
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:SMARCB1-SNW1 (FusionGDB2 ID:HG6598TG22938) |
Fusion Gene Summary for SMARCB1-SNW1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: SMARCB1-SNW1 | Fusion gene ID: hg6598tg22938 | Hgene | Tgene | Gene symbol | SMARCB1 | SNW1 | Gene ID | 6598 | 22938 |
| Gene name | SWI/SNF related, matrix associated, actin dependent regulator of chromatin, subfamily b, member 1 | SNW domain containing 1 | |
| Synonyms | BAF47|CSS3|INI1|MRD15|PPP1R144|RDT|RTPS1|SNF5|SNF5L1|SWNTS1|Sfh1p|Snr1|hSNFS | Bx42|FUN20|NCOA-62|PRPF45|Prp45|SKIIP|SKIP|SKIP1 | |
| Cytomap | ('SMARCB1')('SNW1') 22q11.23|22q11 | 14q24.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily B member 1BRG1-associated factor 47SNF5 homologSWI/SNF-related matrix-associated proteinhSNF5integrase interactor 1 proteinmalignant rhabdoid tumor suppressorprotein | SNW domain-containing protein 1SKI interacting proteinhomolog of Drosophila BX42nuclear protein SkiPnuclear receptor coactivator NCoA-62nuclear receptor coactivator, 62-kDski-interacting protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000263121, ENST00000344921, ENST00000407082, ENST00000407422, ENST00000477836, | ||
| Fusion gene scores | * DoF score | 14 X 15 X 8=1680 | 20 X 9 X 11=1980 |
| # samples | 19 | 22 | |
| ** MAII score | log2(19/1680*10)=-3.14438990933518 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(22/1980*10)=-3.16992500144231 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: SMARCB1 [Title/Abstract] AND SNW1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SMARCB1(24129449)-SNW1(78201355), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | SMARCB1-SNW1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. SMARCB1-SNW1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | SMARCB1 | GO:0006337 | nucleosome disassembly | 8895581 |
| Hgene | SMARCB1 | GO:0006338 | chromatin remodeling | 11726552 |
| Hgene | SMARCB1 | GO:0039692 | single stranded viral RNA replication via double stranded DNA intermediate | 14963118 |
| Hgene | SMARCB1 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 11950834 |
| Hgene | SMARCB1 | GO:0051091 | positive regulation of DNA-binding transcription factor activity | 11950834 |
| Hgene | SMARCB1 | GO:1902661 | positive regulation of glucose mediated signaling pathway | 22368283 |
| Tgene | SNW1 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 14985122 |
| Tgene | SNW1 | GO:0000398 | mRNA splicing, via spliceosome | 15194481|28076346 |
| Tgene | SNW1 | GO:0030511 | positive regulation of transforming growth factor beta receptor signaling pathway | 11278756 |
| Tgene | SNW1 | GO:0043923 | positive regulation by host of viral transcription | 15905409 |
| Tgene | SNW1 | GO:0045892 | negative regulation of transcription, DNA-templated | 10713164|15878163 |
| Tgene | SNW1 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 14985122|19934264 |
| Tgene | SNW1 | GO:0048384 | retinoic acid receptor signaling pathway | 19934264 |
| Tgene | SNW1 | GO:0048385 | regulation of retinoic acid receptor signaling pathway | 14985122 |
| Tgene | SNW1 | GO:0070562 | regulation of vitamin D receptor signaling pathway | 14985122 |
| Tgene | SNW1 | GO:0070564 | positive regulation of vitamin D receptor signaling pathway | 9632709|11514567 |
| Tgene | SNW1 | GO:0071300 | cellular response to retinoic acid | 19934264 |
| Fusion gene breakpoints across SMARCB1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SNW1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
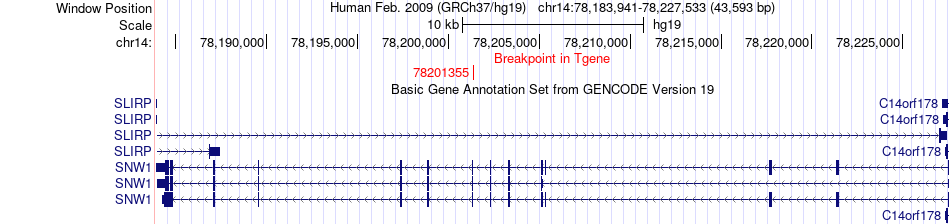 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-UY-A9PE-01A | SMARCB1 | chr22 | 24129449 | - | SNW1 | chr14 | 78201355 | - |
| ChimerDB4 | BLCA | TCGA-UY-A9PE-01A | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
Top |
Fusion Gene ORF analysis for SMARCB1-SNW1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000263121 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000263121 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000263121 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000344921 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000344921 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000344921 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000407082 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000407082 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000407082 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000407422 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000407422 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| In-frame | ENST00000407422 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| intron-3CDS | ENST00000477836 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| intron-3CDS | ENST00000477836 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| intron-3CDS | ENST00000477836 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000344921 | SMARCB1 | chr22 | 24129449 | + | ENST00000261531 | SNW1 | chr14 | 78201355 | - | 1692 | 300 | 207 | 1202 | 331 |
| ENST00000344921 | SMARCB1 | chr22 | 24129449 | + | ENST00000554775 | SNW1 | chr14 | 78201355 | - | 1663 | 300 | 207 | 1202 | 331 |
| ENST00000344921 | SMARCB1 | chr22 | 24129449 | + | ENST00000555761 | SNW1 | chr14 | 78201355 | - | 1418 | 300 | 207 | 1307 | 366 |
| ENST00000263121 | SMARCB1 | chr22 | 24129449 | + | ENST00000261531 | SNW1 | chr14 | 78201355 | - | 1681 | 289 | 196 | 1191 | 331 |
| ENST00000263121 | SMARCB1 | chr22 | 24129449 | + | ENST00000554775 | SNW1 | chr14 | 78201355 | - | 1652 | 289 | 196 | 1191 | 331 |
| ENST00000263121 | SMARCB1 | chr22 | 24129449 | + | ENST00000555761 | SNW1 | chr14 | 78201355 | - | 1407 | 289 | 196 | 1296 | 366 |
| ENST00000407422 | SMARCB1 | chr22 | 24129449 | + | ENST00000261531 | SNW1 | chr14 | 78201355 | - | 1661 | 269 | 176 | 1171 | 331 |
| ENST00000407422 | SMARCB1 | chr22 | 24129449 | + | ENST00000554775 | SNW1 | chr14 | 78201355 | - | 1632 | 269 | 176 | 1171 | 331 |
| ENST00000407422 | SMARCB1 | chr22 | 24129449 | + | ENST00000555761 | SNW1 | chr14 | 78201355 | - | 1387 | 269 | 176 | 1276 | 366 |
| ENST00000407082 | SMARCB1 | chr22 | 24129449 | + | ENST00000261531 | SNW1 | chr14 | 78201355 | - | 1644 | 252 | 159 | 1154 | 331 |
| ENST00000407082 | SMARCB1 | chr22 | 24129449 | + | ENST00000554775 | SNW1 | chr14 | 78201355 | - | 1615 | 252 | 159 | 1154 | 331 |
| ENST00000407082 | SMARCB1 | chr22 | 24129449 | + | ENST00000555761 | SNW1 | chr14 | 78201355 | - | 1370 | 252 | 159 | 1259 | 366 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000344921 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000387265 | 0.99961275 |
| ENST00000344921 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000422942 | 0.9995771 |
| ENST00000344921 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.00109637 | 0.99890363 |
| ENST00000263121 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000378695 | 0.9996213 |
| ENST00000263121 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000420478 | 0.9995795 |
| ENST00000263121 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.001065663 | 0.9989343 |
| ENST00000407422 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000364744 | 0.9996352 |
| ENST00000407422 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000409369 | 0.9995907 |
| ENST00000407422 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.001058415 | 0.9989416 |
| ENST00000407082 | ENST00000261531 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000378673 | 0.9996213 |
| ENST00000407082 | ENST00000554775 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.000412562 | 0.9995875 |
| ENST00000407082 | ENST00000555761 | SMARCB1 | chr22 | 24129449 | + | SNW1 | chr14 | 78201355 | - | 0.001066436 | 0.9989336 |
Top |
Fusion Genomic Features for SMARCB1-SNW1 |
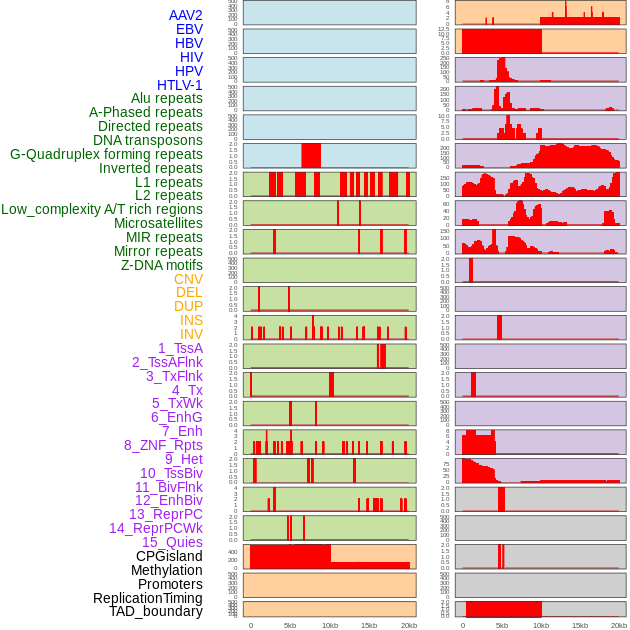
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for SMARCB1-SNW1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:24129449/chr14:78201355) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000263121 | + | 1 | 9 | 183_243 | 31 | 386.0 | Region | Note=HIV-1 integrase-binding |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000263121 | + | 1 | 9 | 186_245 | 31 | 386.0 | Region | MYC-binding |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000263121 | + | 1 | 9 | 186_319 | 31 | 386.0 | Region | Note=2 X approximate tandem repeats |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000263121 | + | 1 | 9 | 1_113 | 31 | 386.0 | Region | DNA-binding |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000407422 | + | 1 | 9 | 183_243 | 31 | 377.0 | Region | Note=HIV-1 integrase-binding |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000407422 | + | 1 | 9 | 186_245 | 31 | 377.0 | Region | MYC-binding |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000407422 | + | 1 | 9 | 186_319 | 31 | 377.0 | Region | Note=2 X approximate tandem repeats |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000407422 | + | 1 | 9 | 1_113 | 31 | 377.0 | Region | DNA-binding |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000263121 | + | 1 | 9 | 259_319 | 31 | 386.0 | Repeat | Note=2 |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000407422 | + | 1 | 9 | 259_319 | 31 | 377.0 | Repeat | Note=2 |
| Tgene | SNW1 | chr22:24129449 | chr14:78201355 | ENST00000261531 | 6 | 14 | 219_233 | 236 | 537.0 | Compositional bias | Note=Pro-rich | |
| Tgene | SNW1 | chr22:24129449 | chr14:78201355 | ENST00000261531 | 6 | 14 | 174_339 | 236 | 537.0 | Region | Note=SNW |
Top |
Fusion Gene Sequence for SMARCB1-SNW1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >83932_83932_1_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000263121_SNW1_chr14_78201355_ENST00000261531_length(transcript)=1681nt_BP=289nt CTGCGCACTGAGGGCGGCCTGGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCA TTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCC CGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTT CTACATGATCGGCTCCGAGATGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTA TACAATTCCATTAGACAAACGTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGC CCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACA TGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACG TGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACT TCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAG GCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGG TAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAA CAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGG TTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGG CAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAAC ACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGGGGATAGAAAAT TCTACTTTGAATTATTTAGTTTTTTTTAAAGAGTGGGTTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACATGCTGCCCCACA TACAAAGTCAAGACCACTTACTTTTATGTGACACTAGTAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGAGTAAAGTTACC CCAACCACAGTGAGGAGGAAGATGTTCACATACTGGAACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTTTAATTTGGAGT GGGCAAAGTAACCTCTTGCTTGGTGCAACTATTTGTTTCAAATAAAAACATTTAGACAAAA >83932_83932_1_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000263121_SNW1_chr14_78201355_ENST00000261531_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_2_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000263121_SNW1_chr14_78201355_ENST00000554775_length(transcript)=1652nt_BP=289nt CTGCGCACTGAGGGCGGCCTGGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCA TTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCC CGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTT CTACATGATCGGCTCCGAGATGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTA TACAATTCCATTAGACAAACGTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGC CCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACA TGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACG TGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACT TCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAG GCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGG TAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAA CAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGG TTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGG CAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAAC ACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGGGGATAGAAAAT TCTACTTTGAATTATTTAGTTTTTTTTAAAGAGTGGGTTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACATGCTGCCCCACA TACAAAGTCAAGACCACTTACTTTTATGTGACACTAGTAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGAGTAAAGTTACC CCAACCACAGTGAGGAGGAAGATGTTCACATACTGGAACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTTTAATTTGGAGT GGGCAAAGTAACCTCTTGCTTGGTGCAACTAT >83932_83932_2_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000263121_SNW1_chr14_78201355_ENST00000554775_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_3_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000263121_SNW1_chr14_78201355_ENST00000555761_length(transcript)=1407nt_BP=289nt CTGCGCACTGAGGGCGGCCTGGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCA TTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCC CGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTT CTACATGATCGGCTCCGAGATGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTA TACAATTCCATTAGACAAACGTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGC CCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACA TGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACG TGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACT TCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAG GCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGG TAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAA CAGGTGCCAAGCCATACAACTCAATTTCAGTGTTTACACTGGTGAAAGCAAAGTAGTTCATAGTTTTTTCTCCTTTTCCTTAGATTTGTT CCCGACAAGGAGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGGTTTGGACAAG TTTTTGGAAGAAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGGCAAGAAGAGG AGGAAGGAATAGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAACACTTTGTAAA TGGTCAGGATAAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTG >83932_83932_3_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000263121_SNW1_chr14_78201355_ENST00000555761_length(amino acids)=366AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRCQAI QLNFSVYTGESKVVHSFFSFSLDLFPTRSFLVQTVDREAEKDQCSLRKILLVWTSFWKKPNSMVALKDPQIAAAPRNTSMKARRGGRNRH RSLQSE -------------------------------------------------------------- >83932_83932_4_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000344921_SNW1_chr14_78201355_ENST00000261531_length(transcript)=1692nt_BP=300nt AACGCCAGCGCCTGCGCACTGAGGGCGGCCTGGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGG CCCGGTCCGCATTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGG CTCCGGCCGCCCGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGAC GACGGCGAGTTCTACATGATCGGCTCCGAGATGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAAT GCAAAGGGTTATACAATTCCATTAGACAAACGTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAA TTGGCAGAAGCCCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAA AAGGAAAAACATGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGAT GGGGAGGCACGTGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAG AGGTCGAAACTTCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAG TATGACCAAAGGCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCC TGGAGAGGTGGTAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGA ATAAAGACCAACAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAA GATCCTTTTGGTTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACAC GAGCATGAAGGCAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCA TATGGGGGAACACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGG GGATAGAAAATTCTACTTTGAATTATTTAGTTTTTTTTAAAGAGTGGGTTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACAT GCTGCCCCACATACAAAGTCAAGACCACTTACTTTTATGTGACACTAGTAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGA GTAAAGTTACCCCAACCACAGTGAGGAGGAAGATGTTCACATACTGGAACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTT TAATTTGGAGTGGGCAAAGTAACCTCTTGCTTGGTGCAACTATTTGTTTCAAATAAAAACATTTAGACAAAA >83932_83932_4_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000344921_SNW1_chr14_78201355_ENST00000261531_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_5_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000344921_SNW1_chr14_78201355_ENST00000554775_length(transcript)=1663nt_BP=300nt AACGCCAGCGCCTGCGCACTGAGGGCGGCCTGGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGG CCCGGTCCGCATTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGG CTCCGGCCGCCCGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGAC GACGGCGAGTTCTACATGATCGGCTCCGAGATGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAAT GCAAAGGGTTATACAATTCCATTAGACAAACGTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAA TTGGCAGAAGCCCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAA AAGGAAAAACATGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGAT GGGGAGGCACGTGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAG AGGTCGAAACTTCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAG TATGACCAAAGGCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCC TGGAGAGGTGGTAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGA ATAAAGACCAACAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAA GATCCTTTTGGTTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACAC GAGCATGAAGGCAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCA TATGGGGGAACACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGG GGATAGAAAATTCTACTTTGAATTATTTAGTTTTTTTTAAAGAGTGGGTTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACAT GCTGCCCCACATACAAAGTCAAGACCACTTACTTTTATGTGACACTAGTAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGA GTAAAGTTACCCCAACCACAGTGAGGAGGAAGATGTTCACATACTGGAACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTT TAATTTGGAGTGGGCAAAGTAACCTCTTGCTTGGTGCAACTAT >83932_83932_5_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000344921_SNW1_chr14_78201355_ENST00000554775_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_6_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000344921_SNW1_chr14_78201355_ENST00000555761_length(transcript)=1418nt_BP=300nt AACGCCAGCGCCTGCGCACTGAGGGCGGCCTGGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGG CCCGGTCCGCATTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGG CTCCGGCCGCCCGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGAC GACGGCGAGTTCTACATGATCGGCTCCGAGATGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAAT GCAAAGGGTTATACAATTCCATTAGACAAACGTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAA TTGGCAGAAGCCCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAA AAGGAAAAACATGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGAT GGGGAGGCACGTGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAG AGGTCGAAACTTCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAG TATGACCAAAGGCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCC TGGAGAGGTGGTAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGA ATAAAGACCAACAGGTGCCAAGCCATACAACTCAATTTCAGTGTTTACACTGGTGAAAGCAAAGTAGTTCATAGTTTTTTCTCCTTTTCC TTAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTG GTTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAG GCAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAA CACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTG >83932_83932_6_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000344921_SNW1_chr14_78201355_ENST00000555761_length(amino acids)=366AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRCQAI QLNFSVYTGESKVVHSFFSFSLDLFPTRSFLVQTVDREAEKDQCSLRKILLVWTSFWKKPNSMVALKDPQIAAAPRNTSMKARRGGRNRH RSLQSE -------------------------------------------------------------- >83932_83932_7_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407082_SNW1_chr14_78201355_ENST00000261531_length(transcript)=1644nt_BP=252nt GCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCATTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCAC GCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCCCGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGC AAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTTCTACATGATCGGCTCCGAGATGACTGTAAAGGAACAA CAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTATACAATTCCATTAGACAAACGTCTGGCTGCTGATGGA AGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGCCCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTG GAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACATGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGG GAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACGTGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAG AGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACTTCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATT GCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAGGCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTT GCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGGTAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAA AATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAACAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGAC CGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGGTTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGT GGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGGCAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCA AAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAACACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGT GCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGGGGATAGAAAATTCTACTTTGAATTATTTAGTTTTTTTTAAAGAGTGGG TTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACATGCTGCCCCACATACAAAGTCAAGACCACTTACTTTTATGTGACACTAG TAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGAGTAAAGTTACCCCAACCACAGTGAGGAGGAAGATGTTCACATACTGGA ACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTTTAATTTGGAGTGGGCAAAGTAACCTCTTGCTTGGTGCAACTATTTGTT TCAAATAAAAACATTTAGACAAAA >83932_83932_7_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407082_SNW1_chr14_78201355_ENST00000261531_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_8_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407082_SNW1_chr14_78201355_ENST00000554775_length(transcript)=1615nt_BP=252nt GCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCATTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCAC GCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCCCGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGC AAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTTCTACATGATCGGCTCCGAGATGACTGTAAAGGAACAA CAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTATACAATTCCATTAGACAAACGTCTGGCTGCTGATGGA AGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGCCCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTG GAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACATGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGG GAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACGTGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAG AGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACTTCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATT GCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAGGCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTT GCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGGTAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAA AATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAACAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGAC CGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGGTTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGT GGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGGCAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCA AAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAACACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGT GCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGGGGATAGAAAATTCTACTTTGAATTATTTAGTTTTTTTTAAAGAGTGGG TTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACATGCTGCCCCACATACAAAGTCAAGACCACTTACTTTTATGTGACACTAG TAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGAGTAAAGTTACCCCAACCACAGTGAGGAGGAAGATGTTCACATACTGGA ACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTTTAATTTGGAGTGGGCAAAGTAACCTCTTGCTTGGTGCAACTAT >83932_83932_8_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407082_SNW1_chr14_78201355_ENST00000554775_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_9_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407082_SNW1_chr14_78201355_ENST00000555761_length(transcript)=1370nt_BP=252nt GCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCATTTCGCCTTCCGGCTTCGGTTTCCCTCGGCCCAGCAC GCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCCCGCCTCTGCCGCCGCAATGATGATGATGGCGCTGAGC AAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTTCTACATGATCGGCTCCGAGATGACTGTAAAGGAACAA CAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTATACAATTCCATTAGACAAACGTCTGGCTGCTGATGGA AGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGCCCTCTACATTGCTGATCGGAAGGCTCGTGAAGCTGTG GAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACATGAAGAGAAACTTAGAGAAATGGCCCAGAAAGCCAGG GAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACGTGAGAGGGATGAAATCCGGCATGACAGGCGAAAAGAG AGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACTTCAGAGAAATGAAAATCGGGATATCAGTGAAGTTATT GCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAGGCTCTTCAACCAATCCAAGGGTATGGACAGTGGATTT GCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGGTAAAGATATGGCCCAGAGTATTTATAGGCCCAGTAAA AATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAACAGGTGCCAAGCCATACAACTCAATTTCAGTGTTTAC ACTGGTGAAAGCAAAGTAGTTCATAGTTTTTTCTCCTTTTCCTTAGATTTGTTCCCGACAAGGAGTTTTCTGGTTCAGACCGTAGACAGA GAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGGTTTGGACAAGTTTTTGGAAGAAGCCAAACAGCATGGTGGCTCTAAAA GACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGGCAAGAAGAGGAGGAAGGAATAGGCACAGGTCTCTCCAAAGTGAATGA ACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAACACTTTGTAAATGGTCAGGATAAAAACCAAATCTGGGTGCCAGATCCC AGCACTACTTTTTATTACTG >83932_83932_9_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407082_SNW1_chr14_78201355_ENST00000555761_length(amino acids)=366AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRCQAI QLNFSVYTGESKVVHSFFSFSLDLFPTRSFLVQTVDREAEKDQCSLRKILLVWTSFWKKPNSMVALKDPQIAAAPRNTSMKARRGGRNRH RSLQSE -------------------------------------------------------------- >83932_83932_10_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407422_SNW1_chr14_78201355_ENST00000261531_length(transcript)=1661nt_BP=269nt GGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCATTTCGCCTTCCGGCTTCGGT TTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCCCGCCTCTGCCGCCGCAATGA TGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTTCTACATGATCGGCTCCGAGA TGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTATACAATTCCATTAGACAAAC GTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGCCCTCTACATTGCTGATCGGA AGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACATGAAGAGAAACTTAGAGAAA TGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACGTGAGAGGGATGAAATCCGGC ATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACTTCAGAGAAATGAAAATCGGG ATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAGGCTCTTCAACCAATCCAAGG GTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGGTAAAGATATGGCCCAGAGTA TTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAACAGATTTGTTCCCGACAAGG AGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGGTTTGGACAAGTTTTTGGAAG AAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGGCAAGAAGAGGAGGAAGGAAT AGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAACACTTTGTAAATGGTCAGGAT AAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGGGGATAGAAAATTCTACTTTGAATTATTTAGT TTTTTTTAAAGAGTGGGTTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACATGCTGCCCCACATACAAAGTCAAGACCACTTA CTTTTATGTGACACTAGTAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGAGTAAAGTTACCCCAACCACAGTGAGGAGGAA GATGTTCACATACTGGAACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTTTAATTTGGAGTGGGCAAAGTAACCTCTTGCT TGGTGCAACTATTTGTTTCAAATAAAAACATTTAGACAAAA >83932_83932_10_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407422_SNW1_chr14_78201355_ENST00000261531_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_11_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407422_SNW1_chr14_78201355_ENST00000554775_length(transcript)=1632nt_BP=269nt GGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCATTTCGCCTTCCGGCTTCGGT TTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCCCGCCTCTGCCGCCGCAATGA TGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTTCTACATGATCGGCTCCGAGA TGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTATACAATTCCATTAGACAAAC GTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGCCCTCTACATTGCTGATCGGA AGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACATGAAGAGAAACTTAGAGAAA TGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACGTGAGAGGGATGAAATCCGGC ATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACTTCAGAGAAATGAAAATCGGG ATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAGGCTCTTCAACCAATCCAAGG GTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGGTAAAGATATGGCCCAGAGTA TTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAACAGATTTGTTCCCGACAAGG AGTTTTCTGGTTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGGTTTGGACAAGTTTTTGGAAG AAGCCAAACAGCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGGCAAGAAGAGGAGGAAGGAAT AGGCACAGGTCTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAACACTTTGTAAATGGTCAGGAT AAAAACCAAATCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTGGAGAAATGGGGGGGATAGAAAATTCTACTTTGAATTATTTAGT TTTTTTTAAAGAGTGGGTTGTGTTTGTGCTTCTCCCACCTTTCAGCATTTATAGAACATGCTGCCCCACATACAAAGTCAAGACCACTTA CTTTTATGTGACACTAGTAGTTTGGGGTTAATGTTTTGTGTAAGAACAGCTGCATATGAGTAAAGTTACCCCAACCACAGTGAGGAGGAA GATGTTCACATACTGGAACTGTCCTGCCAAATAAATTTTGCCCCTATTGTGCTCTGTTTTAATTTGGAGTGGGCAAAGTAACCTCTTGCT TGGTGCAACTAT >83932_83932_11_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407422_SNW1_chr14_78201355_ENST00000554775_length(amino acids)=331AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRFVPD KEFSGSDRRQRGREGPVQFEEDPFGLDKFLEEAKQHGGSKRPSDSSRPKEHEHEGKKRRKE -------------------------------------------------------------- >83932_83932_12_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407422_SNW1_chr14_78201355_ENST00000555761_length(transcript)=1387nt_BP=269nt GGTCGTCGTCTGCGGCGGCGGCGGCGGCTGAGGAGCCCGGCTGAGGCGCCAGTACCCGGCCCGGTCCGCATTTCGCCTTCCGGCTTCGGT TTCCCTCGGCCCAGCACGCCCCGGCCCCGCCCCAGCCCTCCTGATCCCTCGCAGCCCGGCTCCGGCCGCCCGCCTCTGCCGCCGCAATGA TGATGATGGCGCTGAGCAAGACCTTCGGGCAGAAGCCCGTGAAGTTCCAGCTGGAGGACGACGGCGAGTTCTACATGATCGGCTCCGAGA TGACTGTAAAGGAACAACAAGAGTGGAAGATTCCTCCTTGTATTTCTAACTGGAAAAATGCAAAGGGTTATACAATTCCATTAGACAAAC GTCTGGCTGCTGATGGAAGAGGACTACAGACAGTACACATAAATGAAAATTTCGCCAAATTGGCAGAAGCCCTCTACATTGCTGATCGGA AGGCTCGTGAAGCTGTGGAAATGCGTGCCCAAGTAGAGAGAAAAATGGCTCAGAAAGAAAAGGAAAAACATGAAGAGAAACTTAGAGAAA TGGCCCAGAAAGCCAGGGAGAGAAGAGCTGGGATCAAAACTCATGTGGAAAAAGAGGATGGGGAGGCACGTGAGAGGGATGAAATCCGGC ATGACAGGCGAAAAGAGAGACAGCATGACCGGAATCTTTCCAGGGCAGCTCCTGATAAGAGGTCGAAACTTCAGAGAAATGAAAATCGGG ATATCAGTGAAGTTATTGCTCTCGGTGTTCCTAATCCTCGGACTTCCAATGAAGTTCAGTATGACCAAAGGCTCTTCAACCAATCCAAGG GTATGGACAGTGGATTTGCAGGTGGAGAAGATGAAATTTATAATGTTTATGATCAAGCCTGGAGAGGTGGTAAAGATATGGCCCAGAGTA TTTATAGGCCCAGTAAAAATCTGGACAAGGACATGTATGGTGATGACCTAGAAGCCAGAATAAAGACCAACAGGTGCCAAGCCATACAAC TCAATTTCAGTGTTTACACTGGTGAAAGCAAAGTAGTTCATAGTTTTTTCTCCTTTTCCTTAGATTTGTTCCCGACAAGGAGTTTTCTGG TTCAGACCGTAGACAGAGAGGCCGAGAAGGACCAGTGCAGTTTGAGGAAGATCCTTTTGGTTTGGACAAGTTTTTGGAAGAAGCCAAACA GCATGGTGGCTCTAAAAGACCCTCAGATAGCAGCCGCCCCAAGGAACACGAGCATGAAGGCAAGAAGAGGAGGAAGGAATAGGCACAGGT CTCTCCAAAGTGAATGAACTCTTACCCATAACCCTAATGATGCAAGTCATATGGGGGAACACTTTGTAAATGGTCAGGATAAAAACCAAA TCTGGGTGCCAGATCCCAGCACTACTTTTTATTACTG >83932_83932_12_SMARCB1-SNW1_SMARCB1_chr22_24129449_ENST00000407422_SNW1_chr14_78201355_ENST00000555761_length(amino acids)=366AA_BP=29 MMMMALSKTFGQKPVKFQLEDDGEFYMIGSEMTVKEQQEWKIPPCISNWKNAKGYTIPLDKRLAADGRGLQTVHINENFAKLAEALYIAD RKAREAVEMRAQVERKMAQKEKEKHEEKLREMAQKARERRAGIKTHVEKEDGEARERDEIRHDRRKERQHDRNLSRAAPDKRSKLQRNEN RDISEVIALGVPNPRTSNEVQYDQRLFNQSKGMDSGFAGGEDEIYNVYDQAWRGGKDMAQSIYRPSKNLDKDMYGDDLEARIKTNRCQAI QLNFSVYTGESKVVHSFFSFSLDLFPTRSFLVQTVDREAEKDQCSLRKILLVWTSFWKKPNSMVALKDPQIAAAPRNTSMKARRGGRNRH RSLQSE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for SMARCB1-SNW1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000263121 | + | 1 | 9 | 304_318 | 31.0 | 386.0 | PPP1R15A |
| Hgene | SMARCB1 | chr22:24129449 | chr14:78201355 | ENST00000407422 | + | 1 | 9 | 304_318 | 31.0 | 377.0 | PPP1R15A |
| Tgene | SNW1 | chr22:24129449 | chr14:78201355 | ENST00000261531 | 6 | 14 | 59_79 | 236.0 | 537.0 | PPIL1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for SMARCB1-SNW1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for SMARCB1-SNW1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | SMARCB1 | C0206743 | Rhabdoid Tumor | 10 | CGI;CLINGEN;CTD_human |
| Hgene | SMARCB1 | C1836327 | RHABDOID TUMOR PREDISPOSITION SYNDROME 1 (disorder) | 10 | CLINGEN;CTD_human;GENOMICS_ENGLAND |
| Hgene | SMARCB1 | C1266184 | Atypical Teratoid Rhabdoid Tumor | 8 | CLINGEN;ORPHANET |
| Hgene | SMARCB1 | C1836326 | Teratoid Tumor, Atypical | 8 | CLINGEN |
| Hgene | SMARCB1 | C2750405 | Malignant Rhabdoid Tumor, Somatic | 8 | CLINGEN;CTD_human |
| Hgene | SMARCB1 | C1335929 | Schwannomatosis | 4 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | SMARCB1 | C3553248 | MENTAL RETARDATION, AUTOSOMAL DOMINANT 15 | 3 | GENOMICS_ENGLAND;UNIPROT |
| Hgene | SMARCB1 | C0917817 | Neurofibromatosis 3 | 2 | ORPHANET |
| Hgene | SMARCB1 | C2931480 | Neurofibromatosis, Type 3, mixed central and peripheral | 2 | ORPHANET |
| Hgene | SMARCB1 | C0025286 | Meningioma | 1 | ORPHANET |
| Hgene | SMARCB1 | C0265338 | Coffin-Siris syndrome | 1 | CTD_human;GENOMICS_ENGLAND |
| Hgene | SMARCB1 | C2985524 | Rhabdoid tumor predisposition syndrome | 1 | ORPHANET |
| Hgene | SMARCB1 | C4048809 | SCHWANNOMATOSIS 1 | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies