
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:TBCD-CSNK1D (FusionGDB2 ID:HG6904TG1453) |
Fusion Gene Summary for TBCD-CSNK1D |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: TBCD-CSNK1D | Fusion gene ID: hg6904tg1453 | Hgene | Tgene | Gene symbol | TBCD | CSNK1D | Gene ID | 6904 | 1453 |
| Gene name | tubulin folding cofactor D | casein kinase 1 delta | |
| Synonyms | PEBAT|SSD-1|tfcD | ASPS|CKI-delta|CKId|CKIdelta|FASPS2|HCKID | |
| Cytomap | ('TBCD')('CSNK1D') 17q25.3 | 17q25.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | tubulin-specific chaperone Dbeta-tubulin cofactor D | casein kinase I isoform deltacasein kinase Itau-protein kinase CSNK1D | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000355528, ENST00000539345, ENST00000397466, ENST00000576691, | ||
| Fusion gene scores | * DoF score | 20 X 23 X 13=5980 | 20 X 19 X 9=3420 |
| # samples | 27 | 22 | |
| ** MAII score | log2(27/5980*10)=-4.46911417203464 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(22/3420*10)=-3.9584208962486 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: TBCD [Title/Abstract] AND CSNK1D [Title/Abstract] AND fusion [Title/Abstract] | ||
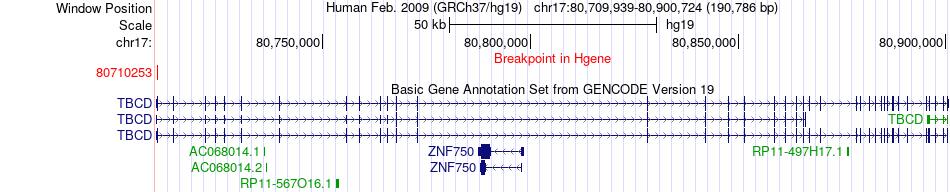
| Most frequent breakpoint | TBCD(80710253)-CSNK1D(80223672), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | TBCD-CSNK1D seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. TBCD-CSNK1D seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. TBCD-CSNK1D seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. TBCD-CSNK1D seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. TBCD-CSNK1D seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. TBCD-CSNK1D seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. TBCD-CSNK1D seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. TBCD-CSNK1D seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. TBCD-CSNK1D seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | TBCD | GO:0006457 | protein folding | 20740604 |
| Hgene | TBCD | GO:0007021 | tubulin complex assembly | 28158450 |
| Hgene | TBCD | GO:0007023 | post-chaperonin tubulin folding pathway | 11847227 |
| Hgene | TBCD | GO:0031115 | negative regulation of microtubule polymerization | 10831612|20740604 |
| Tgene | CSNK1D | GO:0006468 | protein phosphorylation | 16618118 |
| Tgene | CSNK1D | GO:0018105 | peptidyl-serine phosphorylation | 25500533 |
| Tgene | CSNK1D | GO:0051225 | spindle assembly | 10826492 |
| Fusion gene breakpoints across TBCD (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CSNK1D (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | UVM | TCGA-V4-A9EA-01A | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| ChimerDB4 | UVM | TCGA-V4-A9EA | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
Top |
Fusion Gene ORF analysis for TBCD-CSNK1D |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000355528 | ENST00000578904 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| 5CDS-intron | ENST00000539345 | ENST00000578904 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| 5UTR-3CDS | ENST00000397466 | ENST00000314028 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| 5UTR-3CDS | ENST00000397466 | ENST00000392334 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| 5UTR-3CDS | ENST00000397466 | ENST00000398519 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| 5UTR-intron | ENST00000397466 | ENST00000578904 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| Frame-shift | ENST00000355528 | ENST00000392334 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| Frame-shift | ENST00000539345 | ENST00000392334 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| In-frame | ENST00000355528 | ENST00000314028 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| In-frame | ENST00000355528 | ENST00000398519 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| In-frame | ENST00000539345 | ENST00000314028 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| In-frame | ENST00000539345 | ENST00000398519 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| intron-3CDS | ENST00000576691 | ENST00000314028 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| intron-3CDS | ENST00000576691 | ENST00000392334 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| intron-3CDS | ENST00000576691 | ENST00000398519 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| intron-intron | ENST00000576691 | ENST00000578904 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000355528 | TBCD | chr17 | 80710253 | + | ENST00000398519 | CSNK1D | chr17 | 80223672 | - | 1771 | 314 | 130 | 1521 | 463 |
| ENST00000355528 | TBCD | chr17 | 80710253 | + | ENST00000314028 | CSNK1D | chr17 | 80223672 | - | 3600 | 314 | 130 | 1485 | 451 |
| ENST00000539345 | TBCD | chr17 | 80710253 | + | ENST00000398519 | CSNK1D | chr17 | 80223672 | - | 1677 | 220 | 36 | 1427 | 463 |
| ENST00000539345 | TBCD | chr17 | 80710253 | + | ENST00000314028 | CSNK1D | chr17 | 80223672 | - | 3506 | 220 | 36 | 1391 | 451 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000355528 | ENST00000398519 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - | 0.012426401 | 0.98757356 |
| ENST00000355528 | ENST00000314028 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - | 0.002844014 | 0.997156 |
| ENST00000539345 | ENST00000398519 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - | 0.010742223 | 0.98925775 |
| ENST00000539345 | ENST00000314028 | TBCD | chr17 | 80710253 | + | CSNK1D | chr17 | 80223672 | - | 0.002503793 | 0.9974962 |
Top |
Fusion Genomic Features for TBCD-CSNK1D |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
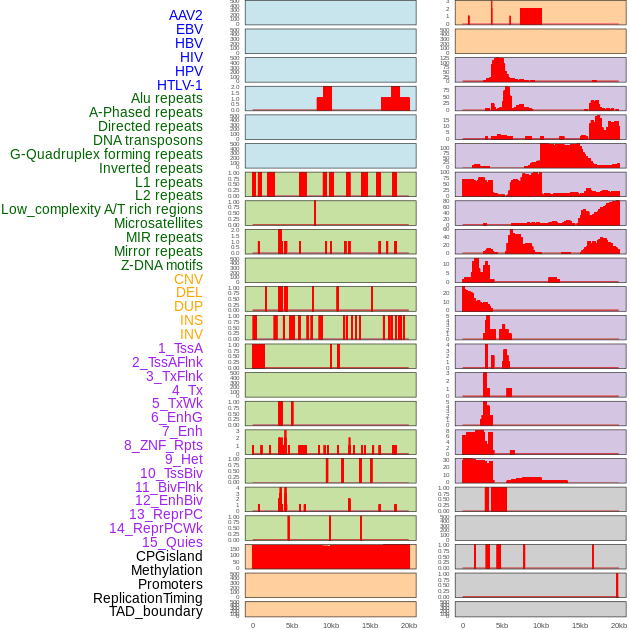
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for TBCD-CSNK1D |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr17:80710253/chr17:80223672) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000314028 | 0 | 9 | 278_364 | 25 | 416.0 | Region | Note=Centrosomal localization signal (CLS) | |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000314028 | 0 | 9 | 317_342 | 25 | 416.0 | Region | Autoinhibitory | |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000392334 | 0 | 10 | 278_364 | 25 | 420.3333333333333 | Region | Note=Centrosomal localization signal (CLS) | |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000392334 | 0 | 10 | 317_342 | 25 | 420.3333333333333 | Region | Autoinhibitory |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | TBCD | chr17:80710253 | chr17:80223672 | ENST00000355528 | + | 1 | 39 | 361_399 | 61 | 1193.0 | Repeat | Note=HEAT 1 |
| Hgene | TBCD | chr17:80710253 | chr17:80223672 | ENST00000355528 | + | 1 | 39 | 557_594 | 61 | 1193.0 | Repeat | Note=HEAT 2 |
| Hgene | TBCD | chr17:80710253 | chr17:80223672 | ENST00000355528 | + | 1 | 39 | 596_632 | 61 | 1193.0 | Repeat | Note=HEAT 3 |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000314028 | 0 | 9 | 9_277 | 25 | 416.0 | Domain | Protein kinase | |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000392334 | 0 | 10 | 9_277 | 25 | 420.3333333333333 | Domain | Protein kinase | |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000314028 | 0 | 9 | 15_23 | 25 | 416.0 | Nucleotide binding | ATP | |
| Tgene | CSNK1D | chr17:80710253 | chr17:80223672 | ENST00000392334 | 0 | 10 | 15_23 | 25 | 420.3333333333333 | Nucleotide binding | ATP |
Top |
Fusion Gene Sequence for TBCD-CSNK1D |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >89464_89464_1_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000355528_CSNK1D_chr17_80223672_ENST00000314028_length(transcript)=3600nt_BP=314nt GGCCAGCGTCGGTTGCCGCCTTAGCGGGCGCCTCCTTTTCATCCCTCATCCTTCATCCCTGGCTTTCGCGCTCTAGCGGAGTGGGATCTG CGAACACGTGAGGCGGGGGCGCGGTCCCCAGGCTGCCGAGATGGCCCTGAGCGACGAACCGGCCGCGGGCGGCCCCGAGGAGGAGGCGGA GGACGAGACACTGGCCTTTGGCGCGGCGCTGGAAGCGTTCGGCGAGAGCGCGGAGACCCGGGCGCTGCTGGGCCGCCTGCGGGAGGTGCA CGGCGGCGGCGCGGAGCGCGAGGTGGCCCTGGAGCGGTTCCGCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATG TGTCAAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTG CGGGGCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAG CCTCAAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCC AGACAACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCAC CCACCAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATC CCGAAGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAA GAGACAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATA CCTGAATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGG CTTCTCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTGGTGCCAGCCGGGCCGCCGATGACGCCGAGCGGGAGCGCAGGGACCG AGAGGAGCGGCTGAGACACTCGCGGAACCCGGCTACCCGCGGCCTCCCTTCCACAGCCTCCGGCCGCCTGCGGGGGACGCAGGAAGTGGC TCCCCCCACACCCCTCACCCCTACCTCACACACGGCTAACACCTCCCCCCGGCCCGTCTCCGGCATGGAGAGAGAGCGGAAAGTGAGTAT GCGGCTGCACCGCGGGGCCCCCGTCAACATCTCCTCGTCCGACCTCACAGGCCGACAAGATACCTCTCGCATGTCCACCTCACAGATTCC TGGTCGGGTGGCTTCCAGTGGTCTTCAGTCTGTCGTGCACCGATGAGAACTCTCCTTATTGCTGTGAAGGGCAGACAATGCATGGCTGAT CTACTCTGTTACCAATGGCTTTACTAGTGACACGTCCCCCGGTCTAGGATCGAAATGTTAACACCGGGAGCTCTCCAGGCCACTCACCCA GCGACGCTCGTGGGGGAAACATACTAAACGGACAGACTCCAAGAGCTGCCACCGCTGGGGCTGCACTGCGGCCCCCCACGTGAACTCGGT TGTAACGGGGCTGGGAAGAAAAGCAGAGAGAGAATTGCAGAGAATCAGACTCCTTTTCCAGGGCCTCAGCTCCCTCCAGTGGTGGCCGCC CTGTACTCCCTGACGATTCCACTGTAACTACCAATCTTCTACTTGGTTAAGACAGTTTTGTATCATTTTGCTAAAAATTATTGGCTTAAA TCTGTGTAAAGAAAATCTGTCTTTTTATTGTTTCTTGTCTGTTTTTGCAGTCTTACAAAAAAAATGTTGACTAAGGAATTCTGAGACAGG CTGGCTTGGAGTTAGTGTATGAGGTGGAGTCGGGCAGGGAGAAGGTGCAGGTGGATCTCAAGGGTGTGTGCTGTGTTTGTTTTGCAGTGT TTTATTGTCCGCTTTGGAGAGGAGATTTCTCATCAAAAGTCCGTGGTGTGTGTGTGTGCCCGTGTGTGGTGGGACCTCTTCAACCTGATT TTGGCGTCTCACCCTCCCTCCTCCCGTAATTGACATGCCTGCTGTCAGGAACTCTTGAGGCCCTCGGAGAGCAGTTAGGGACCGCAGGCT GCCGCGGGGCAGGGGTGCAGTGGGTGTTACCAGGCAAAGCACTGCGCGCTTCTTCCCCAGGAGGTGGGCAGGCAGCTGAGAGCTTGGAAG CAGAGGCTTTGAGACCCTAGCAGGACAATTGGGAGTCCCAGGATTCAAGGTGGAAGATGCGTTTCTGGTCCCTTGGGAGAGGACTGTGAA CCGAGAGGTGGTTACTGTAGTGTTTGTTGCCTTGCTGCCTTTGCACTCAGTCCATTTTCTCAGCACTCAATGCTCCTGTGCGGATTGGCA CTCCGTCTGTATGAATGCCTGTGCTTAAAACCAGGAGCGGGGCTGTCCTTGCCACGTGCCAAGACTAGCTCAGAAAAGCCGGCAGGCCAG AAGGACCCACCCTGAGGTGCCAAGGAGCAGGTGACTCTCCCAACCGGACCCAGAACCTTCACGGCCAGAAAGTAGAGTCTGCGCTGTGAC CTTCTGTTGGGCGCGTGTCTGTTGGTCAGAAGTGAAGCAGCGTGCGTGGGGCCGAGTCCCACCAGAAGGCAGGTGGCCTCCGTGAGCTGG TGCTGCCCCAGGCTCCATGCTGCTGTGCCCTGAGGTTCCCAGGATGCCTTCTCGCCTCTCACTCCGCAGCACTTGGGCGGTAGCCAGTGG CCATGTGCTCCCAACCCCAATGCGCAGGGCAGTCTGTGTTCGTGGGCACTTCGGCTGGACCCCATCACGATGGACGATGTTCCCTTTGGA CTCTAGGGCTTCGAAGGTGTGCACCTTGGTTCTCCCTTCTCCTCCCCAGAGTTCCCCGGATGCCATAACTGGCTGGCGTCCCAGAACACA GTTGTTCACCCCCCCACCAGCTGGCTGGCCGTCTGCCTGAGCCCATGGATGCTTTCTCAATCCTAGGCTGGTTACTGTGTAAGCGTTTTG GAGTACGGGGCCTTGAGCGGGTGGGAGCTGTGTGTTGAAGTACAGAGGGAGGTTGGGGTGGGTCAGAGCCGAGTTAAGAGATTTTCTTTG TTGCTGGACCCCTTCTTGAAGGTAGACGTCCCCCACCCGGAGAGACGTCGCGCTGTGGCCTGAAGTGGCGCAAGCTTGCTTTGTAAATAT CTGTGGTCCCGATGTAGTGCCCAGAACGTTTGTGCGAGGCAGCTCTGCGCCCGGGTTCCAGCCCGAGCCTCGCCGGGTCGCGTCTTCGGA GTGCTTGTGACAGTCCTTGCCCAGTATCTAGTCCCCGTCGCCCCGTGCAGGAGACGTAGGTAGGACGTCGTGTCAGCTGTGCACTGACGG CCAGTCTCCGAGCTGTGCGTTTGTATCGCCACTGTATTTGTGTACTTTAACAATCGTGTAAATAATAAATTCATAATGACTTCTACCTTT >89464_89464_1_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000355528_CSNK1D_chr17_80223672_ENST00000314028_length(amino acids)=451AA_BP=61 MALSDEPAAGGPEEEAEDETLAFGAALEAFGESAETRALLGRLREVHGGGAEREVALERFRGTDIAAGEEVAIKLECVKTKHPQLHIESK IYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNL VYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMS TPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLRQLFRNLFHRQGFSYDYVFDWNMLKFGASRAADDAERERRDREERLRHSRNPATR GLPSTASGRLRGTQEVAPPTPLTPTSHTANTSPRPVSGMERERKVSMRLHRGAPVNISSSDLTGRQDTSRMSTSQIPGRVASSGLQSVVH R -------------------------------------------------------------- >89464_89464_2_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000355528_CSNK1D_chr17_80223672_ENST00000398519_length(transcript)=1771nt_BP=314nt GGCCAGCGTCGGTTGCCGCCTTAGCGGGCGCCTCCTTTTCATCCCTCATCCTTCATCCCTGGCTTTCGCGCTCTAGCGGAGTGGGATCTG CGAACACGTGAGGCGGGGGCGCGGTCCCCAGGCTGCCGAGATGGCCCTGAGCGACGAACCGGCCGCGGGCGGCCCCGAGGAGGAGGCGGA GGACGAGACACTGGCCTTTGGCGCGGCGCTGGAAGCGTTCGGCGAGAGCGCGGAGACCCGGGCGCTGCTGGGCCGCCTGCGGGAGGTGCA CGGCGGCGGCGCGGAGCGCGAGGTGGCCCTGGAGCGGTTCCGCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATG TGTCAAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTG CGGGGCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAG CCTCAAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCC AGACAACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCAC CCACCAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATC CCGAAGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAA GAGACAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATA CCTGAATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGG CTTCTCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTGGTGCCAGCCGGGCCGCCGATGACGCCGAGCGGGAGCGCAGGGACCG AGAGGAGCGGCTGAGACACTCGCGGAACCCGGCTACCCGCGGCCTCCCTTCCACAGCCTCCGGCCGCCTGCGGGGGACGCAGGAAGTGGC TCCCCCCACACCCCTCACCCCTACCTCACACACGGCTAACACCTCCCCCCGGCCCGTCTCCGGCATGGAGAGAGAGCGGAAAGTGAGTAT GCGGCTGCACCGCGGGGCCCCCGTCAACATCTCCTCGTCCGACCTCACAGGCCGACAAGATACCTCTCGCATGTCCACCTCACAGAGGAG CAGGGACATGGCATCTCTCCGGCTGCACGCGGCCCGCCAGGGCACCCGCTGCCGTCCCCAGCGCCCACGACGCACCTACTGAGGGCCCCG GCGGCCTCTGACCGGGCTCCCAGCCACGCAGGCCACTGCTGGCCACGAGGGCAGGTGGGTGTTAGGTGTCCAGGACAAGCCCAAGCGCTG GGCCGGGCTGGATGGAGGACAGGGTGCAAAGACCAGCCCTGGGCACTGACCACACCACGCACACTGCCAGCCAGGCAGAGGGGCGAAAAA GGGAAGGCAGGAGGGTCCTGTTTCTTAAACACAGCAGTGAATAAAGTGGCTTGTTCCACCT >89464_89464_2_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000355528_CSNK1D_chr17_80223672_ENST00000398519_length(amino acids)=463AA_BP=61 MALSDEPAAGGPEEEAEDETLAFGAALEAFGESAETRALLGRLREVHGGGAEREVALERFRGTDIAAGEEVAIKLECVKTKHPQLHIESK IYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNL VYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMS TPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLRQLFRNLFHRQGFSYDYVFDWNMLKFGASRAADDAERERRDREERLRHSRNPATR GLPSTASGRLRGTQEVAPPTPLTPTSHTANTSPRPVSGMERERKVSMRLHRGAPVNISSSDLTGRQDTSRMSTSQRSRDMASLRLHAARQ GTRCRPQRPRRTY -------------------------------------------------------------- >89464_89464_3_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000539345_CSNK1D_chr17_80223672_ENST00000314028_length(transcript)=3506nt_BP=220nt CACGTGAGGCGGGGGCGCGGTCCCCAGGCTGCCGAGATGGCCCTGAGCGACGAACCGGCCGCGGGCGGCCCCGAGGAGGAGGCGGAGGAC GAGACACTGGCCTTTGGCGCGGCGCTGGAAGCGTTCGGCGAGAGCGCGGAGACCCGGGCGCTGCTGGGCCGCCTGCGGGAGGTGCACGGC GGCGGCGCGGAGCGCGAGGTGGCCCTGGAGCGGTTCCGCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATGTGTC AAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTGCGGG GCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAGCCTC AAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCCAGAC AACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCACCCAC CAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATCCCGA AGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAAGAGA CAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATACCTG AATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGGCTTC TCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTGGTGCCAGCCGGGCCGCCGATGACGCCGAGCGGGAGCGCAGGGACCGAGAG GAGCGGCTGAGACACTCGCGGAACCCGGCTACCCGCGGCCTCCCTTCCACAGCCTCCGGCCGCCTGCGGGGGACGCAGGAAGTGGCTCCC CCCACACCCCTCACCCCTACCTCACACACGGCTAACACCTCCCCCCGGCCCGTCTCCGGCATGGAGAGAGAGCGGAAAGTGAGTATGCGG CTGCACCGCGGGGCCCCCGTCAACATCTCCTCGTCCGACCTCACAGGCCGACAAGATACCTCTCGCATGTCCACCTCACAGATTCCTGGT CGGGTGGCTTCCAGTGGTCTTCAGTCTGTCGTGCACCGATGAGAACTCTCCTTATTGCTGTGAAGGGCAGACAATGCATGGCTGATCTAC TCTGTTACCAATGGCTTTACTAGTGACACGTCCCCCGGTCTAGGATCGAAATGTTAACACCGGGAGCTCTCCAGGCCACTCACCCAGCGA CGCTCGTGGGGGAAACATACTAAACGGACAGACTCCAAGAGCTGCCACCGCTGGGGCTGCACTGCGGCCCCCCACGTGAACTCGGTTGTA ACGGGGCTGGGAAGAAAAGCAGAGAGAGAATTGCAGAGAATCAGACTCCTTTTCCAGGGCCTCAGCTCCCTCCAGTGGTGGCCGCCCTGT ACTCCCTGACGATTCCACTGTAACTACCAATCTTCTACTTGGTTAAGACAGTTTTGTATCATTTTGCTAAAAATTATTGGCTTAAATCTG TGTAAAGAAAATCTGTCTTTTTATTGTTTCTTGTCTGTTTTTGCAGTCTTACAAAAAAAATGTTGACTAAGGAATTCTGAGACAGGCTGG CTTGGAGTTAGTGTATGAGGTGGAGTCGGGCAGGGAGAAGGTGCAGGTGGATCTCAAGGGTGTGTGCTGTGTTTGTTTTGCAGTGTTTTA TTGTCCGCTTTGGAGAGGAGATTTCTCATCAAAAGTCCGTGGTGTGTGTGTGTGCCCGTGTGTGGTGGGACCTCTTCAACCTGATTTTGG CGTCTCACCCTCCCTCCTCCCGTAATTGACATGCCTGCTGTCAGGAACTCTTGAGGCCCTCGGAGAGCAGTTAGGGACCGCAGGCTGCCG CGGGGCAGGGGTGCAGTGGGTGTTACCAGGCAAAGCACTGCGCGCTTCTTCCCCAGGAGGTGGGCAGGCAGCTGAGAGCTTGGAAGCAGA GGCTTTGAGACCCTAGCAGGACAATTGGGAGTCCCAGGATTCAAGGTGGAAGATGCGTTTCTGGTCCCTTGGGAGAGGACTGTGAACCGA GAGGTGGTTACTGTAGTGTTTGTTGCCTTGCTGCCTTTGCACTCAGTCCATTTTCTCAGCACTCAATGCTCCTGTGCGGATTGGCACTCC GTCTGTATGAATGCCTGTGCTTAAAACCAGGAGCGGGGCTGTCCTTGCCACGTGCCAAGACTAGCTCAGAAAAGCCGGCAGGCCAGAAGG ACCCACCCTGAGGTGCCAAGGAGCAGGTGACTCTCCCAACCGGACCCAGAACCTTCACGGCCAGAAAGTAGAGTCTGCGCTGTGACCTTC TGTTGGGCGCGTGTCTGTTGGTCAGAAGTGAAGCAGCGTGCGTGGGGCCGAGTCCCACCAGAAGGCAGGTGGCCTCCGTGAGCTGGTGCT GCCCCAGGCTCCATGCTGCTGTGCCCTGAGGTTCCCAGGATGCCTTCTCGCCTCTCACTCCGCAGCACTTGGGCGGTAGCCAGTGGCCAT GTGCTCCCAACCCCAATGCGCAGGGCAGTCTGTGTTCGTGGGCACTTCGGCTGGACCCCATCACGATGGACGATGTTCCCTTTGGACTCT AGGGCTTCGAAGGTGTGCACCTTGGTTCTCCCTTCTCCTCCCCAGAGTTCCCCGGATGCCATAACTGGCTGGCGTCCCAGAACACAGTTG TTCACCCCCCCACCAGCTGGCTGGCCGTCTGCCTGAGCCCATGGATGCTTTCTCAATCCTAGGCTGGTTACTGTGTAAGCGTTTTGGAGT ACGGGGCCTTGAGCGGGTGGGAGCTGTGTGTTGAAGTACAGAGGGAGGTTGGGGTGGGTCAGAGCCGAGTTAAGAGATTTTCTTTGTTGC TGGACCCCTTCTTGAAGGTAGACGTCCCCCACCCGGAGAGACGTCGCGCTGTGGCCTGAAGTGGCGCAAGCTTGCTTTGTAAATATCTGT GGTCCCGATGTAGTGCCCAGAACGTTTGTGCGAGGCAGCTCTGCGCCCGGGTTCCAGCCCGAGCCTCGCCGGGTCGCGTCTTCGGAGTGC TTGTGACAGTCCTTGCCCAGTATCTAGTCCCCGTCGCCCCGTGCAGGAGACGTAGGTAGGACGTCGTGTCAGCTGTGCACTGACGGCCAG TCTCCGAGCTGTGCGTTTGTATCGCCACTGTATTTGTGTACTTTAACAATCGTGTAAATAATAAATTCATAATGACTTCTACCTTT >89464_89464_3_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000539345_CSNK1D_chr17_80223672_ENST00000314028_length(amino acids)=451AA_BP=61 MALSDEPAAGGPEEEAEDETLAFGAALEAFGESAETRALLGRLREVHGGGAEREVALERFRGTDIAAGEEVAIKLECVKTKHPQLHIESK IYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNL VYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMS TPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLRQLFRNLFHRQGFSYDYVFDWNMLKFGASRAADDAERERRDREERLRHSRNPATR GLPSTASGRLRGTQEVAPPTPLTPTSHTANTSPRPVSGMERERKVSMRLHRGAPVNISSSDLTGRQDTSRMSTSQIPGRVASSGLQSVVH R -------------------------------------------------------------- >89464_89464_4_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000539345_CSNK1D_chr17_80223672_ENST00000398519_length(transcript)=1677nt_BP=220nt CACGTGAGGCGGGGGCGCGGTCCCCAGGCTGCCGAGATGGCCCTGAGCGACGAACCGGCCGCGGGCGGCCCCGAGGAGGAGGCGGAGGAC GAGACACTGGCCTTTGGCGCGGCGCTGGAAGCGTTCGGCGAGAGCGCGGAGACCCGGGCGCTGCTGGGCCGCCTGCGGGAGGTGCACGGC GGCGGCGCGGAGCGCGAGGTGGCCCTGGAGCGGTTCCGCGGTACGGACATTGCTGCAGGAGAAGAGGTTGCCATCAAGCTTGAATGTGTC AAAACCAAACACCCTCAGCTCCACATTGAGAGCAAAATCTACAAGATGATGCAGGGAGGAGTGGGCATCCCCACCATCAGATGGTGCGGG GCAGAGGGGGACTACAACGTCATGGTGATGGAGCTGCTGGGGCCAAGCCTGGAGGACCTCTTCAACTTCTGCTCCAGGAAATTCAGCCTC AAAACCGTCCTGCTGCTTGCTGACCAAATGATCAGTCGCATCGAATACATTCATTCAAAGAACTTCATCCACCGGGATGTGAAGCCAGAC AACTTCCTCATGGGCCTGGGGAAGAAGGGCAACCTGGTGTACATCATCGACTTCGGGCTGGCCAAGAAGTACCGGGATGCACGCACCCAC CAGCACATCCCCTATCGTGAGAACAAGAACCTCACGGGGACGGCGCGGTACGCCTCCATCAACACGCACCTTGGAATTGAACAATCCCGA AGAGATGACTTGGAGTCTCTGGGCTACGTGCTAATGTACTTCAACCTGGGCTCTCTCCCCTGGCAGGGGCTGAAGGCTGCCACCAAGAGA CAGAAATACGAAAGGATTAGCGAGAAGAAAATGTCCACCCCCATCGAAGTGTTGTGTAAAGGCTACCCTTCCGAATTTGCCACATACCTG AATTTCTGCCGTTCCTTGCGTTTTGACGACAAGCCTGACTACTCGTACCTGCGGCAGCTTTTCCGGAATCTGTTCCATCGCCAGGGCTTC TCCTATGACTACGTGTTCGACTGGAACATGCTCAAATTTGGTGCCAGCCGGGCCGCCGATGACGCCGAGCGGGAGCGCAGGGACCGAGAG GAGCGGCTGAGACACTCGCGGAACCCGGCTACCCGCGGCCTCCCTTCCACAGCCTCCGGCCGCCTGCGGGGGACGCAGGAAGTGGCTCCC CCCACACCCCTCACCCCTACCTCACACACGGCTAACACCTCCCCCCGGCCCGTCTCCGGCATGGAGAGAGAGCGGAAAGTGAGTATGCGG CTGCACCGCGGGGCCCCCGTCAACATCTCCTCGTCCGACCTCACAGGCCGACAAGATACCTCTCGCATGTCCACCTCACAGAGGAGCAGG GACATGGCATCTCTCCGGCTGCACGCGGCCCGCCAGGGCACCCGCTGCCGTCCCCAGCGCCCACGACGCACCTACTGAGGGCCCCGGCGG CCTCTGACCGGGCTCCCAGCCACGCAGGCCACTGCTGGCCACGAGGGCAGGTGGGTGTTAGGTGTCCAGGACAAGCCCAAGCGCTGGGCC GGGCTGGATGGAGGACAGGGTGCAAAGACCAGCCCTGGGCACTGACCACACCACGCACACTGCCAGCCAGGCAGAGGGGCGAAAAAGGGA AGGCAGGAGGGTCCTGTTTCTTAAACACAGCAGTGAATAAAGTGGCTTGTTCCACCT >89464_89464_4_TBCD-CSNK1D_TBCD_chr17_80710253_ENST00000539345_CSNK1D_chr17_80223672_ENST00000398519_length(amino acids)=463AA_BP=61 MALSDEPAAGGPEEEAEDETLAFGAALEAFGESAETRALLGRLREVHGGGAEREVALERFRGTDIAAGEEVAIKLECVKTKHPQLHIESK IYKMMQGGVGIPTIRWCGAEGDYNVMVMELLGPSLEDLFNFCSRKFSLKTVLLLADQMISRIEYIHSKNFIHRDVKPDNFLMGLGKKGNL VYIIDFGLAKKYRDARTHQHIPYRENKNLTGTARYASINTHLGIEQSRRDDLESLGYVLMYFNLGSLPWQGLKAATKRQKYERISEKKMS TPIEVLCKGYPSEFATYLNFCRSLRFDDKPDYSYLRQLFRNLFHRQGFSYDYVFDWNMLKFGASRAADDAERERRDREERLRHSRNPATR GLPSTASGRLRGTQEVAPPTPLTPTSHTANTSPRPVSGMERERKVSMRLHRGAPVNISSSDLTGRQDTSRMSTSQRSRDMASLRLHAARQ GTRCRPQRPRRTY -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for TBCD-CSNK1D |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for TBCD-CSNK1D |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for TBCD-CSNK1D |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | TBCD | C4310671 | ENCEPHALOPATHY, PROGRESSIVE, EARLY-ONSET, WITH BRAIN ATROPHY AND THIN CORPUS CALLOSUM | 4 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | TBCD | C0025958 | Microcephaly | 2 | CTD_human |
| Hgene | TBCD | C0036572 | Seizures | 2 | CTD_human;GENOMICS_ENGLAND |
| Hgene | TBCD | C1956147 | Microlissencephaly | 2 | CTD_human |
| Hgene | TBCD | C3853041 | Severe Congenital Microcephaly | 2 | CTD_human |
| Hgene | TBCD | C0008073 | Developmental Disabilities | 1 | CTD_human |
| Hgene | TBCD | C0020796 | Profound Mental Retardation | 1 | CTD_human |
| Hgene | TBCD | C0022333 | Jacksonian Seizure | 1 | CTD_human |
| Hgene | TBCD | C0023944 | Locked-In Syndrome | 1 | CTD_human |
| Hgene | TBCD | C0025363 | Mental Retardation, Psychosocial | 1 | CTD_human |
| Hgene | TBCD | C0029124 | Optic Atrophy | 1 | CTD_human |
| Hgene | TBCD | C0034372 | Quadriplegia | 1 | CTD_human |
| Hgene | TBCD | C0035229 | Respiratory Insufficiency | 1 | CTD_human |
| Hgene | TBCD | C0037769 | West Syndrome | 1 | GENOMICS_ENGLAND |
| Hgene | TBCD | C0085996 | Child Development Deviations | 1 | CTD_human |
| Hgene | TBCD | C0085997 | Child Development Disorders, Specific | 1 | CTD_human |
| Hgene | TBCD | C0149958 | Complex partial seizures | 1 | CTD_human |
| Hgene | TBCD | C0151786 | Muscle Weakness | 1 | CTD_human |
| Hgene | TBCD | C0234533 | Generalized seizures | 1 | CTD_human |
| Hgene | TBCD | C0234535 | Clonic Seizures | 1 | CTD_human |
| Hgene | TBCD | C0235063 | Respiratory Depression | 1 | CTD_human |
| Hgene | TBCD | C0270715 | Degenerative Diseases, Central Nervous System | 1 | CTD_human |
| Hgene | TBCD | C0270790 | Quadriparesis | 1 | CTD_human |
| Hgene | TBCD | C0270824 | Visual seizure | 1 | CTD_human |
| Hgene | TBCD | C0270844 | Tonic Seizures | 1 | CTD_human |
| Hgene | TBCD | C0270846 | Epileptic drop attack | 1 | CTD_human |
| Hgene | TBCD | C0422850 | Seizures, Somatosensory | 1 | CTD_human |
| Hgene | TBCD | C0422852 | Seizures, Auditory | 1 | CTD_human |
| Hgene | TBCD | C0422853 | Olfactory seizure | 1 | CTD_human |
| Hgene | TBCD | C0422854 | Gustatory seizure | 1 | CTD_human |
| Hgene | TBCD | C0422855 | Vertiginous seizure | 1 | CTD_human |
| Hgene | TBCD | C0426970 | Spastic Quadriplegia | 1 | CTD_human |
| Hgene | TBCD | C0431380 | Cortical Dysplasia | 1 | CTD_human |
| Hgene | TBCD | C0494475 | Tonic - clonic seizures | 1 | CTD_human |
| Hgene | TBCD | C0524851 | Neurodegenerative Disorders | 1 | CTD_human |
| Hgene | TBCD | C0751056 | Non-epileptic convulsion | 1 | CTD_human |
| Hgene | TBCD | C0751110 | Single Seizure | 1 | CTD_human |
| Hgene | TBCD | C0751123 | Atonic Absence Seizures | 1 | CTD_human |
| Hgene | TBCD | C0751460 | Flaccid Quadriplegia | 1 | CTD_human |
| Hgene | TBCD | C0751461 | Paralysis, Spinal, Quadriplegic | 1 | CTD_human |
| Hgene | TBCD | C0751494 | Convulsive Seizures | 1 | CTD_human |
| Hgene | TBCD | C0751495 | Seizures, Focal | 1 | CTD_human |
| Hgene | TBCD | C0751496 | Seizures, Sensory | 1 | CTD_human |
| Hgene | TBCD | C0751733 | Degenerative Diseases, Spinal Cord | 1 | CTD_human |
| Hgene | TBCD | C0917816 | Mental deficiency | 1 | CTD_human |
| Hgene | TBCD | C1145670 | Respiratory Failure | 1 | CTD_human |
| Hgene | TBCD | C1955869 | Malformations of Cortical Development | 1 | CTD_human |
| Hgene | TBCD | C3495874 | Nonepileptic Seizures | 1 | CTD_human |
| Hgene | TBCD | C3714756 | Intellectual Disability | 1 | CTD_human |
| Hgene | TBCD | C4048158 | Convulsions | 1 | CTD_human |
| Hgene | TBCD | C4316903 | Absence Seizures | 1 | CTD_human |
| Hgene | TBCD | C4317109 | Epileptic Seizures | 1 | CTD_human |
| Hgene | TBCD | C4317123 | Myoclonic Seizures | 1 | CTD_human |
| Hgene | TBCD | C4505436 | Generalized Absence Seizures | 1 | CTD_human |
| Tgene | C3808874 | ADVANCED SLEEP PHASE SYNDROME, FAMILIAL, 2 | 3 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C1858496 | Advanced Sleep-Phase Syndrome, Familial | 1 | CTD_human;ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies