
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C1QC-MYO1F (FusionGDB2 ID:HG714TG4542) |
Fusion Gene Summary for C1QC-MYO1F |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C1QC-MYO1F | Fusion gene ID: hg714tg4542 | Hgene | Tgene | Gene symbol | C1QC | MYO1F | Gene ID | 714 | 4542 |
| Gene name | complement C1q C chain | myosin IF | |
| Synonyms | C1Q-C|C1QG | - | |
| Cytomap | ('C1QC')('MYO1F') 1p36.12 | 19p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | complement C1q subcomponent subunit Ccomplement component 1, q subcomponent, C chaincomplement component 1, q subcomponent, gamma polypeptide | unconventional myosin-Ifmyosin-IDmyosin-Ie | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | O00160 | |
| Ensembl transtripts involved in fusion gene | ENST00000374637, ENST00000374639, ENST00000374640, | ||
| Fusion gene scores | * DoF score | 4 X 5 X 4=80 | 9 X 9 X 5=405 |
| # samples | 5 | 10 | |
| ** MAII score | log2(5/80*10)=-0.678071905112638 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/405*10)=-2.01792190799726 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: C1QC [Title/Abstract] AND MYO1F [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C1QC(22974184)-MYO1F(8617015), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | C1QC-MYO1F seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C1QC-MYO1F seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C1QC-MYO1F seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. C1QC-MYO1F seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | C1QC | GO:0030853 | negative regulation of granulocyte differentiation | 10961870 |
| Hgene | C1QC | GO:0045650 | negative regulation of macrophage differentiation | 10961870 |
| Fusion gene breakpoints across C1QC (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MYO1F (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
Top |
Fusion Gene ORF analysis for C1QC-MYO1F |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000374640 | ENST00000338257 | C1QC | chr1 | 22974184 | - | MYO1F | chr19 | 8617015 | + | 0.28153875 | 0.7184612 |
| ENST00000374639 | ENST00000338257 | C1QC | chr1 | 22974184 | - | MYO1F | chr19 | 8617015 | + | 0.2831338 | 0.71686625 |
Top |
Fusion Genomic Features for C1QC-MYO1F |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
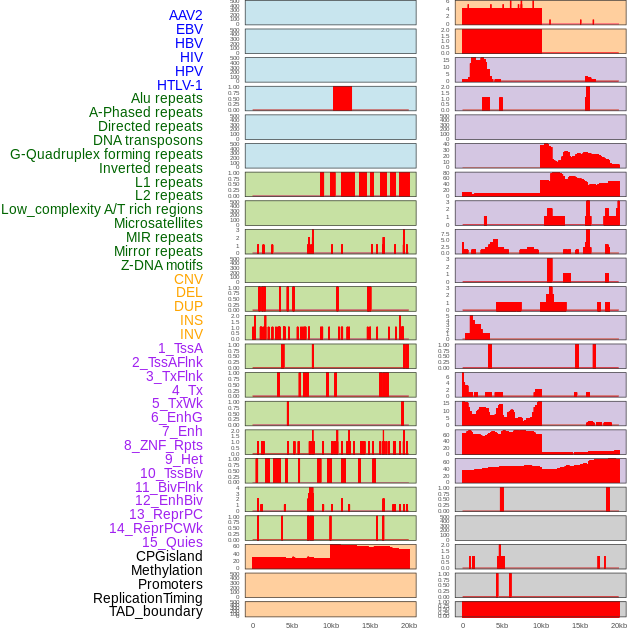 |
Top |
Fusion Protein Features for C1QC-MYO1F |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:22974184/chr19:8617015) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | MYO1F |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Myosins are actin-based motor molecules with ATPase activity. Unconventional myosins serve in intracellular movements. Their highly divergent tails are presumed to bind to membranous compartments, which would be moved relative to actin filaments (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | MYO1F | chr1:22974184 | chr19:8617015 | ENST00000338257 | 0 | 28 | 1041_1098 | 0 | 1099.0 | Domain | SH3 | |
| Tgene | MYO1F | chr1:22974184 | chr19:8617015 | ENST00000338257 | 0 | 28 | 17_690 | 0 | 1099.0 | Domain | Myosin motor | |
| Tgene | MYO1F | chr1:22974184 | chr19:8617015 | ENST00000338257 | 0 | 28 | 693_722 | 0 | 1099.0 | Domain | IQ | |
| Tgene | MYO1F | chr1:22974184 | chr19:8617015 | ENST00000338257 | 0 | 28 | 728_917 | 0 | 1099.0 | Domain | TH1 | |
| Tgene | MYO1F | chr1:22974184 | chr19:8617015 | ENST00000338257 | 0 | 28 | 110_117 | 0 | 1099.0 | Nucleotide binding | ATP | |
| Tgene | MYO1F | chr1:22974184 | chr19:8617015 | ENST00000338257 | 0 | 28 | 579_589 | 0 | 1099.0 | Region | Actin-binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | C1QC | chr1:22974184 | chr19:8617015 | ENST00000374637 | - | 1 | 3 | 115_245 | 0 | 246.0 | Domain | C1q |
| Hgene | C1QC | chr1:22974184 | chr19:8617015 | ENST00000374637 | - | 1 | 3 | 31_112 | 0 | 246.0 | Domain | Note=Collagen-like |
| Hgene | C1QC | chr1:22974184 | chr19:8617015 | ENST00000374639 | - | 1 | 3 | 115_245 | 0 | 246.0 | Domain | C1q |
| Hgene | C1QC | chr1:22974184 | chr19:8617015 | ENST00000374639 | - | 1 | 3 | 31_112 | 0 | 246.0 | Domain | Note=Collagen-like |
| Hgene | C1QC | chr1:22974184 | chr19:8617015 | ENST00000374640 | - | 1 | 3 | 115_245 | 0 | 246.0 | Domain | C1q |
| Hgene | C1QC | chr1:22974184 | chr19:8617015 | ENST00000374640 | - | 1 | 3 | 31_112 | 0 | 246.0 | Domain | Note=Collagen-like |
Top |
Fusion Gene Sequence for C1QC-MYO1F |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >11426_11426_1_C1QC-MYO1F_C1QC_chr1_22974184_ENST00000374639_MYO1F_chr19_8617015_ENST00000338257_length(transcript)=4216nt_BP=718nt AGACACCGTGTCCTCTTGCCTGGGAGAGGGGAAGCAGATCTGAGGACATCTCTGTGCCAGGCCAGAAACCGCCCACCTGCAGGTGAGGCC CGGACCCCTGCCCAGTTCCTTCTCCGGGATGGACGTGGGGCCCAGCTCCCTGCCCCACCTTGGGCTGAAGCTGCTGCTGCTCCTGCTGCT GCTGCCCCTCAGGGGCCAAGCCAACACAGGCTGCTACGGGATCCCAGGGATGCCCGGCCTGCCCGGGGCACCAGGGAAGGATGGGTACGA CGGACTGCCGGGGCCCAAGGGGGAGCCAGAGGTGTGGCTGGCTGTCAATGACTACTACGACATGGTGGGCATCCAGGGCTCTGACAGCGT CTTCTCCGGCTTCCTGCTCTTCCCCGACTAGGGCGGGCAGATGCGCTCGAGCCCCACGGGCCTTCCACCTCCCTCAGCTTCCTGCATGGA CCCACCTTACTGGCCAGTCTGCATCCTTGCCTAGACCATTCTCCCCACCAGATGGACTTCTCCTCCAGGGAGCCCACCCTGACCCACCCC CACTGCACCCCCTCCCCATGGGTTCTCTCCTTCCTCTGAACTTCTTTAGGAGTCACTGCTTGTGTGGTTCCTGGGACACTTAACCAATGC CTTCTGGTACTGCCATTCTTTTTTTTTTTTTTTTCAAGTATTGGAAGGGGTGGGGAGATATATAAATAAATCATGAAATCAATACATAAT CCCTCGGGCTGGTGGAAGGGCCGGCTTCACGGCCAGGAGGGCCTTTTCCCAGGAAACTACGTGGAGAAGATCTGAGCTGGGCCCTGGGAT ACTGCCTTCTCTTTCGCCCGCCTATCTGCCTGCCGGCCTGGTGGGGAGCCAGGCCCTGCCAATGAGAGCCTCGTTTACCTGGGCTGCAAT AGCCTAAAAGTCCAGTCCTTTGGCCTCCAGTCCTGCCCAGGCCCTGGGTCACCAGGTCACTGCTGCAGCCCCCGCCCCTGGGCCCTGGTC TTCCTCCAACATCACACCTGCTGCCCATTCTCCATTTCTGTGTGTGTCAAAGGGGACTAACAGCAGAATCTACCTCCCAACTGCCATGTG ATTAAGAAATGGGTCTTGAGTCCTGTGCTGTTGGCAAAGTGCCAGGCACAGTTGGGGAGGGGGGGGTCCTTAACAAGCGTGACTTTGCTC ATTCTGTCATCACTAAGGCAATAAACCTTTGCCAGGTGAAAGCACGAGTTAACTTACTAAGTGCCCAACAAGGACGATGTTTTCACAGCC CTGTGAGGTAGGAGCTGTGAAGGACCCCATCTTACAGGTGGAACAATGGAGGTTCAGAGAGGTTCACTGACCCAAGACTGCACAGAGCCA TGCCTTGCATTCATATGTGACCATAAAGCTTGAATTTGTCCCAGTTTGGGCTGGGCGCAGTGGCTCACGCCTGTAATCCCAGCACTTTGG GAGGCTGAGGCGGGCAGATCACGTGAGACCAGGAGTTCAAGACCAGCCTGGATAACACAGCAAAACCCTGTTTCTACTAAAAATTTAAAA AAGCATGCAGAGGAAGCGCAGCGTGGGGCAACGGCCAGTGCCTGGTGTGGGCCGACCCAAGCCCCAGCCTCGGACACATGGTCCCAGGTG CCGGGCCCTATACCAGTACGTGGGCCAAGATGTGGACGAGCTGAGCTTCAACGTGAACGAGGTCATTGAGATCCTCATGGAAGGCATGGA TCGCAATGGGGTGCCCCCCTCTGCCAGAGGGGGCCCCCTGCCCCTGGAGATCATGTCTGGAGGGGGCACCCACAGGCCTCCCCGGGGCCC TCCGTCCACATCCCTGGGAGCCAGCAGACGACCCCGGGCACGTCCGCCCTCAGAGCACAACACAGAATTCCTCAACGTGCCTGACCAGGG CATGGCCGGAGCCTACGCGGAAGGGAATGGCCAAGGGAAAACCTCGGAGGTCGTCCCAAGCCCCTACCCGGGCGGCCCCTGCGCCCCCCA GAGACTACAGTTTCGGGTGAAGAAGGAGGGCTGGGGCGGTGGCGGCACCCGCAGCGTCACCTTCTCCCGCGGCTTCGGCGACTTGGCAGT GCTCAAGGTTGGCGGTCGGACCCTCACGGTCAGCGTGGGCGATGGGCTGCCCAAGAGCTCCACACGCGACAGGACGACTTCTTCATCCTC CAAGAGGATGCCGCCGACAGCTTCCTGGAGAGCGTCTTCAAGACCGAGTTTGTCAGCCTTCTGTGCAAGCGCTTCGAGGAGGCGACGCGG AGGCCCCTGCCCCTCACCTTCAGCGACACCCCATCAAGCGGGACTTGATCCTGACGCCCAAGTGTGTGTATGTGATTGGGCGAGAGAAAG TGAAGAAGGGACCTGAGAAGGGCCAGGTGTGTGAAGTCTTGAAGAAGAAAGTGGACATCCAGGCTCTGCGGGGAGTCTCCCTCAGCTTCC AACATCCTGCTGAACAAGAAGGAGCGGAGGCGCAACAGCATCAATCGGAACTTCGTCGGGGACTACCTGGGGCTGGAGGAGCGGCCCGAG CTGCGTCAGTTCCTGGGCAAGAGGGAGCGGGTGGACTTCGCCGATTCGGTCACCAAGTACGACCGCCGCTTCAAGCTTTTCCTCCTGGAG GAGGTGCGAGAGCGAAAGTTCGATGGCTTTGCCCGAACCATCCAGAAGGCCTGGCGGCGCCACGTGGCTGTCCGGAAGTACGAGGAGATG CGGGAGGAAGGTATGCCATTCTGACCCCCGAGACGTGGCCGCGGTGGCGTGGGGACGAACGCCAGGGCGTCCAGCACCTGCTTCGGGCGG TCAACATGGAGCCCGACCAGTACCAGATGGGGAGCACCAAGGTCTTTGTCAAGAACCCAGAGTCGAGTCAAGCACCAGGTGGAATACCTG GGCCTGAAGGAGAACATCAGGGTGCGCAGAGCCGGCTTCGCCTACCGCCGCCAGTTCGCCAAATTCCTGCAGAGAAACAAGCCAACGACC TGGTGGCCACACTGATGAGGTGCACACCCCACTACATCCGCTGCATCAAACCCAACGAGACCAAGAGGCCCCGAGACTGGGAGGAGAACA GGGCCTTCCTCCGGATGCTCTTCCCCGAGAAGCTGGATGGAGACAAGAAGGGGCGCCCCAGCACCGCCGGCTCCAAGATCAAGGTCTCCT ACGACGTCAGCGGCTTCTGCGAGAGGAACCGAGACGTTCTCTTCTCCGACCTCATAGAGCTGATGCAGACCAGTGAGCAAGCCCCCCAGG CATCATGAGCGTCTTGGACGACGTGTGCGCCACCATGCACGCCACGGGCGGGGGAGCAGACCAGACACTGCTGCAGAAGCTGCAGGCGGC TGTGGGGACCCACGAGCATTTCAACAGCTGGAGCGCCGGCTTCGTCATCCACCACTACGCTGGCAAGGAGGAGTATGTGCAGGAAGGCAT CCGCTGGACTCCAATCCAGTACTTCAACAACAAGGTCGTCTGTGACCTCATCGAAAACAAGCTGAAAAATGGCTTCGAGCAGTTTTGCAT CAACTTCGTCAATGAGAAGCTGCAGCAAATCTTTATCGAACTTACCCTGAAGGCCGAGCAGGCCATCAACCGTGCTATGCAGAAACCCCA GGAAGAGTACAGCATCGGTGTGCTGGACATTTACGGCTTCGAGATCTTCCAGTCCTGGCCTTTCCCGCCTACCTGCTGGGCATTGACAGC GGGCGACTGCAGGAGAAGCTGACCAGCCGCAAGATGGACAGCCGCTGGGGCGGGCGCAGCGAGTCCATCAATGTGACCCTCAACGTGGAG CAGGCAGCCTACACCCGTGATGCCCTGGCCAAGGGGCTCTATGCCCGCCTCTTCGACTTCCTCGTGGAGAGTGCTATGCAGGTTATTGGG ATCCCGCCCAGCATCCAGCAGCTGGTCCTGCAGCTCGTGGCGGGGATCTTGCACCTGGGGAACATCAGTTTCTGTGAAGACGGGAATTAC GCCCGAGTGGAGAGTGTGGACCCTGCTGGAAGGGGCCTCCCAGGAGCAAAGGCAGAACCTGGGCCTCATGACACCGGACTACTATTACTA CCTCAACCAATCGGACACCTACCAGGTGGACGGCACGGACGACAGAAGCGACTTTGGTGAGACTCTGGGGGAGCCAGATGGGGGCAAGAT CTCCAACTTCTTGCTGGAGAAGTCCCGCGTGGTCATGCAAAATGAAAATGAGAGGAACTTCCACATCTACTACCAG >11426_11426_1_C1QC-MYO1F_C1QC_chr1_22974184_ENST00000374639_MYO1F_chr19_8617015_ENST00000338257_length(amino acids)=389AA_BP=164 MAVGPSRSAWAMGCPRAPHATGRLLHPPRGCRRQLPGERLQDRVCQPSVQALRGGDAEAPAPHLQRHPIKRDLILTPKCVYVIGREKVKK GPEKGQVCEVLKKKVDIQALRGVSLSFQHPAEQEGAEAQQHQSELRRGLPGAGGAARAASVPGQEGAGGLRRFGHQVRPPLQAFPPGGGA RAKVRWLCPNHPEGLAAPRGCPEVRGDAGGRYAILTPETWPRWRGDERQGVQHLLRAVNMEPDQYQMGSTKVFVKNPESSQAPGGIPGPE GEHQGAQSRLRLPPPVRQIPAEKQANDLVATLMRCTPHYIRCIKPNETKRPRDWEENRAFLRMLFPEKLDGDKKGRPSTAGSKIKVSYDV SGFCERNRDVLFSDLIELMQTSEQAPQAS -------------------------------------------------------------- >11426_11426_2_C1QC-MYO1F_C1QC_chr1_22974184_ENST00000374640_MYO1F_chr19_8617015_ENST00000338257_length(transcript)=4196nt_BP=698nt CTCAGACACCGTGTCCTCTTGCCTGGGAGAGGGGAAGCAGATCTGAGGACATCTCTGTGCCAGGCCAGAAACCGCCCACCTGCAGTTCCT TCTCCGGGATGGACGTGGGGCCCAGCTCCCTGCCCCACCTTGGGCTGAAGCTGCTGCTGCTCCTGCTGCTGCTGCCCCTCAGGGGCCAAG CCAACACAGGCTGCTACGGGATCCCAGGGATGCCCGGCCTGCCCGGGGCACCAGGGAAGGATGGGTACGACGGACTGCCGGGGCCCAAGG GGGAGCCAGAGGTGTGGCTGGCTGTCAATGACTACTACGACATGGTGGGCATCCAGGGCTCTGACAGCGTCTTCTCCGGCTTCCTGCTCT TCCCCGACTAGGGCGGGCAGATGCGCTCGAGCCCCACGGGCCTTCCACCTCCCTCAGCTTCCTGCATGGACCCACCTTACTGGCCAGTCT GCATCCTTGCCTAGACCATTCTCCCCACCAGATGGACTTCTCCTCCAGGGAGCCCACCCTGACCCACCCCCACTGCACCCCCTCCCCATG GGTTCTCTCCTTCCTCTGAACTTCTTTAGGAGTCACTGCTTGTGTGGTTCCTGGGACACTTAACCAATGCCTTCTGGTACTGCCATTCTT TTTTTTTTTTTTTTCAAGTATTGGAAGGGGTGGGGAGATATATAAATAAATCATGAAATCAATACATAATCCCTCGGGCTGGTGGAAGGG CCGGCTTCACGGCCAGGAGGGCCTTTTCCCAGGAAACTACGTGGAGAAGATCTGAGCTGGGCCCTGGGATACTGCCTTCTCTTTCGCCCG CCTATCTGCCTGCCGGCCTGGTGGGGAGCCAGGCCCTGCCAATGAGAGCCTCGTTTACCTGGGCTGCAATAGCCTAAAAGTCCAGTCCTT TGGCCTCCAGTCCTGCCCAGGCCCTGGGTCACCAGGTCACTGCTGCAGCCCCCGCCCCTGGGCCCTGGTCTTCCTCCAACATCACACCTG CTGCCCATTCTCCATTTCTGTGTGTGTCAAAGGGGACTAACAGCAGAATCTACCTCCCAACTGCCATGTGATTAAGAAATGGGTCTTGAG TCCTGTGCTGTTGGCAAAGTGCCAGGCACAGTTGGGGAGGGGGGGGTCCTTAACAAGCGTGACTTTGCTCATTCTGTCATCACTAAGGCA ATAAACCTTTGCCAGGTGAAAGCACGAGTTAACTTACTAAGTGCCCAACAAGGACGATGTTTTCACAGCCCTGTGAGGTAGGAGCTGTGA AGGACCCCATCTTACAGGTGGAACAATGGAGGTTCAGAGAGGTTCACTGACCCAAGACTGCACAGAGCCATGCCTTGCATTCATATGTGA CCATAAAGCTTGAATTTGTCCCAGTTTGGGCTGGGCGCAGTGGCTCACGCCTGTAATCCCAGCACTTTGGGAGGCTGAGGCGGGCAGATC ACGTGAGACCAGGAGTTCAAGACCAGCCTGGATAACACAGCAAAACCCTGTTTCTACTAAAAATTTAAAAAAGCATGCAGAGGAAGCGCA GCGTGGGGCAACGGCCAGTGCCTGGTGTGGGCCGACCCAAGCCCCAGCCTCGGACACATGGTCCCAGGTGCCGGGCCCTATACCAGTACG TGGGCCAAGATGTGGACGAGCTGAGCTTCAACGTGAACGAGGTCATTGAGATCCTCATGGAAGGCATGGATCGCAATGGGGTGCCCCCCT CTGCCAGAGGGGGCCCCCTGCCCCTGGAGATCATGTCTGGAGGGGGCACCCACAGGCCTCCCCGGGGCCCTCCGTCCACATCCCTGGGAG CCAGCAGACGACCCCGGGCACGTCCGCCCTCAGAGCACAACACAGAATTCCTCAACGTGCCTGACCAGGGCATGGCCGGAGCCTACGCGG AAGGGAATGGCCAAGGGAAAACCTCGGAGGTCGTCCCAAGCCCCTACCCGGGCGGCCCCTGCGCCCCCCAGAGACTACAGTTTCGGGTGA AGAAGGAGGGCTGGGGCGGTGGCGGCACCCGCAGCGTCACCTTCTCCCGCGGCTTCGGCGACTTGGCAGTGCTCAAGGTTGGCGGTCGGA CCCTCACGGTCAGCGTGGGCGATGGGCTGCCCAAGAGCTCCACACGCGACAGGACGACTTCTTCATCCTCCAAGAGGATGCCGCCGACAG CTTCCTGGAGAGCGTCTTCAAGACCGAGTTTGTCAGCCTTCTGTGCAAGCGCTTCGAGGAGGCGACGCGGAGGCCCCTGCCCCTCACCTT CAGCGACACCCCATCAAGCGGGACTTGATCCTGACGCCCAAGTGTGTGTATGTGATTGGGCGAGAGAAAGTGAAGAAGGGACCTGAGAAG GGCCAGGTGTGTGAAGTCTTGAAGAAGAAAGTGGACATCCAGGCTCTGCGGGGAGTCTCCCTCAGCTTCCAACATCCTGCTGAACAAGAA GGAGCGGAGGCGCAACAGCATCAATCGGAACTTCGTCGGGGACTACCTGGGGCTGGAGGAGCGGCCCGAGCTGCGTCAGTTCCTGGGCAA GAGGGAGCGGGTGGACTTCGCCGATTCGGTCACCAAGTACGACCGCCGCTTCAAGCTTTTCCTCCTGGAGGAGGTGCGAGAGCGAAAGTT CGATGGCTTTGCCCGAACCATCCAGAAGGCCTGGCGGCGCCACGTGGCTGTCCGGAAGTACGAGGAGATGCGGGAGGAAGGTATGCCATT CTGACCCCCGAGACGTGGCCGCGGTGGCGTGGGGACGAACGCCAGGGCGTCCAGCACCTGCTTCGGGCGGTCAACATGGAGCCCGACCAG TACCAGATGGGGAGCACCAAGGTCTTTGTCAAGAACCCAGAGTCGAGTCAAGCACCAGGTGGAATACCTGGGCCTGAAGGAGAACATCAG GGTGCGCAGAGCCGGCTTCGCCTACCGCCGCCAGTTCGCCAAATTCCTGCAGAGAAACAAGCCAACGACCTGGTGGCCACACTGATGAGG TGCACACCCCACTACATCCGCTGCATCAAACCCAACGAGACCAAGAGGCCCCGAGACTGGGAGGAGAACAGGGCCTTCCTCCGGATGCTC TTCCCCGAGAAGCTGGATGGAGACAAGAAGGGGCGCCCCAGCACCGCCGGCTCCAAGATCAAGGTCTCCTACGACGTCAGCGGCTTCTGC GAGAGGAACCGAGACGTTCTCTTCTCCGACCTCATAGAGCTGATGCAGACCAGTGAGCAAGCCCCCCAGGCATCATGAGCGTCTTGGACG ACGTGTGCGCCACCATGCACGCCACGGGCGGGGGAGCAGACCAGACACTGCTGCAGAAGCTGCAGGCGGCTGTGGGGACCCACGAGCATT TCAACAGCTGGAGCGCCGGCTTCGTCATCCACCACTACGCTGGCAAGGAGGAGTATGTGCAGGAAGGCATCCGCTGGACTCCAATCCAGT ACTTCAACAACAAGGTCGTCTGTGACCTCATCGAAAACAAGCTGAAAAATGGCTTCGAGCAGTTTTGCATCAACTTCGTCAATGAGAAGC TGCAGCAAATCTTTATCGAACTTACCCTGAAGGCCGAGCAGGCCATCAACCGTGCTATGCAGAAACCCCAGGAAGAGTACAGCATCGGTG TGCTGGACATTTACGGCTTCGAGATCTTCCAGTCCTGGCCTTTCCCGCCTACCTGCTGGGCATTGACAGCGGGCGACTGCAGGAGAAGCT GACCAGCCGCAAGATGGACAGCCGCTGGGGCGGGCGCAGCGAGTCCATCAATGTGACCCTCAACGTGGAGCAGGCAGCCTACACCCGTGA TGCCCTGGCCAAGGGGCTCTATGCCCGCCTCTTCGACTTCCTCGTGGAGAGTGCTATGCAGGTTATTGGGATCCCGCCCAGCATCCAGCA GCTGGTCCTGCAGCTCGTGGCGGGGATCTTGCACCTGGGGAACATCAGTTTCTGTGAAGACGGGAATTACGCCCGAGTGGAGAGTGTGGA CCCTGCTGGAAGGGGCCTCCCAGGAGCAAAGGCAGAACCTGGGCCTCATGACACCGGACTACTATTACTACCTCAACCAATCGGACACCT ACCAGGTGGACGGCACGGACGACAGAAGCGACTTTGGTGAGACTCTGGGGGAGCCAGATGGGGGCAAGATCTCCAACTTCTTGCTGGAGA AGTCCCGCGTGGTCATGCAAAATGAAAATGAGAGGAACTTCCACATCTACTACCAG >11426_11426_2_C1QC-MYO1F_C1QC_chr1_22974184_ENST00000374640_MYO1F_chr19_8617015_ENST00000338257_length(amino acids)=389AA_BP=164 MAVGPSRSAWAMGCPRAPHATGRLLHPPRGCRRQLPGERLQDRVCQPSVQALRGGDAEAPAPHLQRHPIKRDLILTPKCVYVIGREKVKK GPEKGQVCEVLKKKVDIQALRGVSLSFQHPAEQEGAEAQQHQSELRRGLPGAGGAARAASVPGQEGAGGLRRFGHQVRPPLQAFPPGGGA RAKVRWLCPNHPEGLAAPRGCPEVRGDAGGRYAILTPETWPRWRGDERQGVQHLLRAVNMEPDQYQMGSTKVFVKNPESSQAPGGIPGPE GEHQGAQSRLRLPPPVRQIPAEKQANDLVATLMRCTPHYIRCIKPNETKRPRDWEENRAFLRMLFPEKLDGDKKGRPSTAGSKIKVSYDV SGFCERNRDVLFSDLIELMQTSEQAPQAS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C1QC-MYO1F |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C1QC-MYO1F |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C1QC-MYO1F |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | C1QC | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
| Hgene | C1QC | C0272242 | Complement deficiency disease | 1 | GENOMICS_ENGLAND |
| Hgene | C1QC | C3150902 | C1q DEFICIENCY | 1 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Tgene | C3711374 | Nonsyndromic Deafness | 3 | CLINGEN | |
| Tgene | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies