
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:C10orf11-NRG3 (FusionGDB2 ID:HG83938TG10718) |
Fusion Gene Summary for C10orf11-NRG3 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: C10orf11-NRG3 | Fusion gene ID: hg83938tg10718 | Hgene | Tgene | Gene symbol | C10orf11 | NRG3 | Gene ID | 83938 | 10718 |
| Gene name | leucine rich melanocyte differentiation associated | neuregulin 3 | |
| Synonyms | C10orf11|CDA017 | HRG3|pro-NRG3 | |
| Cytomap | ('C10orf11')('NRG3') 10q22.2-q22.3 | 10q23.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | leucine-rich melanocyte differentiation-associated proteinleucine-rich repeat-containing protein C10orf11 | pro-neuregulin-3, membrane-bound isoformneuregulin-3-like polypeptide | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | P56975 | |
| Ensembl transtripts involved in fusion gene | ENST00000593699, ENST00000372499, ENST00000496424, | ||
| Fusion gene scores | * DoF score | 28 X 20 X 9=5040 | 16 X 15 X 5=1200 |
| # samples | 32 | 16 | |
| ** MAII score | log2(32/5040*10)=-3.97727992349992 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(16/1200*10)=-2.90689059560852 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: C10orf11 [Title/Abstract] AND NRG3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | C10orf11(78084243)-NRG3(84711225), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | C10orf11-NRG3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C10orf11-NRG3 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. C10orf11-NRG3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. C10orf11-NRG3 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across C10orf11 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
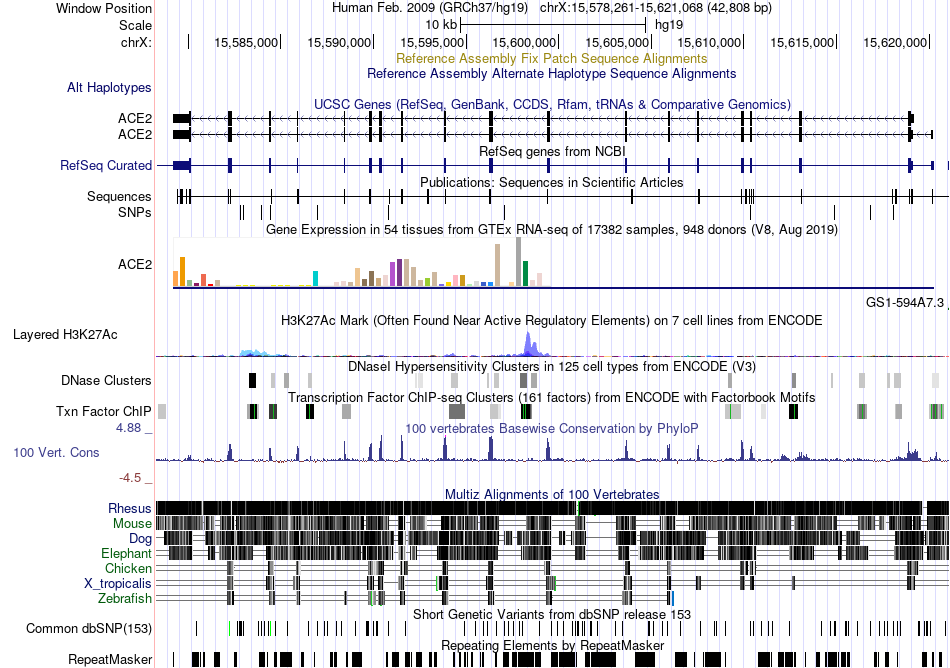 |
| Fusion gene breakpoints across NRG3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
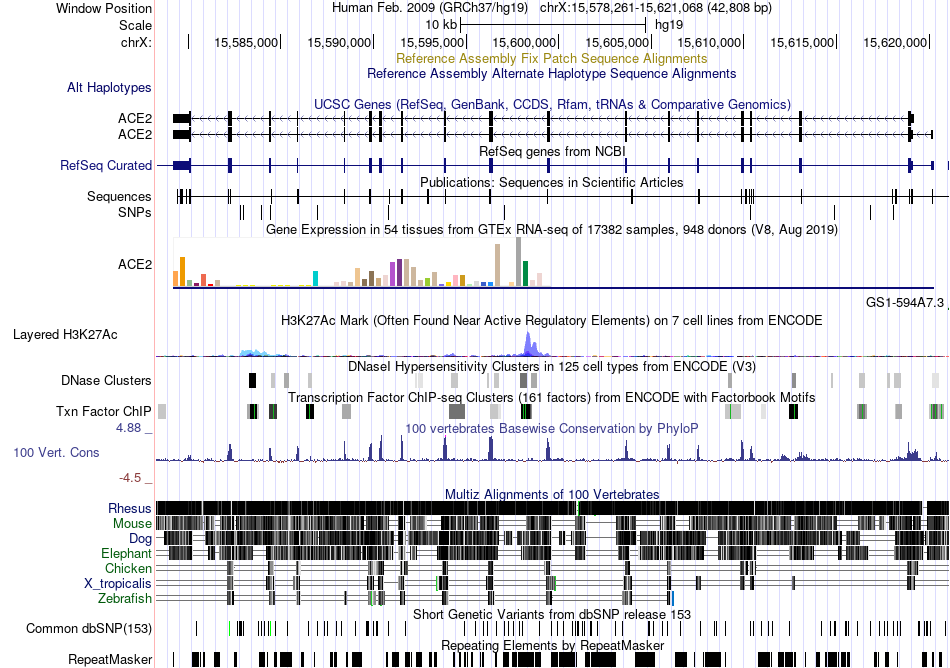 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A8-A06Q-01A | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
Top |
Fusion Gene ORF analysis for C10orf11-NRG3 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000593699 | ENST00000372141 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| 3UTR-3CDS | ENST00000593699 | ENST00000372142 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| 3UTR-3CDS | ENST00000593699 | ENST00000404547 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| 3UTR-3CDS | ENST00000593699 | ENST00000404576 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| 3UTR-3CDS | ENST00000593699 | ENST00000537893 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| 3UTR-3CDS | ENST00000593699 | ENST00000545131 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| 3UTR-3CDS | ENST00000593699 | ENST00000556918 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000372499 | ENST00000372141 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000372499 | ENST00000372142 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000372499 | ENST00000404547 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000372499 | ENST00000404576 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000372499 | ENST00000537893 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000372499 | ENST00000545131 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000372499 | ENST00000556918 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000496424 | ENST00000372141 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000496424 | ENST00000372142 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000496424 | ENST00000404547 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000496424 | ENST00000404576 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000496424 | ENST00000537893 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000496424 | ENST00000545131 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| In-frame | ENST00000496424 | ENST00000556918 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000372499 | C10orf11 | chr10 | 78084243 | + | ENST00000372141 | NRG3 | chr10 | 84711225 | + | 1809 | 732 | 215 | 1768 | 517 |
| ENST00000372499 | C10orf11 | chr10 | 78084243 | + | ENST00000404547 | NRG3 | chr10 | 84711225 | + | 1841 | 732 | 215 | 1840 | 542 |
| ENST00000372499 | C10orf11 | chr10 | 78084243 | + | ENST00000372142 | NRG3 | chr10 | 84711225 | + | 3203 | 732 | 215 | 1840 | 541 |
| ENST00000372499 | C10orf11 | chr10 | 78084243 | + | ENST00000404576 | NRG3 | chr10 | 84711225 | + | 1769 | 732 | 215 | 1768 | 518 |
| ENST00000372499 | C10orf11 | chr10 | 78084243 | + | ENST00000556918 | NRG3 | chr10 | 84711225 | + | 1769 | 732 | 215 | 1768 | 518 |
| ENST00000372499 | C10orf11 | chr10 | 78084243 | + | ENST00000537893 | NRG3 | chr10 | 84711225 | + | 1769 | 732 | 215 | 1768 | 518 |
| ENST00000372499 | C10orf11 | chr10 | 78084243 | + | ENST00000545131 | NRG3 | chr10 | 84711225 | + | 1998 | 732 | 215 | 1768 | 517 |
| ENST00000496424 | C10orf11 | chr10 | 78084243 | + | ENST00000372141 | NRG3 | chr10 | 84711225 | + | 2041 | 964 | 876 | 2000 | 374 |
| ENST00000496424 | C10orf11 | chr10 | 78084243 | + | ENST00000404547 | NRG3 | chr10 | 84711225 | + | 2073 | 964 | 876 | 2072 | 398 |
| ENST00000496424 | C10orf11 | chr10 | 78084243 | + | ENST00000372142 | NRG3 | chr10 | 84711225 | + | 3435 | 964 | 876 | 2072 | 398 |
| ENST00000496424 | C10orf11 | chr10 | 78084243 | + | ENST00000404576 | NRG3 | chr10 | 84711225 | + | 2001 | 964 | 876 | 2000 | 374 |
| ENST00000496424 | C10orf11 | chr10 | 78084243 | + | ENST00000556918 | NRG3 | chr10 | 84711225 | + | 2001 | 964 | 876 | 2000 | 374 |
| ENST00000496424 | C10orf11 | chr10 | 78084243 | + | ENST00000537893 | NRG3 | chr10 | 84711225 | + | 2001 | 964 | 876 | 2000 | 374 |
| ENST00000496424 | C10orf11 | chr10 | 78084243 | + | ENST00000545131 | NRG3 | chr10 | 84711225 | + | 2230 | 964 | 876 | 2000 | 374 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000372499 | ENST00000372141 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.003659523 | 0.9963405 |
| ENST00000372499 | ENST00000404547 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.003954568 | 0.9960454 |
| ENST00000372499 | ENST00000372142 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.000585201 | 0.9994148 |
| ENST00000372499 | ENST00000404576 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.004038645 | 0.99596137 |
| ENST00000372499 | ENST00000556918 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.004038645 | 0.99596137 |
| ENST00000372499 | ENST00000537893 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.004038645 | 0.99596137 |
| ENST00000372499 | ENST00000545131 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.002301209 | 0.99769884 |
| ENST00000496424 | ENST00000372141 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.003107868 | 0.99689215 |
| ENST00000496424 | ENST00000404547 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.002581651 | 0.9974183 |
| ENST00000496424 | ENST00000372142 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.000525287 | 0.9994747 |
| ENST00000496424 | ENST00000404576 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.003286909 | 0.99671304 |
| ENST00000496424 | ENST00000556918 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.003286909 | 0.99671304 |
| ENST00000496424 | ENST00000537893 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.003286909 | 0.99671304 |
| ENST00000496424 | ENST00000545131 | C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711225 | + | 0.002018303 | 0.99798167 |
Top |
Fusion Genomic Features for C10orf11-NRG3 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711224 | + | 0.000806042 | 0.99919397 |
| C10orf11 | chr10 | 78084243 | + | NRG3 | chr10 | 84711224 | + | 0.000806042 | 0.99919397 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
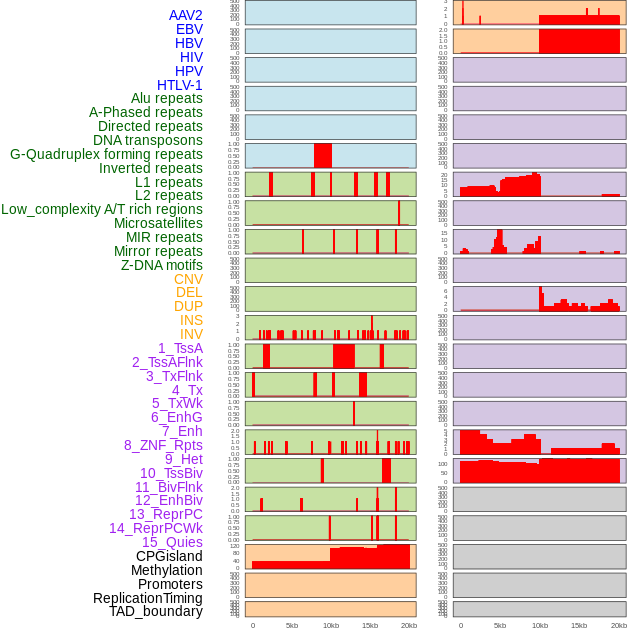 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
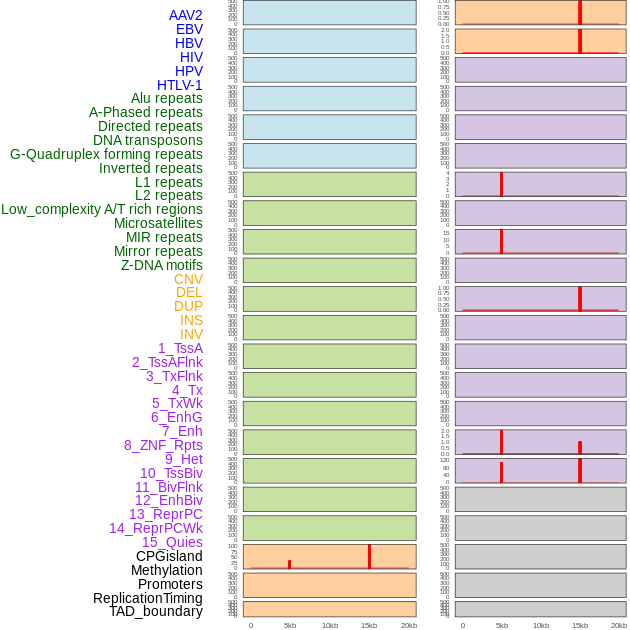 |
Top |
Fusion Protein Features for C10orf11-NRG3 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:78084243/chr10:84711225) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | NRG3 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Direct ligand for the ERBB4 tyrosine kinase receptor. Binding results in ligand-stimulated tyrosine phosphorylation and activation of the receptor. Does not bind to the EGF receptor, ERBB2 or ERBB3 receptors. May be a survival factor for oligodendrocytes. {ECO:0000269|PubMed:16478787, ECO:0000269|PubMed:9275162}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | C10orf11 | chr10:78084243 | chr10:84711225 | ENST00000372499 | + | 5 | 6 | 96_134 | 172 | 199.0 | Domain | Note=LRRCT |
| Hgene | C10orf11 | chr10:78084243 | chr10:84711225 | ENST00000372499 | + | 5 | 6 | 26_47 | 172 | 199.0 | Repeat | Note=LRR 2 |
| Hgene | C10orf11 | chr10:78084243 | chr10:84711225 | ENST00000372499 | + | 5 | 6 | 2_22 | 172 | 199.0 | Repeat | Note=LRR 1 |
| Hgene | C10orf11 | chr10:78084243 | chr10:84711225 | ENST00000372499 | + | 5 | 6 | 48_69 | 172 | 199.0 | Repeat | Note=LRR 3 |
| Hgene | C10orf11 | chr10:78084243 | chr10:84711225 | ENST00000372499 | + | 5 | 6 | 75_95 | 172 | 199.0 | Repeat | Note=LRR 4 |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 252_260 | 130 | 500.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 262_265 | 130 | 500.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 286_329 | 130 | 500.0 | Domain | EGF-like | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 382_720 | 351 | 697.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 382_720 | 130 | 500.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 382_720 | 351 | 721.0 | Topological domain | Cytoplasmic | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 361_381 | 351 | 697.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 361_381 | 130 | 500.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 361_381 | 351 | 721.0 | Transmembrane | Helical%3B Note%3DInternal signal sequence |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 105_285 | 351 | 697.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 127_135 | 351 | 697.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 13_21 | 351 | 697.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 252_260 | 351 | 697.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 262_265 | 351 | 697.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 26_34 | 351 | 697.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 5_8 | 351 | 697.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 105_285 | 130 | 500.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 127_135 | 130 | 500.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 13_21 | 130 | 500.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 26_34 | 130 | 500.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 5_8 | 130 | 500.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 105_285 | 351 | 721.0 | Compositional bias | Note=Ser/Thr-rich | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 127_135 | 351 | 721.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 13_21 | 351 | 721.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 252_260 | 351 | 721.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 262_265 | 351 | 721.0 | Compositional bias | Note=Poly-Thr | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 26_34 | 351 | 721.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 5_8 | 351 | 721.0 | Compositional bias | Note=Poly-Ala | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 286_329 | 351 | 697.0 | Domain | EGF-like | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 286_329 | 351 | 721.0 | Domain | EGF-like | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372141 | 3 | 9 | 1_360 | 351 | 697.0 | Topological domain | Extracellular | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000372142 | 4 | 11 | 1_360 | 130 | 500.0 | Topological domain | Extracellular | |
| Tgene | NRG3 | chr10:78084243 | chr10:84711225 | ENST00000404547 | 3 | 10 | 1_360 | 351 | 721.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for C10orf11-NRG3 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >10636_10636_1_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000372141_length(transcript)=1809nt_BP=732nt GTTGAAGAAAGAGGATCTGGCTGAAAGACCCGCAACTTTCACTTGTTGAGAACCTTTAGCCAGCGCCGGCGTGCATGTGTTTTAGTTTTA TTCTTTTTCCCTTGCCCCCAAAGCCGTGGAGTACCTGCTGTTGCTCTCATGCCTCTTGCCAACAGTGGCATCTGCTCAGTGTAGCCATCA AGAATTTGAATGTCAATATCTTTGCCTTGAAATGAATGGAAAAGTATTTGTCACTCAGCGGCAATCATTCTTCAAATAAAAGGTCACTGG AAGGACTGAGCGCATTCAGGAGCCTGGAGGAACTCATCTTGGACAACAATCAGCTGGGGGACGACCTTGTGTTGCCAGGGTTACCCAGAC TGCATACCTTAACCCTCAACAAGAACCGAATCACTGATTTGGAGAACCTGCTGGATCACTTGGCAGAAGTGACACCAGCTCTGGAGTACC TCAGTCTGCTGGGCAACGTGGCCTGTCCCAACGAGCTGGTCAGCTTGGAAAAGGATGAGGAAGACTACAAGAGATACAGATGCTTTGTTC TGTACAAGCTGCCCAACTTGAAATTTCTGGATGCCCAGAAAGTAACCAGACAAGAACGAGAGGAGGCGTTGGTCAGAGGAGTCTTCATGA AGGTGGTGAAGCCCAAGGCTTCTAGTGAGGACGTTGCCAGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCA CCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAGGTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCT GTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAACAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCA AAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTGAAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGA CTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGCCCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCA AACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGGCAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCAC CCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATATCAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAG GGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACATCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCT TGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGC AAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCG ATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAG AAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAAC GAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAGTGACTTGAGATGTAGGAATCTGTGCATTCTATGC TTTGCTCAA >10636_10636_1_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000372141_length(amino acids)=517AA_BP=172 MEKYLSLSGNHSSNKRSLEGLSAFRSLEELILDNNQLGDDLVLPGLPRLHTLTLNKNRITDLENLLDHLAEVTPALEYLSLLGNVACPNE LVSLEKDEEDYKRYRCFVLYKLPNLKFLDAQKVTRQEREEALVRGVFMKVVKPKASSEDVASSPERHYTPLPSASRELTSHQESEEVYQR QVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASSTMAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFV GPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRLGGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRN TSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKI LLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_2_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000372142_length(transcript)=3203nt_BP=732nt GTTGAAGAAAGAGGATCTGGCTGAAAGACCCGCAACTTTCACTTGTTGAGAACCTTTAGCCAGCGCCGGCGTGCATGTGTTTTAGTTTTA TTCTTTTTCCCTTGCCCCCAAAGCCGTGGAGTACCTGCTGTTGCTCTCATGCCTCTTGCCAACAGTGGCATCTGCTCAGTGTAGCCATCA AGAATTTGAATGTCAATATCTTTGCCTTGAAATGAATGGAAAAGTATTTGTCACTCAGCGGCAATCATTCTTCAAATAAAAGGTCACTGG AAGGACTGAGCGCATTCAGGAGCCTGGAGGAACTCATCTTGGACAACAATCAGCTGGGGGACGACCTTGTGTTGCCAGGGTTACCCAGAC TGCATACCTTAACCCTCAACAAGAACCGAATCACTGATTTGGAGAACCTGCTGGATCACTTGGCAGAAGTGACACCAGCTCTGGAGTACC TCAGTCTGCTGGGCAACGTGGCCTGTCCCAACGAGCTGGTCAGCTTGGAAAAGGATGAGGAAGACTACAAGAGATACAGATGCTTTGTTC TGTACAAGCTGCCCAACTTGAAATTTCTGGATGCCCAGAAAGTAACCAGACAAGAACGAGAGGAGGCGTTGGTCAGAGGAGTCTTCATGA AGGTGGTGAAGCCCAAGGCTTCTAGTGAGGACGTTGCCAGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCA CCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAGGTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCT GTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAACAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCA AAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTGAAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGA CTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGCCCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCA AACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGGCAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCAC CCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATATCAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAG GGATAGAGGTCAGGAAGACTATATCCCACCTGCCTATACAGCTGTGGTGTGTTGAAAGACCCCTGGACTTAAAGTATTCATCCAGTGGTT TAAAAACCCAACGAAATACATCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGG TGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTG AAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAAC AACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCA GCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCT TAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAGTGACTTGAGATGTAGGAATCTGTGCATTCTATGCTTTGCTCAACAGGAAAGA GAGGAAATCAAATACAAATTATTTATATGCATTAATTTAAGAGCATCTACTTAGAAGAAACCAAATAGTCTATCGCCCTCATATCATAGT GTTTTTTAACAAAATATTTTTTTAAGGGAAAGAAATGTTTCAGGAGGGATAAAGCTTACCATTAAAGCTTTTGGGTAGAATTCTGAATCC AATTTCGTTTAGTCCCAACACTGTCCTCTTTGGCTCTTAGAAGATGTGGGCAATTCAGACCCTTGGCCCCACAGTGCCAGTGTCTCATTA AAAAACACTGGCAGTTACCTGGTTTCAAAAAGAGGAGAGCTGCATCCCGCAGGTGGATGCACCAGTGAGCAGGTGGCTCTTGCCATTTGG CTTGCCAGTCCCAAGCCCTAAATTTCTATTCACCCAATAGCCTCATCACAGGTTATGTCATGTCGACACATGTAGTGTTTTCTATTTGAT TTTTGGAGAATGCCACAAAAGACTCTGCAATGGGAAGGAGGACAGGAGATAGAAGGAGAAACCGGGGGCAATCTTAACTACTCTTGTGTG CCACCTTCCTCTGAGATTTGAATGCACAGATCTCAGCTGGAGGTATGAAATTATTACAGAAAAAGAGACAAAAAAATCCTTATATCGTGT CACTAAAATCATGCTAATAGAAATGTTTTTCCTTGAGATTGTTTAGAGGCTCTGGAGGAGCGTTTCTCAGTTTTTGTGTGCCTGTGTGCA CATGTGTGTGCGAGCGTGTGTGTGTGTGGACTTGCTCACGCGGGCACATATGCTGTAAGCACATGTGTTCATTGTGCGTATGTGTGTGCA TGTGTGCGCGTATTACGCTTGCTAAAATTTGTTCTGAAACATCAGGGAATCTACTATTCAGAAAAATTATTTCCCTCTTAGATCTTTTCA CTTTAAATTTTTCCATTAAGTATAAAGTTCAGTTAGTTCTTAAATCAAGGTCACTTGCATGGTGGGGTCGTATAAAACTCTTGACACTGT CTAGACCATTTTCTGATGTGAATACTTTTGAGAGGATCAACTATTGGCTCATTAATGATATCAGTATCATAAGGTGAGTTCATCAAGGAT GTGTGTTTATTTTGAATCATGCCTACTTAAATTATTAATACAAGACAATTAACAAATTGACAGTTACCATTTGCTTTCTCATCATCCTCA TTACCATTTATTTTATAGCAAGTCTGCTATGTGTGGACCAAGGCTTCGGCTTCTGTGGTTAGTATGGGAAGAATAAATTGTTGAAATAAA AATACCCAGACTATTCAGTTCACAAGAAGCCCCCCAAAAGAACAGTAAATTGT >10636_10636_2_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000372142_length(amino acids)=541AA_BP=172 MEKYLSLSGNHSSNKRSLEGLSAFRSLEELILDNNQLGDDLVLPGLPRLHTLTLNKNRITDLENLLDHLAEVTPALEYLSLLGNVACPNE LVSLEKDEEDYKRYRCFVLYKLPNLKFLDAQKVTRQEREEALVRGVFMKVVKPKASSEDVASSPERHYTPLPSASRELTSHQESEEVYQR QVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASSTMAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFV GPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRLGGIVGPAYQQLEESRIPDQDTIPCQGIEVRKTISHLP IQLWCVERPLDLKYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSY SADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALT K -------------------------------------------------------------- >10636_10636_3_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000404547_length(transcript)=1841nt_BP=732nt GTTGAAGAAAGAGGATCTGGCTGAAAGACCCGCAACTTTCACTTGTTGAGAACCTTTAGCCAGCGCCGGCGTGCATGTGTTTTAGTTTTA TTCTTTTTCCCTTGCCCCCAAAGCCGTGGAGTACCTGCTGTTGCTCTCATGCCTCTTGCCAACAGTGGCATCTGCTCAGTGTAGCCATCA AGAATTTGAATGTCAATATCTTTGCCTTGAAATGAATGGAAAAGTATTTGTCACTCAGCGGCAATCATTCTTCAAATAAAAGGTCACTGG AAGGACTGAGCGCATTCAGGAGCCTGGAGGAACTCATCTTGGACAACAATCAGCTGGGGGACGACCTTGTGTTGCCAGGGTTACCCAGAC TGCATACCTTAACCCTCAACAAGAACCGAATCACTGATTTGGAGAACCTGCTGGATCACTTGGCAGAAGTGACACCAGCTCTGGAGTACC TCAGTCTGCTGGGCAACGTGGCCTGTCCCAACGAGCTGGTCAGCTTGGAAAAGGATGAGGAAGACTACAAGAGATACAGATGCTTTGTTC TGTACAAGCTGCCCAACTTGAAATTTCTGGATGCCCAGAAAGTAACCAGACAAGAACGAGAGGAGGCGTTGGTCAGAGGAGTCTTCATGA AGGTGGTGAAGCCCAAGGCTTCTAGTGAGGACGTTGCCAGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCA CCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAGGTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCT GTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAACAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCA AAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTGAAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGA CTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGCCCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCA AACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGGCAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCAC CCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATATCAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAG GGATAGAGGTCAGGAAGACTATATCCCACCTGCCTATACAGCTGTGGTGTGTTGAAAGACCCCTGGACTTAAAGTATTCATCCAGTGGTT TAAAAACCCAACGAAATACATCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGG TGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTG AAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAAC AACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCA GCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCT TAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAGTGA >10636_10636_3_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000404547_length(amino acids)=542AA_BP=172 MEKYLSLSGNHSSNKRSLEGLSAFRSLEELILDNNQLGDDLVLPGLPRLHTLTLNKNRITDLENLLDHLAEVTPALEYLSLLGNVACPNE LVSLEKDEEDYKRYRCFVLYKLPNLKFLDAQKVTRQEREEALVRGVFMKVVKPKASSEDVASSPERHYTPLPSASRELTSHQESEEVYQR QVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASSTMAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFV GPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRLGGIVGPAYQQLEESRIPDQDTIPCQGIEVRKTISHLP IQLWCVERPLDLKYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSY SADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALT KX -------------------------------------------------------------- >10636_10636_4_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000404576_length(transcript)=1769nt_BP=732nt GTTGAAGAAAGAGGATCTGGCTGAAAGACCCGCAACTTTCACTTGTTGAGAACCTTTAGCCAGCGCCGGCGTGCATGTGTTTTAGTTTTA TTCTTTTTCCCTTGCCCCCAAAGCCGTGGAGTACCTGCTGTTGCTCTCATGCCTCTTGCCAACAGTGGCATCTGCTCAGTGTAGCCATCA AGAATTTGAATGTCAATATCTTTGCCTTGAAATGAATGGAAAAGTATTTGTCACTCAGCGGCAATCATTCTTCAAATAAAAGGTCACTGG AAGGACTGAGCGCATTCAGGAGCCTGGAGGAACTCATCTTGGACAACAATCAGCTGGGGGACGACCTTGTGTTGCCAGGGTTACCCAGAC TGCATACCTTAACCCTCAACAAGAACCGAATCACTGATTTGGAGAACCTGCTGGATCACTTGGCAGAAGTGACACCAGCTCTGGAGTACC TCAGTCTGCTGGGCAACGTGGCCTGTCCCAACGAGCTGGTCAGCTTGGAAAAGGATGAGGAAGACTACAAGAGATACAGATGCTTTGTTC TGTACAAGCTGCCCAACTTGAAATTTCTGGATGCCCAGAAAGTAACCAGACAAGAACGAGAGGAGGCGTTGGTCAGAGGAGTCTTCATGA AGGTGGTGAAGCCCAAGGCTTCTAGTGAGGACGTTGCCAGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCA CCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAGGTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCT GTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAACAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCA AAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTGAAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGA CTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGCCCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCA AACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGGCAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCAC CCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATATCAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAG GGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACATCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCT TGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGC AAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCG ATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAG AAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAAC GAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAGTGA >10636_10636_4_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000404576_length(amino acids)=518AA_BP=172 MEKYLSLSGNHSSNKRSLEGLSAFRSLEELILDNNQLGDDLVLPGLPRLHTLTLNKNRITDLENLLDHLAEVTPALEYLSLLGNVACPNE LVSLEKDEEDYKRYRCFVLYKLPNLKFLDAQKVTRQEREEALVRGVFMKVVKPKASSEDVASSPERHYTPLPSASRELTSHQESEEVYQR QVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASSTMAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFV GPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRLGGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRN TSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKI LLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALTKX -------------------------------------------------------------- >10636_10636_5_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000537893_length(transcript)=1769nt_BP=732nt GTTGAAGAAAGAGGATCTGGCTGAAAGACCCGCAACTTTCACTTGTTGAGAACCTTTAGCCAGCGCCGGCGTGCATGTGTTTTAGTTTTA TTCTTTTTCCCTTGCCCCCAAAGCCGTGGAGTACCTGCTGTTGCTCTCATGCCTCTTGCCAACAGTGGCATCTGCTCAGTGTAGCCATCA AGAATTTGAATGTCAATATCTTTGCCTTGAAATGAATGGAAAAGTATTTGTCACTCAGCGGCAATCATTCTTCAAATAAAAGGTCACTGG AAGGACTGAGCGCATTCAGGAGCCTGGAGGAACTCATCTTGGACAACAATCAGCTGGGGGACGACCTTGTGTTGCCAGGGTTACCCAGAC TGCATACCTTAACCCTCAACAAGAACCGAATCACTGATTTGGAGAACCTGCTGGATCACTTGGCAGAAGTGACACCAGCTCTGGAGTACC TCAGTCTGCTGGGCAACGTGGCCTGTCCCAACGAGCTGGTCAGCTTGGAAAAGGATGAGGAAGACTACAAGAGATACAGATGCTTTGTTC TGTACAAGCTGCCCAACTTGAAATTTCTGGATGCCCAGAAAGTAACCAGACAAGAACGAGAGGAGGCGTTGGTCAGAGGAGTCTTCATGA AGGTGGTGAAGCCCAAGGCTTCTAGTGAGGACGTTGCCAGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCA CCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAGGTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCT GTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAACAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCA AAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTGAAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGA CTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGCCCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCA AACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGGCAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCAC CCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATATCAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAG GGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACATCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCT TGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGC AAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCG ATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAG AAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAAC GAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAGTGA >10636_10636_5_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000537893_length(amino acids)=518AA_BP=172 MEKYLSLSGNHSSNKRSLEGLSAFRSLEELILDNNQLGDDLVLPGLPRLHTLTLNKNRITDLENLLDHLAEVTPALEYLSLLGNVACPNE LVSLEKDEEDYKRYRCFVLYKLPNLKFLDAQKVTRQEREEALVRGVFMKVVKPKASSEDVASSPERHYTPLPSASRELTSHQESEEVYQR QVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASSTMAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFV GPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRLGGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRN TSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKI LLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALTKX -------------------------------------------------------------- >10636_10636_6_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000545131_length(transcript)=1998nt_BP=732nt GTTGAAGAAAGAGGATCTGGCTGAAAGACCCGCAACTTTCACTTGTTGAGAACCTTTAGCCAGCGCCGGCGTGCATGTGTTTTAGTTTTA TTCTTTTTCCCTTGCCCCCAAAGCCGTGGAGTACCTGCTGTTGCTCTCATGCCTCTTGCCAACAGTGGCATCTGCTCAGTGTAGCCATCA AGAATTTGAATGTCAATATCTTTGCCTTGAAATGAATGGAAAAGTATTTGTCACTCAGCGGCAATCATTCTTCAAATAAAAGGTCACTGG AAGGACTGAGCGCATTCAGGAGCCTGGAGGAACTCATCTTGGACAACAATCAGCTGGGGGACGACCTTGTGTTGCCAGGGTTACCCAGAC TGCATACCTTAACCCTCAACAAGAACCGAATCACTGATTTGGAGAACCTGCTGGATCACTTGGCAGAAGTGACACCAGCTCTGGAGTACC TCAGTCTGCTGGGCAACGTGGCCTGTCCCAACGAGCTGGTCAGCTTGGAAAAGGATGAGGAAGACTACAAGAGATACAGATGCTTTGTTC TGTACAAGCTGCCCAACTTGAAATTTCTGGATGCCCAGAAAGTAACCAGACAAGAACGAGAGGAGGCGTTGGTCAGAGGAGTCTTCATGA AGGTGGTGAAGCCCAAGGCTTCTAGTGAGGACGTTGCCAGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCA CCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAGGTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCT GTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAACAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCA AAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTGAAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGA CTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGCCCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCA AACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGGCAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCAC CCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATATCAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAG GGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACATCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCT TGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGC AAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCG ATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAG AAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAAC GAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAGTGACTTGAGATGTAGGAATCTGTGCATTCTATGC TTTGCTCAACAGGAAAGAGAGGAAATCAAATACAAATTATTTATATGCATTAATTTAAGAGCATCTACTTAGAAGAAACCAAATAGTCTA TCGCCCTCATATCATAGTGTTTTTTAACAAAATATTTTTTTAAGGGAAAGAAATGTTTCAGGAGGGATAAAGCTTACCATTAAAGCTTTT GGGTAGAATTCTGAATCC >10636_10636_6_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000545131_length(amino acids)=517AA_BP=172 MEKYLSLSGNHSSNKRSLEGLSAFRSLEELILDNNQLGDDLVLPGLPRLHTLTLNKNRITDLENLLDHLAEVTPALEYLSLLGNVACPNE LVSLEKDEEDYKRYRCFVLYKLPNLKFLDAQKVTRQEREEALVRGVFMKVVKPKASSEDVASSPERHYTPLPSASRELTSHQESEEVYQR QVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASSTMAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFV GPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRLGGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRN TSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKI LLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_7_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000556918_length(transcript)=1769nt_BP=732nt GTTGAAGAAAGAGGATCTGGCTGAAAGACCCGCAACTTTCACTTGTTGAGAACCTTTAGCCAGCGCCGGCGTGCATGTGTTTTAGTTTTA TTCTTTTTCCCTTGCCCCCAAAGCCGTGGAGTACCTGCTGTTGCTCTCATGCCTCTTGCCAACAGTGGCATCTGCTCAGTGTAGCCATCA AGAATTTGAATGTCAATATCTTTGCCTTGAAATGAATGGAAAAGTATTTGTCACTCAGCGGCAATCATTCTTCAAATAAAAGGTCACTGG AAGGACTGAGCGCATTCAGGAGCCTGGAGGAACTCATCTTGGACAACAATCAGCTGGGGGACGACCTTGTGTTGCCAGGGTTACCCAGAC TGCATACCTTAACCCTCAACAAGAACCGAATCACTGATTTGGAGAACCTGCTGGATCACTTGGCAGAAGTGACACCAGCTCTGGAGTACC TCAGTCTGCTGGGCAACGTGGCCTGTCCCAACGAGCTGGTCAGCTTGGAAAAGGATGAGGAAGACTACAAGAGATACAGATGCTTTGTTC TGTACAAGCTGCCCAACTTGAAATTTCTGGATGCCCAGAAAGTAACCAGACAAGAACGAGAGGAGGCGTTGGTCAGAGGAGTCTTCATGA AGGTGGTGAAGCCCAAGGCTTCTAGTGAGGACGTTGCCAGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCA CCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAGGTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCT GTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAACAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCA AAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTGAAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGA CTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGCCCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCA AACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGGCAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCAC CCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATATCAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAG GGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACATCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCT TGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGC AAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCG ATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAG AAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAAC GAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAGTGA >10636_10636_7_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000372499_NRG3_chr10_84711225_ENST00000556918_length(amino acids)=518AA_BP=172 MEKYLSLSGNHSSNKRSLEGLSAFRSLEELILDNNQLGDDLVLPGLPRLHTLTLNKNRITDLENLLDHLAEVTPALEYLSLLGNVACPNE LVSLEKDEEDYKRYRCFVLYKLPNLKFLDAQKVTRQEREEALVRGVFMKVVKPKASSEDVASSPERHYTPLPSASRELTSHQESEEVYQR QVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASSTMAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFV GPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRLGGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRN TSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKI LLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALTKX -------------------------------------------------------------- >10636_10636_8_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000372141_length(transcript)=2041nt_BP=964nt AGATGCCACTGTGGGCACTGGCAGAACTGGGCCCCCTGTAGATCAGATAGAAACAAATGGGAAGCTCTGGGCCATTGCCTTCAAAAGGCT TTCTTATTCCAGAGAGGTTTTTGACATAATCCTCCCCTCCCCACCAGCCTCTGCTGTGACCAGCTTCTTACTTGAATTACCCTTCAGCTC CCTCGCTCAGCTTCATGCTCAGCATTTGCCCAGACTCTGACCTCTTCTCCATTGGGATCTTTTTCTTGGTCTCTTGGTTCCAGACTCACC CTCATCCCTACCTTGCCTTTTGTTTTCCTCCCAATTTCTTGGCTTCTGGCTCTAGACAGGATATGGCTGTTCCTGCTTTCAAACCTGTCT ATTATTCCCAACTTAATCTGTCTGTCAGTGACACCTTCTCTCTTGCTTTACTGAAAGGCATGGCACCTTAATCTGTGAGAGGGGTGGGAA GCTTCAGCCTTCTACCTGGTTCTTTAGTTTCTCTAACTTAATCCTTCAGAAGATGGCAAGTCTTTACTTTTGGATTCTGGCAATGTGGCC CACACTTTCGTGTTGAATTACAGTCATGGTATGTAGTTTTTTTTTTGTTTGTTTGAGACAGAGTCTGGCTCTGTCGCCCAGGCTGGAGTG GAGTGGCACGATCTCGGCTCACTGCAAGCTCCGCCTCCTGGGCTCACGCCATTCTCCTGCCTTAGCCTCCAGAATAGCTGGGACTACAGG CACCCGCCACCATGCCTGGAGAAGTTTTTGTATTTTTAGTGGAGACAGGGTTTCACCATGTTAACCAGGATGGTCTCGATCTCCTGACCT CGTGATCCACCCGTCTCGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACTGCGCCCAGCCCATGGCTTCTAGTGAGGACGTTGCC AGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCACCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAG GTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCTGTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAA CAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCAAAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTG AAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGACTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGC CCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCAAACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGG CAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCACCCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATAT CAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAGGGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACA TCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGG GCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGG TGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTG CTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGT GCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGA GACTCTGCATTGACCAAGTGACTTGAGATGTAGGAATCTGTGCATTCTATGCTTTGCTCAA >10636_10636_8_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000372141_length(amino acids)=374AA_BP=29 MASSEDVASSPERHYTPLPSASRELTSHQESEEVYQRQVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASST MAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFVGPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRL GGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGI SEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQF VLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_9_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000372142_length(transcript)=3435nt_BP=964nt AGATGCCACTGTGGGCACTGGCAGAACTGGGCCCCCTGTAGATCAGATAGAAACAAATGGGAAGCTCTGGGCCATTGCCTTCAAAAGGCT TTCTTATTCCAGAGAGGTTTTTGACATAATCCTCCCCTCCCCACCAGCCTCTGCTGTGACCAGCTTCTTACTTGAATTACCCTTCAGCTC CCTCGCTCAGCTTCATGCTCAGCATTTGCCCAGACTCTGACCTCTTCTCCATTGGGATCTTTTTCTTGGTCTCTTGGTTCCAGACTCACC CTCATCCCTACCTTGCCTTTTGTTTTCCTCCCAATTTCTTGGCTTCTGGCTCTAGACAGGATATGGCTGTTCCTGCTTTCAAACCTGTCT ATTATTCCCAACTTAATCTGTCTGTCAGTGACACCTTCTCTCTTGCTTTACTGAAAGGCATGGCACCTTAATCTGTGAGAGGGGTGGGAA GCTTCAGCCTTCTACCTGGTTCTTTAGTTTCTCTAACTTAATCCTTCAGAAGATGGCAAGTCTTTACTTTTGGATTCTGGCAATGTGGCC CACACTTTCGTGTTGAATTACAGTCATGGTATGTAGTTTTTTTTTTGTTTGTTTGAGACAGAGTCTGGCTCTGTCGCCCAGGCTGGAGTG GAGTGGCACGATCTCGGCTCACTGCAAGCTCCGCCTCCTGGGCTCACGCCATTCTCCTGCCTTAGCCTCCAGAATAGCTGGGACTACAGG CACCCGCCACCATGCCTGGAGAAGTTTTTGTATTTTTAGTGGAGACAGGGTTTCACCATGTTAACCAGGATGGTCTCGATCTCCTGACCT CGTGATCCACCCGTCTCGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACTGCGCCCAGCCCATGGCTTCTAGTGAGGACGTTGCC AGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCACCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAG GTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCTGTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAA CAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCAAAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTG AAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGACTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGC CCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCAAACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGG CAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCACCCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATAT CAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAGGGATAGAGGTCAGGAAGACTATATCCCACCTGCCTATA CAGCTGTGGTGTGTTGAAAGACCCCTGGACTTAAAGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACATCAATAAATATGCAACTG CCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATC ATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCA GCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAG CAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCC TTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAG TGACTTGAGATGTAGGAATCTGTGCATTCTATGCTTTGCTCAACAGGAAAGAGAGGAAATCAAATACAAATTATTTATATGCATTAATTT AAGAGCATCTACTTAGAAGAAACCAAATAGTCTATCGCCCTCATATCATAGTGTTTTTTAACAAAATATTTTTTTAAGGGAAAGAAATGT TTCAGGAGGGATAAAGCTTACCATTAAAGCTTTTGGGTAGAATTCTGAATCCAATTTCGTTTAGTCCCAACACTGTCCTCTTTGGCTCTT AGAAGATGTGGGCAATTCAGACCCTTGGCCCCACAGTGCCAGTGTCTCATTAAAAAACACTGGCAGTTACCTGGTTTCAAAAAGAGGAGA GCTGCATCCCGCAGGTGGATGCACCAGTGAGCAGGTGGCTCTTGCCATTTGGCTTGCCAGTCCCAAGCCCTAAATTTCTATTCACCCAAT AGCCTCATCACAGGTTATGTCATGTCGACACATGTAGTGTTTTCTATTTGATTTTTGGAGAATGCCACAAAAGACTCTGCAATGGGAAGG AGGACAGGAGATAGAAGGAGAAACCGGGGGCAATCTTAACTACTCTTGTGTGCCACCTTCCTCTGAGATTTGAATGCACAGATCTCAGCT GGAGGTATGAAATTATTACAGAAAAAGAGACAAAAAAATCCTTATATCGTGTCACTAAAATCATGCTAATAGAAATGTTTTTCCTTGAGA TTGTTTAGAGGCTCTGGAGGAGCGTTTCTCAGTTTTTGTGTGCCTGTGTGCACATGTGTGTGCGAGCGTGTGTGTGTGTGGACTTGCTCA CGCGGGCACATATGCTGTAAGCACATGTGTTCATTGTGCGTATGTGTGTGCATGTGTGCGCGTATTACGCTTGCTAAAATTTGTTCTGAA ACATCAGGGAATCTACTATTCAGAAAAATTATTTCCCTCTTAGATCTTTTCACTTTAAATTTTTCCATTAAGTATAAAGTTCAGTTAGTT CTTAAATCAAGGTCACTTGCATGGTGGGGTCGTATAAAACTCTTGACACTGTCTAGACCATTTTCTGATGTGAATACTTTTGAGAGGATC AACTATTGGCTCATTAATGATATCAGTATCATAAGGTGAGTTCATCAAGGATGTGTGTTTATTTTGAATCATGCCTACTTAAATTATTAA TACAAGACAATTAACAAATTGACAGTTACCATTTGCTTTCTCATCATCCTCATTACCATTTATTTTATAGCAAGTCTGCTATGTGTGGAC CAAGGCTTCGGCTTCTGTGGTTAGTATGGGAAGAATAAATTGTTGAAATAAAAATACCCAGACTATTCAGTTCACAAGAAGCCCCCCAAA AGAACAGTAAATTGT >10636_10636_9_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000372142_length(amino acids)=398AA_BP=29 MASSEDVASSPERHYTPLPSASRELTSHQESEEVYQRQVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASST MAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFVGPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRL GGIVGPAYQQLEESRIPDQDTIPCQGIEVRKTISHLPIQLWCVERPLDLKYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSS TRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETE DSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_10_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000404547_length(transcript)=2073nt_BP=964nt AGATGCCACTGTGGGCACTGGCAGAACTGGGCCCCCTGTAGATCAGATAGAAACAAATGGGAAGCTCTGGGCCATTGCCTTCAAAAGGCT TTCTTATTCCAGAGAGGTTTTTGACATAATCCTCCCCTCCCCACCAGCCTCTGCTGTGACCAGCTTCTTACTTGAATTACCCTTCAGCTC CCTCGCTCAGCTTCATGCTCAGCATTTGCCCAGACTCTGACCTCTTCTCCATTGGGATCTTTTTCTTGGTCTCTTGGTTCCAGACTCACC CTCATCCCTACCTTGCCTTTTGTTTTCCTCCCAATTTCTTGGCTTCTGGCTCTAGACAGGATATGGCTGTTCCTGCTTTCAAACCTGTCT ATTATTCCCAACTTAATCTGTCTGTCAGTGACACCTTCTCTCTTGCTTTACTGAAAGGCATGGCACCTTAATCTGTGAGAGGGGTGGGAA GCTTCAGCCTTCTACCTGGTTCTTTAGTTTCTCTAACTTAATCCTTCAGAAGATGGCAAGTCTTTACTTTTGGATTCTGGCAATGTGGCC CACACTTTCGTGTTGAATTACAGTCATGGTATGTAGTTTTTTTTTTGTTTGTTTGAGACAGAGTCTGGCTCTGTCGCCCAGGCTGGAGTG GAGTGGCACGATCTCGGCTCACTGCAAGCTCCGCCTCCTGGGCTCACGCCATTCTCCTGCCTTAGCCTCCAGAATAGCTGGGACTACAGG CACCCGCCACCATGCCTGGAGAAGTTTTTGTATTTTTAGTGGAGACAGGGTTTCACCATGTTAACCAGGATGGTCTCGATCTCCTGACCT CGTGATCCACCCGTCTCGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACTGCGCCCAGCCCATGGCTTCTAGTGAGGACGTTGCC AGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCACCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAG GTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCTGTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAA CAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCAAAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTG AAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGACTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGC CCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCAAACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGG CAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCACCCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATAT CAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAGGGATAGAGGTCAGGAAGACTATATCCCACCTGCCTATA CAGCTGTGGTGTGTTGAAAGACCCCTGGACTTAAAGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACATCAATAAATATGCAACTG CCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGGGCCAGTTCTGTGCCCATC ATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGGTGCAAAAACTCCTATTCA GCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTGCTAGAAACTGTCCAGGAG CAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGTGCAAGCGAAAACACAGCC TTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGAGACTCTGCATTGACCAAG TGA >10636_10636_10_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000404547_length(amino acids)=398AA_BP=29 MASSEDVASSPERHYTPLPSASRELTSHQESEEVYQRQVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASST MAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFVGPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRL GGIVGPAYQQLEESRIPDQDTIPCQGIEVRKTISHLPIQLWCVERPLDLKYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSS TRASSVPIIPSVGLEETCLQMPGISEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETE DSASENTAFLPLSPTAKSEREAQFVLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_11_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000404576_length(transcript)=2001nt_BP=964nt AGATGCCACTGTGGGCACTGGCAGAACTGGGCCCCCTGTAGATCAGATAGAAACAAATGGGAAGCTCTGGGCCATTGCCTTCAAAAGGCT TTCTTATTCCAGAGAGGTTTTTGACATAATCCTCCCCTCCCCACCAGCCTCTGCTGTGACCAGCTTCTTACTTGAATTACCCTTCAGCTC CCTCGCTCAGCTTCATGCTCAGCATTTGCCCAGACTCTGACCTCTTCTCCATTGGGATCTTTTTCTTGGTCTCTTGGTTCCAGACTCACC CTCATCCCTACCTTGCCTTTTGTTTTCCTCCCAATTTCTTGGCTTCTGGCTCTAGACAGGATATGGCTGTTCCTGCTTTCAAACCTGTCT ATTATTCCCAACTTAATCTGTCTGTCAGTGACACCTTCTCTCTTGCTTTACTGAAAGGCATGGCACCTTAATCTGTGAGAGGGGTGGGAA GCTTCAGCCTTCTACCTGGTTCTTTAGTTTCTCTAACTTAATCCTTCAGAAGATGGCAAGTCTTTACTTTTGGATTCTGGCAATGTGGCC CACACTTTCGTGTTGAATTACAGTCATGGTATGTAGTTTTTTTTTTGTTTGTTTGAGACAGAGTCTGGCTCTGTCGCCCAGGCTGGAGTG GAGTGGCACGATCTCGGCTCACTGCAAGCTCCGCCTCCTGGGCTCACGCCATTCTCCTGCCTTAGCCTCCAGAATAGCTGGGACTACAGG CACCCGCCACCATGCCTGGAGAAGTTTTTGTATTTTTAGTGGAGACAGGGTTTCACCATGTTAACCAGGATGGTCTCGATCTCCTGACCT CGTGATCCACCCGTCTCGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACTGCGCCCAGCCCATGGCTTCTAGTGAGGACGTTGCC AGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCACCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAG GTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCTGTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAA CAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCAAAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTG AAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGACTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGC CCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCAAACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGG CAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCACCCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATAT CAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAGGGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACA TCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGG GCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGG TGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTG CTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGT GCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGA GACTCTGCATTGACCAAGTGA >10636_10636_11_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000404576_length(amino acids)=374AA_BP=29 MASSEDVASSPERHYTPLPSASRELTSHQESEEVYQRQVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASST MAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFVGPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRL GGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGI SEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQF VLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_12_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000537893_length(transcript)=2001nt_BP=964nt AGATGCCACTGTGGGCACTGGCAGAACTGGGCCCCCTGTAGATCAGATAGAAACAAATGGGAAGCTCTGGGCCATTGCCTTCAAAAGGCT TTCTTATTCCAGAGAGGTTTTTGACATAATCCTCCCCTCCCCACCAGCCTCTGCTGTGACCAGCTTCTTACTTGAATTACCCTTCAGCTC CCTCGCTCAGCTTCATGCTCAGCATTTGCCCAGACTCTGACCTCTTCTCCATTGGGATCTTTTTCTTGGTCTCTTGGTTCCAGACTCACC CTCATCCCTACCTTGCCTTTTGTTTTCCTCCCAATTTCTTGGCTTCTGGCTCTAGACAGGATATGGCTGTTCCTGCTTTCAAACCTGTCT ATTATTCCCAACTTAATCTGTCTGTCAGTGACACCTTCTCTCTTGCTTTACTGAAAGGCATGGCACCTTAATCTGTGAGAGGGGTGGGAA GCTTCAGCCTTCTACCTGGTTCTTTAGTTTCTCTAACTTAATCCTTCAGAAGATGGCAAGTCTTTACTTTTGGATTCTGGCAATGTGGCC CACACTTTCGTGTTGAATTACAGTCATGGTATGTAGTTTTTTTTTTGTTTGTTTGAGACAGAGTCTGGCTCTGTCGCCCAGGCTGGAGTG GAGTGGCACGATCTCGGCTCACTGCAAGCTCCGCCTCCTGGGCTCACGCCATTCTCCTGCCTTAGCCTCCAGAATAGCTGGGACTACAGG CACCCGCCACCATGCCTGGAGAAGTTTTTGTATTTTTAGTGGAGACAGGGTTTCACCATGTTAACCAGGATGGTCTCGATCTCCTGACCT CGTGATCCACCCGTCTCGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACTGCGCCCAGCCCATGGCTTCTAGTGAGGACGTTGCC AGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCACCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAG GTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCTGTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAA CAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCAAAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTG AAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGACTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGC CCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCAAACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGG CAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCACCCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATAT CAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAGGGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACA TCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGG GCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGG TGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTG CTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGT GCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGA GACTCTGCATTGACCAAGTGA >10636_10636_12_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000537893_length(amino acids)=374AA_BP=29 MASSEDVASSPERHYTPLPSASRELTSHQESEEVYQRQVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASST MAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFVGPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRL GGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGI SEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQF VLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_13_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000545131_length(transcript)=2230nt_BP=964nt AGATGCCACTGTGGGCACTGGCAGAACTGGGCCCCCTGTAGATCAGATAGAAACAAATGGGAAGCTCTGGGCCATTGCCTTCAAAAGGCT TTCTTATTCCAGAGAGGTTTTTGACATAATCCTCCCCTCCCCACCAGCCTCTGCTGTGACCAGCTTCTTACTTGAATTACCCTTCAGCTC CCTCGCTCAGCTTCATGCTCAGCATTTGCCCAGACTCTGACCTCTTCTCCATTGGGATCTTTTTCTTGGTCTCTTGGTTCCAGACTCACC CTCATCCCTACCTTGCCTTTTGTTTTCCTCCCAATTTCTTGGCTTCTGGCTCTAGACAGGATATGGCTGTTCCTGCTTTCAAACCTGTCT ATTATTCCCAACTTAATCTGTCTGTCAGTGACACCTTCTCTCTTGCTTTACTGAAAGGCATGGCACCTTAATCTGTGAGAGGGGTGGGAA GCTTCAGCCTTCTACCTGGTTCTTTAGTTTCTCTAACTTAATCCTTCAGAAGATGGCAAGTCTTTACTTTTGGATTCTGGCAATGTGGCC CACACTTTCGTGTTGAATTACAGTCATGGTATGTAGTTTTTTTTTTGTTTGTTTGAGACAGAGTCTGGCTCTGTCGCCCAGGCTGGAGTG GAGTGGCACGATCTCGGCTCACTGCAAGCTCCGCCTCCTGGGCTCACGCCATTCTCCTGCCTTAGCCTCCAGAATAGCTGGGACTACAGG CACCCGCCACCATGCCTGGAGAAGTTTTTGTATTTTTAGTGGAGACAGGGTTTCACCATGTTAACCAGGATGGTCTCGATCTCCTGACCT CGTGATCCACCCGTCTCGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACTGCGCCCAGCCCATGGCTTCTAGTGAGGACGTTGCC AGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCACCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAG GTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCTGTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAA CAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCAAAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTG AAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGACTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGC CCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCAAACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGG CAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCACCCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATAT CAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAGGGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACA TCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGG GCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGG TGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTG CTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGT GCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGA GACTCTGCATTGACCAAGTGACTTGAGATGTAGGAATCTGTGCATTCTATGCTTTGCTCAACAGGAAAGAGAGGAAATCAAATACAAATT ATTTATATGCATTAATTTAAGAGCATCTACTTAGAAGAAACCAAATAGTCTATCGCCCTCATATCATAGTGTTTTTTAACAAAATATTTT TTTAAGGGAAAGAAATGTTTCAGGAGGGATAAAGCTTACCATTAAAGCTTTTGGGTAGAATTCTGAATCC >10636_10636_13_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000545131_length(amino acids)=374AA_BP=29 MASSEDVASSPERHYTPLPSASRELTSHQESEEVYQRQVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASST MAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFVGPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRL GGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGI SEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQF VLRNEIQRDSALTK -------------------------------------------------------------- >10636_10636_14_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000556918_length(transcript)=2001nt_BP=964nt AGATGCCACTGTGGGCACTGGCAGAACTGGGCCCCCTGTAGATCAGATAGAAACAAATGGGAAGCTCTGGGCCATTGCCTTCAAAAGGCT TTCTTATTCCAGAGAGGTTTTTGACATAATCCTCCCCTCCCCACCAGCCTCTGCTGTGACCAGCTTCTTACTTGAATTACCCTTCAGCTC CCTCGCTCAGCTTCATGCTCAGCATTTGCCCAGACTCTGACCTCTTCTCCATTGGGATCTTTTTCTTGGTCTCTTGGTTCCAGACTCACC CTCATCCCTACCTTGCCTTTTGTTTTCCTCCCAATTTCTTGGCTTCTGGCTCTAGACAGGATATGGCTGTTCCTGCTTTCAAACCTGTCT ATTATTCCCAACTTAATCTGTCTGTCAGTGACACCTTCTCTCTTGCTTTACTGAAAGGCATGGCACCTTAATCTGTGAGAGGGGTGGGAA GCTTCAGCCTTCTACCTGGTTCTTTAGTTTCTCTAACTTAATCCTTCAGAAGATGGCAAGTCTTTACTTTTGGATTCTGGCAATGTGGCC CACACTTTCGTGTTGAATTACAGTCATGGTATGTAGTTTTTTTTTTGTTTGTTTGAGACAGAGTCTGGCTCTGTCGCCCAGGCTGGAGTG GAGTGGCACGATCTCGGCTCACTGCAAGCTCCGCCTCCTGGGCTCACGCCATTCTCCTGCCTTAGCCTCCAGAATAGCTGGGACTACAGG CACCCGCCACCATGCCTGGAGAAGTTTTTGTATTTTTAGTGGAGACAGGGTTTCACCATGTTAACCAGGATGGTCTCGATCTCCTGACCT CGTGATCCACCCGTCTCGGCCTCCCAAAGTGCTGGGATTACAGGCGTGAGCCACTGCGCCCAGCCCATGGCTTCTAGTGAGGACGTTGCC AGCTCCCCGGAGCGCCACTACACGCCCTTGCCTTCTGCTTCCAGGGAACTCACCAGTCACCAAGAGAGTGAAGAAGTTTATCAAAGGCAG GTGCTGTCAATTTCATGTATCATCTTTGGAATTGTCATCGTGGGCATGTTCTGTGCAGCATTCTACTTCAAAAGCAAGAAACAAGCTAAA CAAATCCAAGAGCAGCTGAAAGTGCCACAAAATGGTAAAAGCTACAGTCTCAAAGCATCCAGCACAATGGCAAAGTCAGAGAACTTGGTG AAGAGCCATGTCCAGCTGCAAAATTATTCAAAGGTGGAAAGGCATCCTGTGACTGCATTGGAGAAAATGATGGAGTCAAGTTTTGTCGGC CCCCAGTCATTCCCTGAGGTCCCTTCTCCTGACAGAGGAAGCCAGTCTGTCAAACACCACAGGAGTCTATCCTCTTGCTGCAGCCCAGGG CAAAGAAGTGGCATGCTCCATAGGAATGCCTTCAGAAGGACACCCCCGTCACCCCGAAGTAGGCTAGGTGGAATTGTGGGACCAGCATAT CAGCAACTCGAAGAATCAAGGATCCCAGACCAGGATACGATACCTTGCCAAGGGTATTCATCCAGTGGTTTAAAAACCCAACGAAATACA TCAATAAATATGCAACTGCCTTCAAGAGAGACAAACCCCTATTTTAATAGCTTGGAGCAAAAGGACCTGGTGGGCTATTCATCCACAAGG GCCAGTTCTGTGCCCATCATCCCTTCAGTGGGTTTAGAGGAAACCTGCCTGCAAATGCCAGGGATTTCTGAAGTCAAAAGCATCAAATGG TGCAAAAACTCCTATTCAGCTGACGTTGTCAATGTGAGTATTCCAGTCAGCGATTGTCTTATAGCAGAACAACAAGAAGTGAAAATATTG CTAGAAACTGTCCAGGAGCAGATCCGAATTCTGACTGATGCCAGACGGTCAGAAGACTACGAACTGGCCAGCGTAGAAACCGAGGACAGT GCAAGCGAAAACACAGCCTTTCTCCCCCTGAGTCCCACAGCCAAATCAGAACGAGAGGCGCAATTTGTCTTAAGAAATGAAATACAAAGA GACTCTGCATTGACCAAGTGA >10636_10636_14_C10orf11-NRG3_C10orf11_chr10_78084243_ENST00000496424_NRG3_chr10_84711225_ENST00000556918_length(amino acids)=374AA_BP=29 MASSEDVASSPERHYTPLPSASRELTSHQESEEVYQRQVLSISCIIFGIVIVGMFCAAFYFKSKKQAKQIQEQLKVPQNGKSYSLKASST MAKSENLVKSHVQLQNYSKVERHPVTALEKMMESSFVGPQSFPEVPSPDRGSQSVKHHRSLSSCCSPGQRSGMLHRNAFRRTPPSPRSRL GGIVGPAYQQLEESRIPDQDTIPCQGYSSSGLKTQRNTSINMQLPSRETNPYFNSLEQKDLVGYSSTRASSVPIIPSVGLEETCLQMPGI SEVKSIKWCKNSYSADVVNVSIPVSDCLIAEQQEVKILLETVQEQIRILTDARRSEDYELASVETEDSASENTAFLPLSPTAKSEREAQF VLRNEIQRDSALTK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for C10orf11-NRG3 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for C10orf11-NRG3 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for C10orf11-NRG3 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0005586 | Bipolar Disorder | 2 | PSYGENET | |
| Tgene | C0036341 | Schizophrenia | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies