
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ARAP3-CTBP2 (FusionGDB2 ID:HG64411TG1488) |
Fusion Gene Summary for ARAP3-CTBP2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ARAP3-CTBP2 | Fusion gene ID: hg64411tg1488 | Hgene | Tgene | Gene symbol | ARAP3 | CTBP2 | Gene ID | 64411 | 1488 |
| Gene name | ArfGAP with RhoGAP domain, ankyrin repeat and PH domain 3 | C-terminal binding protein 2 | |
| Synonyms | CENTD3|DRAG1 | - | |
| Cytomap | ('ARAP3')('CTBP2') 5q31.3 | 10q26.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | arf-GAP with Rho-GAP domain, ANK repeat and PH domain-containing protein 3ARF-GAP, RHO-GAP, ankyrin repeat and plekstrin homology domains-containing protein 3Arf and Rho GAP adapter protein 3PtdIns(3,4,5)P3-binding proteincentaurin-delta-3phosphoinos | C-terminal-binding protein 2ribeye | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | . | P56545 | |
| Ensembl transtripts involved in fusion gene | ENST00000239440, ENST00000508305, ENST00000513878, ENST00000512390, | ||
| Fusion gene scores | * DoF score | 3 X 3 X 3=27 | 11 X 9 X 4=396 |
| # samples | 3 | 13 | |
| ** MAII score | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(13/396*10)=-1.60698880705116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ARAP3 [Title/Abstract] AND CTBP2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ARAP3(141045991)-CTBP2(126678267), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | ARAP3-CTBP2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARAP3-CTBP2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ARAP3-CTBP2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ARAP3-CTBP2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ARAP3-CTBP2 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. ARAP3-CTBP2 seems lost the major protein functional domain in Tgene partner, which is a epigenetic factor due to the frame-shifted ORF. ARAP3-CTBP2 seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ARAP3 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CTBP2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UCEC | TCGA-AP-A5FX-01A | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
Top |
Fusion Gene ORF analysis for ARAP3-CTBP2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000239440 | ENST00000309035 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000239440 | ENST00000334808 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000239440 | ENST00000476817 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000508305 | ENST00000309035 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000508305 | ENST00000334808 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000508305 | ENST00000476817 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000513878 | ENST00000309035 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000513878 | ENST00000334808 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5CDS-intron | ENST00000513878 | ENST00000476817 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5UTR-3CDS | ENST00000512390 | ENST00000337195 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5UTR-3CDS | ENST00000512390 | ENST00000411419 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5UTR-3CDS | ENST00000512390 | ENST00000494626 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5UTR-3CDS | ENST00000512390 | ENST00000531469 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5UTR-intron | ENST00000512390 | ENST00000309035 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5UTR-intron | ENST00000512390 | ENST00000334808 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| 5UTR-intron | ENST00000512390 | ENST00000476817 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| Frame-shift | ENST00000239440 | ENST00000337195 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| Frame-shift | ENST00000239440 | ENST00000411419 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| Frame-shift | ENST00000239440 | ENST00000531469 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| Frame-shift | ENST00000508305 | ENST00000494626 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| Frame-shift | ENST00000513878 | ENST00000494626 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| In-frame | ENST00000239440 | ENST00000494626 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| In-frame | ENST00000508305 | ENST00000337195 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| In-frame | ENST00000508305 | ENST00000411419 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| In-frame | ENST00000508305 | ENST00000531469 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| In-frame | ENST00000513878 | ENST00000337195 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| In-frame | ENST00000513878 | ENST00000411419 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| In-frame | ENST00000513878 | ENST00000531469 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000508305 | ARAP3 | chr5 | 141045991 | - | ENST00000337195 | CTBP2 | chr10 | 126678267 | - | 4375 | 2528 | 34 | 2610 | 858 |
| ENST00000508305 | ARAP3 | chr5 | 141045991 | - | ENST00000531469 | CTBP2 | chr10 | 126678267 | - | 3002 | 2528 | 34 | 2610 | 858 |
| ENST00000508305 | ARAP3 | chr5 | 141045991 | - | ENST00000411419 | CTBP2 | chr10 | 126678267 | - | 3002 | 2528 | 34 | 2610 | 858 |
| ENST00000239440 | ARAP3 | chr5 | 141045991 | - | ENST00000494626 | CTBP2 | chr10 | 126678267 | - | 3112 | 2638 | 66 | 2720 | 884 |
| ENST00000513878 | ARAP3 | chr5 | 141045991 | - | ENST00000337195 | CTBP2 | chr10 | 126678267 | - | 3474 | 1627 | 54 | 1709 | 551 |
| ENST00000513878 | ARAP3 | chr5 | 141045991 | - | ENST00000531469 | CTBP2 | chr10 | 126678267 | - | 2101 | 1627 | 54 | 1709 | 551 |
| ENST00000513878 | ARAP3 | chr5 | 141045991 | - | ENST00000411419 | CTBP2 | chr10 | 126678267 | - | 2101 | 1627 | 54 | 1709 | 551 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000508305 | ENST00000337195 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - | 0.004115798 | 0.9958841 |
| ENST00000508305 | ENST00000531469 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - | 0.015352499 | 0.9846475 |
| ENST00000508305 | ENST00000411419 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - | 0.015352499 | 0.9846475 |
| ENST00000239440 | ENST00000494626 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - | 0.014228651 | 0.9857714 |
| ENST00000513878 | ENST00000337195 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - | 0.05559494 | 0.9444051 |
| ENST00000513878 | ENST00000531469 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - | 0.20850664 | 0.7914934 |
| ENST00000513878 | ENST00000411419 | ARAP3 | chr5 | 141045991 | - | CTBP2 | chr10 | 126678267 | - | 0.20850664 | 0.7914934 |
Top |
Fusion Genomic Features for ARAP3-CTBP2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
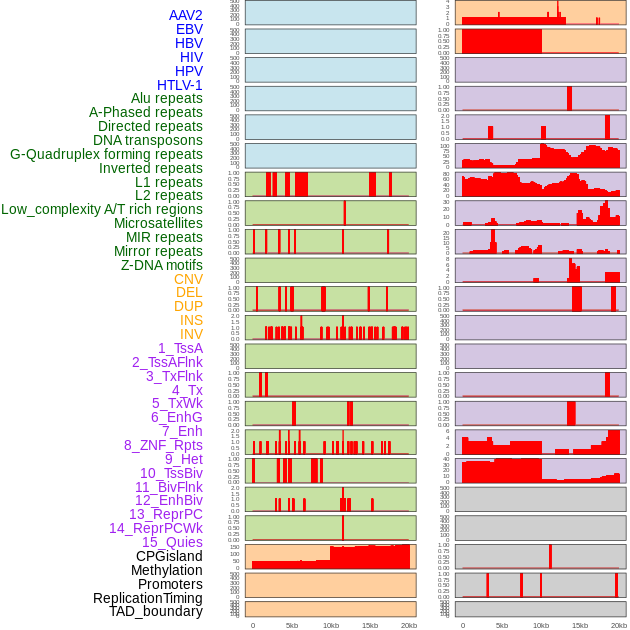 |
Top |
Fusion Protein Features for ARAP3-CTBP2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:141045991/chr10:126678267) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CTBP2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Corepressor targeting diverse transcription regulators. Functions in brown adipose tissue (BAT) differentiation (By similarity). {ECO:0000250}.; FUNCTION: Isoform 2 probably acts as a scaffold for specialized synapses. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 81_139 | 857 | 1545.0 | Compositional bias | Note=Pro-rich |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 287_379 | 857 | 1545.0 | Domain | PH 1 |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 394_483 | 857 | 1545.0 | Domain | PH 2 |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 480_611 | 857 | 1545.0 | Domain | Arf-GAP |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 4_68 | 857 | 1545.0 | Domain | SAM |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 504_527 | 857 | 1545.0 | Zinc finger | C4-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 1462_1542 | 857 | 1545.0 | Compositional bias | Note=Pro-rich |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 1117_1210 | 857 | 1545.0 | Domain | Ras-associating |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 1223_1325 | 857 | 1545.0 | Domain | PH 3 |
| Hgene | ARAP3 | chr5:141045991 | chr10:126678267 | ENST00000239440 | - | 17 | 33 | 907_1088 | 857 | 1545.0 | Domain | Rho-GAP |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000309035 | 7 | 9 | 186_191 | 925 | 986.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000309035 | 7 | 9 | 243_249 | 925 | 986.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000309035 | 7 | 9 | 270_272 | 925 | 986.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000309035 | 7 | 9 | 321_324 | 925 | 986.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000337195 | 9 | 11 | 186_191 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000337195 | 9 | 11 | 243_249 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000337195 | 9 | 11 | 270_272 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000337195 | 9 | 11 | 321_324 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000411419 | 9 | 11 | 186_191 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000411419 | 9 | 11 | 243_249 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000411419 | 9 | 11 | 270_272 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000411419 | 9 | 11 | 321_324 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000494626 | 9 | 11 | 186_191 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000494626 | 9 | 11 | 243_249 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000494626 | 9 | 11 | 270_272 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000494626 | 9 | 11 | 321_324 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000531469 | 9 | 11 | 186_191 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000531469 | 9 | 11 | 243_249 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000531469 | 9 | 11 | 270_272 | 385 | 446.0 | Nucleotide binding | NAD | |
| Tgene | CTBP2 | chr5:141045991 | chr10:126678267 | ENST00000531469 | 9 | 11 | 321_324 | 385 | 446.0 | Nucleotide binding | NAD |
Top |
Fusion Gene Sequence for ARAP3-CTBP2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5773_5773_1_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000239440_CTBP2_chr10_126678267_ENST00000494626_length(transcript)=3112nt_BP=2638nt CTCGGACGAGCGGCGGGCACCCGCGAGCGGACGGCGGCCGCGTAGTGAGCAATGGCCTGAGCCCCCATGGCTGCCCCTCAGGACCTGGAC ATCGCTGTGTGGCTGGCCACGGTGCACCTGGAGCAGTATGCAGACACGTTCCGACGGCATGGCCTGGCTACAGCAGGTGCAGCCCGGGGC CTGGGCCACGAGGAGTTGAAGCAGTTGGGCATCAGCGCCACAGGGCACCGGAAACGCATTCTACGCCTGCTACAGACAGGCACCGAAGAG GGCTCCCTGGATCCCAAATCAGATAGTGCCATGGAACCATCCCCCAGCCCAGCCCCGCAAGCCCAGCCCCCTAAGCCCGTGCCGAAGCCC AGGACCGTGTTTGGTGGACTCAGTGGCCCTGCCACCACTCAGAGACCTGGGCTGAGCCCAGCCCTCGGGGGACCAGGAGTGTCCAGGAGC CCAGAGCCCAGCCCAAGGCCTCCTCCTCTCCCCACTTCCTCCTCTGAGCAGTCTTCAGCCCTAAATACTGTGGAGATGATGCCTAATTCC ATCTACTTCGGCCTGGACTCAAGAGGCAGGGCACAGGCAGCTCAGGACAAGGCCCCAGACAGCTCCCAAATCTCTGCCCCCACCCCTGCC CTCAGGCCCACAACAGGCACAGTGCACATCATGGATCCTGGTTGCCTGTACTATGGTGTCCAACCTGTGGGGACTCCAGGAGCCCCCGAC AGAAGAGAGAGCAGAGGTGTTTGTCAGGGCAGGGCTGAACACAGGCTCAGCAGACAGGATCTGGAGGCACGGGAGGATGCTGGCTATGCC AGCCTTGAGCTACCTGGAGACTCCACCCTCTTATCGCCCACCCTGGAAACAGAGGAGACCAGTGATGACCTCATTTCACCCTATGCCAGC TTCTCCTTCACGGCAGACCGCCTCACGCCCCTGCTCAGTGGCTGGCTAGACAAGCTCTCCCCTCAGGGAAACTATGTCTTCCAGAGACGC TTTGTGCAGTTCAATGGGAGGAGTCTGATGTACTTTGGCAGTGACAAGGACCCCTTCCCTAAGGGTGTGATACCTTTGACTGCCATTGAG ATGACCCGCAGCAGCAAGGACAACAAGTTCCAGGTCATCACCGGCCAGAGGGTGTTCGTGTTCCGCACAGAGAGCGAGGCTCAGCGGGAC ATGTGGTGCTCCACGCTGCAGTCCTGTCTGAAGGAGCAGCGCCTCCTGGGCCACCCCCGGCCCCCCCAACCACCCCGACCCCTCCGCACG GGCATGCTGGAGCTGCGTGGACACAAGGCCAAGGTGTTTGCTGCCTTGAGCCCTGGAGAGCTGGCACTGTACAAGAGTGAGCAGGCCTTC TCTCTGGGCATCGGGATCTGCTTCATCGAACTGCAGGGCTGCAGCGTCCGGGAGACCAAGAGTCGAAGCTTTGACCTGCTCACACCCCAT CGCTGCTTCAGCTTCACAGCCGAGTCTGGGGGTGCTCGGCAGAGCTGGGCGGCCGCTCTGCAGGAAGCAGTAACCGAGACCCTGTCTGAC TACGAGGTGGCTGAGAAGATCTGGTCTAATCGGGCCAACCGGCAGTGTGCGGACTGTGGGTCCTCCCGCCCAGATTGGGCTGCTGTCAAT TTGGGGGTGGTCATCTGCAAGCAGTGTGCAGGTCAGCACCGGGCCCTGGGTTCTGGGATCTCCAAGGTGCAGAGCCTGAAGCTGGACACG AGTGTCTGGAGTAATGAGATAGTACAGTTATTCATTGTCCTGGGAAATGATCGTGCCAACCGCTTCTGGGCAGGGACCCTACCCCCAGGT GAGGGACTACATCCAGATGCGACCCCTGGCCCCCGGGGAGAGTTCATCTCCCGAAAGTACCGTCTGGGTCTCTTCCGGAAGCCCCACCCT CAGTACCCAGATCATAGCCAGCTTCTCCAGGCACTGTGTGCAGCTGTGGCAAGACCCAACCTGCTGAAGAACATGACCCAGCTCCTCTGT GTTGAGGCCTTTGAAGGCGAGGAGCCCTGGTTCCCCCCAGCCCCTGATGGCAGCTGCCCTGGCCTCTTGCCCTCAGACCCCTCCCCTGGT GTGTACAATGAGGTGGTGGTGCGTGCTACTTACAGCGGCTTCCTGTACTGCAGTCCCGTCAGCAACAAAGCTGGACCCTCACCCCCTCGC AGGGGCCGGGATGCTCCCCCGCGCCTTTGGTGTGTGCTGGGAGCAGCTCTGGAAATGTTTGCATCGGAAAACAGCCCTGAACCCCTCAGC CTCATACAGCCCCAGGATATTGTATGTCTGGGTGTGAGCCCCCCACCCACTGACCCAGGTGACAGGTTCCCCTTTTCCTTTGAGCTCATC CTCGCTGGGGGGAGGATCCAGCATTTTGGCACAGATGGAGCTGACAGTCTGGAGGCCTGGACTAGTGCTGTGGGCAAGTGGTTCTCCCCG CTGAGCTGCCACCAGCTGCTGGGCCCCGGGCTGCTGCGGCTGGGCCGCCTATGGCTGCGGTCCCCCTCCCATACAGCCCCGGCCCCTGGT CTCTGGCTGTCAGGGTTTGGCCTCCTTCGTGGTGACCACCTCTTCCTGTGCTCAGCGCCGGGCCCAGGCCCCCCAGCCCCTGAGGACATG GTGCATCTGCGGCGGCTACAGGAGATCAATATCCGCCAGGCATCGTGGGTGTGGCTCCAGGAGGACTTCCTGCAGCCATGGAAGGGATCA TCCCTGGAGGCATCCCAGTGACTCACAACCTCCCGACAGTGGCACATCCTTCCCAAGCGCCCTCTCCCAACCAGCCCACAAAACACGGGG ACAATCGAGAGCACCCCAACGAGCAATAGCAGAGAATGCCAGAAGGTAATCACTCAGATACACTTGGGACCAAGAGACAGTGAAAAATAG ATGAACTAAGAGAAAAAGAATCGGATGGTCTTTGTAACTGATTCTGGACATATGCATCATTGATGTTGCAGTGTTGAAACTACAAGAGCT AGAAAACTGAAGATGTCGTCTGCTTACGGAAGCGCTGAAAGACTAGGATGTGATTTATTAACGACCAACTTCTGTTATTGTGTGTTAAGT TTTTCATCTGTGCATCAAATCACAAAAAGAATAAATAGAGCTTTTTCCTTTA >5773_5773_1_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000239440_CTBP2_chr10_126678267_ENST00000494626_length(amino acids)=884AA_BP=858 MAAPQDLDIAVWLATVHLEQYADTFRRHGLATAGAARGLGHEELKQLGISATGHRKRILRLLQTGTEEGSLDPKSDSAMEPSPSPAPQAQ PPKPVPKPRTVFGGLSGPATTQRPGLSPALGGPGVSRSPEPSPRPPPLPTSSSEQSSALNTVEMMPNSIYFGLDSRGRAQAAQDKAPDSS QISAPTPALRPTTGTVHIMDPGCLYYGVQPVGTPGAPDRRESRGVCQGRAEHRLSRQDLEAREDAGYASLELPGDSTLLSPTLETEETSD DLISPYASFSFTADRLTPLLSGWLDKLSPQGNYVFQRRFVQFNGRSLMYFGSDKDPFPKGVIPLTAIEMTRSSKDNKFQVITGQRVFVFR TESEAQRDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYKSEQAFSLGIGICFIELQGCSVRETKSR SFDLLTPHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPDWAAVNLGVVICKQCAGQHRALGSGISK VQSLKLDTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLFRKPHPQYPDHSQLLQALCAAVARPNLL KNMTQLLCVEAFEGEEPWFPPAPDGSCPGLLPSDPSPGVYNEVVVRATYSGFLYCSPVSNKAGPSPPRRGRDAPPRLWCVLGAALEMFAS ENSPEPLSLIQPQDIVCLGVSPPPTDPGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVGKWFSPLSCHQLLGPGLLRLGRLWLRSP SHTAPAPGLWLSGFGLLRGDHLFLCSAPGPGPPAPEDMVHLRRLQEINIRQASWVWLQEDFLQPWKGSSLEASQ -------------------------------------------------------------- >5773_5773_2_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000508305_CTBP2_chr10_126678267_ENST00000337195_length(transcript)=4375nt_BP=2528nt ACCCGCGAGCGGACGGCGGCCGCGTAGTGAGGACCTGGACATCGCTGTGTGGCTGGCCACGGTGCACCTGGAGCAGTATGCAGACACGTT CCGACGGCATGGCCTGGCTACAGCAGGTGCAGCCCGGGGCCTGGGCCACGAGGAGTTGAAGCAGTTGGGCATCAGCGCCACAGGGCACCG GAAACGCATTCTACGCCTGCTACAGACAGGCACCGAAGAGGGCTCCCTGGATCCCAAATCAGATAGTGCCATGGAACCATCCCCCAGCCC AGCCCCGCAAGCCCAGCCCCCTAAGCCCGTGCCGAAGCCCAGGACCGTGTTTGGTGGACTCAGTGGCCCTGCCACCACTCAGAGACCTGG GCTGAGCCCAGCCCTCGGGGGACCAGGAGTGTCCAGGAGCCCAGAGCCCAGCCCAAGGCCTCCTCCTCTCCCCACTTCCTCCTCTGAGCA GTCTTCAGCCCTAAATACTGTGGAGATGATGCCTAATTCCATCTACTTCGGCCTGGACTCAAGAGGCAGGGCACAGGCAGCTCAGGACAA GGCCCCAGACAGCTCCCAAATCTCTGCCCCCACCCCTGCCCTCAGGCCCACAACAGGCACAGTGCACATCATGGATCCTGGTTGCCTGTA CTATGGTGTCCAACCTGTGGGGACTCCAGGAGCCCCCGACAGAAGAGAGAGCAGAGGTGTTTGTCAGGGCAGGGCTGAACACAGGCTCAG CAGACAGGATCTGGAGGCACGGGAGGATGCTGGCTATGCCAGCCTTGAGCTACCTGGAGACTCCACCCTCTTATCGCCCACCCTGGAAAC AGAGGAGACCAGTGATGACCTCATTTCACCCTATGCCAGCTTCTCCTTCACGGCAGACCGCCTCACGCCCCTGCTCAGTGGCTGGCTAGA CAAGCTCTCCCCTCAGGGAAACTATGTCTTCCAGAGACGCTTTGTGCAGTTCAATGGGAGGAGTCTGATGTACTTTGGCAGTGACAAGGA CCCCTTCCCTAAGGGTGTGATACCTTTGACTGCCATTGAGATGACCCGCAGCAGCAAGGACAACAAGTTCCAGGTCATCACCGGCCAGAG GGTGTTCGTGTTCCGCACAGAGAGCGAGGCTCAGCGGGACATGTGGTGCTCCACGCTGCAGTCCTGTCTGAAGGAGCAGCGCCTCCTGGG CCACCCCCGGCCCCCCCAACCACCCCGACCCCTCCGCACGGGCATGCTGGAGCTGCGTGGACACAAGGCCAAGGTGTTTGCTGCCTTGAG CCCTGGAGAGCTGGCACTGTACAAGAGTGAGCAGGCCTTCTCTCTGGGCATCGGGATCTGCTTCATCGAACTGCAGGGCTGCAGCGTCCG GGAGACCAAGAGTCGAAGCTTTGACCTGCTCACACCCCATCGCTGCTTCAGCTTCACAGCCGAGTCTGGGGGTGCTCGGCAGAGCTGGGC GGCCGCTCTGCAGGAAGCAGTAACCGAGACCCTGTCTGACTACGAGGTGGCTGAGAAGATCTGGTCTAATCGGGCCAACCGGCAGTGTGC GGACTGTGGGTCCTCCCGCCCAGATTGGGCTGCTGTCAATTTGGGGGTGGTCATCTGCAAGCAGTGTGCAGGTCAGCACCGGGCCCTGGG TTCTGGGATCTCCAAGGTGCAGAGCCTGAAGCTGGACACGAGTGTCTGGAGTAATGAGATAGTACAGTTATTCATTGTCCTGGGAAATGA TCGTGCCAACCGCTTCTGGGCAGGGACCCTACCCCCAGGTGAGGGACTACATCCAGATGCGACCCCTGGCCCCCGGGGAGAGTTCATCTC CCGAAAGTACCGTCTGGGTCTCTTCCGGAAGCCCCACCCTCAGTACCCAGATCATAGCCAGCTTCTCCAGGCACTGTGTGCAGCTGTGGC AAGACCCAACCTGCTGAAGAACATGACCCAGCTCCTCTGTGTTGAGGCCTTTGAAGACCCCTCCCCTGGTGTGTACAATGAGGTGGTGGT GCGTGCTACTTACAGCGGCTTCCTGTACTGCAGTCCCGTCAGCAACAAAGCTGGACCCTCACCCCCTCGCAGGGGCCGGGATGCTCCCCC GCGCCTTTGGTGTGTGCTGGGAGCAGCTCTGGAAATGTTTGCATCGGAAAACAGCCCTGAACCCCTCAGCCTCATACAGCCCCAGGATAT TGTATGTCTGGGTGTGAGCCCCCCACCCACTGACCCAGGTGACAGGTTCCCCTTTTCCTTTGAGCTCATCCTCGCTGGGGGGAGGATCCA GCATTTTGGCACAGATGGAGCTGACAGTCTGGAGGCCTGGACTAGTGCTGTGGGCAAGTGGTTCTCCCCGCTGAGCTGCCACCAGCTGCT GGGCCCCGGGCTGCTGCGGCTGGGCCGCCTATGGCTGCGGTCCCCCTCCCATACAGCCCCGGCCCCTGGTCTCTGGCTGTCAGGGTTTGG CCTCCTTCGTGGTGACCACCTCTTCCTGTGCTCAGCGCCGGGCCCAGGCCCCCCAGCCCCTGAGGACATGGTGCATCTGCGGCGGCTACA GGAGATCAATATCCGCCAGGCATCGTGGGTGTGGCTCCAGGAGGACTTCCTGCAGCCATGGAAGGGATCATCCCTGGAGGCATCCCAGTG ACTCACAACCTCCCGACAGTGGCACATCCTTCCCAAGCGCCCTCTCCCAACCAGCCCACAAAACACGGGGACAATCGAGAGCACCCCAAC GAGCAATAGCAGAGAATGCCAGAAGGTAATCACTCAGATACACTTGGGACCAAGAGACAGTGAAAAATAGATGAACTAAGAGAAAAAGAA TCGGATGGTCTTTGTAACTGATTCTGGACATATGCATCATTGATGTTGCAGTGTTGAAACTACAAGAGCTAGAAAACTGAAGATGTCGTC TGCTTACGGAAGCGCTGAAAGACTAGGATGTGATTTATTAACGACCAACTTCTGTTATTGTGTGTTAAGTTTTTCATCTGTGCATCAAAT CACAAAAAGAATAAATAGAGCTTTTTCCTTTATCAGTCCCTTGGGCACAGCAGGTCCTGAACACCCTGCTCTACAATGTTGCATCAAGAG TTCAAACAACAAAATAAAAAATATTAAGAGGAAATCCCCATCCTGTGACTTGAGTCCCTTAAGTCTACAGGGGCTGGTGACCTCTTTTTG CTAATAGGAAAATCACATTACTACAAAATGGGGAGAAAACTGTTTGCCTGTGGTAGACACCTGCACGCATAGGATTGAAGACAGTACAGG CTGCTGTACAGAGAAGCGCCTCTCACATCTGAACTGCATACTGAGCGGGCAAGTCGGTTGTAAGTTCAGTAAAACCCTCTGATGATGCAA AAAAAAAAAAAAAAGTATTAAGTTTCACAAGCTGTTTGTACTCAAATATATTTTCTCAGTTTCAGATCCTCTGCTATTTTATTGAGTGGA AAGTCTTGAGCTAAAAGGGTTCAAGAAGAATAATGTTGCATTTCCTTATGTCTCAGGAAACACTTTTTATGGTAACTTGTCAGATTGTCT ATGAACAAACCCACTTTTTTAGACATTGATAAAGTCTTCTTTTCTTCACGTGATATTTTATACAAGAACACTTCAGATGTATTAGATGTG ACTGATTTTAACAAATCCTATTAGATTTGTATCAACTAGTTACATGTTCTATTCATAGTCTTTTGTGAATCATTGCCTTTTTGTTTAAAA AGATGGCCTATTTTGAGCCTTTGTATAGGTACATTCCTGTTTTTGTGACAAAAGAAAAACTTTAAAATTGTCCCAAACAGAAAAATAATG GCTATCAGAAGTATGTTTTGTTTTAGTGTGAGTTACCGTTACTGTATTTGTTTATTGTAAAGGTGGACATTTAGCGTTCAGTGCAGTTTT CAATAAAAAGTAATTAAAATTTGTTAAGTTCTGAAATTCAAGTACATCTCACTAATGTAAATGTTCTCTACTTGAGATGTTTAAGGCAAT TGCATTGTCAATTAGCCAATTTCCAGCTCTTGTTACTACAGGGTTCCATAACCAGACTCAAGACCGCTGACAATTAATTACCTGTGATAA CAAAAAGTTTAATTGAAAAATCAAAACCTCACACAAGTCCATCATTATCACGTCATGCCATCCTTAAGATGCAATGGTGGGTTAGTGCTA AATCAATTCAAAAAAAAACAAAGTTGCTCAACTTTTAGAGTTCTGACTTTAATCTACCCCAAAGCAAAATGACCTGGACCTGGTTCAAGG GAGGGAAGTGAACCTTGAAACTGTTTTGCCAATAACCTAACAAACAAAATGATATTTACAAAGAAGTGTTGCAAATAGTCCCATGAGTTA AGAGCTTGATTTAATGGATCTTCTTTTTAAATAGAATTAAACCTTTATACTAAAA >5773_5773_2_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000508305_CTBP2_chr10_126678267_ENST00000337195_length(amino acids)=858AA_BP=832 MDIAVWLATVHLEQYADTFRRHGLATAGAARGLGHEELKQLGISATGHRKRILRLLQTGTEEGSLDPKSDSAMEPSPSPAPQAQPPKPVP KPRTVFGGLSGPATTQRPGLSPALGGPGVSRSPEPSPRPPPLPTSSSEQSSALNTVEMMPNSIYFGLDSRGRAQAAQDKAPDSSQISAPT PALRPTTGTVHIMDPGCLYYGVQPVGTPGAPDRRESRGVCQGRAEHRLSRQDLEAREDAGYASLELPGDSTLLSPTLETEETSDDLISPY ASFSFTADRLTPLLSGWLDKLSPQGNYVFQRRFVQFNGRSLMYFGSDKDPFPKGVIPLTAIEMTRSSKDNKFQVITGQRVFVFRTESEAQ RDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYKSEQAFSLGIGICFIELQGCSVRETKSRSFDLLT PHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPDWAAVNLGVVICKQCAGQHRALGSGISKVQSLKL DTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLFRKPHPQYPDHSQLLQALCAAVARPNLLKNMTQL LCVEAFEDPSPGVYNEVVVRATYSGFLYCSPVSNKAGPSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTD PGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVGKWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCS APGPGPPAPEDMVHLRRLQEINIRQASWVWLQEDFLQPWKGSSLEASQ -------------------------------------------------------------- >5773_5773_3_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000508305_CTBP2_chr10_126678267_ENST00000411419_length(transcript)=3002nt_BP=2528nt ACCCGCGAGCGGACGGCGGCCGCGTAGTGAGGACCTGGACATCGCTGTGTGGCTGGCCACGGTGCACCTGGAGCAGTATGCAGACACGTT CCGACGGCATGGCCTGGCTACAGCAGGTGCAGCCCGGGGCCTGGGCCACGAGGAGTTGAAGCAGTTGGGCATCAGCGCCACAGGGCACCG GAAACGCATTCTACGCCTGCTACAGACAGGCACCGAAGAGGGCTCCCTGGATCCCAAATCAGATAGTGCCATGGAACCATCCCCCAGCCC AGCCCCGCAAGCCCAGCCCCCTAAGCCCGTGCCGAAGCCCAGGACCGTGTTTGGTGGACTCAGTGGCCCTGCCACCACTCAGAGACCTGG GCTGAGCCCAGCCCTCGGGGGACCAGGAGTGTCCAGGAGCCCAGAGCCCAGCCCAAGGCCTCCTCCTCTCCCCACTTCCTCCTCTGAGCA GTCTTCAGCCCTAAATACTGTGGAGATGATGCCTAATTCCATCTACTTCGGCCTGGACTCAAGAGGCAGGGCACAGGCAGCTCAGGACAA GGCCCCAGACAGCTCCCAAATCTCTGCCCCCACCCCTGCCCTCAGGCCCACAACAGGCACAGTGCACATCATGGATCCTGGTTGCCTGTA CTATGGTGTCCAACCTGTGGGGACTCCAGGAGCCCCCGACAGAAGAGAGAGCAGAGGTGTTTGTCAGGGCAGGGCTGAACACAGGCTCAG CAGACAGGATCTGGAGGCACGGGAGGATGCTGGCTATGCCAGCCTTGAGCTACCTGGAGACTCCACCCTCTTATCGCCCACCCTGGAAAC AGAGGAGACCAGTGATGACCTCATTTCACCCTATGCCAGCTTCTCCTTCACGGCAGACCGCCTCACGCCCCTGCTCAGTGGCTGGCTAGA CAAGCTCTCCCCTCAGGGAAACTATGTCTTCCAGAGACGCTTTGTGCAGTTCAATGGGAGGAGTCTGATGTACTTTGGCAGTGACAAGGA CCCCTTCCCTAAGGGTGTGATACCTTTGACTGCCATTGAGATGACCCGCAGCAGCAAGGACAACAAGTTCCAGGTCATCACCGGCCAGAG GGTGTTCGTGTTCCGCACAGAGAGCGAGGCTCAGCGGGACATGTGGTGCTCCACGCTGCAGTCCTGTCTGAAGGAGCAGCGCCTCCTGGG CCACCCCCGGCCCCCCCAACCACCCCGACCCCTCCGCACGGGCATGCTGGAGCTGCGTGGACACAAGGCCAAGGTGTTTGCTGCCTTGAG CCCTGGAGAGCTGGCACTGTACAAGAGTGAGCAGGCCTTCTCTCTGGGCATCGGGATCTGCTTCATCGAACTGCAGGGCTGCAGCGTCCG GGAGACCAAGAGTCGAAGCTTTGACCTGCTCACACCCCATCGCTGCTTCAGCTTCACAGCCGAGTCTGGGGGTGCTCGGCAGAGCTGGGC GGCCGCTCTGCAGGAAGCAGTAACCGAGACCCTGTCTGACTACGAGGTGGCTGAGAAGATCTGGTCTAATCGGGCCAACCGGCAGTGTGC GGACTGTGGGTCCTCCCGCCCAGATTGGGCTGCTGTCAATTTGGGGGTGGTCATCTGCAAGCAGTGTGCAGGTCAGCACCGGGCCCTGGG TTCTGGGATCTCCAAGGTGCAGAGCCTGAAGCTGGACACGAGTGTCTGGAGTAATGAGATAGTACAGTTATTCATTGTCCTGGGAAATGA TCGTGCCAACCGCTTCTGGGCAGGGACCCTACCCCCAGGTGAGGGACTACATCCAGATGCGACCCCTGGCCCCCGGGGAGAGTTCATCTC CCGAAAGTACCGTCTGGGTCTCTTCCGGAAGCCCCACCCTCAGTACCCAGATCATAGCCAGCTTCTCCAGGCACTGTGTGCAGCTGTGGC AAGACCCAACCTGCTGAAGAACATGACCCAGCTCCTCTGTGTTGAGGCCTTTGAAGACCCCTCCCCTGGTGTGTACAATGAGGTGGTGGT GCGTGCTACTTACAGCGGCTTCCTGTACTGCAGTCCCGTCAGCAACAAAGCTGGACCCTCACCCCCTCGCAGGGGCCGGGATGCTCCCCC GCGCCTTTGGTGTGTGCTGGGAGCAGCTCTGGAAATGTTTGCATCGGAAAACAGCCCTGAACCCCTCAGCCTCATACAGCCCCAGGATAT TGTATGTCTGGGTGTGAGCCCCCCACCCACTGACCCAGGTGACAGGTTCCCCTTTTCCTTTGAGCTCATCCTCGCTGGGGGGAGGATCCA GCATTTTGGCACAGATGGAGCTGACAGTCTGGAGGCCTGGACTAGTGCTGTGGGCAAGTGGTTCTCCCCGCTGAGCTGCCACCAGCTGCT GGGCCCCGGGCTGCTGCGGCTGGGCCGCCTATGGCTGCGGTCCCCCTCCCATACAGCCCCGGCCCCTGGTCTCTGGCTGTCAGGGTTTGG CCTCCTTCGTGGTGACCACCTCTTCCTGTGCTCAGCGCCGGGCCCAGGCCCCCCAGCCCCTGAGGACATGGTGCATCTGCGGCGGCTACA GGAGATCAATATCCGCCAGGCATCGTGGGTGTGGCTCCAGGAGGACTTCCTGCAGCCATGGAAGGGATCATCCCTGGAGGCATCCCAGTG ACTCACAACCTCCCGACAGTGGCACATCCTTCCCAAGCGCCCTCTCCCAACCAGCCCACAAAACACGGGGACAATCGAGAGCACCCCAAC GAGCAATAGCAGAGAATGCCAGAAGGTAATCACTCAGATACACTTGGGACCAAGAGACAGTGAAAAATAGATGAACTAAGAGAAAAAGAA TCGGATGGTCTTTGTAACTGATTCTGGACATATGCATCATTGATGTTGCAGTGTTGAAACTACAAGAGCTAGAAAACTGAAGATGTCGTC TGCTTACGGAAGCGCTGAAAGACTAGGATGTGATTTATTAACGACCAACTTCTGTTATTGTGTGTTAAGTTTTTCATCTGTGCATCAAAT CACAAAAAGAATAAATAGAGCTTTTTCCTTTA >5773_5773_3_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000508305_CTBP2_chr10_126678267_ENST00000411419_length(amino acids)=858AA_BP=832 MDIAVWLATVHLEQYADTFRRHGLATAGAARGLGHEELKQLGISATGHRKRILRLLQTGTEEGSLDPKSDSAMEPSPSPAPQAQPPKPVP KPRTVFGGLSGPATTQRPGLSPALGGPGVSRSPEPSPRPPPLPTSSSEQSSALNTVEMMPNSIYFGLDSRGRAQAAQDKAPDSSQISAPT PALRPTTGTVHIMDPGCLYYGVQPVGTPGAPDRRESRGVCQGRAEHRLSRQDLEAREDAGYASLELPGDSTLLSPTLETEETSDDLISPY ASFSFTADRLTPLLSGWLDKLSPQGNYVFQRRFVQFNGRSLMYFGSDKDPFPKGVIPLTAIEMTRSSKDNKFQVITGQRVFVFRTESEAQ RDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYKSEQAFSLGIGICFIELQGCSVRETKSRSFDLLT PHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPDWAAVNLGVVICKQCAGQHRALGSGISKVQSLKL DTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLFRKPHPQYPDHSQLLQALCAAVARPNLLKNMTQL LCVEAFEDPSPGVYNEVVVRATYSGFLYCSPVSNKAGPSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTD PGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVGKWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCS APGPGPPAPEDMVHLRRLQEINIRQASWVWLQEDFLQPWKGSSLEASQ -------------------------------------------------------------- >5773_5773_4_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000508305_CTBP2_chr10_126678267_ENST00000531469_length(transcript)=3002nt_BP=2528nt ACCCGCGAGCGGACGGCGGCCGCGTAGTGAGGACCTGGACATCGCTGTGTGGCTGGCCACGGTGCACCTGGAGCAGTATGCAGACACGTT CCGACGGCATGGCCTGGCTACAGCAGGTGCAGCCCGGGGCCTGGGCCACGAGGAGTTGAAGCAGTTGGGCATCAGCGCCACAGGGCACCG GAAACGCATTCTACGCCTGCTACAGACAGGCACCGAAGAGGGCTCCCTGGATCCCAAATCAGATAGTGCCATGGAACCATCCCCCAGCCC AGCCCCGCAAGCCCAGCCCCCTAAGCCCGTGCCGAAGCCCAGGACCGTGTTTGGTGGACTCAGTGGCCCTGCCACCACTCAGAGACCTGG GCTGAGCCCAGCCCTCGGGGGACCAGGAGTGTCCAGGAGCCCAGAGCCCAGCCCAAGGCCTCCTCCTCTCCCCACTTCCTCCTCTGAGCA GTCTTCAGCCCTAAATACTGTGGAGATGATGCCTAATTCCATCTACTTCGGCCTGGACTCAAGAGGCAGGGCACAGGCAGCTCAGGACAA GGCCCCAGACAGCTCCCAAATCTCTGCCCCCACCCCTGCCCTCAGGCCCACAACAGGCACAGTGCACATCATGGATCCTGGTTGCCTGTA CTATGGTGTCCAACCTGTGGGGACTCCAGGAGCCCCCGACAGAAGAGAGAGCAGAGGTGTTTGTCAGGGCAGGGCTGAACACAGGCTCAG CAGACAGGATCTGGAGGCACGGGAGGATGCTGGCTATGCCAGCCTTGAGCTACCTGGAGACTCCACCCTCTTATCGCCCACCCTGGAAAC AGAGGAGACCAGTGATGACCTCATTTCACCCTATGCCAGCTTCTCCTTCACGGCAGACCGCCTCACGCCCCTGCTCAGTGGCTGGCTAGA CAAGCTCTCCCCTCAGGGAAACTATGTCTTCCAGAGACGCTTTGTGCAGTTCAATGGGAGGAGTCTGATGTACTTTGGCAGTGACAAGGA CCCCTTCCCTAAGGGTGTGATACCTTTGACTGCCATTGAGATGACCCGCAGCAGCAAGGACAACAAGTTCCAGGTCATCACCGGCCAGAG GGTGTTCGTGTTCCGCACAGAGAGCGAGGCTCAGCGGGACATGTGGTGCTCCACGCTGCAGTCCTGTCTGAAGGAGCAGCGCCTCCTGGG CCACCCCCGGCCCCCCCAACCACCCCGACCCCTCCGCACGGGCATGCTGGAGCTGCGTGGACACAAGGCCAAGGTGTTTGCTGCCTTGAG CCCTGGAGAGCTGGCACTGTACAAGAGTGAGCAGGCCTTCTCTCTGGGCATCGGGATCTGCTTCATCGAACTGCAGGGCTGCAGCGTCCG GGAGACCAAGAGTCGAAGCTTTGACCTGCTCACACCCCATCGCTGCTTCAGCTTCACAGCCGAGTCTGGGGGTGCTCGGCAGAGCTGGGC GGCCGCTCTGCAGGAAGCAGTAACCGAGACCCTGTCTGACTACGAGGTGGCTGAGAAGATCTGGTCTAATCGGGCCAACCGGCAGTGTGC GGACTGTGGGTCCTCCCGCCCAGATTGGGCTGCTGTCAATTTGGGGGTGGTCATCTGCAAGCAGTGTGCAGGTCAGCACCGGGCCCTGGG TTCTGGGATCTCCAAGGTGCAGAGCCTGAAGCTGGACACGAGTGTCTGGAGTAATGAGATAGTACAGTTATTCATTGTCCTGGGAAATGA TCGTGCCAACCGCTTCTGGGCAGGGACCCTACCCCCAGGTGAGGGACTACATCCAGATGCGACCCCTGGCCCCCGGGGAGAGTTCATCTC CCGAAAGTACCGTCTGGGTCTCTTCCGGAAGCCCCACCCTCAGTACCCAGATCATAGCCAGCTTCTCCAGGCACTGTGTGCAGCTGTGGC AAGACCCAACCTGCTGAAGAACATGACCCAGCTCCTCTGTGTTGAGGCCTTTGAAGACCCCTCCCCTGGTGTGTACAATGAGGTGGTGGT GCGTGCTACTTACAGCGGCTTCCTGTACTGCAGTCCCGTCAGCAACAAAGCTGGACCCTCACCCCCTCGCAGGGGCCGGGATGCTCCCCC GCGCCTTTGGTGTGTGCTGGGAGCAGCTCTGGAAATGTTTGCATCGGAAAACAGCCCTGAACCCCTCAGCCTCATACAGCCCCAGGATAT TGTATGTCTGGGTGTGAGCCCCCCACCCACTGACCCAGGTGACAGGTTCCCCTTTTCCTTTGAGCTCATCCTCGCTGGGGGGAGGATCCA GCATTTTGGCACAGATGGAGCTGACAGTCTGGAGGCCTGGACTAGTGCTGTGGGCAAGTGGTTCTCCCCGCTGAGCTGCCACCAGCTGCT GGGCCCCGGGCTGCTGCGGCTGGGCCGCCTATGGCTGCGGTCCCCCTCCCATACAGCCCCGGCCCCTGGTCTCTGGCTGTCAGGGTTTGG CCTCCTTCGTGGTGACCACCTCTTCCTGTGCTCAGCGCCGGGCCCAGGCCCCCCAGCCCCTGAGGACATGGTGCATCTGCGGCGGCTACA GGAGATCAATATCCGCCAGGCATCGTGGGTGTGGCTCCAGGAGGACTTCCTGCAGCCATGGAAGGGATCATCCCTGGAGGCATCCCAGTG ACTCACAACCTCCCGACAGTGGCACATCCTTCCCAAGCGCCCTCTCCCAACCAGCCCACAAAACACGGGGACAATCGAGAGCACCCCAAC GAGCAATAGCAGAGAATGCCAGAAGGTAATCACTCAGATACACTTGGGACCAAGAGACAGTGAAAAATAGATGAACTAAGAGAAAAAGAA TCGGATGGTCTTTGTAACTGATTCTGGACATATGCATCATTGATGTTGCAGTGTTGAAACTACAAGAGCTAGAAAACTGAAGATGTCGTC TGCTTACGGAAGCGCTGAAAGACTAGGATGTGATTTATTAACGACCAACTTCTGTTATTGTGTGTTAAGTTTTTCATCTGTGCATCAAAT CACAAAAAGAATAAATAGAGCTTTTTCCTTTA >5773_5773_4_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000508305_CTBP2_chr10_126678267_ENST00000531469_length(amino acids)=858AA_BP=832 MDIAVWLATVHLEQYADTFRRHGLATAGAARGLGHEELKQLGISATGHRKRILRLLQTGTEEGSLDPKSDSAMEPSPSPAPQAQPPKPVP KPRTVFGGLSGPATTQRPGLSPALGGPGVSRSPEPSPRPPPLPTSSSEQSSALNTVEMMPNSIYFGLDSRGRAQAAQDKAPDSSQISAPT PALRPTTGTVHIMDPGCLYYGVQPVGTPGAPDRRESRGVCQGRAEHRLSRQDLEAREDAGYASLELPGDSTLLSPTLETEETSDDLISPY ASFSFTADRLTPLLSGWLDKLSPQGNYVFQRRFVQFNGRSLMYFGSDKDPFPKGVIPLTAIEMTRSSKDNKFQVITGQRVFVFRTESEAQ RDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYKSEQAFSLGIGICFIELQGCSVRETKSRSFDLLT PHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPDWAAVNLGVVICKQCAGQHRALGSGISKVQSLKL DTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLFRKPHPQYPDHSQLLQALCAAVARPNLLKNMTQL LCVEAFEDPSPGVYNEVVVRATYSGFLYCSPVSNKAGPSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTD PGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVGKWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCS APGPGPPAPEDMVHLRRLQEINIRQASWVWLQEDFLQPWKGSSLEASQ -------------------------------------------------------------- >5773_5773_5_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000513878_CTBP2_chr10_126678267_ENST00000337195_length(transcript)=3474nt_BP=1627nt ATGGGTCATTGAGCTCTCTCTCTCCAGGACCCCTTCCCTAAGGGTGTGATACCTTTGACTGCCATTGAGATGACCCGCAGCAGCAAGGAC AACAAGTTCCAGGTCATCACCGGCCAGAGGGTGTTCGTGTTCCGCACAGAGAGCGAGGCTCAGCGGGACATGTGGTGCTCCACGCTGCAG TCCTGTCTGAAGGAGCAGCGCCTCCTGGGCCACCCCCGGCCCCCCCAACCACCCCGACCCCTCCGCACGGGCATGCTGGAGCTGCGTGGA CACAAGGCCAAGGTGTTTGCTGCCTTGAGCCCTGGAGAGCTGGCACTGTACAAGAGTGAGCAGGCCTTCTCTCTGGGCATCGGGATCTGC TTCATCGAACTGCAGGGCTGCAGCGTCCGGGAGACCAAGAGTCGAAGCTTTGACCTGCTCACACCCCATCGCTGCTTCAGCTTCACAGCC GAGTCTGGGGGTGCTCGGCAGAGCTGGGCGGCCGCTCTGCAGGAAGCAGTAACCGAGACCCTGTCTGACTACGAGGTGGCTGAGAAGATC TGGTCTAATCGGGCCAACCGGCAGTGTGCGGACTGTGGGTCCTCCCGCCCAGATTGGGCTGCTGTCAATTTGGGGGTGGTCATCTGCAAG CAGTGTGCAGGTCAGCACCGGGCCCTGGGTTCTGGGATCTCCAAGGTGCAGAGCCTGAAGCTGGACACGAGTGTCTGGAGTAATGAGATA GTACAGTTATTCATTGTCCTGGGAAATGATCGTGCCAACCGCTTCTGGGCAGGGACCCTACCCCCAGGTGAGGGACTACATCCAGATGCG ACCCCTGGCCCCCGGGGAGAGTTCATCTCCCGAAAGTACCGTCTGGGTCTCTTCCGGAAGCCCCACCCTCAGTACCCAGATCATAGCCAG CTTCTCCAGGCACTGTGTGCAGCTGTGGCAAGACCCAACCTGCTGAAGAACATGACCCAGCTCCTCTGTGTTGAGGCCTTTGAAGGCGAG GAGCCCTGGTTCCCCCCAGCCCCTGATGGCAGCTGCCCTGGCCTCTTGCCCTCAGACCCCTCCCCTGGTGTGTACAATGAGGTGGTGGTG CGTGCTACTTACAGCGGCTTCCTGTACTGCAGTCCCGTCAGCAACAAAGCTGGACCCTCACCCCCTCGCAGGGGCCGGGATGCTCCCCCG CGCCTTTGGTGTGTGCTGGGAGCAGCTCTGGAAATGTTTGCATCGGAAAACAGCCCTGAACCCCTCAGCCTCATACAGCCCCAGGATATT GTATGTCTGGGTGTGAGCCCCCCACCCACTGACCCAGGTGACAGGTTCCCCTTTTCCTTTGAGCTCATCCTCGCTGGGGGGAGGATCCAG CATTTTGGCACAGATGGAGCTGACAGTCTGGAGGCCTGGACTAGTGCTGTGGGCAAGTGGTTCTCCCCGCTGAGCTGCCACCAGCTGCTG GGCCCCGGGCTGCTGCGGCTGGGCCGCCTATGGCTGCGGTCCCCCTCCCATACAGCCCCGGCCCCTGGTCTCTGGCTGTCAGGGTTTGGC CTCCTTCGTGGTGACCACCTCTTCCTGTGCTCAGCGCCGGGCCCAGGCCCCCCAGCCCCTGAGGACATGGTGCATCTGCGGCGGCTACAG GAGATCAATATCCGCCAGGCATCGTGGGTGTGGCTCCAGGAGGACTTCCTGCAGCCATGGAAGGGATCATCCCTGGAGGCATCCCAGTGA CTCACAACCTCCCGACAGTGGCACATCCTTCCCAAGCGCCCTCTCCCAACCAGCCCACAAAACACGGGGACAATCGAGAGCACCCCAACG AGCAATAGCAGAGAATGCCAGAAGGTAATCACTCAGATACACTTGGGACCAAGAGACAGTGAAAAATAGATGAACTAAGAGAAAAAGAAT CGGATGGTCTTTGTAACTGATTCTGGACATATGCATCATTGATGTTGCAGTGTTGAAACTACAAGAGCTAGAAAACTGAAGATGTCGTCT GCTTACGGAAGCGCTGAAAGACTAGGATGTGATTTATTAACGACCAACTTCTGTTATTGTGTGTTAAGTTTTTCATCTGTGCATCAAATC ACAAAAAGAATAAATAGAGCTTTTTCCTTTATCAGTCCCTTGGGCACAGCAGGTCCTGAACACCCTGCTCTACAATGTTGCATCAAGAGT TCAAACAACAAAATAAAAAATATTAAGAGGAAATCCCCATCCTGTGACTTGAGTCCCTTAAGTCTACAGGGGCTGGTGACCTCTTTTTGC TAATAGGAAAATCACATTACTACAAAATGGGGAGAAAACTGTTTGCCTGTGGTAGACACCTGCACGCATAGGATTGAAGACAGTACAGGC TGCTGTACAGAGAAGCGCCTCTCACATCTGAACTGCATACTGAGCGGGCAAGTCGGTTGTAAGTTCAGTAAAACCCTCTGATGATGCAAA AAAAAAAAAAAAAGTATTAAGTTTCACAAGCTGTTTGTACTCAAATATATTTTCTCAGTTTCAGATCCTCTGCTATTTTATTGAGTGGAA AGTCTTGAGCTAAAAGGGTTCAAGAAGAATAATGTTGCATTTCCTTATGTCTCAGGAAACACTTTTTATGGTAACTTGTCAGATTGTCTA TGAACAAACCCACTTTTTTAGACATTGATAAAGTCTTCTTTTCTTCACGTGATATTTTATACAAGAACACTTCAGATGTATTAGATGTGA CTGATTTTAACAAATCCTATTAGATTTGTATCAACTAGTTACATGTTCTATTCATAGTCTTTTGTGAATCATTGCCTTTTTGTTTAAAAA GATGGCCTATTTTGAGCCTTTGTATAGGTACATTCCTGTTTTTGTGACAAAAGAAAAACTTTAAAATTGTCCCAAACAGAAAAATAATGG CTATCAGAAGTATGTTTTGTTTTAGTGTGAGTTACCGTTACTGTATTTGTTTATTGTAAAGGTGGACATTTAGCGTTCAGTGCAGTTTTC AATAAAAAGTAATTAAAATTTGTTAAGTTCTGAAATTCAAGTACATCTCACTAATGTAAATGTTCTCTACTTGAGATGTTTAAGGCAATT GCATTGTCAATTAGCCAATTTCCAGCTCTTGTTACTACAGGGTTCCATAACCAGACTCAAGACCGCTGACAATTAATTACCTGTGATAAC AAAAAGTTTAATTGAAAAATCAAAACCTCACACAAGTCCATCATTATCACGTCATGCCATCCTTAAGATGCAATGGTGGGTTAGTGCTAA ATCAATTCAAAAAAAAACAAAGTTGCTCAACTTTTAGAGTTCTGACTTTAATCTACCCCAAAGCAAAATGACCTGGACCTGGTTCAAGGG AGGGAAGTGAACCTTGAAACTGTTTTGCCAATAACCTAACAAACAAAATGATATTTACAAAGAAGTGTTGCAAATAGTCCCATGAGTTAA GAGCTTGATTTAATGGATCTTCTTTTTAAATAGAATTAAACCTTTATACTAAAA >5773_5773_5_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000513878_CTBP2_chr10_126678267_ENST00000337195_length(amino acids)=551AA_BP=525 MTAIEMTRSSKDNKFQVITGQRVFVFRTESEAQRDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYK SEQAFSLGIGICFIELQGCSVRETKSRSFDLLTPHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPD WAAVNLGVVICKQCAGQHRALGSGISKVQSLKLDTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLF RKPHPQYPDHSQLLQALCAAVARPNLLKNMTQLLCVEAFEGEEPWFPPAPDGSCPGLLPSDPSPGVYNEVVVRATYSGFLYCSPVSNKAG PSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTDPGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVG KWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCSAPGPGPPAPEDMVHLRRLQEINIRQASWVWLQEDFLQ PWKGSSLEASQ -------------------------------------------------------------- >5773_5773_6_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000513878_CTBP2_chr10_126678267_ENST00000411419_length(transcript)=2101nt_BP=1627nt ATGGGTCATTGAGCTCTCTCTCTCCAGGACCCCTTCCCTAAGGGTGTGATACCTTTGACTGCCATTGAGATGACCCGCAGCAGCAAGGAC AACAAGTTCCAGGTCATCACCGGCCAGAGGGTGTTCGTGTTCCGCACAGAGAGCGAGGCTCAGCGGGACATGTGGTGCTCCACGCTGCAG TCCTGTCTGAAGGAGCAGCGCCTCCTGGGCCACCCCCGGCCCCCCCAACCACCCCGACCCCTCCGCACGGGCATGCTGGAGCTGCGTGGA CACAAGGCCAAGGTGTTTGCTGCCTTGAGCCCTGGAGAGCTGGCACTGTACAAGAGTGAGCAGGCCTTCTCTCTGGGCATCGGGATCTGC TTCATCGAACTGCAGGGCTGCAGCGTCCGGGAGACCAAGAGTCGAAGCTTTGACCTGCTCACACCCCATCGCTGCTTCAGCTTCACAGCC GAGTCTGGGGGTGCTCGGCAGAGCTGGGCGGCCGCTCTGCAGGAAGCAGTAACCGAGACCCTGTCTGACTACGAGGTGGCTGAGAAGATC TGGTCTAATCGGGCCAACCGGCAGTGTGCGGACTGTGGGTCCTCCCGCCCAGATTGGGCTGCTGTCAATTTGGGGGTGGTCATCTGCAAG CAGTGTGCAGGTCAGCACCGGGCCCTGGGTTCTGGGATCTCCAAGGTGCAGAGCCTGAAGCTGGACACGAGTGTCTGGAGTAATGAGATA GTACAGTTATTCATTGTCCTGGGAAATGATCGTGCCAACCGCTTCTGGGCAGGGACCCTACCCCCAGGTGAGGGACTACATCCAGATGCG ACCCCTGGCCCCCGGGGAGAGTTCATCTCCCGAAAGTACCGTCTGGGTCTCTTCCGGAAGCCCCACCCTCAGTACCCAGATCATAGCCAG CTTCTCCAGGCACTGTGTGCAGCTGTGGCAAGACCCAACCTGCTGAAGAACATGACCCAGCTCCTCTGTGTTGAGGCCTTTGAAGGCGAG GAGCCCTGGTTCCCCCCAGCCCCTGATGGCAGCTGCCCTGGCCTCTTGCCCTCAGACCCCTCCCCTGGTGTGTACAATGAGGTGGTGGTG CGTGCTACTTACAGCGGCTTCCTGTACTGCAGTCCCGTCAGCAACAAAGCTGGACCCTCACCCCCTCGCAGGGGCCGGGATGCTCCCCCG CGCCTTTGGTGTGTGCTGGGAGCAGCTCTGGAAATGTTTGCATCGGAAAACAGCCCTGAACCCCTCAGCCTCATACAGCCCCAGGATATT GTATGTCTGGGTGTGAGCCCCCCACCCACTGACCCAGGTGACAGGTTCCCCTTTTCCTTTGAGCTCATCCTCGCTGGGGGGAGGATCCAG CATTTTGGCACAGATGGAGCTGACAGTCTGGAGGCCTGGACTAGTGCTGTGGGCAAGTGGTTCTCCCCGCTGAGCTGCCACCAGCTGCTG GGCCCCGGGCTGCTGCGGCTGGGCCGCCTATGGCTGCGGTCCCCCTCCCATACAGCCCCGGCCCCTGGTCTCTGGCTGTCAGGGTTTGGC CTCCTTCGTGGTGACCACCTCTTCCTGTGCTCAGCGCCGGGCCCAGGCCCCCCAGCCCCTGAGGACATGGTGCATCTGCGGCGGCTACAG GAGATCAATATCCGCCAGGCATCGTGGGTGTGGCTCCAGGAGGACTTCCTGCAGCCATGGAAGGGATCATCCCTGGAGGCATCCCAGTGA CTCACAACCTCCCGACAGTGGCACATCCTTCCCAAGCGCCCTCTCCCAACCAGCCCACAAAACACGGGGACAATCGAGAGCACCCCAACG AGCAATAGCAGAGAATGCCAGAAGGTAATCACTCAGATACACTTGGGACCAAGAGACAGTGAAAAATAGATGAACTAAGAGAAAAAGAAT CGGATGGTCTTTGTAACTGATTCTGGACATATGCATCATTGATGTTGCAGTGTTGAAACTACAAGAGCTAGAAAACTGAAGATGTCGTCT GCTTACGGAAGCGCTGAAAGACTAGGATGTGATTTATTAACGACCAACTTCTGTTATTGTGTGTTAAGTTTTTCATCTGTGCATCAAATC ACAAAAAGAATAAATAGAGCTTTTTCCTTTA >5773_5773_6_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000513878_CTBP2_chr10_126678267_ENST00000411419_length(amino acids)=551AA_BP=525 MTAIEMTRSSKDNKFQVITGQRVFVFRTESEAQRDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYK SEQAFSLGIGICFIELQGCSVRETKSRSFDLLTPHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPD WAAVNLGVVICKQCAGQHRALGSGISKVQSLKLDTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLF RKPHPQYPDHSQLLQALCAAVARPNLLKNMTQLLCVEAFEGEEPWFPPAPDGSCPGLLPSDPSPGVYNEVVVRATYSGFLYCSPVSNKAG PSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTDPGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVG KWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCSAPGPGPPAPEDMVHLRRLQEINIRQASWVWLQEDFLQ PWKGSSLEASQ -------------------------------------------------------------- >5773_5773_7_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000513878_CTBP2_chr10_126678267_ENST00000531469_length(transcript)=2101nt_BP=1627nt ATGGGTCATTGAGCTCTCTCTCTCCAGGACCCCTTCCCTAAGGGTGTGATACCTTTGACTGCCATTGAGATGACCCGCAGCAGCAAGGAC AACAAGTTCCAGGTCATCACCGGCCAGAGGGTGTTCGTGTTCCGCACAGAGAGCGAGGCTCAGCGGGACATGTGGTGCTCCACGCTGCAG TCCTGTCTGAAGGAGCAGCGCCTCCTGGGCCACCCCCGGCCCCCCCAACCACCCCGACCCCTCCGCACGGGCATGCTGGAGCTGCGTGGA CACAAGGCCAAGGTGTTTGCTGCCTTGAGCCCTGGAGAGCTGGCACTGTACAAGAGTGAGCAGGCCTTCTCTCTGGGCATCGGGATCTGC TTCATCGAACTGCAGGGCTGCAGCGTCCGGGAGACCAAGAGTCGAAGCTTTGACCTGCTCACACCCCATCGCTGCTTCAGCTTCACAGCC GAGTCTGGGGGTGCTCGGCAGAGCTGGGCGGCCGCTCTGCAGGAAGCAGTAACCGAGACCCTGTCTGACTACGAGGTGGCTGAGAAGATC TGGTCTAATCGGGCCAACCGGCAGTGTGCGGACTGTGGGTCCTCCCGCCCAGATTGGGCTGCTGTCAATTTGGGGGTGGTCATCTGCAAG CAGTGTGCAGGTCAGCACCGGGCCCTGGGTTCTGGGATCTCCAAGGTGCAGAGCCTGAAGCTGGACACGAGTGTCTGGAGTAATGAGATA GTACAGTTATTCATTGTCCTGGGAAATGATCGTGCCAACCGCTTCTGGGCAGGGACCCTACCCCCAGGTGAGGGACTACATCCAGATGCG ACCCCTGGCCCCCGGGGAGAGTTCATCTCCCGAAAGTACCGTCTGGGTCTCTTCCGGAAGCCCCACCCTCAGTACCCAGATCATAGCCAG CTTCTCCAGGCACTGTGTGCAGCTGTGGCAAGACCCAACCTGCTGAAGAACATGACCCAGCTCCTCTGTGTTGAGGCCTTTGAAGGCGAG GAGCCCTGGTTCCCCCCAGCCCCTGATGGCAGCTGCCCTGGCCTCTTGCCCTCAGACCCCTCCCCTGGTGTGTACAATGAGGTGGTGGTG CGTGCTACTTACAGCGGCTTCCTGTACTGCAGTCCCGTCAGCAACAAAGCTGGACCCTCACCCCCTCGCAGGGGCCGGGATGCTCCCCCG CGCCTTTGGTGTGTGCTGGGAGCAGCTCTGGAAATGTTTGCATCGGAAAACAGCCCTGAACCCCTCAGCCTCATACAGCCCCAGGATATT GTATGTCTGGGTGTGAGCCCCCCACCCACTGACCCAGGTGACAGGTTCCCCTTTTCCTTTGAGCTCATCCTCGCTGGGGGGAGGATCCAG CATTTTGGCACAGATGGAGCTGACAGTCTGGAGGCCTGGACTAGTGCTGTGGGCAAGTGGTTCTCCCCGCTGAGCTGCCACCAGCTGCTG GGCCCCGGGCTGCTGCGGCTGGGCCGCCTATGGCTGCGGTCCCCCTCCCATACAGCCCCGGCCCCTGGTCTCTGGCTGTCAGGGTTTGGC CTCCTTCGTGGTGACCACCTCTTCCTGTGCTCAGCGCCGGGCCCAGGCCCCCCAGCCCCTGAGGACATGGTGCATCTGCGGCGGCTACAG GAGATCAATATCCGCCAGGCATCGTGGGTGTGGCTCCAGGAGGACTTCCTGCAGCCATGGAAGGGATCATCCCTGGAGGCATCCCAGTGA CTCACAACCTCCCGACAGTGGCACATCCTTCCCAAGCGCCCTCTCCCAACCAGCCCACAAAACACGGGGACAATCGAGAGCACCCCAACG AGCAATAGCAGAGAATGCCAGAAGGTAATCACTCAGATACACTTGGGACCAAGAGACAGTGAAAAATAGATGAACTAAGAGAAAAAGAAT CGGATGGTCTTTGTAACTGATTCTGGACATATGCATCATTGATGTTGCAGTGTTGAAACTACAAGAGCTAGAAAACTGAAGATGTCGTCT GCTTACGGAAGCGCTGAAAGACTAGGATGTGATTTATTAACGACCAACTTCTGTTATTGTGTGTTAAGTTTTTCATCTGTGCATCAAATC ACAAAAAGAATAAATAGAGCTTTTTCCTTTA >5773_5773_7_ARAP3-CTBP2_ARAP3_chr5_141045991_ENST00000513878_CTBP2_chr10_126678267_ENST00000531469_length(amino acids)=551AA_BP=525 MTAIEMTRSSKDNKFQVITGQRVFVFRTESEAQRDMWCSTLQSCLKEQRLLGHPRPPQPPRPLRTGMLELRGHKAKVFAALSPGELALYK SEQAFSLGIGICFIELQGCSVRETKSRSFDLLTPHRCFSFTAESGGARQSWAAALQEAVTETLSDYEVAEKIWSNRANRQCADCGSSRPD WAAVNLGVVICKQCAGQHRALGSGISKVQSLKLDTSVWSNEIVQLFIVLGNDRANRFWAGTLPPGEGLHPDATPGPRGEFISRKYRLGLF RKPHPQYPDHSQLLQALCAAVARPNLLKNMTQLLCVEAFEGEEPWFPPAPDGSCPGLLPSDPSPGVYNEVVVRATYSGFLYCSPVSNKAG PSPPRRGRDAPPRLWCVLGAALEMFASENSPEPLSLIQPQDIVCLGVSPPPTDPGDRFPFSFELILAGGRIQHFGTDGADSLEAWTSAVG KWFSPLSCHQLLGPGLLRLGRLWLRSPSHTAPAPGLWLSGFGLLRGDHLFLCSAPGPGPPAPEDMVHLRRLQEINIRQASWVWLQEDFLQ PWKGSSLEASQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ARAP3-CTBP2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ARAP3-CTBP2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ARAP3-CTBP2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ARAP3 | C0019693 | HIV Infections | 1 | CTD_human |
| Hgene | ARAP3 | C4505456 | HIV Coinfection | 1 | CTD_human |
| Tgene | C0007621 | Neoplastic Cell Transformation | 1 | CTD_human | |
| Tgene | C0027626 | Neoplasm Invasiveness | 1 | CTD_human | |
| Tgene | C0033578 | Prostatic Neoplasms | 1 | CTD_human | |
| Tgene | C0376358 | Malignant neoplasm of prostate | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies