
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:KAT2B-KANSL1 (FusionGDB2 ID:HG8850TG284058) |
Fusion Gene Summary for KAT2B-KANSL1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: KAT2B-KANSL1 | Fusion gene ID: hg8850tg284058 | Hgene | Tgene | Gene symbol | KAT2B | KANSL1 | Gene ID | 8850 | 284058 |
| Gene name | lysine acetyltransferase 2B | KAT8 regulatory NSL complex subunit 1 | |
| Synonyms | CAF|P/CAF|PCAF | CENP-36|KDVS|KIAA1267|MSL1v1|NSL1|hMSL1v1 | |
| Cytomap | ('KAT2B')('KANSL1') 3p24.3 | 17q21.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | histone acetyltransferase KAT2BCREBBP-associated factorK(lysine) acetyltransferase 2Bhistone acetylase PCAFhistone acetyltransferase PCAFp300/CBP-associated factorspermidine acetyltransferase KAT2B | KAT8 regulatory NSL complex subunit 1MLL1/MLL complex subunit KANSL1MSL1 homolog 1NSL complex protein NSL1centromere protein 36male-specific lethal 1 homolognon-specific lethal 1 homolog | |
| Modification date | 20200313 | 20200327 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000426228, ENST00000263754, | ||
| Fusion gene scores | * DoF score | 4 X 4 X 2=32 | 17 X 18 X 11=3366 |
| # samples | 4 | 28 | |
| ** MAII score | log2(4/32*10)=0.321928094887362 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(28/3366*10)=-3.58753644438498 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: KAT2B [Title/Abstract] AND KANSL1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | KAT2B(20136900)-KANSL1(44145033), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | KAT2B-KANSL1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. KAT2B-KANSL1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. KAT2B-KANSL1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. KAT2B-KANSL1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | KAT2B | GO:0006338 | chromatin remodeling | 17707232 |
| Hgene | KAT2B | GO:0006473 | protein acetylation | 15273251|26867678 |
| Hgene | KAT2B | GO:0008285 | negative regulation of cell proliferation | 8684459 |
| Hgene | KAT2B | GO:0010835 | regulation of protein ADP-ribosylation | 19470756 |
| Hgene | KAT2B | GO:0018076 | N-terminal peptidyl-lysine acetylation | 12435739 |
| Hgene | KAT2B | GO:0018393 | internal peptidyl-lysine acetylation | 23932781|27796307|29174768 |
| Hgene | KAT2B | GO:0018394 | peptidyl-lysine acetylation | 19303849|19470756 |
| Hgene | KAT2B | GO:0032869 | cellular response to insulin stimulus | 19303849 |
| Hgene | KAT2B | GO:0043966 | histone H3 acetylation | 18838386 |
| Hgene | KAT2B | GO:0045944 | positive regulation of transcription by RNA polymerase II | 19470756 |
| Hgene | KAT2B | GO:0046600 | negative regulation of centriole replication | 27796307 |
| Hgene | KAT2B | GO:2000233 | negative regulation of rRNA processing | 26867678 |
| Tgene | KANSL1 | GO:0043981 | histone H4-K5 acetylation | 20018852 |
| Tgene | KANSL1 | GO:0043982 | histone H4-K8 acetylation | 20018852 |
| Tgene | KANSL1 | GO:0043984 | histone H4-K16 acetylation | 20018852 |
| Fusion gene breakpoints across KAT2B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across KANSL1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | ERR315398 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
Top |
Fusion Gene ORF analysis for KAT2B-KANSL1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000426228 | ENST00000262419 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 3UTR-3CDS | ENST00000426228 | ENST00000432791 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 3UTR-3CDS | ENST00000426228 | ENST00000572904 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 3UTR-3CDS | ENST00000426228 | ENST00000574590 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 3UTR-3CDS | ENST00000426228 | ENST00000575318 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 3UTR-5UTR | ENST00000426228 | ENST00000393476 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 3UTR-intron | ENST00000426228 | ENST00000576248 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 5CDS-5UTR | ENST00000263754 | ENST00000393476 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| 5CDS-intron | ENST00000263754 | ENST00000576248 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| In-frame | ENST00000263754 | ENST00000262419 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| In-frame | ENST00000263754 | ENST00000432791 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| In-frame | ENST00000263754 | ENST00000572904 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| In-frame | ENST00000263754 | ENST00000574590 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| In-frame | ENST00000263754 | ENST00000575318 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000263754 | KAT2B | chr3 | 20136900 | + | ENST00000574590 | KANSL1 | chr17 | 44145033 | - | 4376 | 1031 | 455 | 2815 | 786 |
| ENST00000263754 | KAT2B | chr3 | 20136900 | + | ENST00000575318 | KANSL1 | chr17 | 44145033 | - | 4175 | 1031 | 455 | 2623 | 722 |
| ENST00000263754 | KAT2B | chr3 | 20136900 | + | ENST00000572904 | KANSL1 | chr17 | 44145033 | - | 4339 | 1031 | 455 | 2815 | 786 |
| ENST00000263754 | KAT2B | chr3 | 20136900 | + | ENST00000262419 | KANSL1 | chr17 | 44145033 | - | 4336 | 1031 | 455 | 2815 | 786 |
| ENST00000263754 | KAT2B | chr3 | 20136900 | + | ENST00000432791 | KANSL1 | chr17 | 44145033 | - | 4324 | 1031 | 455 | 2815 | 786 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000263754 | ENST00000574590 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - | 0.007110466 | 0.9928895 |
| ENST00000263754 | ENST00000575318 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - | 0.010896575 | 0.98910344 |
| ENST00000263754 | ENST00000572904 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - | 0.007892 | 0.9921079 |
| ENST00000263754 | ENST00000262419 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - | 0.007859941 | 0.9921401 |
| ENST00000263754 | ENST00000432791 | KAT2B | chr3 | 20136900 | + | KANSL1 | chr17 | 44145033 | - | 0.008444278 | 0.99155575 |
Top |
Fusion Genomic Features for KAT2B-KANSL1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
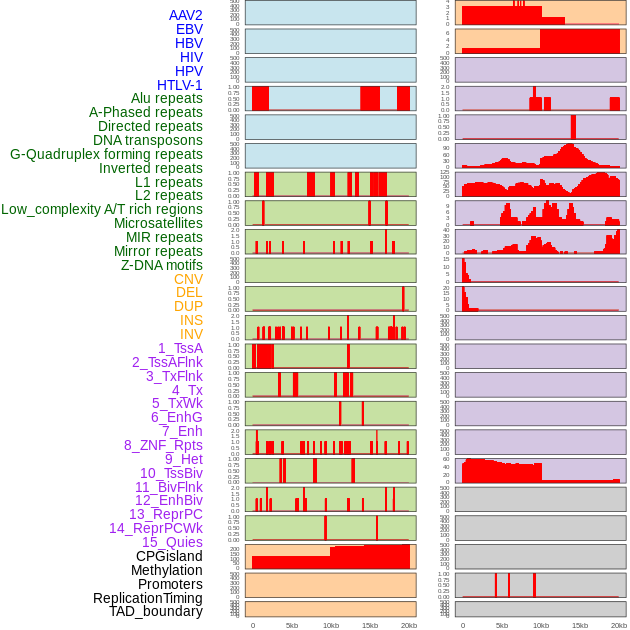
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for KAT2B-KANSL1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:20136900/chr17:44145033) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000262419 | 3 | 15 | 850_882 | 511 | 1106.0 | Region | Note=Required for activation of KAT8 histone acetyltransferase activity | |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000432791 | 2 | 14 | 850_882 | 511 | 1106.0 | Region | Note=Required for activation of KAT8 histone acetyltransferase activity | |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000572904 | 3 | 15 | 850_882 | 511 | 1106.0 | Region | Note=Required for activation of KAT8 histone acetyltransferase activity | |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000574590 | 3 | 15 | 850_882 | 511 | 1106.0 | Region | Note=Required for activation of KAT8 histone acetyltransferase activity |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KAT2B | chr3:20136900 | chr17:44145033 | ENST00000263754 | + | 3 | 18 | 503_651 | 192 | 833.0 | Domain | N-acetyltransferase |
| Hgene | KAT2B | chr3:20136900 | chr17:44145033 | ENST00000263754 | + | 3 | 18 | 740_810 | 192 | 833.0 | Domain | Bromo |
| Hgene | KAT2B | chr3:20136900 | chr17:44145033 | ENST00000263754 | + | 3 | 18 | 574_576 | 192 | 833.0 | Region | Acetyl-CoA binding |
| Hgene | KAT2B | chr3:20136900 | chr17:44145033 | ENST00000263754 | + | 3 | 18 | 581_587 | 192 | 833.0 | Region | Acetyl-CoA binding |
| Hgene | KAT2B | chr3:20136900 | chr17:44145033 | ENST00000263754 | + | 3 | 18 | 612_615 | 192 | 833.0 | Region | Acetyl-CoA binding |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000262419 | 3 | 15 | 283_314 | 511 | 1106.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000432791 | 2 | 14 | 283_314 | 511 | 1106.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000572904 | 3 | 15 | 283_314 | 511 | 1106.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | KANSL1 | chr3:20136900 | chr17:44145033 | ENST00000574590 | 3 | 15 | 283_314 | 511 | 1106.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for KAT2B-KANSL1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >41186_41186_1_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000262419_length(transcript)=4336nt_BP=1031nt CCGCGGGCAGCGGAAAAGAGGCCGTGGGGGGCCTCCCAGCGCTGGCAGACACCGTGAGGCTGGCAGCCGCCGGCACGCACACCTAGTCCG CAGTCCCGAGGAACATGTCCGCAGCCAGGGCGCGGAGCAGAGTCCCGGGCAGGAGAACCAAGGGAGGGCGTGTGCTGTGGCGGCGGCGGC AGCGGCAGCGGAGCCGCTAGTCCCCTCCCTCCTGGGGGAGCAGCTGCCGCCGCTGCCGCCGCCGCCACCACCATCAGCGCGCGGGGCCCG GCCAGAGCGAGCCGGGCGAGCGGCGCGCTAGGGGGAGGGCGGGGGCGGGGAGGGGGGTGGGCGAAGGGGGCGGGAGGGCGTGGGGGGAGG GTCTCGCTCTCCCGACTACCAGAGCCCGAGAGGGAGACCCTGGCGGCGGCGGCGGCGCCTGACACTCGGCGCCTCCTGCCGTGCTCCGGG GCGGCATGTCCGAGGCTGGCGGGGCCGGGCCGGGCGGCTGCGGGGCAGGAGCCGGGGCAGGGGCCGGGCCCGGGGCGCTGCCCCCGCAGC CTGCGGCGCTTCCGCCCGCGCCCCCGCAGGGCTCCCCCTGCGCCGCTGCCGCCGGGGGCTCGGGCGCCTGCGGTCCGGCGACGGCAGTGG CTGCAGCGGGCACGGCCGAAGGACCGGGAGGCGGTGGCTCGGCCCGAATCGCCGTGAAGAAAGCGCAACTACGCTCCGCTCCGCGGGCCA AGAAACTGGAGAAACTCGGAGTGTACTCCGCCTGCAAGGCCGAGGAGTCTTGTAAATGTAATGGCTGGAAAAACCCTAACCCCTCACCCA CTCCCCCCAGAGCCGACCTGCAGCAAATAATTGTCAGTCTAACAGAATCCTGTCGGAGTTGTAGCCATGCCCTAGCTGCTCATGTTTCCC ACCTGGAGAATGTGTCAGAGGAAGAAATGAACAGACTCCTGGGAATAGTATTGGATGTGGAATATCTCTTTACCTGTGTCCACAAGGAAG AAGATGCAGATACCAAACAAGTTTATTTCTATCTATTTAAGATTGAGTCTGTTTCTCAGCCATTGGAAAACCATGGTGCCCGTATTATTG GTCATATTTCAGAGTCACTGTCTACCAAATCATGTGGAGCACTCAGACCTGTCAATGGAGTTATTAACACTCTTCAGCCTGTCTTGGCAG ACCACATTCCAGGTGACAGCTCTGATGCTGAGGAACAATTACATAAGAAGCAACGACTGAATCTCGTCTCTTCATCATCTGATGGCACCT GTGTGGCAGCCCGGACACGTCCTGTACTGAGCTGTAAGAAGCGGAGGCTTGTTCGACCCAACAGCATCGTTCCTCTTTCCAAGAAGGTTC ACCGGAACAGCACAATCCGCCCTGGCTGTGATGTGAATCCCTCCTGCGCACTGTGTGGTTCAGGCAGCATCAACACCATGCCTCCCGAAA TTCACTATGAAGCCCCTCTGTTGGAACGTCTTTCCCAGTTGGACTCTTGTGTTCATCCTGTTCTAGCATTTCCAGATGATGTTCCCACAA GCCTGCATTTCCAGAGCATGCTGAAATCTCAGTGGCAGAACAAGCCTTTTGACAAAATCAAACCTCCCAAAAAGTTATCGCTTAAGCACA GAGCACCCATGCCGGGCAGTCTGCCAGATTCAGCTCGTAAGGACAGGCACAAATTGGTCAGCTCCTTCCTAACAACAGCCAAGCTGTCCC ATCACCAAACCCGGCCTGACAGGACCCACAGGCAGCACTTAGACGATGTGGGGGCCGTGCCCATGGTGGAGCGAGTGACAGCGCCAAAAG CAGAGCGCTTGCTCAACCCACCACCACCCGTGCATGACCCAAACCACAGCAAAATGAGATTGCGAGACCATTCATCTGAGAGAAGTGAAG TGTTGAAGCATCACACAGACATGAGCAGTTCGAGCTACTTGGCAGCCACCCACCATCCTCCACACAGTCCCTTGGTGCGACAGCTCTCCA CCTCCTCAGATTCCCCTGCACCCGCCAGCTCTAGCTCACAGGTTACAGCCAGCACATCGCAGCAGCCAGTAAGGAGGAGAAGGGGAGAGA GCTCATTTGATATTAACAACATTGTCATCCCAATGTCTGTTGCTGCAACAACTCGCGTAGAGAAACTGCAATACAAGGAAATCCTTACGC CCAGCTGGCGGGAGGTTGATCTTCAGTCTCTGAAGGGGAGTCCTGATGAGGAGAATGAAGAGATTGAGGACCTATCCGACGCAGCCTTCG CCGCCCTGCATGCCAAATGTGAGGAGATGGAGAGGGCACGGTGGCTGTGGACCACGAGTGTGCCACCCCAGCGGCGGGGCAGCAGGTCCT ACAGGTCATCAGACGGCCGGACAACCCCCCAGCTGGGCAGTGCCAACCCCTCCACCCCCCAGCCTGCCTCCCCTGATGTCAGCAGTAGCC ACTCTTTGTCAGAATACTCCCATGGTCAGTCCCCTAGGAGCCCCATTAGCCCGGAACTGCACTCAGCACCCCTCACCCCTGTGGCTCGGG ACACTCCGCGACACTTAGCCAGTGAGGATACCCGTTGTTCCACACCAGAGCTGGGGCTGGATGAACAGTCTGTCCAGCCCTGGGAGCGGC GGACCTTCCCCCTGGCGCACAGTCCCCAGGCGGAGTGTGAGGACCAGCTGGATGCACAGGAGCGAGCAGCCCGCTGCACTCGACGCACCT CAGGCAGCAAGACTGGCCGGGAGACAGAGGCAGCGCCCACCTCGCCTCCCATTGTCCCCCTCAAGAGTCGGCATCTGGTGGCAGCAGCCA CAGCTCAGCGCCCGACTCACAGATGAGCGGGAGACAGCCATCTAAACAGACTCACTAACTATTGGCATTAAAGCTTCAGAAATCTCTGCG TTTGATATTCAAACATCATATGCCGGAAATTTTCACAGTTTTTAGTGAACTTAAGGAATTTAGATCCTACTTTGGTATTTTTTTTTCTTG TTTTAATTTTTGTTTTGTTTTTGTTTCCATGTTTTCTTGTCACACACCTGAGCACTTCCTCCCGTTGGCAAACAGAAGTTCAGGATGAGA CCCTGCTGGCCTGGTCCTGGCACATCCTCTGCACTGTTGAATCACTGGACTTACTGATCTTAGATGACCACCCCCTCCCTCACACCTGTG GGCAGGGCAGAACAGCCTGGCGGGCTACAGTTTAGCATGGCCTTCTTGAGCTAGGGTGGAATGGGGCAGGGTGCTCTGGACTCTTACCCC CTCCCCTCCCATCTGTGGCTTGGCTCTGCTGTGGCCCTCCTGGCTGGGTCCCCTTGGTTTTTCGTGCTGGAACATCCCCACCAGAGCCTC TCTGCCATAACTGCCAGCTGCTCTCCCCGAGTGCTCAGCTGGCAGAACACCTTTCCTTTCTCACCCAGAACTTAAGAGACTGATTTTTTG TTTCATCTGCATTTGGTCTTCTCTGTTTTGACTCTTTCACTGCAGTAACCTGGCTGTGGCTGCTCAGGTTCCCCTCCTCATGCCCCTTGG TACCCTTCCCTGTCTGCTCTCCCATGCCATGTACACACCCACAACCCGTCCTTCCACTTGGAATATTTTTACCACCTATCCTGATCTTTG AAGGTAGGGTTAGGACTACTTAACCTCTATTCCCACTCCCCTGCAAACTGGGGGTTGTGGGAAGTGAGCAGCCATCTCCCTGTGTGATTT TTTTTTTTTTTCCCTCTGATTCACTTTGCCATGTTTCCTTCACATCCAGATCCCTGTCGGTGTTAGTTCCACTCTTGGTCTTTCACGCTC CCCTTGCCTGTGGAACATTGTCTGGTCCTAGCTGTGGTTCCCATTGTTCCCCCTTCACCCTTCTCTGTTAACCTTGTGCCTGTCTCCTGT ATGATCACATCACCAAAAAGGGGGAGGGGGGAGAAGACTCTTTTTTTTTGGCCATTTTGTAATCGTATAAAAATAGTAGACAACTGCTTA ATGGTTGGGGTTTTTTCACAATTTTCAACATTAGTGATTTTTTTTTCTGTTTGCAAGTTAAAGGGTTTGTCATTGTTTCTTTAAAAAAAA ATACAATAATGCACCATATCCCTATGCATAAAGTGCTTCTTCTATTTATAAGGTTGAAAATTCTGAATAACCCTTTTAGCATTGAAAAAA AAAACAAAAACAAAAAATGGAAAAAAAAAACCTTGTATTTTGTAAATATTTTCTTTTCCTGCTTTGGAGCTGTGTAATGGCAGCGAAACA TGTAGCTGTCTTTGTTCTATAGAAATGCTTTTCTTCAGAGAAGCTGATCTTTGTTAATGTCTTGATTCTGTTCGCAAAGCACAGACTAGT GCTTAAAAAAAAAAAA >41186_41186_1_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000262419_length(amino acids)=786AA_BP=192 MSEAGGAGPGGCGAGAGAGAGPGALPPQPAALPPAPPQGSPCAAAAGGSGACGPATAVAAAGTAEGPGGGGSARIAVKKAQLRSAPRAKK LEKLGVYSACKAEESCKCNGWKNPNPSPTPPRADLQQIIVSLTESCRSCSHALAAHVSHLENVSEEEMNRLLGIVLDVEYLFTCVHKEED ADTKQVYFYLFKIESVSQPLENHGARIIGHISESLSTKSCGALRPVNGVINTLQPVLADHIPGDSSDAEEQLHKKQRLNLVSSSSDGTCV AARTRPVLSCKKRRLVRPNSIVPLSKKVHRNSTIRPGCDVNPSCALCGSGSINTMPPEIHYEAPLLERLSQLDSCVHPVLAFPDDVPTSL HFQSMLKSQWQNKPFDKIKPPKKLSLKHRAPMPGSLPDSARKDRHKLVSSFLTTAKLSHHQTRPDRTHRQHLDDVGAVPMVERVTAPKAE RLLNPPPPVHDPNHSKMRLRDHSSERSEVLKHHTDMSSSSYLAATHHPPHSPLVRQLSTSSDSPAPASSSSQVTASTSQQPVRRRRGESS FDINNIVIPMSVAATTRVEKLQYKEILTPSWREVDLQSLKGSPDEENEEIEDLSDAAFAALHAKCEEMERARWLWTTSVPPQRRGSRSYR SSDGRTTPQLGSANPSTPQPASPDVSSSHSLSEYSHGQSPRSPISPELHSAPLTPVARDTPRHLASEDTRCSTPELGLDEQSVQPWERRT FPLAHSPQAECEDQLDAQERAARCTRRTSGSKTGRETEAAPTSPPIVPLKSRHLVAAATAQRPTHR -------------------------------------------------------------- >41186_41186_2_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000432791_length(transcript)=4324nt_BP=1031nt CCGCGGGCAGCGGAAAAGAGGCCGTGGGGGGCCTCCCAGCGCTGGCAGACACCGTGAGGCTGGCAGCCGCCGGCACGCACACCTAGTCCG CAGTCCCGAGGAACATGTCCGCAGCCAGGGCGCGGAGCAGAGTCCCGGGCAGGAGAACCAAGGGAGGGCGTGTGCTGTGGCGGCGGCGGC AGCGGCAGCGGAGCCGCTAGTCCCCTCCCTCCTGGGGGAGCAGCTGCCGCCGCTGCCGCCGCCGCCACCACCATCAGCGCGCGGGGCCCG GCCAGAGCGAGCCGGGCGAGCGGCGCGCTAGGGGGAGGGCGGGGGCGGGGAGGGGGGTGGGCGAAGGGGGCGGGAGGGCGTGGGGGGAGG GTCTCGCTCTCCCGACTACCAGAGCCCGAGAGGGAGACCCTGGCGGCGGCGGCGGCGCCTGACACTCGGCGCCTCCTGCCGTGCTCCGGG GCGGCATGTCCGAGGCTGGCGGGGCCGGGCCGGGCGGCTGCGGGGCAGGAGCCGGGGCAGGGGCCGGGCCCGGGGCGCTGCCCCCGCAGC CTGCGGCGCTTCCGCCCGCGCCCCCGCAGGGCTCCCCCTGCGCCGCTGCCGCCGGGGGCTCGGGCGCCTGCGGTCCGGCGACGGCAGTGG CTGCAGCGGGCACGGCCGAAGGACCGGGAGGCGGTGGCTCGGCCCGAATCGCCGTGAAGAAAGCGCAACTACGCTCCGCTCCGCGGGCCA AGAAACTGGAGAAACTCGGAGTGTACTCCGCCTGCAAGGCCGAGGAGTCTTGTAAATGTAATGGCTGGAAAAACCCTAACCCCTCACCCA CTCCCCCCAGAGCCGACCTGCAGCAAATAATTGTCAGTCTAACAGAATCCTGTCGGAGTTGTAGCCATGCCCTAGCTGCTCATGTTTCCC ACCTGGAGAATGTGTCAGAGGAAGAAATGAACAGACTCCTGGGAATAGTATTGGATGTGGAATATCTCTTTACCTGTGTCCACAAGGAAG AAGATGCAGATACCAAACAAGTTTATTTCTATCTATTTAAGATTGAGTCTGTTTCTCAGCCATTGGAAAACCATGGTGCCCGTATTATTG GTCATATTTCAGAGTCACTGTCTACCAAATCATGTGGAGCACTCAGACCTGTCAATGGAGTTATTAACACTCTTCAGCCTGTCTTGGCAG ACCACATTCCAGGTGACAGCTCTGATGCTGAGGAACAATTACATAAGAAGCAACGACTGAATCTCGTCTCTTCATCATCTGATGGCACCT GTGTGGCAGCCCGGACACGTCCTGTACTGAGCTGTAAGAAGCGGAGGCTTGTTCGACCCAACAGCATCGTTCCTCTTTCCAAGAAGGTTC ACCGGAACAGCACAATCCGCCCTGGCTGTGATGTGAATCCCTCCTGCGCACTGTGTGGTTCAGGCAGCATCAACACCATGCCTCCCGAAA TTCACTATGAAGCCCCTCTGTTGGAACGTCTTTCCCAGTTGGACTCTTGTGTTCATCCTGTTCTAGCATTTCCAGATGATGTTCCCACAA GCCTGCATTTCCAGAGCATGCTGAAATCTCAGTGGCAGAACAAGCCTTTTGACAAAATCAAACCTCCCAAAAAGTTATCGCTTAAGCACA GAGCACCCATGCCGGGCAGTCTGCCAGATTCAGCTCGTAAGGACAGGCACAAATTGGTCAGCTCCTTCCTAACAACAGCCAAGCTGTCCC ATCACCAAACCCGGCCTGACAGGACCCACAGGCAGCACTTAGACGATGTGGGGGCCGTGCCCATGGTGGAGCGAGTGACAGCGCCAAAAG CAGAGCGCTTGCTCAACCCACCACCACCCGTGCATGACCCAAACCACAGCAAAATGAGATTGCGAGACCATTCATCTGAGAGAAGTGAAG TGTTGAAGCATCACACAGACATGAGCAGTTCGAGCTACTTGGCAGCCACCCACCATCCTCCACACAGTCCCTTGGTGCGACAGCTCTCCA CCTCCTCAGATTCCCCTGCACCCGCCAGCTCTAGCTCACAGGTTACAGCCAGCACATCGCAGCAGCCAGTAAGGAGGAGAAGGGGAGAGA GCTCATTTGATATTAACAACATTGTCATCCCAATGTCTGTTGCTGCAACAACTCGCGTAGAGAAACTGCAATACAAGGAAATCCTTACGC CCAGCTGGCGGGAGGTTGATCTTCAGTCTCTGAAGGGGAGTCCTGATGAGGAGAATGAAGAGATTGAGGACCTATCCGACGCAGCCTTCG CCGCCCTGCATGCCAAATGTGAGGAGATGGAGAGGGCACGGTGGCTGTGGACCACGAGTGTGCCACCCCAGCGGCGGGGCAGCAGGTCCT ACAGGTCATCAGACGGCCGGACAACCCCCCAGCTGGGCAGTGCCAACCCCTCCACCCCCCAGCCTGCCTCCCCTGATGTCAGCAGTAGCC ACTCTTTGTCAGAATACTCCCATGGTCAGTCCCCTAGGAGCCCCATTAGCCCGGAACTGCACTCAGCACCCCTCACCCCTGTGGCTCGGG ACACTCCGCGACACTTAGCCAGTGAGGATACCCGTTGTTCCACACCAGAGCTGGGGCTGGATGAACAGTCTGTCCAGCCCTGGGAGCGGC GGACCTTCCCCCTGGCGCACAGTCCCCAGGCGGAGTGTGAGGACCAGCTGGATGCACAGGAGCGAGCAGCCCGCTGCACTCGACGCACCT CAGGCAGCAAGACTGGCCGGGAGACAGAGGCAGCGCCCACCTCGCCTCCCATTGTCCCCCTCAAGAGTCGGCATCTGGTGGCAGCAGCCA CAGCTCAGCGCCCGACTCACAGATGAGCGGGAGACAGCCATCTAAACAGACTCACTAACTATTGGCATTAAAGCTTCAGAAATCTCTGCG TTTGATATTCAAACATCATATGCCGGAAATTTTCACAGTTTTTAGTGAACTTAAGGAATTTAGATCCTACTTTGGTATTTTTTTTTCTTG TTTTAATTTTTGTTTTGTTTTTGTTTCCATGTTTTCTTGTCACACACCTGAGCACTTCCTCCCGTTGGCAAACAGAAGTTCAGGATGAGA CCCTGCTGGCCTGGTCCTGGCACATCCTCTGCACTGTTGAATCACTGGACTTACTGATCTTAGATGACCACCCCCTCCCTCACACCTGTG GGCAGGGCAGAACAGCCTGGCGGGCTACAGTTTAGCATGGCCTTCTTGAGCTAGGGTGGAATGGGGCAGGGTGCTCTGGACTCTTACCCC CTCCCCTCCCATCTGTGGCTTGGCTCTGCTGTGGCCCTCCTGGCTGGGTCCCCTTGGTTTTTCGTGCTGGAACATCCCCACCAGAGCCTC TCTGCCATAACTGCCAGCTGCTCTCCCCGAGTGCTCAGCTGGCAGAACACCTTTCCTTTCTCACCCAGAACTTAAGAGACTGATTTTTTG TTTCATCTGCATTTGGTCTTCTCTGTTTTGACTCTTTCACTGCAGTAACCTGGCTGTGGCTGCTCAGGTTCCCCTCCTCATGCCCCTTGG TACCCTTCCCTGTCTGCTCTCCCATGCCATGTACACACCCACAACCCGTCCTTCCACTTGGAATATTTTTACCACCTATCCTGATCTTTG AAGGTAGGGTTAGGACTACTTAACCTCTATTCCCACTCCCCTGCAAACTGGGGGTTGTGGGAAGTGAGCAGCCATCTCCCTGTGTGATTT TTTTTTTTTTTCCCTCTGATTCACTTTGCCATGTTTCCTTCACATCCAGATCCCTGTCGGTGTTAGTTCCACTCTTGGTCTTTCACGCTC CCCTTGCCTGTGGAACATTGTCTGGTCCTAGCTGTGGTTCCCATTGTTCCCCCTTCACCCTTCTCTGTTAACCTTGTGCCTGTCTCCTGT ATGATCACATCACCAAAAAGGGGGAGGGGGGAGAAGACTCTTTTTTTTTGGCCATTTTGTAATCGTATAAAAATAGTAGACAACTGCTTA ATGGTTGGGGTTTTTTCACAATTTTCAACATTAGTGATTTTTTTTTCTGTTTGCAAGTTAAAGGGTTTGTCATTGTTTCTTTAAAAAAAA ATACAATAATGCACCATATCCCTATGCATAAAGTGCTTCTTCTATTTATAAGGTTGAAAATTCTGAATAACCCTTTTAGCATTGAAAAAA AAAACAAAAACAAAAAATGGAAAAAAAAAACCTTGTATTTTGTAAATATTTTCTTTTCCTGCTTTGGAGCTGTGTAATGGCAGCGAAACA TGTAGCTGTCTTTGTTCTATAGAAATGCTTTTCTTCAGAGAAGCTGATCTTTGTTAATGTCTTGATTCTGTTCGCAAAGCACAGACTAGT GCTT >41186_41186_2_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000432791_length(amino acids)=786AA_BP=192 MSEAGGAGPGGCGAGAGAGAGPGALPPQPAALPPAPPQGSPCAAAAGGSGACGPATAVAAAGTAEGPGGGGSARIAVKKAQLRSAPRAKK LEKLGVYSACKAEESCKCNGWKNPNPSPTPPRADLQQIIVSLTESCRSCSHALAAHVSHLENVSEEEMNRLLGIVLDVEYLFTCVHKEED ADTKQVYFYLFKIESVSQPLENHGARIIGHISESLSTKSCGALRPVNGVINTLQPVLADHIPGDSSDAEEQLHKKQRLNLVSSSSDGTCV AARTRPVLSCKKRRLVRPNSIVPLSKKVHRNSTIRPGCDVNPSCALCGSGSINTMPPEIHYEAPLLERLSQLDSCVHPVLAFPDDVPTSL HFQSMLKSQWQNKPFDKIKPPKKLSLKHRAPMPGSLPDSARKDRHKLVSSFLTTAKLSHHQTRPDRTHRQHLDDVGAVPMVERVTAPKAE RLLNPPPPVHDPNHSKMRLRDHSSERSEVLKHHTDMSSSSYLAATHHPPHSPLVRQLSTSSDSPAPASSSSQVTASTSQQPVRRRRGESS FDINNIVIPMSVAATTRVEKLQYKEILTPSWREVDLQSLKGSPDEENEEIEDLSDAAFAALHAKCEEMERARWLWTTSVPPQRRGSRSYR SSDGRTTPQLGSANPSTPQPASPDVSSSHSLSEYSHGQSPRSPISPELHSAPLTPVARDTPRHLASEDTRCSTPELGLDEQSVQPWERRT FPLAHSPQAECEDQLDAQERAARCTRRTSGSKTGRETEAAPTSPPIVPLKSRHLVAAATAQRPTHR -------------------------------------------------------------- >41186_41186_3_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000572904_length(transcript)=4339nt_BP=1031nt CCGCGGGCAGCGGAAAAGAGGCCGTGGGGGGCCTCCCAGCGCTGGCAGACACCGTGAGGCTGGCAGCCGCCGGCACGCACACCTAGTCCG CAGTCCCGAGGAACATGTCCGCAGCCAGGGCGCGGAGCAGAGTCCCGGGCAGGAGAACCAAGGGAGGGCGTGTGCTGTGGCGGCGGCGGC AGCGGCAGCGGAGCCGCTAGTCCCCTCCCTCCTGGGGGAGCAGCTGCCGCCGCTGCCGCCGCCGCCACCACCATCAGCGCGCGGGGCCCG GCCAGAGCGAGCCGGGCGAGCGGCGCGCTAGGGGGAGGGCGGGGGCGGGGAGGGGGGTGGGCGAAGGGGGCGGGAGGGCGTGGGGGGAGG GTCTCGCTCTCCCGACTACCAGAGCCCGAGAGGGAGACCCTGGCGGCGGCGGCGGCGCCTGACACTCGGCGCCTCCTGCCGTGCTCCGGG GCGGCATGTCCGAGGCTGGCGGGGCCGGGCCGGGCGGCTGCGGGGCAGGAGCCGGGGCAGGGGCCGGGCCCGGGGCGCTGCCCCCGCAGC CTGCGGCGCTTCCGCCCGCGCCCCCGCAGGGCTCCCCCTGCGCCGCTGCCGCCGGGGGCTCGGGCGCCTGCGGTCCGGCGACGGCAGTGG CTGCAGCGGGCACGGCCGAAGGACCGGGAGGCGGTGGCTCGGCCCGAATCGCCGTGAAGAAAGCGCAACTACGCTCCGCTCCGCGGGCCA AGAAACTGGAGAAACTCGGAGTGTACTCCGCCTGCAAGGCCGAGGAGTCTTGTAAATGTAATGGCTGGAAAAACCCTAACCCCTCACCCA CTCCCCCCAGAGCCGACCTGCAGCAAATAATTGTCAGTCTAACAGAATCCTGTCGGAGTTGTAGCCATGCCCTAGCTGCTCATGTTTCCC ACCTGGAGAATGTGTCAGAGGAAGAAATGAACAGACTCCTGGGAATAGTATTGGATGTGGAATATCTCTTTACCTGTGTCCACAAGGAAG AAGATGCAGATACCAAACAAGTTTATTTCTATCTATTTAAGATTGAGTCTGTTTCTCAGCCATTGGAAAACCATGGTGCCCGTATTATTG GTCATATTTCAGAGTCACTGTCTACCAAATCATGTGGAGCACTCAGACCTGTCAATGGAGTTATTAACACTCTTCAGCCTGTCTTGGCAG ACCACATTCCAGGTGACAGCTCTGATGCTGAGGAACAATTACATAAGAAGCAACGACTGAATCTCGTCTCTTCATCATCTGATGGCACCT GTGTGGCAGCCCGGACACGTCCTGTACTGAGCTGTAAGAAGCGGAGGCTTGTTCGACCCAACAGCATCGTTCCTCTTTCCAAGAAGGTTC ACCGGAACAGCACAATCCGCCCTGGCTGTGATGTGAATCCCTCCTGCGCACTGTGTGGTTCAGGCAGCATCAACACCATGCCTCCCGAAA TTCACTATGAAGCCCCTCTGTTGGAACGTCTTTCCCAGTTGGACTCTTGTGTTCATCCTGTTCTAGCATTTCCAGATGATGTTCCCACAA GCCTGCATTTCCAGAGCATGCTGAAATCTCAGTGGCAGAACAAGCCTTTTGACAAAATCAAACCTCCCAAAAAGTTATCGCTTAAGCACA GAGCACCCATGCCGGGCAGTCTGCCAGATTCAGCTCGTAAGGACAGGCACAAATTGGTCAGCTCCTTCCTAACAACAGCCAAGCTGTCCC ATCACCAAACCCGGCCTGACAGGACCCACAGGCAGCACTTAGACGATGTGGGGGCCGTGCCCATGGTGGAGCGAGTGACAGCGCCAAAAG CAGAGCGCTTGCTCAACCCACCACCACCCGTGCATGACCCAAACCACAGCAAAATGAGATTGCGAGACCATTCATCTGAGAGAAGTGAAG TGTTGAAGCATCACACAGACATGAGCAGTTCGAGCTACTTGGCAGCCACCCACCATCCTCCACACAGTCCCTTGGTGCGACAGCTCTCCA CCTCCTCAGATTCCCCTGCACCCGCCAGCTCTAGCTCACAGGTTACAGCCAGCACATCGCAGCAGCCAGTAAGGAGGAGAAGGGGAGAGA GCTCATTTGATATTAACAACATTGTCATCCCAATGTCTGTTGCTGCAACAACTCGCGTAGAGAAACTGCAATACAAGGAAATCCTTACGC CCAGCTGGCGGGAGGTTGATCTTCAGTCTCTGAAGGGGAGTCCTGATGAGGAGAATGAAGAGATTGAGGACCTATCCGACGCAGCCTTCG CCGCCCTGCATGCCAAATGTGAGGAGATGGAGAGGGCACGGTGGCTGTGGACCACGAGTGTGCCACCCCAGCGGCGGGGCAGCAGGTCCT ACAGGTCATCAGACGGCCGGACAACCCCCCAGCTGGGCAGTGCCAACCCCTCCACCCCCCAGCCTGCCTCCCCTGATGTCAGCAGTAGCC ACTCTTTGTCAGAATACTCCCATGGTCAGTCCCCTAGGAGCCCCATTAGCCCGGAACTGCACTCAGCACCCCTCACCCCTGTGGCTCGGG ACACTCCGCGACACTTAGCCAGTGAGGATACCCGTTGTTCCACACCAGAGCTGGGGCTGGATGAACAGTCTGTCCAGCCCTGGGAGCGGC GGACCTTCCCCCTGGCGCACAGTCCCCAGGCGGAGTGTGAGGACCAGCTGGATGCACAGGAGCGAGCAGCCCGCTGCACTCGACGCACCT CAGGCAGCAAGACTGGCCGGGAGACAGAGGCAGCGCCCACCTCGCCTCCCATTGTCCCCCTCAAGAGTCGGCATCTGGTGGCAGCAGCCA CAGCTCAGCGCCCGACTCACAGATGAGCGGGAGACAGCCATCTAAACAGACTCACTAACTATTGGCATTAAAGCTTCAGAAATCTCTGCG TTTGATATTCAAACATCATATGCCGGAAATTTTCACAGTTTTTAGTGAACTTAAGGAATTTAGATCCTACTTTGGTATTTTTTTTTCTTG TTTTAATTTTTGTTTTGTTTTTGTTTCCATGTTTTCTTGTCACACACCTGAGCACTTCCTCCCGTTGGCAAACAGAAGTTCAGGATGAGA CCCTGCTGGCCTGGTCCTGGCACATCCTCTGCACTGTTGAATCACTGGACTTACTGATCTTAGATGACCACCCCCTCCCTCACACCTGTG GGCAGGGCAGAACAGCCTGGCGGGCTACAGTTTAGCATGGCCTTCTTGAGCTAGGGTGGAATGGGGCAGGGTGCTCTGGACTCTTACCCC CTCCCCTCCCATCTGTGGCTTGGCTCTGCTGTGGCCCTCCTGGCTGGGTCCCCTTGGTTTTTCGTGCTGGAACATCCCCACCAGAGCCTC TCTGCCATAACTGCCAGCTGCTCTCCCCGAGTGCTCAGCTGGCAGAACACCTTTCCTTTCTCACCCAGAACTTAAGAGACTGATTTTTTG TTTCATCTGCATTTGGTCTTCTCTGTTTTGACTCTTTCACTGCAGTAACCTGGCTGTGGCTGCTCAGGTTCCCCTCCTCATGCCCCTTGG TACCCTTCCCTGTCTGCTCTCCCATGCCATGTACACACCCACAACCCGTCCTTCCACTTGGAATATTTTTACCACCTATCCTGATCTTTG AAGGTAGGGTTAGGACTACTTAACCTCTATTCCCACTCCCCTGCAAACTGGGGGTTGTGGGAAGTGAGCAGCCATCTCCCTGTGTGATTT TTTTTTTTTTTCCCTCTGATTCACTTTGCCATGTTTCCTTCACATCCAGATCCCTGTCGGTGTTAGTTCCACTCTTGGTCTTTCACGCTC CCCTTGCCTGTGGAACATTGTCTGGTCCTAGCTGTGGTTCCCATTGTTCCCCCTTCACCCTTCTCTGTTAACCTTGTGCCTGTCTCCTGT ATGATCACATCACCAAAAAGGGGGAGGGGGGAGAAGACTCTTTTTTTTTGGCCATTTTGTAATCGTATAAAAATAGTAGACAACTGCTTA ATGGTTGGGGTTTTTTCACAATTTTCAACATTAGTGATTTTTTTTTCTGTTTGCAAGTTAAAGGGTTTGTCATTGTTTCTTTAAAAAAAA ATACAATAATGCACCATATCCCTATGCATAAAGTGCTTCTTCTATTTATAAGGTTGAAAATTCTGAATAACCCTTTTAGCATTGAAAAAA AAAACAAAAACAAAAAATGGAAAAAAAAAACCTTGTATTTTGTAAATATTTTCTTTTCCTGCTTTGGAGCTGTGTAATGGCAGCGAAACA TGTAGCTGTCTTTGTTCTATAGAAATGCTTTTCTTCAGAGAAGCTGATCTTTGTTAATGTCTTGATTCTGTTCGCAAAGCACAGACTAGT GCTTAAAAAAAAAAAAGAA >41186_41186_3_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000572904_length(amino acids)=786AA_BP=192 MSEAGGAGPGGCGAGAGAGAGPGALPPQPAALPPAPPQGSPCAAAAGGSGACGPATAVAAAGTAEGPGGGGSARIAVKKAQLRSAPRAKK LEKLGVYSACKAEESCKCNGWKNPNPSPTPPRADLQQIIVSLTESCRSCSHALAAHVSHLENVSEEEMNRLLGIVLDVEYLFTCVHKEED ADTKQVYFYLFKIESVSQPLENHGARIIGHISESLSTKSCGALRPVNGVINTLQPVLADHIPGDSSDAEEQLHKKQRLNLVSSSSDGTCV AARTRPVLSCKKRRLVRPNSIVPLSKKVHRNSTIRPGCDVNPSCALCGSGSINTMPPEIHYEAPLLERLSQLDSCVHPVLAFPDDVPTSL HFQSMLKSQWQNKPFDKIKPPKKLSLKHRAPMPGSLPDSARKDRHKLVSSFLTTAKLSHHQTRPDRTHRQHLDDVGAVPMVERVTAPKAE RLLNPPPPVHDPNHSKMRLRDHSSERSEVLKHHTDMSSSSYLAATHHPPHSPLVRQLSTSSDSPAPASSSSQVTASTSQQPVRRRRGESS FDINNIVIPMSVAATTRVEKLQYKEILTPSWREVDLQSLKGSPDEENEEIEDLSDAAFAALHAKCEEMERARWLWTTSVPPQRRGSRSYR SSDGRTTPQLGSANPSTPQPASPDVSSSHSLSEYSHGQSPRSPISPELHSAPLTPVARDTPRHLASEDTRCSTPELGLDEQSVQPWERRT FPLAHSPQAECEDQLDAQERAARCTRRTSGSKTGRETEAAPTSPPIVPLKSRHLVAAATAQRPTHR -------------------------------------------------------------- >41186_41186_4_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000574590_length(transcript)=4376nt_BP=1031nt CCGCGGGCAGCGGAAAAGAGGCCGTGGGGGGCCTCCCAGCGCTGGCAGACACCGTGAGGCTGGCAGCCGCCGGCACGCACACCTAGTCCG CAGTCCCGAGGAACATGTCCGCAGCCAGGGCGCGGAGCAGAGTCCCGGGCAGGAGAACCAAGGGAGGGCGTGTGCTGTGGCGGCGGCGGC AGCGGCAGCGGAGCCGCTAGTCCCCTCCCTCCTGGGGGAGCAGCTGCCGCCGCTGCCGCCGCCGCCACCACCATCAGCGCGCGGGGCCCG GCCAGAGCGAGCCGGGCGAGCGGCGCGCTAGGGGGAGGGCGGGGGCGGGGAGGGGGGTGGGCGAAGGGGGCGGGAGGGCGTGGGGGGAGG GTCTCGCTCTCCCGACTACCAGAGCCCGAGAGGGAGACCCTGGCGGCGGCGGCGGCGCCTGACACTCGGCGCCTCCTGCCGTGCTCCGGG GCGGCATGTCCGAGGCTGGCGGGGCCGGGCCGGGCGGCTGCGGGGCAGGAGCCGGGGCAGGGGCCGGGCCCGGGGCGCTGCCCCCGCAGC CTGCGGCGCTTCCGCCCGCGCCCCCGCAGGGCTCCCCCTGCGCCGCTGCCGCCGGGGGCTCGGGCGCCTGCGGTCCGGCGACGGCAGTGG CTGCAGCGGGCACGGCCGAAGGACCGGGAGGCGGTGGCTCGGCCCGAATCGCCGTGAAGAAAGCGCAACTACGCTCCGCTCCGCGGGCCA AGAAACTGGAGAAACTCGGAGTGTACTCCGCCTGCAAGGCCGAGGAGTCTTGTAAATGTAATGGCTGGAAAAACCCTAACCCCTCACCCA CTCCCCCCAGAGCCGACCTGCAGCAAATAATTGTCAGTCTAACAGAATCCTGTCGGAGTTGTAGCCATGCCCTAGCTGCTCATGTTTCCC ACCTGGAGAATGTGTCAGAGGAAGAAATGAACAGACTCCTGGGAATAGTATTGGATGTGGAATATCTCTTTACCTGTGTCCACAAGGAAG AAGATGCAGATACCAAACAAGTTTATTTCTATCTATTTAAGATTGAGTCTGTTTCTCAGCCATTGGAAAACCATGGTGCCCGTATTATTG GTCATATTTCAGAGTCACTGTCTACCAAATCATGTGGAGCACTCAGACCTGTCAATGGAGTTATTAACACTCTTCAGCCTGTCTTGGCAG ACCACATTCCAGGTGACAGCTCTGATGCTGAGGAACAATTACATAAGAAGCAACGACTGAATCTCGTCTCTTCATCATCTGATGGCACCT GTGTGGCAGCCCGGACACGTCCTGTACTGAGCTGTAAGAAGCGGAGGCTTGTTCGACCCAACAGCATCGTTCCTCTTTCCAAGAAGGTTC ACCGGAACAGCACAATCCGCCCTGGCTGTGATGTGAATCCCTCCTGCGCACTGTGTGGTTCAGGCAGCATCAACACCATGCCTCCCGAAA TTCACTATGAAGCCCCTCTGTTGGAACGTCTTTCCCAGTTGGACTCTTGTGTTCATCCTGTTCTAGCATTTCCAGATGATGTTCCCACAA GCCTGCATTTCCAGAGCATGCTGAAATCTCAGTGGCAGAACAAGCCTTTTGACAAAATCAAACCTCCCAAAAAGTTATCGCTTAAGCACA GAGCACCCATGCCGGGCAGTCTGCCAGATTCAGCTCGTAAGGACAGGCACAAATTGGTCAGCTCCTTCCTAACAACAGCCAAGCTGTCCC ATCACCAAACCCGGCCTGACAGGACCCACAGGCAGCACTTAGACGATGTGGGGGCCGTGCCCATGGTGGAGCGAGTGACAGCGCCAAAAG CAGAGCGCTTGCTCAACCCACCACCACCCGTGCATGACCCAAACCACAGCAAAATGAGATTGCGAGACCATTCATCTGAGAGAAGTGAAG TGTTGAAGCATCACACAGACATGAGCAGTTCGAGCTACTTGGCAGCCACCCACCATCCTCCACACAGTCCCTTGGTGCGACAGCTCTCCA CCTCCTCAGATTCCCCTGCACCCGCCAGCTCTAGCTCACAGGTTACAGCCAGCACATCGCAGCAGCCAGTAAGGAGGAGAAGGGGAGAGA GCTCATTTGATATTAACAACATTGTCATCCCAATGTCTGTTGCTGCAACAACTCGCGTAGAGAAACTGCAATACAAGGAAATCCTTACGC CCAGCTGGCGGGAGGTTGATCTTCAGTCTCTGAAGGGGAGTCCTGATGAGGAGAATGAAGAGATTGAGGACCTATCCGACGCAGCCTTCG CCGCCCTGCATGCCAAATGTGAGGAGATGGAGAGGGCACGGTGGCTGTGGACCACGAGTGTGCCACCCCAGCGGCGGGGCAGCAGGTCCT ACAGGTCATCAGACGGCCGGACAACCCCCCAGCTGGGCAGTGCCAACCCCTCCACCCCCCAGCCTGCCTCCCCTGATGTCAGCAGTAGCC ACTCTTTGTCAGAATACTCCCATGGTCAGTCCCCTAGGAGCCCCATTAGCCCGGAACTGCACTCAGCACCCCTCACCCCTGTGGCTCGGG ACACTCCGCGACACTTAGCCAGTGAGGATACCCGTTGTTCCACACCAGAGCTGGGGCTGGATGAACAGTCTGTCCAGCCCTGGGAGCGGC GGACCTTCCCCCTGGCGCACAGTCCCCAGGCGGAGTGTGAGGACCAGCTGGATGCACAGGAGCGAGCAGCCCGCTGCACTCGACGCACCT CAGGCAGCAAGACTGGCCGGGAGACAGAGGCAGCGCCCACCTCGCCTCCCATTGTCCCCCTCAAGAGTCGGCATCTGGTGGCAGCAGCCA CAGCTCAGCGCCCGACTCACAGATGAGCGGGAGACAGCCATCTAAACAGACTCACTAACTATTGGCATTAAAGCTTCAGAAATCTCTGCG TTTGATATTCAAACATCATATGCCGGAAATTTTCACAGTTTTTAGTGAACTTAAGGAATTTAGATCCTACTTTGGTATTTTTTTTTCTTG TTTTAATTTTTGTTTTGTTTTTGTTTCCATGTTTTCTTGTCACACACCTGAGCACTTCCTCCCGTTGGCAAACAGAAGTTCAGGATGAGA CCCTGCTGGCCTGGTCCTGGCACATCCTCTGCACTGTTGAATCACTGGACTTACTGATCTTAGATGACCACCCCCTCCCTCACACCTGTG GGCAGGGCAGAACAGCCTGGCGGGCTACAGTTTAGCATGGCCTTCTTGAGCTAGGGTGGAATGGGGCAGGGTGCTCTGGACTCTTACCCC CTCCCCTCCCATCTGTGGCTTGGCTCTGCTGTGGCCCTCCTGGCTGGGTCCCCTTGGTTTTTCGTGCTGGAACATCCCCACCAGAGCCTC TCTGCCATAACTGCCAGCTGCTCTCCCCGAGTGCTCAGCTGGCAGAACACCTTTCCTTTCTCACCCAGAACTTAAGAGACTGATTTTTTG TTTCATCTGCATTTGGTCTTCTCTGTTTTGACTCTTTCACTGCAGTAACCTGGCTGTGGCTGCTCAGGTTCCCCTCCTCATGCCCCTTGG TACCCTTCCCTGTCTGCTCTCCCATGCCATGTACACACCCACAACCCGTCCTTCCACTTGGAATATTTTTACCACCTATCCTGATCTTTG AAGGTAGGGTTAGGACTACTTAACCTCTATTCCCACTCCCCTGCAAACTGGGGGTTGTGGGAAGTGAGCAGCCATCTCCCTGTGTGATTT TTTTTTTTTTTCCCTCTGATTCACTTTGCCATGTTTCCTTCACATCCAGATCCCTGTCGGTGTTAGTTCCACTCTTGGTCTTTCACGCTC CCCTTGCCTGTGGAACATTGTCTGGTCCTAGCTGTGGTTCCCATTGTTCCCCCTTCACCCTTCTCTGTTAACCTTGTGCCTGTCTCCTGT ATGATCACATCACCAAAAAGGGGGAGGGGGGAGAAGACTCTTTTTTTTTGGCCATTTTGTAATCGTATAAAAATAGTAGACAACTGCTTA ATGGTTGGGGTTTTTTCACAATTTTCAACATTAGTGATTTTTTTTTCTGTTTGCAAGTTAAAGGGTTTGTCATTGTTTCTTTAAAAAAAA ATACAATAATGCACCATATCCCTATGCATAAAGTGCTTCTTCTATTTATAAGGTTGAAAATTCTGAATAACCCTTTTAGCATTGAAAAAA AAAACAAAAACAAAAAATGGAAAAAAAAAACCTTGTATTTTGTAAATATTTTCTTTTCCTGCTTTGGAGCTGTGTAATGGCAGCGAAACA TGTAGCTGTCTTTGTTCTATAGAAATGCTTTTCTTCAGAGAAGCTGATCTTTGTTAATGTCTTGATTCTGTTCGCAAAGCACAGACTAGT GCTTAAAAAAAAAAAAGAAGGAAAAATTGAAAAAAATAAAAAAAAAAGTTACAGAA >41186_41186_4_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000574590_length(amino acids)=786AA_BP=192 MSEAGGAGPGGCGAGAGAGAGPGALPPQPAALPPAPPQGSPCAAAAGGSGACGPATAVAAAGTAEGPGGGGSARIAVKKAQLRSAPRAKK LEKLGVYSACKAEESCKCNGWKNPNPSPTPPRADLQQIIVSLTESCRSCSHALAAHVSHLENVSEEEMNRLLGIVLDVEYLFTCVHKEED ADTKQVYFYLFKIESVSQPLENHGARIIGHISESLSTKSCGALRPVNGVINTLQPVLADHIPGDSSDAEEQLHKKQRLNLVSSSSDGTCV AARTRPVLSCKKRRLVRPNSIVPLSKKVHRNSTIRPGCDVNPSCALCGSGSINTMPPEIHYEAPLLERLSQLDSCVHPVLAFPDDVPTSL HFQSMLKSQWQNKPFDKIKPPKKLSLKHRAPMPGSLPDSARKDRHKLVSSFLTTAKLSHHQTRPDRTHRQHLDDVGAVPMVERVTAPKAE RLLNPPPPVHDPNHSKMRLRDHSSERSEVLKHHTDMSSSSYLAATHHPPHSPLVRQLSTSSDSPAPASSSSQVTASTSQQPVRRRRGESS FDINNIVIPMSVAATTRVEKLQYKEILTPSWREVDLQSLKGSPDEENEEIEDLSDAAFAALHAKCEEMERARWLWTTSVPPQRRGSRSYR SSDGRTTPQLGSANPSTPQPASPDVSSSHSLSEYSHGQSPRSPISPELHSAPLTPVARDTPRHLASEDTRCSTPELGLDEQSVQPWERRT FPLAHSPQAECEDQLDAQERAARCTRRTSGSKTGRETEAAPTSPPIVPLKSRHLVAAATAQRPTHR -------------------------------------------------------------- >41186_41186_5_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000575318_length(transcript)=4175nt_BP=1031nt CCGCGGGCAGCGGAAAAGAGGCCGTGGGGGGCCTCCCAGCGCTGGCAGACACCGTGAGGCTGGCAGCCGCCGGCACGCACACCTAGTCCG CAGTCCCGAGGAACATGTCCGCAGCCAGGGCGCGGAGCAGAGTCCCGGGCAGGAGAACCAAGGGAGGGCGTGTGCTGTGGCGGCGGCGGC AGCGGCAGCGGAGCCGCTAGTCCCCTCCCTCCTGGGGGAGCAGCTGCCGCCGCTGCCGCCGCCGCCACCACCATCAGCGCGCGGGGCCCG GCCAGAGCGAGCCGGGCGAGCGGCGCGCTAGGGGGAGGGCGGGGGCGGGGAGGGGGGTGGGCGAAGGGGGCGGGAGGGCGTGGGGGGAGG GTCTCGCTCTCCCGACTACCAGAGCCCGAGAGGGAGACCCTGGCGGCGGCGGCGGCGCCTGACACTCGGCGCCTCCTGCCGTGCTCCGGG GCGGCATGTCCGAGGCTGGCGGGGCCGGGCCGGGCGGCTGCGGGGCAGGAGCCGGGGCAGGGGCCGGGCCCGGGGCGCTGCCCCCGCAGC CTGCGGCGCTTCCGCCCGCGCCCCCGCAGGGCTCCCCCTGCGCCGCTGCCGCCGGGGGCTCGGGCGCCTGCGGTCCGGCGACGGCAGTGG CTGCAGCGGGCACGGCCGAAGGACCGGGAGGCGGTGGCTCGGCCCGAATCGCCGTGAAGAAAGCGCAACTACGCTCCGCTCCGCGGGCCA AGAAACTGGAGAAACTCGGAGTGTACTCCGCCTGCAAGGCCGAGGAGTCTTGTAAATGTAATGGCTGGAAAAACCCTAACCCCTCACCCA CTCCCCCCAGAGCCGACCTGCAGCAAATAATTGTCAGTCTAACAGAATCCTGTCGGAGTTGTAGCCATGCCCTAGCTGCTCATGTTTCCC ACCTGGAGAATGTGTCAGAGGAAGAAATGAACAGACTCCTGGGAATAGTATTGGATGTGGAATATCTCTTTACCTGTGTCCACAAGGAAG AAGATGCAGATACCAAACAAGTTTATTTCTATCTATTTAAGATTGAGTCTGTTTCTCAGCCATTGGAAAACCATGGTGCCCGTATTATTG GTCATATTTCAGAGTCACTGTCTACCAAATCATGTGGAGCACTCAGACCTGTCAATGGAGTTATTAACACTCTTCAGCCTGTCTTGGCAG ACCACATTCCAGGTGACAGCTCTGATGCTGAGGAACAATTACATAAGAAGCAACGACTGAATCTCGTCTCTTCATCATCTGATGGCACCT GTGTGGCAGCCCGGACACGTCCTGTACTGAGCTGTAAGAAGCGGAGGCTTGTTCGACCCAACAGCATCGTTCCTCTTTCCAAGAAGGTTC ACCGGAACAGCACAATCCGCCCTGGCTGTGATGTGAATCCCTCCTGCGCACTGTGTGGTTCAGGCAGCATCAACACCATGCCTCCCGAAA TTCACTATGAAGCCCCTCTGTTGGAACGTCTTTCCCAGTTGGACTCTTGTGTTCATCCTGTTCTAGCATTTCCAGATGATGTTCCCACAA GCCTGCATTTCCAGAGCATGCTGAAATCTCAGTGGCAGAACAAGCCTTTTGACAAAATCAAACCTCCCAAAAAGTTATCGCTTAAGCACA GAGCACCCATGCCGGGCAGTCTGCCAGATTCAGCTCGTAAGGACAGGCACAAATTGGTCAGCTCCTTCCTAACAACAGCCATGTTGAAGC ATCACACAGACATGAGCAGTTCGAGCTACTTGGCAGCCACCCACCATCCTCCACACAGTCCCTTGGTGCGACAGCTCTCCACCTCCTCAG ATTCCCCTGCACCCGCCAGCTCTAGCTCACAGGTTACAGCCAGCACATCGCAGCCAGTAAGGAGGAGAAGGGGAGAGAGCTCATTTGATA TTAACAACATTGTCATCCCAATGTCTGTTGCTGCAACAACTCGCGTAGAGAAACTGCAATACAAGGAAATCCTTACGCCCAGCTGGCGGG AGGTTGATCTTCAGTCTCTGAAGGGGAGTCCTGATGAGGAGAATGAAGAGATTGAGGACCTATCCGACGCAGCCTTCGCCGCCCTGCATG CCAAATGTGAGGAGATGGAGAGGGCACGGTGGCTGTGGACCACGAGTGTGCCACCCCAGCGGCGGGGCAGCAGGTCCTACAGGTCATCAG ACGGCCGGACAACCCCCCAGCTGGGCAGTGCCAACCCCTCCACCCCCCAGCCTGCCTCCCCTGATGTCAGCAGTAGCCACTCTTTGTCAG AATACTCCCATGGTCAGTCCCCTAGGAGCCCCATTAGCCCGGAACTGCACTCAGCACCCCTCACCCCTGTGGCTCGGGACACTCCGCGAC ACTTAGCCAGTGAGGATACCCGTTGTTCCACACCAGAGCTGGGGCTGGATGAACAGTCTGTCCAGCCCTGGGAGCGGCGGACCTTCCCCC TGGCGCACAGTCCCCAGGCGGAGTGTGAGGACCAGCTGGATGCACAGGAGCGAGCAGCCCGCTGCACTCGACGCACCTCAGGCAGCAAGA CTGGCCGGGAGACAGAGGCAGCGCCCACCTCGCCTCCCATTGTCCCCCTCAAGAGTCGGCATCTGGTGGCAGCAGCCACAGCTCAGCGCC CGACTCACAGATGAGCGGGAGACAGCCATCTAAACAGACTCACTAACTATTGGCATTAAAGCTTCAGAAATCTCTGCGTTTGATATTCAA ACATCATATGCCGGAAATTTTCACAGTTTTTAGTGAACTTAAGGAATTTAGATCCTACTTTGGTATTTTTTTTTCTTGTTTTAATTTTTG TTTTGTTTTTGTTTCCATGTTTTCTTGTCACACACCTGAGCACTTCCTCCCGTTGGCAAACAGAAGTTCAGGATGAGACCCTGCTGGCCT GGTCCTGGCACATCCTCTGCACTGTTGAATCACTGGACTTACTGATCTTAGATGACCACCCCCTCCCTCACACCTGTGGGCAGGGCAGAA CAGCCTGGCGGGCTACAGTTTAGCATGGCCTTCTTGAGCTAGGGTGGAATGGGGCAGGGTGCTCTGGACTCTTACCCCCTCCCCTCCCAT CTGTGGCTTGGCTCTGCTGTGGCCCTCCTGGCTGGGTCCCCTTGGTTTTTCGTGCTGGAACATCCCCACCAGAGCCTCTCTGCCATAACT GCCAGCTGCTCTCCCCGAGTGCTCAGCTGGCAGAACACCTTTCCTTTCTCACCCAGAACTTAAGAGACTGATTTTTTGTTTCATCTGCAT TTGGTCTTCTCTGTTTTGACTCTTTCACTGCAGTAACCTGGCTGTGGCTGCTCAGGTTCCCCTCCTCATGCCCCTTGGTACCCTTCCCTG TCTGCTCTCCCATGCCATGTACACACCCACAACCCGTCCTTCCACTTGGAATATTTTTACCACCTATCCTGATCTTTGAAGGTAGGGTTA GGACTACTTAACCTCTATTCCCACTCCCCTGCAAACTGGGGGTTGTGGGAAGTGAGCAGCCATCTCCCTGTGTGATTTTTTTTTTTTTTC CCTCTGATTCACTTTGCCATGTTTCCTTCACATCCAGATCCCTGTCGGTGTTAGTTCCACTCTTGGTCTTTCACGCTCCCCTTGCCTGTG GAACATTGTCTGGTCCTAGCTGTGGTTCCCATTGTTCCCCCTTCACCCTTCTCTGTTAACCTTGTGCCTGTCTCCTGTATGATCACATCA CCAAAAAGGGGGAGGGGGGAGAAGACTCTTTTTTTTTGGCCATTTTGTAATCGTATAAAAATAGTAGACAACTGCTTAATGGTTGGGGTT TTTTCACAATTTTCAACATTAGTGATTTTTTTTTCTGTTTGCAAGTTAAAGGGTTTGTCATTGTTTCTTTAAAAAAAAATACAATAATGC ACCATATCCCTATGCATAAAGTGCTTCTTCTATTTATAAGGTTGAAAATTCTGAATAACCCTTTTAGCATTGAAAAAAAAAACAAAAACA AAAAATGGAAAAAAAAAACCTTGTATTTTGTAAATATTTTCTTTTCCTGCTTTGGAGCTGTGTAATGGCAGCGAAACATGTAGCTGTCTT TGTTCTATAGAAATGCTTTTCTTCAGAGAAGCTGATCTTTGTTAATGTCTTGATTCTGTTCGCAAAGCACAGACTAGTGCTTAAAAAAAA AAAAGAAGGAAAAATTGAAAAAAATAAAAAAAAAA >41186_41186_5_KAT2B-KANSL1_KAT2B_chr3_20136900_ENST00000263754_KANSL1_chr17_44145033_ENST00000575318_length(amino acids)=722AA_BP=192 MSEAGGAGPGGCGAGAGAGAGPGALPPQPAALPPAPPQGSPCAAAAGGSGACGPATAVAAAGTAEGPGGGGSARIAVKKAQLRSAPRAKK LEKLGVYSACKAEESCKCNGWKNPNPSPTPPRADLQQIIVSLTESCRSCSHALAAHVSHLENVSEEEMNRLLGIVLDVEYLFTCVHKEED ADTKQVYFYLFKIESVSQPLENHGARIIGHISESLSTKSCGALRPVNGVINTLQPVLADHIPGDSSDAEEQLHKKQRLNLVSSSSDGTCV AARTRPVLSCKKRRLVRPNSIVPLSKKVHRNSTIRPGCDVNPSCALCGSGSINTMPPEIHYEAPLLERLSQLDSCVHPVLAFPDDVPTSL HFQSMLKSQWQNKPFDKIKPPKKLSLKHRAPMPGSLPDSARKDRHKLVSSFLTTAMLKHHTDMSSSSYLAATHHPPHSPLVRQLSTSSDS PAPASSSSQVTASTSQPVRRRRGESSFDINNIVIPMSVAATTRVEKLQYKEILTPSWREVDLQSLKGSPDEENEEIEDLSDAAFAALHAK CEEMERARWLWTTSVPPQRRGSRSYRSSDGRTTPQLGSANPSTPQPASPDVSSSHSLSEYSHGQSPRSPISPELHSAPLTPVARDTPRHL ASEDTRCSTPELGLDEQSVQPWERRTFPLAHSPQAECEDQLDAQERAARCTRRTSGSKTGRETEAAPTSPPIVPLKSRHLVAAATAQRPT HR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for KAT2B-KANSL1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for KAT2B-KANSL1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for KAT2B-KANSL1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | KAT2B | C0525045 | Mood Disorders | 1 | PSYGENET |
| Tgene | C0020796 | Profound Mental Retardation | 2 | CTD_human | |
| Tgene | C0025363 | Mental Retardation, Psychosocial | 2 | CTD_human | |
| Tgene | C0026825 | Flaccid Muscle Tone | 2 | CTD_human | |
| Tgene | C0026827 | Muscle hypotonia | 2 | CTD_human | |
| Tgene | C0376634 | Craniofacial Abnormalities | 2 | CTD_human | |
| Tgene | C0427201 | Floppy Muscles | 2 | CTD_human | |
| Tgene | C0427202 | Muscle Tone Atonic | 2 | CTD_human | |
| Tgene | C0751330 | Unilateral Hypotonia | 2 | CTD_human | |
| Tgene | C0917816 | Mental deficiency | 2 | CTD_human | |
| Tgene | C1864871 | Chromosome 17q21.31 Deletion Syndrome | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET | |
| Tgene | C2267233 | Neonatal Hypotonia | 2 | CTD_human | |
| Tgene | C2931713 | Chromosome 17 deletion | 2 | CTD_human | |
| Tgene | C3683846 | Chromosome 17p Deletion Syndrome | 2 | CTD_human | |
| Tgene | C3714756 | Intellectual Disability | 2 | CTD_human | |
| Tgene | C0010606 | Adenoid Cystic Carcinoma | 1 | CTD_human | |
| Tgene | C0919267 | ovarian neoplasm | 1 | CTD_human | |
| Tgene | C1140680 | Malignant neoplasm of ovary | 1 | CTD_human | |
| Tgene | C1860789 | Leukemia, Megakaryoblastic, of Down Syndrome | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies