
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:CXorf40A-SPP1 (FusionGDB2 ID:HG91966TG6696) |
Fusion Gene Summary for CXorf40A-SPP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: CXorf40A-SPP1 | Fusion gene ID: hg91966tg6696 | Hgene | Tgene | Gene symbol | CXorf40A | SPP1 | Gene ID | 91966 | 6696 |
| Gene name | endothelium and lymphocyte associated ASCH domain 1 | secreted phosphoprotein 1 | |
| Synonyms | CXorf40|CXorf40A | BNSP|BSPI|ETA-1|OPN | |
| Cytomap | ('CXorf40A')('SPP1') Xq28 | 4q22.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein CXorf40Aendothelial-overexpressed lipopolysaccharide-associated factor 1 | osteopontinSPP1/CALPHA1 fusionearly T-lymphocyte activation 1nephropontinosteopontin/immunoglobulin alpha 1 heavy chain constant region fusion proteinsecreted phosphoprotein 1 (osteopontin, bone sialoprotein I, early T-lymphocyte activation 1)secret | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000359293, ENST00000393985, ENST00000422892, ENST00000423421, ENST00000423540, ENST00000428236, ENST00000434353, ENST00000441248, ENST00000450602, ENST00000514208, ENST00000448332, | ||
| Fusion gene scores | * DoF score | 1 X 1 X 1=1 | 9 X 10 X 3=270 |
| # samples | 1 | 11 | |
| ** MAII score | log2(1/1*10)=3.32192809488736 | log2(11/270*10)=-1.29545588352617 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: CXorf40A [Title/Abstract] AND SPP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | CXorf40A(148628368)-SPP1(88903643), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | CXorf40A-SPP1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CXorf40A-SPP1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. CXorf40A-SPP1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. CXorf40A-SPP1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | CXorf40A | GO:0010468 | regulation of gene expression | 24916366 |
| Hgene | CXorf40A | GO:0032675 | regulation of interleukin-6 production | 24916366 |
| Tgene | SPP1 | GO:0006710 | androgen catabolic process | 26482249 |
| Tgene | SPP1 | GO:0007155 | cell adhesion | 25839998 |
| Tgene | SPP1 | GO:0033280 | response to vitamin D | 16720713 |
| Tgene | SPP1 | GO:0045893 | positive regulation of transcription, DNA-templated | 26482249 |
| Tgene | SPP1 | GO:0071394 | cellular response to testosterone stimulus | 26482249 |
| Tgene | SPP1 | GO:2000866 | positive regulation of estradiol secretion | 26482249 |
| Fusion gene breakpoints across CXorf40A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
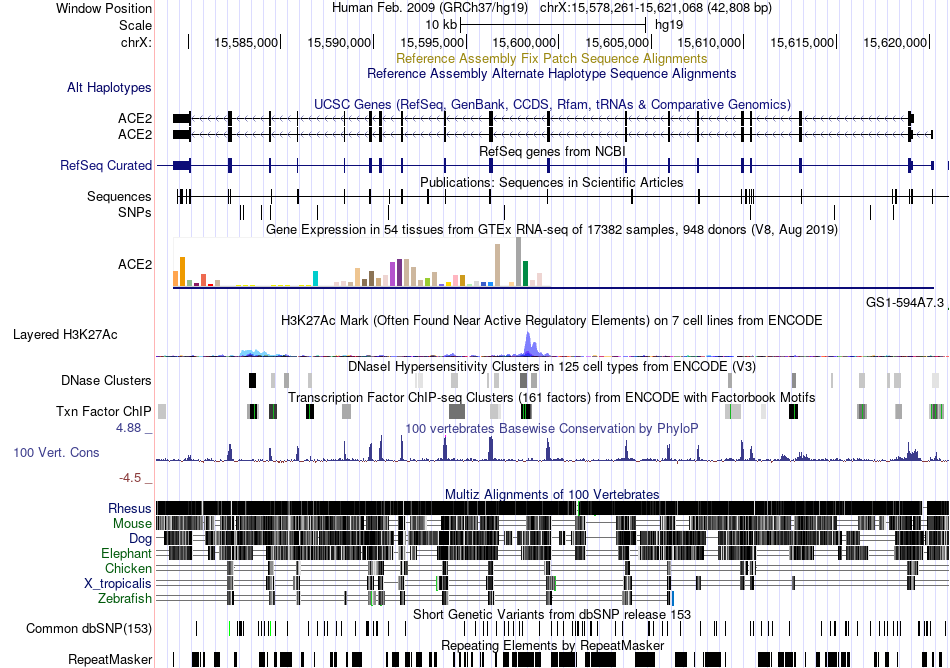 |
| Fusion gene breakpoints across SPP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
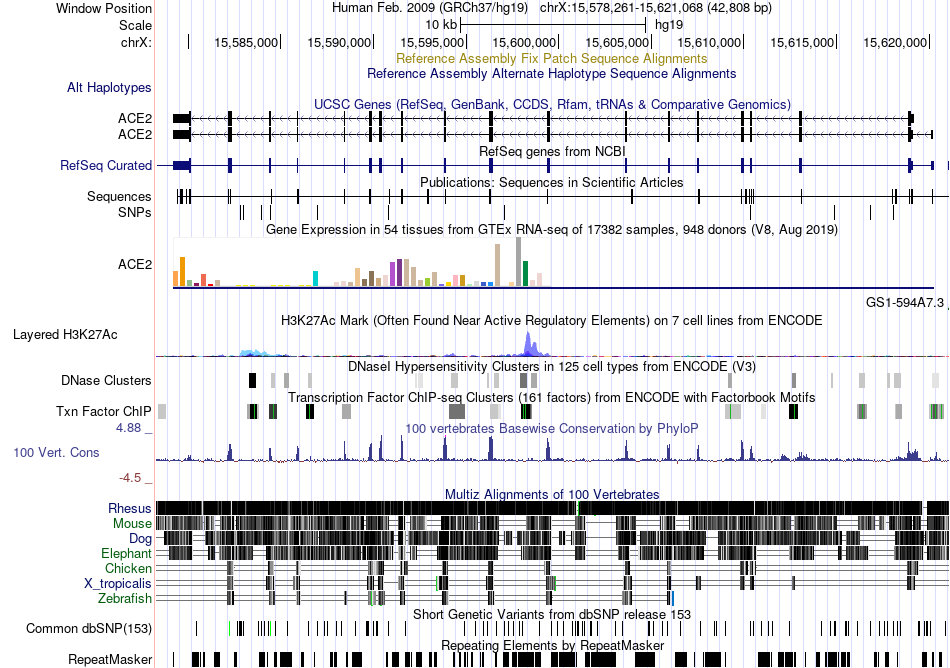 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
Top |
Fusion Gene ORF analysis for CXorf40A-SPP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000450602 | ENST00000237623 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.16105722 | 0.83894277 |
| ENST00000441248 | ENST00000237623 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.5064654 | 0.49353462 |
| ENST00000393985 | ENST00000360804 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.28065526 | 0.7193447 |
| ENST00000423421 | ENST00000237623 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.13590148 | 0.86409855 |
| ENST00000423540 | ENST00000360804 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.100734435 | 0.8992655 |
| ENST00000434353 | ENST00000360804 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.00364686 | 0.99635315 |
| ENST00000514208 | ENST00000360804 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.003482408 | 0.99651754 |
| ENST00000428236 | ENST00000237623 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.009980352 | 0.9900197 |
| ENST00000422892 | ENST00000360804 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.002572579 | 0.9974274 |
| ENST00000359293 | ENST00000237623 | CXorf40A | chrX | 148628368 | + | SPP1 | chr4 | 88903643 | + | 0.11690569 | 0.8830943 |
Top |
Fusion Genomic Features for CXorf40A-SPP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
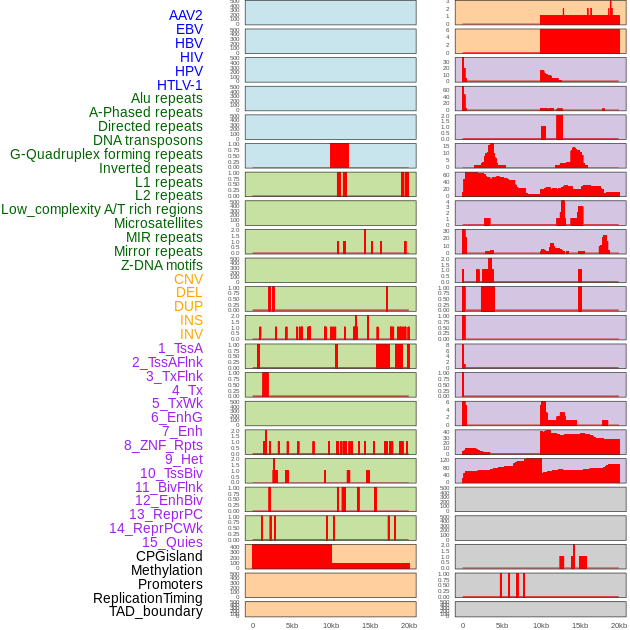 |
Top |
Fusion Protein Features for CXorf40A-SPP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chrX:148628368/chr4:88903643) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SPP1 | chrX:148628368 | chr4:88903643 | ENST00000360804 | 4 | 6 | 159_161 | 153 | 288.0 | Motif | Note=Cell attachment site |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000359293 | + | 1 | 2 | 6_92 | 0 | 159.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000393985 | + | 1 | 5 | 6_92 | 0 | 159.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000422892 | + | 1 | 5 | 6_92 | 0 | 147.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000423421 | + | 1 | 5 | 6_92 | 0 | 159.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000423540 | + | 1 | 5 | 6_92 | 0 | 159.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000434353 | + | 1 | 6 | 6_92 | 0 | 147.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000441248 | + | 1 | 4 | 6_92 | 0 | 159.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000450602 | + | 1 | 5 | 6_92 | 0 | 159.0 | Domain | ASCH |
| Hgene | CXorf40A | chrX:148628368 | chr4:88903643 | ENST00000514208 | + | 1 | 6 | 6_92 | 0 | 147.0 | Domain | ASCH |
| Tgene | SPP1 | chrX:148628368 | chr4:88903643 | ENST00000237623 | 4 | 6 | 159_161 | 166 | 301.0 | Motif | Note=Cell attachment site | |
| Tgene | SPP1 | chrX:148628368 | chr4:88903643 | ENST00000395080 | 5 | 7 | 159_161 | 180 | 315.0 | Motif | Note=Cell attachment site |
Top |
Fusion Gene Sequence for CXorf40A-SPP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >20865_20865_1_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000359293_SPP1_chr4_88903643_ENST00000237623_length(transcript)=1809nt_BP=890nt GACGGAAGCAGGAGACCATCAAGGTCAGTGCGATTTAGGCCACCTGAGAGACACGGGGGGAAGGTCAGGCCACTGCCCATGAGCTTGGAG GGCTGGCGTGTGATGCGCTTCTGTGCTTCCGCAGGCTACGGGAGGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCTGCCTCTCCTTCCGG CAGCCTTATGCTGGCTTTGTCTTAAATGGAATCAAGACTGTGGAGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGCGGAACTGTACCATC GCCGTCCACATTGCTCACAGGGACTGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAG ACCTTGCTCAGGAAAGGGGAAAAGTTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCC AGGTGGTTACTGGAGCCCATACCTAGGAAAGGAGGCAAGGATGTATTCCAGGTAGACATCCCAGAGCACCTGATCCCATTGGGGCATGAA GTGTGACAAGTGTGGGCTCCTGAAAGGAATGTTCCAGAGAAACCAGCTAAATCATGACACCTTCAATTTGCCATCATGACGCAGACCTGT ATACATTAGGTTAAATCTGAATTTCCACTGCTTTGGAGAGTCCCACCCACTAAGCACTGTGCATGTAAACAGGTTCCTTTGCTCAGATGA AGGAAGTAGGGGGTGGGGCTTTCCTTGTGTGATGCCTCCTTAGGCACACAGGCAATGTCTCAAGTACTTTGACCTTAGGGTAGAAGGCAA AGCTGCCAGTAAATGTCTCAGCATTGCTGCTAATTTTGGTCCTGCTAGTTTCTGGATTGTACAAATAAATGTGTTGTAGATACCCTGATG CTACAGACGAGGACATCACCTCACACATGGAAAGCGAGGAGTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGC CTTCTGATTGGGACAGCCGTGGGAAGGACAGTTATGAAACGAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCA GATTATATAAGCGGAAAGCCAATGATGAGAGCAATGAGCATTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCC ACAGCCATGAATTTCACAGCCATGAAGATATGCTGGTTGTAGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTC ATGAATTAGATAGTGCATCTTCTGAGGTCAATTAAAAGGAGAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTT ATAGCAAAATGAAAGAGAACATGAAATGCTTCTTTCTCAGTTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTT TGATAATTAGTTTAGTTTGTGGCTTCATGGAAACTCCCTGTAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGAAATG CAAACTATCACTGTATTTTAATATTTGTTATTCTCTCATGAATAGAAATTTATGTAGAAGCAAACAAAATACTTTTACCCACTTAAAAAG AGAATATAACATTTTATGTCACTATAATCTTTTGTTTTTTAAGTTAGTGTATATTTTGTTGTGATTATCTTTTTGTGGTGTGAATAAATC TTTTATCTTGAATGTAATAAGAATTTGGTGGTGTCAATTGCTTATTTGTTTTCCCACGGTTGTCCAGCAATTAATAAAACATAACCTTTT TTACTGCCT >20865_20865_1_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000359293_SPP1_chr4_88903643_ENST00000237623_length(amino acids)=157AA_BP= MPMSLEGWRVMRFCASAGYGRPGALAKMKFGCLSFRQPYAGFVLNGIKTVETRWRPLLSSQRNCTIAVHIAHRDWEGDAWRELLVERLGM TPAQIQTLLRKGEKFGRGVIAVTNLKQKYLTVISNPRWLLEPIPRKGGKDVFQVDIPEHLIPLGHEV -------------------------------------------------------------- >20865_20865_2_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000393985_SPP1_chr4_88903643_ENST00000360804_length(transcript)=1700nt_BP=1064nt GTTCTTCGTGAAAGGGATGACGGGAGCTGTATGAAAGCGGAAGAGTTATAGACCGCTAACACCTGTCACTGGCCACTGGTTTCCCGGAGT TAGCGGCAACGACCTTGCAGCCTGGACACTAGCCAGGCGCTCCCTCTTCTCACAGCGGCCCACGTCTCCTTGCTTGGGAGCCCATCGTCC TGGCTCCGGTGGCCTCGCTGGGTCTCGGGGAGGCAGAGGACTGTTCTTTCCTGTGGCGAAAAGCCGGAGTCGGCCCTAGACACCCACGAC TCGCAGGGTCCATGGTTCCGGAGGCCGTGAGACCTGCCGGGGCTGACAGGTGCCAGGGCCCATGCTGCGGGAGCCTGTGTGCTCAGCCTT CTTGCGGACGGTAAAGAAGCTAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGGTACTCTCTGCAGCACCAGCTGTCCCCGCCCT ACTCCGGACCGCCCCAAAGACTCCATGGGATGGACCTGAGTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCTGCTGTGGTGCTGGACATC AGTGACAGACGGAAGCAGGAGACCATCAAGGCTACGGGAGGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCTGCCTCTCCTTCCGGCAGC CTTATGCTGGCTTTGTCTTAAATGGAATCAAGACTGTGGAGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGCGGAACTGTACCATCGCCG TCCACATTGCTCACAGGGACTGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAGACCT TGCTCAGGAAAGGGGAAAAGTTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCCAGGT GGTTACTGGAGCCCATACCTAGGAAAGGAGGCAAGGATGTATTCCAGGTAGACATCCCAGAGCACCTGATCCCATTGGGGCATGAAGTGT GACAAGTGTGGGCTCCTGAAAGGAATGTTCCAGAGAAACCAGCTAAATCATGACACCTTCAATTTGCCATCATGTACCCTGATGCTACAG ACGAGGACATCACCTCACACATGGAAAGCGAGGAGTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGCCTTCTG ATTGGGACAGCCGTGGGAAGGACAGTTATGAAACGAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCAGATTAT ATAAGCGGAAAGCCAATGATGAGAGCAATGAGCATTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCCACAGCC ATGAATTTCACAGCCATGAAGATATGCTGGTTGTAGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTCATGAAT TAGATAGTGCATCTTCTGAGGTCAATTAAAAGGAGAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTTATAGCA AAATGAAAGAGAACATGAAATGCTTCTTTCTCAGTTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTTTGATAA TTAGTTTAGTTTGTGGCTTCATGGAAACTCCCTGTAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGA >20865_20865_2_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000393985_SPP1_chr4_88903643_ENST00000360804_length(amino acids)=196AA_BP= MLREPVCSAFLRTVKKLSGRVFPPLAVKQVLSAAPAVPALLRTAPKTPWDGPESAESQPLPLGLLWCWTSVTDGSRRPSRLREARGACED EVWLPLLPAALCWLCLKWNQDCGDALASPAEQPAELYHRRPHCSQGLGRRCLAGAAGGETRDDSCSDSDLAQERGKVWSRSDSGDQPEAE VPDCDFKPQVVTGAHT -------------------------------------------------------------- >20865_20865_3_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000422892_SPP1_chr4_88903643_ENST00000360804_length(transcript)=1511nt_BP=875nt ATTAGGTGCCACGTACTGGGCTGGGTGCTCTTGGTGCCTTATCTCCCTTCCTCACAGCCATGTGGAAACTGAGGCATCTCAAGAGTCTAT GACTGGGCTGAGGTTCTGGTTTCGAGCCCAGGGTTCCTTCCAAGGCACAGGGCCGTCCTCCATGCAAGAGGAGGGGACCCTCTCCCAAGC CACACACGCAGGAGGCTGGGCAAGAGTTGTGGGAAGTCAGAGCCCGTGTGACTGTGGGCTGGTGCCTCATTCTCCTCAGCCATAGAGTGG GCCTCACAGTACCACTGACCCTGCTGGGTTACTTGAAGATTCAATTTGATGATCCGAGGATCATGCCATCCCAGAGGCTGGCACGTGGAA GGCATCTGTCCCCGCCCTACTCCGGACCGCCCCAAAGACTCCATGGGATGGACCTGAGTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCT GCTGTGGTGCTGGACATCAGTGACAGACGGAAGCAGGAGACCATCAAGGCTACGGGAGGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCT GCCTCTCCTTCCGGCAGCCTTATGCTGGCTTTGTCTTAAATGGAATCAAGACTGTGGAGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGC GGAACTGTACCATCGCCGTCCACATTGCTCACAGGGACTGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTC CTGCTCAGATTCAGACCTTGCTCAGGAAAGGGGAAAAGTTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTG TGATTTCAAACCCCAGGTGGTTACTGGAGCCCATACCTAGGAAAGGAGGCAAGGATGTATTCCAGTACCCTGATGCTACAGACGAGGACA TCACCTCACACATGGAAAGCGAGGAGTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGCCTTCTGATTGGGACA GCCGTGGGAAGGACAGTTATGAAACGAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCAGATTATATAAGCGGA AAGCCAATGATGAGAGCAATGAGCATTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCCACAGCCATGAATTTC ACAGCCATGAAGATATGCTGGTTGTAGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTCATGAATTAGATAGTG CATCTTCTGAGGTCAATTAAAAGGAGAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTTATAGCAAAATGAAAG AGAACATGAAATGCTTCTTTCTCAGTTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTTTGATAATTAGTTTAG TTTGTGGCTTCATGGAAACTCCCTGTAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGA >20865_20865_3_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000422892_SPP1_chr4_88903643_ENST00000360804_length(amino acids)=250AA_BP=113 MKFGCLSFRQPYAGFVLNGIKTVETRWRPLLSSQRNCTIAVHIAHRDWEGDAWRELLVERLGMTPAQIQTLLRKGEKFGRGVIAVTNLKQ KYLTVISNPRWLLEPIPRKGGKDVFQYPDATDEDITSHMESEELNGAYKAIPVAQDLNAPSDWDSRGKDSYETSQLDDQSAETHSHKQSR LYKRKANDESNEHSDVIDSQELSKVSREFHSHEFHSHEDMLVVDPKSKEEDKHLKFRISHELDSASSEVN -------------------------------------------------------------- >20865_20865_4_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000423421_SPP1_chr4_88903643_ENST00000237623_length(transcript)=2238nt_BP=1319nt TTCTTCGTGAAAGGGATGACGGGAGCTGTATGAAAGCGGAAGAGTTATAGACCGCTAACACCTGTCACTGGCCACTGGTTTCCCGGAGTT AGCGGCAACGACCTTGCAGCCTGGACACTAGCCAGGCGCTCCCTCTTCTCACAGCGGCCCACGTCTCCTTGCTTGGGAGCCCATCGTCCT GGCTCCGGTGGCCTCGCTGGGTCTCGGGGAGGCAGAGGACTGTTCTTTCCTGTGGCGAAAAGCCGGAGTCGGCCCTAGACACCCACGACT CGCAGGGTCCATGGTTCCGGAGGCCGTGAGACCTGCCGGGGCTGACAGGTGCCAGGGCCCATGCTGCGGGAGCCTGTGTGCTCAGCCTTC TTGCGGACGGTAAAGAAGCTAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGCTGTCCCCGCCCTACTCCGGACCGCCCCAAAGA CTCCATGGGATGGACCTGAGTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCTGCTGTGGTGCTGGACATCAGTGACAGACGGAAGCAGGA GACCATCAAGGCTACGGGAGGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCTGCCTCTCCTTCCGGCAGCCTTATGCTGGCTTTGTCTTA AATGGAATCAAGACTGTGGAGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGCGGAACTGTACCATCGCCGTCCACATTGCTCACAGGGAC TGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAGACCTTGCTCAGGAAAGGGGAAAAG TTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCCAGGTGGTTACTGGAGCCCATACCT AGGAAAGGAGGCAAGGATGTATTCCAGGTAGACATCCCAGAGCACCTGATCCCATTGGGGCATGAAGTGTGACAAGTGTGGGCTCCTGAA AGGAATGTTCCAGAGAAACCAGCTAAATCATGACACCTTCAATTTGCCATCATGACGCAGACCTGTATACATTAGGTTAAATCTGAATTT CCACTGCTTTGGAGAGTCCCACCCACTAAGCACTGTGCATGTAAACAGGTTCCTTTGCTCAGATGAAGGAAGTAGGGGGTGGGGCTTTCC TTGTGTGATGCCTCCTTAGGCACACAGGCAATGTCTCAAGTACTTTGACCTTAGGGTAGAAGGCAAAGCTGCCAGTAAATGTCTCAGCAT TGCTGCTAATTTTGGTCCTGCTAGTTTCTGGATTGTACAAATAAATGTGTTGTAGATGATACCCTGATGCTACAGACGAGGACATCACCT CACACATGGAAAGCGAGGAGTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGCCTTCTGATTGGGACAGCCGTG GGAAGGACAGTTATGAAACGAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCAGATTATATAAGCGGAAAGCCA ATGATGAGAGCAATGAGCATTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCCACAGCCATGAATTTCACAGCC ATGAAGATATGCTGGTTGTAGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTCATGAATTAGATAGTGCATCTT CTGAGGTCAATTAAAAGGAGAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTTATAGCAAAATGAAAGAGAACA TGAAATGCTTCTTTCTCAGTTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTTTGATAATTAGTTTAGTTTGTG GCTTCATGGAAACTCCCTGTAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGAAATGCAAACTATCACTGTATTTTAA TATTTGTTATTCTCTCATGAATAGAAATTTATGTAGAAGCAAACAAAATACTTTTACCCACTTAAAAAGAGAATATAACATTTTATGTCA CTATAATCTTTTGTTTTTTAAGTTAGTGTATATTTTGTTGTGATTATCTTTTTGTGGTGTGAATAAATCTTTTATCTTGAATGTAATAAG AATTTGGTGGTGTCAATTGCTTATTTGTTTTCCCACGGTTGTCCAGCAATTAATAAAACATAACCTTTTTTACTGCCT >20865_20865_4_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000423421_SPP1_chr4_88903643_ENST00000237623_length(amino acids)=199AA_BP= MPGLTGARAHAAGACVLSLLADGKEAKWKSVSSSGRKAAVPALLRTAPKTPWDGPESAESQPLPLGLLWCWTSVTDGSRRPSRLREARGA CEDEVWLPLLPAALCWLCLKWNQDCGDALASPAEQPAELYHRRPHCSQGLGRRCLAGAAGGETRDDSCSDSDLAQERGKVWSRSDSGDQP EAEVPDCDFKPQVVTGAHT -------------------------------------------------------------- >20865_20865_5_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000423540_SPP1_chr4_88903643_ENST00000360804_length(transcript)=1760nt_BP=1124nt GAAAGGGATGACGGGAGCTGTATGAAAGCGGAAGAGTTATAGACCGCTAACACCTGTCACTGGCCACTGGTTTCCCGGAGTTAGCGGCAA CGACCTTGCAGCCTGGACACTAGCCAGGCGCTCCCTCTTCTCACAGCGGCCCACGTCTCCTTGCTTGGGAGCCCATCGTCCTGGCTCCGG TGGCCTCGCTGGGTCTCGGGGAGGCAGAGGACTGTTCTTTCCTGTGGCGAAAAGCCGGAGTCGGCCCTAGACACCCACGACTCGCAGGGT CCATGGTTCCGGAGGCCGTGAGACCTGCCGGGGCTGACAGGTAAAGAAGCTAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGGT ACTCTCTGCAGCACCAGCTGTCCCCGCCCTACTCCGGACCGCCCCAAAGACTCCATGGGATGGACCTGAGTCAGCCGAATCCCAGCCCCT TCCCTTGGGCCTGCTGTGGTGCTGGACATCAGTGACAGACGGAAGCAGGAGACCATCAAGGCTACGGGAGGCCCGGGGCGCTTGCGAAGA TGAAGTTTGGCTGCCTCTCCTTCCGGCAGCCTTATGCTGGCTTTGTCTTAAATGGAATCAAGACTGTGGAGACGCGCTGGCGTCCCCTGC TGAGCAGCCAGCGGAACTGTACCATCGCCGTCCACATTGCTCACAGGGACTGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGAC TCGGGATGACTCCTGCTCAGATTCAGACCTTGCTCAGGAAAGGGGAAAAGTTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGA AGTACCTGACTGTGATTTCAAACCCCAGGTGGTTACTGGAGCCCATACCTAGGAAAGGAGGCAAGGATGTATTCCAGGTAGACATCCCAG AGCACCTGATCCCATTGGGGCATGAAGTGTGACAAGTGTGGGCTCCTGAAAGGAATGTTCCAGAGAAACCAGCTAAATCATGACACCTTC AATTTGCCATCATGACGCAGACCTGTATACATTAGGTTAAATCTGAATTTCCACTGCTTTGGAGAGTCCCACCCACTAAGCACTGTGCAT GTAAACAGGTTCCTTTGCTCAGATGAAGGAAGTAGGGGGTGGGGTACCCTGATGCTACAGACGAGGACATCACCTCACACATGGAAAGCG AGGAGTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGCCTTCTGATTGGGACAGCCGTGGGAAGGACAGTTATG AAACGAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCAGATTATATAAGCGGAAAGCCAATGATGAGAGCAATG AGCATTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCCACAGCCATGAATTTCACAGCCATGAAGATATGCTGG TTGTAGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTCATGAATTAGATAGTGCATCTTCTGAGGTCAATTAAA AGGAGAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTTATAGCAAAATGAAAGAGAACATGAAATGCTTCTTTC TCAGTTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTTTGATAATTAGTTTAGTTTGTGGCTTCATGGAAACTC CCTGTAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGA >20865_20865_5_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000423540_SPP1_chr4_88903643_ENST00000360804_length(amino acids)=172AA_BP= MAVKQVLSAAPAVPALLRTAPKTPWDGPESAESQPLPLGLLWCWTSVTDGSRRPSRLREARGACEDEVWLPLLPAALCWLCLKWNQDCGD ALASPAEQPAELYHRRPHCSQGLGRRCLAGAAGGETRDDSCSDSDLAQERGKVWSRSDSGDQPEAEVPDCDFKPQVVTGAHT -------------------------------------------------------------- >20865_20865_6_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000428236_SPP1_chr4_88903643_ENST00000237623_length(transcript)=1722nt_BP=803nt GTAAAGAAGCTAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGGTACTCTCTGCAGCACCAGCTGTCCCCGCCCTACTCCGGACC GCCCCAAAGACTCCATGGGATGGACCTGAGTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCTGCTGTGGTGCTGGACATCAGTGACAGAC GGAAGCAGGAGACCATCAAGGGACTGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAG ACCTTGCTCAGGAAAGGGGAAAAGTTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCC AGGTGGTTACTGGAGCCCATACCTAGGAAAGGAGGCAAGGATGTATTCCAGGTAGACATCCCAGAGCACCTGATCCCATTGGGGCATGAA GTGTGACAAGTGTGGGCTCCTGAAAGGAATGTTCCAGAGAAACCAGCTAAATCATGACACCTTCAATTTGCCATCATGACGCAGACCTGT ATACATTAGGTTAAATCTGAATTTCCACTGCTTTGGAGAGTCCCACCCACTAAGCACTGTGCATGTAAACAGGTTCCTTTGCTCAGATGA AGGAAGTAGGGGGTGGGGCTTTCCTTGTGTGATGCCTCCTTAGGCACACAGGCAATGTCTCAAGTACTTTGACCTTAGGGTAGAAGGCAA AGCTGCCAGTAAATGTCTCAGCATTGCTGCTAATTTTGGTCCTGCTAGTTTCTGGATTGTACAAATAAATGTGTTGTAGATGATACCCTG ATGCTACAGACGAGGACATCACCTCACACATGGAAAGCGAGGAGTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACG CGCCTTCTGATTGGGACAGCCGTGGGAAGGACAGTTATGAAACGAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGT CCAGATTATATAAGCGGAAAGCCAATGATGAGAGCAATGAGCATTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAAT TCCACAGCCATGAATTTCACAGCCATGAAGATATGCTGGTTGTAGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTT CTCATGAATTAGATAGTGCATCTTCTGAGGTCAATTAAAAGGAGAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGC TTTATAGCAAAATGAAAGAGAACATGAAATGCTTCTTTCTCAGTTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGT GTTTGATAATTAGTTTAGTTTGTGGCTTCATGGAAACTCCCTGTAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGAA ATGCAAACTATCACTGTATTTTAATATTTGTTATTCTCTCATGAATAGAAATTTATGTAGAAGCAAACAAAATACTTTTACCCACTTAAA AAGAGAATATAACATTTTATGTCACTATAATCTTTTGTTTTTTAAGTTAGTGTATATTTTGTTGTGATTATCTTTTTGTGGTGTGAATAA ATCTTTTATCTTGAATGTAATAAGAATTTGGTGGTGTCAATTGCTTATTTGTTTTCCCACGGTTGTCCAGCAATTAATAAAACATAACCT TTTTTACTGCCT >20865_20865_6_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000428236_SPP1_chr4_88903643_ENST00000237623_length(amino acids)=140AA_BP= MAVKQVLSAAPAVPALLRTAPKTPWDGPESAESQPLPLGLLWCWTSVTDGSRRPSRDWEGDAWRELLVERLGMTPAQIQTLLRKGEKFGR GVIAVTNLKQKYLTVISNPRWLLEPIPRKGGKDVFQVDIPEHLIPLGHEV -------------------------------------------------------------- >20865_20865_7_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000434353_SPP1_chr4_88903643_ENST00000360804_length(transcript)=1551nt_BP=915nt GGGATGACGGGAGCTGTATGAAAGCGGAAGAGTTATAGACCGCTAACACCTGTCACTGGCCACTGGTTTCCCGGAGTTAGCGGCAACGAC CTTGCAGCCTGGACACTAGCCAGGCGCTCCCTCTTCTCACAGCGGCCCACGTCTCCTTGCTTGGGAGCCCATCGTCCTGGCTCCGGTGGC CTCGCTGGGTCTCGGGGAGGCAGAGGACTGTTCTTTCCTGTGGCGAAAAGCCGGAGTCGGCCCTAGACACCCACGACTCGCAGGGTCCAT GGTTCCGGAGGCCGTGAGACCTGCCGGGGCTGACAGGTGCCAGGGCCCATGCTGCGGGAGCCTGTGTGCTCAGCCTTCTTGCGGACGGTA AAGAAGCTAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGCTGTCCCCGCCCTACTCCGGACCGCCCCAAAGACTCCATGGGATG GACCTGAGTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCTGCTGTGGTGCTGGACATCAGTGACAGACGGAAGCAGGAGACCATCAAGGC TACGGGAGGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCTGCCTCTCCTTCCGGCAGCCTTATGCTGGCTTTGTCTTAAATGGAATCAAG ACTGTGGAGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGCGGAACTGTACCATCGCCGTCCACATTGCTCACAGGGACTGGGAAGGCGAT GCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAGACCTTGCTCAGGAAAGGGGAAAAGTTTGGTCGAGGA GTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCCAGGTGGTTACTGGAGCCCATACCTAGGAAAGGAGGC AAGGATGTATTCCAGTACCCTGATGCTACAGACGAGGACATCACCTCACACATGGAAAGCGAGGAGTTGAATGGTGCATACAAGGCCATC CCCGTTGCCCAGGACCTGAACGCGCCTTCTGATTGGGACAGCCGTGGGAAGGACAGTTATGAAACGAGTCAGCTGGATGACCAGAGTGCT GAAACCCACAGCCACAAGCAGTCCAGATTATATAAGCGGAAAGCCAATGATGAGAGCAATGAGCATTCCGATGTGATTGATAGTCAGGAA CTTTCCAAAGTCAGCCGTGAATTCCACAGCCATGAATTTCACAGCCATGAAGATATGCTGGTTGTAGACCCCAAAAGTAAGGAAGAAGAT AAACACCTGAAATTTCGTATTTCTCATGAATTAGATAGTGCATCTTCTGAGGTCAATTAAAAGGAGAAAAAATACAATTTCTCACTTTGC ATTTAGTCAAAAGAAAAAATGCTTTATAGCAAAATGAAAGAGAACATGAAATGCTTCTTTCTCAGTTTATTGGTTGAATGTGTATCTATT TGAGTCTGGAAATAACTAATGTGTTTGATAATTAGTTTAGTTTGTGGCTTCATGGAAACTCCCTGTAAACTAAAAGCTTCAGGGTTATGT CTATGTTCATTCTATAGAAGA >20865_20865_7_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000434353_SPP1_chr4_88903643_ENST00000360804_length(amino acids)=250AA_BP=113 MKFGCLSFRQPYAGFVLNGIKTVETRWRPLLSSQRNCTIAVHIAHRDWEGDAWRELLVERLGMTPAQIQTLLRKGEKFGRGVIAVTNLKQ KYLTVISNPRWLLEPIPRKGGKDVFQYPDATDEDITSHMESEELNGAYKAIPVAQDLNAPSDWDSRGKDSYETSQLDDQSAETHSHKQSR LYKRKANDESNEHSDVIDSQELSKVSREFHSHEFHSHEDMLVVDPKSKEEDKHLKFRISHELDSASSEVN -------------------------------------------------------------- >20865_20865_8_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000441248_SPP1_chr4_88903643_ENST00000237623_length(transcript)=3246nt_BP=2327nt AGCTCTGGGCCCAAAACTCCTGCCTGGTGTCCTCGTCCCACCCTTCCACTTACTCTTCCTCCCTCCCGTTCCTTTTCCTCCTTCCGGTTC TTCGTCGAGGCTGCCGGTCTCGAGGTCCCCTGGCCTTGGCCTGGTTGGCTGGCGCGCATCAGGGCCAGGTAAAGAGAATAGCGTCTCCTA GCAGCCAGGGCGTGCGTAGGTGCGTGATGTCCTCAGTGCGTGTCTTCGAGAATGCGAGATTCATAATGTTTGCTGTCTATATGCATGGCT GAGTACGTGCCTCCCGCGTACGTGCGTGGTGTGCATACATGCGTGATTGCGAGCCCACGTACGTTCTTCGTGAAAGGGATGACGGGAGCT GTATGAAAGCGGAAGAGTTATAGACCGCTAACACCTGTCACTGGCCACTGGTTTCCCGGAGTTAGCGGCAACGACCTTGCAGCCTGGACA CTAGCCAGGCGCTCCCTCTTCTCACAGCGGCCCACGTCTCCTTGCTTGGGAGCCCATCGTCCTGGCTCCGGTGGCCTCGCTGGGTCTCGG GGAGGCAGAGGACTGTTCTTTCCTGTGGCGAAAAGCCGGAGTCGGCCCTAGACACCCACGACTCGCAGGGTCCATGGTTCCGGAGGCCGT GAGACCTGCCGGGGCTGACAGGTGCCAGGGCCCATGCTGCGGGAGCCTGTGTGCTCAGCCTTCTTGCGGACGGTACCTGAGGGCTGGGGT TTCCCTGGATGTGGGGCTGGGAACTCGTGCGGGGCGCGACCGAGGCGCCTTTTCCTGTCCCCTGCTGTCGGCAGGGTCTCGGCTCCGCTC CTTCTAAGCGCGTGTACCCGCGACGTGCGTCTGCGAGTAGAAAGCCCGTGTACTGCTCCACACACAGCGGCCCCACCTCAGTCCGGTCTT CCCTGCCTCCCGTTGGCCCTTCTGCTGTGAGCTCGCCTGGACCTGAGGCCGGGCGGTGCACAGCTCTGTGGCCTGTGGCGCCGTGCTCAG CGTGACCTACCCAGAATTAAGCTGAGGACAATGGGATTTAGAGTCCCAAACACTCGCCCCGTGACAATGGGAGGGGAAGTGTCATTTTTC TCCCTTCGAATGGAGCATGCTTGGCTGCAAGAATGCTGCTCAACATGGTGAAATGATTTTCTGCCCTGCGGGCTGGTGCACCCTGTGGTC CTTGACCCAGACAGGTGCGGAGGGTCCCACTGCTGTGATTAGCAGAACCAAACTGTGATGTGCACATGTGTGTTACTGATAAGACCAGGC CTCCCAGCTCTTCTTGGTTTCCAATGCCTGCTAAGTACATGACCTTCTTAGGGCCATTAACCAGCTTTGCTGTCTTGCACTTAATGACCT TTCCTCTTTATCTTCCTTGTTGTGCAGGTAAAGAAGCTAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGCTGTCCCCGCCCTAC TCCGGACCGCCCCAAAGACTCCATGGGATGGACCTGAGTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCTGCTGTGGTGCTGGACATCAG TGACAGACGGAAGCAGGAGACCATCAAGGCTACGGGAGGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCTGCCTCTCCTTCCGGCAGCCT TATGCTGGCTTTGTCTTAAATGGAATCAAGACTGTGGAGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGCGGAACTGTACCATCGCCGTC CACATTGCTCACAGGGACTGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAGACCTTG CTCAGGAAAGGGGAAAAGTTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCCAGGTGG TTACTGGAGCCCATACCTAGGAAAGGAGGCAAGGATGTATTCCAGGTAGACATCCCAGAGCACCTGATCCCATTGGGGCATGAAGTGTGA CAAGTGTGGGCTCCTGAAAGGAATGTTCCAGAGAAACCAGCTAAATCATGACACCTTCAATTTGCCATCATGACGCAGACCTGTATACAT TAGGTTAAATCTGAATTTCCACTGCTTTGGAGAGTCCCACCCACTAAGCACTGTGCATGTAAACAGGTTCCTTTGCTCAGATGAAGGAAG TAGGGGGTGGGGCTTTCCTTGTGTGATGCCTCCTTAGGCACACAGGCAATGTCTCAAGTACTTTGACCTTAGGGTAGAAGGCAAAGCTGC CAGTAAATGTCTCAGCATTGCTGCTAATTTTGGTCCTGCTAGTTTCTGGATTGTACAAATAAATGTGTTGTAGATGATACCCTGATGCTA CAGACGAGGACATCACCTCACACATGGAAAGCGAGGAGTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGCCTT CTGATTGGGACAGCCGTGGGAAGGACAGTTATGAAACGAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCAGAT TATATAAGCGGAAAGCCAATGATGAGAGCAATGAGCATTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCCACA GCCATGAATTTCACAGCCATGAAGATATGCTGGTTGTAGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTCATG AATTAGATAGTGCATCTTCTGAGGTCAATTAAAAGGAGAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTTATA GCAAAATGAAAGAGAACATGAAATGCTTCTTTCTCAGTTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTTTGA TAATTAGTTTAGTTTGTGGCTTCATGGAAACTCCCTGTAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGAAATGCAA ACTATCACTGTATTTTAATATTTGTTATTCTCTCATGAATAGAAATTTATGTAGAAGCAAACAAAATACTTTTACCCACTTAAAAAGAGA ATATAACATTTTATGTCACTATAATCTTTTGTTTTTTAAGTTAGTGTATATTTTGTTGTGATTATCTTTTTGTGGTGTGAATAAATCTTT TATCTTGAATGTAATAAGAATTTGGTGGTGTCAATTGCTTATTTGTTTTCCCACGGTTGTCCAGCAATTAATAAAACATAACCTTTTTTA CTGCCT >20865_20865_8_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000441248_SPP1_chr4_88903643_ENST00000237623_length(amino acids)=224AA_BP= MCVTDKTRPPSSSWFPMPAKYMTFLGPLTSFAVLHLMTFPLYLPCCAGKEAKWKSVSSSGRKAAVPALLRTAPKTPWDGPESAESQPLPL GLLWCWTSVTDGSRRPSRLREARGACEDEVWLPLLPAALCWLCLKWNQDCGDALASPAEQPAELYHRRPHCSQGLGRRCLAGAAGGETRD DSCSDSDLAQERGKVWSRSDSGDQPEAEVPDCDFKPQVVTGAHT -------------------------------------------------------------- >20865_20865_9_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000450602_SPP1_chr4_88903643_ENST00000237623_length(transcript)=2039nt_BP=1120nt TGCTGGTATAGCAGCTCTGGGCCCAAAACTCCTGCCTGGTGTCCTCGTCCCACCCTTCCACTTACTCTTCCTCCCTCCCGTTCCTTTTCC TCCTTCCGGTTCTTCGTCGAGGCTGCCGGTCTCGAGGTCCCCTGGCCTTGGCCTGGTTGGCTGGCGCGCATCAGGGCCAGGTAAAGAAGC TAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGCTGTCCCCGCCCTACTCCGGACCGCCCCAAAGACTCCATGGGATGGACCTGA GTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCTGCTGTGGTGCTGGACATCAGTGACAGACGGAAGCAGGAGACCATCAAGGCTACGGGA GGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCTGCCTCTCCTTCCGGCAGCCTTATGCTGGCTTTGTCTTAAATGGAATCAAGACTGTGG AGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGCGGAACTGTACCATCGCCGTCCACATTGCTCACAGGGACTGGGAAGGCGATGCCTGGC GGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAGACCTTGCTCAGGAAAGGGGAAAAGTTTGGTCGAGGAGTGATAG CGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCCAGGTGGTTACTGGAGCCCATACCTAGGAAAGGAGGCAAGGATG TATTCCAGGTAGACATCCCAGAGCACCTGATCCCATTGGGGCATGAAGTGTGACAAGTGTGGGCTCCTGAAAGGAATGTTCCAGAGAAAC CAGCTAAATCATGACACCTTCAATTTGCCATCATGACGCAGACCTGTATACATTAGGTTAAATCTGAATTTCCACTGCTTTGGAGAGTCC CACCCACTAAGCACTGTGCATGTAAACAGGTTCCTTTGCTCAGATGAAGGAAGTAGGGGGTGGGGCTTTCCTTGTGTGATGCCTCCTTAG GCACACAGGCAATGTCTCAAGTACTTTGACCTTAGGGTAGAAGGCAAAGCTGCCAGTAAATGTCTCAGCATTGCTGCTAATTTTGGTCCT GCTAGTTTCTGGATTGTACAAATAAATGTGTTGTAGATGATACCCTGATGCTACAGACGAGGACATCACCTCACACATGGAAAGCGAGGA GTTGAATGGTGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGCCTTCTGATTGGGACAGCCGTGGGAAGGACAGTTATGAAAC GAGTCAGCTGGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCAGATTATATAAGCGGAAAGCCAATGATGAGAGCAATGAGCA TTCCGATGTGATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCCACAGCCATGAATTTCACAGCCATGAAGATATGCTGGTTGT AGACCCCAAAAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTCATGAATTAGATAGTGCATCTTCTGAGGTCAATTAAAAGGA GAAAAAATACAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTTATAGCAAAATGAAAGAGAACATGAAATGCTTCTTTCTCAG TTTATTGGTTGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTTTGATAATTAGTTTAGTTTGTGGCTTCATGGAAACTCCCTG TAAACTAAAAGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGAAATGCAAACTATCACTGTATTTTAATATTTGTTATTCTCTCATG AATAGAAATTTATGTAGAAGCAAACAAAATACTTTTACCCACTTAAAAAGAGAATATAACATTTTATGTCACTATAATCTTTTGTTTTTT AAGTTAGTGTATATTTTGTTGTGATTATCTTTTTGTGGTGTGAATAAATCTTTTATCTTGAATGTAATAAGAATTTGGTGGTGTCAATTG CTTATTTGTTTTCCCACGGTTGTCCAGCAATTAATAAAACATAACCTTTTTTACTGCCT >20865_20865_9_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000450602_SPP1_chr4_88903643_ENST00000237623_length(amino acids)=228AA_BP= MGPKLLPGVLVPPFHLLFLPPVPFPPSGSSSRLPVSRSPGLGLVGWRASGPGKEAKWKSVSSSGRKAAVPALLRTAPKTPWDGPESAESQ PLPLGLLWCWTSVTDGSRRPSRLREARGACEDEVWLPLLPAALCWLCLKWNQDCGDALASPAEQPAELYHRRPHCSQGLGRRCLAGAAGG ETRDDSCSDSDLAQERGKVWSRSDSGDQPEAEVPDCDFKPQVVTGAHT -------------------------------------------------------------- >20865_20865_10_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000514208_SPP1_chr4_88903643_ENST00000360804_length(transcript)=1297nt_BP=661nt GACCGCTAACACCTGTCACTGGCCACTGGTTTCCCGGAGTTAGCGGCAACGACCTTGCAGCCTGGACACTAGCCAGGCGCTCCCTCTTCT CACAGCGGCCCACGTAAAGAAGCTAAGTGGAAGAGTGTTTCCTCCTCTGGCCGTAAAGCAGCTGTCCCCGCCCTACTCCGGACCGCCCCA AAGACTCCATGGGATGGACCTGAGTCAGCCGAATCCCAGCCCCTTCCCTTGGGCCTGCTGTGGTGCTGGACATCAGTGACAGACGGAAGC AGGAGACCATCAAGGCTACGGGAGGCCCGGGGCGCTTGCGAAGATGAAGTTTGGCTGCCTCTCCTTCCGGCAGCCTTATGCTGGCTTTGT CTTAAATGGAATCAAGACTGTGGAGACGCGCTGGCGTCCCCTGCTGAGCAGCCAGCGGAACTGTACCATCGCCGTCCACATTGCTCACAG GGACTGGGAAGGCGATGCCTGGCGGGAGCTGCTGGTGGAGAGACTCGGGATGACTCCTGCTCAGATTCAGACCTTGCTCAGGAAAGGGGA AAAGTTTGGTCGAGGAGTGATAGCGGTGACCAACCTGAAGCAGAAGTACCTGACTGTGATTTCAAACCCCAGGTGGTTACTGGAGCCCAT ACCTAGGAAAGGAGGCAAGGATGTATTCCAGTACCCTGATGCTACAGACGAGGACATCACCTCACACATGGAAAGCGAGGAGTTGAATGG TGCATACAAGGCCATCCCCGTTGCCCAGGACCTGAACGCGCCTTCTGATTGGGACAGCCGTGGGAAGGACAGTTATGAAACGAGTCAGCT GGATGACCAGAGTGCTGAAACCCACAGCCACAAGCAGTCCAGATTATATAAGCGGAAAGCCAATGATGAGAGCAATGAGCATTCCGATGT GATTGATAGTCAGGAACTTTCCAAAGTCAGCCGTGAATTCCACAGCCATGAATTTCACAGCCATGAAGATATGCTGGTTGTAGACCCCAA AAGTAAGGAAGAAGATAAACACCTGAAATTTCGTATTTCTCATGAATTAGATAGTGCATCTTCTGAGGTCAATTAAAAGGAGAAAAAATA CAATTTCTCACTTTGCATTTAGTCAAAAGAAAAAATGCTTTATAGCAAAATGAAAGAGAACATGAAATGCTTCTTTCTCAGTTTATTGGT TGAATGTGTATCTATTTGAGTCTGGAAATAACTAATGTGTTTGATAATTAGTTTAGTTTGTGGCTTCATGGAAACTCCCTGTAAACTAAA AGCTTCAGGGTTATGTCTATGTTCATTCTATAGAAGA >20865_20865_10_CXorf40A-SPP1_CXorf40A_chrX_148628368_ENST00000514208_SPP1_chr4_88903643_ENST00000360804_length(amino acids)=250AA_BP=113 MKFGCLSFRQPYAGFVLNGIKTVETRWRPLLSSQRNCTIAVHIAHRDWEGDAWRELLVERLGMTPAQIQTLLRKGEKFGRGVIAVTNLKQ KYLTVISNPRWLLEPIPRKGGKDVFQYPDATDEDITSHMESEELNGAYKAIPVAQDLNAPSDWDSRGKDSYETSQLDDQSAETHSHKQSR LYKRKANDESNEHSDVIDSQELSKVSREFHSHEFHSHEDMLVVDPKSKEEDKHLKFRISHELDSASSEVN -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for CXorf40A-SPP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for CXorf40A-SPP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for CXorf40A-SPP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C0024141 | Lupus Erythematosus, Systemic | 5 | ORPHANET | |
| Tgene | C0001418 | Adenocarcinoma | 2 | CTD_human | |
| Tgene | C0003949 | Asbestosis | 2 | CTD_human | |
| Tgene | C0006142 | Malignant neoplasm of breast | 2 | CTD_human | |
| Tgene | C0006663 | Calcinosis | 2 | CTD_human | |
| Tgene | C0022650 | Kidney Calculi | 2 | CTD_human | |
| Tgene | C0022660 | Kidney Failure, Acute | 2 | CTD_human | |
| Tgene | C0024121 | Lung Neoplasms | 2 | CTD_human | |
| Tgene | C0025500 | Mesothelioma | 2 | CTD_human | |
| Tgene | C0205641 | Adenocarcinoma, Basal Cell | 2 | CTD_human | |
| Tgene | C0205642 | Adenocarcinoma, Oxyphilic | 2 | CTD_human | |
| Tgene | C0205643 | Carcinoma, Cribriform | 2 | CTD_human | |
| Tgene | C0205644 | Carcinoma, Granular Cell | 2 | CTD_human | |
| Tgene | C0205645 | Adenocarcinoma, Tubular | 2 | CTD_human | |
| Tgene | C0242379 | Malignant neoplasm of lung | 2 | CTD_human | |
| Tgene | C0263628 | Tumoral calcinosis | 2 | CTD_human | |
| Tgene | C0521174 | Microcalcification | 2 | CTD_human | |
| Tgene | C0678222 | Breast Carcinoma | 2 | CTD_human | |
| Tgene | C1257931 | Mammary Neoplasms, Human | 2 | CTD_human | |
| Tgene | C1458155 | Mammary Neoplasms | 2 | CTD_human | |
| Tgene | C1565662 | Acute Kidney Insufficiency | 2 | CTD_human | |
| Tgene | C2609414 | Acute kidney injury | 2 | CTD_human | |
| Tgene | C2930617 | Pulmonary Fibrosis - from Asbestos Exposure | 2 | CTD_human | |
| Tgene | C4704874 | Mammary Carcinoma, Human | 2 | CTD_human | |
| Tgene | C0006118 | Brain Neoplasms | 1 | CTD_human | |
| Tgene | C0007282 | Carotid Stenosis | 1 | CTD_human | |
| Tgene | C0013221 | Drug toxicity | 1 | CTD_human | |
| Tgene | C0017638 | Glioma | 1 | CTD_human | |
| Tgene | C0017668 | Focal glomerulosclerosis | 1 | CTD_human | |
| Tgene | C0018799 | Heart Diseases | 1 | CTD_human | |
| Tgene | C0018824 | Heart valve disease | 1 | CTD_human | |
| Tgene | C0019193 | Hepatitis, Toxic | 1 | CTD_human | |
| Tgene | C0019207 | Hepatoma, Morris | 1 | CTD_human | |
| Tgene | C0019208 | Hepatoma, Novikoff | 1 | CTD_human | |
| Tgene | C0020517 | Hypersensitivity | 1 | CTD_human | |
| Tgene | C0022658 | Kidney Diseases | 1 | CTD_human | |
| Tgene | C0023890 | Liver Cirrhosis | 1 | CTD_human | |
| Tgene | C0023896 | Alcoholic Liver Diseases | 1 | CTD_human | |
| Tgene | C0023904 | Liver Neoplasms, Experimental | 1 | CTD_human | |
| Tgene | C0024668 | Mammary Neoplasms, Experimental | 1 | CTD_human | |
| Tgene | C0027627 | Neoplasm Metastasis | 1 | CTD_human | |
| Tgene | C0027659 | Neoplasms, Experimental | 1 | CTD_human | |
| Tgene | C0030286 | Pancreatic Diseases | 1 | CTD_human | |
| Tgene | C0032229 | Pleural Neoplasms | 1 | CTD_human | |
| Tgene | C0032285 | Pneumonia | 1 | CTD_human | |
| Tgene | C0032300 | Lobar Pneumonia | 1 | CTD_human | |
| Tgene | C0033687 | Proteinuria | 1 | CTD_human | |
| Tgene | C0034069 | Pulmonary Fibrosis | 1 | CTD_human | |
| Tgene | C0041755 | Adverse reaction to drug | 1 | CTD_human | |
| Tgene | C0041948 | Uremia | 1 | CTD_human | |
| Tgene | C0086404 | Experimental Hepatoma | 1 | CTD_human | |
| Tgene | C0086432 | Hyalinosis, Segmental Glomerular | 1 | CTD_human | |
| Tgene | C0153633 | Malignant neoplasm of brain | 1 | CTD_human | |
| Tgene | C0162820 | Dermatitis, Allergic Contact | 1 | CTD_human | |
| Tgene | C0239946 | Fibrosis, Liver | 1 | CTD_human | |
| Tgene | C0259783 | mixed gliomas | 1 | CTD_human | |
| Tgene | C0270612 | Leukoencephalopathy | 1 | CTD_human | |
| Tgene | C0340569 | Internal Carotid Artery Stenosis | 1 | CTD_human | |
| Tgene | C0496899 | Benign neoplasm of brain, unspecified | 1 | CTD_human | |
| Tgene | C0555198 | Malignant Glioma | 1 | CTD_human | |
| Tgene | C0750974 | Brain Tumor, Primary | 1 | CTD_human | |
| Tgene | C0750977 | Recurrent Brain Neoplasm | 1 | CTD_human | |
| Tgene | C0750979 | Primary malignant neoplasm of brain | 1 | CTD_human | |
| Tgene | C0751633 | Carotid Artery Plaque | 1 | CTD_human | |
| Tgene | C0751634 | Carotid Ulcer | 1 | CTD_human | |
| Tgene | C0751635 | Common Carotid Artery Stenosis | 1 | CTD_human | |
| Tgene | C0751636 | External Carotid Artery Stenosis | 1 | CTD_human | |
| Tgene | C0853897 | Diabetic Cardiomyopathies | 1 | CTD_human | |
| Tgene | C0860207 | Drug-Induced Liver Disease | 1 | CTD_human | |
| Tgene | C0887898 | Experimental Lung Inflammation | 1 | CTD_human | |
| Tgene | C1262760 | Hepatitis, Drug-Induced | 1 | CTD_human | |
| Tgene | C1527304 | Allergic Reaction | 1 | CTD_human | |
| Tgene | C1527390 | Neoplasms, Intracranial | 1 | CTD_human | |
| Tgene | C1858991 | Childhood Ataxia with Central Nervous System Hypomyelinization | 1 | CTD_human | |
| Tgene | C2937358 | Cerebral Hemorrhage | 1 | CTD_human | |
| Tgene | C3658290 | Drug-Induced Acute Liver Injury | 1 | CTD_human | |
| Tgene | C3714636 | Pneumonitis | 1 | CTD_human | |
| Tgene | C4277682 | Chemical and Drug Induced Liver Injury | 1 | CTD_human | |
| Tgene | C4279912 | Chemically-Induced Liver Toxicity | 1 | CTD_human | |
| Tgene | C4721411 | Osteolysis | 1 | CTD_human | |
| Tgene | C4721507 | Alveolitis, Fibrosing | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies