
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CRELD2-P2RX4 (FusionGDB2 ID:HG79174TG5025) |
Fusion Gene Summary for CRELD2-P2RX4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CRELD2-P2RX4 | Fusion gene ID: hg79174tg5025 | Hgene | Tgene | Gene symbol | CRELD2 | P2RX4 | Gene ID | 79174 | 5025 |
| Gene name | cysteine rich with EGF like domains 2 | purinergic receptor P2X 4 | |
| Synonyms | - | P2X4|P2X4R | |
| Cytomap | ('CRELD2')('P2RX4') 22q13.33 | 12q24.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein disulfide isomerase CRELD2cysteine-rich with EGF-like domain protein 2 | P2X purinoceptor 4ATP receptorATP-gated cation channel proteinP2X receptor, subunit 4purinergic receptor P2X, ligand gated ion channel, 4purinergic receptor P2X4purinoceptor P2X4 | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000328268, ENST00000403427, ENST00000404488, ENST00000407217, ENST00000444954, | ||
| Fusion gene scores | * DoF score | 1 X 1 X 1=1 | 4 X 6 X 3=72 |
| # samples | 1 | 5 | |
| ** MAII score | log2(1/1*10)=3.32192809488736 | log2(5/72*10)=-0.526068811667588 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CRELD2 [Title/Abstract] AND P2RX4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CRELD2(50320941)-P2RX4(121670259), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | CRELD2-P2RX4 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CRELD2-P2RX4 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | P2RX4 | GO:0007165 | signal transduction | 9016352 |
| Tgene | P2RX4 | GO:0010524 | positive regulation of calcium ion transport into cytosol | 10969036 |
| Tgene | P2RX4 | GO:0033198 | response to ATP | 9016352 |
| Tgene | P2RX4 | GO:0034220 | ion transmembrane transport | 10515189 |
| Tgene | P2RX4 | GO:0034405 | response to fluid shear stress | 10969036 |
| Tgene | P2RX4 | GO:0050850 | positive regulation of calcium-mediated signaling | 10969036 |
| Tgene | P2RX4 | GO:0051899 | membrane depolarization | 9016352 |
| Tgene | P2RX4 | GO:0070588 | calcium ion transmembrane transport | 9016352 |
| Tgene | P2RX4 | GO:0071318 | cellular response to ATP | 10515189 |
| Tgene | P2RX4 | GO:0097190 | apoptotic signaling pathway | 17264311 |
| Fusion gene breakpoints across CRELD2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across P2RX4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
Top |
Fusion Gene ORF analysis for CRELD2-P2RX4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000404488 | ENST00000337233 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.00609119 | 0.99390876 |
| ENST00000404488 | ENST00000359949 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.006542422 | 0.9934576 |
| ENST00000328268 | ENST00000337233 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.004523695 | 0.9954763 |
| ENST00000328268 | ENST00000359949 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.004787044 | 0.9952129 |
| ENST00000403427 | ENST00000337233 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.004305177 | 0.99569476 |
| ENST00000403427 | ENST00000359949 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.004594252 | 0.9954058 |
| ENST00000407217 | ENST00000337233 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.005026492 | 0.99497354 |
| ENST00000407217 | ENST00000359949 | CRELD2 | chr22 | 50320941 | - | P2RX4 | chr12 | 121670259 | - | 0.005297974 | 0.99470204 |
Top |
Fusion Genomic Features for CRELD2-P2RX4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
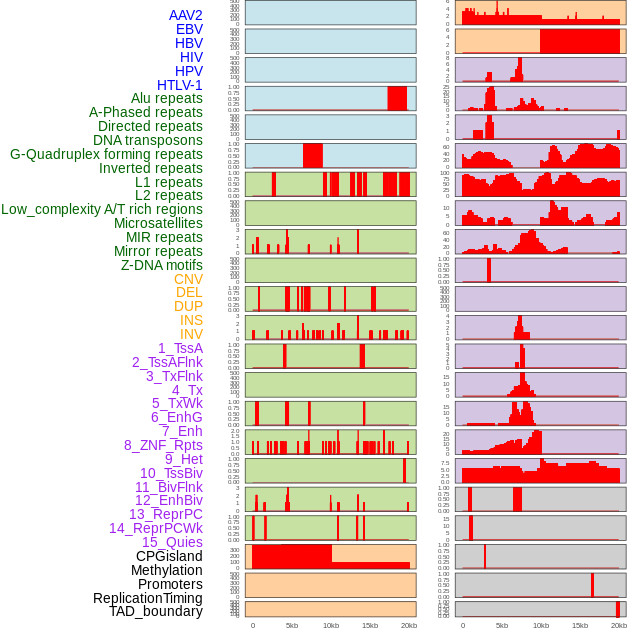 |
Top |
Fusion Protein Features for CRELD2-P2RX4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:50320941/chr12:121670259) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | P2RX4 | chr22:50320941 | chr12:121670259 | ENST00000337233 | 0 | 12 | 1_33 | 0 | 389.0 | Topological domain | Cytoplasmic | |
| Tgene | P2RX4 | chr22:50320941 | chr12:121670259 | ENST00000337233 | 0 | 12 | 360_388 | 0 | 389.0 | Topological domain | Cytoplasmic | |
| Tgene | P2RX4 | chr22:50320941 | chr12:121670259 | ENST00000337233 | 0 | 12 | 55_338 | 0 | 389.0 | Topological domain | Extracellular | |
| Tgene | P2RX4 | chr22:50320941 | chr12:121670259 | ENST00000337233 | 0 | 12 | 339_359 | 0 | 389.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | P2RX4 | chr22:50320941 | chr12:121670259 | ENST00000337233 | 0 | 12 | 34_54 | 0 | 389.0 | Transmembrane | Helical%3B Name%3D1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000328268 | - | 1 | 10 | 136_178 | 0 | 354.0 | Domain | EGF-like 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000328268 | - | 1 | 10 | 290_331 | 0 | 354.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000403427 | - | 1 | 9 | 136_178 | 0 | 326.0 | Domain | EGF-like 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000403427 | - | 1 | 9 | 290_331 | 0 | 326.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000404488 | - | 1 | 11 | 136_178 | 0 | 403.0 | Domain | EGF-like 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000404488 | - | 1 | 11 | 290_331 | 0 | 403.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000407217 | - | 1 | 9 | 136_178 | 0 | 322.0 | Domain | EGF-like 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000407217 | - | 1 | 9 | 290_331 | 0 | 322.0 | Domain | EGF-like 2%3B calcium-binding |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000328268 | - | 1 | 10 | 193_240 | 0 | 354.0 | Repeat | Note=FU 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000328268 | - | 1 | 10 | 253_302 | 0 | 354.0 | Repeat | Note=FU 2 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000403427 | - | 1 | 9 | 193_240 | 0 | 326.0 | Repeat | Note=FU 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000403427 | - | 1 | 9 | 253_302 | 0 | 326.0 | Repeat | Note=FU 2 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000404488 | - | 1 | 11 | 193_240 | 0 | 403.0 | Repeat | Note=FU 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000404488 | - | 1 | 11 | 253_302 | 0 | 403.0 | Repeat | Note=FU 2 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000407217 | - | 1 | 9 | 193_240 | 0 | 322.0 | Repeat | Note=FU 1 |
| Hgene | CRELD2 | chr22:50320941 | chr12:121670259 | ENST00000407217 | - | 1 | 9 | 253_302 | 0 | 322.0 | Repeat | Note=FU 2 |
Top |
Fusion Gene Sequence for CRELD2-P2RX4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >19416_19416_1_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000328268_P2RX4_chr12_121670259_ENST00000337233_length(transcript)=2115nt_BP=1318nt GCGGCCGGGAGGCCGGAGCAGCACGGCCGCAGGACCTGGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCC GGGCCGCGCTGGGGCTCCTGCCGCTTCTGCTGCTGCTGCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGG GGCTGGTGGACAAGTTTAACCAGGGGATGGTGGACACCGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGT CCAAGTACGAGTCCAGCGAGATTCGCCTGCTGGAGATCCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGG CGCAGGAGGAGCACCTGGAGGCCTGGTGGCTGCAGCTGAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAG TGTGCTGCTCTCCAGGAACCTACGGTCCCGACTGTCTCGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCG GAGATGGGAGCAGACAGGGCGACGGGTCCTGCCGGTGCCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCA GCTCGCTCCGGAACGAGACCCACAGCATCTGCACAGCCTGTGACGAGTCCTGCAAGACGTGCTCGGGCCTGACCAACAGAGACTGCGGCG AGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTGTGTGGATGTGGACGAGTGTGCGGCCGAGCCGCCTCCCTGCAGCGCTGCGCAGT TCTGTAAGAACGCCAACGGCTCCTACACGTGCGAAGAGTGTGACTCCAGCTGTGTGGGCTGCACAGGGGAAGGCCCAGGAAACTGTAAAG AGTGTATCTCTGGCTACGCGAGGGAGCACGGACAGTGTGCAGATGTGGACGAGTGCTCACTAGCAGAAAAAACCTGTGTGAGGAAAAACG AAAACTGCTACAATACTCCAGGGAGCTACGTCTGTGTGTGTCCTGACGGCTTCGAAGAAACGGAAGATGCCTGTGTGCCGCCGGCAGAGG CTGGCGAAGACCTGTAATGTGCCGGACTTACCCTTTAAATTATTCAGAAGGATGTCCCGTGGAAAATGTGGCCCTGAGGATGCCGTCTCC TGCAGTGGACAGCGGCGGGGAGAGGCTGCCTGCTCTCTAACGGTTGATTCTCATTTGTCCCTTAAACAGCTGCATTTCTTGGTTGTTCTT AAACAGACTTGTATATTTTGATACAGTTCTTTGTAATAAAATTGACCATTGTAGGTAAACGCTCATCAAGGCCTATGGCATCCGCTTCGA CATCATTGTGTTTGGGAAGGCAGGGAAATTTGACATCATCCCCACTATGATCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGAC CGTGCTGTGTGACATCATAGTCCTCTACTGCATGAAGAAAAGACTCTACTATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCA GGGTCTTGCTAGTGAGCTGGACCAGTGAGGCCTACCCCACACCTGGGCTCTCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAG AAATGGCCACCACATCACCCCAGAGAAATTTCTGGAATCTGATTGAGTCTCCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTG TGTTGTGTGCAGGATCTGTTTGCCCACTCGGCCCAGGAGGTCAGCAGTCTGTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGG GTTGTCGGGGGAGCGCTGGCCCGACGCAGTGGCACTGCTGTGGCTTTCAGGGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGC TCTCTCCAGGACAGGCCCAGTCCTCTGAGGCACGGCGGCTCTGTTCAAGCACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTA GACTTGTAGCAGGCCTGGGCTGCAGGCTTCCCCCCGACCATTCCCTGCAGCCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTG TGCTAAGGTGATCGAGGACCAGACATTAAAGCGTGATTTTCTTAA >19416_19416_1_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000328268_P2RX4_chr12_121670259_ENST00000337233_length(amino acids)=353AA_BP= MELRLRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLE ILEGLCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCR CHMGYQGPLCTDCMDGYFSSLRNETHSICTACDESCKTCSGLTNRDCGECEVGWVLDEGACVDVDECAAEPPPCSAAQFCKNANGSYTCE ECDSSCVGCTGEGPGNCKECISGYAREHGQCADVDECSLAEKTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- >19416_19416_2_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000328268_P2RX4_chr12_121670259_ENST00000359949_length(transcript)=2079nt_BP=1318nt GCGGCCGGGAGGCCGGAGCAGCACGGCCGCAGGACCTGGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCC GGGCCGCGCTGGGGCTCCTGCCGCTTCTGCTGCTGCTGCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGG GGCTGGTGGACAAGTTTAACCAGGGGATGGTGGACACCGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGT CCAAGTACGAGTCCAGCGAGATTCGCCTGCTGGAGATCCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGG CGCAGGAGGAGCACCTGGAGGCCTGGTGGCTGCAGCTGAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAG TGTGCTGCTCTCCAGGAACCTACGGTCCCGACTGTCTCGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCG GAGATGGGAGCAGACAGGGCGACGGGTCCTGCCGGTGCCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCA GCTCGCTCCGGAACGAGACCCACAGCATCTGCACAGCCTGTGACGAGTCCTGCAAGACGTGCTCGGGCCTGACCAACAGAGACTGCGGCG AGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTGTGTGGATGTGGACGAGTGTGCGGCCGAGCCGCCTCCCTGCAGCGCTGCGCAGT TCTGTAAGAACGCCAACGGCTCCTACACGTGCGAAGAGTGTGACTCCAGCTGTGTGGGCTGCACAGGGGAAGGCCCAGGAAACTGTAAAG AGTGTATCTCTGGCTACGCGAGGGAGCACGGACAGTGTGCAGATGTGGACGAGTGCTCACTAGCAGAAAAAACCTGTGTGAGGAAAAACG AAAACTGCTACAATACTCCAGGGAGCTACGTCTGTGTGTGTCCTGACGGCTTCGAAGAAACGGAAGATGCCTGTGTGCCGCCGGCAGAGG CTGGCGAAGACCTGTAATGTGCCGGACTTACCCTTTAAATTATTCAGAAGGATGTCCCGTGGAAAATGTGGCCCTGAGGATGCCGTCTCC TGCAGTGGACAGCGGCGGGGAGAGGCTGCCTGCTCTCTAACGGTTGATTCTCATTTGTCCCTTAAACAGCTGCATTTCTTGGTTGTTCTT AAACAGACTTGTATATTTTGATACAGTTCTTTGTAATAAAATTGACCATTGTAGGTAAACGCTCATCAAGGCCTATGGCATCCGCTTCGA CATCATTGTGTTTGGGAAGGCAGGGAAATTTGACATCATCCCCACTATGATCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGAC CGTGCTGTGTGACATCATAGTCCTCTACTGCATGAAGAAAAGACTCTACTATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCA GGGTCTTGCTAGTGAGCTGGACCAGTGAGGCCTACCCCACACCTGGGCTCTCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAG AAATGGCCACCACATCACCCCAGAGAAATTTCTGGAATCTGATTGAGTCTCCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTG TGTTGTGTGCAGGATCTGTTTGCCCACTCGGCCCAGGAGGTCAGCAGTCTGTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGG GTTGTCGGGGGAGCGCTGGCCCGACGCAGTGGCACTGCTGTGGCTTTCAGGGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGC TCTCTCCAGGACAGGCCCAGTCCTCTGAGGCACGGCGGCTCTGTTCAAGCACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTA GACTTGTAGCAGGCCTGGGCTGCAGGCTTCCCCCCGACCATTCCCTGCAGCCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTG TGCTAAGGT >19416_19416_2_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000328268_P2RX4_chr12_121670259_ENST00000359949_length(amino acids)=353AA_BP= MELRLRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLE ILEGLCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCR CHMGYQGPLCTDCMDGYFSSLRNETHSICTACDESCKTCSGLTNRDCGECEVGWVLDEGACVDVDECAAEPPPCSAAQFCKNANGSYTCE ECDSSCVGCTGEGPGNCKECISGYAREHGQCADVDECSLAEKTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- >19416_19416_3_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000403427_P2RX4_chr12_121670259_ENST00000337233_length(transcript)=2000nt_BP=1203nt GGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCCGGGCCGCGCTGGGGCTCCTGCCGCTTCTGCTGCTGCT GCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGGGGCTGGTGGACAAGTTTAACCAGGGGATGGTGGACAC CGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGTCCAAGTACGAGTCCAGCGAGATTCGCCTGCTGGAGAT CCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGGCGCAGGAGGAGCACCTGGAGGCCTGGTGGCTGCAGCT GAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAGTGTGCTGCTCTCCAGGAACCTACGGTCCCGACTGTCT CGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCGGAGATGGGAGCAGACAGGGCGACGGGTCCTGCCGGTG CCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCAGCTCGCTCCGGAACGAGACCCACAGCATCTGCACAGC CTGTGACGAGTCCTGCAAGACGTGCTCGGGCCTGACCAACAGAGACTGCGGCGAGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTG TGTGGAGTGTGACTCCAGCTGTGTGGGCTGCACAGGGGAAGGCCCAGGAAACTGTAAAGAGTGTATCTCTGGCTACGCGAGGGAGCACGG ACAGTGTGCAGATGTGGACGAGTGCTCACTAGCAGAAAAAACCTGTGTGAGGAAAAACGAAAACTGCTACAATACTCCAGGGAGCTACGT CTGTGTGTGTCCTGACGGCTTCGAAGAAACGGAAGATGCCTGTGTGCCGCCGGCAGAGGCTGGCGAAGACCTGTAATGTGCCGGACTTAC CCTTTAAATTATTCAGAAGGATGTCCCGTGGAAAATGTGGCCCTGAGGATGCCGTCTCCTGCAGTGGACAGCGGCGGGGAGAGGCTGCCT GCTCTCTAACGGTTGATTCTCATTTGTCCCTTAAACAGCTGCATTTCTTGGTTGTTCTTAAACAGACTTGTATATTTTGATACAGTTCTT TGTAATAAAATTGACCATTGTAGGTAATCAGGAACGCTCATCAAGGCCTATGGCATCCGCTTCGACATCATTGTGTTTGGGAAGGCAGGG AAATTTGACATCATCCCCACTATGATCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGACCGTGCTGTGTGACATCATAGTCCTC TACTGCATGAAGAAAAGACTCTACTATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCAGGGTCTTGCTAGTGAGCTGGACCAG TGAGGCCTACCCCACACCTGGGCTCTCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAGAAATGGCCACCACATCACCCCAGAG AAATTTCTGGAATCTGATTGAGTCTCCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTGTGTTGTGTGCAGGATCTGTTTGCCC ACTCGGCCCAGGAGGTCAGCAGTCTGTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGGGTTGTCGGGGGAGCGCTGGCCCGAC GCAGTGGCACTGCTGTGGCTTTCAGGGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGCTCTCTCCAGGACAGGCCCAGTCCTC TGAGGCACGGCGGCTCTGTTCAAGCACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTAGACTTGTAGCAGGCCTGGGCTGCAG GCTTCCCCCCGACCATTCCCTGCAGCCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTGTGCTAAGGTGATCGAGGACCAGACA TTAAAGCGTGATTTTCTTAA >19416_19416_3_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000403427_P2RX4_chr12_121670259_ENST00000337233_length(amino acids)=321AA_BP= MRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLEILEG LCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCRCHMG YQGPLCTDCMDGYFSSLRNETHSICTACDESCKTCSGLTNRDCGECEVGWVLDEGACVECDSSCVGCTGEGPGNCKECISGYAREHGQCA DVDECSLAEKTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- >19416_19416_4_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000403427_P2RX4_chr12_121670259_ENST00000359949_length(transcript)=1964nt_BP=1203nt GGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCCGGGCCGCGCTGGGGCTCCTGCCGCTTCTGCTGCTGCT GCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGGGGCTGGTGGACAAGTTTAACCAGGGGATGGTGGACAC CGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGTCCAAGTACGAGTCCAGCGAGATTCGCCTGCTGGAGAT CCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGGCGCAGGAGGAGCACCTGGAGGCCTGGTGGCTGCAGCT GAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAGTGTGCTGCTCTCCAGGAACCTACGGTCCCGACTGTCT CGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCGGAGATGGGAGCAGACAGGGCGACGGGTCCTGCCGGTG CCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCAGCTCGCTCCGGAACGAGACCCACAGCATCTGCACAGC CTGTGACGAGTCCTGCAAGACGTGCTCGGGCCTGACCAACAGAGACTGCGGCGAGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTG TGTGGAGTGTGACTCCAGCTGTGTGGGCTGCACAGGGGAAGGCCCAGGAAACTGTAAAGAGTGTATCTCTGGCTACGCGAGGGAGCACGG ACAGTGTGCAGATGTGGACGAGTGCTCACTAGCAGAAAAAACCTGTGTGAGGAAAAACGAAAACTGCTACAATACTCCAGGGAGCTACGT CTGTGTGTGTCCTGACGGCTTCGAAGAAACGGAAGATGCCTGTGTGCCGCCGGCAGAGGCTGGCGAAGACCTGTAATGTGCCGGACTTAC CCTTTAAATTATTCAGAAGGATGTCCCGTGGAAAATGTGGCCCTGAGGATGCCGTCTCCTGCAGTGGACAGCGGCGGGGAGAGGCTGCCT GCTCTCTAACGGTTGATTCTCATTTGTCCCTTAAACAGCTGCATTTCTTGGTTGTTCTTAAACAGACTTGTATATTTTGATACAGTTCTT TGTAATAAAATTGACCATTGTAGGTAATCAGGAACGCTCATCAAGGCCTATGGCATCCGCTTCGACATCATTGTGTTTGGGAAGGCAGGG AAATTTGACATCATCCCCACTATGATCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGACCGTGCTGTGTGACATCATAGTCCTC TACTGCATGAAGAAAAGACTCTACTATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCAGGGTCTTGCTAGTGAGCTGGACCAG TGAGGCCTACCCCACACCTGGGCTCTCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAGAAATGGCCACCACATCACCCCAGAG AAATTTCTGGAATCTGATTGAGTCTCCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTGTGTTGTGTGCAGGATCTGTTTGCCC ACTCGGCCCAGGAGGTCAGCAGTCTGTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGGGTTGTCGGGGGAGCGCTGGCCCGAC GCAGTGGCACTGCTGTGGCTTTCAGGGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGCTCTCTCCAGGACAGGCCCAGTCCTC TGAGGCACGGCGGCTCTGTTCAAGCACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTAGACTTGTAGCAGGCCTGGGCTGCAG GCTTCCCCCCGACCATTCCCTGCAGCCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTGTGCTAAGGT >19416_19416_4_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000403427_P2RX4_chr12_121670259_ENST00000359949_length(amino acids)=321AA_BP= MRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLEILEG LCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCRCHMG YQGPLCTDCMDGYFSSLRNETHSICTACDESCKTCSGLTNRDCGECEVGWVLDEGACVECDSSCVGCTGEGPGNCKECISGYAREHGQCA DVDECSLAEKTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- >19416_19416_5_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000404488_P2RX4_chr12_121670259_ENST00000337233_length(transcript)=2335nt_BP=1538nt GGGCCTCGCCGGCGCCGTCAAGTAGCCTGGGGGACAGGCCGGCGCGGCTGGGAGCGGGTGGGCGGCCGGGAGGCCGGAGCAGCACGGCCG CAGGACCTGGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCCGGGCCGCGCTGGGGCTCCTGCCGCTTCTG CTGCTGCTGCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGGGGCTGGTGGACAAGTTTAACCAGGGGATG GTGGACACCGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGTCCAAGTACGAGTCCAGCGAGATTCGCCTG CTGGAGATCCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGGCGCAGGAGGAGCACCTGGAGGCCTGGTGG CTGCAGCTGAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAGTGTGCTGCTCTCCAGGAACCTACGGTCCC GACTGTCTCGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCGGAGATGGGAGCAGACAGGGCGACGGGTCC TGCCGGTGCCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCAGCTCGCTCCGGAACGAGACCCACAGCATC TGCACAGTCAGGACCGGCCTCTCCGATTCTTACCCGCCTTGCTGTCTGTCTCTTGGATGTTGGCGTGGCGTGGGCCACGCATGGATCCGT GGCCGGAACACGCACACCCAGCCAGGCTACAGCTCCAGAGTATGGATAGCTGCCTTCTCTCCAGCCTGTGACGAGTCCTGCAAGACGTGC TCGGGCCTGACCAACAGAGACTGCGGCGAGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTGTGTGGATGTGGACGAGTGTGCGGCC GAGCCGCCTCCCTGCAGCGCTGCGCAGTTCTGTAAGAACGCCAACGGCTCCTACACGTGCGAAGAGTGTGACTCCAGCTGTGTGGGCTGC ACAGGGGAAGGCCCAGGAAACTGTAAAGAGTGTATCTCTGGCTACGCGAGGGAGCACGGACAGTGTGCAGATGTGGACGAGTGCTCACTA GCAGAAAAAACCTGTGTGAGGAAAAACGAAAACTGCTACAATACTCCAGGGAGCTACGTCTGTGTGTGTCCTGACGGCTTCGAAGAAACG GAAGATGCCTGTGTGCCGCCGGCAGAGGCTGGCGAAGACCTGTAATGTGCCGGACTTACCCTTTAAATTATTCAGAAGGATGTCCCGTGG AAAATGTGGCCCTGAGGATGCCGTCTCCTGCAGTGGACAGCGGCGGGGAGAGGCTGCCTGCTCTCTAACGGTTGATTCTCATTTGTCCCT TAAACAGCTGCATTTCTTGGTTGTTCTTAAACAGACTTGTATATTTTGATACAGTTCTTTGTAATAAAATTGACCATTGTAGGTAATCAG GAGGAGAAACGCTCATCAAGGCCTATGGCATCCGCTTCGACATCATTGTGTTTGGGAAGGCAGGGAAATTTGACATCATCCCCACTATGA TCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGACCGTGCTGTGTGACATCATAGTCCTCTACTGCATGAAGAAAAGACTCTACT ATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCAGGGTCTTGCTAGTGAGCTGGACCAGTGAGGCCTACCCCACACCTGGGCTC TCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAGAAATGGCCACCACATCACCCCAGAGAAATTTCTGGAATCTGATTGAGTCT CCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTGTGTTGTGTGCAGGATCTGTTTGCCCACTCGGCCCAGGAGGTCAGCAGTCT GTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGGGTTGTCGGGGGAGCGCTGGCCCGACGCAGTGGCACTGCTGTGGCTTTCAG GGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGCTCTCTCCAGGACAGGCCCAGTCCTCTGAGGCACGGCGGCTCTGTTCAAGC ACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTAGACTTGTAGCAGGCCTGGGCTGCAGGCTTCCCCCCGACCATTCCCTGCAG CCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTGTGCTAAGGTGATCGAGGACCAGACATTAAAGCGTGATTTTCTTAA >19416_19416_5_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000404488_P2RX4_chr12_121670259_ENST00000337233_length(amino acids)=402AA_BP= MELRLRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLE ILEGLCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCR CHMGYQGPLCTDCMDGYFSSLRNETHSICTVRTGLSDSYPPCCLSLGCWRGVGHAWIRGRNTHTQPGYSSRVWIAAFSPACDESCKTCSG LTNRDCGECEVGWVLDEGACVDVDECAAEPPPCSAAQFCKNANGSYTCEECDSSCVGCTGEGPGNCKECISGYAREHGQCADVDECSLAE KTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- >19416_19416_6_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000404488_P2RX4_chr12_121670259_ENST00000359949_length(transcript)=2299nt_BP=1538nt GGGCCTCGCCGGCGCCGTCAAGTAGCCTGGGGGACAGGCCGGCGCGGCTGGGAGCGGGTGGGCGGCCGGGAGGCCGGAGCAGCACGGCCG CAGGACCTGGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCCGGGCCGCGCTGGGGCTCCTGCCGCTTCTG CTGCTGCTGCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGGGGCTGGTGGACAAGTTTAACCAGGGGATG GTGGACACCGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGTCCAAGTACGAGTCCAGCGAGATTCGCCTG CTGGAGATCCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGGCGCAGGAGGAGCACCTGGAGGCCTGGTGG CTGCAGCTGAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAGTGTGCTGCTCTCCAGGAACCTACGGTCCC GACTGTCTCGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCGGAGATGGGAGCAGACAGGGCGACGGGTCC TGCCGGTGCCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCAGCTCGCTCCGGAACGAGACCCACAGCATC TGCACAGTCAGGACCGGCCTCTCCGATTCTTACCCGCCTTGCTGTCTGTCTCTTGGATGTTGGCGTGGCGTGGGCCACGCATGGATCCGT GGCCGGAACACGCACACCCAGCCAGGCTACAGCTCCAGAGTATGGATAGCTGCCTTCTCTCCAGCCTGTGACGAGTCCTGCAAGACGTGC TCGGGCCTGACCAACAGAGACTGCGGCGAGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTGTGTGGATGTGGACGAGTGTGCGGCC GAGCCGCCTCCCTGCAGCGCTGCGCAGTTCTGTAAGAACGCCAACGGCTCCTACACGTGCGAAGAGTGTGACTCCAGCTGTGTGGGCTGC ACAGGGGAAGGCCCAGGAAACTGTAAAGAGTGTATCTCTGGCTACGCGAGGGAGCACGGACAGTGTGCAGATGTGGACGAGTGCTCACTA GCAGAAAAAACCTGTGTGAGGAAAAACGAAAACTGCTACAATACTCCAGGGAGCTACGTCTGTGTGTGTCCTGACGGCTTCGAAGAAACG GAAGATGCCTGTGTGCCGCCGGCAGAGGCTGGCGAAGACCTGTAATGTGCCGGACTTACCCTTTAAATTATTCAGAAGGATGTCCCGTGG AAAATGTGGCCCTGAGGATGCCGTCTCCTGCAGTGGACAGCGGCGGGGAGAGGCTGCCTGCTCTCTAACGGTTGATTCTCATTTGTCCCT TAAACAGCTGCATTTCTTGGTTGTTCTTAAACAGACTTGTATATTTTGATACAGTTCTTTGTAATAAAATTGACCATTGTAGGTAATCAG GAGGAGAAACGCTCATCAAGGCCTATGGCATCCGCTTCGACATCATTGTGTTTGGGAAGGCAGGGAAATTTGACATCATCCCCACTATGA TCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGACCGTGCTGTGTGACATCATAGTCCTCTACTGCATGAAGAAAAGACTCTACT ATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCAGGGTCTTGCTAGTGAGCTGGACCAGTGAGGCCTACCCCACACCTGGGCTC TCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAGAAATGGCCACCACATCACCCCAGAGAAATTTCTGGAATCTGATTGAGTCT CCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTGTGTTGTGTGCAGGATCTGTTTGCCCACTCGGCCCAGGAGGTCAGCAGTCT GTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGGGTTGTCGGGGGAGCGCTGGCCCGACGCAGTGGCACTGCTGTGGCTTTCAG GGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGCTCTCTCCAGGACAGGCCCAGTCCTCTGAGGCACGGCGGCTCTGTTCAAGC ACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTAGACTTGTAGCAGGCCTGGGCTGCAGGCTTCCCCCCGACCATTCCCTGCAG CCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTGTGCTAAGGT >19416_19416_6_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000404488_P2RX4_chr12_121670259_ENST00000359949_length(amino acids)=402AA_BP= MELRLRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLE ILEGLCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCR CHMGYQGPLCTDCMDGYFSSLRNETHSICTVRTGLSDSYPPCCLSLGCWRGVGHAWIRGRNTHTQPGYSSRVWIAAFSPACDESCKTCSG LTNRDCGECEVGWVLDEGACVDVDECAAEPPPCSAAQFCKNANGSYTCEECDSSCVGCTGEGPGNCKECISGYAREHGQCADVDECSLAE KTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- >19416_19416_7_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000407217_P2RX4_chr12_121670259_ENST00000337233_length(transcript)=1988nt_BP=1191nt GGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCCGGGCCGCGCTGGGGCTCCTGCCGCTTCTGCTGCTGCT GCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGGGGCTGGTGGACAAGTTTAACCAGGGGATGGTGGACAC CGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGTCCAAGTACGAGTCCAGCGAGATTCGCCTGCTGGAGAT CCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGGCGCAGGAGGAGCACCTGGAGGCCTGGTGGCTGCAGCT GAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAGTGTGCTGCTCTCCAGGAACCTACGGTCCCGACTGTCT CGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCGGAGATGGGAGCAGACAGGGCGACGGGTCCTGCCGGTG CCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCAGCTCGCTCCGGAACGAGACCCACAGCATCTGCACAGC CTGTGACGAGTCCTGCAAGACGTGCTCGGGCCTGACCAACAGAGACTGCGGCGAGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTG TGTGGATGTGGACGAGTGTGCGGCCGAGCCGCCTCCCTGCAGCGCTGCGCAGTTCTGTAAGAACGCCAACGGCTCCTACACGTGCGAAGA TGTGGACGAGTGCTCACTAGCAGAAAAAACCTGTGTGAGGAAAAACGAAAACTGCTACAATACTCCAGGGAGCTACGTCTGTGTGTGTCC TGACGGCTTCGAAGAAACGGAAGATGCCTGTGTGCCGCCGGCAGAGGCTGGCGAAGACCTGTAATGTGCCGGACTTACCCTTTAAATTAT TCAGAAGGATGTCCCGTGGAAAATGTGGCCCTGAGGATGCCGTCTCCTGCAGTGGACAGCGGCGGGGAGAGGCTGCCTGCTCTCTAACGG TTGATTCTCATTTGTCCCTTAAACAGCTGCATTTCTTGGTTGTTCTTAAACAGACTTGTATATTTTGATACAGTTCTTTGTAATAAAATT GACCATTGTAGGTAATCAGGAACGCTCATCAAGGCCTATGGCATCCGCTTCGACATCATTGTGTTTGGGAAGGCAGGGAAATTTGACATC ATCCCCACTATGATCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGACCGTGCTGTGTGACATCATAGTCCTCTACTGCATGAAG AAAAGACTCTACTATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCAGGGTCTTGCTAGTGAGCTGGACCAGTGAGGCCTACCC CACACCTGGGCTCTCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAGAAATGGCCACCACATCACCCCAGAGAAATTTCTGGAA TCTGATTGAGTCTCCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTGTGTTGTGTGCAGGATCTGTTTGCCCACTCGGCCCAGG AGGTCAGCAGTCTGTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGGGTTGTCGGGGGAGCGCTGGCCCGACGCAGTGGCACTG CTGTGGCTTTCAGGGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGCTCTCTCCAGGACAGGCCCAGTCCTCTGAGGCACGGCG GCTCTGTTCAAGCACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTAGACTTGTAGCAGGCCTGGGCTGCAGGCTTCCCCCCGA CCATTCCCTGCAGCCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTGTGCTAAGGTGATCGAGGACCAGACATTAAAGCGTGAT TTTCTTAA >19416_19416_7_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000407217_P2RX4_chr12_121670259_ENST00000337233_length(amino acids)=317AA_BP= MRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLEILEG LCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCRCHMG YQGPLCTDCMDGYFSSLRNETHSICTACDESCKTCSGLTNRDCGECEVGWVLDEGACVDVDECAAEPPPCSAAQFCKNANGSYTCEDVDE CSLAEKTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- >19416_19416_8_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000407217_P2RX4_chr12_121670259_ENST00000359949_length(transcript)=1952nt_BP=1191nt GGAGCTCCGGCTGCGTCTTCCCGCAGCGCTACCCGCCATGCGCCTGCCGCGCCGGGCCGCGCTGGGGCTCCTGCCGCTTCTGCTGCTGCT GCCGCCCGCGCCGGAGGCCGCCAAGAAGCCGACGCCCTGCCACCGGTGCCGGGGGCTGGTGGACAAGTTTAACCAGGGGATGGTGGACAC CGCAAAGAAGAACTTTGGCGGCGGGAACACGGCTTGGGAGGAAAAGACGCTGTCCAAGTACGAGTCCAGCGAGATTCGCCTGCTGGAGAT CCTGGAGGGGCTGTGCGAGAGCAGCGACTTCGAATGCAATCAGATGCTAGAGGCGCAGGAGGAGCACCTGGAGGCCTGGTGGCTGCAGCT GAAGAGCGAATATCCTGACTTATTCGAGTGGTTTTGTGTGAAGACACTGAAAGTGTGCTGCTCTCCAGGAACCTACGGTCCCGACTGTCT CGCATGCCAGGGCGGATCCCAGAGGCCCTGCAGCGGGAATGGCCACTGCAGCGGAGATGGGAGCAGACAGGGCGACGGGTCCTGCCGGTG CCACATGGGGTACCAGGGCCCGCTGTGCACTGACTGCATGGACGGCTACTTCAGCTCGCTCCGGAACGAGACCCACAGCATCTGCACAGC CTGTGACGAGTCCTGCAAGACGTGCTCGGGCCTGACCAACAGAGACTGCGGCGAGTGTGAAGTGGGCTGGGTGCTGGACGAGGGCGCCTG TGTGGATGTGGACGAGTGTGCGGCCGAGCCGCCTCCCTGCAGCGCTGCGCAGTTCTGTAAGAACGCCAACGGCTCCTACACGTGCGAAGA TGTGGACGAGTGCTCACTAGCAGAAAAAACCTGTGTGAGGAAAAACGAAAACTGCTACAATACTCCAGGGAGCTACGTCTGTGTGTGTCC TGACGGCTTCGAAGAAACGGAAGATGCCTGTGTGCCGCCGGCAGAGGCTGGCGAAGACCTGTAATGTGCCGGACTTACCCTTTAAATTAT TCAGAAGGATGTCCCGTGGAAAATGTGGCCCTGAGGATGCCGTCTCCTGCAGTGGACAGCGGCGGGGAGAGGCTGCCTGCTCTCTAACGG TTGATTCTCATTTGTCCCTTAAACAGCTGCATTTCTTGGTTGTTCTTAAACAGACTTGTATATTTTGATACAGTTCTTTGTAATAAAATT GACCATTGTAGGTAATCAGGAACGCTCATCAAGGCCTATGGCATCCGCTTCGACATCATTGTGTTTGGGAAGGCAGGGAAATTTGACATC ATCCCCACTATGATCAACATCGGCTCTGGCCTGGCACTGCTAGGCATGGCGACCGTGCTGTGTGACATCATAGTCCTCTACTGCATGAAG AAAAGACTCTACTATCGGGAGAAGAAATATAAATATGTGGAAGATTACGAGCAGGGTCTTGCTAGTGAGCTGGACCAGTGAGGCCTACCC CACACCTGGGCTCTCCACAGCCCCATCAAAGAACAGAGAGGAGGAGGAGGGAGAAATGGCCACCACATCACCCCAGAGAAATTTCTGGAA TCTGATTGAGTCTCCACTCCACAAGCACTCAGGGTTCCCCAGCAGCTCCTGTGTGTTGTGTGCAGGATCTGTTTGCCCACTCGGCCCAGG AGGTCAGCAGTCTGTTCTTGGCTGGGTCAACTCTGCTTTTCCCGCAACCTGGGGTTGTCGGGGGAGCGCTGGCCCGACGCAGTGGCACTG CTGTGGCTTTCAGGGCTGGAGCTGGCTTTGCTCAGAAGCCTCCTGTCTCCAGCTCTCTCCAGGACAGGCCCAGTCCTCTGAGGCACGGCG GCTCTGTTCAAGCACTTTATGCGGCAGGGGAGGCCGCCTGGCTGCAGTCACTAGACTTGTAGCAGGCCTGGGCTGCAGGCTTCCCCCCGA CCATTCCCTGCAGCCATGCGGCAGAGCTGGCATTTCTCCTCAGAGAAGCGCTGTGCTAAGGT >19416_19416_8_CRELD2-P2RX4_CRELD2_chr22_50320941_ENST00000407217_P2RX4_chr12_121670259_ENST00000359949_length(amino acids)=317AA_BP= MRLPAALPAMRLPRRAALGLLPLLLLLPPAPEAAKKPTPCHRCRGLVDKFNQGMVDTAKKNFGGGNTAWEEKTLSKYESSEIRLLEILEG LCESSDFECNQMLEAQEEHLEAWWLQLKSEYPDLFEWFCVKTLKVCCSPGTYGPDCLACQGGSQRPCSGNGHCSGDGSRQGDGSCRCHMG YQGPLCTDCMDGYFSSLRNETHSICTACDESCKTCSGLTNRDCGECEVGWVLDEGACVDVDECAAEPPPCSAAQFCKNANGSYTCEDVDE CSLAEKTCVRKNENCYNTPGSYVCVCPDGFEETEDACVPPAEAGEDL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CRELD2-P2RX4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CRELD2-P2RX4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CRELD2-P2RX4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0014544 | Epilepsy | 1 | CTD_human | |
| Tgene | C0014556 | Epilepsy, Temporal Lobe | 1 | CTD_human | |
| Tgene | C0014558 | Uncinate Epilepsy | 1 | CTD_human | |
| Tgene | C0086237 | Epilepsy, Cryptogenic | 1 | CTD_human | |
| Tgene | C0236018 | Aura | 1 | CTD_human | |
| Tgene | C0393672 | Epilepsy, Benign Psychomotor, Childhood | 1 | CTD_human | |
| Tgene | C0393682 | Epilepsy, Lateral Temporal | 1 | CTD_human | |
| Tgene | C0751111 | Awakening Epilepsy | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies