| UTHEALTH HOME ABOUT SBMI A-Z WEBMAIL INSIDE THE UNIVERSITY |

|
|||||||
|

Fusion Protein:LETM2-ERCC2 |
Fusion Protein Summary |
 Fusion gene summary Fusion gene summary |
| Fusion partner gene information | Fusion gene name: LETM2-ERCC2 | FusionPDB ID: 44492 | FusionGDB2.0 ID: 44492 | Hgene | Tgene | Gene symbol | LETM2 | ERCC2 | Gene ID | 137994 | 2068 |
| Gene name | leucine zipper and EF-hand containing transmembrane protein 2 | ERCC excision repair 2, TFIIH core complex helicase subunit | |
| Synonyms | SLC55A2 | COFS2|EM9|TFIIH|TTD|TTD1|XPD | |
| Cytomap | 8p11.23 | 19q13.32 | |
| Type of gene | protein-coding | protein-coding | |
| Description | LETM1 domain-containing protein LETM2, mitochondrialLETM1 and EF-hand domain-containing protein 2leucine zipper-EF-hand containing transmembrane protein 1-like proteinleucine zipper-EF-hand containing transmembrane protein 2 | general transcription and DNA repair factor IIH helicase subunit XPDBTF2 p80CXPDDNA excision repair protein ERCC-2DNA repair protein complementing XP-D cellsTFIIH 80 kDa subunitTFIIH basal transcription factor complex 80 kDa subunitTFIIH basal tran | |
| Modification date | 20200313 | 20200315 | |
| UniProtAcc | Q2VYF4 | P18074 | |
| Ensembl transtripts involved in fusion gene | ENST ids | ENST00000528827, ENST00000297720, ENST00000379957, ENST00000523983, ENST00000524874, ENST00000527710, ENST00000519476, | ENST00000221481, ENST00000391940, ENST00000391944, ENST00000391945, ENST00000485403, |
| Fusion gene scores for assessment (based on all fusion genes of FusionGDB 2.0) | * DoF score | 1 X 1 X 1=1 | 3 X 4 X 3=36 |
| # samples | 1 | 3 | |
| ** MAII score | log2(1/1*10)=3.32192809488736 | log2(3/36*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context (manual curation of fusion genes in FusionPDB) | PubMed: LETM2 [Title/Abstract] AND ERCC2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint (based on all fusion genes of FusionGDB 2.0) | LETM2(38262024)-ERCC2(45872405), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | LETM2-ERCC2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. LETM2-ERCC2 seems lost the major protein functional domain in Hgene partner, which is a CGC by not retaining the major functional domain in the partially deleted in-frame ORF. LETM2-ERCC2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. LETM2-ERCC2 seems lost the major protein functional domain in Hgene partner, which is a essential gene by not retaining the major functional domain in the partially deleted in-frame ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | ERCC2 | GO:0006283 | transcription-coupled nucleotide-excision repair | 8663148 |
| Tgene | ERCC2 | GO:0006366 | transcription by RNA polymerase II | 9852112 |
| Tgene | ERCC2 | GO:0045893 | positive regulation of transcription, DNA-templated | 8692842 |
| Tgene | ERCC2 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 8692841 |
| Fusion gene breakpoints across LETM2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
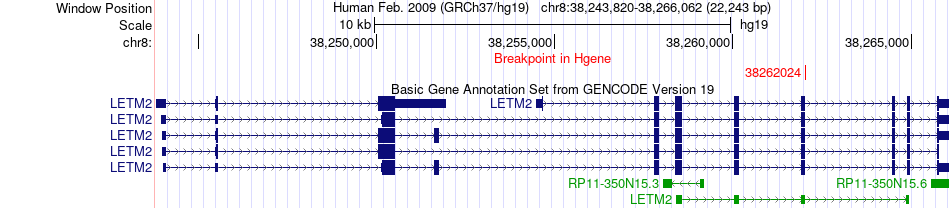 |
| Fusion gene breakpoints across ERCC2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
Top |
Fusion Gene Sample Information |
| Fusion gene information from FusionGDB2.0. |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-85-A53L-01A | LETM2 | chr8 | 38262024 | - | ERCC2 | chr19 | 45872405 | - |
| ChimerDB4 | LUSC | TCGA-85-A53L-01A | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - |
Top |
Fusion ORF Analysis |
| Fusion information from ORFfinder translation from full-length transcript sequence from FusionPDB. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000297720 | LETM2 | chr8 | 38262024 | + | ENST00000391945 | ERCC2 | chr19 | 45872405 | - | 5135 | 1165 | 196 | 3342 | 1048 |
| ENST00000297720 | LETM2 | chr8 | 38262024 | + | ENST00000391944 | ERCC2 | chr19 | 45872405 | - | 3135 | 1165 | 196 | 3108 | 970 |
| ENST00000297720 | LETM2 | chr8 | 38262024 | + | ENST00000485403 | ERCC2 | chr19 | 45872405 | - | 2451 | 1165 | 196 | 2349 | 717 |
| ENST00000297720 | LETM2 | chr8 | 38262024 | + | ENST00000391940 | ERCC2 | chr19 | 45872405 | - | 2350 | 1165 | 196 | 2349 | 718 |
| ENST00000297720 | LETM2 | chr8 | 38262024 | + | ENST00000221481 | ERCC2 | chr19 | 45872405 | - | 1788 | 1165 | 196 | 1443 | 415 |
| ENST00000524874 | LETM2 | chr8 | 38262024 | + | ENST00000391945 | ERCC2 | chr19 | 45872405 | - | 5171 | 1201 | 127 | 3378 | 1083 |
| ENST00000524874 | LETM2 | chr8 | 38262024 | + | ENST00000391944 | ERCC2 | chr19 | 45872405 | - | 3171 | 1201 | 127 | 3144 | 1005 |
| ENST00000524874 | LETM2 | chr8 | 38262024 | + | ENST00000485403 | ERCC2 | chr19 | 45872405 | - | 2487 | 1201 | 127 | 2385 | 752 |
| ENST00000524874 | LETM2 | chr8 | 38262024 | + | ENST00000391940 | ERCC2 | chr19 | 45872405 | - | 2386 | 1201 | 127 | 2385 | 753 |
| ENST00000524874 | LETM2 | chr8 | 38262024 | + | ENST00000221481 | ERCC2 | chr19 | 45872405 | - | 1824 | 1201 | 127 | 1479 | 450 |
| ENST00000379957 | LETM2 | chr8 | 38262024 | + | ENST00000391945 | ERCC2 | chr19 | 45872405 | - | 5315 | 1345 | 127 | 3522 | 1131 |
| ENST00000379957 | LETM2 | chr8 | 38262024 | + | ENST00000391944 | ERCC2 | chr19 | 45872405 | - | 3315 | 1345 | 127 | 3288 | 1053 |
| ENST00000379957 | LETM2 | chr8 | 38262024 | + | ENST00000485403 | ERCC2 | chr19 | 45872405 | - | 2631 | 1345 | 127 | 2529 | 800 |
| ENST00000379957 | LETM2 | chr8 | 38262024 | + | ENST00000391940 | ERCC2 | chr19 | 45872405 | - | 2530 | 1345 | 127 | 2529 | 801 |
| ENST00000379957 | LETM2 | chr8 | 38262024 | + | ENST00000221481 | ERCC2 | chr19 | 45872405 | - | 1968 | 1345 | 127 | 1623 | 498 |
| ENST00000523983 | LETM2 | chr8 | 38262024 | + | ENST00000391945 | ERCC2 | chr19 | 45872405 | - | 5219 | 1249 | 136 | 3426 | 1096 |
| ENST00000523983 | LETM2 | chr8 | 38262024 | + | ENST00000391944 | ERCC2 | chr19 | 45872405 | - | 3219 | 1249 | 136 | 3192 | 1018 |
| ENST00000523983 | LETM2 | chr8 | 38262024 | + | ENST00000485403 | ERCC2 | chr19 | 45872405 | - | 2535 | 1249 | 136 | 2433 | 765 |
| ENST00000523983 | LETM2 | chr8 | 38262024 | + | ENST00000391940 | ERCC2 | chr19 | 45872405 | - | 2434 | 1249 | 136 | 2433 | 766 |
| ENST00000523983 | LETM2 | chr8 | 38262024 | + | ENST00000221481 | ERCC2 | chr19 | 45872405 | - | 1872 | 1249 | 136 | 1527 | 463 |
| ENST00000527710 | LETM2 | chr8 | 38262024 | + | ENST00000391945 | ERCC2 | chr19 | 45872405 | - | 4703 | 733 | 157 | 2910 | 917 |
| ENST00000527710 | LETM2 | chr8 | 38262024 | + | ENST00000391944 | ERCC2 | chr19 | 45872405 | - | 2703 | 733 | 157 | 2676 | 839 |
| ENST00000527710 | LETM2 | chr8 | 38262024 | + | ENST00000485403 | ERCC2 | chr19 | 45872405 | - | 2019 | 733 | 157 | 1917 | 586 |
| ENST00000527710 | LETM2 | chr8 | 38262024 | + | ENST00000391940 | ERCC2 | chr19 | 45872405 | - | 1918 | 733 | 157 | 1917 | 587 |
| ENST00000527710 | LETM2 | chr8 | 38262024 | + | ENST00000221481 | ERCC2 | chr19 | 45872405 | - | 1356 | 733 | 157 | 1011 | 284 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000297720 | ENST00000391945 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.002511913 | 0.997488 |
| ENST00000297720 | ENST00000391944 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.005105723 | 0.99489427 |
| ENST00000297720 | ENST00000485403 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.013727638 | 0.98627234 |
| ENST00000297720 | ENST00000391940 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.014754696 | 0.9852453 |
| ENST00000297720 | ENST00000221481 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.007143834 | 0.99285614 |
| ENST00000524874 | ENST00000391945 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.002229977 | 0.9977701 |
| ENST00000524874 | ENST00000391944 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.004374853 | 0.9956252 |
| ENST00000524874 | ENST00000485403 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.01664628 | 0.98335373 |
| ENST00000524874 | ENST00000391940 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.017517326 | 0.9824827 |
| ENST00000524874 | ENST00000221481 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.016701063 | 0.98329896 |
| ENST00000379957 | ENST00000391945 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.002399993 | 0.9976 |
| ENST00000379957 | ENST00000391944 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.004125802 | 0.9958742 |
| ENST00000379957 | ENST00000485403 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.012049618 | 0.98795044 |
| ENST00000379957 | ENST00000391940 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.012983243 | 0.98701674 |
| ENST00000379957 | ENST00000221481 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.015064913 | 0.98493505 |
| ENST00000523983 | ENST00000391945 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.002563831 | 0.9974362 |
| ENST00000523983 | ENST00000391944 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.004573881 | 0.9954261 |
| ENST00000523983 | ENST00000485403 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.012065391 | 0.9879346 |
| ENST00000523983 | ENST00000391940 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.013504951 | 0.986495 |
| ENST00000523983 | ENST00000221481 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.008979631 | 0.9910204 |
| ENST00000527710 | ENST00000391945 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.002617021 | 0.99738294 |
| ENST00000527710 | ENST00000391944 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.010655447 | 0.98934454 |
| ENST00000527710 | ENST00000485403 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.013524831 | 0.98647517 |
| ENST00000527710 | ENST00000391940 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.014764972 | 0.985235 |
| ENST00000527710 | ENST00000221481 | LETM2 | chr8 | 38262024 | + | ERCC2 | chr19 | 45872405 | - | 0.006548031 | 0.99345195 |
Top |
Fusion Amino Acid Sequences |
| For individual full-length fusion transcript sequence from FusionPDB, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >FusionGDB ID_FusionGDB isoform ID_FGname_Hgene_Hchr_Hbp_Henst_Tgene_Tchr_Tbp_Tenst_length(fusion AA) seq_BP >44492_44492_1_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000297720_ERCC2_chr19_45872405_ENST00000221481_length(amino acids)=415AA_BP=323 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQ TGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMR SLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIY -------------------------------------------------------------- >44492_44492_2_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000297720_ERCC2_chr19_45872405_ENST00000391940_length(amino acids)=718AA_BP=323 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQ TGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMR SLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIY CSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFD AHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLT RRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKW -------------------------------------------------------------- >44492_44492_3_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000297720_ERCC2_chr19_45872405_ENST00000391944_length(amino acids)=970AA_BP=323 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQ TGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMR SLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIY CSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNID NVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFL GFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHTLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEP FDDRTPTIANPILHFSCMDASLAIKPVFERFQSVIITSGTLSPLDIYPKILDFHPVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFET REDIAVIRNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVASWYEQGILENIQRNKLLFIETQDGAETSVALEKYQEACENGRGAILLSVA RGKVSEGIDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLRDQFQIRENDFLTFDAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKR -------------------------------------------------------------- >44492_44492_4_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000297720_ERCC2_chr19_45872405_ENST00000391945_length(amino acids)=1048AA_BP=323 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQ TGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMR SLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIY CSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFD AHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLT RRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKW RLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHTLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPI LHFSCMDASLAIKPVFERFQSVIITSGTLSPLDIYPKILDFHPVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGN LLLEMSAVVPDGIVAFFTSYQYMESTVASWYEQGILENIQRNKLLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEGIDFVH HYGRAVIMFGVPYVYTQSRILKARLEYLRDQFQIRENDFLTFDAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLT -------------------------------------------------------------- >44492_44492_5_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000297720_ERCC2_chr19_45872405_ENST00000485403_length(amino acids)=717AA_BP=323 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQ TGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMR SLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIY CSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFD AHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLT RRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKW -------------------------------------------------------------- >44492_44492_6_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000379957_ERCC2_chr19_45872405_ENST00000221481_length(amino acids)=498AA_BP=406 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVP FMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKKEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPST KEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEE QLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPE -------------------------------------------------------------- >44492_44492_7_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000379957_ERCC2_chr19_45872405_ENST00000391940_length(amino acids)=801AA_BP=406 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVP FMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKKEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPST KEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEE QLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPE IEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVP LPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRC QGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHV -------------------------------------------------------------- >44492_44492_8_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000379957_ERCC2_chr19_45872405_ENST00000391944_length(amino acids)=1053AA_BP=406 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVP FMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKKEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPST KEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEE QLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPE IEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSM SVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLL EYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHTLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPT IANPILHFSCMDASLAIKPVFERFQSVIITSGTLSPLDIYPKILDFHPVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVI RNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVASWYEQGILENIQRNKLLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEG IDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLRDQFQIRENDFLTFDAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWI -------------------------------------------------------------- >44492_44492_9_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000379957_ERCC2_chr19_45872405_ENST00000391945_length(amino acids)=1131AA_BP=406 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVP FMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKKEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPST KEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEE QLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPE IEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVP LPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRC QGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHV VQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHTLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPILHFSCMD ASLAIKPVFERFQSVIITSGTLSPLDIYPKILDFHPVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGNLLLEMSA VVPDGIVAFFTSYQYMESTVASWYEQGILENIQRNKLLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEGIDFVHHYGRAVI MFGVPYVYTQSRILKARLEYLRDQFQIRENDFLTFDAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLTDANLNLT -------------------------------------------------------------- >44492_44492_10_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000379957_ERCC2_chr19_45872405_ENST00000485403_length(amino acids)=800AA_BP=406 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVP FMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKKEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPST KEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEE QLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPE IEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVP LPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRC QGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHV -------------------------------------------------------------- >44492_44492_11_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000523983_ERCC2_chr19_45872405_ENST00000221481_length(amino acids)=463AA_BP=371 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVPFMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKK EEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQT FGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVK PKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKN -------------------------------------------------------------- >44492_44492_12_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000523983_ERCC2_chr19_45872405_ENST00000391940_length(amino acids)=766AA_BP=371 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVPFMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKK EEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQT FGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVK PKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKN LCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANV VVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLRE ASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLH -------------------------------------------------------------- >44492_44492_13_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000523983_ERCC2_chr19_45872405_ENST00000391944_length(amino acids)=1018AA_BP=371 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVPFMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKK EEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQT FGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVK PKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKN LCIHPEILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLR DEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPL RFCAERLRSLLHTLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPILHFSCMDASLAIKPVFERFQSVIITSGTLS PLDIYPKILDFHPVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVASW YEQGILENIQRNKLLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEGIDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLRD QFQIRENDFLTFDAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLTDANLNLTVDEGVQVAKYFLRQMAQPFHRED -------------------------------------------------------------- >44492_44492_14_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000523983_ERCC2_chr19_45872405_ENST00000391945_length(amino acids)=1096AA_BP=371 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVPFMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKK EEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQT FGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVK PKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKN LCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANV VVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLRE ASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLH TLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPILHFSCMDASLAIKPVFERFQSVIITSGTLSPLDIYPKILDFH PVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVASWYEQGILENIQRN KLLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEGIDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLRDQFQIRENDFLTF DAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLTDANLNLTVDEGVQVAKYFLRQMAQPFHREDQLGLSLLSLEQL -------------------------------------------------------------- >44492_44492_15_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000523983_ERCC2_chr19_45872405_ENST00000485403_length(amino acids)=765AA_BP=371 MLEQDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGKPQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQK IMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRRLLRTCVDFFRLVPFMVFLIVPFMEFLLPVFLKLFPEMLPSTFESESKK EEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQT FGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVK PKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKN LCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANV VVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLRE ASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLH -------------------------------------------------------------- >44492_44492_16_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000524874_ERCC2_chr19_45872405_ENST00000221481_length(amino acids)=450AA_BP=358 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLE LAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLM KLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGH GVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPETTSASTP -------------------------------------------------------------- >44492_44492_17_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000524874_ERCC2_chr19_45872405_ENST00000391940_length(amino acids)=753AA_BP=358 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLE LAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLM KLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGH GVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFG KDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKI ADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLAN PVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHTLEITDLADFSPL -------------------------------------------------------------- >44492_44492_18_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000524874_ERCC2_chr19_45872405_ENST00000391944_length(amino acids)=1005AA_BP=358 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLE LAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLM KLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGH GVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEILHANVV VYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREA SAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHT LEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPILHFSCMDASLAIKPVFERFQSVIITSGTLSPLDIYPKILDFHP VTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVASWYEQGILENIQRNK LLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEGIDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLRDQFQIRENDFLTFD AMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLTDANLNLTVDEGVQVAKYFLRQMAQPFHREDQLGLSLLSLEQLE -------------------------------------------------------------- >44492_44492_19_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000524874_ERCC2_chr19_45872405_ENST00000391945_length(amino acids)=1083AA_BP=358 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLE LAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLM KLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGH GVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFG KDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKI ADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLAN PVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHTLEITDLADFSPL TLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPILHFSCMDASLAIKPVFERFQSVIITSGTLSPLDIYPKILDFHPVTMATFTMTLAR VCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVASWYEQGILENIQRNKLLFIETQDGAET SVALEKYQEACENGRGAILLSVARGKVSEGIDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLRDQFQIRENDFLTFDAMRHAAQCVGRA IRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLTDANLNLTVDEGVQVAKYFLRQMAQPFHREDQLGLSLLSLEQLESEETLKRIEQIA -------------------------------------------------------------- >44492_44492_20_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000524874_ERCC2_chr19_45872405_ENST00000485403_length(amino acids)=752AA_BP=358 MAFYSYNSVLAIARTRFPSHFVHPTCSSYSPSCAFLHLPDSHLNKTCMKNYESKKYSDPSQPGNTVLHPGTRLIQKLHTSTCWLQEVPGK PQLEQATKHPQVTSPQATKETGMEIKEGKQSYRQKIMDELKYYYNGFYLLWIDAKVAARMVWRLLHGQVLTRRERRREEKQKKKMAVKLE LAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQTFGTNNLLRFQLLM KLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDVKPKPIEIPLSGEGH GVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRKNLCIHPEVTPLRFG KDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHANVVVYSYHYLLDPKI ADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLREASAARETDAHLAN PVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLLHTLEITDLADFSPL -------------------------------------------------------------- >44492_44492_21_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000527710_ERCC2_chr19_45872405_ENST00000221481_length(amino acids)=284AA_BP=192 MEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQ TFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDV KPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRK -------------------------------------------------------------- >44492_44492_22_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000527710_ERCC2_chr19_45872405_ENST00000391940_length(amino acids)=587AA_BP=192 MEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQ TFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDV KPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRK NLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHAN VVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLR EASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLL -------------------------------------------------------------- >44492_44492_23_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000527710_ERCC2_chr19_45872405_ENST00000391944_length(amino acids)=839AA_BP=192 MEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQ TFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDV KPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRK NLCIHPEILHANVVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRL RDEYRRLVEGLREASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKP LRFCAERLRSLLHTLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPILHFSCMDASLAIKPVFERFQSVIITSGTL SPLDIYPKILDFHPVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVAS WYEQGILENIQRNKLLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEGIDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLR DQFQIRENDFLTFDAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLTDANLNLTVDEGVQVAKYFLRQMAQPFHRE -------------------------------------------------------------- >44492_44492_24_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000527710_ERCC2_chr19_45872405_ENST00000391945_length(amino acids)=917AA_BP=192 MEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQ TFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDV KPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRK NLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHAN VVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLR EASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLL HTLEITDLADFSPLTLLANFATLVSTYAKGFTIIIEPFDDRTPTIANPILHFSCMDASLAIKPVFERFQSVIITSGTLSPLDIYPKILDF HPVTMATFTMTLARVCLCPMIIGRGNDQVAISSKFETREDIAVIRNYGNLLLEMSAVVPDGIVAFFTSYQYMESTVASWYEQGILENIQR NKLLFIETQDGAETSVALEKYQEACENGRGAILLSVARGKVSEGIDFVHHYGRAVIMFGVPYVYTQSRILKARLEYLRDQFQIRENDFLT FDAMRHAAQCVGRAIRGKTDYGLMVFADKRFARGDKRGKLPRWIQEHLTDANLNLTVDEGVQVAKYFLRQMAQPFHREDQLGLSLLSLEQ -------------------------------------------------------------- >44492_44492_25_LETM2-ERCC2_LETM2_chr8_38262024_ENST00000527710_ERCC2_chr19_45872405_ENST00000485403_length(amino acids)=586AA_BP=192 MEEKQKKKMAVKLELAKFLQETMTEMARRNRAKMGDASTQLSSYVKQVQTGHKPSTKEIVRFSKLFEDQLALEHLDRPQLVALCKLLELQ TFGTNNLLRFQLLMKLKSIKADDEIIAKEGVTALSVSELQAACRARGMRSLGLTEEQLRQQLTEWQDLHLKENVPPSLLLLSRTFYLIDV KPKPIEIPLSGEGHGVLEMPSGTGKTVSLLALIMAYQRAYPLEVTKLIYCSRTVPEIEKVIEELRKLLNFYEKQEGEKLPFLGLALSSRK NLCIHPEVTPLRFGKDVDGKCHSLTASYVRAQYQHDTSLPHCRFYEEFDAHGREVPLPAGIYNLDDLKALGRRQGWCPYFLARYSILHAN VVVYSYHYLLDPKIADLVSKELARKAVVVFDEAHNIDNVCIDSMSVNLTRRTLDRCQGNLETLQKTVLRIKETDEQRLRDEYRRLVEGLR EASAARETDAHLANPVLPDEVLQEAVPGSIRTAEHFLGFLRRLLEYVKWRLRVQHVVQESPPAFLSGLAQRVCIQRKPLRFCAERLRSLL -------------------------------------------------------------- |
Top |
Fusion Protein Functional Features |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:38262024/chr19:45872405) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| LETM2 | ERCC2 |
| FUNCTION: ATP-dependent 5'-3' DNA helicase, component of the general transcription and DNA repair factor IIH (TFIIH) core complex, which is involved in general and transcription-coupled nucleotide excision repair (NER) of damaged DNA and, when complexed to CAK, in RNA transcription by RNA polymerase II. In NER, TFIIH acts by opening DNA around the lesion to allow the excision of the damaged oligonucleotide and its replacement by a new DNA fragment. The ATP-dependent helicase activity of XPD/ERCC2 is required for DNA opening. In transcription, TFIIH has an essential role in transcription initiation. When the pre-initiation complex (PIC) has been established, TFIIH is required for promoter opening and promoter escape. Phosphorylation of the C-terminal tail (CTD) of the largest subunit of RNA polymerase II by the kinase module CAK controls the initiation of transcription. XPD/ERCC2 acts by forming a bridge between CAK and the core-TFIIH complex. Involved in the regulation of vitamin-D receptor activity. As part of the mitotic spindle-associated MMXD complex it plays a role in chromosome segregation. Might have a role in aging process and could play a causative role in the generation of skin cancers. {ECO:0000269|PubMed:10024882, ECO:0000269|PubMed:15494306, ECO:0000269|PubMed:20797633, ECO:0000269|PubMed:8413672}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - Retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000297720 | + | 7 | 10 | 208_235 | 311.0 | 397.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000379957 | + | 8 | 11 | 208_235 | 406.0 | 492.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000523983 | + | 8 | 11 | 208_235 | 359.0 | 445.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000379957 | + | 8 | 11 | 382_385 | 406.0 | 492.0 | Compositional bias | Note=Poly-Leu |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000297720 | + | 7 | 10 | 26_177 | 311.0 | 397.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000379957 | + | 8 | 11 | 26_177 | 406.0 | 492.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000523983 | + | 8 | 11 | 26_177 | 359.0 | 445.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000527710 | + | 5 | 8 | 26_177 | 192.0 | 278.0 | Topological domain | Mitochondrial intermembrane |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000297720 | + | 7 | 10 | 178_198 | 311.0 | 397.0 | Transmembrane | Helical |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000379957 | + | 8 | 11 | 178_198 | 406.0 | 492.0 | Transmembrane | Helical |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000523983 | + | 8 | 11 | 178_198 | 359.0 | 445.0 | Transmembrane | Helical |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391940 | 1 | 13 | 234_237 | 11.0 | 406.0 | Motif | Note=DEAH box | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391940 | 1 | 13 | 682_695 | 11.0 | 406.0 | Motif | Nuclear localization signal | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391945 | 1 | 23 | 234_237 | 35.0 | 761.0 | Motif | Note=DEAH box | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391945 | 1 | 23 | 682_695 | 35.0 | 761.0 | Motif | Nuclear localization signal | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000485403 | 0 | 12 | 234_237 | 11.0 | 406.0 | Motif | Note=DEAH box | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000485403 | 0 | 12 | 682_695 | 11.0 | 406.0 | Motif | Nuclear localization signal | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391940 | 1 | 13 | 42_49 | 11.0 | 406.0 | Nucleotide binding | ATP | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391945 | 1 | 23 | 42_49 | 35.0 | 761.0 | Nucleotide binding | ATP | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000485403 | 0 | 12 | 42_49 | 11.0 | 406.0 | Nucleotide binding | ATP |
| - Not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000527710 | + | 5 | 8 | 208_235 | 192.0 | 278.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000297720 | + | 7 | 10 | 382_385 | 311.0 | 397.0 | Compositional bias | Note=Poly-Leu |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000523983 | + | 8 | 11 | 382_385 | 359.0 | 445.0 | Compositional bias | Note=Poly-Leu |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000527710 | + | 5 | 8 | 382_385 | 192.0 | 278.0 | Compositional bias | Note=Poly-Leu |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000297720 | + | 7 | 10 | 221_438 | 311.0 | 397.0 | Domain | Letm1 RBD |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000379957 | + | 8 | 11 | 221_438 | 406.0 | 492.0 | Domain | Letm1 RBD |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000523983 | + | 8 | 11 | 221_438 | 359.0 | 445.0 | Domain | Letm1 RBD |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000527710 | + | 5 | 8 | 221_438 | 192.0 | 278.0 | Domain | Letm1 RBD |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000297720 | + | 7 | 10 | 199_491 | 311.0 | 397.0 | Topological domain | Mitochondrial matrix |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000379957 | + | 8 | 11 | 199_491 | 406.0 | 492.0 | Topological domain | Mitochondrial matrix |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000523983 | + | 8 | 11 | 199_491 | 359.0 | 445.0 | Topological domain | Mitochondrial matrix |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000527710 | + | 5 | 8 | 199_491 | 192.0 | 278.0 | Topological domain | Mitochondrial matrix |
| Hgene | LETM2 | chr8:38262024 | chr19:45872405 | ENST00000527710 | + | 5 | 8 | 178_198 | 192.0 | 278.0 | Transmembrane | Helical |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391940 | 1 | 13 | 7_283 | 11.0 | 406.0 | Domain | Helicase ATP-binding | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000391945 | 1 | 23 | 7_283 | 35.0 | 761.0 | Domain | Helicase ATP-binding | |
| Tgene | ERCC2 | chr8:38262024 | chr19:45872405 | ENST00000485403 | 0 | 12 | 7_283 | 11.0 | 406.0 | Domain | Helicase ATP-binding |
Top |
Fusion Protein-Protein Interaction |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type from validated records (BIOGRID-3.4.160) |
| Gene | PPI interactors |
| Protein-protein interactors based on sequence similarity (STRING) |
| Gene | STRING network |
| LETM2 | |
| ERCC2 |
| - Retained interactions in fusion protein (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost interactions due to fusion (protein functional feature from UniProt). |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs to LETM2-ERCC2 |
| Drugs used for this fusion-positive patient. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Drug | Source | PMID |
Top |
Related Diseases to LETM2-ERCC2 |
| Diseases that have this fusion gene. (Manual curation of PubMed, 04-30-2022 + MyCancerGenome) |
| Hgene | Tgene | Disease | Source | PMID |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies