_141 | 0 | 146.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374710 | 5 | 13 | 196_300 | 163 | 499.0 | Domain | Fibronectin type-III | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374710 | 5 | 13 | 300_506 | 163 | 499.0 | Domain | B30.2/SPRY | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374716 | 0 | 4 | 137_194 | 0 | 146.0 | Domain | COS | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374716 | 0 | 4 | 196_300 | 0 | 146.0 | Domain | Fibronectin type-III | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374716 | 0 | 4 | 300_506 | 0 | 146.0 | Domain | B30.2/SPRY | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000481272 | 6 | 14 | 196_300 | 195 | 531.0 | Domain | Fibronectin type-III | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000481272 | 6 | 14 | 300_506 | 195 | 531.0 | Domain | B30.2/SPRY | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000484973 | 5 | 13 | 196_300 | 163 | 498.0 | Domain | Fibronectin type-III | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000484973 | 5 | 13 | 300_506 | 163 | 498.0 | Domain | B30.2/SPRY |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CLSTN2 | chr3:139894915 | chr9:108268679 | ENST00000458420 | + | 2 | 17 | 889_929 | 77 | 956.0 | Compositional bias | Note=Glu-rich (highly acidic) |
| Hgene | CLSTN2 | chr3:139894915 | chr9:108268679 | ENST00000458420 | + | 2 | 17 | 161_280 | 77 | 956.0 | Domain | Cadherin 2 |
| Hgene | CLSTN2 | chr3:139894915 | chr9:108268679 | ENST00000458420 | + | 2 | 17 | 44_160 | 77 | 956.0 | Domain | Cadherin 1 |
| Hgene | CLSTN2 | chr3:139894915 | chr9:108268679 | ENST00000458420 | + | 2 | 17 | 21_831 | 77 | 956.0 | Topological domain | Extracellular |
| Hgene | CLSTN2 | chr3:139894915 | chr9:108268679 | ENST00000458420 | + | 2 | 17 | 853_955 | 77 | 956.0 | Topological domain | Cytoplasmic |
| Hgene | CLSTN2 | chr3:139894915 | chr9:108268679 | ENST00000458420 | + | 2 | 17 | 832_852 | 77 | 956.0 | Transmembrane | Helical |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374710 | 5 | 13 | 102_141 | 163 | 499.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000481272 | 6 | 14 | 102_141 | 195 | 531.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000484973 | 5 | 13 | 102_141 | 163 | 498.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000374710 | 5 | 13 | 137_194 | 163 | 499.0 | Domain | COS | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000481272 | 6 | 14 | 137_194 | 195 | 531.0 | Domain | COS | |
| Tgene | FSD1L | chr3:139894915 | chr9:108268679 | ENST00000484973 | 5 | 13 | 137_194 | 163 | 498.0 | Domain | COS |
Top |
Fusion Gene Sequence for CLSTN2-FSD1L |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >17353_17353_1_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000374710_length(transcript)=7379nt_BP=422nt AGTGAGCGCGGCTGCTGCCGGCGAGCTAGCGGCGCAGCGGCGGGAACCCGAGGCCGAGCGCCGCGGCGGCAGCGCTAGAAGCGCACCCAT CGGGCACGGCGAGGCGGCCCACGGTGCGGCAGGCACCGGGAGGCGAGAGCCGGCGCGGACAGTAGGCGGCGGCTGCAGCTCGTTGGCGGC TGCTGCGAGGATGCTGCCTGGGCGGCTGTGCTGGGTGCCGCTCCTGCTGGCGCTGGGCGTGGGGAGCGGCAGCGGCGGTGGCGGGGACAG CCGGCAGCGCCGCCTCCTCGCGGCTAAAGTCAATAAGCACAAGCCATGGATCGAGACTTCATATCATGGAGTCATAACTGAGAACAATGA CACAGTCATTTTGGACCCACCACTGGTAGCCCTGGATAAAGATGCACCGGTTCCTTTTGCAGTCCCCAAAGCTCCAGAGATAGATCCAGT AGAGTGTTTGGTGGCAGATAACTCTGTAACAGTGGCTTGGAGAATGCCAGAAGAAGATAATAAGATTGACCATTTTATACTGGAACATAG GAAGACTAATTTTGATGGACTTCCACGTGTAAAGGATGAGCGATGCTGGGAGATAATTGATAATATTAAGGGTACTGAATATACACTATC AGGCTTAAAATTTGATTCAAAGTATATGAATTTCAGAGTGCGAGCTTGTAACAAGGCTGTGGCTGGAGAGTATTCTGATCCAGTGACTCT AGAGACCAAAGCACTTAACTTCAATTTGGATAACTCCTCATCCCATTTGAACCTGAAAGTTGAAGATACATGTGTAGAGTGGGATCCTAC TGGAGGAAAAGGTCAAGAAAGTAAAATTAAAGGAAAAGAGAACAAGGGCAGAAGTGGTACACCATCCCCAAAACGAACATCTGTAGGCTC CAGGCCACCAGCAGTAAGAGGCAGTAGAGATCGTTTTACTGGAGAATCATACACAGTGCTGGGAGACACTGCTATTGAAAGTGGACAACA TTATTGGGAGGTCAAGGCCCAGAAGGATTGTAAATCCTACAGTGTGGGAGTAGCATACAAAACGTTGGGGAAATTTGACCAATTGGGAAA GACAAACACTAGTTGGTGTATCCATGTCAACAACTGGCTACAAAACACATTTGCAGCAAAGCATAATAATAAAGTCAAAGCTTTGGATGT TACTGTTCCTGAAAAAATAGGTGTATTTTGTGATTTTGATGGGGGTCAACTTTCATTCTATGATGCAAATTCTAAACAGTTGCTATATTC CTTTAAGACAAAATTTACTCAGCCAGTACTACCTGGTTTCATGGTATGGTGTGGTGGACTTTCTTTGAGTACTGGGATGCAGGTTCCAAG TGCTGTGAGAACACTTCAGAAAAGTGAAAATGGAATGACTGGTTCAGCTAGCAGCCTGAACAATGTTGTTACTCAATAGTGTCTACTCAG AATACGTTTACCCTCCGTCTTGATTAGGTGGCCTTTTCTGTGCAGTTACTAATCACAGGAATTTGGTAGTAGTGAAAATCAGGTTTGCTG TGTTCTGCTTTGAGGCCTGGAATCTTTTATCATTAAACACCTAGTACGAAGCATTTGCAGGAACCTACTGTGCAGTATCATAGAAGCAAG CAGATACCAAGCAAAAAACTGATGATTGAAGAGTAAATGGGGGAAAAGGCAGTGTTTAATTAACATAAAAACTCATTTTTGTATTTCTTG GATTACTTTGACTATTCTAATGTTTAATTACATATGGTAACCCTAAGGCCTGGGGAGAAAAGCTTTTAAATCTTGCCTTCTTTCTTCTGT ACTTTGTCTTTTTAAAATCTCATTACTATCTATTATTTAGTTCTAACACAGAAGCTTTAAAAATACATAGTCATCCAAGGTTTTCTAAAA ATTGAAATCATATGTTGGGAATGGTAAAAAGGTTTTCAAATGGTTTATTTTTCCTCTTTTATAAATAAGTTTTACAAAATTTTCCTCTTT TGTTTATTGACTAGATTGTATATAATTTTCTTTTTTCCAAAATATTGTGATAAGAAATTTCTAGACACAACAGCTTAAAATCACCCAAAT TTCAGTTCTTTACCTACTGCACTAACAATGGCAAGGGGGGTATTCTTTATATGTTGCCTTGTTTAACTACAGTTCTTTTCATTCCATCAC TTTAGGTGATGGGTAAGATTTTTGAAAGCCTTATATTTTTTGATTTTGTTGTCTAGTTTAATCCTACCTTTAATAGTTGTGTTTGGTAAA ATTCCCACTTGAATGTGACACTGATAATAATTATGCTGATTTTTAGCATCTCTTATAGGAATCAAAGTTTATTAAAGTTACATAGAGGAT TGAAAAATGTATATCACTCAATTTTTATCTAAGAAGGATAGGTTATAAAGGGAGGTACCTAAATACTCAAATAATGTATATATTCTTTTT CATAACATATGGAATGCTTTAAGCAATTGTTTTGAAAAAAATCTGCGTATCTTTGACTTAATTGGCACATGACTTTTTCAAGCAGCCATT CATTCAGAGGTTTGTTTTCTCTCAGTCCTTTTGCTACATTCACTTTCTTTTCAAAGAAATGTTAATTATTACAAAAATTGACATAGATAT CTTTCCCAAACTTGGGGTAAAACCCATGGTTATGTGGAACATAACTGTTCTTAAAAAGTCAATTATAATTTGTAACTCACATCCTTTGAG CTAAACTAAATTAAAATTACAGTATTTAATAATTCTTTGGGCATTTTTAAGAGGTCTGAATTTGTATTTTTCTTCATTTTTGAAACTTTA CATTTGTTGACTTTTTTTCATTCTCATTTAAAATATATTGTGCTATGATAACCAACCTTCTTCCAAGGAGTGACCATTACTGCCTACATT TGCGTTGCTTTCTACATAGAGACTTGTATAATAGTATTAATAGTAGCTCATTCTCTCTAAAAATTTACTGCCCACTGATAGGATGTTTTG TTTCCTTGATAAAACAAATGTAAATGAGGAATTTTATTTGAATTGGAATATTGTTTTTCTAGAGGACATTCATATCTGCACTATTATCTG ATGACATGTTGGTAATTTTAAAGACTGCAAGGCAGTTTAGAGAATGAAGTAAACCAATAGATACTCTTTTGATTCTCCAAAGAAATATAA TTTTGGTTTTTGTTCCTCAGAGAGAGTTTGAAAGAAATTTTCAGATGTTCTGTTCCCTATAGAGGGCCTATTCCAGGATCTAAATGAATG GGAATTTATAATTCCTTTCATAGACTCAAACCTGAAAGCAGAAATTTTTAGTAGTTGAGTTGCTTTAAGTGAATTTTAACAAATATGACA CAGAAAAGGTCAGATGCTGTTGTATAAAATTTTTTACTAGTGTGTCTTATATAATTCTTTCTTCTCATTAATTCAGTGCCTTTTTCCTCT AAGCATACTCTTGGTCCATGCCCCATGCAGTGTCAACTGATGTTTAAGCTACAGAGCATTGTTGTAGTGGTGAGGGCCCTCTGTTGCAGG GGCATGGGGAAATGCATATATTAATCAGGGGCTGGAGGAGTATACATGATTCTTGTGTTCATGTTGTCATTTGAAACTCTTCACATAAAA TTTTCTAATATTCATTTGGAAAACCTCTCCACTGGAGAGGTTTCATCTCTGAGAGGTTTTGTAATAATAGTGTAAGTTCAGTAAATCCAG TCCAAATTCTCATCACATGTATTATTTGATACTAAATTTTCAATTATTACTTCAAAATAAGAGTCTGAGGATTTCTTCTTACTGGCGTTC TTAAAGGTCTCTAAAATTAAAGAACAAGATGTGGTTTTTTGTTTAAGACGTTTTTAGTTTATTTGTTGTTAAGTTAAACTGGAGAAAGTT TGTCATCCTCATTTTCAAACTGAAAACTAATCAAATATAGTGCCTATTTAGTCTCAAAATAAGGTAACTATTAACTTGATTATACTATAT AATATTCTCAATTACATTTGAATTTAAAAATATTGAGCTCTTGATTACAATTTAATACATTGTAAAAAGTATTAAATCCTTTGAAACATC TTTTGTTGCTTATTTAGTTTTTGTTTCTACAGGTCAAACATGATTGCTTTCTATAAAAGAAATGCTTGAGAGGTTGACTATAATGGATAT GTCACAGGTATAAAACAGTTGTTTTCTAAAAACATGCATTTAGTATGGCATTCTCTTTTAGCAACTGAATTCCCAACGAGTTTTATTAAG CTGGATATCGAAATGAAGGAGCTGCCTTAAGCACTTTAGAAAAAGAATTTTTTTACAATTCATTTTGACTCTCATGGCTGACCATGTCAT TATGTCTTTAAATTTTGGTAAATATGTAGATACCAAGCATTAATAACTAATGCACACAGAAATTTAATATACAGCAATTCTTTGAATGTT CCAGGTGTACGTAAACTAACTGAAAGTATTAAGGACATGCCTGTCTATACATGGGTTTCATTGATGGTATCTGTATCATCTTGACAAATC GTGAACTGCTGCTGTATGGCTAGACTTTGCCTATTTACTCTGTTATGCAAACAGTAATTTTTCCCTATGTTATGAAGAGAGACATATTGG CTTGCTTTAATTTACTTATTTATGAAATTAAAGCATGAATAATATGTATAATTTGAATTTTTTGTGACTGATCCTTGGCAGTATAAATGA TAAAAGTAAATGTAATGGAATCTTTTAATTAGGCTAAGATATGCTATTTCATAACTTATGTAGAATGATTTTTATCTATATACTTTGTCC ATAAAATTATAATTGTTTATGTAATTTTATTGTTTCTTATGGAAACAATTGGAAAAGTATATGGAAAATGATTATTTCAAAGAATATTTA TTTAAAGAGGGAAGTGTAGACTTCTTACTGTAAAATATGTGATTCCAGGCTTAAGAAATTGATTATATTTTAAAATAATTATTTTTTTAA AAACGTAATTTGTTTTTAAAAGATGAGTCTCCATTCATTGGCTAATCCATACAGCAAATATTTGAGTGTTTGTGATATGGCAGTAAAAAT GTGATTACTTTGTATGTACATTAACCAAAACCAGTGAAGTTTGATGGACTGTGCATAGAGTTTTGCAGCTTTTGAGTAGTGTGACAGAGT TTGCCTCTTAAAATTGTTTTGCTAATAAGTCAGAAGTTTAAAATGTGTTATAGTTTGCTAAAAAAAAATCAAATTAACTGCATATAAAAT GGTTCACTTTTATATAGTCACATGTAATGGGCCTGAAAAAGTTTCTTCTTTGATTATGTAGTTACTCTAGATACATTCTTTTAGGGAAGT GTATGGTCAACATATATTTACTCAGTATACAGATAACCACAAAGTTGTTATTTTTAACCAAAATATACATTTCATAATGTTGGCACTGGA GTATTATAAGAGATCATGAATGTTTCCTTAATTATCATGGCAAGATTACCTCACGTTCAGTATAGTTTAGTTTTGTGTGTATCTTACAGT ATGCATGTTCTGAAATTATTTGTGATCCTGATATGTCACATATAATAGCTTTGTTACCTGGAGTATTTGATTAACCTAAACAGTTTAAGC ATTTTGAATTAGTTGGAGTTTAAATGGATTACATTTGGTGTATATTGTCTTCATTGAAAAGATATTGTTGGATATGCCACATCAGAGTTA GCATTGACTTATAAATAAATACCAGAATTTACCAGAGTACACTTTTCTCTTCAGATGACTCAATTATTAAATAAAAGAATATTTCTTATT TCTGGGTCAATATAAGGTACTGACTTCTGATGCATAATCACTTAAGCTATGTGAGTTTAAACTGGTATCTTTTCTTAGTGGTACCCATTC AATGTAAGCTGGTCCATGGGAATGGACATGAAGAGGATTTCACAGTATGTAGAGCAGAAGGCACGTGAATGTGTTTGCTTTGGCTTGGAG CTTATTAAGTTTTGACTACGGTTAAAATAAGTCAAATAGTAAGTGGTAAAACACATTTTTGTTAGTATTGGAACTTTCTGGAGAACATAA GGGCTATGAGAATGCATATATATATTTTTTAACATTTCCTATATATCTAAGGTACCAAAGCACTGAGTCTAATTTACCTATTAAGGGAGA CTCTTTAAAATCAACTTTATAACTAATTCATACTATAAGACAGATAATAGCTAAAGTTTTGGAATAATTTATATTAAAAGCCGCAAGTCT TAAAAATCCCTGGATATGACATAAAAAGGATTTTGGCTTCTTTTTTGAAGTATTTAAAATTAATCACCTTAGCTCTACCATATACTAGAT CTGTGACCGCTACACAAATTGTTTATCATCTTTGGGTCTCTATTGCCTTCTTTATAAAATAAGTGTAAGTTGTTCAGCCTGCCTCACAGG GCTGTTGTGAGGAAATAAAATGAAATGGAGTATGTGAAATTGCTTCAGCAACAGCAAAGTGCTACGTAAATGTAAAGTGTTGTTTTTAGC TAATAATGGATTTAAGTGTTTGGATAATTGTAGATGCATTTACTTTGATAAAGCGTGTGCTTAAAGTGGTATCACCAGTGATTTCTAACA TGATTTTAAAAAAATAAAACCCCAATTAAAATGTTCTTTAATATTCATTTAATTTGTGCATGACTTGTGGCCTTTTTGTATTTTCTCAAG CCTATTACTCTAGAGCTGTAAAAGCTCTTGCACAGCATTGTTGTGTCAGTGTAGAATAGTGGCATAAATAAATGAATTAAGCTACATTTC CATGCAGGCATTTGCACTTTGAAGTTAGGGCTGCCCAGTGCCACATGCAAAGAGTGTATTTGGTCTAAACAGTTCTTTCCAAACAACCAA ATGGCTGGGCAGCTTGTTGTCACGGATAAATGATATAAAATGTAACCACTGAACATTTGACAACTTTGTTGCATTATCATTTTTAAAAAA AGATGAAGCATTTCAAAATCTTGTTAACCTGGTTATCTCTTGGTATCTCTCCTGACATATTTGTTTTGCTTTAAATTGGATTAAATGGTT TACAGGTTATCTGAATCTACAGATTTAGTATGTCTATTATCTGGACATGATTTTGCTATGCAGTTGTGATAATAAAAATTCTAATTCCTC AGGTTTGGCCTTTTAAGTTATGGCTGAAGACCTTTAATGATACTTATGATGCACTCAGTGCCATACAATAGTGTTTTAAGAAGCACATGG CCTCATTTTCCTTAGAAACAAGACAAAGCCTTTTTAAAATGTTTTTTTTTCACTTTAAAATAGGGTATTCAAAGTGGAGTAACGTGTATT TTGAAATGATTTTGTGTTCTATATAGAATGTCCCAGTTAAGATTTTACAGAAGCACCTGGAATATCTCATTAAAAATTTAAAAACTCTT >17353_17353_1_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000374710_length(amino acids)=418AA_BP=81 MAAAARMLPGRLCWVPLLLALGVGSGSGGGGDSRQRRLLAAKVNKHKPWIETSYHGVITENNDTVILDPPLVALDKDAPVPFAVPKAPEI DPVECLVADNSVTVAWRMPEEDNKIDHFILEHRKTNFDGLPRVKDERCWEIIDNIKGTEYTLSGLKFDSKYMNFRVRACNKAVAGEYSDP VTLETKALNFNLDNSSSHLNLKVEDTCVEWDPTGGKGQESKIKGKENKGRSGTPSPKRTSVGSRPPAVRGSRDRFTGESYTVLGDTAIES GQHYWEVKAQKDCKSYSVGVAYKTLGKFDQLGKTNTSWCIHVNNWLQNTFAAKHNNKVKALDVTVPEKIGVFCDFDGGQLSFYDANSKQL LYSFKTKFTQPVLPGFMVWCGGLSLSTGMQVPSAVRTLQKSENGMTGSASSLNNVVTQ -------------------------------------------------------------- >17353_17353_2_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000394926_length(transcript)=1781nt_BP=422nt AGTGAGCGCGGCTGCTGCCGGCGAGCTAGCGGCGCAGCGGCGGGAACCCGAGGCCGAGCGCCGCGGCGGCAGCGCTAGAAGCGCACCCAT CGGGCACGGCGAGGCGGCCCACGGTGCGGCAGGCACCGGGAGGCGAGAGCCGGCGCGGACAGTAGGCGGCGGCTGCAGCTCGTTGGCGGC TGCTGCGAGGATGCTGCCTGGGCGGCTGTGCTGGGTGCCGCTCCTGCTGGCGCTGGGCGTGGGGAGCGGCAGCGGCGGTGGCGGGGACAG CCGGCAGCGCCGCCTCCTCGCGGCTAAAGTCAATAAGCACAAGCCATGGATCGAGACTTCATATCATGGAGTCATAACTGAGAACAATGA CACAGTCATTTTGGACCCACCACTGGTAGCCCTGGATAAAGATGCACCGGTTCCTTTTGCAGTCCCCAAAGCTCCAGAGATAGATCCAGT AGAGTGTTTGGTGGCAGATAACTCTGTAACAGTGGCTTGGAGAATGCCAGAAGAAGATAATAAGATTGACCATTTTATACTGGAACATAG GAAGACTAATTTTGATGGACTTCCACGTGTAAAGGATGAGCGATGCTGGGAGATAATTGATAATATTAAGGGTACTGAATATACACTATC AGGCTTAAAATTTGATTCAAAGTATATGAATTTCAGAGTGCGAGCTTGTAACAAGGCTGTGGCTGGAGAGTATTCTGATCCAGTGACTCT AGAGACCAAAGCACTTAACTTCAATTTGGATAACTCCTCATCCCATTTGAACCTGAAAGTTGAAGATACATGTGTAGAGTGGGATCCTAC TGGAGGAAAAGGTCAAGAAAGTAAAATTAAAGGAAAAGAGAACAAGGGCAGTGTCCATGTTACTTCACTGAAGAAACATACAAGAAGTGG TACACCATCCCCAAAACGAACATCTGTAGGCTCCAGGCCACCAGCAGTAAGAGGCAGTAGAGATCGTTTTACTGGAGAATCATACACAGT GCTGGGAGACACTGCTATTGAAAGTGGACAACATTATTGGGAGGTCAAGGCCCAGAAGGATTGTAAATCCTACAGTGTGGGAGTAGCATA CAAAACGTTGGGGAAATTTGACCAATTGGGAAAGACAAACACTAGTTGGTGTATCCATGTCAACAACTGGCTACAAAACACATTTGCAGC AAAGCATAATAATAAAGTCAAAGCTTTGGATGTTACTGTTCCTGAAAAAATAGGTGTATTTTGTGATTTTGATGGGGGTCAACTTTCATT CTATGATGCAAATTCTAAACAGTTGCTATATTCCTTTAAGACAAAATTTACTCAGCCAGTACTACCTGGTTTCATGGTATGGTGTGGTGG ACTTTCTTTGAGTACTGGGATGCAGGTTCCAAGTGCTGTGAGAACACTTCAGAAAAGTGAAAATGGAATGACTGGTTCAGCTAGCAGCCT GAACAATGTTGTTACTCAATAGTGTCTACTCAGAATACGTTTACCCTCCGTCTTGATTAGGTGGCCTTTTCTGTGCAGTTACTAATCACA GGAATTTGGTAGTAGTGAAAATCAGGTTTGCTGTGTTCTGCTTTGAGGCCTGGAATCTTTTATCATTAAACACCTAGTACGAAGCATTTG CAGGAACCTACTGTGCAGTATCATAGAAGCAAGCAGATACCAAGCAAAAAACTGATGATTGAAGAGTAAATGGGGGAAAAGGCAGTGTTT AATTAACATAAAAACTCATTTTTGTATTTCTTGGATTACTTTGACTATTCTAATGTTTAATTACATATGGT >17353_17353_2_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000394926_length(amino acids)=429AA_BP=81 MAAAARMLPGRLCWVPLLLALGVGSGSGGGGDSRQRRLLAAKVNKHKPWIETSYHGVITENNDTVILDPPLVALDKDAPVPFAVPKAPEI DPVECLVADNSVTVAWRMPEEDNKIDHFILEHRKTNFDGLPRVKDERCWEIIDNIKGTEYTLSGLKFDSKYMNFRVRACNKAVAGEYSDP VTLETKALNFNLDNSSSHLNLKVEDTCVEWDPTGGKGQESKIKGKENKGSVHVTSLKKHTRSGTPSPKRTSVGSRPPAVRGSRDRFTGES YTVLGDTAIESGQHYWEVKAQKDCKSYSVGVAYKTLGKFDQLGKTNTSWCIHVNNWLQNTFAAKHNNKVKALDVTVPEKIGVFCDFDGGQ LSFYDANSKQLLYSFKTKFTQPVLPGFMVWCGGLSLSTGMQVPSAVRTLQKSENGMTGSASSLNNVVTQ -------------------------------------------------------------- >17353_17353_3_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000481272_length(transcript)=1521nt_BP=422nt AGTGAGCGCGGCTGCTGCCGGCGAGCTAGCGGCGCAGCGGCGGGAACCCGAGGCCGAGCGCCGCGGCGGCAGCGCTAGAAGCGCACCCAT CGGGCACGGCGAGGCGGCCCACGGTGCGGCAGGCACCGGGAGGCGAGAGCCGGCGCGGACAGTAGGCGGCGGCTGCAGCTCGTTGGCGGC TGCTGCGAGGATGCTGCCTGGGCGGCTGTGCTGGGTGCCGCTCCTGCTGGCGCTGGGCGTGGGGAGCGGCAGCGGCGGTGGCGGGGACAG CCGGCAGCGCCGCCTCCTCGCGGCTAAAGTCAATAAGCACAAGCCATGGATCGAGACTTCATATCATGGAGTCATAACTGAGAACAATGA CACAGTCATTTTGGACCCACCACTGGTAGCCCTGGATAAAGATGCACCGGTTCCTTTTGCAGTCCCCAAAGCTCCAGAGATAGATCCAGT AGAGTGTTTGGTGGCAGATAACTCTGTAACAGTGGCTTGGAGAATGCCAGAAGAAGATAATAAGATTGACCATTTTATACTGGAACATAG GAAGACTAATTTTGATGGACTTCCACGTGTAAAGGATGAGCGATGCTGGGAGATAATTGATAATATTAAGGGTACTGAATATACACTATC AGGCTTAAAATTTGATTCAAAGTATATGAATTTCAGAGTGCGAGCTTGTAACAAGGCTGTGGCTGGAGAGTATTCTGATCCAGTGACTCT AGAGACCAAAGCACTTAACTTCAATTTGGATAACTCCTCATCCCATTTGAACCTGAAAGTTGAAGATACATGTGTAGAGTGGGATCCTAC TGGAGGAAAAGGTCAAGAAAGTAAAATTAAAGGAAAAGAGAACAAGGGCAGAAGTGGTACACCATCCCCAAAACGAACATCTGTAGGCTC CAGGCCACCAGCAGTAAGAGGCAGTAGAGATCGTTTTACTGGAGAATCATACACAGTGCTGGGAGACACTGCTATTGAAAGTGGACAACA TTATTGGGAGGTCAAGGCCCAGAAGGATTGTAAATCCTACAGTGTGGGAGTAGCATACAAAACGTTGGGGAAATTTGACCAATTGGGAAA GACAAACACTAGTTGGTGTATCCATGTCAACAACTGGCTACAAAACACATTTGCAGCAAAGCATAATAATAAAGTCAAAGCTTTGGATGT TACTGTTCCTGAAAAAATAGGTGTATTTTGTGATTTTGATGGGGGTCAACTTTCATTCTATGATGCAAATTCTAAACAGTTGCTATATTC CTTTAAGACAAAATTTACTCAGCCAGTACTACCTGGTTTCATGGTATGGTGTGGTGGACTTTCTTTGAGTACTGGGATGCAGGTTCCAAG TGCTGTGAGAACACTTCAGAAAAGTGAAAATGGAATGACTGGTTCAGCTAGCAGCCTGAACAATGTTGTTACTCAATAGTGTCTACTCAG AATACGTTTACCCTCCGTCTTGATTAGGTGGCCTTTTCTGTGCAGTTACTAATCACAGGAATTTGGTAGTAGTGAAAATCA >17353_17353_3_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000481272_length(amino acids)=418AA_BP=81 MAAAARMLPGRLCWVPLLLALGVGSGSGGGGDSRQRRLLAAKVNKHKPWIETSYHGVITENNDTVILDPPLVALDKDAPVPFAVPKAPEI DPVECLVADNSVTVAWRMPEEDNKIDHFILEHRKTNFDGLPRVKDERCWEIIDNIKGTEYTLSGLKFDSKYMNFRVRACNKAVAGEYSDP VTLETKALNFNLDNSSSHLNLKVEDTCVEWDPTGGKGQESKIKGKENKGRSGTPSPKRTSVGSRPPAVRGSRDRFTGESYTVLGDTAIES GQHYWEVKAQKDCKSYSVGVAYKTLGKFDQLGKTNTSWCIHVNNWLQNTFAAKHNNKVKALDVTVPEKIGVFCDFDGGQLSFYDANSKQL LYSFKTKFTQPVLPGFMVWCGGLSLSTGMQVPSAVRTLQKSENGMTGSASSLNNVVTQ -------------------------------------------------------------- >17353_17353_4_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000484973_length(transcript)=1545nt_BP=422nt AGTGAGCGCGGCTGCTGCCGGCGAGCTAGCGGCGCAGCGGCGGGAACCCGAGGCCGAGCGCCGCGGCGGCAGCGCTAGAAGCGCACCCAT CGGGCACGGCGAGGCGGCCCACGGTGCGGCAGGCACCGGGAGGCGAGAGCCGGCGCGGACAGTAGGCGGCGGCTGCAGCTCGTTGGCGGC TGCTGCGAGGATGCTGCCTGGGCGGCTGTGCTGGGTGCCGCTCCTGCTGGCGCTGGGCGTGGGGAGCGGCAGCGGCGGTGGCGGGGACAG CCGGCAGCGCCGCCTCCTCGCGGCTAAAGTCAATAAGCACAAGCCATGGATCGAGACTTCATATCATGGAGTCATAACTGAGAACAATGA CACAGTCATTTTGGACCCACCACTGGTAGCCCTGGATAAAGATGCACCGGTTCCTTTTGCAGTCCCCAAAGCTCCAGAGATAGATCCAGT AGAGTGTTTGGTGGCAGATAACTCTGTAACAGTGGCTTGGAGAATGCCAGAAGAAGATAATAAGATTGACCATTTTATACTGGAACATAG GAAGACTAATTTTGATGGACTTCCACGTGTAAAGGATGAGCGATGCTGGGAGATAATTGATAATATTAAGGGTACTGAATATACACTATC AGGCTTAAAATTTGATTCAAAGTATATGAATTTCAGAGTGCGAGCTTGTAACAAGGCTGTGGCTGGAGAGTATTCTGATCCAGTGACTCT AGAGACCAAAGCACTTAACTTCAATTTGGATAACTCCTCATCCCATTTGAACCTGAAAGTTGAAGATACATGTGTAGAGTGGGATCCTAC TGGAGGAAAAGGTCAAGAAAGTAAAATTAAAGGAAAAGAGAACAAGGGCAGTGGTACACCATCCCCAAAACGAACATCTGTAGGCTCCAG GCCACCAGCAGTAAGAGGCAGTAGAGATCGTTTTACTGGAGAATCATACACAGTGCTGGGAGACACTGCTATTGAAAGTGGACAACATTA TTGGGAGGTCAAGGCCCAGAAGGATTGTAAATCCTACAGTGTGGGAGTAGCATACAAAACGTTGGGGAAATTTGACCAATTGGGAAAGAC AAACACTAGTTGGTGTATCCATGTCAACAACTGGCTACAAAACACATTTGCAGCAAAGCATAATAATAAAGTCAAAGCTTTGGATGTTAC TGTTCCTGAAAAAATAGGTGTATTTTGTGATTTTGATGGGGGTCAACTTTCATTCTATGATGCAAATTCTAAACAGTTGCTATATTCCTT TAAGACAAAATTTACTCAGCCAGTACTACCTGGTTTCATGGTATGGTGTGGTGGACTTTCTTTGAGTACTGGGATGCAGGTTCCAAGTGC TGTGAGAACACTTCAGAAAAGTGAAAATGGAATGACTGGTTCAGCTAGCAGCCTGAACAATGTTGTTACTCAATAGTGTCTACTCAGAAT ACGTTTACCCTCCGTCTTGATTAGGTGGCCTTTTCTGTGCAGTTACTAATCACAGGAATTTGGTAGTAGTGAAAATCAGGTTTGCTGTGT TCTGCTTTGAGGCCT >17353_17353_4_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000484973_length(amino acids)=417AA_BP=81 MAAAARMLPGRLCWVPLLLALGVGSGSGGGGDSRQRRLLAAKVNKHKPWIETSYHGVITENNDTVILDPPLVALDKDAPVPFAVPKAPEI DPVECLVADNSVTVAWRMPEEDNKIDHFILEHRKTNFDGLPRVKDERCWEIIDNIKGTEYTLSGLKFDSKYMNFRVRACNKAVAGEYSDP VTLETKALNFNLDNSSSHLNLKVEDTCVEWDPTGGKGQESKIKGKENKGSGTPSPKRTSVGSRPPAVRGSRDRFTGESYTVLGDTAIESG QHYWEVKAQKDCKSYSVGVAYKTLGKFDQLGKTNTSWCIHVNNWLQNTFAAKHNNKVKALDVTVPEKIGVFCDFDGGQLSFYDANSKQLL YSFKTKFTQPVLPGFMVWCGGLSLSTGMQVPSAVRTLQKSENGMTGSASSLNNVVTQ -------------------------------------------------------------- >17353_17353_5_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000495708_length(transcript)=1317nt_BP=422nt AGTGAGCGCGGCTGCTGCCGGCGAGCTAGCGGCGCAGCGGCGGGAACCCGAGGCCGAGCGCCGCGGCGGCAGCGCTAGAAGCGCACCCAT CGGGCACGGCGAGGCGGCCCACGGTGCGGCAGGCACCGGGAGGCGAGAGCCGGCGCGGACAGTAGGCGGCGGCTGCAGCTCGTTGGCGGC TGCTGCGAGGATGCTGCCTGGGCGGCTGTGCTGGGTGCCGCTCCTGCTGGCGCTGGGCGTGGGGAGCGGCAGCGGCGGTGGCGGGGACAG CCGGCAGCGCCGCCTCCTCGCGGCTAAAGTCAATAAGCACAAGCCATGGATCGAGACTTCATATCATGGAGTCATAACTGAGAACAATGA CACAGTCATTTTGGACCCACCACTGGTAGCCCTGGATAAAGATGCACCGGTTCCTTTTGCAGTCCCCAAAGCTCCAGAGATAGATCCAGT AGAGTGTTTGGTGGCAGATAACTCTGTAACAGTGGCTTGGAGAATGCCAGAAGAAGATAATAAGATTGACCATTTTATACTGGAACATAG GAAGACTAATTTTGATGGACTTCCACGTGTAAAGGATGAGCGATGCTGGGAGATAATTGATAATATTAAGGGTACTGAATATACACTATC AGGCTTAAAATTTGATTCAAAGTATATGAATTTCAGAGTGCGAGCTTGTAACAAGGCTGTGGCTGGAGAGTATTCTGATCCAGTGACTCT AGAGACCAAAGCACTTAACTTCAATTTGGATAACTCCTCATCCCATTTGAACCTGAAAGTTGAAGATACATGTGTAGAGTGGGATCCTAC TGGAGGAAAAGGTCAAGAAAGTAAAATTAAAGGAAAAGAGAACAAGGGCAGTTACAAATTTTTAAAAATTGTTTTTCTGTTATCAAAAGA GCTCTTAATACATTTTGAAGCAGTGCTAAGTGAAATTTTTCTCTTTATTTGTATGACGTTCACTTTCTATTTGTTGCCCTGAGTTACTTG GGAAATATTTTTCAGAATGCATGTTTCCTCTCAGCAGACACTCTGACCACCAGTTGGGGAGGCAAACTATCAGTGTATTTTGAAAAAGTT TCCTGATTGTTTCTGAATCTGCTGTGCCTTTTCAGTTGACAATCATTGATTTATTACAAAATGCCAAAGGCCTTTGTTTTTTCAATTTAG TACTTTGGCTCAGGAAGATACAGGTGTTCCTTAATTGATAGTATCACATACTCTACTCAGCTGAGCTCATTCTAGTCAGATATTGTACAC CTACTCTGTACTGAGGATACAGAGATGAGATGTGGTTCCTAGCAACAGTTAGTTCCC >17353_17353_5_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000495708_length(amino acids)=269AA_BP=81 MAAAARMLPGRLCWVPLLLALGVGSGSGGGGDSRQRRLLAAKVNKHKPWIETSYHGVITENNDTVILDPPLVALDKDAPVPFAVPKAPEI DPVECLVADNSVTVAWRMPEEDNKIDHFILEHRKTNFDGLPRVKDERCWEIIDNIKGTEYTLSGLKFDSKYMNFRVRACNKAVAGEYSDP VTLETKALNFNLDNSSSHLNLKVEDTCVEWDPTGGKGQESKIKGKENKGSYKFLKIVFLLSKELLIHFEAVLSEIFLFICMTFTFYLLP -------------------------------------------------------------- >17353_17353_6_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000539376_length(transcript)=1778nt_BP=422nt AGTGAGCGCGGCTGCTGCCGGCGAGCTAGCGGCGCAGCGGCGGGAACCCGAGGCCGAGCGCCGCGGCGGCAGCGCTAGAAGCGCACCCAT CGGGCACGGCGAGGCGGCCCACGGTGCGGCAGGCACCGGGAGGCGAGAGCCGGCGCGGACAGTAGGCGGCGGCTGCAGCTCGTTGGCGGC TGCTGCGAGGATGCTGCCTGGGCGGCTGTGCTGGGTGCCGCTCCTGCTGGCGCTGGGCGTGGGGAGCGGCAGCGGCGGTGGCGGGGACAG CCGGCAGCGCCGCCTCCTCGCGGCTAAAGTCAATAAGCACAAGCCATGGATCGAGACTTCATATCATGGAGTCATAACTGAGAACAATGA CACAGTCATTTTGGACCCACCACTGGTAGCCCTGGATAAAGATGCACCGGTTCCTTTTGCAGTCCCCAAAGCTCCAGAGATAGATCCAGT AGAGTGTTTGGTGGCAGATAACTCTGTAACAGTGGCTTGGAGAATGCCAGAAGAAGATAATAAGATTGACCATTTTATACTGGAACATAG GAAGACTAATTTTGATGGACTTCCACGTGTAAAGGATGAGCGATGCTGGGAGATAATTGATAATATTAAGGGTACTGAATATACACTATC AGGCTTAAAATTTGATTCAAAGTATATGAATTTCAGAGTGCGAGCTTGTAACAAGGCTGTGGCTGGAGAGTATTCTGATCCAGTGACTCT AGAGACCAAAGCACTTAACTTCAATTTGGATAACTCCTCATCCCATTTGAACCTGAAAGTTGAAGATACATGTGTAGAGTGGGATCCTAC TGGAGGAAAAGGTCAAGAAAGTAAAATTAAAGGAAAAGAGAACAAGGGCAGTGTCCATGTTACTTCACTGAAGAAACATACAAGTGGTAC ACCATCCCCAAAACGAACATCTGTAGGCTCCAGGCCACCAGCAGTAAGAGGCAGTAGAGATCGTTTTACTGGAGAATCATACACAGTGCT GGGAGACACTGCTATTGAAAGTGGACAACATTATTGGGAGGTCAAGGCCCAGAAGGATTGTAAATCCTACAGTGTGGGAGTAGCATACAA AACGTTGGGGAAATTTGACCAATTGGGAAAGACAAACACTAGTTGGTGTATCCATGTCAACAACTGGCTACAAAACACATTTGCAGCAAA GCATAATAATAAAGTCAAAGCTTTGGATGTTACTGTTCCTGAAAAAATAGGTGTATTTTGTGATTTTGATGGGGGTCAACTTTCATTCTA TGATGCAAATTCTAAACAGTTGCTATATTCCTTTAAGACAAAATTTACTCAGCCAGTACTACCTGGTTTCATGGTATGGTGTGGTGGACT TTCTTTGAGTACTGGGATGCAGGTTCCAAGTGCTGTGAGAACACTTCAGAAAAGTGAAAATGGAATGACTGGTTCAGCTAGCAGCCTGAA CAATGTTGTTACTCAATAGTGTCTACTCAGAATACGTTTACCCTCCGTCTTGATTAGGTGGCCTTTTCTGTGCAGTTACTAATCACAGGA ATTTGGTAGTAGTGAAAATCAGGTTTGCTGTGTTCTGCTTTGAGGCCTGGAATCTTTTATCATTAAACACCTAGTACGAAGCATTTGCAG GAACCTACTGTGCAGTATCATAGAAGCAAGCAGATACCAAGCAAAAAACTGATGATTGAAGAGTAAATGGGGGAAAAGGCAGTGTTTAAT TAACATAAAAACTCATTTTTGTATTTCTTGGATTACTTTGACTATTCTAATGTTTAATTACATATGGT >17353_17353_6_CLSTN2-FSD1L_CLSTN2_chr3_139894915_ENST00000458420_FSD1L_chr9_108268679_ENST00000539376_length(amino acids)=428AA_BP=81 MAAAARMLPGRLCWVPLLLALGVGSGSGGGGDSRQRRLLAAKVNKHKPWIETSYHGVITENNDTVILDPPLVALDKDAPVPFAVPKAPEI DPVECLVADNSVTVAWRMPEEDNKIDHFILEHRKTNFDGLPRVKDERCWEIIDNIKGTEYTLSGLKFDSKYMNFRVRACNKAVAGEYSDP VTLETKALNFNLDNSSSHLNLKVEDTCVEWDPTGGKGQESKIKGKENKGSVHVTSLKKHTSGTPSPKRTSVGSRPPAVRGSRDRFTGESY TVLGDTAIESGQHYWEVKAQKDCKSYSVGVAYKTLGKFDQLGKTNTSWCIHVNNWLQNTFAAKHNNKVKALDVTVPEKIGVFCDFDGGQL SFYDANSKQLLYSFKTKFTQPVLPGFMVWCGGLSLSTGMQVPSAVRTLQKSENGMTGSASSLNNVVTQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CLSTN2-FSD1L |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CLSTN2-FSD1L |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CLSTN2-FSD1L |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CLSTN2 | C0023903 | Liver neoplasms | 1 | CTD_human |
| Hgene | CLSTN2 | C0345904 | Malignant neoplasm of liver | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies