
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:BAG4-FGFR1 (FusionGDB2 ID:HG9530TG2260) |
Fusion Gene Summary for BAG4-FGFR1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: BAG4-FGFR1 | Fusion gene ID: hg9530tg2260 | Hgene | Tgene | Gene symbol | BAG4 | FGFR1 | Gene ID | 9530 | 2260 |
| Gene name | BAG cochaperone 4 | fibroblast growth factor receptor 1 | |
| Synonyms | BAG-4|SODD | BFGFR|CD331|CEK|ECCL|FGFBR|FGFR-1|FLG|FLT-2|FLT2|HBGFR|HH2|HRTFDS|KAL2|N-SAM|OGD|bFGF-R-1 | |
| Cytomap | ('BAG4')('FGFR1') 8p11.23 | 8p11.23 | |
| Type of gene | protein-coding | protein-coding | |
| Description | BAG family molecular chaperone regulator 4BCL2 associated athanogene 4bcl-2-associated athanogene 4silencer of death domains | fibroblast growth factor receptor 1FGFR1/PLAG1 fusionFMS-like tyrosine kinase 2basic fibroblast growth factor receptor 1fms-related tyrosine kinase 2heparin-binding growth factor receptorhydroxyaryl-protein kinaseproto-oncogene c-Fgr | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | P11362 | |
| Ensembl transtripts involved in fusion gene | ENST00000521282, ENST00000287322, ENST00000432471, | ||
| Fusion gene scores | * DoF score | 12 X 5 X 7=420 | 25 X 34 X 7=5950 |
| # samples | 15 | 22 | |
| ** MAII score | log2(15/420*10)=-1.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(22/5950*10)=-4.75731423955801 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: BAG4 [Title/Abstract] AND FGFR1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | BAG4(38050313)-FGFR1(38283763), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | BAG4-FGFR1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. BAG4-FGFR1 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. BAG4-FGFR1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. BAG4-FGFR1 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | BAG4 | GO:0071356 | cellular response to tumor necrosis factor | 21712384 |
| Tgene | FGFR1 | GO:0008284 | positive regulation of cell proliferation | 8663044 |
| Tgene | FGFR1 | GO:0008543 | fibroblast growth factor receptor signaling pathway | 8663044 |
| Tgene | FGFR1 | GO:0010863 | positive regulation of phospholipase C activity | 18480409 |
| Tgene | FGFR1 | GO:0018108 | peptidyl-tyrosine phosphorylation | 8622701|18480409 |
| Tgene | FGFR1 | GO:0043406 | positive regulation of MAP kinase activity | 8622701|18480409 |
| Tgene | FGFR1 | GO:0046777 | protein autophosphorylation | 8622701 |
| Tgene | FGFR1 | GO:2000546 | positive regulation of endothelial cell chemotaxis to fibroblast growth factor | 21885851 |
| Fusion gene breakpoints across BAG4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across FGFR1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
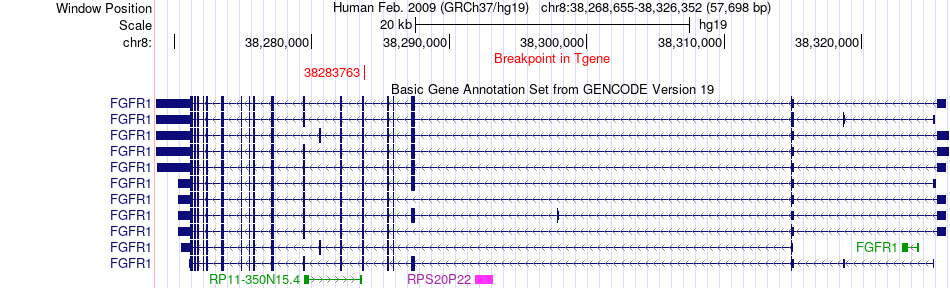 |
| Fusion gene information * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-22-5480-01A | BAG4 | chr8 | 38050313 | - | FGFR1 | chr8 | 38283763 | - |
| ChimerDB4 | LUSC | TCGA-22-5480-01A | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| ChimerDB4 | LUSC | TCGA-22-5480 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| ChimerKB4 | . | . | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
Top |
Fusion Gene ORF analysis for BAG4-FGFR1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000521282 | ENST00000326324 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000335922 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000341462 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000356207 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000397091 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000397103 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000397108 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000397113 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000425967 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000447712 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-3CDS | ENST00000521282 | ENST00000532791 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-intron | ENST00000521282 | ENST00000326324 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000335922 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000341462 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000356207 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000397091 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000397103 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000397108 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000397113 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000425967 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000447712 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000496629 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| 3UTR-intron | ENST00000521282 | ENST00000496629 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 3UTR-intron | ENST00000521282 | ENST00000532791 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| 5CDS-intron | ENST00000287322 | ENST00000496629 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000326324 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000335922 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000341462 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000356207 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000397091 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000397103 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000397108 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000397113 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000425967 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000447712 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| In-frame | ENST00000287322 | ENST00000532791 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000326324 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000335922 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000341462 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000356207 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000397091 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000397103 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000397108 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000397113 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000425967 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000447712 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-3CDS | ENST00000432471 | ENST00000532791 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-intron | ENST00000287322 | ENST00000326324 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000335922 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000341462 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000356207 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000397091 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000397103 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000397108 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000397113 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000425967 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000447712 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000496629 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000287322 | ENST00000532791 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000326324 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000335922 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000341462 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000356207 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000397091 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000397103 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000397108 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000397113 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000425967 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000447712 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000496629 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - |
| intron-intron | ENST00000432471 | ENST00000496629 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| intron-intron | ENST00000432471 | ENST00000532791 | BAG4 | chr8 | 38034105 | + | FGFR1 | chr8 | 38034105 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000425967 | FGFR1 | chr8 | 38283763 | - | 4987 | 649 | 148 | 2496 | 782 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000397091 | FGFR1 | chr8 | 38283763 | - | 4987 | 649 | 148 | 2496 | 782 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000447712 | FGFR1 | chr8 | 38283763 | - | 4986 | 649 | 148 | 2496 | 782 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000341462 | FGFR1 | chr8 | 38283763 | - | 4983 | 649 | 148 | 2493 | 781 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000532791 | FGFR1 | chr8 | 38283763 | - | 4888 | 649 | 148 | 2490 | 780 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000397113 | FGFR1 | chr8 | 38283763 | - | 3397 | 649 | 148 | 2496 | 782 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000356207 | FGFR1 | chr8 | 38283763 | - | 3395 | 649 | 148 | 2496 | 782 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000335922 | FGFR1 | chr8 | 38283763 | - | 3388 | 649 | 148 | 2490 | 780 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000326324 | FGFR1 | chr8 | 38283763 | - | 3393 | 649 | 148 | 2496 | 782 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000397103 | FGFR1 | chr8 | 38283763 | - | 3197 | 649 | 148 | 2502 | 784 |
| ENST00000287322 | BAG4 | chr8 | 38050313 | + | ENST00000397108 | FGFR1 | chr8 | 38283763 | - | 2603 | 649 | 148 | 2496 | 782 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000287322 | ENST00000425967 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001224652 | 0.9987753 |
| ENST00000287322 | ENST00000397091 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001224652 | 0.9987753 |
| ENST00000287322 | ENST00000447712 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.00121896 | 0.998781 |
| ENST00000287322 | ENST00000341462 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001001701 | 0.99899834 |
| ENST00000287322 | ENST00000532791 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001144625 | 0.99885535 |
| ENST00000287322 | ENST00000397113 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001933774 | 0.99806625 |
| ENST00000287322 | ENST00000356207 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001926463 | 0.99807346 |
| ENST00000287322 | ENST00000335922 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001657016 | 0.998343 |
| ENST00000287322 | ENST00000326324 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.001912086 | 0.99808794 |
| ENST00000287322 | ENST00000397103 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.002177979 | 0.99782205 |
| ENST00000287322 | ENST00000397108 | BAG4 | chr8 | 38050313 | + | FGFR1 | chr8 | 38283763 | - | 0.003479041 | 0.996521 |
Top |
Fusion Genomic Features for BAG4-FGFR1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
Top |
Fusion Protein Features for BAG4-FGFR1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:38050313/chr8:38283763) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | FGFR1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Tyrosine-protein kinase that acts as cell-surface receptor for fibroblast growth factors and plays an essential role in the regulation of embryonic development, cell proliferation, differentiation and migration. Required for normal mesoderm patterning and correct axial organization during embryonic development, normal skeletogenesis and normal development of the gonadotropin-releasing hormone (GnRH) neuronal system. Phosphorylates PLCG1, FRS2, GAB1 and SHB. Ligand binding leads to the activation of several signaling cascades. Activation of PLCG1 leads to the production of the cellular signaling molecules diacylglycerol and inositol 1,4,5-trisphosphate. Phosphorylation of FRS2 triggers recruitment of GRB2, GAB1, PIK3R1 and SOS1, and mediates activation of RAS, MAPK1/ERK2, MAPK3/ERK1 and the MAP kinase signaling pathway, as well as of the AKT1 signaling pathway. Promotes phosphorylation of SHC1, STAT1 and PTPN11/SHP2. In the nucleus, enhances RPS6KA1 and CREB1 activity and contributes to the regulation of transcription. FGFR1 signaling is down-regulated by IL17RD/SEF, and by FGFR1 ubiquitination, internalization and degradation. {ECO:0000250|UniProtKB:P16092, ECO:0000269|PubMed:10830168, ECO:0000269|PubMed:11353842, ECO:0000269|PubMed:12181353, ECO:0000269|PubMed:1379697, ECO:0000269|PubMed:1379698, ECO:0000269|PubMed:15117958, ECO:0000269|PubMed:16597617, ECO:0000269|PubMed:17311277, ECO:0000269|PubMed:17623664, ECO:0000269|PubMed:18480409, ECO:0000269|PubMed:19224897, ECO:0000269|PubMed:19261810, ECO:0000269|PubMed:19665973, ECO:0000269|PubMed:20133753, ECO:0000269|PubMed:20139426, ECO:0000269|PubMed:21765395, ECO:0000269|PubMed:8622701, ECO:0000269|PubMed:8663044}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 158_246 | 116 | 732.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 255_357 | 116 | 732.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 478_767 | 116 | 732.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 255_357 | 199 | 813.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 478_767 | 199 | 813.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 158_246 | 118 | 734.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 255_357 | 118 | 734.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 478_767 | 118 | 734.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 255_357 | 205 | 821.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 478_767 | 205 | 821.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 255_357 | 205 | 821.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 478_767 | 205 | 821.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 255_357 | 205 | 821.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 478_767 | 205 | 821.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 255_357 | 238 | 854.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 478_767 | 238 | 854.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 255_357 | 207 | 823.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 478_767 | 207 | 823.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 255_357 | 207 | 821.0 | Domain | Note=Ig-like C2-type 3 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 478_767 | 207 | 821.0 | Domain | Protein kinase | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 484_490 | 116 | 732.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 562_564 | 116 | 732.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 484_490 | 199 | 813.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 562_564 | 199 | 813.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 484_490 | 118 | 734.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 562_564 | 118 | 734.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 484_490 | 205 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 562_564 | 205 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 484_490 | 205 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 562_564 | 205 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 484_490 | 205 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 562_564 | 205 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 484_490 | 238 | 854.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 562_564 | 238 | 854.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 484_490 | 207 | 823.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 562_564 | 207 | 823.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 484_490 | 207 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 562_564 | 207 | 821.0 | Nucleotide binding | Note=ATP | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 160_177 | 116 | 732.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 160_177 | 118 | 734.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 398_822 | 116 | 732.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 398_822 | 199 | 813.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 398_822 | 118 | 734.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 398_822 | 205 | 821.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 398_822 | 205 | 821.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 398_822 | 205 | 821.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 398_822 | 238 | 854.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 398_822 | 207 | 823.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 398_822 | 207 | 821.0 | Topological domain | Cytoplasmic | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 377_397 | 116 | 732.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 377_397 | 199 | 813.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 377_397 | 118 | 734.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 377_397 | 205 | 821.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 377_397 | 205 | 821.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 377_397 | 205 | 821.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 377_397 | 238 | 854.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 377_397 | 207 | 823.0 | Transmembrane | Helical | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 377_397 | 207 | 821.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | BAG4 | chr8:38050313 | chr8:38283763 | ENST00000287322 | + | 2 | 5 | 379_456 | 126 | 458.0 | Domain | BAG |
| Hgene | BAG4 | chr8:38050313 | chr8:38283763 | ENST00000432471 | + | 1 | 4 | 379_456 | 0 | 422.0 | Domain | BAG |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 25_119 | 116 | 732.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 158_246 | 199 | 813.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 25_119 | 199 | 813.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 25_119 | 118 | 734.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 158_246 | 205 | 821.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 25_119 | 205 | 821.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 158_246 | 205 | 821.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 25_119 | 205 | 821.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 158_246 | 205 | 821.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 25_119 | 205 | 821.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 158_246 | 238 | 854.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 25_119 | 238 | 854.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 158_246 | 207 | 823.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 25_119 | 207 | 823.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 158_246 | 207 | 821.0 | Domain | Note=Ig-like C2-type 2 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 25_119 | 207 | 821.0 | Domain | Note=Ig-like C2-type 1 | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 160_177 | 199 | 813.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 160_177 | 205 | 821.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 160_177 | 205 | 821.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 160_177 | 205 | 821.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 160_177 | 238 | 854.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 160_177 | 207 | 823.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 160_177 | 207 | 821.0 | Region | Note=Heparin-binding | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000326324 | 3 | 17 | 22_376 | 116 | 732.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000335922 | 5 | 19 | 22_376 | 199 | 813.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000356207 | 3 | 17 | 22_376 | 118 | 734.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397091 | 4 | 18 | 22_376 | 205 | 821.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397108 | 5 | 19 | 22_376 | 205 | 821.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000397113 | 4 | 18 | 22_376 | 205 | 821.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000425967 | 5 | 19 | 22_376 | 238 | 854.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000447712 | 4 | 18 | 22_376 | 207 | 823.0 | Topological domain | Extracellular | |
| Tgene | FGFR1 | chr8:38050313 | chr8:38283763 | ENST00000532791 | 4 | 18 | 22_376 | 207 | 821.0 | Topological domain | Extracellular |
Top |
Fusion Gene Sequence for BAG4-FGFR1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >8854_8854_1_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000326324_length(transcript)=3393nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGT TCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTG GGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGA CAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGA AATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGT GGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCC AGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACA CCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACAT CGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAG TGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAA GCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCC CTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCAT GCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCT GCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCA GACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCG GCTGCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGG TGCAAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAG GGCAGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATA AGCCCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTC TGCCCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCG AAGGCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTAT AAATCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCA TCAGTTGCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATT TTTTTAAATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTT >8854_8854_1_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000326324_length(amino acids)=782AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFG QVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPG LEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPE ALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVAL TSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_2_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000335922_length(transcript)=3388nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGTTCTTCT GGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTGGGAGCT GCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGACAAGGA CAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGAAATGGA GATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGTGGAGTA TGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCCAGAGGA GCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACACCGAGA CCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACATCGACTA CTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAGTGATGT GTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAAGCTGCT GAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCCCTCACA GAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCATGCCCCT GGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCTGCCCGA GGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCAGACTCC ACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCGGCTGCC TACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGGTGCAAA GAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAGGGCAGG GAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATAAGCCCC TCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTCTGCCCC AGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCGAAGGCC AGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTATAAATCT GAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCATCAGTT GCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATTTTTTTA AATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTC >8854_8854_2_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000335922_length(amino acids)=780AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFGQV VLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPGLE YCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPEAL FDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVALTS NQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_3_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000341462_length(transcript)=4983nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGCATTCGGGGATTAATAGCTCGGATGC GGAGGTGCTGACCCTGTTCAATGTGACAGAGGCCCAGAGCGGGGAGTATGTGTGTAAGGTTTCCAATTATATTGGTGAAGCTAACCAGTC TGCGTGGCTCACTGTCACCAGACCTGTGCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTGCAC AGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCAGAT GGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGTTCT TCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTGGGA GCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGACAA GGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGAAAT GGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGTGGA GTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCCAGA GGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACACCG AGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACATCGA CTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAGTGA TGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAAGCT GCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCCCTC ACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCATGCC CCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCTGCC CGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCAGAC TCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCGGCT GCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGGTGC AAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAGGGC AGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATAAGC CCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTCTGC CCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCGAAG GCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTATAAA TCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCATCA GTTGCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATTTTT TTAAATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTCATTTATCTATGGGCTGTATGAAAAGGGTG GGAATGTCCACTGGAAAGAAGGGACACCCACGGGCCCTGGGGCTAGGTCTGTCCCGAGGGCACCGCATGCTCCCGGCGCAGGTTCCTTGT AACCTCTTCTTCCTAGGTCCTGCACCCAGACCTCACGACGCACCTCCTGCCTCTCCGCTGCTTTTGGAAAGTCAGAAAAAGAAGATGTCT GCTTCGAGGGCAGGAACCCCATCCATGCAGTAGAGGCGCTGGGCAGAGAGTCAAGGCCCAGCAGCCATCGACCATGGATGGTTTCCTCCA AGGAAACCGGTGGGGTTGGGCTGGGGAGGGGGCACCTACCTAGGAATAGCCACGGGGTAGAGCTACAGTGATTAAGAGGAAAGCAAGGGC GCGGTTGCTCACGCCTGTAATCCCAGCACTTTGGGACACCGAGGTGGGCAGATCACTTCAGGTCAGGAGTTTGAGACCAGCCTGGCCAAC TTAGTGAAACCCCATCTCTACTAAAAATGCAAAAATTATCCAGGCATGGTGGCACACGCCTGTAATCCCAGCTCCACAGGAGGCTGAGGC AGAATCCCTTGAAGCTGGGAGGCGGAGGTTGCAGTGAGCCGAGATTGCGCCATTGCACTCCAGCCTGGGCAACAGAGAAAACAAAAAGGA AAACAAATGATGAAGGTCTGCAGAAACTGAAACCCAGACATGTGTCTGCCCCCTCTATGTGGGCATGGTTTTGCCAGTGCTTCTAAGTGC AGGAGAACATGTCACCTGAGGCTAGTTTTGCATTCAGGTCCCTGGCTTCGTTTCTTGTTGGTATGCCTCCCCAGATCGTCCTTCCTGTAT CCATGTGACCAGACTGTATTTGTTGGGACTGTCGCAGATCTTGGCTTCTTACAGTTCTTCCTGTCCAAACTCCATCCTGTCCCTCAGGAA CGGGGGGAAAATTCTCCGAATGTTTTTGGTTTTTTGGCTGCTTGGAATTTACTTCTGCCACCTGCTGGTCATCACTGTCCTCACTAAGTG GATTCTGGCTCCCCCGTACCTCATGGCTCAAACTACCACTCCTCAGTCGCTATATTAAAGCTTATATTTTGCTGGATTACTGCTAAATAC AAAAGAAAGTTCAATATGTTTTCATTTCTGTAGGGAAAATGGGATTGCTGCTTTAAATTTCTGAGCTAGGGATTTTTTGGCAGCTGCAGT GTTGGCGACTATTGTAAAATTCTCTTTGTTTCTCTCTGTAAATAGCACCTGCTAACATTACAATTTGTATTTATGTTTAAAGAAGGCATC ATTTGGTGAACAGAACTAGGAAATGAATTTTTAGCTCTTAAAAGCATTTGCTTTGAGACCGCACAGGAGTGTCTTTCCTTGTAAAACAGT GATGATAATTTCTGCCTTGGCCCTACCTTGAAGCAATGTTGTGTGAAGGGATGAAGAATCTAAAAGTCTTCATAAGTCCTTGGGAGAGGT GCTAGAAAAATATAAGGCACTATCATAATTACAGTGATGTCCTTGCTGTTACTACTCAAATCACCCACAAATTTCCCCAAAGACTGCGCT AGCTGTCAAATAAAAGACAGTGAAATTGACCTG >8854_8854_3_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000341462_length(amino acids)=781AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKHSGINSSDAEVLTLFNVTEAQSGEYVCKVSNYIGEANQSAWLTVTRPVLEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMKS GTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFGQ VVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPGL EYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPEA LFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVALT SNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_4_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000356207_length(transcript)=3395nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGT TCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTG GGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGA CAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGA AATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGT GGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCC AGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACA CCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACAT CGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAG TGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAA GCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCC CTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCAT GCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCT GCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCA GACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCG GCTGCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGG TGCAAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAG GGCAGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATA AGCCCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTC TGCCCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCG AAGGCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTAT AAATCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCA TCAGTTGCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATT TTTTTAAATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTCA >8854_8854_4_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000356207_length(amino acids)=782AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFG QVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPG LEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPE ALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVAL TSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_5_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397091_length(transcript)=4987nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGT TCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTG GGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGA CAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGA AATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGT GGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCC AGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACA CCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACAT CGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAG TGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAA GCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCC CTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCAT GCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCT GCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCA GACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCG GCTGCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGG TGCAAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAG GGCAGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATA AGCCCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTC TGCCCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCG AAGGCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTAT AAATCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCA TCAGTTGCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATT TTTTTAAATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTCATTTATCTATGGGCTGTATGAAAAGG GTGGGAATGTCCACTGGAAAGAAGGGACACCCACGGGCCCTGGGGCTAGGTCTGTCCCGAGGGCACCGCATGCTCCCGGCGCAGGTTCCT TGTAACCTCTTCTTCCTAGGTCCTGCACCCAGACCTCACGACGCACCTCCTGCCTCTCCGCTGCTTTTGGAAAGTCAGAAAAAGAAGATG TCTGCTTCGAGGGCAGGAACCCCATCCATGCAGTAGAGGCGCTGGGCAGAGAGTCAAGGCCCAGCAGCCATCGACCATGGATGGTTTCCT CCAAGGAAACCGGTGGGGTTGGGCTGGGGAGGGGGCACCTACCTAGGAATAGCCACGGGGTAGAGCTACAGTGATTAAGAGGAAAGCAAG GGCGCGGTTGCTCACGCCTGTAATCCCAGCACTTTGGGACACCGAGGTGGGCAGATCACTTCAGGTCAGGAGTTTGAGACCAGCCTGGCC AACTTAGTGAAACCCCATCTCTACTAAAAATGCAAAAATTATCCAGGCATGGTGGCACACGCCTGTAATCCCAGCTCCACAGGAGGCTGA GGCAGAATCCCTTGAAGCTGGGAGGCGGAGGTTGCAGTGAGCCGAGATTGCGCCATTGCACTCCAGCCTGGGCAACAGAGAAAACAAAAA GGAAAACAAATGATGAAGGTCTGCAGAAACTGAAACCCAGACATGTGTCTGCCCCCTCTATGTGGGCATGGTTTTGCCAGTGCTTCTAAG TGCAGGAGAACATGTCACCTGAGGCTAGTTTTGCATTCAGGTCCCTGGCTTCGTTTCTTGTTGGTATGCCTCCCCAGATCGTCCTTCCTG TATCCATGTGACCAGACTGTATTTGTTGGGACTGTCGCAGATCTTGGCTTCTTACAGTTCTTCCTGTCCAAACTCCATCCTGTCCCTCAG GAACGGGGGGAAAATTCTCCGAATGTTTTTGGTTTTTTGGCTGCTTGGAATTTACTTCTGCCACCTGCTGGTCATCACTGTCCTCACTAA GTGGATTCTGGCTCCCCCGTACCTCATGGCTCAAACTACCACTCCTCAGTCGCTATATTAAAGCTTATATTTTGCTGGATTACTGCTAAA TACAAAAGAAAGTTCAATATGTTTTCATTTCTGTAGGGAAAATGGGATTGCTGCTTTAAATTTCTGAGCTAGGGATTTTTTGGCAGCTGC AGTGTTGGCGACTATTGTAAAATTCTCTTTGTTTCTCTCTGTAAATAGCACCTGCTAACATTACAATTTGTATTTATGTTTAAAGAAGGC ATCATTTGGTGAACAGAACTAGGAAATGAATTTTTAGCTCTTAAAAGCATTTGCTTTGAGACCGCACAGGAGTGTCTTTCCTTGTAAAAC AGTGATGATAATTTCTGCCTTGGCCCTACCTTGAAGCAATGTTGTGTGAAGGGATGAAGAATCTAAAAGTCTTCATAAGTCCTTGGGAGA GGTGCTAGAAAAATATAAGGCACTATCATAATTACAGTGATGTCCTTGCTGTTACTACTCAAATCACCCACAAATTTCCCCAAAGACTGC GCTAGCTGTCAAATAAAAGACAGTGAAATTGACCTGA >8854_8854_5_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397091_length(amino acids)=782AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFG QVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPG LEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPE ALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVAL TSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_6_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397103_length(transcript)=3197nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGCATTCGGGGATTAATAGCTCGGATGC GGAGGTGCTGACCCTGTTCAATGTGACAGAGGCCCAGAGCGGGGAGTATGTGTGTAAGGTTTCCAATTATATTGGTGAAGCTAACCAGTC TGCGTGGCTCACTGTCACCAGACCTGTGGCAAAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCAT CTATTGCACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCA CAGCCAGATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTC TGGGGTTCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCC TCGCTGGGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGG GCTGGACAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGAT CTCAGAAATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGT CATCGTGGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCA CAACCCAGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTG CATACACCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCA CCACATCGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCA CCAGAGTGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACT TTTCAAGCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGC AGTGCCCTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCT GTCCATGCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGA GCCGCTGCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCC TCCCCAGACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAG GAGCCGGCTGCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGT GAGAGGTGCAAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGC CTGGAGGGCAGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCA CCCATAAGCCCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGT GACCTCTGCCCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGT GAGGCGAAGGCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAA GTGTATAAATCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGT >8854_8854_6_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397103_length(amino acids)=784AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKHSGINSSDAEVLTLFNVTEAQSGEYVCKVSNYIGEANQSAWLTVTRPVAKALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYK MKSGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGC FGQVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRP PGLEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMA PEALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIV ALTSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_7_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397108_length(transcript)=2603nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGT TCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTG GGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGA CAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGA AATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGT GGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCC AGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACA CCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACAT CGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAG TGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAA GCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCC CTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCAT GCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCT GCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCA GACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCA >8854_8854_7_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397108_length(amino acids)=782AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFG QVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPG LEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPE ALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVAL TSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_8_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397113_length(transcript)=3397nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGT TCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTG GGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGA CAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGA AATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGT GGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCC AGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACA CCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACAT CGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAG TGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAA GCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCC CTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCAT GCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCT GCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCA GACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCG GCTGCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGG TGCAAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAG GGCAGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATA AGCCCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTC TGCCCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCG AAGGCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTAT AAATCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCA TCAGTTGCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATT TTTTTAAATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTCATT >8854_8854_8_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000397113_length(amino acids)=782AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFG QVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPG LEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPE ALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVAL TSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_9_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000425967_length(transcript)=4987nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGT TCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTG GGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGA CAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGA AATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGT GGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCC AGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACA CCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACAT CGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAG TGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAA GCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCC CTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCAT GCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCT GCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCA GACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCG GCTGCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGG TGCAAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAG GGCAGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATA AGCCCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTC TGCCCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCG AAGGCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTAT AAATCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCA TCAGTTGCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATT TTTTTAAATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTCATTTATCTATGGGCTGTATGAAAAGG GTGGGAATGTCCACTGGAAAGAAGGGACACCCACGGGCCCTGGGGCTAGGTCTGTCCCGAGGGCACCGCATGCTCCCGGCGCAGGTTCCT TGTAACCTCTTCTTCCTAGGTCCTGCACCCAGACCTCACGACGCACCTCCTGCCTCTCCGCTGCTTTTGGAAAGTCAGAAAAAGAAGATG TCTGCTTCGAGGGCAGGAACCCCATCCATGCAGTAGAGGCGCTGGGCAGAGAGTCAAGGCCCAGCAGCCATCGACCATGGATGGTTTCCT CCAAGGAAACCGGTGGGGTTGGGCTGGGGAGGGGGCACCTACCTAGGAATAGCCACGGGGTAGAGCTACAGTGATTAAGAGGAAAGCAAG GGCGCGGTTGCTCACGCCTGTAATCCCAGCACTTTGGGACACCGAGGTGGGCAGATCACTTCAGGTCAGGAGTTTGAGACCAGCCTGGCC AACTTAGTGAAACCCCATCTCTACTAAAAATGCAAAAATTATCCAGGCATGGTGGCACACGCCTGTAATCCCAGCTCCACAGGAGGCTGA GGCAGAATCCCTTGAAGCTGGGAGGCGGAGGTTGCAGTGAGCCGAGATTGCGCCATTGCACTCCAGCCTGGGCAACAGAGAAAACAAAAA GGAAAACAAATGATGAAGGTCTGCAGAAACTGAAACCCAGACATGTGTCTGCCCCCTCTATGTGGGCATGGTTTTGCCAGTGCTTCTAAG TGCAGGAGAACATGTCACCTGAGGCTAGTTTTGCATTCAGGTCCCTGGCTTCGTTTCTTGTTGGTATGCCTCCCCAGATCGTCCTTCCTG TATCCATGTGACCAGACTGTATTTGTTGGGACTGTCGCAGATCTTGGCTTCTTACAGTTCTTCCTGTCCAAACTCCATCCTGTCCCTCAG GAACGGGGGGAAAATTCTCCGAATGTTTTTGGTTTTTTGGCTGCTTGGAATTTACTTCTGCCACCTGCTGGTCATCACTGTCCTCACTAA GTGGATTCTGGCTCCCCCGTACCTCATGGCTCAAACTACCACTCCTCAGTCGCTATATTAAAGCTTATATTTTGCTGGATTACTGCTAAA TACAAAAGAAAGTTCAATATGTTTTCATTTCTGTAGGGAAAATGGGATTGCTGCTTTAAATTTCTGAGCTAGGGATTTTTTGGCAGCTGC AGTGTTGGCGACTATTGTAAAATTCTCTTTGTTTCTCTCTGTAAATAGCACCTGCTAACATTACAATTTGTATTTATGTTTAAAGAAGGC ATCATTTGGTGAACAGAACTAGGAAATGAATTTTTAGCTCTTAAAAGCATTTGCTTTGAGACCGCACAGGAGTGTCTTTCCTTGTAAAAC AGTGATGATAATTTCTGCCTTGGCCCTACCTTGAAGCAATGTTGTGTGAAGGGATGAAGAATCTAAAAGTCTTCATAAGTCCTTGGGAGA GGTGCTAGAAAAATATAAGGCACTATCATAATTACAGTGATGTCCTTGCTGTTACTACTCAAATCACCCACAAATTTCCCCAAAGACTGC GCTAGCTGTCAAATAAAAGACAGTGAAATTGACCTGA >8854_8854_9_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000425967_length(amino acids)=782AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFG QVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPG LEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPE ALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVAL TSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_10_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000447712_length(transcript)=4986nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTAACAGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGT TCTTCTGGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTG GGAGCTGCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGA CAAGGACAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGA AATGGAGATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGT GGAGTATGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCC AGAGGAGCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACA CCGAGACCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACAT CGACTACTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAG TGATGTGTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAA GCTGCTGAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCC CTCACAGAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCAT GCCCCTGGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCT GCCCGAGGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCA GACTCCACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCG GCTGCCTACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGG TGCAAAGAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAG GGCAGGGAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATA AGCCCCTCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTC TGCCCCAGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCG AAGGCCAGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTAT AAATCTGAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCA TCAGTTGCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATT TTTTTAAATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTCATTTATCTATGGGCTGTATGAAAAGG GTGGGAATGTCCACTGGAAAGAAGGGACACCCACGGGCCCTGGGGCTAGGTCTGTCCCGAGGGCACCGCATGCTCCCGGCGCAGGTTCCT TGTAACCTCTTCTTCCTAGGTCCTGCACCCAGACCTCACGACGCACCTCCTGCCTCTCCGCTGCTTTTGGAAAGTCAGAAAAAGAAGATG TCTGCTTCGAGGGCAGGAACCCCATCCATGCAGTAGAGGCGCTGGGCAGAGAGTCAAGGCCCAGCAGCCATCGACCATGGATGGTTTCCT CCAAGGAAACCGGTGGGGTTGGGCTGGGGAGGGGGCACCTACCTAGGAATAGCCACGGGGTAGAGCTACAGTGATTAAGAGGAAAGCAAG GGCGCGGTTGCTCACGCCTGTAATCCCAGCACTTTGGGACACCGAGGTGGGCAGATCACTTCAGGTCAGGAGTTTGAGACCAGCCTGGCC AACTTAGTGAAACCCCATCTCTACTAAAAATGCAAAAATTATCCAGGCATGGTGGCACACGCCTGTAATCCCAGCTCCACAGGAGGCTGA GGCAGAATCCCTTGAAGCTGGGAGGCGGAGGTTGCAGTGAGCCGAGATTGCGCCATTGCACTCCAGCCTGGGCAACAGAGAAAACAAAAA GGAAAACAAATGATGAAGGTCTGCAGAAACTGAAACCCAGACATGTGTCTGCCCCCTCTATGTGGGCATGGTTTTGCCAGTGCTTCTAAG TGCAGGAGAACATGTCACCTGAGGCTAGTTTTGCATTCAGGTCCCTGGCTTCGTTTCTTGTTGGTATGCCTCCCCAGATCGTCCTTCCTG TATCCATGTGACCAGACTGTATTTGTTGGGACTGTCGCAGATCTTGGCTTCTTACAGTTCTTCCTGTCCAAACTCCATCCTGTCCCTCAG GAACGGGGGGAAAATTCTCCGAATGTTTTTGGTTTTTTGGCTGCTTGGAATTTACTTCTGCCACCTGCTGGTCATCACTGTCCTCACTAA GTGGATTCTGGCTCCCCCGTACCTCATGGCTCAAACTACCACTCCTCAGTCGCTATATTAAAGCTTATATTTTGCTGGATTACTGCTAAA TACAAAAGAAAGTTCAATATGTTTTCATTTCTGTAGGGAAAATGGGATTGCTGCTTTAAATTTCTGAGCTAGGGATTTTTTGGCAGCTGC AGTGTTGGCGACTATTGTAAAATTCTCTTTGTTTCTCTCTGTAAATAGCACCTGCTAACATTACAATTTGTATTTATGTTTAAAGAAGGC ATCATTTGGTGAACAGAACTAGGAAATGAATTTTTAGCTCTTAAAAGCATTTGCTTTGAGACCGCACAGGAGTGTCTTTCCTTGTAAAAC AGTGATGATAATTTCTGCCTTGGCCCTACCTTGAAGCAATGTTGTGTGAAGGGATGAAGAATCTAAAAGTCTTCATAAGTCCTTGGGAGA GGTGCTAGAAAAATATAAGGCACTATCATAATTACAGTGATGTCCTTGCTGTTACTACTCAAATCACCCACAAATTTCCCCAAAGACTGC GCTAGCTGTCAAATAAAAGACAGTGAAATTGACCTG >8854_8854_10_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000447712_length(amino acids)=782AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVTVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFG QVVLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPG LEYCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPE ALFDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVAL TSNQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- >8854_8854_11_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000532791_length(transcript)=4888nt_BP=649nt AACTCCATTGGATAAATGGCGAGGAAACGTATACTCCCTCTTAAGGAACACGGTGTCTTCCTTCGTCTCCGGGTTCCCGAGACCCCAGAG TCACTGACCTCCGTCCCTCAGCTTTCGGGGTTCGGCAGCAGAAGGGGCGGGCCCGGGCCTGGGATTGGCTGGCGTCGTCCGACCCCCTTC GCTGCTCTCCATTCGCAATCGCCCGCGGGCGCCTGCGCGATGGGTCGGCCGTGGGGAGCGGGGCGGGAAGCGCTTCAGGGCAGCGGATCC CATGTCGGCCCTGAGGCGCTCGGGCTACGGCCCCAGTGACGGTCCGTCCTACGGCCGCTACTACGGGCCTGGGGGTGGAGATGTGCCGGT ACACCCACCTCCACCCTTATATCCTCTTCGCCCTGAACCTCCCCAGCCTCCCATTTCCTGGCGGGTGCGCGGGGGCGGCCCGGCGGAGAC CACCTGGCTGGGAGAAGGCGGAGGAGGCGATGGCTACTATCCCTCGGGAGGCGCCTGGCCAGAGCCTGGTCGAGCCGGAGGAAGCCACCA GGAGCAGCCACCATATCCTAGCTACAATTCTAACTATTGGAATTCTACTGCGAGATCTAGGGCTCCTTACCCAAGTACATATCCTGTAAG ACCAGAATTGCAAGGCCAGGTCCGTTATGCCACCTGGAGCATCATAATGGACTCTGTGGTGCCCTCTGACAAGGGCAACTACACCTGCAT TGTGGAGAATGAGTACGGCAGCATCAACCACACATACCAGCTGGATGTCGTGGAGCGGTCCCCTCACCGGCCCATCCTGCAAGCAGGGTT GCCCGCCAACAAAACAGTGGCCCTGGGTAGCAACGTGGAGTTCATGTGTAAGGTGTACAGTGACCCGCAGCCGCACATCCAGTGGCTAAA GCACATCGAGGTGAATGGGAGCAAGATTGGCCCAGACAACCTGCCTTATGTCCAGATCTTGAAGACTGCTGGAGTTAATACCACCGACAA AGAGATGGAGGTGCTTCACTTAAGAAATGTCTCCTTTGAGGACGCAGGGGAGTATACGTGCTTGGCGGGTAACTCTATCGGACTCTCCCA TCACTCTGCATGGTTGACCGTTCTGGAAGCCCTGGAAGAGAGGCCGGCAGTGATGACCTCGCCCCTGTACCTGGAGATCATCATCTATTG CACAGGGGCCTTCCTCATCTCCTGCATGGTGGGGTCGGTCATCGTCTACAAGATGAAGAGTGGTACCAAGAAGAGTGACTTCCACAGCCA GATGGCTGTGCACAAGCTGGCCAAGAGCATCCCTCTGCGCAGACAGGTGTCTGCTGACTCCAGTGCATCCATGAACTCTGGGGTTCTTCT GGTTCGGCCATCACGGCTCTCCTCCAGTGGGACTCCCATGCTAGCAGGGGTCTCTGAGTATGAGCTTCCCGAAGACCCTCGCTGGGAGCT GCCTCGGGACAGACTGGTCTTAGGCAAACCCCTGGGAGAGGGCTGCTTTGGGCAGGTGGTGTTGGCAGAGGCTATCGGGCTGGACAAGGA CAAACCCAACCGTGTGACCAAAGTGGCTGTGAAGATGTTGAAGTCGGACGCAACAGAGAAAGACTTGTCAGACCTGATCTCAGAAATGGA GATGATGAAGATGATCGGGAAGCATAAGAATATCATCAACCTGCTGGGGGCCTGCACGCAGGATGGTCCCTTGTATGTCATCGTGGAGTA TGCCTCCAAGGGCAACCTGCGGGAGTACCTGCAGGCCCGGAGGCCCCCAGGGCTGGAATACTGCTACAACCCCAGCCACAACCCAGAGGA GCAGCTCTCCTCCAAGGACCTGGTGTCCTGCGCCTACCAGGTGGCCCGAGGCATGGAGTATCTGGCCTCCAAGAAGTGCATACACCGAGA CCTGGCAGCCAGGAATGTCCTGGTGACAGAGGACAATGTGATGAAGATAGCAGACTTTGGCCTCGCACGGGACATTCACCACATCGACTA CTATAAAAAGACAACCAACGGCCGACTGCCTGTGAAGTGGATGGCACCCGAGGCATTATTTGACCGGATCTACACCCACCAGAGTGATGT GTGGTCTTTCGGGGTGCTCCTGTGGGAGATCTTCACTCTGGGCGGCTCCCCATACCCCGGTGTGCCTGTGGAGGAACTTTTCAAGCTGCT GAAGGAGGGTCACCGCATGGACAAGCCCAGTAACTGCACCAACGAGCTGTACATGATGATGCGGGACTGCTGGCATGCAGTGCCCTCACA GAGACCCACCTTCAAGCAGCTGGTGGAAGACCTGGACCGCATCGTGGCCTTGACCTCCAACCAGGAGTACCTGGACCTGTCCATGCCCCT GGACCAGTACTCCCCCAGCTTTCCCGACACCCGGAGCTCTACGTGCTCCTCAGGGGAGGATTCCGTCTTCTCTCATGAGCCGCTGCCCGA GGAGCCCTGCCTGCCCCGACACCCAGCCCAGCTTGCCAATGGCGGACTCAAACGCCGCTGACTGCCACCCACACGCCCTCCCCAGACTCC ACCGTCAGCTGTAACCCTCACCCACAGCCCCTGCTGGGCCCACCACCTGTCCGTCCCTGTCCCCTTTCCTGCTGGCAGGAGCCGGCTGCC TACCAGGGGCCTTCCTGTGTGGCCTGCCTTCACCCCACTCAGCTCACCTCTCCCTCCACCTCCTCTCCACCTGCTGGTGAGAGGTGCAAA GAGGCAGATCTTTGCTGCCAGCCACTTCATCCCCTCCCAGATGTTGGACCAACACCCCTCCCTGCCACCAGGCACTGCCTGGAGGGCAGG GAGTGGGAGCCAATGAACAGGCATGCAAGTGAGAGCTTCCTGAGCTTTCTCCTGTCGGTTTGGTCTGTTTTGCCTTCACCCATAAGCCCC TCGCACTCTGGTGGCAGGTGCCTTGTCCTCAGGGCTACAGCAGTAGGGAGGTCAGTGCTTCGTGCCTCGATTGAAGGTGACCTCTGCCCC AGATAGGTGGTGCCAGTGGCTTATTAATTCCGATACTAGTTTGCTTTGCTGACCAAATGCCTGGTACCAGAGGATGGTGAGGCGAAGGCC AGGTTGGGGGCAGTGTTGTGGCCCTGGGGCCCAGCCCCAAACTGGGGGCTCTGTATATAGCTATGAAGAAAACACAAAGTGTATAAATCT GAGTATATATTTACATGTCTTTTTAAAAGGGTCGTTACCAGAGATTTACCCATCGGGTAAGATGCTCCTGGTGGCTGGGAGGCATCAGTT GCTATATATTAAAAACAAAAAAGAAAAAAAAGGAAAATGTTTTTAAAAAGGTCATATATTTTTTGCTACTTTTGCTGTTTTATTTTTTTA AATTATGTTCTAAACCTATTTTCAGTTTAGGTCCCTCAATAAAAATTGCTGCTGCTTCATTTATCTATGGGCTGTATGAAAAGGGTGGGA ATGTCCACTGGAAAGAAGGGACACCCACGGGCCCTGGGGCTAGGTCTGTCCCGAGGGCACCGCATGCTCCCGGCGCAGGTTCCTTGTAAC CTCTTCTTCCTAGGTCCTGCACCCAGACCTCACGACGCACCTCCTGCCTCTCCGCTGCTTTTGGAAAGTCAGAAAAAGAAGATGTCTGCT TCGAGGGCAGGAACCCCATCCATGCAGTAGAGGCGCTGGGCAGAGAGTCAAGGCCCAGCAGCCATCGACCATGGATGGTTTCCTCCAAGG AAACCGGTGGGGTTGGGCTGGGGAGGGGGCACCTACCTAGGAATAGCCACGGGGTAGAGCTACAGTGATTAAGAGGAAAGCAAGGGCGCG GTTGCTCACGCCTGTAATCCCAGCACTTTGGGACACCGAGGTGGGCAGATCACTTCAGGTCAGGAGTTTGAGACCAGCCTGGCCAACTTA GTGAAACCCCATCTCTACTAAAAATGCAAAAATTATCCAGGCATGGTGGCACACGCCTGTAATCCCAGCTCCACAGGAGGCTGAGGCAGA ATCCCTTGAAGCTGGGAGGCGGAGGTTGCAGTGAGCCGAGATTGCGCCATTGCACTCCAGCCTGGGCAACAGAGAAAACAAAAAGGAAAA CAAATGATGAAGGTCTGCAGAAACTGAAACCCAGACATGTGTCTGCCCCCTCTATGTGGGCATGGTTTTGCCAGTGCTTCTAAGTGCAGG AGAACATGTCACCTGAGGCTAGTTTTGCATTCAGGTCCCTGGCTTCGTTTCTTGTTGGTATGCCTCCCCAGATCGTCCTTCCTGTATCCA TGTGACCAGACTGTATTTGTTGGGACTGTCGCAGATCTTGGCTTCTTACAGTTCTTCCTGTCCAAACTCCATCCTGTCCCTCAGGAACGG GGGGAAAATTCTCCGAATGTTTTTGGTTTTTTGGCTGCTTGGAATTTACTTCTGCCACCTGCTGGTCATCACTGTCCTCACTAAGTGGAT TCTGGCTCCCCCGTACCTCATGGCTCAAACTACCACTCCTCAGTCGCTATATTAAAGCTTATATTTTGCTGGATTACTGCTAAATACAAA AGAAAGTTCAATATGTTTTCATTTCTGTAGGGAAAATGGGATTGCTGCTTTAAATTTCTGAGCTAGGGATTTTTTGGCAGCTGCAGTGTT GGCGACTATTGTAAAATTCTCTTTGTTTCTCTCTGTAAATAGCACCTGCTAACATTACAATTTGTATTTATGTTTAAAGAAGGCATCATT TGGTGAACAGAACTAGGAAATGAATTTTTAGCTCTTAAAAGCATTTGCTTTGAGACCGCACAGGAGTGTCTTTCCTTGTAAAACAGTGAT GATAATTTCTGCCTTGGCCCTACCTTGAAGCAATGTTGTGTGAAGGGATGAAGAATCTAAAAGTCTTCATAAGTCCTTGGGAGAGGTGCT AGAAAAATATAAGGCACTATCATAATTA >8854_8854_11_BAG4-FGFR1_BAG4_chr8_38050313_ENST00000287322_FGFR1_chr8_38283763_ENST00000532791_length(amino acids)=780AA_BP=166 MGLAGVVRPPSLLSIRNRPRAPARWVGRGERGGKRFRAADPMSALRRSGYGPSDGPSYGRYYGPGGGDVPVHPPPPLYPLRPEPPQPPIS WRVRGGGPAETTWLGEGGGGDGYYPSGGAWPEPGRAGGSHQEQPPYPSYNSNYWNSTARSRAPYPSTYPVRPELQGQVRYATWSIIMDSV VPSDKGNYTCIVENEYGSINHTYQLDVVERSPHRPILQAGLPANKTVALGSNVEFMCKVYSDPQPHIQWLKHIEVNGSKIGPDNLPYVQI LKTAGVNTTDKEMEVLHLRNVSFEDAGEYTCLAGNSIGLSHHSAWLTVLEALEERPAVMTSPLYLEIIIYCTGAFLISCMVGSVIVYKMK SGTKKSDFHSQMAVHKLAKSIPLRRQVSADSSASMNSGVLLVRPSRLSSSGTPMLAGVSEYELPEDPRWELPRDRLVLGKPLGEGCFGQV VLAEAIGLDKDKPNRVTKVAVKMLKSDATEKDLSDLISEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLQARRPPGLE YCYNPSHNPEEQLSSKDLVSCAYQVARGMEYLASKKCIHRDLAARNVLVTEDNVMKIADFGLARDIHHIDYYKKTTNGRLPVKWMAPEAL FDRIYTHQSDVWSFGVLLWEIFTLGGSPYPGVPVEELFKLLKEGHRMDKPSNCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRIVALTS NQEYLDLSMPLDQYSPSFPDTRSSTCSSGEDSVFSHEPLPEEPCLPRHPAQLANGGLKRR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for BAG4-FGFR1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for BAG4-FGFR1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
| Tgene | FGFR1 | P11362 | DB00039 | Palifermin | Agonist | Biotech | Approved |
| Tgene | FGFR1 | P11362 | DB00039 | Palifermin | Agonist | Biotech | Approved |
| Tgene | FGFR1 | P11362 | DB00039 | Palifermin | Agonist | Biotech | Approved |
| Tgene | FGFR1 | P11362 | DB00039 | Palifermin | Agonist | Biotech | Approved |
| Tgene | FGFR1 | P11362 | DB00039 | Palifermin | Agonist | Biotech | Approved |
| Tgene | FGFR1 | P11362 | DB00039 | Palifermin | Agonist | Biotech | Approved |
| Tgene | FGFR1 | P11362 | DB00039 | Palifermin | Agonist | Biotech | Approved |
| Tgene | FGFR1 | P11362 | DB08896 | Regorafenib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB08896 | Regorafenib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB08896 | Regorafenib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB08896 | Regorafenib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB08896 | Regorafenib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB08896 | Regorafenib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB08896 | Regorafenib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB09079 | Nintedanib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB09079 | Nintedanib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB09079 | Nintedanib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB09079 | Nintedanib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB09079 | Nintedanib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB09079 | Nintedanib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB09079 | Nintedanib | Inhibitor | Small molecule | Approved |
| Tgene | FGFR1 | P11362 | DB00398 | Sorafenib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB00398 | Sorafenib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB00398 | Sorafenib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB00398 | Sorafenib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB00398 | Sorafenib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB00398 | Sorafenib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB00398 | Sorafenib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB01109 | Heparin | Small molecule | Approved|Investigational | |
| Tgene | FGFR1 | P11362 | DB01109 | Heparin | Small molecule | Approved|Investigational | |
| Tgene | FGFR1 | P11362 | DB01109 | Heparin | Small molecule | Approved|Investigational | |
| Tgene | FGFR1 | P11362 | DB01109 | Heparin | Small molecule | Approved|Investigational | |
| Tgene | FGFR1 | P11362 | DB01109 | Heparin | Small molecule | Approved|Investigational | |
| Tgene | FGFR1 | P11362 | DB01109 | Heparin | Small molecule | Approved|Investigational | |
| Tgene | FGFR1 | P11362 | DB01109 | Heparin | Small molecule | Approved|Investigational | |
| Tgene | FGFR1 | P11362 | DB08901 | Ponatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB08901 | Ponatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB08901 | Ponatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB08901 | Ponatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB08901 | Ponatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB08901 | Ponatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB08901 | Ponatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB09078 | Lenvatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB09078 | Lenvatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB09078 | Lenvatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB09078 | Lenvatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB09078 | Lenvatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB09078 | Lenvatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB09078 | Lenvatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12010 | Fostamatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12010 | Fostamatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12010 | Fostamatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12010 | Fostamatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12010 | Fostamatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12010 | Fostamatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12010 | Fostamatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12147 | Erdafitinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12147 | Erdafitinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12147 | Erdafitinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12147 | Erdafitinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12147 | Erdafitinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12147 | Erdafitinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB12147 | Erdafitinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15102 | Pemigatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15102 | Pemigatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15102 | Pemigatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15102 | Pemigatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15102 | Pemigatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15102 | Pemigatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15102 | Pemigatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15685 | Selpercatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15685 | Selpercatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15685 | Selpercatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15685 | Selpercatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15685 | Selpercatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15685 | Selpercatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15685 | Selpercatinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15822 | Pralsetinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15822 | Pralsetinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15822 | Pralsetinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15822 | Pralsetinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15822 | Pralsetinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15822 | Pralsetinib | Inhibitor | Small molecule | Approved|Investigational |
| Tgene | FGFR1 | P11362 | DB15822 | Pralsetinib | Inhibitor | Small molecule | Approved|Investigational |
Top |
Related Diseases for BAG4-FGFR1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Tgene | C1563720 | Kallmann Syndrome 2 (disorder) | 18 | CTD_human;GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C1845146 | Holoprosencephaly, Ectrodactyly, and Bilateral Cleft Lip-Palate | 6 | GENOMICS_ENGLAND;ORPHANET;UNIPROT | |
| Tgene | C0011570 | Mental Depression | 5 | PSYGENET | |
| Tgene | C0011581 | Depressive disorder | 5 | CTD_human;PSYGENET | |
| Tgene | C0220658 | Pfeiffer Syndrome | 5 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C0432283 | Osteoglophonic dwarfism | 5 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT | |
| Tgene | C0041696 | Unipolar Depression | 4 | CTD_human;PSYGENET | |
| Tgene | C0406612 | Encephalocraniocutaneous lipomatosis | 4 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT | |
| Tgene | C0005586 | Bipolar Disorder | 3 | PSYGENET | |
| Tgene | C0795998 | JACKSON-WEISS SYNDROME | 3 | CTD_human;GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C1269683 | Major Depressive Disorder | 3 | PSYGENET | |
| Tgene | C0006142 | Malignant neoplasm of breast | 2 | CGI;CTD_human | |
| Tgene | C0007131 | Non-Small Cell Lung Carcinoma | 2 | CTD_human | |
| Tgene | C0007137 | Squamous cell carcinoma | 2 | CTD_human | |
| Tgene | C0027022 | Myeloproliferative disease | 2 | CTD_human | |
| Tgene | C0162809 | Kallmann Syndrome | 2 | CTD_human;ORPHANET | |
| Tgene | C0432122 | Interfrontal craniofaciosynostosis | 2 | GENOMICS_ENGLAND;UNIPROT | |
| Tgene | C0678222 | Breast Carcinoma | 2 | CGI;CTD_human | |
| Tgene | C1257931 | Mammary Neoplasms, Human | 2 | CTD_human | |
| Tgene | C1458155 | Mammary Neoplasms | 2 | CTD_human | |
| Tgene | C4704874 | Mammary Carcinoma, Human | 2 | CTD_human | |
| Tgene | C0004114 | Astrocytoma | 1 | CTD_human | |
| Tgene | C0008924 | Cleft upper lip | 1 | CTD_human | |
| Tgene | C0008925 | Cleft Palate | 1 | CTD_human | |
| Tgene | C0010278 | Craniosynostosis | 1 | CTD_human;GENOMICS_ENGLAND | |
| Tgene | C0011573 | Endogenous depression | 1 | CTD_human | |
| Tgene | C0017638 | Glioma | 1 | CTD_human | |
| Tgene | C0018824 | Heart valve disease | 1 | CTD_human | |
| Tgene | C0024121 | Lung Neoplasms | 1 | CTD_human | |
| Tgene | C0025193 | Melancholia | 1 | CTD_human | |
| Tgene | C0036341 | Schizophrenia | 1 | CTD_human | |
| Tgene | C0085682 | Hypophosphatemia | 1 | GENOMICS_ENGLAND | |
| Tgene | C0086133 | Depressive Syndrome | 1 | CTD_human | |
| Tgene | C0149925 | Small cell carcinoma of lung | 1 | CTD_human | |
| Tgene | C0205768 | Subependymal Giant Cell Astrocytoma | 1 | CTD_human | |
| Tgene | C0206726 | gliosarcoma | 1 | ORPHANET | |
| Tgene | C0242379 | Malignant neoplasm of lung | 1 | CTD_human | |
| Tgene | C0259783 | mixed gliomas | 1 | CTD_human | |
| Tgene | C0265535 | Trigonocephaly | 1 | CTD_human;ORPHANET | |
| Tgene | C0280783 | Juvenile Pilocytic Astrocytoma | 1 | CTD_human | |
| Tgene | C0280785 | Diffuse Astrocytoma | 1 | CTD_human | |
| Tgene | C0282126 | Depression, Neurotic | 1 | CTD_human | |
| Tgene | C0334579 | Anaplastic astrocytoma | 1 | CTD_human | |
| Tgene | C0334580 | Protoplasmic astrocytoma | 1 | CTD_human | |
| Tgene | C0334581 | Gemistocytic astrocytoma | 1 | CTD_human | |
| Tgene | C0334582 | Fibrillary Astrocytoma | 1 | CTD_human | |
| Tgene | C0334583 | Pilocytic Astrocytoma | 1 | CTD_human | |
| Tgene | C0334588 | Giant Cell Glioblastoma | 1 | ORPHANET | |
| Tgene | C0338070 | Childhood Cerebral Astrocytoma | 1 | CTD_human | |
| Tgene | C0338503 | Septo-Optic Dysplasia | 1 | ORPHANET | |
| Tgene | C0342384 | Idiopathic hypogonadotropic hypogonadism | 1 | GENOMICS_ENGLAND | |
| Tgene | C0376634 | Craniofacial Abnormalities | 1 | CTD_human | |
| Tgene | C0431362 | Lobar Holoprosencephaly | 1 | ORPHANET | |
| Tgene | C0547065 | Mixed oligoastrocytoma | 1 | CTD_human | |
| Tgene | C0555198 | Malignant Glioma | 1 | CTD_human | |
| Tgene | C0750935 | Cerebral Astrocytoma | 1 | CTD_human | |
| Tgene | C0750936 | Intracranial Astrocytoma | 1 | CTD_human | |
| Tgene | C0751617 | Semilobar Holoprosencephaly | 1 | ORPHANET | |
| Tgene | C1519086 | Pilomyxoid astrocytoma | 1 | ORPHANET | |
| Tgene | C1704230 | Grade I Astrocytoma | 1 | CTD_human | |
| Tgene | C1837218 | Cleft palate, isolated | 1 | CTD_human | |
| Tgene | C1852406 | Cutis Gyrata Syndrome of Beare And Stevenson | 1 | GENOMICS_ENGLAND | |
| Tgene | C2931196 | Craniofacial dysostosis type 1 | 1 | GENOMICS_ENGLAND | |
| Tgene | C3150773 | CHROMOSOME 8p11 MYELOPROLIFERATIVE SYNDROME | 1 | ORPHANET |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies