
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CACNA1D-PRKCD (FusionGDB2 ID:HG776TG5580) |
Fusion Gene Summary for CACNA1D-PRKCD |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CACNA1D-PRKCD | Fusion gene ID: hg776tg5580 | Hgene | Tgene | Gene symbol | CACNA1D | PRKCD | Gene ID | 776 | 5580 |
| Gene name | calcium voltage-gated channel subunit alpha1 D | protein kinase C delta | |
| Synonyms | CACH3|CACN4|CACNL1A2|CCHL1A2|Cav1.3|PASNA|SANDD | ALPS3|CVID9|MAY1|PKCD|nPKC-delta | |
| Cytomap | ('CACNA1D')('PRKCD') 3p21.1 | 3p21.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | voltage-dependent L-type calcium channel subunit alpha-1Dcalcium channel, L type, alpha-1 polypeptidecalcium channel, neuroendocrine/brain-type, alpha 1 subunitcalcium channel, voltage-dependent, L type, alpha 1D subunitvoltage-gated calcium channel a | protein kinase C delta typeprotein kinase C delta VIIItyrosine-protein kinase PRKCD | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000288139, ENST00000350061, ENST00000422281, ENST00000498251, ENST00000540742, ENST00000544977, | ||
| Fusion gene scores | * DoF score | 11 X 9 X 5=495 | 7 X 7 X 5=245 |
| # samples | 15 | 7 | |
| ** MAII score | log2(15/495*10)=-1.72246602447109 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/245*10)=-1.8073549220576 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CACNA1D [Title/Abstract] AND PRKCD [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CACNA1D(53535747)-PRKCD(53217468), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | CACNA1D-PRKCD seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CACNA1D-PRKCD seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CACNA1D-PRKCD seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CACNA1D-PRKCD seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CACNA1D | GO:0006816 | calcium ion transport | 11160515 |
| Hgene | CACNA1D | GO:0051928 | positive regulation of calcium ion transport | 1309651 |
| Hgene | CACNA1D | GO:0070509 | calcium ion import | 1309651 |
| Tgene | PRKCD | GO:0006468 | protein phosphorylation | 10713049|16611985 |
| Tgene | PRKCD | GO:0006915 | apoptotic process | 10770950 |
| Tgene | PRKCD | GO:0016572 | histone phosphorylation | 19059439 |
| Tgene | PRKCD | GO:0018105 | peptidyl-serine phosphorylation | 18285462 |
| Tgene | PRKCD | GO:0018107 | peptidyl-threonine phosphorylation | 10770950 |
| Tgene | PRKCD | GO:0032147 | activation of protein kinase activity | 10713049 |
| Tgene | PRKCD | GO:0042119 | neutrophil activation | 10770950 |
| Tgene | PRKCD | GO:0070301 | cellular response to hydrogen peroxide | 10713049 |
| Tgene | PRKCD | GO:0071447 | cellular response to hydroperoxide | 19059439 |
| Tgene | PRKCD | GO:1904385 | cellular response to angiotensin | 18285462 |
| Fusion gene breakpoints across CACNA1D (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PRKCD (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-GM-A2DD-01A | CACNA1D | chr3 | 53535747 | - | PRKCD | chr3 | 53217468 | + |
| ChimerDB4 | BRCA | TCGA-GM-A2DD-01A | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
Top |
Fusion Gene ORF analysis for CACNA1D-PRKCD |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000288139 | ENST00000477794 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| 5CDS-intron | ENST00000350061 | ENST00000477794 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| 5CDS-intron | ENST00000422281 | ENST00000477794 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| In-frame | ENST00000288139 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| In-frame | ENST00000288139 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| In-frame | ENST00000350061 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| In-frame | ENST00000350061 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| In-frame | ENST00000422281 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| In-frame | ENST00000422281 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-3CDS | ENST00000498251 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-3CDS | ENST00000498251 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-3CDS | ENST00000540742 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-3CDS | ENST00000540742 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-3CDS | ENST00000544977 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-3CDS | ENST00000544977 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-intron | ENST00000498251 | ENST00000477794 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-intron | ENST00000540742 | ENST00000477794 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| intron-intron | ENST00000544977 | ENST00000477794 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000350061 | CACNA1D | chr3 | 53535747 | + | ENST00000394729 | PRKCD | chr3 | 53217468 | + | 2819 | 994 | 511 | 2367 | 618 |
| ENST00000350061 | CACNA1D | chr3 | 53535747 | + | ENST00000330452 | PRKCD | chr3 | 53217468 | + | 2656 | 994 | 511 | 2367 | 618 |
| ENST00000288139 | CACNA1D | chr3 | 53535747 | + | ENST00000394729 | PRKCD | chr3 | 53217468 | + | 2426 | 601 | 118 | 1974 | 618 |
| ENST00000288139 | CACNA1D | chr3 | 53535747 | + | ENST00000330452 | PRKCD | chr3 | 53217468 | + | 2263 | 601 | 118 | 1974 | 618 |
| ENST00000422281 | CACNA1D | chr3 | 53535747 | + | ENST00000394729 | PRKCD | chr3 | 53217468 | + | 2308 | 483 | 0 | 1856 | 618 |
| ENST00000422281 | CACNA1D | chr3 | 53535747 | + | ENST00000330452 | PRKCD | chr3 | 53217468 | + | 2145 | 483 | 0 | 1856 | 618 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000350061 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + | 0.007955666 | 0.9920443 |
| ENST00000350061 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + | 0.01149645 | 0.9885035 |
| ENST00000288139 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + | 0.009161945 | 0.990838 |
| ENST00000288139 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + | 0.013259606 | 0.9867404 |
| ENST00000422281 | ENST00000394729 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + | 0.008286502 | 0.9917135 |
| ENST00000422281 | ENST00000330452 | CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217468 | + | 0.012437096 | 0.9875629 |
Top |
Fusion Genomic Features for CACNA1D-PRKCD |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217467 | + | 0.013505162 | 0.9864949 |
| CACNA1D | chr3 | 53535747 | + | PRKCD | chr3 | 53217467 | + | 0.013505162 | 0.9864949 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
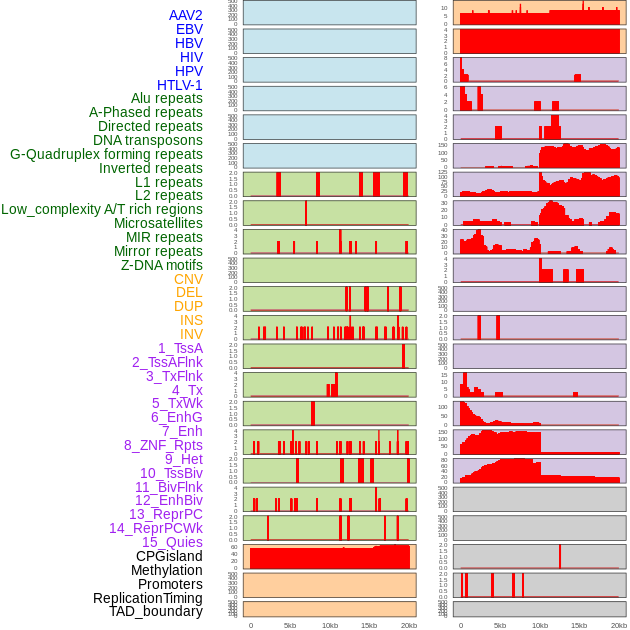 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
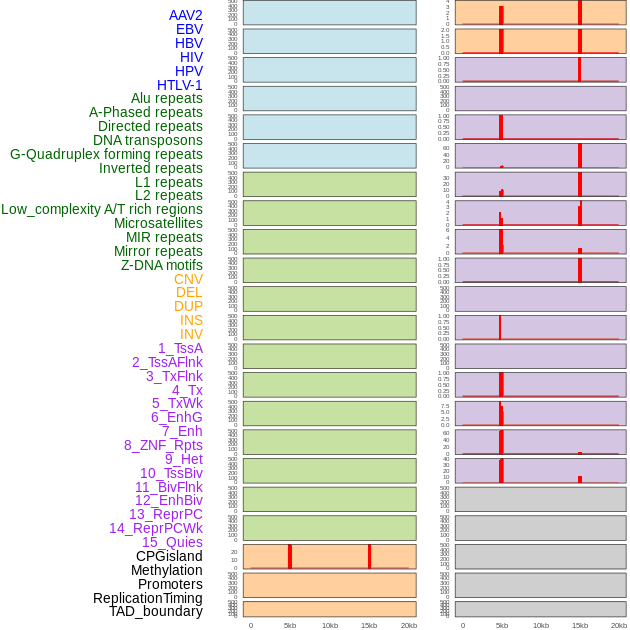 |
Top |
Fusion Protein Features for CACNA1D-PRKCD |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:53535747/chr3:53217468) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1_7 | 161 | 2182.0 | Compositional bias | Note=Poly-Met |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1_7 | 161 | 2162.0 | Compositional bias | Note=Poly-Met |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1_7 | 161 | 2138.0 | Compositional bias | Note=Poly-Met |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 146_163 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1_126 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 146_163 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1_126 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 146_163 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1_126 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 127_145 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS1 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 127_145 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS1 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 127_145 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS1 of repeat I |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000330452 | 7 | 19 | 349_603 | 219 | 677.0 | Domain | Protein kinase | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000330452 | 7 | 19 | 604_675 | 219 | 677.0 | Domain | AGC-kinase C-terminal | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000394729 | 6 | 18 | 349_603 | 219 | 677.0 | Domain | Protein kinase | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000394729 | 6 | 18 | 604_675 | 219 | 677.0 | Domain | AGC-kinase C-terminal | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000330452 | 7 | 19 | 355_363 | 219 | 677.0 | Nucleotide binding | ATP | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000394729 | 6 | 18 | 355_363 | 219 | 677.0 | Nucleotide binding | ATP | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000330452 | 7 | 19 | 230_280 | 219 | 677.0 | Zinc finger | Phorbol-ester/DAG-type 2 | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000394729 | 6 | 18 | 230_280 | 219 | 677.0 | Zinc finger | Phorbol-ester/DAG-type 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1493_1504 | 161 | 2182.0 | Calcium binding | Ontology_term=ECO:0000250 |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1493_1504 | 161 | 2162.0 | Calcium binding | Ontology_term=ECO:0000250 |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1493_1504 | 161 | 2138.0 | Calcium binding | Ontology_term=ECO:0000250 |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 653_659 | 161 | 2182.0 | Compositional bias | Note=Poly-Leu |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 827_838 | 161 | 2182.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 653_659 | 161 | 2162.0 | Compositional bias | Note=Poly-Leu |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 827_838 | 161 | 2162.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 653_659 | 161 | 2138.0 | Compositional bias | Note=Poly-Leu |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 827_838 | 161 | 2138.0 | Compositional bias | Note=Poly-Glu |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1075_1165 | 161 | 2182.0 | Region | Dihydropyridine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1420_1486 | 161 | 2182.0 | Region | Dihydropyridine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1432_1475 | 161 | 2182.0 | Region | Phenylalkylamine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 429_446 | 161 | 2182.0 | Region | Binding to the beta subunit |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1075_1165 | 161 | 2162.0 | Region | Dihydropyridine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1420_1486 | 161 | 2162.0 | Region | Dihydropyridine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1432_1475 | 161 | 2162.0 | Region | Phenylalkylamine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 429_446 | 161 | 2162.0 | Region | Binding to the beta subunit |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1075_1165 | 161 | 2138.0 | Region | Dihydropyridine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1420_1486 | 161 | 2138.0 | Region | Dihydropyridine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1432_1475 | 161 | 2138.0 | Region | Phenylalkylamine binding |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 429_446 | 161 | 2138.0 | Region | Binding to the beta subunit |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 113_409 | 161 | 2182.0 | Repeat | Note=I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1192_1467 | 161 | 2182.0 | Repeat | Note=IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 509_755 | 161 | 2182.0 | Repeat | Note=II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 873_1155 | 161 | 2182.0 | Repeat | Note=III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 113_409 | 161 | 2162.0 | Repeat | Note=I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1192_1467 | 161 | 2162.0 | Repeat | Note=IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 509_755 | 161 | 2162.0 | Repeat | Note=II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 873_1155 | 161 | 2162.0 | Repeat | Note=III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 113_409 | 161 | 2138.0 | Repeat | Note=I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1192_1467 | 161 | 2138.0 | Repeat | Note=IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 509_755 | 161 | 2138.0 | Repeat | Note=II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 873_1155 | 161 | 2138.0 | Repeat | Note=III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1038_1127 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1149_1205 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1225_1239 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1260_1266 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1289_1313 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1334_1352 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1373_1439 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1465_2161 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 184_195 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 215_235 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 255_273 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 294_381 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 407_523 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 544_558 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 578_585 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 605_614 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 634_652 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 674_727 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 753_886 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 906_921 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 942_953 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 973_978 | 161 | 2182.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 999_1017 | 161 | 2182.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1038_1127 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1149_1205 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1225_1239 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1260_1266 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1289_1313 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1334_1352 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1373_1439 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1465_2161 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 184_195 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 215_235 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 255_273 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 294_381 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 407_523 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 544_558 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 578_585 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 605_614 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 634_652 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 674_727 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 753_886 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 906_921 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 942_953 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 973_978 | 161 | 2162.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 999_1017 | 161 | 2162.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1038_1127 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1149_1205 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1225_1239 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1260_1266 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1289_1313 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1334_1352 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1373_1439 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1465_2161 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 184_195 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 215_235 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 255_273 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 294_381 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 407_523 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 544_558 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 578_585 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 605_614 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 634_652 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 674_727 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 753_886 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 906_921 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 942_953 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 973_978 | 161 | 2138.0 | Topological domain | Extracellular |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 999_1017 | 161 | 2138.0 | Topological domain | Cytoplasmic |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1018_1037 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS5 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1128_1148 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS6 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1206_1224 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS1 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1240_1259 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS2 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1267_1288 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS3 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1314_1333 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS4 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1353_1372 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS5 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 1440_1464 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS6 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 164_183 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS2 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 196_214 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS3 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 236_254 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS4 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 274_293 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS5 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 382_406 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS6 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 524_543 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS1 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 559_577 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS2 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 586_604 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS3 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 615_633 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS4 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 653_673 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS5 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 728_752 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS6 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 887_905 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS1 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 922_941 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS2 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 954_972 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS3 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000288139 | + | 3 | 49 | 979_998 | 161 | 2182.0 | Transmembrane | Helical%3B Name%3DS4 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1018_1037 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS5 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1128_1148 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS6 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1206_1224 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS1 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1240_1259 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS2 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1267_1288 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS3 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1314_1333 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS4 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1353_1372 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS5 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 1440_1464 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS6 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 164_183 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS2 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 196_214 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS3 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 236_254 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS4 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 274_293 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS5 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 382_406 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS6 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 524_543 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS1 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 559_577 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS2 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 586_604 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS3 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 615_633 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS4 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 653_673 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS5 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 728_752 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS6 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 887_905 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS1 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 922_941 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS2 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 954_972 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS3 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000350061 | + | 3 | 48 | 979_998 | 161 | 2162.0 | Transmembrane | Helical%3B Name%3DS4 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1018_1037 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS5 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1128_1148 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS6 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1206_1224 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS1 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1240_1259 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS2 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1267_1288 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS3 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1314_1333 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS4 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1353_1372 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS5 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 1440_1464 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS6 of repeat IV |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 164_183 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS2 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 196_214 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS3 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 236_254 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS4 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 274_293 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS5 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 382_406 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS6 of repeat I |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 524_543 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS1 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 559_577 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS2 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 586_604 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS3 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 615_633 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS4 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 653_673 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS5 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 728_752 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS6 of repeat II |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 887_905 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS1 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 922_941 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS2 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 954_972 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS3 of repeat III |
| Hgene | CACNA1D | chr3:53535747 | chr3:53217468 | ENST00000422281 | + | 3 | 46 | 979_998 | 161 | 2138.0 | Transmembrane | Helical%3B Name%3DS4 of repeat III |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000330452 | 7 | 19 | 1_106 | 219 | 677.0 | Domain | C2 | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000394729 | 6 | 18 | 1_106 | 219 | 677.0 | Domain | C2 | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000330452 | 7 | 19 | 158_208 | 219 | 677.0 | Zinc finger | Phorbol-ester/DAG-type 1 | |
| Tgene | PRKCD | chr3:53535747 | chr3:53217468 | ENST00000394729 | 6 | 18 | 158_208 | 219 | 677.0 | Zinc finger | Phorbol-ester/DAG-type 1 |
Top |
Fusion Gene Sequence for CACNA1D-PRKCD |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12324_12324_1_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000288139_PRKCD_chr3_53217468_ENST00000330452_length(transcript)=2263nt_BP=601nt AGAATAAGGGCAGGGACCGCGGCTCCTACCTCTTGGTGATCCCCTTCCCCATTCCGCCCCCGCCTCAACGCCCAGCACAGTGCCCTGCAC ACAGTAGTCGCTCAATAAATGTTCGTGGATGATGATGATGATGATGATGAAAAAAATGCAGCATCAACGGCAGCAGCAAGCGGACCACGC GAACGAGGCAAACTATGCAAGAGGCACCAGACTTCCTCTTTCTGGTGAAGGACCAACTTCTCAGCCGAATAGCTCCAAGCAAACTGTCCT GTCTTGGCAAGCTGCAATCGATGCTGCTAGACAGGCCAAGGCTGCCCAAACTATGAGCACCTCTGCACCCCCACCTGTAGGATCTCTCTC CCAAAGAAAACGTCAGCAATACGCCAAGAGCAAAAAACAGGGTAACTCGTCCAACAGCCGACCTGCCCGCGCCCTTTTCTGTTTATCACT CAATAACCCCATCCGAAGAGCCTGCATTAGTATAGTGGAATGGAAACCATTTGACATATTTATATTATTGGCTATTTTTGCCAATTGTGT GGCCTTAGCTATTTACATCCCATTCCCTGAAGATGATTCTAATTCAACAAATCATAACTTGTTCCAGAAAGAACGCTTCAACATCGACAT GCCGCACCGCTTCAAGGTTCACAACTACATGAGCCCCACCTTCTGTGACCACTGCGGCAGCCTGCTCTGGGGACTGGTGAAGCAGGGATT AAAGTGTGAAGACTGCGGCATGAATGTGCACCATAAATGCCGGGAGAAGGTGGCCAACCTCTGCGGCATCAACCAGAAGCTTTTGGCTGA GGCCTTGAACCAAGTCACCCAGAGAGCCTCCCGGAGATCAGACTCAGCCTCCTCAGAGCCTGTTGGGATATATCAGGGTTTCGAGAAGAA GACCGGAGTTGCTGGGGAGGACATGCAAGACAACAGTGGGACCTACGGCAAGATCTGGGAGGGCAGCAGCAAGTGCAACATCAACAACTT CATCTTCCACAAGGTCCTGGGCAAAGGCAGCTTCGGGAAGGTGCTGCTTGGAGAGCTGAAGGGCAGAGGAGAGTACTTTGCCATCAAGGC CCTCAAGAAGGATGTGGTCCTGATCGACGACGACGTGGAGTGCACCATGGTTGAGAAGCGGGTGCTGACACTTGCCGCAGAGAATCCCTT TCTCACCCACCTCATCTGCACCTTCCAGACCAAGGACCACCTGTTCTTTGTGATGGAGTTCCTCAACGGGGGGGACCTGATGTACCACAT CCAGGACAAAGGCCGCTTTGAACTCTACCGTGCCACGTTTTATGCCGCTGAGATAATGTGTGGACTGCAGTTTCTACACAGCAAGGGCAT CATTTACAGGGACCTCAAACTGGACAATGTGCTGCTGGACCGGGATGGCCACATCAAGATTGCCGACTTTGGGATGTGCAAAGAGAACAT ATTCGGGGAGAGCCGGGCCAGCACCTTCTGCGGCACCCCTGACTATATCGCCCCTGAGATCCTACAGGGCCTGAAGTACACATTCTCTGT GGACTGGTGGTCTTTCGGGGTCCTTCTGTACGAGATGCTCATTGGCCAGTCCCCCTTCCATGGTGATGATGAGGATGAACTCTTCGAGTC CATCCGTGTGGACACGCCACATTATCCCCGCTGGATCACCAAGGAGTCCAAGGACATCCTGGAGAAGCTCTTTGAAAGGGAACCAACCAA GAGGCTGGGAGTGACCGGAAACATCAAAATCCACCCCTTCTTCAAGACCATAAACTGGACTCTGCTGGAAAAGCGGAGGTTGGAGCCACC TTTCAGGCCCAAAGTGAAGTCACCCAGAGACTACAGTAACTTTGACCAGGAGTTCCTGAACGAGAAGGCGCGCCTCTCCTACAGCGACAA GAACCTCATCGACTCCATGGACCAGTCTGCATTCGCTGGCTTCTCCTTTGTGAACCCCAAATTCGAGCACCTCCTGGAAGATTGAGGTTC CTGGACAGATCAGGCTAGCCCTGCCCTCCACCCACACCTGCCCGCTCCCCACGATAAGCACCAGTGGGACTGTGGTGACTTCTGCTGCTG GCCCCGCCCCTGCCCCCAGAGCGTCCTTGGCTGCCGTCTGGCCGGGCTCTCATGGTACTTCCTCTGTGAACTGTGTGTGAATCTGCTTTT CCTCTGCCTTCGGAGGGAAATTGTAAATCCTGTGTTTCATTACTTGAATGTAGTTATCTATTGAAAATATATATTATATACATAGACATA TATATATATATAA >12324_12324_1_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000288139_PRKCD_chr3_53217468_ENST00000330452_length(amino acids)=618AA_BP=161 MMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAK SKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLFQKERFNIDMPHRFKVHNY MSPTFCDHCGSLLWGLVKQGLKCEDCGMNVHHKCREKVANLCGINQKLLAEALNQVTQRASRRSDSASSEPVGIYQGFEKKTGVAGEDMQ DNSGTYGKIWEGSSKCNINNFIFHKVLGKGSFGKVLLGELKGRGEYFAIKALKKDVVLIDDDVECTMVEKRVLTLAAENPFLTHLICTFQ TKDHLFFVMEFLNGGDLMYHIQDKGRFELYRATFYAAEIMCGLQFLHSKGIIYRDLKLDNVLLDRDGHIKIADFGMCKENIFGESRASTF CGTPDYIAPEILQGLKYTFSVDWWSFGVLLYEMLIGQSPFHGDDEDELFESIRVDTPHYPRWITKESKDILEKLFEREPTKRLGVTGNIK IHPFFKTINWTLLEKRRLEPPFRPKVKSPRDYSNFDQEFLNEKARLSYSDKNLIDSMDQSAFAGFSFVNPKFEHLLED -------------------------------------------------------------- >12324_12324_2_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000288139_PRKCD_chr3_53217468_ENST00000394729_length(transcript)=2426nt_BP=601nt AGAATAAGGGCAGGGACCGCGGCTCCTACCTCTTGGTGATCCCCTTCCCCATTCCGCCCCCGCCTCAACGCCCAGCACAGTGCCCTGCAC ACAGTAGTCGCTCAATAAATGTTCGTGGATGATGATGATGATGATGATGAAAAAAATGCAGCATCAACGGCAGCAGCAAGCGGACCACGC GAACGAGGCAAACTATGCAAGAGGCACCAGACTTCCTCTTTCTGGTGAAGGACCAACTTCTCAGCCGAATAGCTCCAAGCAAACTGTCCT GTCTTGGCAAGCTGCAATCGATGCTGCTAGACAGGCCAAGGCTGCCCAAACTATGAGCACCTCTGCACCCCCACCTGTAGGATCTCTCTC CCAAAGAAAACGTCAGCAATACGCCAAGAGCAAAAAACAGGGTAACTCGTCCAACAGCCGACCTGCCCGCGCCCTTTTCTGTTTATCACT CAATAACCCCATCCGAAGAGCCTGCATTAGTATAGTGGAATGGAAACCATTTGACATATTTATATTATTGGCTATTTTTGCCAATTGTGT GGCCTTAGCTATTTACATCCCATTCCCTGAAGATGATTCTAATTCAACAAATCATAACTTGTTCCAGAAAGAACGCTTCAACATCGACAT GCCGCACCGCTTCAAGGTTCACAACTACATGAGCCCCACCTTCTGTGACCACTGCGGCAGCCTGCTCTGGGGACTGGTGAAGCAGGGATT AAAGTGTGAAGACTGCGGCATGAATGTGCACCATAAATGCCGGGAGAAGGTGGCCAACCTCTGCGGCATCAACCAGAAGCTTTTGGCTGA GGCCTTGAACCAAGTCACCCAGAGAGCCTCCCGGAGATCAGACTCAGCCTCCTCAGAGCCTGTTGGGATATATCAGGGTTTCGAGAAGAA GACCGGAGTTGCTGGGGAGGACATGCAAGACAACAGTGGGACCTACGGCAAGATCTGGGAGGGCAGCAGCAAGTGCAACATCAACAACTT CATCTTCCACAAGGTCCTGGGCAAAGGCAGCTTCGGGAAGGTGCTGCTTGGAGAGCTGAAGGGCAGAGGAGAGTACTTTGCCATCAAGGC CCTCAAGAAGGATGTGGTCCTGATCGACGACGACGTGGAGTGCACCATGGTTGAGAAGCGGGTGCTGACACTTGCCGCAGAGAATCCCTT TCTCACCCACCTCATCTGCACCTTCCAGACCAAGGACCACCTGTTCTTTGTGATGGAGTTCCTCAACGGGGGGGACCTGATGTACCACAT CCAGGACAAAGGCCGCTTTGAACTCTACCGTGCCACGTTTTATGCCGCTGAGATAATGTGTGGACTGCAGTTTCTACACAGCAAGGGCAT CATTTACAGGGACCTCAAACTGGACAATGTGCTGCTGGACCGGGATGGCCACATCAAGATTGCCGACTTTGGGATGTGCAAAGAGAACAT ATTCGGGGAGAGCCGGGCCAGCACCTTCTGCGGCACCCCTGACTATATCGCCCCTGAGATCCTACAGGGCCTGAAGTACACATTCTCTGT GGACTGGTGGTCTTTCGGGGTCCTTCTGTACGAGATGCTCATTGGCCAGTCCCCCTTCCATGGTGATGATGAGGATGAACTCTTCGAGTC CATCCGTGTGGACACGCCACATTATCCCCGCTGGATCACCAAGGAGTCCAAGGACATCCTGGAGAAGCTCTTTGAAAGGGAACCAACCAA GAGGCTGGGAGTGACCGGAAACATCAAAATCCACCCCTTCTTCAAGACCATAAACTGGACTCTGCTGGAAAAGCGGAGGTTGGAGCCACC TTTCAGGCCCAAAGTGAAGTCACCCAGAGACTACAGTAACTTTGACCAGGAGTTCCTGAACGAGAAGGCGCGCCTCTCCTACAGCGACAA GAACCTCATCGACTCCATGGACCAGTCTGCATTCGCTGGCTTCTCCTTTGTGAACCCCAAATTCGAGCACCTCCTGGAAGATTGAGGTTC CTGGACAGATCAGGCTAGCCCTGCCCTCCACCCACACCTGCCCGCTCCCCACGATAAGCACCAGTGGGACTGTGGTGACTTCTGCTGCTG GCCCCGCCCCTGCCCCCAGAGCGTCCTTGGCTGCCGTCTGGCCGGGCTCTCATGGTACTTCCTCTGTGAACTGTGTGTGAATCTGCTTTT CCTCTGCCTTCGGAGGGAAATTGTAAATCCTGTGTTTCATTACTTGAATGTAGTTATCTATTGAAAATATATATTATATACATAGACATA TATATATATATAATAGGCTGTATATATTGCTCAGTAGAGAAAAACCATGGGGGACTGGTGATATGTTGATCTTTTTCAAAAAAATATATA TATGACAAAAAAAAAAAAAAAGGAGCACAAGCTGTTTGAACCACCAGGTTTATTTGTGTGTCTAAATAAACACCAAATAGTACCAA >12324_12324_2_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000288139_PRKCD_chr3_53217468_ENST00000394729_length(amino acids)=618AA_BP=161 MMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAK SKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLFQKERFNIDMPHRFKVHNY MSPTFCDHCGSLLWGLVKQGLKCEDCGMNVHHKCREKVANLCGINQKLLAEALNQVTQRASRRSDSASSEPVGIYQGFEKKTGVAGEDMQ DNSGTYGKIWEGSSKCNINNFIFHKVLGKGSFGKVLLGELKGRGEYFAIKALKKDVVLIDDDVECTMVEKRVLTLAAENPFLTHLICTFQ TKDHLFFVMEFLNGGDLMYHIQDKGRFELYRATFYAAEIMCGLQFLHSKGIIYRDLKLDNVLLDRDGHIKIADFGMCKENIFGESRASTF CGTPDYIAPEILQGLKYTFSVDWWSFGVLLYEMLIGQSPFHGDDEDELFESIRVDTPHYPRWITKESKDILEKLFEREPTKRLGVTGNIK IHPFFKTINWTLLEKRRLEPPFRPKVKSPRDYSNFDQEFLNEKARLSYSDKNLIDSMDQSAFAGFSFVNPKFEHLLED -------------------------------------------------------------- >12324_12324_3_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000350061_PRKCD_chr3_53217468_ENST00000330452_length(transcript)=2656nt_BP=994nt GGGCGAGCGCCTCCGTCCCCGGATGTGAGCTCCGGCTGCCCGCGGTCCCGAGCCAGCGGCGGCGCGGGCGGCGGCGGCGGGCACCGGGCA CCGCGGCGGGCGGGCAGACGGGCGGGCATGGGGGGAGCGCCGAGCGGCCCCGGCGGCCGGGCCGGCATCACCGCGGCGTCTCTCCGCTAG AGGAGGGGACAAGCCAGTTCTCCTTTGCAGCAAAAAATTACATGTATATATTATTAAGATAATATATACATTGGATTTTATTTTTTTAAA AAGTTTATTTTGCTCCATTTTTGAAAAAGAGAGAGCTTGGGTGGCGAGCGGTTTTTTTTTTAAATCAATTATCCTTATTTTCTGTTATTT GTCCCCGTCCCTCCCCACCCCCCTGCTGAAGCGAGAATAAGGGCAGGGACCGCGGCTCCTACCTCTTGGTGATCCCCTTCCCCATTCCGC CCCCGCCTCAACGCCCAGCACAGTGCCCTGCACACAGTAGTCGCTCAATAAATGTTCGTGGATGATGATGATGATGATGATGAAAAAAAT GCAGCATCAACGGCAGCAGCAAGCGGACCACGCGAACGAGGCAAACTATGCAAGAGGCACCAGACTTCCTCTTTCTGGTGAAGGACCAAC TTCTCAGCCGAATAGCTCCAAGCAAACTGTCCTGTCTTGGCAAGCTGCAATCGATGCTGCTAGACAGGCCAAGGCTGCCCAAACTATGAG CACCTCTGCACCCCCACCTGTAGGATCTCTCTCCCAAAGAAAACGTCAGCAATACGCCAAGAGCAAAAAACAGGGTAACTCGTCCAACAG CCGACCTGCCCGCGCCCTTTTCTGTTTATCACTCAATAACCCCATCCGAAGAGCCTGCATTAGTATAGTGGAATGGAAACCATTTGACAT ATTTATATTATTGGCTATTTTTGCCAATTGTGTGGCCTTAGCTATTTACATCCCATTCCCTGAAGATGATTCTAATTCAACAAATCATAA CTTGTTCCAGAAAGAACGCTTCAACATCGACATGCCGCACCGCTTCAAGGTTCACAACTACATGAGCCCCACCTTCTGTGACCACTGCGG CAGCCTGCTCTGGGGACTGGTGAAGCAGGGATTAAAGTGTGAAGACTGCGGCATGAATGTGCACCATAAATGCCGGGAGAAGGTGGCCAA CCTCTGCGGCATCAACCAGAAGCTTTTGGCTGAGGCCTTGAACCAAGTCACCCAGAGAGCCTCCCGGAGATCAGACTCAGCCTCCTCAGA GCCTGTTGGGATATATCAGGGTTTCGAGAAGAAGACCGGAGTTGCTGGGGAGGACATGCAAGACAACAGTGGGACCTACGGCAAGATCTG GGAGGGCAGCAGCAAGTGCAACATCAACAACTTCATCTTCCACAAGGTCCTGGGCAAAGGCAGCTTCGGGAAGGTGCTGCTTGGAGAGCT GAAGGGCAGAGGAGAGTACTTTGCCATCAAGGCCCTCAAGAAGGATGTGGTCCTGATCGACGACGACGTGGAGTGCACCATGGTTGAGAA GCGGGTGCTGACACTTGCCGCAGAGAATCCCTTTCTCACCCACCTCATCTGCACCTTCCAGACCAAGGACCACCTGTTCTTTGTGATGGA GTTCCTCAACGGGGGGGACCTGATGTACCACATCCAGGACAAAGGCCGCTTTGAACTCTACCGTGCCACGTTTTATGCCGCTGAGATAAT GTGTGGACTGCAGTTTCTACACAGCAAGGGCATCATTTACAGGGACCTCAAACTGGACAATGTGCTGCTGGACCGGGATGGCCACATCAA GATTGCCGACTTTGGGATGTGCAAAGAGAACATATTCGGGGAGAGCCGGGCCAGCACCTTCTGCGGCACCCCTGACTATATCGCCCCTGA GATCCTACAGGGCCTGAAGTACACATTCTCTGTGGACTGGTGGTCTTTCGGGGTCCTTCTGTACGAGATGCTCATTGGCCAGTCCCCCTT CCATGGTGATGATGAGGATGAACTCTTCGAGTCCATCCGTGTGGACACGCCACATTATCCCCGCTGGATCACCAAGGAGTCCAAGGACAT CCTGGAGAAGCTCTTTGAAAGGGAACCAACCAAGAGGCTGGGAGTGACCGGAAACATCAAAATCCACCCCTTCTTCAAGACCATAAACTG GACTCTGCTGGAAAAGCGGAGGTTGGAGCCACCTTTCAGGCCCAAAGTGAAGTCACCCAGAGACTACAGTAACTTTGACCAGGAGTTCCT GAACGAGAAGGCGCGCCTCTCCTACAGCGACAAGAACCTCATCGACTCCATGGACCAGTCTGCATTCGCTGGCTTCTCCTTTGTGAACCC CAAATTCGAGCACCTCCTGGAAGATTGAGGTTCCTGGACAGATCAGGCTAGCCCTGCCCTCCACCCACACCTGCCCGCTCCCCACGATAA GCACCAGTGGGACTGTGGTGACTTCTGCTGCTGGCCCCGCCCCTGCCCCCAGAGCGTCCTTGGCTGCCGTCTGGCCGGGCTCTCATGGTA CTTCCTCTGTGAACTGTGTGTGAATCTGCTTTTCCTCTGCCTTCGGAGGGAAATTGTAAATCCTGTGTTTCATTACTTGAATGTAGTTAT CTATTGAAAATATATATTATATACATAGACATATATATATATATAA >12324_12324_3_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000350061_PRKCD_chr3_53217468_ENST00000330452_length(amino acids)=618AA_BP=161 MMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAK SKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLFQKERFNIDMPHRFKVHNY MSPTFCDHCGSLLWGLVKQGLKCEDCGMNVHHKCREKVANLCGINQKLLAEALNQVTQRASRRSDSASSEPVGIYQGFEKKTGVAGEDMQ DNSGTYGKIWEGSSKCNINNFIFHKVLGKGSFGKVLLGELKGRGEYFAIKALKKDVVLIDDDVECTMVEKRVLTLAAENPFLTHLICTFQ TKDHLFFVMEFLNGGDLMYHIQDKGRFELYRATFYAAEIMCGLQFLHSKGIIYRDLKLDNVLLDRDGHIKIADFGMCKENIFGESRASTF CGTPDYIAPEILQGLKYTFSVDWWSFGVLLYEMLIGQSPFHGDDEDELFESIRVDTPHYPRWITKESKDILEKLFEREPTKRLGVTGNIK IHPFFKTINWTLLEKRRLEPPFRPKVKSPRDYSNFDQEFLNEKARLSYSDKNLIDSMDQSAFAGFSFVNPKFEHLLED -------------------------------------------------------------- >12324_12324_4_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000350061_PRKCD_chr3_53217468_ENST00000394729_length(transcript)=2819nt_BP=994nt GGGCGAGCGCCTCCGTCCCCGGATGTGAGCTCCGGCTGCCCGCGGTCCCGAGCCAGCGGCGGCGCGGGCGGCGGCGGCGGGCACCGGGCA CCGCGGCGGGCGGGCAGACGGGCGGGCATGGGGGGAGCGCCGAGCGGCCCCGGCGGCCGGGCCGGCATCACCGCGGCGTCTCTCCGCTAG AGGAGGGGACAAGCCAGTTCTCCTTTGCAGCAAAAAATTACATGTATATATTATTAAGATAATATATACATTGGATTTTATTTTTTTAAA AAGTTTATTTTGCTCCATTTTTGAAAAAGAGAGAGCTTGGGTGGCGAGCGGTTTTTTTTTTAAATCAATTATCCTTATTTTCTGTTATTT GTCCCCGTCCCTCCCCACCCCCCTGCTGAAGCGAGAATAAGGGCAGGGACCGCGGCTCCTACCTCTTGGTGATCCCCTTCCCCATTCCGC CCCCGCCTCAACGCCCAGCACAGTGCCCTGCACACAGTAGTCGCTCAATAAATGTTCGTGGATGATGATGATGATGATGATGAAAAAAAT GCAGCATCAACGGCAGCAGCAAGCGGACCACGCGAACGAGGCAAACTATGCAAGAGGCACCAGACTTCCTCTTTCTGGTGAAGGACCAAC TTCTCAGCCGAATAGCTCCAAGCAAACTGTCCTGTCTTGGCAAGCTGCAATCGATGCTGCTAGACAGGCCAAGGCTGCCCAAACTATGAG CACCTCTGCACCCCCACCTGTAGGATCTCTCTCCCAAAGAAAACGTCAGCAATACGCCAAGAGCAAAAAACAGGGTAACTCGTCCAACAG CCGACCTGCCCGCGCCCTTTTCTGTTTATCACTCAATAACCCCATCCGAAGAGCCTGCATTAGTATAGTGGAATGGAAACCATTTGACAT ATTTATATTATTGGCTATTTTTGCCAATTGTGTGGCCTTAGCTATTTACATCCCATTCCCTGAAGATGATTCTAATTCAACAAATCATAA CTTGTTCCAGAAAGAACGCTTCAACATCGACATGCCGCACCGCTTCAAGGTTCACAACTACATGAGCCCCACCTTCTGTGACCACTGCGG CAGCCTGCTCTGGGGACTGGTGAAGCAGGGATTAAAGTGTGAAGACTGCGGCATGAATGTGCACCATAAATGCCGGGAGAAGGTGGCCAA CCTCTGCGGCATCAACCAGAAGCTTTTGGCTGAGGCCTTGAACCAAGTCACCCAGAGAGCCTCCCGGAGATCAGACTCAGCCTCCTCAGA GCCTGTTGGGATATATCAGGGTTTCGAGAAGAAGACCGGAGTTGCTGGGGAGGACATGCAAGACAACAGTGGGACCTACGGCAAGATCTG GGAGGGCAGCAGCAAGTGCAACATCAACAACTTCATCTTCCACAAGGTCCTGGGCAAAGGCAGCTTCGGGAAGGTGCTGCTTGGAGAGCT GAAGGGCAGAGGAGAGTACTTTGCCATCAAGGCCCTCAAGAAGGATGTGGTCCTGATCGACGACGACGTGGAGTGCACCATGGTTGAGAA GCGGGTGCTGACACTTGCCGCAGAGAATCCCTTTCTCACCCACCTCATCTGCACCTTCCAGACCAAGGACCACCTGTTCTTTGTGATGGA GTTCCTCAACGGGGGGGACCTGATGTACCACATCCAGGACAAAGGCCGCTTTGAACTCTACCGTGCCACGTTTTATGCCGCTGAGATAAT GTGTGGACTGCAGTTTCTACACAGCAAGGGCATCATTTACAGGGACCTCAAACTGGACAATGTGCTGCTGGACCGGGATGGCCACATCAA GATTGCCGACTTTGGGATGTGCAAAGAGAACATATTCGGGGAGAGCCGGGCCAGCACCTTCTGCGGCACCCCTGACTATATCGCCCCTGA GATCCTACAGGGCCTGAAGTACACATTCTCTGTGGACTGGTGGTCTTTCGGGGTCCTTCTGTACGAGATGCTCATTGGCCAGTCCCCCTT CCATGGTGATGATGAGGATGAACTCTTCGAGTCCATCCGTGTGGACACGCCACATTATCCCCGCTGGATCACCAAGGAGTCCAAGGACAT CCTGGAGAAGCTCTTTGAAAGGGAACCAACCAAGAGGCTGGGAGTGACCGGAAACATCAAAATCCACCCCTTCTTCAAGACCATAAACTG GACTCTGCTGGAAAAGCGGAGGTTGGAGCCACCTTTCAGGCCCAAAGTGAAGTCACCCAGAGACTACAGTAACTTTGACCAGGAGTTCCT GAACGAGAAGGCGCGCCTCTCCTACAGCGACAAGAACCTCATCGACTCCATGGACCAGTCTGCATTCGCTGGCTTCTCCTTTGTGAACCC CAAATTCGAGCACCTCCTGGAAGATTGAGGTTCCTGGACAGATCAGGCTAGCCCTGCCCTCCACCCACACCTGCCCGCTCCCCACGATAA GCACCAGTGGGACTGTGGTGACTTCTGCTGCTGGCCCCGCCCCTGCCCCCAGAGCGTCCTTGGCTGCCGTCTGGCCGGGCTCTCATGGTA CTTCCTCTGTGAACTGTGTGTGAATCTGCTTTTCCTCTGCCTTCGGAGGGAAATTGTAAATCCTGTGTTTCATTACTTGAATGTAGTTAT CTATTGAAAATATATATTATATACATAGACATATATATATATATAATAGGCTGTATATATTGCTCAGTAGAGAAAAACCATGGGGGACTG GTGATATGTTGATCTTTTTCAAAAAAATATATATATGACAAAAAAAAAAAAAAAGGAGCACAAGCTGTTTGAACCACCAGGTTTATTTGT GTGTCTAAATAAACACCAAATAGTACCAA >12324_12324_4_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000350061_PRKCD_chr3_53217468_ENST00000394729_length(amino acids)=618AA_BP=161 MMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAK SKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLFQKERFNIDMPHRFKVHNY MSPTFCDHCGSLLWGLVKQGLKCEDCGMNVHHKCREKVANLCGINQKLLAEALNQVTQRASRRSDSASSEPVGIYQGFEKKTGVAGEDMQ DNSGTYGKIWEGSSKCNINNFIFHKVLGKGSFGKVLLGELKGRGEYFAIKALKKDVVLIDDDVECTMVEKRVLTLAAENPFLTHLICTFQ TKDHLFFVMEFLNGGDLMYHIQDKGRFELYRATFYAAEIMCGLQFLHSKGIIYRDLKLDNVLLDRDGHIKIADFGMCKENIFGESRASTF CGTPDYIAPEILQGLKYTFSVDWWSFGVLLYEMLIGQSPFHGDDEDELFESIRVDTPHYPRWITKESKDILEKLFEREPTKRLGVTGNIK IHPFFKTINWTLLEKRRLEPPFRPKVKSPRDYSNFDQEFLNEKARLSYSDKNLIDSMDQSAFAGFSFVNPKFEHLLED -------------------------------------------------------------- >12324_12324_5_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000422281_PRKCD_chr3_53217468_ENST00000330452_length(transcript)=2145nt_BP=483nt ATGATGATGATGATGATGATGAAAAAAATGCAGCATCAACGGCAGCAGCAAGCGGACCACGCGAACGAGGCAAACTATGCAAGAGGCACC AGACTTCCTCTTTCTGGTGAAGGACCAACTTCTCAGCCGAATAGCTCCAAGCAAACTGTCCTGTCTTGGCAAGCTGCAATCGATGCTGCT AGACAGGCCAAGGCTGCCCAAACTATGAGCACCTCTGCACCCCCACCTGTAGGATCTCTCTCCCAAAGAAAACGTCAGCAATACGCCAAG AGCAAAAAACAGGGTAACTCGTCCAACAGCCGACCTGCCCGCGCCCTTTTCTGTTTATCACTCAATAACCCCATCCGAAGAGCCTGCATT AGTATAGTGGAATGGAAACCATTTGACATATTTATATTATTGGCTATTTTTGCCAATTGTGTGGCCTTAGCTATTTACATCCCATTCCCT GAAGATGATTCTAATTCAACAAATCATAACTTGTTCCAGAAAGAACGCTTCAACATCGACATGCCGCACCGCTTCAAGGTTCACAACTAC ATGAGCCCCACCTTCTGTGACCACTGCGGCAGCCTGCTCTGGGGACTGGTGAAGCAGGGATTAAAGTGTGAAGACTGCGGCATGAATGTG CACCATAAATGCCGGGAGAAGGTGGCCAACCTCTGCGGCATCAACCAGAAGCTTTTGGCTGAGGCCTTGAACCAAGTCACCCAGAGAGCC TCCCGGAGATCAGACTCAGCCTCCTCAGAGCCTGTTGGGATATATCAGGGTTTCGAGAAGAAGACCGGAGTTGCTGGGGAGGACATGCAA GACAACAGTGGGACCTACGGCAAGATCTGGGAGGGCAGCAGCAAGTGCAACATCAACAACTTCATCTTCCACAAGGTCCTGGGCAAAGGC AGCTTCGGGAAGGTGCTGCTTGGAGAGCTGAAGGGCAGAGGAGAGTACTTTGCCATCAAGGCCCTCAAGAAGGATGTGGTCCTGATCGAC GACGACGTGGAGTGCACCATGGTTGAGAAGCGGGTGCTGACACTTGCCGCAGAGAATCCCTTTCTCACCCACCTCATCTGCACCTTCCAG ACCAAGGACCACCTGTTCTTTGTGATGGAGTTCCTCAACGGGGGGGACCTGATGTACCACATCCAGGACAAAGGCCGCTTTGAACTCTAC CGTGCCACGTTTTATGCCGCTGAGATAATGTGTGGACTGCAGTTTCTACACAGCAAGGGCATCATTTACAGGGACCTCAAACTGGACAAT GTGCTGCTGGACCGGGATGGCCACATCAAGATTGCCGACTTTGGGATGTGCAAAGAGAACATATTCGGGGAGAGCCGGGCCAGCACCTTC TGCGGCACCCCTGACTATATCGCCCCTGAGATCCTACAGGGCCTGAAGTACACATTCTCTGTGGACTGGTGGTCTTTCGGGGTCCTTCTG TACGAGATGCTCATTGGCCAGTCCCCCTTCCATGGTGATGATGAGGATGAACTCTTCGAGTCCATCCGTGTGGACACGCCACATTATCCC CGCTGGATCACCAAGGAGTCCAAGGACATCCTGGAGAAGCTCTTTGAAAGGGAACCAACCAAGAGGCTGGGAGTGACCGGAAACATCAAA ATCCACCCCTTCTTCAAGACCATAAACTGGACTCTGCTGGAAAAGCGGAGGTTGGAGCCACCTTTCAGGCCCAAAGTGAAGTCACCCAGA GACTACAGTAACTTTGACCAGGAGTTCCTGAACGAGAAGGCGCGCCTCTCCTACAGCGACAAGAACCTCATCGACTCCATGGACCAGTCT GCATTCGCTGGCTTCTCCTTTGTGAACCCCAAATTCGAGCACCTCCTGGAAGATTGAGGTTCCTGGACAGATCAGGCTAGCCCTGCCCTC CACCCACACCTGCCCGCTCCCCACGATAAGCACCAGTGGGACTGTGGTGACTTCTGCTGCTGGCCCCGCCCCTGCCCCCAGAGCGTCCTT GGCTGCCGTCTGGCCGGGCTCTCATGGTACTTCCTCTGTGAACTGTGTGTGAATCTGCTTTTCCTCTGCCTTCGGAGGGAAATTGTAAAT CCTGTGTTTCATTACTTGAATGTAGTTATCTATTGAAAATATATATTATATACATAGACATATATATATATATAA >12324_12324_5_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000422281_PRKCD_chr3_53217468_ENST00000330452_length(amino acids)=618AA_BP=161 MMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAK SKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLFQKERFNIDMPHRFKVHNY MSPTFCDHCGSLLWGLVKQGLKCEDCGMNVHHKCREKVANLCGINQKLLAEALNQVTQRASRRSDSASSEPVGIYQGFEKKTGVAGEDMQ DNSGTYGKIWEGSSKCNINNFIFHKVLGKGSFGKVLLGELKGRGEYFAIKALKKDVVLIDDDVECTMVEKRVLTLAAENPFLTHLICTFQ TKDHLFFVMEFLNGGDLMYHIQDKGRFELYRATFYAAEIMCGLQFLHSKGIIYRDLKLDNVLLDRDGHIKIADFGMCKENIFGESRASTF CGTPDYIAPEILQGLKYTFSVDWWSFGVLLYEMLIGQSPFHGDDEDELFESIRVDTPHYPRWITKESKDILEKLFEREPTKRLGVTGNIK IHPFFKTINWTLLEKRRLEPPFRPKVKSPRDYSNFDQEFLNEKARLSYSDKNLIDSMDQSAFAGFSFVNPKFEHLLED -------------------------------------------------------------- >12324_12324_6_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000422281_PRKCD_chr3_53217468_ENST00000394729_length(transcript)=2308nt_BP=483nt ATGATGATGATGATGATGATGAAAAAAATGCAGCATCAACGGCAGCAGCAAGCGGACCACGCGAACGAGGCAAACTATGCAAGAGGCACC AGACTTCCTCTTTCTGGTGAAGGACCAACTTCTCAGCCGAATAGCTCCAAGCAAACTGTCCTGTCTTGGCAAGCTGCAATCGATGCTGCT AGACAGGCCAAGGCTGCCCAAACTATGAGCACCTCTGCACCCCCACCTGTAGGATCTCTCTCCCAAAGAAAACGTCAGCAATACGCCAAG AGCAAAAAACAGGGTAACTCGTCCAACAGCCGACCTGCCCGCGCCCTTTTCTGTTTATCACTCAATAACCCCATCCGAAGAGCCTGCATT AGTATAGTGGAATGGAAACCATTTGACATATTTATATTATTGGCTATTTTTGCCAATTGTGTGGCCTTAGCTATTTACATCCCATTCCCT GAAGATGATTCTAATTCAACAAATCATAACTTGTTCCAGAAAGAACGCTTCAACATCGACATGCCGCACCGCTTCAAGGTTCACAACTAC ATGAGCCCCACCTTCTGTGACCACTGCGGCAGCCTGCTCTGGGGACTGGTGAAGCAGGGATTAAAGTGTGAAGACTGCGGCATGAATGTG CACCATAAATGCCGGGAGAAGGTGGCCAACCTCTGCGGCATCAACCAGAAGCTTTTGGCTGAGGCCTTGAACCAAGTCACCCAGAGAGCC TCCCGGAGATCAGACTCAGCCTCCTCAGAGCCTGTTGGGATATATCAGGGTTTCGAGAAGAAGACCGGAGTTGCTGGGGAGGACATGCAA GACAACAGTGGGACCTACGGCAAGATCTGGGAGGGCAGCAGCAAGTGCAACATCAACAACTTCATCTTCCACAAGGTCCTGGGCAAAGGC AGCTTCGGGAAGGTGCTGCTTGGAGAGCTGAAGGGCAGAGGAGAGTACTTTGCCATCAAGGCCCTCAAGAAGGATGTGGTCCTGATCGAC GACGACGTGGAGTGCACCATGGTTGAGAAGCGGGTGCTGACACTTGCCGCAGAGAATCCCTTTCTCACCCACCTCATCTGCACCTTCCAG ACCAAGGACCACCTGTTCTTTGTGATGGAGTTCCTCAACGGGGGGGACCTGATGTACCACATCCAGGACAAAGGCCGCTTTGAACTCTAC CGTGCCACGTTTTATGCCGCTGAGATAATGTGTGGACTGCAGTTTCTACACAGCAAGGGCATCATTTACAGGGACCTCAAACTGGACAAT GTGCTGCTGGACCGGGATGGCCACATCAAGATTGCCGACTTTGGGATGTGCAAAGAGAACATATTCGGGGAGAGCCGGGCCAGCACCTTC TGCGGCACCCCTGACTATATCGCCCCTGAGATCCTACAGGGCCTGAAGTACACATTCTCTGTGGACTGGTGGTCTTTCGGGGTCCTTCTG TACGAGATGCTCATTGGCCAGTCCCCCTTCCATGGTGATGATGAGGATGAACTCTTCGAGTCCATCCGTGTGGACACGCCACATTATCCC CGCTGGATCACCAAGGAGTCCAAGGACATCCTGGAGAAGCTCTTTGAAAGGGAACCAACCAAGAGGCTGGGAGTGACCGGAAACATCAAA ATCCACCCCTTCTTCAAGACCATAAACTGGACTCTGCTGGAAAAGCGGAGGTTGGAGCCACCTTTCAGGCCCAAAGTGAAGTCACCCAGA GACTACAGTAACTTTGACCAGGAGTTCCTGAACGAGAAGGCGCGCCTCTCCTACAGCGACAAGAACCTCATCGACTCCATGGACCAGTCT GCATTCGCTGGCTTCTCCTTTGTGAACCCCAAATTCGAGCACCTCCTGGAAGATTGAGGTTCCTGGACAGATCAGGCTAGCCCTGCCCTC CACCCACACCTGCCCGCTCCCCACGATAAGCACCAGTGGGACTGTGGTGACTTCTGCTGCTGGCCCCGCCCCTGCCCCCAGAGCGTCCTT GGCTGCCGTCTGGCCGGGCTCTCATGGTACTTCCTCTGTGAACTGTGTGTGAATCTGCTTTTCCTCTGCCTTCGGAGGGAAATTGTAAAT CCTGTGTTTCATTACTTGAATGTAGTTATCTATTGAAAATATATATTATATACATAGACATATATATATATATAATAGGCTGTATATATT GCTCAGTAGAGAAAAACCATGGGGGACTGGTGATATGTTGATCTTTTTCAAAAAAATATATATATGACAAAAAAAAAAAAAAAGGAGCAC AAGCTGTTTGAACCACCAGGTTTATTTGTGTGTCTAAATAAACACCAAATAGTACCAA >12324_12324_6_CACNA1D-PRKCD_CACNA1D_chr3_53535747_ENST00000422281_PRKCD_chr3_53217468_ENST00000394729_length(amino acids)=618AA_BP=161 MMMMMMMKKMQHQRQQQADHANEANYARGTRLPLSGEGPTSQPNSSKQTVLSWQAAIDAARQAKAAQTMSTSAPPPVGSLSQRKRQQYAK SKKQGNSSNSRPARALFCLSLNNPIRRACISIVEWKPFDIFILLAIFANCVALAIYIPFPEDDSNSTNHNLFQKERFNIDMPHRFKVHNY MSPTFCDHCGSLLWGLVKQGLKCEDCGMNVHHKCREKVANLCGINQKLLAEALNQVTQRASRRSDSASSEPVGIYQGFEKKTGVAGEDMQ DNSGTYGKIWEGSSKCNINNFIFHKVLGKGSFGKVLLGELKGRGEYFAIKALKKDVVLIDDDVECTMVEKRVLTLAAENPFLTHLICTFQ TKDHLFFVMEFLNGGDLMYHIQDKGRFELYRATFYAAEIMCGLQFLHSKGIIYRDLKLDNVLLDRDGHIKIADFGMCKENIFGESRASTF CGTPDYIAPEILQGLKYTFSVDWWSFGVLLYEMLIGQSPFHGDDEDELFESIRVDTPHYPRWITKESKDILEKLFEREPTKRLGVTGNIK IHPFFKTINWTLLEKRRLEPPFRPKVKSPRDYSNFDQEFLNEKARLSYSDKNLIDSMDQSAFAGFSFVNPKFEHLLED -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CACNA1D-PRKCD |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CACNA1D-PRKCD |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CACNA1D-PRKCD |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CACNA1D | C3554018 | SINOATRIAL NODE DYSFUNCTION AND DEAFNESS | 5 | CLINGEN;GENOMICS_ENGLAND;ORPHANET |
| Hgene | CACNA1D | C0001430 | Adenoma | 2 | CTD_human |
| Hgene | CACNA1D | C0205646 | Adenoma, Basal Cell | 2 | CTD_human |
| Hgene | CACNA1D | C0205647 | Follicular adenoma | 2 | CTD_human |
| Hgene | CACNA1D | C0205648 | Adenoma, Microcystic | 2 | CTD_human |
| Hgene | CACNA1D | C0205649 | Adenoma, Monomorphic | 2 | CTD_human |
| Hgene | CACNA1D | C0205650 | Papillary adenoma | 2 | CTD_human |
| Hgene | CACNA1D | C0205651 | Adenoma, Trabecular | 2 | CTD_human |
| Hgene | CACNA1D | C3809609 | PRIMARY ALDOSTERONISM, SEIZURES, AND NEUROLOGIC ABNORMALITIES | 2 | GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | CACNA1D | C0004331 | Auriculo-Ventricular Dissociation | 1 | CTD_human |
| Hgene | CACNA1D | C0005586 | Bipolar Disorder | 1 | CTD_human |
| Hgene | CACNA1D | C0005587 | Depression, Bipolar | 1 | CTD_human |
| Hgene | CACNA1D | C0011052 | Prelingual Deafness | 1 | CTD_human |
| Hgene | CACNA1D | C0011053 | Deafness | 1 | CTD_human |
| Hgene | CACNA1D | C0018794 | Heart Block | 1 | CTD_human |
| Hgene | CACNA1D | C0020428 | Hyperaldosteronism | 1 | CTD_human |
| Hgene | CACNA1D | C0024713 | Manic Disorder | 1 | CTD_human |
| Hgene | CACNA1D | C0037052 | Sick Sinus Syndrome | 1 | CTD_human |
| Hgene | CACNA1D | C0039240 | Supraventricular tachycardia | 1 | CTD_human |
| Hgene | CACNA1D | C0086395 | Hearing Loss, Extreme | 1 | CTD_human |
| Hgene | CACNA1D | C0338831 | Manic | 1 | CTD_human |
| Hgene | CACNA1D | C0428908 | Sinus Node Dysfunction (disorder) | 1 | CTD_human |
| Hgene | CACNA1D | C0428977 | Bradycardia | 1 | CTD_human |
| Hgene | CACNA1D | C0525045 | Mood Disorders | 1 | PSYGENET |
| Hgene | CACNA1D | C0581883 | Complete Hearing Loss | 1 | CTD_human |
| Hgene | CACNA1D | C0751068 | Deafness, Acquired | 1 | CTD_human |
| Hgene | CACNA1D | C1384514 | Conn Syndrome | 1 | CTD_human |
| Hgene | CACNA1D | C3665473 | Bilateral Deafness | 1 | CTD_human |
| Hgene | CACNA1D | C4082305 | Deaf Mutism | 1 | CTD_human |
| Tgene | C0002152 | Alloxan Diabetes | 1 | CTD_human | |
| Tgene | C0009447 | Common Variable Immunodeficiency | 1 | ORPHANET | |
| Tgene | C0011853 | Diabetes Mellitus, Experimental | 1 | CTD_human | |
| Tgene | C0019193 | Hepatitis, Toxic | 1 | CTD_human | |
| Tgene | C0020538 | Hypertensive disease | 1 | CTD_human | |
| Tgene | C0020672 | Hypothermia, natural | 1 | CTD_human | |
| Tgene | C0021841 | Intestinal Neoplasms | 1 | CTD_human | |
| Tgene | C0022333 | Jacksonian Seizure | 1 | CTD_human | |
| Tgene | C0023893 | Liver Cirrhosis, Experimental | 1 | CTD_human | |
| Tgene | C0036572 | Seizures | 1 | CTD_human | |
| Tgene | C0038433 | Streptozotocin Diabetes | 1 | CTD_human | |
| Tgene | C0149504 | Encephalopathy, Toxic | 1 | CTD_human | |
| Tgene | C0149958 | Complex partial seizures | 1 | CTD_human | |
| Tgene | C0154659 | Toxic Encephalitis | 1 | CTD_human | |
| Tgene | C0234533 | Generalized seizures | 1 | CTD_human | |
| Tgene | C0234535 | Clonic Seizures | 1 | CTD_human | |
| Tgene | C0235032 | Neurotoxicity Syndromes | 1 | CTD_human | |
| Tgene | C0242422 | Parkinsonian Disorders | 1 | CTD_human | |
| Tgene | C0242423 | Ramsay Hunt Paralysis Syndrome | 1 | CTD_human | |
| Tgene | C0270824 | Visual seizure | 1 | CTD_human | |
| Tgene | C0270844 | Tonic Seizures | 1 | CTD_human | |
| Tgene | C0270846 | Epileptic drop attack | 1 | CTD_human | |
| Tgene | C0346627 | Intestinal Cancer | 1 | CTD_human | |
| Tgene | C0400966 | Non-alcoholic Fatty Liver Disease | 1 | CTD_human | |
| Tgene | C0422850 | Seizures, Somatosensory | 1 | CTD_human | |
| Tgene | C0422852 | Seizures, Auditory | 1 | CTD_human | |
| Tgene | C0422853 | Olfactory seizure | 1 | CTD_human | |
| Tgene | C0422854 | Gustatory seizure | 1 | CTD_human | |
| Tgene | C0422855 | Vertiginous seizure | 1 | CTD_human | |
| Tgene | C0494475 | Tonic - clonic seizures | 1 | CTD_human | |
| Tgene | C0751056 | Non-epileptic convulsion | 1 | CTD_human | |
| Tgene | C0751110 | Single Seizure | 1 | CTD_human | |
| Tgene | C0751123 | Atonic Absence Seizures | 1 | CTD_human | |
| Tgene | C0751494 | Convulsive Seizures | 1 | CTD_human | |
| Tgene | C0751495 | Seizures, Focal | 1 | CTD_human | |
| Tgene | C0751496 | Seizures, Sensory | 1 | CTD_human | |
| Tgene | C0752097 | Autosomal Dominant Juvenile Parkinson Disease | 1 | CTD_human | |
| Tgene | C0752098 | Autosomal Dominant Parkinsonism | 1 | CTD_human | |
| Tgene | C0752100 | Autosomal Recessive Parkinsonism | 1 | CTD_human | |
| Tgene | C0752101 | Parkinsonism, Experimental | 1 | CTD_human | |
| Tgene | C0752104 | Familial Juvenile Parkinsonism | 1 | CTD_human | |
| Tgene | C0752105 | Parkinsonism, Juvenile | 1 | CTD_human | |
| Tgene | C0860207 | Drug-Induced Liver Disease | 1 | CTD_human | |
| Tgene | C1262760 | Hepatitis, Drug-Induced | 1 | CTD_human | |
| Tgene | C1328840 | Autoimmune Lymphoproliferative Syndrome | 1 | ORPHANET | |
| Tgene | C1868675 | PARKINSON DISEASE 2, AUTOSOMAL RECESSIVE JUVENILE | 1 | CTD_human | |
| Tgene | C3241937 | Nonalcoholic Steatohepatitis | 1 | CTD_human | |
| Tgene | C3280742 | SYSTEMIC LUPUS ERYTHEMATOSUS 16 | 1 | ORPHANET | |
| Tgene | C3495874 | Nonepileptic Seizures | 1 | CTD_human | |
| Tgene | C3658290 | Drug-Induced Acute Liver Injury | 1 | CTD_human | |
| Tgene | C3809928 | AUTOIMMUNE LYMPHOPROLIFERATIVE SYNDROME, TYPE III | 1 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C4048158 | Convulsions | 1 | CTD_human | |
| Tgene | C4277682 | Chemical and Drug Induced Liver Injury | 1 | CTD_human | |
| Tgene | C4279912 | Chemically-Induced Liver Toxicity | 1 | CTD_human | |
| Tgene | C4316903 | Absence Seizures | 1 | CTD_human | |
| Tgene | C4317109 | Epileptic Seizures | 1 | CTD_human | |
| Tgene | C4317123 | Myoclonic Seizures | 1 | CTD_human | |
| Tgene | C4505436 | Generalized Absence Seizures | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies