
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CAPZA1-CLCC1 (FusionGDB2 ID:HG829TG23155) |
Fusion Gene Summary for CAPZA1-CLCC1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CAPZA1-CLCC1 | Fusion gene ID: hg829tg23155 | Hgene | Tgene | Gene symbol | CAPZA1 | CLCC1 | Gene ID | 829 | 23155 |
| Gene name | capping actin protein of muscle Z-line subunit alpha 1 | chloride channel CLIC like 1 | |
| Synonyms | CAPPA1|CAPZ|CAZ1 | MCLC | |
| Cytomap | ('CAPZA1')('CLCC1') 1p13.2 | 1p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | F-actin-capping protein subunit alpha-1Cap ZcapZ alpha-1capping actin protein of muscle Z-line alpha subunit 1capping protein (actin filament) muscle Z-line, alpha 1 | chloride channel CLIC-like protein 1Mid-1-related chloride channel protein 1 | |
| Modification date | 20200327 | 20200313 | |
| UniProtAcc | P52907 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000476936, ENST00000263168, | ||
| Fusion gene scores | * DoF score | 15 X 8 X 7=840 | 2 X 2 X 2=8 |
| # samples | 15 | 2 | |
| ** MAII score | log2(15/840*10)=-2.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(2/8*10)=1.32192809488736 | |
| Context | PubMed: CAPZA1 [Title/Abstract] AND CLCC1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CAPZA1(113162505)-CLCC1(109490340), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across CAPZA1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
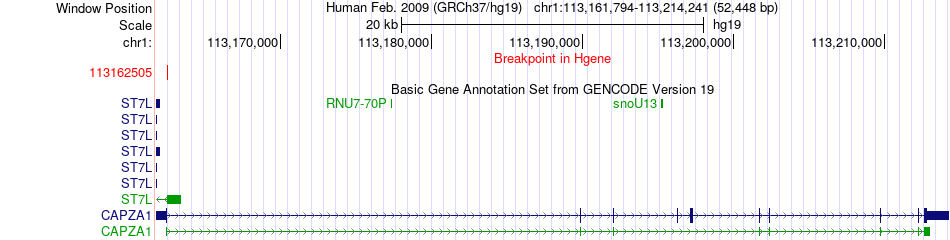 |
| Fusion gene breakpoints across CLCC1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
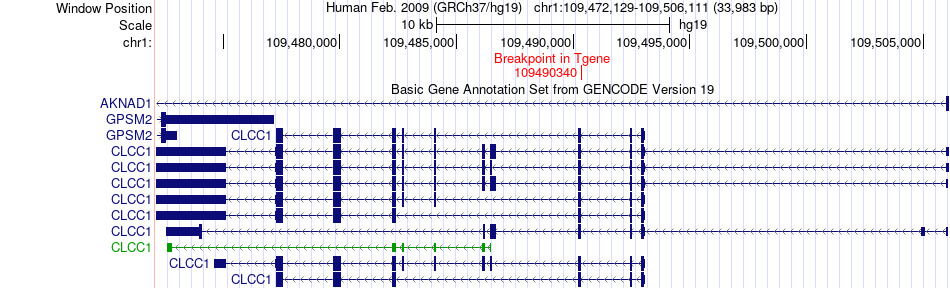 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ESCA | TCGA-L5-A891 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
Top |
Fusion Gene ORF analysis for CAPZA1-CLCC1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000476936 | ENST00000356970 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-3CDS | ENST00000476936 | ENST00000369968 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-3CDS | ENST00000476936 | ENST00000369969 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-3CDS | ENST00000476936 | ENST00000369971 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-3CDS | ENST00000476936 | ENST00000369976 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-3CDS | ENST00000476936 | ENST00000415331 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-intron | ENST00000476936 | ENST00000302500 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-intron | ENST00000476936 | ENST00000348264 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-intron | ENST00000476936 | ENST00000369970 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 3UTR-intron | ENST00000476936 | ENST00000482889 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 5CDS-intron | ENST00000263168 | ENST00000302500 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 5CDS-intron | ENST00000263168 | ENST00000348264 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 5CDS-intron | ENST00000263168 | ENST00000369970 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| 5CDS-intron | ENST00000263168 | ENST00000482889 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| In-frame | ENST00000263168 | ENST00000356970 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| In-frame | ENST00000263168 | ENST00000369968 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| In-frame | ENST00000263168 | ENST00000369969 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| In-frame | ENST00000263168 | ENST00000369971 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| In-frame | ENST00000263168 | ENST00000369976 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| In-frame | ENST00000263168 | ENST00000415331 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000263168 | CAPZA1 | chr1 | 113162505 | + | ENST00000369968 | CLCC1 | chr1 | 109490340 | - | 4620 | 711 | 558 | 1580 | 340 |
| ENST00000263168 | CAPZA1 | chr1 | 113162505 | + | ENST00000369969 | CLCC1 | chr1 | 109490340 | - | 4812 | 711 | 558 | 1772 | 404 |
| ENST00000263168 | CAPZA1 | chr1 | 113162505 | + | ENST00000356970 | CLCC1 | chr1 | 109490340 | - | 5175 | 711 | 558 | 2135 | 525 |
| ENST00000263168 | CAPZA1 | chr1 | 113162505 | + | ENST00000415331 | CLCC1 | chr1 | 109490340 | - | 5025 | 711 | 558 | 1985 | 475 |
| ENST00000263168 | CAPZA1 | chr1 | 113162505 | + | ENST00000369971 | CLCC1 | chr1 | 109490340 | - | 5175 | 711 | 558 | 2135 | 525 |
| ENST00000263168 | CAPZA1 | chr1 | 113162505 | + | ENST00000369976 | CLCC1 | chr1 | 109490340 | - | 2686 | 711 | 558 | 1268 | 236 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000263168 | ENST00000369968 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - | 0.000785461 | 0.99921453 |
| ENST00000263168 | ENST00000369969 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - | 0.000855934 | 0.9991441 |
| ENST00000263168 | ENST00000356970 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - | 0.000279156 | 0.9997209 |
| ENST00000263168 | ENST00000415331 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - | 0.000788036 | 0.9992119 |
| ENST00000263168 | ENST00000369971 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - | 0.000279156 | 0.9997209 |
| ENST00000263168 | ENST00000369976 | CAPZA1 | chr1 | 113162505 | + | CLCC1 | chr1 | 109490340 | - | 0.001809127 | 0.9981908 |
Top |
Fusion Genomic Features for CAPZA1-CLCC1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
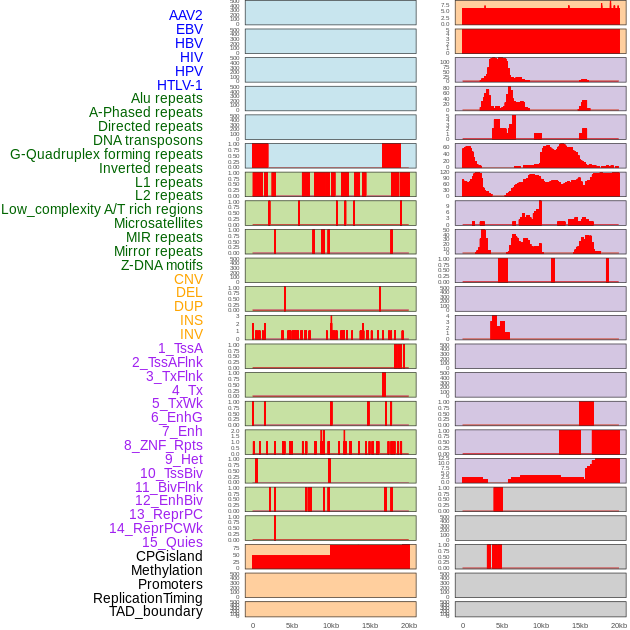 |
Top |
Fusion Protein Features for CAPZA1-CLCC1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:113162505/chr1:109490340) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| CAPZA1 | . |
| FUNCTION: F-actin-capping proteins bind in a Ca(2+)-independent manner to the fast growing ends of actin filaments (barbed end) thereby blocking the exchange of subunits at these ends. Unlike other capping proteins (such as gelsolin and severin), these proteins do not sever actin filaments. May play a role in the formation of epithelial cell junctions. {ECO:0000269|PubMed:22891260}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000302500 | 1 | 8 | 185_205 | 77 | 431.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000302500 | 1 | 8 | 217_237 | 77 | 431.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000302500 | 1 | 8 | 330_350 | 77 | 431.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000348264 | 1 | 6 | 185_205 | 77 | 367.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000348264 | 1 | 6 | 217_237 | 77 | 367.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000348264 | 1 | 6 | 330_350 | 77 | 367.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000356970 | 2 | 12 | 185_205 | 77 | 1577.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000356970 | 2 | 12 | 217_237 | 77 | 1577.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000356970 | 2 | 12 | 330_350 | 77 | 1577.0 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369968 | 1 | 7 | 185_205 | 77 | 1393.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369968 | 1 | 7 | 217_237 | 77 | 1393.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369968 | 1 | 7 | 330_350 | 77 | 1393.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369969 | 1 | 9 | 185_205 | 77 | 1457.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369969 | 1 | 9 | 217_237 | 77 | 1457.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369969 | 1 | 9 | 330_350 | 77 | 1457.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369970 | 1 | 11 | 185_205 | 77 | 699.3333333333334 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369970 | 1 | 11 | 217_237 | 77 | 699.3333333333334 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369970 | 1 | 11 | 330_350 | 77 | 699.3333333333334 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369971 | 2 | 12 | 185_205 | 77 | 1569.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369971 | 2 | 12 | 217_237 | 77 | 1569.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000369971 | 2 | 12 | 330_350 | 77 | 1569.6666666666667 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000415331 | 2 | 12 | 185_205 | 77 | 1516.3333333333333 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000415331 | 2 | 12 | 217_237 | 77 | 1516.3333333333333 | Transmembrane | Helical | |
| Tgene | CLCC1 | chr1:113162505 | chr1:109490340 | ENST00000415331 | 2 | 12 | 330_350 | 77 | 1516.3333333333333 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for CAPZA1-CLCC1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >12961_12961_1_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000356970_length(transcript)=5175nt_BP=711nt GGGAATCCTGGGATAGTGGCGGACCTGAAGTTGGCCTCTGTGAAGGCTGAGTCCTGGGGAACCGGGACCGAGAAGATTTCGAAGGTGGAG GAGCGTGTCTCAAGATTGGGGCTACCTGTTCTTTCGTGGGGCAGGGAAGGGGCGGACAGCAGCGCCTATTCTGGAGGAACTGGACTGAGA TGTGACCCCGAAGTGTTACCGCTTCCAAACGAAATGAGGGTCACCTTTCACACCGCCCCCCCCCCGGGGTTGGAAAAGCCACCGATCGTT CCAGCTGCCGAGCAGCTCTTAAAGCTTTGGATTCGGCTGTCGTGGAGATAACGGGCACCAGAAAAACTTGTAGGAGTAGCAACAGCTATT TGGTCGGATGGAGGCCAGAAGCCAAGAATAATCGAAACACGCTGCCAGCGCCCATTAGATGGATGGGAAATGAGTGTAACTCATTGGGAA AGATATTAGACTTCAAATCACCTAAGGCAAACCCTACTTCCTGGGGCGCGGGCGCGGGCGCTGGCGTTAGGAGACGTCACTCCCGCGCAT AACTGACATGGGGCCCTCTTGGTCGGCGTTTCCGGGCGGGTCCTTCCGACGGCCGCCGCGGTGATTCCATCACTCGGCTTTCTTCCCGGC CTGCCTCGCGCCCGTAGCCGGGCTGGGCCAGAACAGCCCAAGATGGCCGACTTCGATGATCGTGTGTCGGATGAGGAGAAGATTGATGAG TGTGAAAAGAAAAAGAGGGAAGACTATGAAAGTCAAAGCAATCCTGTTTTTAGGAGATACTTAAATAAGATTTTAATTGAAGCTGGAAAG CTTGGACTTCCTGATGAAAACAAAGGCGATATGCATTATGATGCTGAGATTATCCTTAAAAGAGAAACTTTGTTAGAAATACAGAAGTTT CTCAATGGAGAAGACTGGAAACCAGGTGCCTTGGATGATGCACTAAGTGATATTTTAATTAATTTTAAGTTTCATGATTTTGAAACATGG AAGTGGCGATTCGAAGATTCCTTTGGAGTGGATCCATATAATGTGTTAATGGTACTTCTTTGTCTGCTCTGCATCGTGGTTTTAGTGGCT ACTGAGCTGTGGACATATGTACGTTGGTACACTCAGTTGAGACGTGTTTTAATCATCAGCTTTCTGTTCAGTTTGGGATGGAATTGGATG TATTTATATAAGCTAGCTTTTGCACAGCATCAGGCTGAAGTCGCCAAGATGGAGCCATTAAACAATGTGTGTGCCAAAAAGATGGACTGG ACTGGAAGTATCTGGGAATGGTTTAGAAGTTCATGGACCTATAAGGATGACCCATGCCAAAAATACTATGAGCTCTTACTAGTCAACCCT ATTTGGTTGGTCCCACCAACAAAGGCACTTGCAGTTACATTCACCACATTTGTAACGGAGCCATTGAAGCATATTGGAAAAGGAACTGGG GAATTTATTAAAGCACTCATGAAGGAAATTCCAGCGCTGCTTCATCTTCCAGTGCTGATAATTATGGCATTAGCCATCCTGAGTTTCTGC TATGGTGCTGGAAAATCAGTTCATGTGCTGAGACATATAGGCGGTCCTGAGAGCGAACCTCCCCAGGCACTTCGGCCACGGGATAGAAGA CGGCAGGAGGAAATTGATTATAGACCTGATGGTGGAGCAGGTGATGCCGATTTCCATTATAGGGGCCAAATGGGCCCCACTGAGCAAGGC CCTTATGCCAAAACGTATGAGGGTAGAAGAGAGATTTTGAGAGAGAGAGATGTTGACTTGAGATTTCAGACTGGCAACAAGAGCCCTGAA GTGCTCCGGGCATTTGATGTACCAGACGCAGAGGCACGAGAGCATCCCACGGTGGTACCCAGTCATAAATCACCTGTTTTGGATACAAAG CCCAAGGAGACAGGTGGAATCCTGGGGGAAGGCACACCGAAAGAAAGCAGTACTGAAAGCAGCCAGTCGGCCAAGCCTGTCTCTGGCCAA GACACATCAGGGAATACAGAAGGTTCACCCGCAGCGGAAAAGGCCCAGCTCAAGTCTGAAGCCGCAGGCAGCCCAGACCAAGGCAGCACA TACAGCCCCGCAAGAGGTGTGGCTGGACCACGTGGACAGGATCCGGTCAGCAGCCCCTGTGGCTAGAGGAACACCAGCACAAACGACAGC CTCAAGTCTCCTTCGAGCTTTATATCCATTTGGGGATGAAGTCTACTTTGACAGCTAGCAAGGCGACATGCAACTGTTGTTGAATGATGA CAGCAATTCAGGAAAGACTTAAATATGAAAGCAAATTGAACACATCGGGTGTTTGTTATCAGAAAAGAGATGAGATGAGATAAGACTTGT TTATTGACTAGCCAATATGTCATTAAAATTAAGGTTTATATTGTGAAGCTTTTTTGAAATTTTACTTTTTTTTGAGAGTTTTGCTCTGTC ACCCAGGCTGGAGTGAGGTGGTACAATCTCGGCTCACTGCAACCTCCACCTCCCAGGTTCAAGAGATTCTCCTGCCTCAGTCTCCCGAGT AGCTAGGATTACAGATGTGCATCACCATGCCTGGCTAATTTTTGTATTTTTTAGTAGAGATGGGGTTTCACCATGTTGGTCAGGCTGGTC TCGAACTCCTGACCTCAAGTGACCCGCCCTTGTCGGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCATTGTGCCCAGCCTATATAGT GTGAAGCTTTTAGGAAAATCAGAACAGGGTAGACAGCTGTTAAAAACAATGTTTAAATGGAATAATGTTGAATGTTTACAGGCTGTAAGA ACTATTGTATACACAAAATAATACACAAAGTTTGTACTTTGTGTACAAATACAAATTTGTACTTTGTGTACAAATAATACAAAAAGTTTG TATACACAAACTTTTTACGTTGTGGTTTGGTATATTGTCTTAACTGAATTTTCTTATAAGAACCCCATGAAACTTACCTGAGTTTTTAAA ATGCTATCCAGGACATCATACCTTATAGTATACATGAAACATAATGTAATCCAGGTTGTAATTTAGAACTTTTTTTTTTTTTTTAGCTGA GCACTTAATGTAATTAATTCCAGGTTATGACTCTTAAAAAACATTGGCCATTAGAGAAATAGTTCTATTTGCCCATCCAAATCACCTGAA TGACTTTTTGAAAGAATAGGGGTCCACATCCCCAGATCCCATCCCAGCTGTGCACAGTCTGAAGCAAGCAGAGTGAAACAAGTTGGCAAC TTGTTCCAAGCGTGGGCCTTTGCAGTCTGTGATCCAGTGTTACTCCAGGTCCCAGTCTGTCCCATACTTGTCTTTTGCTACAGTTAGTTA GTTACTTTGTTATCATCCCCTTGTAAACTGCCTTCAATATCTGGGATAAGGAAGACAAAGCTTAATGACAACTAAGGTTCTAGCTGACAT CTTTCTTTCATATTTAATTTTTGTGAGTTTTCATCTGTTTTCTGTTTGTTTATGTGTCCTAGGTTCTTGACCTAACCACATGGGTTTTGT TTTTTGTTTTTATATTAGAACTTAGAAAAGTTTGTTTTACAGCAGTATTATGGAACAGAAGAGACCATTTTAAATAATTTTTTTAAACAG CCCAAAACACACAAAAGATACTTGTTTTCTAGAGACAGGGTCTTGCTCTGTCACCCAGGCTGGAGTGCAGTGGCACGATCATAGCTCAGT GCAGCCTCCACCTCCTGGGCTCAAGTGGTCCTCCTGCCTCAGCCTCTTAAGCAGTTGGGACTACAGGTGTGTGCCAGCATGCTTGCTGTT TTTTTTTTTTTTGAGACAGAGTCTTGCTCTGTCACTCAGGCTGGAGTCCAGTGGCTTGGTCTCAGCTCACTGCAATCTCTGCCTCCCAGG GGTTCAAGTGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGAAACTACAGGCGCATGCCACCATGCCCAGCTAATTTTTGTATTTTTAGTA GAGACAGGGTTTCACTATGTTGGCCAGGCTGGTCTCAAACTCCCGACCTCAAGTGATCCGCCCGCTTCGGCCTCCCAAAGTGCTGGGATT ACAGGTGTGAGCCACTGCGCCTGGCTGCTGATTTATTTTTCATAGACACGGGGGTCTATGTTGCCCAGGTTGGTCTTGAACTCCTAGCCT CAAGCGATCCTCCTGCCTCAGCCTCCCAATGTGCTGGGATTACAGGAATGAGCCACCATGCCCAGCCCAAGAAGTAGAGTTTCTTTTATA CTGACTTTGGCCTAAAAAAACAGATTTTCATGGAGGAAAAAAAAACCTAGATTTTTAGTAAGACTATTTTATATACTTTTTTACATTGAT CAAGTACATTATTTTTACCAAACAACATTGTTTCCCACTACATCCATGGTTATGTATAAAAAAACGCCATTGTCAATTAAGATGTTAAAA AATTATTTCCATAAGAGTATTAAATTCTAATCTATGATTCACTTAACTTCCTACTTTATAAACACTAGGTAAAGTAATCTCACAAGCTGC CAAAGAACACATCCCAAGCAGTAATCACAGACGATGAAGCACCTTACAGGACCCCTCCACCCTCAAACGCGCATGTCCAGAGAAGTATTA ATGCCTTAATAGACTACTGAAGGTTAACTATTTACATCATTCTAAAAATATTTTAAGCTGTATTACAGTGCTATAAATTCTCCTTTTAAG GAAAAAAGTAATAGATTGTTTCCTTACCGTGTTTGAAAGGAAAAAAAATAAATCCATAGTAACTAATGGTCTGCCGATTTTTTCCCTGAA TTTTTAAACTCCAACAAAGCATTATTTTGCAAAAAGTCCTTTAGCCCAAAGTCAGTGTCTCTGTTTTGATCTCTTTGTAAAAGAACTCTC TGTTCATCCATTCTCTTTCCCTGGGACCGTAAAATAAGGCTGAAAAAGTCTTCATCTGGTACTGTCGGACCCTTTGTGGTAGCAGGTGGT GGAGCACATCTTTGATCATCTAATCTGGATCCCTAGAAGTTTATGAGAGAGATTAAAAGACATACTGTGGGAAAGAAAGCACCAAGCTAT GTTAAATCTCTCAGTCACAACAAGAAAACGCAGTTGTAAACTTTTATTTGGGGCTTCTCAGAAATTAATCTTTGTTTTTATATTGTTCTC TTTAGTTCCCAGCCTGATTTCTGAAAGAAATAATCTTTAAACCTG >12961_12961_1_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000356970_length(amino acids)=525AA_BP=51 MVGVSGRVLPTAAAVIPSLGFLPGLPRARSRAGPEQPKMADFDDRVSDEEKIDECEKKKREDYESQSNPVFRRYLNKILIEAGKLGLPDE NKGDMHYDAEIILKRETLLEIQKFLNGEDWKPGALDDALSDILINFKFHDFETWKWRFEDSFGVDPYNVLMVLLCLLCIVVLVATELWTY VRWYTQLRRVLIISFLFSLGWNWMYLYKLAFAQHQAEVAKMEPLNNVCAKKMDWTGSIWEWFRSSWTYKDDPCQKYYELLLVNPIWLVPP TKALAVTFTTFVTEPLKHIGKGTGEFIKALMKEIPALLHLPVLIIMALAILSFCYGAGKSVHVLRHIGGPESEPPQALRPRDRRRQEEID YRPDGGAGDADFHYRGQMGPTEQGPYAKTYEGRREILRERDVDLRFQTGNKSPEVLRAFDVPDAEAREHPTVVPSHKSPVLDTKPKETGG ILGEGTPKESSTESSQSAKPVSGQDTSGNTEGSPAAEKAQLKSEAAGSPDQGSTYSPARGVAGPRGQDPVSSPCG -------------------------------------------------------------- >12961_12961_2_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369968_length(transcript)=4620nt_BP=711nt GGGAATCCTGGGATAGTGGCGGACCTGAAGTTGGCCTCTGTGAAGGCTGAGTCCTGGGGAACCGGGACCGAGAAGATTTCGAAGGTGGAG GAGCGTGTCTCAAGATTGGGGCTACCTGTTCTTTCGTGGGGCAGGGAAGGGGCGGACAGCAGCGCCTATTCTGGAGGAACTGGACTGAGA TGTGACCCCGAAGTGTTACCGCTTCCAAACGAAATGAGGGTCACCTTTCACACCGCCCCCCCCCCGGGGTTGGAAAAGCCACCGATCGTT CCAGCTGCCGAGCAGCTCTTAAAGCTTTGGATTCGGCTGTCGTGGAGATAACGGGCACCAGAAAAACTTGTAGGAGTAGCAACAGCTATT TGGTCGGATGGAGGCCAGAAGCCAAGAATAATCGAAACACGCTGCCAGCGCCCATTAGATGGATGGGAAATGAGTGTAACTCATTGGGAA AGATATTAGACTTCAAATCACCTAAGGCAAACCCTACTTCCTGGGGCGCGGGCGCGGGCGCTGGCGTTAGGAGACGTCACTCCCGCGCAT AACTGACATGGGGCCCTCTTGGTCGGCGTTTCCGGGCGGGTCCTTCCGACGGCCGCCGCGGTGATTCCATCACTCGGCTTTCTTCCCGGC CTGCCTCGCGCCCGTAGCCGGGCTGGGCCAGAACAGCCCAAGATGGCCGACTTCGATGATCGTGTGTCGGATGAGGAGAAGATTGATGAG TGTGAAAAGAAAAAGAGGGAAGACTATGAAAGTCAAAGCAATCCTGTTTTTAGGAGATACTTAAATAAGATTTTAATTGAAGCTGGAAAG CTTGGACTTGCACTTGCAGTTACATTCACCACATTTGTAACGGAGCCATTGAAGCATATTGGAAAAGGAACTGGGGAATTTATTAAAGCA CTCATGAAGGAAATTCCAGCGCTGCTTCATCTTCCAGTGCTGATAATTATGGCATTAGCCATCCTGAGTTTCTGCTATGGTGCTGGAAAA TCAGTTCATGTGCTGAGACATATAGGCGGTCCTGAGAGCGAACCTCCCCAGGCACTTCGGCCACGGGATAGAAGACGGCAGGAGGAAATT GATTATAGACCTGATGGTGGAGCAGGTGATGCCGATTTCCATTATAGGGGCCAAATGGGCCCCACTGAGCAAGGCCCTTATGCCAAAACG TATGAGGGTAGAAGAGAGATTTTGAGAGAGAGAGATGTTGACTTGAGATTTCAGACTGGCAACAAGAGCCCTGAAGTGCTCCGGGCATTT GATGTACCAGACGCAGAGGCACGAGAGCATCCCACGGTGGTACCCAGTCATAAATCACCTGTTTTGGATACAAAGCCCAAGGAGACAGGT GGAATCCTGGGGGAAGGCACACCGAAAGAAAGCAGTACTGAAAGCAGCCAGTCGGCCAAGCCTGTCTCTGGCCAAGACACATCAGGGAAT ACAGAAGGTTCACCCGCAGCGGAAAAGGCCCAGCTCAAGTCTGAAGCCGCAGGCAGCCCAGACCAAGGCAGCACATACAGCCCCGCAAGA GGTGTGGCTGGACCACGTGGACAGGATCCGGTCAGCAGCCCCTGTGGCTAGAGGAACACCAGCACAAACGACAGCCTCAAGTCTCCTTCG AGCTTTATATCCATTTGGGGATGAAGTCTACTTTGACAGCTAGCAAGGCGACATGCAACTGTTGTTGAATGATGACAGCAATTCAGGAAA GACTTAAATATGAAAGCAAATTGAACACATCGGGTGTTTGTTATCAGAAAAGAGATGAGATGAGATAAGACTTGTTTATTGACTAGCCAA TATGTCATTAAAATTAAGGTTTATATTGTGAAGCTTTTTTGAAATTTTACTTTTTTTTGAGAGTTTTGCTCTGTCACCCAGGCTGGAGTG AGGTGGTACAATCTCGGCTCACTGCAACCTCCACCTCCCAGGTTCAAGAGATTCTCCTGCCTCAGTCTCCCGAGTAGCTAGGATTACAGA TGTGCATCACCATGCCTGGCTAATTTTTGTATTTTTTAGTAGAGATGGGGTTTCACCATGTTGGTCAGGCTGGTCTCGAACTCCTGACCT CAAGTGACCCGCCCTTGTCGGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCATTGTGCCCAGCCTATATAGTGTGAAGCTTTTAGGA AAATCAGAACAGGGTAGACAGCTGTTAAAAACAATGTTTAAATGGAATAATGTTGAATGTTTACAGGCTGTAAGAACTATTGTATACACA AAATAATACACAAAGTTTGTACTTTGTGTACAAATACAAATTTGTACTTTGTGTACAAATAATACAAAAAGTTTGTATACACAAACTTTT TACGTTGTGGTTTGGTATATTGTCTTAACTGAATTTTCTTATAAGAACCCCATGAAACTTACCTGAGTTTTTAAAATGCTATCCAGGACA TCATACCTTATAGTATACATGAAACATAATGTAATCCAGGTTGTAATTTAGAACTTTTTTTTTTTTTTTAGCTGAGCACTTAATGTAATT AATTCCAGGTTATGACTCTTAAAAAACATTGGCCATTAGAGAAATAGTTCTATTTGCCCATCCAAATCACCTGAATGACTTTTTGAAAGA ATAGGGGTCCACATCCCCAGATCCCATCCCAGCTGTGCACAGTCTGAAGCAAGCAGAGTGAAACAAGTTGGCAACTTGTTCCAAGCGTGG GCCTTTGCAGTCTGTGATCCAGTGTTACTCCAGGTCCCAGTCTGTCCCATACTTGTCTTTTGCTACAGTTAGTTAGTTACTTTGTTATCA TCCCCTTGTAAACTGCCTTCAATATCTGGGATAAGGAAGACAAAGCTTAATGACAACTAAGGTTCTAGCTGACATCTTTCTTTCATATTT AATTTTTGTGAGTTTTCATCTGTTTTCTGTTTGTTTATGTGTCCTAGGTTCTTGACCTAACCACATGGGTTTTGTTTTTTGTTTTTATAT TAGAACTTAGAAAAGTTTGTTTTACAGCAGTATTATGGAACAGAAGAGACCATTTTAAATAATTTTTTTAAACAGCCCAAAACACACAAA AGATACTTGTTTTCTAGAGACAGGGTCTTGCTCTGTCACCCAGGCTGGAGTGCAGTGGCACGATCATAGCTCAGTGCAGCCTCCACCTCC TGGGCTCAAGTGGTCCTCCTGCCTCAGCCTCTTAAGCAGTTGGGACTACAGGTGTGTGCCAGCATGCTTGCTGTTTTTTTTTTTTTTGAG ACAGAGTCTTGCTCTGTCACTCAGGCTGGAGTCCAGTGGCTTGGTCTCAGCTCACTGCAATCTCTGCCTCCCAGGGGTTCAAGTGATTCT CCTGCCTCAGCCTCCCAAGTAGCTGAAACTACAGGCGCATGCCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAGACAGGGTTTCAC TATGTTGGCCAGGCTGGTCTCAAACTCCCGACCTCAAGTGATCCGCCCGCTTCGGCCTCCCAAAGTGCTGGGATTACAGGTGTGAGCCAC TGCGCCTGGCTGCTGATTTATTTTTCATAGACACGGGGGTCTATGTTGCCCAGGTTGGTCTTGAACTCCTAGCCTCAAGCGATCCTCCTG CCTCAGCCTCCCAATGTGCTGGGATTACAGGAATGAGCCACCATGCCCAGCCCAAGAAGTAGAGTTTCTTTTATACTGACTTTGGCCTAA AAAAACAGATTTTCATGGAGGAAAAAAAAACCTAGATTTTTAGTAAGACTATTTTATATACTTTTTTACATTGATCAAGTACATTATTTT TACCAAACAACATTGTTTCCCACTACATCCATGGTTATGTATAAAAAAACGCCATTGTCAATTAAGATGTTAAAAAATTATTTCCATAAG AGTATTAAATTCTAATCTATGATTCACTTAACTTCCTACTTTATAAACACTAGGTAAAGTAATCTCACAAGCTGCCAAAGAACACATCCC AAGCAGTAATCACAGACGATGAAGCACCTTACAGGACCCCTCCACCCTCAAACGCGCATGTCCAGAGAAGTATTAATGCCTTAATAGACT ACTGAAGGTTAACTATTTACATCATTCTAAAAATATTTTAAGCTGTATTACAGTGCTATAAATTCTCCTTTTAAGGAAAAAAGTAATAGA TTGTTTCCTTACCGTGTTTGAAAGGAAAAAAAATAAATCCATAGTAACTAATGGTCTGCCGATTTTTTCCCTGAATTTTTAAACTCCAAC AAAGCATTATTTTGCAAAAAGTCCTTTAGCCCAAAGTCAGTGTCTCTGTTTTGATCTCTTTGTAAAAGAACTCTCTGTTCATCCATTCTC TTTCCCTGGGACCGTAAAATAAGGCTGAAAAAGTCTTCATCTGGTACTGTCGGACCCTTTGTGGTAGCAGGTGGTGGAGCACATCTTTGA TCATCTAATCTGGATCCCTAGAAGTTTATGAGAGAGATTAAAAGACATACTGTGGGAAAGAAAGCACCAAGCTATGTTAAATCTCTCAGT CACAACAAGAAAACGCAGTTGTAAACTTTTATTTGGGGCTTCTCAGAAATTAATCTTTGTTTTTATATTGTTCTCTTTAGTTCCCAGCCT GATTTCTGAAAGAAATAATCTTTAAACCTG >12961_12961_2_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369968_length(amino acids)=340AA_BP=51 MVGVSGRVLPTAAAVIPSLGFLPGLPRARSRAGPEQPKMADFDDRVSDEEKIDECEKKKREDYESQSNPVFRRYLNKILIEAGKLGLALA VTFTTFVTEPLKHIGKGTGEFIKALMKEIPALLHLPVLIIMALAILSFCYGAGKSVHVLRHIGGPESEPPQALRPRDRRRQEEIDYRPDG GAGDADFHYRGQMGPTEQGPYAKTYEGRREILRERDVDLRFQTGNKSPEVLRAFDVPDAEAREHPTVVPSHKSPVLDTKPKETGGILGEG TPKESSTESSQSAKPVSGQDTSGNTEGSPAAEKAQLKSEAAGSPDQGSTYSPARGVAGPRGQDPVSSPCG -------------------------------------------------------------- >12961_12961_3_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369969_length(transcript)=4812nt_BP=711nt GGGAATCCTGGGATAGTGGCGGACCTGAAGTTGGCCTCTGTGAAGGCTGAGTCCTGGGGAACCGGGACCGAGAAGATTTCGAAGGTGGAG GAGCGTGTCTCAAGATTGGGGCTACCTGTTCTTTCGTGGGGCAGGGAAGGGGCGGACAGCAGCGCCTATTCTGGAGGAACTGGACTGAGA TGTGACCCCGAAGTGTTACCGCTTCCAAACGAAATGAGGGTCACCTTTCACACCGCCCCCCCCCCGGGGTTGGAAAAGCCACCGATCGTT CCAGCTGCCGAGCAGCTCTTAAAGCTTTGGATTCGGCTGTCGTGGAGATAACGGGCACCAGAAAAACTTGTAGGAGTAGCAACAGCTATT TGGTCGGATGGAGGCCAGAAGCCAAGAATAATCGAAACACGCTGCCAGCGCCCATTAGATGGATGGGAAATGAGTGTAACTCATTGGGAA AGATATTAGACTTCAAATCACCTAAGGCAAACCCTACTTCCTGGGGCGCGGGCGCGGGCGCTGGCGTTAGGAGACGTCACTCCCGCGCAT AACTGACATGGGGCCCTCTTGGTCGGCGTTTCCGGGCGGGTCCTTCCGACGGCCGCCGCGGTGATTCCATCACTCGGCTTTCTTCCCGGC CTGCCTCGCGCCCGTAGCCGGGCTGGGCCAGAACAGCCCAAGATGGCCGACTTCGATGATCGTGTGTCGGATGAGGAGAAGATTGATGAG TGTGAAAAGAAAAAGAGGGAAGACTATGAAAGTCAAAGCAATCCTGTTTTTAGGAGATACTTAAATAAGATTTTAATTGAAGCTGGAAAG CTTGGACTTCTAGCTTTTGCACAGCATCAGGCTGAAGTCGCCAAGATGGAGCCATTAAACAATGTGTGTGCCAAAAAGATGGACTGGACT GGAAGTATCTGGGAATGGTTTAGAAGTTCATGGACCTATAAGGATGACCCATGCCAAAAATACTATGAGCTCTTACTAGTCAACCCTATT TGGTTGGTCCCACCAACAAAGGCACTTGCAGTTACATTCACCACATTTGTAACGGAGCCATTGAAGCATATTGGAAAAGGAACTGGGGAA TTTATTAAAGCACTCATGAAGGAAATTCCAGCGCTGCTTCATCTTCCAGTGCTGATAATTATGGCATTAGCCATCCTGAGTTTCTGCTAT GGTGCTGGAAAATCAGTTCATGTGCTGAGACATATAGGCGGTCCTGAGAGCGAACCTCCCCAGGCACTTCGGCCACGGGATAGAAGACGG CAGGAGGAAATTGATTATAGACCTGATGGTGGAGCAGGTGATGCCGATTTCCATTATAGGGGCCAAATGGGCCCCACTGAGCAAGGCCCT TATGCCAAAACGTATGAGGGTAGAAGAGAGATTTTGAGAGAGAGAGATGTTGACTTGAGATTTCAGACTGGCAACAAGAGCCCTGAAGTG CTCCGGGCATTTGATGTACCAGACGCAGAGGCACGAGAGCATCCCACGGTGGTACCCAGTCATAAATCACCTGTTTTGGATACAAAGCCC AAGGAGACAGGTGGAATCCTGGGGGAAGGCACACCGAAAGAAAGCAGTACTGAAAGCAGCCAGTCGGCCAAGCCTGTCTCTGGCCAAGAC ACATCAGGGAATACAGAAGGTTCACCCGCAGCGGAAAAGGCCCAGCTCAAGTCTGAAGCCGCAGGCAGCCCAGACCAAGGCAGCACATAC AGCCCCGCAAGAGGTGTGGCTGGACCACGTGGACAGGATCCGGTCAGCAGCCCCTGTGGCTAGAGGAACACCAGCACAAACGACAGCCTC AAGTCTCCTTCGAGCTTTATATCCATTTGGGGATGAAGTCTACTTTGACAGCTAGCAAGGCGACATGCAACTGTTGTTGAATGATGACAG CAATTCAGGAAAGACTTAAATATGAAAGCAAATTGAACACATCGGGTGTTTGTTATCAGAAAAGAGATGAGATGAGATAAGACTTGTTTA TTGACTAGCCAATATGTCATTAAAATTAAGGTTTATATTGTGAAGCTTTTTTGAAATTTTACTTTTTTTTGAGAGTTTTGCTCTGTCACC CAGGCTGGAGTGAGGTGGTACAATCTCGGCTCACTGCAACCTCCACCTCCCAGGTTCAAGAGATTCTCCTGCCTCAGTCTCCCGAGTAGC TAGGATTACAGATGTGCATCACCATGCCTGGCTAATTTTTGTATTTTTTAGTAGAGATGGGGTTTCACCATGTTGGTCAGGCTGGTCTCG AACTCCTGACCTCAAGTGACCCGCCCTTGTCGGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCATTGTGCCCAGCCTATATAGTGTG AAGCTTTTAGGAAAATCAGAACAGGGTAGACAGCTGTTAAAAACAATGTTTAAATGGAATAATGTTGAATGTTTACAGGCTGTAAGAACT ATTGTATACACAAAATAATACACAAAGTTTGTACTTTGTGTACAAATACAAATTTGTACTTTGTGTACAAATAATACAAAAAGTTTGTAT ACACAAACTTTTTACGTTGTGGTTTGGTATATTGTCTTAACTGAATTTTCTTATAAGAACCCCATGAAACTTACCTGAGTTTTTAAAATG CTATCCAGGACATCATACCTTATAGTATACATGAAACATAATGTAATCCAGGTTGTAATTTAGAACTTTTTTTTTTTTTTTAGCTGAGCA CTTAATGTAATTAATTCCAGGTTATGACTCTTAAAAAACATTGGCCATTAGAGAAATAGTTCTATTTGCCCATCCAAATCACCTGAATGA CTTTTTGAAAGAATAGGGGTCCACATCCCCAGATCCCATCCCAGCTGTGCACAGTCTGAAGCAAGCAGAGTGAAACAAGTTGGCAACTTG TTCCAAGCGTGGGCCTTTGCAGTCTGTGATCCAGTGTTACTCCAGGTCCCAGTCTGTCCCATACTTGTCTTTTGCTACAGTTAGTTAGTT ACTTTGTTATCATCCCCTTGTAAACTGCCTTCAATATCTGGGATAAGGAAGACAAAGCTTAATGACAACTAAGGTTCTAGCTGACATCTT TCTTTCATATTTAATTTTTGTGAGTTTTCATCTGTTTTCTGTTTGTTTATGTGTCCTAGGTTCTTGACCTAACCACATGGGTTTTGTTTT TTGTTTTTATATTAGAACTTAGAAAAGTTTGTTTTACAGCAGTATTATGGAACAGAAGAGACCATTTTAAATAATTTTTTTAAACAGCCC AAAACACACAAAAGATACTTGTTTTCTAGAGACAGGGTCTTGCTCTGTCACCCAGGCTGGAGTGCAGTGGCACGATCATAGCTCAGTGCA GCCTCCACCTCCTGGGCTCAAGTGGTCCTCCTGCCTCAGCCTCTTAAGCAGTTGGGACTACAGGTGTGTGCCAGCATGCTTGCTGTTTTT TTTTTTTTTGAGACAGAGTCTTGCTCTGTCACTCAGGCTGGAGTCCAGTGGCTTGGTCTCAGCTCACTGCAATCTCTGCCTCCCAGGGGT TCAAGTGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGAAACTACAGGCGCATGCCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAG ACAGGGTTTCACTATGTTGGCCAGGCTGGTCTCAAACTCCCGACCTCAAGTGATCCGCCCGCTTCGGCCTCCCAAAGTGCTGGGATTACA GGTGTGAGCCACTGCGCCTGGCTGCTGATTTATTTTTCATAGACACGGGGGTCTATGTTGCCCAGGTTGGTCTTGAACTCCTAGCCTCAA GCGATCCTCCTGCCTCAGCCTCCCAATGTGCTGGGATTACAGGAATGAGCCACCATGCCCAGCCCAAGAAGTAGAGTTTCTTTTATACTG ACTTTGGCCTAAAAAAACAGATTTTCATGGAGGAAAAAAAAACCTAGATTTTTAGTAAGACTATTTTATATACTTTTTTACATTGATCAA GTACATTATTTTTACCAAACAACATTGTTTCCCACTACATCCATGGTTATGTATAAAAAAACGCCATTGTCAATTAAGATGTTAAAAAAT TATTTCCATAAGAGTATTAAATTCTAATCTATGATTCACTTAACTTCCTACTTTATAAACACTAGGTAAAGTAATCTCACAAGCTGCCAA AGAACACATCCCAAGCAGTAATCACAGACGATGAAGCACCTTACAGGACCCCTCCACCCTCAAACGCGCATGTCCAGAGAAGTATTAATG CCTTAATAGACTACTGAAGGTTAACTATTTACATCATTCTAAAAATATTTTAAGCTGTATTACAGTGCTATAAATTCTCCTTTTAAGGAA AAAAGTAATAGATTGTTTCCTTACCGTGTTTGAAAGGAAAAAAAATAAATCCATAGTAACTAATGGTCTGCCGATTTTTTCCCTGAATTT TTAAACTCCAACAAAGCATTATTTTGCAAAAAGTCCTTTAGCCCAAAGTCAGTGTCTCTGTTTTGATCTCTTTGTAAAAGAACTCTCTGT TCATCCATTCTCTTTCCCTGGGACCGTAAAATAAGGCTGAAAAAGTCTTCATCTGGTACTGTCGGACCCTTTGTGGTAGCAGGTGGTGGA GCACATCTTTGATCATCTAATCTGGATCCCTAGAAGTTTATGAGAGAGATTAAAAGACATACTGTGGGAAAGAAAGCACCAAGCTATGTT AAATCTCTCAGTCACAACAAGAAAACGCAGTTGTAAACTTTTATTTGGGGCTTCTCAGAAATTAATCTTTGTTTTTATATTGTTCTCTTT AGTTCCCAGCCTGATTTCTGAAAGAAATAATCTTTAAACCTG >12961_12961_3_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369969_length(amino acids)=404AA_BP=51 MVGVSGRVLPTAAAVIPSLGFLPGLPRARSRAGPEQPKMADFDDRVSDEEKIDECEKKKREDYESQSNPVFRRYLNKILIEAGKLGLLAF AQHQAEVAKMEPLNNVCAKKMDWTGSIWEWFRSSWTYKDDPCQKYYELLLVNPIWLVPPTKALAVTFTTFVTEPLKHIGKGTGEFIKALM KEIPALLHLPVLIIMALAILSFCYGAGKSVHVLRHIGGPESEPPQALRPRDRRRQEEIDYRPDGGAGDADFHYRGQMGPTEQGPYAKTYE GRREILRERDVDLRFQTGNKSPEVLRAFDVPDAEAREHPTVVPSHKSPVLDTKPKETGGILGEGTPKESSTESSQSAKPVSGQDTSGNTE GSPAAEKAQLKSEAAGSPDQGSTYSPARGVAGPRGQDPVSSPCG -------------------------------------------------------------- >12961_12961_4_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369971_length(transcript)=5175nt_BP=711nt GGGAATCCTGGGATAGTGGCGGACCTGAAGTTGGCCTCTGTGAAGGCTGAGTCCTGGGGAACCGGGACCGAGAAGATTTCGAAGGTGGAG GAGCGTGTCTCAAGATTGGGGCTACCTGTTCTTTCGTGGGGCAGGGAAGGGGCGGACAGCAGCGCCTATTCTGGAGGAACTGGACTGAGA TGTGACCCCGAAGTGTTACCGCTTCCAAACGAAATGAGGGTCACCTTTCACACCGCCCCCCCCCCGGGGTTGGAAAAGCCACCGATCGTT CCAGCTGCCGAGCAGCTCTTAAAGCTTTGGATTCGGCTGTCGTGGAGATAACGGGCACCAGAAAAACTTGTAGGAGTAGCAACAGCTATT TGGTCGGATGGAGGCCAGAAGCCAAGAATAATCGAAACACGCTGCCAGCGCCCATTAGATGGATGGGAAATGAGTGTAACTCATTGGGAA AGATATTAGACTTCAAATCACCTAAGGCAAACCCTACTTCCTGGGGCGCGGGCGCGGGCGCTGGCGTTAGGAGACGTCACTCCCGCGCAT AACTGACATGGGGCCCTCTTGGTCGGCGTTTCCGGGCGGGTCCTTCCGACGGCCGCCGCGGTGATTCCATCACTCGGCTTTCTTCCCGGC CTGCCTCGCGCCCGTAGCCGGGCTGGGCCAGAACAGCCCAAGATGGCCGACTTCGATGATCGTGTGTCGGATGAGGAGAAGATTGATGAG TGTGAAAAGAAAAAGAGGGAAGACTATGAAAGTCAAAGCAATCCTGTTTTTAGGAGATACTTAAATAAGATTTTAATTGAAGCTGGAAAG CTTGGACTTCCTGATGAAAACAAAGGCGATATGCATTATGATGCTGAGATTATCCTTAAAAGAGAAACTTTGTTAGAAATACAGAAGTTT CTCAATGGAGAAGACTGGAAACCAGGTGCCTTGGATGATGCACTAAGTGATATTTTAATTAATTTTAAGTTTCATGATTTTGAAACATGG AAGTGGCGATTCGAAGATTCCTTTGGAGTGGATCCATATAATGTGTTAATGGTACTTCTTTGTCTGCTCTGCATCGTGGTTTTAGTGGCT ACTGAGCTGTGGACATATGTACGTTGGTACACTCAGTTGAGACGTGTTTTAATCATCAGCTTTCTGTTCAGTTTGGGATGGAATTGGATG TATTTATATAAGCTAGCTTTTGCACAGCATCAGGCTGAAGTCGCCAAGATGGAGCCATTAAACAATGTGTGTGCCAAAAAGATGGACTGG ACTGGAAGTATCTGGGAATGGTTTAGAAGTTCATGGACCTATAAGGATGACCCATGCCAAAAATACTATGAGCTCTTACTAGTCAACCCT ATTTGGTTGGTCCCACCAACAAAGGCACTTGCAGTTACATTCACCACATTTGTAACGGAGCCATTGAAGCATATTGGAAAAGGAACTGGG GAATTTATTAAAGCACTCATGAAGGAAATTCCAGCGCTGCTTCATCTTCCAGTGCTGATAATTATGGCATTAGCCATCCTGAGTTTCTGC TATGGTGCTGGAAAATCAGTTCATGTGCTGAGACATATAGGCGGTCCTGAGAGCGAACCTCCCCAGGCACTTCGGCCACGGGATAGAAGA CGGCAGGAGGAAATTGATTATAGACCTGATGGTGGAGCAGGTGATGCCGATTTCCATTATAGGGGCCAAATGGGCCCCACTGAGCAAGGC CCTTATGCCAAAACGTATGAGGGTAGAAGAGAGATTTTGAGAGAGAGAGATGTTGACTTGAGATTTCAGACTGGCAACAAGAGCCCTGAA GTGCTCCGGGCATTTGATGTACCAGACGCAGAGGCACGAGAGCATCCCACGGTGGTACCCAGTCATAAATCACCTGTTTTGGATACAAAG CCCAAGGAGACAGGTGGAATCCTGGGGGAAGGCACACCGAAAGAAAGCAGTACTGAAAGCAGCCAGTCGGCCAAGCCTGTCTCTGGCCAA GACACATCAGGGAATACAGAAGGTTCACCCGCAGCGGAAAAGGCCCAGCTCAAGTCTGAAGCCGCAGGCAGCCCAGACCAAGGCAGCACA TACAGCCCCGCAAGAGGTGTGGCTGGACCACGTGGACAGGATCCGGTCAGCAGCCCCTGTGGCTAGAGGAACACCAGCACAAACGACAGC CTCAAGTCTCCTTCGAGCTTTATATCCATTTGGGGATGAAGTCTACTTTGACAGCTAGCAAGGCGACATGCAACTGTTGTTGAATGATGA CAGCAATTCAGGAAAGACTTAAATATGAAAGCAAATTGAACACATCGGGTGTTTGTTATCAGAAAAGAGATGAGATGAGATAAGACTTGT TTATTGACTAGCCAATATGTCATTAAAATTAAGGTTTATATTGTGAAGCTTTTTTGAAATTTTACTTTTTTTTGAGAGTTTTGCTCTGTC ACCCAGGCTGGAGTGAGGTGGTACAATCTCGGCTCACTGCAACCTCCACCTCCCAGGTTCAAGAGATTCTCCTGCCTCAGTCTCCCGAGT AGCTAGGATTACAGATGTGCATCACCATGCCTGGCTAATTTTTGTATTTTTTAGTAGAGATGGGGTTTCACCATGTTGGTCAGGCTGGTC TCGAACTCCTGACCTCAAGTGACCCGCCCTTGTCGGCCTCCCAAAGTGCTGGGATTACAGGCATGAGCCATTGTGCCCAGCCTATATAGT GTGAAGCTTTTAGGAAAATCAGAACAGGGTAGACAGCTGTTAAAAACAATGTTTAAATGGAATAATGTTGAATGTTTACAGGCTGTAAGA ACTATTGTATACACAAAATAATACACAAAGTTTGTACTTTGTGTACAAATACAAATTTGTACTTTGTGTACAAATAATACAAAAAGTTTG TATACACAAACTTTTTACGTTGTGGTTTGGTATATTGTCTTAACTGAATTTTCTTATAAGAACCCCATGAAACTTACCTGAGTTTTTAAA ATGCTATCCAGGACATCATACCTTATAGTATACATGAAACATAATGTAATCCAGGTTGTAATTTAGAACTTTTTTTTTTTTTTTAGCTGA GCACTTAATGTAATTAATTCCAGGTTATGACTCTTAAAAAACATTGGCCATTAGAGAAATAGTTCTATTTGCCCATCCAAATCACCTGAA TGACTTTTTGAAAGAATAGGGGTCCACATCCCCAGATCCCATCCCAGCTGTGCACAGTCTGAAGCAAGCAGAGTGAAACAAGTTGGCAAC TTGTTCCAAGCGTGGGCCTTTGCAGTCTGTGATCCAGTGTTACTCCAGGTCCCAGTCTGTCCCATACTTGTCTTTTGCTACAGTTAGTTA GTTACTTTGTTATCATCCCCTTGTAAACTGCCTTCAATATCTGGGATAAGGAAGACAAAGCTTAATGACAACTAAGGTTCTAGCTGACAT CTTTCTTTCATATTTAATTTTTGTGAGTTTTCATCTGTTTTCTGTTTGTTTATGTGTCCTAGGTTCTTGACCTAACCACATGGGTTTTGT TTTTTGTTTTTATATTAGAACTTAGAAAAGTTTGTTTTACAGCAGTATTATGGAACAGAAGAGACCATTTTAAATAATTTTTTTAAACAG CCCAAAACACACAAAAGATACTTGTTTTCTAGAGACAGGGTCTTGCTCTGTCACCCAGGCTGGAGTGCAGTGGCACGATCATAGCTCAGT GCAGCCTCCACCTCCTGGGCTCAAGTGGTCCTCCTGCCTCAGCCTCTTAAGCAGTTGGGACTACAGGTGTGTGCCAGCATGCTTGCTGTT TTTTTTTTTTTTGAGACAGAGTCTTGCTCTGTCACTCAGGCTGGAGTCCAGTGGCTTGGTCTCAGCTCACTGCAATCTCTGCCTCCCAGG GGTTCAAGTGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGAAACTACAGGCGCATGCCACCATGCCCAGCTAATTTTTGTATTTTTAGTA GAGACAGGGTTTCACTATGTTGGCCAGGCTGGTCTCAAACTCCCGACCTCAAGTGATCCGCCCGCTTCGGCCTCCCAAAGTGCTGGGATT ACAGGTGTGAGCCACTGCGCCTGGCTGCTGATTTATTTTTCATAGACACGGGGGTCTATGTTGCCCAGGTTGGTCTTGAACTCCTAGCCT CAAGCGATCCTCCTGCCTCAGCCTCCCAATGTGCTGGGATTACAGGAATGAGCCACCATGCCCAGCCCAAGAAGTAGAGTTTCTTTTATA CTGACTTTGGCCTAAAAAAACAGATTTTCATGGAGGAAAAAAAAACCTAGATTTTTAGTAAGACTATTTTATATACTTTTTTACATTGAT CAAGTACATTATTTTTACCAAACAACATTGTTTCCCACTACATCCATGGTTATGTATAAAAAAACGCCATTGTCAATTAAGATGTTAAAA AATTATTTCCATAAGAGTATTAAATTCTAATCTATGATTCACTTAACTTCCTACTTTATAAACACTAGGTAAAGTAATCTCACAAGCTGC CAAAGAACACATCCCAAGCAGTAATCACAGACGATGAAGCACCTTACAGGACCCCTCCACCCTCAAACGCGCATGTCCAGAGAAGTATTA ATGCCTTAATAGACTACTGAAGGTTAACTATTTACATCATTCTAAAAATATTTTAAGCTGTATTACAGTGCTATAAATTCTCCTTTTAAG GAAAAAAGTAATAGATTGTTTCCTTACCGTGTTTGAAAGGAAAAAAAATAAATCCATAGTAACTAATGGTCTGCCGATTTTTTCCCTGAA TTTTTAAACTCCAACAAAGCATTATTTTGCAAAAAGTCCTTTAGCCCAAAGTCAGTGTCTCTGTTTTGATCTCTTTGTAAAAGAACTCTC TGTTCATCCATTCTCTTTCCCTGGGACCGTAAAATAAGGCTGAAAAAGTCTTCATCTGGTACTGTCGGACCCTTTGTGGTAGCAGGTGGT GGAGCACATCTTTGATCATCTAATCTGGATCCCTAGAAGTTTATGAGAGAGATTAAAAGACATACTGTGGGAAAGAAAGCACCAAGCTAT GTTAAATCTCTCAGTCACAACAAGAAAACGCAGTTGTAAACTTTTATTTGGGGCTTCTCAGAAATTAATCTTTGTTTTTATATTGTTCTC TTTAGTTCCCAGCCTGATTTCTGAAAGAAATAATCTTTAAACCTG >12961_12961_4_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369971_length(amino acids)=525AA_BP=51 MVGVSGRVLPTAAAVIPSLGFLPGLPRARSRAGPEQPKMADFDDRVSDEEKIDECEKKKREDYESQSNPVFRRYLNKILIEAGKLGLPDE NKGDMHYDAEIILKRETLLEIQKFLNGEDWKPGALDDALSDILINFKFHDFETWKWRFEDSFGVDPYNVLMVLLCLLCIVVLVATELWTY VRWYTQLRRVLIISFLFSLGWNWMYLYKLAFAQHQAEVAKMEPLNNVCAKKMDWTGSIWEWFRSSWTYKDDPCQKYYELLLVNPIWLVPP TKALAVTFTTFVTEPLKHIGKGTGEFIKALMKEIPALLHLPVLIIMALAILSFCYGAGKSVHVLRHIGGPESEPPQALRPRDRRRQEEID YRPDGGAGDADFHYRGQMGPTEQGPYAKTYEGRREILRERDVDLRFQTGNKSPEVLRAFDVPDAEAREHPTVVPSHKSPVLDTKPKETGG ILGEGTPKESSTESSQSAKPVSGQDTSGNTEGSPAAEKAQLKSEAAGSPDQGSTYSPARGVAGPRGQDPVSSPCG -------------------------------------------------------------- >12961_12961_5_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369976_length(transcript)=2686nt_BP=711nt GGGAATCCTGGGATAGTGGCGGACCTGAAGTTGGCCTCTGTGAAGGCTGAGTCCTGGGGAACCGGGACCGAGAAGATTTCGAAGGTGGAG GAGCGTGTCTCAAGATTGGGGCTACCTGTTCTTTCGTGGGGCAGGGAAGGGGCGGACAGCAGCGCCTATTCTGGAGGAACTGGACTGAGA TGTGACCCCGAAGTGTTACCGCTTCCAAACGAAATGAGGGTCACCTTTCACACCGCCCCCCCCCCGGGGTTGGAAAAGCCACCGATCGTT CCAGCTGCCGAGCAGCTCTTAAAGCTTTGGATTCGGCTGTCGTGGAGATAACGGGCACCAGAAAAACTTGTAGGAGTAGCAACAGCTATT TGGTCGGATGGAGGCCAGAAGCCAAGAATAATCGAAACACGCTGCCAGCGCCCATTAGATGGATGGGAAATGAGTGTAACTCATTGGGAA AGATATTAGACTTCAAATCACCTAAGGCAAACCCTACTTCCTGGGGCGCGGGCGCGGGCGCTGGCGTTAGGAGACGTCACTCCCGCGCAT AACTGACATGGGGCCCTCTTGGTCGGCGTTTCCGGGCGGGTCCTTCCGACGGCCGCCGCGGTGATTCCATCACTCGGCTTTCTTCCCGGC CTGCCTCGCGCCCGTAGCCGGGCTGGGCCAGAACAGCCCAAGATGGCCGACTTCGATGATCGTGTGTCGGATGAGGAGAAGATTGATGAG TGTGAAAAGAAAAAGAGGGAAGACTATGAAAGTCAAAGCAATCCTGTTTTTAGGAGATACTTAAATAAGATTTTAATTGAAGCTGGAAAG CTTGGACTTCCTGATGAAAACAAAGGCGATATGCATTATGATGCTGAGATTATCCTTAAAAGAGAAACTTTGTTAGAAATACAGAAGTTT CTCAATGGAGAAGACTGGAAACCAGGTGCCTTGGATGATGCACTAAGTGATATTTTAATTAATTTTAAGTTTCATGATTTTGAAACATGG AAGTGGCGATTCGAAGATTCCTTTGGAGTGGATCCATATAATGTGTTAATGGTACTTCTTTGTCTGCTCTGCATCGTGGTTTTAGTGGCT ACTGAGCTGTGGACATATGTACGTTGGTACACTCAGTTGAGACGTGTTTTAATCATCAGCTGTGCACAGTCTGAAGCAAGCAGAGTGAAA CAAGTTGGCAACTTGTTCCAAGCGTGGGCCTTTGCAGTCTGTGATCCAGTGTTACTCCAGGTCCCAGTCTGTCCCATACTTGTCTTTTGC TACAGTTAGTTAGTTACTTTGTTATCATCCCCTTGTAAACTGCCTTCAATATCTGGGATAAGGAAGACAAAGCTTAATGACAACTAAGGT TCTAGCTGACATCTTTCTTTCATATTTAATTTTTGTGAGTTTTCATCTGTTTTCTGTTTGTTTATGTGTCCTAGGTTCTTGACCTAACCA CATGGGTTTTGTTTTTTGTTTTTATATTAGAACTTAGAAAAGTTTGTTTTACAGCAGTATTATGGAACAGAAGAGACCATTTTAAATAAT TTTTTTAAACAGCCCAAAACACACAAAAGATACTTGTTTTCTAGAGACAGGGTCTTGCTCTGTCACCCAGGCTGGAGTGCAGTGGCACGA TCATAGCTCAGTGCAGCCTCCACCTCCTGGGCTCAAGTGGTCCTCCTGCCTCAGCCTCTTAAGCAGTTGGGACTACAGGTGTGTGCCAGC ATGCTTGCTGTTTTTTTTTTTTTTGAGACAGAGTCTTGCTCTGTCACTCAGGCTGGAGTCCAGTGGCTTGGTCTCAGCTCACTGCAATCT CTGCCTCCCAGGGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGAAACTACAGGCGCATGCCACCATGCCCAGCTAATTTTT GTATTTTTAGTAGAGACAGGGTTTCACTATGTTGGCCAGGCTGGTCTCAAACTCCCGACCTCAAGTGATCCGCCCGCTTCGGCCTCCCAA AGTGCTGGGATTACAGGTGTGAGCCACTGCGCCTGGCTGCTGATTTATTTTTCATAGACACGGGGGTCTATGTTGCCCAGGTTGGTCTTG AACTCCTAGCCTCAAGCGATCCTCCTGCCTCAGCCTCCCAATGTGCTGGGATTACAGGAATGAGCCACCATGCCCAGCCCAAGAAGTAGA GTTTCTTTTATACTGACTTTGGCCTAAAAAAACAGATTTTCATGGAGGAAAAAAAAACCTAGATTTTTAGTAAGACTATTTTATATACTT TTTTACATTGATCAAGTACATTATTTTTACCAAACAACATTGTTTCCCACTACATCCATGGTTATGTATAAAAAAACGCCATTGTCAATT AAGATGTTAAAAAATTATTTCCATAAGAGTATTAAATTCTAATCTATGATTCACTTAACTTCCTACTTTATAAACACTAGGTAAAGTAAT CTCACAAGCTGCCAAAGAACACATCCCAAGCAGTAATCACAGACGATGAAGCACCTTACAGGACCCCTCCACCCTCAAACGCGCATGTCC AGAGAAGTATTAATGCCTTAATAGACTACTGAAGGTTAACTATTTACATCATTCTAAAAATATTTTAAGCTGTATTACAGTGCTATAAAT TCTCCTTTTAAGGAAAAAAGTAATAGATTGTTTCCTTACCGTGTTTGAAAGGAAAAAAAATAAATCCATAGTAACT >12961_12961_5_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000369976_length(amino acids)=236AA_BP=51 MVGVSGRVLPTAAAVIPSLGFLPGLPRARSRAGPEQPKMADFDDRVSDEEKIDECEKKKREDYESQSNPVFRRYLNKILIEAGKLGLPDE NKGDMHYDAEIILKRETLLEIQKFLNGEDWKPGALDDALSDILINFKFHDFETWKWRFEDSFGVDPYNVLMVLLCLLCIVVLVATELWTY VRWYTQLRRVLIISCAQSEASRVKQVGNLFQAWAFAVCDPVLLQVPVCPILVFCYS -------------------------------------------------------------- >12961_12961_6_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000415331_length(transcript)=5025nt_BP=711nt GGGAATCCTGGGATAGTGGCGGACCTGAAGTTGGCCTCTGTGAAGGCTGAGTCCTGGGGAACCGGGACCGAGAAGATTTCGAAGGTGGAG GAGCGTGTCTCAAGATTGGGGCTACCTGTTCTTTCGTGGGGCAGGGAAGGGGCGGACAGCAGCGCCTATTCTGGAGGAACTGGACTGAGA TGTGACCCCGAAGTGTTACCGCTTCCAAACGAAATGAGGGTCACCTTTCACACCGCCCCCCCCCCGGGGTTGGAAAAGCCACCGATCGTT CCAGCTGCCGAGCAGCTCTTAAAGCTTTGGATTCGGCTGTCGTGGAGATAACGGGCACCAGAAAAACTTGTAGGAGTAGCAACAGCTATT TGGTCGGATGGAGGCCAGAAGCCAAGAATAATCGAAACACGCTGCCAGCGCCCATTAGATGGATGGGAAATGAGTGTAACTCATTGGGAA AGATATTAGACTTCAAATCACCTAAGGCAAACCCTACTTCCTGGGGCGCGGGCGCGGGCGCTGGCGTTAGGAGACGTCACTCCCGCGCAT AACTGACATGGGGCCCTCTTGGTCGGCGTTTCCGGGCGGGTCCTTCCGACGGCCGCCGCGGTGATTCCATCACTCGGCTTTCTTCCCGGC CTGCCTCGCGCCCGTAGCCGGGCTGGGCCAGAACAGCCCAAGATGGCCGACTTCGATGATCGTGTGTCGGATGAGGAGAAGATTGATGAG TGTGAAAAGAAAAAGAGGGAAGACTATGAAAGTCAAAGCAATCCTGTTTTTAGGAGATACTTAAATAAGATTTTAATTGAAGCTGGAAAG CTTGGACTTTTTCATGATTTTGAAACATGGAAGTGGCGATTCGAAGATTCCTTTGGAGTGGATCCATATAATGTGTTAATGGTACTTCTT TGTCTGCTCTGCATCGTGGTTTTAGTGGCTACTGAGCTGTGGACATATGTACGTTGGTACACTCAGTTGAGACGTGTTTTAATCATCAGC TTTCTGTTCAGTTTGGGATGGAATTGGATGTATTTATATAAGCTAGCTTTTGCACAGCATCAGGCTGAAGTCGCCAAGATGGAGCCATTA AACAATGTGTGTGCCAAAAAGATGGACTGGACTGGAAGTATCTGGGAATGGTTTAGAAGTTCATGGACCTATAAGGATGACCCATGCCAA AAATACTATGAGCTCTTACTAGTCAACCCTATTTGGTTGGTCCCACCAACAAAGGCACTTGCAGTTACATTCACCACATTTGTAACGGAG CCATTGAAGCATATTGGAAAAGGAACTGGGGAATTTATTAAAGCACTCATGAAGGAAATTCCAGCGCTGCTTCATCTTCCAGTGCTGATA ATTATGGCATTAGCCATCCTGAGTTTCTGCTATGGTGCTGGAAAATCAGTTCATGTGCTGAGACATATAGGCGGTCCTGAGAGCGAACCT CCCCAGGCACTTCGGCCACGGGATAGAAGACGGCAGGAGGAAATTGATTATAGACCTGATGGTGGAGCAGGTGATGCCGATTTCCATTAT AGGGGCCAAATGGGCCCCACTGAGCAAGGCCCTTATGCCAAAACGTATGAGGGTAGAAGAGAGATTTTGAGAGAGAGAGATGTTGACTTG AGATTTCAGACTGGCAACAAGAGCCCTGAAGTGCTCCGGGCATTTGATGTACCAGACGCAGAGGCACGAGAGCATCCCACGGTGGTACCC AGTCATAAATCACCTGTTTTGGATACAAAGCCCAAGGAGACAGGTGGAATCCTGGGGGAAGGCACACCGAAAGAAAGCAGTACTGAAAGC AGCCAGTCGGCCAAGCCTGTCTCTGGCCAAGACACATCAGGGAATACAGAAGGTTCACCCGCAGCGGAAAAGGCCCAGCTCAAGTCTGAA GCCGCAGGCAGCCCAGACCAAGGCAGCACATACAGCCCCGCAAGAGGTGTGGCTGGACCACGTGGACAGGATCCGGTCAGCAGCCCCTGT GGCTAGAGGAACACCAGCACAAACGACAGCCTCAAGTCTCCTTCGAGCTTTATATCCATTTGGGGATGAAGTCTACTTTGACAGCTAGCA AGGCGACATGCAACTGTTGTTGAATGATGACAGCAATTCAGGAAAGACTTAAATATGAAAGCAAATTGAACACATCGGGTGTTTGTTATC AGAAAAGAGATGAGATGAGATAAGACTTGTTTATTGACTAGCCAATATGTCATTAAAATTAAGGTTTATATTGTGAAGCTTTTTTGAAAT TTTACTTTTTTTTGAGAGTTTTGCTCTGTCACCCAGGCTGGAGTGAGGTGGTACAATCTCGGCTCACTGCAACCTCCACCTCCCAGGTTC AAGAGATTCTCCTGCCTCAGTCTCCCGAGTAGCTAGGATTACAGATGTGCATCACCATGCCTGGCTAATTTTTGTATTTTTTAGTAGAGA TGGGGTTTCACCATGTTGGTCAGGCTGGTCTCGAACTCCTGACCTCAAGTGACCCGCCCTTGTCGGCCTCCCAAAGTGCTGGGATTACAG GCATGAGCCATTGTGCCCAGCCTATATAGTGTGAAGCTTTTAGGAAAATCAGAACAGGGTAGACAGCTGTTAAAAACAATGTTTAAATGG AATAATGTTGAATGTTTACAGGCTGTAAGAACTATTGTATACACAAAATAATACACAAAGTTTGTACTTTGTGTACAAATACAAATTTGT ACTTTGTGTACAAATAATACAAAAAGTTTGTATACACAAACTTTTTACGTTGTGGTTTGGTATATTGTCTTAACTGAATTTTCTTATAAG AACCCCATGAAACTTACCTGAGTTTTTAAAATGCTATCCAGGACATCATACCTTATAGTATACATGAAACATAATGTAATCCAGGTTGTA ATTTAGAACTTTTTTTTTTTTTTTAGCTGAGCACTTAATGTAATTAATTCCAGGTTATGACTCTTAAAAAACATTGGCCATTAGAGAAAT AGTTCTATTTGCCCATCCAAATCACCTGAATGACTTTTTGAAAGAATAGGGGTCCACATCCCCAGATCCCATCCCAGCTGTGCACAGTCT GAAGCAAGCAGAGTGAAACAAGTTGGCAACTTGTTCCAAGCGTGGGCCTTTGCAGTCTGTGATCCAGTGTTACTCCAGGTCCCAGTCTGT CCCATACTTGTCTTTTGCTACAGTTAGTTAGTTACTTTGTTATCATCCCCTTGTAAACTGCCTTCAATATCTGGGATAAGGAAGACAAAG CTTAATGACAACTAAGGTTCTAGCTGACATCTTTCTTTCATATTTAATTTTTGTGAGTTTTCATCTGTTTTCTGTTTGTTTATGTGTCCT AGGTTCTTGACCTAACCACATGGGTTTTGTTTTTTGTTTTTATATTAGAACTTAGAAAAGTTTGTTTTACAGCAGTATTATGGAACAGAA GAGACCATTTTAAATAATTTTTTTAAACAGCCCAAAACACACAAAAGATACTTGTTTTCTAGAGACAGGGTCTTGCTCTGTCACCCAGGC TGGAGTGCAGTGGCACGATCATAGCTCAGTGCAGCCTCCACCTCCTGGGCTCAAGTGGTCCTCCTGCCTCAGCCTCTTAAGCAGTTGGGA CTACAGGTGTGTGCCAGCATGCTTGCTGTTTTTTTTTTTTTTGAGACAGAGTCTTGCTCTGTCACTCAGGCTGGAGTCCAGTGGCTTGGT CTCAGCTCACTGCAATCTCTGCCTCCCAGGGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCAAGTAGCTGAAACTACAGGCGCATGCCAC CATGCCCAGCTAATTTTTGTATTTTTAGTAGAGACAGGGTTTCACTATGTTGGCCAGGCTGGTCTCAAACTCCCGACCTCAAGTGATCCG CCCGCTTCGGCCTCCCAAAGTGCTGGGATTACAGGTGTGAGCCACTGCGCCTGGCTGCTGATTTATTTTTCATAGACACGGGGGTCTATG TTGCCCAGGTTGGTCTTGAACTCCTAGCCTCAAGCGATCCTCCTGCCTCAGCCTCCCAATGTGCTGGGATTACAGGAATGAGCCACCATG CCCAGCCCAAGAAGTAGAGTTTCTTTTATACTGACTTTGGCCTAAAAAAACAGATTTTCATGGAGGAAAAAAAAACCTAGATTTTTAGTA AGACTATTTTATATACTTTTTTACATTGATCAAGTACATTATTTTTACCAAACAACATTGTTTCCCACTACATCCATGGTTATGTATAAA AAAACGCCATTGTCAATTAAGATGTTAAAAAATTATTTCCATAAGAGTATTAAATTCTAATCTATGATTCACTTAACTTCCTACTTTATA AACACTAGGTAAAGTAATCTCACAAGCTGCCAAAGAACACATCCCAAGCAGTAATCACAGACGATGAAGCACCTTACAGGACCCCTCCAC CCTCAAACGCGCATGTCCAGAGAAGTATTAATGCCTTAATAGACTACTGAAGGTTAACTATTTACATCATTCTAAAAATATTTTAAGCTG TATTACAGTGCTATAAATTCTCCTTTTAAGGAAAAAAGTAATAGATTGTTTCCTTACCGTGTTTGAAAGGAAAAAAAATAAATCCATAGT AACTAATGGTCTGCCGATTTTTTCCCTGAATTTTTAAACTCCAACAAAGCATTATTTTGCAAAAAGTCCTTTAGCCCAAAGTCAGTGTCT CTGTTTTGATCTCTTTGTAAAAGAACTCTCTGTTCATCCATTCTCTTTCCCTGGGACCGTAAAATAAGGCTGAAAAAGTCTTCATCTGGT ACTGTCGGACCCTTTGTGGTAGCAGGTGGTGGAGCACATCTTTGATCATCTAATCTGGATCCCTAGAAGTTTATGAGAGAGATTAAAAGA CATACTGTGGGAAAGAAAGCACCAAGCTATGTTAAATCTCTCAGTCACAACAAGAAAACGCAGTTGTAAACTTTTATTTGGGGCTTCTCA GAAATTAATCTTTGTTTTTATATTGTTCTCTTTAGTTCCCAGCCTGATTTCTGAAAGAAATAATCTTTAAACCTG >12961_12961_6_CAPZA1-CLCC1_CAPZA1_chr1_113162505_ENST00000263168_CLCC1_chr1_109490340_ENST00000415331_length(amino acids)=475AA_BP=51 MVGVSGRVLPTAAAVIPSLGFLPGLPRARSRAGPEQPKMADFDDRVSDEEKIDECEKKKREDYESQSNPVFRRYLNKILIEAGKLGLFHD FETWKWRFEDSFGVDPYNVLMVLLCLLCIVVLVATELWTYVRWYTQLRRVLIISFLFSLGWNWMYLYKLAFAQHQAEVAKMEPLNNVCAK KMDWTGSIWEWFRSSWTYKDDPCQKYYELLLVNPIWLVPPTKALAVTFTTFVTEPLKHIGKGTGEFIKALMKEIPALLHLPVLIIMALAI LSFCYGAGKSVHVLRHIGGPESEPPQALRPRDRRRQEEIDYRPDGGAGDADFHYRGQMGPTEQGPYAKTYEGRREILRERDVDLRFQTGN KSPEVLRAFDVPDAEAREHPTVVPSHKSPVLDTKPKETGGILGEGTPKESSTESSQSAKPVSGQDTSGNTEGSPAAEKAQLKSEAAGSPD QGSTYSPARGVAGPRGQDPVSSPCG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CAPZA1-CLCC1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CAPZA1-CLCC1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CAPZA1-CLCC1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | CAPZA1 | C0279626 | Squamous cell carcinoma of esophagus | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies