
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ALDH4A1-CAPZB (FusionGDB2 ID:HG8659TG832) |
Fusion Gene Summary for ALDH4A1-CAPZB |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ALDH4A1-CAPZB | Fusion gene ID: hg8659tg832 | Hgene | Tgene | Gene symbol | ALDH4A1 | CAPZB | Gene ID | 8659 | 832 |
| Gene name | aldehyde dehydrogenase 4 family member A1 | capping actin protein of muscle Z-line subunit beta | |
| Synonyms | ALDH4|P5CD|P5CDh | CAPB|CAPPB|CAPZ | |
| Cytomap | ('ALDH4A1')('CAPZB') 1p36.13 | 1p36.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | delta-1-pyrroline-5-carboxylate dehydrogenase, mitochondrialL-glutamate gamma-semialdehyde dehydrogenaseP5C dehydrogenasealdehyde dehydrogenase family 4 member A1epididymis secretory sperm binding proteinmitochondrial delta-1-pyrroline 5-carboxylate | F-actin-capping protein subunit betacapZ betacapping actin protein of muscle Z-line beta subunitcapping protein (actin filament) muscle Z-line, betaepididymis secretory sperm binding protein | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | P47756 | |
| Ensembl transtripts involved in fusion gene | ENST00000290597, ENST00000375341, ENST00000538839, ENST00000454547, ENST00000538309, | ||
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 23 X 15 X 8=2760 |
| # samples | 2 | 27 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(27/2760*10)=-3.3536369546147 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ALDH4A1 [Title/Abstract] AND CAPZB [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ALDH4A1(19228956)-CAPZB(19712120), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ALDH4A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CAPZB (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
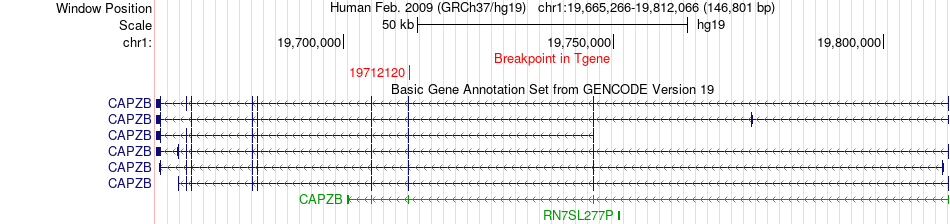 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-BR-A4QI-01A | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
Top |
Fusion Gene ORF analysis for ALDH4A1-CAPZB |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000290597 | ENST00000375144 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| 5CDS-5UTR | ENST00000290597 | ENST00000482808 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| 5CDS-5UTR | ENST00000375341 | ENST00000375144 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| 5CDS-5UTR | ENST00000375341 | ENST00000482808 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| 5CDS-5UTR | ENST00000538839 | ENST00000375144 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| 5CDS-5UTR | ENST00000538839 | ENST00000482808 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000290597 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000290597 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000290597 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000290597 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000290597 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000375341 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000375341 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000375341 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000375341 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000375341 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000538839 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000538839 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000538839 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000538839 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| In-frame | ENST00000538839 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000454547 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000454547 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000454547 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000454547 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000454547 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000538309 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000538309 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000538309 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000538309 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-3CDS | ENST00000538309 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-5UTR | ENST00000454547 | ENST00000375144 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-5UTR | ENST00000454547 | ENST00000482808 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-5UTR | ENST00000538309 | ENST00000375144 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| intron-5UTR | ENST00000538309 | ENST00000482808 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000538839 | ALDH4A1 | chr1 | 19228956 | - | ENST00000401084 | CAPZB | chr1 | 19712120 | - | 1550 | 67 | 52 | 792 | 246 |
| ENST00000538839 | ALDH4A1 | chr1 | 19228956 | - | ENST00000264203 | CAPZB | chr1 | 19712120 | - | 1470 | 67 | 52 | 678 | 208 |
| ENST00000538839 | ALDH4A1 | chr1 | 19228956 | - | ENST00000375142 | CAPZB | chr1 | 19712120 | - | 1613 | 67 | 52 | 807 | 251 |
| ENST00000538839 | ALDH4A1 | chr1 | 19228956 | - | ENST00000433834 | CAPZB | chr1 | 19712120 | - | 964 | 67 | 52 | 792 | 246 |
| ENST00000538839 | ALDH4A1 | chr1 | 19228956 | - | ENST00000264202 | CAPZB | chr1 | 19712120 | - | 808 | 67 | 52 | 807 | 252 |
| ENST00000290597 | ALDH4A1 | chr1 | 19228956 | - | ENST00000401084 | CAPZB | chr1 | 19712120 | - | 1575 | 92 | 77 | 817 | 246 |
| ENST00000290597 | ALDH4A1 | chr1 | 19228956 | - | ENST00000264203 | CAPZB | chr1 | 19712120 | - | 1495 | 92 | 77 | 703 | 208 |
| ENST00000290597 | ALDH4A1 | chr1 | 19228956 | - | ENST00000375142 | CAPZB | chr1 | 19712120 | - | 1638 | 92 | 77 | 832 | 251 |
| ENST00000290597 | ALDH4A1 | chr1 | 19228956 | - | ENST00000433834 | CAPZB | chr1 | 19712120 | - | 989 | 92 | 77 | 817 | 246 |
| ENST00000290597 | ALDH4A1 | chr1 | 19228956 | - | ENST00000264202 | CAPZB | chr1 | 19712120 | - | 833 | 92 | 77 | 832 | 252 |
| ENST00000375341 | ALDH4A1 | chr1 | 19228956 | - | ENST00000401084 | CAPZB | chr1 | 19712120 | - | 1803 | 320 | 122 | 1045 | 307 |
| ENST00000375341 | ALDH4A1 | chr1 | 19228956 | - | ENST00000264203 | CAPZB | chr1 | 19712120 | - | 1723 | 320 | 122 | 931 | 269 |
| ENST00000375341 | ALDH4A1 | chr1 | 19228956 | - | ENST00000375142 | CAPZB | chr1 | 19712120 | - | 1866 | 320 | 122 | 1060 | 312 |
| ENST00000375341 | ALDH4A1 | chr1 | 19228956 | - | ENST00000433834 | CAPZB | chr1 | 19712120 | - | 1217 | 320 | 122 | 1045 | 307 |
| ENST00000375341 | ALDH4A1 | chr1 | 19228956 | - | ENST00000264202 | CAPZB | chr1 | 19712120 | - | 1061 | 320 | 122 | 1060 | 313 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000538839 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002998826 | 0.9970011 |
| ENST00000538839 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.016996907 | 0.9830031 |
| ENST00000538839 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002391856 | 0.9976082 |
| ENST00000538839 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002315382 | 0.9976846 |
| ENST00000538839 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002592827 | 0.99740714 |
| ENST00000290597 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.003114664 | 0.99688536 |
| ENST00000290597 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.01537896 | 0.98462105 |
| ENST00000290597 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002444061 | 0.99755585 |
| ENST00000290597 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002686351 | 0.9973137 |
| ENST00000290597 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002717613 | 0.9972824 |
| ENST00000375341 | ENST00000401084 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.003428001 | 0.996572 |
| ENST00000375341 | ENST00000264203 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.018290503 | 0.98170954 |
| ENST00000375341 | ENST00000375142 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.00284807 | 0.99715185 |
| ENST00000375341 | ENST00000433834 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002387616 | 0.99761236 |
| ENST00000375341 | ENST00000264202 | ALDH4A1 | chr1 | 19228956 | - | CAPZB | chr1 | 19712120 | - | 0.002716939 | 0.9972831 |
Top |
Fusion Genomic Features for ALDH4A1-CAPZB |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
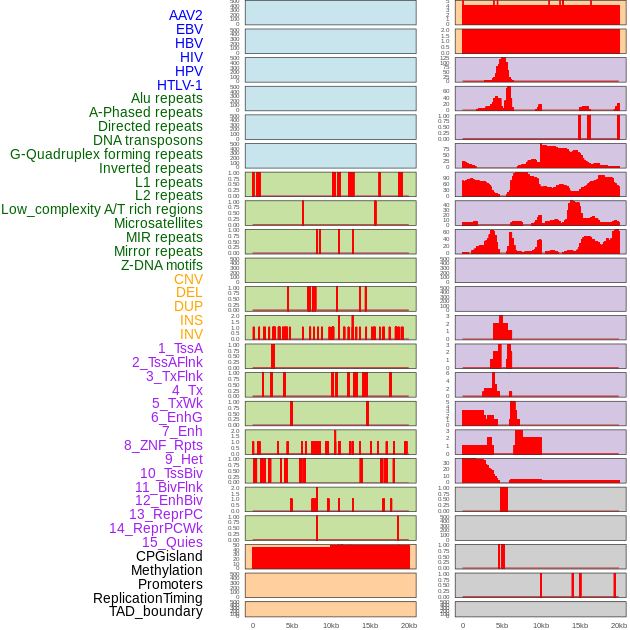 |
Top |
Fusion Protein Features for ALDH4A1-CAPZB |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:19228956/chr1:19712120) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CAPZB |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: F-actin-capping proteins bind in a Ca(2+)-independent manner to the fast growing ends of actin filaments (barbed end) thereby blocking the exchange of subunits at these ends. Unlike other capping proteins (such as gelsolin and severin), these proteins do not sever actin filaments. Plays a role in the regulation of cell morphology and cytoskeletal organization. {ECO:0000269|PubMed:21834987}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ALDH4A1 | chr1:19228956 | chr1:19712120 | ENST00000290597 | - | 1 | 16 | 286_290 | 20 | 673.0 | Nucleotide binding | NAD |
| Hgene | ALDH4A1 | chr1:19228956 | chr1:19712120 | ENST00000375341 | - | 1 | 15 | 286_290 | 20 | 564.0 | Nucleotide binding | NAD |
| Hgene | ALDH4A1 | chr1:19228956 | chr1:19712120 | ENST00000538309 | - | 1 | 15 | 286_290 | 0 | 504.0 | Nucleotide binding | NAD |
| Hgene | ALDH4A1 | chr1:19228956 | chr1:19712120 | ENST00000538839 | - | 1 | 14 | 286_290 | 20 | 513.0 | Nucleotide binding | NAD |
Top |
Fusion Gene Sequence for ALDH4A1-CAPZB |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >3913_3913_1_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000264202_length(transcript)=833nt_BP=92nt TCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCC GGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTT TGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAG CTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACC TCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCA TCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACA AATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAG CCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCA ATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGA TCTACATCCAGCCTGATAATTAA >3913_3913_1_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000264202_length(amino acids)=252AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDNX -------------------------------------------------------------- >3913_3913_2_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000264203_length(transcript)=1495nt_BP=92nt TCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCC GGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTT TGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAG CTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACC TCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCA TCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACA AATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAG CCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTG AAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCT GCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGC CGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTT GTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTT TGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATT CCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCG CAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTC AATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTC CATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAACTGGGGCGCAGTT >3913_3913_2_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000264203_length(amino acids)=208AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEVCADFCRQIKTRSSEE -------------------------------------------------------------- >3913_3913_3_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000375142_length(transcript)=1638nt_BP=92nt TCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCC GGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTT TGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAG CTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACC TCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCA TCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACA AATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAG CCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCA ATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGA TCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGT GGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAA CTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTG AGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCG TGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCT CCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGG AAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTG CCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTG CTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATA CTTGAGCCTCCATACTTA >3913_3913_3_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000375142_length(amino acids)=251AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDN -------------------------------------------------------------- >3913_3913_4_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000401084_length(transcript)=1575nt_BP=92nt TCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCC GGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTT TGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAG CTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACC TCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCA TCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACA AATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAG CCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCA ATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGC AATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTC GTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCT CCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCC CCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTG TAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTG GGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGT CCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAA TGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAA AGAAAAGAAAAGAAATCAATAAAAAGAAACTGGGGCGCAGTTAGC >3913_3913_4_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000401084_length(amino acids)=246AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- >3913_3913_5_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000433834_length(transcript)=989nt_BP=92nt TCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCC GGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTT TGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAG CTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACC TCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCA TCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACA AATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAG CCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCA ATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGC AATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTC GTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCC >3913_3913_5_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000290597_CAPZB_chr1_19712120_ENST00000433834_length(amino acids)=246AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- >3913_3913_6_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000264202_length(transcript)=1061nt_BP=320nt GGGAAAACGCATGCATTTCAGGACTTCGCTTTCGGGTTCCCTTGTCCTGTGTTGTGTAATGCCCCCGTTATGGCACTAGAAATATTTTTT ATTAGCCGAAGCTAAATATAGTGGGACTTTGGCTGATCCCGAGCTCGGAGGACAGCCGGGGTGATCCGTTTCCCCCCGAGGATCGAGGTG GTGCGCTCTGGACGGGGTTGTGCATTCTCGCCGCGCCCGGGCGGACGATCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCG GCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGT TTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAA >3913_3913_6_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000264202_length(amino acids)=313AA_BP=66 MIPSSEDSRGDPFPPEDRGGALWTGLCILAAPGRTIQRTAPLLTRDAAAGARAPPRPAVPPLDRGRVPSLCEDLLSSVDQPLKIARDKVV GKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIK GCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGK TKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDNX -------------------------------------------------------------- >3913_3913_7_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000264203_length(transcript)=1723nt_BP=320nt GGGAAAACGCATGCATTTCAGGACTTCGCTTTCGGGTTCCCTTGTCCTGTGTTGTGTAATGCCCCCGTTATGGCACTAGAAATATTTTTT ATTAGCCGAAGCTAAATATAGTGGGACTTTGGCTGATCCCGAGCTCGGAGGACAGCCGGGGTGATCCGTTTCCCCCCGAGGATCGAGGTG GTGCGCTCTGGACGGGGTTGTGCATTCTCGCCGCGCCCGGGCGGACGATCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCG GCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGTCTGTGCAGACTTTTGCA GACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCA GACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAA CAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACA CCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTA TAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATG AACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGG ACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGG GGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGT TTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAA CTGGGGCGCAGTT >3913_3913_7_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000264203_length(amino acids)=269AA_BP=66 MIPSSEDSRGDPFPPEDRGGALWTGLCILAAPGRTIQRTAPLLTRDAAAGARAPPRPAVPPLDRGRVPSLCEDLLSSVDQPLKIARDKVV GKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIK GCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEVCADFCRQIKTRSSEE -------------------------------------------------------------- >3913_3913_8_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000375142_length(transcript)=1866nt_BP=320nt GGGAAAACGCATGCATTTCAGGACTTCGCTTTCGGGTTCCCTTGTCCTGTGTTGTGTAATGCCCCCGTTATGGCACTAGAAATATTTTTT ATTAGCCGAAGCTAAATATAGTGGGACTTTGGCTGATCCCGAGCTCGGAGGACAGCCGGGGTGATCCGTTTCCCCCCGAGGATCGAGGTG GTGCGCTCTGGACGGGGTTGTGCATTCTCGCCGCGCCCGGGCGGACGATCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCG GCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTATCCCTGACAACCAAAAGT TTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAAGCCGATCCAGGTCTGTGCA GACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTC ATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACA GGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGC TTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTC CCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAA AAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGG GGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGT GGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGT TTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTA >3913_3913_8_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000375142_length(amino acids)=312AA_BP=66 MIPSSEDSRGDPFPPEDRGGALWTGLCILAAPGRTIQRTAPLLTRDAAAGARAPPRPAVPPLDRGRVPSLCEDLLSSVDQPLKIARDKVV GKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIK GCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGK TKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDN -------------------------------------------------------------- >3913_3913_9_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000401084_length(transcript)=1803nt_BP=320nt GGGAAAACGCATGCATTTCAGGACTTCGCTTTCGGGTTCCCTTGTCCTGTGTTGTGTAATGCCCCCGTTATGGCACTAGAAATATTTTTT ATTAGCCGAAGCTAAATATAGTGGGACTTTGGCTGATCCCGAGCTCGGAGGACAGCCGGGGTGATCCGTTTCCCCCCGAGGATCGAGGTG GTGCGCTCTGGACGGGGTTGTGCATTCTCGCCGCGCCCGGGCGGACGATCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCG GCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAAC AAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCA CTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATT GACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGT TCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATC CACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGT GTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCT CTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCG ACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGC TTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAAGAAACTGGGGCGCAGTT AGC >3913_3913_9_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000401084_length(amino acids)=307AA_BP=66 MIPSSEDSRGDPFPPEDRGGALWTGLCILAAPGRTIQRTAPLLTRDAAAGARAPPRPAVPPLDRGRVPSLCEDLLSSVDQPLKIARDKVV GKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIK GCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGK TKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- >3913_3913_10_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000433834_length(transcript)=1217nt_BP=320nt GGGAAAACGCATGCATTTCAGGACTTCGCTTTCGGGTTCCCTTGTCCTGTGTTGTGTAATGCCCCCGTTATGGCACTAGAAATATTTTTT ATTAGCCGAAGCTAAATATAGTGGGACTTTGGCTGATCCCGAGCTCGGAGGACAGCCGGGGTGATCCGTTTCCCCCCGAGGATCGAGGTG GTGCGCTCTGGACGGGGTTGTGCATTCTCGCCGCGCCCGGGCGGACGATCCAGCGAACAGCCCCGCTTCTAACCCGAGATGCTGCTGCCG GCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCTCCTGTCTTCTGTTGACC AGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGACTCCTATAGGTCACCAT GGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGAAGCCAACAATGCCTTTG ACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGCTGGAGTGATCCTCATAA AGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAAATCCAGCGGTCGCACCG CCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCTCGGAGGCAGCCTTACCA GACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGACATGGAAAATAAAATCA GAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTTTGCAGACAAATCAAAAC AAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCA CTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATT GACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCC >3913_3913_10_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000375341_CAPZB_chr1_19712120_ENST00000433834_length(amino acids)=307AA_BP=66 MIPSSEDSRGDPFPPEDRGGALWTGLCILAAPGRTIQRTAPLLTRDAAAGARAPPRPAVPPLDRGRVPSLCEDLLSSVDQPLKIARDKVV GKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGVSSVYLWDLDHGFAGVILIKKAGDGSKKIK GCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDCSPHIANIGRLVEDMENKIRSTLNEIYFGK TKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- >3913_3913_11_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000264202_length(transcript)=808nt_BP=67nt CCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCT CCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGA CTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGA AGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGC TGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAA ATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCT CGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGA CATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTAT CCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAA >3913_3913_11_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000264202_length(amino acids)=252AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDNX -------------------------------------------------------------- >3913_3913_12_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000264203_length(transcript)=1470nt_BP=67nt CCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCT CCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGA CTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGA AGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGC TGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAA ATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCT CGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGT CTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCT CTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTC CCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCG AGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCT CCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAA AACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGG GGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCC GCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGG TTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAG AAATCAATAAAAAGAAACTGGGGCGCAGTT >3913_3913_12_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000264203_length(amino acids)=208AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEVCADFCRQIKTRSSEE -------------------------------------------------------------- >3913_3913_13_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000375142_length(transcript)=1613nt_BP=67nt CCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCT CCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGA CTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGA AGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGC TGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAA ATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCT CGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGA CATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGATCTATTGATGCTAT CCCTGACAACCAAAAGTTTAAGCAGTTGCAGAGGGAGCTCTCTCAAGTGCTGACCCAGCGCCAGATCTACATCCAGCCTGATAATTAAGC CGATCCAGGTCTGTGCAGACTTTTGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAA TGCTAAACCTCTGTTTCATGCTAACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGT CCCTTCCCTCCCCGACAGGTCACATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCC TCCGGCTCCGAGCCTGCTTCTGCCACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCC CCGTCTTCCTCCCTGTCCCCCCATTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTA AAAAATGTAAAACAAAAAAATTTTATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGG AGTTGCTTGGGGTTGGGGGTCGTGGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCC CACGGAGGCCGCGGGGTGGGGGCTGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATG CAAAAGGAGGTTTTTGTTTTATTTTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTA >3913_3913_13_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000375142_length(amino acids)=251AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSIDAIPDNQKFKQLQRELSQVLTQRQIYIQPDN -------------------------------------------------------------- >3913_3913_14_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000401084_length(transcript)=1550nt_BP=67nt CCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCT CCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGA CTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGA AGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGC TGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAA ATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCT CGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGA CATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTT TGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTA ACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCAC ATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCCTCCTCCGGCTCCGAGCCTGCTTCTGC CACACCTCGCTCTCAGTTCTCTCCACATTTCCATAGAGACCGTGTGGTTTTTGTTCACCCGGGCCCCCCGTCTTCCTCCCTGTCCCCCCA TTTATAGGCATAAAATCCACTGTCTGCCAGCCTCCCTTCCCTCCCACCTTTTTGGTACATTGGTGTAAAAAATGTAAAACAAAAAAATTT TATGAACTAACTGTGGTGTGTGAAAGAGAGAAGAAAAACTGGAAATCTTATTCCGTGTGTGTTTGGGAGTTGCTTGGGGTTGGGGGTCGT GGGGACAGGGGACAGCTCTGGGAGCAGAGGTGGCCCTCGGTGCCGTCCTGCGCAGACTCTCCCGTCCCACGGAGGCCGCGGGGTGGGGGC TGGGGGGGGTGCCGCCGACCGTTCCGCTCTTCCGGCCAGGTGCTTTTCTGTCAATTTCTATGGAATGCAAAAGGAGGTTTTTGTTTTATT TTGTTTTTTTGTAAAGCTTAAGAAAAAAATCTACATCTTATACTTGAGCCTCCATACTTAAAAAAAGAAAAGAAAAGAAATCAATAAAAA GAAACTGGGGCGCAGTTAGC >3913_3913_14_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000401084_length(amino acids)=246AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- >3913_3913_15_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000433834_length(transcript)=964nt_BP=67nt CCGAGATGCTGCTGCCGGCGCCCGCGCTCCGCCGCGCCCTGCTGTCCCGCCCCTGGACCGGGGCCGGGTCCCCAGTCTATGTGAGGATCT CCTGTCTTCTGTTGACCAGCCACTGAAAATTGCCAGAGACAAGGTGGTGGGAAAGGATTACCTTTTGTGTGACTACAACAGAGATGGGGA CTCCTATAGGTCACCATGGAGTAACAAGTATGACCCTCCCTTGGAGGATGGGGCCATGCCGTCAGCTCGGCTGAGAAAGCTGGAGGTGGA AGCCAACAATGCCTTTGACCAGTATCGAGACCTGTATTTTGAAGGTGGCGTCTCATCTGTCTACCTCTGGGATCTGGATCATGGCTTTGC TGGAGTGATCCTCATAAAGAAGGCTGGAGATGGATCAAAGAAGATCAAAGGCTGCTGGGATTCCATCCACGTGGTAGAAGTGCAGGAGAA ATCCAGCGGTCGCACCGCCCATTACAAGTTGACCTCCACGGTGATGCTGTGGCTGCAGACCAACAAATCTGGCTCTGGCACCATGAACCT CGGAGGCAGCCTTACCAGACAGATGGAGAAGGATGAAACTGTGAGTGACTGCTCCCCACACATAGCCAACATCGGGCGCCTGGTAGAGGA CATGGAAAATAAAATCAGAAGTACGCTGAACGAGATCTACTTTGGAAAAACAAAGGATATCGTCAATGGGCTGAGGTCTGTGCAGACTTT TGCAGACAAATCAAAACAAGAAGCTCTGAAGAATGACCTGGTGGAGGCTTTGAAGAGAAAGCAGCAATGCTAAACCTCTGTTTCATGCTA ACCAGACACGCCGTGCACTCGTTAGATTCCTTTCTTAGAAAACTCGTTTTCTGCTCCCTTCCCTCGTCCCTTCCCTCCCCGACAGGTCAC ATAACAGCTGCATCATTGACCGCACAGCGCCATCTCTCCCTGAGAATAAAGCCGATAGCCACCC >3913_3913_15_ALDH4A1-CAPZB_ALDH4A1_chr1_19228956_ENST00000538839_CAPZB_chr1_19712120_ENST00000433834_length(amino acids)=246AA_BP=5 MDRGRVPSLCEDLLSSVDQPLKIARDKVVGKDYLLCDYNRDGDSYRSPWSNKYDPPLEDGAMPSARLRKLEVEANNAFDQYRDLYFEGGV SSVYLWDLDHGFAGVILIKKAGDGSKKIKGCWDSIHVVEVQEKSSGRTAHYKLTSTVMLWLQTNKSGSGTMNLGGSLTRQMEKDETVSDC SPHIANIGRLVEDMENKIRSTLNEIYFGKTKDIVNGLRSVQTFADKSKQEALKNDLVEALKRKQQC -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ALDH4A1-CAPZB |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ALDH4A1-CAPZB |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ALDH4A1-CAPZB |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | ALDH4A1 | C2931835 | Hyperprolinemia type 2 | 6 | CLINGEN;CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Hgene | ALDH4A1 | C0032927 | Precancerous Conditions | 1 | CTD_human |
| Hgene | ALDH4A1 | C0282313 | Condition, Preneoplastic | 1 | CTD_human |
| Hgene | ALDH4A1 | C0400966 | Non-alcoholic Fatty Liver Disease | 1 | CTD_human |
| Hgene | ALDH4A1 | C3241937 | Nonalcoholic Steatohepatitis | 1 | CTD_human |
| Hgene | ALDH4A1 | C3714756 | Intellectual Disability | 1 | GENOMICS_ENGLAND |
| Tgene | C0007097 | Carcinoma | 1 | CTD_human | |
| Tgene | C0024667 | Animal Mammary Neoplasms | 1 | CTD_human | |
| Tgene | C0024668 | Mammary Neoplasms, Experimental | 1 | CTD_human | |
| Tgene | C0205696 | Anaplastic carcinoma | 1 | CTD_human | |
| Tgene | C0205697 | Carcinoma, Spindle-Cell | 1 | CTD_human | |
| Tgene | C0205698 | Undifferentiated carcinoma | 1 | CTD_human | |
| Tgene | C0205699 | Carcinomatosis | 1 | CTD_human | |
| Tgene | C0948089 | Acute Coronary Syndrome | 1 | CTD_human | |
| Tgene | C1257925 | Mammary Carcinoma, Animal | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies