
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:DIXDC1-ARCN1 (FusionGDB2 ID:HG85458TG372) |
Fusion Gene Summary for DIXDC1-ARCN1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: DIXDC1-ARCN1 | Fusion gene ID: hg85458tg372 | Hgene | Tgene | Gene symbol | DIXDC1 | ARCN1 | Gene ID | 85458 | 372 |
| Gene name | DIX domain containing 1 | archain 1 | |
| Synonyms | CCD1 | COPD|SRMMD | |
| Cytomap | ('DIXDC1')('ARCN1') 11q23.1 | 11q23.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | dixincoiled-coil protein DIX1 | coatomer subunit deltaCOPI coat complex subunit deltaarchain vesicle transport protein 1coatomer delta subunitcoatomer protein complex, subunit deltacoatomer protein delta-COPdelta-COPdelta-coat protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000389821, ENST00000440460, ENST00000531396, ENST00000315253, ENST00000529225, | ||
| Fusion gene scores | * DoF score | 7 X 6 X 4=168 | 10 X 10 X 5=500 |
| # samples | 9 | 11 | |
| ** MAII score | log2(9/168*10)=-0.900464326449086 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(11/500*10)=-2.18442457113743 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: DIXDC1 [Title/Abstract] AND ARCN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | DIXDC1(111808283)-ARCN1(118463424), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | DIXDC1-ARCN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DIXDC1-ARCN1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. DIXDC1-ARCN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. DIXDC1-ARCN1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | DIXDC1 | GO:0060070 | canonical Wnt signaling pathway | 21189423 |
| Fusion gene breakpoints across DIXDC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ARCN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-23-2084-01A | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
Top |
Fusion Gene ORF analysis for DIXDC1-ARCN1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000389821 | ENST00000359415 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| 3UTR-3CDS | ENST00000389821 | ENST00000392859 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| 3UTR-intron | ENST00000389821 | ENST00000264028 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| 3UTR-intron | ENST00000389821 | ENST00000534182 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| 5CDS-intron | ENST00000440460 | ENST00000264028 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| 5CDS-intron | ENST00000440460 | ENST00000534182 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| 5CDS-intron | ENST00000531396 | ENST00000264028 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| 5CDS-intron | ENST00000531396 | ENST00000534182 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| In-frame | ENST00000440460 | ENST00000359415 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| In-frame | ENST00000440460 | ENST00000392859 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| In-frame | ENST00000531396 | ENST00000359415 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| In-frame | ENST00000531396 | ENST00000392859 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-3CDS | ENST00000315253 | ENST00000359415 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-3CDS | ENST00000315253 | ENST00000392859 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-3CDS | ENST00000529225 | ENST00000359415 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-3CDS | ENST00000529225 | ENST00000392859 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-intron | ENST00000315253 | ENST00000264028 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-intron | ENST00000315253 | ENST00000534182 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-intron | ENST00000529225 | ENST00000264028 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| intron-intron | ENST00000529225 | ENST00000534182 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000440460 | DIXDC1 | chr11 | 111808283 | + | ENST00000392859 | ARCN1 | chr11 | 118463424 | + | 1188 | 357 | 760 | 47 | 237 |
| ENST00000440460 | DIXDC1 | chr11 | 111808283 | + | ENST00000359415 | ARCN1 | chr11 | 118463424 | + | 3123 | 357 | 760 | 47 | 237 |
| ENST00000531396 | DIXDC1 | chr11 | 111808283 | + | ENST00000392859 | ARCN1 | chr11 | 118463424 | + | 964 | 133 | 37 | 684 | 215 |
| ENST00000531396 | DIXDC1 | chr11 | 111808283 | + | ENST00000359415 | ARCN1 | chr11 | 118463424 | + | 2899 | 133 | 37 | 684 | 215 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000440460 | ENST00000392859 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + | 0.007141957 | 0.99285805 |
| ENST00000440460 | ENST00000359415 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + | 0.001536022 | 0.998464 |
| ENST00000531396 | ENST00000392859 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + | 0.005744206 | 0.99425584 |
| ENST00000531396 | ENST00000359415 | DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463424 | + | 0.001179072 | 0.99882096 |
Top |
Fusion Genomic Features for DIXDC1-ARCN1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463423 | + | 7.81E-07 | 0.99999917 |
| DIXDC1 | chr11 | 111808283 | + | ARCN1 | chr11 | 118463423 | + | 7.81E-07 | 0.99999917 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
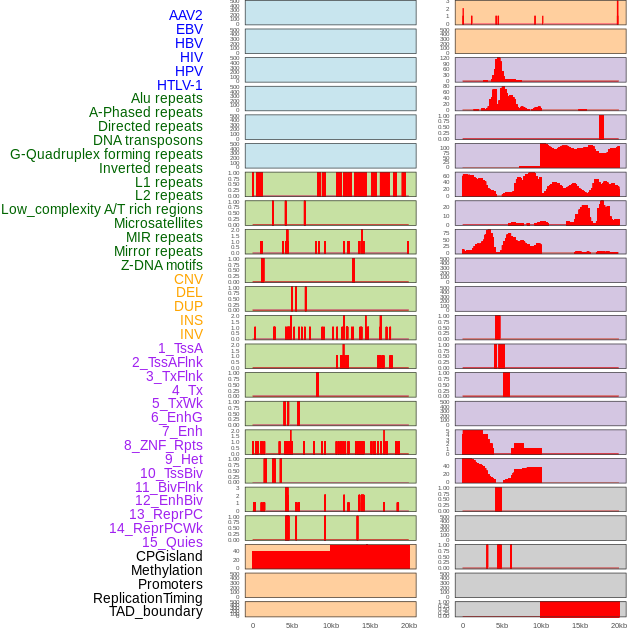 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
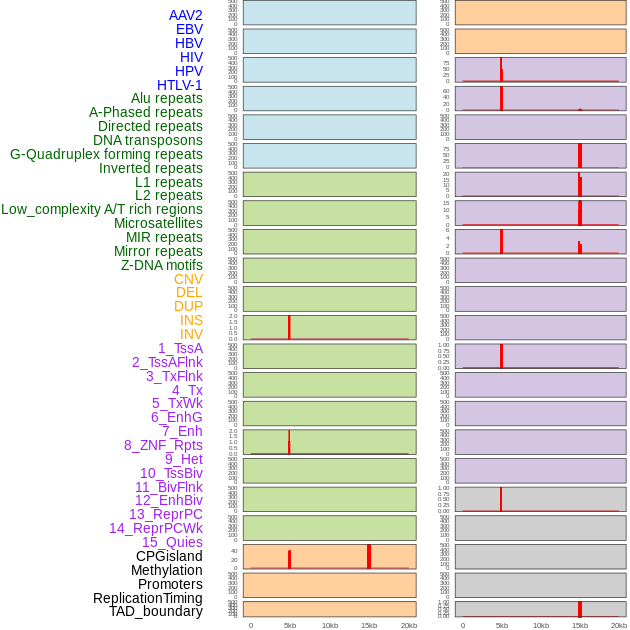 |
Top |
Fusion Protein Features for DIXDC1-ARCN1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:111808283/chr11:118463424) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ARCN1 | chr11:111808283 | chr11:118463424 | ENST00000392859 | 4 | 9 | 271_511 | 240 | 424.0 | Domain | MHD |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | DIXDC1 | chr11:111808283 | chr11:118463424 | ENST00000531396 | + | 1 | 5 | 279_452 | 20 | 220.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | DIXDC1 | chr11:111808283 | chr11:118463424 | ENST00000531396 | + | 1 | 5 | 20_127 | 20 | 220.0 | Domain | Calponin-homology (CH) |
| Hgene | DIXDC1 | chr11:111808283 | chr11:118463424 | ENST00000531396 | + | 1 | 5 | 600_680 | 20 | 220.0 | Domain | DIX |
| Hgene | DIXDC1 | chr11:111808283 | chr11:118463424 | ENST00000531396 | + | 1 | 5 | 127_300 | 20 | 220.0 | Region | Note=Actin-binding |
| Tgene | ARCN1 | chr11:111808283 | chr11:118463424 | ENST00000264028 | 5 | 10 | 271_511 | 328 | 512.0 | Domain | MHD |
Top |
Fusion Gene Sequence for DIXDC1-ARCN1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >22949_22949_1_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000440460_ARCN1_chr11_118463424_ENST00000359415_length(transcript)=3123nt_BP=357nt TCCCGCAGGAAAGCGGGGCTGGGGGCAGCCCGGCAGCGCCGCTCAACCTAGTGCGCGCCCAGTTGTTTCCATAGGAACCGCGACCGCGCC GGGCCCCTCCAGCGGAGGCCCCCGTGCGAGCATGCCCAGTGCAAGCCGCTAGTTTGGCTCCAGTCTAGGTTTCCAGTAAGTGGCATGCGG GACTCCGGAGGGATCCCAATGAGCTGAGCCGAGAGCCTTTGTGTGCAGAGGGAGGAGGAGGAGGCGGCGGCGGCCGCCGGGCTGGAGACC CCGCCCGGGGAGCCCCCAGCAGGAACAATGCTAGCCTGCCTGACCCGAGGGAACTTACTGGACGTCCTGCAGGAGGGCTTCAATGAGACC CATCCAAATGTGGATAAAAAACTTTTCACTGCAGAGTCTCTAATTGGCCTGAAGAATCCAGAGAAGTCATTTCCAGTCAACAGTGACGTA GGGGTGCTAAAGTGGAGACTACAAACCACAGAGGAATCTTTTATTCCACTGACAATTAATTGCTGGCCCTCGGAGAGTGGAAATGGCTGT GATGTCAACATAGAATATGAGCTACAAGAAGATAATTTAGAACTGAATGATGTGGTTATCACCATCCCACTCCCGTCTGGTGTCGGCGCG CCTGTTATCGGTGAGATCGATGGGGAGTATCGACATGACAGTCGACGAAATACCCTGGAGTGGTGCCTGCCTGTGATTGATGCCAAAAAT AAGAGTGGCAGCCTGGAGTTTAGCATTGCTGGGCAGCCCAATGACTTCTTCCCTGTTCAAGTTTCCTTTGTCTCCAAGAAAAATTACTGT AACATACAGGTTACCAAAGTGACCCAGGTAGATGGAAACAGCCCCGTCAGGTTTTCCACAGAGACCACTTTCCTAGTGGATAAGTATGAA ATTCTGTAATACCAAGAAGAGGGAGCTGAAAAGGAAAATTTTCAGATTAATAAAGAAGACGCCAATGATGGCTGAAGAGTTTTTCCCAGA TTTACAAGCCACTGGAGACCCCTTTTTTCTGATACAATGCACGATTCTCTGCGCGCAAGGACCCTCGACTCACCCCCATGTTTCAGTGTC ACAGAGACATTCTTTGATAAGGAAATGGCACAAACATAAAGGGAAAGGCTGCTAATTTTCTTTGGCAGATTGTATTGGCCAGCAGGAAAG CAAGCTCTCCAGAGAATGCCCCCAGTTAAATACCTCCTCTACCTTTACCTAAGTTGCTCCTTTATTTTTATTTTATTATTATTATTATTA TTATTATTATTTTTTGAGATGGAGTCTCACTTTGTAACCCAGGCTGGAATGCAATGGCATGATCTCAGCTCACTGCAACCTCCGCCTCCT GGGTTCAAGCAAGTCTCCTGCCTCAGCCTCCGAGTAGCTGGGACTACAGGTGCACGCCACCACGCCTGGCTAATTTTTTGTATTTTAGTA GAGACGGGGTTTCACCGTGTTGCCCAGGCTGGTCGCGAACTCCTGAGCTCAGGCAATCCGCCCACCTCAGCCTCCCAAAGTGTTGGGATT ACAGGCATGAGCCACCATGCCCAGCTGCTCCTTTATTTTAATCCCTAAATATAATCCCTAAATATAGTTATATTTCATACTTAGTTTGTT TTTAAAAAGTTTTCTCTGTAGAAAATTTTAATCATTCATACCCTTTACCTTTAGGTTTTTCTTTCTATACATTCAGTCAGGCACTGGGAT CATCTGTTTACAGGCATTATATTTATTTGGCACTCCTGGAACAAGTATATCTAACCCATTCTTGATTTTTGGACTATTCAGGTGAACTAT TTGAGGGGTATGGGGTCTAGAAGTTAAAAGATACGCATGTCTTCTGTTCTTTTCCCGTATCAATTCATTCCTTCATCTCTTTGCCAAGTT GTTTTCCTTTCAGGGCCTGTCCTTCCAGTTTAGAACAGTACCATGAATCCCACTTGTGTCAATATTAAAGATAGCTGAGAAGCACCTTTC AAATGGCACAGTCCCTCTTCAAGATGTCTAAAAGAATGGTTATGTCTGTCCAGTTAGGGATTTCACATCCACATGTAATCATGTCTGCTG CTGTTGCTACCCAAATTTTCATTTCTCCACATTTTGGGTACTTAAGCTAAAACGTAATGGCCACAGTCTGTAATCCATTCACATTCCTCA GTTTCACCACCTCCCTCTTCCAGACTGCACTCTCTGTCATCAGTCCCCTCCTTTCTAACAGAAATGGGGTTATGATTTTGAAGGCTGTGG GTTCAGGGAGTCTTTGCCAATCCTGTTGGCCCTAAACTATCAAGGAGGCTCCATTTCACCATTTGATTTTTTGCATTTCAGGAGGCAACT GATTGTTTCGATATGTACATATTACTCACGTATACCCCATTTCCTTCCAGTCAGCCCAACATTTTCCACCAGTCTGTCCCCATCTCTGAA ATCCTTCCTTCTCTTTCCCCCTAAGTCTTTTGAGTGTCATCATGTACTGGTGGTTTCTCGGTTCCATCTCATCCATTTCCTTTTCAATGG AGACTACAGCGTCAGCCAGCTCAGCCTTGGCTTTTAACTCAATATTCCAGTCCATAGGGGTGGTTAAAAGTTGCTGCAAGGCTGCAGGCA CTGGCAGTGGGAAGAGGCAGACGACTAGATGACTTCTGCACTTTTAGCTGGTTGAAAAGTACCACTCCCACTCTGAACATCTGGCCGTCC CTGCAAAGAGTGTACTGTGCTTGAAGCAGAGCACTCACACATAAATGGCTGTGTGTGGAATTGCTTGCCAAAGAAGTTTCTAGCCTTTCC CTTTCCCCTAACTGCATCAGGGAAGAATTCTTATCTCTAGCTTGGTTTCCACATGAGGTTTTTCTGAGAAGGGCTTGGGACAAGAAGTCT GTCATGTTAGTTAAGCAGGCAAGAAATCCTACTAATCCAGTTTTGTTTGAAAGTTGTTTGTCCGTATGATTTTTTAAAAGTCAAGTTTAA TTTCAAAAAACCTTTTTTTTCTGAGATTACTTTTGGGGTAATATTTAAAATGAGAGACATTTTGTAACCCTGTAAAATACATAGGGAATA TAACATTCCAGTGTATACAAAGAAGGCAAATTCTTTAATCAAATAAAGCGCATTATAAAATGA >22949_22949_1_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000440460_ARCN1_chr11_118463424_ENST00000359415_length(amino acids)=237AA_BP=1 MGCPAMLNSRLPLLFLASITGRHHSRVFRRLSCRYSPSISPITGAPTPDGSGMVITTSFSSKLSSCSSYSMLTSQPFPLSEGQQLIVSGI KDSSVVCSLHFSTPTSLLTGNDFSGFFRPIRDSAVKSFLSTFGWVSLKPSCRTSSKFPRVRQASIVPAGGSPGGVSSPAAAAASSSSLCT QRLSAQLIGIPPESRMPLTGNLDWSQTSGLHWACSHGGLRWRGPARSRFLWKQLGAH -------------------------------------------------------------- >22949_22949_2_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000440460_ARCN1_chr11_118463424_ENST00000392859_length(transcript)=1188nt_BP=357nt TCCCGCAGGAAAGCGGGGCTGGGGGCAGCCCGGCAGCGCCGCTCAACCTAGTGCGCGCCCAGTTGTTTCCATAGGAACCGCGACCGCGCC GGGCCCCTCCAGCGGAGGCCCCCGTGCGAGCATGCCCAGTGCAAGCCGCTAGTTTGGCTCCAGTCTAGGTTTCCAGTAAGTGGCATGCGG GACTCCGGAGGGATCCCAATGAGCTGAGCCGAGAGCCTTTGTGTGCAGAGGGAGGAGGAGGAGGCGGCGGCGGCCGCCGGGCTGGAGACC CCGCCCGGGGAGCCCCCAGCAGGAACAATGCTAGCCTGCCTGACCCGAGGGAACTTACTGGACGTCCTGCAGGAGGGCTTCAATGAGACC CATCCAAATGTGGATAAAAAACTTTTCACTGCAGAGTCTCTAATTGGCCTGAAGAATCCAGAGAAGTCATTTCCAGTCAACAGTGACGTA GGGGTGCTAAAGTGGAGACTACAAACCACAGAGGAATCTTTTATTCCACTGACAATTAATTGCTGGCCCTCGGAGAGTGGAAATGGCTGT GATGTCAACATAGAATATGAGCTACAAGAAGATAATTTAGAACTGAATGATGTGGTTATCACCATCCCACTCCCGTCTGGTGTCGGCGCG CCTGTTATCGGTGAGATCGATGGGGAGTATCGACATGACAGTCGACGAAATACCCTGGAGTGGTGCCTGCCTGTGATTGATGCCAAAAAT AAGAGTGGCAGCCTGGAGTTTAGCATTGCTGGGCAGCCCAATGACTTCTTCCCTGTTCAAGTTTCCTTTGTCTCCAAGAAAAATTACTGT AACATACAGGTTACCAAAGTGACCCAGGTAGATGGAAACAGCCCCGTCAGGTTTTCCACAGAGACCACTTTCCTAGTGGATAAGTATGAA ATTCTGTAATACCAAGAAGAGGGAGCTGAAAAGGAAAATTTTCAGATTAATAAAGAAGACGCCAATGATGGCTGAAGAGTTTTTCCCAGA TTTACAAGCCACTGGAGACCCCTTTTTTCTGATACAATGCACGATTCTCTGCGCGCAAGGACCCTCGACTCACCCCCATGTTTCAGTGTC ACAGAGACATTCTTTGATAAGGAAATGGCACAAACATAAAGGGAAAGGCTGCTAATTTTCTTTGGCAGATTGTATTGGCCAGCAGGAAAG CAAGCTCTCCAGAGAATG >22949_22949_2_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000440460_ARCN1_chr11_118463424_ENST00000392859_length(amino acids)=237AA_BP=1 MGCPAMLNSRLPLLFLASITGRHHSRVFRRLSCRYSPSISPITGAPTPDGSGMVITTSFSSKLSSCSSYSMLTSQPFPLSEGQQLIVSGI KDSSVVCSLHFSTPTSLLTGNDFSGFFRPIRDSAVKSFLSTFGWVSLKPSCRTSSKFPRVRQASIVPAGGSPGGVSSPAAAAASSSSLCT QRLSAQLIGIPPESRMPLTGNLDWSQTSGLHWACSHGGLRWRGPARSRFLWKQLGAH -------------------------------------------------------------- >22949_22949_3_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000531396_ARCN1_chr11_118463424_ENST00000359415_length(transcript)=2899nt_BP=133nt GCAGAGGGAGGAGGAGGAGGCGGCGGCGGCCGCCGGGCTGGAGACCCCGCCCGGGGAGCCCCCAGCAGGAACAATGCTAGCCTGCCTGAC CCGAGGGAACTTACTGGACGTCCTGCAGGAGGGCTTCAATGAGACCCATCCAAATGTGGATAAAAAACTTTTCACTGCAGAGTCTCTAAT TGGCCTGAAGAATCCAGAGAAGTCATTTCCAGTCAACAGTGACGTAGGGGTGCTAAAGTGGAGACTACAAACCACAGAGGAATCTTTTAT TCCACTGACAATTAATTGCTGGCCCTCGGAGAGTGGAAATGGCTGTGATGTCAACATAGAATATGAGCTACAAGAAGATAATTTAGAACT GAATGATGTGGTTATCACCATCCCACTCCCGTCTGGTGTCGGCGCGCCTGTTATCGGTGAGATCGATGGGGAGTATCGACATGACAGTCG ACGAAATACCCTGGAGTGGTGCCTGCCTGTGATTGATGCCAAAAATAAGAGTGGCAGCCTGGAGTTTAGCATTGCTGGGCAGCCCAATGA CTTCTTCCCTGTTCAAGTTTCCTTTGTCTCCAAGAAAAATTACTGTAACATACAGGTTACCAAAGTGACCCAGGTAGATGGAAACAGCCC CGTCAGGTTTTCCACAGAGACCACTTTCCTAGTGGATAAGTATGAAATTCTGTAATACCAAGAAGAGGGAGCTGAAAAGGAAAATTTTCA GATTAATAAAGAAGACGCCAATGATGGCTGAAGAGTTTTTCCCAGATTTACAAGCCACTGGAGACCCCTTTTTTCTGATACAATGCACGA TTCTCTGCGCGCAAGGACCCTCGACTCACCCCCATGTTTCAGTGTCACAGAGACATTCTTTGATAAGGAAATGGCACAAACATAAAGGGA AAGGCTGCTAATTTTCTTTGGCAGATTGTATTGGCCAGCAGGAAAGCAAGCTCTCCAGAGAATGCCCCCAGTTAAATACCTCCTCTACCT TTACCTAAGTTGCTCCTTTATTTTTATTTTATTATTATTATTATTATTATTATTATTTTTTGAGATGGAGTCTCACTTTGTAACCCAGGC TGGAATGCAATGGCATGATCTCAGCTCACTGCAACCTCCGCCTCCTGGGTTCAAGCAAGTCTCCTGCCTCAGCCTCCGAGTAGCTGGGAC TACAGGTGCACGCCACCACGCCTGGCTAATTTTTTGTATTTTAGTAGAGACGGGGTTTCACCGTGTTGCCCAGGCTGGTCGCGAACTCCT GAGCTCAGGCAATCCGCCCACCTCAGCCTCCCAAAGTGTTGGGATTACAGGCATGAGCCACCATGCCCAGCTGCTCCTTTATTTTAATCC CTAAATATAATCCCTAAATATAGTTATATTTCATACTTAGTTTGTTTTTAAAAAGTTTTCTCTGTAGAAAATTTTAATCATTCATACCCT TTACCTTTAGGTTTTTCTTTCTATACATTCAGTCAGGCACTGGGATCATCTGTTTACAGGCATTATATTTATTTGGCACTCCTGGAACAA GTATATCTAACCCATTCTTGATTTTTGGACTATTCAGGTGAACTATTTGAGGGGTATGGGGTCTAGAAGTTAAAAGATACGCATGTCTTC TGTTCTTTTCCCGTATCAATTCATTCCTTCATCTCTTTGCCAAGTTGTTTTCCTTTCAGGGCCTGTCCTTCCAGTTTAGAACAGTACCAT GAATCCCACTTGTGTCAATATTAAAGATAGCTGAGAAGCACCTTTCAAATGGCACAGTCCCTCTTCAAGATGTCTAAAAGAATGGTTATG TCTGTCCAGTTAGGGATTTCACATCCACATGTAATCATGTCTGCTGCTGTTGCTACCCAAATTTTCATTTCTCCACATTTTGGGTACTTA AGCTAAAACGTAATGGCCACAGTCTGTAATCCATTCACATTCCTCAGTTTCACCACCTCCCTCTTCCAGACTGCACTCTCTGTCATCAGT CCCCTCCTTTCTAACAGAAATGGGGTTATGATTTTGAAGGCTGTGGGTTCAGGGAGTCTTTGCCAATCCTGTTGGCCCTAAACTATCAAG GAGGCTCCATTTCACCATTTGATTTTTTGCATTTCAGGAGGCAACTGATTGTTTCGATATGTACATATTACTCACGTATACCCCATTTCC TTCCAGTCAGCCCAACATTTTCCACCAGTCTGTCCCCATCTCTGAAATCCTTCCTTCTCTTTCCCCCTAAGTCTTTTGAGTGTCATCATG TACTGGTGGTTTCTCGGTTCCATCTCATCCATTTCCTTTTCAATGGAGACTACAGCGTCAGCCAGCTCAGCCTTGGCTTTTAACTCAATA TTCCAGTCCATAGGGGTGGTTAAAAGTTGCTGCAAGGCTGCAGGCACTGGCAGTGGGAAGAGGCAGACGACTAGATGACTTCTGCACTTT TAGCTGGTTGAAAAGTACCACTCCCACTCTGAACATCTGGCCGTCCCTGCAAAGAGTGTACTGTGCTTGAAGCAGAGCACTCACACATAA ATGGCTGTGTGTGGAATTGCTTGCCAAAGAAGTTTCTAGCCTTTCCCTTTCCCCTAACTGCATCAGGGAAGAATTCTTATCTCTAGCTTG GTTTCCACATGAGGTTTTTCTGAGAAGGGCTTGGGACAAGAAGTCTGTCATGTTAGTTAAGCAGGCAAGAAATCCTACTAATCCAGTTTT GTTTGAAAGTTGTTTGTCCGTATGATTTTTTAAAAGTCAAGTTTAATTTCAAAAAACCTTTTTTTTCTGAGATTACTTTTGGGGTAATAT TTAAAATGAGAGACATTTTGTAACCCTGTAAAATACATAGGGAATATAACATTCCAGTGTATACAAAGAAGGCAAATTCTTTAATCAAAT AAAGCGCATTATAAAATGA >22949_22949_3_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000531396_ARCN1_chr11_118463424_ENST00000359415_length(amino acids)=215AA_BP=32 METPPGEPPAGTMLACLTRGNLLDVLQEGFNETHPNVDKKLFTAESLIGLKNPEKSFPVNSDVGVLKWRLQTTEESFIPLTINCWPSESG NGCDVNIEYELQEDNLELNDVVITIPLPSGVGAPVIGEIDGEYRHDSRRNTLEWCLPVIDAKNKSGSLEFSIAGQPNDFFPVQVSFVSKK NYCNIQVTKVTQVDGNSPVRFSTETTFLVDKYEIL -------------------------------------------------------------- >22949_22949_4_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000531396_ARCN1_chr11_118463424_ENST00000392859_length(transcript)=964nt_BP=133nt GCAGAGGGAGGAGGAGGAGGCGGCGGCGGCCGCCGGGCTGGAGACCCCGCCCGGGGAGCCCCCAGCAGGAACAATGCTAGCCTGCCTGAC CCGAGGGAACTTACTGGACGTCCTGCAGGAGGGCTTCAATGAGACCCATCCAAATGTGGATAAAAAACTTTTCACTGCAGAGTCTCTAAT TGGCCTGAAGAATCCAGAGAAGTCATTTCCAGTCAACAGTGACGTAGGGGTGCTAAAGTGGAGACTACAAACCACAGAGGAATCTTTTAT TCCACTGACAATTAATTGCTGGCCCTCGGAGAGTGGAAATGGCTGTGATGTCAACATAGAATATGAGCTACAAGAAGATAATTTAGAACT GAATGATGTGGTTATCACCATCCCACTCCCGTCTGGTGTCGGCGCGCCTGTTATCGGTGAGATCGATGGGGAGTATCGACATGACAGTCG ACGAAATACCCTGGAGTGGTGCCTGCCTGTGATTGATGCCAAAAATAAGAGTGGCAGCCTGGAGTTTAGCATTGCTGGGCAGCCCAATGA CTTCTTCCCTGTTCAAGTTTCCTTTGTCTCCAAGAAAAATTACTGTAACATACAGGTTACCAAAGTGACCCAGGTAGATGGAAACAGCCC CGTCAGGTTTTCCACAGAGACCACTTTCCTAGTGGATAAGTATGAAATTCTGTAATACCAAGAAGAGGGAGCTGAAAAGGAAAATTTTCA GATTAATAAAGAAGACGCCAATGATGGCTGAAGAGTTTTTCCCAGATTTACAAGCCACTGGAGACCCCTTTTTTCTGATACAATGCACGA TTCTCTGCGCGCAAGGACCCTCGACTCACCCCCATGTTTCAGTGTCACAGAGACATTCTTTGATAAGGAAATGGCACAAACATAAAGGGA AAGGCTGCTAATTTTCTTTGGCAGATTGTATTGGCCAGCAGGAAAGCAAGCTCTCCAGAGAATG >22949_22949_4_DIXDC1-ARCN1_DIXDC1_chr11_111808283_ENST00000531396_ARCN1_chr11_118463424_ENST00000392859_length(amino acids)=215AA_BP=32 METPPGEPPAGTMLACLTRGNLLDVLQEGFNETHPNVDKKLFTAESLIGLKNPEKSFPVNSDVGVLKWRLQTTEESFIPLTINCWPSESG NGCDVNIEYELQEDNLELNDVVITIPLPSGVGAPVIGEIDGEYRHDSRRNTLEWCLPVIDAKNKSGSLEFSIAGQPNDFFPVQVSFVSKK NYCNIQVTKVTQVDGNSPVRFSTETTFLVDKYEIL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for DIXDC1-ARCN1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for DIXDC1-ARCN1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for DIXDC1-ARCN1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | DIXDC1 | C0003469 | Anxiety Disorders | 1 | CTD_human |
| Hgene | DIXDC1 | C0004352 | Autistic Disorder | 1 | CTD_human |
| Hgene | DIXDC1 | C0005586 | Bipolar Disorder | 1 | CTD_human |
| Hgene | DIXDC1 | C0005587 | Depression, Bipolar | 1 | CTD_human |
| Hgene | DIXDC1 | C0011573 | Endogenous depression | 1 | CTD_human |
| Hgene | DIXDC1 | C0011581 | Depressive disorder | 1 | CTD_human |
| Hgene | DIXDC1 | C0024713 | Manic Disorder | 1 | CTD_human |
| Hgene | DIXDC1 | C0025193 | Melancholia | 1 | CTD_human |
| Hgene | DIXDC1 | C0036341 | Schizophrenia | 1 | CTD_human |
| Hgene | DIXDC1 | C0041696 | Unipolar Depression | 1 | CTD_human |
| Hgene | DIXDC1 | C0086133 | Depressive Syndrome | 1 | CTD_human |
| Hgene | DIXDC1 | C0282126 | Depression, Neurotic | 1 | CTD_human |
| Hgene | DIXDC1 | C0338831 | Manic | 1 | CTD_human |
| Hgene | DIXDC1 | C0376280 | Anxiety States, Neurotic | 1 | CTD_human |
| Hgene | DIXDC1 | C1279420 | Anxiety neurosis (finding) | 1 | CTD_human |
| Tgene | C0004134 | Ataxia | 1 | CTD_human | |
| Tgene | C0240991 | Ataxia, Sensory | 1 | CTD_human | |
| Tgene | C0278161 | Ataxia, Motor | 1 | CTD_human | |
| Tgene | C0427190 | Ataxia, Truncal | 1 | CTD_human | |
| Tgene | C0520966 | Abnormal coordination | 1 | CTD_human | |
| Tgene | C0750937 | Ataxia, Appendicular | 1 | CTD_human | |
| Tgene | C0750940 | Tremor, Rubral | 1 | CTD_human | |
| Tgene | C4310686 | SHORT STATURE, RHIZOMELIC, WITH MICROCEPHALY, MICROGNATHIA, AND DEVELOPMENTAL DELAY | 1 | GENOMICS_ENGLAND |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies