| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:KMT2A-AFF4 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: KMT2A-AFF4 | FusionPDB ID: 43140 | FusionGDB2.0 ID: 43140 | Hgene | Tgene | Gene symbol | KMT2A | AFF4 | Gene ID | 4297 | 27125 |
| Gene name | lysine methyltransferase 2A | AF4/FMR2 family member 4 | |
| Synonyms | ALL-1|CXXC7|HRX|HTRX1|MLL|MLL1|MLL1A|TRX1|WDSTS | AF5Q31|CHOPS|MCEF | |
| Cytomap | 11q23.3 | 5q31.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | histone-lysine N-methyltransferase 2ACXXC-type zinc finger protein 7lysine (K)-specific methyltransferase 2Alysine N-methyltransferase 2Amixed lineage leukemia 1myeloid/lymphoid or mixed-lineage leukemia (trithorax homolog, Drosophila)trithorax-like | AF4/FMR2 family member 4ALL1-fused gene from chromosome 5q31 proteinmajor CDK9 elongation factor-associated protein | |
| Modification date | 20200319 | 20200315 | |
| UniProtAcc | Q03164 | Q9UHB7 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000420751, ENST00000354520, ENST00000389506, ENST00000534358, | ENST00000265343, ENST00000378595, ENST00000491831, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 79 X 196 X 13=201292 | 8 X 9 X 3=216 |
| # samples | 241 | 8 | |
| ** MAII score | log2(241/201292*10)=-6.38411287931608 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/216*10)=-1.43295940727611 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: KMT2A [Title/Abstract] AND AFF4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | |||
| Anticipated loss of major functional domain due to fusion event. | KMT2A-AFF4 seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. KMT2A-AFF4 seems lost the major protein functional domain in Hgene partner, which is a epigenetic factor due to the frame-shifted ORF. KMT2A-AFF4 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. KMT2A-AFF4 seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. KMT2A-AFF4 seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. KMT2A-AFF4 seems lost the major protein functional domain in Tgene partner, which is a CGC due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | KMT2A | GO:0044648 | histone H3-K4 dimethylation | 25561738 |
| Hgene | KMT2A | GO:0045944 | positive regulation of transcription by RNA polymerase II | 20861184 |
| Hgene | KMT2A | GO:0051568 | histone H3-K4 methylation | 19556245 |
| Hgene | KMT2A | GO:0065003 | protein-containing complex assembly | 15199122 |
| Hgene | KMT2A | GO:0080182 | histone H3-K4 trimethylation | 20861184 |
| Hgene | KMT2A | GO:0097692 | histone H3-K4 monomethylation | 25561738|26324722 |
| Fusion gene breakpoints across KMT2A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
| Fusion gene breakpoints across AFF4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerKB3 | . | . | KMT2A | chr11 | 118352807 | + | AFF4 | chr5 | 132240096 | - |
| ChimerKB3 | . | . | KMT2A | chr11 | 118353210 | + | AFF4 | chr5 | 132240096 | - |
| ChimerKB3 | . | . | KMT2A | chr11 | 118353210 | + | AFF4 | chr5 | 132262899 | - |
| ChimerKB3 | . | . | KMT2A | chr11 | 118355029 | + | AFF4 | chr5 | 132240096 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000534358 | KMT2A | chr11 | 118353210 | + | ENST00000265343 | AFF4 | chr5 | 132262899 | - | 12318 | 4109 | 23 | 6637 | 2204 |
| ENST00000534358 | KMT2A | chr11 | 118353210 | + | ENST00000378595 | AFF4 | chr5 | 132262899 | - | 6130 | 4109 | 23 | 5848 | 1941 |
| ENST00000389506 | KMT2A | chr11 | 118353210 | + | ENST00000265343 | AFF4 | chr5 | 132262899 | - | 12295 | 4086 | 0 | 6614 | 2204 |
| ENST00000389506 | KMT2A | chr11 | 118353210 | + | ENST00000378595 | AFF4 | chr5 | 132262899 | - | 6107 | 4086 | 0 | 5825 | 1941 |
| ENST00000354520 | KMT2A | chr11 | 118353210 | + | ENST00000265343 | AFF4 | chr5 | 132262899 | - | 12295 | 4086 | 0 | 6614 | 2204 |
| ENST00000354520 | KMT2A | chr11 | 118353210 | + | ENST00000378595 | AFF4 | chr5 | 132262899 | - | 6107 | 4086 | 0 | 5825 | 1941 |
| ENST00000534358 | KMT2A | chr11 | 118353210 | + | ENST00000265343 | AFF4 | chr5 | 132240096 | - | 12231 | 4109 | 23 | 6550 | 2175 |
| ENST00000534358 | KMT2A | chr11 | 118353210 | + | ENST00000378595 | AFF4 | chr5 | 132240096 | - | 6043 | 4109 | 23 | 5761 | 1912 |
| ENST00000389506 | KMT2A | chr11 | 118353210 | + | ENST00000265343 | AFF4 | chr5 | 132240096 | - | 12208 | 4086 | 0 | 6527 | 2175 |
| ENST00000389506 | KMT2A | chr11 | 118353210 | + | ENST00000378595 | AFF4 | chr5 | 132240096 | - | 6020 | 4086 | 0 | 5738 | 1912 |
| ENST00000354520 | KMT2A | chr11 | 118353210 | + | ENST00000265343 | AFF4 | chr5 | 132240096 | - | 12208 | 4086 | 0 | 6527 | 2175 |
| ENST00000354520 | KMT2A | chr11 | 118353210 | + | ENST00000378595 | AFF4 | chr5 | 132240096 | - | 6020 | 4086 | 0 | 5738 | 1912 |
| ENST00000534358 | KMT2A | chr11 | 118355029 | + | ENST00000265343 | AFF4 | chr5 | 132240096 | - | 12363 | 4241 | 23 | 6682 | 2219 |
| ENST00000534358 | KMT2A | chr11 | 118355029 | + | ENST00000378595 | AFF4 | chr5 | 132240096 | - | 6175 | 4241 | 23 | 5893 | 1956 |
| ENST00000389506 | KMT2A | chr11 | 118355029 | + | ENST00000265343 | AFF4 | chr5 | 132240096 | - | 12340 | 4218 | 0 | 6659 | 2219 |
| ENST00000389506 | KMT2A | chr11 | 118355029 | + | ENST00000378595 | AFF4 | chr5 | 132240096 | - | 6152 | 4218 | 0 | 5870 | 1956 |
| ENST00000354520 | KMT2A | chr11 | 118355029 | + | ENST00000265343 | AFF4 | chr5 | 132240096 | - | 12340 | 4218 | 0 | 6659 | 2219 |
| ENST00000354520 | KMT2A | chr11 | 118355029 | + | ENST00000378595 | AFF4 | chr5 | 132240096 | - | 6152 | 4218 | 0 | 5870 | 1956 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >43140_43140_1_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000354520_AFF4_chr5_132240096_ENST00000265343_length(amino acids)=2175AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDS SSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDT SGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGS RKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEE KELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEV KEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEKAVYYLDAVVSFIECGNALEKNAQESKSPFP MYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLTEHLKNSYNNSQAPSPGLGSKAVGMPSPVS PKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFLYATEIWDQAEQLSKEQKEFFAELDKVMGPLIFNASIMTDLVRYT -------------------------------------------------------------- >43140_43140_2_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000354520_AFF4_chr5_132240096_ENST00000378595_length(amino acids)=1912AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDS SSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDT SGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGS RKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEE KELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEV -------------------------------------------------------------- >43140_43140_3_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000354520_AFF4_chr5_132262899_ENST00000265343_length(amino acids)=2204AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCD KTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPA SSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPR GGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYP ESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNK ETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEKA VYYLDAVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLT EHLKNSYNNSQAPSPGLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFLYATEIWDQAEQLSKE -------------------------------------------------------------- >43140_43140_4_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000354520_AFF4_chr5_132262899_ENST00000378595_length(amino acids)=1941AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCD KTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPA SSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPR GGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYP ESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNK -------------------------------------------------------------- >43140_43140_5_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000389506_AFF4_chr5_132240096_ENST00000265343_length(amino acids)=2175AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDS SSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDT SGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGS RKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEE KELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEV KEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEKAVYYLDAVVSFIECGNALEKNAQESKSPFP MYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLTEHLKNSYNNSQAPSPGLGSKAVGMPSPVS PKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFLYATEIWDQAEQLSKEQKEFFAELDKVMGPLIFNASIMTDLVRYT -------------------------------------------------------------- >43140_43140_6_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000389506_AFF4_chr5_132240096_ENST00000378595_length(amino acids)=1912AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDS SSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDT SGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGS RKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEE KELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEV -------------------------------------------------------------- >43140_43140_7_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000389506_AFF4_chr5_132262899_ENST00000265343_length(amino acids)=2204AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCD KTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPA SSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPR GGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYP ESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNK ETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEKA VYYLDAVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLT EHLKNSYNNSQAPSPGLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFLYATEIWDQAEQLSKE -------------------------------------------------------------- >43140_43140_8_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000389506_AFF4_chr5_132262899_ENST00000378595_length(amino acids)=1941AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCD KTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPA SSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPR GGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYP ESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNK -------------------------------------------------------------- >43140_43140_9_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000534358_AFF4_chr5_132240096_ENST00000265343_length(amino acids)=2175AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDS SSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDT SGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGS RKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEE KELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEV KEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEKAVYYLDAVVSFIECGNALEKNAQESKSPFP MYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLTEHLKNSYNNSQAPSPGLGSKAVGMPSPVS PKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFLYATEIWDQAEQLSKEQKEFFAELDKVMGPLIFNASIMTDLVRYT -------------------------------------------------------------- >43140_43140_10_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000534358_AFF4_chr5_132240096_ENST00000378595_length(amino acids)=1912AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDS SSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDT SGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGS RKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEE KELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEV -------------------------------------------------------------- >43140_43140_11_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000534358_AFF4_chr5_132262899_ENST00000265343_length(amino acids)=2204AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCD KTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPA SSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPR GGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYP ESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNK ETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEKA VYYLDAVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLT EHLKNSYNNSQAPSPGLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFLYATEIWDQAEQLSKE -------------------------------------------------------------- >43140_43140_12_KMT2A-AFF4_KMT2A_chr11_118353210_ENST00000534358_AFF4_chr5_132262899_ENST00000378595_length(amino acids)=1941AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCD KTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPA SSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPR GGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESLPPSSQTPKYP ESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNK -------------------------------------------------------------- >43140_43140_13_KMT2A-AFF4_KMT2A_chr11_118355029_ENST00000354520_AFF4_chr5_132240096_ENST00000265343_length(amino acids)=2219AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHRIRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDL KLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQL DNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGK KQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSD ESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRT ISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKK LKHNADALSDRFEKAVYYLDAVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLF KLKKENALKYSKTLTEHLKNSYNNSQAPSPGLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFL -------------------------------------------------------------- >43140_43140_14_KMT2A-AFF4_KMT2A_chr11_118355029_ENST00000354520_AFF4_chr5_132240096_ENST00000378595_length(amino acids)=1956AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHRIRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDL KLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQL DNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGK KQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSD ESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRT -------------------------------------------------------------- >43140_43140_15_KMT2A-AFF4_KMT2A_chr11_118355029_ENST00000389506_AFF4_chr5_132240096_ENST00000265343_length(amino acids)=2219AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHRIRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDL KLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQL DNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGK KQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSD ESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRT ISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKK LKHNADALSDRFEKAVYYLDAVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLF KLKKENALKYSKTLTEHLKNSYNNSQAPSPGLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFL -------------------------------------------------------------- >43140_43140_16_KMT2A-AFF4_KMT2A_chr11_118355029_ENST00000389506_AFF4_chr5_132240096_ENST00000378595_length(amino acids)=1956AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHRIRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDL KLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQL DNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGK KQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSD ESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRT -------------------------------------------------------------- >43140_43140_17_KMT2A-AFF4_KMT2A_chr11_118355029_ENST00000534358_AFF4_chr5_132240096_ENST00000265343_length(amino acids)=2219AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHRIRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDL KLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQL DNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGK KQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSD ESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRT ISQSSSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKK LKHNADALSDRFEKAVYYLDAVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLLYLRLF KLKKENALKYSKTLTEHLKNSYNNSQAPSPGLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFL -------------------------------------------------------------- >43140_43140_18_KMT2A-AFF4_KMT2A_chr11_118355029_ENST00000534358_AFF4_chr5_132240096_ENST00000378595_length(amino acids)=1956AA_BP=57 MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGGPGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSAS SSSSSSSSASSGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLGFGSDEEVRVRSPTRSPSVKTSPRKPRGRPR SGSDRNSAILSDPSVFSPLNKSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKEDSLKKIKRTPSATFQQATKI KKLRAGKLSPLKSKFKTGKLQIGRKGVQIVRRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQSPRRIKPVRI IPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVKTQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLPEERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGS RTTKKLSTLQSAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPASTAPMQGKRKSILREPTFRWTSLKHSRSEPQ YFSSAKYAKEGLIRKPIFDNFRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAPRFTPSEAHSRIFESVTLPSN RTSAGTSSSGVSNRKRKRKVFSPIRSEPRSPSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPSHSLTQSGESA EKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRNKDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTLGDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLC LSTPSSSTVKHSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPKAQGQESDSSETSVRGPRIKHVCRRAAVALG RKRAVFPDDMPTLSALPWEEREKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGRRSRRCGQCPGCQVPEDCGVC TNCLDKPKFGGRNIKKQCCKMRKCQNLQWMPSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSAREDPAPKKSSSE PPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQPALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHRIRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDL KLSSSEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQL DNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQRRTVGK KQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSD ESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRT -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:/chr5:) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| KMT2A | AFF4 |
| FUNCTION: Histone methyltransferase that plays an essential role in early development and hematopoiesis (PubMed:15960975, PubMed:12453419, PubMed:15960975, PubMed:19556245, PubMed:19187761, PubMed:20677832, PubMed:21220120, PubMed:26886794). Catalytic subunit of the MLL1/MLL complex, a multiprotein complex that mediates both methylation of 'Lys-4' of histone H3 (H3K4me) complex and acetylation of 'Lys-16' of histone H4 (H4K16ac) (PubMed:15960975, PubMed:12453419, PubMed:15960975, PubMed:19556245, PubMed:24235145, PubMed:19187761, PubMed:20677832, PubMed:21220120, PubMed:26886794). Catalyzes methyl group transfer from S-adenosyl-L-methionine to the epsilon-amino group of 'Lys-4' of histone H3 (H3K4) via a non-processive mechanism. Part of chromatin remodeling machinery predominantly forms H3K4me1 and H3K4me2 methylation marks at active chromatin sites where transcription and DNA repair take place (PubMed:25561738, PubMed:15960975, PubMed:12453419, PubMed:15960975, PubMed:19556245, PubMed:19187761, PubMed:20677832, PubMed:21220120, PubMed:26886794). Has weak methyltransferase activity by itself, and requires other component of the MLL1/MLL complex to obtain full methyltransferase activity (PubMed:19187761, PubMed:26886794). Has no activity toward histone H3 phosphorylated on 'Thr-3', less activity toward H3 dimethylated on 'Arg-8' or 'Lys-9', while it has higher activity toward H3 acetylated on 'Lys-9' (PubMed:19187761). Binds to unmethylated CpG elements in the promoter of target genes and helps maintain them in the nonmethylated state (PubMed:20010842). Required for transcriptional activation of HOXA9 (PubMed:12453419, PubMed:20677832, PubMed:20010842). Promotes PPP1R15A-induced apoptosis (PubMed:10490642). Plays a critical role in the control of circadian gene expression and is essential for the transcriptional activation mediated by the CLOCK-ARNTL/BMAL1 heterodimer (By similarity). Establishes a permissive chromatin state for circadian transcription by mediating a rhythmic methylation of 'Lys-4' of histone H3 (H3K4me) and this histone modification directs the circadian acetylation at H3K9 and H3K14 allowing the recruitment of CLOCK-ARNTL/BMAL1 to chromatin (By similarity). Also has auto-methylation activity on Cys-3882 in absence of histone H3 substrate (PubMed:24235145). {ECO:0000250|UniProtKB:P55200, ECO:0000269|PubMed:10490642, ECO:0000269|PubMed:12453419, ECO:0000269|PubMed:15960975, ECO:0000269|PubMed:19187761, ECO:0000269|PubMed:19556245, ECO:0000269|PubMed:20010842, ECO:0000269|PubMed:21220120, ECO:0000269|PubMed:24235145, ECO:0000269|PubMed:26886794, ECO:0000305|PubMed:20677832}. | FUNCTION: Key component of the super elongation complex (SEC), a complex required to increase the catalytic rate of RNA polymerase II transcription by suppressing transient pausing by the polymerase at multiple sites along the DNA. In the SEC complex, AFF4 acts as a central scaffold that recruits other factors through direct interactions with ELL proteins (ELL, ELL2 or ELL3) and the P-TEFb complex. In case of infection by HIV-1 virus, the SEC complex is recruited by the viral Tat protein to stimulate viral gene expression. {ECO:0000269|PubMed:20159561, ECO:0000269|PubMed:20471948, ECO:0000269|PubMed:23251033}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Protein Structures |
| PDB and CIF files of the predicted fusion proteins * Here we show the 3D structure of the fusion proteins using Mol*. AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. Model confidence is shown from the pLDDT values per residue. pLDDT corresponds to the model’s prediction of its score on the local Distance Difference Test. It is a measure of local accuracy (from AlphfaFold website). To color code individual residues, we transformed individual PDB files into CIF format. |
| Fusion protein PDB link (fusion AA seq ID in FusionPDB) | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | AA seq | Len(AA seq) |
| PDB file (1060) >>>1060.pdbFusion protein BP residue: 57 CIF file (1060) >>>1060.cif | KMT2A | chr11 | 118353210 | + | AFF4 | chr5 | 132240096 | - | MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGG PGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSASSSSSSSSSAS SGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLG FGSDEEVRVRSPTRSPSVKTSPRKPRGRPRSGSDRNSAILSDPSVFSPLN KSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKE DSLKKIKRTPSATFQQATKIKKLRAGKLSPLKSKFKTGKLQIGRKGVQIV RRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQ SPRRIKPVRIIPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVK TQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLP EERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGSRTTKKLSTLQ SAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPAS TAPMQGKRKSILREPTFRWTSLKHSRSEPQYFSSAKYAKEGLIRKPIFDN FRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAP RFTPSEAHSRIFESVTLPSNRTSAGTSSSGVSNRKRKRKVFSPIRSEPRS PSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPS HSLTQSGESAEKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRN KDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTL GDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLCLSTPSSSTVK HSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPK AQGQESDSSETSVRGPRIKHVCRRAAVALGRKRAVFPDDMPTLSALPWEE REKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGR RSRRCGQCPGCQVPEDCGVCTNCLDKPKFGGRNIKKQCCKMRKCQNLQWM PSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSARE DPAPKKSSSEPPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQ PALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSS SEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSS GSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSP ASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQK GSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESET PVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQ KSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFF RQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPK GEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQS SSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEVKVKCWGPGAF | 1912 |
| 3D view using mol* of 1060 (AA BP:57) | ||||||||||
 | ||||||||||
| PDB file (1070) | KMT2A | chr11 | 118353210 | + | AFF4 | chr5 | 132262899 | - | MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGG PGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSASSSSSSSSSAS SGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLG FGSDEEVRVRSPTRSPSVKTSPRKPRGRPRSGSDRNSAILSDPSVFSPLN KSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKE DSLKKIKRTPSATFQQATKIKKLRAGKLSPLKSKFKTGKLQIGRKGVQIV RRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQ SPRRIKPVRIIPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVK TQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLP EERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGSRTTKKLSTLQ SAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPAS TAPMQGKRKSILREPTFRWTSLKHSRSEPQYFSSAKYAKEGLIRKPIFDN FRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAP RFTPSEAHSRIFESVTLPSNRTSAGTSSSGVSNRKRKRKVFSPIRSEPRS PSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPS HSLTQSGESAEKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRN KDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTL GDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLCLSTPSSSTVK HSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPK AQGQESDSSETSVRGPRIKHVCRRAAVALGRKRAVFPDDMPTLSALPWEE REKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGR RSRRCGQCPGCQVPEDCGVCTNCLDKPKFGGRNIKKQCCKMRKCQNLQWM PSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSARE DPAPKKSSSEPPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQ PALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGT GEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGS NSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQS ASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQ GTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQR RTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSR KPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESL PPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPD DRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEK DLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSS | 1941 |
| PDB file (1075) | KMT2A | chr11 | 118355029 | + | AFF4 | chr5 | 132240096 | - | MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGG PGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSASSSSSSSSSAS SGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLG FGSDEEVRVRSPTRSPSVKTSPRKPRGRPRSGSDRNSAILSDPSVFSPLN KSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKE DSLKKIKRTPSATFQQATKIKKLRAGKLSPLKSKFKTGKLQIGRKGVQIV RRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQ SPRRIKPVRIIPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVK TQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLP EERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGSRTTKKLSTLQ SAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPAS TAPMQGKRKSILREPTFRWTSLKHSRSEPQYFSSAKYAKEGLIRKPIFDN FRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAP RFTPSEAHSRIFESVTLPSNRTSAGTSSSGVSNRKRKRKVFSPIRSEPRS PSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPS HSLTQSGESAEKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRN KDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTL GDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLCLSTPSSSTVK HSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPK AQGQESDSSETSVRGPRIKHVCRRAAVALGRKRAVFPDDMPTLSALPWEE REKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGR RSRRCGQCPGCQVPEDCGVCTNCLDKPKFGGRNIKKQCCKMRKCQNLQWM PSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSARE DPAPKKSSSEPPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQ PALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHR IRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDG EQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSES ESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDS NIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGR GRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLAS SMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREII ETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFS PMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKP SSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSS SNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEVKVKCWGPGAFENHSTC | 1956 |
| PDB file (1107) | KMT2A | chr11 | 118353210 | + | AFF4 | chr5 | 132240096 | - | MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGG PGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSASSSSSSSSSAS SGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLG FGSDEEVRVRSPTRSPSVKTSPRKPRGRPRSGSDRNSAILSDPSVFSPLN KSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKE DSLKKIKRTPSATFQQATKIKKLRAGKLSPLKSKFKTGKLQIGRKGVQIV RRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQ SPRRIKPVRIIPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVK TQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLP EERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGSRTTKKLSTLQ SAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPAS TAPMQGKRKSILREPTFRWTSLKHSRSEPQYFSSAKYAKEGLIRKPIFDN FRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAP RFTPSEAHSRIFESVTLPSNRTSAGTSSSGVSNRKRKRKVFSPIRSEPRS PSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPS HSLTQSGESAEKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRN KDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTL GDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLCLSTPSSSTVK HSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPK AQGQESDSSETSVRGPRIKHVCRRAAVALGRKRAVFPDDMPTLSALPWEE REKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGR RSRRCGQCPGCQVPEDCGVCTNCLDKPKFGGRNIKKQCCKMRKCQNLQWM PSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSARE DPAPKKSSSEPPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQ PALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSS SEDSDGEQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSS GSDSESESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSP ASSVDSNIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQK GSESGRGRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESET PVDLASSMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQ KSREIIETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFF RQRMFSPMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPK GEKKNVPEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKN SAGHKPSSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQS SSLKSSSNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSN CPPSAPTLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEK AVYYLDAVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLA PDATAADKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLTEHLKNSYNN SQAPSPGLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQK IHQMAASYVQVTSNFLYATEIWDQAEQLSKEQKEFFAELDKVMGPLIFNA | 2175 |
| PDB file (1111) | KMT2A | chr11 | 118353210 | + | AFF4 | chr5 | 132262899 | - | MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGG PGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSASSSSSSSSSAS SGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLG FGSDEEVRVRSPTRSPSVKTSPRKPRGRPRSGSDRNSAILSDPSVFSPLN KSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKE DSLKKIKRTPSATFQQATKIKKLRAGKLSPLKSKFKTGKLQIGRKGVQIV RRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQ SPRRIKPVRIIPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVK TQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLP EERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGSRTTKKLSTLQ SAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPAS TAPMQGKRKSILREPTFRWTSLKHSRSEPQYFSSAKYAKEGLIRKPIFDN FRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAP RFTPSEAHSRIFESVTLPSNRTSAGTSSSGVSNRKRKRKVFSPIRSEPRS PSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPS HSLTQSGESAEKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRN KDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTL GDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLCLSTPSSSTVK HSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPK AQGQESDSSETSVRGPRIKHVCRRAAVALGRKRAVFPDDMPTLSALPWEE REKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGR RSRRCGQCPGCQVPEDCGVCTNCLDKPKFGGRNIKKQCCKMRKCQNLQWM PSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSARE DPAPKKSSSEPPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQ PALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEMTHSWPPPLTAIHTPCKTEPSKFPFPTKESQQSNFGT GEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDGEQDCDKTMPRSTPGS NSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSESESSSSDSEANEPSQS ASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDSNIPSSQGYKKEGREQ GTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGRGRQKSPAQSDSTTQR RTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLASSMPSSRHKAATKGSR KPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREIIETDTSSSDSDESESL PPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFSPMEEKELLSPLSEPD DRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNVPEKHTREAQKQASEK VSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKPSSNRESSKQSAAKEK DLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSSSNSNKETSGSSKNSS STSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAPTLDSSKPRRTKLVFD DRNYSADHYLQEAKKLKHNADALSDRFEKAVYYLDAVVSFIECGNALEKN AQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAADKRLTVLCLRCESLL YLRLFKLKKENALKYSKTLTEHLKNSYNNSQAPSPGLGSKAVGMPSPVSP KLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAASYVQVTSNFLYATEI WDQAEQLSKEQKEFFAELDKVMGPLIFNASIMTDLVRYTRQGLHWLRQDA | 2204 |
| PDB file (1114)CIF file (1114) >>>1114.cif | KMT2A | chr11 | 118355029 | + | AFF4 | chr5 | 132240096 | - | MAHSCRWRFPARPGTTGGGGGGGRRGLGGAPRQRVPALLLPPGPPVGGGG PGAPPSPPAVAAAAAAAGSSGAGVPGGAAAASAASSSSASSSSSSSSSAS SGPALLRVGPGFDAALQVSAAIGTNLRRFRAVFGESGGGGGSGEDEQFLG FGSDEEVRVRSPTRSPSVKTSPRKPRGRPRSGSDRNSAILSDPSVFSPLN KSETKSGDKIKKKDSKSIEKKRGRPPTFPGVKIKITHGKDISELPKGNKE DSLKKIKRTPSATFQQATKIKKLRAGKLSPLKSKFKTGKLQIGRKGVQIV RRRGRPPSTERIKTPSGLLINSELEKPQKVRKDKEGTPPLTKEDKTVVRQ SPRRIKPVRIIPSSKRTDATIAKQLLQRAKKGAQKKIEKEAAQLQGRKVK TQVKNIRQFIMPVVSAISSRIIKTPRRFIEDEDYDPPIKIARLESTPNSR FSAPSCGSSEKSSAASQHSSQMSSDSSRSSSPSVDTSTDSQASEEIQVLP EERSDTPEVHPPLPISQSPENESNDRRSRRYSVSERSFGSRTTKKLSTLQ SAPQQQTSSSPPPPLLTPPPPLQPASSISDHTPWLMPPTIPLASPFLPAS TAPMQGKRKSILREPTFRWTSLKHSRSEPQYFSSAKYAKEGLIRKPIFDN FRPPPLTPEDVGFASGFSASGTAASARLFSPLHSGTRFDMHKRSPLLRAP RFTPSEAHSRIFESVTLPSNRTSAGTSSSGVSNRKRKRKVFSPIRSEPRS PSHSMRTRSGRLSSSELSPLTPPSSVSSSLSISVSPLATSALNPTFTFPS HSLTQSGESAEKNQRPRKQTSAPAEPFSSSSPTPLFPWFTPGSQTERGRN KDKAPEELSKDRDADKSVEKDKSRERDREREKENKRESRKEKRKKGSEIQ SSSALYPVGRVSKEKVVGEDVATSSSAKKATGRKKSSSHDSGTDITSVTL GDTTAVKTKILIKKGRGNLEKTNLDLGPTAPSLEKEKTLCLSTPSSSTVK HSTSSIGSMLAQADKLPMTDKRVASLLKKAKAQLCKIEKSKSLKQTDQPK AQGQESDSSETSVRGPRIKHVCRRAAVALGRKRAVFPDDMPTLSALPWEE REKILSSMGNDDKSSIAGSEDAEPLAPPIKPIKPVTRNKAPQEPPVKKGR RSRRCGQCPGCQVPEDCGVCTNCLDKPKFGGRNIKKQCCKMRKCQNLQWM PSKAYLQKQAKAVKKKEKKSKTSEKKDSKESSVVKNVVDSSQKPTPSARE DPAPKKSSSEPPPRKPVEEKSEEGNVSAPGPESKQATTPASRKSSKQVSQ PALVIPPQPPTTGPPRKEVPKTTPSEPKKKQPPPPESGPEQSKQKKVAPR PSIPVKQKPKEKEKPPPVNKQENAGTLNILSTLSNGNSSKQKIPADGVHR IRVDFKESQQSNFGTGEQKRYNPSKTSNGHQSKSMLKDDLKLSSSEDSDG EQDCDKTMPRSTPGSNSEPSHHNSEGADNSRDDSSSHSGSESSSGSDSES ESSSSDSEANEPSQSASPEPEPPPTNKWQLDNWLNKVNPHKVSPASSVDS NIPSSQGYKKEGREQGTGNSYTDTSGPKETSSATPGRDSKTIQKGSESGR GRQKSPAQSDSTTQRRTVGKKQPKKAEKAAAEEPRGGLKIESETPVDLAS SMPSSRHKAATKGSRKPNIKKESKSSPRPTAEKKKYKSTSKSSQKSREII ETDTSSSDSDESESLPPSSQTPKYPESNRTPVKPSSVEEEDSFFRQRMFS PMEEKELLSPLSEPDDRYPLIVKIDLNLLTRIPGKPYKETEPPKGEKKNV PEKHTREAQKQASEKVSNKGKRKHKNEDDNRASESKKPKTEDKNSAGHKP SSNRESSKQSAAKEKDLLPSPAGPVPSKDPKTEHGSRKRTISQSSSLKSS SNSNKETSGSSKNSSSTSKQKKTEGKTSSSSKEVKEKAPSSSSNCPPSAP TLDSSKPRRTKLVFDDRNYSADHYLQEAKKLKHNADALSDRFEKAVYYLD AVVSFIECGNALEKNAQESKSPFPMYSETVDLIKYTMKLKNYLAPDATAA DKRLTVLCLRCESLLYLRLFKLKKENALKYSKTLTEHLKNSYNNSQAPSP GLGSKAVGMPSPVSPKLSPGNSGNYSSGASSASASGSSVTIPQKIHQMAA SYVQVTSNFLYATEIWDQAEQLSKEQKEFFAELDKVMGPLIFNASIMTDL | 2219 |
| 3D view using mol* of 1114 (AA BP:) | ||||||||||
| ||||||||||
Top |
pLDDT score distribution |
| pLDDT score distribution of the predicted wild-type structures of two partner proteins from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
KMT2A_pLDDT.png  |
AFF4_pLDDT.png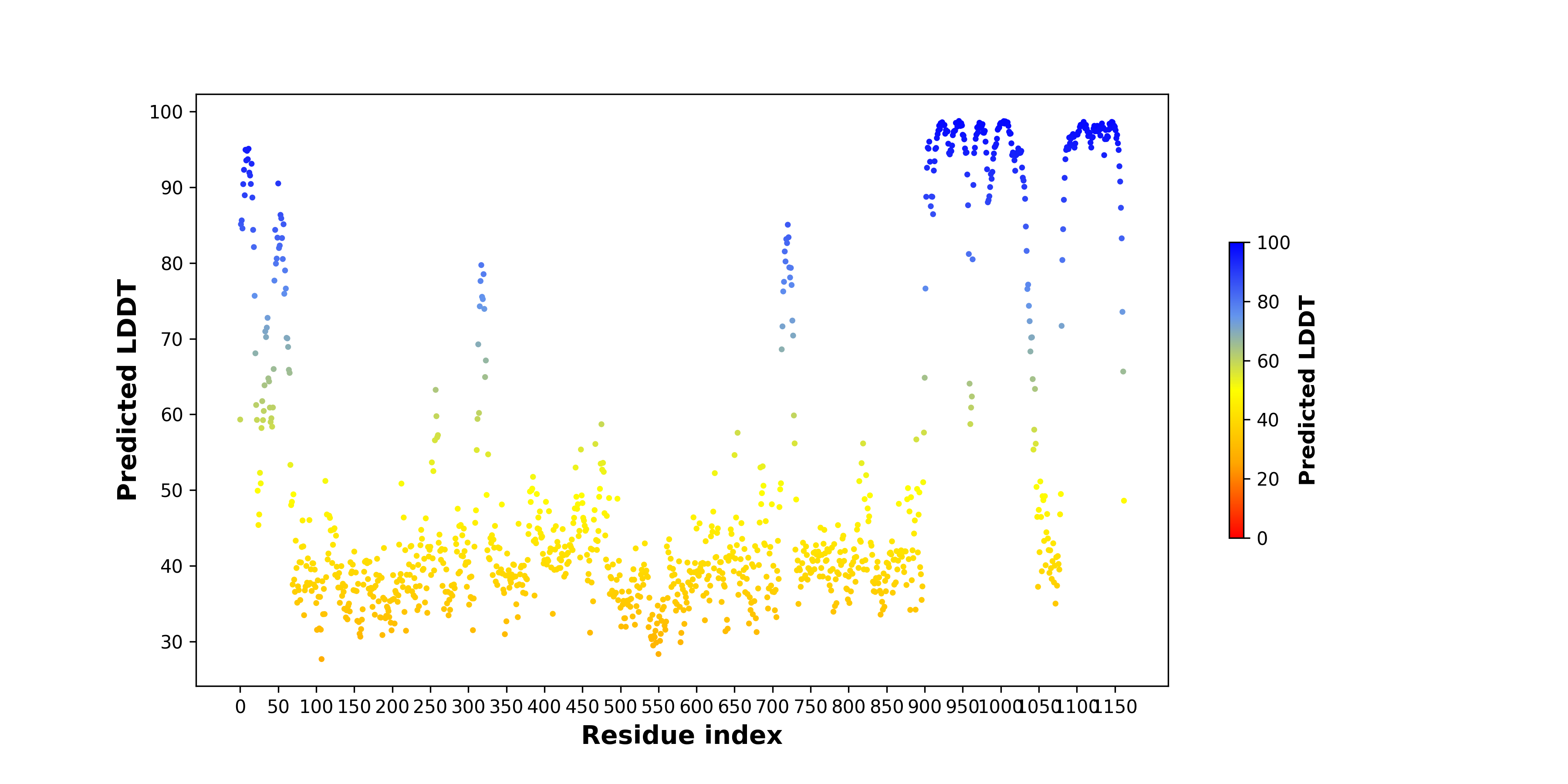 |
| pLDDT score distribution of the predicted fusion protein structures from AlphaFold2 * AlphaFold produces a per-residue confidence score (pLDDT) between 0 and 100. |
KMT2A_AFF4_1060_pLDDT.png (AA BP:57)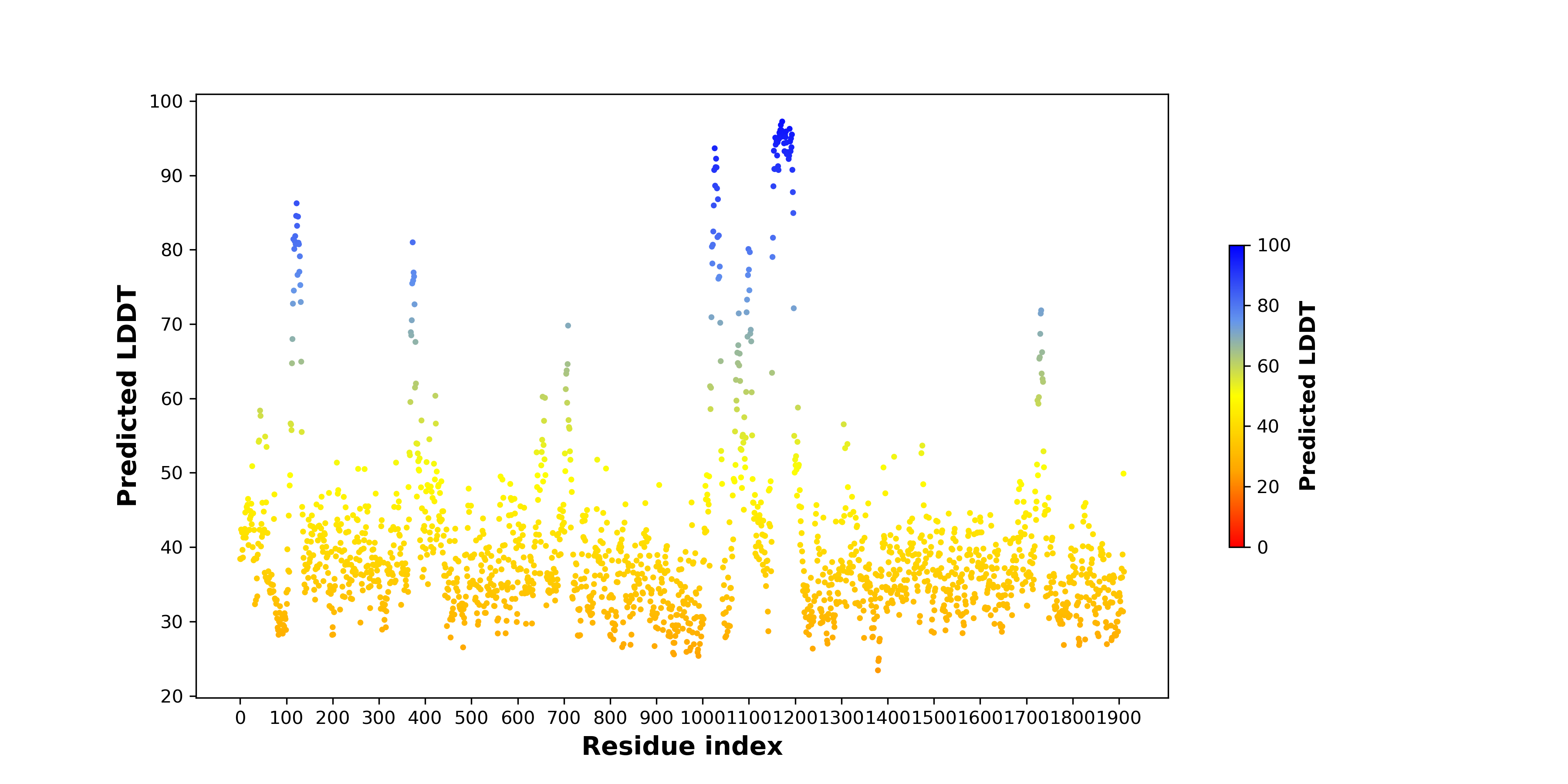 |
KMT2A_AFF4_1060_pLDDT_and_active_sites.png (AA BP:57)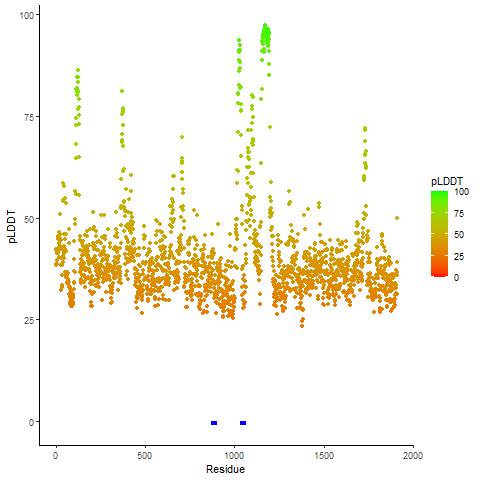 |
KMT2A_AFF4_1060_violinplot.png (AA BP:57)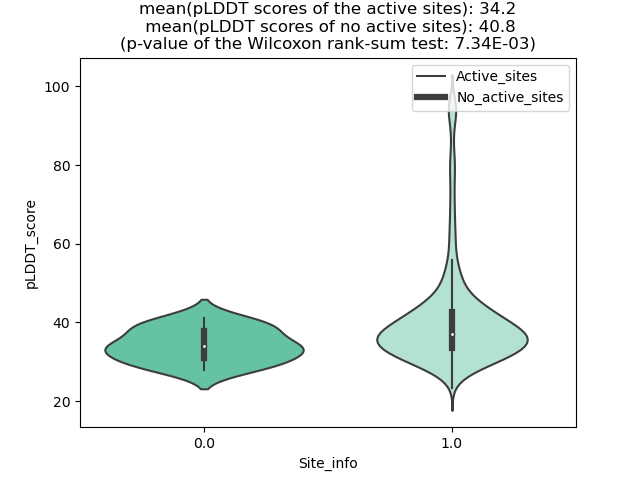 |
KMT2A_AFF4_1107_pLDDT_and_active_sites.png (AA BP:)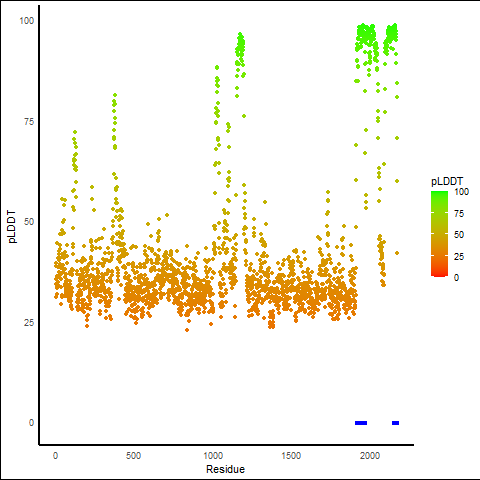 |
KMT2A_AFF4_1107_violinplot.png (AA BP:)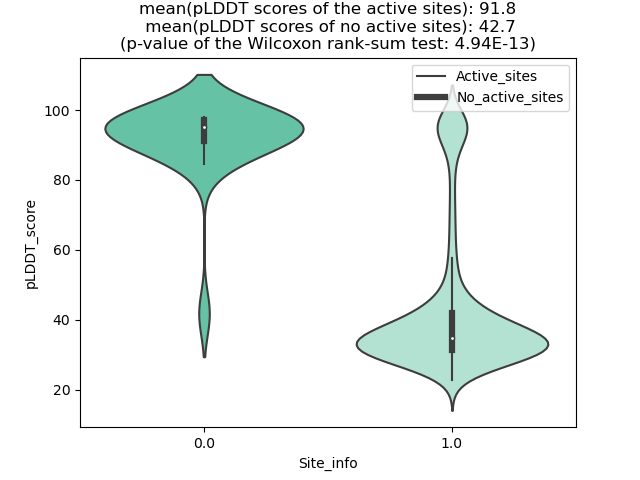 |
KMT2A_AFF4_1111_pLDDT_and_active_sites.png (AA BP:)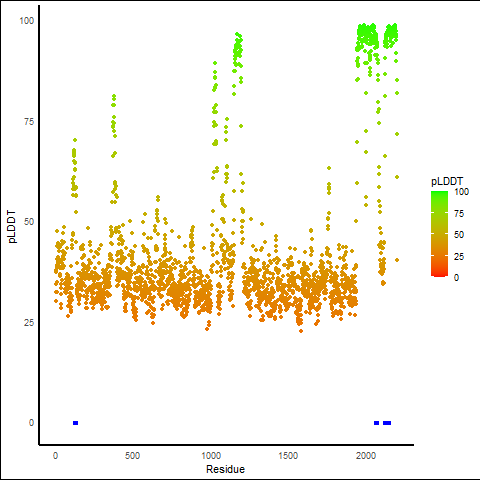 |
KMT2A_AFF4_1111_violinplot.png (AA BP:)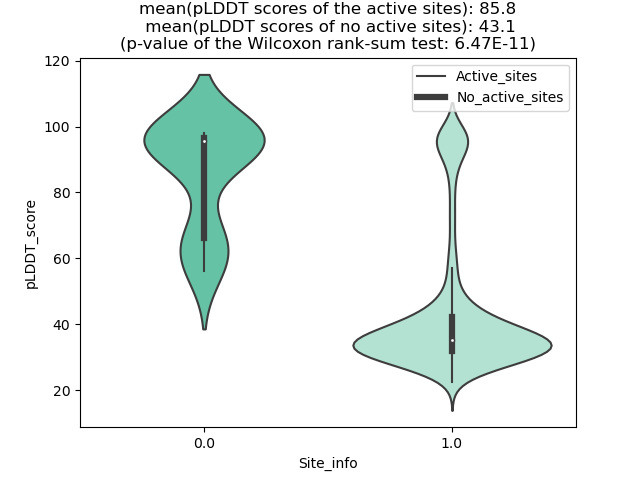 |
KMT2A_AFF4_1114_pLDDT_and_active_sites.png (AA BP:)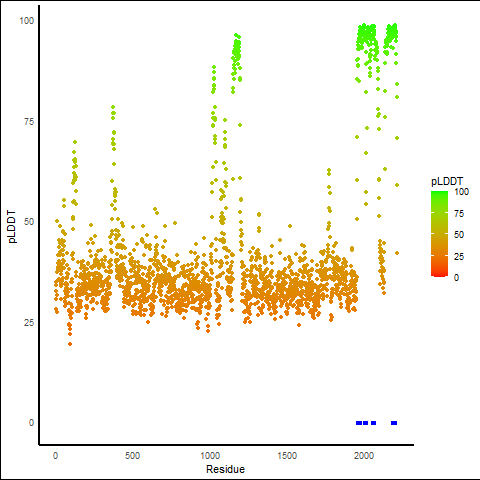 |
KMT2A_AFF4_1114_violinplot.png (AA BP:)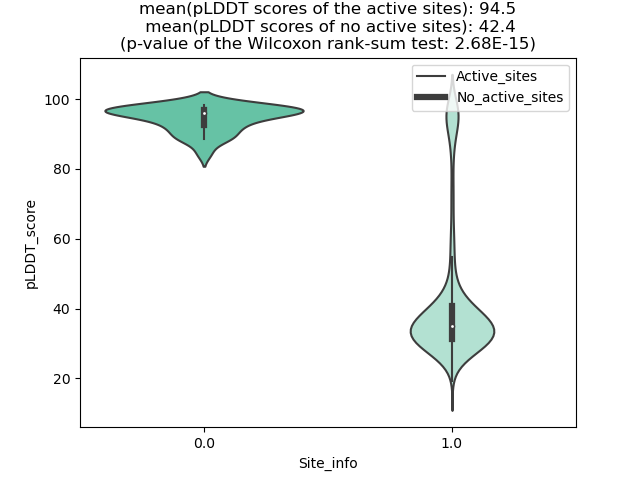 |
Top |
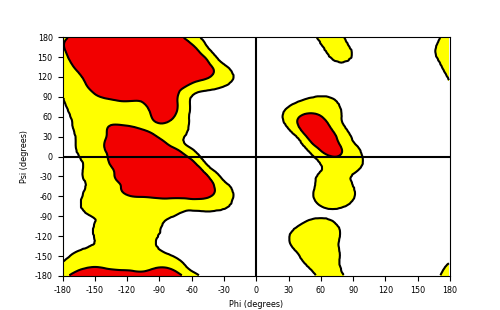
Ramachandran Plot of Fusion Protein Structure |
| Ramachandran plot of the torsional angles - phi (φ)and psi (ψ) - of the residues (amino acids) contained in this fusion protein peptide. |
| Fusion AA seq ID in FusionPDB and their Ramachandran plots |
| KMT2A_AFF4_1060.png |
 |
Top |
Potential Active Site Information |
| The potential binding sites of these fusion proteins were identified using SiteMap, a module of the Schrodinger suite. |
| Fusion AA seq ID in FusionPDB | Site score | Size | D score | Volume | Exposure | Enclosure | Contact | Phobic | Philic | Balance | Don/Acc | Residues |
| 1060 | 0.78 | 75 | 0.777 | 159.152 | 0.758 | 0.516 | 0.654 | 0.053 | 1.065 | 0.05 | 0.793 | Chain A: 880,883,884,885,886,887,888,889,890,1045, 1046,1047,1048,1049,1050,1051,1052,1053,1054 |
| 1060 | 0.75 | 68 | 0.738 | 139 | 0.776 | 0.516 | 0.654 | 0.01 | 1.065 | 0.01 | 0.793 | Chain A: 880,883,884,885,886,887,888,889,890,1045, 1046,1047,1049,1050,1051,1052,1053,1054 |
| 1070 | 0.865 | 80 | 0.829 | 170.471 | 0.563 | 0.611 | 0.88 | 0.288 | 1.16 | 0.248 | 0.905 | Chain A: 419,420,421,422,423,643,644,645,646,647,6 48,649,871,872,874,875 |
| 1075 | 0.929 | 124 | 0.958 | 242.501 | 0.66 | 0.587 | 0.774 | 0.175 | 1.025 | 0.171 | 0.7 | Chain A: 1150,1151,1152,1153,1195,1196,1197,1198,1 199,1200,1201,1202,1203,1398,1399,1400,1401,1402,1 403,1404,1406 |
| 1107 | 0.957 | 95 | 0.959 | 230.496 | 0.675 | 0.662 | 0.761 | 0.298 | 1.088 | 0.274 | 0.436 | Chain A: 1918,1920,1921,1922,1923,1924,1925,1929,1 930,1933,1956,1963,1966,1967,1970,2154,2157,2158,2 161,2164,2165,2168,2175 |
| 1111 | 1.11 | 87 | 1.202 | 261.709 | 0.482 | 0.743 | 1.026 | 2.754 | 0.369 | 7.463 | 1.092 | Chain A: 121,122,125,126,128,129,2066,2069,2070,20 73,2074,2126,2130,2134,2137,2138,2141,2144,2145,21 48 |
| 1114 | 0.991 | 120 | 0.97 | 237.699 | 0.592 | 0.685 | 0.85 | 0.237 | 1.17 | 0.203 | 0.465 | Chain A: 1964,1965,1966,1967,1968,1969,1974,2007,2 010,2011,2013,2014,2064,2067,2068,2071,2192,2193,2 194,2195,2196,2197,2198,2201,2202,2205 |
Top |
Potentially Interacting Small Molecules through Virtual Screening |
| The FDA-approved small molecule library molecules were subjected to virtual screening using the Glide. |
| Fusion AA seq ID in FusionPDB | ZINC ID | DrugBank ID | Drug name | Docking score | Glide gscore |
| 1114 | ZINC000008577218 | DB00158 | Folic acid | -6.58019 | -6.75889 |
| 1114 | ZINC000003801919 | DB00630 | Alendronic acid | -5.66593 | -6.40893 |
| 1114 | ZINC000003830813 | DB01077 | Etidronic acid | -6.02125 | -6.26735 |
| 1114 | ZINC000019632917 | DB00475 | Chlordiazepoxide | -4.68833 | -6.26433 |
| 1114 | ZINC000005733652 | DB11259 | Diosmetin | -6.01872 | -6.05472 |
| 1114 | ZINC000000901736 | DB08847 | Hydroxyproline | -6.01487 | -6.01487 |
| 1114 | ZINC000008015016 | DB14078 | Medronic acid | -5.65718 | -5.97078 |
| 1114 | ZINC000000895081 | DB04272 | Citric acid | -5.94607 | -5.94607 |
| 1114 | ZINC000100009383 | DB01914 | D-glucose | -5.94319 | -5.94319 |
| 1114 | ZINC000008101109 | DB00529 | Foscarnet | -5.88451 | -5.89091 |
| 1114 | ZINC000005844788 | DB04861 | Nebivolol | -5.81731 | -5.83711 |
| 1114 | ZINC000000057147 | DB00651 | Dyphylline | -5.82581 | -5.82581 |
| 1114 | ZINC000008143864 | DB09134 | Ioversol | -5.79299 | -5.79299 |
| 1114 | ZINC000000895457 | DB08847 | Hydroxyproline | -5.78631 | -5.78631 |
| 1114 | ZINC000000034157 | DB06707 | Levonordefrin | -5.74835 | -5.76585 |
| 1114 | ZINC000085537017 | DB06441 | Cangrelor | -3.51477 | -5.74107 |
| 1114 | ZINC000000002005 | DB00339 | Pyrazinamide | -5.72409 | -5.72409 |
| 1114 | ZINC000000607986 | DB04861 | Nebivolol | -5.69857 | -5.71837 |
| 1114 | ZINC000006382803 | DB00352 | Tioguanine | -5.53903 | -5.68943 |
| 1114 | ZINC000003823492 | DB01280 | Nelarabine | -5.64271 | -5.64271 |
Top |
| Drug information from DrugBank of the top 20 interacting small molecules. |
| ZINC ID | DrugBank ID | Drug name | Drug type | SMILES | Drug group |
| ZINC000008577218 | DB00158 | Folic acid | Small molecule | NC1=NC(=O)C2=NC(CNC3=CC=C(C=C3)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CN=C2N1 | Approved|Nutraceutical|Vet_approved |
| ZINC000003801919 | DB00630 | Alendronic acid | Small molecule | NCCCC(O)(P(O)(O)=O)P(O)(O)=O | Approved |
| ZINC000003830813 | DB01077 | Etidronic acid | Small molecule | CC(O)(P(O)(O)=O)P(O)(O)=O | Approved |
| ZINC000019632917 | DB00475 | Chlordiazepoxide | Small molecule | CNC1=NC2=C(C=C(Cl)C=C2)C(C2=CC=CC=C2)=[N+]([O-])C1 | Approved|Illicit|Investigational |
| ZINC000005733652 | DB11259 | Diosmetin | Small molecule | COC1=C(O)C=C(C=C1)C1=CC(=O)C2=C(O1)C=C(O)C=C2O | Experimental |
| ZINC000008015016 | DB14078 | Medronic acid | Small molecule | OP(O)(=O)CP(O)(O)=O | Approved|Investigational |
| ZINC000000895081 | DB04272 | Citric acid | Small molecule | OC(=O)CC(O)(CC(O)=O)C(O)=O | Approved|Nutraceutical|Vet_approved |
| ZINC000100009383 | DB01914 | D-glucose | Small molecule | [H][C@@](O)(CO)[C@@]([H])(O)[C@]([H])(O)[C@@]([H])(O)C=O | Approved|Investigational|Vet_approved |
| ZINC000008101109 | DB00529 | Foscarnet | Small molecule | OC(=O)P(O)(O)=O | Approved |
| ZINC000000057147 | DB00651 | Dyphylline | Small molecule | CN1C2=C(N(CC(O)CO)C=N2)C(=O)N(C)C1=O | Approved |
| ZINC000008143864 | DB09134 | Ioversol | Small molecule | OCCN(C(=O)CO)C1=C(I)C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C1I | Approved |
| ZINC000000895457 | DB08847 | Hydroxyproline | Small molecule | O[C@H]1CN[C@@H](C1)C(O)=O | Experimental |
| ZINC000000034157 | DB06707 | Levonordefrin | Small molecule | C[C@H](N)[C@H](O)C1=CC(O)=C(O)C=C1 | Approved |
| ZINC000085537017 | DB06441 | Cangrelor | Small molecule | CSCCNC1=C2N=CN([C@@H]3O[C@H](COP(O)(=O)OP(O)(=O)C(Cl)(Cl)P(O)(O)=O)[C@@H](O)[C@H]3O)C2=NC(SCCC(F)(F)F)=N1 | Approved |
| ZINC000000002005 | DB00339 | Pyrazinamide | Small molecule | NC(=O)C1=NC=CN=C1 | Approved|Investigational |
| ZINC000006382803 | DB00352 | Tioguanine | Small molecule | NC1=NC(=S)C2=C(N1)N=CN2 | Approved |
| ZINC000003823492 | DB01280 | Nelarabine | Small molecule | COC1=NC(N)=NC2=C1N=CN2[C@@H]1O[C@H](CO)[C@@H](O)[C@@H]1O | Approved|Investigational |
Top |
Biochemical Features of Small Molecules |
| ADME (Absorption, Distribution, Metabolism, and Excretion) of drugs using QikProp(v3.9) |
| ZINC ID | mol_MW | dipole | SASA | FOSA | FISA | PISA | WPSA | volume | donorHB | accptHB | IP | Human Oral Absorption | Percent Human Oral Absorption | Rule Of Five | Rule Of Three |
| ZINC000008577218 | 441.402 | 13.51 | 755.446 | 101.238 | 451.657 | 202.551 | 0 | 1308.074 | 6.25 | 12.75 | 8.35 | 1 | 0 | 2 | 1 |
| ZINC000008577218 | 441.402 | 14.14 | 754.923 | 100.926 | 451.592 | 202.405 | 0 | 1306.451 | 6.25 | 12.75 | 8.302 | 1 | 0 | 2 | 1 |
| ZINC000008577218 | 441.402 | 14.323 | 755.349 | 100.67 | 452.288 | 202.391 | 0 | 1307.577 | 6.25 | 12.75 | 8.399 | 1 | 0 | 2 | 1 |
| ZINC000003801919 | 249.097 | 6.598 | 414.717 | 86.372 | 321.667 | 0 | 6.679 | 680 | 3 | 7.75 | 9.26 | 1 | 0 | 1 | 1 |
| ZINC000003801919 | 249.097 | 13.583 | 415.33 | 88.33 | 320.807 | 0 | 6.194 | 681.18 | 3 | 7.75 | 9.122 | 1 | 0 | 1 | 1 |
| ZINC000003801919 | 249.097 | 7.425 | 414.525 | 87.312 | 321.455 | 0 | 5.758 | 680.611 | 3 | 7.75 | 9.244 | 1 | 0 | 1 | 1 |
| ZINC000003830813 | 206.029 | 8.234 | 343.926 | 58.866 | 278.645 | 0 | 6.414 | 541.497 | 1 | 6.75 | 9.379 | 1 | 20.728 | 0 | 1 |
| ZINC000003830813 | 206.029 | 8.446 | 343.742 | 59.548 | 277.922 | 0 | 6.271 | 541.502 | 1 | 6.75 | 9.388 | 1 | 20.88 | 0 | 1 |
| ZINC000003830813 | 206.029 | 7.127 | 340.461 | 65.078 | 269.49 | 0 | 5.893 | 540.584 | 1 | 6.75 | 9.311 | 1 | 22.658 | 0 | 1 |
| ZINC000019632917 | 299.759 | 4.645 | 553.04 | 137.022 | 64.707 | 279.788 | 71.524 | 941.819 | 1 | 3 | 8.565 | 3 | 100 | 0 | 0 |
| ZINC000019632917 | 299.759 | 5.502 | 549.003 | 118.965 | 74.766 | 283.82 | 71.453 | 935.577 | 1 | 3 | 8.408 | 3 | 100 | 0 | 0 |
| ZINC000005733652 | 300.267 | 4.88 | 528.855 | 93.31 | 204.424 | 231.12 | 0 | 896.841 | 2 | 4.5 | 8.9 | 3 | 73.982 | 0 | 0 |
| ZINC000005733652 | 300.267 | 6.652 | 527.118 | 93.294 | 202.511 | 231.313 | 0 | 894.005 | 2 | 4.5 | 8.908 | 3 | 74.287 | 0 | 0 |
| ZINC000000901736 | 131.131 | 7.153 | 314.17 | 135.996 | 178.173 | 0 | 0 | 473.484 | 3 | 5.2 | 10.208 | 2 | 29.805 | 0 | 1 |
| ZINC000008015016 | 176.002 | 3.602 | 323.868 | 34.991 | 281.713 | 0 | 7.164 | 486.492 | 0 | 6 | 9.674 | 1 | 16.795 | 0 | 1 |
| ZINC000008015016 | 176.002 | 13.068 | 326.073 | 33.644 | 285.397 | 0 | 7.032 | 489.653 | 0 | 6 | 9.876 | 1 | 16.139 | 0 | 1 |
| ZINC000000895081 | 192.125 | 7.318 | 360.538 | 63.461 | 297.077 | 0 | 0 | 576.012 | 3 | 5.75 | 11.1 | 1 | 16.425 | 0 | 1 |
| ZINC000100009383 | 180.157 | 3.592 | 379.456 | 116.158 | 263.298 | 0 | 0 | 602.288 | 4 | 9.5 | 10.555 | 2 | 40.878 | 0 | 0 |
| ZINC000008101109 | 126.005 | 6.9 | 264.917 | 0 | 260.554 | 0 | 4.362 | 372.032 | 3 | 7 | 9.757 | 1 | 17.558 | 0 | 1 |
| ZINC000008101109 | 126.005 | 11.927 | 257.279 | 0 | 253.345 | 0 | 3.934 | 359.323 | 3 | 7 | 9.932 | 1 | 18.931 | 0 | 1 |
| ZINC000005844788 | 405.441 | 1.102 | 724.6 | 273.703 | 87.795 | 269.339 | 93.762 | 1272.257 | 3 | 6.4 | 9.305 | 3 | 94.995 | 0 | 0 |
| ZINC000005844788 | 405.441 | 3.204 | 688.14 | 293.004 | 60.761 | 240.615 | 93.76 | 1244.959 | 3 | 6.4 | 9.151 | 3 | 100 | 0 | 0 |
| ZINC000000057147 | 254.245 | 5.711 | 471.42 | 234.45 | 192.156 | 44.814 | 0 | 796.575 | 2 | 8.4 | 9.04 | 3 | 63.753 | 0 | 0 |
| ZINC000008143864 | 807.116 | 5.478 | 759.618 | 304.239 | 335.909 | 6.136 | 113.333 | 1427.748 | 8 | 18.2 | 9.211 | 1 | 0 | 3 | 1 |
| ZINC000000895457 | 131.131 | 7.237 | 313.333 | 137.57 | 175.763 | 0 | 0 | 472.628 | 3 | 5.2 | 10.259 | 2 | 30.299 | 0 | 1 |
| ZINC000000034157 | 183.207 | 1.584 | 399.847 | 106.772 | 186.848 | 106.227 | 0 | 646.199 | 5 | 4.2 | 8.948 | 2 | 52.109 | 0 | 0 |
| ZINC000000034157 | 183.207 | 2.284 | 398.836 | 105.841 | 186.106 | 106.889 | 0 | 643.154 | 5 | 4.2 | 8.781 | 2 | 52.19 | 0 | 0 |
| ZINC000085537017 | 776.353 | 7.43 | 927.054 | 287.655 | 393.585 | 54.42 | 191.394 | 1783.369 | 3 | 20.6 | 8.462 | 1 | 0 | 3 | 1 |
| ZINC000085537017 | 776.353 | 5.036 | 918.307 | 262.294 | 312.532 | 51.82 | 291.661 | 1775.566 | 3 | 20.6 | 8.603 | 1 | 0 | 3 | 1 |
| ZINC000000002005 | 123.114 | 5.397 | 301.507 | 0 | 160.969 | 140.538 | 0 | 446.636 | 2 | 5 | 9.967 | 2 | 67.429 | 0 | 0 |
| ZINC000000607986 | 405.441 | 5.004 | 705.664 | 273.428 | 84.542 | 253.931 | 93.763 | 1255.212 | 3 | 6.4 | 9.141 | 3 | 95.029 | 0 | 0 |
| ZINC000000607986 | 405.441 | 6.242 | 723.401 | 276.421 | 85.145 | 268.07 | 93.764 | 1269.446 | 3 | 6.4 | 9.103 | 3 | 95.442 | 0 | 0 |
| ZINC000006382803 | 167.188 | 2.913 | 334.099 | 0 | 174.672 | 82.562 | 76.865 | 508.157 | 4 | 5 | 8.609 | 3 | 68.386 | 0 | 0 |
| ZINC000006382803 | 167.188 | 10.353 | 334.237 | 0 | 175.326 | 82.487 | 76.423 | 508.122 | 4 | 5 | 8.464 | 3 | 68.28 | 0 | 0 |
| ZINC000006382803 | 167.188 | 3.972 | 333.764 | 0 | 164.061 | 91.943 | 77.76 | 507.032 | 3.8 | 4 | 8.378 | 3 | 69.616 | 0 | 0 |
| ZINC000003823492 | 297.27 | 4.928 | 515.902 | 202.166 | 251.355 | 62.381 | 0 | 870.054 | 5 | 10.8 | 8.334 | 2 | 47.735 | 0 | 0 |
Top |
Drug Toxicity Information |
| Toxicity information of individual drugs using eToxPred |
| ZINC ID | Smile | Surface Accessibility | Toxicity |
| ZINC000008577218 | Nc1nc(O)c2nc(CNc3ccc(C(=O)N[C@@H](CCC(=O)O)C(=O)O)cc3)cnc2n1 | 0.127688186 | 0.392534973 |
| ZINC000003801919 | NCCCC(O)(P(=O)(O)O)P(=O)(O)O | 0.111910059 | 0.475661392 |
| ZINC000003830813 | CC(O)(P(=O)(O)O)P(=O)(O)O | 0.095573527 | 0.535505529 |
| ZINC000019632917 | CNC1=Nc2ccc(Cl)cc2C(c2ccccc2)=[N+]([O-])C1 | 0.147320673 | 0.447326601 |
| ZINC000005733652 | COc1ccc(-c2cc(=O)c3c(O)cc(O)cc3o2)cc1O | 0.260199086 | 0.67867566 |
| ZINC000000901736 | O=C(O)[C@@H]1C[C@H](O)CN1 | 0.099278267 | 0.470163896 |
| ZINC000008015016 | O=P(O)(O)CP(=O)(O)O | 0.097212655 | 0.606313084 |
| ZINC000000895081 | O=C(O)CC(O)(CC(=O)O)C(=O)O | 0.234141836 | 0.605941862 |
| ZINC000100009383 | O=C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO | 0.054738851 | 0.662712322 |
| ZINC000008101109 | O=C(O)P(=O)(O)O | 0.151109156 | 0.530839371 |
| ZINC000005844788 | O[C@@H](CNC[C@@H](O)[C@H]1CCc2cc(F)ccc2O1)[C@@H]1CCc2cc(F)ccc2O1 | 0.055550082 | 0.198725964 |
| ZINC000000057147 | Cn1c(=O)c2c(ncn2C[C@@H](O)CO)n(C)c1=O | 0.143170855 | 0.263526965 |
| ZINC000008143864 | O=C(NC[C@H](O)CO)c1c(I)c(C(=O)NC[C@H](O)CO)c(I)c(N(CCO)C(=O)CO)c1I | 0.051780669 | 0.23149478 |
| ZINC000000895457 | O=C(O)[C@H]1C[C@H](O)CN1 | 0.099278267 | 0.470163896 |
| ZINC000000034157 | C[C@H](N)[C@H](O)c1ccc(O)c(O)c1 | 0.135079192 | 0.302260037 |
| ZINC000085537017 | CSCCNc1nc(SCCC(F)(F)F)nc2c1ncn2[C@@H]1O[C@H](CO[P@@](=O)(O)O[P@](=O)(O)C(Cl)(Cl)P(=O)(O)O)[C@@H](O)[C@H]1O | 0.017889541 | 0.259362736 |
| ZINC000000002005 | N=C(O)c1cnccn1 | 0.163558036 | 0.672419783 |
| ZINC000000607986 | O[C@@H](CNC[C@@H](O)[C@H]1CCc2cc(F)ccc2O1)[C@H]1CCc2cc(F)ccc2O1 | 0.055550082 | 0.198725964 |
| ZINC000006382803 | Nc1nc2nc[nH]c2c(=S)[nH]1 | 0.10005457 | 0.571375233 |
| ZINC000003823492 | COc1nc(N)nc2c1ncn2[C@@H]1O[C@H](CO)[C@@H](O)[C@@H]1O | 0.069290924 | 0.249414472 |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| KMT2A | PPIE, PPP1R15A, KMT2A, ASH2L, HCFC1, HCFC2, MEN1, RBBP5, WDR5, AVP, INS, OXT, MAP3K5, HDAC1, CTBP1, CBX4, BMI1, CREBBP, SMARCB1, CXXC1, MYB, CTNNB1, SNW1, E2F2, E2F4, E2F6, PSIP1, MLLT4, POLR2A, KAT8, RNF2, TP53, tat, SBF1, MTM1, SET, HIST1H3A, HIST1H4A, KAT6A, ELL, AFF1, AFF4, CDK9, CCNT1, CTR9, LEO1, PAF1, CDC73, WDR61, MLLT3, DOT1L, SKP2, HIST3H3, SVIL, HIST2H3C, SIN3A, MLLT1, RUNX1, CBFB, H3F3A, SIRT7, ASB2, TCEB1, TCEB2, CBX8, TOP1, TAF6, NCL, HECW2, LGR4, CSNK2A2, SENP3, SYMPK, PKN1, PIH1D1, KRAS, TAF1, CHD3, SMARCA2, SMARCC2, SMARCC1, HDAC2, RBBP4, RBBP7, TBP, MBD3, SAP30, RAN, TAF9, TASP1, HIST1H2BG, EWSR1, DYNLT1, KIF11, ING4, Cbx1, Set, ZNF131, ASB7, AR, CSNK2A1, OGT, BRD4, KDM5B, KDM5D, KDM6B, CKS1B, CKS2, CHD4, ESR2, AGR2, EZH2, FBXW7, SOX2, MED17, WDR82, ACTR8, GEMIN5, RUVBL1, MCM2, RTF1, MED15, MED8, MRGBP, MED14, HIST1H2BB, HIST1H2AB, KIAA1429, SP1, MYC, NR2C2, IRF2, PLEKHA4, DPY30, PTEN, NPM1, RPL13, CCT6A, TMCO1, ITGB1, ESR1, MYCN, SUPT5H, CIT, Pik3r2, FASN, LDLR, CDC27, KMT2B, SETD1A, KDM6A, KANSL2, BUB3, SETD1B, KANSL1, RERE, MCRS1, KMT2C, ZZZ3, MBIP, YEATS2, PAXIP1, KANSL3, KMT2D, BOD1L1, CSRP2BP, ZNF608, ATN1, PHF20L1, PHF20, NCOA6, TADA3, APEX1, ASF1A, CBX3, CD3EAP, CENPA, NUP50, POLR1E, TERF2IP, ZNF330, NAA40, PRKRA, SRSF4, KRR1, RPL13A, ABT1, CSNK2B, OASL, SRSF5, SRSF6, RPS9, FGFBP1, RPLP0, RPL36, KAL1, RPL3, PML, ELF1, ELF2, FEV, NHLH1, EN1, KLF12, KLF3, NFIX, NFYC, YY1, BRD3, |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| KMT2A |  |
| AFF4 |  |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to KMT2A-AFF4 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to KMT2A-AFF4 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
| Hgene | KMT2A | C2826025 | Mixed phenotype acute leukemia | 3 | ORPHANET |
| Hgene | KMT2A | C0023418 | leukemia | 2 | CTD_human |
| Hgene | KMT2A | C0023452 | Childhood Acute Lymphoblastic Leukemia | 2 | CTD_human |
| Hgene | KMT2A | C0023453 | L2 Acute Lymphoblastic Leukemia | 2 | CTD_human |
| Hgene | KMT2A | C0023466 | Leukemia, Monocytic, Chronic | 2 | CTD_human |
| Hgene | KMT2A | C0023467 | Leukemia, Myelocytic, Acute | 2 | CTD_human |
| Hgene | KMT2A | C0023470 | Myeloid Leukemia | 2 | CTD_human |
| Hgene | KMT2A | C0026998 | Acute Myeloid Leukemia, M1 | 2 | CTD_human |
| Hgene | KMT2A | C1854630 | Growth Deficiency and Mental Retardation with Facial Dysmorphism | 2 | CTD_human;GENOMICS_ENGLAND;ORPHANET |
| Hgene | KMT2A | C1879321 | Acute Myeloid Leukemia (AML-M2) | 2 | CTD_human |
| Hgene | KMT2A | C1961102 | Precursor Cell Lymphoblastic Leukemia Lymphoma | 2 | CTD_human |
| Hgene | KMT2A | C0001418 | Adenocarcinoma | 1 | CTD_human |
| Hgene | KMT2A | C0004403 | Autosome Abnormalities | 1 | CTD_human |
| Hgene | KMT2A | C0005684 | Malignant neoplasm of urinary bladder | 1 | CTD_human |
| Hgene | KMT2A | C0005695 | Bladder Neoplasm | 1 | CTD_human |
| Hgene | KMT2A | C0007138 | Carcinoma, Transitional Cell | 1 | CTD_human |
| Hgene | KMT2A | C0008625 | Chromosome Aberrations | 1 | CTD_human |
| Hgene | KMT2A | C0023448 | Lymphoid leukemia | 1 | CTD_human |
| Hgene | KMT2A | C0023465 | Acute monocytic leukemia | 1 | CTD_human |
| Hgene | KMT2A | C0023479 | Acute myelomonocytic leukemia | 1 | CTD_human |
| Hgene | KMT2A | C0024623 | Malignant neoplasm of stomach | 1 | CTD_human |
| Hgene | KMT2A | C0033578 | Prostatic Neoplasms | 1 | CTD_human |
| Hgene | KMT2A | C0036341 | Schizophrenia | 1 | PSYGENET |
| Hgene | KMT2A | C0038356 | Stomach Neoplasms | 1 | CTD_human |
| Hgene | KMT2A | C0149925 | Small cell carcinoma of lung | 1 | CTD_human |
| Hgene | KMT2A | C0205641 | Adenocarcinoma, Basal Cell | 1 | CTD_human |
| Hgene | KMT2A | C0205642 | Adenocarcinoma, Oxyphilic | 1 | CTD_human |
| Hgene | KMT2A | C0205643 | Carcinoma, Cribriform | 1 | CTD_human |
| Hgene | KMT2A | C0205644 | Carcinoma, Granular Cell | 1 | CTD_human |
| Hgene | KMT2A | C0205645 | Adenocarcinoma, Tubular | 1 | CTD_human |
| Hgene | KMT2A | C0270972 | Cornelia De Lange Syndrome | 1 | ORPHANET |
| Hgene | KMT2A | C0280141 | Acute Undifferentiated Leukemia | 1 | ORPHANET |
| Hgene | KMT2A | C0376358 | Malignant neoplasm of prostate | 1 | CTD_human |
| Hgene | KMT2A | C0856823 | Undifferentiated type acute leukemia | 1 | ORPHANET |
| Hgene | KMT2A | C1535926 | Neurodevelopmental Disorders | 1 | CTD_human |
| Hgene | KMT2A | C1708349 | Hereditary Diffuse Gastric Cancer | 1 | CTD_human |
| Hgene | KMT2A | C2239176 | Liver carcinoma | 1 | CTD_human |
| Hgene | KMT2A | C2930974 | Acute erythroleukemia | 1 | CTD_human |
| Hgene | KMT2A | C2930975 | Acute erythroleukemia - M6a subtype | 1 | CTD_human |
| Hgene | KMT2A | C2930976 | Acute myeloid leukemia FAB-M6 | 1 | CTD_human |
| Hgene | KMT2A | C2930977 | Acute erythroleukemia - M6b subtype | 1 | CTD_human |
| Tgene | AFF4 | C0000772 | Multiple congenital anomalies | 1 | CTD_human |
| Tgene | AFF4 | C0005941 | Bone Diseases, Developmental | 1 | CTD_human |
| Tgene | AFF4 | C0009241 | Cognition Disorders | 1 | CTD_human |
| Tgene | AFF4 | C0018273 | Growth Disorders | 1 | CTD_human |
| Tgene | AFF4 | C0018798 | Congenital Heart Defects | 1 | CTD_human |
| Tgene | AFF4 | C0024115 | Lung diseases | 1 | CTD_human |
| Tgene | AFF4 | C0028754 | Obesity | 1 | CTD_human |
| Tgene | AFF4 | C0282631 | Facies | 1 | CTD_human |
| Tgene | AFF4 | C4085597 | CHOPS SYNDROME | 1 | CTD_human;ORPHANET;UNIPROT |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies