| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:PCM1-RET |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: PCM1-RET | FusionPDB ID: 63341 | FusionGDB2.0 ID: 63341 | Hgene | Tgene | Gene symbol | PCM1 | RET | Gene ID | 5108 | 5979 |
| Gene name | pericentriolar material 1 | ret proto-oncogene | |
| Synonyms | PTC4|RET/PCM-1 | CDHF12|CDHR16|HSCR1|MEN2A|MEN2B|MTC1|PTC|RET-ELE1 | |
| Cytomap | 8p22 | 10q11.21 | |
| Type of gene | protein-coding | protein-coding | |
| Description | pericentriolar material 1 proteinPCM-1hPCM-1pericentriolar material 1, PCM1 | proto-oncogene tyrosine-protein kinase receptor RetRET receptor tyrosine kinasecadherin family member 12cadherin-related family member 16proto-oncogene c-Retrearranged during transfectionret proto-oncogene (multiple endocrine neoplasia and medullary | |
| Modification date | 20200327 | 20200322 | |
| UniProtAcc | Q15154 | RTL1 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000325083, ENST00000327578, ENST00000519253, ENST00000524226, ENST00000518537, ENST00000518936, | ENST00000340058, ENST00000355710, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 16 X 16 X 12=3072 | 32 X 31 X 11=10912 |
| # samples | 16 | 48 | |
| ** MAII score | log2(16/3072*10)=-4.26303440583379 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(48/10912*10)=-4.50673733341565 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: PCM1 [Title/Abstract] AND RET [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | PCM1(17851129)-RET(43612030), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | PCM1-RET seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. PCM1-RET seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. PCM1-RET seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. PCM1-RET seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. PCM1-RET seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. PCM1-RET seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. PCM1-RET seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. PCM1-RET seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. PCM1-RET seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | RET | GO:0030155 | regulation of cell adhesion | 21357690 |
| Tgene | RET | GO:0030335 | positive regulation of cell migration | 20702524 |
| Tgene | RET | GO:0033619 | membrane protein proteolysis | 21357690 |
| Tgene | RET | GO:0033630 | positive regulation of cell adhesion mediated by integrin | 20702524 |
| Tgene | RET | GO:0035860 | glial cell-derived neurotrophic factor receptor signaling pathway | 28953886 |
| Tgene | RET | GO:0043410 | positive regulation of MAPK cascade | 28846099 |
| Fusion gene breakpoints across PCM1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RET (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | adenocarcinoma | AJ297349 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | ||
| ChimerKB3 | . | . | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + |
| ChimerKB3 | . | . | PCM1 | chr8 | 17851129 | + | RET | chr10 | 43612030 | + |
| ChimerKB3 | . | . | PCM1 | chr8 | 17867253 | + | RET | chr10 | 43619118 | + |
| ChiTaRS5.0 | N/A | AJ297349 | PCM1 | chr8 | 17851129 | + | RET | chr10 | 43612030 | + |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000325083 | PCM1 | chr8 | 17851128 | + | ENST00000355710 | RET | chr10 | 43612031 | + | 8557 | 5266 | 439 | 6474 | 2011 |
| ENST00000325083 | PCM1 | chr8 | 17851128 | + | ENST00000340058 | RET | chr10 | 43612031 | + | 7099 | 5266 | 439 | 6348 | 1969 |
| ENST00000519253 | PCM1 | chr8 | 17851128 | + | ENST00000355710 | RET | chr10 | 43612031 | + | 8345 | 5054 | 251 | 6262 | 2003 |
| ENST00000519253 | PCM1 | chr8 | 17851128 | + | ENST00000340058 | RET | chr10 | 43612031 | + | 6887 | 5054 | 251 | 6136 | 1961 |
| ENST00000524226 | PCM1 | chr8 | 17851128 | + | ENST00000355710 | RET | chr10 | 43612031 | + | 8015 | 4724 | 59 | 5932 | 1957 |
| ENST00000524226 | PCM1 | chr8 | 17851128 | + | ENST00000340058 | RET | chr10 | 43612031 | + | 6557 | 4724 | 59 | 5806 | 1915 |
| ENST00000327578 | PCM1 | chr8 | 17851128 | + | ENST00000355710 | RET | chr10 | 43612031 | + | 4337 | 1046 | 23 | 2254 | 743 |
| ENST00000327578 | PCM1 | chr8 | 17851128 | + | ENST00000340058 | RET | chr10 | 43612031 | + | 2879 | 1046 | 23 | 2128 | 701 |
| ENST00000325083 | PCM1 | chr8 | 17851129 | + | ENST00000355710 | RET | chr10 | 43612030 | + | 8557 | 5266 | 439 | 6474 | 2011 |
| ENST00000325083 | PCM1 | chr8 | 17851129 | + | ENST00000340058 | RET | chr10 | 43612030 | + | 7099 | 5266 | 439 | 6348 | 1969 |
| ENST00000519253 | PCM1 | chr8 | 17851129 | + | ENST00000355710 | RET | chr10 | 43612030 | + | 8345 | 5054 | 251 | 6262 | 2003 |
| ENST00000519253 | PCM1 | chr8 | 17851129 | + | ENST00000340058 | RET | chr10 | 43612030 | + | 6887 | 5054 | 251 | 6136 | 1961 |
| ENST00000524226 | PCM1 | chr8 | 17851129 | + | ENST00000355710 | RET | chr10 | 43612030 | + | 8015 | 4724 | 59 | 5932 | 1957 |
| ENST00000524226 | PCM1 | chr8 | 17851129 | + | ENST00000340058 | RET | chr10 | 43612030 | + | 6557 | 4724 | 59 | 5806 | 1915 |
| ENST00000327578 | PCM1 | chr8 | 17851129 | + | ENST00000355710 | RET | chr10 | 43612030 | + | 4337 | 1046 | 23 | 2254 | 743 |
| ENST00000327578 | PCM1 | chr8 | 17851129 | + | ENST00000340058 | RET | chr10 | 43612030 | + | 2879 | 1046 | 23 | 2128 | 701 |
| ENST00000325083 | PCM1 | chr8 | 17851129 | ENST00000355710 | RET | chr10 | 43612030 | 8557 | 5266 | 439 | 6474 | 2011 | ||
| ENST00000325083 | PCM1 | chr8 | 17851129 | ENST00000340058 | RET | chr10 | 43612030 | 7099 | 5266 | 439 | 6348 | 1969 | ||
| ENST00000519253 | PCM1 | chr8 | 17851129 | ENST00000355710 | RET | chr10 | 43612030 | 8345 | 5054 | 251 | 6262 | 2003 | ||
| ENST00000519253 | PCM1 | chr8 | 17851129 | ENST00000340058 | RET | chr10 | 43612030 | 6887 | 5054 | 251 | 6136 | 1961 | ||
| ENST00000524226 | PCM1 | chr8 | 17851129 | ENST00000355710 | RET | chr10 | 43612030 | 8015 | 4724 | 59 | 5932 | 1957 | ||
| ENST00000524226 | PCM1 | chr8 | 17851129 | ENST00000340058 | RET | chr10 | 43612030 | 6557 | 4724 | 59 | 5806 | 1915 | ||
| ENST00000327578 | PCM1 | chr8 | 17851129 | ENST00000355710 | RET | chr10 | 43612030 | 4337 | 1046 | 23 | 2254 | 743 | ||
| ENST00000327578 | PCM1 | chr8 | 17851129 | ENST00000340058 | RET | chr10 | 43612030 | 2879 | 1046 | 23 | 2128 | 701 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000325083 | ENST00000355710 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.001280147 | 0.99871993 | ||
| ENST00000325083 | ENST00000340058 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.002939305 | 0.9970607 | ||
| ENST00000519253 | ENST00000355710 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.00055998 | 0.99944 | ||
| ENST00000519253 | ENST00000340058 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.003033075 | 0.9969669 | ||
| ENST00000524226 | ENST00000355710 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.001147287 | 0.9988527 | ||
| ENST00000524226 | ENST00000340058 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.001508619 | 0.9984914 | ||
| ENST00000327578 | ENST00000355710 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.001542255 | 0.9984578 | ||
| ENST00000327578 | ENST00000340058 | PCM1 | chr8 | 17851129 | RET | chr10 | 43612030 | 0.006744309 | 0.9932556 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >63341_63341_1_PCM1-RET_PCM1_chr8_17851128_ENST00000325083_RET_chr10_43612031_ENST00000340058_length(amino acids)=1969AA_BP=1609 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKN LVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLR GFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEED SYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPD -------------------------------------------------------------- >63341_63341_2_PCM1-RET_PCM1_chr8_17851128_ENST00000325083_RET_chr10_43612031_ENST00000355710_length(amino acids)=2011AA_BP=1609 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKN LVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLR GFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEED SYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPD KRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPGESPVPLTRADGT -------------------------------------------------------------- >63341_63341_3_PCM1-RET_PCM1_chr8_17851128_ENST00000327578_RET_chr10_43612031_ENST00000340058_length(amino acids)=701AA_BP=341 MASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRKNHEQLEKIIKCNRSTEISSAHARRILQ QSNRNACNEAPETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVN SGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNS NMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI -------------------------------------------------------------- >63341_63341_4_PCM1-RET_PCM1_chr8_17851128_ENST00000327578_RET_chr10_43612031_ENST00000355710_length(amino acids)=743AA_BP=341 MASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRKNHEQLEKIIKCNRSTEISSAHARRILQ QSNRNACNEAPETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVN SGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNS NMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI SKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPGESPVPLTRADGTNTGFPRYP -------------------------------------------------------------- >63341_63341_5_PCM1-RET_PCM1_chr8_17851128_ENST00000519253_RET_chr10_43612031_ENST00000340058_length(amino acids)=1961AA_BP=1601 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI -------------------------------------------------------------- >63341_63341_6_PCM1-RET_PCM1_chr8_17851128_ENST00000519253_RET_chr10_43612031_ENST00000355710_length(amino acids)=2003AA_BP=1601 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI SKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPGESPVPLTRADGTNTGFPRYP -------------------------------------------------------------- >63341_63341_7_PCM1-RET_PCM1_chr8_17851128_ENST00000524226_RET_chr10_43612031_ENST00000340058_length(amino acids)=1915AA_BP=1555 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLADCRYNREGEQEIHVAQGEDDEEEEEEAE EEGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANK TQKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSV FEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALD EEGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSE LSYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQML NELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQN SSGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLE SFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIKTGSDFSMFEALRDTIYSEVATLISQNESRPHFLI ELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNAS VLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIP CPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFN VLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAE MKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPP ERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAP -------------------------------------------------------------- >63341_63341_8_PCM1-RET_PCM1_chr8_17851128_ENST00000524226_RET_chr10_43612031_ENST00000355710_length(amino acids)=1957AA_BP=1555 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLADCRYNREGEQEIHVAQGEDDEEEEEEAE EEGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANK TQKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSV FEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALD EEGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSE LSYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQML NELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQN SSGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLE SFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIKTGSDFSMFEALRDTIYSEVATLISQNESRPHFLI ELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNAS VLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIP CPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFN VLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAE MKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPP ERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAP -------------------------------------------------------------- >63341_63341_9_PCM1-RET_PCM1_chr8_17851129_ENST00000325083_RET_chr10_43612030_ENST00000340058_length(amino acids)=1969AA_BP=1609 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKN LVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLR GFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEED SYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPD -------------------------------------------------------------- >63341_63341_10_PCM1-RET_PCM1_chr8_17851129_ENST00000325083_RET_chr10_43612030_ENST00000355710_length(amino acids)=2011AA_BP=1609 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKN LVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLR GFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEED SYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPD KRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPGESPVPLTRADGT -------------------------------------------------------------- >63341_63341_11_PCM1-RET_PCM1_chr8_17851129_ENST00000327578_RET_chr10_43612030_ENST00000340058_length(amino acids)=701AA_BP=341 MASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRKNHEQLEKIIKCNRSTEISSAHARRILQ QSNRNACNEAPETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVN SGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNS NMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI -------------------------------------------------------------- >63341_63341_12_PCM1-RET_PCM1_chr8_17851129_ENST00000327578_RET_chr10_43612030_ENST00000355710_length(amino acids)=743AA_BP=341 MASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRKNHEQLEKIIKCNRSTEISSAHARRILQ QSNRNACNEAPETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVN SGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNS NMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI SKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPGESPVPLTRADGTNTGFPRYP -------------------------------------------------------------- >63341_63341_13_PCM1-RET_PCM1_chr8_17851129_ENST00000519253_RET_chr10_43612030_ENST00000340058_length(amino acids)=1961AA_BP=1601 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI -------------------------------------------------------------- >63341_63341_14_PCM1-RET_PCM1_chr8_17851129_ENST00000519253_RET_chr10_43612030_ENST00000355710_length(amino acids)=2003AA_BP=1601 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLDCRYNREGEQEIHVAQGEDDEEEEEEAEE EGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANKT QKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSVF EPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSEL SYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQMLN ELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQNS SGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLES FSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEK GENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLDQALARMREYERM KTEAESNSNMRCTCRIIEDGDGAGAETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLG EGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADI SKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPGESPVPLTRADGTNTGFPRYP -------------------------------------------------------------- >63341_63341_15_PCM1-RET_PCM1_chr8_17851129_ENST00000524226_RET_chr10_43612030_ENST00000340058_length(amino acids)=1915AA_BP=1555 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLADCRYNREGEQEIHVAQGEDDEEEEEEAE EEGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANK TQKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSV FEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALD EEGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSE LSYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQML NELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQN SSGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLE SFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIKTGSDFSMFEALRDTIYSEVATLISQNESRPHFLI ELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNAS VLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIP CPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFN VLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAE MKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPP ERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAP -------------------------------------------------------------- >63341_63341_16_PCM1-RET_PCM1_chr8_17851129_ENST00000524226_RET_chr10_43612030_ENST00000355710_length(amino acids)=1957AA_BP=1555 MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKKKFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMS QMSVPEQAELEKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINTNKSKDASTNPPNRETIGSAQCKELFASALS NDLLQNCQVSEEDGRGEPAMESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQEKSYMKFLKKILARDPQQEPM EEIENLKKQHDLLKRMLQQQEQLRALQGRQAALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFHNQLRDSQPPA VPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKMRVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRLNELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHE NSEPVTNIRNPQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPSLADCRYNREGEQEIHVAQGEDDEEEEEEAE EEGVSGASLSSHRSSLVDEHPEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFYPAEEDTKQNSNNTRGNANK TQKDTGVNEKAREKFYEAKLQQQQRELKQLQEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQHETSTSKSV FEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEHQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALD EEGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETKNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSE LSYVEEKEQWQEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQVHFIMHQLNQCYTQLTWQQNNVQRLKQML NELMRQQNQHPEKPGGKERGSSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFGDFSQNISTPSEQQQPLAQN SSGKTEYMAFPKPFESSSSIGAEKPRNKKLPEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRRRQFDEESLE SFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSKKRNSTQLKSRVKNIKTGSDFSMFEALRDTIYSEVATLISQNESRPHFLI ELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSGTWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNAS VLSVSSNFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIP CPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRDLLSEFN VLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAE MKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPP ERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAP -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:17851129/chr10:43612030) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| PCM1 | RET |
| FUNCTION: Required for centrosome assembly and function (PubMed:12403812, PubMed:15659651, PubMed:16943179). Essential for the correct localization of several centrosomal proteins including CEP250, CETN3, PCNT and NEK2 (PubMed:12403812, PubMed:15659651). Required to anchor microtubules to the centrosome (PubMed:12403812, PubMed:15659651). Also involved in cilium biogenesis by recruiting the BBSome, a ciliary protein complex involved in cilium biogenesis, to the centriolar satellites (PubMed:20551181, PubMed:24121310, PubMed:27979967). {ECO:0000269|PubMed:12403812, ECO:0000269|PubMed:15659651, ECO:0000269|PubMed:16943179, ECO:0000269|PubMed:20551181, ECO:0000269|PubMed:24121310, ECO:0000269|PubMed:27979967}. | 1358 |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 1063_1089 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 1515_1539 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 218_301 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 400_424 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 487_543 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 651_682 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 726_769 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 824_858 | 1609.0 | 2025.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000340058 | 10 | 19 | 724_1016 | 712.0 | 1073.0 | Domain | Protein kinase | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000355710 | 10 | 20 | 724_1016 | 712.0 | 1115.0 | Domain | Protein kinase | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000340058 | 10 | 19 | 730_738 | 712.0 | 1073.0 | Nucleotide binding | ATP | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000355710 | 10 | 20 | 730_738 | 712.0 | 1115.0 | Nucleotide binding | ATP | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000340058 | 10 | 19 | 805_807 | 712.0 | 1073.0 | Region | Note=Inhibitors binding | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000355710 | 10 | 20 | 805_807 | 712.0 | 1115.0 | Region | Note=Inhibitors binding |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000340058 | 10 | 19 | 168_272 | 712.0 | 1073.0 | Domain | Cadherin | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000355710 | 10 | 20 | 168_272 | 712.0 | 1115.0 | Domain | Cadherin | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000340058 | 10 | 19 | 29_635 | 712.0 | 1073.0 | Topological domain | Extracellular | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000340058 | 10 | 19 | 658_1114 | 712.0 | 1073.0 | Topological domain | Cytoplasmic | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000355710 | 10 | 20 | 29_635 | 712.0 | 1115.0 | Topological domain | Extracellular | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000355710 | 10 | 20 | 658_1114 | 712.0 | 1115.0 | Topological domain | Cytoplasmic | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000340058 | 10 | 19 | 636_657 | 712.0 | 1073.0 | Transmembrane | Helical | |
| Tgene | RET | chr8:17851129 | chr10:43612030 | ENST00000355710 | 10 | 20 | 636_657 | 712.0 | 1115.0 | Transmembrane | Helical |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file (574) >>>574.pdbFusion protein BP residue: 341 CIF file (574) >>>574.cif | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQ TEEPVQAKVFSRKNHEQLEKIIKCNRSTEISSAHARRILQQSNRNACNEA PETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYL RQRALYALQDIVSRHISESHEKGENVKSVNSGTWIASNSELTPSESLATT DDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLD QALARMREYERMKTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVI ENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPR KNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRD LLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLV HRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIE SLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRME RPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAAS TPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGRISHAFTR | 701 |
| 3D view using mol* of 574 (AA BP:341) | ||||||||||
 | ||||||||||
| PDB file (608) >>>608.pdbFusion protein BP residue: 341 CIF file (608) >>>608.cif | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MASKDKTPKSKSKKRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQ TEEPVQAKVFSRKNHEQLEKIIKCNRSTEISSAHARRILQQSNRNACNEA PETGSDFSMFEALRDTIYSEVATLISQNESRPHFLIELFHELQLLNTDYL RQRALYALQDIVSRHISESHEKGENVKSVNSGTWIASNSELTPSESLATT DDETFEKNFERETHKISEQNDADNASVLSVSSNFEPFATDDLGNTVIHLD QALARMREYERMKTEAESNSNMRCTCRIIEDGDGAGAGTTVNNLEETPVI ENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFLKEDPKWEFPR KNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLKENASPSELRD LLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGSLRGFLRESRK VGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQGMQYLAEMKLV HRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQGRIPVKWMAIE SLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLFNLLKTGHRME RPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVKRRDYLDLAAS TPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKLYGMSDPNWPG | 743 |
| 3D view using mol* of 608 (AA BP:341) | ||||||||||
| ||||||||||
| PDB file (1063) | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKK KFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMSQMSVPEQAEL EKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINT NKSKDASTNPPNRETIGSAQCKELFASALSNDLLQNCQVSEEDGRGEPAM ESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQE KSYMKFLKKILARDPQQEPMEEIENLKKQHDLLKRMLQQQEQLRALQGRQ AALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFH NQLRDSQPPAVPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKM RVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRL NELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHENSEPVTNIRN PQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPS LADCRYNREGEQEIHVAQGEDDEEEEEEAEEEGVSGASLSSHRSSLVDEH PEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDF YPAEEDTKQNSNNTRGNANKTQKDTGVNEKAREKFYEAKLQQQQRELKQL QEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVN QHETSTSKSVFEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAE HQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALD EEGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKET KNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSELSYVEEKEQW QEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASP QVHFIMHQLNQCYTQLTWQQNNVQRLKQMLNELMRQQNQHPEKPGGKERG SSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNF GDFSQNISTPSEQQQPLAQNSSGKTEYMAFPKPFESSSSIGAEKPRNKKL PEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGR RRQFDEESLESFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKS KKRNSTQLKSRVKNIKTGSDFSMFEALRDTIYSEVATLISQNESRPHFLI ELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSGTWIA SNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEP FATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDGDGAG AGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEV IPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAV KMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYA KYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQ ISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVK RSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPP ERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEK MMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWI | 1915 |
| PDB file (1076) | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKK KFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMSQMSVPEQAEL EKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINT NKSKDASTNPPNRETIGSAQCKELFASALSNDLLQNCQVSEEDGRGEPAM ESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQE KSYMKFLKKILARDPQQEPMEEIENLKKQHDLLKRMLQQQEQLRALQGRQ AALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFH NQLRDSQPPAVPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKM RVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRL NELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHENSEPVTNIRN PQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPS LADCRYNREGEQEIHVAQGEDDEEEEEEAEEEGVSGASLSSHRSSLVDEH PEDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDF YPAEEDTKQNSNNTRGNANKTQKDTGVNEKAREKFYEAKLQQQQRELKQL QEERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVN QHETSTSKSVFEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAE HQRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALD EEGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKET KNRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSELSYVEEKEQW QEQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASP QVHFIMHQLNQCYTQLTWQQNNVQRLKQMLNELMRQQNQHPEKPGGKERG SSASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNF GDFSQNISTPSEQQQPLAQNSSGKTEYMAFPKPFESSSSIGAEKPRNKKL PEEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGR RRQFDEESLESFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKS KKRNSTQLKSRVKNIKTGSDFSMFEALRDTIYSEVATLISQNESRPHFLI ELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSGTWIA SNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSSNFEP FATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDGDGAG AGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEV IPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAV KMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYA KYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQ ISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVK RSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPP ERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEK MMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWI ENKLYGMSDPNWPGESPVPLTRADGTNTGFPRYPNDSVYANWMLSPSAAK | 1957 |
| PDB file (1078) | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKK KFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMSQMSVPEQAEL EKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINT NKSKDASTNPPNRETIGSAQCKELFASALSNDLLQNCQVSEEDGRGEPAM ESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQE KSYMKFLKKILARDPQQEPMEEIENLKKQHDLLKRMLQQQEQLRALQGRQ AALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFH NQLRDSQPPAVPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKM RVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRL NELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHENSEPVTNIRN PQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPS LDCRYNREGEQEIHVAQGEDDEEEEEEAEEEGVSGASLSSHRSSLVDEHP EDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFY PAEEDTKQNSNNTRGNANKTQKDTGVNEKAREKFYEAKLQQQQRELKQLQ EERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQ HETSTSKSVFEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEH QRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETK NRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSELSYVEEKEQWQ EQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQ VHFIMHQLNQCYTQLTWQQNNVQRLKQMLNELMRQQNQHPEKPGGKERGS SASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFG DFSQNISTPSEQQQPLAQNSSGKTEYMAFPKPFESSSSIGAEKPRNKKLP EEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRR RQFDEESLESFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSK KRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRP HFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSG TWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSS NFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDG DGAGAETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFL KEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLK ENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGS LRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQG MQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLF NLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVK RRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKL | 1961 |
| PDB file (1080) | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKK KFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMSQMSVPEQAEL EKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINT NKSKDASTNPPNRETIGSAQCKELFASALSNDLLQNCQVSEEDGRGEPAM ESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQE KSYMKFLKKILARDPQQEPMEEIENLKKQHDLLKRMLQQQEQLRALQGRQ AALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFH NQLRDSQPPAVPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKM RVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRL NELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHENSEPVTNIRN PQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPS LDCRYNREGEQEIHVAQGEDDEEEEEEAEEEGVSGASLSSHRSSLVDEHP EDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFY PAEEDTKQNSNNTRGNANKTQKDTGVNEKAREKFYEAKLQQQQRELKQLQ EERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQ HETSTSKSVFEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEH QRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETK NRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSELSYVEEKEQWQ EQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQ VHFIMHQLNQCYTQLTWQQNNVQRLKQMLNELMRQQNQHPEKPGGKERGS SASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFG DFSQNISTPSEQQQPLAQNSSGKTEYMAFPKPFESSSSIGAEKPRNKKLP EEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRR RQFDEESLESFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSK KRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRP HFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSG TWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSS NFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDG DGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAI MKEVIPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYT TVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLI VEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLIS FAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEED SYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYP GIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISK DLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALP | 1969 |
| PDB file (1084) >>>1084.pdbFusion protein BP residue: 1601 CIF file (1084) >>>1084.cif | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKK KFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMSQMSVPEQAEL EKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINT NKSKDASTNPPNRETIGSAQCKELFASALSNDLLQNCQVSEEDGRGEPAM ESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQE KSYMKFLKKILARDPQQEPMEEIENLKKQHDLLKRMLQQQEQLRALQGRQ AALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFH NQLRDSQPPAVPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKM RVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRL NELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHENSEPVTNIRN PQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPS LDCRYNREGEQEIHVAQGEDDEEEEEEAEEEGVSGASLSSHRSSLVDEHP EDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFY PAEEDTKQNSNNTRGNANKTQKDTGVNEKAREKFYEAKLQQQQRELKQLQ EERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQ HETSTSKSVFEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEH QRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETK NRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSELSYVEEKEQWQ EQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQ VHFIMHQLNQCYTQLTWQQNNVQRLKQMLNELMRQQNQHPEKPGGKERGS SASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFG DFSQNISTPSEQQQPLAQNSSGKTEYMAFPKPFESSSSIGAEKPRNKKLP EEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRR RQFDEESLESFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSK KRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRP HFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSG TWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSS NFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDG DGAGAETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAIMKEVIPFL KEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYTTVAVKMLK ENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLIVEYAKYGS LRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLISFAWQISQG MQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEEDSYVKRSQG RIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYPGIPPERLF NLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISKDLEKMMVK RRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALPSTWIENKL YGMSDPNWPGESPVPLTRADGTNTGFPRYPNDSVYANWMLSPSAAKLMDT | 2003 |
| 3D view using mol* of 1084 (AA BP:1601) | ||||||||||
| ||||||||||
| PDB file (1086) >>>1086.pdbFusion protein BP residue: 1609 CIF file (1086) >>>1086.cif | PCM1 | chr8 | 17851128 | + | RET | chr10 | 43612031 | + | MATGGGPFEDGMNDQDLPNWSNENVDDRLNNMDWGAQQKKANRSSEKNKK KFGVESDKRVTNDISPESSPGVGRRRTKTPHTFPHSRYMSQMSVPEQAEL EKLKQRINFSDLDQRSIGSDSQGRATAANNKRQLSENRKPFNFLPMQINT NKSKDASTNPPNRETIGSAQCKELFASALSNDLLQNCQVSEEDGRGEPAM ESSQIVSRLVQIRDYITKASSMREDLVEKNERSANVERLTHLIDHLKEQE KSYMKFLKKILARDPQQEPMEEIENLKKQHDLLKRMLQQQEQLRALQGRQ AALLALQHKAEQAIAVMDDSVVAETAGSLSGVSITSELNEELNDLIQRFH NQLRDSQPPAVPDNRRQAESLSLTREVSQSRKPSASERLPDEKVELFSKM RVLQEKKQKMDKLLGELHTLRDQHLNNSSSSPQRSVDQRSTSAPSASVGL APVVNGESNSLTSSVPYPTASLVSQNESENEGHLNPSEKLQKLNEVRKRL NELRELVHYYEQTSDMMTDAVNENRKDEETEESEYDSEHENSEPVTNIRN PQVASTWNEVNSHSNAQCVSNNRDGRTVNSNCEINNRSAANIRALNMPPS LDCRYNREGEQEIHVAQGEDDEEEEEEAEEEGVSGASLSSHRSSLVDEHP EDAEFEQKINRLMAAKQKLRQLQDLVAMVQDDDAAQGVISASASNLDDFY PAEEDTKQNSNNTRGNANKTQKDTGVNEKAREKFYEAKLQQQQRELKQLQ EERKKLIDIQEKIQALQTACPDLQLSAASVGNCPTKKYMPAVTSTPTVNQ HETSTSKSVFEPEDSSIVDNELWSEMRRHEMLREELRQRRKQLEALMAEH QRRQGLAETASPVAVSLRSDGSENLCTPQQSRTEKTMATWGGSTQCALDE EGDEDGYLSEGIVRTDEEEEEEQDASSNDNFSVCPSNSVNHNSYNGKETK NRWKNNCPFSADENYRPLAKTRQQNISMQRQENLRWVSELSYVEEKEQWQ EQINQLKKQLDFSVSICQTLMQDQQTLSCLLQTLLTGPYSVMPSNVASPQ VHFIMHQLNQCYTQLTWQQNNVQRLKQMLNELMRQQNQHPEKPGGKERGS SASHPPSPSLFCPFSFPTQPVNLFNIPGFTNFSSFAPGMNFSPLFPSNFG DFSQNISTPSEQQQPLAQNSSGKTEYMAFPKPFESSSSIGAEKPRNKKLP EEEVESSRTPWLYEQEGEVEKPFIKTGFSVSVEKSTSSNRKNQLDTNGRR RQFDEESLESFSSMPDPVDPTTVTKTFKTRKASAQASLASKDKTPKSKSK KRNSTQLKSRVKNIRYESASMSSTCEPCKSRNRHSAQTEEPVQAKVFSRK NHEQLEKIIKCNRSTEISSETGSDFSMFEALRDTIYSEVATLISQNESRP HFLIELFHELQLLNTDYLRQRALYALQDIVSRHISESHEKGENVKSVNSG TWIASNSELTPSESLATTDDETFEKNFERETHKISEQNDADNASVLSVSS NFEPFATDDLGNTVIHLDQALARMREYERMKTEAESNSNMRCTCRIIEDG DGAGAGTTVNNLEETPVIENRSSQQPVSEVSTIPCPRIDTQQLDRQIKAI MKEVIPFLKEDPKWEFPRKNLVLGKTLGEGEFGKVVKATAFHLKGRAGYT TVAVKMLKENASPSELRDLLSEFNVLKQVNHPHVIKLYGACSQDGPLLLI VEYAKYGSLRGFLRESRKVGPGYLGSGGSRNSSSLDHPDERALTMGDLIS FAWQISQGMQYLAEMKLVHRDLAARNILVAEGRKMKISDFGLSRDVYEED SYVKRSQGRIPVKWMAIESLFDHIYTTQSDVWSFGVLLWEIVTLGGNPYP GIPPERLFNLLKTGHRMERPDNCSEEMYRLMLQCWKQEPDKRPVFADISK DLEKMMVKRRDYLDLAASTPSDSLIYDDGLSEEETPLVDCNNAPLPRALP STWIENKLYGMSDPNWPGESPVPLTRADGTNTGFPRYPNDSVYANWMLSP | 2011 |
| 3D view using mol* of 1086 (AA BP:1609) | ||||||||||
| ||||||||||
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
PCM1_pLDDT.png  |
RET_pLDDT.png  |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
PCM1_RET_574_pLDDT.png (AA BP:341) |
PCM1_RET_574_pLDDT_and_active_sites.png (AA BP:341)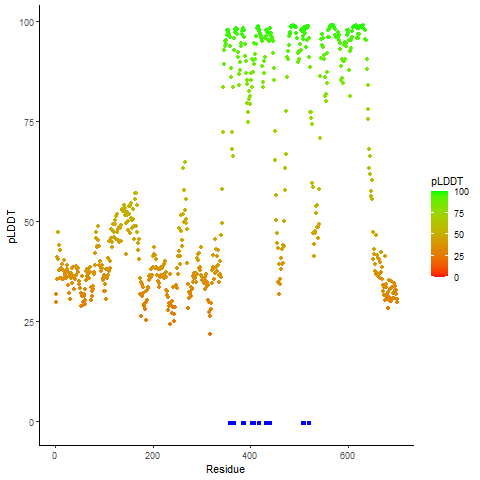 |
PCM1_RET_574_violinplot.png (AA BP:341) |
PCM1_RET_608_pLDDT.png (AA BP:341) |
PCM1_RET_608_pLDDT_and_active_sites.png (AA BP:341) |
PCM1_RET_608_violinplot.png (AA BP:341)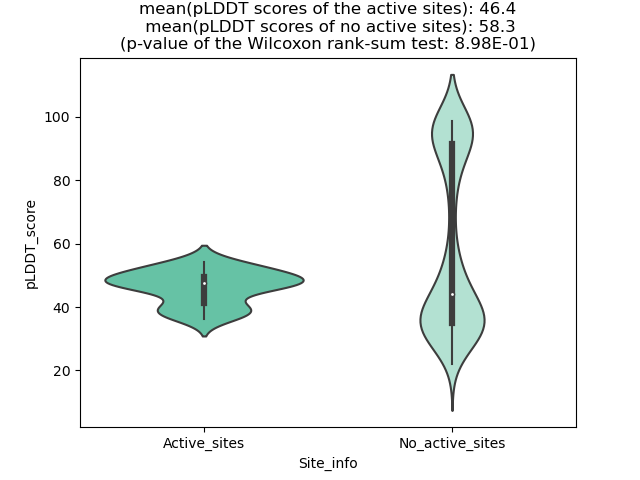 |
PCM1_RET_1084_pLDDT.png (AA BP:1601) |
PCM1_RET_1084_pLDDT_and_active_sites.png (AA BP:1601) |
PCM1_RET_1084_violinplot.png (AA BP:1601) |
PCM1_RET_1086_pLDDT.png (AA BP:1609) |
PCM1_RET_1086_pLDDT_and_active_sites.png (AA BP:1609) |
PCM1_RET_1086_violinplot.png (AA BP:1609) |
Top |
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
| PCM1_RET_574.png |
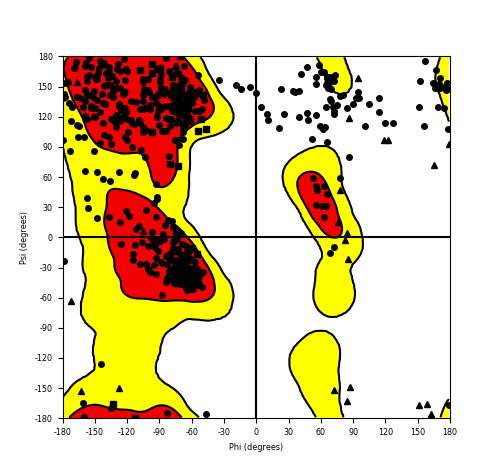 |
| PCM1_RET_608.png |
 |
| PCM1_RET_1086.png |
 |
Top |
Potential Active Site Information |
| The potential binding sites of these fusion proteins were identified using SiteMap, a module of the Schrodinger suite. |
| Fusion AA seq ID in FusionPDB | Site score | Size | D score | Volume | Exposure | Enclosure | Contact | Phobic | Philic | Balance | Don/Acc | Residues |
| 574 | 1.104 | 112 | 1.159 | 294.294 | 0.489 | 0.766 | 0.97 | 1.701 | 0.74 | 2.298 | 0.897 | Chain A: 359,360,361,362,363,364,365,366,367,385,3 87,404,408,417,431,433,434,435,436,437,439,440,507 ,508,510,520,521 |
| 608 | 1.182 | 171 | 1.291 | 469.91 | 0.455 | 0.768 | 0.987 | 2.917 | 0.338 | 8.626 | 1.161 | Chain A: 109,110,113,114,116,117,118,120,121,124,1 35,138,139,142,143,145,148,151,152,155,156,158,159 ,161,162,325,328,329,332 |
| 1063 | 1.162 | 278 | 1.243 | 546.742 | 0.42 | 0.793 | 1.026 | 2.743 | 0.53 | 5.176 | 1.636 | Chain A: 1324,1327,1328,1330,1331,1332,1334,1335,1 338,1339,1342,1344,1345,1348,1349,1350,1352,1353,1 356,1357,1362,1365,1366,1369,1370,1372,1373,1375,1 376,1378,1379,1470,1473,1474,1476,1477,1480,1547 |
| 1076 | 1.073 | 238 | 1.15 | 461.335 | 0.567 | 0.688 | 0.878 | 1.693 | 0.623 | 2.719 | 1.307 | Chain A: 1327,1331,1334,1335,1337,1338,1341,1342,1 344,1345,1348,1349,1352,1353,1356,1369,1370,1372,1 373,1375,1376,1379,1380,1382,1383,1384,1387,1529,1 530,1531,1532,1533,1534,1535,1536,1538,1539,1540,1 543 |
| 1078 | 1.069 | 659 | 1.139 | 2440.102 | 0.59 | 0.694 | 0.849 | 1.244 | 0.668 | 1.863 | 1.062 | Chain A: 311,314,317,318,335,336,338,339,342,343,3 46,1359,1374,1375,1377,1378,1380,1381,1382,1384,13 85,1388,1389,1391,1392,1395,1396,1397,1398,1399,14 02,1403,1406,1407,1409,1410,1411,1413,1414,1415,14 16,1418,1419,1420,1421,1422,1423,1424,1425,1426,14 27,1429,1430,1433,1434,1510,1511,1512,1513,1514,15 15,1516,1517,1518,1519,1520,1522,1523,1524,1525,15 26,1529,1530,1580,1581,1582,1583,1584,1585,1586,15 87,1588,1589,1590,1592,1593,1594,1595,1596,1597,15 99,1600,1601,1602,1603,1604,1658,1659,1662,1665,16 66,1669,1684,1685,1689 |
| 1080 | 1.108 | 328 | 1.181 | 1435.455 | 0.539 | 0.737 | 0.939 | 1.588 | 0.615 | 2.581 | 1.349 | Chain A: 1385,1388,1389,1392,1396,1398,1399,1402,1 403,1406,1407,1409,1410,1412,1413,1414,1415,1418,1 420,1421,1422,1423,1424,1425,1426,1427,1429,1430,1 433,1434,1587,1588,1589,1590,1592,1593,1594,1596,1 597,1600,1601,1604,1605,1607,1608,1609,1610,1611,1 614,1615,1657,1661,1662,1663,1666,1670,1673,1674,1 677,1690,1692,1693,1694,1695,1696,1697 |
| 1084 | 1.159 | 159 | 1.273 | 535.766 | 0.489 | 0.729 | 0.963 | 2.714 | 0.319 | 8.506 | 4.563 | Chain A: 1352,1355,1356,1358,1359,1362,1377,1380,1 381,1384,1385,1388,1389,1391,1392,1393,1403,1406,1 407,1410,1423,1426,1427,1430,1431,1433,1434 |
| 1084 | 1.159 | 159 | 1.273 | 535.766 | 0.489 | 0.729 | 0.963 | 2.714 | 0.319 | 8.506 | 4.563 | Chain A: 1352,1355,1356,1358,1359,1362,1377,1380,1 381,1384,1385,1388,1389,1391,1392,1393,1403,1406,1 407,1410,1423,1426,1427,1430,1431,1433,1434 |
| 1086 | 1.055 | 113 | 1.095 | 275.086 | 0.531 | 0.73 | 0.911 | 1.186 | 0.867 | 1.369 | 1.561 | Chain A: 1625,1627,1628,1629,1630,1631,1632,1633,1 635,1653,1655,1672,1676,1685,1699,1701,1702,1703,1 704,1705,1706,1707,1708,1711,1775,1776,1778,1788,1 789 |
| 1086 | 1.055 | 113 | 1.095 | 275.086 | 0.531 | 0.73 | 0.911 | 1.186 | 0.867 | 1.369 | 1.561 | Chain A: 1625,1627,1628,1629,1630,1631,1632,1633,1 635,1653,1655,1672,1676,1685,1699,1701,1702,1703,1 704,1705,1706,1707,1708,1711,1775,1776,1778,1788,1 789 |
Top |
Potentially Interacting Small Molecules through Virtual Screening |
| The FDA-approved small molecule library molecules were subjected to virtual screening using the Glide. |
| Fusion AA seq ID in FusionPDB | ZINC ID | DrugBank ID | Drug name | Docking score | Glide gscore |
| 574 | ZINC000150338698 | DB00314 | Capreomycin | -5.82562 | -6.33792 |
| 574 | ZINC000008214418 | DB09135 | Ioxilan | -6.30589 | -6.30589 |
| 574 | ZINC000003830944 | DB01362 | Iohexol | -6.24962 | -6.24962 |
| 574 | ZINC000049637509 | DB06636 | Isavuconazonium | -4.21336 | -6.11806 |
| 574 | ZINC000085540215 | DB09135 | Ioxilan | -5.86054 | -5.86054 |
| 574 | ZINC000085537017 | DB06441 | Cangrelor | -5.80015 | -5.81415 |
| 574 | ZINC000000388081 | DB05381 | Histamine | -5.3292 | -5.7842 |
| 574 | ZINC000003830943 | DB01362 | Iohexol | -5.71356 | -5.71356 |
| 574 | ZINC000148723177 | DB12267 | Brigatinib | -3.41672 | -5.66422 |
| 574 | ZINC000008143864 | DB09134 | Ioversol | -5.59641 | -5.59641 |
| 574 | ZINC000003830946 | DB01362 | Iohexol | -5.53147 | -5.53147 |
| 574 | ZINC000008214629 | DB06804 | Nonoxynol-9 | -5.51171 | -5.51171 |
| 574 | ZINC000000895457 | DB08847 | Hydroxyproline | -5.50114 | -5.50114 |
| 574 | ZINC000150588351 | DB11574 | Elbasvir | -4.2298 | -5.4734 |
| 574 | ZINC000096006023 | DB06590 | Ceftaroline fosamil | -4.89702 | -5.44212 |
| 574 | ZINC000253632968 | DB06290 | Simeprevir | -5.35706 | -5.36366 |
| 574 | ZINC000000057624 | DB00368 | Norepinephrine | -5.31643 | -5.33393 |
| 574 | ZINC000001530775 | DB00738 | Pentamidine | -5.3304 | -5.3304 |
| 574 | ZINC000029571072 | DB06636 | Isavuconazonium | -4.85984 | -5.29184 |
| 574 | ZINC000004097343 | DB01167 | Itraconazole | -5.24995 | -5.27155 |
Top |
| Drug information from DrugBank of the top 20 interacting small molecules. |
| ZINC ID | DrugBank ID | Drug name | Drug type | SMILES | Drug group |
| ZINC000150338698 | DB00314 | Capreomycin | Small molecule | [H][C@@]1(CCN=C(N)N1)[C@]1([H])NC(=O)C(NC(=O)[C@H](CNC(=O)C[C@@H](N)CCCN)NC(=O)[C@H](C)NC(=O)[C@@H](N)CNC1=O)=C/NC(N)=O.[H][C@@]1(CCN=C(N)N1)[C@]1([H])NC(=O)C(NC(=O)[C@H](CNC(=O)C[C@@H](N)CCCN)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CNC1=O)=C/NC(N)=O | Approved |
| ZINC000008214418 | DB09135 | Ioxilan | Small molecule | CC(=O)N(CC(O)CO)C1=C(I)C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCCO)=C1I | Approved |
| ZINC000049637509 | DB06636 | Isavuconazonium | Small molecule | [H]C(C)(OC(=O)N(C)C1=C(COC(=O)CNC)C=CC=N1)[N+]1=CN(C[C@](O)(C2=C(F)C=CC(F)=C2)[C@@]([H])(C)C2=NC(=CS2)C2=CC=C(C=C2)C#N)N=C1 | Approved|Investigational |
| ZINC000085537017 | DB06441 | Cangrelor | Small molecule | CSCCNC1=C2N=CN([C@@H]3O[C@H](COP(O)(=O)OP(O)(=O)C(Cl)(Cl)P(O)(O)=O)[C@@H](O)[C@H]3O)C2=NC(SCCC(F)(F)F)=N1 | Approved |
| ZINC000000388081 | DB05381 | Histamine | Small molecule | NCCC1=CNC=N1 | Approved|Investigational |
| ZINC000148723177 | DB12267 | Brigatinib | Small molecule | COC1=CC(=CC=C1NC1=NC=C(Cl)C(NC2=CC=CC=C2P(C)(C)=O)=N1)N1CCC(CC1)N1CCN(C)CC1 | Approved|Investigational |
| ZINC000008143864 | DB09134 | Ioversol | Small molecule | OCCN(C(=O)CO)C1=C(I)C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C1I | Approved |
| ZINC000008214629 | DB06804 | Nonoxynol-9 | Small molecule | CCCCCCCCCC1=CC=C(OCCOCCOCCOCCOCCOCCOCCOCCOCCO)C=C1 | Approved|Withdrawn |
| ZINC000000895457 | DB08847 | Hydroxyproline | Small molecule | O[C@H]1CN[C@@H](C1)C(O)=O | Experimental |
| ZINC000150588351 | DB11574 | Elbasvir | Small molecule | [H][C@]1(CCCN1C(=O)[C@@H](NC(=O)OC)C(C)C)C1=NC=C(N1)C1=CC2=C(C=C1)N1[C@@H](OC3=C(C=CC(=C3)C3=CN=C(N3)[C@]3([H])CCCN3C(=O)[C@@H](NC(=O)OC)C(C)C)C1=C2)C1=CC=CC=C1 | Approved |
| ZINC000253632968 | DB06290 | Simeprevir | Small molecule | [H][C@]12C[C@]1(NC(=O)[C@]1([H])C[C@H](C[C@@]1([H])C(=O)N(C)CCCCC=C/2)OC1=CC(=NC2=C1C=CC(OC)=C2C)C1=NC(=CS1)C(C)C)C(=O)NS(=O)(=O)C1CC1 | Approved |
| ZINC000000057624 | DB00368 | Norepinephrine | Small molecule | NC[C@H](O)C1=CC(O)=C(O)C=C1 | Approved |
| ZINC000001530775 | DB00738 | Pentamidine | Small molecule | NC(=N)C1=CC=C(OCCCCCOC2=CC=C(C=C2)C(N)=N)C=C1 | Approved|Investigational |
Top |
Biochemical Features of Small Molecules |
| ADME (Absorption, Distribution, Metabolism, and Excretion) of drugs using QikProp(v3.9) |
| ZINC ID | mol_MW | dipole | SASA | FOSA | FISA | PISA | WPSA | volume | donorHB | accptHB | IP | Human Oral Absorption | Percent Human Oral Absorption | Rule Of Five | Rule Of Three |
| ZINC000150338698 | 668.712 | 6.387 | 969.107 | 438.187 | 507.607 | 23.314 | 0 | 1886.358 | 10 | 14.7 | 8.085 | 1 | 0 | 3 | 2 |
| ZINC000150338698 | 668.712 | 1.97 | 1011.384 | 430.014 | 557.991 | 23.379 | 0 | 1920.75 | 10 | 14.7 | 8.063 | 1 | 0 | 3 | 2 |
| ZINC000008214418 | 791.116 | 1.945 | 763.111 | 318.983 | 317.048 | 9.77 | 117.31 | 1418.936 | 7 | 16.5 | 9.199 | 1 | 1.209 | 3 | 1 |
| ZINC000003830944 | 821.143 | 3.746 | 800.499 | 332.755 | 343.824 | 9.483 | 114.436 | 1490.981 | 8 | 18.2 | 9.701 | 1 | 0 | 3 | 1 |
| ZINC000085540215 | 791.116 | 10.896 | 769.61 | 332.376 | 308.422 | 9.811 | 119.002 | 1424.341 | 7 | 16.5 | 9.579 | 1 | 3.142 | 3 | 1 |
| ZINC000085537017 | 776.353 | 7.43 | 927.054 | 287.655 | 393.585 | 54.42 | 191.394 | 1783.369 | 3 | 20.6 | 8.462 | 1 | 0 | 3 | 1 |
| ZINC000085537017 | 776.353 | 5.036 | 918.307 | 262.294 | 312.532 | 51.82 | 291.661 | 1775.566 | 3 | 20.6 | 8.603 | 1 | 0 | 3 | 1 |
| ZINC000000388081 | 111.146 | 4.788 | 315.231 | 92.229 | 118.535 | 104.468 | 0 | 466.776 | 3 | 2.5 | 9.295 | 2 | 65.253 | 0 | 0 |
| ZINC000000388081 | 111.146 | 5.535 | 313.532 | 90.818 | 116.688 | 106.026 | 0 | 465.559 | 3 | 3 | 9.188 | 2 | 64.917 | 0 | 0 |
| ZINC000000388081 | 111.146 | 4.794 | 316.569 | 91.628 | 116.549 | 108.393 | 0 | 470.468 | 3 | 2.5 | 9.292 | 2 | 65.823 | 0 | 0 |
| ZINC000003830943 | 821.143 | 2.11 | 797.152 | 329.149 | 341.979 | 8.796 | 117.227 | 1489.14 | 8 | 18.2 | 9.356 | 1 | 0 | 3 | 1 |
| ZINC000148723177 | 584.1 | 5.166 | 976.551 | 585.471 | 60.71 | 276.127 | 54.243 | 1801.327 | 1 | 12.75 | 7.731 | 3 | 78.047 | 1 | 1 |
| ZINC000148723177 | 584.1 | 5.799 | 978.721 | 539.735 | 84.801 | 306.938 | 47.247 | 1814.982 | 1 | 12.75 | 7.869 | 2 | 73.551 | 1 | 1 |
| ZINC000008143864 | 807.116 | 5.478 | 759.618 | 304.239 | 335.909 | 6.136 | 113.333 | 1427.748 | 8 | 18.2 | 9.211 | 1 | 0 | 3 | 1 |
| ZINC000003830946 | 821.143 | 5.327 | 787.47 | 294 | 369.208 | 9.789 | 114.474 | 1488.253 | 8 | 18.2 | 9.631 | 1 | 0 | 3 | 1 |
| ZINC000008214629 | 616.831 | 4.125 | 1348.375 | 1161.401 | 55.343 | 131.632 | 0 | 2307.973 | 1 | 16.05 | 9.02 | 1 | 100 | 2 | 2 |
| ZINC000000895457 | 131.131 | 7.237 | 313.333 | 137.57 | 175.763 | 0 | 0 | 472.628 | 3 | 5.2 | 10.259 | 2 | 30.299 | 0 | 1 |
| ZINC000150588351 | 882.03 | 6.572 | 1345.74 | 717.517 | 186.345 | 441.878 | 0 | 2635.972 | 2.5 | 13.25 | 8.001 | 1 | 68.973 | 3 | 1 |
| ZINC000150588351 | 882.03 | 15.581 | 1298.014 | 670.728 | 196.39 | 430.896 | 0 | 2598.655 | 2.5 | 13.25 | 8.107 | 1 | 65.891 | 3 | 1 |
| ZINC000150588351 | 882.03 | 7.694 | 1389.327 | 750.107 | 173.462 | 465.758 | 0 | 2673.848 | 2.5 | 13.25 | 8.124 | 1 | 73.085 | 3 | 1 |
| ZINC000150588351 | 882.03 | 2.219 | 1373.023 | 721.483 | 195.055 | 456.485 | 0 | 2655.192 | 2.5 | 13.25 | 8.091 | 1 | 68.497 | 3 | 1 |
| ZINC000150588351 | 882.03 | 13.761 | 1347.364 | 706.26 | 205.501 | 435.603 | 0 | 2635.257 | 2.5 | 13.25 | 8.253 | 1 | 64.824 | 3 | 1 |
| ZINC000150588351 | 882.03 | 6.922 | 1403.807 | 740.212 | 182.531 | 481.064 | 0 | 2678.744 | 2.5 | 13.25 | 8.307 | 1 | 71.991 | 3 | 1 |
| ZINC000150588351 | 882.03 | 13.99 | 1367.982 | 729.766 | 188.685 | 449.531 | 0 | 2678.673 | 2.5 | 13.25 | 7.973 | 1 | 70.208 | 3 | 2 |
| ZINC000150588351 | 882.03 | 10.656 | 1391.126 | 719.587 | 194.166 | 477.373 | 0 | 2673.624 | 2.5 | 13.25 | 7.937 | 1 | 69.244 | 3 | 2 |
| ZINC000150588351 | 882.03 | 8.233 | 1375.056 | 718.117 | 197.908 | 459.032 | 0 | 2655.63 | 2.5 | 13.25 | 7.962 | 1 | 67.787 | 3 | 2 |
| ZINC000253632968 | 749.939 | 6.957 | 1148.652 | 820.732 | 134.162 | 154.915 | 38.842 | 2228.629 | 1.25 | 13.75 | 8.419 | 1 | 62.525 | 3 | 2 |
| ZINC000253632968 | 749.939 | 11.135 | 1103.653 | 772.655 | 146.278 | 144.582 | 40.138 | 2184.383 | 1.25 | 13.75 | 8.499 | 1 | 57.804 | 3 | 2 |
| ZINC000253632968 | 749.939 | 9.298 | 1114.226 | 794.485 | 125.878 | 154.692 | 39.17 | 2200.5 | 1.25 | 13.75 | 8.41 | 1 | 63.806 | 3 | 2 |
| ZINC000253632968 | 749.939 | 8.17 | 1081.392 | 774.076 | 143.601 | 146.311 | 17.404 | 2179.154 | 1.25 | 13.75 | 8.604 | 1 | 61.006 | 3 | 2 |
| ZINC000000057624 | 169.18 | 3.43 | 375.225 | 57.715 | 204.72 | 112.79 | 0 | 592.168 | 5 | 4.2 | 8.952 | 2 | 46.791 | 0 | 0 |
| ZINC000000057624 | 169.18 | 2.409 | 366.478 | 58.999 | 201.357 | 106.122 | 0 | 584.369 | 5 | 4.2 | 8.77 | 2 | 47.306 | 0 | 0 |
| ZINC000001530775 | 340.424 | 8.052 | 698.011 | 179.111 | 218.326 | 300.574 | 0 | 1179.95 | 6 | 4.5 | 8.662 | 2 | 63.344 | 1 | 0 |
| ZINC000004097343 | 705.642 | 7.181 | 1151.617 | 480.956 | 96.274 | 452.325 | 122.062 | 2102.052 | 0 | 10.25 | 8.242 | 1 | 77.792 | 3 | 1 |
| ZINC000004097343 | 705.642 | 2.898 | 1052.809 | 447.535 | 82.593 | 408.226 | 114.455 | 2020.51 | 0 | 10.25 | 8.414 | 1 | 79.553 | 3 | 1 |
Top |
Drug Toxicity Information |
| Toxicity information of individual drugs using eToxPred |
| ZINC ID | Smile | Surface Accessibility | Toxicity |
| ZINC000150338698 | NCCC[C@H](N)CC(=O)NC[C@@H]1NC(=O)[C@H](CO)NC(=O)[C@@H](N)CNC(=O)[C@H]([C@H]2CCN=C(N)N2)NC(=O)/C(=CNC(N)=O)NC1=O | 0.008886696 | 0.175052227 |
| ZINC000008214418 | CC(=O)N(C[C@H](O)CO)c1c(I)c(C(=O)NCCO)c(I)c(C(=O)NC[C@H](O)CO)c1I | 0.055075912 | 0.216199147 |
| ZINC000003830944 | CC(=O)N(C[C@@H](O)CO)c1c(I)c(C(=O)NC[C@H](O)CO)c(I)c(C(=O)NC[C@H](O)CO)c1I | 0.042332243 | 0.211666342 |
| ZINC000049637509 | CNCC(=O)OCc1cccnc1N(C)C(=O)O[C@@H](C)[n+]1cnn(C[C@](O)(c2cc(F)ccc2F)[C@@H](C)c2nc(-c3ccc(C#N)cc3)cs2)c1 | 0.025416027 | 0.235213823 |
| ZINC000085540215 | CC(=O)N(C[C@@H](O)CO)c1c(I)c(C(=O)NCCO)c(I)c(C(=O)NC[C@H](O)CO)c1I | 0.055075912 | 0.216199147 |
| ZINC000085537017 | CSCCNc1nc(SCCC(F)(F)F)nc2c1ncn2[C@@H]1O[C@H](CO[P@@](=O)(O)O[P@](=O)(O)C(Cl)(Cl)P(=O)(O)O)[C@@H](O)[C@H]1O | 0.017889541 | 0.259362736 |
| ZINC000000388081 | NCCc1cnc[nH]1 | 0.212944784 | 0.352067312 |
| ZINC000003830943 | CC(=O)N(C[C@H](O)CO)c1c(I)c(C(=O)NC[C@H](O)CO)c(I)c(C(=O)NC[C@H](O)CO)c1I | 0.042332243 | 0.211666342 |
| ZINC000148723177 | COc1cc(N2CCC(N3CCN(C)CC3)CC2)ccc1Nc1ncc(Cl)c(Nc2ccccc2P(C)(C)=O)n1 | 0.142553556 | 0.1573686 |
| ZINC000008143864 | O=C(NC[C@H](O)CO)c1c(I)c(C(=O)NC[C@H](O)CO)c(I)c(N(CCO)C(=O)CO)c1I | 0.051780669 | 0.23149478 |
| ZINC000003830946 | CC(=O)N(C[C@@H](O)CO)c1c(I)c(C(=O)NC[C@H](O)CO)c(I)c(C(=O)NC[C@@H](O)CO)c1I | 0.042332243 | 0.211666342 |
| ZINC000008214629 | CCCCCCCCCc1ccc(OCCOCCOCCOCCOCCOCCOCCOCCOCCO)cc1 | 0.197886659 | 0.439158961 |
| ZINC000000895457 | O=C(O)[C@H]1C[C@H](O)CN1 | 0.099278267 | 0.470163896 |
| ZINC000150588351 | COC(=O)N[C@H](C(=O)N1CCC[C@H]1c1nc(-c2ccc3c(c2)O[C@@H](c2ccccc2)n2c-3cc3cc(-c4c[nH]c([C@@H]5CCCN5C(=O)[C@@H](NC(=O)OC)C(C)C)n4)ccc32)c[nH]1)C(C)C | 0.015875917 | 0.217012798 |
| ZINC000096006023 | CCO/N=C(/C(=O)N[C@@H]1C(=O)N2C(C(=O)O)=C(Sc3nc(-c4cc[n+](C)cc4)cs3)CS[C@H]12)c1nsc(NP(=O)(O)O)n1 | 0.027233582 | 0.191312451 |
| ZINC000253632968 | COc1ccc2c(O[C@@H]3C[C@H]4C(=O)N[C@]5(C(=O)NS(=O)(=O)C6CC6)C[C@H]5C=CCCCCN(C)C(=O)[C@@H]4C3)cc(-c3nc(C(C)C)cs3)nc2c1C | 0.014845215 | 0.273382605 |
| ZINC000000057624 | NC[C@H](O)c1ccc(O)c(O)c1 | 0.18714743 | 0.309816979 |
| ZINC000001530775 | N=C(N)c1ccc(OCCCCCOc2ccc(C(=N)N)cc2)cc1 | 0.37035821 | 0.393925825 |
| ZINC000029571072 | CNCC(=O)OCc1cccnc1N(C)C(=O)O[C@H](C)[n+]1cnn(C[C@](O)(c2cc(F)ccc2F)[C@@H](C)c2nc(-c3ccc(C#N)cc3)cs2)c1 | 0.025416027 | 0.235213823 |
| ZINC000004097343 | CC[C@@H](C)n1ncn(-c2ccc(N3CCN(c4ccc(OC[C@H]5CO[C@](Cn6cncn6)(c6ccc(Cl)cc6Cl)O5)cc4)CC3)cc2)c1=O | 0.044363286 | 0.444547752 |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| PCM1 | BBS4, KRT15, ING5, KIAA0368, KRT19, CCDC53, ABI2, EXOC8, EPS8, CEP72, PCNT, HAP1, Haus4, Cep170, Haus1, Ndc80, Cep131, EWSR1, HNRNPUL1, CLTC, MIB1, FUS, CEP131, PPIB, SIRT7, NEURL4, PAN2, CASK, E2F4, YWHAQ, LATS2, SAV1, CEP250, HAUS2, OBSL1, CCDC8, CSPP1, CCDC183, SLC25A41, SSFA2, RASSF8, RASSF7, IFT81, NTRK1, BTRC, MED4, HERC2, AHI1, CEP162, RPGRIP1L, CC2D2A, CEP128, LCA5, OFD1, CCDC138, CEP170, PIBF1, SSX2IP, WRAP73, HAUS1, HAUS4, KIAA0753, CCDC77, CCNB2, CEP350, CEP95, CSNK1A1, DSP, KIF20A, LUZP1, MCM10, MCRS1, MPRIP, NDC80, SMARCD2, TPGS1, SUPT5H, SSBP1, KIF7, SKA1, TSPYL1, SREK1IP1, CSNK1D, IFT172, CEP55, IFT20, CCDC14, HMMR, CFAP97, IPO5, KCTD12, SNRPE, SPICE1, ABCD3, ACOT9, ATP5L, CAMSAP1, CC2D1A, CCDC66, CEP120, CKAP2, FGFR1OP, HAUS3, HAUS5, HAUS6, HAUS7, HAUS8, IDH3B, IFT57, IFT74, NCKAP5L, RAE1, STAU1, TP53BP2, TTK, TXLNA, TXLNG, TBC1D31, WDR83, XRN1, ZNF280C, ACTR2, ANKRD26, BAIAP2, BICD1, BICD2, BTF3, C11orf49, KNSTRN, C2CD3, CAMSAP2, CCDC112, CCDC18, CCDC22, CCDC85C, CCDC92, CCNB1, CCP110, CDC123, CEP164, CEP192, CEP57L1, CEP63, CEP85, CEP89, CEP97, CKAP2L, CNOT10, COMMD2, COMMD4, CSNK1E, DAPK3, DIAPH3, ERC1, EXOC4, FOPNL, GNAO1, GPATCH1, IBTK, IQCB1, KIAA1328, KIF14, LRRC49, LRRCC1, MAGED1, MAP7D3, MED29, MIS18A, MIS18BP1, MOB4, MPHOSPH9, MYO9A, NAV1, NEDD1, NME7, NOL11, NUF2, ODF2L, ODF2, PCBP3, PKN2, PLK1, KIZ, PPP1R9B, IFT22, RRM2, SCLT1, SDCCAG3, SECISBP2, SMG5, SMG7, SPATA24, SPATS2, SPC24, SRGAP2, STRN4, TANC1, TCHP, TEX9, TNIP1, TRAF3IP1, TTC12, TTF2, TTLL4, TTLL5, CEP104, CEP290, CEP152, CEP135, CNTRL, FBF1, NINL, NIN, POC5, SASS6, RPGRIP1, STIL, CENPJ, CENPE, PPP2CA, PRKAR2B, DYNLL1, MAPRE1, SLAIN2, CEP170P1, PPP2R3C, Cit, Nedd1, Prkacb, Prkar2a, Cetn2, Ppp2r1a, Uso1, Ccdc77, Dlg5, Lrrcc1, Cep55, Cep72, Fgfr1op, Immt, Sdccag8, Myh10, Cep152, Ccp110, Cep78, Bag2, Cdk5rap2, Cep290, Mib1, Cep120, Cenpe, Cep104, Ankrd26, Cep135, YWHAE, YWHAZ, MTMR7, C6orf118, BIN3, CCDC172, LPXN, FAM81B, COG5, ING2, CCDC65, LCA5L, CCDC40, DKK3, NECAB2, ATG14, TSC1, RNF168, HNRNPL, LNX1, EGLN3, GABARAP, PRC1, AKAP9, KLC4, PRKCI, FXR2, CDC42, KLC1, DDX23, RPA2, RBM5, USP9X, RNF31, ABI1, TFIP11, DDIT3, CCHCR1, RINT1, GOLGA2, KRT24, FAM188B, SPDL1, MYO6, ESR2, UBR7, TUBG1, EEA1, KIAA1429, ATG16L1, HOOK3, APEX1, SCARB2, VMP1, ETAA1, MTM1, TPTE2, CYLD, SPATA2, nsp2ab, RALBP1, CYTH4, FAM81A, PINK1, ACTB, nsp12, nsp16, nsp2, nsp7, ORF6, RQCD1, FAM120C, BRD1, SP110, SREBF2, nsp13ab, NDN, NUPR1, FAM184A, YBEY, DDX58, TRIM37, AR, ISG15, GOLGA1, LATS1, CAMSAP3, CCDC57, CDK5RAP2, CEP112, CEP295, CEP85L, CNTLN, CNTROB, DLG5, FAM184B, GAS8, GCC2, KIAA0586, KIAA1217, KIAA1671, KIF15, KIF1B, NYNRIN, PDZRN3, PLEKHG1, PPP1R13B, RGPD6, SRGAP1, TRIOBP, TRO, TTC3, WDR90, CEP170B, SPAG5, SEPT10, NAA40, VPS33B, KRT2, FAM9B, KRT86, KRT83, DISC1, DUSP16, FILIP1, NEBL, KRT73, SNAP91, KRT38, MAP7, KRT81, CCDC96, STX10, S100A2, KRT16, BFSP1, GOLGA6A, KRT14, C9orf16, USP28, KRT1, CETN1, REPIN1, TXNDC11, STRN, CCNB1IP1, ZNF24, LSM2, LARP4, ZNF830, PRPF6, DENND1A, INTS4, MORF4L1, PPIE, ALG13, GRN, NDUFA9, KAT5, Uba1, 2700060E02Rik, Bbs5, Fez2, Klc4, CDK1, TAX1BP1, GLI2, SPZ1, RB1CC1, MAGEL2, |
| RET | STAT3, DOK6, DOK5, SRC, SHC1, PTPRF, DOK2, DOK4, DOK1, GRB2, CRK, PLCG1, PDLIM7, GRB7, FRS2, NRTN, GFRA1, GRB10, IKBKG, MCRS1, CBL, CBLC, RET, HSP90AA1, NOTCH2NL, NOTCH3, AIP, EGFR, NTRK1, ZBTB48, HNRNPD, SORT1, SYNCRIP, SGTB, BAG6, HIST1H3A, KYNU, TXNL4A, ZCCHC8, ICE2, MAPK3, PTK2, MAPK1, PTPRR, DUSP26, Shc1, PIK3R1, FBXO7, NEDD4, SHANK2, LRRK1, PTK6, CTNNB1, SHC4, ERBB2, ADAM10, SPINT2, PCDH7, LRIG2, APP, GDNF, IGF1R, CLU, EPCAM, CDH2, TGFBR1, PTK7, FAT1, DHCR24, SMN1, PCDH19, NCSTN, CERS2, CHP1, FANCD2, ITM2C, SEL1L, PCDHGB5, CKB, NRP1, PLXNB2, NCK2, CTNND1, TULP3, PTPN1, NF2, CRKL, CAMLG, NUMB, BASP1, ROR2, NOTCH2, PTPN13, ANK3, RAB3GAP1, PEA15, LLGL1, GPRIN3, RAPH1, MARK2, CYFIP1, ARC, GPRIN1, ANKLE2, VRK2, MIB1, PHACTR4, UNC5B, TMEM57, SYAP1, FAF2, ERBB2IP, FAM129B, KIAA1715, PEAK1, VANGL2, BAIAP2, EPN1, NUMBL, PRKAR2A, GAB1, PTPRA, DDX39A, TIMP1, EPHB4, MANEA, SRY, RABAC1, LEMD3, TMEM214, PDZD8, GPR50, SMIM5, RNF149, SDF2L1, BMPR1A, PLEKHH3, ACVR2A, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| PCM1 |  |
| RET |  |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 1913_2024 | 1609.0 | 2025.0 | BBS4 |
| Hgene | PCM1 | chr8:17851129 | chr10:43612030 | ENST00000325083 | + | 29 | 39 | 1279_1799 | 1609.0 | 2025.0 | HAP1 |
Top |
Related Drugs to PCM1-RET |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to PCM1-RET |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| PCM1 | RET | Lung Adenocarcinoma | MyCancerGenome | |
| PCM1 | RET | Breast Invasive Ductal Carcinoma | MyCancerGenome | |
| PCM1 | RET | Thyroid Gland Papillary Carcinoma | MyCancerGenome | |
| PCM1 | RET | Adenocarcinoma Of Unknown Primary | MyCancerGenome | |
| PCM1 | RET | Bladder Urothelial Carcinoma | MyCancerGenome |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | PCM1 | C0036341 | Schizophrenia | 1 | CTD_human |
| Hgene | PCM1 | C0238463 | Papillary thyroid carcinoma | 1 | ORPHANET |
| Tgene | RET | C1833921 | Familial medullary thyroid carcinoma | 23 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Tgene | RET | C3888239 | HIRSCHSPRUNG DISEASE, SUSCEPTIBILITY TO, 1 | 16 | GENOMICS_ENGLAND;UNIPROT |
| Tgene | RET | C0025268 | Multiple Endocrine Neoplasia Type 2a | 15 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Tgene | RET | C1708353 | Hereditary Paraganglioma-Pheochromocytoma Syndrome | 12 | CLINGEN |
| Tgene | RET | C0025269 | Multiple Endocrine Neoplasia Type 2b | 10 | CTD_human;GENOMICS_ENGLAND;ORPHANET;UNIPROT |
| Tgene | RET | C0238463 | Papillary thyroid carcinoma | 3 | CTD_human;ORPHANET |
| Tgene | RET | C1275808 | Congenital central hypoventilation | 3 | CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Tgene | RET | C1859049 | CCHS WITH HIRSCHSPRUNG DISEASE | 3 | CTD_human;ORPHANET |
| Tgene | RET | C0009402 | Colorectal Carcinoma | 2 | CTD_human;UNIPROT |
| Tgene | RET | C0009404 | Colorectal Neoplasms | 2 | CTD_human |
| Tgene | RET | C0019569 | Hirschsprung Disease | 2 | CTD_human |
| Tgene | RET | C0027662 | Multiple Endocrine Neoplasia | 2 | CTD_human;GENOMICS_ENGLAND |
| Tgene | RET | C0085758 | Aganglionosis, Colonic | 2 | CTD_human |
| Tgene | RET | C0266294 | Unilateral agenesis of kidney | 2 | ORPHANET |
| Tgene | RET | C1257840 | Aganglionosis, Rectosigmoid Colon | 2 | CTD_human |
| Tgene | RET | C3661523 | Congenital Intestinal Aganglionosis | 2 | CTD_human |
| Tgene | RET | C0006413 | Burkitt Lymphoma | 1 | CTD_human |
| Tgene | RET | C0031511 | Pheochromocytoma | 1 | CGI;CTD_human;GENOMICS_ENGLAND;UNIPROT |
| Tgene | RET | C0038220 | Status Epilepticus | 1 | CTD_human |
| Tgene | RET | C0040136 | Thyroid Neoplasm | 1 | CGI;CTD_human |
| Tgene | RET | C0151468 | Thyroid Gland Follicular Adenoma | 1 | CTD_human |
| Tgene | RET | C0206693 | Medullary carcinoma | 1 | CTD_human |
| Tgene | RET | C0238462 | Medullary carcinoma of thyroid | 1 | CGI;CTD_human |
| Tgene | RET | C0270823 | Petit mal status | 1 | CTD_human |
| Tgene | RET | C0311335 | Grand Mal Status Epilepticus | 1 | CTD_human |
| Tgene | RET | C0343640 | African Burkitt's lymphoma | 1 | CTD_human |
| Tgene | RET | C0393734 | Complex Partial Status Epilepticus | 1 | CTD_human |
| Tgene | RET | C0549473 | Thyroid carcinoma | 1 | CGI;CTD_human;UNIPROT |
| Tgene | RET | C0740340 | Amyloidosis, Familial | 1 | CTD_human |
| Tgene | RET | C0751522 | Status Epilepticus, Subclinical | 1 | CTD_human |
| Tgene | RET | C0751523 | Non-Convulsive Status Epilepticus | 1 | CTD_human |
| Tgene | RET | C0751524 | Simple Partial Status Epilepticus | 1 | CTD_human |
| Tgene | RET | C1257877 | Pheochromocytoma, Extra-Adrenal | 1 | CTD_human |
| Tgene | RET | C1609433 | Congenital absence of kidneys syndrome | 1 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Tgene | RET | C3501843 | Nonmedullary Thyroid Carcinoma | 1 | CTD_human |
| Tgene | RET | C3501844 | Familial Nonmedullary Thyroid Cancer | 1 | CTD_human |
| Tgene | RET | C4721444 | Burkitt Leukemia | 1 | CTD_human |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies