
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ADAM23-PPAP2A (FusionGDB2 ID:HG8745TG8611) |
Fusion Gene Summary for ADAM23-PPAP2A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ADAM23-PPAP2A | Fusion gene ID: hg8745tg8611 | Hgene | Tgene | Gene symbol | ADAM23 | PPAP2A | Gene ID | 8745 | 8611 |
| Gene name | ADAM metallopeptidase domain 23 | phospholipid phosphatase 1 | |
| Synonyms | MDC-3|MDC3 | LLP1a|LPP1|PAP-2a|PAP2|PPAP2A | |
| Cytomap | ('ADAM23')('PPAP2A') 2q33.3 | 5q11.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | disintegrin and metalloproteinase domain-containing protein 23metalloproteinase-like, disintegrin-like, and cysteine-rich protein 3 | phospholipid phosphatase 1lipid phosphate phosphohydrolase 1aphosphatidate phosphohydrolase type 2aphosphatidic acid phosphatase 2aphosphatidic acid phosphatase type 2Aphosphatidic acid phosphohydrolase type 2atype-2 phosphatidic acid phosphatase al | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000264377, ENST00000374415, ENST00000374416, | ||
| Fusion gene scores | * DoF score | 4 X 4 X 3=48 | 10 X 5 X 6=300 |
| # samples | 5 | 10 | |
| ** MAII score | log2(5/48*10)=0.0588936890535686 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(10/300*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ADAM23 [Title/Abstract] AND PPAP2A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ADAM23(207432046)-PPAP2A(54721162), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ADAM23-PPAP2A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ADAM23-PPAP2A seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. ADAM23-PPAP2A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. ADAM23-PPAP2A seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | PPAP2A | GO:0006644 | phospholipid metabolic process | 9305923|9705349|15461590 |
| Tgene | PPAP2A | GO:0006670 | sphingosine metabolic process | 9705349 |
| Tgene | PPAP2A | GO:0006672 | ceramide metabolic process | 9305923|9705349 |
| Tgene | PPAP2A | GO:0046839 | phospholipid dephosphorylation | 9305923|9705349|15461590|16464866 |
| Fusion gene breakpoints across ADAM23 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PPAP2A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-CR-7397-01A | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
Top |
Fusion Gene ORF analysis for ADAM23-PPAP2A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000264377 | ENST00000515132 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| 5CDS-intron | ENST00000374415 | ENST00000515132 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| 5CDS-intron | ENST00000374416 | ENST00000515132 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| In-frame | ENST00000264377 | ENST00000264775 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| In-frame | ENST00000264377 | ENST00000307259 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| In-frame | ENST00000374415 | ENST00000264775 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| In-frame | ENST00000374415 | ENST00000307259 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| In-frame | ENST00000374416 | ENST00000264775 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| In-frame | ENST00000374416 | ENST00000307259 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000264377 | ADAM23 | chr2 | 207432046 | - | ENST00000264775 | PPAP2A | chr5 | 54721162 | - | 2303 | 1822 | 328 | 1950 | 540 |
| ENST00000264377 | ADAM23 | chr2 | 207432046 | - | ENST00000307259 | PPAP2A | chr5 | 54721162 | - | 2272 | 1822 | 328 | 1950 | 540 |
| ENST00000374416 | ADAM23 | chr2 | 207432046 | - | ENST00000264775 | PPAP2A | chr5 | 54721162 | - | 2027 | 1546 | 52 | 1674 | 540 |
| ENST00000374416 | ADAM23 | chr2 | 207432046 | - | ENST00000307259 | PPAP2A | chr5 | 54721162 | - | 1996 | 1546 | 52 | 1674 | 540 |
| ENST00000374415 | ADAM23 | chr2 | 207432046 | - | ENST00000264775 | PPAP2A | chr5 | 54721162 | - | 1975 | 1494 | 0 | 1622 | 540 |
| ENST00000374415 | ADAM23 | chr2 | 207432046 | - | ENST00000307259 | PPAP2A | chr5 | 54721162 | - | 1944 | 1494 | 0 | 1622 | 540 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000264377 | ENST00000264775 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - | 0.01116371 | 0.98883635 |
| ENST00000264377 | ENST00000307259 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - | 0.01202669 | 0.98797333 |
| ENST00000374416 | ENST00000264775 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - | 0.006232606 | 0.9937674 |
| ENST00000374416 | ENST00000307259 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - | 0.00661048 | 0.9933895 |
| ENST00000374415 | ENST00000264775 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - | 0.005983968 | 0.99401605 |
| ENST00000374415 | ENST00000307259 | ADAM23 | chr2 | 207432046 | - | PPAP2A | chr5 | 54721162 | - | 0.006341505 | 0.9936585 |
Top |
Fusion Genomic Features for ADAM23-PPAP2A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
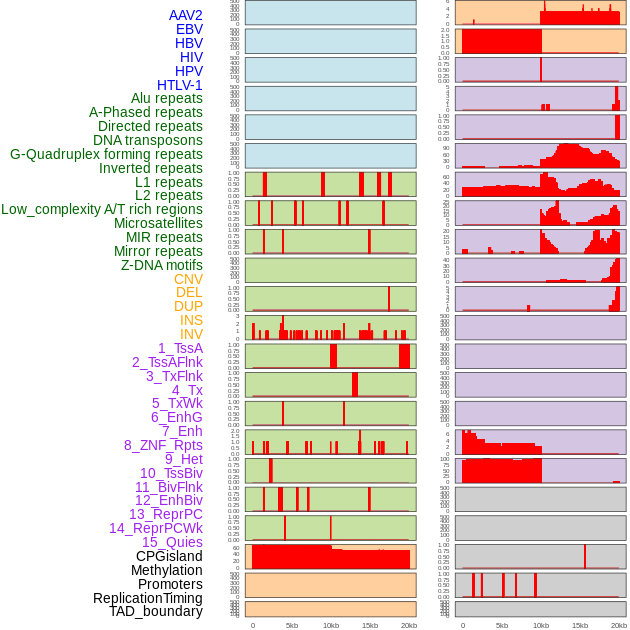 |
Top |
Fusion Protein Features for ADAM23-PPAP2A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:207432046/chr5:54721162) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 299_496 | 498 | 833.0 | Domain | Peptidase M12B |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 299_496 | 498 | 833.0 | Domain | Peptidase M12B |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 251_284 | 243 | 286.0 | Topological domain | Cytoplasmic | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 251_284 | 242 | 285.0 | Topological domain | Cytoplasmic |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 589_611 | 498 | 833.0 | Compositional bias | Note=Cys-rich |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 589_611 | 498 | 833.0 | Compositional bias | Note=Cys-rich |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 502_588 | 498 | 833.0 | Domain | Disintegrin |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 732_769 | 498 | 833.0 | Domain | EGF-like |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 502_588 | 498 | 833.0 | Domain | Disintegrin |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 732_769 | 498 | 833.0 | Domain | EGF-like |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 563_568 | 498 | 833.0 | Region | Note=May bind the integrin receptor |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 563_568 | 498 | 833.0 | Region | Note=May bind the integrin receptor |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 287_792 | 498 | 833.0 | Topological domain | Extracellular |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 814_832 | 498 | 833.0 | Topological domain | Cytoplasmic |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 287_792 | 498 | 833.0 | Topological domain | Extracellular |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 814_832 | 498 | 833.0 | Topological domain | Cytoplasmic |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000264377 | - | 15 | 26 | 793_813 | 498 | 833.0 | Transmembrane | Helical |
| Hgene | ADAM23 | chr2:207432046 | chr5:54721162 | ENST00000374416 | - | 15 | 25 | 793_813 | 498 | 833.0 | Transmembrane | Helical |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 5_7 | 243 | 286.0 | Motif | PDZ-binding%3B involved in localization to the apical cell membrane | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 5_7 | 242 | 285.0 | Motif | PDZ-binding%3B involved in localization to the apical cell membrane | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 120_128 | 243 | 286.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 168_171 | 243 | 286.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 216_227 | 243 | 286.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 120_128 | 242 | 285.0 | Region | Phosphatase sequence motif I | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 168_171 | 242 | 285.0 | Region | Phosphatase sequence motif II | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 216_227 | 242 | 285.0 | Region | Phosphatase sequence motif III | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 116_164 | 243 | 286.0 | Topological domain | Extracellular | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 186_199 | 243 | 286.0 | Topological domain | Cytoplasmic | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 1_6 | 243 | 286.0 | Topological domain | Cytoplasmic | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 221_229 | 243 | 286.0 | Topological domain | Extracellular | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 28_53 | 243 | 286.0 | Topological domain | Extracellular | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 75_94 | 243 | 286.0 | Topological domain | Cytoplasmic | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 116_164 | 242 | 285.0 | Topological domain | Extracellular | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 186_199 | 242 | 285.0 | Topological domain | Cytoplasmic | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 1_6 | 242 | 285.0 | Topological domain | Cytoplasmic | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 221_229 | 242 | 285.0 | Topological domain | Extracellular | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 28_53 | 242 | 285.0 | Topological domain | Extracellular | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 75_94 | 242 | 285.0 | Topological domain | Cytoplasmic | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 165_185 | 243 | 286.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 200_220 | 243 | 286.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 230_250 | 243 | 286.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 54_74 | 243 | 286.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 7_27 | 243 | 286.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000264775 | 4 | 6 | 95_115 | 243 | 286.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 165_185 | 242 | 285.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 200_220 | 242 | 285.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 230_250 | 242 | 285.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 54_74 | 242 | 285.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 7_27 | 242 | 285.0 | Transmembrane | Helical | |
| Tgene | PPAP2A | chr2:207432046 | chr5:54721162 | ENST00000307259 | 4 | 6 | 95_115 | 242 | 285.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for ADAM23-PPAP2A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >1997_1997_1_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000264377_PPAP2A_chr5_54721162_ENST00000264775_length(transcript)=2303nt_BP=1822nt GGCCCGGCGGCAGCCCCCGCAGTCGCTGAAGCGGCCGCGCCCGCCGGGGGAGGGAGTAGCCGCTGGGGAGGCTCCAAGTTGGCGGAGCGG CGAGGACCCCTGGACTCCTCTGCGTCCCGCCCCGGGAGTGGCTGCGAGGCTAGGCGAGCCGGGAAAGGGGGCGCCGCCCAGCCCCGAGCC CCGCGCCCCGTGCCCCGAGCCCGGAGCCCCCTGCCCGCCGCGGCACCATGCGCGCCGAGCCGGCGTGACCGGCTCCGCCCGCGGCCGCCC CGCAGCTAGCCCGGCGCTCTCGCCGGCCACACGGAGCGGCGCCCGGGAGCTATGAGCCATGAAGCCGCCCGGCAGCAGCTCGCGGCAGCC GCCCCTGGCGGGCTGCAGCCTTGCCGGCGCTTCCTGCGGCCCCCAACGCGGCCCCGCCGGCTCGGTGCCTGCCAGCGCCCCGGCCCGCAC GCCGCCCTGCCGCCTGCTTCTCGTCCTTCTCCTGCTGCCTCCGCTCGCCGCCTCGTCCCGGCCCCGCGCCTGGGGGGCTGCTGCGCCCAG CGCTCCGCATTGGAATGAAACTGCAGAAAAAAATTTGGGAGTCCTGGCAGATGAAGACAATACATTGCAACAGAATAGCAGCAGTAATAT CAGTTACAGCAATGCAATGCAGAAAGAAATCACACTGCCTTCAAGACTCATATATTACATCAACCAAGACTCGGAAAGCCCTTATCACGT TCTTGACACAAAGGCAAGACACCAGCAAAAACATAATAAGGCTGTCCATCTGGCCCAGGCAAGCTTCCAGATTGAAGCCTTCGGCTCCAA ATTCATTCTTGACCTCATACTGAACAATGGTTTGTTGTCTTCTGATTATGTGGAGATTCACTACGAAAATGGGAAACCACAGTACTCTAA GGGTGGAGAGCACTGTTACTACCATGGAAGCATCAGAGGCGTCAAAGACTCCAAGGTGGCTCTGTCAACCTGCAATGGACTTCATGGCAT GTTTGAAGATGATACCTTCGTGTATATGATAGAGCCACTAGAGCTGGTTCATGATGAGAAAAGCACAGGTCGACCACATATAATCCAGAA AACCTTGGCAGGACAGTATTCTAAGCAAATGAAGAATCTCACTATGGAAAGAGGTGACCAGTGGCCCTTTCTCTCTGAATTACAGTGGTT GAAAAGAAGGAAGAGAGCAGTGAATCCATCACGTGGTATATTTGAAGAAATGAAATATTTGGAACTTATGATTGTTAATGATCACAAAAC GTATAAGAAGCATCGCTCTTCTCATGCACATACCAACAACTTTGCAAAGTCCGTGGTCAACCTTGTGGATTCTATTTACAAGGAGCAGCT CAACACCAGGGTTGTCCTGGTGGCTGTAGAGACCTGGACTGAGAAGGATCAGATTGACATCACCACCAACCCTGTGCAGATGCTCCATGA GTTCTCAAAATACCGGCAGCGCATTAAGCAGCATGCTGATGCTGTGCACCTCATCTCGCGGGTGACATTTCACTATAAGAGAAGCAGTCT GAGTTACTTTGGAGGTGTCTGTTCTCGCACAAGAGGAGTTGGTGTGAATGAGTATGGTCTTCCAATGGCAGTGGCACAAGTATTATCGCA GAGCCTGGCTCAAAACCTTGGAATCCAATGGGAACCTTCTAGCAGAAAGCCAAAATGTGACTGCACAGAATCCTGGGGTGGCTGCATCAT GGAGGAAACAGGGGTGTCCCATTCTCGAAAATTTTCAAAGTGCAGCATTTTGGAGTATAGAGACTTTTTACAGAGAGGAGGTGGAGCCTG CCTTTTCAACAGGCCAACAAAGGCTGTATATGTATCGGATTTCTTCAAAGAAAGAACTTCTTTTAAAGAAAGAAAAGAGGAGGACTCTCA TACAACTCTGCATGAAACACCAACAACTGGGAATCACTATCCGAGCAATCACCAGCCTTGAAAGGCAGCAGGGTGCCCAGGTGAAGCTGG CCTGTTTTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTCTTCCTGGTGTACAAGCCTTTAAAGACTTCTGCTGCTGCT ATGCCTCTTGGATGCACACTTTGTGTGTACATAGTTACCTTTAACTCAGTGGTTATCTAATAGCTCTAAACTCATTAAAAAAACTCCAAG CCTTCCACCAAAACAGTGCCCCACCTGTATACATTTTTATTAAAAAAATGTAATGCTTATGTATAAACATGTATGTAATATGCTTTCTAT GAATGATGTTTGATTTAAATATAATACATATTAAAATGTATGGGAGAACCAAA >1997_1997_1_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000264377_PPAP2A_chr5_54721162_ENST00000264775_length(amino acids)=540AA_BP=498 MKPPGSSSRQPPLAGCSLAGASCGPQRGPAGSVPASAPARTPPCRLLLVLLLLPPLAASSRPRAWGAAAPSAPHWNETAEKNLGVLADED NTLQQNSSSNISYSNAMQKEITLPSRLIYYINQDSESPYHVLDTKARHQQKHNKAVHLAQASFQIEAFGSKFILDLILNNGLLSSDYVEI HYENGKPQYSKGGEHCYYHGSIRGVKDSKVALSTCNGLHGMFEDDTFVYMIEPLELVHDEKSTGRPHIIQKTLAGQYSKQMKNLTMERGD QWPFLSELQWLKRRKRAVNPSRGIFEEMKYLELMIVNDHKTYKKHRSSHAHTNNFAKSVVNLVDSIYKEQLNTRVVLVAVETWTEKDQID ITTNPVQMLHEFSKYRQRIKQHADAVHLISRVTFHYKRSSLSYFGGVCSRTRGVGVNEYGLPMAVAQVLSQSLAQNLGIQWEPSSRKPKC DCTESWGGCIMEETGVSHSRKFSKCSILEYRDFLQRGGGACLFNRPTKAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP -------------------------------------------------------------- >1997_1997_2_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000264377_PPAP2A_chr5_54721162_ENST00000307259_length(transcript)=2272nt_BP=1822nt GGCCCGGCGGCAGCCCCCGCAGTCGCTGAAGCGGCCGCGCCCGCCGGGGGAGGGAGTAGCCGCTGGGGAGGCTCCAAGTTGGCGGAGCGG CGAGGACCCCTGGACTCCTCTGCGTCCCGCCCCGGGAGTGGCTGCGAGGCTAGGCGAGCCGGGAAAGGGGGCGCCGCCCAGCCCCGAGCC CCGCGCCCCGTGCCCCGAGCCCGGAGCCCCCTGCCCGCCGCGGCACCATGCGCGCCGAGCCGGCGTGACCGGCTCCGCCCGCGGCCGCCC CGCAGCTAGCCCGGCGCTCTCGCCGGCCACACGGAGCGGCGCCCGGGAGCTATGAGCCATGAAGCCGCCCGGCAGCAGCTCGCGGCAGCC GCCCCTGGCGGGCTGCAGCCTTGCCGGCGCTTCCTGCGGCCCCCAACGCGGCCCCGCCGGCTCGGTGCCTGCCAGCGCCCCGGCCCGCAC GCCGCCCTGCCGCCTGCTTCTCGTCCTTCTCCTGCTGCCTCCGCTCGCCGCCTCGTCCCGGCCCCGCGCCTGGGGGGCTGCTGCGCCCAG CGCTCCGCATTGGAATGAAACTGCAGAAAAAAATTTGGGAGTCCTGGCAGATGAAGACAATACATTGCAACAGAATAGCAGCAGTAATAT CAGTTACAGCAATGCAATGCAGAAAGAAATCACACTGCCTTCAAGACTCATATATTACATCAACCAAGACTCGGAAAGCCCTTATCACGT TCTTGACACAAAGGCAAGACACCAGCAAAAACATAATAAGGCTGTCCATCTGGCCCAGGCAAGCTTCCAGATTGAAGCCTTCGGCTCCAA ATTCATTCTTGACCTCATACTGAACAATGGTTTGTTGTCTTCTGATTATGTGGAGATTCACTACGAAAATGGGAAACCACAGTACTCTAA GGGTGGAGAGCACTGTTACTACCATGGAAGCATCAGAGGCGTCAAAGACTCCAAGGTGGCTCTGTCAACCTGCAATGGACTTCATGGCAT GTTTGAAGATGATACCTTCGTGTATATGATAGAGCCACTAGAGCTGGTTCATGATGAGAAAAGCACAGGTCGACCACATATAATCCAGAA AACCTTGGCAGGACAGTATTCTAAGCAAATGAAGAATCTCACTATGGAAAGAGGTGACCAGTGGCCCTTTCTCTCTGAATTACAGTGGTT GAAAAGAAGGAAGAGAGCAGTGAATCCATCACGTGGTATATTTGAAGAAATGAAATATTTGGAACTTATGATTGTTAATGATCACAAAAC GTATAAGAAGCATCGCTCTTCTCATGCACATACCAACAACTTTGCAAAGTCCGTGGTCAACCTTGTGGATTCTATTTACAAGGAGCAGCT CAACACCAGGGTTGTCCTGGTGGCTGTAGAGACCTGGACTGAGAAGGATCAGATTGACATCACCACCAACCCTGTGCAGATGCTCCATGA GTTCTCAAAATACCGGCAGCGCATTAAGCAGCATGCTGATGCTGTGCACCTCATCTCGCGGGTGACATTTCACTATAAGAGAAGCAGTCT GAGTTACTTTGGAGGTGTCTGTTCTCGCACAAGAGGAGTTGGTGTGAATGAGTATGGTCTTCCAATGGCAGTGGCACAAGTATTATCGCA GAGCCTGGCTCAAAACCTTGGAATCCAATGGGAACCTTCTAGCAGAAAGCCAAAATGTGACTGCACAGAATCCTGGGGTGGCTGCATCAT GGAGGAAACAGGGGTGTCCCATTCTCGAAAATTTTCAAAGTGCAGCATTTTGGAGTATAGAGACTTTTTACAGAGAGGAGGTGGAGCCTG CCTTTTCAACAGGCCAACAAAGGCTGTATATGTATCGGATTTCTTCAAAGAAAGAACTTCTTTTAAAGAAAGAAAAGAGGAGGACTCTCA TACAACTCTGCATGAAACACCAACAACTGGGAATCACTATCCGAGCAATCACCAGCCTTGAAAGGCAGCAGGGTGCCCAGGTGAAGCTGG CCTGTTTTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTCTTCCTGGTGTACAAGCCTTTAAAGACTTCTGCTGCTGCT ATGCCTCTTGGATGCACACTTTGTGTGTACATAGTTACCTTTAACTCAGTGGTTATCTAATAGCTCTAAACTCATTAAAAAAACTCCAAG CCTTCCACCAAAACAGTGCCCCACCTGTATACATTTTTATTAAAAAAATGTAATGCTTATGTATAAACATGTATGTAATATGCTTTCTAT GAATGATGTTTGATTTAAATAT >1997_1997_2_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000264377_PPAP2A_chr5_54721162_ENST00000307259_length(amino acids)=540AA_BP=498 MKPPGSSSRQPPLAGCSLAGASCGPQRGPAGSVPASAPARTPPCRLLLVLLLLPPLAASSRPRAWGAAAPSAPHWNETAEKNLGVLADED NTLQQNSSSNISYSNAMQKEITLPSRLIYYINQDSESPYHVLDTKARHQQKHNKAVHLAQASFQIEAFGSKFILDLILNNGLLSSDYVEI HYENGKPQYSKGGEHCYYHGSIRGVKDSKVALSTCNGLHGMFEDDTFVYMIEPLELVHDEKSTGRPHIIQKTLAGQYSKQMKNLTMERGD QWPFLSELQWLKRRKRAVNPSRGIFEEMKYLELMIVNDHKTYKKHRSSHAHTNNFAKSVVNLVDSIYKEQLNTRVVLVAVETWTEKDQID ITTNPVQMLHEFSKYRQRIKQHADAVHLISRVTFHYKRSSLSYFGGVCSRTRGVGVNEYGLPMAVAQVLSQSLAQNLGIQWEPSSRKPKC DCTESWGGCIMEETGVSHSRKFSKCSILEYRDFLQRGGGACLFNRPTKAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP -------------------------------------------------------------- >1997_1997_3_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374415_PPAP2A_chr5_54721162_ENST00000264775_length(transcript)=1975nt_BP=1494nt ATGAAGCCGCCCGGCAGCAGCTCGCGGCAGCCGCCCCTGGCGGGCTGCAGCCTTGCCGGCGCTTCCTGCGGCCCCCAACGCGGCCCCGCC GGCTCGGTGCCTGCCAGCGCCCCGGCCCGCACGCCGCCCTGCCGCCTGCTTCTCGTCCTTCTCCTGCTGCCTCCGCTCGCCGCCTCGTCC CGGCCCCGCGCCTGGGGGGCTGCTGCGCCCAGCGCTCCGCATTGGAATGAAACTGCAGAAAAAAATTTGGGAGTCCTGGCAGATGAAGAC AATACATTGCAACAGAATAGCAGCAGTAATATCAGTTACAGCAATGCAATGCAGAAAGAAATCACACTGCCTTCAAGACTCATATATTAC ATCAACCAAGACTCGGAAAGCCCTTATCACGTTCTTGACACAAAGGCAAGACACCAGCAAAAACATAATAAGGCTGTCCATCTGGCCCAG GCAAGCTTCCAGATTGAAGCCTTCGGCTCCAAATTCATTCTTGACCTCATACTGAACAATGGTTTGTTGTCTTCTGATTATGTGGAGATT CACTACGAAAATGGGAAACCACAGTACTCTAAGGGTGGAGAGCACTGTTACTACCATGGAAGCATCAGAGGCGTCAAAGACTCCAAGGTG GCTCTGTCAACCTGCAATGGACTTCATGGCATGTTTGAAGATGATACCTTCGTGTATATGATAGAGCCACTAGAGCTGGTTCATGATGAG AAAAGCACAGGTCGACCACATATAATCCAGAAAACCTTGGCAGGACAGTATTCTAAGCAAATGAAGAATCTCACTATGGAAAGAGGTGAC CAGTGGCCCTTTCTCTCTGAATTACAGTGGTTGAAAAGAAGGAAGAGAGCAGTGAATCCATCACGTGGTATATTTGAAGAAATGAAATAT TTGGAACTTATGATTGTTAATGATCACAAAACGTATAAGAAGCATCGCTCTTCTCATGCACATACCAACAACTTTGCAAAGTCCGTGGTC AACCTTGTGGATTCTATTTACAAGGAGCAGCTCAACACCAGGGTTGTCCTGGTGGCTGTAGAGACCTGGACTGAGAAGGATCAGATTGAC ATCACCACCAACCCTGTGCAGATGCTCCATGAGTTCTCAAAATACCGGCAGCGCATTAAGCAGCATGCTGATGCTGTGCACCTCATCTCG CGGGTGACATTTCACTATAAGAGAAGCAGTCTGAGTTACTTTGGAGGTGTCTGTTCTCGCACAAGAGGAGTTGGTGTGAATGAGTATGGT CTTCCAATGGCAGTGGCACAAGTATTATCGCAGAGCCTGGCTCAAAACCTTGGAATCCAATGGGAACCTTCTAGCAGAAAGCCAAAATGT GACTGCACAGAATCCTGGGGTGGCTGCATCATGGAGGAAACAGGGGTGTCCCATTCTCGAAAATTTTCAAAGTGCAGCATTTTGGAGTAT AGAGACTTTTTACAGAGAGGAGGTGGAGCCTGCCTTTTCAACAGGCCAACAAAGGCTGTATATGTATCGGATTTCTTCAAAGAAAGAACT TCTTTTAAAGAAAGAAAAGAGGAGGACTCTCATACAACTCTGCATGAAACACCAACAACTGGGAATCACTATCCGAGCAATCACCAGCCT TGAAAGGCAGCAGGGTGCCCAGGTGAAGCTGGCCTGTTTTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTCTTCCTGG TGTACAAGCCTTTAAAGACTTCTGCTGCTGCTATGCCTCTTGGATGCACACTTTGTGTGTACATAGTTACCTTTAACTCAGTGGTTATCT AATAGCTCTAAACTCATTAAAAAAACTCCAAGCCTTCCACCAAAACAGTGCCCCACCTGTATACATTTTTATTAAAAAAATGTAATGCTT ATGTATAAACATGTATGTAATATGCTTTCTATGAATGATGTTTGATTTAAATATAATACATATTAAAATGTATGGGAGAACCAAA >1997_1997_3_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374415_PPAP2A_chr5_54721162_ENST00000264775_length(amino acids)=540AA_BP=498 MKPPGSSSRQPPLAGCSLAGASCGPQRGPAGSVPASAPARTPPCRLLLVLLLLPPLAASSRPRAWGAAAPSAPHWNETAEKNLGVLADED NTLQQNSSSNISYSNAMQKEITLPSRLIYYINQDSESPYHVLDTKARHQQKHNKAVHLAQASFQIEAFGSKFILDLILNNGLLSSDYVEI HYENGKPQYSKGGEHCYYHGSIRGVKDSKVALSTCNGLHGMFEDDTFVYMIEPLELVHDEKSTGRPHIIQKTLAGQYSKQMKNLTMERGD QWPFLSELQWLKRRKRAVNPSRGIFEEMKYLELMIVNDHKTYKKHRSSHAHTNNFAKSVVNLVDSIYKEQLNTRVVLVAVETWTEKDQID ITTNPVQMLHEFSKYRQRIKQHADAVHLISRVTFHYKRSSLSYFGGVCSRTRGVGVNEYGLPMAVAQVLSQSLAQNLGIQWEPSSRKPKC DCTESWGGCIMEETGVSHSRKFSKCSILEYRDFLQRGGGACLFNRPTKAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP -------------------------------------------------------------- >1997_1997_4_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374415_PPAP2A_chr5_54721162_ENST00000307259_length(transcript)=1944nt_BP=1494nt ATGAAGCCGCCCGGCAGCAGCTCGCGGCAGCCGCCCCTGGCGGGCTGCAGCCTTGCCGGCGCTTCCTGCGGCCCCCAACGCGGCCCCGCC GGCTCGGTGCCTGCCAGCGCCCCGGCCCGCACGCCGCCCTGCCGCCTGCTTCTCGTCCTTCTCCTGCTGCCTCCGCTCGCCGCCTCGTCC CGGCCCCGCGCCTGGGGGGCTGCTGCGCCCAGCGCTCCGCATTGGAATGAAACTGCAGAAAAAAATTTGGGAGTCCTGGCAGATGAAGAC AATACATTGCAACAGAATAGCAGCAGTAATATCAGTTACAGCAATGCAATGCAGAAAGAAATCACACTGCCTTCAAGACTCATATATTAC ATCAACCAAGACTCGGAAAGCCCTTATCACGTTCTTGACACAAAGGCAAGACACCAGCAAAAACATAATAAGGCTGTCCATCTGGCCCAG GCAAGCTTCCAGATTGAAGCCTTCGGCTCCAAATTCATTCTTGACCTCATACTGAACAATGGTTTGTTGTCTTCTGATTATGTGGAGATT CACTACGAAAATGGGAAACCACAGTACTCTAAGGGTGGAGAGCACTGTTACTACCATGGAAGCATCAGAGGCGTCAAAGACTCCAAGGTG GCTCTGTCAACCTGCAATGGACTTCATGGCATGTTTGAAGATGATACCTTCGTGTATATGATAGAGCCACTAGAGCTGGTTCATGATGAG AAAAGCACAGGTCGACCACATATAATCCAGAAAACCTTGGCAGGACAGTATTCTAAGCAAATGAAGAATCTCACTATGGAAAGAGGTGAC CAGTGGCCCTTTCTCTCTGAATTACAGTGGTTGAAAAGAAGGAAGAGAGCAGTGAATCCATCACGTGGTATATTTGAAGAAATGAAATAT TTGGAACTTATGATTGTTAATGATCACAAAACGTATAAGAAGCATCGCTCTTCTCATGCACATACCAACAACTTTGCAAAGTCCGTGGTC AACCTTGTGGATTCTATTTACAAGGAGCAGCTCAACACCAGGGTTGTCCTGGTGGCTGTAGAGACCTGGACTGAGAAGGATCAGATTGAC ATCACCACCAACCCTGTGCAGATGCTCCATGAGTTCTCAAAATACCGGCAGCGCATTAAGCAGCATGCTGATGCTGTGCACCTCATCTCG CGGGTGACATTTCACTATAAGAGAAGCAGTCTGAGTTACTTTGGAGGTGTCTGTTCTCGCACAAGAGGAGTTGGTGTGAATGAGTATGGT CTTCCAATGGCAGTGGCACAAGTATTATCGCAGAGCCTGGCTCAAAACCTTGGAATCCAATGGGAACCTTCTAGCAGAAAGCCAAAATGT GACTGCACAGAATCCTGGGGTGGCTGCATCATGGAGGAAACAGGGGTGTCCCATTCTCGAAAATTTTCAAAGTGCAGCATTTTGGAGTAT AGAGACTTTTTACAGAGAGGAGGTGGAGCCTGCCTTTTCAACAGGCCAACAAAGGCTGTATATGTATCGGATTTCTTCAAAGAAAGAACT TCTTTTAAAGAAAGAAAAGAGGAGGACTCTCATACAACTCTGCATGAAACACCAACAACTGGGAATCACTATCCGAGCAATCACCAGCCT TGAAAGGCAGCAGGGTGCCCAGGTGAAGCTGGCCTGTTTTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTCTTCCTGG TGTACAAGCCTTTAAAGACTTCTGCTGCTGCTATGCCTCTTGGATGCACACTTTGTGTGTACATAGTTACCTTTAACTCAGTGGTTATCT AATAGCTCTAAACTCATTAAAAAAACTCCAAGCCTTCCACCAAAACAGTGCCCCACCTGTATACATTTTTATTAAAAAAATGTAATGCTT ATGTATAAACATGTATGTAATATGCTTTCTATGAATGATGTTTGATTTAAATAT >1997_1997_4_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374415_PPAP2A_chr5_54721162_ENST00000307259_length(amino acids)=540AA_BP=498 MKPPGSSSRQPPLAGCSLAGASCGPQRGPAGSVPASAPARTPPCRLLLVLLLLPPLAASSRPRAWGAAAPSAPHWNETAEKNLGVLADED NTLQQNSSSNISYSNAMQKEITLPSRLIYYINQDSESPYHVLDTKARHQQKHNKAVHLAQASFQIEAFGSKFILDLILNNGLLSSDYVEI HYENGKPQYSKGGEHCYYHGSIRGVKDSKVALSTCNGLHGMFEDDTFVYMIEPLELVHDEKSTGRPHIIQKTLAGQYSKQMKNLTMERGD QWPFLSELQWLKRRKRAVNPSRGIFEEMKYLELMIVNDHKTYKKHRSSHAHTNNFAKSVVNLVDSIYKEQLNTRVVLVAVETWTEKDQID ITTNPVQMLHEFSKYRQRIKQHADAVHLISRVTFHYKRSSLSYFGGVCSRTRGVGVNEYGLPMAVAQVLSQSLAQNLGIQWEPSSRKPKC DCTESWGGCIMEETGVSHSRKFSKCSILEYRDFLQRGGGACLFNRPTKAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP -------------------------------------------------------------- >1997_1997_5_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374416_PPAP2A_chr5_54721162_ENST00000264775_length(transcript)=2027nt_BP=1546nt TAGCCCGGCGCTCTCGCCGGCCACACGGAGCGGCGCCCGGGAGCTATGAGCCATGAAGCCGCCCGGCAGCAGCTCGCGGCAGCCGCCCCT GGCGGGCTGCAGCCTTGCCGGCGCTTCCTGCGGCCCCCAACGCGGCCCCGCCGGCTCGGTGCCTGCCAGCGCCCCGGCCCGCACGCCGCC CTGCCGCCTGCTTCTCGTCCTTCTCCTGCTGCCTCCGCTCGCCGCCTCGTCCCGGCCCCGCGCCTGGGGGGCTGCTGCGCCCAGCGCTCC GCATTGGAATGAAACTGCAGAAAAAAATTTGGGAGTCCTGGCAGATGAAGACAATACATTGCAACAGAATAGCAGCAGTAATATCAGTTA CAGCAATGCAATGCAGAAAGAAATCACACTGCCTTCAAGACTCATATATTACATCAACCAAGACTCGGAAAGCCCTTATCACGTTCTTGA CACAAAGGCAAGACACCAGCAAAAACATAATAAGGCTGTCCATCTGGCCCAGGCAAGCTTCCAGATTGAAGCCTTCGGCTCCAAATTCAT TCTTGACCTCATACTGAACAATGGTTTGTTGTCTTCTGATTATGTGGAGATTCACTACGAAAATGGGAAACCACAGTACTCTAAGGGTGG AGAGCACTGTTACTACCATGGAAGCATCAGAGGCGTCAAAGACTCCAAGGTGGCTCTGTCAACCTGCAATGGACTTCATGGCATGTTTGA AGATGATACCTTCGTGTATATGATAGAGCCACTAGAGCTGGTTCATGATGAGAAAAGCACAGGTCGACCACATATAATCCAGAAAACCTT GGCAGGACAGTATTCTAAGCAAATGAAGAATCTCACTATGGAAAGAGGTGACCAGTGGCCCTTTCTCTCTGAATTACAGTGGTTGAAAAG AAGGAAGAGAGCAGTGAATCCATCACGTGGTATATTTGAAGAAATGAAATATTTGGAACTTATGATTGTTAATGATCACAAAACGTATAA GAAGCATCGCTCTTCTCATGCACATACCAACAACTTTGCAAAGTCCGTGGTCAACCTTGTGGATTCTATTTACAAGGAGCAGCTCAACAC CAGGGTTGTCCTGGTGGCTGTAGAGACCTGGACTGAGAAGGATCAGATTGACATCACCACCAACCCTGTGCAGATGCTCCATGAGTTCTC AAAATACCGGCAGCGCATTAAGCAGCATGCTGATGCTGTGCACCTCATCTCGCGGGTGACATTTCACTATAAGAGAAGCAGTCTGAGTTA CTTTGGAGGTGTCTGTTCTCGCACAAGAGGAGTTGGTGTGAATGAGTATGGTCTTCCAATGGCAGTGGCACAAGTATTATCGCAGAGCCT GGCTCAAAACCTTGGAATCCAATGGGAACCTTCTAGCAGAAAGCCAAAATGTGACTGCACAGAATCCTGGGGTGGCTGCATCATGGAGGA AACAGGGGTGTCCCATTCTCGAAAATTTTCAAAGTGCAGCATTTTGGAGTATAGAGACTTTTTACAGAGAGGAGGTGGAGCCTGCCTTTT CAACAGGCCAACAAAGGCTGTATATGTATCGGATTTCTTCAAAGAAAGAACTTCTTTTAAAGAAAGAAAAGAGGAGGACTCTCATACAAC TCTGCATGAAACACCAACAACTGGGAATCACTATCCGAGCAATCACCAGCCTTGAAAGGCAGCAGGGTGCCCAGGTGAAGCTGGCCTGTT TTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTCTTCCTGGTGTACAAGCCTTTAAAGACTTCTGCTGCTGCTATGCCT CTTGGATGCACACTTTGTGTGTACATAGTTACCTTTAACTCAGTGGTTATCTAATAGCTCTAAACTCATTAAAAAAACTCCAAGCCTTCC ACCAAAACAGTGCCCCACCTGTATACATTTTTATTAAAAAAATGTAATGCTTATGTATAAACATGTATGTAATATGCTTTCTATGAATGA TGTTTGATTTAAATATAATACATATTAAAATGTATGGGAGAACCAAA >1997_1997_5_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374416_PPAP2A_chr5_54721162_ENST00000264775_length(amino acids)=540AA_BP=498 MKPPGSSSRQPPLAGCSLAGASCGPQRGPAGSVPASAPARTPPCRLLLVLLLLPPLAASSRPRAWGAAAPSAPHWNETAEKNLGVLADED NTLQQNSSSNISYSNAMQKEITLPSRLIYYINQDSESPYHVLDTKARHQQKHNKAVHLAQASFQIEAFGSKFILDLILNNGLLSSDYVEI HYENGKPQYSKGGEHCYYHGSIRGVKDSKVALSTCNGLHGMFEDDTFVYMIEPLELVHDEKSTGRPHIIQKTLAGQYSKQMKNLTMERGD QWPFLSELQWLKRRKRAVNPSRGIFEEMKYLELMIVNDHKTYKKHRSSHAHTNNFAKSVVNLVDSIYKEQLNTRVVLVAVETWTEKDQID ITTNPVQMLHEFSKYRQRIKQHADAVHLISRVTFHYKRSSLSYFGGVCSRTRGVGVNEYGLPMAVAQVLSQSLAQNLGIQWEPSSRKPKC DCTESWGGCIMEETGVSHSRKFSKCSILEYRDFLQRGGGACLFNRPTKAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP -------------------------------------------------------------- >1997_1997_6_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374416_PPAP2A_chr5_54721162_ENST00000307259_length(transcript)=1996nt_BP=1546nt TAGCCCGGCGCTCTCGCCGGCCACACGGAGCGGCGCCCGGGAGCTATGAGCCATGAAGCCGCCCGGCAGCAGCTCGCGGCAGCCGCCCCT GGCGGGCTGCAGCCTTGCCGGCGCTTCCTGCGGCCCCCAACGCGGCCCCGCCGGCTCGGTGCCTGCCAGCGCCCCGGCCCGCACGCCGCC CTGCCGCCTGCTTCTCGTCCTTCTCCTGCTGCCTCCGCTCGCCGCCTCGTCCCGGCCCCGCGCCTGGGGGGCTGCTGCGCCCAGCGCTCC GCATTGGAATGAAACTGCAGAAAAAAATTTGGGAGTCCTGGCAGATGAAGACAATACATTGCAACAGAATAGCAGCAGTAATATCAGTTA CAGCAATGCAATGCAGAAAGAAATCACACTGCCTTCAAGACTCATATATTACATCAACCAAGACTCGGAAAGCCCTTATCACGTTCTTGA CACAAAGGCAAGACACCAGCAAAAACATAATAAGGCTGTCCATCTGGCCCAGGCAAGCTTCCAGATTGAAGCCTTCGGCTCCAAATTCAT TCTTGACCTCATACTGAACAATGGTTTGTTGTCTTCTGATTATGTGGAGATTCACTACGAAAATGGGAAACCACAGTACTCTAAGGGTGG AGAGCACTGTTACTACCATGGAAGCATCAGAGGCGTCAAAGACTCCAAGGTGGCTCTGTCAACCTGCAATGGACTTCATGGCATGTTTGA AGATGATACCTTCGTGTATATGATAGAGCCACTAGAGCTGGTTCATGATGAGAAAAGCACAGGTCGACCACATATAATCCAGAAAACCTT GGCAGGACAGTATTCTAAGCAAATGAAGAATCTCACTATGGAAAGAGGTGACCAGTGGCCCTTTCTCTCTGAATTACAGTGGTTGAAAAG AAGGAAGAGAGCAGTGAATCCATCACGTGGTATATTTGAAGAAATGAAATATTTGGAACTTATGATTGTTAATGATCACAAAACGTATAA GAAGCATCGCTCTTCTCATGCACATACCAACAACTTTGCAAAGTCCGTGGTCAACCTTGTGGATTCTATTTACAAGGAGCAGCTCAACAC CAGGGTTGTCCTGGTGGCTGTAGAGACCTGGACTGAGAAGGATCAGATTGACATCACCACCAACCCTGTGCAGATGCTCCATGAGTTCTC AAAATACCGGCAGCGCATTAAGCAGCATGCTGATGCTGTGCACCTCATCTCGCGGGTGACATTTCACTATAAGAGAAGCAGTCTGAGTTA CTTTGGAGGTGTCTGTTCTCGCACAAGAGGAGTTGGTGTGAATGAGTATGGTCTTCCAATGGCAGTGGCACAAGTATTATCGCAGAGCCT GGCTCAAAACCTTGGAATCCAATGGGAACCTTCTAGCAGAAAGCCAAAATGTGACTGCACAGAATCCTGGGGTGGCTGCATCATGGAGGA AACAGGGGTGTCCCATTCTCGAAAATTTTCAAAGTGCAGCATTTTGGAGTATAGAGACTTTTTACAGAGAGGAGGTGGAGCCTGCCTTTT CAACAGGCCAACAAAGGCTGTATATGTATCGGATTTCTTCAAAGAAAGAACTTCTTTTAAAGAAAGAAAAGAGGAGGACTCTCATACAAC TCTGCATGAAACACCAACAACTGGGAATCACTATCCGAGCAATCACCAGCCTTGAAAGGCAGCAGGGTGCCCAGGTGAAGCTGGCCTGTT TTCTAAAGGAAAATGATTGCCACAAGGCAAGAGGATGCATCTTTCTTCCTGGTGTACAAGCCTTTAAAGACTTCTGCTGCTGCTATGCCT CTTGGATGCACACTTTGTGTGTACATAGTTACCTTTAACTCAGTGGTTATCTAATAGCTCTAAACTCATTAAAAAAACTCCAAGCCTTCC ACCAAAACAGTGCCCCACCTGTATACATTTTTATTAAAAAAATGTAATGCTTATGTATAAACATGTATGTAATATGCTTTCTATGAATGA TGTTTGATTTAAATAT >1997_1997_6_ADAM23-PPAP2A_ADAM23_chr2_207432046_ENST00000374416_PPAP2A_chr5_54721162_ENST00000307259_length(amino acids)=540AA_BP=498 MKPPGSSSRQPPLAGCSLAGASCGPQRGPAGSVPASAPARTPPCRLLLVLLLLPPLAASSRPRAWGAAAPSAPHWNETAEKNLGVLADED NTLQQNSSSNISYSNAMQKEITLPSRLIYYINQDSESPYHVLDTKARHQQKHNKAVHLAQASFQIEAFGSKFILDLILNNGLLSSDYVEI HYENGKPQYSKGGEHCYYHGSIRGVKDSKVALSTCNGLHGMFEDDTFVYMIEPLELVHDEKSTGRPHIIQKTLAGQYSKQMKNLTMERGD QWPFLSELQWLKRRKRAVNPSRGIFEEMKYLELMIVNDHKTYKKHRSSHAHTNNFAKSVVNLVDSIYKEQLNTRVVLVAVETWTEKDQID ITTNPVQMLHEFSKYRQRIKQHADAVHLISRVTFHYKRSSLSYFGGVCSRTRGVGVNEYGLPMAVAQVLSQSLAQNLGIQWEPSSRKPKC DCTESWGGCIMEETGVSHSRKFSKCSILEYRDFLQRGGGACLFNRPTKAVYVSDFFKERTSFKERKEEDSHTTLHETPTTGNHYPSNHQP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ADAM23-PPAP2A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ADAM23-PPAP2A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ADAM23-PPAP2A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies